
Abstract
Philosophers of science have long questioned how collective scientific knowledge grows. Although disparate answers have been posited, empirical validation has been challenging due to limitations in collecting and systematizing large historical records. Here, we introduce new methods to analyze scientific knowledge formulated as a growing network of articles on Wikipedia and their hyperlinks. We demonstrate that in Wikipedia, concept networks in subdisciplines of science do not grow by expanding from their central core to reach an ancillary periphery. Instead, science concept networks in Wikipedia grow by creating and filling knowledge gaps. Notably, the process of gap formation and closure may be valued by the scientific community, as evidenced by the fact that it produces discoveries that are more frequently awarded Nobel prizes than other processes. To determine whether and how the gap process is interrupted by paradigm shifts, we operationalize a paradigm as a particular subdivision of scientific concepts into network modules. Hence, paradigm shifts are reconfigurations of those modules. The approach allows us to identify a temporal signature in structural stability across scientific subjects in Wikipedia. In a network formulation of scientific discovery, our findings suggest that data-driven conditions underlying scientific breakthroughs depend as much on exploring uncharted gaps as on exploiting existing disciplines and support policies that encourage new interdisciplinary research.
Philosophers of science question the way science works and why. For millennia, they have posited mechanisms and offered explanations. Several recent and particularly compelling theories have been difficult to validate, in large part due to challenges in collecting and systemizing large historical records. Fortunately, Wikipedia—the largest online encyclopedia—contains millions of articles that not only form hyperlinked networks of concepts but also include a history of when a concept was discovered. We use this resource to formulate the process of science in terms of knowledge growth, or—more precisely—the growth of concept networks. Across scientific subjects, we demonstrate that networks in Wikipedia, as an important and interesting case, grow both by expanding frontiers and by filling knowledge gaps, striking a balance between bubbling out and bubbling in.Significance Statement
Introduction
In the philosophy of science, thinkers from disparate eras have attempted to reason about the various processes underlying scientific progress. Some of the most compelling theories have come from the last 50 years. For example, in 1959 Karl Popper described the development of scientific ideas as a sequence in which previous theories are falsified (Popper, 2008). In 1962, Kuhn suggested instead that progress was best described as periods of normal science, in which researchers “solved puzzles” within a paradigm, separated from one another by paradigm shifts that overturn the existing paradigm (Kuhn and Hacking, 2012). In 1970, Lakatos balanced the two theories by suggesting that science progresses according to a research programme in which knowledge expands from a common core set of theoretical commitments and practices (Lakatos, 1976). In 1975, Feyerabend differed from the thinkers who had come before by discounting any single mechanism for scientific progress (Feyerabend, 2010). Even more recently, the field of science of science has begun to use a more quantitative approach to probe the cultural, societal, institutional, and personal conditions that support (or do not support) scientific discovery, dissemination, and impact (Astegiano et al., 2019; Clauset et al., 2017; Fortunato et al., 2018; Helmer et al., 2017; Nagaraj et al., 2020; Robinson-Garcia et al., 2020; Wang and Barabási, 2021; Zeng et al., 2017).
Despite the variety of theories regarding scientific progress, such as cultural accounts of scientific practice (Chemla and Keller, 2017), many suggest a dependence of new discoveries on the existing body of knowledge. Newton writes in 1675, “If I have seen further, it is by standing on the shoulders of giants” (Newton, 1675). Indeed, discoveries, including calculus, are often multiples, discovered independently and contemporaneously by several scholars, sometimes quite geographically separated (Merton, 1974). These observations prompt the question of how an existing body of knowledge influences the discovery of new scientific knowledge.
Here, we expand upon the concept of a body of knowledge, not as amorphous, but as comprised of distinct relationships between concepts. We formalize this structured body of knowledge as a concept network whose nodes represent concepts and whose edges represent inter-concept relations (Siew et al., 2019). Concept networks have proven to be powerful tools for probing questions about topological structure and the exploration of knowledge (Christianson et al., 2020; Lydon-Staley et al., 2021). To begin to study the process of science, we build growing concept networks from Wikipedia, a free online encyclopedia (Figure 1(a); Methods). Each Wikipedia article explains a concept and contains hyperlinks to other Wikipedia articles, thereby intuitively forming a directed network of concepts. To formally represent this network, we treat each article as a node. Further, we treat each hyperlink from an article’s lead section (i.e. the introduction) as a directed edge from the hyperlinked article to the hyperlinking article. We weight the directed edges according to the similarity between the two nodes or concepts. More specifically, we calculate the cosine similarity between two articles’ vector representations, which are derived from a term frequency-inverse document frequency (tf-idf) encoding. Focusing on the article’s history and lead sections, we parse the