
Abstract
Personality traits are often measured using person-descriptive terms, but data are limited regarding the frequency of usage for these terms in everyday language. This project reports on the relative frequency of usage for a large pool of American English terms (N = 18,241) using count estimates from search engine results and in books cataloged by Google. These estimates are based on the ngrams formed when each descriptor is combined with a common person-related noun (person, woman, man, girl, boy). Results are reported for each noun form and a frequency index in an online database that can be sorted, searched, and downloaded. We report on associations among the different noun forms and data types and propose recommendations for the use of these data in conjunction with other resources. In particular, we encourage collaborative approaches among research teams using large language models in psycholexical research related to personality structure.
Keywords
Many prominent personality models have a theoretical basis in the lexical hypothesis, which assumes that relevant personality characteristics have become instantiated in natural language, thereby allowing the structure of human personality to be studied with person-descriptor terms. Based on this idea, trait descriptive terms have often been compiled into lists that were subsequently sorted, grouped, clustered, factor analyzed, and later revised (see John et al. (1988) for a detailed review). In order to address the limitations of cumbersome data collection based on self- and other-ratings with these terms, longer (and more diverse) lists were usually reduced down to only a few hundred descriptors at most. Typically, the procedures used to shorten these lists have relied upon subjective judgments of various criteria — one of the most prominent being the perceived, relative familiarity of terms (e.g., Ostendorf et al., 1990).
The quality of familiarity is challenging, however, in at least two respects. The first relates to the source of the familiarity judgment. Personality science has largely relied on expert judgments involving one or two researchers working independently — e.g., Cattell (1943, 1945), Goldberg (1981, 1982, 1992), Norman (1963, 1967), Peabody (1967, 1984). The degree to which these and other researchers have been accurate in their assessments of population-level familiarity is itself a subjective question. Occasionally, data from larger samples of raters have been gathered to determine consensus about the meaning of terms (Condon et al., 2022) or their usefulness (Ashton & Lee, 2001), but few resources have been developed with the specific goal of evaluating the familiarity of personality descriptors across a large population.
The second challenge stems from a lack of clarity about how familiarity should be operationalized. In our view, the familiarity of a term is best estimated by the likelihood that a speaker would encounter the term, either in written form or conversation. In other words, familiarity is approximated by frequency of usage.
This operationalization is related to the notion of lexical difficulty, though the ideas are importantly distinct. Words with lower lexical difficulty will, on average, be used more widely as they are accessible to a wider range of people; less difficult words tend to be more frequently used and more familiar, all else being equal. The concepts are not interchangeable, however, as they will sometimes be conflated with other characteristics, such as ambiguity in the meaning of terms across time and/or sub-populations (e.g., “cool”) or the relative salience of the underlying personality aspects. In the latter case, compare the terms “nosy” and “optimistic.” The former is typically acquired at a much younger age than the latter (4th vs. 10th year of schooling; Brysbaert & Biemiller, 2017), but the present work suggests that the latter is used more frequently as a personality descriptor. With these two challenges in mind, the aims of the current project were to operationalize the frequency of personality-descriptive terms as a quantifiable characteristic, if possible, and to make the results available for use in subsequent personality research.
Relevance of frequency for personality descriptors
One of the primary motivations for identifying the frequency of usage of person-descriptors is because of its relevance to factor analysis. It has long been recognized that the results of these analyses are highly dependent on the subset of variables chosen for factoring (i.e., the correlations among the variables). For many psychologists, this observation may seem intuitive, but its consequence is paramount in that the models produced by factoring influence the scales/instruments that are later used for measurement. Saucier (1997), for instance, found that stable three-factor structures of personality could be reliably produced from subsets of large personality-descriptor terms regardless of the selection criteria used for subsetting. Five-factor structures, by contrast, were much less stably produced, and depended more on the nature of the selection criteria used to subset the pool of terms. While this work (Saucier, 1997) focused mainly on the content of terms, others have shown similar evidence for the term-frequency criteria specifically (De Raad et al., 2018; Thalmayer et al., 2021). These findings serve to emphasize the importance of using selection criteria that are transparent, empirically-informed, and robust.
