
Abstract
As generative AI and machine learning reshape industries, interpreters are required to navigate a dynamic ecosystem where interpreting skills and digital solutions converge. While extensive research has explored the effects of technologies on the interpreting process and output quality, the ergonomic needs of interpreting learners interacting with different technologies have received less scholarly attention. This is particularly evident in training on computer-assisted simultaneous interpreting (CASI), where the successful interaction between human interpreters and technology is crucial for enhancing student interpreters’ learning outcomes and training effectiveness. This study examines the impact of two live captioning systems on student interpreters’ performance during English-to-Chinese simultaneous interpreting (SI) tasks: YouTube’s monolingual Automatic Speech Recognition (ASR) captions and iFLYTEK’s bilingual machine interpreting outputs. Twenty second-year postgraduate students participated in the experiment under these two CASI conditions. Accuracy, fluency, target language quality, and overall performance of the participants’ interpreting outputs were assessed. In the present study, the introduction of live captioning significantly reduced student interpreters’ performance. Furthermore, students working with monolingual captioning demonstrated better performance across all quality dimensions relative to those utilising bilingual captioning. This study highlights the critical role of ergonomics in the CASI tool and the need for comprehensive interpreter training.
Keywords
1. Introduction
The advent of artificial intelligence and machine learning has transformed the interpreting landscape, giving rise to three distinct modes: fully automated machine interpreting, computer-assisted human interpreting, and human-assisted machine interpreting (Downie, 2023). In light of this, computer-assisted interpreting (CAI) tools, such as automatic speech recognition (ASR) and machine interpreting (MI), have been introduced to the interpreting profession (Defrancq & Fantinuoli, 2021; Fantinuoli, 2023). The benefits of technology use during the interpreting process have been verified in number rendition (Pisani & Fantinuoli, 2021) and interpreting output quality enhancement (Li & Chmiel, 2024), suggesting that the integration of AI-driven tools into the interpreting workflow can lead to improved performance.
Concerning these proven advantages, interpreter education has begun to respond to this evolving landscape. It has become increasingly imperative to integrate technology into interpreting classrooms to better prepare future interpreters for technology-mediated working environments. However, educational institutions face challenges in bridging the gap between traditional pedagogical approaches and the technological competencies demanded by the modern interpreting market, which attracts scholars’ attention to exploring how interpreting education can be transformed and enhanced through technologies. This pedagogical transformation manifests in several key areas: the incorporation of CAI tools in interpreter training (Chen & Kruger, 2024; Yuan & Wang, 2024), the introduction of virtual reality into interpreting exercise (Chan, 2023; Gerber et al., 2021; Hu et al., 2024), and the implementation of AI-assisted quality assessment, especially for student self-learning (Deysel & Lesch, 2018). These technological interventions hold the potential to not only enhance the authenticity of training scenarios but also provide students with hands-on experience to improve their AI literacy.
While research on technology’s impact on interpreting practice and pedagogy continues to expand, there remains a significant gap in understanding the ergonomic dimensions related to the application of CAI tools, particularly regarding its effects on student interpreters’ output quality when comparing different captioning modalities and content presentation formats. The ergonomic framework for translation and interpreting studies, established by Lavault-Olléon (2011) and further developed by Seeber and Arbona (2020), provides a theoretical foundation for examining how various computer assistance tools influence interpreting performance. This framework emphasises the critical relationship between tool organisation, accessibility, and usability and their collective impact on cognitive processing and physical interaction patterns. In CASI environments, the cognitive and physical dimensions are fundamentally intertwined, as content organisation and presentation methods directly influence interpreters’ cognitive load management and real-time task execution capabilities. The ergonomic implications become particularly salient when considering how interface design and interaction patterns affect both immediate performance and long-term learning outcomes.
This study addresses these theoretical and practical considerations by conducting a comparative analysis of interpreting performance under two distinct CASI conditions: AI-powered monolingual live captioning (where only the source language text is presented) and AI-powered bilingual live captioning (where both source and target languages texts are presented). ASR technology, as suggested by Pöchhacker (2022, p. 197), has “considerable potential for changing the way interpreting is practiced.” ASR-enhanced computer-assisted interpreting (CAI) tools, representing the third generation of CAI technology, offer advanced human-machine interaction capabilities that surpass traditional CAI systems (Fantinuoli, 2023). A critical aspect of these advanced systems lies in their text presentation modalities of the source speech. While previous research has extensively examined various CAI tools, there remains a need to investigate different CASI conditions systematically. Thus, this study focuses on comparing specific CASI conditions to evaluate their respective effectiveness and implications for interpreting practice.
Meanwhile, through an ergonomic lens, this research examines how the varying cognitive demands and user-interface interactions associated with each live captioning system affect interpreting quality. The comparative methodology enables a systematic investigation of how ergonomic variations in CAI tools influence student interpreters’ performance. This research contributes to the theoretical understanding of ergonomic principles in CAI tool design and their practical applications in interpreting education.
2. Literature review
2.1 Interpreting technology: ASR and machine interpreting
Automatic speech recognition (ASR), or live captioning, has emerged as a significant tool in interpreting. This technological innovation fundamentally alters the traditional interpreting paradigm by introducing real-time, moving transcripts of spoken language, thereby co-creating a multimodal input environment for interpreters. Unlike conventional interpreting training settings that rely predominantly on auditory input processing, ASR integration facilitates a new and challenging dual-modal approach, presenting both ceaseless auditory and visual information streams simultaneously (Yuan & Wang, 2024). Furthermore, in contrast to conventional ASR applications, which utilise editorially reviewed subtitles (Chan et al., 2020; Matthew, 2020), implementing ASR technology in interpreting contexts exhibits distinctive operational characteristics that establish a fundamentally different paradigm of real-time language processing (Li & Chmiel, 2024). While conventional ASR systems are primarily designed to facilitate end-user comprehension (Matthew, 2024), their application in SI serves a distinct function as a cognitive support mechanism. This specialised application is particularly significant given that interpreters must execute complex cross-linguistic processing and reformulation tasks under substantial temporal pressures, necessitating careful consideration of how ASR integration affects their cognitive load and processing capacity.
The integration of ASR technology in SI environments presents complex implications for interpreting processes and outputs, particularly problem triggers such as numbers and proper nouns, as conceptualised by Gile (2009). Several key studies have illuminated a critical paradox in ASR-assisted interpreting: the complex relationship between improved output accuracy and cognitive processing demands. Cheung and Li’s (2022) investigation of ASR-generated monolingual subtitles demonstrated this paradox: while ASR support significantly improved interpreting accuracy, it simultaneously led to decreased delivery fluency. This seemingly contradictory outcome can be attributed to the advantages and disadvantages of captions. On the one hand, captions have the potential to relieve the effort exerted for source language listening and comprehension, but on the other hand, captions are presented in a way that is not full sentences, which could potentially hinder the interpreter’s renditions while using a chunking strategy.
The relationship between visual attention and cognitive load presents another layer of complexity. Yuan and Wang’s (2023) examination of remote interpreting via Zoom revealed that while interpreters strategically shifted attention to captioned areas for numerical data and proper nouns, resulting in improved accuracy for these elements, they simultaneously experienced elevated cognitive load. This increased cognitive burden, evidenced by more fixation counts in their eye-tracking data, suggests that the integration of visual information demands additional processing resources. The observed pattern indicates that interpreters actively engage in selective attention processes, allocating cognitive resources to identify and extract critical information from captions.
Li and Chmiel’s (2024) comprehensive study, employing triangulated data from multiple sources: output accuracy, self-reporting, eye-tracking, and EEG data in English-Polish SI, identified specific conditions under which ASR support becomes beneficial. They found that subtitle precision rates of 90% or higher correlate with enhanced interpreting accuracy while reducing cognitive load. It suggested that the effectiveness of ASR support is highly dependent on technical quality parameters.
