
Abstract
Despite many studies on trip inference using call detail record (CDR) data, a fundamental understanding of their limitations is lacking. In particular, because of the sparse nature of CDR data, users may travel to a location without being revealed in the data, which we refer to as a hidden visit. The existence of hidden visits hinders our ability to extract reliable information about human mobility and travel behavior from CDR data. In this study, we propose a data fusion approach to obtain labeled data for statistical inference of hidden visits. In the absence of complementary data, this can be accomplished by extracting labeled observations from more granular cellular data access records, and extracting features from voice call and text messaging records. The proposed approach is demonstrated using a real-world CDR dataset of 3 million users from a large Chinese city. Different machine learning models are used to infer whether a hidden visit exists during an observed displacement. The test results show significant improvement over the naive no-hidden-visit rule, which is an implicit assumption adopted by most existing studies. Based on the proposed model, we estimate that over 10% of the displacements extracted from CDR data involve hidden visits.
Introduction
Enabled by the increasing availability of large-scale datasets on human movements, human mobility has become an emerging field dedicated to extracting patterns that describe individual trajectories in time and space. In its essence, human movements are results of spatiotemporal choices (e.g., the decision to go somewhere at some time) made by individuals with diverse preferences and lifestyles. Trips reflect critical travel decisions, and thus are basic behavioral units of human mobility. A trip is defined as “the travel required from an origin location to access a destination for the purpose of performing some activity” (McNally, 2007). The ability to extract trips from large-scale spatiotemporal data sources is important for urban planning, transportation management, and location-based services.
One of the most commonly used data sources for human mobility studies is call detail record (CDR) data, which are collected by cellular service operators primarily for billing information collection and network management. CDR data are one type of event-driven mobile phone network data (Calabrese et al., 2014). The generative events typically include incoming and outgoing voice calls, text messages (or Short Message Service, SMS), and, in some cases, cellular data usage (e.g., 3G/4G). In this study, we treat cellular data usage records as referred to in Ranjan et al. (2012), as part of CDR data. Whenever a cellular transaction is made, the CDR database records its time and approximate location, in the form of the connected cell tower or antenna. Thus, CDR data offer the opportunity to capture spatiotemporal patterns of mobile phone users over time at a large scale.
In recent years, CDR data have been used extensively to extract useful human mobility patterns and urban transportation information. The related studies cover diverse topics ranging from origin-destination (OD) estimation (Caceres et al., 2007; Calabrese et al., 2011; Iqbal et al., 2014; Mellegard et al., 2011; Wang et al., 2013) and travel time estimation (Hasan and Ali, 2017) to meaningful place detection (Ahas et al., 2010; Isaacman et al., 2011) and human activity discovery (Csáji et al., 2013; González et al., 2008; Phithakkitnukoon et al., 2010; Schneider et al., 2013). The majority of these studies depend on the ability to accurately extract trips from CDR data. However, unlike Global Positioning System (GPS) data (Zhao et al., 2015), CDRs are recordings of people’s telecommunication activities, which are not perfectly aligned with their travel behavior (Xu et al., 2018). This raises the need to translate a series of telecommunication activities into a series of travel activities, which is not a straightforward task (Zhao et al., 2016a).
One critical limitation of CDR data for trip extraction is its sparsity. Phone usage tends to be sporadic in nature (Barabási, 2005). For most users, their mobile phone records are sparsely and irregularly distributed over time, resulting in periods when users may travel but have no phone records to reveal it in the CDR data. We call these time periods elapsed time intervals, or ETIs. An ETI is defined as the period between two consecutive mobile phone records that is long enough for a user to potentially make a trip unobservable from the CDR data. When ETIs occur, the observed spatiotemporal traces of the user are likely incomplete, and the trip estimations based on such incomplete observations are prone to errors. For example, because of the sparsity issue, the fact that two locations are sequentially observed in CDR data does not mean that they are connected by a direct trip. They may not be an OD pair if the user makes an unobserved trip to another location between them. In other words, there may be a hidden visit, which occurs when a user visits a place but has no CDR associated with it. By definition, hidden visits can only occur during ETIs. This issue has received limited attention in existing literature (Bayir et al., 2010; Chen et al., 2019). Without properly considering hidden visits, the extracted OD pairs may be incorrect, the trip generation rate may be underestimated, and the spatiotemporal distribution of trips is likely to be skewed based on individual preferences of mobile phone usage (Zhao et al., 2016b). This calls for methods that can infer the existence of hidden visits based on spatiotemporal context of the ETI as well as the individual characteristics of the user.
The objective of this study is to highlight the issue of hidden visits, and develop an approach to infer the existence of hidden visits during ETIs. Inferring something unobservable in the data, using the said data, is a challenging task. Typically, an unsupervised approach (Chen et al., 2019) is the only choice. However, the heterogeneity across different subsets of CDR data, e.g., voice call vs data access records, raises the opportunity to adopt a supervised approach based on data fusion for hidden visit inference. Specifically, for a subgroup of users with passively generated data activities, their data access records may be used to recover the portion of travel that is hidden from actively generated voice call records, which can then be used to train hidden visit inference models applied to general user population. In this paper, we focus on the problem of inferring whether hidden visits exist or not. The ability to identify hidden visits is important for ensuring the quality of the trip-level information extracted from CDR data. For example, if a hidden visit exists, the extracted OD pair should not be used for OD estimation. By identifying hidden visits during ETIs, we may distinguish OD pairs that are accurately inferred from those that are not. It is worth emphasizing that this paper focuses on identifying the existence of hidden visits, i.e., a binary problem, which is of great value for trip extraction by itself. It will provide a foundation for the inference of the exact time and location of the hidden visits, which is a relatively more challenging problem and should be further studied in future research.
The specific contributions of this study are summarized as follows. First, we define the problem of hidden visit inference as part of the trip detection process using sparse CDR data. We show that estimated trip characteristics, such as average trip distance, would be biased without hidden visit inference. Second, we propose a data fusion approach to obtain labeled training data from CDR data alone for supervised statistical inference of hidden visits. More specifically, labeled observations are extracted from more frequently sampled cellular data access records, and features from voice call and text messaging records. Third, we demonstrate the proposed data fusion approach for predicting whether observed displacements contain hidden visits, and identify a range of spatial, temporal, and personal features for the prediction task. Based on a large-scale real-world dataset, we estimate that over 10% of the displacements extracted from CDR data involve hidden visits.
Methodology
Trip extraction from CDR data
Despite its increasing popularity in human mobility and transportation studies, CDR data have several limitations that hinder the ability to accurately extract individual trips. First, CDR data typically provides spatial information at the cell tower level, while the precise location of the user is unknown. It is also well documented that positioning noise exists in CDR data, which stems from signal movements (Calabrese et al., 2011; Iqbal et al., 2014). Low spatial resolution and signal noise both contribute to localization error. Second, the status of travel is not provided in CDR data. A mobile phone record may be generated during a visit to a place or during a trip between two places. This poses a challenge for identifying trip origins and destinations. Third, the sparse nature of CDR data makes it impossible to obtain a complete profile of user mobility. Even when complete records of the mobile phone activities of an individual are available, not every trip of the user is observable. Only those trips that occur in tandem with mobile phone activities are recoverable.
All the aforementioned limitations are, to various degrees, recognized and discussed in the literature. While terminologies and methodologies vary across specific studies, this section synthesizes them into a unified framework shown in Figure 1. Generally, to extract trips from CDR data, three stages are needed—localization, movement state identification, and hidden visit inference. Each is intended to address one of the three limitations. The results obtained after each stage are closer to actual individual travel behavior.
