
Abstract
Although item-response-theory (IRT) models offer well-established psychometric advantages over traditional scoring methods, they remain underused in practice. Following a brief introduction to the IRT framework, we emphasize its major advantages and explore potential applications in various research areas. The main part of this tutorial provides a comprehensive, step-by-step guide to Monte Carlo simulation-based sample-size estimation in IRT, which is essential for obtaining precise estimates of item and person parameters, structural effects, and model fit. Accurate a priori sample-size estimation is also crucial for effective study planning, especially in preregistration and registered reports. We highlight 10 key decisions, organized into four areas: (a) determining the data-generation model, (b) defining the test design and the process of missing values, (c) selecting the IRT model and parameters of interest, and (d) setting up and running the Monte Carlo simulation. The procedure is illustrated with examples from educational, personality, and clinical psychology. An extensively annotated and easily customizable syntax is available in an online repository.
Keywords
The measurement of psychological attributes provides the foundation of research on individual differences in human cognition, personality, and clinical symptoms. Before a study can address substantive research questions, for example, on risk factors associated with depression or the effectiveness of intervention programs to improve adolescents’ mental health, it is necessary to accurately estimate the relevant psychological characteristics. Despite this foundational importance, aspects of psychological measurement, including construct coverage or content validity, are often neglected (Clifton, 2020; Steger et al., 2023), sometimes resulting in a “measurement schmeasurement attitude” (Flake & Fried, 2020, p. 459). Appropriate measurement models for estimating trait scores are rarely given detailed attention; instead, researchers often use statistical methods of classical test theory implemented in standard statistical software without evaluating whether the implied response process is suitable for the observed item responses.
Item-response theory (IRT) provides a comprehensive framework for developing, evaluating, and refining psychological measures. Particularly, when combined with modern assessment designs, such as domain sampling (Markus & Borsboom, 2013), multimatrix booklet designs (Gonzalez & Rutkowski, 2010), or adaptive measurements (Magis et al., 2017), IRT can lead to more reliable and valid measurements that comprehensively cover the construct of interest. Despite its well-documented advantages, IRT is largely confined to specific areas of psychology, such as educational assessment and personnel selection. One reason for the limited use of IRT may be the challenge posed by its larger sample-size requirements, especially in complex measurement designs. A priori sample-size planning, therefore, plays a crucial role in the wider adoption of IRT models. By determining the required sample size in advance, researchers can avoid issues such as biased item-parameter estimates, inaccurate person estimates, and reduced generalizability of findings. In addition, careful planning of test design and sample size is a key component of preregistration and registered reports. To support this effort, we present a comprehensive guide outlining key decisions for simulation-based sample-size estimation. In this tutorial, we address a range of questions that require sample-size estimation and illustrate the procedure with application examples from educational, personality, and clinical psychology. Annotated analysis syntax in R (R Core Team, 2024) is provided, which can be easily customized to meet the needs of individual researchers. All resources are also available online at https://ulrich-schroeders.github.io/IRT-sample-size/.
A Short Recap on IRT Modeling
A variety of IRT models that describe the relationship between observed item responses and latent traits are included in a general IRT framework (Thissen & Steinberg, 1986). Depending on the IRT model chosen, different assumptions are made about the latent traits (e.g., unidimensional or multidimensional, metric or categorical trait estimates), item characteristics (e.g., difficulty, discrimination, guessing), and response process (e.g., dominance or ideal point). It is important to emphasize that IRT models can be used not only to scale performance test data but also to analyze self-report data, such as clinical or personality ratings with Likert-type or even nominal or count responses. Here, only a brief reminder is provided to introduce some of the most commonly used IRT models, which will be revisited in the subsequent examples (for more thorough introductions, see De Ayala, 2022; DeMars, 2010; van der Linden, 2018).
For dichotomous item responses that may indicate whether an item in an achievement test was correctly solved or an item in a questionnaire was endorsed, probably the most popular IRT model is the two-parameter-logistic (2PL) model (Birnbaum, 1968). The 2PL model assumes that the probability of a person p to receive an item score Xpi of 1, that is, correctly answering item i or showing a symptom in a clinical rating, depends on the latent trait θ p , the item’s difficulty bi, and the item’s discrimination ai:

A special case of this model, which is sometimes preferred in educational cognitive tests (Robitzsch & Lüdtke, 2022), assumes a constant discrimination parameter for all items and, thus, constrains ai to 1, resulting in the one-parameter-logistic (1PL) model (Rasch, 1960). The 1PL, or Rasch, model has the advantage that the total score (sum of the item responses) serves as a sufficient statistic for the person’s ability.
