
Abstract
We present the first part of a fully parametrized mathematical model of person judgment, in an attempt to streamline and better organize theory in this research area. This first part focuses on the emergence of substantive information (“cues”) about target persons that perceivers may use in forming judgments. It incorporates time as a continuous variable, and accounts for the effects of targets, situations and their interactions. It also accounts for randomness overall, between-target differences in randomness, and overlap between observation intervals. We discuss how all of this influences the rank-order similarity of targets’ substance levels in any two observation intervals, enabling predictions regarding retest reliability, inter-rater agreement, cross-situational consistency, and predictive validity. We also explain how the model relates to existing theories, and to key concepts from the person judgment literature.
Introduction
In this paper, we present the first part of an integrative mathematical model of person judgment. Our first aim is to help streamline and better organize the vast literature in this field, by connecting previously unconnected strands of theory with one another, and by formalizing some key concepts that, so far, have mainly featured in the literature in „narrative“ (i.e., natural language) form. Our second aim is to demonstrate that, despite being fairly challenging, such formalization is actually possible and bears great potential for making personality research a more cumulative science. Among the gains to be expected from stricter formalization are a higher level of exactness and a lower level of conceptual redundancy.
In terms of content, most of the parameters in the model are not new. What is new is the strict mathematical form in which we present them. In fact, we believe that many of our colleagues in the field at least implicitly subscribe to a model that is quite similar to what we present here. What we hope to be able to add is a greater level of explicitness, conceptual clarity and parsimony.
We present this model in two different forms: The present paper introduces and explains the core components of the model in a manner that should be accessible to most readers with a background in personality research. Throughout it, we try to elucidate how the model‘s parameters relate to key concepts from the personality literature. In addition, we also offer a full mathematical account as an online Technical Supplement (Leising & Schilling, 2024). This latter version is more abstract, goes into greater mathematical detail, and only occasionally touches on specific concepts from the personality literature. Its purpose is to demonstrate that the analysis overall is mathematically sound and that all components of the model are connected within a coherent framework, leaving no room for ambiguities in terms of meaning. To make it as easy as possible to read the paper and the Technical Supplement side-by-side, we reference mathematical formulas by the same consecutive numbering in both documents. However, most of the more specific formulas from the Technical Supplement do not appear in the present paper. The Technical Supplement was peer-reviewed and approved alongside the present paper.
Most psychologists are only just beginning to discover and fully appreciate the advantages of formal scientific models over the “narrative” ones that still dominate the field: Formal models are able to capture greater complexity with greater exactness. They are better specified and thus better falsifiable. They enable a clearer organization of how research findings relate to each another, and an easier identification of contradictions, circularity, redundancy, specification gaps, and compatibility between different models (Borgstede & Eggert, 2023a, 2023b; Leising et al., 2022a; Rodgers, 2010). For all of these reasons, formal models at least have the potential to be more conducive to cumulative knowledge growth than narrative ones, which is why a stricter formalization of psychological theory has been called for many times (e.g., Glöckner & Betsch, 2011; Oberauer & Lewandowsky, 2019; Robinaugh et al., 2021; Smaldino, 2020).
There have been several prior attempts at formalizing theoretical thinking on person judgment processes. Among the most ambitious and successful of these are David Kenny‘s Weighted Average (1994) and PERSON (2004, 2019) models. Brunswik’s (1956) Lens Model has also been highly influential as a conceptual framework in this field (Back & Nestler, 2016; Funder, 1995). This paper presents the first part of a model that is supposed to jointly capture most of the key components from these earlier models and integrate them in a coherent, formalized fashion.
Note that this first part of the model only deals with the substantive bases of person judgments which are called “cues” in the Lens Model. However, the cues in the model do not necessarily relate to some joint, underlying cause variable. They simply represent “the facts” about targets that perceivers may or may not base their judgments on. Modelling what perceivers do with that information will be the subject of a follow-up paper.
