
Abstract
In this study, we adopt a monolingual, comparable, and cross-modal approach to investigate the use of hedges in interpreted and non-interpreted English speeches. To achieve this, we compile a corpus comprising speech data sourced from the interpreter-mediated Chinese government press conferences and the White House press conferences, respectively. Two research questions are formulated to guide our examination of hedging-related features in the corpus: (1) How does the use of hedges differ between interpreted English produced in different modes of interpreting (i.e., consecutive and simultaneous)? (2) How does the use of hedges in interpreted English differ from non-interpreted English? The results of our study show that interpreters, regardless of the consecutive and simultaneous mode, tend to employ significantly fewer hedges than spontaneous speakers of English. In addition, a vast majority of hedges in interpreted English stem from a relatively narrow range of core hedging devices. We posit that the underuse of hedges in interpreted English may be linked to constraints such as high cognitive pressure, rigid interactive structure, and source-language-related speech rhetoric conventions. Preliminary findings also suggest that the interpreting mode appears to exert little influence on the hedging patterns in the interpreters’ renditions. Potential factors underlying such a trend are briefly discussed.
1. Introduction
The phenomenon of hedging has been a long-standing topic of interest in the field of applied linguistics and discourse studies. Hedges are typically employed by writers or speakers to indicate a level of uncertainty or reservation in their statements (Crismore et al., 1993; Hyland, 2005; Vande Kopple, 1985). Historically, research on hedging has been largely devoted to interactive communication in monolingual settings such as academic writing (e.g., Crompton, 1997; Hyland, 1996; Markkanen & Schröder, 2010) and public speaking (e.g., Fraser, 2010; Schäffner, 1998; Tchizmarova, 2005). And it was only in the past two decades that scholars began to be interested in the use of hedges in translation (Auwera et al., 2005; G. Hu & Cao, 2011; Kranich, 2009, 2011; Peterlin, 2010) and more recently in interpreting (Fu & Wang, 2022; J. Hu, 2022; Magnifico & Defrancq, 2017; Pan & Zheng, 2017).
As far as interpreting is concerned, the limited research on hedging primarily focuses on source–target shifts, the occurrence of which presumably contributes to the understanding of the translator or interpreter’s role. However, little is known about how hedging in interpreting may differ from that in non-interpreting speech production. Notably, two studies by Magnifico and Defrancq (2017) and Fu and Wang (2022) are exceptions in this regard. The former adopts a parallel approach by comparing hedging behaviours between source and target speeches while the latter employs a comparable approach, juxtaposing interpreted English by non-natives with spontaneous English by native speakers. Both studies yield fresh insights, identifying features that typify interpreted speech as a distinct variety of “oral translation products” (Shlesinger, 1998, p. 3). That said, there is still room for further investigation. The present corpus-based study seeks to shed light on hedging in interpreting by taking a monolingual, comparable, and cross-modal approach. In this study, “cross-modal” refers to the comparison between two classic interpreting modes, namely consecutive and simultaneous interpreting (cf. Dam, 2010). It should be noted that this definition slightly differs from Shlesinger’s (2008) conception of “intermodal” which focuses on comparing oral and written modalities of translation (i.e., interpreting and written translation). The rationale behind conducting a cross-modal study is evident: different modes of interpreting call for distinct skill sets necessary for successful performance and impose varying cognitive processing requirements on the interpreter (Gile, 2009). In addition, the study collects spontaneous speech data from native English speakers in similar settings to increase the dimensions of comparison and provide novel insights into the differences between constrained and unconstrained language use (Kruger & van Rooy, 2016).
The remainder of the article is organised as follows: Section 2 provides the context for the present research by reviewing relevant studies on hedging in written and spoken communication, as well as features and constraints of interpreted speeches. Based on the research questions, Section 3 introduces the corpus data and methodology used in the subsequent analysis. Section 4 presents the results of the quantitative corpus-based analyses, which is followed by a detailed discussion of the findings in Section 5. Finally, Section 6 summarises the key findings and suggests possible directions of future research.
2. Literature review
2.1 Hedging in written and spoken communication
Human communication, whether written or spoken, frequently employs hedges to convey varying degrees of “tentativeness,” “uncertainty,” and “imprecision” regarding a given proposition (Beeching, 2002; Brinton, 1996; Brown & Levinson, 1987; Coates, 1993, 1996; Hyland, 1998; Salager-Meyer, 1994). It is thus no surprise that, over the decades, the use of hedges has captured researchers’ attention across diverse linguistic contexts, including textbooks and student discourse (Hyland, 1996; Myers, 1992), economic texts (Bloor & Bloor, 1993; McLaren-Hankin, 2008), legal discourse (Vass, 2004), medical discourse (Salager-Meyer, 1994; Varttala, 1999), and academic discourse (Crompton, 1997; G. Hu & Cao, 2011; Hyland, 1996), among others. Notably, the field of academic writing has been the focal point of a considerable number of hedge-related studies, as research articles play a central role in scientific knowledge production across various disciplines. It is generally agreed that hedges are instrumental in both withholding the author’s commitment and convincing readers to accept certain arguments (Hyland, 2005).
Unlike writing, however, speech-making occurs in a wide range of contexts, from formal public speeches to informal private chats. Moreover, the process of writing differs from speaking in that writing typically involves an imagined reader, while speaking entails the constant co-presence of both the speaker and the audience. Consequently, both parties often rely on each others’ immediate responses to shape and constrain the evolving discourse during interaction. This suggests an increased potential for interpersonal engagement in spoken communication and, more specifically, speaking requires a more dynamic balance between tentativeness and assurance to avoid threatening the listener’s face. In this context, the role of hedges becomes crucial to fulfilling such a purpose.
However, although researchers have explored the use of hedges in various spoken contexts, such as daily conversation (Coates, 1996, 2013), talk shows (Tchizmarova, 2005), business negotiations (Charles, 1996), and presidential speeches (Alavi-Nia & Jalilifar, 2013; Fraser, 2010), the number of such endeavours remains relatively limited compared with similar studies conducted on written discourse.
A promising line of research in understanding the use of hedges involves adopting a translational perspective, which extends the research scope from monolingual spontaneous texts to translated and interpreted ones. In this regard, researchers often focus on shifts in hedging by comparing corresponding elements between source and target texts in translation. Among others, Schäffner (1998) examines authentic examples of German-to-English translations of political speeches, elaborating on four categories of hedges peculiar to such a setting and the strategies used in their rendition into the target language. Focusing on the translation of research articles, Kranich (2011) analyses the use of epidemic modal markers between English popular scientific papers and their German translations and finds noticeable differences in the usage of these features. She attributes such differences to divergent communicative preferences between the two language communities. Moreover, in the domain of news translation, Peterlin and Zlatnar Moe (2016) investigate trainee translators’ performance and motivations when handling hedging devices. They conclude that translators often omit and modify these elements in the target texts due to factors such as pragmatic competence, discourse position, and intentional intervention.
On the contrary, hedging in interpreting has only started to attract attention very recently. For example, Magnifico and Defrancq (2017) conduct a corpus-based study to explore the impact of gender difference on simultaneous interpreters’ use of hedges in the European Parliament. Their findings suggest that, on the whole, interpreters tended to over-hedge in their production compared with the original speeches. In addition, they found that female interpreters use more hedges than their male counterparts. Pan and Zheng (2017) also investigate gender-related differences in hedging in consecutively interpreted Chinese government press conferences. They find that male interpreters used significantly more hedges than female interpreters in the setting. J. Hu’s (2022) systematic study on hedging in interpreting focused on the link between shifts of hedging devices in Chinese-to-English government press conference interpreting and the role deviation of interpreters. Her findings shed light on the agency of conference interpreters, providing new linguistic evidence that contradicts the traditional perception of their role as invisible non-persons in conference settings. In a different approach to examining hedges in interpreting, Fu and Wang (2022) compare the usage of such linguistic items between interpreted English in the Chinese context and spontaneous English in the American context. They suggest that hedges in interpreted texts are not only fewer in number but also narrower in range compared with spontaneous English.
In sum, it seems clear that while research on hedging has offered considerable insight into the way in which language functions in different contexts and communities, much of the focus has been directed towards the domain of written communication, with relatively less emphasis on the area of spoken communication.
