
Abstract
Background
Meta-analysis of systematically reviewed studies on interventions is the cornerstone of evidence based medicine. In the following, we will introduce the common-beta beta-binomial (BB) model for meta-analysis with binary outcomes and elucidate its equivalence to panel count data models.
Methods
We present a variation of the standard “common-rho” BB (BBST model) for meta-analysis, namely a “common-beta” BB model. This model has an interesting connection to fixed-effect negative binomial regression models (FE-NegBin) for panel count data. Using this equivalence, it is possible to estimate an extension of the FE-NegBin with an additional multiplicative overdispersion term (RE-NegBin), while preserving a closed form likelihood. An advantage due to the connection to econometric models is, that the models can be easily implemented because “standard” statistical software for panel count data can be used. We illustrate the methods with two real-world example datasets. Furthermore, we show the results of a small-scale simulation study that compares the new models to the BBST. The input parameters of the simulation were informed by actually performed meta-analysis.
Results
In both example data sets, the NegBin, in particular the RE-NegBin showed a smaller effect and had narrower 95%-confidence intervals. In our simulation study, median bias was negligible for all methods, but the upper quartile for median bias suggested that BBST is most affected by positive bias. Regarding coverage probability, BBST and the RE-NegBin model outperformed the FE-NegBin model.
Conclusion
For meta-analyses with binary outcomes, the considered common-beta BB models may be valuable extensions to the family of BB models.
Background
Meta-analysis of systematically reviewed studies on interventions is the cornerstone of evidence based medicine. With respect to statistical analysis, random effect models are meanwhile the preferred approach for meta-analysis because their assumptions are more plausible than assuming a common, constant treatment effect across all studies as in the fixed-effect model. 1 In case of binary outcomes, usually inverse-variance weighting approaches to meta-analysis are used. Inverse variance models have the disadvantage that they ignore the estimation uncertainty from estimating the weights in the first stage. Since in case of binary outcomes each single study can be conceived as a cross-fold table, one-stage models, in essence logistic regression models for correlated data, can be used instead. In the last decade one-stage random effect models have received increasing attention (see for example Bakbergenuly and Kulinskaya, 2 Jackson et al., 3 Kuss, 4 and Stijnen 5 ) One important reason for this interest is that meta-analysis of a small number of studies, rare events or both are rather the rule than the exception in practice and most inverse-variance weighting random effects methods have shown limitations in such sparse data situations.6–9
The beta-binomial model (BB) is a random effects logistic regression model that can be applied for meta-analysis of binary outcomes and which has several advantages. First, it is a “true” random-effects model, which will never fall back to a fixed effect model. Second, it has a closed-form log-likelihood function. Third, it allows including studies with no events in one or even both treatment arms without the need for a continuity correction. Previous simulations studies of our group have shown small bias and good coverage of the BB models for meta-analysis of a small number of studies as well as meta-analysis including studies with zero events.4,6
In our previous papers on BB models for meta-analysis we used the standard version of the model, which assumes the same correlation for individual outcomes in treatment and control groups (“common-rho”). 10 However, other versions of BB models have been described in the literature, and Guimaraes showed that one version of the BB model (“common-beta”) is equivalent to a fixed-effect negative binomial regression model (FE-NegBin).11,12 This model is used mainly for the analysis of panel count data in econometrics.
In the following we will introduce the common-beta BB model for meta-analysis. We elucidate its equivalence to panel count data models and that the model can be easily extended to a model with an additional multiplicative random overdispersion parameter (RE-NegBin), while preserving the closed form likelihood. We illustrate this BB models by two examples. Finally, to assess the potential of the new models and thus their value to be further investigated, we present the results of a small simulation study to get initial insights in their statistical performance in comparison to the standard “common-rho” BB model (BBST).
Methods
Preliminaries
We are interested in the estimation of the overall treatment effect
Beta-binomial regression models
In general, for BB models we assume that we observe proportion of events yi/ni from binominal distributions Bin(πi, ni) for 2*I groups.
4
The πi are assumed to be beta distributed across groups with parameters α and β. The mean and variance of πi are then given by E(πi) = μ = α∕(α + β) and Var(πi) = μ (1 − μ)
Marginally, yi is beta-binominal distributed with mean E(yi) = niμ and variance Var(yi) = niμ (1−μ)(1+[ni−1]
The beta-binomial regression model links μ via a link function g(μ) to the covariates, here only the treatment effect (bT) by g(μi) = b0 + bTxi. For the logit, the log or the identity link, the resulting effect estimates are the log odds ratio, the log relative risk or the risk difference. In the following we consider the logit link, because only then the equivalence between the beta-binomial regression models and the NegBin regression models hold.