A second motivation stems from recognition that the frequency of terms has sometimes been excluded as a relevant characteristic of personality stimuli. For example, some of the most influential subsets of terms used in identification of the Big Five (Goldberg, 1990, 1992) were formed with dimensional bipolarity as a more central characteristic than frequency of use in everyday descriptions of personality. Bipolarity simply means that some terms were retained/chosen in order to allow for dimensional assessment across paired antonyms: “cautious” was paired with “uncautious” and “maidenly” with “unmaidenly.” In several cases, this resulted in the inclusion of terms that cannot be reliably understood, even in context, by most native English speakers (“unmercenary”, “unimpressible”; Condon et al., 2022). At the same time, many terms were excluded despite frequent usage in everyday language (e.g., “discouraging”, “nerdy”). In our view, the centrality of term frequency has likely been overlooked due to the lack of a comprehensive analysis of the relative frequency of the full pool of terms. Thus, the goal of the present study was to provide frequency usage data for person-descriptive terms spanning the entire English language.
Quantifying term frequency
Multiple methods have been proposed to determine the frequency-of-usage for terms (Leising et al., 2014; Motschenbacher & Roivainen, 2020; Wood, 2015), but we focus especially on the approach suggested by Roivainen (2013). He proposed that internet search results and frequencies in books are useful indices of the relative frequency of usage across descriptors, and reported these values for the 435-term list previously used by Goldberg (1992) and Saucier and Goldberg (1996). To get these values, Roivainen (2013) performed a Google Web Search™ for “bigrams” consisting of one of 435 trait adjectives given by Saucier and Goldberg (1996) and the noun ‘person’ (e.g., “friendly person”). For the top 100 bigrams, he then extracted the yearly counts from the Google Books™ Ngram Viewer (Michel et al., 2011), a tool charting the yearly count of bigrams in books digitized by Google.
Despite search engine results and book frequencies being substantially correlated in his work (r = .58 for search results in 2012 and counts in the books cataloged in 2000), these approaches reflect different contexts of language use. Frequencies in books should be expected to reflect usage among more literate, published authors, and – for Google Books – this approach has the benefit of being permanently archived. Search engine results, by comparison, should be expected to capture frequencies of usage in less formal contexts, on average. Furthermore, they tap into knowledge graphs (Hogan et al., 2021) with broader domain coverage than published books (Paulheim, 2017; Pechenick, 2015). That said, these results are more difficult to interpret and track, as search engines use unique, opaque, evolving, and proprietary algorithms. This might contribute to the observation that thousands of research projects have made use of Google Books Ngram data (Michel et al., 2011), but counts from search engine results have been less widely reported in scientific research. Note, that additional resources are available for evaluating the frequency of use of specific words (Brysbaert et al., 2019; Davies et al., 2010), but these are less useful for evaluating the frequency of usage in specific contexts, such as personality description. For example, they do not allow for the evaluation of bigram frequency.
To expand the search-results approach introduced by Roivainen (2013), we included a larger pool of trait descriptive terms, with the expectation that this may broaden the utility of our data to personality structure research making use of language models (aka natural language processing techniques; Cutler & Condon, 2023; Jackson et al., 2021). Such models include, for example, “AI” transformer-encoder models (Brown et al., 2020; Devlin et al., 2019; He et al., 2021) that are unlike traditional survey-based approaches which require ratings of each descriptor from individual raters. Large language models allow for analyses of much larger sets of terms because they are not constrained by the attention and fatigue limits of human raters. Therefore, it is possible to include many thousands of trait descriptive adjectives in analyses of personality structure (Cutler & Condon, 2023) and in turn characterize the full universe of person descriptors on various features, including the extent to which they are commonly used. While it may also be important to characterize the descriptors according to other criteria as well, the frequency of usage estimates are particularly useful for identifying a subset of terms that can be considered reasonably comprehensive. In other words, knowing the frequency of use statistics will allow us to focus on the terms that matter and ignore the terms that are not widely used.
In addition to broadening the pool of trait descriptive terms, we also sought to include more than just one bigram. This is because the noun “person” is overly general and it seems likely that frequency of use varies depending on the gender and age of the target being described. (Similarly, frequency of use is likely to vary according to characteristics of the individual making the description, but these data are not available in the current context.) For example, both stereotypes and prior personality research may prompt expectations that the term “friendly” is used more frequently in combination with the nouns “woman” and “girl”, whereas the term “assertive” might be more frequently used in combination with the nouns “man” or “boy”. 1 Capturing frequency estimates for the personality terms in combination with these additional nouns (man, woman, boy, girl) would allow for the evaluation of such effects.
Thus, the current work sought to estimate the frequencies of use for a maximally inclusive set of person descriptors. This was done by generating two indices of frequency estimates that are considerably more extensive than prior reports, with five “descriptor + noun” forms instead of one and 42 times as many descriptors.