2.2 Features and constraints of interpreted speeches
The significance of identifying linguistic patterns specific to interpreted speeches was foreseen by Shlesinger (1998) in her seminal essay, which echoed Baker’s (1993) call for a corpus-based approach to translation studies. More specifically, this idea can be traced to the well-known hypothesis of “universal features of translation,” which posits that translated texts are characterised by features “which typically occur in translated text rather than original utterances and which are not the result of interference from specific linguistic systems” (Baker, 1993, p. 243).
Over the years, despite some criticisms of the application of corpus-based approaches to the study of so-called translation universals (e.g., House, 2008; Mauranen & Kujamäki, 2004) researchers have continued to investigate explicitation and simplification in translation, encompassing various language pairs and text types. Importantly, compelling evidence supporting the assumption that translated language differs from non-translated language has been put forward, although occasional conflicting results have also been reported (e.g., D. Williams, 2005).
As far as the unique features of interpreted speeches are concerned, research findings have been limited due to the lack of sufficient authentic interpreting data as well as the intrinsic difficulties in processing spoken speech materials. However, advancements in modern technology have gradually removed some of the hurdles, enabling researchers to identify “patterns specific to interpreted texts (regardless of their source language) as pieces of oral discourse, in relation to comparable texts in the same language” (Shlesinger, 1998, p. 3). The motivation to study the unique characteristics of interpreted language, as opposed to non-interpreted language, is similar to the search for universal features of translation “linked to the nature of the translation process” (Baker, 1993, p. 243). This is particularly clear when considering that the practice of interpreting often takes place under adverse conditions, involving great cognitive, psycholinguistic, and social constraints. These complexities necessitate a deeper understanding of the unique linguistic features that may emerge in the interpreted speeches compared with non-interpreted forms of communication.
In their discussion of the features of translated language, Kruger and van Rooy (2016) emphasise the cognitive complexity involved in translation, which they believe contributes to the uniqueness of its product. This point becomes even more relevant to interpreting, as written translation affords the translator the luxury of consulting documents or resources before finalising the product; by contrast, the interpreter has to “make the decision him/herself on the spot” (Gile, 2009, p. 63). The cognitively demanding nature of interpreting is closely associated with the limited processing capacity available to working interpreters, whether in consecutive or simultaneous interpreting. Interpreters are constantly engaged in multi-tasking, dividing, and allocating attentional resources to various concurrent tasks, including the reception, storage, retrieval, and reproduction of verbal information. The cognitive tension between processing capacity supply and demand is best explained by Gile’s (2009) Effort Models of interpreting. According to Gile’s framework, production in interpreting requires the interpreter to balance available mental resources while managing tasks of listening, memorisation, and speaking. Failure to do so will risk cognitive saturation, resulting in “production crises” such as pauses, restarts, repetitions, and redirections (Goffman, 1981, p. 172). While speaking in spontaneous situations also presents similar challenges, they are more likely to occur in interpreting, particularly in the simultaneous mode due to the heavy cognitive load and time pressure imposed on the interpreter (Ahrens, 2005; Nafá Waasaf, 2007; S. Williams, 1995). As such, researchers propose various text production strategies designed to alleviate working memory capacity and ensure a smooth and fluent output, including compression, paraphrasing, calque, transcoding, and so on (see Kalina, 2015). It is this complexity of cognitive processing that arguably distinguishes interpreted language from non-interpreted language.
In addition to the cognitively constrained nature of interpreting, its psycholinguistic peculiarities may also contribute to its distinctiveness in relation to spontaneous oral production. The product of interpreting is not merely a result of usual bilingual processing, where two languages are activated to varying degrees based on production circumstances. Rather, it comes as a consequence of continuous interlinguistic transfer, requiring the interpreter to constantly switch between two languages—listening in one and speaking in the other. Such rapid switching between the source and target languages, as Toury (2012, p. 311) suggests, may lie at the root of the universality of translated product. Unlike spontaneous speakers, interpreters must verbalise a message based on their analysis of a pre-existing utterance in the source language. This condition creates another factor that can impact the structure of interpreted language, because the influence of the source language may limit the choices available to the interpreter in producing the target speech. A clear example of this is the linearity constraint in simultaneous interpreting, where syntactic similarities between the source and target languages can restrict the interpreter’s ability to adjust sentence structure.
In the broader context, the production of interpreted speeches is different from that of non-interpreted ones in that interpreters are specially trained to serve as mediating communicators (Kohn & Kalina, 1996). Their responsibility is to facilitate communication between two monolingual parties, which requires them to constantly balance the needs of the audience and the intentions of the speaker. In doing so, interpreters often assume various social roles aimed at constructing appropriate interpersonal relationships between both parties (see Pöllabauer, 2015). This dynamic role of interpreters frequently leads them to make deliberate choices during the interpreting process, which can result in modifications to the information being conveyed. As a consequence, target speeches may exhibit increased explicitness or simplicity when compared with their source counterparts (Defrancq et al., 2015). Such strategic adjustments, as Pym (2008) highlights in his reanalysis of Gile’s study, are motivated by the aim of mitigating potential risks of communicative failure. These adaptations can become even more apparent during triadic face-to-face interactions, where the ongoing communication heavily relies on the interpreter’s mediation to proceed. In such situations, any breakdowns in communication can impact the parties’ trust in the interpreter’s professional competence and expertise.
All of these factors may account for the features assumed to distinguish between interpreted and non-interpreted speech. In view of the above analysis, the present corpus-based research aims to answer the following two questions, with a specific focus on the use of hedges:
(1)Does the use of hedges differ between interpreted English produced in different modes of interpreting (i.e., consecutive and simultaneous, abbreviated to CI and SI, respectively)?
(2)Does the use of hedges differ between interpreted (CI and SI) English and non-interpreted English?
3. Methodology
3.1 Corpus data
This study uses a self-compiled monolingual, comparable, and cross-modal corpus comprising interpreted and non-interpreted English speeches. The corpus is divided into three sub-corpora: consecutively interpreted English speeches from Chinese (CI), simultaneously interpreted English speeches from Chinese (SI), and native spontaneous English speeches (ORG). In total, the corpus contains 248,425 tokens, with the CI, SI, and ORG sub-corpora consisting of 83,412, 81,669, and 83,344 tokens, respectively.
The speech materials for our corpus are mainly drawn from two distinct data sources. Specifically, the CI and SI sub-corpora include English interpretations of speeches delivered by Chinese officials from various government ministries during government press conferences held at the National People’s Congress (NPC) and Chinese People’s Political Consultative Conference (CPPCC). The ORG sub-corpus, on the contrary, comprises spontaneous spoken English speeches from regular U.S. government press conferences, delivered by U.S. presidents, ministers, and White House spokespersons. All press conferences included in the corpus span the time frame from 2008 to 2022. These press conferences cover a diverse range of topics, such as economy, trade, finance, social security, employment, politics, diplomacy, environment protection, agriculture, medical reform, and more. To ensure comparable coverage and maximum comparability, the distribution of these topics among the three sub-corpora is managed purposefully. However, achieving absolute sameness is challenging due to the limited availability of authentic interpreting data from the aforementioned settings.
During the data processing phase, all speeches were transcribed in an orthographic manner, with each press conference transcribed into a separate text. The corpus is made up of 61 texts, distributed across the three sub-corpora with 20 texts for CI, 16 texts for SI, and 25 texts for ORG, respectively. Given the purpose of this study, paralinguistic features, such as hesitations, false starts, repetitions, repairs, filled, and unfilled pauses, were not considered during the transcription process. Furthermore, opening remarks made by speakers before question–answer sessions, as well as the questions raised by journalists during the question–answer sessions, were excluded to ensure data consistency. Consequently, only the interpretations for the speakers’ words were retained in the transcribed texts. A summary of the corpus is provided in Table 1, offering an overview of its composition and distribution across the sub-corpora.
Outline of the Corpus.