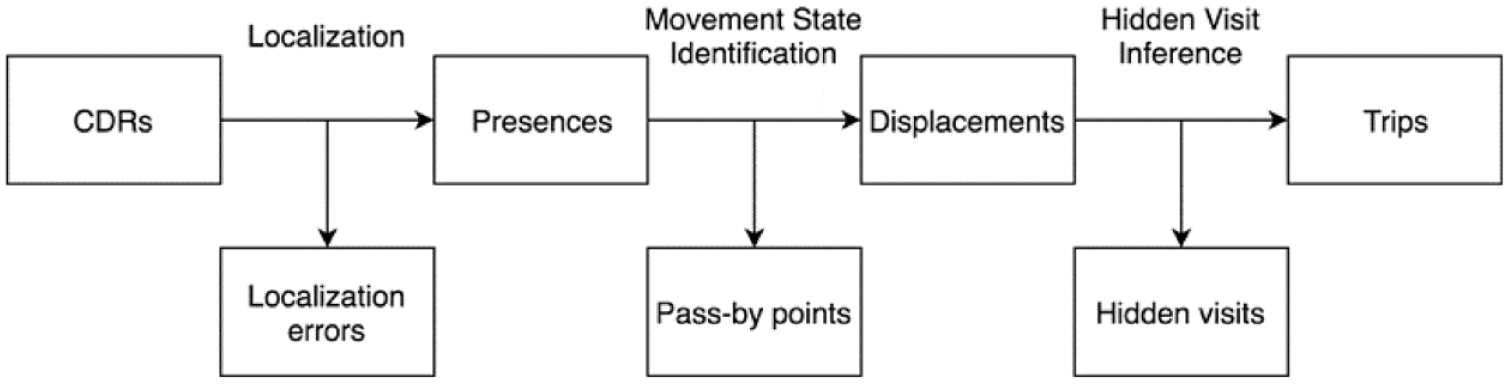
A general process for extracting trips from CDR data.
The first stage, localization, intends to mitigate localization errors and estimate user locations. A plethora of different methods have been used in the literature to reduce localization error (Csáji et al., 2013; Isaacman et al., 2011; Jiang et al., 2013; Wang et al., 2013). They typically include two steps—trajectory smoothing and spatial clustering. In trajectory smoothing, one takes a sequence of CDRs within a certain time threshold and applies smoothing or filtering algorithms to reduce “jumps” in the location sequence. These algorithms include speed-based filtering (Wang et al., 2013), time-weighted smoothing (Csáji et al., 2013), or assigning a single medoid location to every record in the sequence if they are close by (Jiang et al., 2013). All of them produce smoothed location sequences. In spatial clustering, one ignores the ordering or the temporal distribution of CDRs and clusters data points based on their spatial distribution only. In this way, we can consolidate points that may represent the same location but are visited on different days. Agglomerative clustering (Hariharan and Toyama, 2004; Jiang et al., 2013) and leader clustering (Csáji et al., 2013; Isaacman et al., 2011) are two common spatial clustering algorithms used in prior research. The former clusters a sequence of locations based on a distance matrix only, while the latter can prioritize some locations over others usually based on the visit frequency. Cluster diameters need to be specified in both algorithms. In some cases, the location of a mobile phone may be recorded as triangulated coordinates computed based on the locations of multiple cell towers that the device connects to. When triangulated coordinates are available, a model-based clustering method, proposed by Chen et al. (2014), is more flexible as it does not require predetermined threshold values and allows for probabilistic cluster assignments.
After localization, the location of a user at a certain time is represented by a clustered location, instead of a cell tower location. A time-stamped user location is called a presence. Each presence can either occur during a trip or during an activity at a meaningful place. Jiang et al. (2013) referred to the former category as “pass-by” points, and the latter “stay” points. The goal of the second stage, movement state identification, is to distinguish between the two categories and extract visits from presences. A visit is a series of “stay” points correspond to the same location. The most common way to do this in prior literature is simply to apply a dwell time threshold (Calabrese et al., 2011; Jiang et al., 2013; Mellegard et al., 2011; Wang et al., 2013). For example, a threshold of 10 min is used in Jiang et al. (2013). A sequence of presences that are associated with the same location and span over 10 min is classified as a visit. Otherwise, they are flagged as pass-bys. This method works well for high-frequency data, such as GPS data. However, for sparse CDR data, it may cause most presences to be labeled as pass-by points. One way to improve this is to further identify “potential stays”, the presences that are classified as pass-bys using the dwell time criterion but are associated with a previously visited location (Jiang et al., 2013).
Whereas most existing methods only cover the first two stages, we argue that a third stage, hidden visit inference, is needed to distinguish between trips and displacements. A displacement occurs between two consecutive visits observed in the data, while a trip occurs between two consecutive visits regardless they are observed or not. In other words, a displacement may correspond to one or more trips. Using displacements extracted from sparse CDR data to directly estimate mobility patterns may lead to biases (Zhao et al., 2016b). The discrepancy between displacements and trips is a non-trivial obstacle in applying CDR data for travel behavior analysis (Chen et al., 2016). Hidden visit inference is a problem that has been largely overlooked in the literature. Bayir et al. (2010) is the first study that explicitly defines the problem of hidden visits. They make the distinction between “observed end-locations” and “hidden end-locations”. Based on their definition, “a hidden location occurs when a significant amount of time is elapsed during cell transition.” In an attempt to address the issue, they propose the use of a transition time threshold to determine whether a hidden location exists during an ETI, which heavily relies on personal judgment and lacks statistical robustness. While several statistical methods have been developed to fill in the gaps in sparse CDR trajectories by estimating the length of stay at each observed location, they do not explicitly consider hidden visits to a different location (Chen et al., 2018; Hoteit et al., 2016). More recently, Chen et al. (2019) proposed a tensor decomposition method for complete CDR trajectory reconstruction. Specifically, a 3-dimensional tensor is constructed for each user and the missing locations are estimated based on the assumption of user behavior regularity. Unsupervised learning methods, such as tensor decomposition, are often necessary because the ground-truth data about hidden visits are typically not available. However, unsupervised learning methods are generally difficult to calibrate and do not perform as well as supervised learning methods for prediction tasks. In this study, we will present a novel data fusion approach that makes it possible to infer hidden visits using supervised learning methods. In addition, unlike Chen et al. (2019), our hidden visit inference method will combine both individual-specific features and other spatiotemporal features under a universal model to allow learning across users.
Hidden visit inference based on data fusion
To infer whether a hidden visit exists is essentially a classification problem. It involves building a statistical model for predicting a binary output based on one or more inputs (James et al., 2013). This requires a set of training examples, each being a pair consisting of a feature vector,
Specifically for hidden visit inference, the complete travel profile of a user is required, along with the sparse CDR data, in order to form labeled observations. One way to achieve this is to find another data source that complements the characteristics of CDR data. CDR data are one example of large-scale urban mobility data sources that cover large user population and long observation period, but the individual-level information that is captured in such data is relatively coarse. In contrast, another type of data may be collected from a smaller sample of individuals over a shorter observation period, but can provide richer and more detailed information at the individual level, e.g., the Reality Mining dataset (Eagle and Pentland, 2006). These two types of data are complementary to each other. In this study, we refer them as coarse big data and rich small data, respectively. Whenever both types of data are available, we can maximize their value by combining the two for statistical learning, which involves forming training examples with
Given these practical challenges, this study proposes a new way to apply data fusion using only CDR data. This is possible because multiple types of mobile phone transactions are recorded in CDR data, including voice calls, SMS, and data activities. While many of the datasets analyzed in the literature consist of voice calls only (Barabási, 2005; Csáji et al., 2013; González et al., 2008; Iqbal et al., 2014), or voice calls in combination with SMS records (Isaacman et al., 2011), records of data activities are becoming more available (Calabrese et al., 2011, 2014; Ranjan et al., 2012). Unlike voice call and SMS activities, data activities do not always require user initiation or participation (Ranjan et al., 2012). On devices with enabled cellular data capability, a plethora of mobile applications, if allowed by users, make periodic or sporadic connections to the cellular network automatically. These data activities are recorded as data access records, and they tend to be less sparse than voice call or SMS records. Furthermore, voice call and SMS records are determined by mobile phone usage preferences. As a result, the mobility patterns observed from such data may be confounded with the user’s mobile phone usage behavior (Williams et al., 2015). On the other and, data access records can be generated passively. For example, a user may prefer not to make voice calls at certain locations or at a certain time of the day, and thus, the travel associated with these locations and periods may be hidden from the voice call records. However, these otherwise “hidden” visits can be captured by passively generated data access records. For these reasons, data access records can be used to capture complete travel profiles, at least for a small group of smartphone users with passively generated cellular data activities. Therefore, despite the lack of a complementary data source, it is still possible to obtain labeled data by extracting
Problem Formulation
After localization and movement state identification, we obtain a series of stay points for each user,
For a given user, the superscript u is omitted for clarity. Let
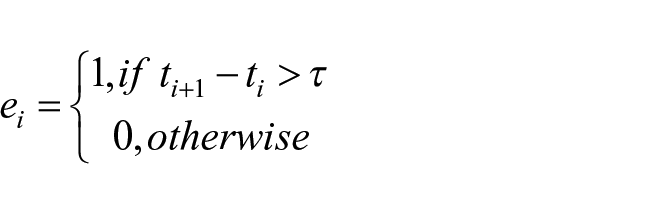
where
Assume that both coarse big data and rich small data are available for a group of users. A series of stay points can be obtained from the former. For each time interval
To ensure that the location sequences in the two data sources are comparable, we may transform them into discrete time series, for example, by binning the timestamps into hours. Also, in reality, even in the frequently sampled data access records, user locations may be missing in certain periods. For example, if the mobile phone of a user is out of battery for a period, all the travel activities during the period would be missing. We call these periods unrecoverable. Only hidden visits within the recoverable ETIs can be identified. This process of obtaining labeled observations is illustrated using the example in Figure 2.