Common-rho beta-binomial model
In the model given above it is assumed that ρ = 1∕(α+β+1) is the same for all observations, 4 regardless whether the observations came from the control or the treatment group. This is the reason why the model is termed the “common-rho” model. In the I control groups, we have xi = 0, and we see that the parameters α and β, as given above, actually describe the (beta) distribution of the event probabilities in these groups. Modelling the treatment by bT implies a second beta distribution with parameters αT and βT in the I treatment groups, and by the common-rho assumption the four different beta distribution parameters are linked by (αC + βC) = (α + β) = (αT + βT). Fixing three of the beta distribution parameters gives the fourth, and so the number of parameters from the regression model equals the number of beta distribution parameters to be estimated. Essentially, because of g(μiC) = b0 and g(μiT) = b0 + bT, we can write bT = g(μiT) – g(μiC) = g(αT/(αT+βT)) – g(αC/(αC+βC)) = g(αT/(αC+βC)) – g(αC/(αC+βC)), and the treatment effect bT only depends on the three parameters αT, αC, and βC, regardless of the link function used.
The log-likelihood written as a function of α and β is given by Skellam,
14
where we additionally use α = g(μi)[1− ρ]/ρ and β = [1 − g(μi)] [1− ρ]/ρ
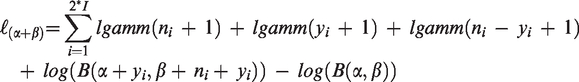
Common-beta model
Instead of assuming the two beta distributions in control and treatment groups to share the same correlation parameter ρ, we can assume that they share the same β, that is β = βT = βC. The three parameters to be estimated are then αT, αC, and β. Analogously to the “common-rho” model, we term this model the “common-beta” model. In the common-beta model the correlations (ρC, ρT) between individual observations in the control and the treatment groups would be different if αT and αC are different.
Unfortunately, this model can no longer be written as a regression model as above, but treatment effects must be estimated from αT, αC, and β by using μC = αC/(αC + β) and μT = αT/(αT + β). To be concrete, μT/μC describes the treatment effect as a relative risk, μT–μC as a risk difference, and μT(1–μC)/μC(1–μT) as an odds ratio. For the odds ratio, the log odds ratio can be conveniently estimated by αT/αC.
The log-likelihood of the model is
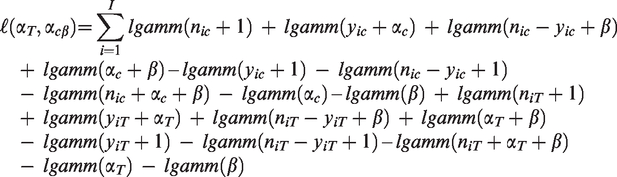
Connection between the common-beta beta-binomial model and the fixed-effect negative binomial regression model
In econometrics and the social sciences negative binomial regression models for panel count data models are often specified depending on the mean event rate per time unit.12,15 If we parametrize the model with λfailure = exp(c0) and λsuccess = exp(c0 + c1 + cT), where c0 is an intercept, c1 is a binary indicator for success, and cT is the interaction of c1 and the treatment group, then Guimaraes could show that the common-beta model can be interpreted as a fixed-effect negative binomial regression (FE-NegBin) model for panel count data. 12 To be concrete, if we set β = exp(c0), αT = exp(c0 + c1 + cT), and αC = exp(c0 + c1), then the likelihood of the common-beta model and that of a FE-NegBin coincide, premised the FE-NegBin is estimated by conditional maximum likelihood. 16
For the considered FE-NegBin the conditional log-likelihood function can be written as
17
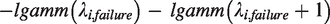
Setting λfailure = β and λsuccess = α in this log-likelihood function makes the equivalence between the models obvious (compare log-likelihood function in section “Common-beta model”). 12
The estimate of the interaction term of c1 and cT from the FE-NegBin model equals the log odds ratio from the common-beta model αT/αC. The main treatment effect is not included in the model, and the term to be conditioned on here is the number of total counts in the group. Consequently, and similar to the BBST, the FE-NegBin ignores the fact that each control group is connected to a treatment group from the same study.
The equivalence between the models makes it possible to use panel count data estimation procedures as usually used in econometrics for estimating the common-beta BB/FE-NegBin model. Noteworthy, in panel count data the term fixed effects does not refer to the distribution of the variables but means that for each group an individual intercept is estimated.
