
Abstract
Research on online news consumption has long focused on improving people’s ability to select accurate news sources. However, people who consume accurate information do not necessarily make an accurate collective. Reliable information aggregation and collective decision-making also benefit from independence between judgments. We tested whether collective incentives can improve collective accuracy by reducing judgment correlation, even when average individual accuracy remains unchanged. We define collective incentives as reward structures that tie an individual’s payoff to the accuracy of their group’s aggregated decision rather than their own personal accuracy. In an online experiment (N = 232), participants made forecasts after viewing realistic tweets from correlated or independent news sources. Shared tweets among group members were more accurate but fully correlated across group members; local tweets were less accurate but independent between participants. When rewarded for collective accuracy, participants used more independent local tweets, improving collective but not individual accuracy. Generalizing our findings, an exploratory analysis of public news datasets found a greater content correlation among larger publishers, modulated by accuracy. These findings highlight the overlooked importance of judgment independence alongside accuracy in creating thriving information ecologies online. Collective incentives may complement accuracy-based interventions by nudging news consumption towards diverse, local, and independent sources. We discuss how future research should implement collective incentives to improve collective decisions in real-world settings.
Keywords
Introduction
This paper examines how reward structures influence collective accuracy in online news consumption. We introduce and test the concept of collective incentives—rewarding individuals based on the accuracy of their group’s aggregated decisions rather than their personal performance. Using an online forecasting experiment (N = 232) with realistic news stimuli, we show that collective incentives prompt individuals to rely on more independent, less correlated information sources, thereby improving collective accuracy without changing individual accuracy. We further corroborate these findings with exploratory analyses of public news datasets, revealing systematic patterns of content correlation in mainstream and local publishers. Together, these results highlight the overlooked role of judgment independence in information aggregation and suggest new strategies for designing healthier online information ecosystems.
How people consume information has dramatically changed over the past decade. Local journalism is facing an alarming decline, especially at the community level. In the United States, more than one-third of all newspapers have vanished since 2005 (Metzger, 2024). In 2024, 127 local papers shut down—roughly 2–3 closures every week—contributing to the rise of “news deserts” with no local coverage. Over half of U.S. counties now have only one or no local news outlet, leaving an estimated 55 million Americans with little to no access to vital local news. Mainstream media has gained trust at the expense of independent news outlets (Cellan-Jones, 2019; Fletcher and Park, 2017; Martin and McCrain, 2019; Newman et al., 2019; Park et al., 2020). This crisis is not confined to the U.S. In the United Kingdom, for example, more than 320 local newspapers closed between 2009 and 2019 as advertising revenues for regional media plummeted by about 70%. As a result, the share of UK adults who read a local or regional newspaper each week fell from 22% in 2015 to just 12% by 2023. Similar patterns of decline are evident across much of the world as audiences migrate online, where news spread is better predicted by partisanship and emotional content than factual accuracy (Lazer et al., 2018; Vosoughi et al., 2018). How these changes will affect collective information dynamics is still under debate (Bak-Coleman et al., 2021).
Information accuracy and independence are two pillars of accurate collective information aggregation and decision-making. Previous studies on online information environments have largely focused on improving news accuracy, for example, improving the detection of inaccurate news and motivating people to disseminate accurate information (Pennycook et al., 2021; Pennycook and Rand, 2021), enhancing content moderation (Garrett and Poulsen, 2019; Gillespie, 2018), innovating fact-checking approaches (Pennycook and Rand, 2019), emphasizing a publisher’s reliability (Dias et al., 2020), and predicting the spread of rumors and misinformation (P Resnick, 2015; Ciampaglia et al., 2015; Bessi et al., 2016; Del Vicario et al., 2016; Bessi et al., 2015; Oh et al., 2010; Roozenbeek et al., 2020).
However, focusing solely on information accuracy overlooks the importance of information independence in settings requiring collective information aggregation and decision-making, such as forecasting, risk assessments, or public consultations on policy. Although mainstream sources often maintain high accuracy due to greater public scrutiny, they can also foster homogeneous opinions among readers. This can influence the quality of collective decisions by making the group vulnerable when the news source is wrong. Independent information sources can improve collective accuracy by reducing correlated errors (Becker et al., 2017; Bernstein et al., 2018; Dalkey and Helmer, 1963; Mann and Helbing, 2017). Smaller groups benefit from prioritizing an accurate but correlated source, whereas larger groups benefit from incorporating less accurate but more diverse sources (Lamberson and Page, 2012).