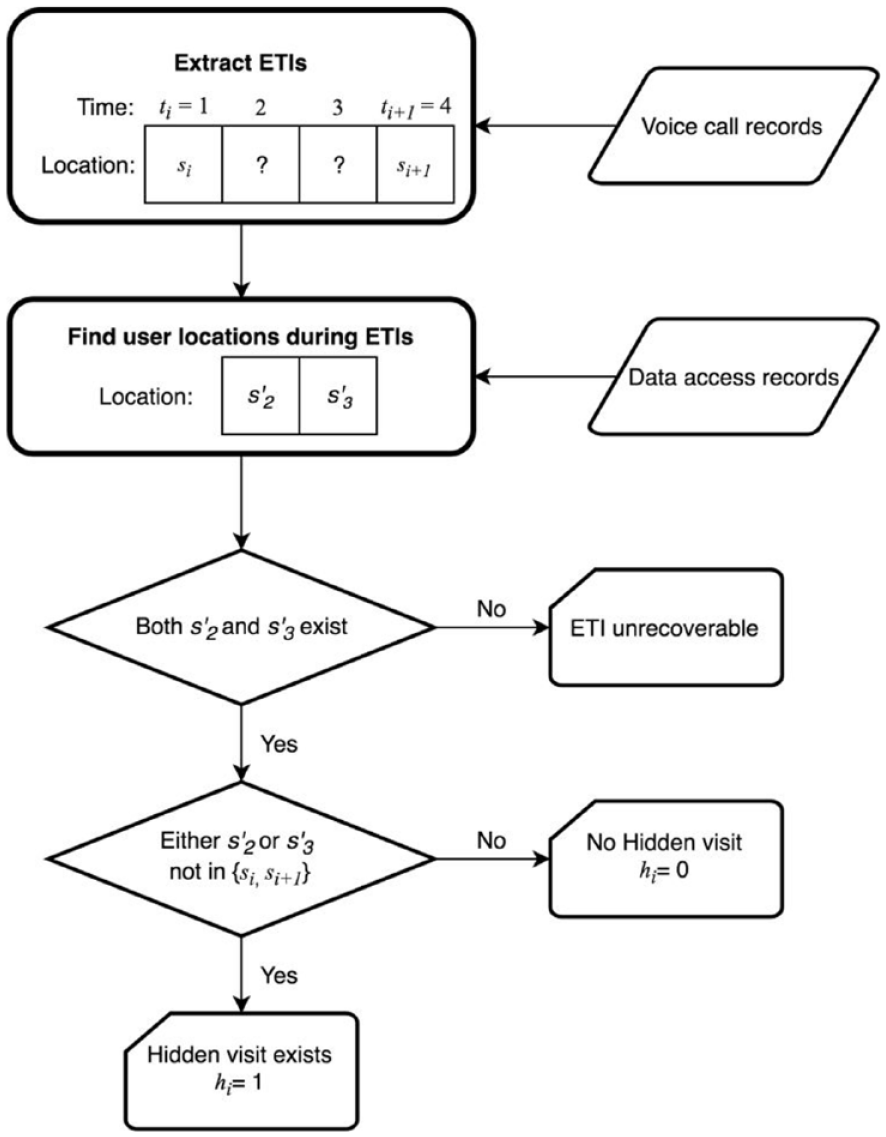
Illustration of the process for identifying the existence of hidden visits.
With labeled observations, a model can be trained to estimate
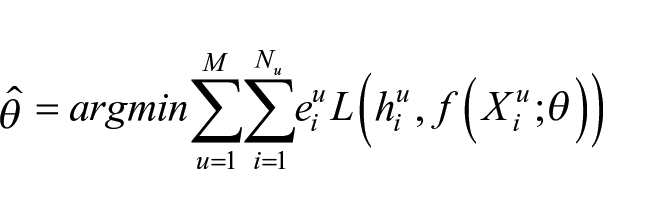
where
It is important to consider two different scenarios depending on whether
Application
Data
The dataset used for this study is collected by one of the major cellular service operators from a Chinese city with a population of 6 million. The dataset contains over 2 billion mobile phone transaction records generated by 3 million users during November 2013. Only voice call and data access records are available; SMS records are not available, exacerbating the sparsity problem at the individual level. The key fields in the CDR data include:
ID—encrypted unique identifier for each phone number
Location Area Code (LAC)—location area code, used in combination with Cell ID to identify the cell tower used for the transaction
Cell ID—used in combination with LAC to identify the cell tower used for the transaction
Date Time—the timestamp of the mobile phone transaction
Event ID—the type of the event that triggers the transaction, which may be an outgoing call, incoming call, or data usage (2G/3G).
In addition to the CDR dataset, we have a cell tower database documenting the attributes (including geographic location) of the cell towers. This makes it possible to query the coordinates (in the form of longitude and latitude) of the tower associated with each mobile phone record using LAC and Cell ID. In total, we are able identify the locations of over 9,000 cell towers that appear in the CDR dataset. The distribution of the cell towers is shown together with the 607 traffic analysis zones (TAZs) of the city in Figure 3(a). It is clear that the distribution of the cell towers is highly uneven and concentrated in the city center, where most activities take places. In Figure 3(b), each TAZ is represented as a node, and the edge between two nodes represents the number of displacements between TAZs. The size of the node describes the total number of displacements from/to the TAZ.