When using the COUNTREG procedure in SAS® to fit the common-beta BB/FE-NegBin model, the dataset has to be structured so that each cell from a 2-by-2-table of a single study constitutes a single observation. To be exact, there should be two columns with binary indicators for treatment and success and a column (here: y) that gives the number of events in the respective cell. In addition, we need a column to indicate the study group. The structure of these dataset is illustrated in box 1. Input dataset for two example studies to estimate a common-beta BB/FE-NegBin model in SAS® PROC COUNTREG.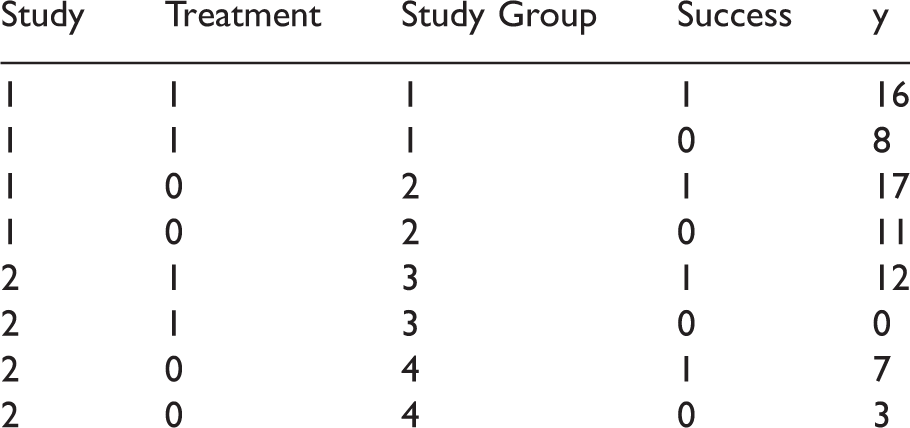
Box 2 contains an example SAS-code for re-structuring the dataset, and parameter estimation using PROC COUNTREG for the common-beta BB/FE-NegBin model for an example dataset (see below). Example SAS-code for the FE-NegBin.
Random-effects negative binomial regression
Using the equivalence of the common-beta and the FE-NegBin model allows for some further insights from econometrics, the field where NegBin models are frequently used. For example, it is straightforward to generalize the FE-NegBin to a random effects negative binomial regression (RE-NegBin) model, namely a random effects negative binomial model for panel count data. Random effect in this model does not mean that there is an additional random effect included in the linear predictor, but that for the multiplicative dispersion parameter ξ for the expected number of counts (intercept) a random distribution is assumed. In the FE-NegBin model, this dispersion parameter ξ is also part of the model but can take on any value. Explicitly modelling ξ in the RE-NegBin model accounts for some additional unexplained overdispersion. Hausman et al. showed that if ξ/(1+ ξ) follows a beta distribution, then the resulting likelihood function has still closed form. 16 It should be noted that this beta distribution for the additional overdispersion parameter has nothing to do with the initial beta distributions from the parallel common-beta model.
Example
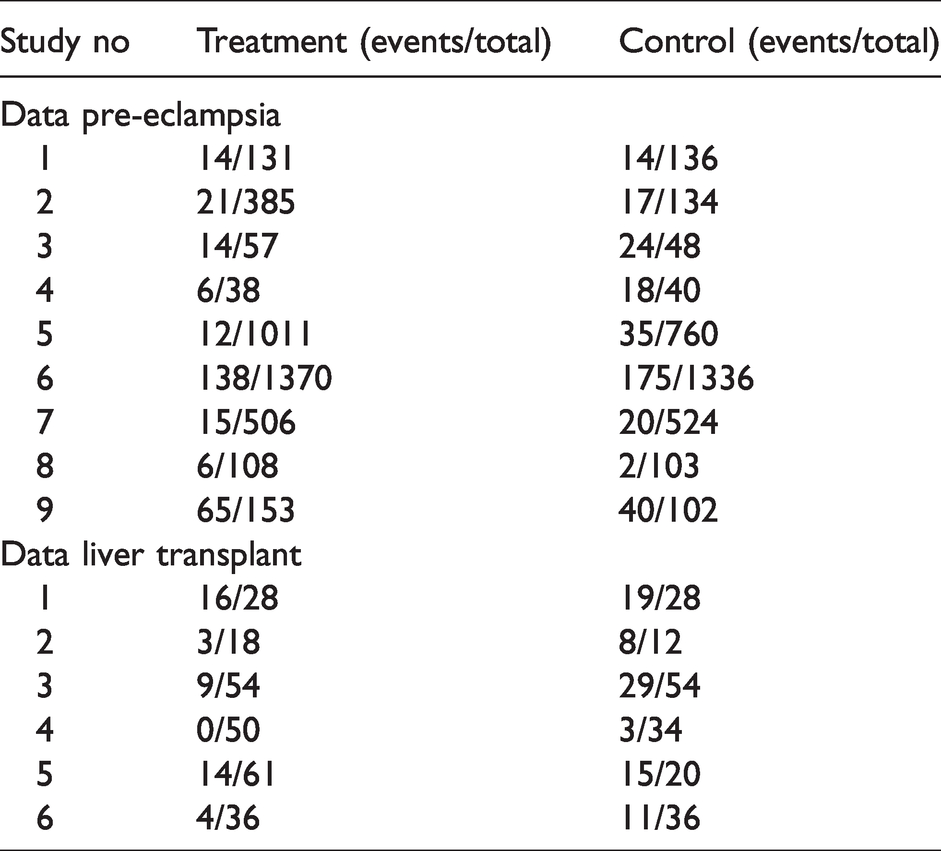
We illustrate the methods with two example datasets from actually performed meta-analysis. The first example is a meta-analysis of nine randomized controlled trials on diuretics for prevention of pre-eclampsia. 18 The second example is a meta-analysis of six observational studies assessing interleukin-2 receptor antagonists for paediatric liver transplant recipients to avoid acute rejection. 19 The example datasets are presented in Table 1.