Collective accuracy improves as group size increases, assuming that individuals have a probability of being correct greater than chance
Low correlation (and increased group accuracy) can stem from increased variance of group members’ estimates (Page, 2007) or from the degree to which individuals’ errors are dependent on one another across repeated decisions. In our study, we use a repeated-measure approach, controlling inter-judge correlation via repeated forecasting tasks. Additionally, we extend this framework beyond individual judgments to examine the correlation of news sources themselves—whether relying on a single highly accurate but widely shared news source introduces dependencies that affect group decision-making.
Building on this theoretical framework, we hypothesize that under specific conditions, listening to multiple, somewhat less accurate but independent local news sources—we call this a sleuth strategy—can be more beneficial for collective decision-making than relying on highly accurate but correlated mainstream sources—a consumer strategy (Figure 1(a)). (a) Individuals select one news source to gather more information to make a binary forecast about a future event. The global news source on the left is more accurate, on average over time, than local news sources on the right. However, when the majority of newsreaders consume it, it generates high correlations among individuals in the population, correlating judgments. When individual judgments are aggregated (e.g., via majority rule), aggregating local sources generates higher collective accuracy (although not necessarily higher individual accuracy). (b) An accurate graphic representation of the experiment’s interface. Participants were shown a sequence of forecasting problems involving realistic events (e.g., “Will there be a case of Zika virus before August 2018?”). One correlated and one uncorrelated information sources provided relevant information to make an accurate forecast. Each source either supported a positive outcome (e.g., source on the right) or opposed it (e.g., source on the left). (c) Average individual and group accuracy (left and right panel, respectively) for each incentive condition (color) and group size (x-axis). Group sizes are displayed as three tertiles—small, medium, and large groups—based on the average number of active users. See also Supplemental Table S1 for experimentally assigned group sizes.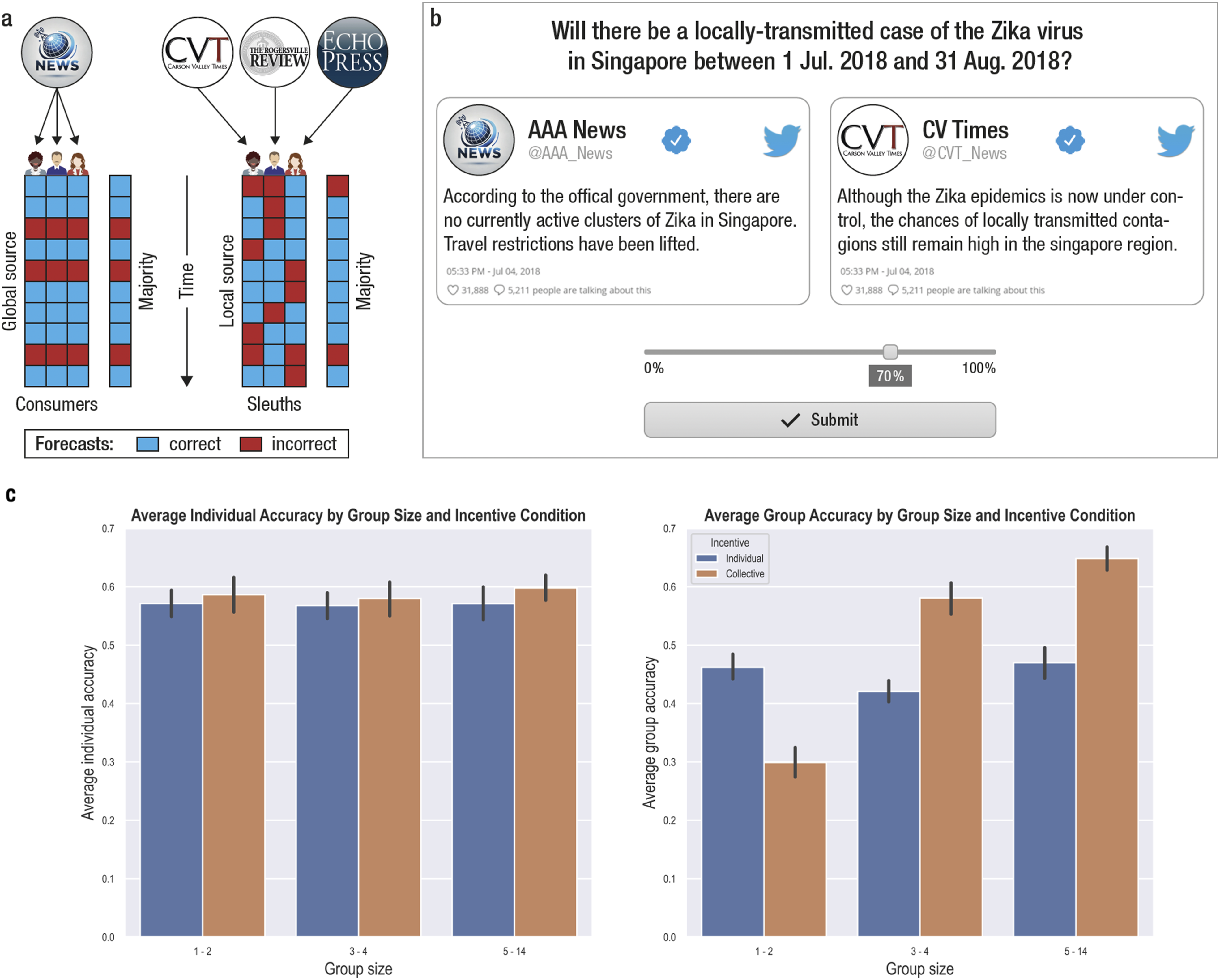
Recent behavioral evidence and theoretical work show that incentives can influence individuals’ choice of information sources. Individual incentives tend to produce judgment correlation and herding behavior as individuals tend to copy the single most accurate available source of information to maximize their performance (Bazazi et al., 2019; Mann and Helbing, 2017). On the contrary, other incentive structures, including rewarding individuals for their collective accuracy, reduce herding and nudges individuals to better use all information available, including lower-accuracy uncorrelated sources (Bazazi et al., 2019; Hong et al., 2012; Kao et al., 2014; Stasser and Titus, 2003). Whether these findings can be applied to nudge newsreaders’ preferences and improve group decisions is currently unknown.
We tested these hypotheses using human volunteer groups in sequential forecasting judgments, studying the effects of incentives (individual vs. collective) and group size on accuracy and news source preference. On each round, participants (N = 232) were shown two news sources: a high-accuracy source shared with others in their group (the “Global” source), and a lower-accuracy but independent source unique to them (the “Local” source). Both sources aimed for truth, with accuracy rates above chance (70% for the mainstream and 65% for the local source). Sources provided information as fictional tweets, based on which participants made realistic geopolitical judgments on a probability scale (Figure 1(b)). The fictional forecasting approach ensured accuracy was dictated by sources’ accuracy and not participants’ prior knowledge.
