
Abstract
Improving the generalizability of psychology findings to a culture requires sampling participants in that culture. Yet psychology studies rarely sample from Africa even though Africa represents 17% of the global population. Although Africans can leverage the credibility-revolution initiatives to increase rigor and global representation, capacity building might speed the spread of these initiatives. In this study, we investigated an African-wide replication study to test whether Rottman and Young’s “mere-trace” hypothesis of moral reasoning (that people are more sensitive to the dosage of harm-based transgressions than purity transgressions) extends to several African communities. We used a training method developed by the Collaborative Replication and Education Project to train 23 African collaborators. During this process, we conducted a paradigmatic replication of Rottman and Young’s test of the mere-trace hypothesis in 12 contributing African sites from Burkina Faso, Kenya, Morocco, Nigeria, and Tanzania that sampled 783 participants after exclusions. Consistent with the original claim using U.S. samples, our African participants judged severe harm transgressions as more wrong than less severe ones but were not as sensitive to severity for purity transgressions (Domain × Dose: b = −4.63; p < .01). Moreover, the effect of dosage was smaller than reported among the U.S. sample, and our African participants rated all transgression scenarios more wrong than the U.S. sample. Resource constraints limited our sample to five African countries and to Africans dwelling in urban communities. Moral psychology should transcend the moral issues prioritized in the original study to include those considered important in African societies.
Keywords
In recent years, psychological scientists have successfully pushed for greater rigor throughout the research life cycle, especially better replicability (Munafò et al., 2017). Although scholars have had some success improving replicability (Protzko et al., 2020), progress toward better generalizability has lagged. In a recent audit of top psychology journals, fully 82% of both the first authors and research samples were from North America and Europe (Thalmayer et al., 2021) even though these world regions comprise 17% of the global population (Ritchie et al., 2023). This means that researchers cannot know whether the theories generated from North America and Europe apply outside of these world regions. This is especially true for Africa; despite comprising 18% of the global population, Africa contributed fewer than 1% of first authors and research samples in the above audit (Thalmayer et al., 2021).
One potential reason for the lack of African researchers and participants is that psychology research is “nascent” in most African countries (Nsamenang, 2007), a state of affairs that reflects a continent starved of the resources to compete with its contemporaries (United Nations Educational, Scientific and Cultural Organization [UNESCO], 2021). This nascent status means that there is limited capacity to conduct psychology research in Africa (Adetula et al., 2026). A first step to address this challenge is to conduct research in which the methods are well developed, as is the case of replication studies, while involving researchers from the target populations. In the present project, we conducted a paradigmatic replication (Vohs et al., 2021) of studies of purity- and harm-based moral judgments from Rottman and Young (2019) in five African countries. We used a training model developed by the Collaborative Replications and Education Project (CREP), a platform that emphasizes “big team” replication studies to teach cutting-edge research practices (Wagge, Baciu, et al., 2019; Wagge, Brandt, et al., 2019), to test the generalizability to Africans on a set of findings (Rottman & Young, 2019) on moral reasoning about harm and purity transgressions.
The CREP Model
In this project, we used a model developed by the CREP. We chose the CREP model because it is a highly structured model for training in cutting-edge research methods and gives users many opportunities to provide feedback to improve the model. The latter is particularly useful when deployed in new environments. The CREP model was originally developed for new trainees with little to no prior research experience in scientific psychology (see Wagge, Brandt, et al., 2019).
The trainees organize their project and its materials via a page on the OSF. In the first stage of organizing their project, trainees create a copy of the general CREP project by “forking” it. The trainees organize their study materials by filling out each component in the forked project. This includes the full study materials, including any surveys, protocols, and pictures of the materials; a videotape of an experimenter completing the procedure; ethics approval; and a written preregistration. The project is then reviewed for accuracy by an instructor, who submits the page to the CREP board. The CREP board conducts a second set of reviews and gives the trainees feedback about the structure and accuracy of the OSF page.
After the pre-data-collection review process is complete, the trainees preregister the study by creating a frozen copy of the complete OSF project and then proceed to data collection. Under the traditional CREP model, each trainee recruits at least 100 participants, whose responses are stored in a data set that the trainees themselves manage. Trainees document their data set with a codebook and create their own data-analysis script. These materials are uploaded to their project pages, which are submitted to the CREP board for another round of review. Once the post-data-collection reviews are complete, the trainees receive a certificate of completion from the CREP board. The full CREP project consists of a meta-analytic synthesis of the results reported by each trainee.
We adapted this model to help build research capacity among our collaborating researchers. Instead of meta-analyzing the effect sizes, we decided to manage a single data set centrally to allow for the use of linear mixed-effects models on the central data set in an effort minimize errors in the merging of the data set and in the analysis pipeline. To gain the benefits of the CREP training, our collaborators completed the other elements of the CREP procedure. We provided materials—such as methods, instruments, or training materials—needed for the present study. To ensure the studies were feasible, we decided that researchers could participate if they had basic infrastructure and required resources, such as access to a lab and research facilities, space for in-person survey, reliable internet service, and internet-connecting devices.
Preparatory Work
For each site, there was at least one coordinating researcher who was responsible for coordinating all local research activities, including providing study documentation, translating and adapting instruments, and collecting data (for an overview of sites, see Supplementary Table 2S at https://osf.io/p3yq7). Because most of our collaborators were not yet familiar with the CREP model, we first trained 15 of our participating collaborators in open science and the CREP model using a series of four CREP training videos subtitled in six African languages that described from start to finish how to conduct a CREP project. To ensure that researchers who joined later had access to this training, we made the training materials and reports of the training available at https://osf.io/b2pz6/ and https://osf.io/8akz5/. Then, we assessed whether interested sites had the necessary facilities and resources to be able to successfully conduct a CREP study locally. The assessment report is available at https://osf.io/gds7b/.
To select which studies to replicate, we engaged in a three-stage study-selection procedure. In the first stage, we nominated 26 articles published in Psychological Science between 2015 and 2020 using the following set criteria: sampled no or few Africans, were preregistered, reported a p value of < .01, and we considered moderately feasible, applicable, relevant, and ethically acceptable in Africa. In the second stage, we shortlisted three out of eight top-ranked articles we considered to meet these criteria. In the third stage, 18 African researchers assessed the studies reported in these articles for feasibility, adaptability, applicability, interest, and relevance in their local context. Finally, they were asked to pick preferred studies to replicate. Based on their responses, we selected Studies 2 and 3 of Rottman and Young’s (2019) article “Specks of Dirt and Tons of Pain: Dosage Distinguishes Impurity From Harm.” The study-selection materials and the study-assessment report are available at https://osf.io/vwxu3/.