earliest year associated with the concept’s discovery and set that year as an attribute for each node. We use this information about the year of a concept’s discovery to create a growing network across time, adding edges at the same time as the addition of the edges’ associated nodes. Building a growing concept network from Wikipedia. (a) Each network is made up of Wikipedia articles that are indexed by subject in the natural sciences, mathematics, and the social sciences. Each node corresponds to an article; the node’s name is the title of the article, and the node’s birth year is the first year listed in the introduction or history sections as the year when the concept was conceived (highlighted in yellow). Each directed edge corresponds to a hyperlink, from the article that is hyperlinked to the article that hyperlinks. (b) The final concept networks display greater clustering, modularity, and coreness than null networks constructed to reflect Fereyabend’s hypothesis that science lacks a characteristic pattern of discovery. (c) By comparing the birth year of core nodes to those of neighboring peripheral nodes, we observed that there is no clear lead-lag relationship between a core node and its neighboring peripheral nodes. Violin plots show distributions of the years of core nodes minus the years of neighboring peripheral nodes, for each core-periphery edge. Some large differences (e.g. 5000 to 10,000 years) are due to articles about recently discovered topics referencing articles about topics discovered much earlier. Vertical lines indicate outliers, which are less than 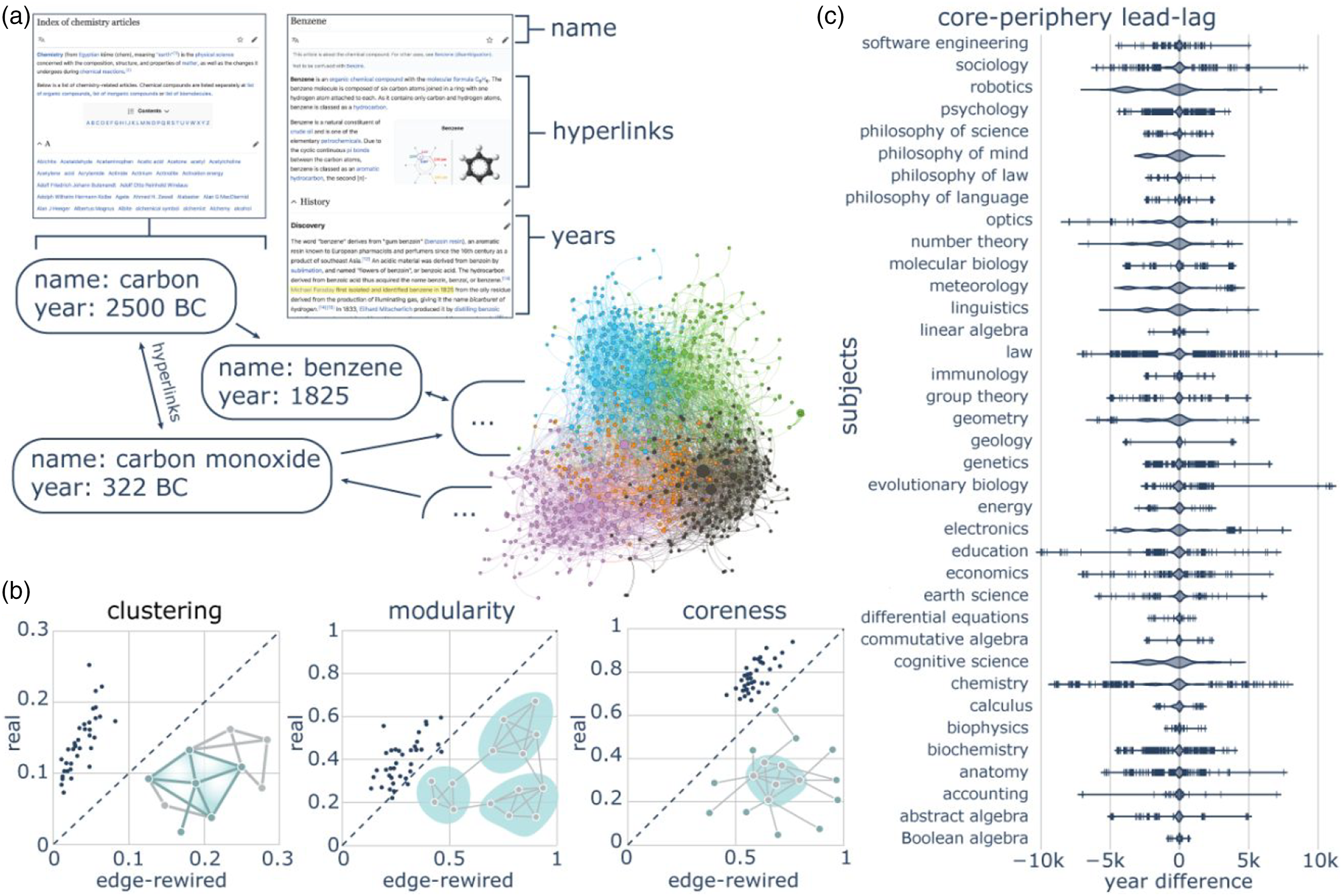
In this study, we develop methods to operationalize the theories of the philosophers Kuhn, Feyerabend, and Lakatos as falsifiable hypotheses using network theory. We then test each hypothesis—from which we infer the theories that are most supported by the data—in Wikipedia as an important and interesting case. To operationalize and test these hypotheses, we use cutting-edge methods in network science, algebraic topology, and control theory. Here, we find that science concept networks grow by creating and filling knowledge gaps, a process which is valued by the scientific community. Moreover, we operationalize a paradigm as a particular subdivision of scientific concepts into network modules and find that paradigm shifts vary in their magnitude in a similar temporal signature across scientific subjects. Our findings not only shed light upon the large-scale, empirical evidence of classical philosophies of science but also demonstrate operationalizations of qualitative social phenomena that may be readily applied in other contexts.
Results
Given the notions of characteristic patterns in discovery by Kuhn and Lakatos, or the lack thereof by Feyerabend, we first quantified the structure of concept networks using computational tools and concepts from network science. As an initial test of Kuhn’s hypothesis of normal science, we measured whether concepts form clusters, in which scientists “solve puzzles” within an existing paradigm. At the node level, we operationalized this idea using the clustering coefficient, which quantifies the local density of connections (Fagiolo, 2007); at the network level, we operationalized this idea using modularity, which quantifies the degree to which groups of nodes are densely connected within distinct modules (Clauset et al., 2004). Additionally, we used a core-periphery measure (Borgatti and Everett, 2000) to assess whether networks form a “common core” as suggested by Lakatos’s research programme, where core nodes are densely connected to each other, and where peripheral nodes are loosely connected to the core. We compared these measures in real networks to those in null networks that destroy existing topology through random rewiring. Randomized null networks may be one way to operationalize Fereyabend’s hypothesis of a lack of characteristic pattern to discovery. We found that real networks have greater clustering coefficients, modularity, and coreness than those in the edge-rewired networks (Figure 1(b)). These findings underscore the existence of nontrivial topological structure in concept networks, whereby concepts can either be core to the field or peripheral to the field, and are clustered within modules (akin to subfields).
How might the structure of concept networks arise through the course of history? Might core concepts emerge first, followed by peripheral concepts, in a cumulative growth pattern in which we build deeply upon foundational early discoveries in the field? Or might the “foundational” concepts change as the field grows and changes, such that new discoveries can sometimes replace earlier discoveries as more central to the field? To address this question, we compared the birth year of core nodes to the birth year of neighboring peripheral nodes. We observed that there is no clear lead-lag relationship between a core node and its neighboring peripheral nodes (Figure 1(c)). That is, core nodes do not necessarily precede neighboring peripheral nodes in their discovery, suggesting that the discoveries viewed as “central” to a field can change throughout the field’s lifetime. Notably, there is similarly no clear lead-lag relationship between core and periphery nodes within specific modules (Figure S1). Interestingly, a few core nodes are born consistently earlier than most peripheral nodes. These nodes, such as the node “Hydrology” in the subject “Earth Science”, may serve as concepts that are central to the subject as a whole and comprise a “hard inner” part of the core (Figure S2). Taken together, these results point to both an outward expansion and an inward exploration of concepts, in which the core of a research programme is often updated by new discoveries that are influenced by discoveries that occur in the periphery.
