
Abstract
Numbers are regarded as a common problem trigger in simultaneous interpreting (SI). Their low predictability and high information density can generate additional cognitive loads for interpreters, especially for trainees. The data of this study were collected from the English into Mandarin Chinese SI performances by trainees over a semester-long period of training to explore if there was a correlation between training and the accuracy with which numbers are rendered in SI. Specifically, this study adopts a longitudinal approach to investigate the impact of a 13-week formal training course on trainees’ ability to render numbers, and to determine the accuracy of different number types in renditions using six accuracy indicators. Two research questions were answered: (a) The 13-week formal training course did not significantly improve trainees’ accuracy in rendering numbers; (b) among number types, part of name, ranges, and small and whole numbers led to the poorest performance, which were attributed to source-text factors and lack of visual reference points. These results suggest that SI training could combine numbers with additional challenges, such as accents or fast speech delivery, and focus more on ranges and small numbers. Future studies could further control the influential variables identified in this research to validate their impact on the rendition of numbers.
1. Introduction
Numbers are known as a problem trigger in simultaneous interpreting (SI; Gile, 2009). In authentic interpreting scenarios, they can place additional burdens on professionals’ working memory, interfering in the normal encoding, storing and retrieval of other information in the source speech (Mazza, 2001). The intrinsic difficulty of number interpretation has provided a fruitful source of research avenues in interpreting studies. Several studies examine which factors may affect the rendition of numbers and how (Cheung, 2009, 2014, 2023; Jones, 2002; Korpal & Stachowiak-Szymczak, 2019; Mazza, 2001; Pinochi, 2009), with some further unveiling the possibility of reducing the cognitive load posed by numbers via technical or visual support such as slides (Desmet et al., 2018; Stachowiak-Szymczak & Korpal, 2019). The study carried out by Kajzer-Wietrzny et al. (2024) showed that certain number types and omission (not rendering numbers at all) have a significant impact on interpreting fluency. Large numbers, for example. would impede interpreters’ overall delivery quality. However, the authors noticed the limited generalisability of such a result to different language pairs and expertise. Language pairs with more divergent numerical systems may result in a greater variability of impact. Moreover, numbers may prove less of a challenge to experienced interpreters in comparison with trainees.
To fully capture the intricacy of number rendition, special attention should be paid to diverse language pairs and different levels of expertise. Yet, research in this area is marked by Euro-centrism. Only a few studies have concentrated on the way in which numbers affect interpreting trainees’ renditions (Cheung, 2009; Korpal & Stachowiak-Szymczak, 2018). However, interpreting trainees’ performance in number rendition merits more investigation as conclusions drawn from it could inform interpreting pedagogy and further help interpreting trainees conquer challenges caused by numerals. As such, this study sets out to address the gap by exploring number rendition in institutional settings. Specifically, we examined how interpreting trainees’ accuracy in numbers is affected by formal training, which includes basic curriculum components such as sight translation, consecutive interpreting (CI) and SI with the aim to enhance their expertise-related skills. In the SI course, trainees were required to practice SI with texts and without texts both from and into their native language. It is noteworthy that the formal training did not particularly centre on imparting trainees the specific ways to deal with numbers in different scenarios, yet the materials used for practice purposes did contain some numbers. Trainees’ renditions at different stages of the training course are compared to ascertain whether they have made any progress in interpreting numbers without error over one semester of SI training. Moreover, six different types of numbers are observed to see which type poses the greatest challenge for trainees. The authors obtained the data from a self-compiled corpus that consisted of authentic, in-class SI renditions by trainees on a master’s programme in translation and interpreting at a university in Chinese Hong Kong. The results demonstrate that a 13-week period of formal training may be insufficient for interpreting trainees to improve the accuracy of number rendition. Numbers shown in parts of names, ranges, and small and whole numbers seem harder for trainees to cope with, as evidenced by the lower accuracy rate found in these number renditions.
The remaining part of the article is structured as follows. Section 2 provides an overview of the research about numbers in interpreting studies. Section 3 sets out the methods applied including the tools used to compile and analyse the corpus, whereas Section 4 presents the results of data analysis, followed by a discussion of the relations between variables and accuracy levels in Section 5. Section 6 concludes the work and provides some suggestions for training focusing on rendering numbers in SI.
2. Literature review
2.1 Number and the accuracy of number renditions in SI
As stated by Gile (2009), there are varying problem triggers in SI, including fast speech delivery, strong accents, names, enumerations, and numbers. Numbers can require greater cognitive effort to process during interpreting and thus may lead to poorer interpreting performance (Gile, 2009).
Gile’s (1999) Effort Model and Seeber’s (2011) Cognitive Load Model attempt to describe cognitive management problems in SI as interpreters juggle several tasks simultaneously, including listening and analysis (L), short-term memory (M), speech production (P), and coordination (C). In light of this, numbers, which are characterised by low predictability, low redundancy, and high informative content, pose additional challenges that require extra effort to interpret (Mazza, 2001). Jones (2002) also noted five distinctive elements of numbers that can generate significant processing effort: the arithmetic value, the order of magnitude, the unit, the extra-linguist element that the number refers to, and the relative value of a numeral. Other influential factors include language pairs with different numerical systems, interpreting environment (hub or home), speaker’s accent, delivery rates of the original speech, and visual materials (Cheung, 2009, 2014, 2023; Gile, 2009; Pinochi, 2009; Stachowiak-Szymczak & Korpal, 2019). These are factors found to have significant impact on number renditions. Number types, however, as another number-related factor that may cause additional cognitive load, has not been fully discussed yet. This study thus sets out to explore which number type may cause a greater challenge in interpreting, which may provide insights into number-related research and interpreter training.
