
Abstract
Musicians are often regarded as a positive example of brain plasticity and associated cognitive benefits. This emerges when experienced musicians (e.g., musicians with more than 10 years of music training and practice) are compared with nonmusicians. A frequently observed behavioral finding is a short-term memory advantage of the former over the latter. Although available meta-analysis reported that the effect size of this advantage is medium (Hedges’s g = 0.5), no literature study was adequately powered to estimate reliably an effect of such size. This multilab study has been ideated, realized, and conducted in lab by several groups that have been working on this topic. Our ultimate goal was to provide a community-driven shared and reliable estimate of the musicians’ short-term memory advantage (if any) and set a method and a standard for future studies in neuroscience and psychology comparing musicians and nonmusicians. Thirty-three research units recruited a total of 600 experienced musicians and 600 nonmusicians, a number that is sufficiently large to estimate a small effect size (Hedges’s g = 0.3) with a high statistical power (i.e., 95%). Subsequently, we measured the difference in short-term memory for musical, verbal, and visuospatial stimuli. We also looked at cognitive, personality, and socioeconomic factors that might mediate the difference. Musicians had better short-term memory than nonmusicians for musical, verbal, and visuospatial stimuli with an effect size of, respectively, Hedges’s gs = 1.08 (95% confidence interval [CI] = [0.94, 1.22]; large), 0.16 (95% CI = [0.02 0.30]; very small), and 0.28 (95% CI = [0.15, 0.41]; small). This work sets the basis for sound research practices in studies comparing musicians and nonmusicians and contributes to the ongoing debate on the possible cognitive benefits of musical training.
Keywords
Do experienced musicians have better short-term memory than nonmusicians? A recent meta-analysis (e.g., Talamini et al., 2017) said so, although none of the behavioral studies included in it had a sufficiently large number of participants to capture the size of the calculated advantage. Our study emerged from the shared need of the neuroscience and psychology-of-music community to shed light on this and similar issues, in which the possible effects of lifelong music training are investigated by comparing musicians and nonmusicians. With the present multilab study, conceptualized, realized, and conducted by several groups that worked on this topic in the recent past, we aimed to provide a sound answer to the above question by recruiting a number of participants that was large enough to provide a reasonable estimate of the advantage (if any). We also investigated possible interindividual differences in cognitive abilities, personality, and socioeconomic status (SES) of the family that may modulate this advantage.
In psychology and neuroscience, experts are studied to understand the effect of extensive, lifelong activity on behavior and brain plasticity (e.g., London taxi drivers, Maguire et al., 2000; Braille readers, Pascual-Leone & Torres, 1993; chess players, De Groot, 2014; athletes, for an overview, see Chang, 2014; Voss et al., 2010). A class of skilled individuals that is often studied is musicians. Musicians and their abilities have been studied since more than a century ago because the training to become a musician is long, complex, and structured. It requires performing fine motor actions and developing fine auditory skills and multisensory integration. Noticeably, musicians are required to coordinate all these abilities in synchrony. Furthermore, music has its own language and theory, which varies across musical cultures: Musicians may be required to learn to read the music notation and the rules of melody, harmony, and temporal organization (Hannon & Trainor, 2007). In addition, music is taught in dedicated schools, and the study of music can end with a high education degree, such as a bachelor’s or a master’s.
In line with studies that have compared experts and nonexperts in other domains (De Groot, 2014; Maguire et al., 2000; Pascual-Leone & Torres, 1993), musicians outperform nonmusicians when tasks tap into the domain of their expertise. For example, musicians are better than nonmusicians in understanding whether a melody is presented in transposition (Halpern et al., 1995) or at a faster or slower tempo (Andrews et al., 1998) and better in detecting mistuned notes in chords and melodies (Koelsch et al., 1999; Schellenberg & Moreno, 2010). The expertise of musicians often transfers to skills and tasks that are similar to musical skills and tasks. Musicians perform better than nonmusicians in classic psychoacoustic tasks, such as frequency (Micheyl et al., 2006) and temporal discrimination (Rammsayer & Altenmüller, 2006). Better auditory ability in musicians is also reflected in speech-perception tasks because musicians seem better than nonmusicians at judging the prosody of a sentence (Deguchi et al., 2012; Jansen et al., 2023; Schön et al., 2004) and, to some extent, perceiving speech in noise (Başkent & Gaudrain, 2016; Hennessy et al., 2022; Parbery-Clark et al., 2009).
Musicians also seem to perform better than nonmusicians in tasks that tap into general cognitive skills. One of the cognitive skills often investigated is short-term/working memory, for which musicians were found to perform better than nonmusicians. Here, we adopt the same terminology used by Talamini et al. (2017) to distinguish between short-term-memory (assessed with tasks that require to store and recall the stimuli verbatim, e.g., the forward digit span) and working-memory tasks (tapped by tasks that require to store and manipulate information during encoding and/or recalling, e.g., the backward digit span). In short-term-memory and/or working-memory tasks, musicians perform better than nonmusicians in tasks that require to memorize musical stimuli (i.e., stimuli within the domain of expertise; see Pallesen et al., 2010; Schulze et al., 2012; Schulze, Mueller, & Koelsch, 2011; Schulze, Zysset, et al., 2011), but they also do so in tasks that require memorizing and manipulating verbal stimuli, such as the digit span, nonword span, and operation span (e.g., Fennell et al., 2021; George & Coch, 2011; Hansen et al., 2013; Lee et al., 2007; Ramachandra et al., 2012; Talamini et al., 2016). In contrast, findings with visuospatial short-term- and working-memory tasks are mixed (Amer et al., 2013; Criscuolo et al., 2019; Grassi et al., 2017; Hansen et al., 2013; Lee et al., 2007).
In a recent meta-analysis, Talamini et al. (2017) revealed that the memory advantage of musicians unfolds along two main dimensions: the type of stimuli (i.e., musical, verbal, visual/spatial) and the memory system (i.e., long, short, working memory). Musicians show a large advantage over nonmusicians when the test stimuli are music stimuli (e.g., melodies), a moderate advantage when the stimuli are verbal (e.g., digits, words), and a small to null advantage when the stimuli are visual and/or spatial. The meta-analysis revealed also that the advantage is of moderate effect size for working memory and short-term memory and of small effect size for long-term memory.
Why should musicians be better than nonmusicians in memory tasks that involve nonmusical stimuli? There are two main positions: one supporting the hypothesis of a cause-effect relationship (i.e., music training improves memory) and one supporting the hypothesis of preexisting differences (i.e., people with better memory and/or better general cognitive abilities are more likely to engage and succeed in music training). For individuals who support the first position (e.g., Herholz & Zatorre, 2012; Hyde et al., 2009; Jäncke, 2009; Münte et al., 2002; Schlaug, 2001; Strait & Kraus, 2014), music training represents a good to ideal model of brain plasticity (for a review on neuroanatomical differences between musicians and nonmusicians, see Criscuolo et al., 2022), and the better performance observed in memory tasks (with different materials) is due to training-related neuroplasticity. In contrast, proponents of the second position (e.g., Schellenberg, 2020; Swaminathan & Schellenberg, 2018, 2019) argue that individuals with a combination of traits—including above-average cognitive skills—are more likely to choose and succeed in long-term training (e.g., the training required to become a musician). As a result, when these individuals become musicians, they tend to outperform nonmusicians in cognitive tasks.
Regardless of either position, it is also possible that other variables explain/mediate the relationship between better short-term/working memory and musical expertise. For example, the memory advantage could be a by-product of an advantage in a higher-order cognitive skill, such as intelligence (e.g., fluid intelligence, Schellenberg, 2020), or executive functions (Okada & Slevc, 2018), or both (Criscuolo et al., 2019). The advantage may be related to individual differences in personality or sensitivity to music (e.g., enjoyment or pleasure derived from musical-related activities), which might have a genetic basis (e.g., Hansen et al., 2024). The length of music training is positively associated with the open-mindedness trait (Corrigall et al., 2013; Corrigall & Schellenberg, 2015): Musically trained individuals may perform well on experimental tasks because, at least in part, they tend to be curious and particularly interested in learning new things. The memory advantage observed in musicians may also be related to music aptitude (instead of music training), that is, the ability to perceive, remember, and discriminate melodies and rhythms (e.g., Swaminathan et al., 2017; Swaminathan & Schellenberg, 2018). Music aptitude may be just another declination of the so-called positive manifold (i.e., the positive association between the various abilities tested by intelligence tests; see Spearman, 1904). Music aptitude and short-term/working memory could be correlated, and individuals with music aptitude could be more likely to undergo and succeed in music training and later become musicians (Swaminathan et al., 2017; Swaminathan & Schellenberg, 2018).
Finally, an open issue emerges across literature: Who can be labeled as a musician, and who cannot? Music-aptitude tests (Law & Zentner, 2012; Wallentin et al., 2010) and sophistication inventories (Müllensiefen et al., 2014) suggest a continuum, but the literature often treats musical expertise as binary, dividing participants into musicians and nonmusicians. However, the criteria to define both groups vary from study to study. Recently, Zhang and colleagues (Zhang et al., 2020; Zhang & Schubert, 2019; for a discussion, see also Baker et al., 2020) investigated the issue. Zhang and Schubert (2019) suggested a parsimonious tripartition of the music-expertise continuum and divided individuals among people with no musical identity (fewer than 6 years of music training), people with musical identity (6–10 years of music training), and people with strong musical identity (SMI; music training longer than 10 years).
