
Abstract
Testing is used to inform a range of critical decisions that help structure much of contemporary society. An unavoidable aspect of testing is that test scores are not infallible. As a result, individual test scores should be accompanied by an interval that indicates the uncertainty surrounding the score. There are a number of different test-score intervals that can be created from different error terms. Unfortunately, there are pervasive misinterpretations of these errors and their intervals. Many of these interpretations can be found in authoritative sources on psychological measurement, which has resulted in stubborn and persistent confusion about what these intervals mean. In the current article, we clarify two important error terms and their intervals: (a) the Standard Error of Estimation and (b) the Standard Error of Measurement. We explicate the meaning and interpretation of these errors by examining their statistical foundations. Specifically, we detail how these terms are formulated from different statistical models and the implications of these models for their different interpretations. We use classical test theory, bivariate linear regression, R activities, and algebra to illustrate the key concepts and differences.
Keywords
Until I know this sure uncertainty, I’ll entertain the offer’d fallacy.
In contemporary society, psychometric testing is a nearly unavoidable part of life and is used to inform important decisions. Because testing is used to inform many important life decisions, it plays an important role in determining how much of modern society is structured. For instance, the use of testing can be found at nearly every major transition point in life; from school success and achievement in the form of exams and standardized exams (i.e., SAT) to the acquisition of various permits and licenses (i.e., driver’s exam) to decisions around occupational and career success (e.g., personnel-selection tests and performance appraisals). A key part of testing is recognizing the inherent uncertainty associated with any test result. Consequently, when interpreting an individual’s test score, it is generally recommended that some type of interval be used to indicate this uncertainty (American Education Research Association et al., 2014).
Unfortunately, when trying to index uncertainty around test scores, there can be much uncertainty about (a) which error term should be used to construct the interval and (b) how the interval should be interpreted. In the branch of testing informed by classical test theory, there are generally four types of errors to choose from, each with a different interpretation (Gulliksen, 1950). These four errors are sometimes referred to by different names across different sources but are generally known as “standard error of estimation,” “standard error of measurement,” “standard error of prediction,” and “standard error of the difference” (cf. Dudek, 1979; Guilford, 1936; Gulliksen, 1950; T. L. Kelley, 1927; Nunnally & Bernstein, 1994). In this article, we focus on intervals constructed from the two closely related error terms: Standard Error of Estimation and Standard Error of Measurement. Throughout this article, we capitalize these terms to aid in reading comprehension by distinguishing them from similar-looking regression terms.
Given the importance of testing, it may be surprising to learn that there is a history of disagreement surrounding what these error terms mean and how they should be interpreted (e.g., Dudek, 1979; Harvill, 1991). For example, some sources state that the Standard Error of Measurement interval is designed to capture future observed scores with a specified probability (e.g., Harvill, 1991; Murphy & Davidshofer, 2005; Nunnally & Bernstein, 1994), whereas others have argued that the Standard Error of Measurement interval is designed to capture true scores at a specified probability (e.g., Furr, 2018; Gregory, 2013; Kaplan & Saccuzzo, 2013; Reynolds & Livingston, 2012). Complicating things further, the Standard Error of Estimation interval is often described in terms that seem to overlap with the Standard Error of Measurement interval. Specifically, it has been argued that the Standard Error of Estimation interval is designed to capture true scores with a specified probability and that individuals who interpret the Standard Error of Measurement interval in this same way are in error (e.g., Dudek, 1979; Harvill, 1991). These conflicts, or what may appear to be cases of mistaken identity, can present readers with a dilemma when deciding which interval they should use and how they should interpret its meaning.
For example, in the United States, to get a license to practice medicine, individuals must take a United States Medical Licensing Examination (USMLE). To help examinees interpret their scores, some documentation is provided that explains to examinees that “measurement error is present on all tests” (USMLE, 2023, p. 4) and describes three intervals that index “the imprecision of scores” (USMLE, 2023, p. 4). The “Standard Error of Measurement,” “Standard Error of the Estimate,” and “Standard Error of the Difference” are presented. The documentation states that the Standard Error of Measurement “indicates how much a score might vary across repeated testing using different sets of items covering similar content” (USMLE, 2023, p. 4). The Standard Error of the Difference “assess[es] whether the difference between two scores is statistically meaningful” (USMLE, 2023, p. 4). And the Standard Error of the Estimate “is an additional index of the amount of uncertainty in the scores used to gauge the likelihood of performing similarly on a repeat attempt” (USMLE, 2023, p. 4). From these short descriptions, one can see how the Standard Error of Measurement and Standard Error of the Estimate are presented as being virtually redundant with each other, indexing the same type of uncertainty.
In the current article, our aim is to build consensus around how intervals based on the Standard Error of Estimation and Standard Error of Measurement are understood and properly interpreted. We begin by noting that these two error terms can be used to construct three intervals. This imbalance between the number of error terms and number of intervals has caused considerable confusion when trying to understand the statistical and conceptual frameworks underlying these intervals. Consequently, in this article, we use three interval labels (of our own creation) that are suggestive of the correct interpretations to help with clarity: SEE (Standard Error of the Estimate) Many-Test-Takers Interval, SEM (Standard Error of Measurement) Many-Test-Takers Interval, and SEM (Standard Error of Measurement) Single-Test-Taker Interval. In Table 1, we introduce how the intervals vary with respect to their interpretations and characteristics. We also provide numerical examples in Table 1 that are later explicated.
We want to emphasize that the three intervals presented in Table 1 are formulated from fundamentally different statistical models that have profound implications for how they are understood and interpreted. Specifically, the SEE Many-Test-Takers and SEM Many-Test-Takers Intervals are both formulated on different bivariate regression models (Gulliksen, 1950). Understanding these different regression models is essential to understanding the difference between these two intervals. In contrast, the SEM Single-Test-Taker Interval uses an entirely different approach; it follows from the logic associated with estimating a population mean using a sample mean. Thus, before examining the statistical foundations for the intervals, we provide a brief summary of important classical test-theory principles. Following this, we touch on a few key but esoteric regression principles that are needed to understand the nature of Many-Test-Takers Intervals. Consequently, extensive prior knowledge of regression and classical test theory are not required. Accompanying this article, we also provide details and exercises in supplemental materials (https://dstanley4.github.io/comedyerrors/) for readers who wish additional pedagogical resources. Table 1 presents a summary of the interval interpretations that will be explained and supported in the sections that follow.
Three Measurement Intervals