Hypotheses
This work was intended to be primarily descriptive in that we pre-registered the intention to collect the term frequency data and make it easily usable for future research. Despite the descriptive character of the project, however, several hypotheses were included with the pre-registration (https://osf.io/9br67). First, we expected all forms of the descriptor + noun ngrams to be highly correlated in the Google Books results and, separately, in the Google Web Search results. Specifically, we expected all correlations to be above .7 for “[descriptor] + person”, “+ woman”, “+ man”, “+ girl”, and “+ boy”. Second, we expected the search results to be moderately to highly correlated with the frequencies in Google Books (rs > .5; Michel et al., 2011), and for both types to be highly correlated with the frequencies reported by Roivainen (2013) for the overlapping terms (rs > .7). Third, we expected to find differences among the correlations between ngrams such that (1) “man” and “woman” would be more closely associated to “person” than “boy” and “girl” are associated with “person”; (2) “man” and “woman” would be more closely associated to one another than they are to either “boy” or “girl” and vice versa; (3) the terms would be more highly correlated within gender (i.e., “man” to “boy”) than across (“woman” to “boy”); and (4) each of the five forms would be most highly correlated with the overall index derived using a “leave one out” average. For the last of these, the index was calculated by dropping the ngram with the most counts (leave one out), and this was done to reduce the influence of outlier ngrams (e.g., those that formed proper nouns or works of art).
We also pre-registered less well-specified, directional expectations that ordering of the ngram variables by z-score difference relative to the index for each descriptor would reflect stereotypical age and gender social roles (for extended review of this topic, see Motschenbacher & Roivainen, 2020). For example, “man” and “woman” were expected to have higher z-scores for “dangerous” and “experienced”; “boy” and “girl” were expected to have higher relative z-scores for “youthful” and “innocent.” However, we generally expected similar averages of search results (across all terms) for the “woman”, “man”, “girl”, and “boy” forms.
Finally, and perhaps most importantly, we expected that many of the descriptors would have consistently low counts for 4 or 5 of the ngram forms. Of the 2818 terms in Condon et al. (2022), we expected 10%–30% would produce relatively few search results and/or no occurrences in recent books. This would suggest that these terms are rarely, if ever, used to describe personality in everyday language. To clarify the rationale for specifying 4 or 5 of the 5 possible ngram forms, we expected that some ngrams would have an unpredictably large number of search results for only one form due to the unexpected formation of culturally meaningful ngrams, such as proper nouns or works of arts (e.g., song titles, fictional characters). Put simply, we expected the raw frequency data to be very noisy.
Note that data collection deviated from the pre-registration in one important respect. The initial scope of the project included only the 2818 descriptors reported in Condon et al. (2022). However, the results of a related project (Cutler & Condon, 2023) demonstrated that future research on personality structure need not be limited to relatively small sets of person-descriptive terms, and this prompted the decision to proceed with data collection for a much more comprehensive list, as described below.
Method
Materials
A total of 18,241 person-descriptors were used to form ngrams with each of 5 nouns indicating individual persons. The nouns were “person”, “woman”, “man”, “girl”, and “boy”. The person descriptors were aggregated from several resources, though the majority of content overlapped with the large pool of descriptors published by Allport and Odbert (1936), who provided “a tabulation of all the trait-names in the English language, — all at least that are included in Webster’s [1925] unabridged New International Dictionary” (p. vi, Allport & Odbert, 1936). Note that the number of unique terms in this list – 17,913 – is slightly less than the count claimed in the original publication (17,953). To account for the possibility that the Allport and Odbert list was incomplete, many additional lists were considered, including the overlapping lists of Norman (2797 terms; 1967), Anderson (555 terms; 1968); Goldberg (1710 terms; 1982), Chandler (1042 terms; 2018), and Condon et al. (2818 terms; 2022). Collectively, these lists contained approximately 600 terms that were not included in the Allport and Odbert list, but only 359 additions remained after removing alternate spellings, type-nouns, and slang or vulgar terms. Similarly, 31 terms from the Allport and Odbert list were deprecated because they were alternative spellings of a single descriptor (i.e., only one form of a hyphenated and non-hyphenated version of the descriptor was kept), or because they were no longer widely accepted for use as descriptors (i.e., derogatory or excessively inappropriate descriptors).
It is also important to emphasize the over-inclusive nature of this list. Despite stating that “each single term specifies in some way a form of human behavior” (p. vi, Allport & Odbert, 1936), the authors later clarify (and close inspection confirms) that the main criteria for inclusion were based on “the capacity of any term to distinguish the behavior of one human being from that of another” (p. 24). The difference is slight but meaningful, as few of the terms specify behavior. Most could be classified as qualifiers or descriptors of behavior, though a substantial minority of the terms are non-psychological (e.g., demographic or occupational classifiers, physical attributes). Similarly, most of the terms are adjectives (specifically, descriptive adjectives, including many past and present participles), though there are also many “type” nouns (e.g., martyr, slob, clown). Several of the terms are not typically considered part of American English (e.g., acharné, auld-farrant, concitato, dégagé).