Main Study: Paradigmatic Replication of Rottman and Young
In their research, Rottman and Young (2019) investigated whether people’s moral judgments about purity violations are less sensitive to increases in frequency and severity than moral judgments about harm. Harm violation can be described as a physical/bodily harmful infraction directed toward a target (e.g., stoning a puppy or poking oneself with a needle), and purity violations involve someone acting or engaging in impure, nonphysical/nonbodily harmful acts (e.g., throwing feces at a dog or licking one’s blood; see Horberg et al., 2009; Rozin et al., 1999).
Rottman and Young (2019) proposed the “mere-trace hypothesis” such that moral evaluation of purity-based and harm-based violations differ in their dependence on the severity of the violation. According to this mere-trace hypothesis, the moral wrongness of impure acts (e.g., incest; see Chakroff et al., 2013; Haidt, 2007) should not matter; if they occur, they are judged as wrong regardless of whether the “dosage” of the violation was low (a less severe violation) or high (a more severe violation). In contrast, the moral wrongness of acts that are harmful rather than impure should be more sensitive to dosage. Harmful acts (e.g., assault) should be judged as more wrong if they have a higher dosage (i.e., if the violation is more severe). In Rottman and Young’s Study 2, they presented participants with eight harm-based violations and eight purity-based violations. Each violation had a “low dose” version (i.e., the violation was either infrequent or mild; “A person throws a small rock at a farm animal”) and a “high dose” version (i.e., the violation was either more frequent or severe; “A person throws a large rock at a farm animal”). Study 3 used 16 new violations, eight harm-based and eight purity-based, each of which once again had low-dose and high-dose versions. In each study, participants judged how wrong, harmful, and impure each violation was using a slider scale from 0 to 100. Across the two studies, participants judged purity-based violations to be similarly wrong regardless of dosage. However, they judged high-dose harm-based violations to be more wrong than low-dose harm-based violations.
We were able to reproduce Rottman and Young’s (2019) findings using their data set and analysis scripts available at https://osf.io/zxp9k/. However, after reviewing Rottman and Young’s statistical models, we believe that they are implausible assumptions that produce inflated nominal rates of false positives (Judd et al., 2012) by omitting by-person random slopes for domain, dose, and their interaction and by-item random slopes for dose. We therefore reanalyzed the data and accounted for random slopes. This reanalysis showed that the p values of the focal domain by dose interaction were larger than reported in the original studies. In the case of Study 3, the focal p value was no longer significant. Because the effect in one of the studies was no longer robust compared with what we regarded as a more accurate statistical model, we therefore examined the robustness of the evidence across all studies. After extracting each coefficient in a random-slopes model and synthesizing it using random-effects meta-analysis, we obtained a meta-analytic estimate of −7.7, 95% confidence interval [CI] = [−11.9, −3.5]. 1 This suggests that although the evidence within studies is not as robust as originally reported, the evidence across studies is robust. The full report of the reanalysis and meta-analysis is available at https://osf.io/e9uwp/.
Our reanalysis revealed that the original design of Rottman and Young (2019) underestimates the amount of by-item variability. In the presence of by-item variability, the number of items places a hard upper limit on the statistical power a study can achieve (Westfall et al., 2014). We therefore shifted to a “paradigmatic replication” approach involving modifying an original (to-be-replicated) study’s method, design, or materials and potentially correcting flaws in the method, design, or materials so that the new study is diagnostic of the original study’s claims as a best-faith-effort interpretation of the original studies (see Vohs et al., 2021). Instead of a close replication of Rottman and Young’s Study 2 or Study 3, which involves faithfully following the original study procedure and method as closely as possible (see Brandt et al., 2014; Schmidt, 2009), we created a new design with additional stimuli to increase statistical power. This modified design combines the items from both Study 2 and Study 3 for a total of 32 items (16 harm-based violations, 16 purity-based violatoins). In addition, instead of using the same statistical model as Rottman and Young, we used one that includes random slopes for by-participants for domain, dose, and their interaction; by-item for dose; and by-site for domain, dose, and their interaction, which is not a factor in Rottman and Young’s design.
Even if Rottman and Young’s (2019) findings could be robust and replicable among U.S. samples, the findings may not generalize to other countries. To date, only a few studies on purity-based violations have been conducted in Africa. Stankov and Lee (2016) provided a notable exception in their study of social attitudes and values across 33 countries, including participants from Egypt, Ethiopia, Kenya, Morocco, and Tanzania. They conducted exploratory and confirmatory factor analyses of 20 social-attitudes and values measures. They found that factors of morality, religiosity, and nastiness cut across these countries’ cultures.
The psychological literature on moral theorizing rarely provides insight into African morality, including how Africans think about harm and purity (see also Wareham, 2017). The extent to which moral norms, in relation to harm and purity, are universal or particular is thus mostly unknown. Hence, we are agnostic about studying how and whether Rottman and Young’s (2019) effects apply to the African populations we study. The main goal, therefore, is to explore moral concerns in a variety of African populations. In the current study, we collaborated with African researchers to test the generalizability of Rottman and Young’s findings in African populations. We used the CREP model to ensure that the research we conducted is of comparable quality across sites.
Method
Power analysis
We conducted a simulated-based power analysis using the simr package (Green & MacLeod, 2016) to determine the sample size required to test the effect at 90% power. We assumed a moderate level of variance of 25 in the by-site random intercepts and slopes and that each site would recruit 100 participants in line with the CREP requirement. Only when we combined the Study 2 and Study 3 items to increase the number of items to 32 for a simulation did we detect 90% power to test the focal dosage by domain interaction if we were to run the study at 10 sites (see full power-analysis report at https://osf.io/bjhv6/). Moreover, we overrecruited by 15% to allow for exclusion. Therefore, we decided to recruit at least 10 sites, each of which would recruit at least 115 participants, for a minimum of 1,150 participants.
Participants
We recruited a total of 1,320 participants from 12 sites in five African countries (Burkina Faso, Kenya, Morocco, Nigeria, and Tanzania) for the study. 2 In the Rottman and Young (2019) studies, participants were recruited via MTurk. However, because some of our participants did not have access to stable internet or devices such as smartphones or computers, sites were allowed to decide their own participant-recruitment approach. In one approach, sites recruited participants via online social media platforms (e.g., Whatsapp, Facebook, X [formerly Twitter]) by soliciting participation and sharing the Qualtrics survey link with potential participants to take the survey. In another approach, coordinators set up a workroom and device(s) connected to the internet, where participants without access or devices to connect to the internet could take the survey online. We did not compensate participants for their participation.
Materials
We combined all 32 items from Rottman and Young’s (2019) Study 2 (16 items) and Study 3 (16 items); see Table 1. Half the items present harm-based violations, and the other half present purity-based violations. An “item” consists of a single violation with a low-dose and a high-dose version.
A Set of 32 Scenarios for Harm and Purity Violations

Note: Each set has low and high versions of the violations, which are shown in brackets.
