
Abstract
Background
There is little consensus on how to measure fatigue.
Objectives
To standardize the measurement of fatigue across populations, we aimed to assess the psychometric properties of the PROMIS Fatigue item bank in the Dutch general population and obtain reference values.
Methods
A sample of 1006 people participating in an internet panel completed the full v1.0 PROMIS Fatigue item bank (95 items). Structural validity (item response theory (IRT) assumptions and IRT model fit), measurement invariance/cross-cultural validity (absence of differential items functioning (DIF) for demographic variables and language, compared to data from US participants in PROMIS wave 1), and (internal) reliability (percentage of respondents with reliable estimates) were assessed.
Results
The IRT model assumptions were considered met (ECV 0.86, Omega-H 0.92), all items fitted the IRT model, no items showed DIF for demographic variables and seven for language, but with negligible impact on T-scores. Reliable fatigue T-scores were found for 98.3%, 69.8–82.6%, and 96.5% of the respondents with the full item bank, the standard short forms, and a simulated computerized adaptive test (CAT), respectively. The CAT administered on average only five items. A T-score of 49.1 represented the average score of the Dutch general population, T-scores <55 are considered within normal limits, T-scores of 55–59 indicate mild fatigue, T-scores of 60–70 indicate moderate fatigue, and T-scores >70 indicate severe fatigue.
Conclusions
The PROMIS Fatigue item bank showed sufficient structural validity, no measurement invariance for demographic characteristics, sufficient cross-cultural validity, and sufficient (internal) reliability in the Dutch general population.
Introduction
Fatigue is a common symptom in multiple conditions, such as cancer, 1 cardiovascular disease,2,3 chronic obstructive pulmonary disease (COPD), 4 inflammatory bowel disease, 5 skin disease, 6 multiple sclerosis, 7 rheumatoid arthritis, 8 and many others. It has been included as one of the core outcomes, that is, outcomes that matter most to patients, in about one third of the Standard Sets developed by the International Consortium for Health Outcomes Measurement (ICHOM). 9
Despite the importance of fatigue, there is little consensus on how to measure it. Numerous generic and disease-specific patient-reported outcome measures (PROMs) exist to measure fatigue. For example, systematic reviews identified 25 PROMs for measuring cancer-related fatigue, 10 43 PROMs for measuring fatigue in hemodialysis patients, 11 10 PROMs for measuring fatigue in non-cancer gastrointestinal disorders, 12 and 31 fatigue questionnaires for multiple sclerosis, Parkinson’s disease and stroke. 13 In nine ICHOM Standard Sets recommending the measurement of fatigue, six different PROMs were suggested. 9 The available fatigue questionnaires differ in content and quality (i.e., psychometric properties) and total scores are not comparable, hindering benchmarking and quality of care improvements.
The severity and impact of fatigue on daily activities, should be measured with instruments that have sufficient psychometric properties, including validity (content, structural, construct, and cross-cultural validity), reliability (internal consistency, test–retest reliability, and measurement error), responsiveness, interpretability, and low completion burden for patients. Furthermore, the measurement of fatigue should, wherever possible, be standardized in research and clinical practice, in order to enable comparison of the burden of disease and treatment within and across populations.
To improve the quality of fatigue measurement and standardize its measurement across populations, the Patient-Reported Outcomes Measurement Information System (PROMIS)® initiative developed a highly precise and universal applicable (or generic) fatigue PROM that can be used in healthy persons as well as patients with varying medical conditions. The PROMIS Fatigue measure was built on items from existing PROMs that had undergone testing previously, identified in an extensive literature search as well as focus groups with a mixed sample of patients. 14 In addition, cognitive interviews were performed with patients with a diverse range of chronic health conditions. 15 Using a modern psychometric technique (item response theory (IRT)) an “item bank” of 95 fatigue items was created, measuring a range of self-reported symptoms, from mild subjective feelings of tiredness to an overwhelming, debilitating, and sustained sense of exhaustion that likely decreases one’s ability to execute daily activities and function normally in family or social roles. 16 With IRT analyses items in an item bank are ordered on a scale, according to the fatigue level they address (also called item “location” or item “difficulty”). For example, the item “How often did you have enough energy to exercise strenuously?” indicates a low level of fatigue because even patients with a little fatigue may answer “sometimes,” while the item “How often were you too tired to watch television?” indicates a high level of fatigue because only patients with high levels of fatigue will answer “sometimes.” Each item has its unique location on the scale and also a unique discriminative ability. 17 Once the item locations and discriminative abilities are defined, fixed subsets of items can be administered to patients as short forms (standard short forms of 4, 6, 7, and 8 items were developed), or the item bank can be administered as computerized adaptive test (CAT). In a CAT items are selected from the item bank by a computer based on a person’s responses to previous items. 18 Scores of short forms and CAT are computed taking the item location and discriminative ability of the items into account. Scores of short forms and CAT are on the same scale (or metric), which makes them comparable.