For polytomous items (i.e., multiple ordered categories), such as rating scales, Equation 1 can be modified to model the probability of obtaining a category score, for example, as in the graded-response model (GRM; Samejima, 1969):

where bik is the threshold parameter for modeling the probability of scoring at or above category k on item i.
Depending on the assumptions regarding the latent trait, the item characteristics, or the assumed response process, various extensions of these basic IRT models can be considered. For example, in achievement tests with multiple-choice items, it might be reasonable to acknowledge a guessing parameter that indicates the probability of solving an item correctly by mere chance. Or in clinical applications, an additional slipping parameter can account for the fact that some symptoms do not manifest themselves all the time, even for respondents with the most severe symptoms (Reise & Waller, 2003). Other IRT models have been developed to handle items with nominal (unordered) response categories (Bock, 1972), items with count responses, such as the number of symptoms (Forthmann et al., 2020), or items with forced-choice responses (Brown & Maydeu-Olivares, 2013). IRT models can even abandon the assumption that item-response probabilities increase with the latent trait across the entire trait scale. For example, responses to measures of noncognitive constructs (e.g., emotion, vocational interests) may be better represented by ideal-point models, in which the response probabilities peak where the latent trait matches the item difficulty (e.g., Tay et al., 2009). Finally, extensions of IRT models that account for different types of response styles (e.g., acquiescence, midpoint responding), disengagement, or careless responding can provide more accurate trait estimates (e.g., Scharl & Gnambs, 2024; Welling et al., 2024). Thus, IRT represents a highly flexible framework that allows specifying variable-latent-trait models depending on the assumptions about the relationship between observed responses and latent traits.
Compared with other methods, such as ordinal-factor analysis, the joint scaling of individuals and items on a common scale and the focus on the individual items rather than the test as a whole offer several advantages for test construction and individual assessment. First, IRT facilitates test equating, which allows scores from different test forms to be compared, which is essential for maintaining score consistency over time and across different versions of a test (Kolen & Brennan, 2014). Thus, IRT models can even be used to convert test scores obtained with different measurement instruments to a common metric, thereby improving comparability and interpretability (Choi et al., 2014; Wahl et al., 2014). Second, IRT allows for the construction of parallel test forms with identical test-information curves to ensure consistency and comparability across test forms (Zimny et al., 2024). Third, through computerized adaptive testing, IRT tailors item selection to an individual’s ability, thereby optimizing test efficiency (Magis et al., 2017). Fourth, IRT helps to identify items that perform differently for subgroups of test takers (e.g., gender or cultural groups), which is useful for ensuring test fairness and test validity across groups (Berrío et al., 2020). Finally, IRT models provide information about the precision of ability or trait estimates for individuals at different ability levels. This enables the precision of the measurement instrument to be quantified and enhanced across different parts of the trait distribution (e.g., by selecting appropriate items). These advantages make the use of IRT models attractive in various application contexts.
Simulation-Based Sample-Size Determination for IRT Analyses
Several textbooks on IRT provide general recommendations on the required sample size for different models (De Ayala, 2022; DeMars, 2010; van der Linden, 2018), which often culminate in suggesting at least 250 or 500 respondents (e.g., DeMars, 2010; Valdivia & Dai, 2024) or having a sufficient ratio of respondents to model parameters, such as 10:1 or 20:1 (De Ayala & Sava-Bolesta, 1999; DeMars, 2003). However, simulation studies examining the minimum required sample size for IRT analyses have consistently shown that these are context-dependent. For instance, some studies have suggested that IRT can yield accurate parameter estimates with as few as 100 respondents if prior information is incorporated into the estimation (König et al., 2020; Sheng, 2013) or estimation methods that are robust to missing values are employed (Finch & French, 2019). In contrast, other studies have indicated that for IRT models including guessing or slipping parameters (Cuhadar, 2022) or those representing mixtures of multiple latent classes (Kutscher et al., 2019; Sen & Cohen, 2023), even sample sizes of 2,000 may be insufficient. As a result, general rules of thumb are often not practical because the required sample size is influenced by multiple factors, such as (a) the item type (e.g., dichotomous, polytomous), (b) the assumed-response model (e.g., 1PL, 2PL), (c) the estimation method (e.g., marginal maximum likelihood, joint maximum likelihood, Bayesian methods), (d) the dimensionality of the model (unidimensional vs. multidimensional), (e) the distribution of the latent trait(s), (f) the size and homogeneity of the item pool, and (g) the test design (including the amount of missing data and item coverage). Because findings from published simulation studies may not generalize to the unique circumstances of a planned study, researchers need to conduct context-specific sample-size estimations tailored to their own model specifications and study design.