Although there is no direct measure of cognitive effort made during SI (Pym, 2008), indirect measures, including accuracy and fluency, are chosen as yardsticks to evaluate the influence of those variables on renditions (Kajzer-Wietrzny et al., 2024; Stachowiak-Szymczak & Korpal, 2019). Studies that explore various features of SI, namely source text and numbers, reported that SI with numbers leads to poorer accuracy or fluency in the rendition of numbers.
Regarding accuracy, previous experimental studies designed to investigate the success rate of number renditions have found that trainees’ performance is relatively poor, with approximately 40% error rate on average (Braun & Clarici, 1996; Korpal, 2017; Mazza, 2001; Pinochi, 2009); however, when it came to measuring accuracy, these studies adopted slightly different parameters. The taxonomy by Braun and Clarici (1996) underlies the following studies on number accuracy. They listed accuracy indicators as omission, approximation, lexical and syntactic errors, inversion errors, phonemic errors, structural errors, and others. Pinochi (2009) adopted this classification with a little adaptation, whereas others removed certain indicators. Mazza (2001) divided the accuracy of numbers into six types by excluding structural mistakes and incorporating inversion errors into lexical errors, which was defined as misplaced or inverted figures of the numeral. Cheung (2009) further excluded phonological errors and established subtypes for approximation, namely quantitative approximation and qualitative approximation, partly due to the distance between the numerical systems of English and Chinese. Korpal and Stachowiak-Szymczak (2018) further simplified accuracy into three types: error, acceptable approximation, and correct rendition. This taxonomy is relatively simple yet sufficient for testing their hypothesis. Noticing that the variation in the taxonomy leads to mixed results, the authors replicated the same classification proposed by Korpal and Stachowiak-Szymczak (2018) to exclude the influence of isolated measurements.
Nevertheless, relevant studies, either corpus-based or experimental, cannot fully represent the impact of numbers on interpreting trainees’ renditions as most of the research subjects were seasoned interpreters. To examine actual trainee performance in rendering numbers, this study, which draws on authentic and corpus-based approaches, regards interpreting trainees as research subjects and investigates their accuracy in interpreting numbers in the English–Chinese language pair.
2.2 The impact of the training process on interpreting
Over the years, there has been a notable increase in research seeking to discern the impact of training in general or interpreting specialised advantages such as working memory, prediction, and on the accuracy or fluency of the interpreting outputs (Amos et al., 2023; Cheung, 2016; Chmiel, 2018; Dong et al., 2018). Some scholars have provided evidence to confirm that significant improvements can be achieved through interpreter training. For instance, Chmiel (2018) conducted a longitudinal study on the working memory (WM) of interpreting trainees and found their WM improved substantially after training. Other studies have investigated the potential benefits of training. For instance, research conducted by Babcock et al. (2017), Cheung (2019), Mackintosh (1999), and Yamada (2020) are just a few examples that have discussed this positive impact. Notwithstanding this research, measuring the impact of training on improving trainees’ competence in certain areas is a complex process, which may be affected by various factors such as investigated competence and observed time. For example, a study carried out by Amos et al. (2023) investigated the influence of training on the predictive process by measuring prediction fixation time. In contrast to previous studies that are supportive of the positive effect of training, their findings showed the extent of prediction of interpreting trainees did not differ significantly before and after the training. The authors ascribed the findings to the inconsistent level of predictability of the stimuli. The relatively limited impact of training was also reported in the study by Fang et al. (2023) that examined how training affects reading behaviour and performance in sight translation. Their study showed two-semester training barely altered trainees’ reading behaviour or enhanced their sight translation skills. Taken as a whole, the question as to whether training has a beneficial impact remains unclear in academia, and merits further investigation from more thematic angles.
On a different note, how training is delivered was identified by existing studies as an essential factor that affects its effectiveness. In a controlled experiment, Cheung (2016) examined the impact of paraphrasing exercises on trainees’ CI quality. The finding pointed out that trainees who received specialised paraphrasing practice performed better in CI. Dong et al. (2018) found interpreting strategies recommended by teachers could help improve trainees’ CI performance at the end of the semester, indicating an increasingly effective acquisition of those strategies by trainees as the training proceeds. With particular focus on the impact of training on the rendition of numbers, Cheung (2009, 2014) found that trainees who were trained to practice interpreting number-in-referents or transcoding anglicised numbers into Chinese performed better than those who were not trained in the application of tailored strategies.
Overall, these studies seemed to point to the effectiveness of specialised training on the improvement of trainees’ interpreting quality. Still, the benefits that formal training can provide were seldom measured by scholars working in this area. The primary reason for this might be that the majority of studies in this field have adopted an experimental design. This design treats certain training methods as the observed variable to validate their effectiveness in improving trainees’ competence. However, the experimental method could lead to a loss of ecological validity. Diverging from previous lines of research, this study is based on a self-compiled corpus, ensuring the data reflect the authentic environment of interpreter training classroom. By comparing the data collected from trainees’ in-class recordings, the study examines each week’s practice of SI with numbers. This study narrows the research scope to numbers, a problem-trigger that is deemed to pose challenges to interpreting trainees and thus demands professional training. The findings of this study may enhance our understanding of numbers from the perspective of the impact of formal training and provide insights into SI training on numbers. To achieve these goals, two research questions will be explored in the following sections:
RQ1: How does the 13-week formal training course affect interpreting trainees’ capability in rendering numbers?
RQ2: What number type poses the greatest challenge for interpreting trainees in SI?