This body of research collectively indicates that the relationship between ASR technology and interpreting performance is more complex than initially theorised, with implications spanning accuracy, cognitive load, and attention management. The varying outcomes across studies can be attributed to two primary factors: the technical parameters of ASR implementation, such as precision rates and different ASR systems, and the presentation of ASR output, such as scrolling text. While current ASR integration in interpreting primarily focuses on monolingual support, recent technological advances have pushed beyond simple speech-to-text conversion. This evolution in machine assistance has led to the development of more sophisticated systems that attempt to address not only speech recognition but also translation needs, marking a significant transition in computer-assisted interpreting technology.
MI, or “speech-to-text interpreting” (Pöchhacker, 2023, p. 277), has emerged as another significant technological intervention in SI settings. Unlike ASR systems that primarily provide textual support in the original language, MI systems attempt to generate both source texts and translations in real-time, potentially serving as either a complementary tool or, in some contexts, an alternative to human interpreting. The evolution of ASR implementation in interpreting contexts has recently entered a new phase with the integration of MI capabilities, creating a hybrid interpreting support system. These advanced platforms combine ASR-generated transcriptions with real-time machine translation output, providing interpreters with multilingual textual support during SI. This technological convergence represents a significant departure from traditional ASR-only support systems, introducing additional layers of complexity to the interpreter’s cognitive processing environment. In Chen and Kruger’s (2024) computer-assisted consecutive interpreting (CACI) workflow, interpreters’ target language production was supported by a self-built quasi-MI system consisting of two separate components: an original speech transcription from iFLYTEK and a corresponding machine translation (MT) output from Baidu Translate. Preferential attention allocation was revealed towards MT text compared to ASR text. Particularly interesting was the directional asymmetry in the relationship between MT text attention and interpreting quality: while a positive correlation was observed in the L2-L1 direction, no corresponding correlation was found in the L1-L2 interpretating. This initial investigation into these hybrid systems suggests that combining ASR and MT might present both benefits and new challenges to interpreters. For instance, while MT output can provide rapid access to terminology and structural suggestions in the target language, it may also require additional cognitive resources for MT quality assessment and selective integration. The interaction between human interpreters and these multilingual support tools raises fundamental questions about optimal information presentation, attention distribution, and cognitive resource allocation in technology-enhanced interpreting environments.
The collective findings from these empirical investigations show the potentially facilitative effects of both ASR-generated subtitles, that is, monolingual live captioning, and MI outputs, that is, bilingual live captioning, on human interpreting performance. However, there remains a significant gap in the literature regarding the comparative efficacy of different caption modalities, specifically the relative benefits of monolingual versus bilingual live captioning systems in computer-assisted interpreting environments. As we see “a turn to ergonomics” (van Egdom et al., 2020, p. 363) in technology-mediated interpreting training, the next section reviews existing literature on ergonomic factors in interpreting, which can provide insights for comparison of the two live captioning in CAI.
2.2 Ergonomics in interpreting: Advancing human-machine integration
According to the International Ergonomics & Human Factors Association (IEA, 2024), ergonomics refers to “physical, cognitive, sociotechnical, organisational, environmental and other relevant factors, as well as the complex interactions between the human and other humans, the environment, tools, products, equipment, and technology.” From this comprehensive spectrum of ergonomic factors, researchers in translation have primarily concentrated their efforts on physical, cognitive, and organisational aspects (Ehrensberger-Dow, 2017). Research on physical ergonomics in translation practice encompasses workstation configuration and postural considerations, biomechanical stress from repetitive motions, and environmental parameters, which address interpreters’ discomfort from equipment use (Ehrensberger-Dow & Jääskeläinen, 2018). Cognitive ergonomics in translation primarily focuses on the interface between human cognition and technological tools, particularly emphasising the human-computer interaction paradigm. This domain investigates the cognitive processes of translators as they interact with translation technologies, emphasising the design and implementation of user interfaces, the structural organisation of technological features, and the cognitive load resulting from the system complexity. The interaction between these elements fundamentally influences translators’ information processing, decision-making patterns, and overall cognitive performance (Kappus & Ehrensberger-Dow, 2020). Organisational ergonomics in translation operates across institutional and freelance contexts through three key dimensions: workplace autonomy, technological integration, and feedback mechanisms. Specifically, freelancers enjoy greater scheduling flexibility but limited resources, while institutional translators benefit from collaborative support despite workflow constraints. These organisational structures, combined with technology implementation and feedback systems, directly influence translation quality and professional development (Ehrensberger-Dow, 2017). In summary, physical, cognitive, and organisational dimensions of translation ergonomics weave an interconnected system. Physical workspace configurations directly influence cognitive performance, while organisational policies shape both the physical environment and cognitive demands. Similarly, cognitive load affects physical well-being, and organisational structures determine both the cognitive resources available and the physical conditions under which translators work.
Relative to the extensive body of ergonomic research in translation studies, the ergonomic factors in interpreting remain underexplored, with relevant literature mainly focusing on interpreting training (Seeber & Arbona, 2020), interpreters’ ergonomic demands and stress (Gieshoff et al., 2021), and agencies’ ergonomic impact (Dong & Turner, 2016). For instance, Seeber and Arbona (2020) demonstrated that cognitive ergonomics influences learning performance through instructional design aligned with learners’ cognitive architecture and proposed a training model of simultaneous interpreting that relies on multimodal activities based on cognitive ergonomics. Gieshoff et al. (2021) included ergonomic demands as one of the four key constructs measured through physiological indicators to better understand how workplace conditions and task designs affect interpreters physically and physiologically. Besides, Dong and Turner (2016) examined the ergonomic interfaces within interpreting systems, focusing on agency-interpreter dynamics in British public services. They identified critical organisational imperatives affecting interpreter performance through multiple ergonomic layers, including agency operations, workplace environments, and systemic interactions.
While previous interpreting studies have laid the groundwork for understanding several facets of ergonomics, the ergonomic implications of employing different captioning conditions in CASI have yet to be thoroughly scrutinised. In addition, while cognitive ergonomics has been investigated in traditional interpreting contexts and training environments, its application to technological mediation, particularly in comparing monolingual versus bilingual live captioning, represents an understudied domain. The importance of this research gap is highlighted by two critical factors: the growing integration of technology in interpreting settings, and the need for interpreters to optimise their interaction with captioning systems. This gap is particularly significant in interpreting training contexts, where student interpreters are increasingly expected to simultaneously develop foundational skills and adapt to technological development. Examining the ergonomic interface between student interpreters and captioning systems is crucial due to the documented challenges in achieving optimal ergonomic interaction between interpreters and technology (Gieshoff et al., 2024), and the need to develop evidence-based pedagogical approaches that effectively manage cognitive load during skill acquisition.
Therefore, the present study inquiries into the ergonomic implications of captioning in interpreting technology by examining student interpreters’ performance with and without such support, and in particular, different caption display conditions of monolingual versus bilingual live captioning systems. This comparative analysis aims to identify optimal display conditions that can better enhance the interpreter’s performance. The findings will contribute to the optimisation of technology-mediated interpreting training, thus preparing student interpreters for increasingly technology-dependent professional environments. The research questions (RQs) are as follows:
RQ1. Does the inclusion of live captioning affect student interpreters’ performance in English-to-Chinese simultaneous interpreting compared to traditional non-assisted interpreting?
RQ2. Do student interpreters’ holistic English-to-Chinese simultaneous interpreting performances differ when provided with monolingual live captioning compared to bilingual live captioning?