How then does a body of knowledge grow? Thus far, we understand that real concept networks are highly clustered and display processes of both inward and outward growth. Might concept networks fill gaps in knowledge (Fontana et al., 2020) in a manner that is conceptually akin to Kuhn’s puzzle-solving normal science? To test this possibility, we formalize knowledge gaps in the language of algebraic topology (Hatcher, 2002) and assess the relevance of gaps to discovery. Specifically and in this mathematical parlance, a gap corresponds to a topological cavity in any dimension n (Figure 2(a) and (b); Methods) (Sizemore et al., 2018). To detect gaps within the growing concept network, we use persistent homology, which chronicles the birth, evolution, and collapse of topological cavities across a growth process (Zomorodian and Carlsson, 2005). In general, a cavity in a Wikipedia network is a set of articles (i) that form a single connected component, but (ii) no article in the set connects all articles of the cavity. Real concept networks maintain shorter and fewer gaps. (a) Examples of cavities in 0, 1, and 2 dimensions. Cavities are born when a new, added node creates a topological gap; cavities die when the gap is closed by a new node and its edges tessellate the gap. (b) Barcode for the biophysics network. The left and right points of each bar are the birth and death times of a persistent cavity. (c) Illustration of our genetic model for concept network growth and evolution. (d) Real networks have knowledge gaps for shorter duration than either randomly rewired 
After computing the persistent homology of real networks (Figure 2(b)), we next wished to determine whether the observed gap formation and closure was similar to (or different from) the same processes expected in network null models. We consider two network null models. The first is a randomly rewired null model, in which the edges are relocated uniformly at random. The second is a genetic null model that explicitly examines the process of scientific discovery. The genetic null model simulates the process by which scientists learn about existing concepts and then slowly mutates those concepts to create new ones. Importantly—and unlike true science—, the genetic null model contains no preference for how new concepts are mutated, for example as could be operationalized by an objective or fitness function (Figure 2(c)). The model is initialized as a subset of a real network, containing “core nodes” that were born before a predetermined year (500 BC in our simulations). For each node, we iteratively mutate a tf-idf vector representation of the node’s Wikipedia article. We then create a new node from the mutated vector and connect it to similar nodes in the network (Methods; Figure S3). This process continues until the number of nodes in the simulated network is equal to that of the true network.
At this point, the topology of the real, rewired, and genetic null model networks can be compared. We find that for persistent cavities that have already died by t
max
, those in real networks have significantly shorter lifetimes than those in either randomly rewired networks (Kolmogorov-Smirnov statistic,
Whereas the first part of Kuhn’s theory regards puzzle-solving, the second part regards paradigm shifts that radically change the way scientists view concepts. In our network formulation, we operationalized paradigms as temporally varying modular structure, where an “incommensurable” paradigm shift would drastically change the membership of nodes to modules. Accordingly, we built a multilayer network with each layer containing the concept network at each year (Bianconi, 2018) and used multilayer community detection to identify modules at each year and understand how those modules change in constitution over years (Mucha et al., 2010). To summarize these data, we followed prior work to calculate the number of times that a node changes its membership to a module for each year (Figure 3(a)) (Killick et al., 2012). Then, we performed change point detection on the number of changes observed to identify epochs of stability in module membership (Figure 3(b); Methods) (Killick and Eckley, 2014). We found that after an initial, short epoch of little change, the network enters an epoch of moderate and lasting change (Figure 3(c)). Then, the network enters a short epoch of much greater change, after which the network stabilizes in the last epoch. This signature is not observed in randomly rewired networks (Figure S4). The data demonstrate that shifts in the structure of concepts occur not as abrupt Kuhnian reconfigurations but as gradual Lakatosian modifications (Daston, 2016). Moreover, the findings demonstrate that subjects (or fields) display a shared signature of structural stability and instability across time. Concept networks undergo a signature pattern in structural stability. (a) Module membership (colored) of nodes across years for the biophysics network. (b) The number of changes in module membership for the biophysics network. Dashed lines are changepoints in epochs, and the teal line is the mean for each epoch. (c) The mean number of changes within an epoch (top) and the duration of each epoch (bottom) reveals a signature (dark green) averaged across subjects (teal).