Note: SEE = Standard Error of Estimation; SEM = Standard Error of Measurement.
Classical Test Theory
In classical test theory, observed scores result from the combination of true scores and random error, as illustrated in Equation 1. In this formula, the random errors have a mean of zero, and the standard deviation of the errors is indicated by the term

There are a number of implications that follow from Equation 1. Some of these implications are presented in Table 2; however, we encourage readers to consult Gulliksen (1950) for a complete discussion.
Classical Test Theory Implications

We note that among the implications presented in Table 2 is that there are various mathematically equivalent definitions of reliability (i.e.,
Bivariate Regression: A Lens for Understanding Intervals
To properly understand what Standard Error of Estimation and Standard Error of Measurement are and their corresponding differences, it is crucial to understand bivariate linear regression. The reason for this is because both Standard Error of Estimation and Standard Error of Measurement are errors of prediction that arise from two different regression models (Gulliksen, 1950). Specifically, Standard Error of Estimation is the error in predicting true scores from observed scores, whereas Standard Error of Measurement is the error in predicting observed scores from true scores (Gulliksen, 1950). In the sections below, we explain these distinctions more comprehensively and thoroughly. Because Standard Error of Estimation and Standard Error of Measurement are errors that are derived from bivariate linear regression, we begin by reviewing a few key concepts from linear regression that are necessary to understand what the Standard Error of Estimation and Standard Error of Measurement are—and how they are different.
Model
When analyzing data, researchers often use a linear model, or a regression line, to describe the relation between two variables. In a measurement context, one can create a regression line that relates true scores to observed scores or vice versa. The slope of the regression line in this model is important because the regression line serves as the center point for a variety of measurement intervals.
In a two-variable regression, one variable serves as the criterion (i.e., the dependent variable), and one variable serves as the predictor. When graphing a regression, one places the criterion on the
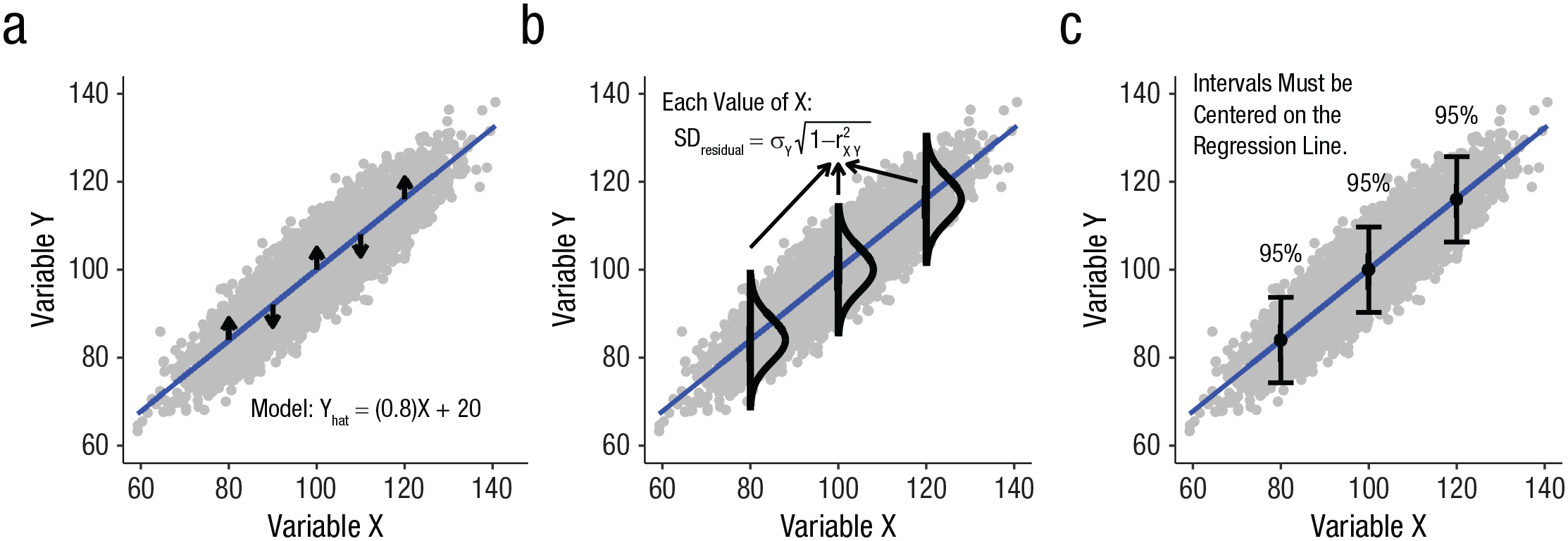
(a) Model. (b) Population for each x-axis value. (c) Capturing scores on y. Regression is the basis for many measurement models.
Describing the model: slope and intercept
In Figure 1a, we present a model in which the regression line has a slope of .80 and an intercept of 20. The slope refers to the angle of regression line, and the intercept refers to the elevation of the regression line (indicated by the position at which the line crosses the
Slope is typically presented as the change in