Although some studies have reported that musicians are better than nonmusicians in memory tasks, this result may not be as clear as it may seem. In the meta-analysis by Talamini et al. (2017), the largest and most robust memory advantage was that for short-term-memory tasks. For these types of tasks, the mean effect size of the advantage was Hedges’s g = 0.57, 1 and the effect size varied depending on the stimuli presented in the memory tasks (i.e., musical stimuli: g = 1.15; verbal stimuli: g = 0.54; visual and spatial stimuli: g = 0.28). If one calculates the number of participants that is needed to estimate an effect as such (i.e., g = 0.57) via a t test that compares the memory performance of musicians and nonmusicians and adopt ordinary standards for controlling for Type II error (e.g., a statistical power equal to .8; Cohen, 1988), the number of participants needed is 100 (50 per group). If one adopts contemporary standards for power (e.g., power equal to .90 or .95; see Sawilowsky, 2009), the number of participants per group rises to, respectively, 130 (65 per group) and 160 (80 per group). Figure 1 represents the number of participants that are needed to estimate various possible effect sizes with a statistical power of .80, .90, and .95 via an independent-sample t test and assuming a classic approach: only one laboratory collecting the data.

Number of participants (musicians + nonmusicians) as a function of the effect size targeted by the study for three levels of statistical power. Note that the y-axis is logarithmic. The analysis hypothesizes groups of equal size and that the memory performance of the two groups is compared with a t test. It also hypothesizes that one single laboratory collects the data. The black circles represent the empirical studies included in the meta-analysis by Talamini et al. (2017): Each circle represents the number of participants and effect size observed by the study. Note how studies in the literature are underpowered to target the possible advantage of the musicians over nonmusicians. Note also how the size of the literature studies is negatively correlated with the effect size of the musicians’ advantage (r = −.70): The smallest studies observed the largest effect size. The three horizontal dotted lines represent the number of participants one research unit needs to recruit to target, respectively, .80, .90, and .95 power with an effect size of 0.3, the effect size targeted in the current study.
How many participants were recruited in the studies on musicians’ memory that are available in literature? Far fewer. To our knowledge, the largest laboratory study (Okhrei et al., 2016) recruited 64 participants (28 musicians). Noticeably, the effect size calculated by Talamini et al. (2017) for short-term memory shows a strong negative correlation between number of participants and effect size observed by a given study (i.e., r = −.70), a trend that is often observed in recent literature and that could hide statistical errors of both Type I and Type II (Cohen, 1988; Gelfand & Smith, 1990; Pastore et al., 2015).
In brief, before any theoretical discussion on the reasons for the short-term-memory advantage of musicians over nonmusicians, the studies conducted so far seem too small in terms of number of participants to assess a potential advantage. Moreover, there is a lack of systematic comparisons across stimuli, making it difficult to understand how the advantage might generalize for different types of materials. In the present study, we aim at revealing whether musicians have better short-term memory than nonmusicians with an adequately large sample size and how this advantage unfolds across different types of stimuli, while controlling for possible confounding variables. In addition, we aim at targeting a number of participants that is large enough to provide a good and reliable estimate of this advantage. Indeed, any theoretical discussion about the possible beneficial effects of music training would be of little interest if the musicians’ advantage is actually negligible in size.
Here, based on data and results in previous literature, we expected to observe an advantage of musicians in short-term-memory tasks. This advantage should be larger for music stimuli than for verbal stimuli. The smallest advantage (if any) should be observed for visuospatial stimuli. The effect size of this advantage could be smaller than that estimated by Talamini et al. (2017), a possibility supported by a recent study that compared effect sizes of meta-analyses with those of successive, empirical, large-N multilab registered reports replications investigating the same phenomena directly (see Kvarven et al., 2020). Because journals are more likely to publish false-positive than null results (e.g., Smaldino & McElreath, 2016) and because meta-analyses are calculated based on available literature (that might consequently be inflated by false positives), current meta-analyses might often overestimate the effect size of phenomena. Moreover, meta-analyses alone cannot overcome some of the limitations of the single studies included in them (e.g., heterogeneous inclusion/exclusion criteria, tools, stimuli). For a table showing this heterogeneity, see the supplemental material in the OSF repository. This table lists the main characteristics of the studies (e.g., characteristics of the musicians, the nonmusicians, the task) that compared the short-term memory of musicians and nonmusicians.
In the present study, we decided to target an effect size of Hedges’s g = 0.3, which approximates the lowest effect size detected in the meta-analysis by Talamini et al. (2017) for visuospatial stimuli. For a summary of expected results see Table 1.
Expected Results and Effect Sizes of the Musicians’ Short-Term-Memory Advantage

Note: Because Question 3 requires the largest number of participants to be tested, in the current multilab study, we opted to recruit that number of participants to answer all three questions (see Power Analysis and Participants section).
We also expected to replicate the positive associations observed in the literature, such as a positive relationship between cognitive performance and music aptitude (e.g., Swaminathan & Schellenberg, 2018), cognitive performance and “open-mindedness” (e.g., Corrigall et al., 2013), and perhaps cognitive performance and the SES of the family (Osler et al., 2013). We also estimated the contribution of factors that might explain the memory advantage and that are suggested by the literature (e.g., intelligence, executive functions, and individual differences in sensitivity to musical experiences).
The present correlational study will not reveal whether music training may boost the short-term memory of individuals. However, current experimental research also seems unable to provide an answer to this question: Longitudinal studies that implement training of a sufficient duration to guarantee an SMI (i.e., 10 years or more of music training; Zhang & Schubert, 2019) are unlikely to ever be conducted. In the present study, nonetheless, we aimed to return a sound answer to the question whether musicians have better short-term memory than nonmusicians and, above all, the size of the advantage for different classes of stimuli (music, verbal, visuospatial).
Method
Ethics information
The research protocol complied with all relevant ethical regulations. The overarching ethical approval (No. 5305) was granted by the Ethics Committee (Comitato Etico della Ricerca Psicologica, Area 17) of the University of Padova, and the research was conducted in accordance with the Declaration of Helsinki. When the primary ethical approval could not be applied by a unit, the units obtained their own ethical approval for data collection. The study protocol was approved by the Durham University Music Department Ethics Committee; the Research Ethics Board at the University of New Brunswick (File No. 2023-016); the local Ethics Committee of the Université libre de Bruxelles (1668/2024); the PPLS Research Ethics Committee of the University of Edinburgh (203-2324/2); the Brazilian National Ethical Committee at Plataforma Brasil (No. 70181123.8.0000.5411); the Ethics Review Committee Psychology and Neuroscience, Maastricht University (External Approval 76B8BA7B9078DF27CF46CDC26FA9E5); the Ethics Council of the Max Planck Society (No. 2023_18); the Non-Medical Research Ethics Board of the University of Western Ontario; the Institutional Review Board of the University of Minnesota (0605S85872); the Institutional Review Board of Vanderbilt University (No. 162002); the Leiden University Psychology Research Ethics Committee (2023-11-24-F.L. Bouwer-V1-5105); the Ethics Committee of Research in Education and Psychology of the University of Montreal (Study Protocol No. 2023-4765); the Research Ethics Committee of the University of Sheffield (Alternative Ethics Approval No. 860); the Norwegian Agency for Shared Services in Education and Research SIKT (reference: 805630); the Central ethics Review Board non-WMO studies of the University Medical Center Groningen (Research Register No. 18645); and the Board for Ethical Questions in Science of the University of Innsbruck (28/2023).
Design
In the study, we compared a group of adult musicians with a group of adult nonmusicians. The experiment was carried out in person in the laboratories of the various units. All experimenters of the various units followed a shared written protocol to test the participant in the various tasks of the experiment. All the tasks were presented on a Google page that redirected to the various platforms used for the tasks (i.e., JsPsych, LimeSurvey). A clone of the page is accessible at https://sites.google.com/view/the-memory-experiment-clone/home.
Tasks
Each participant was asked to complete individually all of the following tasks. Participants could not skip any task, trial, or question of the following tools.
Memory tasks
Participants completed three short-term memory tasks: one testing the memory for musical material, one testing verbal memory, and the third testing visuospatial memory. The verbal and the visuospatial tasks were recall tasks in which the participant had to reproduce the to-be-remembered stimuli. The music task was a recognition task in which the participant had to compare two melodies and judge whether they were identical or different. The reason for this difference (i.e., recall vs. recognition) is that music-recall tasks are difficult to conduct with nonmusicians: The participant should sing (or play with a music instrument or software) the to-be-remembered stimuli. Note also that the pace of the tasks was different: In verbal and visuospatial tasks, stimuli were presented at a pace of 1 per s. This same pace would produce extremely slow melodies in the music task, hence the pace for this task was one note every 500 ms. Participants received written feedback about their performance after each trial (i.e., correct/wrong) and the score they achieved at the end of each block (sum of correct responses over the total number of trials done). All the memory tasks were implemented in JSPSYCH (de Leeuw, 2015).
Music short-term memory
In each trial, the program presented a melody (called “standard”), followed after 2 s by a comparison melody of identical duration and number of notes. The notes of the melodies were piano tones with a duration of 500 ms created with the software Cubase 5.1 and Halion Sampler (Steinberg Media Technologies), presented in succession with no silent interval separating the notes. At the end of the comparison melody, the participant had to judge whether the comparison melody was identical (or not) to the standard melody. At the beginning of the task, the length of the melody was two notes. Each melody length was presented four times to the participant. Out of four trials for each melody length, for one, two, or three trials, the expected answer was “the two melodies are different,” whereas for the remaining trial(s), the expected answer was “the two melodies are identical.” This was implemented to avoid the participant adopting a strategy that balances the number of “identical” and “different” responses for each melody length. The task continued until the third incorrect response given by the participant. Melodies were fixed for all participants (i.e., melodies were not generated in real time). To prevent possible ceiling performances, the program could present melodies up to 40 notes long. Melodies were both preceded and followed by a signal (i.e., a visual cross) that informed the participant on the beginning/end of the standard comparison pair and a label (i.e., “standard melody,” “comparison melody”) that was presented simultaneously with the stimulus. Participants completed the task twice with different sets of melodies.