3. Methods
3.1 Corpus compilation
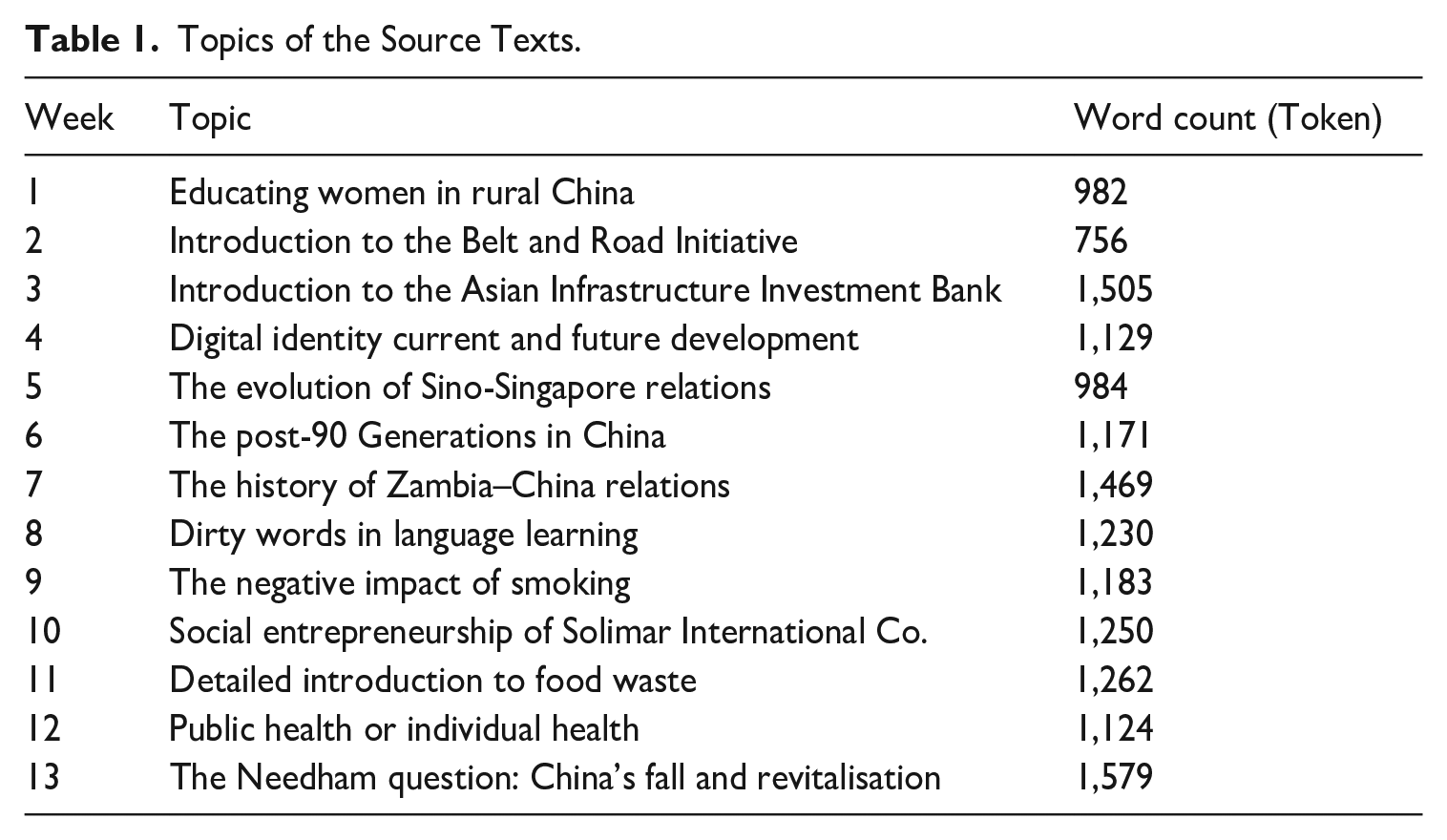
To examine interpreting trainees’ accuracy in rendering numbers, this study compiled the English–Chinese Simultaneous Interpreting Learners Corpus (ECSIL). ECSIL involves 13 weeks of in-class recordings of 21 trainees (17 female, 4 male) on an MA programme in Translation and Interpreting at a university in Chinese Hong Kong. All of these trainees offer Mandarin Chinese as their L1 and English as L2. Prior to taking the SI course, they had been trained for a semester in sight translation and CI and were selected for the training stream specialised in interpreting in the second semester. Altogether, 875 recordings were transcribed via IFLYREC, an automatic machine transcription software with over 98% accuracy rate. The transcribed speeches were manually checked to ensure accuracy. Also, any distracting speech features that may affect the analysis such as hesitations, fillers, mispronunciations, and false starts were removed. Considering the rendition of numbers is of particular concern in the study, a self-written Python code was employed to extract interpreted sentences containing numbers. These sentences were aligned with the source speech for accuracy analysis. The detailed information of ECSIL is summarised in Table 1.
Topics of the Source Texts.