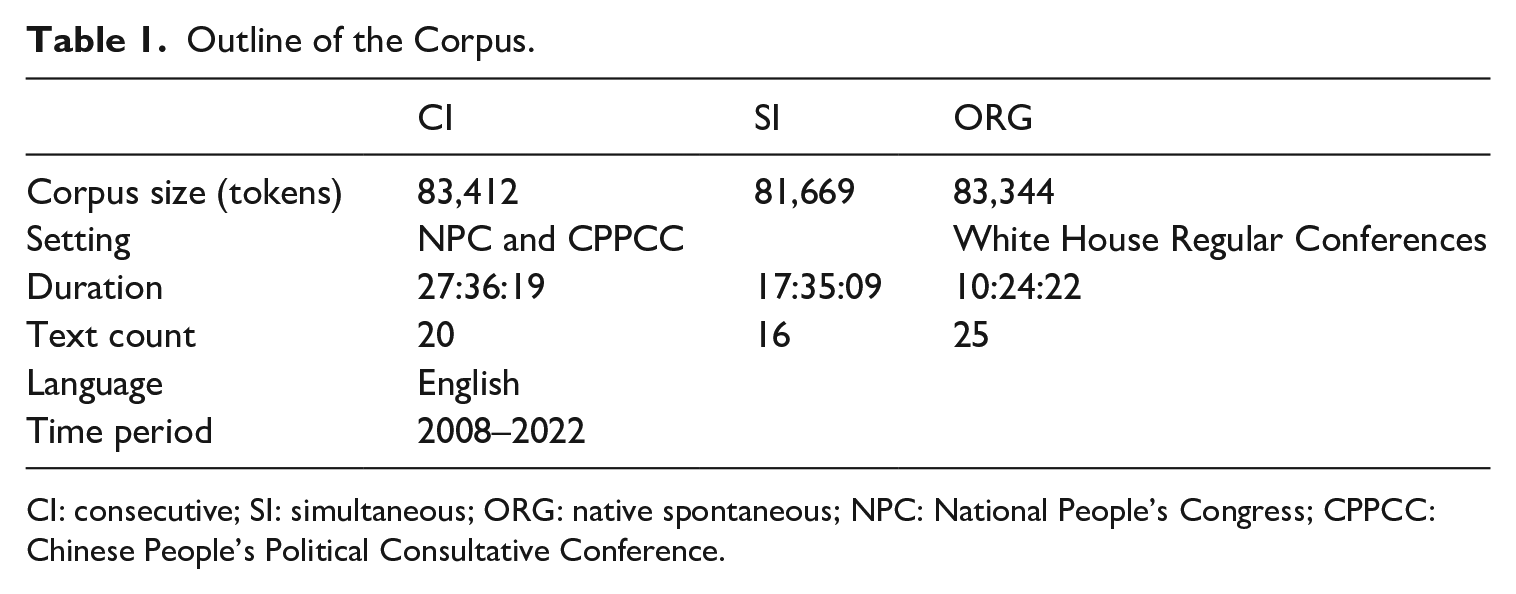
CI: consecutive; SI: simultaneous; ORG: native spontaneous; NPC: National People’s Congress; CPPCC: Chinese People’s Political Consultative Conference.
It is noteworthy that the number of interpreters involved in the two interpreting sub-corpora remains unclear due to limited metadata available in the Chinese context. Moreover, identifying interpreters based solely on recorded voices poses an even bigger challenge, particularly in SI where several interpreters work in shifts to facilitate seamless communication. That said, the interpreting data still offer a rich collection of topics covered, providing sufficient representativeness in the corpus.
3.2 Operationalisation of hedges
The quest to find a definition for hedges has been long, yet universal consensus on their boundaries and classifications remains elusive. Given that our goal is to identify operational criteria for recognising various hedging expressions in the corpus, we seek to uncover the common principles that different researchers apply when approaching the phenomenon of hedges.
Typically, hedges are referred to as “words whose job is to make things fuzzier or less fuzzy” (Lakoff, 1973, p. 471). The use of hedges is believed to be associated with the speaker’s (un)certainty about the proposition being discussed and their reluctance to show full commitment to the truth of statements (Coates, 2013; Holmes, 1988; Hyland, 2005). From a pragmatic perspective, hedging is also linked to the strategy of politeness and face protection, allowing for the mitigation or weakening face-threatening acts (Brown & Levinson, 1987; Holmes, 1990). Hence, a linguistic item can be considered a hedge if its primary function is to withhold commitment, express tentativeness, and mitigate face-threatening speech acts. This perception of hedges will consistently guide our determination of whether a linguistic item in a specific utterance can be classified as a hedge.
To streamline the search process, a list of potential hedging candidates was initially created by synthesising findings from previous studies (Hyland, 1998, 2005; Hyland & Tse, 2004; Pan & Zheng, 2017). This list served as the basis for identifying linguistic expressions used for hedging purposes in our data. However, it should be noted that the list was not applied blindly to query our corpus data, as, in the words of Lakoff (1973, p. 484), “any adequate treatment of hedges will have to take context into account.” Instead, both authors collaborated to review all concordances containing the search items from the list, ensuring their function as hedges within their respective contexts. In cases where disagreement arose, a consensus was reached through discussion by the two authors. The following taxonomy of hedges was established based on the identified search items of potential hedges from the final list (for more information, refer to Table 2; the complete list can be found in the Appendix).
The Taxonomy of Hedges in the Study.
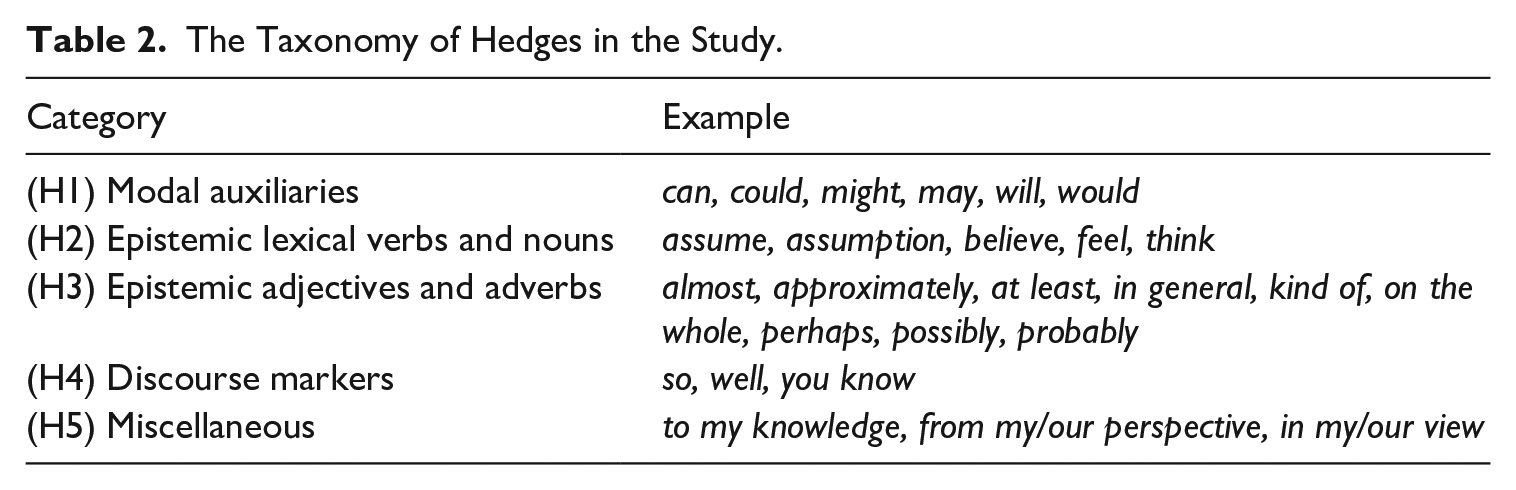
3.3 Data retrieval and statistical testing
The process of identifying hedges in this study involved several key steps. First, concordance lines were extracted based on the provided list of potential hedges using AntConc 4.2.0 (Anthony, 2022). Then, these concordance results were carefully reviewed within their respective contexts to exclude any irrelevant instances that do not serve hedging purposes. Finally, each valid hedging device’s occurrence was coded according to the aforementioned categorisation before being tallied for further statistical analysis.