The notes of the melodies were taken from the C major diatonic scale (i.e., lower-do/C, re/D, mi/E, fa/F, sol/G, la/A, si/B, upper-do/C) and extended from do4/C4 (f = 261.6 Hz) to do5/C5 (f = 523.3 Hz). Melodies were pseudorandom melodies. The note succession did not follow any aesthetic tonal sense. Melodies longer than two notes had at least one rising and one falling pitch interval, and melodies up to the length of eight notes did not have repeated notes. In longer melodies, notes could be repeated (e.g., two mi, or E, notes were included in the melody), but the repeated notes were never adjacent. When the comparison melody was different from the standard melody, the difference was created by reversing the order of two consecutive notes of the standard melody (e.g., standard: do, fa, sol, re; comparison: do, sol, fa, re). Comparison melodies were constructed with the constraint that this reversal did not result in adjacent repeated notes, which would be very salient.
Verbal short-term memory
We implemented a forward digit span with custom sequences of digits presented visually to the participants. The digits were presented only visually because when stimuli are presented auditorily, musicians might exploit their better auditory processing, including a possible confound in the measure of verbal short-term memory (Caclin & Tillmann, 2018; Talamini et al., 2016, 2022). The participant was presented with a sequence of digits (1–9), and the task was to look at the sequence and when the sequence was over, type on the keyboard the digits of the sequence in the same order they were presented. Digits were presented one after the other at the center of the screen at a pace of 1 digit per second. Each digit remained on the screen for 500 ms, followed by a 500 ms blank. The digit span began with a sequence of two digits (sequence length = 2). Each sequence length was presented twice to the participant. When the participant reported correctly at least one out of two sequences, then they were presented with the successive sequence length that was one digit longer than the previous sequence. For sequences up to nine digits, digits were not repeated. For sequence lengths longer than nine digits (i.e., sequence length of 10 digits or more), digits could be repeated; however, the repeated digits were never concatenated. Sequences were also controlled for salient and “easy-to-chunk” patterns (e.g., “5-4-3-2,” “4-6-8”), which were eliminated and replaced. The task stopped when the participant gave two incorrect responses for a given sequence length. Sequences were fixed for all participants (i.e., sequences were not generated randomly in real time). Maximum sequence length was 18 digits (a number that the authors hypothesized was large enough to have no single ceiling performance). Sequences were preceded and followed by a signal (an auditory beep) that informed the participant on the beginning/end of the sequence. Participants completed the task twice with different sets of sequences of digits.
Visuospatial short-term memory
We implemented a forward matrix span. The participant was presented with a four-by-four matrix grid. In each trial, a dot was switched on and off in the cells of the matrix grid highlighting—one after the other—several positions on the grid. The task of the participant was to look at the positions where the dot appeared and reproduce them in the same order. As soon as the last dot disappeared, the participant could click with the mouse on the matrix on all the positions occupied by the dot. The dots were presented at a pace of 1 dot per second. Dot onset-to-onset interval was 1 s. Each dot remained on the screen for 500 ms, followed by a 500 ms blank. In the experiment, the participant began the task with a sequence length of two positions. Each sequence length was presented twice to the participant. When the participant reproduced correctly at least one out of the two sequences presented, they moved to the next sequence length, and an additional spatial position was added to the sequence. The task ended when the participant made two errors for a given sequence length. Sequences were fixed for all participants (i.e., sequences were not generated randomly in real time). Up to a sequence length of 16, spatial positions were not repeated. In longer sequences, the spatial positions could be repeated, but repeated positions were never concatenated. Sequences were also controlled for salient and easy-to-chunk geometric patterns (e.g., the dot touching one after the other the four corners of the matrix grid), which were eliminated and replaced. Maximum sequence length was 32 (a number that the authors hypothesized was large enough to have no single ceiling performance). Sequences were preceded/followed by a signal (i.e., an auditory beep) that informed the participant about the beginning/end of the sequence. The visuospatial span was run twice by the participants.
Music aptitude, music sophistication, and music reward
We assessed music aptitude, music sophistication, and music reward with three tools: the Profile of Music Perception Skills - mini (Mini-PROMS; Zentner & Strauss, 2017), the Goldsmiths Musical Sophistication Index (Gold-MSI; Müllensiefen et al., 2014), and the extended Barcelona Music Reward Questionnaire (eBMRQ; Cardona et al., 2022). The Mini-PROMS is a shorter version of PROMS (Law & Zentner, 2012), a performance test of music-perception skills. It includes four listening subtests (Melody, Tuning, Beat, and Speed) investigating different aspects of music perception and memory. In each subtest, the participant listens twice to a standard stimulus, followed by a comparison stimulus. The participant has to judge whether the comparison stimulus is identical or different from the standard on a five-options scale (i.e., definitively same, probably same, I don’t know, probably different, definitively different). The Melody subtest assesses the ability of recognizing whether two short melodies are identical. The Tuning subtest requires comparing chords. In the case of different trials, one of the middle notes of the comparison chord is different in frequency (i.e., it is mistuned). The Beat subtest requires comparing rhythmic patterns of clicks: The accent that defines the beat is produced by raising the intensity of a subset of the clicks. In the Speed subtest, the participant compares the speed (i.e., beats per minute) of both synthetic rhythmic structures and recorded samples of music. The Gold-MSI is a 38-item self-report questionnaire that aims to capture individual differences in musical sophistication. The Gold-MSI is a questionnaire developed to collect information about common and skilled behaviors related to music in the Western population, such as interest in music and music-related activities (Müllensiefen et al., 2014). The Gold-MSI includes five subscales of self-assessment on active engagement (e.g., resources spent on music), perceptual abilities (i.e., music-listening abilities), musical training (e.g., formal music training received), singing abilities, and emotional engagement with music (e.g., ability to talk about music-evoked emotions). The eBMRQ (Cardona et al., 2022) extends the former Barcelona Music Reward Questionnaire (Mas-Herrero et al., 2012) and is a 24-item questionnaire to quantify reward in music-related activities. The eBMRQ includes six subscales: Music Seeking (e.g., the tendency to engage in music-related activities), Emotion Evocation (e.g., music’s capacity to induce relevant emotional responses), Mood Regulation (e.g., how music is employed to regulate mood), Sensory-Motor (e.g., the capacity of music to intuitively induce body movements), Social Reward (e.g., ability of music to promote and enhance social interaction), and Musical Absorption (e.g., willingness to be deeply drawn in by sensory stimuli, experiencing immersion without distraction). These three music assessment tools were implemented in LimeSurvey.
Measure of personality
The Big Five Inventory - 2 (BFI-2) questionnaire (Soto & John, 2017) was used in the study. The questionnaire includes 60 items and returns scores for the following personality traits: open-mindedness, conscientiousness, extraversion, agreeableness, and negative emotionality. The questionnaire was implemented in LimeSurvey.
Measures of intelligence
We used the Raven Advanced Progressive Matrices (Raven, 1965), which is a common test to measure fluid intelligence in a language-independent way. Participants were given 10 min to respond to as many items as possible. We concatenated the last 10 items of Set I and all the items of Set II (36 items) to have a single block of 46 items. Items of the two sets were concatenated to avoid ceiling effects. The first two items of Set I were used for two familiarization trials before the task. The test was implemented in LimeSurvey. We also used a measure of crystallized intelligence. Participants were asked to complete the vocabulary subtest of the Wechsler Adult Intelligence Scale (WAIS-IV; Wechsler, 2008; maximum 30 items). In Portuguese-speaking countries, this version of the test was not available; therefore, we used the latest version available (WAIS-III; Wechsler, 1997; maximum 33 items). The WAIS vocabulary test was administered by the experimenter.
Measures of executive functions
We used a visual two-back task to measure the updating component of executive functions. This component seems the most strongly linked to music aptitude and sophistication, in particular when it is tapped with the n-back task (Okada & Slevc, 2018; Slevc et al., 2016). The participant saw a series of 22 single letters drawn from a set of eight capital letters (“C,” “D,” “G,” “K,” “P,” “Q,” “T,” “V”). Each letter remained on the screen for 500 ms, followed by 1,500 ms blank screen (i.e., letter onset-to-onset interval: 2,000 ms). The participants’ task was to press a button when the letter they were currently seeing matched the letter seen two letters before. The task was repeated five times, and it was preceded by one familiarization series. Each series included six targets. This task was implemented in JSPSYCH (de Leeuw, 2015).
Measures of SES
We controlled for the role of this factor with the Hollingshead four-factor index (Hollingshead, 1975). The four-factor index can be used to ask details about the family of origin of the participant, such as parents’ education, occupational status, and relationship (e.g., married, separated). Furthermore, we asked about the education and the occupational status of the participant. These questions were implemented in LimeSurvey.
Further custom questions
We asked all participants further demographic questions: sex, age, type of nonmusical education (e.g., type of bachelor’s degree). The musicians were asked the number of years of music training in an official music school, conservatory, or private lessons; the number of hours of music practice per day at the moment of testing; which instrument they played; whether they sang; and whether the music activity in the last 12 months had been continuous with no interruptions. In the case the musicians played multiple instruments, they were asked the above questions for only the main instrument they played. All participants were further asked whether they had relative and absolute pitch and one question from the Ollen Musical Sophistication Index (Ollen, 2006; “Which title best describes you?”), which considered the individual’s self-assessed level of musical identity. This question can be answered in six ways (1 = nonmusician, 2 = music-loving nonmusician, 3 = amateur musician, 4 = serious amateur musician, 5 = semiprofessional musician, 6 = professional musician). The custom questionnaire included also a question on expertise, that is, whether the participant self-rated to be expert (on a scale from 1 to 6, similar to the question of the Ollen Sophistication Index) in one or more of the following domains: art (including music but not played), sport, game, and others.
Translations of the various tools into the different languages
Table S1 (in the Supplemental Material available online) includes the various tools that were used in the study and (if available) the existence of the official translation of the tool. For the remaining tools, units were asked to provide a translation based on two independent translations followed by back-translation.