Example datasets.
Simulation
To get initial insights in the performance of the models introduced here, we performed a small simulation study.
Design of simulation
We considered an “effect” scenario (H1) and a “no-effect” scenario (H0). All other parameters of the simulation were varied randomly and informed by actually performed meta-analyses to reflect realistic meta-analysis scenarios. The distribution of the number of studies was taken from a publication of Page et al., who analysed 119 non-Cochrane systematic reviews of randomized controlled trials and observational studies.7,8 For all other design factors we used the review of Turner et al., which analysed 1,991 systematic reviews from the Cochrane Database of Systematic Reviews. 8 The factors varied and the distributions from which the respective values were drawn are shown in Table 2.
Description of the simulation.

Q1: first quartile; Q3: third quartile.
We generated 10,000 meta-analyses for each scenario (H0 and H1).
Procedures for estimation
For estimation of the common-rho beta-binominal model we use SAS PROC NLMIXED and computed the starting values from raw proportions and their variances. For estimation of the common-beta common-beta/NegBin models we used SAS PROC COUNTREG.
Measures to assess performance of the methods
We used t-distributed confidence intervals (CIs) using I*2
We counted the number of converged runs to assess the numerical robustness. We estimated median bias with quartiles and the mean empirical coverage to the 95%-CIs to assess the performance of the models. 4 All results are reported on the log odds ratio scale.
Results
Example
The pooled results for all methods for the two examples are shown in Figures 1 and 2.
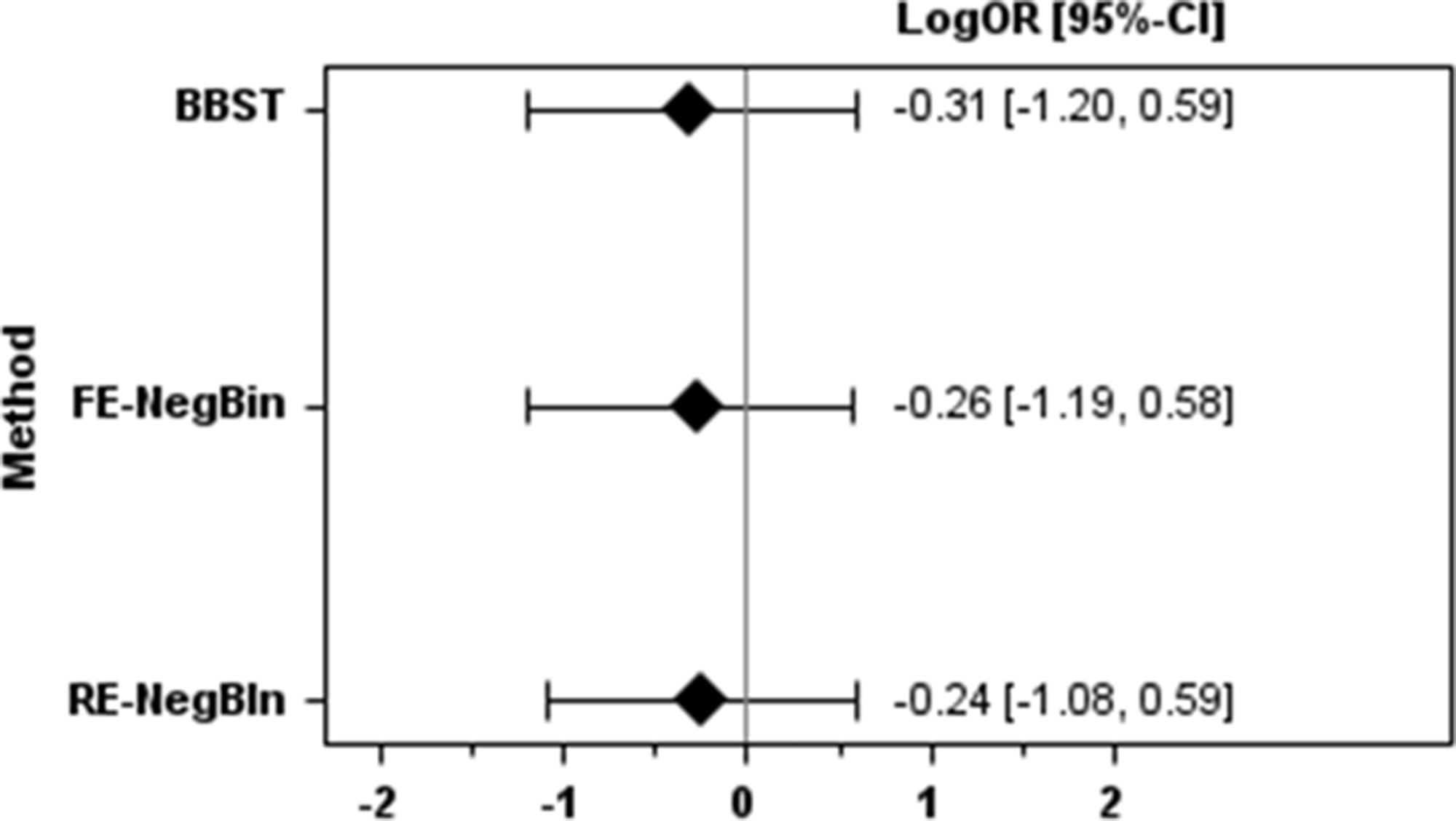
Results for the pre-eclampsia example.
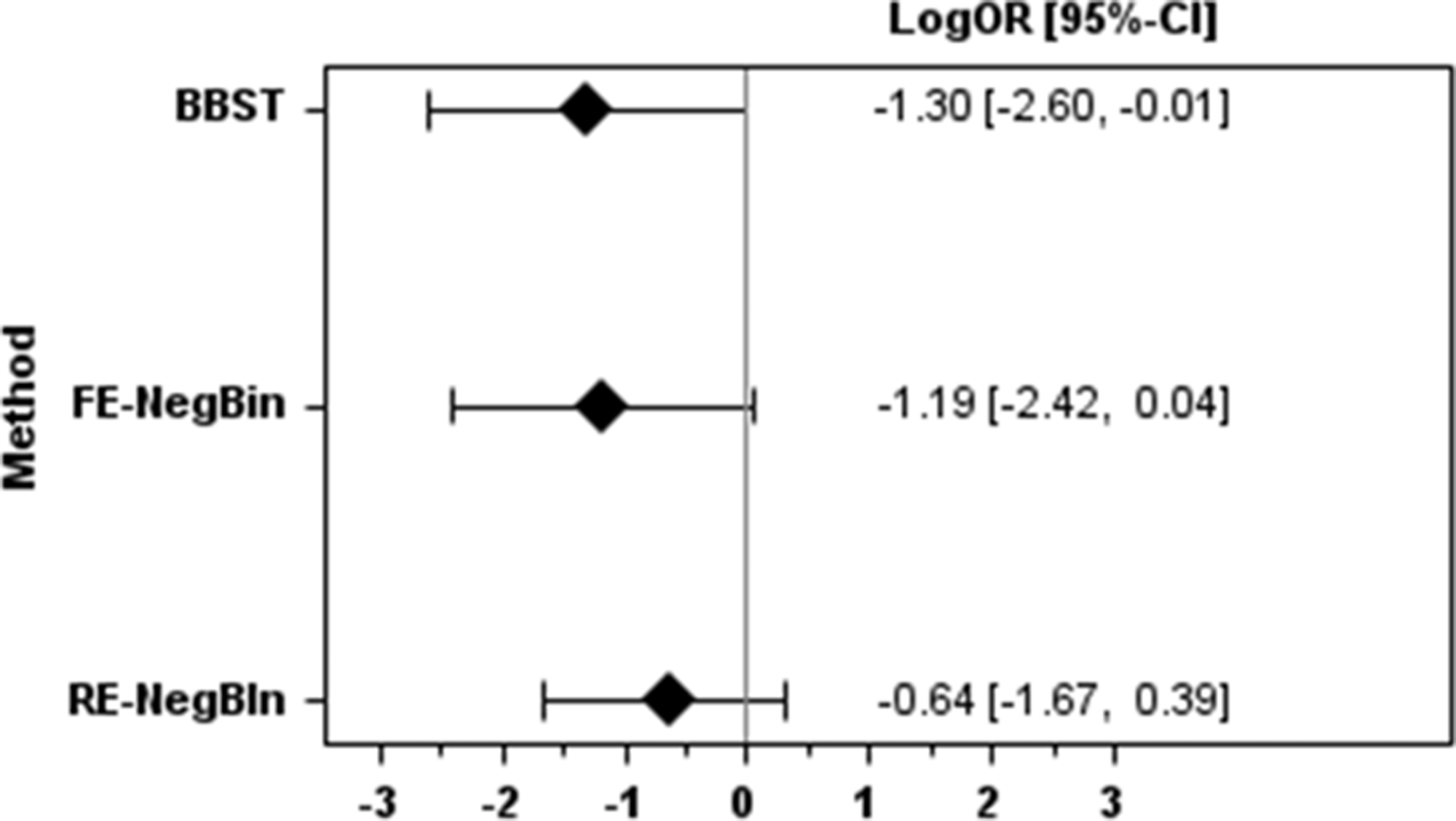
Results for the liver transplantation example.
