
Abstract
Background/Aims:
Randomisation in small clinical trials is a delicate matter, due to the tension between the conflicting aims of balanced groups and unpredictable allocations. The commonly used method of permuted block randomisation has been heavily criticised for its high predictability. This article introduces merged block randomisation, a novel and conceptually simple restricted randomisation design for small clinical trials (less than 100 patients per stratum). Merged block randomisation is a simple procedure that can be carried out without need for a computer. Merged block randomisation is not restricted to 1:1 randomisation, but is readily applied to unequal target allocations and to more than two treatment groups.
Methods:
The position of merged block randomisation on the spectrum of balance and predictability is investigated in a simulation study, in two common situations: a single-centre study and a multicentre study (with sampling stratified per centre). Methods included for comparison were permuted block randomisation, Efron’s biased coin design, the maximal procedure, the block urn design and the big stick design.
Results:
Compared to permuted block randomisation with blocks of size 4, merged block randomisation has the same maximum tolerated imbalance and is thus as impervious to chronological bias, with the added benefit of being less predictable. Each method in the study takes a different position on the balance/determinism spectrum, and none was uniformly best. Merged block randomisation was either less predictable or more balanced than the other methods, in all simulation settings.
Conclusion:
Merged block randomisation is a versatile restricted randomisation method that outperforms permuted block randomisation and is a good choice for small clinical trials where imbalance is a main concern, especially in multicentre trials where the number of patients per centre may be small.
Keywords
Background
With great balance comes great predictability. This is the crux of the difficulty of selecting a randomisation method for small clinical trials. There is a tension between the two main desiderata of (1) balanced group sizes and (2) unpredictability. Balance, which in case of 1:1 randomisation means that each group has approximately the same number of subjects, is desirable because balanced group sizes typically yield the highest power and help to minimise confounding. Unbalanced allocations may incur inefficiency, and the results of the study may be perceived as less reliable. 1 The importance of balance is magnified in very small clinical trials, where the loss of power due to unequal group sizes may be detrimental to a study.
When is a trial small enough to warrant special consideration? Numbers stated range from 100 to 200;2,3 for larger numbers, complete randomisation, where each allocation is decided by a fair coin flip, is considered adequate. The need for improved statistical methods for small trials was deemed great enough that the European Union (EU) initiated a research programme to address these issues in 2013. 4 Small sample sizes occur not only when the total number of subjects is limited due to perhaps rarity of a disease or lack of funding but also at the early stages of larger clinical trials where interim analyses are planned or in case of planned stratified analyses with randomisation per stratum. An important study design in which strata may be small is that of multicentre trials. The European Medicines Agency (EMA) guidelines recommend randomising separately for each participating centre, 5 which may lead to multiple smaller randomisation strata, where imbalances in each stratum may add up to an imbalanced total sample.
The other side of the coin of balanced allocation is that of determinism. Perfect balance can be easily guaranteed by alternating treatment allocations, but such an allocation flies in the face of (2) unpredictability. Determinism is a risk to clinical trials because it leaves trials vulnerable to selection bias, where the supervising clinician may be able to influence a patients’ allocated treatment, subconsciously or otherwise. 6 This concern arises in trials where perfect blinding is impossible, such as a trial where the treatment is surgery, and untreated patients do not undergo a sham surgery for practical or ethical reasons. Multiple instances of trials that were influenced by selection bias have been reported, 7 and 16% of clinicians and research nurses admitted to attempting to predict future allocations by keeping track of previous ones, citing reasons concerning patient convenience and perceived benefit from one of the treatments. 8