Procedure
Participants were recruited in different ways (e.g., word of mouth, advertisement). Inclusion criteria were assessed at the recruitment stage. The experiment took place in person in the laboratory in one session. At the beginning of the experiment, the participant was asked to read and sign the informed consent. Then, to ensure that the participant was in an unaltered psychophysiological state, a few questions were asked (i.e., about drug/alcohol intake, amount of sleep in the past 24 hr, and current sickness). If the participant reported to have used any drug and/or taken an excessive amount of alcohol in the 24 hr preceding the experiment or reported insufficient sleep (i.e., <6 hr) or sickness, they were not allowed to continue with the experiment. Subsequently, the participant completed the memory tasks: the music-memory task, the verbal-memory task, and the visuospatial-memory task. The order of the three tasks was counterbalanced within each participant group and data-collection unit in a Latin square way. After the memory tasks, the participant took the Raven test and the WAIS vocabulary test. Next, the participant was asked to take the n-back task and the PROMS test and complete all the self-report questionnaires (custom questions, Gold-MSI, eBMRQ, BFI-2, and Holligshead). Participants were allowed to take short breaks in between any of the tasks of the experiment. The approximate duration of the whole experiment was 2 hr.
Power analysis and participants
Given the multilevel data structure of the study (i.e., a multilab study), the required sample size and number of units was calculated with a power analysis in a meta-analysis framework. We used the approach by Hedges and Pigott (2001) and Borenstein et al. (2009). We fixed the α level to .05 and power to 90%. The average effect size was fixed to Hedges’s g = 0.3, which approximates the estimated effect size observed by Talamini et al. (2017) for visuospatial stimuli. Although smaller effect sizes could be targeted, differences in memory smaller than g = 0.3 would reveal a nonsubstantial memory advantage for musicians such as the individuals recruited in the study (see the criteria below). To account for the possible heterogeneity across data-collection units, we fixed τ (the index that reflects the true heterogeneity across research units) to .11. This value is half of the estimated heterogeneity by Talamini et al. and was selected given the identical experimental protocol shared by all units participating in the current study. This present power analysis requires a minimum of 21 participants per group (i.e., 21 musicians and 21 nonmusicians) collected by a minimum of 13 research units.
As inclusion criteria, participants had to be healthy young adults ranging from 18 to 30 years of age. They had to have normal hearing and normal or corrected-to-normal vision (both assessed via self-report). As far as the classification of musicians and nonmusicians is concerned, we adopted stricter criteria than those suggested by Zhang and Schubert (2019). Musicians had to have 10 years (or more) of music lessons (voice or instrument) in music schools or with a private teacher (SMI; Zhang & Schubert, 2019) and had to be musically active at the moment of the experiment with no interruption in the music activity in the year preceding the experiment. Nonmusicians should not have received more than 2 years of music lessons, except for compulsory school activities (a criterion that is stricter than that suggested by Zhang & Schubert, 2019, for the “no musical identity”), and had to be musically inactive for at least the 5 years before the day of the experiment. 2 Musicians and nonmusicians were individually matched for gender, age, and years of education with a tolerance of ±1 year. 3 For example, a male 22-year-old musician with 16 years of education could be approximately matched with a male 21-year-old nonmusician with 17 years of education. Years of education included music training. If the music training was parallel to another type of school (e.g., in some countries, students can be enrolled at the same time in the conservatory of music and at a different high school), each overlapping year of education between music and nonmusic school counted as 1 year of education. Participants were compensated for their participation according to the standards of the recruiting unit (e.g., money, university credits).
At the end of data collection, 1,357 participants were recruited. Of these, 157 were excluded because the unit could not find a corresponding matched musician (or nonmusician) or the participant did not complete all the tasks. This resulted in a final sample of 1,200 participants, comprising 600 adult musicians and 600 adult nonmusicians. A total of 33 units collected the data: one in Australia, one in Austria, one in Belgium, one in Brazil, four in Canada, two in Germany, two in Spain, one in Finland, four in France, three in Italy, three in the Netherlands, one in Norway, one in Portugal, four in the United Kingdom, and four in the United States. For the number of participants collected by each unit, see Table 2. This number of units and participants enabled us to target an effect size of Hedges’s g = 0.3 with over 95% power at a α level to .05. For smaller effect sizes (Hedges’s g = 0.2), the statistical power we achieved is above 70%.
Units That Participated in the Data Collection and the Number of Musicians and Nonmusicians Included in the Analysis for Each Unit

Note: AU = Australia; AT = Austria; BE = Belgium; BR = Brazil; CA = Canada; DE = Germany; ES = Spain; FI = Finland; FR = France; IT = Italy; NL = the Netherlands; NO = Norway; PT = Portugal; UK = United Kingdom; US = United States.
For a synthesis of the demographic variables of both groups, see Table 3.
Demographic Data of the Participants of the Study

Note: Shown are means with standard deviations in parentheses. Number of years is truncated after the first decimal. F = females; M = males; NB = nonbinary.
Analyses and Results
From raw data to data for statistical analysis
The following values were calculated from the raw data, separately for each participant. For each memory task, we calculated the average of the sums of the correct responses of each block of trials. 4 Subsequently, we calculated the PROMS score in two ways by including all subtests (i.e., sum of the raw scores of each of the subtests divided by 2; range = 0–36) or excluding the Melody subtest from the total score (range = 0–26). Hereafter, these two scores are referred to as “PROMS” and “PROMS-noMelody.” These two scores were calculated because of the similarity between the Melody subtest and the music-memory test, both requiring memorizing and comparing different melodies. Then, we calculated the general Gold-MSI score (range = 18–126), Raven score (sum of the number of the correct responses; range = 0–48), two-back score (the sum of hits minus the sum of false alarms; range = −75 to +30), BFI-2 open-mindedness score (range = 12–60), eBMRQ score (range = 24–120), and Hollingshead Index for the SES of the family (range = 8–66; for the calculation algorithm, see Hollingshead, 1975). 5 Concerning the WAIS vocabulary score, because WAIS-III and WAIS-IV have different maximum scores (respectively, 66 and 57), the individual scores were transformed into proportion of the maximum score (range = 0–1). The remaining subscores of questionnaire and tests (e.g., the Melody, Tuning, Beat, and Speed subscales of PROMS; the conscientiousness, extraversion, agreeableness, and negative-emotionality scores of the BFI-2 6 ) were analyzed exploratorily. All the variables collected are reported in the final data set (when the variable is analyzed here or in the supplemental materials) or provided as raw data. All data files are available on OSF.
Preregistered analyses and results
We compared the memory performance of musicians and nonmusicians with three separate random-effects meta-analyses (i.e., for musical, verbal, and visuospatial stimuli) using the Metafor R Package (Viechtbauer, 2010). This analysis takes into account the multilevel data structure of the current study. First, we calculated the standardized effect (i.e., Hedges’s g) and the sampling variance (Borenstein et al., 2009; Hedges, 1981) for each research unit. We interpreted the Hedges’s g as follows: very small (<0.2), small (0.2–0.5), medium (0.5–0.8), large (0.8–1.2), very large (1.2–2), and huge (>2; see Sawilowsky, 2009).
The average effect size for each meta-analysis was tested for significance using two-tailed Wald-type z tests. The α value was set to .05 for all the analyses. For each meta-analysis, we also report the Q test for the heterogeneity (Berkey et al., 1995) and the I2 statistic that represents the percentage of total variation because of real heterogeneity (i.e., τ).
Musicians performed better than nonmusicians in music short-term memory, with a large effect size (Hedges’s g = 1.08, SE = 0.07, 95% confidence interval [CI] = [0.94, 1.22], z = 15.11, p < .001); they also performed better in verbal short-term memory, with a very small effect size (Hedges’s g = 0.16, SE = 0.07, 95% CI = [0.02, 0.30], z = 2.21, p = .027), and in visuospatial short-term memory, with a small effect size (Hedges’s g = 0.28, SE = 0.06, 95% CI = [0.15, 0.41], z = 4.33, p < .001). For music and visuospatial short-term memory, the heterogeneity was not significantly different from zero according to the Q statistics, and the

Forest plots of the random-effect meta-analysis for each memory task. For each research unit, the plot reports the average effect with the 95% confidence interval. The diamond represents the meta-analytic effect and the 95% confidence interval. The error bar of the diamond represents the 95% prediction interval. For each unit, the forest plot reports the number of participants recruited by the unit. Within each unit, there was an equal number of musicians and nonmusicians.
Meta-Analysis Models Results

Note: For each memory task, we report the effect size (g), the standard error, the z statistics, the two-sided p value, and the 95% CI. In terms of heterogeneity, we report the Q statistics with the associated p value. The Q test for heterogeneity tests the null hypothesis of no heterogeneity (

Short-term memory for music, verbal, and visuospatial stimuli of musicians and nonmusicians. Scores were converted into z scores for easier comparisons across stimulus types. In each graph, from left to right, dots represent individual observations; box plots represent the median (i.e., the horizontal lines inside the box), the 25th and 75th percentiles (i.e., the edges of the box), and the interquartile range Q1-Q3 augmented by 50% (i.e., the whiskers); and the gray area represents density plots. For graphical reasons, the plots do not represent 16 outlier performances (|z| score >3; music: N = 6; verbal: N = 5; visuospatial: N = 5).
Next, Pearson correlations were calculated for the following variables, separately for musicians and nonmusicians: music, verbal, and visuospatial short-term-memory scores; PROMS score; PROMS-noMelody score; Gold-MSI score; Raven and WAIS vocabulary scores; n-back score; BFI-2 open-mindedness score; eBMRQ score; SES of the family of the participant; age; and years of education. Correlations are reported in Figure 4.