Research supports the psychometric properties of the generic PROMIS Fatigue measures in the general population and across varying conditions. One psychometric property, content validity, of the PROMIS Fatigue item bank was supported in patients with rheumatoid arthritis and multiple sclerosis.19,20 Other psychometric properties, internal consistency, structural validity, test–retest reliability, construct validity, and responsiveness, of different PROMIS Fatigue short forms and CAT were supported across patient populations with a wide range of conditions, such as rheumatologic conditions, back pain, Myalgic Encephalomyelitis/Chronic Fatigue Syndrome, cancer, HIV, chronic heart failure, COPD, depression, and others.21–36 Egerton et al. evaluated the measurement properties of self-report questionnaires for measuring fatigue in older people. PROMIS Fatigue item bank and short forms performed best out of 77 identified questionnaires. 37 Because of the innovative psychometric methods used to develop item banks and its universal applicability, PROMIS CATs may be able to replace disease-specific PROMs. Since a CAT selects items that are most informative for each patient, reliability and responsiveness are high. PROMIS CATS have found to be as responsive as disease-specific PROMs.34,36,38,39
However, all of these studies so far, addressing the development and psychometric properties of the PROMIS fatigue item bank in multiple populations, were performed in the US. There is no evidence yet for the psychometric properties of the PROMIS Fatigue measures outside of the US. There is also limited evidence for measurement invariance across demographic variables and across countries (cross-cultural validity), which is important because item parameters may be different across countries, which could impact scores and hinder comparisons between groups differing with respect to demographic variables or cultural background. The aim of this study was therefore to assess the psychometric properties structural validity, measurement invariance/cross-cultural validity, and (internal) reliability of the Dutch-Flemish version of the v1.0 PROMIS Fatigue item bank in the Dutch general population, and to assess Dutch reference values, to facilitate large-scale international implementation of this item bank as short form or CAT in research and clinical practice.
Methods
The Medical Ethical Committee of Amsterdam UMC, location VUmc, the Netherlands, confirmed that the study protocol was exempted from ethical approval according to the Dutch Medical Research in Human Subjects Act (WMO), as no experiments were conducted. The study adhered to the tenets of the Declaration of Helsinki.
Participants and procedures
A cross-sectional study was performed. A data collection company (Desan Research Solutions) recruited people of the Dutch general population from an existing internet panel in 2016 (more details about the panel can be found here). 40 We considered a sample of at least 1000 people sufficient for item parameter estimation. The study sample was selected to be representative for the Dutch general population with respect to age distribution (18–40; 40–65; >65), gender, educational level (low, middle, high), region of residence (north, east, south, west) and ethnicity (native Dutch, first- and second-generation western immigrant, first- and second-generation non-western immigrant). We compared the characteristics of the participants to data from Statistics Netherlands in 2016 41 to check for a maximum allowable deviation of 2.5% per variable.
Measures
A web-based survey was used, in which skipping items was not allowed. Participants completed the full v1.0 PROMIS Fatigue item bank, consisting of 95 items, or more specifically statements or questions referring to the severity or impact of fatigue. All items have five response options, higher scores indicate more fatigue, except for eight items referring to having energy to do things, which were recoded. Example items and response options are provided in Box 1. The recall period is the past 7 days. Additionally, participants completed questions regarding sociodemographic characteristics (age, gender, education, region of residence, and ethnicity). Example items of the v1.0 PROMIS Fatigue item bank During/in the past 7 days… HI7 I feel fatigued (not at all, a little bit, somewhat, quite a bit, very much) AN3 I have trouble starting things because I am tired (not at all, a little bit, somewhat, quite a bit, very much) FATEXP20 How often do you feel tired? (never, rarely, sometimes, often, always) FATIMP30 How often were you too tired to think clearly? (never, rarely, sometimes, often, always)
Statistical analyses
Psychometric properties studied, criteria, software, or R-packages used.