Another important factor going into the decision for a randomisation method is the nature of the recruitment process. If the number of included subjects is known in advance and will certainly be attained, then the maximum imbalance that can be incurred at an inbetween point in the allocation sequence is less relevant. However, in many circumstances, the total number of patients is not known in advance. In such circumstances, commonly occuring in multicentre trials, limits on imbalance over the entire allocation are typically of higher value. Thus, a third property of randomisation methods that is often desired is (3) near-perfect balance guarantees even with early stopping, where deviation from perfect balance is only tolerated up to a prespecified amount of deviation. The early stopping balance property ensures that the allocation is (almost) perfectly balanced over time, which alleviates not only imbalance but also chronological bias, which may occur if patient characteristics evolve over time and the allocation is imbalanced at intermediate time points.9–11
A fourth, often undiscussed, consideration that goes into selecting a randomisation method is (4) simplicity in practice. 1 The desire for (near-perfect) balance in small trials led to the development of a variety of restricted randomisation methods, in which the reference set (all possible final allocation sequences) is either decreased so that allocations that are deemed too unbalanced are excluded (e.g. permuted block randomisation, 12 the big stick design, 13 the block urn design 14 and the maximal procedure 9 ) or the distribution over the allocations is designed so that highly unbalanced allocations become unlikely (e.g. Efron’s biased coin design 15 and the adjustable biased coin design 16 ). Much research effort has gone into developing methods that achieve a reasonable compromise between perfect balance and predictability, yet none has been able to replace the conceptually and practically simple method of permuted block randomisation. 12
The basis of permuted block randomisation consists of perfectly balanced blocks. The block size(s) is a parameter. For example, if patients are randomised in equal proportions to treatments A and B and blocks of size 4 are selected, then blocks from the set {AABB, BBAA, ABAB, BABA, ABBA, BAAB} are selected uniformly at random until the final allocation size is reached. There is also a randomised version, where blocks of multiple sizes are included, with a stated goal of decreasing predictability. 17 Permuted block randomisation comes with clear balance guarantees, with a maximum imbalance of half the block size. It is frequently recommended,18–20 yet has been heavily criticised mostly due to its high propensity of selection bias.7,21,22 The block structure allows for certain prediction of the final element of each block and sometimes for earlier elements as well. Berger et al. 11 describe the position of permuted block randomisation as that it is uniformly favoured in actual practice, yet all scientific arguments are in favour of other procedures.
The reasons for the continued popularity of permuted block randomisation, besides its robustness against chronological bias, are considered to be its simplicity, together with convenience, familiarity, inertia and an overly optimistic idea of the circumstances under which it works well.11,23 An additional reason may be distrust towards the computer software required to use more advanced techniques, possibly exacerbated by the malfunction of the minimisation software used for the COMET study.2,24,25
This article introduces merged block randomisation, which merges two permuted block randomisation-based sequences like two lanes of traffic, resulting in a conceptually simple method with less predictable allocations than permuted block randomisation while preserving good balance guarantees up to a maximum tolerated imbalance (MTI). Merged block randomisation does not require the investigator to know the total number of subjects in advance, since the (near-perfect) balance guarantees extend to early stopping. Another favourable property of merged block randomisation is that it can be readily used for unequal target allocations or more than two groups, which is a limiting factor to the large-scale deployment of methods other than permuted block randomisation. Trial designs with unequal target allocations or more than two treatment arms abound yet do not have many methods available for randomisation, nor have they been studied much. 26
Despite these benefits, merged block randomisation, like any restricted randomisation method, picks a point on the spectrum between predictability and balance and is not uniformly best in all situations. A situation for which merged block randomisation is eminently suitable is that of stratified randomisation, as will be shown in this article. It is shown that merged block randomisation is a good choice for studies where imbalance is a concern, improving on permuted block randomisation, while retaining the conceptual and practical simplicity of permuted block randomisation.