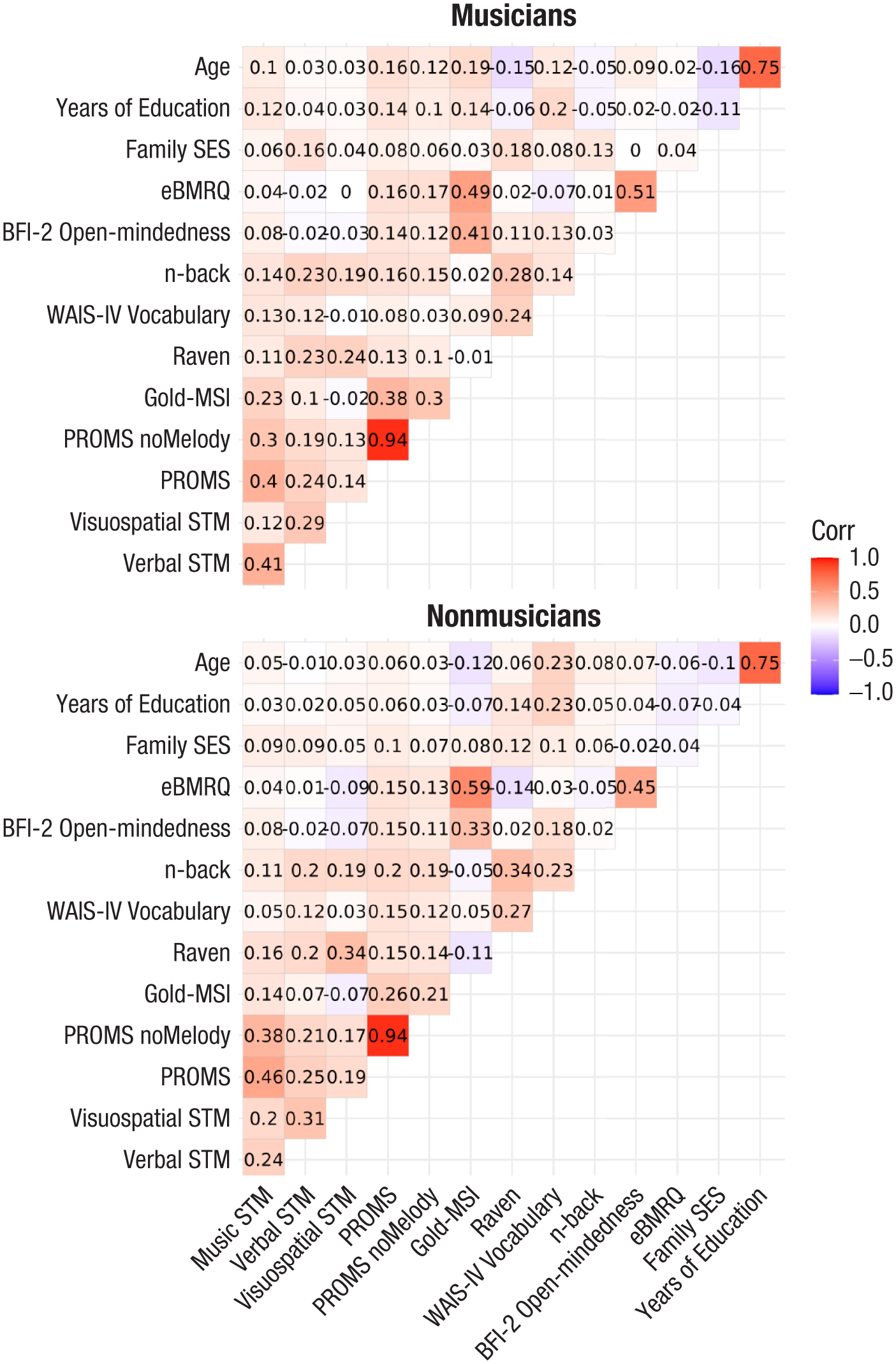
Pearson correlations among the main measures collected in the study. STM = short-term memory.
Subsequently, we calculated three separate multilevel regression models for each memory task including the research unit as random effect and a random slope for the group (musicians vs. nonmusicians) effect. As predictors, we included the main effects of Raven, WAIS vocabulary, n-back, BFI-2 open-mindedness, eBMRQ, SES, age, and years of education and their interaction with the group (musicians and nonmusicians). Using a model-comparison approach, we selected the best model predicting each memory outcome (see Tables 5, 6, and 7). PROMS and Gold-MSI were not included in the regression models because both are strongly related to musical expertise (possibly dependent on it). In fact, music-perception skills are highly correlated with music expertise (Zentner & Strauss, 2017), and the Gold-MSI includes items exploring the relationship with music, for example, music-training history, self-reported perceptual skills, and active engagement, leading to much higher scores in musicians (Müllensiefen et al., 2014). Numerical predictors have been centered on the grand mean, and the group factor has been coded using sum-to-zero contrasts for better interpreting main effects and interactions.
Summary of the Best Regression Model for Music Short-Term Memory, Selected Using the Backward Stepwise Procedure

Note: β is the parameter value, t is the Student’s t statistics, and df is the degrees of freedom calculated using the Satterthwaite method (Kuznetsova et al., 2017). σ is the random-intercepts standard deviation, σGroup (if present) is the standard deviation of the random slopes for the group effect, and σϵ is the residual standard deviation. We also report the marginal (variance explained by the fixed effects) and conditional (variance explained by the fixed plus random effects) R2 values (Nakagawa et al., 2017). WAIS = Wechsler Adult Intelligence Scale; BFI-2 = Big Five Inventory - 2; SES = socioeconomic status.
Summary of the Best Regression Model for Verbal Short-Term Memory, Selected Using the Backward Stepwise Procedure

Note: β is the parameter value, t is the Student’s t statistics, and df is the degrees of freedom calculated using the Satterthwaite method (Kuznetsova et al., 2017). σ is the random-intercepts standard deviation, and σϵ is the residual standard deviation. We also report the marginal (variance explained by the fixed effects) and conditional (variance explained by the fixed plus random effects) R2 values (Nakagawa et al., 2017). SES = socioeconomic status.
Summary of the Best Regression Model for Visuospatial Short-Term Memory, Selected Using the Backward Stepwise Procedure

Note: β is the parameter value, t is the Student’s t statistics, and df is the degrees of freedom calculated using the Satterthwaite method (Kuznetsova et al., 2017). σ is the random-intercepts standard deviation, and σϵ is the residual standard deviation. We also report the marginal (variance explained by the fixed effects) and conditional (variance explained by the fixed plus random effects) R2 values (Nakagawa et al., 2017). BFI-2 = Big Five Inventory - 2.
For all calculated models, we selected the best model with a backward model selection starting from the full model containing all the main effects, all the two-way interactions between the group factor and the other predictors, and the random slope for the group factor and random intercept for units. The procedure was implemented in the “step()” function from the lmerTest R package (Kuznetsova et al., 2017). The “step()” function implements a backward elimination based on the likelihood ratio test between nested models. For the random-effects stepwise selection, the final music-memory model contained the random intercept for the unit and a random slope for the group effect. Because the correlation between slopes and intercepts was not properly estimated (i.e., singular fit), we fixed the correlation to zero (intercepts and slopes are independent). Tables 5 to 7 report the results of the best models for music short-term memory, verbal short-term memory, and visuospatial short-term memory, respectively.
The best model for music short-term memory included the following predictors: group, fluid intelligence (Raven), crystallized intelligence (WAIS vocabulary), executive functions (n-back), BFI-2 open-mindedness, SES of the family, years of education, and the interaction between group and crystallized intelligence. The model explains 26.2% of the variance through fixed effects and 29.3% when both fixed and random effects are considered. The best verbal-short-term-memory model included the following predictors: fluid intelligence (Raven), executive functions (n-back), the SES of the family, and age. The model explains 9.3% of the variance through fixed effects and 14.6% when both fixed and random effects are considered. As far as the visuospatial short-term memory is concerned, the best model included the following predictors: group, fluid intelligence (Raven), executive functions (n-back), and BFI-2 open-mindedness. The model explains 11.7% of the variance through fixed effects and 14.8% when both fixed and random effects are considered. For the graphical representations of the effects of these predictors on the three short-term memory performances, see Figures S1 through S3 in the Supplemental Material.
Exploratory analyses and results
We compared musicians and nonmusicians along the various measures we collected. For each measure, we calculated a random-effect meta-analysis using the Metafor R Package (Viechtbauer, 2010). Figures 5 and 6 report the differences between musicians and nonmusicians for the musical measures (i.e., PROMS and its subscales, Gold-MSI and its subscales, eBMRQ and its subscales) and for the remaining measures (i.e., Raven and WAIS vocabulary, n-back, the five subscales of the BFI-2, and the SES of the family). We highlight here the major differences between musicians and nonmusicians emerging from these meta-analyses. For the full statistics for these meta-analyses, see Tables S2 through S7 in the Supplemental Material. Musicians were “more musical” (as emerged from the results of the Gold-MSI and the PROMS) than nonmusicians. The effect sizes (g) of the difference between musicians and nonmusicians in the music-related measures (including questionnaires’ subscales) ranged from 0.38 to 5.83, and the majority were large or more than large (see the Supplemental Material). Musicians performed better than nonmusicians in the PROMS test, with a very large effect size (Hedges’s g = 1.69, 95% CI = [1.50, 1.88]; see Fig. 5, left); were more musically sophisticated than nonmusicians, with a huge effect size (Gold-MSI; Hedges’s g = 3.28, 95% CI = [3.02, 3.55]; see Fig. 5, right); and were more sensitive to music reward, with a large effect size (eBMRQ; Hedges’s g = 1.07, 95% CI = [0.93, 1.20]; see Fig. 5, center). These differences could be observed also in almost all subscales of the three tools.

(Left to right) Differences between musicians and nonmusicians in music-perception skills (PROMS), music reward (eBMRQ), and music sophistication (Gold-MSI). For each test, the total score (on the top of each plot) and the subscales scores are represented. The dots represent the mean effect sizes (Hedges’s g), and the bars represent the 95% confidence interval. PROMS = Profile of Music Perception Skills; eBMRQ = extended Barcelona Music Reward Questionnaire; Gold-MSI = Goldsmiths Musical Sophistication Index.