When rewarded for their collective accuracy (as opposed to their individual accuracy), people displayed a preference for less accurate, but independent news sources over shared, correlated ones, despite the latter’s higher accuracy. We also observed an interaction between group size and incentive type, demonstrating that collective incentives amplify the effect of group size on collective accuracy. This interaction highlights how incentive structures can shape the effectiveness of group decision-making as group size increases.
Additionally, we conducted an exploratory analysis based on publicly available news datasets. We find a negative correlation between two measures of media locality and content similarity, which was modulated by news source accuracy. Although with many limitations, this result hints at the relevance of our findings for the real online information environment.
Our findings draw attention to a previously unexplored area of intervention for building healthy online information environments. We conclude by discussing possible applications and limitations.
Method
Procedure
The study was approved by the Massachusetts Institute of Technology Institutional Review Board. The complete procedure is reported in Supplemental Information. Participants (N = 232) were recruited on Amazon Mechanical Turk and were compensated for their time ($9.5 per hour) and performance (£0.05 for every correct answer). They gave informed consent before starting the game. The game was implemented using the Empirica platform for group experimentation, developed at the MIT Media Lab, and publicly available at empirica.ly (Almaatouq et al., 2021). The experiment consisted of a series of realistic binary forecasting problems regarding geopolitical events (Figure 1(b)). Forecasts were initially collected on a 0–100 probability scale (0: impossible event, 100: certain event) to elicit both a participant’s choice (the event is more likely vs unlikely to happen) and confidence in the choice (confident vs uncertain). This allowed us to analyze first-order and second-order judgments separately (Carlebach and Yeung, 2023; Fleming and Daw, 2017; Fleming et al., 2014). Questions were independently generated by the IARPA Hybrid Forecasting Competition, a national forecasting competition aiming at improving the prediction accuracy of global events of geopolitical relevance. Outcomes were unknown at the time of the experiment. The computer simulated each event’s outcome and calculated performance based on the participants’ predictions. In other words, prior knowledge could not improve accuracy, and only news sources reliably predicted event outcomes. Participants were informed that the correct outcome of each forecast event was randomly generated by the computer and had no connections with actual real events. They were not explicitly informed about the differences between local and global sources or their accuracies; they had to infer this through trial and error. They were, however, told that the tweets, although fictional, contained key information needed to forecast the fictional events accurately. They were explicitly instructed to avoid using any personal knowledge on the topic and use only the information available in the experiment (i.e., the local and global sources). After every forecasting problem (e.g., “Will there be a locally-transmitted case of the Zika virus in Singapore between 1 Jul 2018 and 31 Aug 2018?”), participants in the individual incentive condition received text feedback on their individual decision (e.g., “You predicted: Yes”) and individual accuracy (e.g., “Your prediction was correct”). Participants in the collective incentive condition received feedback on the group majority’s decision (e.g., “Your group predicted: Yes”) and group accuracy (e.g., “Your group prediction was correct”).
