
Abstract
Introduction
Platform trials have gained prominence, particularly during the COVID-19 pandemic, due to their flexibility and efficiency in evaluating multiple interventions. However, their complex design introduces methodological and regulatory challenges, especially in randomisation when adding new treatment arms.
Method
This study uses simulations based on a real platform trial to assess the performance of different randomisation methods: simple randomisation, stratified block randomisation, stratified block urn design, and minimisation. We evaluate these methods under various allocation ratios, focusing on covariate balance, allocation predictability, and allocation accuracy, particularly for newly added arms. We also examine the trade-off between covariate balance and allocation predictability.
Results
This study highlights the inherent trade-off between achieving good covariate balance and maintaining adequate allocation unpredictability. SBUD slightly outperforms SBR for certain stage 2 allocation ratios, though not consistently across all scenarios. Minimisation achieves the best covariate balance among all methods but at the cost of reduced randomness. Allocating more patients exclusively to the newly added arm does not effectively reduce covariate imbalance; however, allocating more patients to both the control and new arms yields better balance. Additionally, incorporating non-concurrent data in the minimisation process improves covariate balance compared to using only concurrent data.
Conclusion
The findings suggest that when the primary goal is to achieve covariate balance, especially for new arms, trialists should consider using minimisation with non-concurrent data and allocate patients proportionately to control and new arms. Balancing covariate distribution while maintaining sufficient randomness is crucial to ensuring the methodological robustness and reliability of platform trials.
Introduction
Platform trials allow the simultaneous assessment of multiple experimental treatments for a given indication and permit the addition or removal of treatment arms as new information emerges. 1 Interest in these designs has grown rapidly, particularly during the COVID-19 pandemic, leading to important methodological developments in areas such as error control, sample size, and analytical strategies.2–6
Despite this growing literature, there has been limited investigation into randomisation methods specifically for platform trials. Most published platform trials rely on simple randomisation, despite the added complexity of introducing new arms and potential impacts on covariate balance. 7 Randomisation becomes increasingly complex in platform trials with a prespecified total sample size, particularly when additional treatment arms are introduced at later stages and the remaining sample size is limited. Additional challenges arise when sample size is limited or when multiple treatment arms must maintain balance simultaneously. This complexity is compounded when the trial seeks to maintain a high level of covariate balance while comparing multiple treatment arms concurrently. In such settings, simple randomisation may be inappropriate, and more advanced randomisation methods are required to account for covariates balance across both existing and newly introduced arms, especially where the existing arms may already exhibit good balance.
This raises the key question about how best to allocate patients to new arms while maintaining balance relative to the control and existing treatment arms. Additionally, it remains to be seen for a platform design whether a randomisation approach can effectively balance covariates while also preserving randomness in patient assignment. The primary aim of this paper is therefore to identify an efficient randomisation method which, when combined with appropriate allocation ratios, minimises covariate imbalance, achieves accurate adherence to the target allocation, and preserves assignment randomness. We first describe several randomisation methods that have been evaluated for both equal and unequal allocation in multi-arm trials, which are applicable to platform trials, including widely used techniques such as simple randomisation (SR), as well as methods that have shown promise in multi-arm trials (see 8 ), such as stratified block randomisation (SBR), stratified block urn designs (SBUDs) and minimisation. We then present the FLAIR trial as a motivating example, 9 which we use to explore the impact of different allocation ratios and randomisation methods.
Methods
Two-stage platform trials
We consider a two-stage platform trial that initially has K1 = K treatment arms present, with a total planned sample size of N = N1 + N2, where N
s
is the sample size of stage s = 1, 2. An additional treatment is added in stage 2, such that the number of treatment arms is then K2 = K + 1. The randomisation process in this design is described in two steps: • In stage 1, N1 patients are to be allocated to the treatment arms, k1 = 0, 1, …, K − 1, where k1 = 0 is a shared control arm, present throughout the trial, and k1 = 1, …, K − 1 are experimental arms. This is to be realised such that the allocation ratio is r1,0 : r1,1 : ⋯ : r1,K−1. Because equal randomisation is a widely applied allocation ratio in clinical trials, we chose to use it in our study.
10
We assume that patients are to be allocated to each initially-present treatment arm with r1,0 = r1,1 = ⋯ = r1,K−1 = 1. • Stage 2 starts with the introduction of a new treatment; the remaining N2 patients are then to be allocated to the existing arms and the new arm with allocation r2,0 : r2,1 : ⋯ : r2,K. In this stage, we consider various possible allocation ratios, to allow flexibility in directing more patients to the new arm, compared to the initially-present arms.
We set R
s
to be the sum of the allocation ratios in stage s. That is
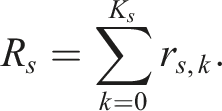
We index the patients in stage s by i = 1, …, N
s
. We will then use
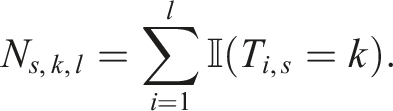
Lastly, for simplicity, we assume that a set of J covariates of interest, indexed j = 1, …, J, will be measured in both stages. We use Xi,j,s for the value of covariate j for patient i in stage s. As many treatment allocation methods work in terms of strata defined through binary covariates, Xi,j,s is assumed to take values 0 or 1.
Considered allocation procedures
We consider four different randomisation methods for the platform trial design under investigation: simple randomisation (SR), stratified block randomisation (SBR), the stratified block urn design (SBUD), and minimisation.
To provide a clear and intuitive illustration of how these randomisation methods operate within a platform trial, we introduce a simple example that will be used consistently throughout this section. Suppose the platform trial begins in stage 1 with a shared control arm and two experimental arms, using an equal allocation ratio of 1 : 1 : 1. In stage 2, a new treatment arm is added. For illustrative purposes, we consider an unequal allocation ratio of 1 : 1: 1 : 2, reflecting a commonly encountered scenario in which a larger proportion of patients is allocated to a newly treatment arm.
This example is used to demonstrate the mechanics of each randomisation method under a consistent platform design. More general and diverse stage specific allocation ratios are considered later in ‘Simulation study' to reflect a broader range of design scenarios encountered in practice.
Simple randomisation (SR)
Under the illustrative platform trial example, simple randomisation assigns patients independently to treatment arms according to the prespecified allocation ratios at each stage. In stage 1, with three treatment arms and equal allocation, each patient is assigned to one of the arms with probability 1/3. In stage 2, after the introduction of a new arm, the allocation ratio changes to 1 : 1: 1 : 2, resulting in assignment probabilities of 1/5, 1/5, 1/5, and 2/5 for the four treatment arms, respectively. In general, under SR, the probability that patient i in stage s is allocated to treatment k is given by
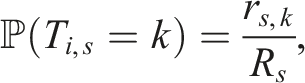
Stratified block randomisation (SBR)
The SBR process in pre-planned platform trials is assumed to function as follows: (1) 2
J
strata are specified, defined from all possible combinations of covariates j = 1, …, J. We use ci,s to denote the strata to which patient i in stage s belongs. (2) A chosen block size B, which is a multiple of the allocation ratios in both stages (see below for an example), is chosen. (3) In stage s, the N
s
patients are allocated into fixed blocks of size B based on their stratum ci,s. Each block contains a random permuted sequence of allocations containing a predetermined number of allocations to each treatment arm based on the desired allocation ratios.
The treatment assignments will therefore differ in each stage depending on the number of arms and the allocation ratio to each arm. Under the illustrative example, if B = 6 is chosen for stage 1, each block contains two assignments to each of the three arms (2:2:2). In stage 2, with allocation ratio 1 : 1: 1 : 2, a block size of B = 10 yields 2 : 2: 2 : 4 allocations within each block. Patients are then randomised within each block based on a permuted sequence.
We define the block to which patient i in stage s is assigned to as bi,s. Then, the probability patient i in stage s is assigned to treatment k is
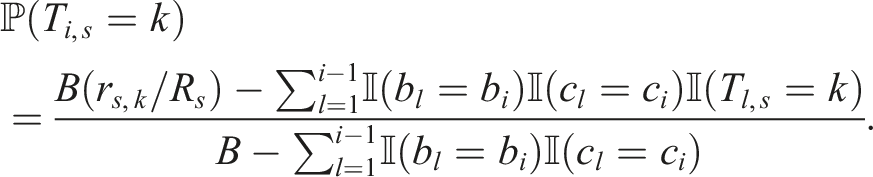
Stratified block urn design (SBUD)
The SBUD combines stratification with a block based urn randomisation approach designed to control covariate imbalance while allowing flexible allocation ratios. 11 As in SBR, patients are first stratified into 2 J strata defined by the binary covariates. Within each stratum, randomisation is conducted independently using block randomisation. A key design parameter in SBUD is λ, which specifies the maximum allowable imbalance between treatment arms within each stratum. This parameter is chosen by investigators to control the tolerance for imbalance (see8,11 for more details on implementing BUD).