To ensure meaningful comparisons, the raw frequencies of hedges in each category within every transcript were normalised on a per 100,000 words basis. Prior to any statistical analysis, all data underwent preliminary tests for normality (Q-Q plots) and homogeneity of variance (Levene’s test). The results indicated that the data followed normal distributions. Consequently, we chose to employ the one-way ANOVA test to compare the normalised frequencies of each hedging type across the three sub-corpora. Moreover, to address potential issues related to multiple comparisons, we applied Bonferroni-corrected post hoc tests which allow us to effectively manage the possibility of obtaining spurious significant results. All the statistical analyses were conducted using R (R Core Team, 2022).
4. Results
In this section, we present the findings of the study based on a quantitative analysis of the use of hedges in the corpus. First, we offer an overview of the general findings regarding the frequency of hedges across all three sub-corpora. This is followed by a comparative analysis of the use of hedges within each individual category. Finally, we examine the distribution of different types of hedges across the three sub-corpora to elucidate the observed tendencies derived from the statistical analysis.
4.1 General findings
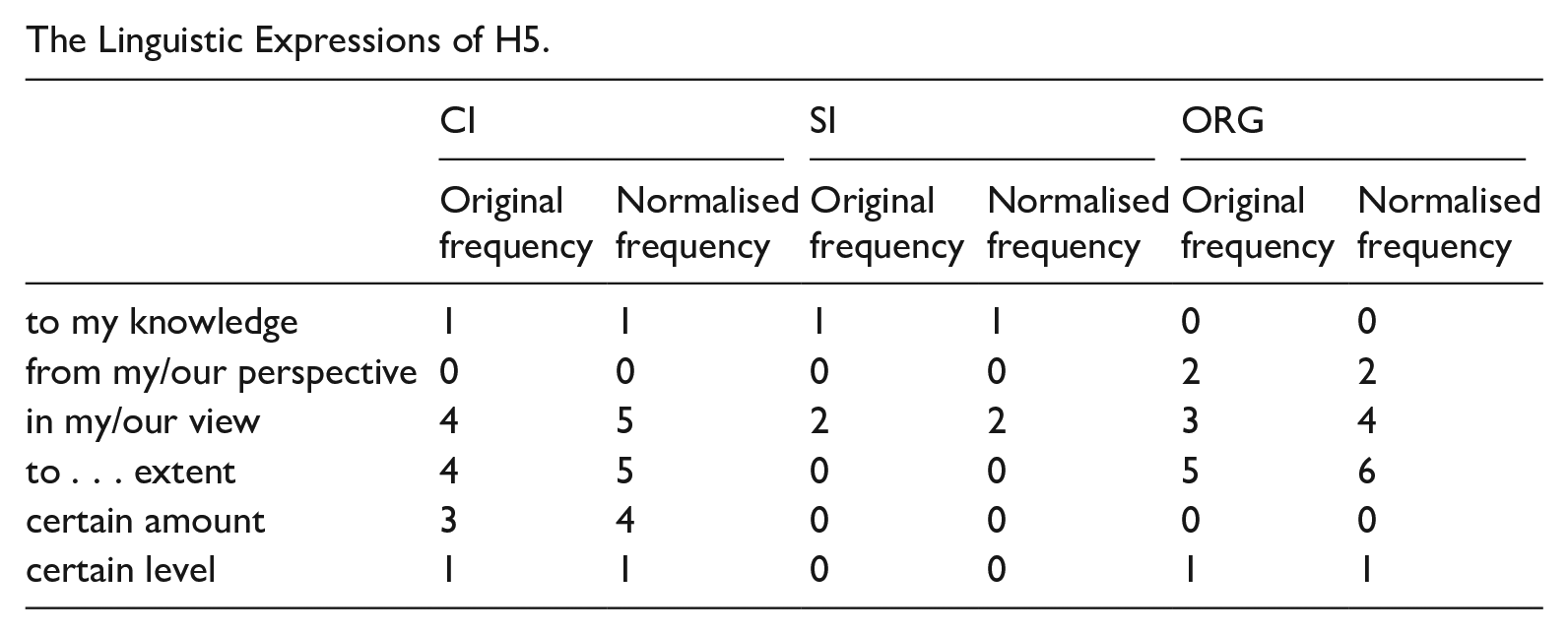
Table 3 shows the normalised frequencies of hedges in each individual category across the three sub-corpora. The percentages of hedges in relation to the total are provided to illustrate the relative distribution of hedges among the various categories. In addition, to offer a comprehensive view of the data’s distribution, we employ boxplots to visually demonstrate the median values of both total and by-category hedging frequencies in different sub-corpora (see Figures 1 to 5). It is worth noting that the category of H5 contains scarce instances in our corpus, and therefore, we have chosen not to present a visualisation of this particular data.
Normalised Frequencies and Percentages of Hedges in CI, SI, and ORG.
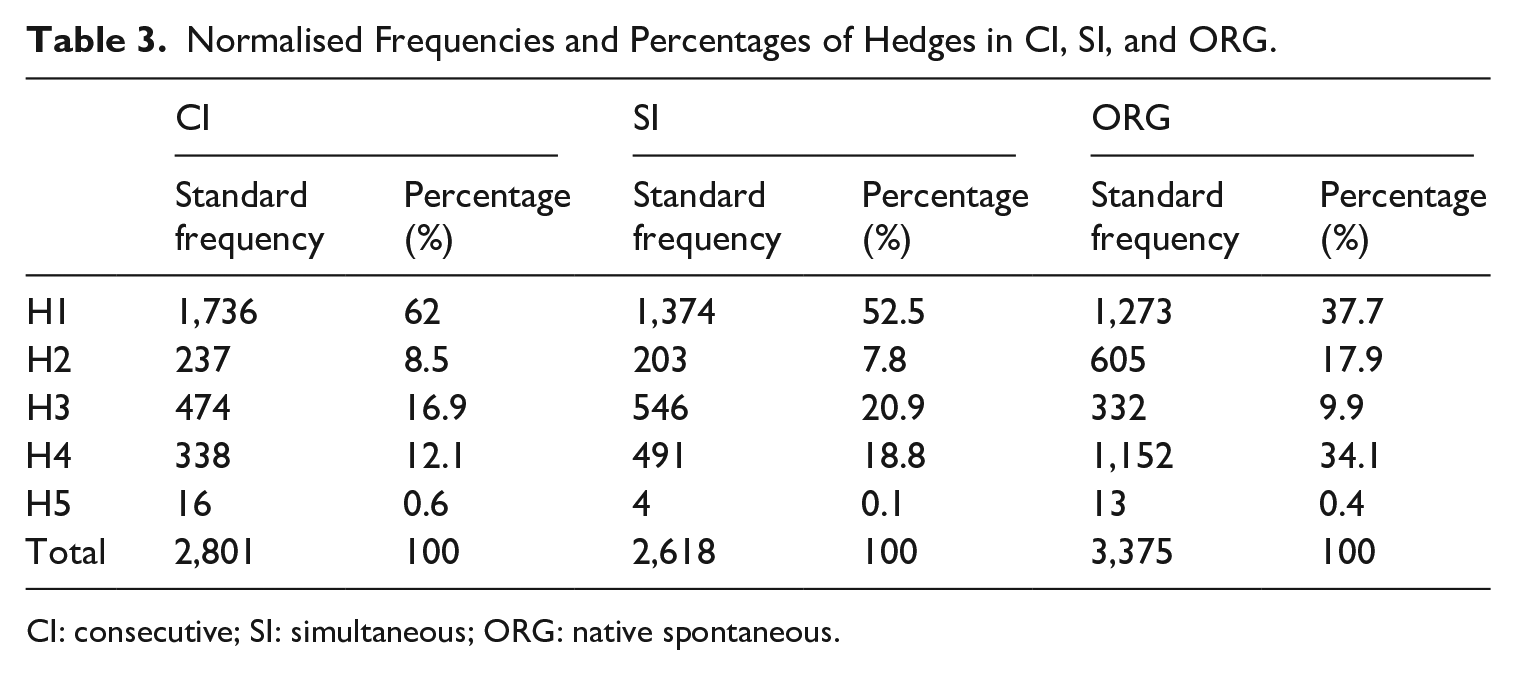
CI: consecutive; SI: simultaneous; ORG: native spontaneous.