3.2 Speech features
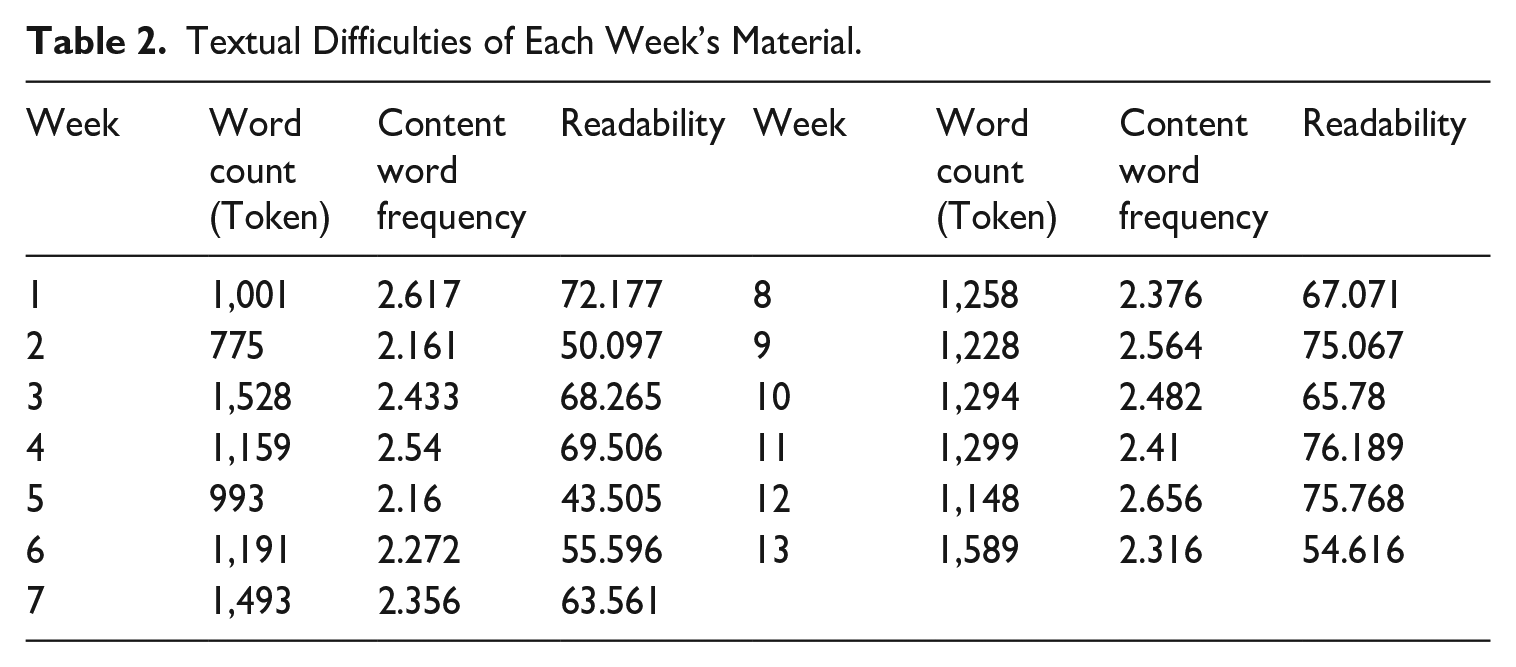
The source speeches were meticulously selected by the SI teacher, who is also an AIIC (Association Internationale des Interprètes de Conférence) member and an experienced interpreter active in the market, in consideration of topic diversity, textual difficulty, and delivery speed for practice purposes. The source speech difficulty, which is believed to be one of the most influential factors that may affect interpreting quality especially for less advanced interpreters (Liu & Chiu, 2009), incrementally increased over the training period in the ECSIL. Table 2 shows the textual complexity tested by the Coh-Metrix, a computational tool that evaluates texts based on certain linguistic criteria (see McNamara et al., 2014 for details). It includes three major calculated metrics, namely word count, word frequency for content, and readability that could represent the overall textual complexity of each paragraph. At lexical level, the value of word count and content word frequency was balanced across the weeks. However, the readability score of materials in later weeks (weeks 8–12, in particular) were evidently higher, indicating they are more difficult to interpret. As for the delivery rate, the majority fall into the low and easy range (< 130 words/min) according to values provided in the studies by Monti et al. (2005) and Setton and Dawrant (2016). Only in four of the weeks was the speech delivery rate over 130 words/min, namely week 9 (169 words/min), week 10 (170 words/min), week 11 (156 words/min), and week 12 (138 words/min). These speeches were intentionally set in the later weeks and to create additional challenges in processing. Taken as a whole, the source speeches used in later weeks are likely to pose more challenges for trainees.
Textual Difficulties of Each Week’s Material.
Moreover, slides of the 13 speeches were provided to trainees 10 min before each interpreting task. Notably, most of the numbers mentioned in the audio were presented on the slides (see Figure 1). Only part of the numbers that are easy to handle, such as the numbers indicating sequence (e.g., “No.1”) and some small numbers (e.g., “two” in the “two countries”), were not on the slides.

Examples of Slides of Week 4 & Week 9.
3.3 Classifications of numbers
To answer the second research question, the authors divided the numbers into six types in line with the taxonomy adopted by Kajzer-Wietrzny et al. (2024), which could cover all the numbers in the ECSIL (see Table 3).
Types of Numbers.

During annotation, values from 1 to 6 were given to each type to facilitate the data analysis. The frequency of these number types was also counted. The distribution of number types and their accuracy scores in renditions were counted to explore the second research question, namely to identify which type of number poses greater difficulty to interpreter trainees.
3.4 Assessing accuracy
Accuracy is a major measure of SI quality and the criteria used to measure it vary in terms of different research subjects. As for numbers, researchers have adopted different indicators to reflect the accuracy of renditions, as introduced in the previous section. For the purpose of this study, the authors mainly combined the criteria of Korpal and Stachowiak-Szymczak (2018) and Cheung (2009), using six indicators to assess the accuracy of each number’s rendition.
Error: The number is rendered completely incorrectly and cannot be tagged as partly accurate, for example, “two thirds” being interpreted as “百分之二十一” (“21 percent” in English).
Omission: The number is wholly omitted in the rendition without any description about the referents it represents.
Numerical omission: The number is substituted by descriptions about the magnitude or volume it implies, for example, “0.05%” being translated as “非常低” (“very low” in English).
Lexical omission: The magnitude of the number is accurately interpreted, yet the constituent elements are omitted, for example, “17 million” being rendered as “一千万多” (“more than ten million” in English).
Syntactic omission: The numerals are rendered correctly, whereas the magnitude is omitted or substituted with descriptions, for example, “20 million” being interpreted as “几千万” (“several ten million” in English).
Correct rendition: The number is rendered accurately, both at a lexical and syntactic level.
Scores of three levels (0, 0.5, 1) were given to each accuracy indicator to reflect the accuracy level of numbers in SI (see Table 4). By comparing the difference in total accuracy scores of numbers rendered by trainees in the first and second half of the semester, the authors aim to identify any trends that could shed light on future training.
Scores of Each Accuracy Indicator.