Translation and cultural adaptation of materials
Given that many African countries have a wide variety of languages, we identified the languages that were the lingua franca and/or one widely spoken language where sites were located for adaptations and translations (for a list of targeted languages, see Supplementary Table 3S, https://osf.io/p3yq7). We translated the study materials into Arabic, Chichewa, French, Portuguese, and Swahili. The translations are available at https://osf.io/wa7ed/.
We adapted our translation and adaptation procedure from the Psychological Science Accelerator’s COVID-Rapid Project translation process (Buchanan et al., 2023). We conducted translation and cultural adaptation simultaneously. This ensured that translators kept the original meaning as closely as possible but that the wordings and terminologies also made sense to the different participants. In the first stage, we had two separate forward-translation versions. Two translators created materials in the target language based on the English materials, including the scenarios, scale anchors, and instructions, sticking to the original meaning as closely as possible. For cultural-adaptation purposes, U.S.-typical names (e.g., Marie, Chris) were replaced with African-typical ones (e.g., Laila, Hassan); terminologies (e.g., genome, mercury, graffiti) were replaced with familiar wordings, phrases, or descriptions; and U.S.-based units of measure (e.g., ounce, quarter-pound) were replaced with units of measure relevant to the target country. In the second stage, a language-wise reconciler reviewed the two versions for cultural appropriateness and produced a final version. Discrepancies between translators were resolved through discussion. In the last stage, a reviewer proofread the final version and compared the adjudicated version with the source text to ensure that (a) the translation was as close as possible to the original meaning, (b) the words and descriptions were culturally appropriate and adapted to the local context, and (c) translated text captured the theoretical variables present in the original version and (d) flagged necessary corrections for the reconciler.
Procedure
Participants signed up for the study online via the recruitment approach determined by that site. Once they started the study, they were presented with one violation at a time and asked to rate how wrong, harmful, and impure it was using a slider that ranged from 0 (not at all) to 100 (extremely). Each violation was created by choosing either the low- or high-dose version of a particular item. Participants thus provided 64 sets of ratings of each item on wrongness, harmfulness, and impurity.
As in Rottman and Young’s (2019) Study 2, the low-dose and high-dose versions of each item were separated into two blocks of 32 sets of ratings. Thus, although each block contained a mixture of low-dose and high-dose violations, a participant did not see the low-dose and high-dose versions of a particular item in the same block. The order of presentation of the two blocks was counterbalanced across participants, and the blocks were separated by a “pen-pal task” in which the participant typed a brief transcription of a handwritten letter to someone’s pen pal. As in the original studies, we included two attention checks, one in each block, that served as the basis for our exclusion criteria. Like the original study, we planned to exclude participants who evaluate the moral wrongness of “A person destroys the entire planet” at below 50 or “A person gives money to a charitable organization” at above 50 on a slider scale from 0 (not at all) to 100 (extremely). In addition, we excluded no-consent entries and participants who spent too little time completing the survey, that is, participants who spent less than one-third of the median time spent completing the survey. To deal with missing data, we used case-wise exclusion. This omits any rows that contain missing data for a particular analysis. At the site level, 12 contributing sites aimed to collect data from a minimum of 115 participants, which is 15% above the CREP-recommended 100 to allow for data exclusions. Sites stopped collecting data after the 115th participant. We planned to collect data in a 6-week time frame, from May 12 to June 30, 2023.
After 6 weeks of data collection, only two of the 12 contributing labs that completed the CREP procedure collected data from 115 participants. We allowed an additional 15 weeks and ended the data collection on November 24, 2023, after which only five out of the 12 contributing labs had gathered at least 115 participants. We did not meet the sample target of a minimum of 10 sites to recruit at least 115 participants each. However, we decided to include data from all sites in the analysis that completed the CREP procedure even if they collected data from fewer than 115 participants (for the sample size per site and country, see Table 3).
For exploratory reasons, we included six questions from Rottman and Young’s (2019) 10 total exploratory questions: (a) “To what extent do you feel that you have close relationships?”; (b) “To what extent do you feel that you are a member of a larger community?”; (c) “How religious are you?”; (d) “I attend a religious service on a regular basis”; (e) “I participate in community service on a regular basis”; and (f) “Have you taken a study on moral judgment before?” All questions are assessed using a slider from 0 to 100 except the last, which had “yes” and “no” responses. We did not include Rottman and Young’s exploratory questions on “political involvement” and “following daily happenings” because they are not applicable in some African contexts and/or there is no appropriate cultural equivalent or interpretation of these concepts. We did include three open-ended questions that were comparable with these, with modifications to make them more relevant to African settings: (g) “Which religion do you belong to?”; (h) “Are the moral issues we asked about amongst the more important ones for your moral context? If not, which issues are?”; and (i) “Do you have any other comments you would like to share?”
To confirm that these exploratory questions are appropriate in African contexts, during the translation process, we asked translators whether the question makes sense in their cultural context. We did not remove any questions. However, because the translators considered them inappropriate in their cultural contexts, we modified (a) “A person [occasionally/regularly] holds meetings in a room with high asbestos levels” to “A person [occasionally/regularly] holds meetings in a very polluted room” and (b) “Liz puts [a gram of/a quarter-pound of] feces into an urn of her grandmother’s ashes” to “Liz puts [a gram of/a quarter-pound of] feces in grandmother’s grave” for all the sites; (c) “A person draws graffiti on [two/50] churches” for Burkina Faso (“graffiti” changed to “des dessins inappropriés” in French), in one Nigerian site (“graffiti” changed to “junk images”), and Morocco (“churches” changed to “mosques”); (d) “Mary secretly puts [a gram of/a quarter-pound of] hot sauce into a restaurant’s ketchup bottle” for Burkina Faso (“restaurant’s ketchup bottle” changed to “l’huile de table d’un restaurant” in French) and in one Nigerian site (“restaurant’s ketchup bottle” changed to “restaurant’s tomatoes sauce bottle”); (e) “Joe whispers vulgar obscenities into a priest’s ear for [an instant/a minute]” for Morocco (“priest” changed to “Sheikh”); and (f) “Adam catches [a single ladybug/10 ladybugs] and poisons [it/them]” for Kenya, Nigeria, and Burkina Faso (“ladybug” changed to “butterfly”).
At the end of the sets of ratings, participants reported the following demographic information: sex, age, country, country-state, and level of education. The questionnaire is available at https://osf.io/98j27. A preregistration for this study is archived at https://osf.io/qhc38. Although we report deviations from the preregistered plan throughout this article, we also adopted the Willroth and Atherton (2024) preregistration-deviation guide to provide a comprehensive report of these deviations (see Supplementary Table 6S at https://osf.io/p3yq7). The study ethics approvals are available at https://osf.io/tjg9w.