The block size in stage s, is defined by: B
s
= λR
s
where
Within each stratum, the SBUD randomisation process uses two urns: an active urn and an inactive urn. At the beginning of stage s, the active urn contains B s balls according to the treatment arms present in that stage, with the number of balls per arm proportional to the allocation ratios rs,k.
For each patient, a ball is drawn at random from the active urn, and the patient is assigned to the corresponding treatment arm. The drawn ball is then placed in the inactive urn. This procedure continues until the inactive urn contains a minimal balanced set—that is, λ allocations proportional to the target allocation ratios. Once this occurs, these R s balls are returned to the active urn, while any remaining balls stay in the inactive urn. The process then repeats: balls are drawn from the active urn and moved to the inactive urn until another minimal balanced set is accumulated, which is again transferred back to the active urn.
Under the illustrative example, if λ = 2 and stage 2 allocation is 1 : 1: 1 : 2, giving R2 = 5, then B2 = 2∗5 = 10, giving a block composition of 2 : 2: 2 : 4. Thus, the stage 2 active urn begins with two balls for each of the first three arms and four balls for the new arm, cycling through minimal balanced sets as patients are randomised.
The probability that patient i in stage s is allocated to treatment k is
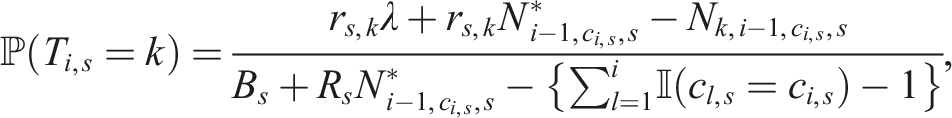
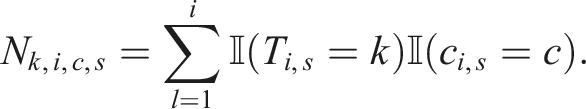
Minimisation
The standard minimisation method was originally proposed 12 and was later extended to unequal allocation ratios using allocation ratio preserving biased coin minimisation (ARP-BCM), which preserves the target allocation ratio at each allocation step.13,14
In platform trials, the minimisation algorithm can be described as follows: in each stage s, patients i = 1, …, qN s are allocated to the k s treatment arms using SR, where q is termed a ‘burn-in’; period, and takes range between 0 and 1. Following this, patients are allocated to a treatment k to minimise the marginal imbalance. The marginal imbalance can be measured by the range, variance, or standard deviation.14,15 For brevity, we focus here on the range as an intuitively simple and commonly used measure of imbalance. 15
To illustrate the application of minimisation within a platform trial, we consider the same example introduced earlier. Suppose the trial begins in stage 1 with a shared control arm and two experimental arms, using an equal allocation ratio of 1 : 1: 1. In stage 2, a new experimental arm is added, and the target allocation ratio becomes 1 : 1: 1 : 2, directing a larger proportion of patients to the newly introduced treatment arm. This example is used to demonstrate how the minimisation algorithm operates under unequal allocation.
After a new arm is introduced (stage 2), minimisation could be implemented in two different ways for stage 2 participants: • The minimisation algorithm could take into account the characteristics and allocation of patients already enrolled in the existing arms of the trial. This historical stage 1 data is considered “non-concurrent” for the new arm since no patients have been assigned to it yet. This might be preferable in some settings, when a high covariate balance is highly desirable for the existing arms. • The minimisation process can be implemented independently at each stage s. This approach ensures balance in treatment allocation across different stages of the trial. Effectively, each stage functions as a separate trial with its own minimisation process.
In this paper, we consider both cases.
The ARP BCM can be illustrated as follows. Set Ni,j,s,k,l as the number of patients who have been assigned, among the first i patients, to treatment k, whose j
th
covariate takes the value l in stage s. That is
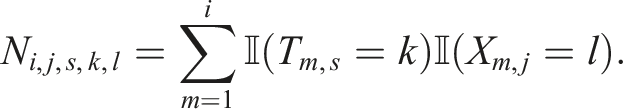
Then, suppose that the next patient, patient i + 1, has covariate information Xi+1,1,s, …, Xi,j,s. The number of patients up to this point at these levels in stage s, for arm k, is given by
The marginal imbalance can then be defined by the range at each level of the covariate j across all treatment arms using ARP BCM to adjust the allocation ratio in each randomisation step. That is:
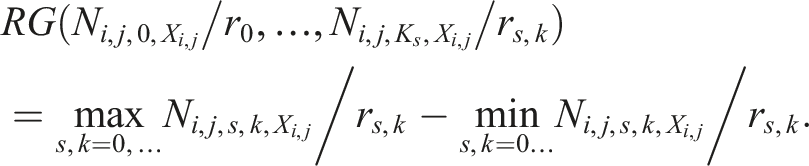
The total hypothetical imbalance, if patient i + 1 is assigned to arm k in stage s, is then defined as a weighted sum of the level-based imbalance for covariates included in the minimisation routine
Performance evaluation metrics
We consider evaluating randomisation methods with a set of allocation ratios in terms of covariate balance and randomness as the trial progresses. We also examine the overall performance for each of the randomisation methods considered, which is the trade-off between covariate balance, allocation predictability and allocation accuracy.
Degree of imbalance according to patient covariates
To evaluate how well the allocation techniques balance covariate factors across treatment arms as the trial progresses, we calculate the proportion of patients up to patient i in each arm with Xi,j,s = 1 as:
Ni,j,k,1 represents the total number of patients assigned to arm k up to patient i who have covariate j, considering both stages. Ni,k is the total number of patients assigned to arm k up to patient i.
To assess covariate imbalance, the maximum absolute difference in these proportions is computed for each experimental arm k = 1, …, K − 1 compared to the control arm (k = 0), for each covariate j, as
These maximum of these differences max(ϒi,1, ϒi,2, …, ϒi,J) is used as a performance metric. A randomisation procedure that results in lower imbalance is preferable. Note that the maximal covariate imbalance is computed after each patient i is allocated, and it is updated cumulatively throughout the trial. At any given point, all previously assigned patients from both trial stages are included in the calculation.
Allocation predictability
The choice of randomisation method has a major impact on predictability, which is a popular indicator for evaluating randomisation routines. Several measures exist, including treatment alternation,16,17 which is most appropriate for designs with fixed or transparent block structures. It is less suitable for methods such as SBUD and minimisation, where no fixed blocks exist and alternation cannot be meaningfully defined.
Accordingly, since the randomisation process for platform trial designs involves different stages, each with different treatment arms and allocation ratios, we calculate predictability independently for each stage s. We measured the predictability through characterising an investigator’s guess as a random variable G
i
:
The predictability for each stage is given by
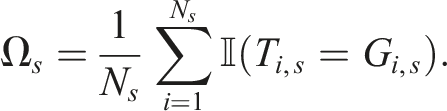
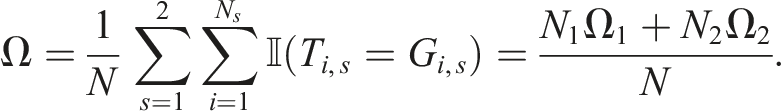
Covariate balance/randomness trade-off
In the simulation study, at the end of the trial, the maximum value of maximum covariate differences for each experimental treatment arm is defined as
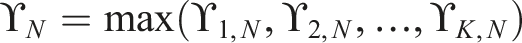
To standardise the results, the values of ϒ
N
and Ω
N
are rescaled to (
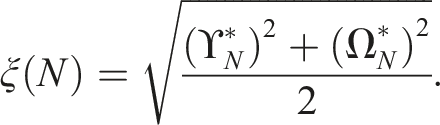
A randomisation procedure with a small ξ(N) is preferable, as this measure captures the balance between covariate distribution and allocation predictability. This metric is useful as it takes into consideration the common trade-off between balance and predictability.