Sample-size estimation is also shaped by the research questions and test designs commonly encountered across different disciplines (see Table 1). Accordingly, IRT applications differ in terms of the traits being measured, the item-response format, the associated models, and the unit of analysis. In large-scale educational assessments, IRT analyses typically focus on evaluating domain-specific knowledge or skills using achievement items with dichotomous-response formats (correct or incorrect answers). In contrast, psychological research primarily employs self-ratings with polytomous-response formats to measure personality traits or clinical-symptom severity. Accordingly, educational assessment often uses basic models, such as the Rasch or 2PL/3PL models, and psychological research often relies on more complex models, such as the GRM. Thus, although the models are simpler in large-scale educational assessment, the analyses are often complicated by a hierarchical sampling structure, with students nested in schools, which, in turn, may be nested in federal states or even countries. As a result, accurately estimating item parameters and ability distributions in these contexts requires IRT-modeling approaches that account for the heterogeneity of hierarchically nested populations. Studies on sample-size recommendations in this field typically focus on test properties, aiming to estimate item difficulties with a certain level of precision (e.g., Finch & French, 2019) or to evaluate differential item functioning (e.g., Belzak, 2020). In contrast, psychological research, particularly in controlled settings, tends to adopt more straightforward test designs with more homogeneous samples. And in applied clinical research, the focus is often on providing individual feedback. This comparison of educational and psychological research, however, is simplified because there are many crossovers. For example, in clinical research, sample-size estimates are also used for group-level analyses, such as reliably detecting treatment effects (Holman et al., 2003). In summary, sample-size calculations need to be tailored to the specific context, taking into account the research question and study characteristics, such as item-response format, test design, or unit of analysis. It is likely that the specific conditions of a planned study have not yet been investigated in the research literature, making it difficult to obtain accurate information on sample-size requirements from published simulations.
Sample-Size Estimation for Example Research Questions in Item-Response-Theory Analyses

Given the challenge in providing sample-size recommendations for each conceivable research scenario, Monte Carlo simulations that are tuned to the requirements of a specific study are increasingly recommended to derive suitable sample-size estimates (e.g., Zimmer & Debelak, 2023; Zimmer et al., 2024). Although good primers for simulation-based sample-size estimations are available for structural equation modeling in Mplus (e.g., Muthén & Muthén, 2002) and the R environment (e.g., Moshagen & Bader, 2024; Wang & Rhemtulla, 2021), there is currently no similar counterpart for IRT. Therefore, we present a generic procedure with 10 key decisions in Table 2 to determine the required sample size using Monte Carlo simulations. The list is not exhaustive, but it provides a comprehensive guide to the most important decisions that need to be made. Four major steps can be distinguished: determining the data generation for the complete data set, defining the test design and the process of missing values, selecting the IRT model and the parameter of interest, and setting up the Monte Carlo simulation.
Decisions in Simulation-Based Sample-Size Estimation for IRT Analyses

Note: IRT = item-response-theory; 1PL = one-parameter-logistic model; 2PL = two-parameter-logistic model.
The Present Tutorial
In this tutorial, we aim to demonstrate how to use Monte Carlo simulations to inform researchers about the sample-size requirements for specific tests and test designs analyzed with IRT models. The decisions to be made are summarized in Table 2 and will be discussed using three application examples, arranged in ascending order of complexity.