In addition, a large proportion of the terms are uncommon and/or unfamiliar. In an attempt to address the cumbersome length of this list, the original authors separated the terms into four groupings based on familiarity and expected utility, though they acknowledge that their procedure relied on several arbitrary decisions. Rather than subset from this list based on these arbitrary criteria or some other method, we used the full list to collect frequency estimates in the current work with the expectation that these estimates will facilitate less arbitrary procedures for subsetting in the future. Still, some of the terms were sufficiently uncommon that they were not used at all with one or more of the noun types (indicated by the absence of numeric values in the available data).
Procedure
The data were collected in January 2022. Data collection procedures generally followed those described by Roivainen (2013). For search engine results, frequency of usage was operationalized as the number of results shown for internet searches for each ngram. Correspondence with Roivainen suggested that commercial/proprietary features of the search engine algorithm may alter the number of search results returned based on attributes of the client. As Google Web SearchTM is a proprietary tool, the method by which it indexes web content is opaque, though the search results are known to be dependent on more factors than just semantic frequency (Paulheim, 2017; Pechenick, 2015). This was confirmed with pilot data collection, as inconsistent results were produced when using different combinations of browsers, operating systems, networking equipment, locations, and ngram forms. Pilot data collection (involving approximately 25 descriptors) also highlighted a tendency of the search engine to redirect searches for uncommon or potentially misspelled ngrams.
To address these concerns from piloting, we introduced three deviations from the procedures described by Roivainen (2013). The first involved extensive use of quotation marks. Specifically, all hyphens were replaced with spaces (causing some bigrams to become 3- or 4- grams), quotes were added around all individual words to ensure that no alternate spellings would be introduced, and additional quotes were included around all phrases to reduce the incidence of results being returned for reordered forms of the phrase. For example, the exact search entry for the bigram “self-reliant person” was: ““self” “reliant” “person””
Second, all searches were made from a novel browsing profile (without a search history) that was set to limit search results to the United States. Finally, we extended Roivainen’s approach beyond using only the noun “person”. This was primarily done to improve the signal/noise ratio produced when using only one noun. However, we also incorporated this change to evaluate the effect of using other common nouns referring to people, in a manner similar to Motschenbacher and Roivainen (2020).
For the Google BooksTM Ngram Viewer, frequency of usage was operationalized as the proportion of occurrences of the ngram in the total corpus of words cataloged for each year (Michel et al., 2011). Using the same example given above, the ngram search entry was: “self - reliant person”
Note that ngram searches require the use of spaces around the hyphen in hyphenated terms. We used the average of the most recently available 10 year period (2010–2019) in the American English corpus. Though data are available for prior years as far back as 1500, changes in frequency over time were not a focus of the current work.
Analyses
Our analyses were conducted in R (R Core Team, 2023), mostly using the “psych” package (Revelle, 2024). The analyses included reporting of descriptive statistics based on the raw data for both the search engine and books results. Prior to testing the preregistered hypotheses, we excluded multivariate outliers from the data. We calculated the Mahalanobis distance (D2) for each term across the five frequency vectors derived from the search engine results as well as across the five frequency vectors derived from the books. If either of these two D 2 values for a term was ≥3SD than the mean of the D 2 values within the respective set (i.e., the books or search engine set), the term was marked as an outlier and excluded from further analyses (Yuan & Zhong, 2008).
The hypotheses related to mean differences by noun form (e.g., “person”, “woman”) were evaluated in the raw data with pairwise t-tests within the two data sources (books or search engine). These results are presented with Holm and (separately) Bonferroni adjustments for multiple comparisons. All remaining analyses – and the publicly available data – were based on z-score transformations of the raw data within type and noun form. Indices of frequency were created for both types (books and search engine results) by averaging z-scores across the noun forms after removing the maximum z-score value across all 5 forms. This method for creating an index was used instead of the simple arithmetic mean to reduce the influence of arbitrarily inflated results that might occur if a specific ngram has meaning beyond the context of personality (i.e., in popular culture or media).
Correlational analyses were used to evaluate many of the hypotheses, including the associations between all of the descriptor + noun forms within the books results, within the search engine results, across the books and search engine results, and with the results reported in Roivainen (2013). As the frequency vectors had zero-inflated distributions more comparable to Poisson than normal distributions, we chose to report Spearman correlation indices along with 95% bootstrapped confidence intervals. Statistically significant differences in correlations were identified based on the absence of overlapping confidence intervals. Hypotheses about the organization of descriptors by noun form relative to the index were evaluated by sorting the z-scores for each bigram.