Results
Analysis plan
We analyzed our data using linear mixed-effects models in the lme4 package (Version 1.1; Bates et al., 2015) and obtained p values (with an α level set to .05) using Satterthwaite’s degrees of freedom obtained via the lmerTest package (Version 3.1-3; Kuznetsova et al., 2017) in R (Version 4.1.1; R Core Team, 2021). These models include wrongness judgments as a dependent variable with fixed effects for domain, dosage, and the interaction between domain and dosage. We used the maximal random-effects structure justified by the design (Barr et al., 2013). Our random effects, therefore, included at the by-participant level, random intercepts and random slopes for domain, dosage, and their interaction; at the by-item level, random intercepts and random slopes for dosage; and at the by-site level, random intercepts and random slopes for domain, dosage, and their interaction. In lme4 syntax, this model is fit as follows:
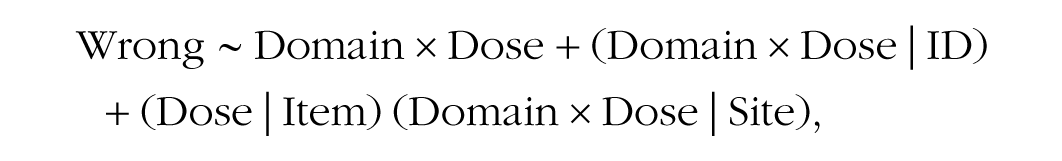
where wrong represents wrongness judgments, domain is an indicator variable for domain coded harm = −.5 and purity = .5, dose is an indicator variable for dosage coded low dose = −.5 and high dose = .5, and ID, item, and site are identifiers for specific participants, items, and sites, respectively. This model yielded the following fixed-effects estimates: bintercept, bdomain, bdose, bdomain × dose; t values: tintercept, tdomain, tdose, tdomain × dose; and their p values. It also yielded the following estimates of the standard deviation of the random intercepts: SD(bintercept)ID, SD(bintercept)Item, SD(bintercept)Site; estimates of the standard deviation of the random slopes: SD(bDomain)ID, SD(bDose)ID, SD(bDomain × Dose)ID, SD(bDose)Item, SD(bDomain)Site, SD(bDose)Site, SD(bDomain × Dose)Site; and 13 correlations between random intercepts and slopes (not labeled).
To ensure convergence, we checked which optimizers yielded convergence using lme4::allFit. To establish if our results replicated Rottman and Young (2019), we computed a profile likelihood 95% CI for the focal interaction coefficient bdomain × dose. We then compared the lower and upper bounds of this CI with 0 and based our interpretation on these comparisons. For our planned interpretations based on where the upper and lower bounds of the CI fall, see Table 2.
Domain by Dose Coefficient Replication Interpretation
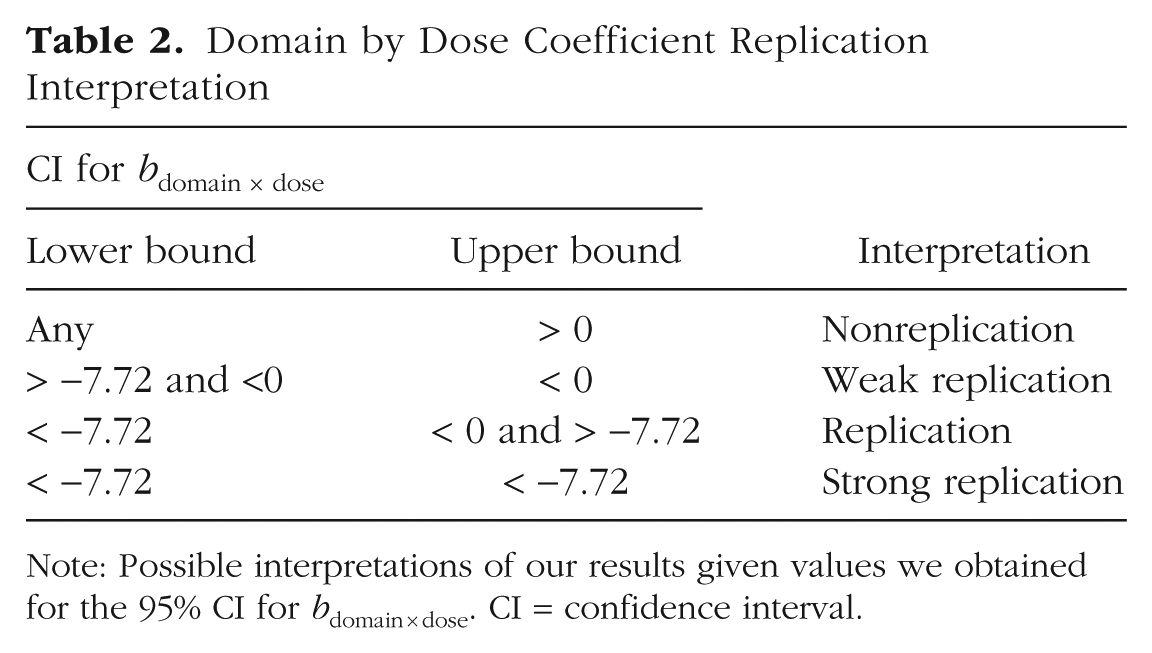
Note: Possible interpretations of our results given values we obtained for the 95% CI for bdomain × dose. CI = confidence interval.
As manipulation checks, we assessed whether participants rated low-dose scenarios as less harmful than high-dose scenarios and purity transgressions as less impure than harm transgressions using the same linear mixed-effects model as the main analysis. As exploratory analyses, we examined the size of the by-participant, by-item, and by-site random effects. The analysis script is archived at https://osf.io/hyavf. 3
Sample and sample demographics
The data set was made up of samples from five African countries (Burkina Faso, Kenya, Morocco, Nigeria, and Tanzania; see Table 3), with N = 1,320 (female = 769, male = 510, other = 2, prefer not to answer = 12, unreported = 27; age: M = 27.85 years, SD = 9.42; average N per site = 110).
Number of Participants per Site, Their Gender Distributions, and Their Average Age

First, we excluded 80 (6.1%) out of the 1,320 participants who spent one-third (≈10 min) of the medium time (≈30 min) participants spent to complete the survey. Next, we excluded 457 (36.9%) out of the remaining 1,240 participants who failed either of the two attention checks as planned. Participants were expected to rate “A person destroys the entire planet” below 50 and “A person gives to a charitable organization” above 50 on a slider scale ranging from 0 (not wrong at all) to 100 (extremely wrong). 4 When we applied only the charity attention check, 243 (19.6%) participants failed. However, only 71 (5.7%) participants failed the planet attention check. Sixteen (1.3%) failed both tasks, and 127 (10.2%) did not answer the attention-check questions. Our final sample comprised 783 participants (female = 487, male = 278, other = 1, prefer not to answer = 6, unreported = 11; age: M = 28.52 years, SD = 9.86), which fell short of the predetermined goal of recruiting a minimum of 100 participants from at least 10 sites. Nevertheless, we decided to use this sample for the confirmatory main analyses because even when we ran the tests without excluding the participants who failed the attention checks (N = 1,240), the results were consistent 5 (see Supplementary Table 4S and Fig. 1S at https://osf.io/p3yq7).