Structural validity
First we checked data assumptions required for IRT modeling. We checked whether the item bank was unidimensional enough for IRT analysis (i.e., measuring only one construct), by using confirmatory and bi-factor analyses. We also evaluated local independence by checking whether residual correlations among the items were not too high. We finally checked the monotonicity assumption, which states that the probability for patients to select higher response categories should increase with increasing levels of fatigue. After assuring that the assumptions were met, we fitted an IRT model (Graded Response Model) to the response data, estimated the IRT item parameters (i.e., item locations/thresholds and item discrimination parameters), and assessed the fit of each item to the model.
Measurement invariance/cross-cultural validity
We examined whether people from different subgroups (e.g., males versus females) with the same level of the fatigue have similar probabilities of giving a certain response to an item (measurement invariance. 42 If that is the case, the same IRT parameters can be used to calculate and compare scores across groups. We evaluated measurement invariance for age, gender, education, region, and ethnicity, by comparing a series of ordinal regression models, assessing whether, when controlling for the level of fatigue, the probability of giving a certain response to an item is the same across groups. 43 We also evaluated measurement invariance for language (Dutch vs American-English), which can be considered evidence for cross-cultural validity. For the latter aim, we compared our sample to a sample of 21.133 individual from the US general population that was used for developing the original item bank 16 (PROMIS Wave 1, obtained from the HealthMeasures Dataverse repository). 