Note that these analyses represent some deviations from the pre-registration that were undertaken after the first submission of the manuscript. These included the use of Mahalanobis distance to identify and remove extreme outliers, the use of Spearman (instead of Pearson) correlations, and the decision to add analyses comparing the data to those described in Roivainen (2015). Another important deviation was undertaken during data collection: we expanded the collection of books data from only one year (our pre-registered plan was to use only 2019 data) to a 10-year window based on the realization that this was more feasible than originally expected.
Results
The supplemental materials for this project include databases containing all frequency estimates for both types in a format that is searchable and sortable. These databases can be found at https://pie-lab.github.io/tdafrequency. Both the data (https://doi.org/10.7910/DVN/BBOLVY) and the analysis code (https://osf.io/uc64v/?view_only=bfb348e3a8424b19bfdf812e4e088b35) are also openly accessible.
Tests for significant differences in means by noun form using the raw values (i.e., before z-scoring) indicated only two significant pairwise differences in means before correcting for multiple comparisons. These differences were between the “boy” and “man” bigrams (p = .01) and the “girl” and “man” bigrams (p = .03) in the books results; the “man” bigram was more frequent in both cases. Neither of these differences remained significant after correcting for multiple comparisons, and none of the means were significantly different in the search engine results.
Prior to analyses of the z-scored results, procedures for detecting outliers identified 21 terms for removal. The excluded terms were mainly not related to personality characteristics (e.g., “athletic”, “black”, “old”, “first”), though 3 of these terms – “reasonable”, “mature”, and “sexy” – were included among the list of 435 terms used in Roivainen (2013) and previously by Saucier and Goldberg (1996) and Goldberg (1990, 1992). Four additional terms were excluded from this list for various reasons (see the analysis code for more details), resulting in a final comparison set of 428 terms that were overlapping with Roivainen’s (2013) results. The full list of person-descriptors included 18,220 terms after removing outliers.
For the 428 overlapping descriptors, both the books and search engine results were highly correlated with the data collected by Roivainen: the search results were correlated .78 (95% CI [.74–.83]) and the books results were correlated .88 (95% CI [.84, .90]). Recall that the Roivainen search results were collected 10 years earlier (2012 vs. 2022), and the books results were based on books published in 2000 compared to the current results, which were averaged from 2010–2019. Note that these results are based only on the noun form common across studies (descriptor + “person”).
Correlations and 95% confidence intervals among noun forms in books and search results.

Note. Values in square brackets indicate the 95% bootstrapped confidence interval for each correlation. Index values for search and books are based on the average of the nouns for each data source after removing the largest value.
For the pairwise hypotheses among noun forms of the search engine results, the results supported only one hypothesis, namely that all of the search engine noun forms were most closely associated with the search engine index (r = .85–.96). Within the books, correlations between the noun forms were mostly higher than their correlation to the index variable, hence contrasting the results within the search engine. Furthermore, in contrast to the search engine results, for the books we found a pronounced gender effect for the female correlation (rwoman-girl = .73 > rman-girl = .60), but not within the male correlations. We also found an age effect, meaning that “woman” and “man” were more closely associated (r = .77) than either was with “girl” (rgirl-woman = .73; rgirl-man = .60) or “boy” (rboy-woman = .62; rboy-man = .59), and “girl” and “boy” were more highly associated (r = .80) than either was with “woman” or “man”. Correlations of the same noun forms across the books and search results were medium sized (Arithmetic Mean r = .57, SD r = .15).
The 10 most exclusive descriptors for each noun form and data type.