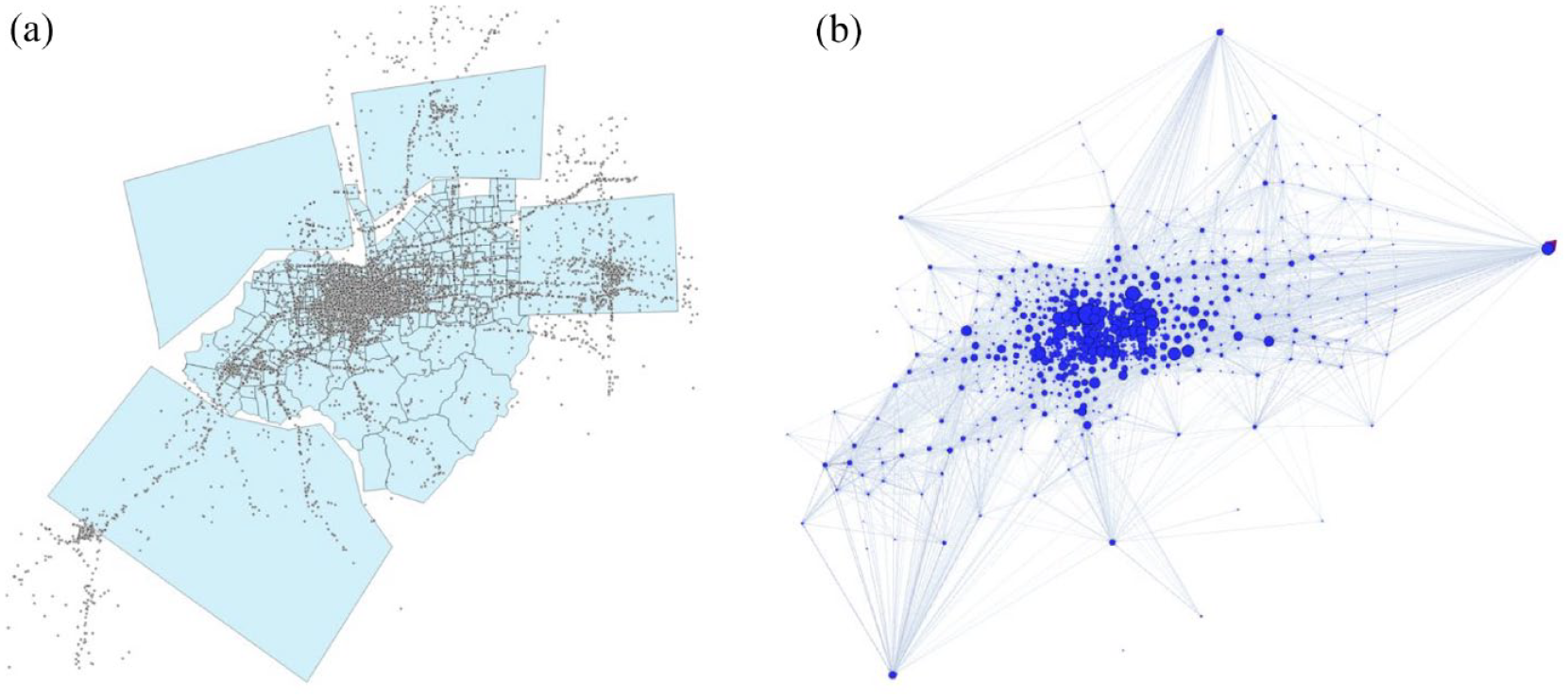
Spatial distribution of cell towers and displacements between TAZs.
Although the total amount of CDR data is large, the number of records per user is sparse. On average, a user generates 0.16 voice call records and 0.40 data access records every hour. Voice call and data access records exhibit different patterns. As shown in Figure 4, data access records are not only larger in number but also more evenly distributed throughout the day than voice call records. Similar to prior findings in Candia et al. (2008), the number of voice call records per user have two peaks, one in the morning and the other in the afternoon, which resembles the distribution of travel demand. It suggests that making phone calls is somewhat correlated with travel, potentially causing biases in travel estimation. For example, if some users only make phone calls before and after their commutes, we may overestimate the proportion of commuting trips and underestimate other trips. Without observing the actual travel behavior from another less biased data source, it is very difficult to correct the bias. Data access records suffer from a similar problem, but to a lesser degree. Therefore, data access records may be used to quantify, and potentially mitigate, the biases of voice call records.
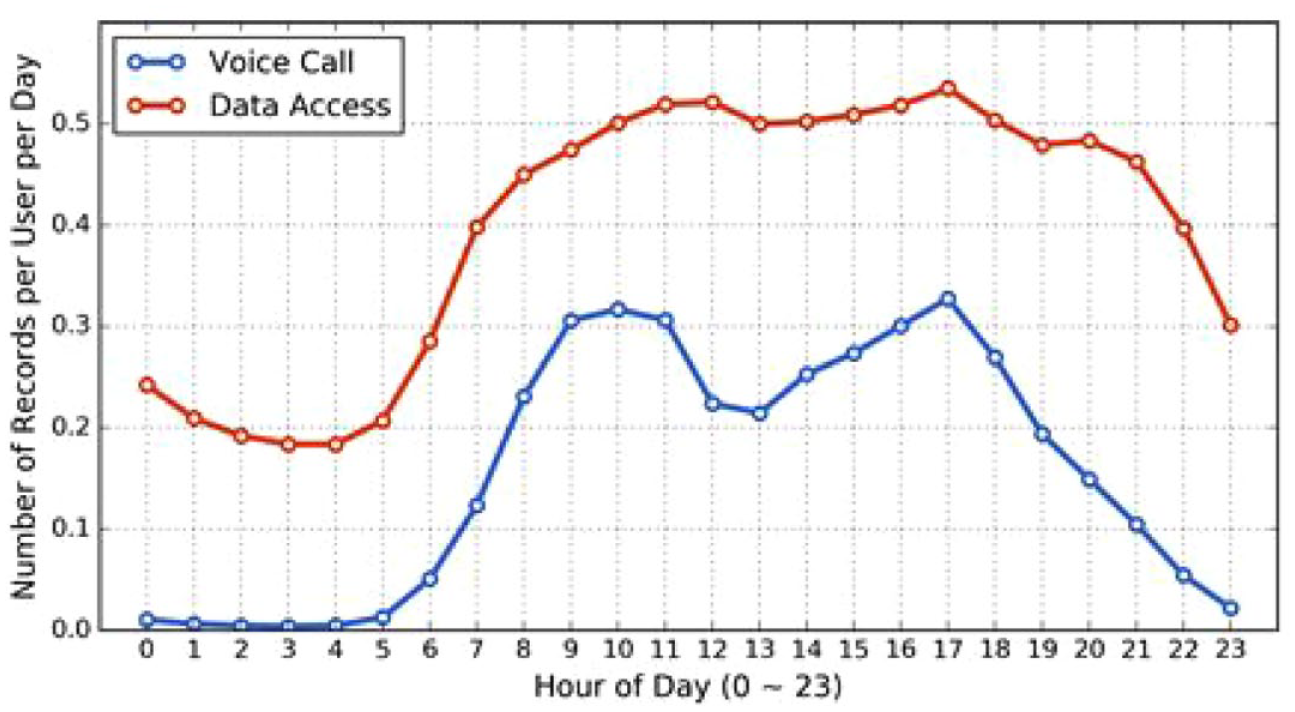
Mobile phone usage pattern over time of day.
The inter-event distribution of the voice call and data activities is also explored. The inter-event time is calculated as the time difference between two consecutive records for the same user. Again, voice call records and data access records are analyzed separately. Figure 5 shows that, whereas the inter-call time is characterized by a smooth distribution curve, the inter-event time for data activities exhibits a few peculiar spikes, the most significant of which being at the 1-hour mark. This is likely caused by the fact that some mobile applications are set up to automatically make hourly connections to the cellular network. This finding suggests that a reasonable choice for ETI threshold τ is 1 hour, at least for this dataset.
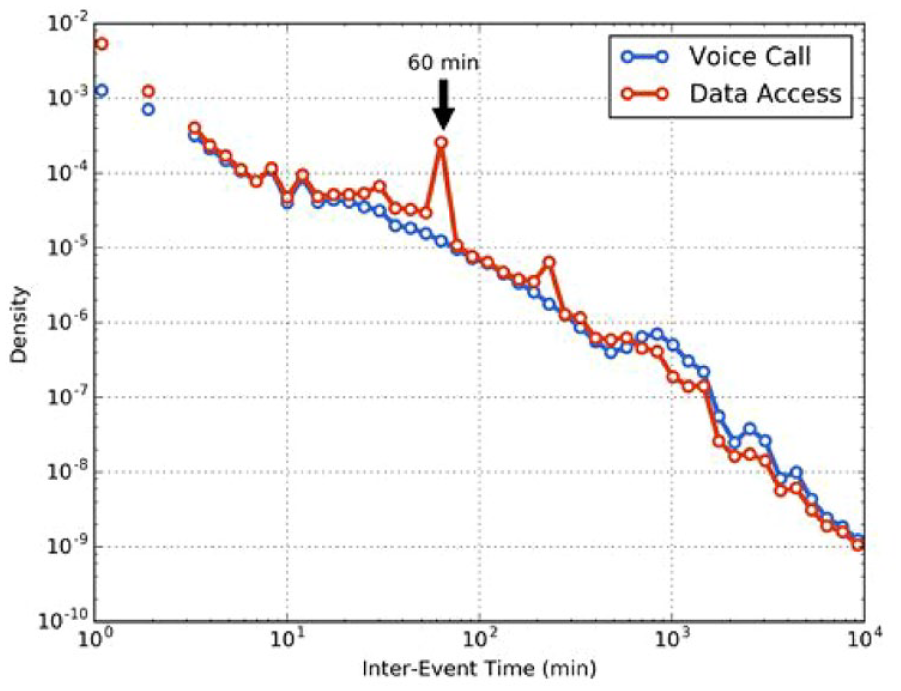
Distribution of inter-event time by transaction type.