Domain categorizations and domain and dose analyses: manipulation checks
To establish whether the violation acts/scenarios presented in the measure were appropriately classified as harmful or impure, we used the same linear mixed-effects model as in our main analysis to compare participants’ ratings of “how harmful a violation is” and “how impure a violation is.” Participants rated harm transgressions to be marginally more harmful (harm: M = 80.18, SD = 27.81) than purity transgressions (purity: M = 78.66, SD = 31.49; b[domain]Harmful = −1.55; t[8.9] = −2.09, p = .065, 95% CI = [−3.09, −0.05]; d = −0.05). In addition, they rated purity transgressions to be more impure (purity: M = 84.46, SD = 26.77) than harm transgressions (harm: M = 76.06, SD = 30.87; b[domain]Impure = 8.37; t[10.9] = 10.11, p < .05, 95% CI = [6.66, 10.04]; d = 0.29). This suggests that these violations were rightly categorized. However, because the mean difference of rated harm between the harm and purity violations was marginal and not statistically significant, we concluded that domain manipulation worked. However, the patterns we observed are different from what was reported in the original study. Our African participants judge the purity transgressions pretty harshly across the variable measures of harm, purity, or wrongness irrespective of whether these were low-dose or high-dose purity transgressions.
To further clarify whether the domain manipulation was successful, we ran an additional (nonpreregistered) analysis to check whether people perceived the scenarios as differentially harmful across the different combinations of both domain and dosage, as would be represented in a domain by dose interaction on ratings of harm. This interaction was significant (bdomain × dose = −5.63, 95% CI = [−9.33, −1.92]; tdomain × dose[32.38] = −2.94, p < .006). Participants rated high-dose harm violations (M = 83.89, SD = 24.86) more harmful than high-dose purity violations (M = 79.53, SD = 30.89) but responded fairly similarly to low-dose harm (M = 76.46, SD = 30.02) and low-dose purity (M = 77.79, SD = 32.05) violations. This suggests that participants perceived some harm scenarios as more harmful than the purity scenarios but that they also perceived the purity scenarios as somewhat harmful. Perhaps our participants incorporate harm somewhat into their conceptions of purity (see Gray et al., 2023). Nevertheless, this analysis suggested that our domain manipulation was successful even if our findings for the manipulation check are somewhat different than those of Rottman and Young (2019).
To check if the transgression-severity manipulations (dose: high vs. low) influence the wrongness ratings for harm and purity transgressions, we compared the moral-wrongness ratings’ mean differences and determined whether the t-test p values are significant (p < .05) for high versus low dosages for both harm and purity transgressions again using the main-analysis linear mixed-effects model. We observed that the mean difference for high dosage (harm: M = 83.89, SD = 24.86) and low dosage (harm: M = 76.46, SD = 30.02) for harm transgressions (MD = 7.43, SD = 0.68; b[dose]Harmful = 4.55; 95% CI = [3.88, 5.21], t[9.5] = 14.13, p ≤ .05; d = 0.15) is larger than the mean difference for high dosage (purity: M = 84.89, SD = 26.50) and low dosage (purity: M = 84.01, SD = 27.04) for purity transgressions (Mdn = 0.88, SD = 0.17; b[dose]Impure = 3.38; 95% CI = [2.92, 3.83], t[76.8] = 14.66, p < .05; d = 0.12). The t tests were significant. These findings imply that the dose manipulations checked out for both harm and purity transgressions’ wrongness ratings.
Main- and interaction-effects analyses: confirming the effect of domain, dose, and domain by dose interaction on moral-wrongness judgment
As a reminder, Rottman and Young (2019) predicted that people should judge high-dose transgressions more wrong than low-dose transgressions for harm transgressions but not for purity transgressions. As planned, we included all of the fixed and random effects in the primary analysis (a maximal model), and the model converged. The interaction effect of domain (harm vs. purity) by dose on wrongness ratings (bdomain × dose = −4.63, tdomain × dose[30.65] = −2.71, p < .011, 95% CI = [−8.06, −0.81]; see Table 4) was significant. When the severity of the transgressions was high, participants rated purity violations (M = 87.45, SD = 23.87) as only slightly more wrong than harm violations (M = 84.78, SD = 24.28; Mdn = 2.67). In contrast, when the severity of the transgressions was low, participants rated purity violations (M = 86.62, SD = 24.69) as much more wrong than harm violations (M = 79.25, SD = 28.51; Mdn = 7.37; see Fig. 1).
Linear Mixed-Effects Model Results for Participants’ Wrongness Judgments and the Original Study Meta-Analysis Aggregate

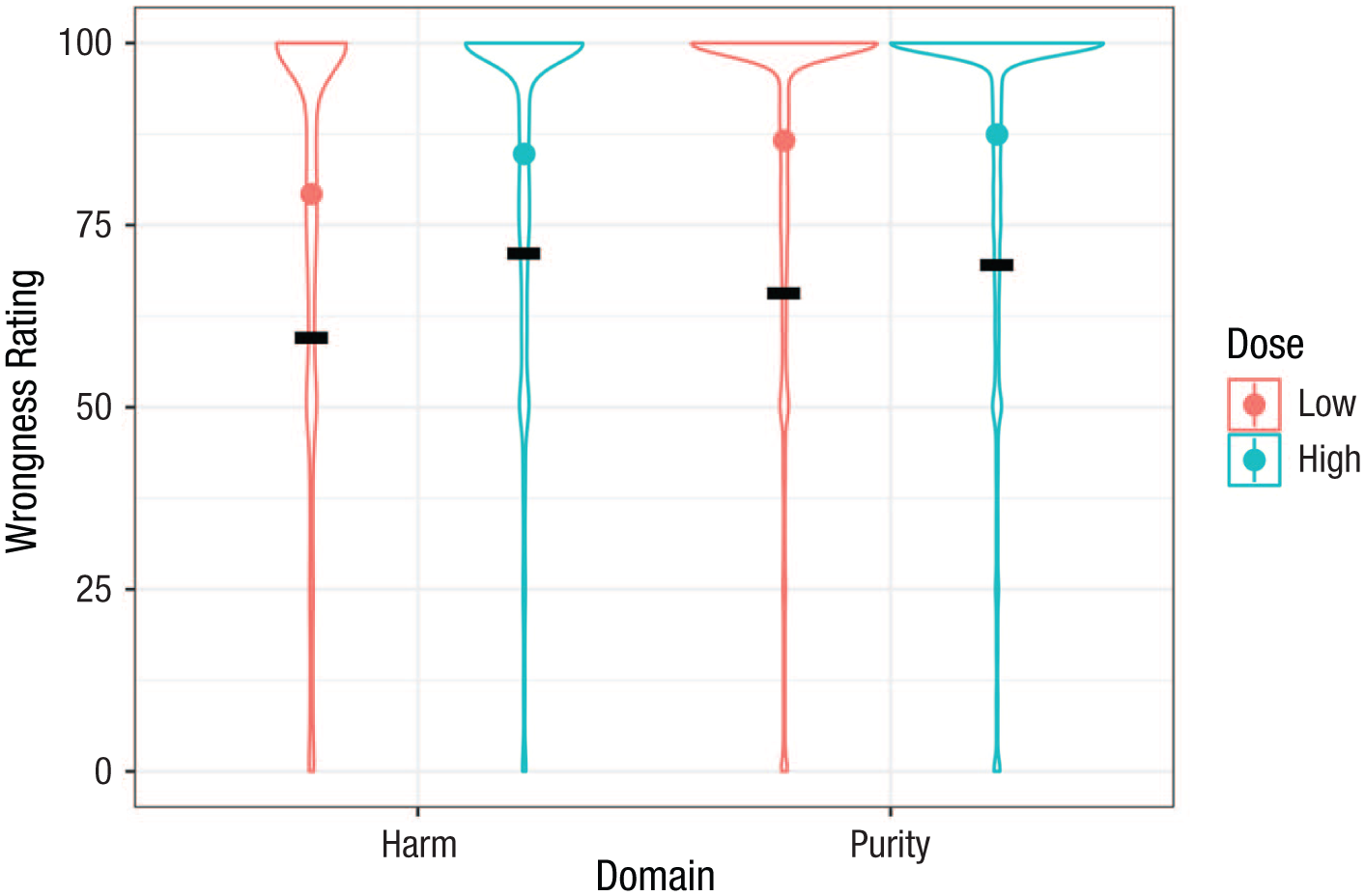
Violin plot of wrongness rating as a function of domain and dosage for our replication and Rottman and Young (2019) predicted means. Probability densities of the wrongness rating are on the y-axis; x-axis shows the domain. On the graph are the violin plots for four conditions; red plots present the low-dose conditions, and blue plots present the high-dose conditions. For each plot are dots for the replication average wrongness rating and black horizontal lines for Rottman and Young’s (2019) predicted means (using the meta-analyzed results across all three studies) for the conditions.