The first application example deals with two test forms of a reasoning test that are linked by a subset of common items. The accuracy of item-difficulty estimation is examined as a function of sample size. The second application example examines the precision of the estimated correlation between a latent personality trait and a metric criterion in a forced-choice personality test. In addition to varying the sample size, also the number of items randomly drawn from the item pool to determine the precision of the estimated correlation is varied. The third and most complex application example investigates the accuracy of the conditional reliability at the boundary between moderate and severe symptom severity for three clinical rating scales of depression in a GRM.
In an online repository (https://ulrich-schroeders.github.io/IRT-sample-size/), the annotated syntax for these examples is provided, which can be easily adapted and reused. We used the excellent and well-documented R packages mirt (Chalmers, 2012) and TAM (Robitzsch et al., 2024) to simulate data and estimate the IRT models. In the online supplement, we offer two additional examples that expand on those discussed in the tutorial by addressing multidimensionality and the missing-data process, specifically, missing at random (MAR). 1 For didactic reasons, we recommend working through the examples in the order presented.
Example 1: piloting an ability test with a linked test design
Determining the data generation for the complete data set
In the first application example, we outline the planning of a pilot study aimed at estimating the item difficulty of a reasoning test. Precise estimation of item parameters is crucial for predicting item difficulty based on item characteristics, which is key to rational test construction. The item parameters for the 30 items are simulated according to the 2PL model given in Equation 1. The true discrimination parameters vary slightly around 1 (with a standard deviation of 0.01), which is essentially a Rasch-compatible model, and the item difficulties are equally spaced between −2 and 2 logits. We have deliberately opted for this somewhat artificial distribution of the b parameters to cover a broad ability range. However, depending on the specific measurement intention of the test, alternative parameter distributions may be more suitable. For instance, in a psychological measure designed to screen for learning disabilities, such as dyslexia or dyscalculia, item-difficulty parameters should be focused on the lower end of the ability distribution.
Defining the test design and the process of missing values
In a noncomputerized test, items cannot be administered to test takers completely at random. To minimize the burden for respondents while still piloting as many items as possible, a multiple-matrix sampling design is often implemented (e.g., Frey et al., 2009). Multiple-matrix designs with common linking items are particularly valuable for parallel tests with items based on the same construction principles, in which, full randomization is not possible (e.g., Schroeders et al., 2024). In this example, two test versions (A and B) are administered, each containing 18 items. Twelve of these items are unique to each test version, and six items are common to both test versions, which ensures that items and persons can be scored on a common scale.
Selecting the IRT model and the parameter of interest
The dichotomously scored performance test is modeled using a Rasch model, which is sometimes used in large-scale educational assessments (Robitzsch & Lüdtke, 2022). Although the assumption of uniform item discrimination is often not strictly met in real data sets, Rasch modeling is popular in practice because of the ease of interpretation of results, the direct comparability of items, and the low data requirements for obtaining stable parameter estimates.
Although sample-size requirements in structural equation modeling often arise from the discussion about the accuracy of model-fit evaluation, that is, the power with which a theoretical model can be accurately fit based on empirical data (Wolf et al., 2013; see also Example 5 online), in IRT, the focus is often on the parameter estimation itself. In the present context, the mean square error (MSE) of the item difficulties is used as the criterion, 2 with acceptable cutoffs generally below .05. Note that the item-difficulty parameters at the extremes of the performance distribution (i.e., very easy and very difficult items) cannot be estimated with the same precision as those of medium difficulty.
Setting up the Monte Carlo simulation
The number of iterations required to obtain robust estimates in a Monte Carlo simulation 3 depends on the expected variability of the parameter of interest (in the current case, MSE), the desired accuracy, and the significance level (see Burton et al., 2006). 4 Because no prior information on the variability of the MSE was available from the literature or previous studies, we first ran 500 iterations to estimate the maximum standard deviation of the MSE, which was found to be 0.523 for the easiest item (Item 1) in the condition with the lowest sample size. Based on the standard deviation of the MSE (σ = 0.523), a specified level of accuracy (δ = 0.05), and a significance level (α = .05), we found that the required number of iterations was calculated as 438. In the Monte Carlo study, the sample size varied between 100 and 600 with intervals of 50.