Finally, we ask whether we can predict the perceived merit of a discovery by measuring the node’s theoretical ability to influence a body of knowledge due to its location within the gappy topology. We operationalize perceived merit in two ways: (i) a network-based measure and (ii) the receipt of a Nobel prize (Jin et al., 2021; Li et al., 2019; Szell et al., 2018), although we acknowledge the imperfect nature of the latter assessment (Nature, 2018, The Lancet, 2018). After constructing a single network containing all nodes from all subjects, we calculated the network’s impulse response as a measure of a node’s potential influence. Arising from dynamical systems theory, the impulse response quantifies how much a network “responds” to an “impulse” that perturbs one node (Figure 4(a); Methods). We observed that nodes that more frequently participate in the birth or the death of cavities have higher impulse responses (birth: Pearson’s correlation coefficient Network topology reveals the impact of concepts. (a) Illustration of the response of a network to an impulse applied to a node. (b) Nodes that more frequently participate in the birth or death of persistent cavities have higher impulse response, which is a dynamical-systems measure of a node’s influence on a network (birth: 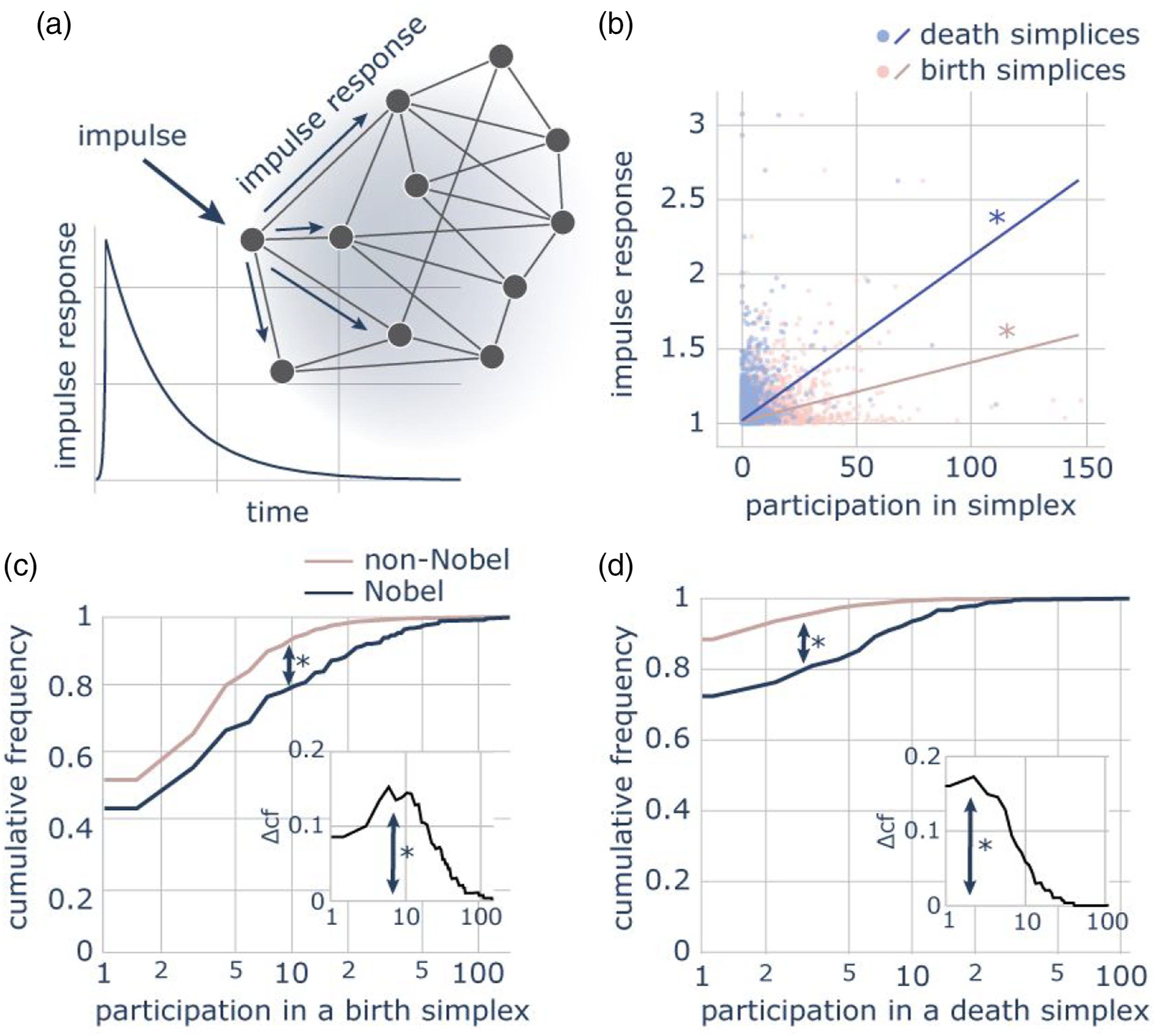
In summary, our findings reveal that human knowledge, in the case of articles in Wikipedia, grows by filling gaps in knowledge, perhaps driven by the collective curiosity of individual scientists (Golman and Loewenstein, 2018; Merton, 1974), through inward and outward exploration and gradual modifications to network structure. Moreover, knowledge discovered while creating and filling knowledge gaps is likely to be more influential and more frequently awarded in the scientific community.
Model assessment
Feyerabend
While Feyerabend’s theory arrived latest in chronological time (1975 vs. Kuhn’s in 1962 and Lakatos’s in 1970), we tested his hypothesis first because his ideas about the growth of scientific knowledge are the most different from the rest. Feyerabend posits that there is no single set of scientific methodologies employed in practice by all scientists (Feyerabend, 2010). Note that this claim stands in stark contrast to the Popperian and Kuhnian positions that science does have a characteristic pattern of discovery. Feyerabend was accepting of—and even promoted—a competition of theories and was careful to not demarcate science and its practice from other human endeavors, including storytelling and myth. These commitments served to counter the effects of a history of power structures and the influence of Western philosophy upon—and in justification of—science. To model Feyerabend’s theory, we use an edge-rewiring process that produces a random network topology (Maslov and Sneppen, 2002). It is critical to note here that we are not modeling the scientific process as a process of random rewiring; instead, we are modeling the network structure resulting from science without a characteristic pattern of discovery (Feyerabend’s thesis) as the culmination of a random rewiring of connections. In comparing edge-rewired networks to their real counterparts, we observed that real networks often display significantly non-random clustering on two topological scales: at the nodal scale, clustering manifests in a high clustering coefficient, whereas at the mesoscale, clustering manifests in the existence of modules and cores (Borgatti and Everett, 2000; Clauset et al., 2004; Fagiolo, 2007). Thus, a network formulation of knowledge suggests that the processes underlying network growth constrain the network topology, in opposition to Feyerabend’s theory.
Further, for Feyerabend new significant discoveries in science come as a result of reframing or seeing nearly all things completely anew, rather than filling otherwise well-recognized gaps in knowledge. In contrast, in our study we have shown that novel discoveries are the result of new cavities being formed or filled in the network and that these cavities are of higher-dimension, shorter period, and decreased frequency in real networks than in random or genetic networks. Hence, our results do not support the Feyerabend position of incommensurability and of novelty in knowledge being about a complete reconfiguration of the concept network. These observed distinctions between the data and Feyerabend’s predictions motivate the examination of other philosophical positions.
Lakatos
Lakatos hypothesized that science progresses as a research programme, which has a common “hard core” of postulates with an auxiliary belt of hypotheses that builds upon the core (Lakatos, 1968, 1976, 1978). He was interested in constructing a methodology of science (less so, an epistemology of science) that focuses less on demarcation (what counts as science or not) than on scientific practice. Within Lakatos’ research programme, the “hard core” is a set of theories, practices, and commitments that most scientists would not want to give up in their research. Auxiliary hypotheses link the “hard core” to experiments and observations. Lakatos held that, in practice, science often chooses to modify auxiliary theories rather than give up on any of the “hard core” set of commitments, theories, and practices.