(Left) Differences between musicians and nonmusicians in the SES of the family, executive functions (n-back), fluid intelligence (Raven Advanced Progressive Matrices), and crystallized intelligence (WAIS vocabulary). (Right) Differences between musicians and nonmusicians in personality (the five dimensions of the BFI-2). In each graph, the dots represent the mean effect sizes (Hedges’s g), and the bars represent the 95% confidence interval. SES = socioeconomic status; WAIS = Wechsler Adult Intelligence Scale; BFI-2 = Big Five Inventory - 2.
As far as the cognitive measures are concerned, musicians performed better than nonmusicians in the Raven test (Hedges’s g = 0.26, 95% CI = [0.11, 0.40]), the WAIS-V vocabulary (Hedges’s g = 0.40, 95% CI = [0.24, 0.56]), and the n-back (Hedges’s g = 0.33, 95% CI = [0.20, 0.47]), and all three effect sizes were small (see Fig. 6, left). Various differences could be observed in the measure of the five dimensions of personality (see Fig. 6, right). Musicians reported higher scores than nonmusicians in open-mindedness, with a large effect size (Hedges’s g = 0.87, 95% CI = [0.73, 1.02]). They also reported higher scores in both extraversion and agreeableness, with a small effect size: Hedges’s g = 0.32, 95% CI = [0.20, 0.43] for extraversion, and Hedges’s g = 0.32, 95% CI = [0.20, 0.44] for agreeableness. In conscientiousness, too, musicians reported higher scores, with a very small effect size (Hedges’s g = 0.17, 95% CI = [0.05, 0.30]), and they reported lower scores in negative emotionality, with a very small effect size (Hedges’s g = −0.06, 95% CI = [−0.17, 0.05]). Finally, musicians reported coming from families of higher SES than nonmusicians, with a small effect size (Hedges’s g = 0.36, 95% CI = [0.25, 0.48]).
In addition, multilevel regression models were calculated separately for each memory task and separately for musicians and nonmusicians with the research unit included as a random effect. These separate models provide a clearer view of the potential effects of all predictors by avoiding issues arising from the association between the group factor and musical variables (i.e., PROMS and Gold-MSI). Specifically, including these predictors in separate models for musicians and nonmusicians allows for a better understanding of whether and how a person’s musicality explains performance in musical, verbal, and visuospatial short-term-memory tasks. The predictors included the main effects of Raven, WAIS vocabulary, n-back, BFI-2 open-mindedness, Gold-MSI, eBMRQ, SES, age, and years of education. For music short-term memory, the model was calculated in two ways: using the overall PROMS score (including all subscales) and using the PROMS score excluding the Melody subscale. Using a model-selection approach, as described above, we selected the best model for predicting each memory outcome. Below, we report only betas, p values, and marginal and conditional R2s. For the full results, see the Supplemental Material.
For musicians, when the full PROMS was included in the analysis, the multilevel regression analysis for music short-term memory identified three significant predictors. WAIS vocabulary (β = 6.01, p = .001), PROMS (β = 0.57, p < .001), and Gold-MSI (β = 0.05, p = .029) were all positively predicting music short-term-memory performance. The model explained 17.6% of the variance through fixed effects and 21.1% when both fixed and random effects are considered. When the model included the PROMS without the Melody subscale, five predictors emerged: WAIS vocabulary (β = 6.05, p = .002), n-back (β = 0.06, p = .025), eBMRQ (β = −0.05, p = .04), PROMS-noMelody (β = 0.47, p < .001), and Gold-MSI (β = 0.10, p < .001). The model explained 14.1% of the variance through fixed effects and 18.8% when both fixed and random effects are considered. The multilevel regression analysis for verbal short-term memory identified five significant predictors: Raven (β = 0.06, p < .001), n-back (β = 0.04, p < .001), SES (β = 0.02, p = .017), age (β = 0.07, p = .014), and PROMS (β = 0.12, p < .001) were all positive predictors of verbal short-term-memory performance. The model explained 13.5% of the variance through fixed effects and 20.5% when both fixed and random effects are considered. The multilevel regression analysis for visuospatial short-term memory identified four significant predictors: Raven (β = 0.07, p < .001), n-back (β = 0.03, p = .001), and PROMS (β = 0.07, p = .003) positively predicted visuospatial short-term-memory performance. In contrast, Gold-MSI (β = −0.016, p = .035) was negatively associated. The model explained 9.1% of the variance through fixed effects and 13.2% when both fixed and random effects are considered.
For nonmusicians, the multilevel regression analysis for music short-term memory using the overall PROMS score identified two significant predictors: Raven (β = 0.09, p = .009) and PROMS (β = 0.53, p < .001) both positively predicted music short-term-memory performance. The model explained 21.9% of the variance through fixed effects and 22% when both fixed and random effects are considered. The multilevel regression analysis for music short-term memory using the PROMS score excluding the Melody subscale identified three significant predictors: Raven (β = 0.11, p = .001) and PROMS-noMelody (β = 0.52, p < .001) were positive predictors, as was Gold-MSI (β = 0.03, p = .031). The model explained 16.2% of the variance through fixed effects and 16.5% when both fixed and random effects are considered. The multilevel regression analysis for verbal short-term memory identified three significant predictors: Raven (β = 0.05, p < .001), n-back (β = 0.02, p = .006), and PROMS (β = 0.09, p < .001) were all positive predictors of verbal short-term-memory performance. The model explained 10.1% of the variance through fixed effects and 15% when both fixed and random effects are considered. The multilevel regression analysis for visuospatial short-term memory identified three significant predictors: Raven (β = 0.10, p < .001) and PROMS (β = 0.60, p < .001) both positively predicted visuospatial short-term-memory performance, and BFI-2 open-mindedness was a negative predictor (β = −0.02, p = .016). The model explained 14.8% of the variance through fixed effects and 19.4% when both fixed and random effects are considered. For the summaries of these models, see the Supplemental Material.
Discussion
In the present multilab study, we collected evidence on whether a domain-specific training and expertise may be associated with superior domain-general abilities such as memory, a classic question of psychology (e.g., Thurstone, 1934). In particular, we investigated whether being an experienced musician may be in a relationship with a better short-term-memory performance for domain-specific stimuli (e.g., music) but also for stimuli that are far or not explicitly connected with the domain of expertise, such as verbal stimuli or visuospatial stimuli. To respond to this question, in the present project, we tried to set a standard for studies in this field. In many cases, past researchers have compared musicians and nonmusicians in studies that recruited too few participants to reliably capture the phenomena they were trying to investigate. Moreover, there has been no consensus on the selection of the possible mediators of the memory advantage or the definition of “musician” and “nonmusician.” Here, in particular, we implemented a comprehensive set of measures, and above all, we preregistered all actions taken before the collection of the data. Thirty-three different units from 15 different countries contributed to the data collection, for a total of 1,200 participants. Measures of musical, verbal, and visuospatial short-term memory were administered together with some questionnaires and tests assessing both possible confounding variables (i.e., measures of crystallized and fluid intelligence, executive functions, SES of the participant’s family, and personality) and music-related variables (i.e., music perception skills, music sophistication, and music reward).
Preregistered analyses: meta-analyses
The study revealed three main results. The first is that the short-term-memory performance of musicians was better than that of nonmusicians for musical stimuli and that the size of this difference was large (Hedges’s g = 1.08). The second is that the short-term-memory performance of musicians was better than that of nonmusicians for verbal stimuli and that the size of this difference was very small (Hedges’s g = 0.16). The third is that the short-term-memory performance of musicians was better than that of nonmusicians for visuospatial stimuli and that the size of this difference was small (Hedges’s g = 0.28). The large short-term-memory advantage of musicians over nonmusicians with musical stimuli is consistent with what was observed in the meta-analysis by Talamini et al. (2017). It is plausible to hypothesize that the musicians’ advantage in music short-term memory is the result of a near-transfer effect of music training (for a recent debate, see Neves et al., 2022; Román-Caballero & Lupiáñez, 2022) given that prior studies have shown that music training enhances auditory processing (e.g., Kraus & Chandrasekaran, 2010). In contrast, the advantage of musicians over nonmusicians in verbal short-term memory was very small, compared with the medium effect size reported in the meta-analysis by Talamini et al. Note that the studies included in the meta-analysis used relatively heterogeneous procedures. Most verbal short-term-memory tasks were presented auditorily, which is the standard modality for this type of task, except for two studies that used visual stimuli (i.e., Okhrei et al., 2016; Talamini et al., 2016). Concerning visuospatial short-term memory, results align with those observed in the meta-analysis, showing a small effect size. However, this result is substantially more robust and reliable in the present study because it is based on a much larger data set and a shared protocol. The meta-analysis included only six studies, and among these, only three involved tasks requiring participants to memorize sequences of spatial positions (Okhrey et al., 2016; Rodrigues et al., 2014; Suárez et al., 2016).
Preregistered analyses: multilevel models
Subsequent analyses revealed that the model that best predicted music short-term memory included the Raven test (i.e., a measure of fluid intelligence), WAIS vocabulary (i.e., a measure of crystallized intelligence), n-back (i.e., a measure of the “updating” component of executive functions), personality trait open-mindedness, SES of the family, years of education, and interaction between group and the vocabulary score: In musicians, music short-term memory was positively related to crystallized intelligence, whereas for nonmusicians, it was negatively related. The model thus suggests that music training explains not only the variance in the music short-term-memory task, as expected, but also several different individual characteristics. For instance, general cognitive abilities (i.e., intelligence, executive functions) explained part of the variance in the music short-term-memory tasks, and this is in line with prior literature showing a connection between short-term memory and general cognitive abilities (e.g., Colom et al., 2005; Miller & Vernon, 1992). Open-mindedness was also found in the past to be linked with higher cognitive abilities and musicianship status (e.g., Corrigall et al., 2013; DeYoung et al., 2013; Harris, 2004; Vincenzi et al., 2024). A high SES can foster access to stimulating environments that are important for cognitive development during critical phases, and in contrast, a low SES can limit access to the same environments (e.g., Osler et al., 2013; Schellenberg, 2020). This could explain its significant role in the best-fitting model.