Note that not every user’s data access records have such regular hourly inter-event intervals. Some users may not have a smartphone, while others may disallow for passive data usage of some mobile applications. An examination of mobile phone usage patterns shows that 9% of the users have only data access records but no voice calls, possibly because they represent tablets or secondary devices. The rest of the users are considered regular mobile users who generated at least one voice call record in November. They can be further divided into call-only users who do not use cellular data (43%) and mixed users who have both voice call and data access records (57%).
By further decomposing mixed users, we find that a large proportion of data access records are generated by a small group of users. Figure 6 shows the distribution of the active hours of mixed users based on their voice call or data access frequency. An active hour denotes an hour when the user generates at least one record, and we break this down by the two transaction types. Note that there are 720 hours in total during our study period (i.e., 30 days). The two distributions shown in the figure are distinctly different, which is highlighted in the log-log plot (see the inset chart of Figure 6). There is virtually no user that has more than half of their hours with at least one voice call, but there are a small group of users that generate data access records in most of the hours, a strong indication that these users have passively generated data activities. In this study, we define frequent data users as the mixed users who have active data usage in at least half of the hours (in this case, 360 hours). The threshold represents a trade-off between certainty and volume—a lower threshold would place more users in this group, but we would be less certain that these users have passively generated data access records. For this group of users, their voice call records are still sparse, but their data access records are not. Therefore, we can to some extent observe their mobility between voice calls based on their data usage. Note that the frequent data users only account for 10% of the regular mobile user population. Nevertheless, hidden visit inference models may be trained based on CDRs of the frequent data users, before being deployed for the large majority of users with sparse CDR data. Note that even a frequent data user may still have ETIs in their trajectories, e.g., when the user is out of cellular coverage or is served by unknown Wi-Fi hotspots. We do not require them to have complete trajectories. Instead, we only extract the complete segments of trajectories for training data. After the model is trained, it can then be deployed for hidden visit inference for all ETIs.
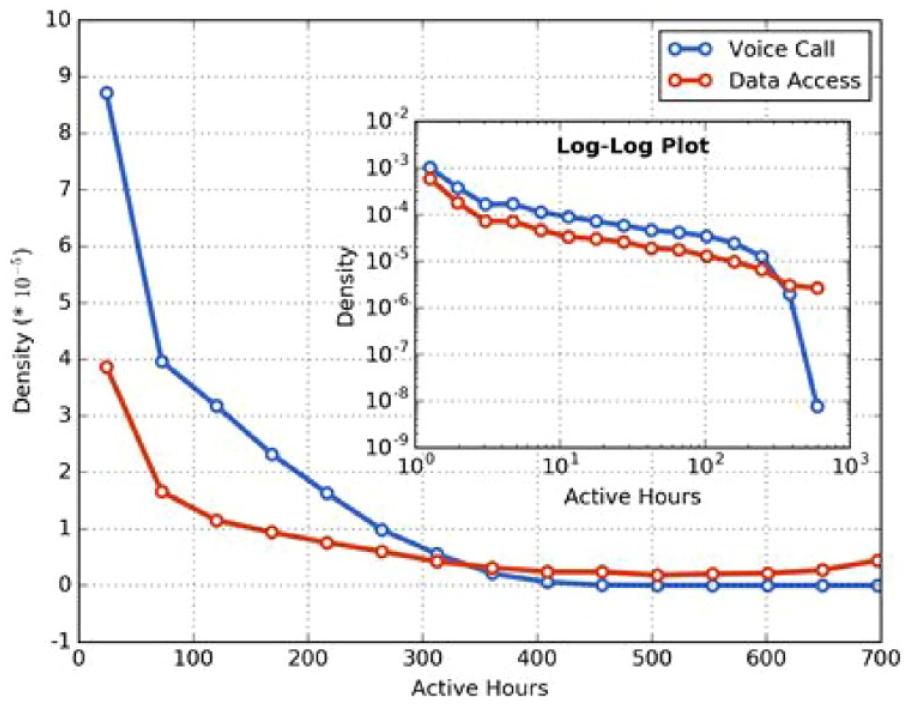
Distribution of mixed users by number of active hours.
Preprocessing
Before hidden visit inference, two previous stages need to be completed—localization and movement state inference. For localization, a method similar to Isaacman et al. (2011) and Csáji et al. (2013) is adopted to perform spatial clustering of cell towers and identify important user locations. The method has two steps. In the first step, the cell towers are ranked based on their importance for each user, where the importance is measured based on the number of “call-days” (i.e., days the cell tower was contacted). In the second step, the leader algorithm is used for clustering analysis. The algorithm starts with the most important cell towers and merges the surrounding towers into the first cluster. Then we move on to the most frequent tower of the remaining towers and repeat, until all towers are assigned a cluster. Unlike the K-means algorithm, the leader algorithm does not require a predefined number of clusters, which is advantageous because localization is performed at the individual level. Compared to the hierarchical clustering algorithm, the leader algorithm allows us to assign higher priority (or weight) to the frequently used cell towers. The weighted centroid of the cell towers with a cluster is used to represent the location of a user.
In the movement state identification stage, we distinguish between stay and pass-by points based on the dwell time and the frequency of appearances at the associated user location. To determine dwell time, presences are aggregated to segments based on location matching and temporal proximity. Two consecutive presences are combined if they are associated with the same location
For model implementation, 10,000 frequent data users are selected to form training samples. For each user in the dataset, we are able to obtain a series of stay points
Model specification
Given a displacement with ETI, a set of attributes need to be defined in order to be used for hidden visit inference. Generally, its attributes can be categorized into three sets—spatial (of the displacement), temporal (of the ETI) and personal (of the user) attributes.
Spatial attributes refer to the characteristics of the displacement
Temporal attributes refer to the characteristics of the ETI
User attributes include both characteristics of mobile phone usage and those related to travel behavior. One specific measure of travel tendency is the number of displacements per active hour, which is a normalized measure of user displacement rate. Table 1 presents numerous attributes that are extracted and tested, and the italicized ones are those that are selected to be included in the final model based on model validation.
Possible features for hidden visit inference.

Note: features with * are derived using individual user data; features in italics are included in final models.
Because different assumptions for loss functions and model structures may yield different results, four commonly used classifiers are tested. They are logistic regression, support vector machine (SVM), random forest, and gradient boosting. The implementation details of these methods are described as follows:
The logistic regression model outputs the probability distribution across the two classes, and thus a cut-off value needs to be chosen to produce a point estimate (i.e., yes or no). Based on preliminary tests, the cut-off value is set at 0.5. To avoid over-fitting, the L2 regularization is used, and the parameter of inverse regularization strength, C, is chosen to be 1.0.
For SVM, the radial basis function kernel is used. It takes the following form:
A random forest is an ensemble method that fits a number of decision tree classifiers on various sub-samples of the dataset and use averaging to improve the predictive accuracy and control over-fitting. The Gini index is used to measure the impurity of a node in a tree, and the number of trees in the forest is set to be 100.
Gradient boosting is an ensemble method that builds an additive model in a forward stage-wise fashion and allows for optimization of an arbitrary differentiable loss function (Friedman, 2001). In each stage, a weak model, typically a decision tree classifier, is fitted based on the negative gradient of the loss function.
All classifiers are implemented in Python through the machine learning package “scikit-learn” (Pedregosa et al., 2011). If not specified, the default model settings are used.
Feature importance analysis
Of the classifiers used, logistic regression has most interpretable model parameters. Thus, the detailed results of the logistic regression model are presented in Table 2 for a better understanding of the relationship between variables. Positive coefficients mean that an increase in attribute values will increase the probability that a hidden visit occurs, and vice versa.
Logistic regression model results.