4. Findings
4.1 The effect of formal training on number renditions
To examine the effect of formal training on trainees’ accuracy rate in the interpreting of numbers, the study used a linear mixed effects modelling in the lme4 package (Doran et al., 2007) in R. The modelling can better handle individual differences between participants and the observed item in comparison with traditional variance analysis. In the model, the week was determined as the fixed effect, the accuracy rate (accuracy score divided by the total score) was the dependent variable, and trainees were treated as the random effect. Both random-intercept and random-slope have been considered given that trainees’ capability in interpreting numbers may vary at the beginning of the period of training and they may benefit to different extents from formal training. The result showed an insignificant training effect (Estimate = –0.005, SE = 0.003, t-value = –1.701, p = .092) with a less accurate rendition of numbers by trainees after formal training as visualised in Figure 2. The finding indicates that trainees’ accuracy in rendering numbers may be affected by the source text difficulty. As the textual complexity and source speech delivery speed increased in later weeks, the accuracy might diminish. In light of this, despite the observed downwards tendency, such a finding could neither be interpreted as a supportive nor negating evidence to the positive influence brought by formal training. However, it helps explain trainees’ inadequate capability in dealing with numbers in challenging conditions.
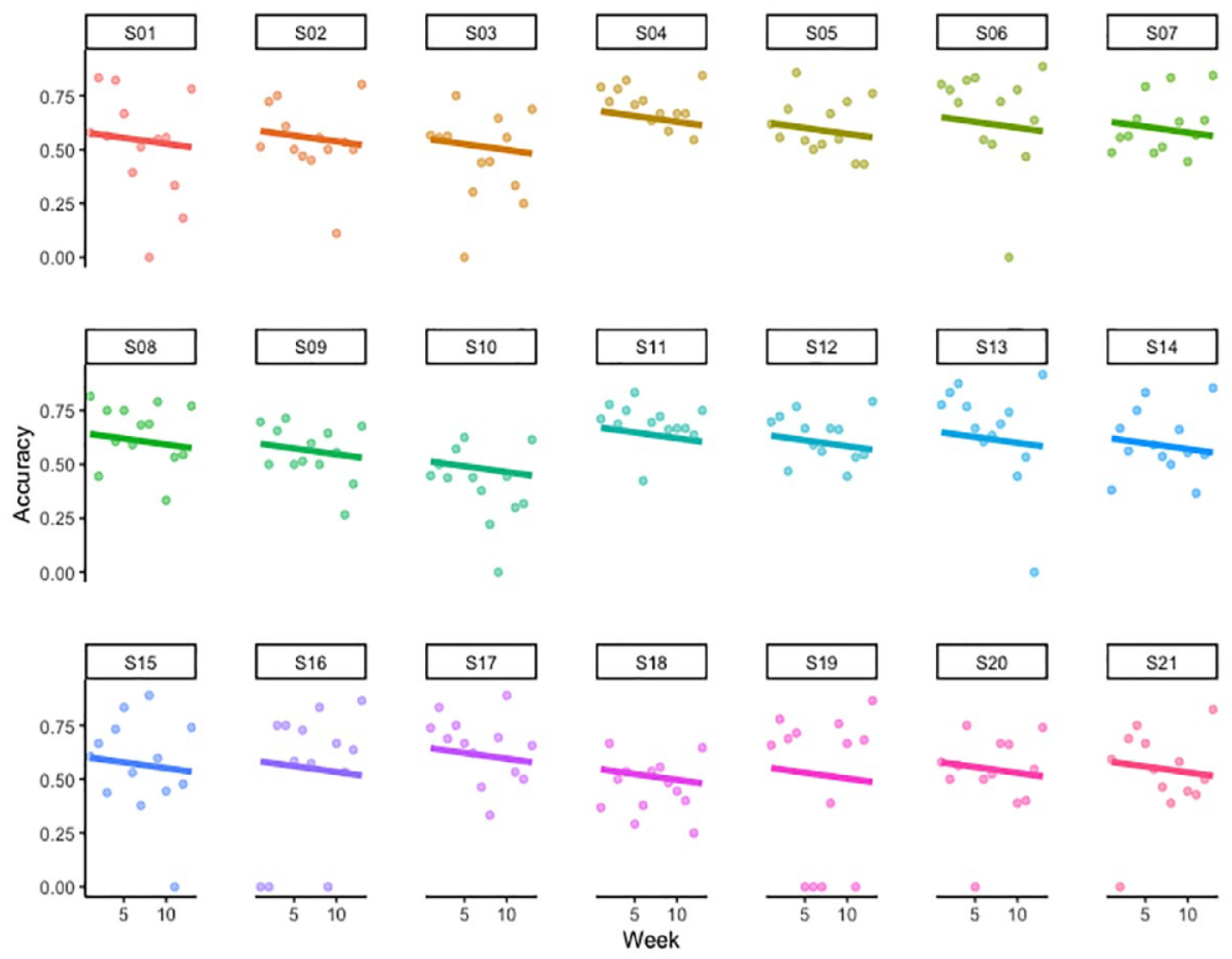
Variation of Accuracy Rate for 21 Trainees Over the 13-Week Period of Formal Training.