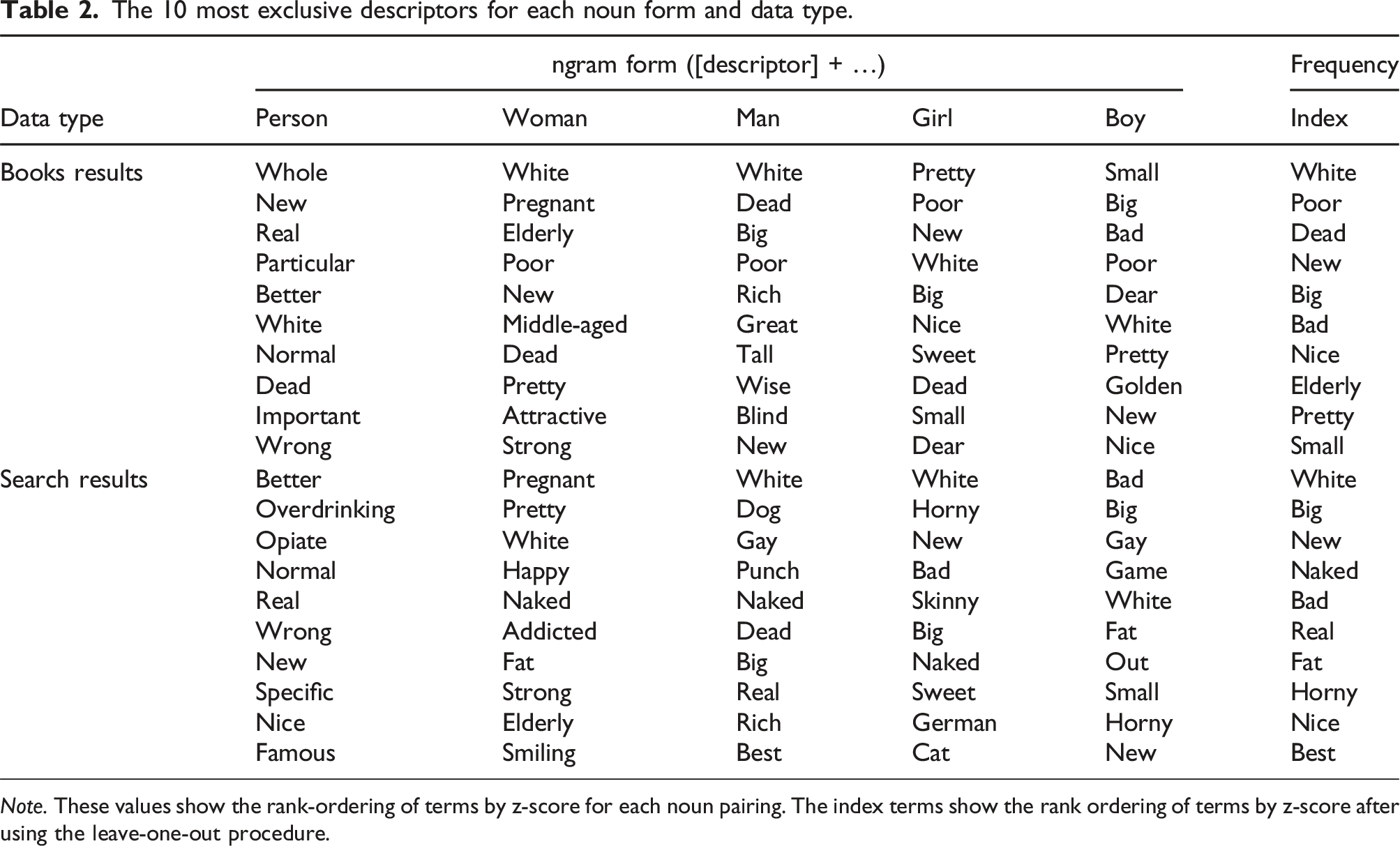
Note. These values show the rank-ordering of terms by z-score for each noun pairing. The index terms show the rank ordering of terms by z-score after using the leave-one-out procedure.
We repeated our analyses using only the 428 terms overlapping with Roivainen’s (2013) terms. We then calculated the difference between the correlations reported in Table 1 for the 18,220 terms and the correlations based on only the 428 terms. Overall, the difference in the correlations was small (AMdiff_r = .02, SDdiff_r = .2) and ranged from −.33 to .52, indicating that correlations based on the smaller set of 428 terms were sometimes smaller and sometimes higher than the values based on the overly inclusive set of terms with 18,220 terms. When inspecting the congruence of the data sources (using the same term + noun forms from each), the average correlation based on the 18,220 terms was at AM r = .56 and based on the 428 terms it was at AM r = .60. More details about these comparative analyses are provided in the Supplemental Materials.