44 PROMIS Wave 1 data were collected in 2006–2007 by a polling firm. Data consisted of 7005 individuals who completed the full PROMIS Fatigue item bank and 14.128 individuals who completed 7 items measuring fatigue experience, 7 measuring fatigue impact, and also 7 items from each of the other 12 domains included in PROMIS wave 1 testing. Mean (SD) age of the sample was 53.1 (17.1) and 52% were women.
Reliability
To evaluate reliability, first fatigue scores were calculated for all study participants based on the PROMIS Fatigue full item bank, derivative short forms (4a, 6a, 8a, and 7a) and a simulated CAT. PROMIS scores are, by default, based on the item parameters of the original IRT model of the US calibration sample on which the item bank was developed (unless large measurement invariance is found), so that scores are comparable across populations and countries. 45 IRT-based scores always have an average of 0 and SD of 1 in the calibration sample (theta scale). PROMIS, however, uses a T-score metric, which is obtained by multiplying the theta score by 10 and adding 50. T-scores of almost all PROMIS domains thereby have a mean of 50 and a standard deviation of 10 in the US reference population. PROMIS T-scores can be calculated from the raw item scores using the online HealthMeasures Scoring Service program, provided by the US Assessment Center. 20 However, for the CAT simulation, we needed the original US item parameters, which were obtained from the HealthMeasures group. 46
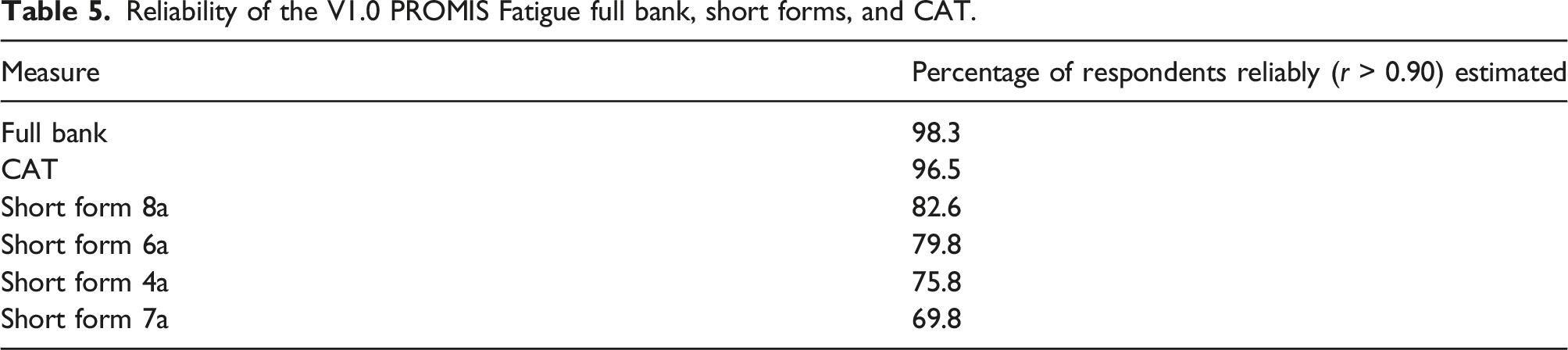
Reliability (or precision) within IRT is inversely related to the standard error (SE) of the estimated fatigue score (this form of reliability is also called internal reliability or internal consistency because it is based on only one measurement). Each score is associated with a SE. The SE differs across the scale, and is usually lower in the middle of the scale than at the ends of the scale.17,47 We calculated the number of participants who got a reliable score on the T-score scale (SE<3.16, which equals