Methods
Merged block randomisation for 1:1 allocation
The basis of merged block randomisation is permuted block randomisation with blocks of size 2 (i.e. either AB or BA). Permuted block randomisation with blocks of size
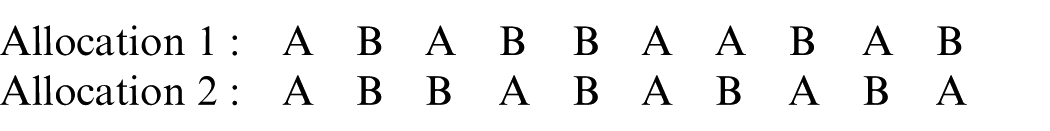
The two allocations are then merged, with the locations of the merging spots decided by flips of an unbiased coin. The number of coin flips equals the length of the final allocation. For each ‘head’, the sequentially first assignment within basis allocation 1 that has not been selected yet is placed in the final allocation, while for each ‘tail’, the sequentially first unused treatment assignment within basis allocation 2 is selected. Continuing the example, we observe 10 flips of an unbiased coin, with outcome HTHTTTHTHT, where H represents heads and T represents tails. Since there are 4 Hs and 6 Ts, the final allocation will use the first four assignments from basis allocation 1 and the first six assignments from basis allocation 2. The first four assignments from basis allocation 1 will be placed in the spots indicated by the Hs, while the first six assignments from basis allocation 2 will be placed in the spots indicated by the Ts. This leads to the following merged allocation
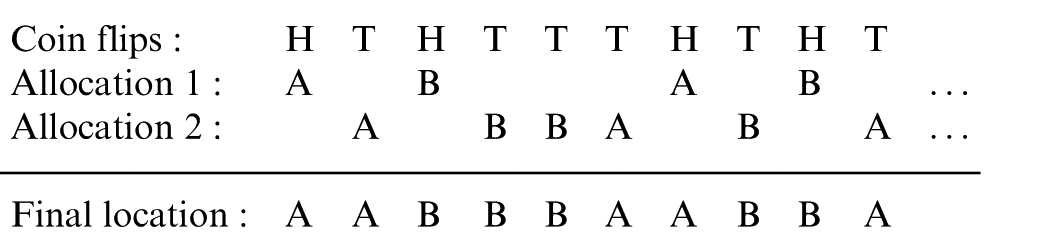
The unused parts of the basis allocations, BAABAB and BABA in the example, are discarded. The essential property of the procedure is that within each basis allocation, only the initial assignments are used, and their ordering is preserved. This ensures that a balanced (up to the MTI, see next section) final allocation is achieved, regardless of the total number of patients that ends up being randomised.
Balance and predictability of MBR(2)
The MTI of a randomisation method is the maximum difference in group sizes that may occur, regardless of when randomisation is stopped. 9 Thus, if recruitment ends sooner than planned, the initial part of the allocation still yields groups with a balance guarantee up to the MTI. It is readily seen that the MTI of MBR(2) is 2. The reason is that each of the basis allocations has an imbalance of at most one; if an odd number of assignments from a basis allocation is used, then one of the groups will have exactly one more member than the other (in the event of an even number, the groups will be exactly equal). If an odd number of assignments from each basis allocation is included in the final MBR(2) allocation, then these imbalances may cancel each other out in the final allocation or may combine so that the imbalance at that point equals the MTI of MBR(2). With an MTI of 2, MBR(2) has a larger MTI than its PBR(2) basis allocations, but the same as PBR(4), or permuted block randomisation with blocks of sizes 2 and 4, since the MTI of permuted block randomisation is half the size of the largest block.
The continuous balance over time makes MBR(2) as unsusceptible to chronological bias as PBR(4). We remark here that the MTI is a worst-case measure, indicating the maximum imbalance that is allowed by the randomisation method. The frequency with which the MTI is seen will be further investigated in the simulation study.
As in any restricted randomisation design, the trade-off for the MTI of 2 is that there is an inherent determinism. To get a better sense of the degree of determinism of MBR(2), we compare the reference sets (the set of all feasible allocation sequences under the restriction of MTI and allocation sequence length) of MBR(2) and PBR(4). The reference set of MBR(2) is clearly larger than that of PBR(4), since already for
Thus, as the reference set of MBR(2) is strictly larger than that of PBR(4), it may be less easy to predict the next allocation with certainty. In the
A decrease in predictability is not guaranteed by the larger reference set, since the distribution over all possible sequences may be such that most of the time allocations are generated that tend to be more predictable than those of permuted block randomisation, such as happens when comparing PBR(4) to the variable block design where blocks of size 2 and 4 are used; the variable block design is more predictable than PBR(4) despite having a larger reference set. 11 However, in case of the variable block design compared to PBR(4), the phenomenon occurs because the addition of blocks of size 2 to PBR(4) enforces more balance, thus making the convergence (guessing) strategy 27 more prone to success. In merged block randomisation, the merging step decreases balance rather than increasing it, and thus a decrease in predictability compared to PBR(4) is expected, of which the larger reference set is a symptom. This is investigated further in the simulation study.