Experimental conditions
Participants were randomized into two incentive conditions (Incentive: collective vs individual) and four different group sizes (Group Size: 1, 3, 7, or 15). In the collective incentive condition, participants were rewarded for their group accuracy. In the individual incentive condition, they were rewarded for their individual accuracy. Group accuracy was calculated round-by-round based on the majority of the assigned group size.
Participants waited in an online waiting room to allow everyone to log in and read the instructions. If the room did not reach the assigned group size by the end of 15 minutes, the experiment started with the participants available. Larger groups were more likely to start with fewer participants than assigned or include idle members, introducing a selective bias that disproportionately affected larger groups. For example, as group accuracy was computed based on the assigned group size, groups that started below capacity had a harder time reaching a correct majority. To address these limitations, we present our effects using an intention-to-treat analysis, which treats group size as randomly assigned, and an as-treated analysis, which treats group size observationally as the average number of active users in a group. To recover the causal effect of group size (rather than the causal effect of being assigned to a given group size), we provide an additional instrumental variable analysis and bootstrapped coefficient estimates in the Supplemental Information. The single-player condition (group size = 1) acted as a control. A no-reward condition was not used because it would have incentivized poor performance and idle participants.
Local and global information sources
The generative model producing the event outcomes is described in Supplemental material. On every round, participants were presented with one uncorrelated (local) and one correlated (global) information source, which provided evidence for or against the forecast event. Participants were presented with both information sources (the correlated and uncorrelated ones) in every round, and evidence was presented as a mock-up tweet. Figure 1(b) represents the actual user interface.
Local and global news sources differed (a) in their error rate and (b) in their correlation among group members (Figure 1(a) and Supplemental Figure S1). A source was incorrect when it provided supporting evidence for an event that did not happen or refuting evidence for an event that happened. Error rates were 35% and 30% for the local and global sources, respectively. The global source provided the same information to every participant. The local source provided information independently for each participant. This design created a limiting case where inter-judge correlation is
Results
Collective rewards favor large groups
Intention-to-treat analysis on group accuracy. A binomial regression model on group accuracy with coefficients for assigned group size, incentive condition (baseline: individual incentive) and the interaction between group size and incentive. Formula: group accuracy ∼ size + incentive + size x incentive. Significance thresholds: . = p < .1, * = p < .05, ** = p < .01, *** = p < .001. p-value thresholds represent two-sided hypothesis testing.

The intention-to-treat analysis in Table 1 estimates the effect of being assigned to a large (or small) group, rather than being in one. We thus replicated our results using an as-treated approach, where we treat the independent variable group size observationally, namely, as the actual number of active users in the group (Supplemental Table S2). The model is also shown in Figure 2(b). The dashed lines represent the accuracy of the local source (65%, in red) and the global source (70%, in blue). We can use the binomial distribution to estimate the expected group accuracy when using a pure sleuth strategy (dotted line). This expected accuracy is the probability that a binomial distribution with n = 15 (our largest group size) and p = .65 (the local news source accuracy rate) returns a majority of eight or more correct votes (89%, in purple). The solid black line represents the model fit. A positive slope representing the effect of group size is observed in the collective incentive condition but not in the individual incentive condition. Group incentives begin to outperform individual incentives with a group size of about three (vertical grey line). This group size is the value of n in a binomial distribution with p = .65, where the probability of a correct majority is larger than the global source’s accuracy (70%). (a) Difference in group accuracy between the last and first decile of trials (y-axis) as a function of as-treated group size (x-axis) and incentive (represented by color). Marker size represents experimentally assigned group size (intention-to-treat group size). Positive values, implying learning, represent increases in group accuracy, while negative values represent decreases in group accuracy. (b) Logistic model quantifying the effect of group size (x-axis) and incentive condition (left-right panel) on collective accuracy (y-axis): group accuracy ∼ size + incentive + size x incentive (single participants removed). Solid black lines represent model fit. (c) Difference in agreement rate with local source between the last and first decile of trials (y-axis) as a function of as-treated group size (x-axis) and incentive (color). Marker color and size follow the convention described in Figure 2(a). Positive values represent increased preference for the local source. (d) Participants’ preference for the local sources when sources disagree with each other as a function of group size and incentive. Preference is defined as the match between participants’ forecasts and a source’s provided information. In Figure 1(b), for instance, the participant’s forecast (70%) matches the source on the right, but not the source on the left.