Determining if we replicated Rottman and Young
As detailed in Table 4, our estimate for the domain by dose interaction is bdomain × dose = −4.63, 95% CI = [−8.06, −0.81]. This estimate and its CI are both below zero and smaller in magnitude than the Rottman and Young (2019) meta-analytic estimate of −7.72. According to the replication criteria (see Table 2), this yields an interpretation of a replication. However, although African participants were more sensitive to the transgressions evidenced by their larger average wrongness rating, they were less sensitive to the dosage for harm and purity transgressions than the original U.S. sample given their smaller mean differences in wrongness rating between the low and high doses for both domains (see Fig. 1).
By-participant, by-item, and by-site random effects
In the original studies, the random effects for by participant, by item, and by site were not accounted for in the model. In this current study, all these random intercepts were fitted in the fully maximal model analysis. We fitted random intercepts by participant for domain, dose, and their interaction; by item for dose; and by site for domain, dose, and their interaction.
By-participant random effect
We indicated that participants’ wrongness judgment of the violation acts should be prone to subjective interpretation because of the evaluators’ subjective perception of the acts. Hence, we examined (a) whether participants would vary when judging how wrong these transgressions were and (b) if their wrongness judgments would be sensitive to the severity of these violations. The model included random slopes by participant for domain, dose, and their interaction. Findings show that the variation in the random by-participant slopes for dose (bdose = 3.16; SD[bDose]ID = 1.58) and the Domain × Dose interaction (bdomain × dose = −4.63; SD[bDomain × Dose]ID = 2.05) were smaller in magnitude than their fixed effects. The variation in the random by-participant slopes for domain (SD[bDomain]ID = 6.77) was larger than the fixed-effect estimate (bdomain = 5.01). These findings indicated a small amount of variability in participants’ wrongness judgments for dose and for the domain by dose interaction. However, participants varied substantially in their reactions to the harm versus purity transgressions.
By-items random effect
We predicted that individual items (violation stimuli) should uniquely prompt different reactions and irrespective of the dose manipulation (high vs. low dosages) would vary the wrongness ratings for these violations. We observed that the variation in the by-item slopes for dose (SD[bDose]Item = 4.68) was larger than the fixed effect of dose (bdose = 3.16). The result showed that the individual items explained variability in the dosage effect to a large degree.
By-site random-effect analysis: participating sites variability check
Although our contributing sites in Africa were not representative of the continent, they are spread across different cultures among participating countries (Burkina Faso, site N = 1, sample n = 123; Kenya, site N = 1, sample n = 113; Morocco, site N = 3, sample n = 435; Nigeria, site N = 6, sample n = 634; Tanzania, site N = 1, sample n = 15) and have their peculiarities (e.g., some labs used the in-person procedure in which participants took the survey in a designated room). We predicted that the location or setup of these lab sites would show up as by-site variation in the effects of domain, dose, and Domain × Dose interaction. Results showed that the variation in the random by-site slopes for domain (bdomain = 5.09; SD[bDomain]Site = 1.51), dose (bdose = 3.16; SD[bDose]Site = 0.31), and the Domain × Dose interaction (bdomain × dose = −4.63; SD[bDomain × Dose]Site = 0.64) were smaller than their respective fixed effects, suggesting a relatively small degree of variation across the sites for dose, domain, and their interaction.
Exploratory analyses: What are important moral issues to Africans?
Because the moral issues described in the original study were U.S.-centric and may not capture most moral issues in Africa, we asked participants, “Are the moral issues we asked about amongst the more important ones for your moral context? If not, which issues are?” A total of 260 of the 688 participants who responded to the question (37.8%) considered the moral issues described in the scenarios not the most important to them. Instead, our participants considered the following moral issues more important: abortion, homosexuality, human trafficking, kidnapping, religious and racial discrimination, ritual killings, domestic violence, child abuse and molestation, social and economic inequalities, corruption and fraud, work-related ethics, sexual violence and harassment, human rights, divorce, premarital sex, unhealthy family and sexual relationships, disrespect for others, infidelity, organ harvesting, (online) harassment and bullying, unhealthy competition, dishonesty/honesty and lying, deception, envy and malice, enemies of success, wasting water, family relations and social ties, being kind to parents, tolerance, women repression and abuse, drug use and abuse, nudity, and starving people.
Discussion
Limitations
There are three unpredicted constraints encountered in the current replication. These limitations and their implications for our findings and interpretations are highlighted below.