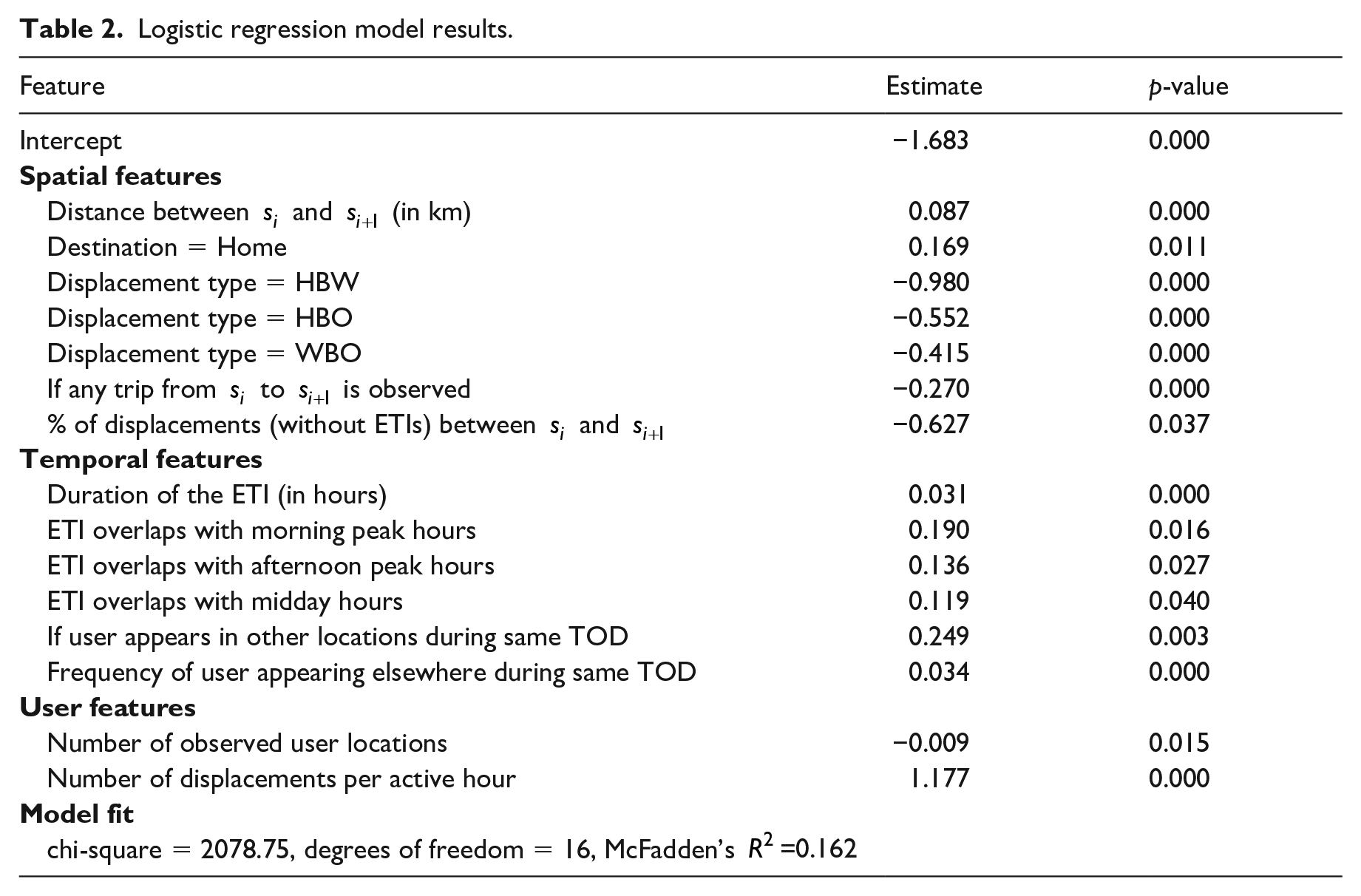
As expected, spatial attributes matter in the classification problem. Hidden visits are more likely to occur when the displacement distance is longer. Interestingly, they also occur more often when the displacement ends at home. One possible explanation is that people are more likely to make a short visit to another place (e.g., grocery store) on their way home. This may be because that people have fewer time constraints when they travel back home. If either
In terms of temporal attributes, the ETI duration has a similar effect as the displacement distance; the longer the ETI, the more likely a hidden visit occurs. If the ETI overlaps with morning peak hours, it is more likely to involve hidden visits. Afternoon peak and midday hours have similar, but lesser, effects, while the coefficient for night hours is insignificant. This finding matches our expectation that people are generally more mobile in peak hours than at midday, and least active during night hours. If the user is observed to appear in other locations during the same period on other days, hidden visits are also more likely to occur.
The number of displacements per active hour approximates the travel rate of a user. As expected, a user with a higher travel rate is more likely to undertake a hidden visit. We find that, although the number of user locations per active hour is not a significant factor in the model, the total number of observed user locations is. This suggests that the more visited locations revealed in the data, the less likely the user has hidden visits. One may argue this is a result of call frequency; a frequent caller reveals more visited locations. However, the frequency of the call activities is also insignificant in the model. A more likely explanation is rooted in the user’s spatial preference regarding phone calls. Regardless of call frequency, some users distribute their phone calls across all locations, while others may prefer to make a phone call only at a few locations. The latter group of users is more likely to have hidden visits in their voice call records. In other words, the distribution of calls matters more rather than the frequency of calls.
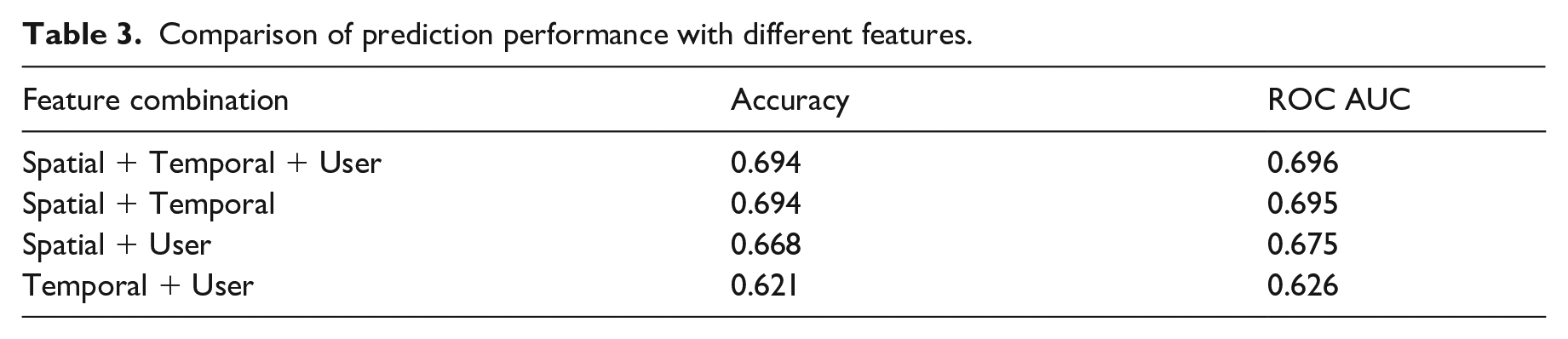
Another way to assess feature importance is to see how much they contribute to the actual prediction of hidden visits. To do this, we evaluate the overall prediction performance, measured by classification accuracy and ROC AUC. Then, we remove spatial, temporal, and personal features from the model, and compare the resulting difference in prediction performance. The results are summarized in Table 3. Based on the results, it seems that spatial features are most important (because of the largest drop in prediction performance), followed by temporal features. User features are least important.
Comparison of prediction performance with different features.