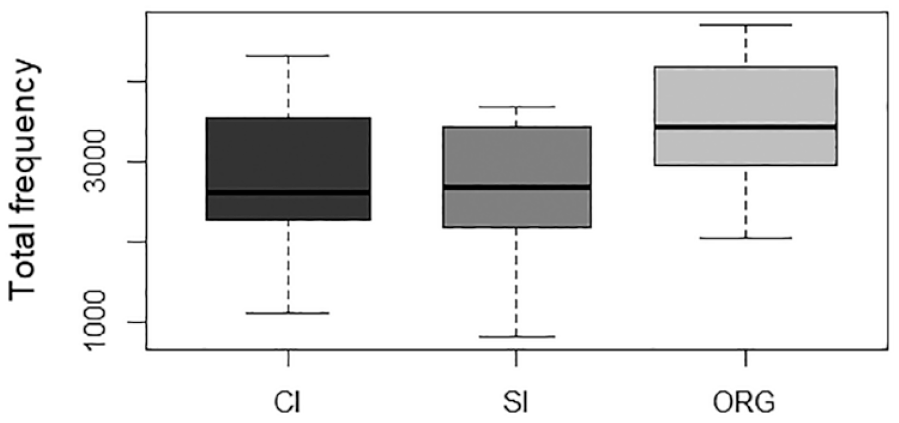
Total Normalised Frequencies of Hedges.
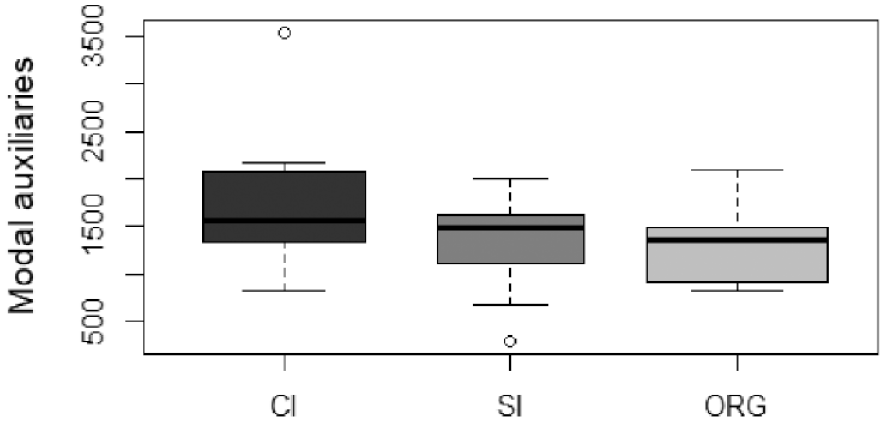
Normalised Frequencies of H1.
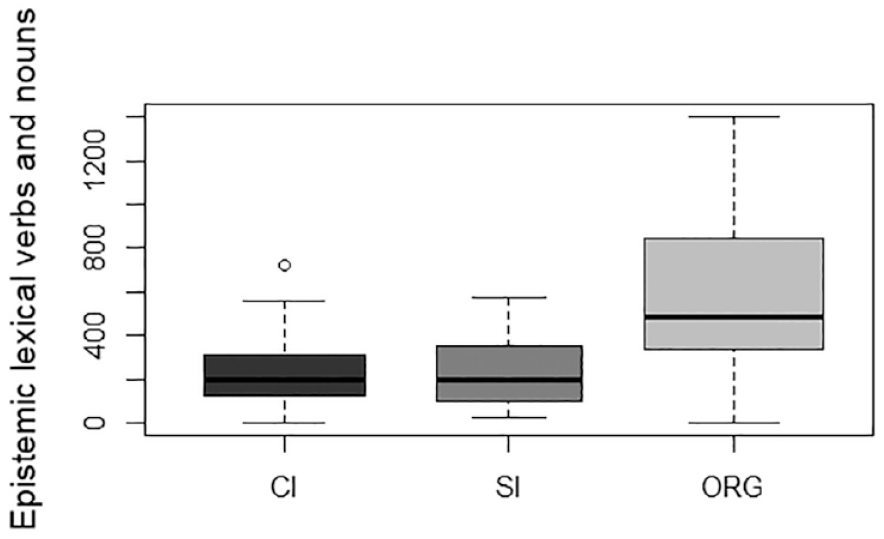
Normalised Frequencies of H2.
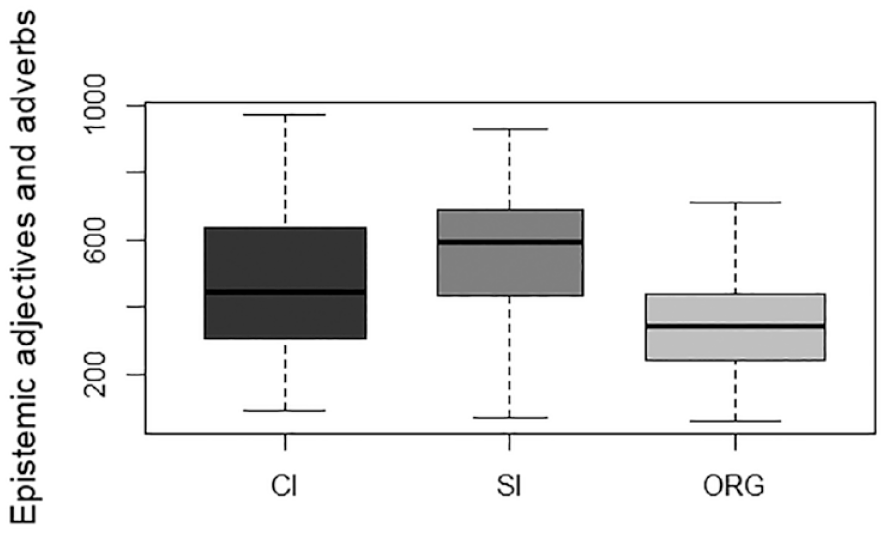
Normalised Frequencies of H3.
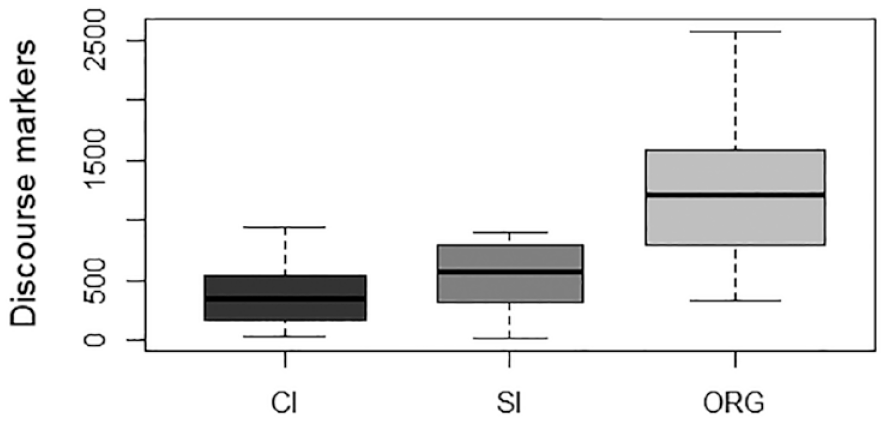
Normalised Frequencies of H4.
Table 3 highlights the notable patterns in hedging usage among the different sub-corpora. Hedges employed in CI and SI exhibit more similarities when compared with the disparities observed between ORG and CI/SI, suggesting a shared approach to conveying uncertainty and vagueness in the two interpreting modes. Among all three sub-corpora, the most prevalent type of hedges falls under the category of H1 (modal auxiliaries). However, significant differences emerge in how hedges are applied in interpreted and non-interpreted English. Specifically, interpreters rely less on category H2 (epistemic lexical verbs and nouns) to convey indeterminacy compared with native speakers who use these resources roughly twice as much. Regarding the usage of category H3 (epistemic adjectives and adverbs), their frequency in ORG is almost halved compared with that in CI and SI. On the contrary, the category of H4 (discourse markers) shows a noteworthy contrast, as fewer linguistic features of this kind are used in interpreted English than non-interpreted English. Finally, hedges pertaining to the category of H5 (miscellaneous) appear to be infrequent across all three sub-corpora.