If person judgments were simply a reflection of substantive reality, then the first part of the model could be directly used to make a large variety of exact predictions about judgments. But research has shown that judgments do reflect a number of strong influences apart from substantive reality (Baird et al., 2017; Heynicke et al., 2022; Rau et al., 2021; Wetzel et al., 2016). For example, judgments express the perceivers’ formal response styles (e.g., using extreme values vs. moderate values on response scales) and the perceivers’ attitudes toward the targets (for an overview, see Leising et al., under review). Also, person-descriptive items differ from one another in many systematic ways that may interact with perceiver-, target- and dyad properties in shaping judgments (e.g., Leising et al., 2014; Wessels et al., 2020). All of these influences may attenuate the influence of the actual substance on judgments. To obtain a rather complete theoretical account of person judgment processes, one needs to cover both their substantive basis (part 1) and the ways in which perceivers make of the substance in deriving their judgments (part 2).
We account for the emergence of cues in a way that is compatible with Classical Test Theory (CTT; Novick, 1966; Lord & Novick, 1968). The model goes beyond CTT, however, in that it decomposes the unobservable “true” (or better: noise-free) score into three sources of variance: target, situation, and their interaction. Thus, it captures the key components of psychology’s person-situation-debate (Kenrick & Funder, 1988; Mischel, 1968; Vazire & Sherman, 2017) and also overlaps significantly with Latent-State-Trait Theory (LST; Hintz et al., 2019; Steyer et al., 1992; Steyer et al., 1999; Steyer et al., 2015). A brief model comparison is provided further down.
We would like to encourage our readers to use the current parametrization in their own work, in order to foster the emergence of a more cumulative personality science (in which different researchers describe the same things using the same labels). We also hope to be able to showcase the enormous amount of complexity permeating this field of study, which remains hidden as long as proper formalization is avoided, and thus illustrate a likely reason why proper formalization has been avoided so far by most researchers working on these issues. Ultimately, all of this is intended to help increase the field’s appreciation for this crucial yet neglected kind of work.
Going through the model components step by step
Notation
This first part of the model accounts for the emergence of cues on which perceivers may base their judgments of targets. We translate the concept of a cue into the average level of some substance variable for a given interval. By “substance”, we simply mean an actual characteristic that the target has – at least temporarily – irrespective of whether or how that characteristic is ever perceived or used in making a judgment.
In line with CTT, we model a target’s level on a substance variable as comprising a systematic component (
As a general rule, we use a tilde (as in
The different types of operations may also be combined, as in
The model’s components
Model parameters and their meanings.

In Table 1, we do list the π parameter, which denotes the perceiver. However, specific perceivers will not play any role in the present analysis but only become relevant later on.
In accordance with CTT, we distinguish between the observable level (
Figure 1 is to illustrate some of the key concepts. We look at the AU12 activations of two target persons as they pass through a number of different situations. The first target ( Two targets’ (
The solid lines in Figure 1 represent the noise-free substance levels of the two targets, and of the average target, in each of the five intervals. They are also captured by parameters
In Figure 1 we see that Trudy (
One of the key tenets of personality psychology is that target persons may differ from one another “in general”, that is, across some kind of longer, relevant time frame (e.g., their entire lifespan). This time frame is represented by another parameter (
Up to this point, we were only talking about the targets’ noise-free substance levels, which may never actually be observed. In Figure 1, the wiggly scatter around the noise-free levels represents random changes of the targets’ substance levels from moment to moment. The model parameters for these would be
The key explanandum of part 1 of the model are the targets’ average observable levels on the substance variable for a given interval (“cues”). In the model, they are represented by the parameter
Putting the components together
The full mathematical account of the model may be found in the Technical Supplement (Leising & Schilling, 2024). In the following, we will only highlight those parts of it that are of immediate importance for personality research and that connect most easily to established concepts in this field.