Allocation accuracy
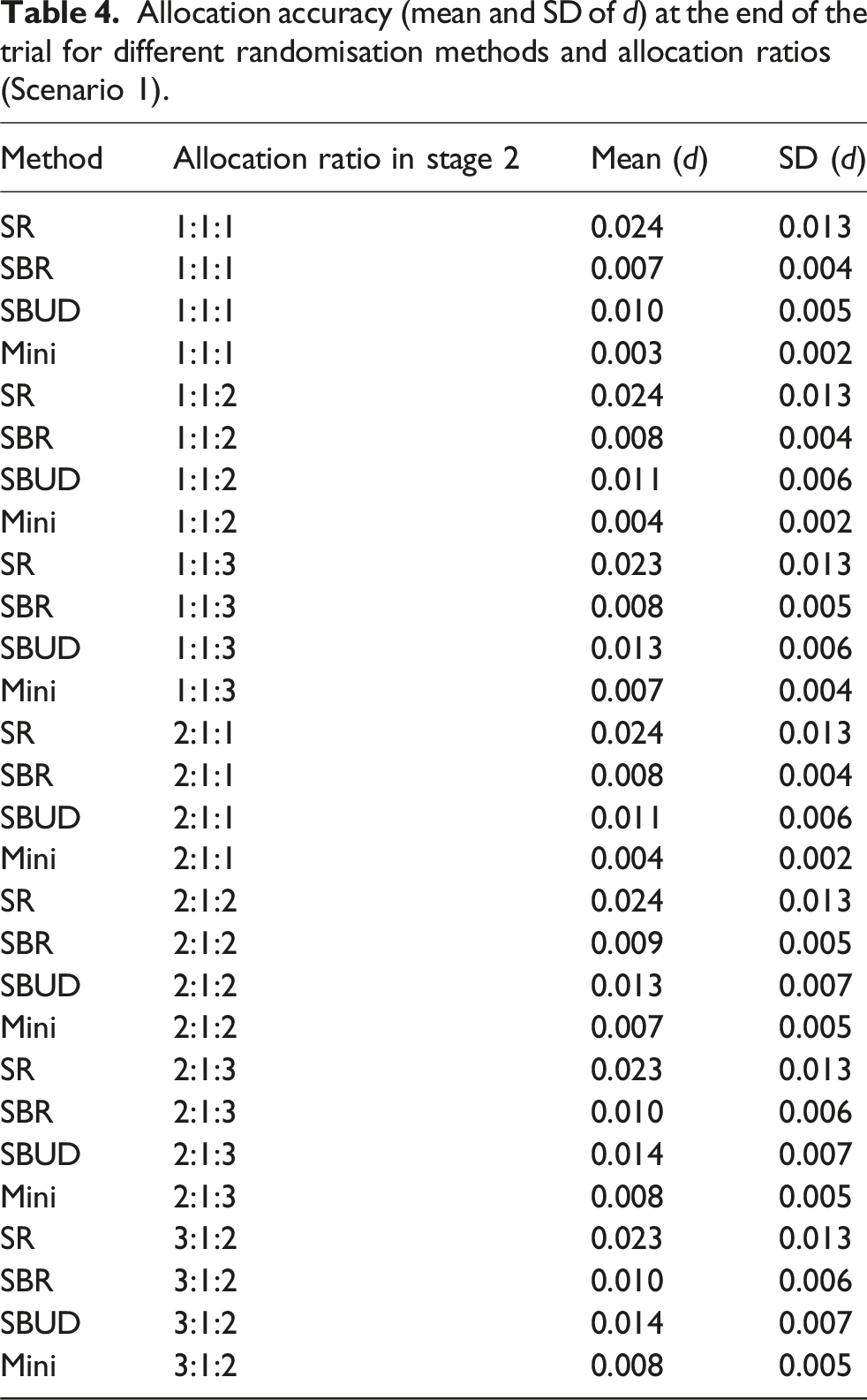
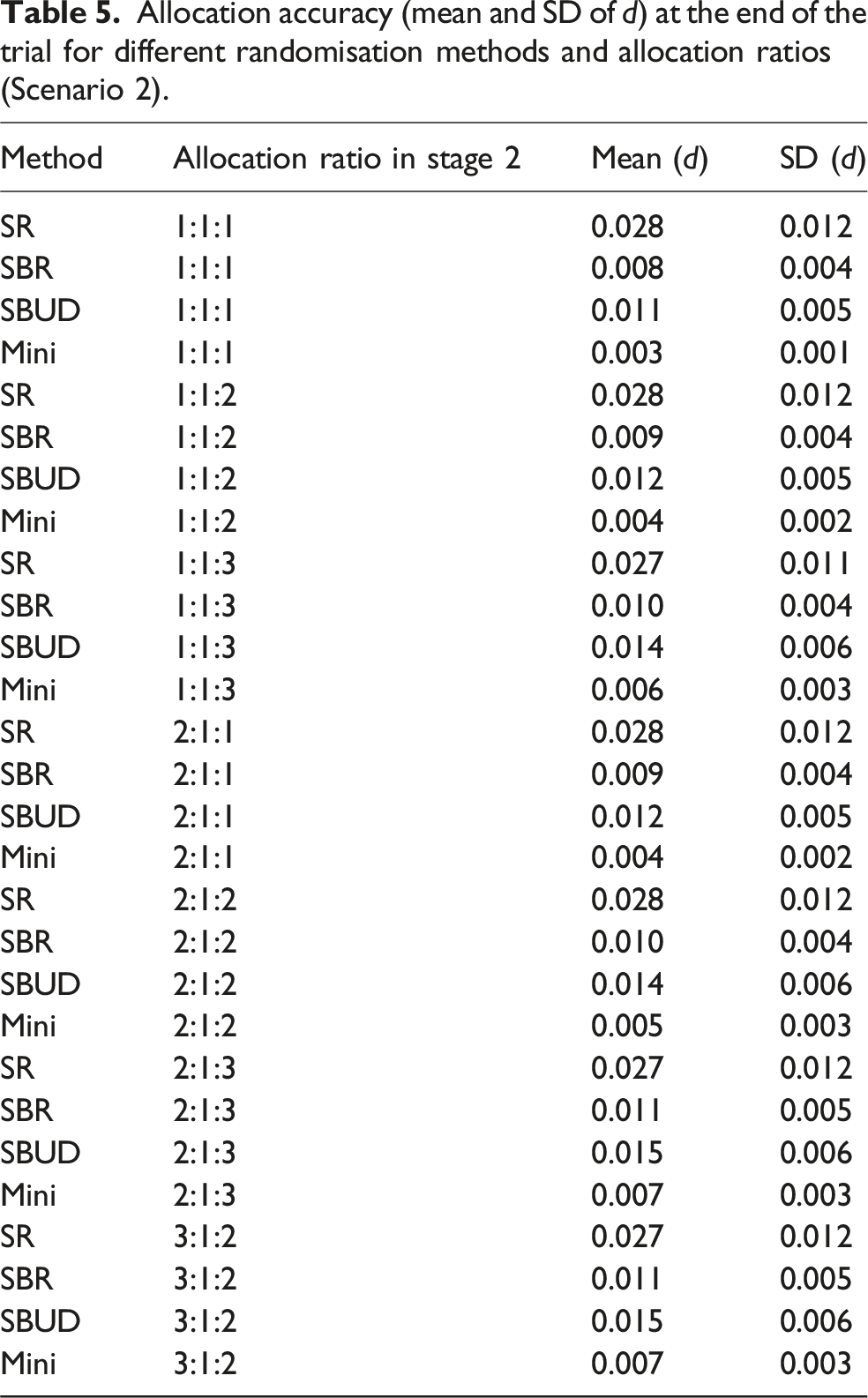
We additionally examined allocation accuracy, to determine how closely the realised sample allocations conformed to the targeted allocation ratios. This property is particularly relevant when unequal allocation ratios are used. To evaluate allocation accuracy, we calculated the Euclidean distance between the targeted allocation ratio and the observed allocation achieved at the end of each simulation run. The mean and standard deviation of this distance were then computed to summarise accuracy and variability across simulations.