Extension to unequal randomisation ratios
Due in part to methodological developments in adaptive designs, and due to trial efficiency or economical reasons, the number of clinical trials with unequal allocation is on the rise. 26 Yet, not many randomisation methods exist besides complete randomisation and permuted block randomisation, and fewer methods still are available for randomisation to more than two treatment arms. Merged block randomisation is readily extended to more than two treatments and to unequal randomisation ratios. This is done by taking two permuted block randomisation allocations with the target randomisation ratio as basis allocations and leaving the rest of the procedure unchanged. For example, for a three-arm trial with 1:2:3 allocation, taking permuted block randomisation with blocks containing 1 A, 2 Bs and 3 Cs as the basis, an instance of merged block randomisation is given as follows
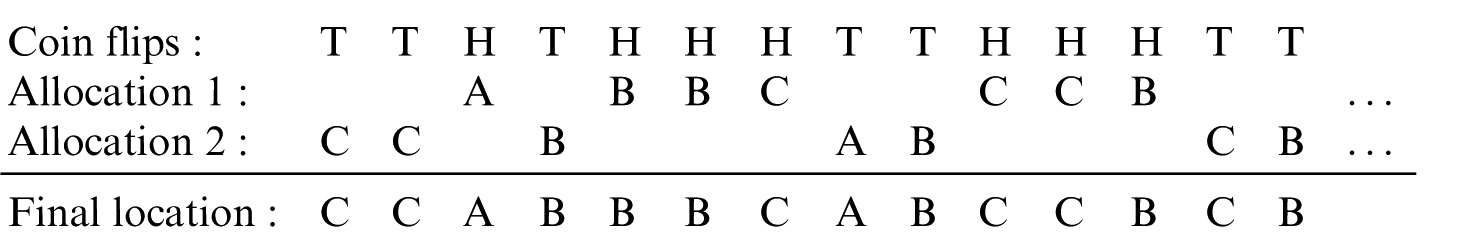
Implementation
The practical complexity of implementing a method is an important factor towards its eventual relevance in practice, and permuted block randomisation’s simplicity is considered an important reason for its pervasiveness in practice despite objections by many.1,11,23 Merged block randomisation shares both the conceptual and the practical simplicity of permuted block randomisation and can easily be implemented by anyone who is able to implement permuted block randomisation, either with or without software.
Computer
Pseudocode and R-code for merged block randomisation are given in the Supplemental material. The code is implemented in the R package ‘mergedblocks’31, and an app will be made available on the author’s website.
If a person already has access to a generator of PBR(2) sequences, MBR(2) sequences can be generated without a need for additional software. The researcher can simply generate two PBR(2) sequences plus a sequence of fair coin flips and use them to merge together the two basis sequences as outlined above.
With envelopes and coin flips
Although here the recent warnings against the use of sealed envelopes must be mentioned, 7 merged block randomisation is conceptually so simple that the randomisation sequences can be created without a computer, resulting in sequentially numbered, opaque sealed envelopes (SNOSE). Combining the procedure described by Doig and Simpson 28 with coin flips as described above leads to the creation of merged block randomisation allocations.
Simulation study setup
In this simulation study, the position of merged block randomisation on the spectrum of balance versus unpredictability is investigated and visualised. Merged block randomisation is compared with other well-known MTI procedures which have done well in previous simulation studies14,29 and one without a limit on the MTI, including the following:
Permuted block randomisation;
Soares and Jeff Wu’s big stick design 13 , where allocations are decided by coin flip until the MTI is reached;
The maximal procedure, where an allocation is selected uniformly at random from all allocation sequences meeting the MTI requirement; 9
The block urn design, which uses an active and inactive urn and has been shown to behave similar to the maximal procedure; 14
Efron’s
15
biased coin design with
The MTI is set equal to 2 for all methods, with the exception of Efron’s biased coin design, since it is not an MTI procedure. With the exception of merged block randomisation and the block urn design, all other randomisation methods were carried out using the randomizeR package. 30
Setting 1: single-centre study
The goal is 1:1 randomisation, studied for each
As a measure of predictability of the allocation, we employ the Blackwell and Hodges 27 convergence strategy, also known as the correct guess probability. An allocation is evaluated at every assignment. Blackwell and Hodges’ convergence strategy predicts that the next assignment will be towards the group that has the fewest members, thus predicting that the total allocation will become more balanced. If the groups are of equal size, a fair coin is flipped. The average correct guess probability is recorded for each allocation.