Let us repeat:
The respective parameters for the other target (
The microscopic model
Formula (1) defines what we call the “miscroscopic model”. The term implies that this formula contains all the relevant components in their most basic form and may not be reduced any further.
Here, the 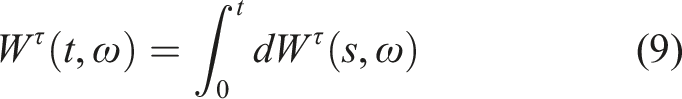
Figure 2 in the Technical Supplement further illustrates what the concept of Brownian Motion is about. Most of this is omitted here. In the present context, one only needs to know that Upper half: the function 
The variance (
Observable substance levels (Cues)
In analyzing actual person judgment data, one will never have to use the microscopic model because person judgments in reality are never based on infinitely small observation intervals. Rather, the substantive base for any person judgment is an average, observable substance level for a given interval (
Recall that the bar above the
Due to the assumed omnipresence of random noise, a target’s observable substance levels (
Substantive similarity
In person judgment research, we are often interested in how similar different judgments of the same target persons are. This similarity is typically assessed in terms of correlation coefficients where the target persons are the cases (e.g., Kenny, 1994). However, the same metric may be used for assessing the factor structure of a set of items, the internal consistency of a psychometric scale, or the predictive validity of some kind of measurement (e.g., of academic potential) with regard to some other kind of measurement (e.g., of academic achievement). In terms of the present model, a common basis for all of these is the substantive rank-order similarity of two different sets of observations, that is, the extent to which the substance levels of the targets in two observation intervals (
Kenny (1994) introduced overlap as a component of his Weighted Average Model. He uses his model to explain consensus, that is, the level of agreement between different perceivers judging the same targets on the same item. Accordingly, Kenny conceptualizes overlap as the extent to which different perceivers base their judgments on the same versus different information about the targets. Obviously, when this overlap becomes larger, the substantive base for the perceivers’ judgments is shared to a greater extent, which should lead to greater inter-rater agreement.
Kenny addresses the topic in terms of the proportion of “acts” that two perceivers have seen a target engage in, as opposed to acts that only one of them has observed. However, this approach entails the problem of defining what an “act” is (e.g., when it begins and when it ends). In contrast, we define overlap more directly in terms of observation intervals, thus circumventing the need for demarcating distinct acts. Note again that the term “observation interval” does not imply that any observation actually takes place. We are still dealing with substance only.
Observation intervals (
The lower half of Figure 2 displays two observation intervals (
In the model, all observation intervals (e.g., 
To understand the implications of this formula, one needs to understand the difference between
Applied to our example, this means that the covariance between Tessa’s and Trudy’s average A12 activation levels in intervals
To ensure comparability (e.g., across studies investigating different substance variables), we recommend using a normalized version of Formula (73) in which everything is divided by the common variance of the noisy substance levels in the two intervals. This leads to Formula (74):
As long as there is no overlap, the denominator on the right-hand side will be larger than the numerator to the extent that targets’ substance levels do contain noise. This is because the denominator “sees” this random variation whereas the numerator does not. However, with longer intervals, this difference between numerator and denominator will become smaller, because the noise will cancel out more. The potential for this to happen will decrease with overlap. When the overlap is perfect, the substantive rank-oder similarity will be one.
Up to this point, we only discussed the role that noise may play in substantive similarity, given different levels of overlap. We will now devote some more attention to the component of the two formulas (73) and (74) that represents all the systematic influences (
In order to understand the role of this component, it is helpful to split these parameters as follows:
Recall that 



The second contribution comes from the target-covariance of the time-averages of the sum of all situation- and interaction-effects in the two intervals (
The third and fourth contributions come from the covariances between the target-effects and the interaction-effects in each interval:
Applicability to typical research questions
Formula (74) is the primary outcome of our current analyses. It enables predictions of the correlation between the targets’ observable substance levels in any two intervals. A few more examples as to why this is relevant will be given in this section.