Comparison of model performance
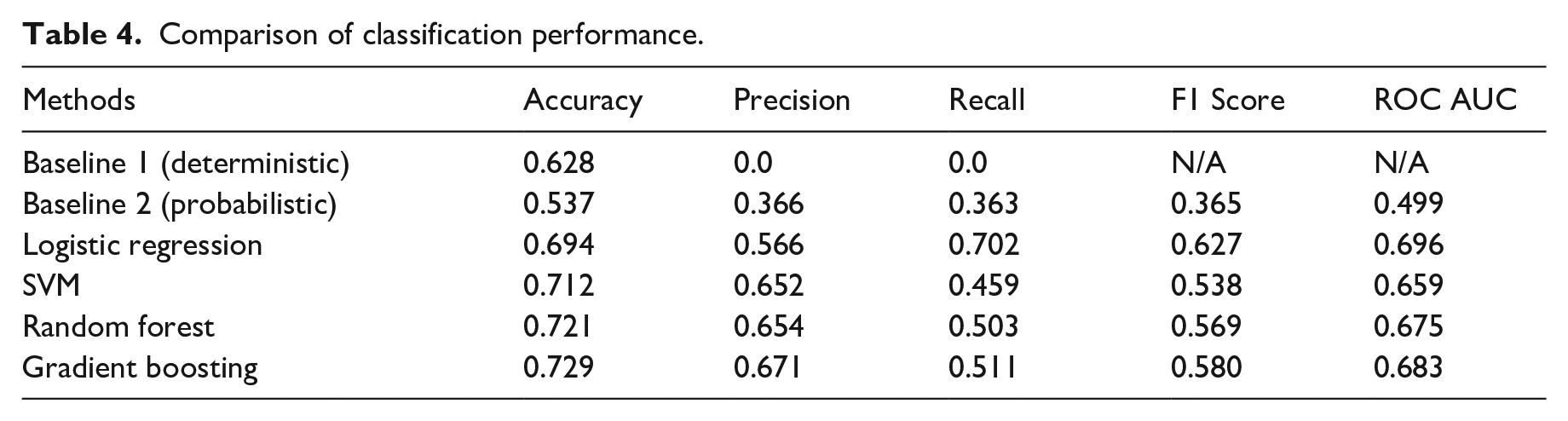
Table 4 shows the performance of the four classifiers. They are compared against two baseline models. Baseline 1 is a deterministic model that assumes no hidden visit, which is the assumption that many prior studies have made when they extracted trips from CDR data. It reaches a classification accuracy of 62.8%, meaning that the naive rule will underestimate the number of trips by at least 37%. Note that the precision and recall are both 0 for Baseline 1, because there are no positive cases predicted. Baseline 2 is a probabilistic model that generates predictions through sampling the marginal distribution of the target variable observed in the training data. Its prediction accuracy is lower, but, unlike Baseline 1, it produces positive precision and recall. Compared to the baseline models, the fitted statistical models significantly improve the prediction performance on all metrics. Among the four classifiers, gradient boosting performs best in terms of overall accuracy and precision, while logistic regression does better in recall, F1 score, and ROC AUC. Because the positive class accounts for a smaller proportion than the negative class, it tends to be under-classified, resulting in a lower recall than precision. Common strategies to address the data imbalance include oversampling or overweighting the positive class, or, for probabilistic models such as logistic regression, adjust the cut-off probability threshold. However, these strategies may worsen the overall accuracy score. This is a trade-off to be assessed depending on specific applications.
Comparison of classification performance.
Many classifiers, such as logistic regression, can produce probabilistic predictions for a new observation. Standard SVM does not provide such probabilities, but it can with Platt scaling (Platt, 2000). Figure 7 shows how the proportions of positive (in red) and negative (in blue) classes vary based on
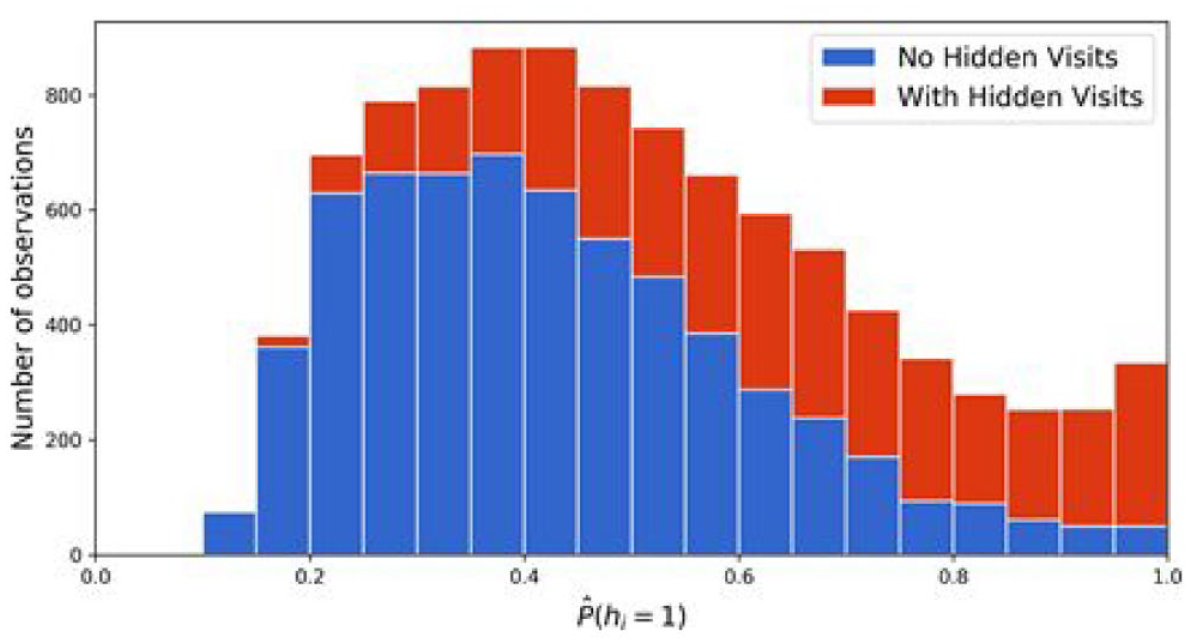
Proportions of positive/negative classes varying by estimated probabilities of hidden visits.
Model deployment for trip extraction
To demonstrate the importance of the hidden visit inference model, we apply the trained logistic regression model to all displacements with ETIs (with unknown
This has two implications. On the one hand, the results show that more than 10% of the displacements are not direct trips, and considering their end-locations
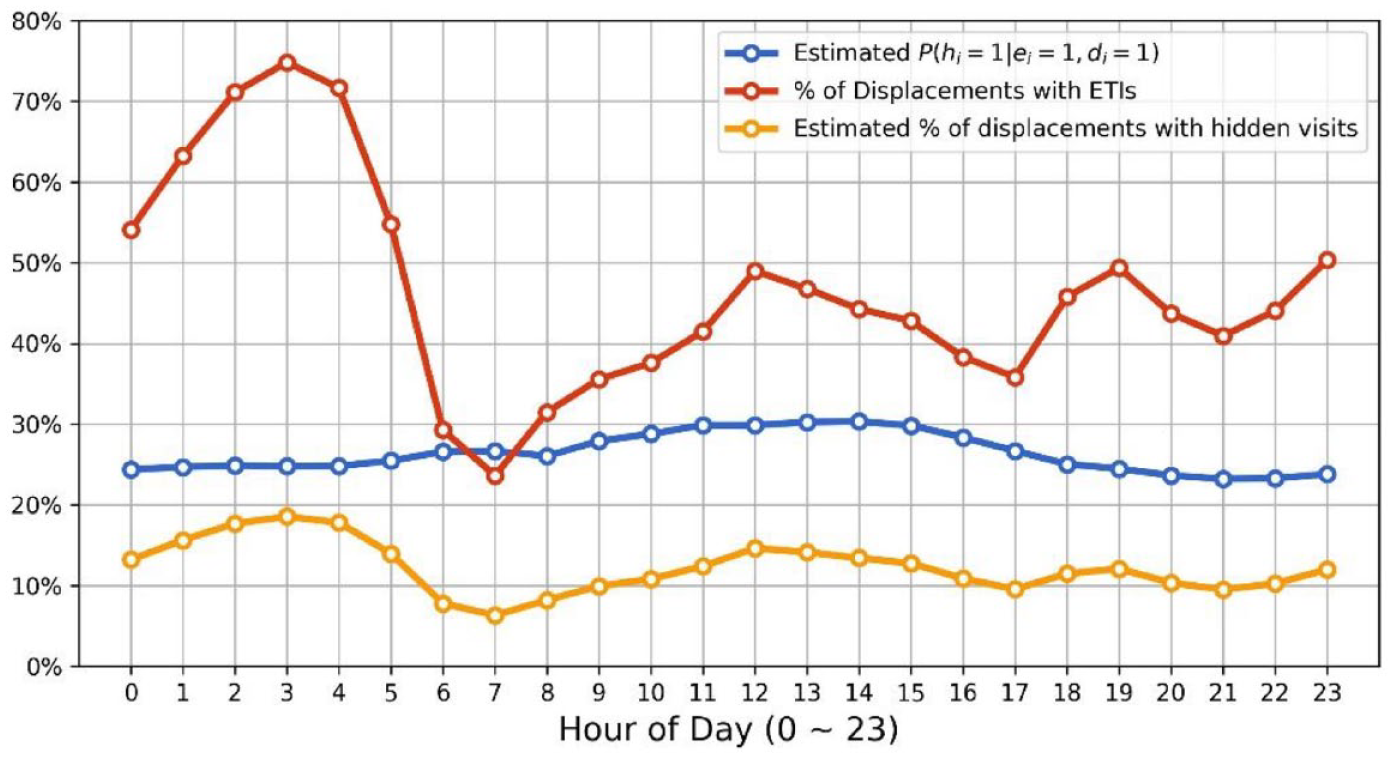
Percentage of inferred hidden visits over time of day.