Different results were observed for verbal and visuospatial short-term memory. For verbal memory, the best model included the Raven test, n-back, SES of the family, and age of the participant. These results support again that higher cognitive abilities may explain a better verbal short-term-memory performance (e.g., Colom et al., 2005). Counterintuitively, age predicted positively the verbal memory performance. However, we note that in our sample, age correlated strongly with the years of education, although this latter factor was not part of the best model. The music group factor was not part of the best model, and this also reflects the very small difference in performance between the two groups observed with the meta-analysis.
The very small difference between groups in verbal short-term memory and the lack of contribution of the group factor in the predictive model contrast with previous literature (e.g., M. Hansen et al., 2013; Talamini et al., 2017). One possible explanation is that unlike most studies, the digit-span task here was presented visually. The previously observed advantages of musicians in verbal short-term memory may be a by-product of superior auditory processing (e.g., Talamini et al., 2016), therefore not necessarily reflecting a general short-term-memory verbal advantage. Understanding the possibility of a (auditory) verbal advantage is, however, challenging: Although in the past the modality of presentation was found to influence verbal short-term-memory performance (e.g., for serial position effects, suggesting that auditory and visual stimuli are represented differently; Macken et al., 2016; Talamini et al., 2022), classic models of working memory (e.g., Baddeley 1992) do not distinguish stimuli based on the sensory channel but, rather, on the type of the stimulus (i.e., verbal or visuospatial). More recent models seem to give importance to the sensory modality and/or discuss possible different representations of auditory versus visual stimuli but are still too recent to change the classic paradigms (e.g., Christophel et al., 2017; Nozari & Martin, 2024). In any case, the comparison between the present results and the results of the small-sized studies of the literature should be made cautiously: Results provided by small-sized studies may be very variable, making the comparison between the present multilab study and those studies extremely inconclusive because of the uncertainty associated in the estimates provided by these latter (see below for an extended explanation).
For visuospatial short-term memory, the best model included group, Raven test, n-back test, and open-mindedness. Here, for all numerical predictors except for open-mindedness, the contribution of the predictor was positive: The higher the value of the predictor, the better the short-term-memory performance was. This result stresses once more the role of higher cognitive functions in short-term-memory performance. Open-mindedness contributed negatively to visuospatial performance. This result is unexpected given that previous literature has observed that open-mindedness is positively associated with cognitive performance (e.g., Harris, 2004) and could be a factor explaining the advantage of the musicians over the nonmusicians in cognitive tasks (Corrigall et al., 2013). Further research is needed to understand the role of open-mindedness in cognitive performance.
Overall, musicians performed better than nonmusicians in all short-term-memory tasks. Only two predictors emerged in all models explaining the difference in performance between groups: a measure of fluid intelligence and a measure of executive functions. Musical expertise contributes to explain differences in music and visuospatial short-term memory but not in verbal short-term memory.
Exploratory analyses: meta-analyses on control variables
In further exploratory analyses, we investigated whether musicians and nonmusicians differed along the various measures collected in the study. Although the two groups were recruited with the aim of being directly comparable (musicians and nonmusicians were matched for gender, age, and education), several differences were observed between musicians and nonmusicians. Musicians were much more musical than nonmusicians in both performance tests and self-assessment tools. Small differences were also observed in higher cognitive faculties, such as fluid and crystallized intelligence, and executive functions (e.g., Arndt et al., 2023; Clayton et al., 2016; Criscuolo et al., 2019). Altogether with the advantages in music, verbal, and visuospatial short-term-memory tasks, these results may remind one of a classic observation in psychology that dates back to Spearman’s “positive manifold” (Spearman, 1904): Individuals performing well in one cognitive task tend to perform well also in other cognitive tasks. In other words, it is possible that the small and constant musicians’ advantage observed throughout the various cognitive measures reflects a general advantage in g-factor (e.g., Floyd et al., 2021), which, in turn, influences performances in the different cognitive tasks. Here, large differences in cognitive performance between musicians and nonmusicians emerged only when the tasks tapped into the musicians’ expertise (e.g., music memory), whereas all other cognitive tasks had small and comparable effect sizes.
Many differences could be observed in personality with musicians that were much more “open to experiences” but also slightly more “extroverted,” “agreeable,” and “conscientious.” The difference in open-mindedness aligns with previous studies that found a link between being a musician and this personality trait (Corrigall et al., 2013; Gjermunds et al., 2020). The effect size of this difference was large, suggesting that this trait is indeed an important dimension that needs to be considered when studying the cognitive differences in musicians and nonmusicians and more generally, the correlates of music training. Finally, musicians came from families of higher SES than nonmusicians. This finding aligns with previous research, such as Müllensiefen et al. (2014), who observed that the SES of an individual’s family correlates with the individual’s musical sophistication.
The multilevel regression models calculated separately for musicians and nonmusicians revealed both commonalities and differences in the predictors of memory performance across tasks. Fluid intelligence emerged as a positive predictor for the majority of memory tasks in musicians and for all memory tasks in nonmusicians. The PROMS was a positive predictor for all tasks in both groups. For musicians, we observed the additional role of crystallized intelligence and general musical sophistication in predicting musical memory performance. For nonmusicians, we also observed a negative association between open-mindedness and visuospatial memory performance, as in the main model on the overall sample. A possible reason explaining why PROMS emerged as a predictor in all models, in both musicians and nonmusicians, is that PROMS implements a recognition paradigm, thus leveraging short-term-memory skills. It is also possible that musical abilities are part of the positive manifold mentioned above. Previous studies have observed, indeed, a correlation between music-perception skills and other cognitive abilities and general intelligence (Swaminathan & Schellenberg, 2018; for a review, see Schellenberg & Weiss, 2013). When comparing musicians and nonmusicians, though, it is challenging to understand to what extent music-perception skills are improved by (and thus dependent on) training or are genetically influenced skills that influence who takes music lessons. Future studies should aim at collecting participants that are equally distributed on a continuum of music-perception skills (note that in the present study, we had instead only the two “extremes” of this continuum) to further investigate the relationship between these abilities, other cognitive abilities, and music training.
Although the variance explained by these models was moderate, the separate models provide a more detailed view of how individual cognitive and personal characteristics contribute to memory performance within each group, avoiding the confounding effects of musical variables inherently linked to the group factor.
General comments on the results
We would like to draw some general comments on the results. The first is that musicians do have a short-term-memory advantage compared with nonmusicians but that existing literature seems to overestimate this advantage for verbal short-term memory. The most comprehensive data on the memory performance of musicians and nonmusicians come from the meta-analysis by Talamini et al. (2017). They observed an advantage for musical stimuli of Hedges’s g = 1.15 and for visuospatial stimuli of g = 0.28, values that are similar to those observed here. However, the meta-analysis observed an advantage of g = 0.57 for verbal stimuli, whereas here, the advantage observed is only g = 0.18, out of the CI estimated by the meta-analysis. In contemporary literature, meta-analyses are often used to get an estimate of the temperature of a given phenomenon. Our results suggest that this practice should be taken with some caution. Empirical evidence collected directly by multilab studies often contrasts with the meta-analyses of the literature, and in general, meta-analyses tend to observe larger effect sizes than multilabs (Kvarven et al., 2020). Journals often favor publishing positive results, and studies comparing musicians and nonmusicians typically involve a limited number of participants because experienced musicians are rare in the population. When a phenomenon has a small effect size, smaller experiments are likely to report positive outcomes only if they observe an inflated effect size—essentially, a large but inaccurate difference between groups (e.g., Button et al., 2013). One further positive aspect of the multilab approach is that it uses a shared research protocol, whereas meta-analyses are often forced to compare studies that may differ substantially. Shared protocols reduce heterogeneity, likely producing clearer results.
Another important point that we would like to raise is why we observe many contrasting results in the literature of psychology/neuroscience of music, in particular, when studies contrast musicians and nonmusicians along nonmusical dimensions. Contrasting results likely emerge because researchers collect too few participants, and if participants are few, studies cannot detect subtle effects and phenomena and, above all, cannot provide a reliable estimate of a phenomenon. Contrasting results are rare when musicians and nonmusicians are confronted in musical tasks and even in many auditory tasks, in which the difference in performance between the groups is likely to be large. In these cases, studies are likely to observe musicians’ advantage even with a small number of participants (although the estimate of the exact size of this advantage may be uncertain). For example, detecting a large effect size, such as g = 1.12 (as observed here for music short-term memory), with substantial statistical power (e.g., 80%) requires recruiting as few as 14 musicians and 14 nonmusicians. In contrast, detecting a smaller effect size, such as g = 0.28 (as observed here for visuospatial short-term memory), with the same statistical power would require a much larger sample: 201 musicians and 201 nonmusicians. 7 In these cases, at the level of the single study, one may observe contrasting results. For example, one study may observe a musician advantage and another study observing a nonmusician advantage. This is clearly evident here. If one observes results at a unit level for verbal and visuospatial short-term memory, the outcome of single units ranges from a nonmusician advantage (occasionally large) to a musician advantage (occasionally large). If literature faces the challenge of understanding whether musicians are cognitively more performing than nonmusicians, studies should aim to have sufficiently large sample sizes.
Another issue in the music psychology/neuroscience literature is the lack of shared standards and protocols. For example, studies in this field often classify participants into two groups: musicians and nonmusicians. However, there is no standard, universally accepted definition of “musician” or “nonmusician,” and studies differ significantly in the inclusion and exclusion criteria used to recruit participants. One could also argue that this binary distinction is overly simplistic because many individuals fall between the two categories (e.g., amateur musicians, music enthusiasts). These individuals are often excluded from studies even though existing tools now allow for the modeling of a “musicianship continuum” (e.g., Gold-MSI). Moreover, it is unclear whether musicians should be studied as a single, homogeneous group or whether specific research questions should target distinct subgroups of musicians. For instance, some musicians play music by manipulating a physical object (e.g., an instrument), whereas others, such as singers, do not. Likewise, some musicians perform melodies, whereas others, such as percussionists, typically do not. Musicians also differ in their training background: Some receive formal music education, whereas others are self-taught (e.g., Jimi Hendrix). These distinctions underscore the diversity within the category of “musician” (e.g., Tervaniemi, 2009). In addition, experimental protocols and measures (e.g., tools for assessing memory performance) vary widely across studies. This heterogeneity often impedes direct comparisons between studies and their results.