Substantive similarity is one of the factors contributing to the similarity of judgments. Thus, Formula (74) may be used to make predictions about all sorts of associations between different types of judgments, including inter-rater agreement. Note, however, that we still ignore all additional influences on people’s self- and other-judgments (such as perceiver attitudes), which will be the subject of a follow-up paper. When making predictions about judgments based solely on substantive similarity, one essentially treats all these other influences as noise. Note further that the same formula may be used to make predictions about the similarity of targets’ substance levels when no judgment takes place (e.g., about reaction times measured in two different intervals).
Retest reliability
A proper test of retest reliability would require repeated assessments of the same substance variable in the same targets, under identical situational circumstances, with the same interval lengths, but with no overlap between intervals. Formula (74) tells us that under these circumstances, substantive similarity will equal the proportion of systematic variance in the overall variance, which is exactly how reliability is commonly defined. Note that the systematic variance does not only include the variance of the target-effects but also the three other covariances from Formula (79). Longer intervals will mean higher reliability, because with longer intervals noise is going to cancel out more. However, the size of this effect will depend on how noisy the data is to begin with.
Cross-situational consistency
Cross-situational consistency is of particular interest to many personality psychologists because “personality” may be conceptualized as the extent to which behavioral differences between people persist across varying circumstances. This view basically equates personality with target-effects. However, the analysis just presented tells us that estimates of cross-situational consistency will also reflect additional influences: the covariance of the respective interaction-effects (
Inter-rater agreement
One reason why different judgments of the same targets may agree with one another is that different judges saw the targets behave similarly. According to the analysis just presented, there are several possible reasons for this to happen, all of which are not mutually exclusive: First, target-variance may be large. Second, there may be overlap, and thus: shared noise. Third, there may be similar interaction-effects in the two observation intervals. Fourth, the situations in which the targets are observed in the two intervals may amplify the existing target-variance. Note that this means there may be good inter-rater agreement based entirely on shared noise.
Validity
The term “validity” is used in a fairly unsystematic fashion throughout the psychometrics literature (e.g., Zachar & Jablensky, 2015). Here, we use it to denote associations between the targets’ observable substance levels in some (“predictor”) interval (
For example, one may use Trudy’s and Tessa’s average AU12 activation levels in the morning (
With regard to interaction-effects, it gets a bit more tricky: If the goal is to forecast stable differences between targets in the criterion interval from their behavior in the predictor interval, then the situational setup in either interval should not elicit too much idiosyncratic behavior (i.e., rare interaction-effects). This is because such behavior would contribute to the variance but not the covariance between observations in the two intervals, which in turn would harm validity. In order to mitigate the possibly detrimental effect of such idiosyncrasies, one should rather use a relatively diverse situational setup, especially in the (usually longer) criterion interval (e.g., Borkenau et al., 2004; Wiedenroth & Leising, 2020). This way, interaction-effects should average out to some extent.
An alternative is to use situational setups for the predictor and criterion intervals that are highly similar, even if they are idiosyncratic. According to the model, doing so should lead to high validity coeffcients as well. However, this should then better be interpreted in terms of the predictor interval being a valid representation of the circumstances that one is actually interested in.