a reliability of 0.90) with the full bank, short forms, and a simulated CAT. We simulated a CAT using the standard PROMIS CAT start and stopping rules. The start item was the item that is most informative (i.e., best reliability) for people with an average level of fatigue, which is item FATIMP3 (“How often did you have to push yourself to get things done because of your fatigue?”). A minimum of 4 items were administered and the CAT stopped when a SE of three on the T-score metric was reached or a maximum of 12 items were administered. We also plotted the SE across T-scores for the entire item bank, the standard short forms and the simulated CAT.
Dutch reference values
To obtain Dutch reference values, we calculated the mean (SD) T-score for the entire group of study participants, and for age-range (18–34 years, 35–44 years, 45–54 years, 55–64 years, 65–74 years, and ≥75 years) and gender subpopulations. We also calculated fatigue scores of 0.5*SD, 1*SD, and 2*SD above the average of the general population as thresholds for mild, moderate and severe fatigue respectively.
Results
Sociodemographic characteristics of the study participants and the Dutch general population.
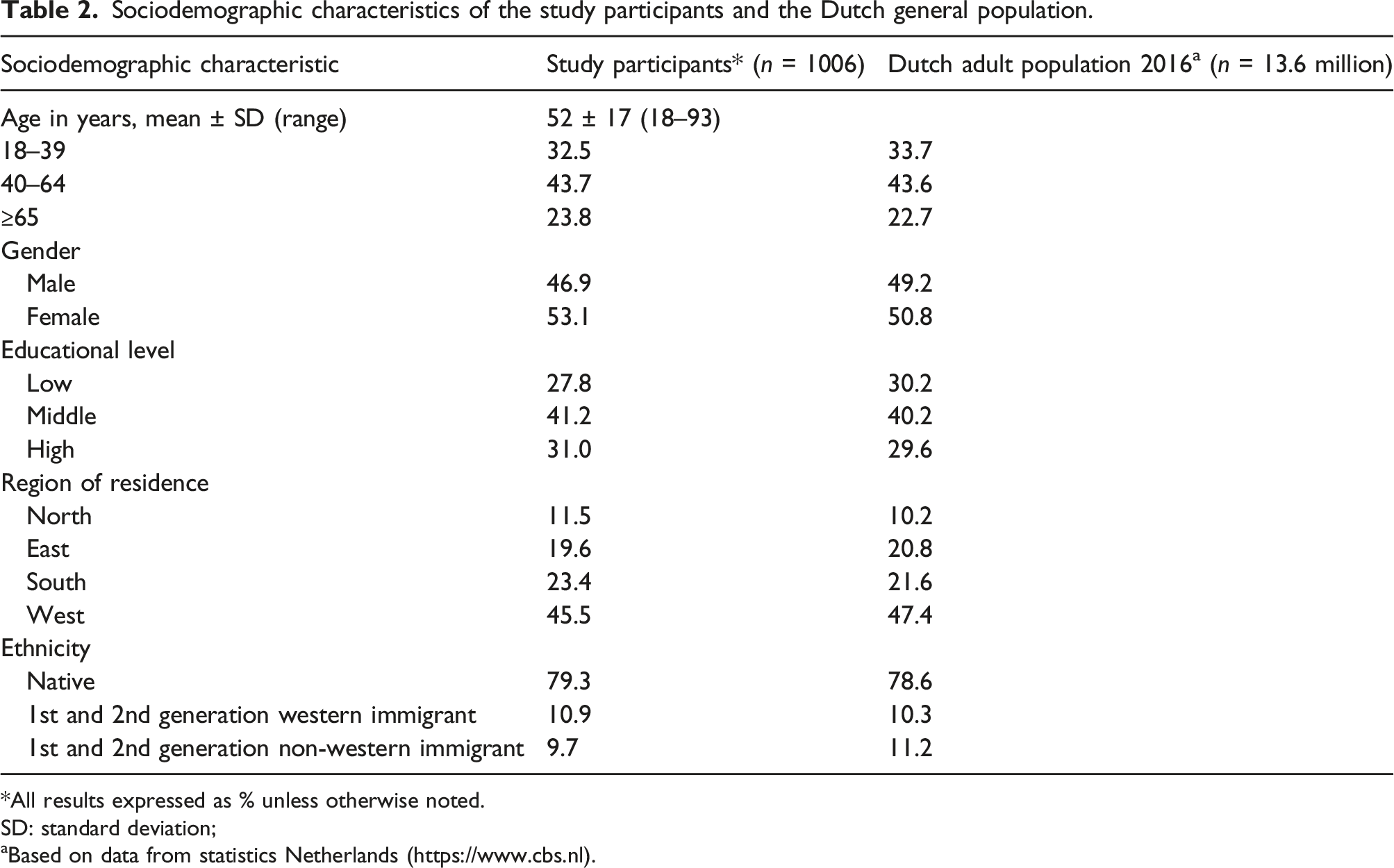
*All results expressed as % unless otherwise noted.
SD: standard deviation;
aBased on data from statistics Netherlands (https://www.cbs.nl).
Structural validity
IRT assumptions and model fit of the V1.0 PROMIS Fatigue Item Bank.

Measurement invariance/cross-cultural validity
Cross-cultural validity: items that showed differential item functioning in the Dutch versus American-English sample.

aAll items showed uniform DIF.
b= also DIF in Spanish language (results obtained from HealthMeasures, personal communication).
Reliability
Reliability of the V1.0 PROMIS Fatigue full bank, short forms, and CAT.
Dutch reference values
PROMIS fatigue reference values a for the Dutch general population by age and gender, and comparisons with the US reference population.