Results and interpretation
Figure 1 shows the MSE of the item difficulty estimates for two items: an easy item with b1 = −2 (proportion correct ≈ .86) and a linking item of moderate difficulty with b15 = −0.07 (proportion correct ≈ .51). The MSE, calculated as the mean square difference between the estimated item difficulty best and the true item difficulty btrue across the iterations (R), provides a comprehensive measure of the precision of these estimates. The confidence intervals were calculated using the Monte Carlo standard error, which is given by
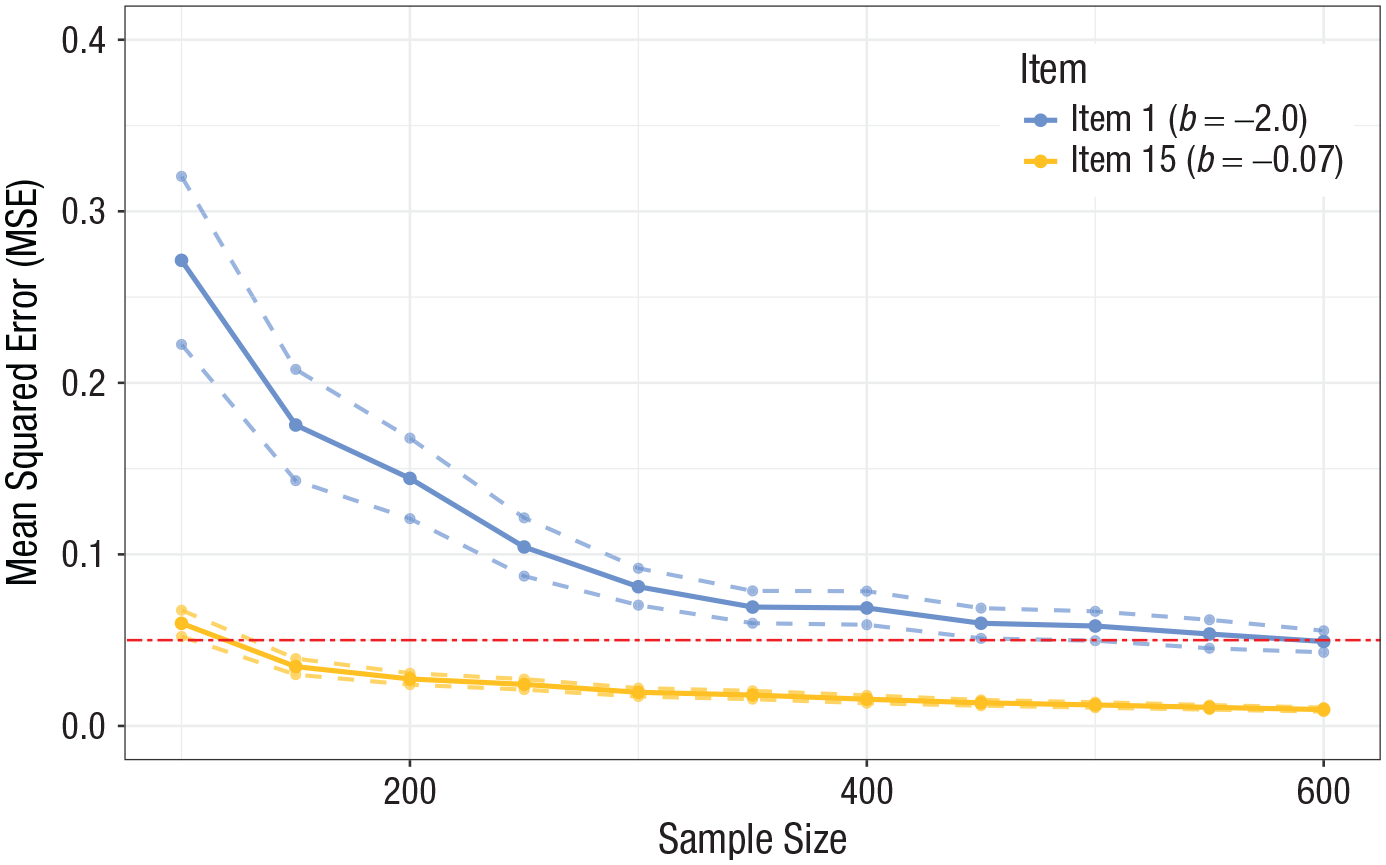
Mean square error of item difficulties with 95% confidence intervals depending on the sample size. Dashed lines indicate the margin of error (MSE ± 1.96 × Monte Carlo standard error).