Setting 2: multicentre study, 10 centres
A stratified multicentre study with 10 centres is considered, where each centre recruits a number of patients that is unknown in advance, but limited to 50 per centre, with 1:1 randomisation. In each simulation run, each method is used to create 10 allocations of length 50, one for each ‘centre’. The actual number of patients recruited for each individual centre was generated from a Poisson distribution with mean
Imbalance is measured as the imbalance of the final allocation, recording the imbalance after pooling the subjects from all ‘centres’. Predictability is again assessed by the correct guess probability, now computed separately for each of the 10 ‘centres’ and then averaged.
Results
The results from the simulation study on average imbalance and predictability are presented for representative sample sizes in Figures 1 and 2. Results for all sample sizes are reported in the Supplemental material.
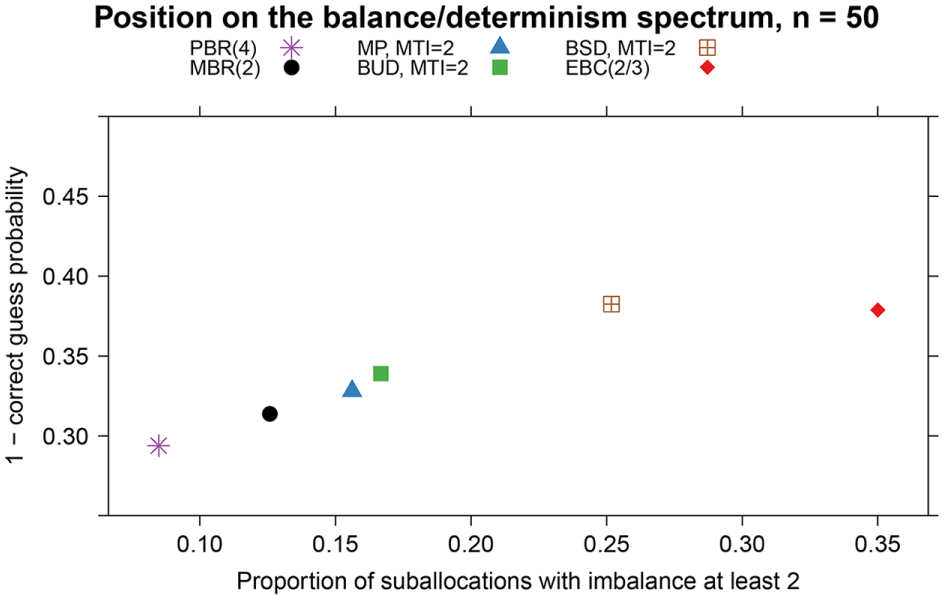
Setting 1 (single-centre study). Balance/determinism spectrum positions at
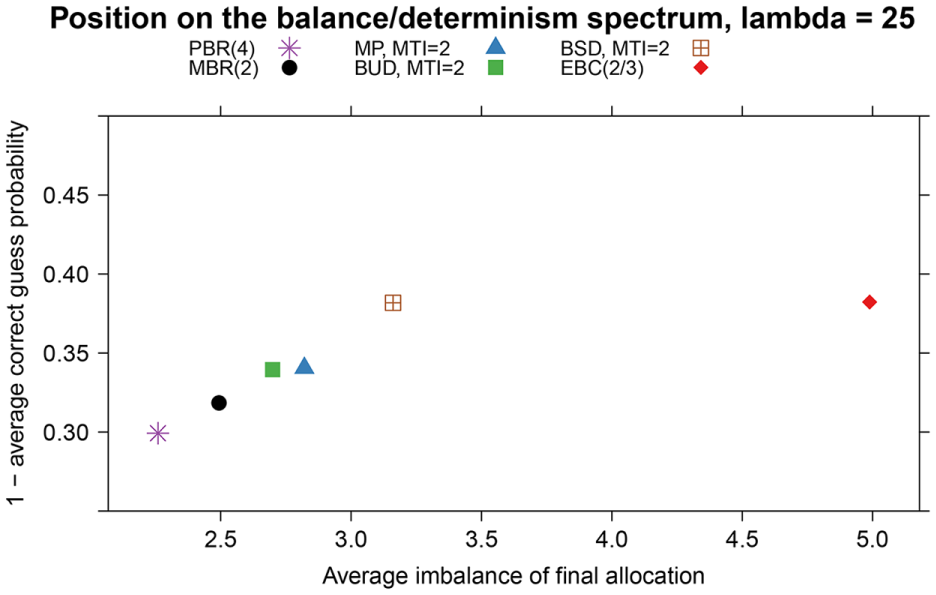
Setting 2 (multicentre study, 10 centres). Balance/determinism spectrum positions for
Figures 1 and 2 illustrate the trade-off between balance and unpredictability, showing scatterplots of measures of imbalance and one minus the correct guess probability for each method in each setting. The axes are such that a position in the upper left corner is optimal. The vertical axis is restricted to
Both figures show that no method is uniformly best, and that the position of MBR(2) on the balance/determinism spectrum is between that of PBR(4) and that of the maximal procedure and block urn design.