There is, however, more than one way to describe the slope of a regression line. Indeed, when there is only one predictor, the correlation between

Using the model: predicted values
The components of the regression model, slope and intercept, are typically presented in a regression equation like the one below:

The regression equation is what one uses to generate the regression line. The regression line is effectively a series of predicted values. For a specified position on the
A predicted value, a

Predicted values without an intercept
When working in a measurement context, one typically knows the slope of the regression line but unfortunately, not the intercept; this will become evident later. Consequently, we illustrate an alternative approach to calculating predicted scores (i.e.,
One can use the (

Moving forward, we refer to Equation 2 as the “no-intercept approach” to predicted values:
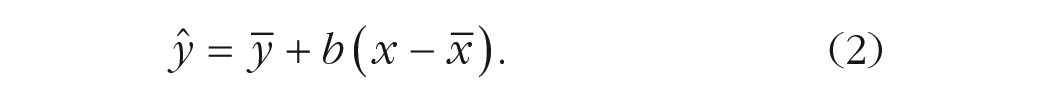
Revisiting the previously described scenario in which we are interested in obtaining a

We can see the
Interpretation of predicted values
The proper interpretation of predicted values (i.e.,
To properly interpret the
Because there is an entire population of
Errors
The vertical distance between each point (representing a person) in the scatter plot and the regression line is called a “residual.” Of particular interest in a regression is how close the points are to the regression line. The overall vertical closeness of all the points to the regression line is indexed by the variance of the residuals. The typical formula for the variance of residuals is presented in Equation 3:

In the measurement context, however, we use an alternative formula for the variance of residuals (see Allen, 1997). This alternative formula, which provides the same result when

Taking the square root, we obtain the formula for the standard deviation of residuals in Equation (5) below:

Homogeneity of residuals
In linear regression, there are several assumptions. One assumption that is relevant for the calculation of measurement intervals is homoscedasticity. Homoscedasticity means that the variance of the residuals around a regression line is the same for all values on the
Summary
Because Standard Error of Measurement and Standard Error of Estimation are derived from different bivariate linear regression models, the regression principles outlined above will make it possible to more clearly understand what Standard Error of Estimation and Standard Error of Measurement intervals are and how they are different.
SEE Many-Test-Takers Model
The Standard Error of Estimation interval provides a way to understand the variability in true-score scores for the many test takers that share a specified observed score. The Standard Error of Estimation interval has sometimes been presented as a preferred interval to construct around test scores (Dudek, 1979). This preference for the Standard Error of Estimation interval is predicated on the misunderstanding that the Standard Error of Measurement interval is not useful for predicting true scores (e.g., Charter & Feldt, 2001; Dudek, 1979; Harvill, 1991). We believe that the misinterpretation of Standard Error of Measurement interval is often rooted in a misunderstanding of the Standard Error of Estimation interval. Consequently, we present an explanation of the Standard Error of Estimation interval and its associated regression model before presenting the Standard Error of Measurement interval.
Standard Error of Estimation is the error made in trying to predict true scores from observed scores (Gulliksen, 1950). Gulliksen (1950) emphasized this orientation when he called it the error in estimating true score. He specifically stated that it is “the error made in using the best fitting regression equation to predict the true score from observed score” (p. 43). Consequently, to understand Standard Error of Estimation, it needs to be viewed in the context of a regression model in which observed scores predict true scores.
Correspondingly, we present in Figure 2 a regression model for the Standard Error of Estimation. In Figure 2, observed scores are represented on the

Standard Error of Estimation Many-Test-Taker regression model.
Note that in an applied measurement context, one does not know true scores. As a result, it is not possible, in an applied context, to construct a measurement regression model like the one in Figure 2. Nonetheless, this conceptual regression model provides the theoretical basis for the Standard Error of Estimation interval.
Model slope
The slope of the regression line in this model is important because it influences the point around which the Standard Error of Estimation interval is centered. In the Standard Error of Estimation regression model presented in Figure 2, the slope of the regression line is equal to the reliability (
To begin, we represent slope as the correlation between X and Y multiplied by the ratio of the standard deviations for Y and X:

Next, we replace X with “observed scores” and Y with “true scores” because this corresponds with the Standard Error of Estimation regression model in which observed scores are on the

Then, drawing from classical test theory, we substitute the correlation between observed scores and true scores with the square root of reliability,

Next, based on the definition of reliability in classical test theory (see classical Test Theory Implication 1 in Table 1), where

Thus, we can see that in Standard Error of Estimation Model, where observed scores predict true scores, the slope of the regression line is equal to the reliability (
Interval center
For the Standard Error of Estimation interval to perform properly, it must be centered on the regression line. That is, for a given observed score (i.e.,
In the Standard Error of Estimation regression model, where the slope of the regression line is the reliability (

In the context of the Standard Error of Estimation, we can replace

Unfortunately, this new equation is still problematic for practical purposes. Although we have an equation that will allow us to generate a prediction of

Thus, we obtain a practical formula for the predicted true score value:

Equation 6 is a way of determining the spot on the regression line,
Note that
Interval length: Standard Error of Estimation as the standard deviation of residuals
The Standard Error of Estimation regression line defines the relation between observed scores on the

An understanding of why the
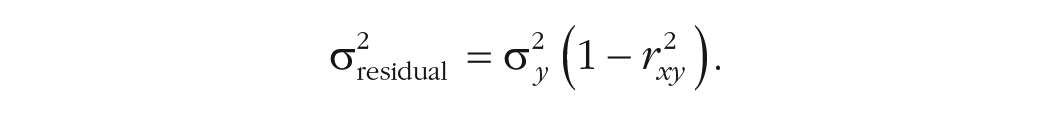
We adapt Equation 4 to the Standard Error of Estimation Model by relabeling the X and Y variables as previously described. In Figure 2, we have true scores along the

Furthermore, we know that the squared correlation between true and observed scores,

In addition, we also know that the variance of true scores,

Taking the square root results in the following:

This is the formula for the Standard Error of Estimation error term. Thus, the formula for the
Interpreting sresidual–SEE
through the lens of homoscedasticity
With the above illustration, we can see how
Second, because of the homoscedasticity assumption, we can consider
Interval construction and interpretation
A Standard Error of Estimation interval can be constructed using Equation 8 below, which uses the previously described predicted true score value,

Typically, the Standard Error of Estimation interval calculation begins with a single observed score for a specific individual. However, it is important to recognize that the Standard Error of Estimation interval does not provide information about that single person’s true score. The Standard Error of Estimation intervals provide information about the true scores for all individuals with that particular observed score.
Consider, for example, that we collected data from a large number of people, and the reliability of observed scores is .80 (

This calculation indicates that our estimate of the mean true score for those individuals with an observed score of 90 is 92 (i.e.,

This second calculation indicates that for those individuals with an observed score of 90, the standard deviation of true scores is 4.0 (i.e.,

Thus, based on an observed score of 90, we obtain 95% Standard Error of Estimation = [84.16, 99.84]. How do we interpret this SEE Many-Test-Takers Interval? In Figure 2, there is more than one person with an observed score of 90. Moreover, people with an observed score of 90 do not all have the same true score. Indeed, for people with an observed score of 90, there is a wide range of true scores that are possible. Thus, the 95% SEE is a range that bounds the middle 95% of true scores for people with a particular observed score. In other words, this interval indicates that for the many individuals with an observed score of 90, 95% of them have true scores between 84.16 and 99.84. Recall that this interval was created using the logic of classical test theory—which is a population-level theory (Lord & Novick, 1968). As result, we need to remember that we are considering the scores presented in Figure 2 as a population. Because of the population assumption of classical test theory, the SEE Many-Test-Takers Interval is effectively a parameter describing a range of the data at a particular point—inference is not involved. Because inference is not involved, this interval is not a confidence interval—just a range. We note that if we considered our data a sample, the resulting interval would be a prediction interval (see Cumming & Calin-Jageman, 2016); however, the population assumption of classical test theory facilitates interpreting it in the way we have described (see Appendix A1).
Standard Error of Measurement
Perhaps the most popular error term that is used to construct intervals around test scores is the Standard Error of Measurement. This error term is regularly covered in psychological-measurement textbooks and psychometric education. Despite the widespread use and teaching of Standard Error of Measurement, intervals based on this error have been subject to a multitude of interpretations. These varying interpretations have led to disagreements in the testing literature with respect to what is a correct interpretation and what is a misinterpretation (Charter & Feldt, 2001; Dudek, 1979; Harvill, 1991; Nunnally & Bernstein, 1994). One potential cause of confusion surrounding Standard Error of Measurement may be that it can be correctly interpreted several different ways. Indeed, Gulliksen (1950) devoted an entire chapter to the topic, appropriately titled “Various Interpretations of the Error of Measurement”; “error of measurement” is the term Gulliksen used for Standard Error of Measurement.
To help understand Standard Error of Measurement, in this section, we focus primarily on two common approaches to conceptualizing it. The first approach considers a scenario in which there are many test takers and the Standard Error of Measurement is the error term in a bivariate regression. The second approach considers a scenario in which there is a single individual and the Standard Error of Measurement is the error term for a population of observed scores for that individual. We begin with the many-test-takers scenario.
SEM Many-Test-Takers model
One approach to conceptualizing Standard Error of Measurement relies on a scenario in which there are many test takers. In this scenario, the true scores are used to predict observed scores via a bivariate regression model. We illustrate this model in Figure 3. This model is an inversion of the model we reviewed for Standard Error of the Estimate, in which observed scores predicted true scores. Consistent with Figure 3, Standard Error of Measurement is the standard error when predicting observed scores using true scores (Gulliksen, 1950; Nunnally & Bernstein, 1994). More practically, the Standard Error of Measurement regression interval can be thought of as a way to understand the variability in observed scores for the many test takers that share a specific true score.
Standard Error of the Measurement Many-Test-Taker regression model.
Model slope
The slope of the regression line in the Standard Error of Measurement regression is 1.00. This deviates with the Standard Error of Estimation scenario in which the slope was equal to the reliability. To understand why the slope is 1.0 in a Standard Error of Measurement Model, we begin by representing slope as the correlation between X and Y multiplied by the ratio of the standard deviations for X and Y:

Following this, we replace X with “true scores” and replace Y with “observed scores” because this corresponds with the Standard Error of Measurement regression model in which observed scores are on the
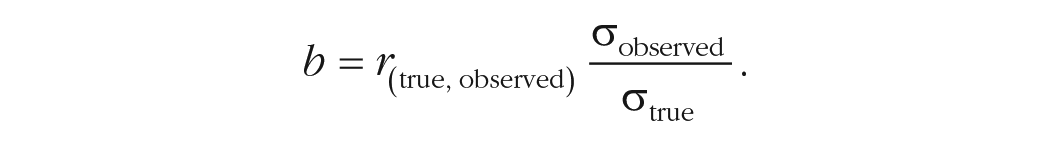
Drawing from classical test theory, we can substitute the correlation between true scores and observed scores with the square root of reliability

However, Classical Test Theory Implication 1 indicates that the square root of the reliability is equal to the ratio of the true-score standard deviation divided by the observed-score standard deviation:

Next, some simple rearranging of terms illustrates that the slope is equal to 1.00:

Thus, we can see that in the regression model, on which the Standard Error of Measurement is based, must have a slope of 1.00. Understanding the slope is 1.00 is critical to determining how to center the interval on the regression line.
Interval center
In the Standard Error of Measurement regression model, if we want to create an interval, we do so at a specific true score along the
Interval length
The length of a vertical interval around the regression line, at a specific true-score value on the

To further understand this definition, we start with Equation 4 for the variance of residuals in a regression line (see Allen, 1997). Then, we replace X and Y with “true scores” and “observed scores,” respectively:

We then take the square root to obtain the final equation below. We note that this equation can also be obtained by rearranging the classical test theory reliability formula—as illustrated in Appendix A2:

Thus, we can see that the Standard Error of Measurement is linked to a regression model in which observed scores are predicted by true scores and is specifically the standard deviation of errors around the regression line of this model. This is consistent with Gulliksen (1950), who stated, “The error of estimate derived from the regression of observed upon true scores is the same as the error of measurement” (p. 49).
Because the Standard Error of Measurement is embedded in a regression model, we can also understand how the assumption of homoscedasticity applies here as well. Homoscedasticity means that the standard deviation of observed scores on the
Interval construction and interpretation
To construct an interval with Standard Error of Measurement, Equation 10 below, which uses the previously described predicted true-score value,

The Standard Error of Measurement regression interval differs in several ways from the Standard Error of Estimation regression interval. Perhaps most important, the Standard Error of Estimation regression interval is arguably a practical interval for individuals interested in interpreting a test score. Although the Standard Error of Estimation regression interval is not specific to a single individual, it can provide useful contextual information for a person with a particular observed score. For example, if an individual received an observed score of 90 on a test, users of a Standard Error of Estimation regression interval could tell the individual that although they do not know the individual’s true score on this test, they do know that 95% of people with this observed score have a true score between 100.16 and 115.84. In contrast, the Standard Error of Measurement regression interval uses a true score as the starting point for the calculation of the interval. Consequently, it does not provide a useful approach for interpreting observed test scores.
The Standard Error of Measurement regression interval is useful, however, for asking theoretical “What if?” questions. An example of a theoretical “What if?” question could be the following: “Imagine we have a very large number of people take a test and we obtain a reliability of .80 and the standard deviation of observed scores is 10. For those test takers with a true score of 90, what is the range of observed scores that could be expected?” To answer a theoretical question of this sort, we construct a 95% Standard Error of Measurement regression interval in the following way:

This results in a 95% SEM-Regression = [81.2, 98.8] for a true score of 90. This interval indicates that of the many individuals with a true score of 90, 95% of them recorded observed scores between 81.2 and 98.8. To aid with the interpretation, it may help to consult Figure 3. Here, we can see that there is more than one person with a true score of 90 and that of the people with a true score of 90, not all of them have the same observed score. Indeed, for people with a true score of 90, there is a wide range of observed scores. The 95% Standard Error of Measurement interval is a range that bounds the middle 95% of observed scores values for people with a particular true score. Again, although this is theoretically interesting, it does not aid in the interpretation of a test taker’s score. As discussed previously, because classical test theory is a population-level theory, this SEM Many-Test-Takers Interval is a range, not a confidence interval; see the SEE Many-Test-Takers Interval section for a full discussion.
Recall this interval was created using the logic of classical test theory—which is a population-level theory (Lord & Novick, 1968). As a result, we need to remember that we are considering the scores presented in Figure 3 as a population. Because of the population assumption of classical test theory, the SEM Many-Test-Takers Interval is effectively a parameter describing a range of the data at a particular point—inference is not involved. Because inference is not involved, this interval is not a confidence interval—it is simply a range. We emphasize that if we considered our data to be a sample, the resulting would be a prediction interval (see Cumming & Calin-Jageman, 2016); however, the population assumption of classical test theory facilitates interpreting it in the way we have described (see Appendix A1).
SEM Single-Test-Taker model
From a practical standpoint, the most critical question for any test taker is the following: Given my observed score, what is my likely true score? Fortunately, it is possible to use the Standard Error of Measurement to create an interval that provides the test taker with this information. Accomplishing this objective requires us to view Standard Error of Measurement through a different lens—one that deviates from the regression-based model. The calculation of the Standard Error of Measurement stays the same in this context. 2
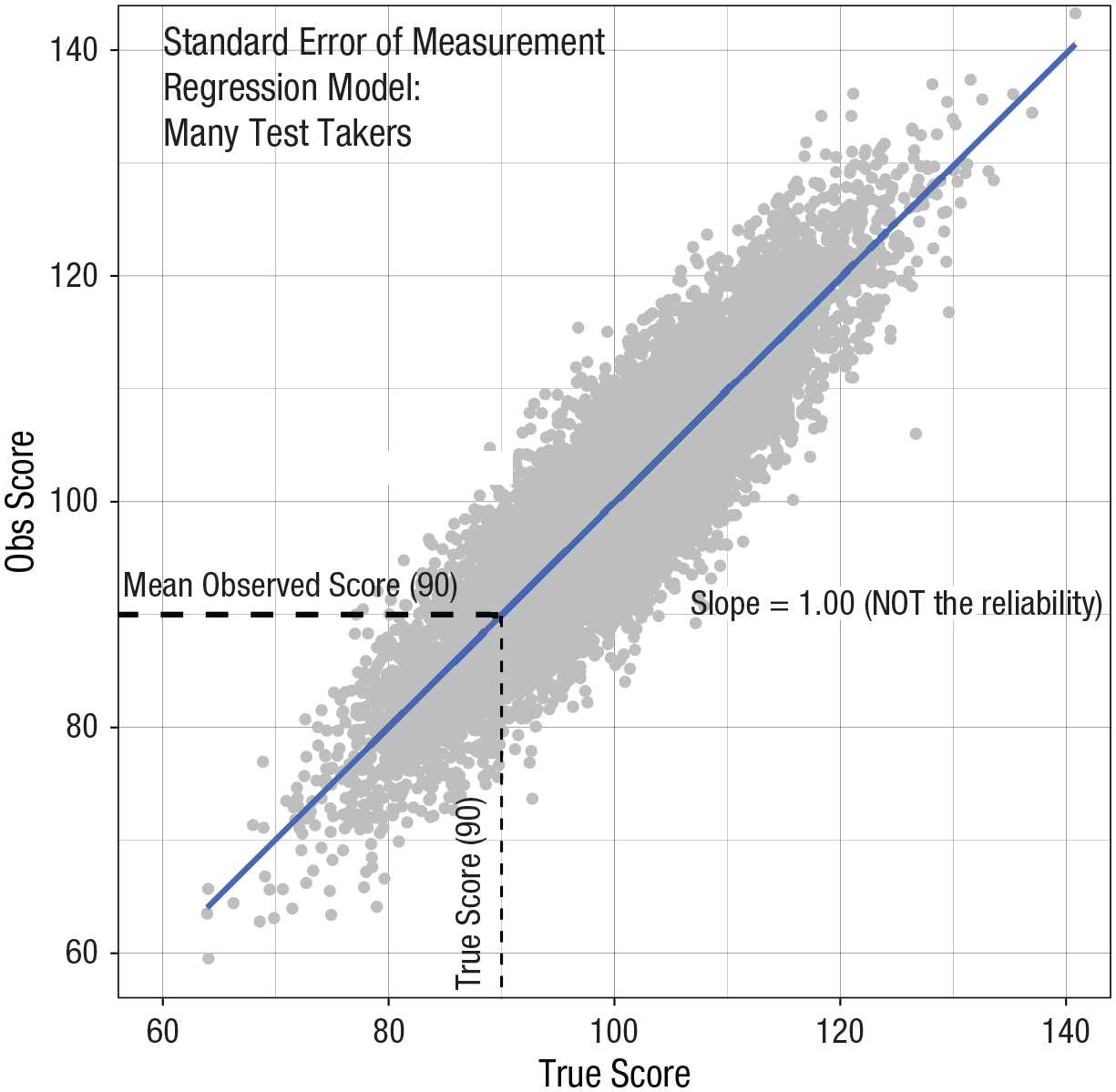
This new lens requires that we imagine a scenario in which there is a single person that takes a test a very large number of times. In this imaginary scenario, each time the person takes a test, the person has no memory of previous attempts and are not influenced by those previous attempts. The result is a large number (i.e., a population) of observed scores for a test taker—a distribution of observed scores (see Figure 4). The true score for this test taker is conceptualized as a population mean (