4.2 Accuracy of different number types in SI renditions
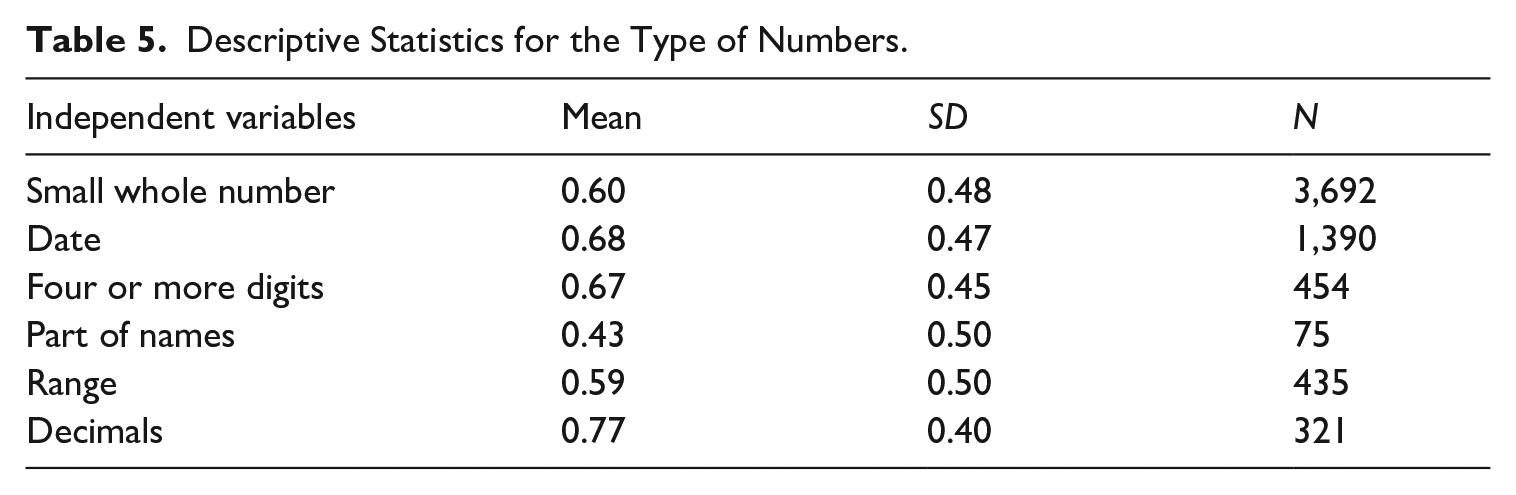
The distribution of different number types in the 13 source texts is presented in Figure 3. The details of the amount of each type of numbers in ECSIL are shown in Table 5.
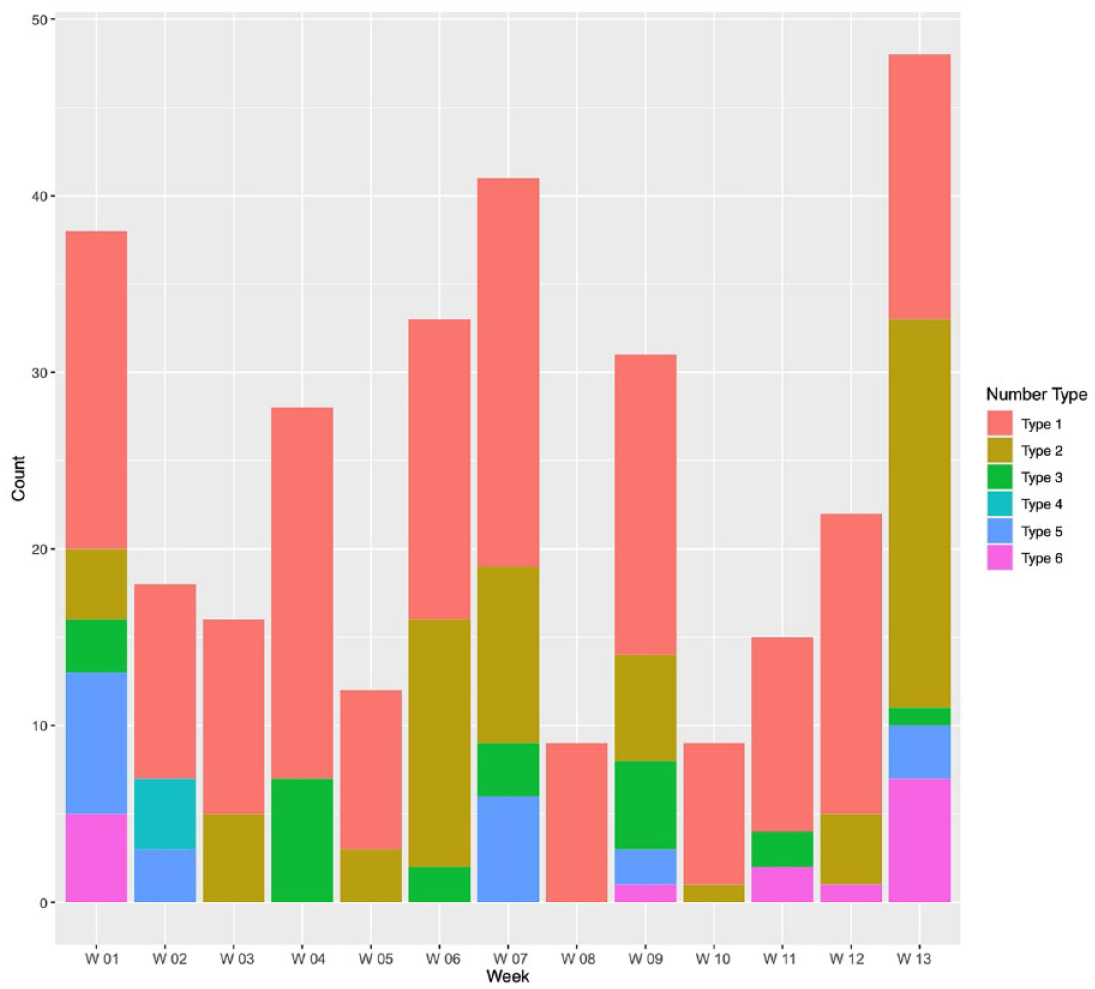
Distribution of Number Types in 13 Weeks.
Descriptive Statistics for the Type of Numbers.
It is apparent that half of the number types are spread in a relatively balanced way among 13 weeks of training materials. The amount of dates (Type 2) and decimals (Type 6) increased significantly in the later half of the semester, posing additional challenges to interpreting trainees, and the type concerning part of names (Type 4) did not occur in the second half of the semester. This distribution shows that trainees met more complex numbers in the later weeks of the semester, which may pose greater difficulties and thus may affect the accuracy scores.