Finally, we want to address the possible reasons why musicians perform better than nonmusicians in short-term-memory tasks, as observed here and reported in the literature. We acknowledge that because of the correlational nature of the present study, the current results cannot provide a definitive answer on whether training to become a musician is the cause for this memory advantage. However, this study, involving the largest sample size to date, provides evidence of musicians outperforming nonmusicians, and in some cases, the advantage emerges even after controlling for potential confounding factors, such as SES, personality, age, gender, and education level. Several possibilities might explain the advantage in short-term memory. First, music training might directly improve short-term-memory performance. This improvement may be stronger for closely related abilities (e.g., short-term memory for musical stimuli) and weaker for abilities that are less related to the domain of expertise (e.g., short-term memory for visuospatial or verbal stimuli). The advantage in music short-term memory is substantial, whereas the advantage for visuospatial and verbal short-term memory is small or very small. A limitation of this hypothesis is that the current literature does not provide clear predictions about the magnitude of the advantage that should result from extensive music training (e.g., that of the participants in this study) or whether this advantage should be greater for visuospatial or verbal stimuli. Another possibility is that music training enhances higher-order cognitive functions, which, in turn, influence other cognitive abilities, such as short-term memory. For example, music training might enhance executive functions (see Frischen et al., 2021), which could mediate the relationship between music training and intelligence (Degé et al., 2011). In the current study, musicians exhibited small advantages in tasks assessing fluid and crystallized intelligence, and executive functions, such as small advantages for musicians in the Raven test (fluid intelligence), WAIS vocabulary scores (crystallized intelligence), and n-back task, which is thought to measure an updating component of working memory. This could have downstream effects on short-term-memory performance. However, the results of our multilevel models suggest that beyond a general cognitive advantage, being a musician predicts superior performance in tasks of music and visuospatial short-term memory (although in music short-term memory, the group was in interaction with crystallized intelligence). Although previous meta-analyses with randomized controlled trials have shown small cognitive benefits of music training (e.g., Jamey et al., 2024; Román-Caballero et al., 2022), the question of whether music training can cause far-transfer (either direct or indirect) effects remains debated (Sala & Gobet, 2020; Schellenberg & Lima, 2024; although the analytical decisions of the latter study were criticized by Bigand & Tillmann, 2022).
A further possible causal explanation, specific to the current experiment and methodology, is that musicians performed better in music tasks because of their training but also outperformed nonmusicians in other tasks (albeit to a lesser degree) because they had received more education overall. Although musicians and nonmusicians were matched for general education, this matching excluded musical education. In practice, many musicians in this study had more education overall because they often received extensive music training alongside regular schooling. Research shows that cognitive performance is associated with education (e.g., Ritchie & Tucker-Drob, 2018). Likewise, other groups of experts, such as master chess players, who receive additional education outside regular schooling tend to perform better on cognitive tasks than individuals without such education (e.g., Sala et al., 2017).
Finally, an alternative hypothesis is that the observed musicians’ advantage is due to preexisting cognitive abilities, that is, cognitively high-performing individuals may be more likely to become musicians, in particular, individuals of higher SES families (who support their musical careers) and individuals with personality traits that are known to be positively associated with the length of music training (Schellenberg & Lima, 2024; Swaminathan & Schellenberg, 2018). These factors were anyway accounted for in some of the present analyses.
As stated above, the present correlational study cannot resolve the “chicken and egg” problem, and the present discussion has been the result of a vibrant debate among the authors, who as far as interpretations are concerned, did not always share the same views. Nonetheless, the present work does provide robust estimates of the differences between experienced musicians and nonmusicians and underlines the importance of the open-science practice fully embraced by this study: Although interpretations might diverge, the data set and analysis pipeline are fully accessible, allowing the reader to form an opinion and interpretation starting from a direct and personal analysis.
Final remarks
We would like to explicitly acknowledge some of the limitations of the present study. Above all, this is a correlational study: Any relationship observed here does not imply causation. In other words, we cannot conclude that the music training (or the lack of it) causes any of the relationships observed here: It is impossible to disentangle the effect of training (or the lack of it) from the specific selection process that made one individual a musician. However, the question targeted by the present study (whether music expertise is in a relationship with short-term-memory performance) seems too challenging to be investigated experimentally. One becomes a skilled musician after long practice. If we assume that the musicians of the current study were studying music only 1 hr per day, the number of hours of practice per musician becomes well over 3,000. It is difficult to imagine an experimental study implementing such a long training. A second limitation is that results observed here cannot be extended to other types of memory, such as working memory or long-term memory. The decision to study short-term memory was driven by available data. In the meta-analysis by Talamini et al. (2017), this advantage was the largest and the least variable, suggesting the existence of a true relationship. This is the reason this relationship was investigated. Another limitation is the specific music culture: the Western one. The sample we recruited underwent training that is typical of Western countries in terms of type of music, type of instruments, type of schools, and so on. We cannot conclude that results observed here could be observed by recruiting musicians of non-Western cultures. Finally, the results of the current experiment are valid for a specific age range, that is, young adults, thus making them not generalizable to younger and older ages.
To conclude, in the present study, we showed that musicians have a short-term-memory advantage compared with nonmusicians, an advantage that is large for music stimuli, small for visuospatial stimuli, and very small for verbal stimuli. Musicians were also different from nonmusicians in many other aspects. They performed better in music-perception tasks, were more musically sophisticated, and got more reward from music. But they also had small advantages in tasks tapping intelligence and executive functions, and they came from families of higher SES. Finally, they differed in personality. Above all, they were substantially more “open to experiences.” The present study sheds light on a topic (i.e., whether music training is associated with enhanced cognitive performance), which revealed weaknesses in the past literature (e.g., heterogeneous designs, small sample sizes, large variation in results). Moreover, the present study can set a standard for future research on the topic, highlighting the importance of collaborative and preregistered studies as a tool to explore controversial but also new phenomena.
Supplemental Material
sj-docx-1-amp-10.1177_25152459251379432 – Supplemental material for Do Musicians Have Better Short-Term Memory Than Nonmusicians? A Multilab Study
Supplemental material, sj-docx-1-amp-10.1177_25152459251379432 for Do Musicians Have Better Short-Term Memory Than Nonmusicians? A Multilab Study by Massimo Grassi, Francesca Talamini, Gianmarco Altoè, Elvira Brattico, Anne Caclin, Barbara Carretti, Véronique Drai-Zerbib, Laura Ferreri, Filippo Gambarota, Jessica Grahn, Lucrezia Guiotto Nai Fovino, Marco Roccato, Antoni Rodriguez-Fornells, Swathi Swaminathan, Barbara Tillmann, Peter Vuust, Jonathan Wilbiks, Marcel Zentner, Karla Aguilar, Christ B. Aryanto, Frederico C. Assis Leite, Aíssa M. Baldé, Deniz Başkent, Laura Bishop, Graziela Kalsi, Fleur L. Bouwer, Axelle Calcus, Giulio Carraturo, Victor Cepero-Escribano, Antonia Čerič, Antonio Criscuolo, Léo Dairain, Simone Dalla Bella, Oscar Daniel, Anne Danielsen, Anne-Isabelle de Parcevaux, Delphine Dellacherie, Tor Endestad, Juliana L. d. B. Fialho, Caitlin Fitzpatrick, Anna Fiveash, Juliette Fortier, Noah R. Fram, Eleonora Fullone, Stefanie Gloggengießer, Lucia Gonzalez Sanchez, Reyna L. Gordon, Mathilde Groussard, Assal Habibi, Heidi M. U. Hansen, Eleanor E. Harding, Kirsty Hawkins, Steffen A. Herff, Veikka P. Holma, Kelly Jakubowski, Maria G. Jol, Aarushi Kalsi, Veronica Kandro, Rosaliina Kelo, Sonja A. Kotz, Gangothri S. Ladegam, Bruno Laeng, André Lee, Miriam Lense, César F. Lima, Simon P. Limmer, Chengran K. Liu, Paulina d. C. Martín Sánchez, Langley McEntyre, Jessica P. Michael, Daniel Mirman, Daniel Müllensiefen, Niloufar Najafi, Jaakko Nokkala, Ndassi Nzonlang, Maria Gabriela M. Oliveira, Katie Overy, Andrew J. Oxenham, Edoardo Passarotto, Marie-Elisabeth Plasse, Herve Platel, Alice Poissonnier, Neha Rajappa, Michaela Ritchie, Italo Ramon Rodrigues Menezes, Rafael Román-Caballero, Paula Roncaglia, Farrah Y. Sa’adullah, Suvi Saarikallio, Daniela Sammler, Séverine Samson, E. G. Schellenberg, Nora R. Serres, L. R. Slevc, Ragnya-Norasoa Souffiane, Florian J. Strauch, Hannah Strauss, Nicholas Tantengco, Mari Tervaniemi, Rachel Thompson, Renee Timmers, Petri Toiviainen, Laurel J. Trainor, Clara Tuske, Jed Villanueva, Claudia C. von Bastian, Kelly L. Whiteford, Emily A. Wood, Florian Worschech and Ana Zappa in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
We commit to share all our raw data upon acceptance for publication of the Stage 2 manuscript. Data, analyses scripts, and materials are stored on OSF, https://osf.io/y97t3/. Repository of all the relevant materials of the project (e.g., data, analysis scripts, digital materials, instruction for units and experimenters) is available at ![]() .
.
Transparency
Action Editor: Katie Corker
Editor: David A. Sbarra
Author Contributions
M. Grassi and F. Talamini share first authorship.
ORCID iDs
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.