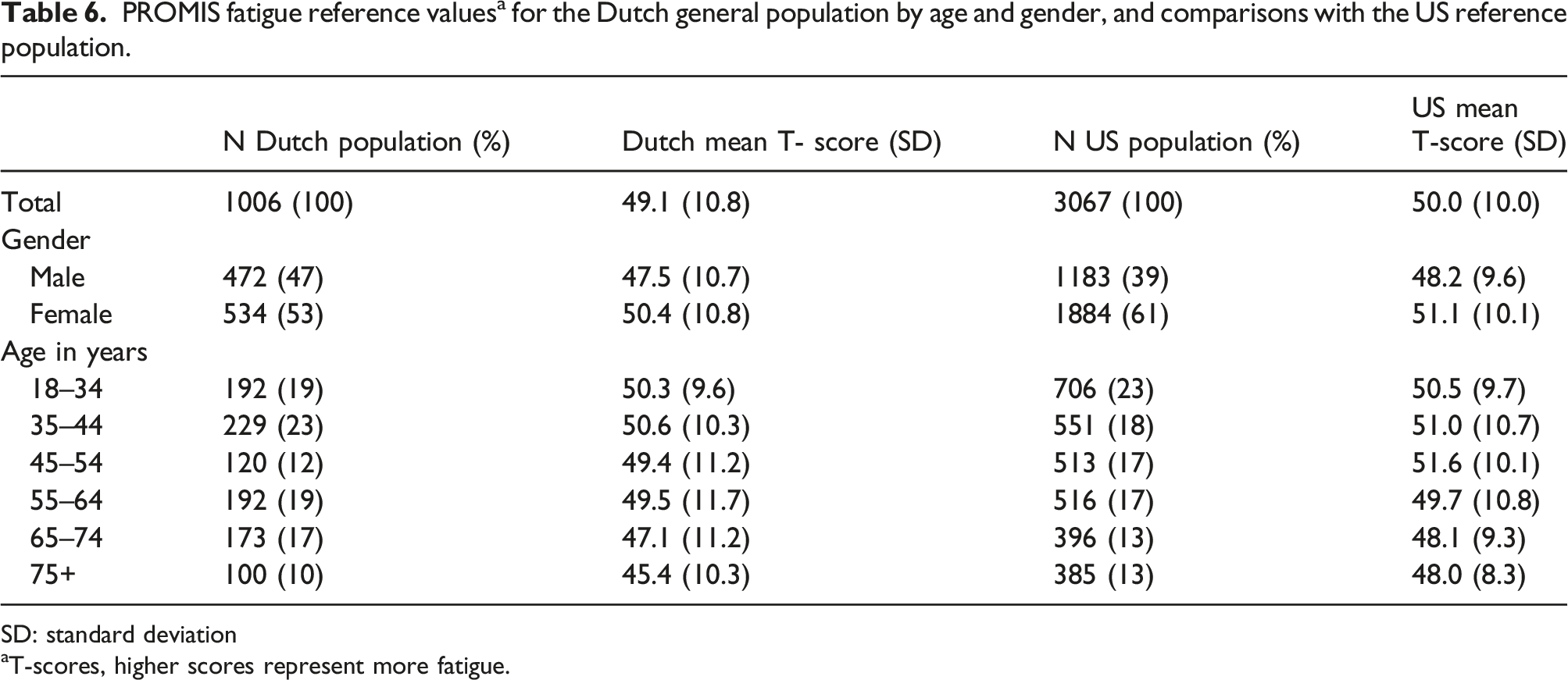
SD: standard deviation
aT-scores, higher scores represent more fatigue.
Discussion
The Dutch-Flemish v1.0 PROMIS Fatigue item bank showed sufficient structural validity, no measurement invariance for important demographic characteristics, sufficient cross-cultural validity, and (internal) reliability. With the full item bank 98.3% of the respondents had reliable (r > 0.90) fatigue scores. With the short forms this was 69.8–82.6% and with the CAT 96.5%, with on average only five items.
This is the first study that evaluated cross-cultural validity of the PROMIS Fatigue item bank, contributing to its international applicability. Seven items showed DIF for language, indicating that Dutch people with on average similar levels of fatigue as US people, are more inclined to respond to these items that they experience fatigue. For some items, this may be due to the translation. For example, item FATEXP2 “How often did you feel run-down” was difficult to translate. In addition, we had difficulty to make two different translations for items AN2 (I feel tired) and HI7 (I feel fatigued) because no distinction is made between tired and fatigued in the Dutch language. 48 However, for other DIF items we did not find any problems with the translation. The magnitude of the DIF for all seven items was small. Of these seven items, only one item (HI7) is included in the most often used standard 8a short form. The magnitude of the DIF of this item was low (R2 0.0207, just slightly above the critical value of 0.02); therefore, the impact of DIF on the short form T-scores is expected to be negligible. Also, only one of the DIF items (AN5) was selected in the simulated CATs (in 13% of the participants). The magnitude of the DIF of this item was also quite low (R2 0.0254), so the impact of DIF on the CAT T-scores is also expected to be very low.