Comparison with other models
Kenny’s (1994) weighted average model
Our model covers much of the same ground that is also covered by David Kenny’s (1994) Weighted Average Model (WAM; see also the closely related PERSON model by Kenny, 2004, 2019). Specifically, versions of the acquaintance (n), overlap (q) and consistency (r1) parameters from Kenny’s WAM feature in our model, as well: Using our terminology, one would represent acquaintance as
In several respects, however, the model that we present here goes beyond WAM in terms of precision and/or generality and/or scope. We only have room here to highlight some of these:
First, we incorporate time as a continuous variable. This enables us to account for both overlap and a core aspect of “acquaintance” (i.e., interval length) objectively and in a more precise fashion than is possible when the targets’ continuous response streams have to be segmented into separate “acts”. Second, our model (specifically the part of it on which the present paper focuses) incorporates a fully formalized account of phenomena at the level of the substance, independent of whether this substance is ever used by perceivers to inform their judgments. It therefore lends itself to establishing a more direct connection to the branch of personality research that uses objective (i.e., non-judgment) data (e.g., Stachl et al., 2021), and even to making exact predictions in that realm. Third, our model does not distinguish between “categorical” information (e.g., biological sex, height, skin color, age) and “behavioral” information but accounts for all different types of substantive information about targets the same way. What is called “categorical information” in Kenny’s WAM model would just be substance variables that are relatively stable across time (i.e., variables with little noise, situation effects, and interaction-effects). Fourth, our model explicitly incorporates target-effects, situation-effects, and interaction-effects. Thus, it establishes a direct connection to key concepts from the so-called “person-situation debate”; Mischel, 1968; Kenrick & Funder, 1988). Some of these connections are discussed in more detail in the next section.
Latent state-trait theory
The present model also has significant overlap with Latent-State-Trait-Theory (LST; Steyer et al., 1992; Steyer et al., 1999; Steyer et al., 2015). Most important, both the current model and LST focus on explaining the level of a variable that is measured at some occasion and assume that person-effects, situation-effects, interaction-effects and random noise contribute to this measured level. In fact, what is called the “latent state” in LST is largely identical in meaning to the
Whereas earlier models within the LST framework did not systematically disentangle situation- and interaction-effects, a recent model by Geiser et al. (2015) does precisely that. Even more recent models (e.g., Koch et al., 2023) do consider time as a continuous factor, but only between measurements, not within the measurement interval itself. While our model was developed independent of LST – we started from Kenny’s (1994) WAM and Brunswik’s (1956) Lens Model – the parallels are obvious and may actually be viewed as encouraging, because independent strands of theory development converge so well.
There are also a few important differences, however: First, the model we present does systematically decompose the (“latent”) noise-free substance levels into target, situation and interaction effects while also accounting for time as a continuous variable. We are not aware of any LST model so far that combines both of these properties. However, in our model, it is the length of the observation intervals rather than the spacing between them that matters. The spacing between observations will only become relevant once it is assumed that the systematic components of what is being measured (especially target- and interaction-effects) may vary over time. The present model may of course be amended in this way, though.
Second, our model allows for any composition of an observation interval in terms of situations whereas the LST models that we are aware of only handle (repeated) assessments of targets in the same situation as opposed to another situation. This feature enables our model to capture situation similarity as a gradual phenomenon (see below). Third, our model expressly covers overlap. Fourth, our model does account for target-specific levels of noisiness.
Brunswik’s (1956) lens model
The present paper describes the part of our model that captures the emergence of a target’s average substance level for a given interval (
Probably the main purpose of Brunswik’s model is to describe how (“proximal”) cues may be expressions of (“distal”) causes, and how judgments based on cues may be used to infer such causes. The cue levels whose emergence we model here are perfectly suited for such analyses. Specifically, if the targets’ levels on different substance variables are found to correlate with one another, this may be due to variation in a third variable that causally affects each of these substance variables. Before this possibility may be seriously considered, however, one has to rule out the alternative possibility that the levels of the different substance variables influence each other directly.
The correlations between the targets’ cue levels and their levels of an underlying cause variable – if it exists – are often called “cue validities” in analyses based on the Lens Model. What the present paper contributes to the understanding of cue validities is that there may be two relevant sources of attenuation involved in this regard: random noise, and target by situation interactions. The influence of both is likely to be reduced with longer observation intervals.
Relationships to key concepts in the personality literature
In the remainder of this paper, we will briefly touch on how some key concepts from the personality literature may either be expressed in terms of the model we introduced so far, or added to it as extensions. Our main goal in this is to showcase how formalization allows for a more precise specification of theoretical concepts that, so far, have mostly been described in terms of the natural language.