RQ3. If disparities are identified in RQ2, how do student interpreters’ English-to-Chinese simultaneous interpreting performances vary between the monolingual and bilingual live captioning conditions, particularly regarding information completeness, fluency of delivery, and target language quality?
3. Research methods
To address the research questions, this study employs between-group and within-group experimental design. The between-group component involves allocating student interpreters to either the monolingual or bilingual live captioning groups based on availability. Besides, a within-group comparison uses participants’ mid-term exam scores as a baseline to measure changes in interpreting performance with and without live captioning assistance. The between-group design allows for the examination of the differences in SI performance between two different conditions (Hale & Napier, 2013), that is, monolingual and bilingual live captioning in the present study, while minimising potential carryover effects that may arise from exposing participants to both conditions (Bordens & Abbott, 2002). The within-group comparison enables control for individual differences and reduces the influence of participant variables, as each interpreter serves as their own control. By employing this design, this study could examine the impact of the presence of live captioning and two kinds of live captioning on interpreters’ English-to-Chinese SI performance in terms of holistic quality and the specific dimensions of information completeness, fluency of delivery, and target language quality.
The experiment was conducted 1 week after the mid-term exam to maintain performance comparability. Preparation materials for both the mid-term exam and the experiment were distributed to students 1 week before each assessment to ensure equal preparation time. Prior to the exam and experiment, we conducted a briefing session for all students. For those participating in the experiment, this session included an introduction to the live captioning system, and they were not required to operate the system during the experiment.
3.1 Participants
The participants were recruited through purposive sampling from a highly competitive Master of Arts in Simultaneous Interpreting (MASI) programme at a renowned university in southern China. To ensure baseline competence, all participants met the programme’s stringent admission requirements (minimum IELTS score of 6.5) and had completed 8 months of intensive SI training. The participants were assigned to two groups for testing different ASR systems based on their class grouping, resulting in 11 participants in the YouTube group and 9 in the iFLYTEK group. While equal group sizes would have been methodologically preferable, the groups were comparable across several key dimensions: similar gender ratios (YouTube: 73% female, 27% male; iFLYTEK: 67% female, 33% male), similar English proficiency levels (all with IELTS ⩾ 6.5), identical period of SI training (8 months), and standardised briefing and preparation time for all participants. Given the exploratory nature of this study and the limited pool of qualified SI students, this distribution was deemed acceptable for the initial investigation into interpreting assisted with monolingual and bilingual live captions, though future studies with larger, equally distributed samples would be more desirable.
3.2 Materials
3.2.1 Source speeches
The present study involved two source speeches in English. The first speech in the mid-term exam serves as a baseline for interpreting performance, while the second speech was administered under live captioning conditions. The first speech was about monetary policy, a topic covered in the previous learning. It lasted 15 min and 40 s and consisted of 1,892 words, with an average speech rate of around 120 words per minute. The second source English speech was delivered by Larry Ellison, the Chairman and CTO of Oracle, to talk about Oracle’s vision to advance global healthcare. 1 The speech was selected due to its relevance to the healthcare field, a topic already covered in the participants’ previous training materials, and its moderate level of technicality and suitable length for a simultaneous interpreting task. The speech had a duration of 22 min and 9 s and consisted of 2,967 words, with an average speech rate of approximately 134 words per minute.
The source speeches were selected based on several comparable parameters to ensure experimental validity. First, both speeches addressed topics covered in the participants’ prior training curriculum. This ensured that all participants had a similar level of familiarity with the topics, minimising the potential impact of domain knowledge on their performance. Second, while the speech rates varied, both fell within two critical parameters: they were within the comfortable listening range of 125–160 words per minute for English as a Foreign Language (EFL) learners (Makarova & Zhou, 2006) and did not exceed the threshold of 155 words per minute, which Han and Riazi (2017) identified as the onset of rapid speech that could impair comprehension during interpreting. Third, both speeches exhibited similar discourse characteristics, featuring moderate technical content and formal presentation structures typical of professional contexts. While the durations differed, both speeches fell within the standard timeframe for interpreter rotation in professional settings, where interpreters typically switch roles every 20–30 min to maintain optimal performance (Horváth, 2012). Fourth, idea density analysis was conducted using the CPIDR 5 programme, 2 an automatic propositional idea density rater. Despite the quantitative disparity in the absolute number of propositions between the two source texts (Mid-term: 907; CASI: 1486), the computational analysis revealed comparable propositional density values (Mid-term: 0.489; CASI: 0.498), indicating structural similarity in terms of information density across both source materials.
3.2.2 Live captioning
The present study employed two types of live captioning: monolingual and bilingual. The monolingual captioning was generated using YouTube’s automatic captioning feature, which provides real-time English subtitles for the source speech (see Figure 1). The bilingual captioning was generated using iFLYTEK, a Chinese AI tool specialising in automatic speech recognition (ASR) and natural language processing (NLP), which provides real-time bilingual subtitles displaying both the original English speech and its Chinese translation simultaneously (see Figure 2). Both captioning systems presented text in comparable font styles and sizes, and the outputs were displayed in their original format without any manual adjustments or modifications to the interface parameters.
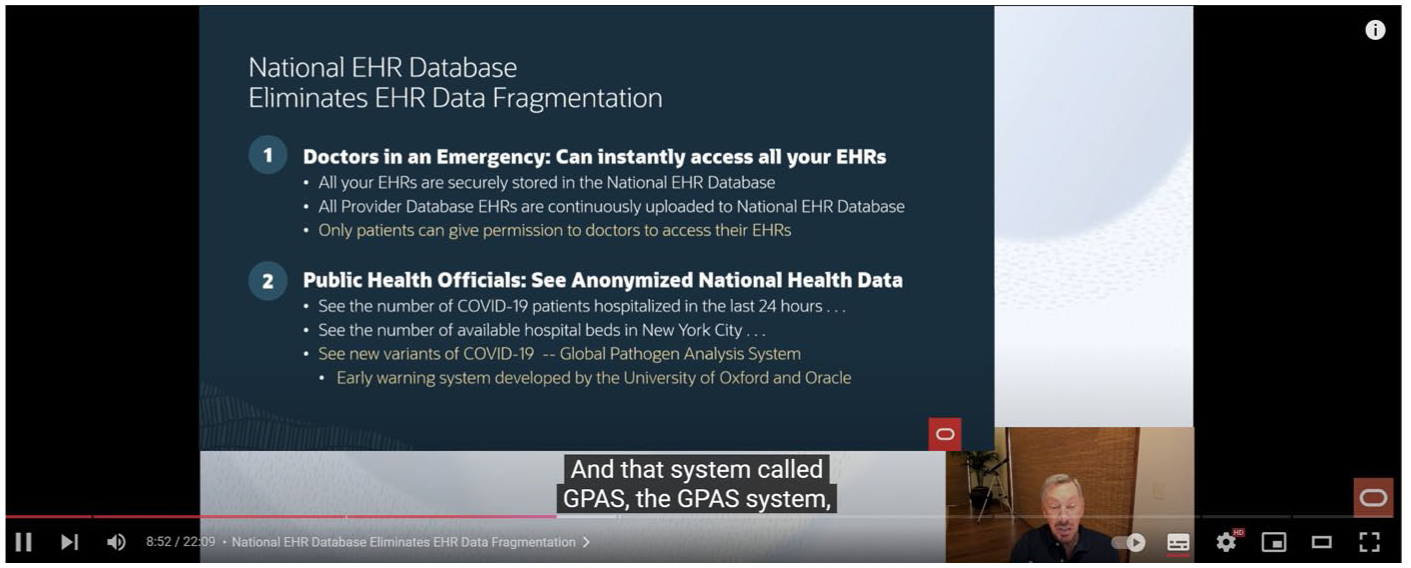
Monolingual Captioning of YouTube ASR.