Example 2: personality-test validation with randomized item sampling
Determining the data generation for the complete data set
In the second example, we describe the validation of a newly developed computerized personality test with a forced-choice response format comparable with the Eysenck Personality Inventory (e.g., “Do you prefer reading to going out?”; yes/no). Forced-choice personality items offer several advantages over rating scales, including minimizing the likelihood of response-pattern bias (Brown & Maydeu-Olivares, 2011), increasing test reliability and validity (Stark et al., 2005), and encouraging honest responses from participants (Christiansen et al., 2005). In this example, forced-choice items measuring extraversion that are randomly selected from a larger 30-item pool are considered. The latent trait was assumed to correlate with an external metric variable at ρ = .50, and accordingly, the persons’ abilities are generated using a multivariate normal distribution. The difficulty parameters are defined as in the first example, and the discrimination parameters are drawn from a log-normal distribution to reflect realistic variation with positive skewness typically observed in empirical data.
Defining the test design and the process of missing values
The items of the computer-administered personality test are randomly drawn from a larger item pool, generally ensuring complete coverage of item covariances for a nontrivial sample size. Such a random sampling design is, for example, used in the Synthetic Aperture Personality Assessment project (Condon et al., 2017) to maximize the breadth and depth of personality assessment by administering a wide range of items. In this simulation, three levels of missingness are examined: 0% (equivalent to 30 administered items), 33% (equivalent to 20 administered items), and 67% (equivalent to 10 administered items). In the simulation, the complete data are generated first, and then observations are deleted under the assumption of missing completely at random (MCAR 5 ).
Selecting the IRT model and the parameter of interest
The model to be estimated is a unidimensional 2PL model with a regression of the latent trait on the z-standardized criterion. The parameter of interest is the standard error of the regression coefficient, which corresponds to the correlation between extraversion and the metric criterion. In addition to the sample size, the amount of missing data is also varied to determine the optimal test design for estimating the standard error with sufficient precision. This example illustrates that the sample-size estimation is also affected by other factors, such as the test design.
Setting up the Monte Carlo simulation
The standard deviation of the standard error of the correlation derived from 500 iterations was low (σ = .0052), also in the most demanding condition (n = 200, missing rate = 67%). Combined with a specified level of accuracy (δ = .001) and a significance level (α = .05), this implies a number of required iterations of approximately 104. The simulation is run for different sample sizes between 200 and 700 (in increments of 50) with three levels of missing rates (0%, 33%, 67%).
Results and interpretation
Figure 2 shows the average standard error of the correlation across all iterations between the forced-choice personality test and the metric criterion. For the full 30-item questionnaire, the threshold is reached with about 500 participants. The lines for none and one-third of missing items are close together, indicating that the absolute number of items is decisive and that a precise estimate of the standard error is already obtained with 20 items. Note, however, that the effect of missingness is not linear. The decision as to whether it is beneficial to include more items per participant or to recruit more participants who work on smaller item sets depends on the specific circumstances of the study and can be determined through a cost analysis (Zimmer & Debelak, 2023; Zimmer et al., 2024).

Average standard error of the correlation depending on the sample size and number of items. The plot shows the average standard error of the correlation as a function of the sample size and the number of items, with varying percentages of missingness. The red dashed line indicates the target standard error of 0.05.
Example 3: conditional reliabilities of three clinical measures
Determining the data generation for the complete data set
In the third example, we describe how to determine the sample size required to estimate the conditional reliability of a test with a specified precision using the GRM (Samejima, 1969). The simulated data are based on the empirical item parameters of three popular clinical-depression measures, as reported in the study by Choi et al. (2014). The measures differ in the number of items; the Beck Depression Inventory–II (BDI) has 21 items, the Center for Epidemiological Studies Depression Scale (CESD) has 20 items, and the Patient Health Questionnaire (PHQ) has nine items. All items are answered on a 4-point, ordered response scale; for example, CESD-1, “I was bothered by things that usually don’t bother me,” had responses from 0 (rarely or none of the time) to 3 (most or all of the time). These instruments are designed to measure accurately in an elevated range of the trait distribution because they are used to screen patients for clinically relevant levels of depression. In clinical assessment, symptom severity is typically characterized as mild (0.5 < θ < 1.0), moderate (1.0 < θ < 2.0), and severe (θ > 2.0).