Let Π denote the vector of targeted allocation proportions for the K treatment arms as Π = (Π1,N, Π2,N, …, ΠK,N) and let
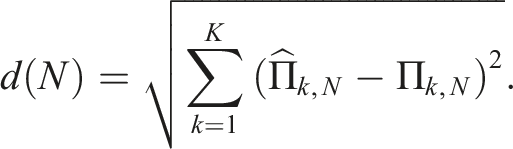
Smaller values of d(N) indicate closer adherence to the targeted allocation. For each randomisation method and simulation scenario, we summarised allocation accuracy across runs using the mean and standard deviation of d(N).
Motivating example: FLAIR
As motivation for many of the assumed parameter values, we use the FLAIR trial. 9 The FLAIR trial is a randomised controlled confirmatory trial in chronic lymphocyte leukaemia. It was originally planned as a two-arm trial (K = 2), with a planned total sample size of N = 754 to achieve 80% power. Then, a new treatment arm was planned to be added halfway through the trial (N1 = N2 = 377). Minimisation was implemented to achieve covariate balance with respect to important categorical covariates such as gender, age, disease severity, and medical centres. In this trial, patients were equally randomised to one of the open treatment arms throughout the trial (i.e., rs,k = 1 for all k and s).
Simulation study
Using the above motivating trial, we examin different randomisation methods with multiple allocation ratios in terms of the performance measures described in ‘Performance evaluation metrics'. The following summarises the common assumptions across the two considered scenarios. We consider N = 754 to be the total sample size, with N1 = N2 = N/2. We assume that four binary covariates, J = 4, were used in the randomisation routine with a value of Xi,j drawn independently for all i and j as Xi,j ∼ Bern(0.25). For minimisation, we considered q = 0.1 and pmin = 0.7 in both scenarios. We selected Mini(0.7) to reduce allocation determinism and improve randomness in multi-arm settings. Moreover, we considered several allocation ratios in Stage 2; these ratios were prespecified a priori as part of the platform trial design and were not influenced by covariate imbalance control.
Summary of the simulation study design.

Furthermore, we also consider evaluating the implications of using Mini(0.7) with non-concurrent data in the stage 2 randomisation process. For each considered set of parameter combinations, 10,000 simulation replicates were performed to empirically estimate the performance metrics. R code to reproduce our results is available from https://github.com/Ruqayya20/platform-trials.git.
Results
Degree of imbalance according to patient covariates
The simulation results comparing the covariate imbalance for the considered scenarios are presented in Figures 1 and 2. As expected, in both scenarios, the maximum covariate imbalance decreases for all randomisation methods as patient allocation progresses. In addition, as expected, we observe that the covariate imbalance for the treatment arms becomes closer to each other as the number of patients allocated increases. This trend is observed for all randomisation methods. The empirical covariate imbalance between the control arm and each of the experimental arms, for each of the randomisation methods, under a variety of allocation ratios in stage 2 (Scenario 1). The maximum covariate imbalance between the control arm and existing arms and between the control arm and newly added arm for each of the randomisation methods and under a variety of allocation ratios in stage 2 (Scenario 2).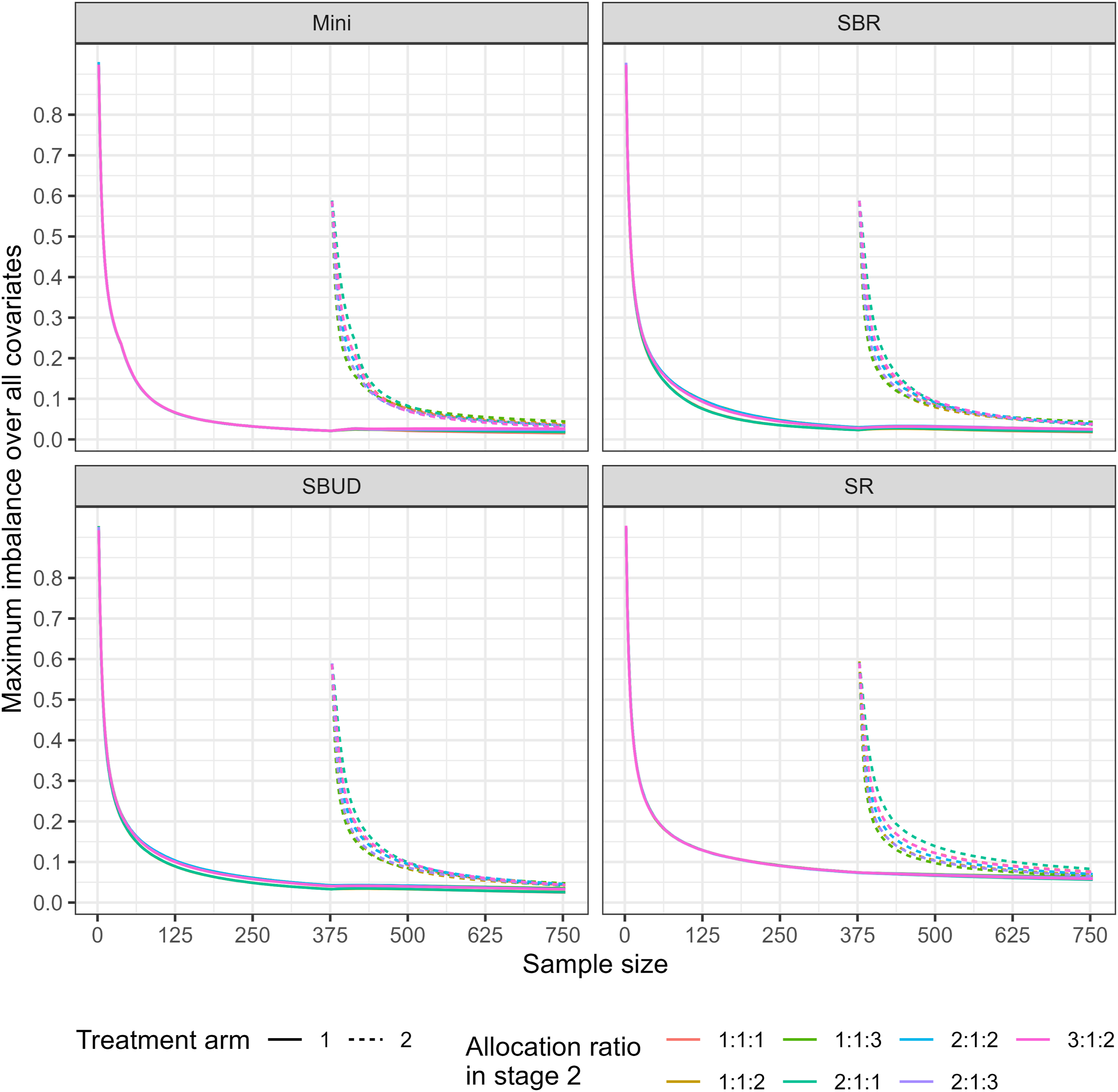