Different patterns in manipulation check
Although the harm-transgression scenarios were rated as significantly more harmful than impure, contrary to the original study manipulation-check pattern—in which the U.S. participants rated purity transgression as more impure than harm transgressions—it was not quite clear if our African participants rated the purity-transgression scenarios more impure than harmful. This pattern suggests that the moral transgression scenarios described may apply to Africans, suggesting they considered purity transgressions as being just as impure as harmful acts. Perhaps purity transgressions are not quite distinguishable as impure or harmful (see also Gray et al., 2023, discussion on the perceived harmfulness of purity violations). We, however, concluded justifiably that these measures apply to our African participants because (a) the harm-transgression manipulation worked and (b) the difference between the high-dose and low-dose ratings for the purity transgression was insignificant, and putting all the weight on the p value (p < .065) may be unwarranted. Finally, (c) our additional analysis suggests that participants perceived some harm scenarios as more harmful than the purity scenarios but that they also perceived the purity scenarios as somewhat harmful. It seems our African participants were sensitive to the purity violations so much so that they incorporated harmful ratings when judging the purity transgressions. Although our preregistration did not provide contingencies for different patterns in domain manipulation checks, we deviated from the preregistered plan to proceed to test the hypothesis even though the manipulation did not exactly work as presented in the original study. Therefore, we encourage readers to apply caution when interpreting these findings in terms of (a) applicability to Africans and (b) that the observed effect can be a direct implication of dosage more than of the domain.
Low data quality
We failed to meet the targeted sample size after excluding 457 out of the 1,240 participants (36.9%) for failing the attention checks. Contributing sites had difficulties in administering the study, and although some sites collected data within the planned 6 weeks, others took roughly 6 months. After data collection, only 1,320 out of ≈4,700 respondents had an 85% completion rate. Some of the participants complained about the sensitive nature of the transgression scenarios used in the study, the survey length, and the need for internet access to complete the study. We observed that collecting data without compensation for participants or local coordinators was challenging. In our attempts to improve the quality of the data, we excluded participants who spent too little time (≈10 min) to complete the study. Despite these shortcomings, the study was successful in sampling participants in five African countries. Notwithstanding, these constraints had a minimal implication on the findings because whether or not we excluded participants who failed the attention checks, the results were consistent (see supplementary information for the results without sample exclusion). Like researchers in any part of the globe, researchers interested in sampling African participants should check for data quality (e.g., by excluding participants who spent little time completing or failed the attention tasks). In addition, it will be good practice to recruit sufficient participants, and if you are working with a target sample size, we recommend including an additional 35% of the predetermined sample size. Finally, when possible, adequate compensation should be provided to participants.
Poor country representation
Only five out of the 54 African countries were sampled in this study. Moreover, we sampled only a small amount of the total variation within these countries. For example, 98% of the participants reported having at least some high school education. They were at least somewhat familiar with the internet and mostly urban dwellers. Because a relatively high proportion of the African population is rural, our results may not generalize well to much of Africa (Ghai et al., 2024). Furthermore, a large number of the issues that our participants considered important, such as ritual killings, envy and malice, and enemyship, were not measured in the current study.
Study findings
In this CREP Africa study, we investigated the replicability of Rottman and Young’s (2019) moral-judgment claim among Africans. We tested Rottman and Young’s mere-trace hypothesis that moral-wrongness ratings are more sensitive to the severity of harmful transgressions than impure transgressions. Because the original study used a U.S. sample, we first examined whether the domain (harm vs. purity) and dose (low vs. high) manipulations were perceived similarly among African participants. Inconsistent with the original study, although participants rated purity and harm transgressions as comparably harmful, they rated purity transgressions more impure than harm transgressions. Overall, most participants were comfortable with the study, although a few questioned the weirdness and sensitivity of the violations and the meaning of “impure.” For example, one participant commented that “it felt weird taking the survey.”
In our replication study, we found empirical support for the mere-trace hypothesis, consistent with the original findings. The interaction effect of domain and dose (bdomain × dose = −4.63, 95% CI = [−8.06, −0.81]) was significant. This finding supports Rottman and Young’s (2019) claims that the effect of dose severity on moral-wrongness judgment depends on whether the transgressions are harm-based or purity-based. On the one hand, participants rated high-severity harm violations more wrong than low-severity harm violations. On the other hand, they rated high-severity and low-severity purity violations equally and highly wrong. Looney et al. (n.d.) reported similar findings in their replication of Rottman and Young. Our findings are consistent with Rottman and Young’s original claim, and according to the criteria we set forth in Table 2, we interpret our results as a successful replication. Notwithstanding, the Africans’ average wrongness rating was considerably larger than the original participants’ average wrongness rating, as shown in Figure 1. Our African sample appeared more sensitive to these transgression scenarios than the original U.S. sample. Our concept of morality in Africa suggests that moral transgressions can harm individuals and communal coexistence (Aden & Olira, 2017) and that African morality is at once metaphysical, ethical, and juridical (Mbaegbu, 2015). More so, African societies strive for good morals/characters, and bad morals/characters are abhorred (Gyekye, 2025; Mbaegbu, 2015). For a collectivistic and religious African society, we think Africans may find it absurd to moderate their judgments of both harm and purity transgressions. It is therefore not out of place that we observe a substantial negative skew because our African participants reported upper-limit ratings for wrongness, impure, and harmful for these transgressions, especially the purity transgressions that include religious and sacred violations, sexual inappropriateness, and human-DNA contamination.
Theoretical implications
Literature on moral-judgment research is largely from the United States, including our focal claim—the mere-trace hypothesis that supports the hypothesis that moral evaluations of purity violations are less sensitive to the severity or outcome of purity violations compared with moral evaluations of harm transgressions (Rottman & Young, 2019). In the current study, we improved on the original study with an increased sample, increased the number of stimuli measured per participant, modified the model to account for by-person random slopes for dose and domain and by-item random slope for dose, and finally, used African samples. We found evidence that supports the mere-trace hypothesis among our participants in Africa to conclude that insensitivity to the severity of purity transgressions could be a shared behavior among African and U.S. populations. However, compared with the original study, our African participants judge the purity transgressions quite harshly across the board, no matter if they are judging how harmful, impure, or wrong and no matter if they are low-dose purity transgressions or high-dose purity transgressions. These harsh wrongness ratings could be a result of existing cultural differences between the African populations and the U.S. populations. Beyond cultural sensitivity, implementing the original methods and procedures in our African setting was methodologically and realistically challenging with potential consequences for applicability and interpretation (Burchett et al., 2013). Conceivably, the lack of participant compensation, participants’ education level, survey experience, and participant-recruitment procedure could have contributed to sample characteristics disparities, poor response rate, and exclusion problems that we encountered working on this study. Unfortunately, investigating whether these factors did or can affect the data quality is beyond the scope of this study.