Assigned group size can be used as an instrumental variable to recover the causal effect of actual group size (rather than assigned group size). We ran a bootstrap analysis using a logistic two-stage residual inclusion (2SRI) model on group accuracy (see Supplemental Information). Results, reported in Supplemental Table S3 and Figure S2, broadly confirm our findings and replicate the interaction between group size and incentive type. We expected these effects to be the result of learning and thus emerge gradually over time (Figure 2(a)). However, adding time (measured as normalized round number) to our model did not significantly improve model fit (χ2 (4) = 4.29, p > .3).
The same models were fitted on individual rather than group accuracy, to test whether the observed improvement in group accuracy was simply the product of improved individual accuracy (Figure 1(c)). The model included group size, incentive and their interaction (Supplemental Table S4). We found no effect of group size (β = 0.004, SE = 0.007, z = 0.57, p > .5), collective incentive (β = 0.04, SE = 0.06, z = 0.67, p = .5) nor a significant interaction between group size and incentive (β = 0.004, SE = 0.01, z = 0.45, p > .6). Overall, the findings suggest that group accuracy improved, notwithstanding the fact that the average individual accuracy was unaffected by our manipulation. A linear model fitted to Brier scores—a quadratic prediction error measure used to assess forecast calibration (Tetlock, 2006)—revealed a significant advantage of large groups (β = −0.002, SE = 0.001, t = −4.039, p < .001) but no interaction with incentive type (see Supplemental Information, Supplemental Table S6).
Collectively rewarded individuals prefer local news
Intention-to-treat analysis on the preference for the local news source when sources are in disagreement. Coefficients of the model on individual preference for local sources. The model’s predictors are assigned group size and incentive condition (baseline: individual incentive). Model formula: agreement with local source ∼ size + incentive + size × incentive. Significance thresholds: . = p < .1, * = p < .05, ** = p < .01, *** = p < .001. P-value thresholds represent two-sided hypothesis testing.

At the end of the experiment, we asked participants to explicitly report what they believed each news source’s accuracy was and which news source they mostly relied on. The proportion of participants reporting having relied more on the local source was smaller in collectively rewarded than individually rewarded three-person groups (Figure 3(a)). In larger groups, the same proportion was larger in collectively rewarded groups than in individually rewarded groups. A two-way analysis of variance revealed a significant effect of group size (F (2, 41) = 7.17, p = .002). When asked to express their perception of each source’s percentage accuracy, participants in the individual reward condition perceived the global source to be more accurate, on average, than the local sources (Figure 3(b)). The reverse was true for collectively rewarded participants, although the effect was not significant. No significant interaction was found between group size and incentive when we analyzed ratings of subjective decision confidence (Supplemental Information). Overall, these findings suggest that higher collective accuracy was achieved even though people could not precisely tell (or only a fraction of them could) which of the two news sources was more accurate. Exit survey results. (a) Proportion of participants (y-axis) who reported having relied more on the local information source, divided by experimental condition. (b) Reported accuracy difference between local and global information source in the two incentive conditions. Error bars represent standard errors of the mean.
Locality, correlation, and accuracy in digital news media
How relevant is our controlled experiment to the real-world complexity of online news? Arguably, reliable mainstream publishers covering the same story may provide less social value than many smaller publishers covering independent stories (Martin and McCrain, 2019; Usher and Ng, 2020; Downing and Philip Schlesinger, 2004). We ran an exploratory analysis using publicly available datasets. We explored the relationship between news media locality (mainstream vs local reach), news media accuracy, and correlation between news sources. The following results are preliminary and analyses were not preregistered.
We used the News Aggregator Dataset, freely available at Kaggle.com, from the UCI Machine Learning Repository (Lichman, 2013). This dataset contains headlines, URLs, and categories for 422,937 news stories collected by a web aggregator between March 10th, 2014 and August 10th, 2014, and 10986 unique publishers, ranging from mainstream ones (e.g., Reuters and The Guardian) to small local ones. The News Aggregator Dataset uniquely identifies news articles that refer to the same news story (e.g., several articles about recently released employment statistics). There are 7230 unique stories covered in this dataset. This feature allowed us to ask whether larger publishers tend to be more correlated in terms of the stories they cover and the content similarity when they cover the same story compared to smaller ones.