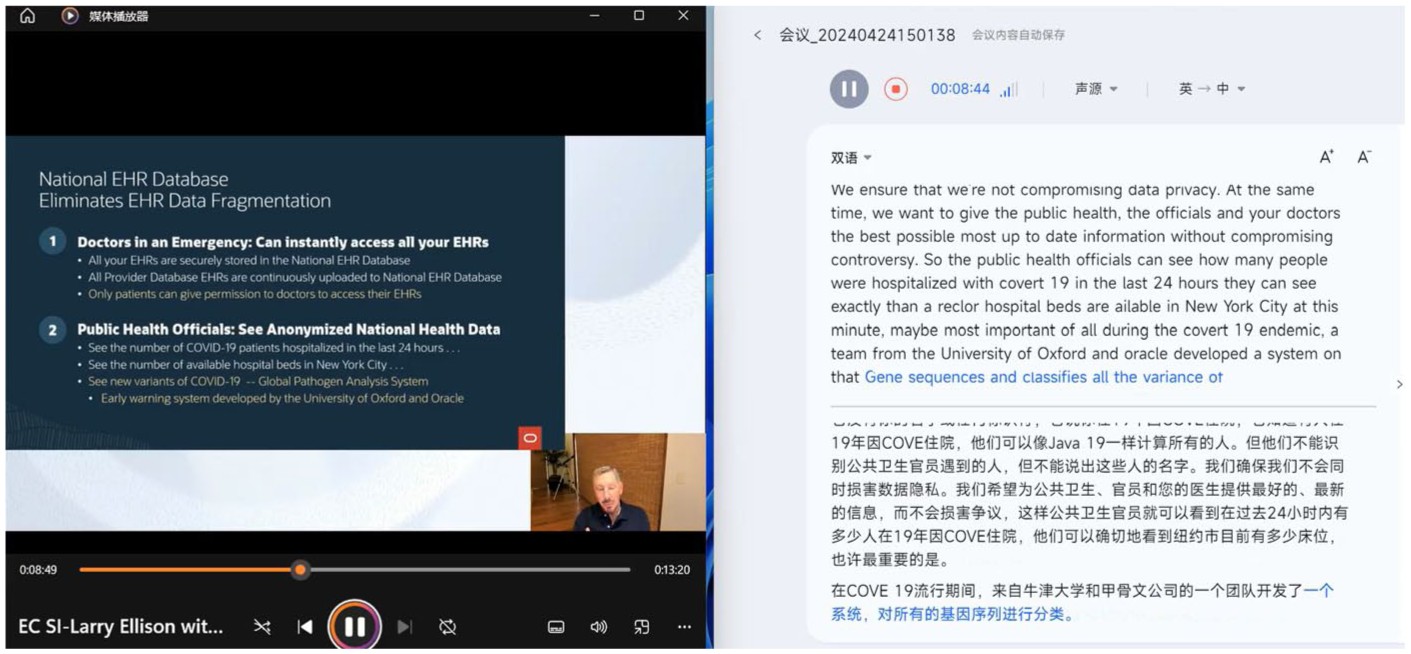
Bilingual Captioning of iFLYTEK Machine Interpreting.
3.3 Procedure
The experiment was conducted in April 2024 in a well-equipped SI classroom featuring state-of-the-art IT facilities and sound-proof booths. The two participant groups were assigned to perform SI under different conditions: one group with monolingual live captioning and the other with bilingual live captioning. Participants’ preparation was supported through speech outlines and presentation slides in PDF format that were distributed 1 week in advance, followed by a pre-test briefing on the speech’s main content. During the experiment, participants were required to interpret the English source speech into Chinese while utilising the assistance of their respective live captioning conditions. All participants completed the experimental tasks during the same time period while being exposed to their respective experimental conditions. All SI performances were audio-recorded and saved for subsequent analysis.
3.4 Assessment
3.4.1 Rating criteria
To answer the research questions, the participants’ SI performances were assessed using a combination of holistic and analytic rating scales (Chen et al., 2022). The assessment criteria consisted of four dimensions: a holistic dimension and three specific dimensions, namely information completeness, fluency of delivery, and target language quality. The holistic dimension provided an overall assessment of the interpreting performance, while the specific dimensions focused on distinct aspects of interpreting. Raters were tasked with evaluating each performance based on the descriptors provided for each dimension. The ratings were categorised into four levels: excellent (7–8), competent (5–6), acceptable (3–4), and unacceptable (1–2) (see Appendix).
3.4.2 Rater selection and training
Three raters, one male and two females, were selected to evaluate the participants’ SI performances based on their expertise and experience in interpreting performance assessments. All three raters had passed the Level 1 China Accreditation Test for Translators and Interpreters (CATTI) Interpreting Exam, which is the highest level of the national standard professional certification examination in China. In addition, the raters were practicing interpreters with a minimum of five years of professional interpreting experience, ensuring their familiarity with SI standards and expectations.
Informed by the previous literature concerned with rater training (e.g., Setton & Dawrant, 2016; Shang & Xie, 2024), a comprehensive training session was conducted for the three raters to maintain consistency in the evaluation process and facilitate accurate scoring. Although the raters had prior experience in performance assessment, the training focused on familiarising them with the specific scoring rubrics employed in this study. The training session included a thorough explanation of the holistic and analytic rating scales, as well as the descriptors for each dimension and proficiency level. Meanwhile, raters practised applying the scoring rubrics to sample SI audios and engaged in moderation sessions to establish a shared understanding of the rating criteria and minimise interrater variability.
3.5 Data analysis
To ensure the reliability of the scoring results, interrater reliability was assessed using intraclass correlation coefficients (ICCs), as the study involved three raters. ICCs were calculated for both the holistic and analytic scores to determine the level of agreement among the raters. To address RQ1, a Wilcoxon signed-rank test was conducted between the CASI holistic scores and the mid-term scores of the participants. To examine RQ2 and RQ3 concerning the effects of live-captioning conditions, independent samples t-tests were performed to analyse potential differences between monolingual and bilingual live-captioning groups. This analysis encompassed both holistic scores and individual analytic dimensions, enabling a comprehensive evaluation of simultaneous interpreting performance. All statistical analyses were performed using R statistical software (R Core Team, 2024).
4. Results
4.1 Rating reliability in performance assessment
Interrater reliability was assessed using the intraclass correlation coefficient (ICC) for each of the four dimensions: holistic score, information completeness (InfoCom), fluency of delivery (FluDel), and target language quality (TLQual). The ICC (2,1) and ICC (2,k) values were calculated to determine the reliability of single raters and the average of multiple raters, respectively (Koo & Li, 2016).