We did not assess the presence of (chronic) conditions in our study sample, but considering a prevalence of chronic diseases of about 40% in the Dutch general population, 49 we assume that our study sample included a large proportion of people with different conditions. Therefore, our study adds to the accumulating evidence that fatigue can be measured validly and reliably across patients with a wide range of conditions with generic PROMIS Fatigue measures.21–36 Previous research showed the relevance of the PROMIS Fatigue items across different patient populations.15,19,20 A study in rheumatoid arthritis patients also showed that most patients would not give a different response when asked about a general sense of fatigue compared to fatigue attributed to their disease. 19
This body of evidence provides an important justification and encouragement for the standardization of patient-reported outcome measurement across medical conditions. It is too time-consuming and costly to build in many different PROMs in electronic health records, it is difficult for healthcare providers to use different PROMs in different setting or for patients with different conditions and interpret the results correctly, and it is burdensome for patients with multiple conditions to complete different PROMs for different healthcare providers.50–52 Standardization is needed for large-scale assessment, comparison of outcomes within and between patient groups, and improvement of the quality of the health care system and the health of patients. To facilitate the transition from using traditional PROMs to PROMIS, so called “crosswalks” can be created to transform scores of currently frequently used fatigue PROMs, such as the Modified Fatigue Impact Scale (MFIS), to the PROMIS Fatigue metric.53,54
Our study also showed that CAT is a very efficient and patient-friendly way of measuring outcomes. With CAT 96.5% of the patients got a reliable score with on average only five items. Moreover, CAT clearly outperformed the short forms. Other studies found similar results for other PROMIS item banks.55–62
This study additionally provided Dutch reference values for the PROMIS Fatigue measures. A T-score of 49.1 represents the average score of the Dutch general population, which is quite similar to the average T-score of 50 in the US population. Also the thresholds for mild, moderate, and severe fatigue of 55, 60, and 70, respectively, were found to be similar in the Dutch population as in the US population. Evidence on the minimal detectable change and minimal important change of PROMIS Fatigue measures is still scarce. Change scores of about 11–13 T-scores points have been found to be minimally detectable and change scores of about 2–4 T-score points have been found to be minimally important.63–66 However, these studies have methodological limitations and more high quality evidence is needed. Evidence on the psychometric properties of the PROMIS Fatigue measures in other countries is also required to enable comparison of outcomes of health care across countries.
A strength of this study is its large sample size and comparison to recent data from the Dutch general population, as well as comparison to a large US general population sample. A limitation is the lack of knowledge about the presence of (chronic) conditions in the study sample. Therefore, we were not able to evaluate measurement invariance for (chronic) conditions.
Conclusion
The Dutch-Flemish v1.0 PROMIS Fatigue item bank showed sufficient structural validity, no measurement invariance for important demographic characteristics, sufficient cross-cultural validity, and sufficient (internal) reliability in the Dutch general population. A T-score of 49.1 represents the average score of the Dutch general population, T-scores <55 are considered within normal limits, T-scores of 55–59 indicate mild fatigue, T-scores of 60–70 indicate moderate fatigue, and T-scores >70 indicate severe fatigue. This study provides additional evidence for the universal applicability of the PROMIS fatigue item banks across populations differing with respect to demographic characteristics, it provides convincing evidence for its international applicability, it contributes to the interpretability of scores, and therewith provides evidence for the use of PROMIS as the international standard for measuring fatigue.
Supplemental Material
Supplemental Material - Towards standardization of fatigue measurement: Psychometric properties and reference values of the PROMIS Fatigue item bank in the Dutch general population
Supplemental Material for Towards standardization of fatigue measurement: Psychometric properties and reference values of the PROMIS Fatigue item bank in the Dutch general population by Caroline B Terwee, Ellen BM Elsman, and Leo D Roorda in Research Methods in Medicine & Health Sciences
Footnotes
Acknowledgment
We would like to thank Michiel Luijten for help with some of the statistical analyses.
Availability of data and material
The dataset is available upon request from the corresponding author.
Ethics approval
The Medical Ethical Committee of Amsterdam UMC, location VUmc, the Netherlands, confirmed that the study protocol was exempted from ethical approval according to the Dutch Medical Research in Human Subjects Act (WMO), as no experiments were conducted
Authors contributions
CB Terwee and LR Roorda designed the study and were responsible for the data collection. CB Terwee and EBM Elsman conducted the analyses. CB Terwee drafted the manuscript and all authors contributed to the writing and finally approved the manuscript.
Declaration of Conflicting Interests
CB Terwee is board member of the Dutch-Flemish PROMIS Organization. CB Terwee and LD Roorda are representatives of the Dutch-Flemish PROMIS National Center. EBM Elsman has nothing to declare.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article. The data collection for this project was financially supported by the Department of Epidemiology and Biostatistics of the VU University Medical Center, Amsterdam, the Netherlands.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.