First, we defined a coarse measure of publisher reach (degree of locality). As information about the size or popularity of the publisher was not available, we used how prolific the publisher was in the period covered (number of entries in the dataset) as a proxy of locality, under the assumption that larger newspapers would be more prolific and thus appear more often in aggregator searches. This measure turned out to be a surprisingly good approximation of a publisher’s size and notoriety. According to this measure, the most prolific publisher was Reuters, followed by several well-known others like Bloomberg. At the bottom of the distribution (with just one entry in the dataset) were several smaller publishers (e.g., Yale Daily News or The Cameron Herald). The measure showed a negative but not significant association with an independent measure of newspapers’ monthly reach in the United Kingdom (Pearson’s ρ(d.f. = 10) = −0.31), as surveyed by Publishers Audience Measurement Company from April 2019 to March 2020. More precise measures—for example., readership volume, social media followers, or geographic indicators—should be investigated in the future.
Second, we defined two measures of correlation among news media, namely, Jaccard’s similarity in the stories covered and headlines’ linguistic similarity. Alternative correlation measures could be defined, like political slant, overlap of stories covered or language used. We first looked at the similarity in the set of stories covered. Arguably, two news media outlets covering the same set of stories provide more correlated information than if they covered different stories. We defined story similarity as the Jaccard index between the sets of stories covered by two publishers. Figure 4(a) shows story similarity between pairs of publishers, among the first 100 publishers ranked by output (prolific or not). A gradient can be observed from the top-left corner to the bottom-right corner, suggesting that the larger the publishers the larger the overlap of the set of stories they covered. We then correlated the difference in locality (i.e., difference in output) and story similarity. We used Reuters, the most prolific news source, as our reference point and calculated these measures for each publisher in the dataset with respect to it. We found a strong negative correlation between story similarity and publisher’s locality (ρ = −0.84, p < .001), confirming our earlier observation that large publishers seem to cover more overlapping stories than smaller ones. (a) Story similarity between pairs of news publishers in the News Aggregator dataset. Story similarity was computed as the Jaccard similarity of the set of stories covered by pairs of publishers. The figure shows the first hundred publishers by output in the dataset. Greater story similarity is shown in the top-left part of the matrix. Data was interpolated with a Gaussian filter (σ = 2). (b) Story similarity as a function of publisher size (i.e., output difference with respect to Reuters) and publisher accuracy (i.e., factual reporting score calculated by Media Bias Fact Checking). Publisher size was calculated with respect to Reuters, the largest publisher in the News Aggregator dataset. Stories similarity was computed as the Jaccard similarity of the set of stories covered by each publisher with respect to the set of stories covered by Reuters. The dataset is publicly available at Kaggle.com Lichman (2013).
We then looked at story headline similarity for newspapers that covered the same story. This measure is better aligned with our experimental results. Our experimental study considered news sources with independent angles on the same story rather than similarity in stories covered. Headline similarity was computed as pairwise cosine similarity of term frequency–inverse document frequency (tf-idf) vectors. A significant negative correlation existed between a publisher’s difference in output with respect to Reuters (i.e., their locality) and the average similarity of the headlines, for each story covered by both publishers (ρ = −0.062, p < .001). In other words, the larger the publisher the more similar its story headlines were to Reuters’ headlines (Supplemental Figure S5). Notice that, as expected, publishers with high degrees of locality (rightmost data points in Figure 4(a)) also show higher variability in their headline similarity. Arguably, smaller outlets may cover more niche topics or serve smaller geographies than global newspapers. Overall, these findings support the notion that smaller news sources tend to be more diverse and independent in their content than larger global news sources.