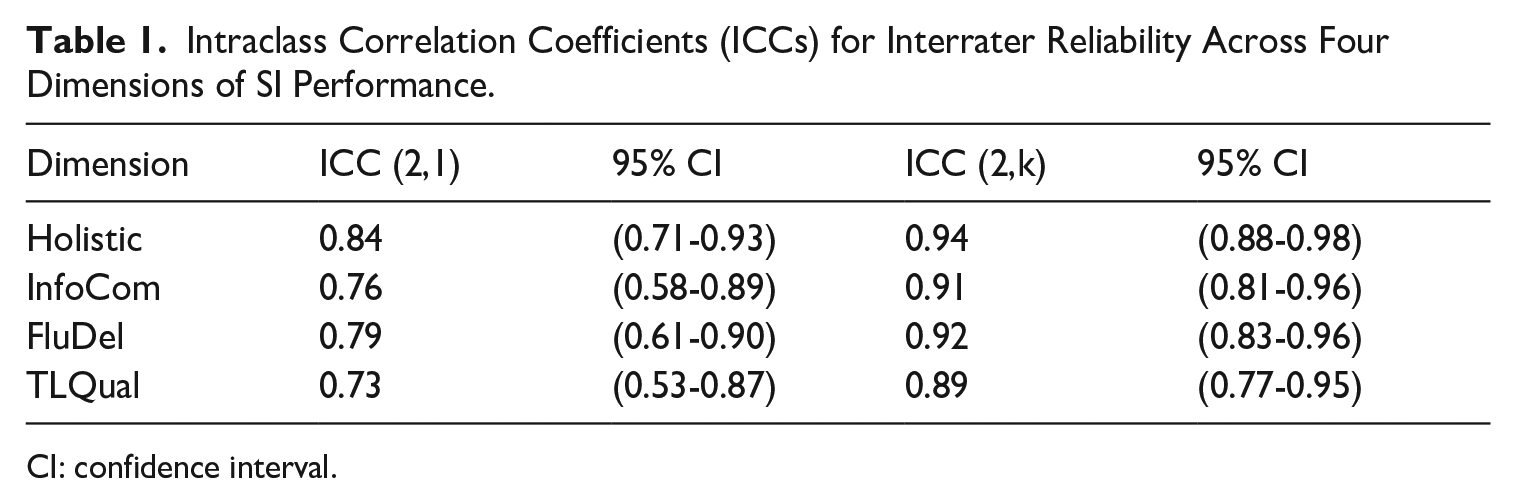
Table 1 presents the intraclass correlation coefficients (ICCs) for interrater reliability across four dimensions of SI performance. The ICC (2,1), which measures absolute agreement among individual raters, ranged from 0.73 to 0.84, indicating moderate to good single-rater reliability for all dimensions. The ICC (2,k) represents the reliability of mean ratings from all three raters and ranged from 0.89 to 0.94, which demonstrates excellent reliability. These findings suggest that the rating process for each dimension was consistent and dependable, both for individual raters and the composite scores of multiple raters.
Intraclass Correlation Coefficients (ICCs) for Interrater Reliability Across Four Dimensions of SI Performance.
CI: confidence interval.
4.2 Wilcoxon signed-rank test
A Wilcoxon signed-rank test was conducted to examine the effect of live captioning on interpreting performance relative to participants’ baseline competence. Participants’ mid-term examination scores served as the baseline measure of interpreting quality without live captioning support (M = 87.75, SD = 3.24), while their performance under the live captioning condition was assessed using holistic scores (M = 4.68, SD = 1.14). The result revealed that students’ mid-term scores were significantly higher than CASI holistic scores (Z = 3.92, p < .001, r = .88), indicating a large effect size. This suggests that the introduction of live captioning significantly diminished interpreting performance compared to participants’ baseline competence levels.
4.3 Independent samples t-test
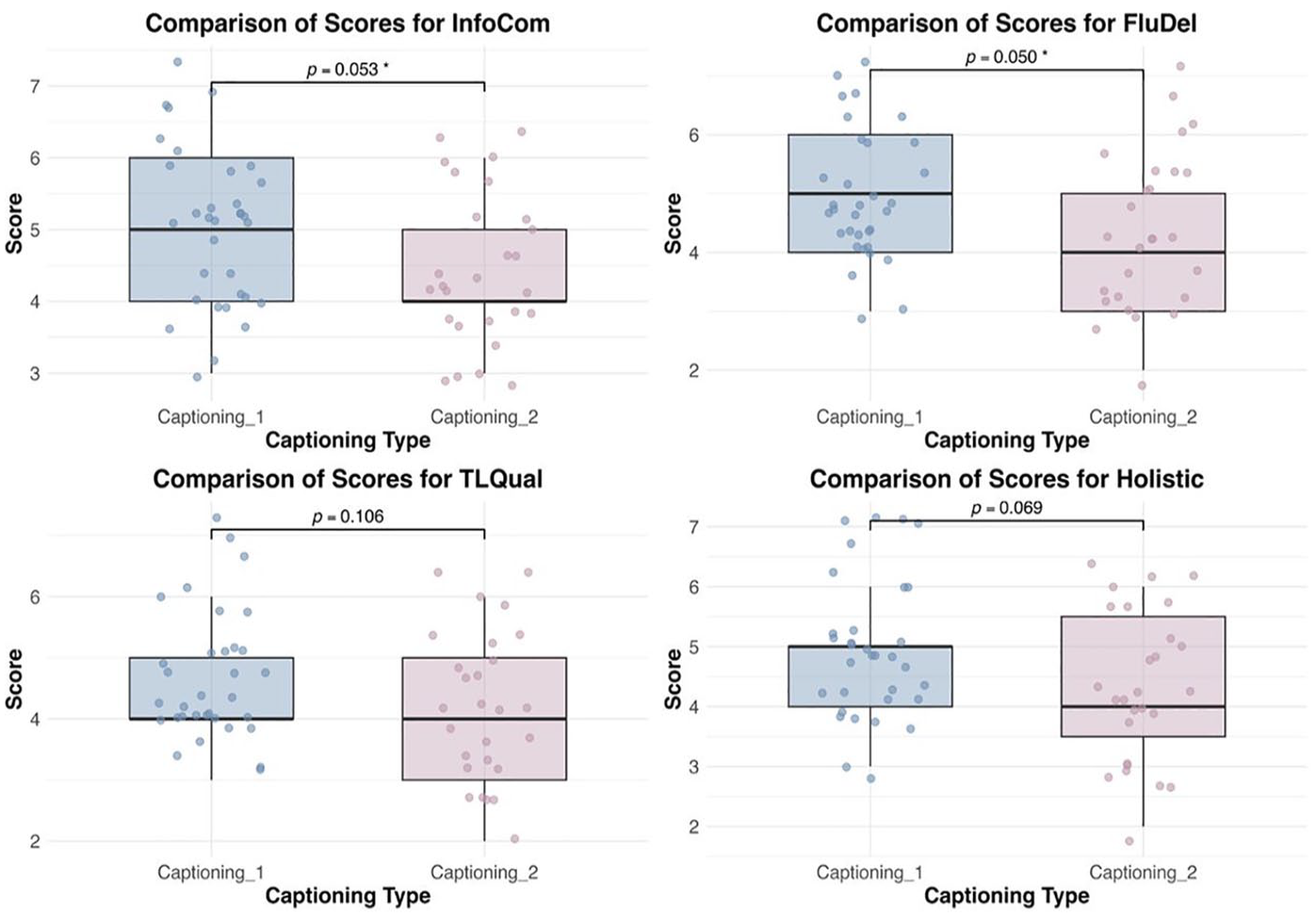
Independent samples t-tests were conducted to compare the performance of two participant groups across four dimensions (see Table 2): Holistic score, Information Completeness (InfoCom), Fluency of Delivery (FluDel), and Target Language Quality (TLQual). Figure 3 shows the visualisation of t-test results across four dimensions.
Independent Samples t-test Results Across Four Dimensions.