The trends depicted in Figures 1 to 5 provide further support for the above analysis. In general, the ORG sub-corpus contains more hedges on average compared with either of the two interpreting sub-corpora, suggesting that native English speakers tend to use hedges more frequently than interpreters working in CI and SI. However, a closer examination of individual categories reveals different patterns in the choice of hedging expressions between interpreted English and non-interpreted English. While both rely on modal auxiliaries as the primary means to express varying degrees of uncertainty, non-interpreted English demonstrates an increased use of non-prototypical forms of hedges, such as epistemic lexical verbs and nouns and discourse markers (see Figures 3 and 5, respectively).
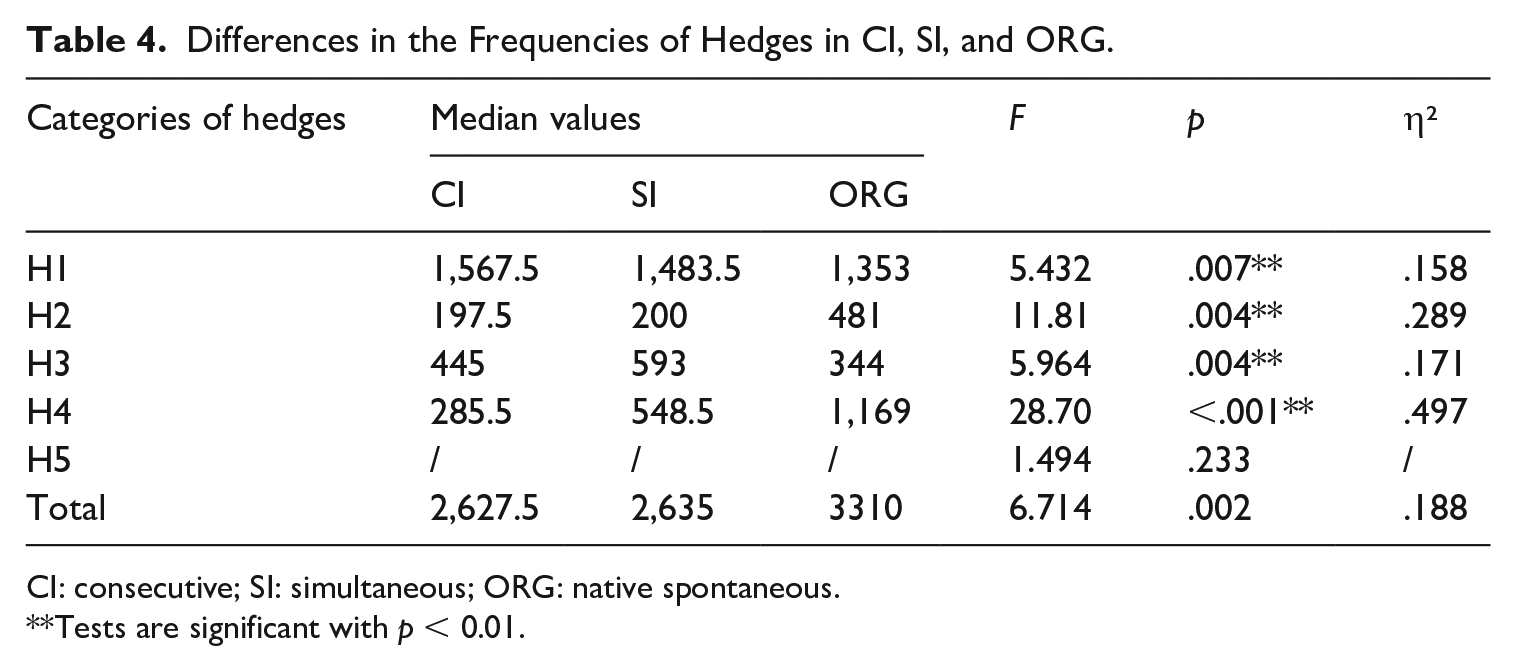
These observations are further corroborated by the results of subsequent statistical testing (see Tables 4 and 5). Specifically, significant differences are found among the three sub-corpora in the use of hedges within the categories of H1, F(2, 58) = 5.432, p = .007, H2, F(2, 58) = 11.81, p = .004, H3, F(2, 58) = 5.964, p = .004, H4, F(2, 58) = 28.70, p < .001, and Totals, F(2,58) = 6.714, p = .002. The effect sizes (η²) for these categories range from 0.158 to 0.497, which can be described as high. However, for the category of H5, the difference does not seem to reach significance in the three sub-corpora, F(2, 58) = 1.494, p = .233.
Differences in the Frequencies of Hedges in CI, SI, and ORG.
CI: consecutive; SI: simultaneous; ORG: native spontaneous.
Tests are significant with p < 0.01.
Pairwise Comparisons of the Frequencies of Hedges in CI, SI, and ORG.
CI: consecutive; SI: simultaneous; ORG: native spontaneous.
Tests are significant with p < 0.05.
Tests are significant with p < 0.01.
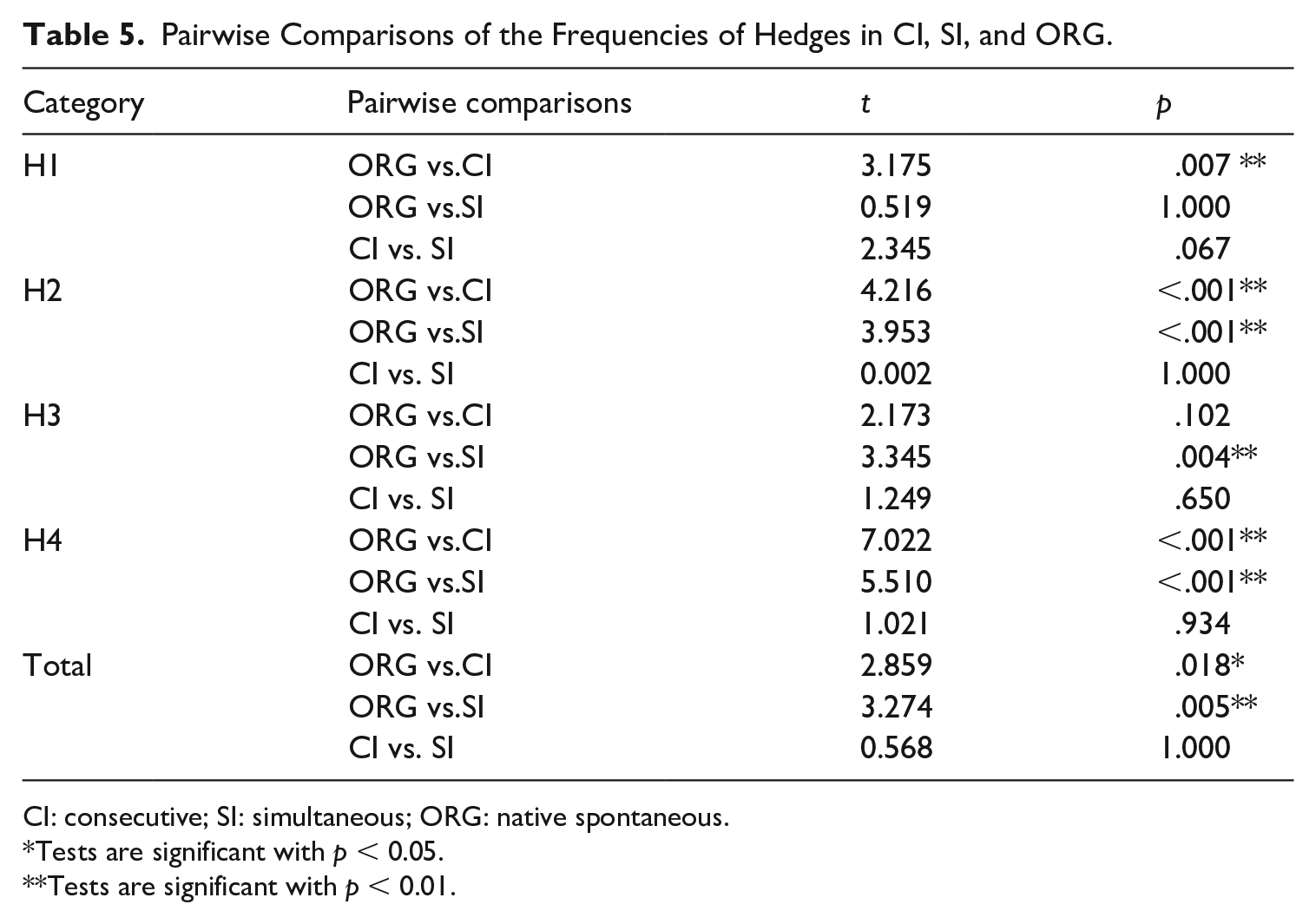
Building upon the results in Table 4, Table 5 provides more insights into the differences in hedges between interpreted and non-interpreted English on one hand, and simultaneously interpreted and consecutively interpreted English on the other. Pairwise post hoc t-tests confirm significant differences in the use of hedges between interpreted English and non-interpreted English. Specifically, in terms of the total normalised frequency of hedges, post hoc pairwise comparisons reveal considerable variations between ORG and the two interpreting corpora, indicating a significantly lower frequency of hedges in both CI (t = 2.859, p = .018) and SI (t = 3.274, p = .005) than in ORG. Moreover, a more detailed analysis of category H2 demonstrates that ORG exhibits significantly higher usage of hedges compared with CI (t = 4.216, p < .001) and SI (t = 3.953, p = .001). Similarly, for the category of H4, significant differences are observed between ORG and CI (t = 7.002, p < .001) and between ORG and SI (t = 5.510, p < .001). All these findings seem to suggest that native speakers tend to employ hedges more frequently than interpreters.