Situation characteristics
Our treatment of situations so far has been fairly simplistic, as we represented them with a single, nominally scaled variable (
Person-, situation- and interaction-effects
Obviously, our model is very closely connected to key concepts from the “person-situation debate” in psychology (Kenrick & Funder, 1988; Mischel, 1968). In fact, the
Situation similarity
Our model does capture the idea that the situations in which targets are observed may be more or less similar to one another, and that this similarity may affect the substantive similarity of the targets’ behavior (Sherman et al., 2010). As we conceptualize it, situation similarity is a property of a pair of observation intervals that are being compared in this regard. If one describes the situation using a single nominal scale (as we did in the present paper), situation similarity may simply be assessed as the percentage of two observation intervals in which sigma has the same value.
Intraindividual variability
For decades, psychologists have been interested in how stable people’s behavior and experiences are across time and situations (Vazire & Sherman, 2017), including the extent to which there are systematic differences between targets in this stability (e.g., Fleeson, 2001). Note again that this concerns the targets’ momentary substance levels, which are the primary focus of the present paper. Research has often used person judgments as a stand-in for these substance levels, but that approach may fall short of its purpose because the variability of interest may not be disentangled from the perceivers’ variability in responding to items (e.g., Baird et al., 2017). Our model also clarifies that there are two possible sources of substantive intra-individual variability (i.e., target-specific noise and interaction-effects) that may and should probably be studied separately, because otherwise one would lump together two components with entirely different meanings.
Personality
Our model connects to several different ways in which the term “personality” is commonly used. The first approach is to simply think of personality in terms of stable differences between targets. Using this approach, a target’s personality may be described for every individual substance variable, as the target-effect. The second approach focuses on interaction-effects instead. Here, a target’s personality is described in terms of the pattern of if-then relationships between specific situational circumstances and the target’s respective response tendencies. This is the approach proposed by Mischel and Shoda (1995), whose concept of a “personality signature” basically comprises a given target’s set of interaction-effects across a number of different situations. Finally, the term “personality” may be used to denote measurable or entirely hypothetical substance variables that causally account for co-variation among cues. This “reflective” idea of personality (Schmittmann et al., 2013) informs most personality researchers’ use of Brunswik’s (1956) Lens Model, and is also consistent with Funder’s (1995) conceptualization. Note that, in contrast, Kenny’s (1994, 2004, 2019) approach is purely “formative” in nature, in that it is only concerned with how perceivers use the information that they receive about targets. In his PERSON model (Kenny, 2004), personality (P) is the judgment that the average perceiver would make if he or she had access to all the relevant cue information.
Strong versus weak persons/situations
The person-situation literature prominently features the idea that both situations and targets may be distinguished from one another in how “strong” versus “weak” they are (e.g., Schmitt et al., 2013). Note that this terminology is not meant to imply any evaluation (e.g., strong being somehow “better” than weak), but only to compare situations with one another, and targets with one another, in terms of how pervasive their respective influences are on substance levels. There is no binding convention as to how these terms are to be used. We suggest the following (Leising & Müller-Plath, 2009): A target (
Good versus bad targets
“Good targets” are targets that are easy to judge (Funder, 1995). According to our model, there are actually two ways in which one may be a good target. First, being a good target could mean that there is little random variation in a target’s behavior stream. Using this understanding, Tessa (
Good versus bad information
Good Information is one of the key moderators of judgment accuracy in Funder’s (1995) Realistic Accuracy Model. However, Funder himself states that the term covers at least two largely distinct concepts: First, information will become “better” with longer observation intervals. This will be the case because longer intervals will result in more cancelling out of random noise, but only to the extent that the substance levels actually are noisy. Longer intervals (which likely, but not necessarily, go along with a more diverse setup of situations) may also be advantageous because interaction-effects will cancel out more. Second, some situations may be more “diagnostic” than others (Borkenau et al., 2004) in that the targets’ substance levels in them predicts the same targets’ substance levels in the criterion interval particularly well.