Effect estimates were largest for the BBST, followed by FE-NegBin and RE-NegBin in both example datasets. The 95%CIs were narrowest for RE-NegBin for both examples. In the pre-eclampsia example all methods showed very similar results with regard to statistical significance. In the liver transplant example BBST reached statistical significance and FE-NegBin was nearly statistical significant. In contrast, the 95% CI of RE-NegBin clearly overlapped the no effect line.
Simulation
In Table 3 we present results for both simulation scenario. Figures 3 and 4 illustrate the performance in terms of bias and coverage for the “effect” scenario (H1).
Results for performance measures.
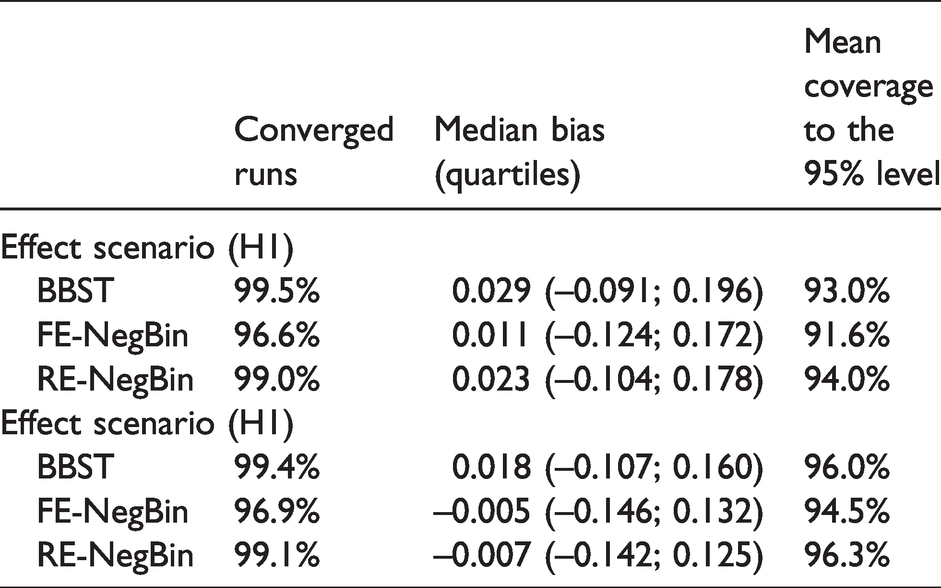
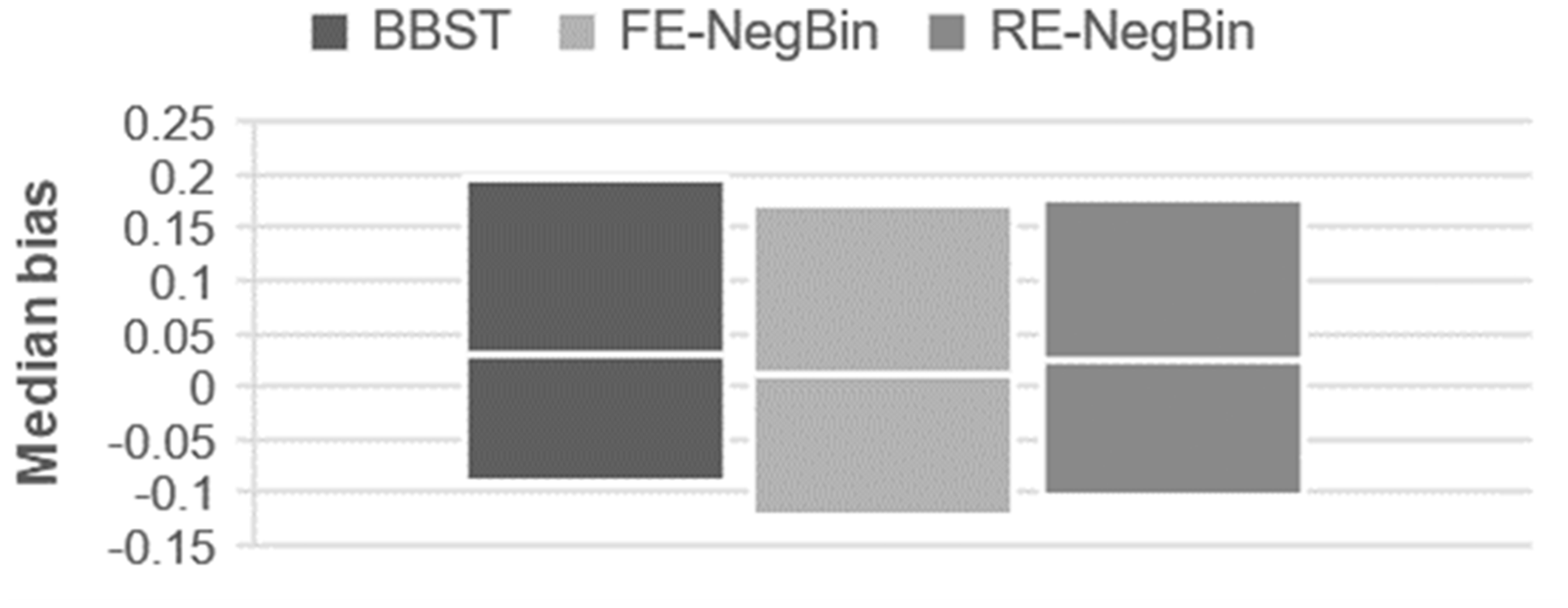
Median bias (with quartiles) in the “effect” scenario (H1).
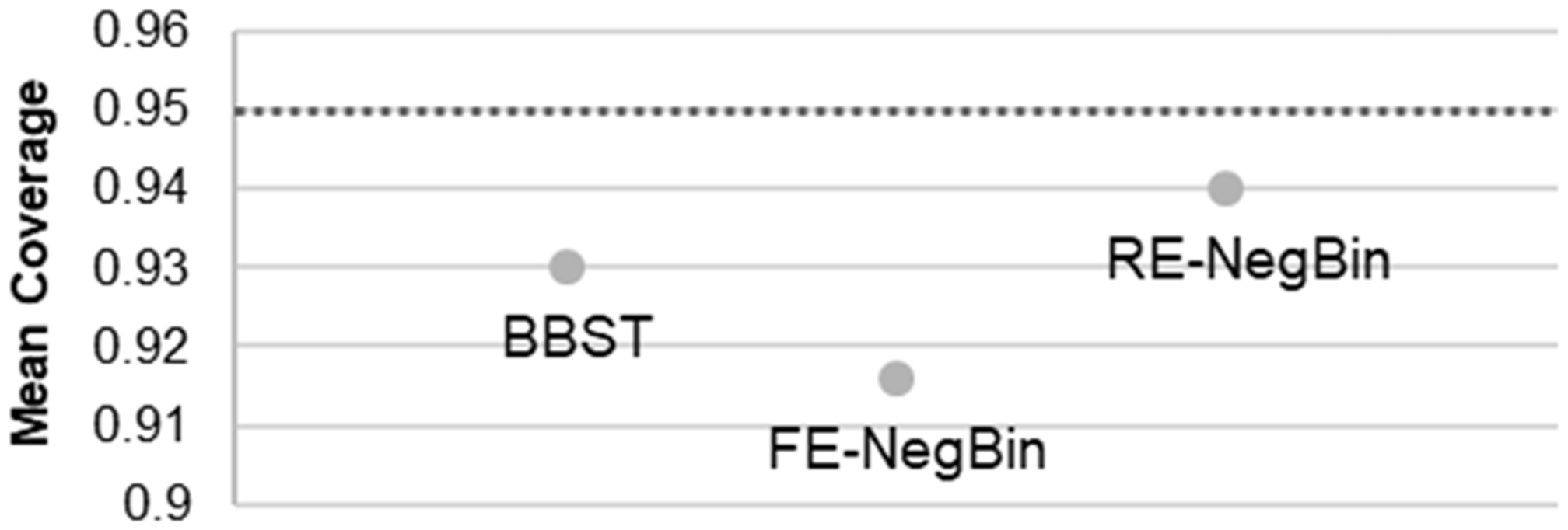
Mean empirical coverage to the 95% level in the “effect” scenario (H1).