Finally, we defined a coarse measure of publisher accuracy. Although a definition of media sources’ accuracy is not straightforward, some news watchdogs provide excellent reliability rating scores. Here, we used the factual reporting score calculated by the Media Bias Fact Check website (MBFC) (Gruppi et al., 2021; Media Bias Fact Check, 2018; Patricia Aires et al., 2019). MBFC is a volunteer run fact-checking site rating websites that assesses political slant and credibility of factual reporting of a large number of news websites. Ratings are subjective but are based on a structured rubric and numerical scoring system to assign labels. We used MBFC scores for the category “Factual/Sourcing”*. Data contained Factual scores for a total of 1570 unique news publishers, divided in three categorical labels for source reliability (“Mixed,” “High,” and “Very High”). We aggregated the High and Very High categories as the latter contained disproportionately fewer elements than the other two categories. We retained only publishers present in the MBFC and the News Aggregator datasets (N = 989). We then tested whether the association between story similarity and publisher locality was modulated by the publisher’s reliability using a regression model. We found that MSBFC publisher reliability modulated the association between story similarity and publisher size (Figure 4(b)). Local news media scored lower on story similarity with respect to Reuters (β = −0.29, SE = 0.09, t = −3.14, p = .002). This effect was stronger for accurate than inaccurate sources, suggesting that accurate mainstream media in our dataset tended to cover more similar stories (β = −0.30, SE = 0.12, t = −2.52, p = .014).
Discussion
This study examined how collective incentives and independent news sources might improve collective accuracy in judgments based on news content. The key findings demonstrate that collective incentives nudged participants to use more independent yet less accurate news sources. This “sleuth strategy” enhanced collective but not individual accuracy, especially for larger groups. An analysis of news datasets revealed that mainstream outlets showed greater content correlation, which was influenced by accuracy.
When incentivized for individual accuracy, participants relied more on the single most accurate news source (the “consumer strategy”), even if the source was correlated with other people. Although beneficial for individuals and expected according to reinforcement learning mechanisms (Behrens et al., 2008; Sutton and Barto, 1998), the consumer strategy made groups sensitive to correlated mistakes (Mann and Helbing, 2017). Wrong majority decisions are expected every time the global news source is wrong. Individual incentives are common in many decisions, from markets to daily life choices. Contrary to earlier studies, recent studies found that individual incentives can produce herding and reduce the diversity of opinions in the population (Bazazi et al., 2019; Gürçay et al., 2015; Mann and Helbing, 2017). Many tasks are characterized by optimally aggregating shared and private information (Stasser and Titus, 2003). Collective rewards may help populations better leverage distributed knowledge.
Group decision-making models and reinforcement learning models in animal groups provide a mechanistic description of this phenomenon (Kao et al., 2014; Mann and Helbing, 2017). Although the importance of information independence in judgment aggregation has long been known, researchers have debated how to achieve it (Asch, 1956; Bernstein et al., 2018; Dalkey and Helmer, 1963; Navajas et al., 2018). Our findings show that promoting shared incentives can increase judgment diversity and reduce herding. Greater attention put into the local news sources likely was the result of learning by association (i.e., by trial and error) which news source was predictive of a positive outcome. The lack of a statistically significant effect of time in our model is likely the result of a lack of statistical power or due to preferences for a particular source developing early on in the experiment and then staying relatively stable.
Our second contribution lies in applying these mechanisms to news media. Our results highlight the overlooked value of judgment independence alongside accuracy when designing interventions to improve the online information ecosystem. While prior work focused on improving news and judgments’ accuracy (Guess et al., 2020; Pennycook et al., 2020, 2021; Van der Linden et al., 2020), our findings suggest that the use of collective incentives is an underexplored avenue for behavioral interventions. Improving news judgment accuracy must be balanced with increased average judgment correlation (Hahn et al., 2019).
In this study, we made three notable design choices. The first is the use of a forecasting task. Arguably, accuracy in news reporting and accuracy in predicting the future are very different things. However, the phenomena highlighted in this paper generalize to all domains where a ground truth is defined and fact-checking is possible, for example, public consultations on some policies or risk assessments.
The second is the use of truth-seeking sources instead of less benign news types (such as fake news). Understanding fake news is undeniably important but outside the scope of this paper. Here, we focus on more common truth-seeking scenarios (Allen et al., 2020; Guess et al., 2019). According to our framework, fake news represents the worst of two worlds because it lowers mean accuracy (spreading misinformation) and increases mean correlation (spreading information widely) (Gabbatt, 2019; Mahone and Napoli, 2020; Nyhan, 2019).
The third design choice was to present both information sources at the same time and infer participants’ preferences from their responses. This design was chosen to closely match Kao et al.’s model (Kao et al., 2014). In the context of online information, individuals are exposed to multiple information sources when scrolling through posts or notifications. Based on these simultaneous stimuli, they choose which piece of information to pay attention to and what news to rely on. An alternative method design is to force the subject to choose between news sources and reveal the news only after a choice is made. This promising method could increase statistical power and give researchers a clearer measure of subjective preferences (Table 2).