In contrast to classical test theory, which assumes that a single reliability estimate applies universally to all levels of a trait, IRT estimates reliability conditionally, specific to a given trait level (e.g., different levels of depressivity; see Fig. 3). The true conditional reliability estimate (ρtrue) can be calculated from the item parameters: High discrimination parameters (ai) enhance reliability by better differentiating between individuals at specific trait levels, and difficulty parameters (bi) determine the trait levels at which items are most informative. The accuracy of the estimated conditional reliability (ρest) depends largely on the sample size.

True conditional reliability across three measures of depressivity. The true conditional reliability calculated from the item parameters is shown. The gray vertical line indicates the value of the latent trait (θ = 2.0) at which the standard error of the conditional reliability is examined.
Defining the test design and the process of missing values
It is assumed that respondents are randomly administered two of the three depression instruments. Thus, this is a special form of a reciprocal linking design in which the linking items comprise the complete instruments.
Selecting the IRT model and the parameter of interest
The GRM is used to analyze ordered categorical responses, typically encountered in clinical-rating scales. The model estimates the probability that respondents will select a particular response category based on their underlying trait level; each item has multiple thresholds corresponding to the different response categories (see Equation 2). The true conditional reliability (ρtrue) at a given point in the trait distribution (θ = 2.0), calculated from the item parameters, was .97 for the BDI, .96 for the CESD, and .91 for the PHQ. To quantify the accuracy of the estimated reliability, the root mean square error (RMSE) of the reliability is used,
Setting up the Monte Carlo simulation
Using an estimated standard deviation for the RMSE of the estimated reliability (σ = .012) derived from 500 iterations, a specified level of accuracy (δ = .001), and a significance level (α = .05), we found that the number of iterations required is approximately 553. The simulation is run for different total sample sizes between 300 and 1,050 (in increments of 75). Because of the chosen test design, the sample size for each individual measure is two-thirds of the total sample size (i.e., 200–700 in increments of 50).
Results and interpretation
For the longer measures, CESD and BDI, the conditional reliability at the relevant trait level is higher, and the associated RMSE is lower than for the short measure. For the PHQ, the required accuracy of RMSE ≤ .01 is achieved with a sample size of approximately 600 participants who completed the instrument (or a total sample size of 900 participants; see Fig. 4). If the accuracy of the conditional reliability of all instruments is to be identical, groups of unequal size would have to complete the instruments.

Accuracy of the conditional reliability estimate at the boundary between moderate and severe symptom severity depending on sample size. The lines for the BDI and CESD largely overlap. BDI = Beck Depression Inventory–II; CESD = Center for Epidemiological Studies Depression Scale; PHQ = Patient Health Questionnaire.
Summary and Outlook
IRT offers a versatile yet often underused toolbox for constructing, evaluating, and refining psychological measures. Current applications range from educational assessment (Hori et al., 2022) to clinical symptom evaluation (Balsis et al., 2017; Thomas, 2019) and organizational-behavior research (Lang & Tay, 2021). Despite its versatility, the IRT framework has not yet been fully embraced across all areas of psychology. A major reason for this may be uncertainty about the sample size required to estimate complex IRT models with many parameters or missing data, especially compared with more familiar factor-analytic approaches (ten Holt et al., 2010). This hesitation is unfortunate given the potential of IRT in many contexts: For example, IRT is prominently used in the Patient-Reported Outcomes Measurement Information System (Cella et al., 2010) to capture patients’ perspectives on their health, quality of life, and treatment outcomes through computer-adaptive testing, thereby, reducing testing time, response burden, and potential memory bias.
Since its invention, the IRT framework has continuously been expanded, now encompassing a wide range of models for specific purposes. For example, cognitive-diagnosis models (Templin & Henson, 2006) assess whether students have mastered specific cognitive skills, conjoint IRT (Klein Entink et al., 2009) integrates response times alongside the accuracy of an answer, and multidimensional zero-inflated GRMs (Magnus & Garnier-Villarreal, 2022) examine symptom frequencies of psychopathology in community samples in which endorsements are rare. To address concerns regarding the use of IRT, we advocate for a simulation-based approach to sample-size planning, tailored to the unique conditions of a given study (for similar calls, see Zimmer & Debelak, 2023; Zimmer et al., 2024).