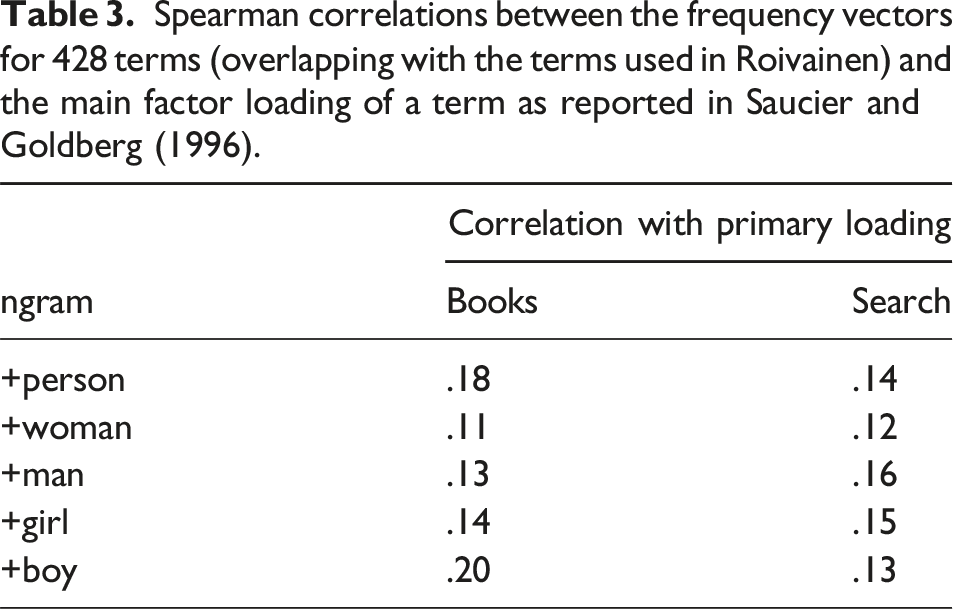
Spearman correlations between the frequency vectors for 428 terms (overlapping with the terms used in Roivainen) and the main factor loading of a term as reported in Saucier and Goldberg (1996).
Discussion
The primary contribution of this project is to make the books and search results available for researchers, especially personality psychologists, who seek information about the frequency of usage for person-descriptive terms. Most prominently, these data can contribute to the long arc of psycholexical research that began in earnest in 1936 (Allport & Odbert) and remains ongoing (Cutler & Condon, 2023). Prior work in this area has led to the identification of several multi-dimensional structural models of personality, including the Big Five (Goldberg, 1992), the HEXACO (Ashton et al., 2004) and the High Dimensional 20 (Saucier & Iurino, 2020). The motivation for more detailed characterization of person-descriptive terms at this stage stems from (1) the availability of novel methods for identifying structure (i.e., language models such as BERT [Devlin et al., 2019] and DeBERTa [He et al., 2021]), and (2) renewed interest in the development of a bottom-up taxonomy of personality traits (Condon et al., 2021).
As two different data sources were used to extract frequency-of-use indices for the terms, an important aspect of our analyses related to their congruence. Though we found moderate to strong congruence within the data from each source, the congruence was only moderate between the books and search results. This suggests, as expected, variability in the frequency of usage of terms in books (i.e., heavily edited content) versus in search results indexing content on the internet. While the book results are easier to obtain and to study over time (with tools like the Google NgramTM viewer), the moderate congruence between the books and search results suggests that some information may be lost if focusing on books content only. It seems likely that search results may capture language use in daily life as well as heavily edited book content, even if these results are less readily interpreted. Our advice is to use both of these data sources, in conjunction with alternative frequency estimates when possible, including tools like the Corpus of Contemporary American English (Davies, 2010) and word prevalence norms (Brysbaert et al., 2019).
The moderate-to-strong congruence levels found between ngrams within each source – that is, between the different ngrams within the books results and within the search results – suggests that the frequencies are largely comparable across noun forms. For instance, we did not find evidence for our hypotheses that certain ngrams might correlate higher due to age or gender effects. In other words, ngrams using person nouns of the same gender (+man and +boy, +woman and +girl) did not correlate more highly with each other than ngrams using different or no gender (e.g., +man and +woman, +boy and +person). This was the case in both the books results and the search results. With respect to age, frequency vectors for matching age groups (+boy and +girl, +man and +woman) were more highly correlated than those with unmatched age groups (e.g., +man and +girl) in the books results, but the differences were not evident in the search results. Given these findings, a reasonable recommendation is to use the frequency index for each data source, especially given the complexity of working with all 5 noun bigrams separately.
Importantly, results of the current work clearly replicated the results of Roivainen (2015) – the extent to which a term loads highly onto factors in the five-factor model of personality has little association with its actual frequency of usage. In fact, the current results expand on the finding, providing more extensive support for Roivainen’s criticism that the terms used by personality researchers to identify and characterize the Big Five are infrequently used to describe personality in real-world contexts. The observation holds for several term + noun ngrams across a longer and more recent period in books and over time in search results indexing content on the web. Roivainen (2015) has proposed a number of non-mutually-exclusive ways to interpret this circumstance, including that everyday descriptions of personality are not very well aligned with Big Five and Big Six models and/or that the Big Five/Big Six models are partial “artifacts” of research design decisions (e.g., variable selection criteria). The current evidence does not provide further insight on these possibilities, but we hope these frequency estimates will enable more research on the effects of variable selection and encourage researchers to account for term frequency during model development.