Interestingly, the statistical analyses also indicate that hedging in CI and SI differs from that in ORG in inconsistent ways. For example, the category of H1 demonstrates a statistically significant difference between ORG and CI (t = 3.175, p = .007), but not between ORG and SI (t = 0.519, p = 1.000). On the contrary, the difference in the category of H3 only approaches significance between ORG and SI (t = 3.345, p = .004), but not between ORG and CI (t = 2.173, p = .102).
To sum up, our quantitative results reveal significant variations in the use of hedges among the three speech types. Comparatively, the frequencies of total hedges, H2, and H4 are significantly higher in ORG than in CI and SI. In contrast, the frequency of H1 is significantly lower in ORG than in CI, while the frequency of H3 is significantly lower in ORG than in SI. From a cross-modal perspective, the use of hedges shows no significant differences between CI and SI across all five categories. This might be seen as an indication that interpreters, whether working in consecutive or simultaneous mode, are highly similar in their choice patterns regarding the use of hedges.
4.2 Comparison of linguistic expressions
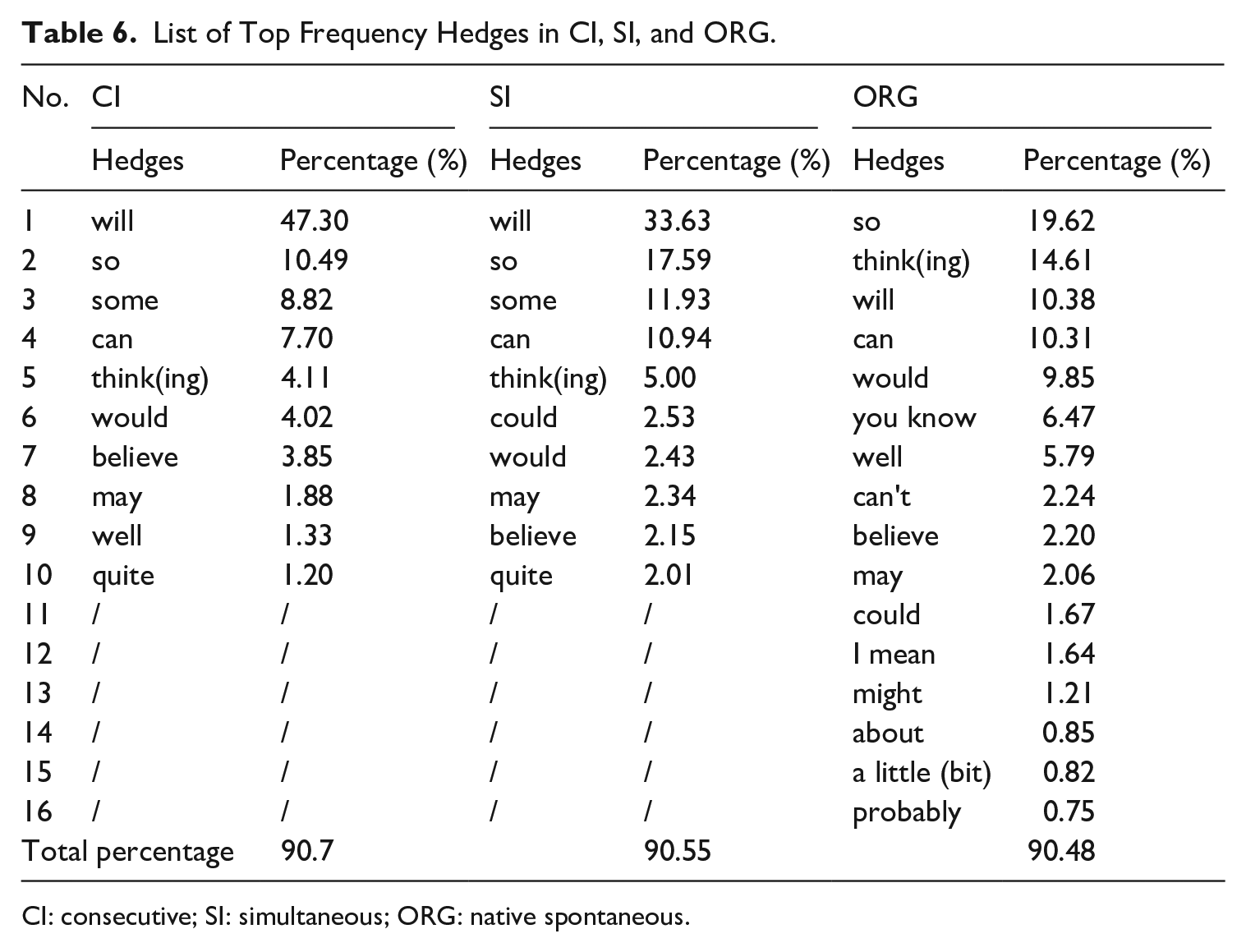
The foregoing analysis has provided a broad overview of the differences in hedging behaviours among the sub-corpora of CI, SI, and ORG. Building upon these findings, this section aims to conduct a more in-depth exploration of such differences at a lexical level. The focus is on identifying major linguistic expressions that contribute significantly to these distinctions. Specifically, we compare hedges that occur with high frequency in each sub-corpora and search for regularities concerning their lexical forms and occurrence patterns. To accomplish this, a list of hedges is generated for each sub-corpus, comprising expressions whose combined frequencies account for more than 90% of the total occurrences of hedges in that sub-corpus. These identified hedges are then arranged in descending order of percentage to facilitate by-corpus comparison (see Table 6 for detailed results).
List of Top Frequency Hedges in CI, SI, and ORG.
CI: consecutive; SI: simultaneous; ORG: native spontaneous.
The majority of vagueness in interpreted English, as can be seen in Table 6, can be attributed to a small set of hedges. This is in stark contrast to non-interpreted English, which showcases a relatively rich collection of similar linguistic devices. The striking disparity in the distribution of hedges echoes the findings in Fu and Wang’s (2022) study, in which they claim that interpreted speeches not only contain far fewer hedges than spontaneous ones but also exhibit reduced lexical diversity in their linguistic choices. The observation thus serves as further evidence for lexical simplification in interpreted language when compared with non-interpreted language.
Surprisingly, the high-frequency hedges in CI and SI are not only similar in number but also in form, with only two exceptions identified. In particular, the top five hedges used in both CI and SI are completely identical. While this finding lends further support to the converging patterns of the use of hedges in CI and SI, it also raises fresh questions about the potential impact of interpreting mode on the interpreter’s output in the target speech. In addition, it is interesting to note that interpreted English and non-interpreted English tend to show distinct preferences for hedges to convey varying degrees of uncertainty. The occurrence of “some,” for example, is highly frequent in CI and SI, making it the dominant form in the H3 category. However, its use is fairly limited in ORG (also see the Appendix). Arguably, the significant difference in the category of H3 between SI and ORG can be attributed to the greater prevalence of “some” in the former compared with the latter. Likewise, the extensive use of “you know” is a distinctive feature of non-interpreted English, in contrast to its occasional appearance in CI and SI. This difference explains why the proportions of the category H4 are significantly lower in CI and SI than that in ORG. In general, these findings suggest that interpreters tend to use similar hedging strategies regardless of the interpreting mode when translating into English. In addition, their interpretations have far fewer hedges and show less variation compared with non-interpreted English.