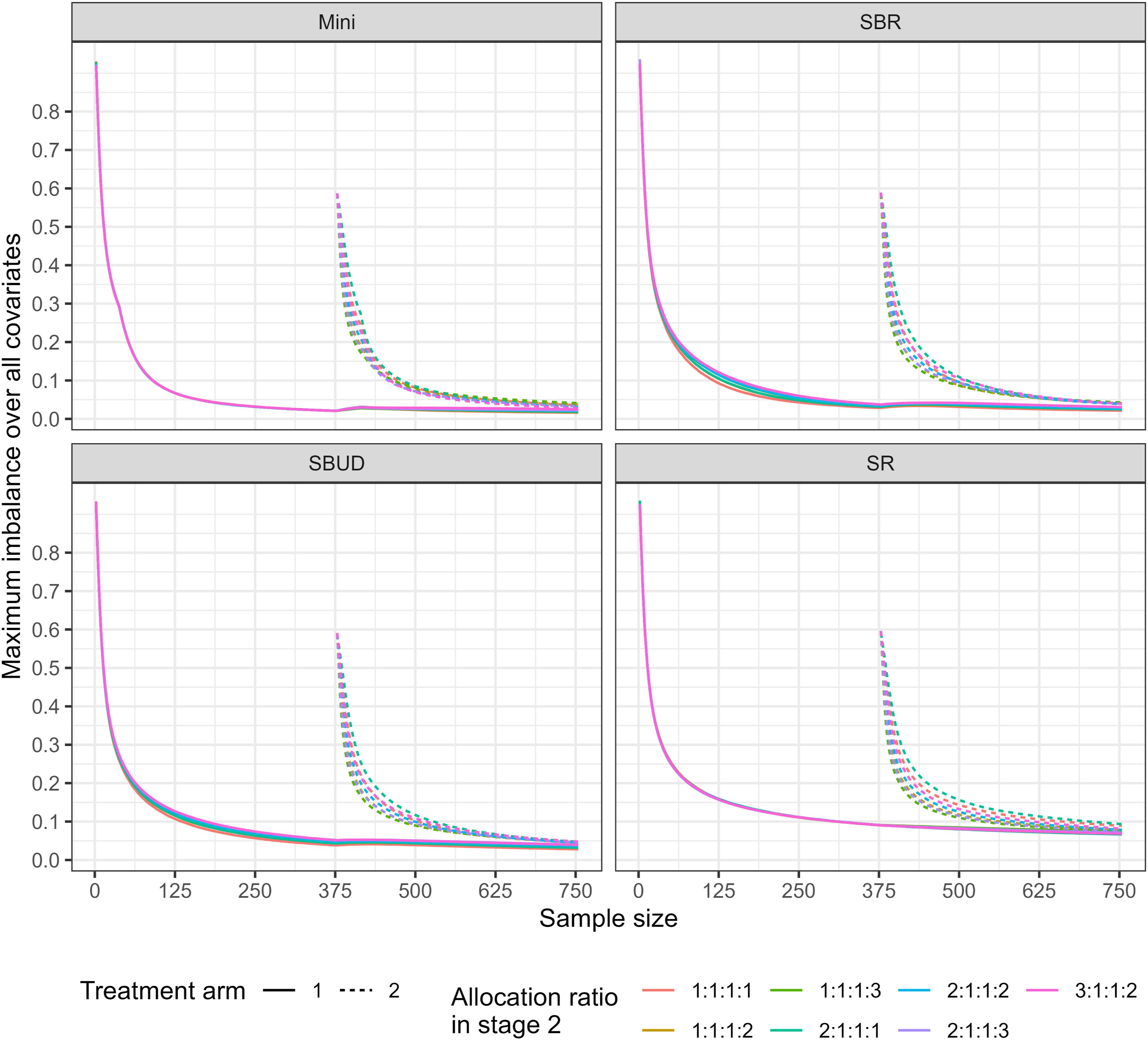
Furthermore, the simulation results illustrate that in both scenarios, SR consistently underperforms compared to other methods in terms of covariate balance in all treatment arms (existing and newly added arms). For example, the maximum covariate imbalance under SR is approximately 0.076, compared with values below 0.05 for SBR, SBUD, and minimisation. This pattern persists across unequal allocation ratios, with SR consistently exhibiting higher imbalance across all treatment arms. This is in line with the expected limitations of SR, as it does not attempt to control the potential imbalances in the covariates. Mini(0.7), on the other hand, appears to consistently perform slightly better in terms of covariate balance for all treatment arms and allocation ratios compared to the other randomisation methods considered. For example, the maximum covariate imbalance is approximately 0.056 for SR, compared with 0.036 for SBR, 0.050 for the SBUD, and 0.035 for Mini(0.7). This demonstrates that Mini(0.7) achieves the lowest imbalance among the methods considered.
Figures 1 and 2 show that allocation ratios that place greater weight on the newly added arm (e.g., 1:1:2, 1:1:3, 1:1:1:2, and 1:1:1:3) do not necessarily lead to higher covariate imbalance for that arm. In fact, under some randomisation methods particularly SR and SBR the imbalance for 1:1:2 and 1:1:3 are slightly lower than those under equal allocation. This occurs because when an arm receives more patients, the larger effective sample size reduces the variability in covariate counts, which in turn leads to slightly lower observed imbalance. Thus, although the allocation is more unequal, the increased sample accrual in the new arm can produce marginally improved balance as the trial progresses.
Moreover, Figure 3 illustrates the impact of incorporating non-concurrent assignments into the Mini(0.7) procedure. For some allocation ratios, particularly 3:1:2 and 2:1:1, the imbalance for the newly added arm at the end of the trial is reduced when non-concurrent data are included, and in these cases the resulting imbalance is comparable to, or lower than, that observed for the existing arms. This suggests that incorporating non-concurrent data into Mini(0.7) may improve covariate balance in certain scenarios relative to using only concurrent data. The empirical covariate imbalance between the control arm and each of the experimental arms, for minimisation method, under of allocation ratios in stage 2, when considering past assignments and without considering past assignments (Scenario 1).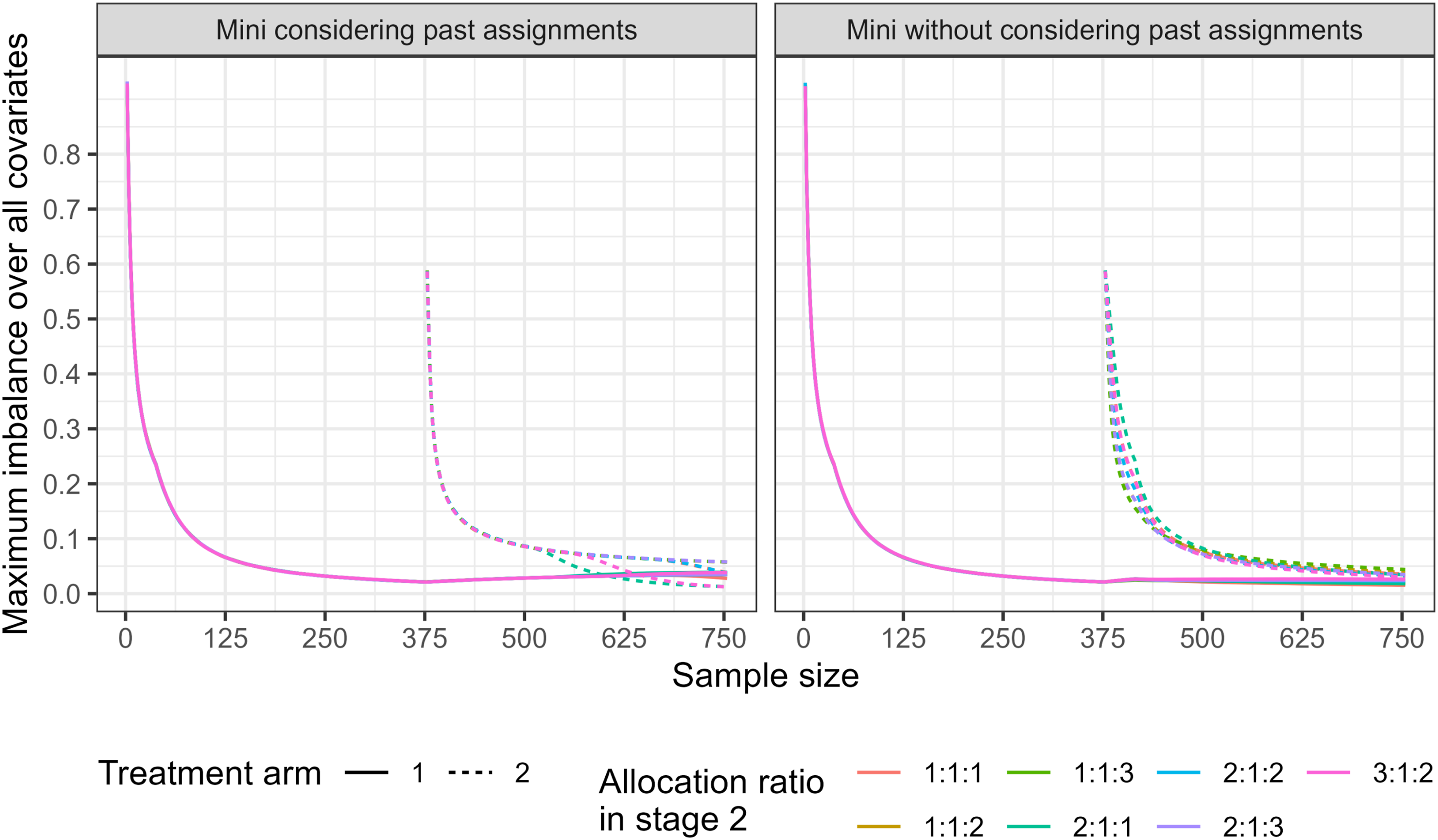
However, the effect is not consistent across all allocation ratios or treatment arms. For example, no improvement is observed for the 2:1:3 allocation ratio, and no substantial benefit is seen for treatment arm 1. Similarly, under the 2:1:2 allocation ratio, both the newly added and existing arms exhibit similar imbalance, indicating that the use of non-concurrent data does not systematically favour existing arms. Overall, these findings demonstrate that the benefit of incorporating non-concurrent data into the Mini(0.7) process is scenario dependent rather than universal.