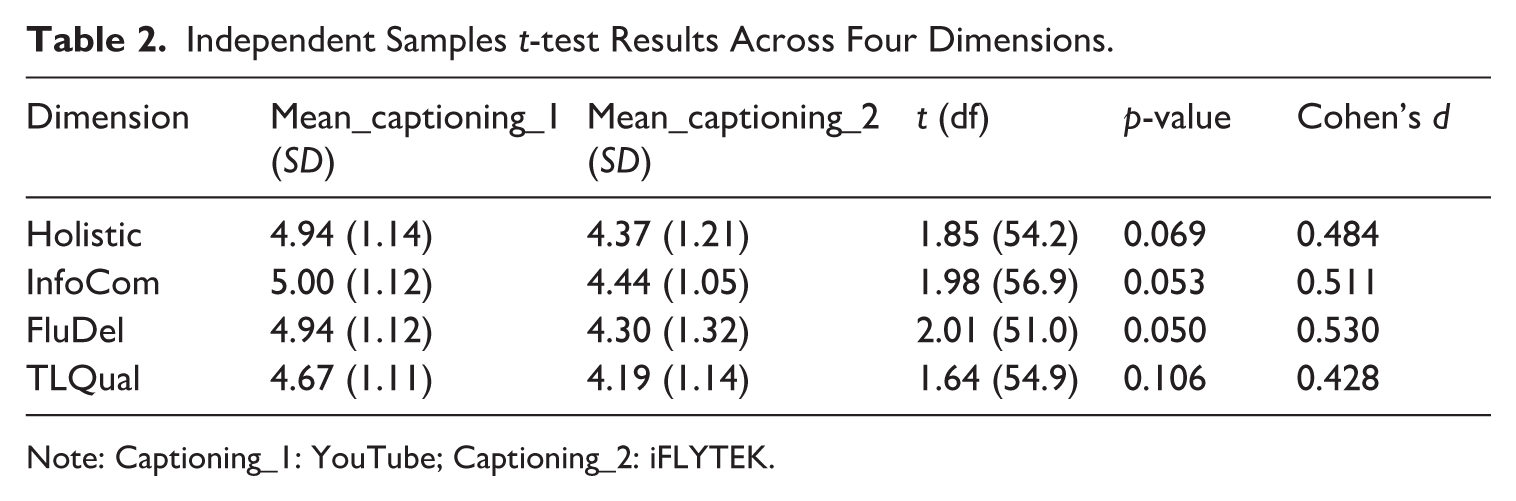
Note: Captioning_1: YouTube; Captioning_2: iFLYTEK.
Comparison of SI Performance Across Four Dimensions.
For Holistic scores, the group assisted by YouTube (M = 4.94, SD = 1.14) had a higher mean score compared to the group assisted by iFLYTEK (M = 4.37, SD = 1.21), but the difference was not statistically significant (p = .069). For Information Completeness, the YouTube group (M = 5.00, SD = 1.12) outperformed the iFLYTEK group (M = 4.44, SD = 1.05), with the difference being marginally significant (p = .053). For Fluency of Delivery, the group assisted by YouTube (M = 4.94, SD = 1.12) had a significantly higher (p = .050) mean score compared to the iFLYTEK group (M = 4.30, SD = 1.32). Finally, regarding Target Language Quality, although the YouTube group (M = 4.67, SD = 1.11) had a higher mean score than the iFLYTEK group (M = 4.19, SD = 1.14), the difference was not statistically significant (p = .106). The effect sizes (Cohen’s d) for the differences between the two groups ranged from 0.428 to 0.530, indicating moderate effects across all dimensions.
5. Discussion
5.1 RQ1: Does the inclusion of live captioning affect student interpreters’ performance in English-to-Chinese simultaneous interpreting compared to traditional non-assisted interpreting?
The results suggest that the live captioning condition did not lead to an improvement in the participants’ interpreting performance compared to their baseline mid-term exam scores. More precisely, student interpreters’ performance was not significantly improved by the live captioning support. This finding is unexpected, as previous literature demonstrates that the live captioning condition would enhance the participants’ interpreting performance (e.g., Su & Li, 2024; Yuan & Wang, 2024). This may be attributed to participants’ lack of sufficient training and familiarity with the latest technology, such as live captioning (Cheung & Li, 2022). The growing popularity of live captioning in interpreting research and settings does not mean that student interpreters have developed adequate knowledge and had sufficient opportunities to practice it. Therefore, they may find it difficult to effectively integrate the continuous visual input from the captions with their auditory input. The lack of coping strategies between the existing and extra inputs may lead to cognitive overload when they are tasked to manage multiple information channels simultaneously (Gile, 2009). Meanwhile, since there would be discrepancies between the captions and the source speech, participants may also have to pay extra attention to differentiate between helpful and wrong information. Furthermore, this also echoes the previous finding that when the source language is visually present, it could potentially distract interpreters or compete for their attention (Agrifoglio, 2004). This distraction would further be compounded by the incongruencies between the visual input and auditory input, as well as the lack of training, thus leading to significantly lower overall interpreting quality in CASI contexts.
5.2 RQ2: Do student interpreters’ holistic English-to-Chinese simultaneous interpreting performances differ when provided with monolingual live captioning compared to bilingual live captioning?
The findings revealed that student interpreters using YouTube’s monolingual live captioning demonstrated marginally better overall performance compared to those using iFLYTEK’s bilingual live captioning, although this difference did not reach statistical significance (p = .069).
Several factors may explain this observed pattern: First, the advantage of monolingual captioning may be attributed to cognitive load management. When interpreting from L2 to L1, monolingual captioning in the source language potentially reduces the cognitive resources required for information processing. This aligns with Cognitive Load Theory (Hollender et al., 2010; Paas et al., 2003; Sweller et al., 1998), which suggests that working memory has a limited capacity for processing simultaneous tasks. Monolingual live captioning eliminates the need to process additional target language information, and student interpreters can allocate more cognitive resources to the core interpreting task. Second, monolingual captioning potentially creates a scenario similar to sight interpreting (Lambert, 2004), or SI with text, where interpreters directly render meaning from written source text and auditory source language information into oral target language. This mode of interpreting may provide interpreters with greater control over their output, as they can focus solely on meaning transfer without managing competing linguistic inputs. Third, bilingual captioning, despite its apparent potential benefits, may introduce additional cognitive processing demands that complicate the interpreting task. ASR errors and incongruencies between ASR outputs can result in interference effects on auditory input processing (Seeber, 2017), necessitating that interpreters actively suppress or filter conflicting information while formulating their target language output. This situation creates a complex cognitive environment where student interpreters must allocate attentional resources to monitor and reconcile discrepancies across multiple input streams. Consequently, interpreters face an additional cognitive subtask of error detection and resolution, which competes for the limited cognitive resources typically reserved for the fundamental subtasks of reading, listening, and production in SI with text (Gile, 2009). The increased cognitive load resulting from these competing demands may adversely affect the fluency and accuracy of interpreting performance and, subsequently, the overall performance of interpreters. The findings thus indicate that technological support tools, while designed to aid interpreting, may inadvertently introduce additional cognitive complexities that need careful consideration in training contexts.
5.3 RQ3: If disparities are identified in RQ2, how do student interpreters’ English-to-Chinese simultaneous interpreting performances vary between the monolingual and bilingual live captioning conditions, particularly in terms of information completeness, fluency of delivery, and target language quality?
The results indicate that there are disparities in the interpreters’ performance between the monolingual and bilingual live captioning conditions across all three dimensions of information completeness, fluency of delivery, and target language quality. Participants performed better in all aspects under the monolingual condition compared to the bilingual condition. For information completeness, the difference between the two conditions approached statistical significance, with a medium effect size. This suggests that interpreters could render and convey more complete information when provided with monolingual live captioning. Different working mechanisms of ASR and MI may account for this contrast. MI, which primarily builds on a cascade model, incorporates both ASR and MT systems and works in a stepwise manner (Fantinuoli, 2021). Such a model would propagate errors across different processing modules (Pöchhacker, 2024). Therefore, in case the same errors occur at the speech recognition stage, the monolingual captioning may produce less confusing information as compared to the bilingual one, and student interpreters, due to their limited cognitive resources and not fully fledged interpreting skills, may find it easier to cope with the presence of the monolingual input instead of the bilingual.