In this study, we operationalized Lakatos’s hypothesis as growth within the core-periphery structure of a concept network (Borgatti and Everett, 2000). From the perspective of network topology, nodes in the “core” are densely connected to each other and form the topological center of the network; in contrast, nodes in the “periphery” tend to connect to the core but not to other peripheral nodes. In general, peripheral nodes have fewer connections than core nodes. The core-periphery structure of a network has important implications for the modification of scientific theories. For example, it is more difficult to modify nodes in the core than those in the periphery because core nodes are densely connected to one another. Similarly, it is easier to modify nodes in the periphery than those in the core because periphery nodes are only loosely connected to the network. The core-periphery structure hence reflects Lakatos’s research programme with respect to both topology and scientific modification. In our study, we observed that concept networks do indeed display a core-periphery structure; however, we also observed that concept networks grow both “outward”, with core nodes preceding neighboring peripheral nodes, and “inward”, with core nodes preceded by neighboring peripheral nodes. This result supports an interesting aspect of Lakatos’s theory of science: it is seen as a layered core with an outer layer that is often updated by new discoveries that are influenced, in turn, by discoveries that occur in the periphery.
Kuhn
Kuhn’s ideas of scientific progress posit that there are two periods of science (Kuhn and Hacking, 2012). One period is called normal science in which scientists “solve puzzles” within the current view of the body of knowledge, which he called a paradigm. The other period is a paradigm shift in which the current paradigm is overturned by another. In our study, we first operationalized “puzzle-solving” normal science as filling knowledge gaps, and we formulated a conceptual gap as a topological cavity. Using persistent homology from the subfield of algebraic topology in mathematics, we identified cavities within a concept network and the times when cavities are created and destroyed throughout history (Zomorodian and Carlsson, 2005). We observed that cavities in real networks are filled more quickly than in edge-rewired networks or in genetic null models of knowledge growth. Moreover, real concept networks reflecting contemporary scientific knowledge have fewer unfilled cavities and more cavities with higher dimensions than edge-rewired or genetic null model networks. These results suggest that scientists create and fill knowledge gaps in the course of scientific progress.
To complement our casting of normal science as creating and filling cavities, we operationalized paradigms in terms of a concept network’s modular structure. Our choice was motivated by an appreciation of the following fact: the view that scientists hold about a body of knowledge can depend upon how a subject is organized into parts or modules. Consider two examples. First, if a certain concept that originally exists in the fringe of a large module can engender enough discoveries, then the concept may start a new field of study and, at the same time, cause nodes to change their membership from the existing module to a new module. Second, when an incommensurable paradigm shift occurs, one might expect that knowledge is reorganized into new, unrecognizable modules. In operationalizing paradigms in terms of a concept network’s modular structure, we appreciate that paradigm shifts would manifest as shifts in modular structure. To detect such shifts, we formulated the growing concept network as a multilayer network wherein each layer contains the concept network as it existed in a given year. When we detected module membership across time (Mucha et al., 2010) and identified regimes of high or low change in module membership (Killick and Eckley, 2014), we observed that concept networks displayed a signature pattern: a short period of little to no change, then a long period of small but constant change, then a short burst of many changes, and finally, a long period of little to no change. Importantly, these dynamics do not result in completely new modules—as one might expect with the “incommensurability” of paradigm shifts—but rather represent gradual changes to the existing modular structure.
Interestingly, the process of cavity filling in real networks reveals the importance of curiosity as a catalyst for scientific progress. Kuhn recognized quite early that “normal science” would push scientists (and knowledge formation) into a constrained and conservative path—one that does not encourage true creativity and innovation (Kuhn, 2000). For Kuhn, the innovation occurred either when iconoclastic individuals were lucky enough to uncover something novel, or when the accumulated failures of a scientific research programme made the search for more creative solutions necessary and better rewarded. In our study, we provide no analysis of individuals, scientific commitments, or practices. Yet, our results on cavity filling and its propensity for being rewarded in the scientific community suggest not two disparate periods of constrained normal science and innovative paradigm shifts but rather a single process in which scientists are continually and collectively driven, perhaps by curiosity, to uncover novel information that “connects the dots” among existing pieces of knowledge.
Discussion
The question of precisely how individuals and groups “do science” has troubled scholars for millennia. In the past century, philosophers of science have proposed several distinct and well-defined processes whereby scientific knowledge might grow. Prominent theories include those by Kuhn, Lakatos, and Feyerabend, which posit different patterns of growth that are supported by historical evidence. However, progress in devising rigorous empirical assessments of these theories has been hampered by difficulties in gathering large amounts of historical data and in operationalizing the theories in a falsifiable way. In this study, we formulated the body of knowledge as a concept network (Hesse, 1974) and operationalized philosophical theories in terms of the network’s growing structure. We demonstrated that, in the case of Wikipedia, concept networks are non-randomly organized, being characterized by high modularity and notable clustering. The networks do not grow strictly outward, as one might have naively expected. Rather, they expand both outward and inward. The inward expansion manifests as a filling of network cavities, which produces concepts that are topologically influential and more often awarded Nobel prizes. Across almost all subjects or fields, the modular structure of concept networks morphs along a signature trajectory of stability and instability consistent with Kuhn’s notion of a paradigm shift. Broadly, our mathematical formulations of historical data pave the way to describe, understand, and even potentially guide scientific progress for individuals and funding agencies (Fortunato et al., 2018). Furthermore, our findings provide a data-driven approach to identifying novel contributions, especially those by underrepresented groups whose works are typically devalued yet are vital for vibrant scientific innovation (Hofstra et al., 2020; Reardon, 2013). In the remainder of this section, we expand upon the insights revealed by our findings.