In this tutorial, we have presented a guide with 10 key decisions, organized into four steps. In the first step, the data-generation process for the complete data set needs to be determined. This requires thinking about the item types included in the test, the assumed response process, and the item parameters (e.g., difficulty, discrimination) to be estimated. The second step involves specifying the concrete test design (e.g., booklet design) and how items are administered (e.g., linking design) to clarify potential processes leading to different types of missing values (MCAR, MAR). In the third step, the IRT model (e.g., 2PL, GRM) and the parameters of interest (e.g., item difficulty) are chosen depending on the research question and the conditions specified in the previous steps. In the fourth step, the design of the Monte Carlo simulation needs to be specified, which includes determining the number of required iterations to obtain stable estimates of the parameters of interest and deciding on the range of sample sizes to consider. To assist researchers in setting up their own simulation, the four steps described in our guide were illustrated with several examples, covering a wide range of applications, that stretched from the simple Rasch modeling of a one-dimensional performance test administered in a linked test design (Example 1) to the criterion validation in a multidimensional 2PL model with randomized item selection (Example 2) to the conditional reliability in a GRM (Example 3). Additional application examples with accompanying syntax are available in the supplement material (https://ulrich-schroeders.github.io/IRT-sample-size/).
Although we agree that simulation-based sample-size planning is more complex and time-consuming than relying on simple rules of thumb provided in the psychometric literature (e.g., DeMars, 2010; Valdivia & Dai, 2024), properly specified simulations will lead to more accurate sample-size estimates for a planned study and ultimately to more robust results because specifics of the research question, test design, and data conditions together influence the required sample size in unique ways. To further lower the technical hurdle for performing IRT sample estimation, a next step could be to make the functions outlined in this tutorial more flexible (e.g., with respect to specifying different test designs) and to develop user-friendly software (e.g., a shiny app). In addition, the functionality of the syntax could be extended to use cases such as adaptive testing with missing data processes that depend on the ability of the person (e.g., using the R packages catR and mirtCAT; see Magis et al., 2017) or modern procedures for differential-item-functioning analyses to address issues of measurement invariance across categorical and metric variables (e.g., based on the R packages GPCMlasso, Schauberger & Mair, 2020; or psychotree, Strobl et al., 2015).
The checklist provided in Table 2 summarizes critical decisions that researchers must make when planning a simulation study to determine the required sample size, which will hopefully assist in the preparation of preregistrations and registered reports and during the review process. However, this checklist should be seen as a flexible template rather than a rigid prescription. Researchers are advised to adapt the framework to fit their specific study conditions. For example, depending on the research question, different IRT models, including multidimensional and mixed models, might need to be specified, or the focus of the simulation may need to shift to a different parameter, such as the mean difference between a treatment group and a control group. In addition, it might be interesting to examine sample-size requirements from a cost-benefit perspective (Zimmer & Debelak, 2023; Zimmer et al., 2024) to decide whether improving precision by assessing more respondents outweighs the additional costs (e.g., in terms of time, money, and participant burden).
Researchers should be reminded that the accuracy of simulations depends on how well the model assumptions reflect real-world conditions and adequately account for the complexities of empirical data. For example, in practice, a measurement instrument may deviate from the assumed unidimensional model (e.g., negatively worded items may introduce method-specific variance; see Gnambs & Schroeders, 2020), or participants may vary in their engagement in answering the questions (e.g., careless/insufficient effort responding; see Schroeders et al., 2022). Simulations often assume more ideal data conditions than empirical data sets, which are plagued by such item- or person-specific effects. Therefore, sample-size planning should take these conditions into account by varying different model assumptions in the Monte Carlo simulation to examine the extent to which they affect the required sample-size estimation. We hope the framework presented in this tutorial will help researchers to do so and encourage the wider adoption of IRT in psychological research, leading to improved measurement practices.
Footnotes
Acknowledgements
We confirm that the work conforms to Standard 8 of the American Psychological Association’s Ethical Principles of Psychologists and Code of Conduct.
Transparency
Action Editor: Yasemin Kisbu-Sakarya
Editor: David A. Sbarra
Author Contributions