For fluency of delivery, interpreters performed significantly better in the monolingual condition than in the bilingual condition, indicating that monolingual live captioning could facilitate fluent delivery in SI. The compromised fluency in bilingual captioning-assisted interpreting can be attributed to system latency in MI. Student interpreters, who are still developing their coordination skills between auditory and visual processing, may tend to wait for MI output before producing their renditions, resulting in extended ear-voice span and disrupted fluency. Moreover, their relative inexperience may make them more susceptible to errors in MI output, leading to inappropriate pauses and hesitations. When latency exceeds a workable threshold, interpreters may struggle to integrate machine suggestions effectively, potentially compromising fluency in their delivery. This empirical observation aligns with the findings of Fantinuoli and Montecchio (2022), who posit that technological assistance characterised by substantial latency can have detrimental effects on interpreter-machine interaction dynamics, cognitive resource allocation, and ultimately, the interpreting quality. Finally, for target language quality, despite the lack of statistical significance, a trend towards better performance in the monolingual condition was observed. Without the interference of machine-generated target language translations, interpreters may maintain greater autonomy in their translation choices and focus more intently on producing appropriate target language expressions.
These findings suggest that the reduction in input processing demands through monolingual captioning creates more favourable conditions for effective SI. The simplified input environment appears to facilitate better coordination of the fundamental interpreting sub-processes, such as comprehension, transfer, and production. The effectiveness of monolingual captioning can also be discussed from an ergonomic perspective.
5.4 Ergonomics at play in CASI
Interpreting performance can be explained by the ergonomic attributes of different display conditions of live captioning: monolingual and bilingual. There are three key aspects. First, the ergonomic design of machine assistance influences interpreters’ cognitive resource allocation among source language comprehension, technological support utilisation, and target language production. Optimal ergonomic design facilitates efficient resource distribution (van Egdom et al., 2020), potentially enhancing interpreting accuracy and fluency, while suboptimal design may induce cognitive strain, manifesting in hesitations, errors, or omissions (Defrancq & Fantinuoli, 2021). The monolingual live captioning system may offer better ergonomic efficiency due to its reduced visual complexity and cognitive processing demands. This is in a similar vein to the CAT (computer-assisted translation) tool design. As suggested by Kappus and Ehrensberger-Dow (2020), when translation assistance tools are user-friendly, translators can focus more of their cognitive resources on making important translation decisions and solving translation problems. However, if these tools or their features are complex and difficult to use, translators may struggle to work effectively with them. This difficulty in human-machine interaction often leads to translators not using the tools to their full potential and feeling frustrated with them. Similarly, when student interpreters view only source language captions, they engage in a more streamlined information verification process that aligns with their natural comprehension workflow. This single-language display minimises the risk of visual interference and reduces the cognitive effort required for attention switching between different language streams. In contrast, bilingual captioning, while providing additional linguistic support, may impose higher cognitive demands through its dual-language presentation. Student interpreters have to process both source and target language texts simultaneously, potentially creating competition for visual attention and working memory resources. This increased cognitive load might interfere with interpreters’ own target language production processes, particularly during complex or rapid speech segments.
Second, the ergonomic presentation of machine-generated content critically affects information retrieval efficiency during SI. The spatial and temporal organisation of machine assistance directly impacts interpreters’ ability to access and incorporate relevant information while maintaining the output flow. Given the current limitations in MI accuracy (Chen & Kruger, 2024; Li & Chmiel, 2024), bilingual captions may introduce additional processing complications. As machine translation systems process longer context windows, they often revise their previous translations, creating a constantly shifting target text. These iterative updates in bilingual displays can be visually distracting and cognitively demanding for interpreters to track. In addition, the machine-generated translations might contain errors or stylistic inconsistencies that could interfere with interpreters’ own target language formulation processes. In contrast, monolingual captioning involves fewer textual iterations, primarily from ASR refinements, making it easier for interpreters to quickly extract relevant information without dealing with multiple versions of machine-generated translations. Therefore, monolingual captioning avoids potential cognitive interference from imperfect machine translations, allowing interpreters to maintain greater autonomy in their target language production while still benefitting from source language support.
Third, the inherent latency in machine-assisted interpreting systems presents unique ergonomic challenges that warrant careful examination from a temporal processing perspective. In monolingual captioning, the system architecture involves a single processing phase where ASR technology introduces a baseline latency during speech recognition and transcription. This single-step delay maintains a relatively consistent temporal relationship between the spoken input and captioned output, creating a predictable processing environment for interpreters. Bilingual captioning, by contrast, necessitates a more complex two-stage processing pipeline. The initial ASR delay is compounded by subsequent machine translation processing, resulting in a cascading latency effect. This compound processing structure introduces additional temporal complexity that student interpreters must manage while maintaining their cognitive resources for core interpreting tasks. The comparative temporal frameworks of these systems suggest distinct implications for interpreting efficiency. Monolingual captioning, with its more streamlined processing path and simpler interface design, enables interpreters to better synchronise their output with the speaker’s pace while still benefitting from textual support. This finding is in line with the observation of Kappus and Ehrensberger-Dow (2020) that a more simplified technology interface seemed to be more ergonomic than a more complicated one. The shorter, more predictable delay and streamlined interface characteristic of monolingual systems appear to better accommodate student interpreters’ cognitive requirements for real-time processing and output production.
6. Conclusion
This study contributes to the ongoing discourse regarding ergonomic considerations in translation and interpreting technology, specifically examining how different live captioning conditions affect student interpreters’ performance. Through a comparative analysis of monolingual and bilingual live captioning systems, we investigate the relationship between technological assistance complexity and interpreting quality across multiple dimensions. Our findings reveal two significant patterns. First, the mere introduction of technological assistance does not automatically enhance performance. Student interpreters require systematic preparation and instruction in tool utilisation to benefit from technological advancement. This observation suggests that technological integration in interpreting practice necessitates a structured pedagogical approach. Second, our comparative analysis demonstrates that monolingual live captioning, with its reduced interface complexity and latency, facilitates better performance across multiple dimensions, including overall delivery, information completeness, and fluency, compared to its bilingual counterpart.
This study carries important theoretical and practical implications for both interpreter education and technological design. From a theoretical perspective, it advances our understanding of interpreters’ SI performance in technology-assisted conditions in three key ways. First, the comparison between monolingual and bilingual live captioning demonstrates how interface design directly influences interpreters’ performance in various dimensions. The simpler interface may grant interpreters more autonomy and advantages in the highly cognitive resources-demanding activity of SI. Second, the findings provide the foundation for understanding specific technology-induced load factors in interpreting tasks in the future. Third, the incorporation of ergonomics in analysing human–computer interaction in interpreting contexts contributes to a more nuanced understanding of how the presence of technology would mediate the relationship between interpreters and interpreting tasks.
Practically, the results offer concrete recommendations for tool development and pedagogy. For tool development, the negative impact of live captioning on SI performance and the relatively positive impact of monolingual captioning may necessitate careful ergonomic consideration of the interface and feature design. The user experience should be fully cared for to ensure that visual inputs and the interaction with features will not increase interpreters’ cognitive load but facilitate their performance. For interpreting training programmes, the findings suggest a structured technology integration framework with three phases: (1) students should master core interpreting skills before their exposure to technological assistance, (2) tools are gradually introduced to students at a later stage when they have learned necessary skills and are able to deliver satisfying interpreting performance, and (3) students should be instructed to utilise technological support during interpreting tasks strategically and understand the strengths and limitations of different tools, and they should be given the opportunities to practice how to operationalise these tools to serve them better. This gradual approach could ensure that AI tools enhance rather than hinder their skill development.