5. Discussion
The present study represents one of the few attempts to juxtapose linguistic features in CI with those in SI, despite the existence of many studies comparing interpreted and non-interpreted speeches. The results of our study show that interpreted English contains significantly fewer hedges than spontaneous spoken English, reaffirming the conclusions of a recent study by Fu and Wang (2022) from a comparable and cross-modal perspective. However, no substantial differences in the occurrence of hedges were found between CI and SI speeches, suggesting that the use of such linguistic devices might be equally constrained in both interpreting modes. In the following part, we will first discuss the potential implications of our findings from a comparable perspective, focusing on interpreted and non-interpreted English. We will then provide reflections on our results from a cross-modal perspective, focusing on the output of CI and SI.
Overall, interpreted English, whether in CI or SI, tends to contain significantly fewer hedges than non-interpreted English by native speakers. Hedging, from a functional perspective, is essentially interpersonal in nature. It does not add to the propositional content, but affects the interpretation of such content (Crismore et al., 1993, p. 40). In the context of interpreting, which is an extreme form of translation, the focus is on conveying messages “centred on information rather than emotions” (Gile, 2009, p. 4). Consequently, the production of hedges, which does not contribute directly to the core information in the target speech, tends to be overshadowed by the transfer of more important meaning-bearing elements. In other words, interpreters may prioritise conveying key information over employing hedges to ensure clarity and avoid potential misinterpretation.
Furthermore, the influence of speech rhetoric conventions on hedges is non-negligible when comparing interpreted and non-interpreted English. While the settings of both types of speeches may appear similar (i.e., political press conferences), the socio-cultural context in which they are embedded can shape communication styles differently. In the Chinese context, philosophical traditions like Confucianism and Taoism may foster a communication style that prioritises understanding truth and reality rather than engaging in verbal debate and argumentation (Peng & Nisbett, 1999, p. 747). It follows that the use of hedges which signal uncertainty in the truth of a statement may be less prevalent in communication within such a context. Interestingly, there is recent evidence showing that interpreters tend to add hedges not present in the corresponding source speech (Magnifico & Defrancq, 2017). What this means for the present study is that the relative underuse of hedges in the interpreted English versus non-interpreted English could be a result of interpreters adding such linguistic devices non-existent in the Chinese source speeches. It suggests, on the surface, that interpreters and native speakers follow divergent patterns in the use of hedges; however, it ultimately reflects the sharp contrast in speech rhetoric conventions between Chinese and American contexts.
On one hand, interpreter-mediated government press conferences in China basically follow a structured format. The question–answer session often commences with the moderator inviting one journalist to raise a question, which is then rendered consecutively into English or Chinese depending on the language the journalist uses. The spokesperson then responds in Chinese, and their response is interpreted either consecutively into English during pauses or simultaneously when the answer is complete. Further interactions between the spokesperson and each questioning journalist are rare once the interpretation of a full response is delivered. This structured setup tends to foster speech production that is mainly one-way. Consequently, speakers, as described by Lauwereyns (2002, p. 242), “are most likely to choose a formal style of language and the use of hedges as solidarity markers may be absent.”
On the other hand, communication in the American government press conferences seems to take a different approach. Spokespersons engage in frequent exchanges with journalists on the same topic and may be more open to abrupt interruptions, follow-ups, cross-questions, and so on. This could forge a communication pattern that allows for debate and discussion, thus increasing the chances to hedge when expressing uncertainty or qualifying statements.
Turning to the cross-modal perspective, the results from the present study fail to distinguish between the linguistic products of CI and SI, aligning with similar findings from recent research (Fu & Wang, 2021; Lv & Liang, 2019). However, the lack of significant differences in hedging between the two interpreting modes, both in total or by category, appears counter-intuitive, considering the presumed disparities in cognitive operations involved in CI and SI (Gile, 2009). In his Effort Models, Gile (2009) posits that the process of interpreting involves the management of different “efforts” (i.e., listening and analysis, memory, production, etc.), each demanding the interpreter’s limited mental resources. To avoid cognitive saturation, the combined requirements of these tasks should not exceed the limits of the available mental energy for each individual effort, especially when multiple-tasking is active. As far as the two interpreting modes under discussion are concerned, such threats are less likely to emerge during the production phase in CI than in SI, because “the effects of interpreting constraints on production are stronger in simultaneous than in consecutive” (Gile, 2009, p. 165). This view has, however, not been borne out by the results of the present study.
From a methodological standpoint, it should be noted that corpus size remains a major challenge for researchers examining the products and processes of interpreting and making safe generalisations. While technological progress has facilitated some aspects of corpus-based interpreting studies, difficulties persist in obtaining and processing a large amount of representative data. Therefore, despite using a larger interpreting dataset compared with similar investigations (cf. Ferraresi et al., 2018; Fu & Wang, 2021; Lv & Liang, 2019), the present study provides only a partial perspective on whether the products of CI differentiate themselves from those of SI. Pending further research based on even larger datasets, the possibility of any diverging patterns of linguistic features between CI and SI should not be ruled out.
6. Conclusion
This study has revealed some interesting tendencies with regard to the use of hedges in interpreted and non-interpreted English speeches produced in the setting of political press conferences. It confirms prior findings, underscoring that interpreted English tends to contain far fewer hedging devices than non-interpreted English. This phenomenon can be attributed to diverse constraints faced by interpreters, including cognitive pressure, interactive structure, and source-language-related speech rhetoric conventions. Consequently, interpreted English in the Chinese context appears to show a higher degree of certainty and assertiveness compared with non-interpreted spoken English in the American context. Moreover, the study indicates that interpreted English, whether in CI or SI, depends on a narrower range of hedging devices, with a handful of linguistic features contributing to the majority of vagueness in the interpreter’s production. This alignment with the simplification hypothesis in corpus-based translation studies, which posits translated texts tend to be simpler than original target language texts (Baker, 1993), supports the notion that interpreted language may exhibit some characteristics of a translated variety.
The finding of interpreters working in consecutive and simultaneous mode demonstrate largely similar hedging patterns comes as somewhat unexpected, as only minor differences were identified in total number and in by-category comparisons of normalised frequency. This preliminary observation might suggest that the interpreting mode has limited impact on the interpreter’s use of fewer propositional items in the target speech. However, drawing definitive conclusions from a comparable and cross-modal perspective is premature, as the distribution of hedges in the Chinese source speeches for the CI and SI sub-corpora remains unknown. Conducting a systematic study involving a source–target language comparison would certainly shed additional light on the potential influence of interpreting mode, but that requires a separate research endeavour.
To further illuminate the distinctiveness of the interpreting product as a variety of translated language, future research is also expected to expand the data for analysis and take more linguistic dimensions into consideration. Although converging patterns of hedging in CI and SI might challenge the notion that the two interpreting modes are cognitively constrained to varying degrees, continued examination of various specifics involved in interpreting will allow us to gather “a consistent body of evidence which will progressively refine the initial hypotheses and give rise to further, more precise predictions” (Laviosa, 2002, pp. 63–64).
Footnotes
Appendix
The Linguistic Expressions of H5.
| CI | SI | ORG | ||||
|---|---|---|---|---|---|---|
| Original frequency | Normalised frequency | Original frequency | Normalised frequency | Original frequency | Normalised frequency | |
| to my knowledge | 1 | 1 | 1 | 1 | 0 | 0 |
| from my/our perspective | 0 | 0 | 0 | 0 | 2 | 2 |
| in my/our view | 4 | 5 | 2 | 2 | 3 | 4 |
| to . . . extent | 4 | 5 | 0 | 0 | 5 | 6 |
| certain amount | 3 | 4 | 0 | 0 | 0 | 0 |
| certain level | 1 | 1 | 0 | 0 | 1 | 1 |
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.