Network science
Our effort to quantitatively evaluate philosophical theories of science was made possible by formalizing large-scale data into well-defined expressions. In our formalization, we primarily employed network science and algebraic topology. Using the former, we extracted graphs from a large database of text in Wikipedia pages, and using the latter, we extracted simplicial complexes from the same. Network representations are intuitive models for concepts and conceptual relations. Such representations have previously proven useful in the study of concept networks from Wikipedia, and in the characterization of their topology using measures of centrality, shortest paths, and clustering (Bellomi and Bonato, 2005; Lydon-Staley et al., 2021; Matas et al., 2017). Further, network representations can reveal patterns in data that are not quantifiable by observing each individual pairwise interaction—in this case, individual pages or hyperlinks—but that are only quantifiable by considering the entire network or subsection of a network. By complementing network science with algebraic topology, one can study higher order structures in concept networks, and thereby quantify the birth and death of topological cavities. This approach has previously proven useful in, for example, understanding the exposition of concepts in college textbooks (Christianson et al., 2020) and the growth of knowledge gaps in the semantic networks of toddlers (Sizemore et al., 2018). By modeling concept networks as units and pairwise or even higher-order relationships among units, one can operationalize hypotheses about the structure of knowledge and its change over time.
Methodological assumptions and limitations
In operationalizing the complex social process of knowledge discovery, we made a several assumptions. Each was chosen to better enable us to form empirically testable hypotheses. These methodological assumptions and limitations are explained more extensively in the Supplemental Discussion and are summarized here. First, to model knowledge discovery, we assume that the growing Wikipedia networks model how minds have collectively built networks of knowledge. Our study thus is not one of realism but one of the practice of science and scientific discovery (Hesse, 1980). Correspondingly, we assume that collective minds, as represented by a Wikipedia network, have been shaped by evolutionary forces to reflect the real as closely as possible.
Furthermore, we acknowledge the limitations and assumptions of modeling scientific discovery as growing concept networks. First, the process of scientific discovery involves a network of commitments and social practices in addition to the concepts themselves (Longino, 2002). Thus, the findings presented here would best be considered complementary to qualitative studies of theory and process. Our approach is useful because it allows us to operationalize and quantitatively test certain dynamics in the structure of concept networks on a large scale. Second, while the network structure is different from the process used to obtain that structure, we aim to infer and constrain the possible processes that produced the concept network that we see today in the structure of Wikipedia. Indeed, concepts can evolve over time in their name or contents or can even be disconnected from the scientific canon (Foster et al., 2015; Shwed and Bearman, 2010).
We note the limitations in our use of Nobel prizes as a measure of impact. As a highly subjective and often biased measure of impact (Lunnemann et al., 2019), we wish to test in future studies the robustness of our results not only in other datasets for Nobel prizes (Li et al., 2019) but also in other prizes (Jin et al., 2021). Moreover, while the goal of prizes is often to award for impact among other things, the effects of Nobel prizes on scientific practice is complex. Nobel prizes do not affect the citation impact of a Nobel laureate (Farys and Wolbring, 2017), but they do produce more papers and entrants in the topic associated with the scientific prize (Jin et al., 2021). Thus, scientific awards influence and are influenced by the body of scientific knowledge.
Finally, we acknowledge limitations in the way we represent Wikipedia pages as a concept network. First, without proper context, the title of a Wikipedia article can be ambiguous, and it may be difficult to infer the concept to which it best relates. This limitation is mitigated by the hyperlinks that connect a Wikipedia page to other pages; yet, even here it is important to acknowledge that the existence of a hyperlink involves some aspect of chance. Second, Wikipedia pages only reflect the current understanding of a concept and its relation to other concepts. Third, Wikipedia itself may be laden with the predispositions of the editors of Wikipedia regarding their philosophies of science. Moreover, their editing of Wikipedia may be affected by their political biases (Harvard Business School et al., 2018) or their styles of information seeking, which may influence which articles they choose to read and later edit (Lydon-Staley et al., 2021). Fourth, Wikipedia articles may actually affect scientific practice itself, an observation that highlights the impact of secondary source information, especially a widely available source like Wikipedia, on primary research (Thompson and Hanley, 2017). Thus, understanding patterns of growth on Wikipedia as they relate to primary sources seems ever more important. In summary, we applied the network methods presented here to Wikipedia as an initial and interesting test case, but we look forward to future efforts applying such methods to other datasets, primary or otherwise.
Future Directions
In summary, we operationalize and test the theories of prominent philosophers of science using concept networks of Wikipedia articles. We significantly extend the state of the field by building upon previous studies that have examined the topology of Wikipedia (Bellomi and Bonato, 2005; Matas et al., 2017; Yamada et al., 2020) and network principles in scientific practices (Clauset et al., 2017; Fontana et al., 2020; Fortunato et al., 2018; Sinatra et al., 2016). Moreover, we depart from prior work by using algebraic topology to test hypotheses regarding the sociology, history, and philosophy of science in a large-scale, empirical study. These methods can readily be applied to related questions about the structure and dynamics of concept networks. For example, differences in language or culture may influence the structure of concepts as encoded in Wikipedia pages. Other investigators may use network structure and document embedding to form more accurate and nuanced models of scientific discovery that explain the qualitative observations and interpretations of philosophers of science. Further, the methods demonstrated here may reveal insights into observed gender disparities in the processes of knowledge generation and scientific engagement (Ford and Wajcman, 2017). Our development of data-driven approaches hence lays the groundwork for others to further describe and understand the process of scientific discovery and its relation to diversity, equity, and inclusion.
Methods
Building growing concept networks from wikipedia
Software package for representing networks. We used the Python software package networkx (version 2.5) for most of our network representation and analysis. We used the Python package igraph (version 0.8.2) for representing networks for temporal module detection (see the later section “Temporal modularity structure”).
Selecting articles for a subject. To build a concept network for a subject, we must first select Wikipedia articles that belong in a subject. Doing so in a principled manner can be difficult because there are no inherent delineations between articles of different subjects. Fortunately, Wikipedia provides indices of subjects, which list articles of a particular subject (https://en.wikipedia.org/wiki/Wikipedia:Contents/Indices). We chose to explore subjects in the areas of Mathematics and Logic, Natural and Physical Sciences, and Subdisciplines of Philosophy. For each subject, we built a network where nodes represented articles that are listed on the subject’s index, and where edges represented the articles’ hyperlinked connections.
Network measures.