Allocation predictability
The allocation predictability is shown in Figures 4 and 5 for Scenarios one and two respectively. Mini(0.7) is more predictable relative to SBR, SBUD, and SR in both stages, according to the simulation results. In addition, in both scenarios, allocation predictability increases as patient allocation progresses except for SR. The empirical mean predictability for each stage, under a variety of stage 2 allocation ratios (Scenario 1). The empirical mean predictability for each stage, under a variety of stage 2 allocation ratios (Scenario 2).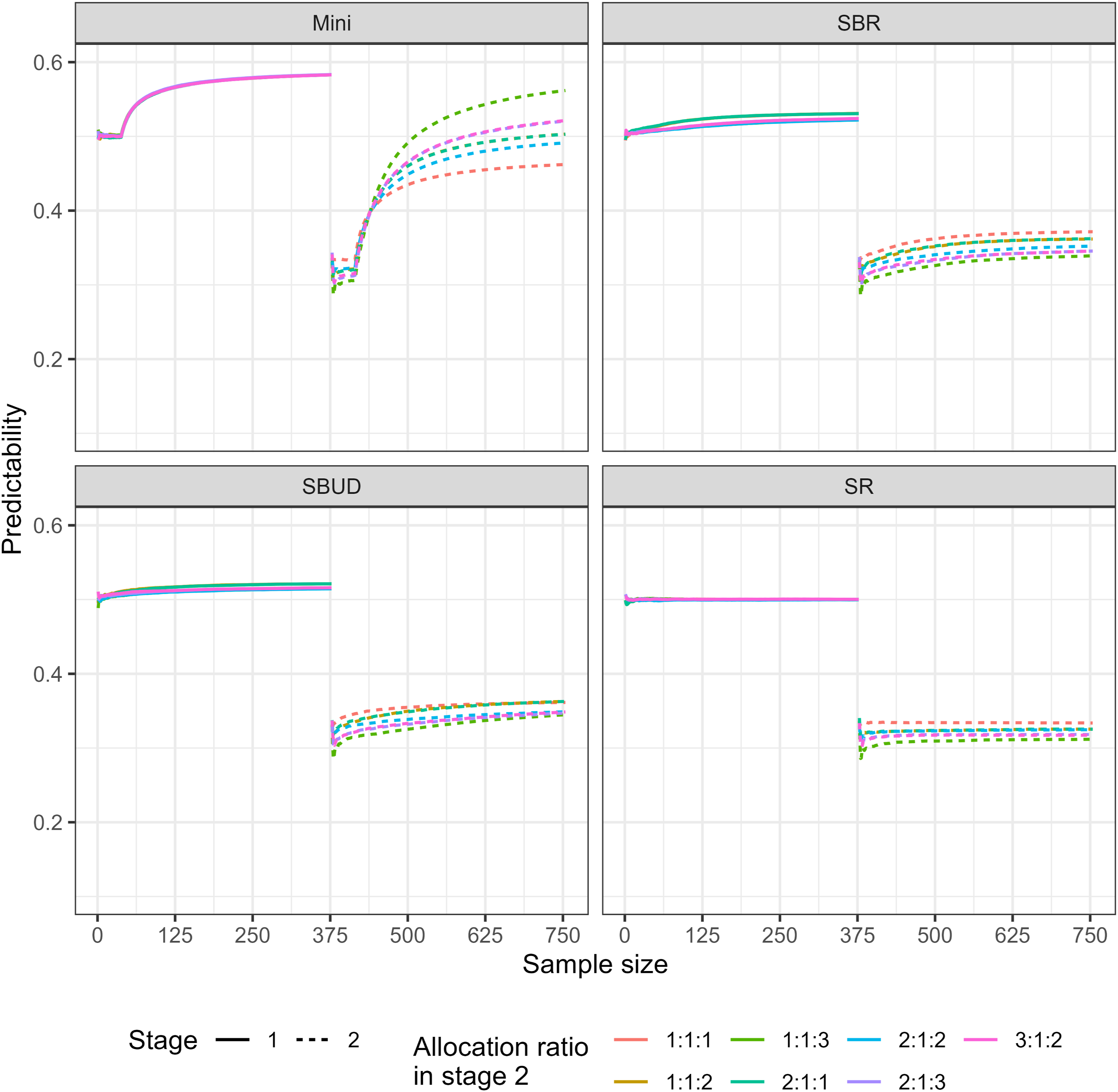
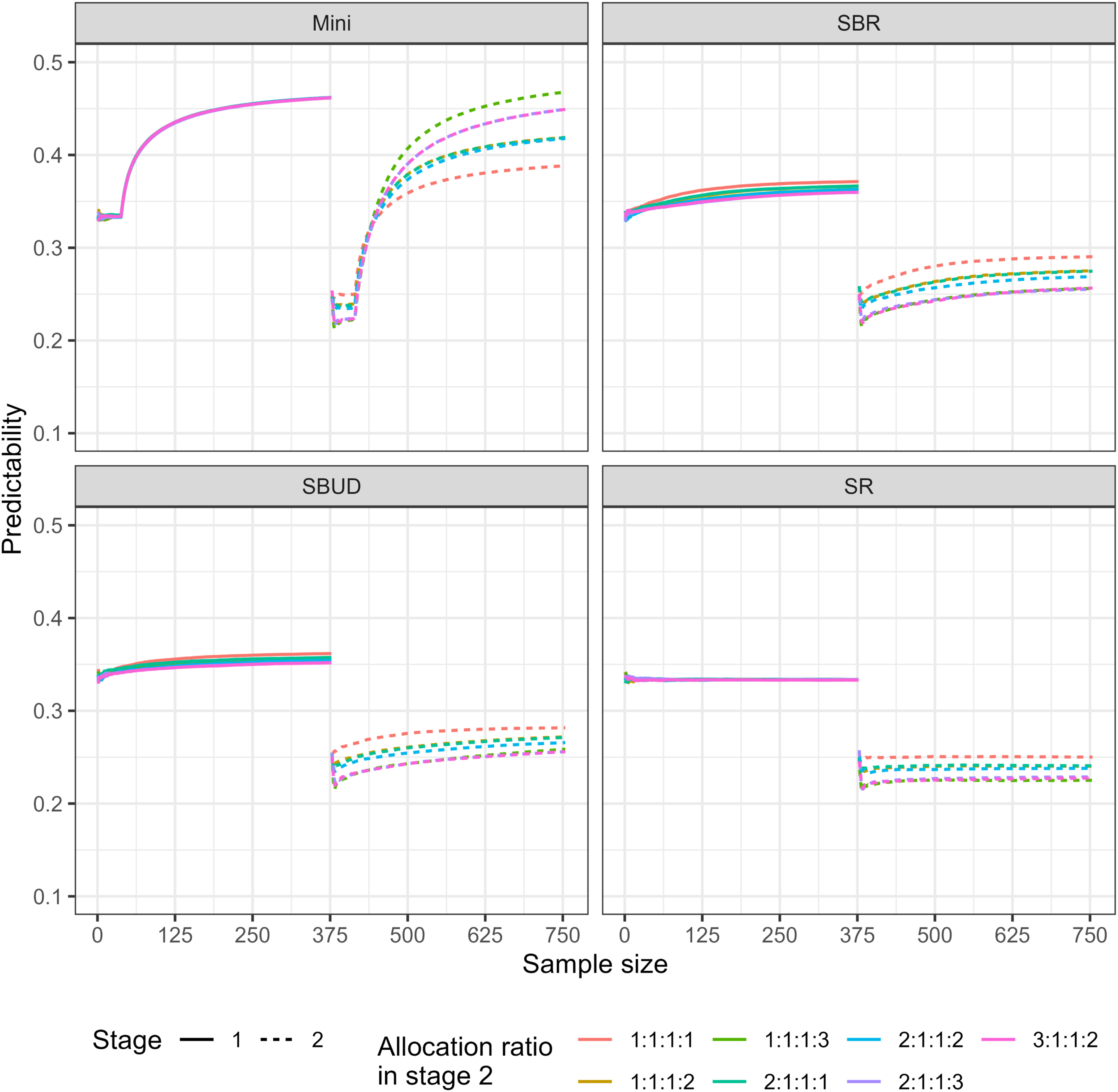
As expected, use of a randomisation method with an unequal allocation ratio can have a considerable impact on predictability. For example, Mini(0.7) with unequal allocation ratios have higher predictability compared to Mini(0.7) with equal allocation ratio.