As another demonstration of the value of hidden visit inference model, we compare the average trip distance for displacements with or without ETIs. Average trip distance is an important indicator of travel demand, useful for transportation planning. Hypothetically, the presence of ETIs should not significantly alter the average trip distance. However, because of potential hidden visits during ETIs, displacements with ETIs are more likely to contain more than one trips, resulting in longer average distance than direct trips. As shown in Table 5, the displacements with ETIs have much longer distance than displacements without ETIs, likely as a result of hidden visits. To address the inconsistency, we adopt the logistic regression model for hidden visit inference, and use the predicted probability of no hidden visit
Comparison of average distance across different types of displacements.
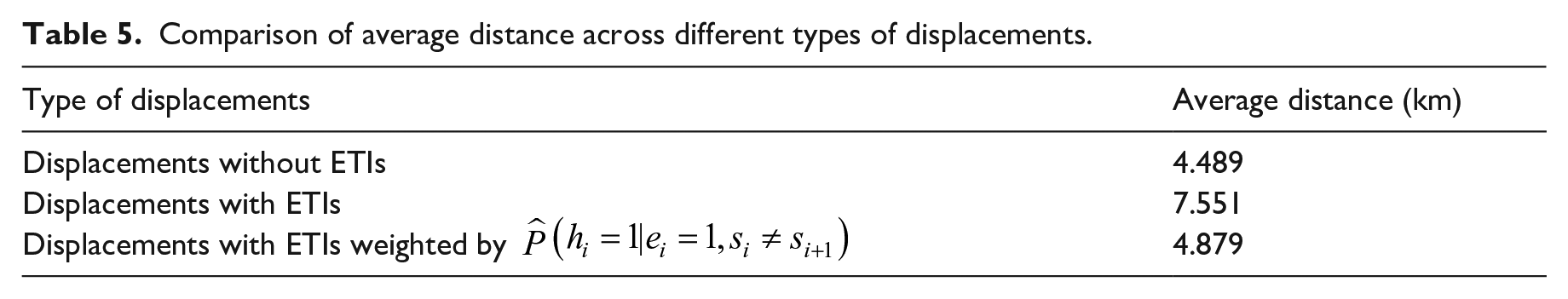
Discussion
In this study, we define the problem of hidden visits caused by data sparsity, and develop a data fusion approach to infer the existence of hidden visit in CDR data. The proposed method works by extracting labeled observation from more granular cellular data access records and features from voice call and/or SMS records. It is demonstrated using the CDR data of 3 million users from a large Chinese city over a one-month period. The records of a sample of 10,000 frequent data users are used to train hidden visit inference models. The test results show that the developed models offer superior performance compared to the implicit assumption of no hidden visit adopted by many prior studies. Furthermore, it allows us to explicitly account for uncertainty in hidden visit inferences via probabilistic estimates. In addition, the results reveal that longer displacements are more likely to involve hidden visits. By applying the trained model to general user population, we find 11.4% of the 56.5 million displacements extracted from CDR data involve hidden visits. This means, without considering hidden visits, the trip distance estimated from CDR data may be over-estimated and more than 10% of the observed OD pairs are potentially inaccurate. These findings provide a better understanding regarding the potential biases of sparse CDR data, especially voice call records, for travel estimation.
The proposed methodology presents a promising research direction, and opens up many opportunities for future advancement. First, the presence of signal noises, or localization errors in particular, in CDR data limits the performance of hidden visit inference models. Better localization methods can further reduce signal noises and potentially improve the performance of the models. Second, incorporating more features and sequential dependence can help improve the performance. Mining of individual-level longitudinal data may reveal more features regarding the user’s activity patterns and routines. Sequential dependence exists across a series of displacements of the same user, and it may be accounted for using methods like conditional random field. Third, as the models are developed based on training samples extracted from frequent data users’ CDRs, it is assumed that the model parameters are applicable to the general user population. The validity of the assumption depends on the problem and model specifications. Future research is needed to examine whether the frequent data users can be used as a reasonable training sample for model development, for which more ground-truth data should be collected. Fourth, in the current models, we assume all users share the same model parameters. However, different groups of people may have different mobility/telecommunication patterns and behavioral preferences. This may be accounted for in two steps—apply user clustering first and then develop models for each of the clusters. This requires a weaker assumption on the representativeness of training samples, as both the frequent data users and general population can be considered as different mixtures of the same underlying user clusters. See Appendix A for one way to cluster users based on their voice call patterns. More generally, a combination of unsupervised learning methods (e.g., Chen et al., 2019) and supervised learning methods (described in this study) can potentially further improve the model performance. Finally, in this case study, we only focus on inferring the existence of hidden visits. This is an important step of trip extraction from CDR data. An extension of this work is to infer, if a hidden visit exists, when and where it occurs. It is a more challenging problem. As each user visits a different set of locations at different time periods, the specific spatiotemporal patterns of hidden visits for one user may not be generalizable for other users. In addition, there can be more than one hidden visit during an ETI, further complicating the task. Future studies are needed to provide a better understanding on individual heterogeneity of spatiotemporal patterns and propose new methods to infer detailed hidden visit information.
Whenever large-scale data is used, user privacy is an important consideration. The target application of our study is trip detection and OD estimation, which are done at aggregate level, not individual level. The developed models can be directly deployed on the database servers of telecom carriers, without need for data transfer. Furthermore, compared to other forms of big data, such as social media or credit card transaction data, CDR data is relatively less intrusive in terms of personal privacy. In addition, its localization error helps to mask the exact user locations, providing another layer of privacy preservation.
With the rapid advance in cellular network technologies and growth in smartphone usage, it is reasonable to expect that the data access records will be increasingly rich and prevalent. Specifically, the increasing prevalence of mobile signaling data, which records all signal jumps between cell towers, should largely reduce the occurrence of ETIs, though data sparsity can still be an issue for parts of the population during certain time periods. The specific parameters may change depending on the configuration of the networks or mobile phone settings, but the proposed data fusion approach is general and should still hold in the foreseeable future. Although CDR data are the focus of this study, the proposed approach can be extended to other types of coarse big data, such as transit smart card data and geo-located social media data. The value of this type of data can be enhanced through data fusion and statistical inference. For example, if we have smart card records and travel survey data for a group of individuals, the same data fusion approach may be applied to infer whether a user makes a hidden visit between two observed transit trips, which makes it possible to estimate individual-level mode shares for public transit.
Footnotes
Appendix A: User cluster analysis
In this section, we show one possible way to cluster users based on their voice call patterns, because different voice call patterns likely indicate different user activity schedules, lifestyles, and to some extent mobility behaviors. Specifically, each user
Acknowledgements
The authors would like to thank the Energy Foundation China and China Sustainable Transportation Center for providing the data and funding support that made this research possible. We also thank the anonymous reviewers for their constructive comments, which helped us to improve the paper.
Authorship contribution
Zhan Zhao: conceptualization, methodology, formal analysis, writing—original draft.
Haris N Koutsopoulos: conceptualization, supervision, writing—review and editing.
Jinhua Zhao: conceptualization, supervision, writing—review and editing.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partly supported by the Energy Foundation China and China Sustainable Transportation Center.