However, this study has several limitations. First, the small sample size may have contributed to the lack of statistical differences in the data. Future research with larger sample sizes and more diverse participant populations is needed to confirm the findings of the present study. Second, the present study only investigated the English-to-Chinese direction in SI. As directionality may influence the effectiveness and use of live captioning, future studies can take directionality into consideration. Third, future studies could explore the interaction between captioning type and other variables, such as the source speech complexity and interpreter expertise, which is currently underexplored in the present study due to researchers’ resource constraints.
Footnotes
Appendix
Holistic and Analytic Rating Scales (Chen et al., 2022).
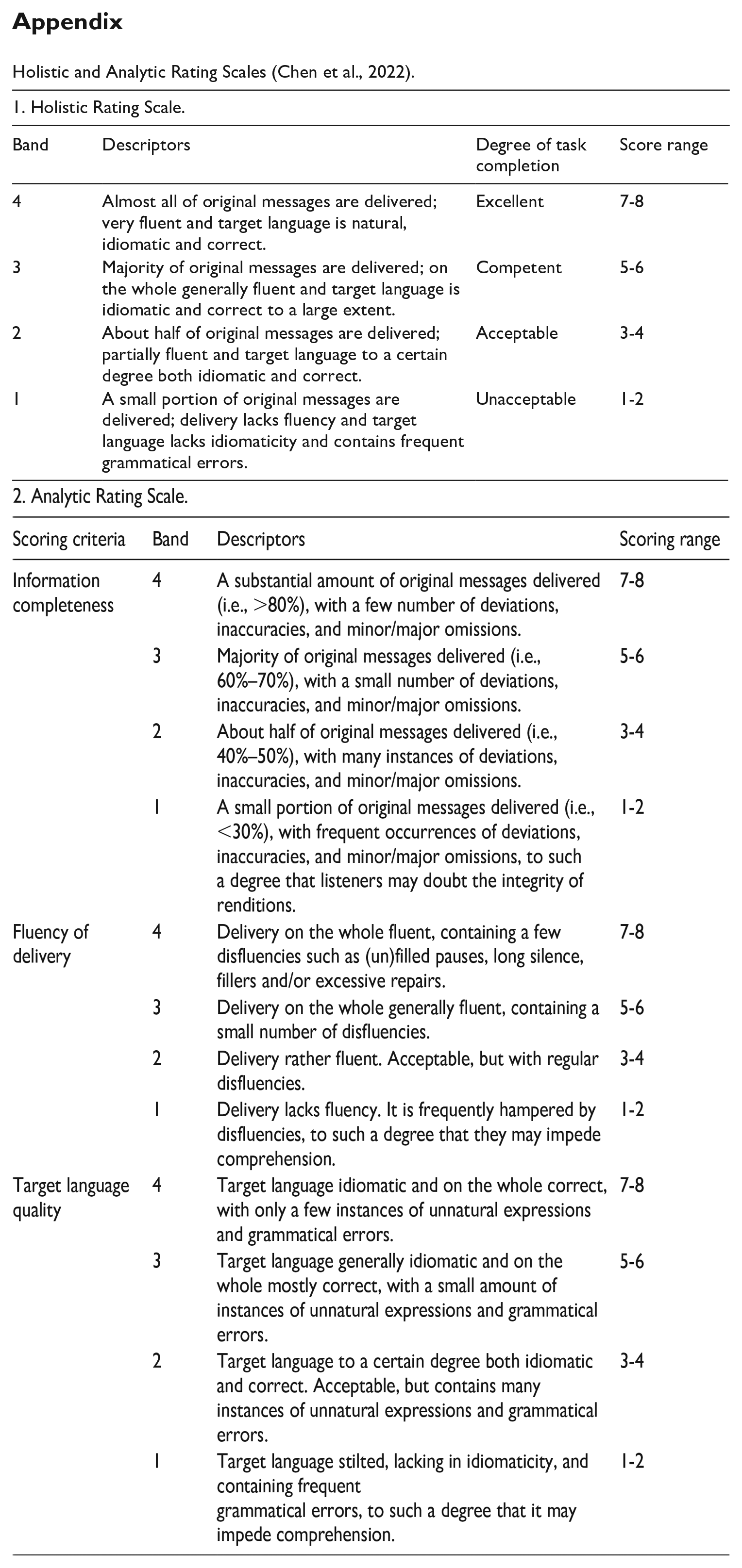
| 1. Holistic Rating Scale. | |||
|---|---|---|---|
| Band | Descriptors | Degree of task completion | Score range |
| 4 | Almost all of original messages are delivered; very fluent and target language is natural, idiomatic and correct. | Excellent | 7-8 |
| 3 | Majority of original messages are delivered; on the whole generally fluent and target language is idiomatic and correct to a large extent. | Competent | 5-6 |
| 2 | About half of original messages are delivered; partially fluent and target language to a certain degree both idiomatic and correct. | Acceptable | 3-4 |
| 1 | A small portion of original messages are delivered; delivery lacks fluency and target language lacks idiomaticity and contains frequent grammatical errors. | Unacceptable | 1-2 |
| 2. Analytic Rating Scale. | |||
| Scoring criteria | Band | Descriptors | Scoring range |
| Information completeness | 4 | A substantial amount of original messages delivered (i.e., >80%), with a few number of deviations, inaccuracies, and minor/major omissions. | 7-8 |
| 3 | Majority of original messages delivered (i.e., 60%–70%), with a small number of deviations, inaccuracies, and minor/major omissions. | 5-6 | |
| 2 | About half of original messages delivered (i.e., 40%–50%), with many instances of deviations, inaccuracies, and minor/major omissions. | 3-4 | |
| 1 | A small portion of original messages delivered (i.e., <30%), with frequent occurrences of deviations, inaccuracies, and minor/major omissions, to such a degree that listeners may doubt the integrity of renditions. | 1-2 | |
| Fluency of delivery | 4 | Delivery on the whole fluent, containing a few disfluencies such as (un)filled pauses, long silence, fillers and/or excessive repairs. | 7-8 |
| 3 | Delivery on the whole generally fluent, containing a small number of disfluencies. | 5-6 | |
| 2 | Delivery rather fluent. Acceptable, but with regular disfluencies. | 3-4 | |
| 1 | Delivery lacks fluency. It is frequently hampered by disfluencies, to such a degree that they may impede comprehension. | 1-2 | |
| Target language quality | 4 | Target language idiomatic and on the whole correct, with only a few instances of unnatural expressions and grammatical errors. | 7-8 |
| 3 | Target language generally idiomatic and on the whole mostly correct, with a small amount of instances of unnatural expressions and grammatical errors. | 5-6 | |
| 2 | Target language to a certain degree both idiomatic and correct. Acceptable, but contains many instances of unnatural expressions and grammatical errors. | 3-4 | |
| 1 | Target language stilted, lacking in idiomaticity, and containing frequent grammatical errors, to such a degree that it may impede comprehension. |
1-2 | |
Acknowledgements
We would like to express our sincere gratitude to the participants for their time and contribution. We also extend our appreciation to the two anonymous reviewers for their constructive feedback and comments, which helped enhance the quality of this work. Finally, we thank Prof. Lan Li and Jiaxing Hu for their valuable suggestions on this research.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethical approval and consent to participate
This study obtained ethical approval from the Ethics Review Committee of The Chinese University of Hong Kong, Shenzhen (EF20241202001). All methods performed in the study were carried out in accordance with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. Informed consent was obtained from all individual participants involved in the study.
Data availability statement
We confirm that the data supporting the findings are available within this article. Raw data are available from the corresponding author, upon reasonable request.