The predictability of Mini(0.7) increases under more imbalanced allocation ratios. Specifically, predictability is approximately 0.238 for the 1:1:3 allocation ratio (Scenario 1), compared with 0.217 for 2:1:2, 0.185 for 2:1:3, and 0.185 for 3:1:2. Similarly, in Scenario 2, Mini(0.7) exhibits higher predictability under the 1:1:1:3 allocation ratio relative to the other allocation ratios considered.
By contrast, the predictability of SBR, SBUD, and SR with different unequal allocation ratios is lower compared to those with equal allocation ratio. This means that these methods rely more heavily on randomisation, especially with unequal allocation ratios. Furthermore, in both scenarios, the SBR and SBUD have similar predictability, although this is slightly lower in SBUD for allocation ratios of 2:1:1:1, 2:1:1:2, and 1:1:1:2.
Covariate balance/randomness trade-off
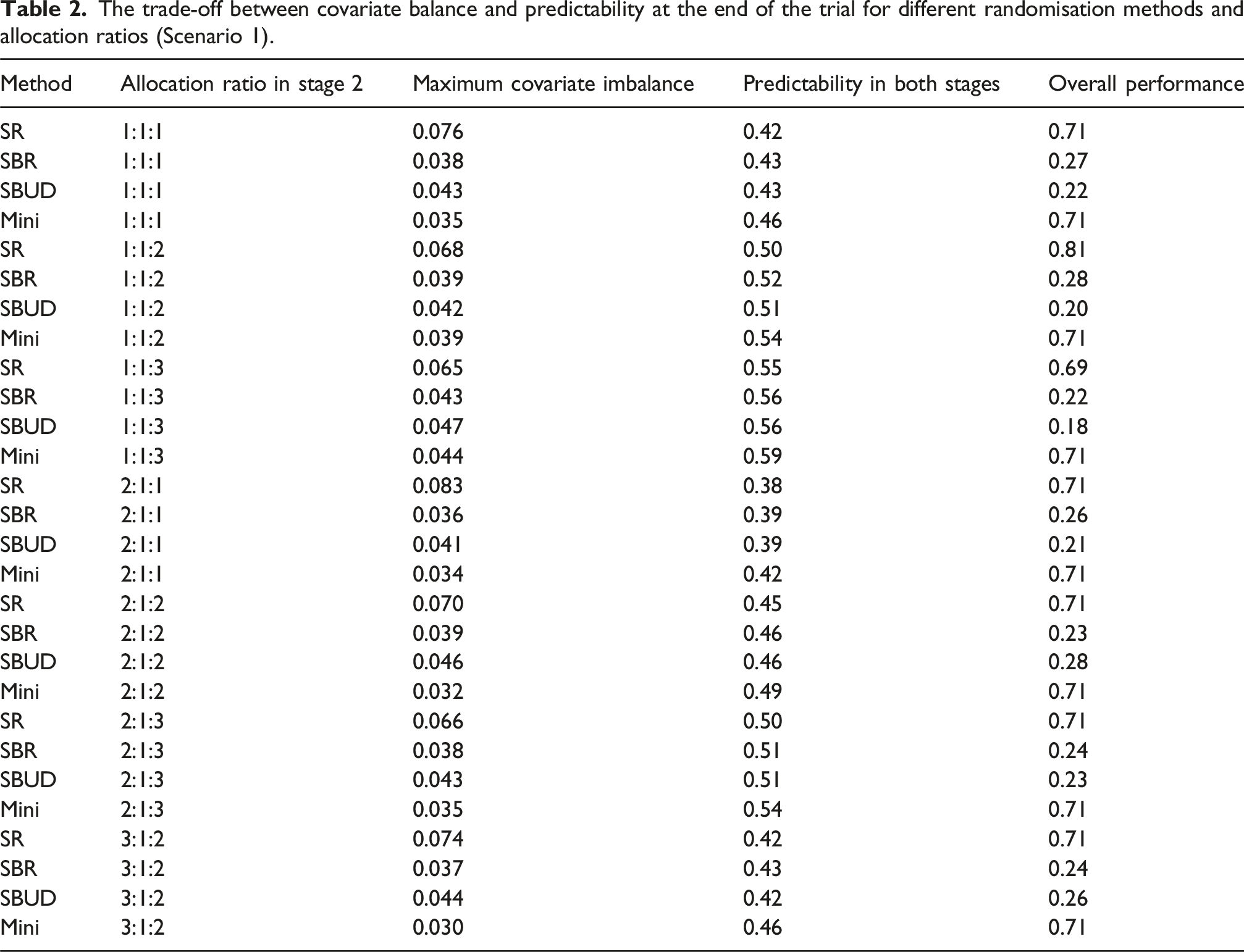
The trade-off between covariate balance and predictability at the end of the trial for different randomisation methods and allocation ratios (Scenario 1).
The trade-off between covariate balance and predictability at the end of the trial for different randomisation methods and allocation ratios (Scenario 2).
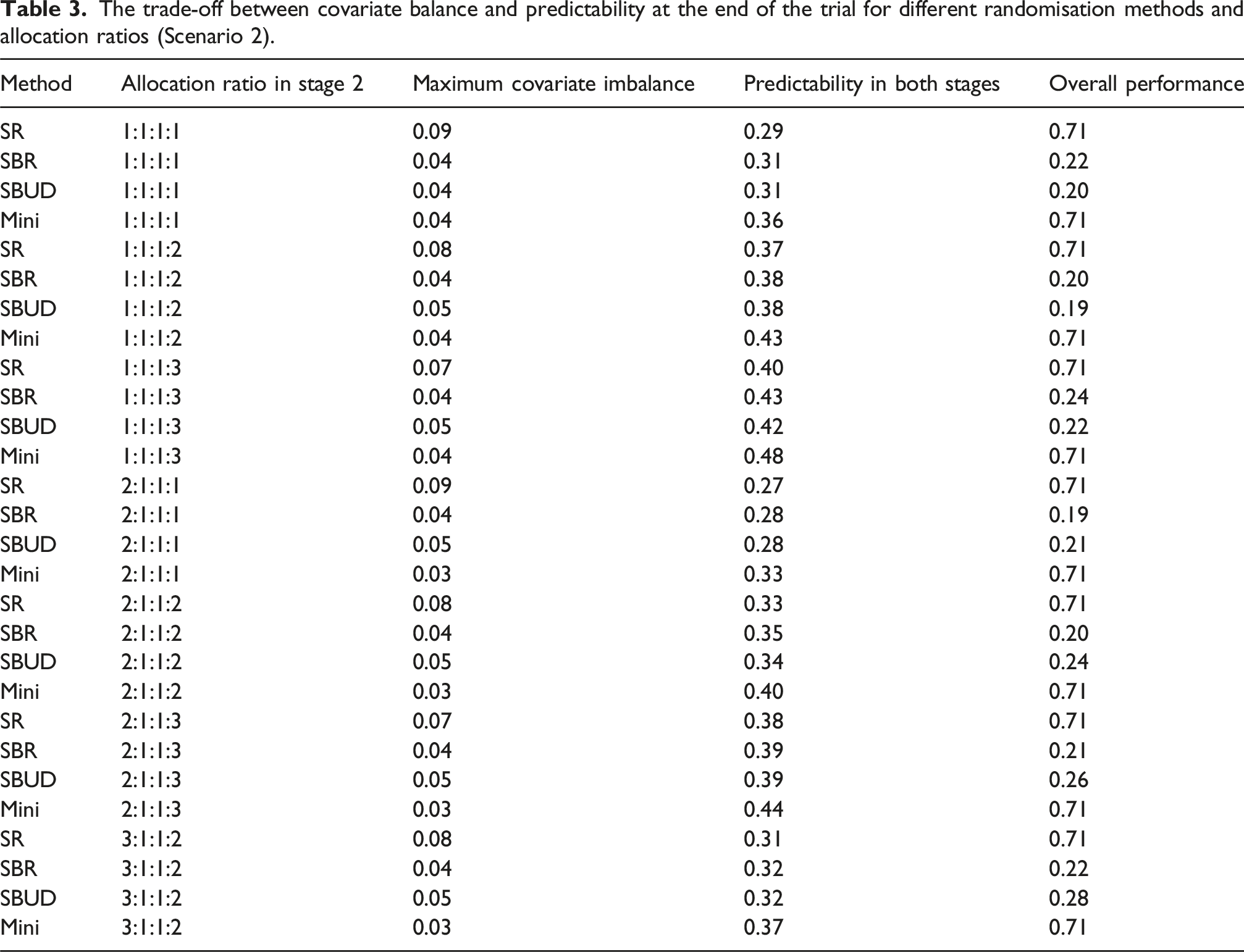
To support the interpretation of the figures, the numerical imbalance and predictability values at sample size 750 (reported in Tables 1 and 2) are referenced throughout this section. These values allow clearer identification of whether covariate balance, predictability, or both contribute to the relative performance of each randomisation method.