Considering there is only one dependent variable (the accuracy score) and one independent variable (the type of number), analysis of variance (ANOVA) was conducted to compare the scores of participants. A significant difference was found: F(5, 6361) = 16.863, p < .001, (partial Eta squared = 0.013). However, the Levene Statistic is significant, p < .001. Therefore, we cannot accept the null hypothesis that there is no significant difference in accuracy scores among the six types of numbers. In other words, the assumption of homogeneity of variance is not met. In this case, Games–Howell was used to determine the nature of the differences among the types.
As demonstrated in Figure 4, significant differences exist in 10 pair comparisons, whereas no significant difference can be found in 5 pair comparisons. Post hoc testing revealed significant differences between types with part of names (M = 0.43, SD = 0.50) and the other five having higher accuracy rates: ranges (M = 0.59, SD = 0.50), small or whole numbers (M = 0.60, SD = 0.48), four or more digits (M = 0.67, SD = 0.45), dates (M = 0.68, SD = 0.47), and decimals (M = 0.77, SD = 0.40). The score of decimals is significantly higher than all the other number types.
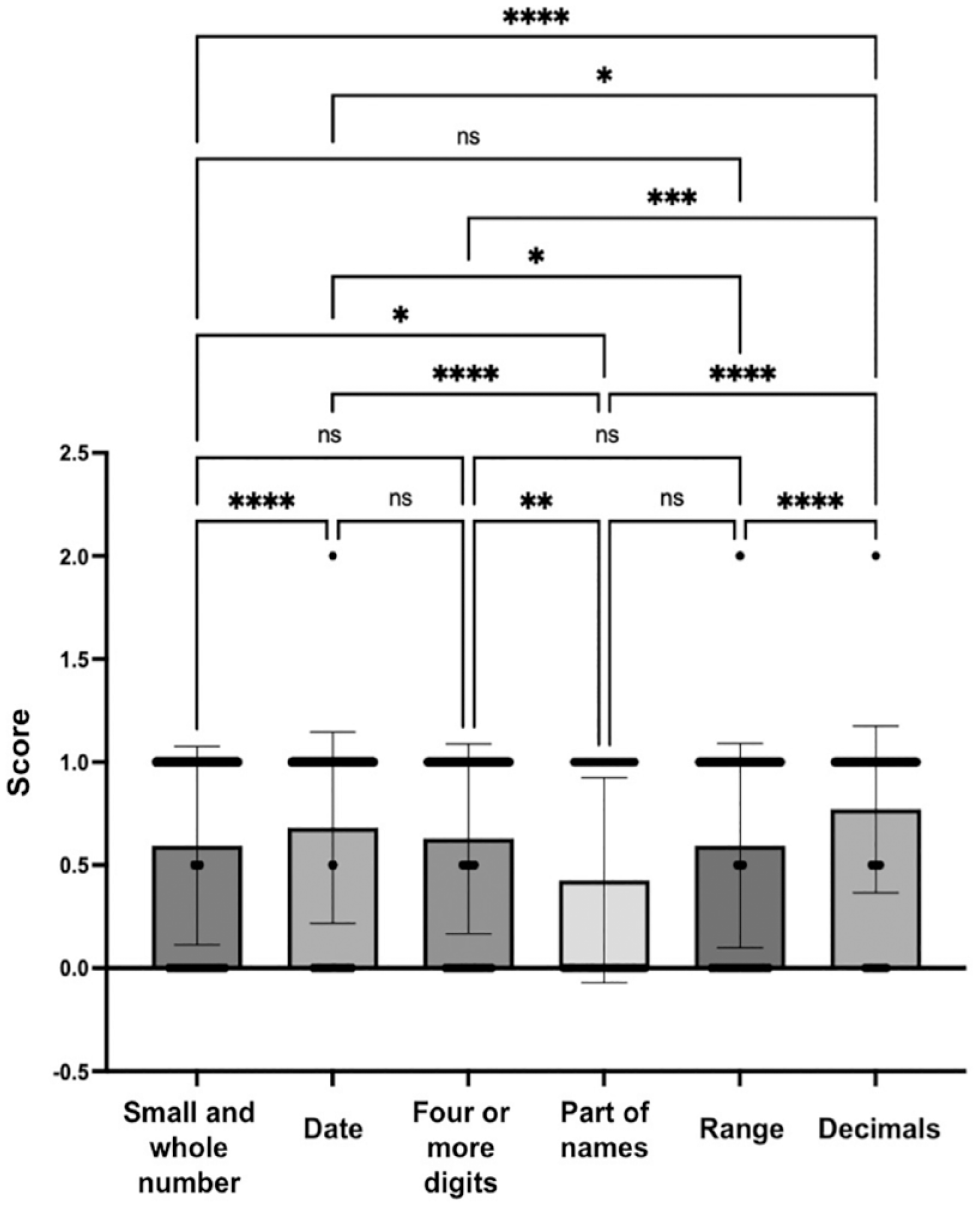
Post hoc Testing for Types of Numbers.
5. Discussion
5.1 Impact of formal training on number renditions
The first research question mainly concerns the impact of formal training on interpreting trainees’ accuracy in rendering numbers. To address this question, each trainee’s number interpreting performance as evidenced by the accuracy rate over the 13-week training period was tracked. The result of linear mixed effect modelling could not provide significant evidence to confirm the positive role played by the formal training to enhance trainees’ accuracy in rendering numbers. Notably, when the textual complexity and speech delivery speed increased in the later weeks, trainees suffered from the elevated difficulty, and their accuracy in number interpreting decreased correspondingly. Such an interesting result substantiates previous studies that found trainees’ interpreting capability may not exhibit apparent improvement as assumed. With more complicated textual and other external factors involved, learners need more time to overcome the newly encountered challenge and internalise a specialised skill such as interpreting numbers (Dong et al., 2018; Su & Li, 2021). Due to insufficient competence, they may find it difficult to allocate attention appropriately when facing problem triggers such as numbers in SI. Moreover, the finding confirms that interpreting trainees are more prone to the influence of source speech-related factors in SI (Rosendo & Galván, 2019). As a result, when they encounter a complex situation when the numbers are presented in a syntactically complex source speech and at a fast delivery speed, their performance deteriorates even though they have the numbers shown on the slides for reference, which might manifest in an inaccurate rendition.