Recommendations
Before conducting the CREP study, we surveyed African researchers and students who attended a workshop on open science and CREP to understand the level of interest in using the CREP model and the feasibility of teaching the CREP model in African institutions. Sixteen trainees from Cameroun (n = 1), Malawi (n = 7), and Nigeria (n = 8) responded to the feedback survey. Among the trainees, 68.8% were definite about the CREP model’s adaptability for their research projects, and 70% indicated that adopting the CREP model for African students’ research work is very feasible. However, they were not very optimistic about African institutions adopting the CREP model for students’ research work; just 25% expressed confidence that they could adopt the CREP model for their students’ research projects. The African trainees noted three key barriers to adopting the CREP model in Africa. These include (a) poor infrastructure and resources, more importantly for African students to participate in CREP studies; (b) low familiarity among African researchers with the CREP model; and (c) (in)availability and (in)accessibility to CREP materials and tools. Based on these CREP-model usability findings and following the feedback received from our African collaborators who worked on the CREP study reviews, the CREP model workflow and tools could improve research management, rigor, and credibility and facilitate collaboration. Despite the facility inadequacies in African labs, we encourage African researchers, tutors, and research institutions to adopt the CREP model because this model provides intellectual infrastructure and resources, for example, our tutorial materials (available at https://osf.io/8akz5/), to learn and educate students on research best practices and to conduct cutting-edge cross-cultural replication.
As a matter of theory generalization and for inclusion, this CREP study represents a common practice whereby African populations are targeted for Western theory generalization and of less priority to Africans. In most cases, such as the moral issues investigated by Rottman and Young (2019), these studies rely on constructs, processes, and theories grounded in Western norms, often overlooking the diverse variations that exist outside the United States and Europe (Adetula et al., 2022). It is important to broaden moral issues, including some of which Africans suggested above, to better understand the underlying psychological processes of moral judgment across global populations. Despite our best efforts and focus on Africa, the below-average participation further underlines the need for funders, scientific associations, and researchers from the rich world and Africa to support increasing participation and capacity building to advance African participation in global psychology. We refer researchers to Adetula’s (2024) extensive recommendations on conducting a replication in Africa that include know-how on selecting the study, designing the study, collecting data in an African setting, and ensuring feasibility.
On a final note, contrary to the original findings that purity transgressions used were distinctively impure versus harmful, our African participants rated these purity transgressions impure and equally harmful, suggesting that purity transgressions could encompass harmful violations (see also Gray et al., 2023). Researchers can investigate comparatively whether the harm and purity domains are (in)distinguishable in the African and Western contexts.
Conclusion
Improving African participation in global psychology requires a better representation of African thoughts and samples. It is equally important to build African researchers’ capacity in global best practices. In this current study, we addressed these needs by engaging African researchers in a pedagogically goal-oriented Africa-wide study of moral judgment concerning harm and purity, which was replicated among African populations with a smaller effect size. Even though Rottman and Young (2019) intended to capture U.S. moral reasoning, the moral issues addressed in their study were limited. Our investigation showed that Africans’ moral concerns and reasoning differ to some extent from those investigated in the original study. Crime- and family/sexual relationship-based issues dominated the moral concerns that were important to Africans. Unsurprisingly, these moral issues are linked to pressing social issues, such as sexually transmitted diseases, gender-based violence, and a history of corruption in government, that have led to poor living standards and poor reproductive-health systems in some African populations (for discourse on moral economies in Africa, see Wiegratz et al., 2024). As the first rollout of a CREP study in Africa, this study could improve African participation in global research and build research capacity in open-science practices to advance African psychology.
Supplemental Material
sj-doc-1-amp-10.1177_25152459261428031 – Supplemental material for The Evaluation of Harm and Purity Transgressions in Africans: A Paradigmatic Replication of Rottman and Young (2019)
Supplemental material, sj-doc-1-amp-10.1177_25152459261428031 for The Evaluation of Harm and Purity Transgressions in Africans: A Paradigmatic Replication of Rottman and Young (2019) by Adeyemi Adetula, Patrick S. Forscher, Dana Basnight-Brown, Jordan R. Wagge, Wickson Thomas Kaliyapa, Chamkat Gopye Polycarp, Winfrida Saimon Malingumu, Soufian Azouaghe, Lenah Sambu, Izuchukwu L.G. Ndukaihe, Gabriel Agboola Adetula, Abdelilah Charyate, Chisom Esther Ogbonnaya, Nwadiogo Chisom Arinze, Olawuyi Patience Shumiye, David Beshel Jack, Nestor Motemba Ouoba, Bukola Victoria Bada, Ahmed Khaoudi, Jaime Nhaguilunguana, Uba Donald Dennis, Asiya Ayoob, Agbasoga Vivian Idu, Yusuf Elson Dinala, Abdulfatai Olalekan Adeyefa, Michael Ibukun Ehinmowo, Amarachi Uchechi Janice Imonigie, Glory Wuraola Agboola, Habila Alfred Daktong, Bisan Musa, Jamal Elouafa, Mohamed Boua, Mohamed Kaddouri, Bako Joseph Dongkek, Houda Grimli, Lamya Mouhssine, Hicham Eddamnati, Teodote Matimbe, Daniela Rocha IJzerman, Anne W. Muchiri-Muchai, Patrícia Arriaga, Maximilian A. Primbs and Hans IJzerman in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
We acknowledge the contributions of Takondwa Namalima, Walusungu Silungwe, Ebaa Alsayed, Milton Kalongonda, Alert Dzuka, Mesay Shanka, Nsi Eze, Oko Enworo, Zione Gold, Saheed Abolade, Moses Agbede, Ayomitan Olotu, Dércio Armando, Ogochukwu Ugwuneke, Afolashade Onunkun, Mutsai Bakali, Precious Ike, Dorcas Ovurevu, Dennis Kibuga, Ahmed Bokkour, F. Kaphesi, K. Mulungu, and Richard Adu. Some of you nominated and assessed the shortlisted studies for selection, revised and provided feedback on the Stage 1 Registered Report, and translated the instrument. Unfortunately, we were unable to continue working with some collaborators because of difficulties obtaining ethics approval or receiving timely feedback from ethics committees, incomplete Collaborative Replications and Education Project OSF page curation, and lack of resources or infrastructure. A. Adetula wants to thank his Patrons (https://www.patreon.com/support_adeyemi_adetula_dream), the psychological-science community (https://www.gofundme.com/f/support-african-scholar-in-financial-distress), Thuy-Vy Nguyen and Charities Aid Foundation America, and researchers from other scientific communities, social-support groups, and individuals for their continued financial support after the grant was concluded. Your support makes this project possible. Thank you! We posted a preprint that included the complete introduction and method sections and a planned data analysis and result presentations. The preprint is accessible at ![]() .
.
Transparency
Action Editor: David A. Sbarra
Editor: David A. Sbarra
Author contributions
ORCID iDs
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.