Weighting network edges. We determine the weight of each edge between two articles by calculating the cosine similarity between the vector of term frequency-inverse document frequencies (tf-idf) for words in one article and the tf-idf vector for words in the other article (Salton et al., 1975). We compute tf-idf by multiplying a local component (term frequency) with a global component (inverse document frequency). The measure is defined as follows: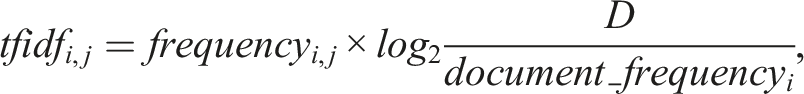
Denoting the birth year of a node. We parse the years from the lead section and from a history section if the article has one. We denote the earliest year as the year when the node was “born” or conceived. There exist articles that do not have years listed in either the lead or the history section. To assign years to these articles, we first select all nodes without years whose parents (i.e. nodes with edges that link to a node) have years. For each such node, we denote its year as the year after the latest year of its parents. Then, we do the same for the remaining nodes without years. If a node still does not have a year, then we denote its year as 2020. The year of each edge is the latest year of either of its nodes. In a sensitivity analysis, we confirmed that our results were robust to small variations in the chosen year, suggesting that our findings were not unduly dependent on the specific algorithmic approach we employed (Supplemental Information section 5; Figure S9). In a further validation analysis, we manually inspected the identified years. Specifically, we randomly sampled the passages containing the date from 40 pages in the following topics: biochemistry, cognitive science, evolutionary biology, genetics, molecular biology, energy, optics, philosophy of language, philosophy of law, philosophy of science, linguistics, software engineering. Those passages are included as Supplemental data.
Parsing years. To better understand how we extracted the birth year of a node, here we provide additional detail about our algorithmic approach. Specifically, to parse the years from the text, we use regex to identify numbers that are preceded by months (e.g. “January”), prepositions of time (e.g. “around”), conjugations (i.e. “and”), articles (i.e. “the”), and other time-related words (i.e. “early”, “mid”, “late”) and followed by the words BC, BCE, or MYA. We also parse centuries (e.g. “19th Century”) and convert them into years (e.g. 1800). We apply a negative sign to all years or centuries followed by BC or BCE for convenience in analysis, such that 1600 BC would become −1600. For Python implementation, see the function filter_years (text) in module/wiki.py in the code repository.
Null networks
To model Feyerabend’s hypothesis of anarchical scientific progress, we used an edge-rewiring process to construct null networks that could then be compared to real networks. Note first that we refer to the two nodes that an edge connects as the origin node and the target node. The rewiring process proceeds by first taking each edge and randomly selecting a new target node exactly once. The process is similar to that developed by Maslov and Sneppen (Maslov and Sneppen, 2002), but differs in that it does not swap the targets between pairs of nodes. In the context of Wikipedia articles, since we create an edge from a hyperlinked article to a hyperlinking article, we are maintaining the connection of an edge from the hyperlinked article but changing the connection of the edge to the hyperlinking article. Thus, we maintain degree distributions (Figure S5) while removing other features of the network topology.
Network methods
The network measures we used are summarized in Table 1. To calculate clustering coefficients, we compute the clustering coefficients of each node in the network with the Python library networkx (Fagiolo, 2007). To calculate modularity, we also convert a network into a weighted, undirected network and maximize the following modularity quality index,
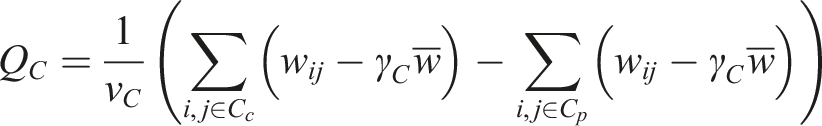
Persistent homology
In our study, we hypothesized that processes of scientific discovery create and fill gaps in concept networks. A tool from applied algebraic topology, called persistent homology, provides a well-defined formulation of such gaps as persistent topological cavities that evolve as a network grows (Hatcher, 2002). To calculate persistent homology for a growing network, we first create a correspondence between k-cliques, which are all-to-all connected subnetworks of k nodes, and (k-1)-simplices. Simplices of increasing dimension can be described as follows: a node is a 0-dimensional simplex, an edge is a 1-dimensional simplex, a 3-clique is a 2-dimensional simplex, and so on for higher dimensions. Using the Python package dionysus2, we add each clique as a simplex into a filtration at the latest year in the clique. A filtration is formally a nested sequence of subspaces and can be thought of as a growing sequence of simplices. We may add more than one simplex to the filtration at each year, resulting in cavities with a lifetime of zero, which we remove for downstream analyses. In network terms, we are adding both nodes and edges across the filtration such that there may not necessarily be any disconnected components in a growing network. Finally, we use the package dionysus2 to compute a reduced matrix which defines the indices of the start and end of cavities.
Temporally varying modularity
To detect modules across time, we first built a multilayer network from our growing networks. In the multilayer network, each layer is the network reflecting concepts discovered up to that year. Each node in a layer (e.g. at time t) is connected to the equivalent node in the next layer (e.g. at time t+1) with weight 0.01. We empirically chose a low weight for the inter-layer links to ensure that we could effectively detect changes in modularity when nodes are only being added and not removed. We then used the Python implementation of Ref. (Mucha et al., 2010) in the software package leidenalg (version 0.8.1) to compute the modules to which each node belongs. We set the parameter partition_type to ModularityVertexPartition to partition the network based on the optimization of a multilayer modularity quality function, with the interslice_weight set to 0.01, and the n_iterations set to −1; the latter choice directs the algorithm to run iterations until there is no improvement in the modularity quality index being optimized. The structural stability signature (Figure 3(c)) is robust to reasonable variations in the choice of the interslice_weight (i.e. keeping the weight on the order of 10−2 or less) (Figure S6). Within this range of interslice_weight values, we find that only the magnitude—not the shape—of the signature changes.