On a different note, the obtained result may have several significant pedagogical implications. First, the observed dwindling accuracy of the rendition of numbers implies that numbers are indeed a problem trigger in SI, which requires specialised training to inform trainees how to deal with different types of numbers under the pressures of working in the simultaneous mode. In addition, number practice should be incorporated in more taxing source speeches such as speeches with strong accents, delivered at a faster delivery speed, and involving increased textual difficulty to help trainees better adapt to the heavy cognitive load.
5.2 Number types and accuracy of number renditions
Accuracy scores of different number types were compared to address the second research question, which is expected to unveil the types likely to pose a greater challenge to trainees in interpreting. As shown in the results, numbers exhibited in parts of names led to the poorest scores, lower than those of ranges and small and whole numbers. Decimals scored significantly higher than the other five types.
In the first and second halves of the semester, the distribution of all number types was relatively balanced, except for “dates,” which increased a lot in the later weeks, and “decimals,” which doubled in the second half of the semester. Although the amount of dates and decimals significantly increased in the later weeks, they seemed not to pose greater challenges for trainees to interpret as their accuracy scores were the highest among all types. Instead, with the most frequent appearance in both the first and second halves of the semester, small and whole numbers led to the third lowest scores of accuracy. This may indicate that high frequency of numbers may cause greater difficulty for trainees to interpret. The poorer performance of rendering small and whole numbers may also be attributed to the non-presence or incongruent presence of small and whole numbers on slides. During training, interpreting trainees were provided slides about each speech 10 min in advance for preparation. Although most numbers were presented, small figures were not shown as they did not correspond to key information. For instance, the “two” of “the relations of two countries . . . ” was not on the slides. Nearly all the dates—the second most frequent number types in ECSIL—were on the slides and this type of number showed the second highest accuracy score. Therefore, it may indicate that no visual reliance may require more cognitive effort on the part of trainees to listen, remember, and transfer the number into another language.
Moreover, source-text factors may play a role in the accurate rendering of different types of numbers. Numbers that are present in parts of names only appeared in Week 1 and were delivered with an accent. This type of number may cause additional difficulty in interpreting due to their contextual meaning, such as the generation of a technology. Interpreting trainees, who still lack experience in dealing with numbers in SI, may not be able to render this type of number accurately, especially when the speakers have accents. As shown in the results, numbers included in ranges also posed greater challenges for interpreting trainees. In this regard, a mix of accents and fast delivery speed of source texts in later weeks may play a part. Nearly all the ranges were shown on the slides provided to trainees, thereby potentially reducing the cognitive difficulty of capturing all the figures within a range. However, trainees may still miss the sequence of numbers in ranges when they were uttered quickly, continuously, or with accents, which was the case in Week 7 and Week 13. This may be the main cause for ranges having the second poorest accuracy score in ECSIL. Accordingly, future training could design more SI tasks including lots of numbers being part of names and ranges, especially with accents or delivered at a fast speed.
6. Conclusion
This article reports on a study on the accuracy of interpreting trainees’ performance of rendering numbers in SI, which is assisted by a self-built learners’ corpus. Thirteen weeks of training was taken as a major variable to investigate the impact of formal training on trainees’ capability to accurately render numbers, whereas number types was another factor assumed to be influential and further analysed.
First, the impact of 13-week period of formal training was not necessarily sufficient. Trainees’ accuracy scores in rendering numbers dropped slightly in the later period of the semester. It suggests that trainees’ accuracy in number rendition is affected by the difficulty of source speeches. For them to fully internalise the skill to cope with numbers even in challenging situations, be it fast delivery speed, unfamiliar accents or numerical conversion, the 13-week training period may not be sufficient. Second, the results indicate that part of names, ranges, and small and whole numbers posed greater challenges for trainees in SI. Source-text factors, including unfamiliar accents, fast delivery speed, and the lack of corresponding numbers used by speakers on slides, were considered the main reasons for inaccuracies in number renditions. In particular, the lack of visual access to small and whole numbers may be the major factor leading to the poorer performance, which suggests that trainees rely on visual materials for numbers thereby negatively affecting their performance when these visual aids are not available. Generally, the findings suggest that SI training could combine numbers with other “problem triggers” such as accents, fast delivery speed, and textual difficulty. The training should particularly focus on parts of names, ranges, and, more importantly, on small and whole numbers when visual references are not available.
In this study, the limitation pertains to the reliance on a custom-made corpus derived from Chinese/English interpreting students at a university in Chinese Hong Kong. Findings of this study may not be generalised to the conditions of other translation and interpreting programmes with different language combinations elsewhere. Unlike experimental studies, this study adopts an authentic perspective, making it challenging to recreate the classes, control variables, or investigate number rendering methods without uncontrollable factors. Furthermore, the importance of pre-research surveys, which could largely replicate real-class situations for improved observations, was not taken into account.
Nevertheless, this research expands relevant studies assisted by corpora by exploring renditions of numbers in SI in the English–Chinese language pair and sheds light on the impact of formal training and number types on interpreter trainees’ performance. Future studies could focus both on controlled experiments or quasi-experiments to investigate the impact of influential factors detected in this study, whereas corpus-based studies are also promoted to leverage the affordances of authentic data and serve pedagogical needs.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.