While the use of these frequency statistics may help to reduce such artifacts in personality structure research, we also recommend considering other characteristics of personality descriptors. These may include a wide range of attributes such as lexical difficulty (Condon et al., 2022), explicit ratings of familiarity, estimates of the semantic ambiguity (of the meaning) of terms, the perceived social desirability of terms, and more. Survey-based sampling methods provide a relatively easy – and often more interpretable – alternative to the approaches used in the current work (Leising et al., 2014; Wood, 2015).
Limitations
A major limitation of the current manuscript is that the distributions of the frequency vectors were highly skewed. This means that differences in the frequency of use among most terms was rather small (often neglible) because they were used infrequently. This circumstance also prompted our use of Spearman correlations for many analyses. Given our aim of collecting and sharing estimates for a comprehensive set of terms, we did not take many steps to mitigate this limitation (aside from the removal of a very small subset of outliers). Further analyses of these data are warranted on this basis, presumably using a range of different subsets.
A similar limitation of these data for personality applications is that the list of terms is highly over-inclusive, at least in English. A non-trivial proportion of the terms seem irrelevant as person-descriptors. For example, it is not fully apparent to the authors why “car” and “elk” are among the list of terms cataloged by prior researchers, yet these terms (and others like them) were retained for the sake of comprehensiveness. Further, a large proportion of the 18,241 terms are unrelated to psychological attributes and/or more related to characteristics of demographic or social groups. Even among the descriptors that may be related to psychological attributes, there is considerable variability with respect to (1) the extent of psychological relevance (consider: “injured”, “overdressed”, and “unclean”); (2) the extent to which the term describes a stable or passing attribute (“flustered”, “giddy”); and (3) the extent to which the term is unambiguously defined or operationalized (“owlish”, “compelling”, “hurting”). Thus, for research on personality structure specifically, it is expected that only a fraction of the terms in this list would have utility – the subset of psychologically relevant terms that are unambiguously used to describe stable attributes.
Further, it is important to acknowledge that the list of terms is far from over-inclusive in an absolute sense – we feel it is important to emphasize that the focus of this work is on American English descriptors only. Relatively little insight can be gained from these data about the “frequency” of personality-related topics (whether terms or constructs) in other languages. That said, we feel that the conduct of similar work in other languages (e.g., Livaniene & De Raad, 2017; Wood et al., 2020; Čolović et al., 2020) would be an invaluable step towards the development of an integrated database of terms that could one day be used to develop a truly integrated personality model. In the meantime, it should be recognized as a limitation of this work that it does not provide evidence with respect to all of the many other languages beyond English.
Finally, there are a large number of terms on the list that reflect the fluid nature of language itself. Some terms were simply outdated, and this highlights the limitation that these results can only provide a snapshot of personality descriptors found online in 2022 and in books published from 2010 to 2019. Of the many ways that language evolves, changes in the words we use to describe ourselves and other people are clearly evident, and the consequences of this for personality science are not yet understood. Sub-populations (e.g., different cohorts, residents of different geographic regions) of English speakers across time use and have used different terms – or the same terms with differing frequencies – to describe the same or different personality-related phenomena. These frequency estimates fail to inform our understanding of such nuance.
Still, these estimates are a step towards the identification of a more transparent and empirically-informed pool of personality descriptors. We encourage readers to use and improve upon these tools collaboratively, helping the field move closer towards the development of a comprehensive personality taxonomy.
Supplemental Material
Supplemental Material - Frequency of use metrics for American English person descriptors: Extensions of Roivainen’s internet search methodology
Supplemental Material for Frequency of use metrics for American English person descriptors: Extensions of Roivainen’s internet search methodology by David M. Condon, Sarah McDougald and Elisa Altgassen in Personality Science
Footnotes
Author note
The handling editor of this manuscript was Anna Baumert, PhD.
Acknowledgements
Not applicable.
Author contributions
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Elisa Altgassen was supported by Financial Support Programmes for Female Researchers, Office for Gender Equality, Ulm University.
Data accessibility statement
Analysis code and other supplemental materials are available at https://pie-lab.github.io/tdafrequency/. Data are available at ![]() .
.
Supplemental material
Supplemental material for this article is available online. Depending on the article type, these usually include a Transparency Checklist, a Transparent Peer Review File, and optional materials from the authors.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.