With respect to numerical robustness, BBST and RE-NegBin converged in over 99% and FE-NegBin in about 97% of simulation runs.
Median bias was negligible for all methods in all scenarios. The upper quartile for bias suggested a marginally stronger bias for the BBST compared to the common-beta/NegBin models. Considering the lower quartile for bias the common-beta/NegBin models showed a slight tendency towards higher negative biases.
No method falls dramatically below the nominal coverage in any situation. Lowest empirical coverage overall was observed for the FE-NegBin in the “effect scenario” (0.92). The RE-NegBin performed best regarding empirical coverage, followed by BBST and FE-NegBin.
Discussion
In this paper we introduce the “common-beta” beta-binomial regression model for meta-analysis of binary outcomes and a new estimation approach by perceiving this common-beta model as a fixed-effect negative binomial (FE-NegBin) regression for panel count data. Generalizing the FE-NegBin to a random-effect negative binomial (RE-NegBin) allows for modelling an additional overdispersion parameter, while retaining a closed log-likelihood function. We illustrated the methods with two examples and a small-scale simulation study mirroring real-world non-Cochrane meta-analyses.
In our simulation study none of the methods had serious problems with parameter estimation, with the FE-NegBin model being a slight exception, probably because one fixed-effect must be estimated for each group.
Median bias was negligible for all methods. The upper quartile in the simulation and the examples suggest that BBST is most affected by positive bias (estimated treatment effects being larger than expected). This positive bias occurs in cases where the event probability is high and the heterogeneity between groups strongly differs. 20
Regarding coverage probability, BBST and the RE-NegBin model outperformed the FE-NegBin model. The reason could be that in the BBST the variance is implicitly bounded by the common-rho assumption. Likewise, the multiplicative beta-distributed random parameter in the RE-NegBin bounds the dispersion of the model by the additional dispersion parameter (variance divided by mean) to be random. Both assumptions mitigate large variance differences between groups and thus the risk for an underestimation of the variance (in one group).
An advantage of the common-beta models introduced in this paper is that its application can be facilitated by using estimation routines for panel count data models (e.g. SAS PROC COUNTREG, Stata xtnbreg, R MASS-Package). This approach requires no extensive programing, only the dataset has to be rearranged. It is of course a limitation that using panel count data estimation methods only allows for odds ratios to be estimated. Noticeable, using a general-purpose procedure that allows coding the likelihood function by hand (e.g. SAS NLMIXED), it is also possible to implement other link functions and hence calculating risk differences or relative risks.
The presented panel count data approach for estimating the NegBin models opens the door for using any other panel count data model (e.g. poison regression) for meta-analysis. The equivalence between the common-beta and the FE-NegBin model is only given when the latter model is estimated by conditional maximum likelihood and when the conditioning is with respect to the single group. However, estimating FE-NegBin, and likewise RE-NegBin models is also possible when using other conditioning units. For example, using the respective study (and not the single study group) as the conditioning unit would estimate a model that avoids the separation of treatment and control group from the same study, an inherent feature of the “common-rho” as well as of the “common-beta” model. This approach would overcome “breaking of randomisation”. Exploring extensions of the BB/NegBin models for panel count data which respect randomisation appears promising for future work.
Our simulation study was only designed to get initial insights into the statistical properties of the newly introduced models for meta-analysis to assess their general potential. Thus, a limitation of our study is that we cannot draw any definitive conclusion regarding the comparative performance of different meta-analytic methods or regarding the performance in specific situations (e.g. rare events). Future studies are necessary that examine the statistical properties of the NegBin models considered here in comparison to other methods for meta-analysis such as the Hartung-Knapp method or generalized linear mixed models. As the BBST proved to perform well for meta-analysis of a small number of studies or rare events, it would be in particular interesting to assess whether the models perform similar well or even better in such situations with sparse data.
Conclusion
The introduced Common-Beta/NegBin models appear valuable extensions to the family of BB models and potential candidates to be included in the meta-analysis toolbox. The feature that they can be quite easily implemented using standard statistical software make them especially appealing. However, before use in practice, future studies are necessary that assess their statistical properties in more depth and in comparison to other meta-analyses methods.
Footnotes
Authors’ contributions
TM: development of methods, writing of simulation and analysis program, conducting analyses, interpretation of data, writing of manuscript.
OK: development of methods, writing of simulation and analysis program, interpretation of data, writing of manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.