From our preliminary data analysis on the News Aggregator and MBFC datasets, news media accuracy predicted greater correlation among mainstream media. Our results suggest that documented “winner-take-all” dynamics in news production and ownership can damage collective decisions (Cellan-Jones, 2019; Downing and Philip Schlesinger, 2004; Libert and Binns, 2019; Martin and McCrain, 2019; Newman et al., 2019; Usher and Ng, 2020).
Mixed strategies are better than pure consumer or sleuth strategies (Figure 1(C) in (Kao et al., 2014)). Participants in our experiment showed evidence of using mixed strategies, alternating between local and global sources even in later stages of the experiment (see Supplemental Material) (Lo, 2013; Newell and Schulze, 2016; Schulz et al., 2015) and did not seem to follow simpler heuristics (Supplemental Information, Figure S4). As participants in the experiment did not follow pure consumer or pure sleuth strategies, we expected some benefit of group size in both conditions—albeit more pronounced in the collective incentive condition (Hogarth, 1978). Thus, the lack of an effect of group size in individually rewarded groups was surprising (Figure 1(c)). A lack of statistical power and the issues around group size manipulation described above might help explain this result.
Limitations
We acknowledge several limitations. First, managing group size proved challenging due to attrition and non-compliance, which disproportionately affected larger groups. Larger groups filled more slowly and often hit the 15-min waiting room cap before reaching the target size, leading to games starting with fewer participants than assigned. These groups were also more likely to include idle participants who did not make forecasts, which impacted majority decisions. The experiment relied on the assigned group size for majority calculations (e.g.,
Individuals in a group never interacted with one another, limiting generalizability to real-world media. Peer-to-peer communication and homophilous selection has been shown to negatively affect aggregate accuracy due to increased herding (Alipourfard et al., 2020; Hahn et al., 2019; Lorenz et al., 2011). News sources may have much less to do with one’s desire for accuracy than with one’s choice of friends. Another difference with real-world settings is the presence of content recommendation algorithms, which were entirely absent from our experiment (Ciampaglia et al., 2018; Pescetelli et al., 2022; Shao et al., 2018; Stella et al., 2018). Arguably, these unique online media features tend to further reduce independence by exploiting correlation patterns between users.
Another limitation is that precisely distinguishing mainstream and independent sources remains difficult outside controlled conditions. Online, news providers are likely to rely on third-party information sources, like AP and Reuters, within a complex web of dependencies that are difficult to untangle (Libert and Binns, 2019). Although the news ecosystem is more complicated than our two-source toy world, we can still design interventions that don’t rely on an a priori definition of local and global sources. Participants in our study did not know in advance which news sources were independent or accurate. Collective incentives turned out to be an effective and agnostic behavioral intervention, shifting people’s preferences to the collective advantage.
Applications
An obvious application of our results is to combat misinformation online. We call for scholars to develop better measures of the quality of online information ecologies that include not only the accuracy of online news but also their correlation. Improved measures of correlation between news media will help us track patterns of mutual influence and assess the health of the digital news ecosystem, providing valuable insights for policymakers. Regulation could require online platforms to provide these measures and penalize algorithms proportionally to the average information correlation of recommended content. Testing these interventions is not straightforward and will require cooperation of news providers, online platforms, policymakers, and scholars (King et al., 2017).
Beyond the online information domain, these results shed light on the role of incentives in collective accuracy that is likely to generalize more broadly. For example, individual investors making private financial decisions are better off by following the most accurate source as this accrues greater individual benefit. However, an investment company might be better off using collective incentives to nudge people to rely on their private, independent sources.
To conclude, prior literature on online information has overlooked the role of news correlation. Accurate but mainstream news content may be problematic when individual preferences are aggregated. Collective incentives may help driving consumption of more independent news sources.
Supplemental Material
Supplemental Material - Collective incentives improve group accuracy by reducing reliance on shared news sources
Supplemental Material for Collective incentives improve group accuracy by reducing reliance on shared news sources by Niccolò Pescetelli, Alex Rutherford, Iyad Rahwan, Albert Kao in Collective Intelligence
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is based upon work supported in part by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via contract number 2017-17061500006. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of ODNI, IARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for governmental purposes notwithstanding any copyright annotation therein.
Open science statement
Reproducibility
Significance statement
This paper demonstrates the overlooked value of independent news sources for improving collective decisions, even if less individually accurate. The findings show collective incentives can nudge consumption towards diverse sources and enhance aggregation resilience. This paper connects research on online news with collective intelligence and reinforcement learning models of animal groups. The results have significance for scholarship on epistemic threats and real-world applications to design thriving online information ecosystems.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.