Acquaintance
The extent to which perceivers know their targets has played a prominent role in the personality judgment literature (e.g., as a predictor of inter-rater agreement; Biesanz et al., 2007; Funder & Colvin, 1988). Interval length (
Limitations
The model as we present it here uses a number of constraints, in order to keep complexity within manageable bounds: First, we assume that the noise-free substance components are stable over time. That is, target-effects do not change, situation-effects do not change, and interaction-effects to do not change, either. In reality, however, it is quite likely that changes in all of these parameters do occur. This may be accounted for by adding more parameters to the model (e.g., ones assessing overall developmental trends with age, and/or ones assessing decreasing predictability). There are now variants of LST that do account for this additional layer of complexity (Koch et al., 2023).
Second, our model (like CTT and LST) operates on the assumption that substance variables have unlimited variability without lower or upper bounds. In reality, however, most the respective continua do have such bounds and this may have important consequences for model accuracy. Most important, target and situation effects will come to limit each others’ influences under these more realistic assumptions (Blum & Schmitt, 2018; Schmitt et al., 2013). For example, when a situation already induces very high levels of anxiety, target-effect can do little to increase that level even further. The model may be amended to reflect these considerations, but this will make subsequent derivations more complicated. The question of how much model complexity is actually needed in this regard is ultimately an empirical one.
Third, in the present paper, we introduced our model using a single substance variable. However, the model may just as well be applied to several substance variables at once, since
Conclusion and outlook
We hope that the presentation so far has shown just how much complexity needs to be accounted for when trying to conceptualize person judgment processes in a strict, formal way. Despite this somewhat daunting complexity, we also hope that the presentation has shown how much clarity and parsimony may be gained by attempting a stricter formalization: A single model comprising a relatively limited set of parameters may go a long way in expressing all sorts of important but previously unconnected theoretical ideas, and connecting them in a seamless manner. The same model enables a large number of exact predictions pertaining to actual behavior (substance) and – by extension – to judgments of behavior. Note again, however, that using this first part of the model to make predictions about judgment data means ignoring all of the additional influences that are also reflected by such data (e.g., response styles and perceiver atttitudes).
We explicitly recommend using the terminology and parametrization presented here in theoretical writing about person judgment. Our hope is this that doing so will help improve on conceptual clarity and thus on the efficiency of scientific communication in this field. Attaining the same level of precision with the more traditional “narrative” writing seems impossible to us.
Of course, it is not necessary to operationalize each and every parameter in every empirical study. But a model like the one presented here may nevertheless be useful because it explicates all the factors that are likely to have an influence on the data. This enables researchers to plan their studies more systematically (e.g., by even only thinking about influences that would previously have been overlooked; by letting the factors they do not measure vary randomly). Doing so may then lead to more valid (e.g., representative) conclusions.
In order to motivate more psychologists to get involved with this crucial but highly demanding kind of academic work, it may be necessary to find ways of incentivizing it better (e.g., Leising et al., 2022a, 2022b). It will also be helpful to turn to colleagues who already possess the required expertise, invite them to collaborate, and learn from them.
Supplemental Material
Supplemental Material - A mathematical model of person judgment
Supplemental Material for A mathematical model of person judgment by Daniel Leising and René L Schilling in Personality Science.
Footnotes
Author note
Not applicable.
Acknowledgements
Not applicable.
Author contributions
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Corrections (May 2025):
This article has been updated with clarifications to the affiliations, Acknowledgments, and Author contributions, as well as with minor grammatical corrections in the text.
Data accessibility statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Supplemental material
Supplemental material for this article is available online. Depending on the article type, these usually include a Transparency Checklist, a Transparent Peer Review File, and optional materials from the authors.
Note
Not applicable.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.