As expected, the allocations created by merged block randomisation are less predictable than those of permuted block randomisation with the same MTI. Compared to merged block randomisation, both the maximal procedure and the block urn design offer further improvements in terms of predictability. The similarity of the maximal procedure and block urn design is expected based on theoretical considerations. 14
The lowest correct guess probability is exhibited by the big stick design, which is on par with Efron’s biased coin design in this respect. The big stick design has the added benefit of a lower average imbalance, although the trade-off between predictability and balance is shown by the difference in position of the big stick design and, for example, the maximal procedure. The good behaviour of the big stick design was reported previously in a large comparison study. 29
The imbalance measure in Figure 1 indicates that even methods with the same MTI differ in the likelihood of hitting the limit of, in this case, an imbalance of 2. The average imbalance of the final allocation over all 10 centres in Figure 2 shows that PBR(4) is on average slightly less imbalanced than MBR(2), possibly due to cancellation effects between the allocations of the different strata. However, the differences in imbalance of the five MTI methods are minor compared to methods without hard limits on the imbalance, as discussed recently by Berger et al. 11 and illustrated by the position of Efron’s biased coin design on the spectra.
Conclusion
There is no one-size-fits-all solution, since an inherent trade-off is forced by the two duelling goals of balance and unpredictability. Thus, the choice of randomisation method in small clinical trials is ultimately guided by the priorities of the researcher. How much of a potential decrease in power can the researcher afford while seeking to diminish selection bias due to predictability? The spectrum plots in this article show what the relative costs are of each decision.
For clinical practice, relevant factors to consider are the number of centres, the extent to which treatment assignment can be blinded and the target allocation ratio. If a large number of centres participate in a study, a method for which low imbalances are typical may be preferred, since in stratified randomisation, overall imbalances can potentially be very large. While the simulation studies in this article show that on average imbalances between centres will cancel each other out, there is still the potential for an unlucky situation in which the imbalances add up across centres. The novel merged block randomisation procedure may be a good choice for randomisation with many centres or strata.
If treatment cannot be perfectly blinded, lack of predictability is critical and may be worth sacrificing some balance for. For that situation, the big stick design showed the best results in this study, and even complete randomisation could be considered despite its potential for imbalance.
If randomisation to three or more groups is desired, the maximal procedure and big stick design cease to be an option in their current implementations. In that case, a researcher may consider permuted block randomisation, merged block randomisation or the block urn design. Their relative performance is expected to be similar as in this study, leading to a preference for either the block urn design or merged block randomisation.
While ideally implementation difficulty would play no role in the selection of a randomisation method, in practice, this factor is important. The recent randomizeR package has made all methods (with the exception of the block urn design) considered in the present simulation study more accessible. 30 Nevertheless, the barrier to the of use of methods other than permuted block randomisation or complete randomisation may still be too high for some.
Randomisation is a topic where while there is still no such a thing as a free lunch, there is at least a cheap lunch: improvement without much effort is possible. The standard permuted block randomisation methods have been argued to be suboptimal in many papers, yet are still pervasive in practice.7,11,21,22 This article again shows that improvement is easily possible, even for a practitioner who does not have access to the methods that are theoretically well-performing but require a bit more specialist training to use. If a researcher is able to perform permuted block randomisation, then he or she can use that skill to create less predictable allocations with merged block randomisation, by simply adding a coin flip to the process.
Supplemental Material
190103_MergedBlockRandomisation_supplement – Supplemental material for Merged block randomisation: A novel randomisation procedure for small clinical trials
Supplemental material, 190103_MergedBlockRandomisation_supplement for Merged block randomisation: A novel randomisation procedure for small clinical trials by Stéphanie L van der Pas in Clinical Trials
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This work was supported by a grant by KiKa project number 275.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.