In performing this analysis, we observed that the module membership of nodes changed at different rates across time, with almost no changes in module membership in the second half of the period evaluated. Hence, we hypothesized that there may be epochs of module stability, with greater stability observed later in history. To identify such epochs, we first computed the number of changes in module membership across time as any time when the module membership is different than in the previous time point. Then, we summed the number of changes for each time point to obtain a single variable across time. Next, we used the R implementation of binary segmentation in the software package changepoint (Killick and Eckley, 2014). We used the function cpt.meanvar to detect changes in both mean and variance of the signal, which is the number of changes in module membership over time. We set the parameter method to “BinSeg” for binary segmentation, Q to three for the maximum number of changepoints, and test.stat to “Poisson” for a Poisson distribution. We chose these settings because the PELT segmentation algorithm, which selects the optimal number of changepoints Q, selected a Q of three for 14 out of 28 networks, with a median and a mode of 3 (Figure S7). Binary segmentation, on the other hand, allows the user to select a value for Q. So, we used binary segmentation with a Q of three for consistency across subjects. Additionally, we used a Poisson distribution because each change in module membership occurs independent of whether a node changes module membership in the previous time step. All other parameters were set to the default values. The algorithm then produces three indices, one for each changepoint, giving us four epochs (Figure 3(b) and (c)).
Impulse response
To quantify the impact of an article-node on the subject network, we use the impulse response measure from linear systems theory (Kailath, 1980). Here, the network is represented as an adjacency matrix A such that an item a
ij
in the matrix, with row i and column j, is the weight of the edge from the j
th
node to the i
th
node. Then, the impulse response of node i at time m is given by the i
th
diagonal element of the controllability Gramian,
To quantify the influence of a node on all topics using the impulse response function, we built a large network that consisted of all nodes in all subjects under study. In addition, we took the impulse response to a time horizon m of five to capture up to five steps in the propagation of the impulse through the network. Because the dimensionality of the network is on the order of 105, it is also computationally prohibitive to compute A m with larger values of m. Shorter time horizons also capture the relationship between impulse response and participation in the birth and death of cavities (Figure S8).
Nobel prizes
We used Nobel prizes in Physics, Chemistry, and Physiology or Medicine as an external measure of influence. To identify which nodes in the concept networks received Nobel prizes, we parsed the Wikipedia articles “List of Nobel laureates in Physics”, “List of Nobel laureates in Chemistry”, and “List of Nobel laureates in Physiology or Medicine”. In the section “Laureates” for each article, there is a table of Nobel laureates that includes a rationale column, which describes the work of a laureate that motivated the Nobel prize with hyperlinks to articles that describe the laureate’s discoveries. For example, for the scientist Maria Skłodowska-Curie, the rationale column states, “for their joint researches on the radiation phenomena discovered by Professor Henri Becquerel” with a hyperlink to the article “Radiation”. By obtaining all hyperlinks to articles in the rationale columns, we identified nodes in the concept networks that were Nobel prize-winning nodes. All other nodes were identified as non-Nobel prize-winning.
Supplemental Material
Supplemental Material - Historical growth of concept networks in Wikipedia
Supplemental Material for Historical growth of concept networks in Wikipedia by Harang Ju, Dale Zho, Ann S Blevins, David M Lydon-Staley, Judith Kaplan, Julio R Tuma and Dani S Bassett in Collective Intelligence
Footnotes
Author Contributions
Conceptualization, H.J., D.Z.; Methodology, H.J., D.Z., A.S.B.; Software, H.J.; Validation, H.J.; Formal analysis, H.J.; Investigation, H.J.; Resources, H.J., D.S.B.; Data curation, H.J.; Writing – Original Draft, H.J.; Writing – Review & Editing, H.J., D.Z., A.S.B., D.M.L.-S., J.K., J.R.T., D.S.B; Visualization, H.J., D.Z., A.S.B., D.S.B.; Supervision, H.J., D.S.B.; Project administration, H.J., D.S.B.; Funding acquisition, D.S.B.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge support from the John D. and Catherine T. MacArthur Foundation, the Alfred P. Sloan Foundation, the ISI Foundation, the Paul Allen Foundation, the Army Research Laboratory (W911NF-10-2-0022), the Army Research Office (Bassett-W911NF-14-1-0679, Grafton-W911NF-16-1-0474, DCIST-W911NF-17-2-0181), the Office of Naval Research, the National Institute of Mental Health (2-R01-DC-009209-11, R01-MH112847, R01-MH107235, R21-MH-106799), the National Institute of Child Health and Human Development (1R01-HD086888-01), National Institute of Neurological Disorders and Stroke (R01-NS099348), the National Science Foundation (BCS-1441502, BCS-1430087, NSF PHY-1554488 and BCS-1631550), and the National Institute on Drug Abuse (K01DA047417).
Data availability statement
All code is available on https://github.com/harangju/wikinet. All data used in the study are available on https://www.dropbox.com/sh/43qg5dop650kdul/AACTz1bRi5t1pWXxSBaurK9La. The latest multistream dumps of Wikipedia are available on ![]() .
.
Diversity statement
Recent work in several fields of science has identified a bias in citation practices such that papers from women and other minority scholars are under-cited relative to the number of such papers in the field (Caplar et al., 2017; Dion et al., 2018; Dworkin et al., 2020; Mitchell et al., 2013). Here, we sought to proactively consider choosing references that reflect the diversity of the field in thought, form of contribution, gender, race, ethnicity, and other factors. First, we obtained the predicted gender of the first and last author of each reference by using databases that store the probability of a first name being carried by a woman (Dworkin et al., 2020). By this measure (and excluding self-citations to the first and last authors of our current paper), our references contain 25.53% woman(first)/woman(last), 9.09% man/woman, 10.64% woman/man, and 54.74% man/man. This method is limited in that a) names, pronouns, and social media profiles used to construct the databases may not, in every case, be indicative of gender identity and b) it cannot account for intersex, non-binary, or transgender people. Second, we obtained predicted racial/ethnic category of the first and last author of each reference by databases that store the probability of a first and last name being carried by an author of color (Ambekar et al., 2009; Sood and Laohaprapanon, 2018). By this measure (and excluding self-citations), our references contain 5.06% author of color (first)/author of color(last), 15.64% white author/author of color, 16.35% author of color/white author, and 62.95% white author/white author. This method is limited in that a) names, Census entries, and Wikipedia profiles used to make the predictions may not be indicative of racial/ethnic identity, b) it cannot account for Indigenous and mixed-race authors, or those who may face differential biases due to the ambiguous racialization or ethnicization of their names, and c) it lacks baselines for this field of study to which to compare measures of probabilities. We look forward to future work that could help us to better understand how to support equitable practices in science.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.