Allocation accuracy
Allocation accuracy (mean and SD of d) at the end of the trial for different randomisation methods and allocation ratios (Scenario 1).
Discussion
It can be advantageous to add new experimental arms to an existing trial, as it avoids the long process of starting a whole new trial.2,18 This means that the evaluation of the newly emerging treatment arm(s) can be sped up, conducted at reduced costs, and with a lower number of patients required. 3
In this paper, we evaluated four randomisation methods that have been extensively studied in multi-arm trial settings. In the context of platform trials, however, the introduction of a new treatment arm raises an additional design consideration: whether covariate balancing should be performed using data from all enrolled patients, including those allocated prior to the addition of the new arm (non-concurrent balancing), or restricted to patients enrolled after the new arm is introduced. This distinction is particularly relevant in adaptive settings and has received limited methodological attention.
Among the methods considered, only minimisation naturally allows the inclusion of non-concurrent patients when assessing covariate imbalance, whereas stratified block randomisation and the stratified block urn design rely on stage specific stratification and therefore control imbalance within strata formed at each stage rather than across stages. As a result, minimisation with non-concurrent data is not directly comparable to stratified procedures, which do not possess an analogous mechanism for incorporating historical assignments. Consequently, the comparisons presented in this study are not intended to suggest that stratified methods could operate under non-concurrent balancing rules, but rather to highlight fundamental methodological differences in how imbalance is controlled when a new arm is added to an ongoing trial.
By considering a range of allocation ratios and balancing strategies, our results highlight the inherent trade-off between covariate balance and allocation predictability in adaptive multi-arm designs. Although alternative approaches such as minimal sufficient balance may offer a more direct comparison with minimisation, 19 the methods examined here reflect commonly implemented procedures in practice. 10 While inspired by the FLAIR trial, the simulation design represents a general two-stage platform setting, and the observed balance–predictability patterns reflect methodological properties rather than trial-specific features.
The results demonstrate that increasing the allocation ratio for only the newly added arm does not minimise the covariate imbalance if all treatment arms finish recruitment simultaneously. To minimise covariate imbalance, it would be preferable to decrease the allocation ratio in the existing arm and increase the allocation ratio in both the control and newly added arms. This is also recommended by 20 to maximise the overall power when adding a new experimental arm, and all treatment arms finish recruitment simultaneously. In the paper, the authors stated that the optimal allocation ratio (in a trial concluding with a control and two treatment arms) would be 1.236:0.566:1. 20 This ratio could be, at least approximately, implemented in practice by using minimisation or through using a large block size.
The results illustrate that Mini(0.7) performs better in terms of covariate balance compared to other randomisation methods for different allocation ratios, particularly when the platform trials initially start with more than two experimental arms, as in scenario 2. On the other hand, Mini(0.7) with unequal allocation ratios is more predictable compared to the other randomisation methods considered. We note that in platform trial designs, it will be unlikely that an investigator will have all of the knowledge needed for the above guessing strategy, even when the trial is open-label. In this study, predictability is rigorously defined to quantify its potential impact. However, in practice, it does not matter whether the next allocation is predictable, but rather whether those in a position to influence recruitment believe that they know what will happen next with higher chance, regardless of this being correct or not.
Although SBR is a common randomisation method in randomised controlled trials due to its advantages, 21 it may be challenging to implement effectively in platform trials with varying numbers of treatment arms and unequal allocation ratios. SBR requires careful assessment of the number of covariates that can be stratified and careful choice of the size of the block, to avoid partially filled blocks and overall imbalances. Similarly, this may also be more challenging for SBUD due to the need to predetermine both the block size and threshold that specifies the maximum acceptable difference within each stratum in the number of patients allocated to each treatment arm.
Tables 2 and 3 show that SR and Mini do about the same at the end of the trial when the goal is to get both high covariate balance and randomness. This is because SR is highly random, while Mini performs best in terms of covariate balance. The overall performance difference between SBR and SBUD depends on the allocation ratio and the number of initial arms. Furthermore, Tables 1 and 2 clarify which measure covariate balance or predictability drives the performance of each method. For example, methods with stronger balance but reduced randomness (e.g., Mini) show lower imbalance but higher predictability scores, whereas more random methods (e.g., SR) achieve poorer balance but minimal predictability. As researchers differ in the relative importance placed on balance versus randomness, understanding the contribution of each measure is essential for selecting an appropriate randomisation strategy.
Allocation accuracy (mean and SD of d) at the end of the trial for different randomisation methods and allocation ratios (Scenario 2).
Before concluding, it is important to recognise the limitations of this work. Although the simulation study focuses on a specific platform trial scenario, the design choices such as the timing of new arm entry, binary stratification factors, and a large sample size were selected because they reflect settings commonly encountered in practice and provide a controlled framework for comparing randomisation methods. These assumptions enable a fair and interpretable evaluation of covariate balance and predictability.
Alternative configurations, such as staggered recruitment completion, different covariate structures, or smaller sample sizes, may influence numerical values, but the qualitative conclusions remain consistent: methods that enforce stronger control of covariate imbalance (e.g., Mini, SBUD) inevitably reduce randomness, whereas methods with greater randomness (e.g., SR) sacrifice balance. This fundamental trade-off, rather than the specific values observed under one scenario, is the central contribution of this work.
In many platform trials, optimal or response-adaptive allocation strategies are increasingly advocated to improve efficiency or ethical performance. However, such allocations often involve non-integer ratios, large integers, or adaptively updated allocation probabilities. Such allocation ratios pose substantial practical challenges for block randomisation methods, including stratified block randomisation and block urn designs, because these methods rely on fixed or moderately sized blocks to maintain allocation balance. As a result, these methods may become impractical or infeasible when allocation targets are complex or frequently updated. In contrast, complete randomisation remains straightforward to implement under such conditions, which may partly explain its widespread use in published platform trials.
Furthermore, all treatment arms were assumed to finish recruitment simultaneously. In practice, existing arms may complete recruitment earlier than newly added arms. Early closure reduces allocation to existing arms, which can delay learning about their treatment effects. Identifying suitable randomisation strategies when recruitment continues unevenly across arms would therefore be a valuable extension.
We also examined covariate balance under a large fixed sample size. As stratified randomisation becomes less effective with increasing numbers of strata and recruiting centres, we restricted the number of binary covariates to maintain comparability. Otherwise, the allocation distribution may closely resemble that of complete randomisation. Future work could explore the impact of different forms of statistical power (marginal, disjunctive, conjunctive) and family-wise error rate under various allocation ratios and randomisation approaches. Similarly, assigning different weights to balance and predictability rather than treating them as equally important could provide a more tailored assessment for specific trial objectives.
In addition, we considered the case where a new treatment arm enters halfway through the trial. In many platform trials, new treatments may enter at different time points, including later stages. When the new arm enters after a substantial portion of the sample has been randomised, larger shifts in allocation ratios may be required to achieve acceptable covariate balance. Evaluating allocation ratios that optimise balance under varying entry times is therefore an important direction for future work. Finally, the study assumed binary covariates shared across stages. Extending the investigation to multi-level or continuous covariates, as well as scenarios with adaptive sample sizes, would broaden the applicability of the findings.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.