Standard Error of the Measurement Single-Test-Taker model.
Interval construction and interpretation
This population model of observed scores for an individual allows us to use Standard Error of Measurement to construct an interval around a specific observed score for a test taker that will capture the test taker’s true score with a specified probability. The logic of using an interval to capture a test taker’s true score from an observed score is the same as that used in inferential statistics to capture a population mean based on a sample mean. Consequently, the Standard Error of Measurement interval in this model is a confidence interval. Confidence intervals are, however, prone to misinterpretation (see Hoekstra et al., 2014; Thompson, 2007).
As outlined above, a Standard-Error-of-Measurement-based confidence interval can be constructed using Equation 11:

To understand how to interpret this interval, we can consider an example. Imagine that we collected data from a large number of people and that for the observed scores, we know the reliability (

Thus, based on Emilia’s observed score of 90, we obtain the 95% SEM = [81.23, 98.76]. How do we interpret this interval? The first step is to recognize that this is a confidence interval. Before Emilia takes the test, we can say there is a 95% chance the interval we obtain after the test will contain her true score. After data collection (i.e., test administration), once we have a specific interval with end points, we can only state that we have an interval estimate of the true score—the 95% probability should not be invoked to interpret the specific end points of this interval (Thompson, 2007). To correctly interpret this interval, it is important to realize that the SEM Single-Test-Taker Interval is a confidence interval. It is a confidence interval because we are trying to estimate a population mean using a sample mean. We consider the set of all possible observed scores for Emilia as a population. Emilia’s single observed score (90) is a sample mean (
Myths: Standard Error of Measurement
Unfortunately, many attempts to clarify and provide direction with respect to the proper interpretation of Standard Error of Measurement have only served to add confusion. One reason for this is that some clarification attempts essentially “mix and match” from the models described above, providing an interpretation that is not consistent with any correct interpretation. In other cases, the interpretation error is idiosyncratic and is simply an incorrect confidence-interval interpretation. In our supplemental materials, we provide computer activities/simulations that provide hands-on exercises to illustrate why these are myths and not facts.
Myth 1: There is a 95% chance your true score is in your interval
Some authors correctly understand that the Standard Error of Measurement can be used to construct a confidence interval for a specific individual’s true score. This type of interval is an SEM-Single-Test-Taker Interval. Unfortunately, however, sometimes these authors then go on to misinterpret the information provided by the confidence interval. For example, Kaplan and Saccuzzo (2013) provided a specific confidence interval and then indicated that it means “we can be 95% confident that the true score falls between 96.9 and 115.1” (p. 124). This interpretation of the confidence interval is incorrect (see Hays, 1994; Thompson, 2007).
A key to understanding confidence intervals is realizing that the 95% does not apply to a specific interval but, rather, a set of intervals. If we tested a single individual 20 times, we would obtain 20 different observed scores with 20 different confidence intervals. These 20 different confidence intervals would each have different end points. However, on average, 95% of the 20 intervals (i.e., 19/20) will overlap the participant’s true score (see Fig. 4). Thus, the 95% does not apply to a specific confidence interval—but, rather, to the set of intervals.
To add more nuance to the proper interpretation of a confidence interval, before taking the test, it is correct to indicate to the future test taker that “the interval we calculate around your observed test score has a 95% chance of containing your true score.” However, once the test has been taken and the interval is constructed, we cannot make this type of statement about the interval. One can correctly say that this specific interval is a plausible range of values for a test taker’s true score—but must not associate a probability with it. The phrasing “plausible range of values” comes from the noncentral-distribution approach to calculating confidence intervals but is really just a way of paraphrasing the more technical term “interval estimate” (see Cumming & Finch, 2001; K. Kelley, 2007; Steiger & Fouladi, 1997). For a specific interval to have a 95% chance of obtaining a participant’s true score, it needs to be a Bayesian credibility interval (or high density interval), not a confidence interval (see McElreath, 2018).
Myth 2: Standard error of measurement captures a test taker’s future observed scores
One common misconception is a Standard Error of Measurement interval can be constructed, based on a test taker’s observed score, that will capture the test taker’s future observed scores with a certain probability. This type of misinterpretation can occur in academic articles or in more applied circumstances—even by the most reputable of sources. To help understand the insidious nature of this type of error—which can be hard to pin down—we provide a concrete example based on the USMLE. We provide this as a prominent example—but note that in our experience, this type of wording is not uncommon. The USMLE provides test takers with a definition of the Standard Error of Measurement to help them interpret their results (USMLE, 2023, p. 4), which is quoted below. This document was updated July 24, 2024: Using the SEM, it is possible to calculate a score interval that indicates how much a score might vary across repeated testing using different sets of items covering similar content. Plus and minus one SEM represents an interval that will encompass about two thirds of the observed scores for an examinee’s given true score. (USMLE, 2023, p. 4)
We note that the quoted text above is technically correct; however, it is also extraordinarily misleading.
Why is the USMLE text technically correct? The wording of the text indicates it is focused on the interpretation of the interval for a single test taker—anchoring it in the SEM Single-Test-Taker Interval, not the regression-based SEM Many-Test-Takers Interval. Within the SEM Single-Test-Taker Model, the text indicates that plus or minus one Standard Error of Measurement will capture roughly two-thirds of observed scores—provided the interval is centered on the test-taker’s true score. This statement is technically correct—if the interval was centered on the test-taker’s true score—as illustrated in Figure 4. The catch is that the test-taker’s true score is unknown—and will always be unknown.
Why is the USMLE text misleading? The wording of the text is misleading because it describes an interval interpretation that depends on knowing a test-taker’s true score. True scores are unknown, and the process of taking a test provides only an observed score, not a true score. Consequently, it is not possible to create an interval for a test taker that is centered on the test taker’s true score. So when a Standard Error Measurement interval is provided to the test taker, it cannot correspond to the interpretation suggested by the USMLE (2023) text. Moreover, the definition the USMLE provided to test takers seems to simultaneously assume no measurement error (so the test taker’s observed score will correspond the true score) but also measurement error (reflected in the belief that that there will be variation in future observed scores). As indicated in Table 1, a SEM Many-Test-Takers Interval cannot be created in practice because true scores are unknown.
Consequently, using an observed score as the center for the Standard Error of Measurement interval will not result in an interval that captures future observed scores at the specified probability. A Standard Error of Measurement Interval that captures future observed scores, at the specified probability, must be centered on the specific test taker’s true score. Using an observed score as the center of the interval means the interval is not centered in the correct spot to capture future observed scores at the specified probability. Specifically, the center of the interval will be “off” to the extent that the test-taker’s observed score deviates from the test taker’s true score:
We note that it is possible to create an interval that will capture a future observed score for a specific individual; however, such an interval is not based on the Standard Error of Measurement error term. An interval that captures future observed scores for a specific individual is based on the Standard Error of the Difference between observed scores (see Estes, 1997; Gulliksen, 1950). Consequently, interpretations of Standard-Error-of-Measurement-based intervals as capturing future observed scores is incorrect in practice.
We stress that the interval provided by the USMLE (2023) is a SEM Single-Test-Taker Interval that is valuable. However, this type of interval must be interpreted as a confidence interval for a test-taker’s true score. We provide an example of correctly interpreting a SEM Single-Test-Taker Interval in the Which Interval Should I Use? section below.
Myth 3: Using an estimated true score provides an interval that captures future observed scores
Some authors might look at Myth 2 and incorrectly see a work-around. They might suggest that if you used an estimate of the test taker’s true score instead of the test taker’s observed score, you would obtain an interval that does capture future observed scores (e.g., Nunnally & Bernstein, 1994). The “work-around” of using an estimated true score to center the interval around is flawed for a number of reasons. The estimated true score associated with this approach is based on the formula below:

Readers may recognize this formula as merely being a relabeled version of Equation 6, repeated below, which provides an estimated true score in the context of the Standard Error of Estimation regression model. When viewed through this regression model, it is clear that the value provided by using Equation 6 is the estimated mean true score (i.e., mˆ
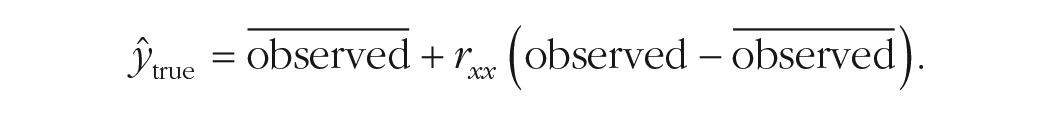
Consequently, using an estimated true score as the center for the Standard Error of Measurement interval will not result in an interval that captures future observed scores at the specified probability. An interval that captures future observed scores at the specified probability must be centered on the specific test taker’s true score. Using an estimated true score (which is really a mean true score) as the center of the interval means the interval is not centered in the correct spot. Specifically, the center of the interval will be “off” to the extent that the test taker’s true score deviates from the mean true score of all test takers with the same observed score:
Myth 4: Using an estimated true score provides an interval that captures true scores
The siren song of the estimated true score has tempted even knowledgeable authors to incorrectly recommend its use inappropriately. For example, Nunnally and Bernstein (1994) indicated that “before establishing confidence intervals, one MUST [capitalization added] obtain estimates of unbiased scores” (p. 259). And echoing this same idea, they stated “Intervals are often erroneously centered about obtained scores rather than estimated true scores” (p. 260) and “Even though the practice in most applied testing has been to center confidence intervals about obtained scores, this is incorrect because obtained scores are biased, high scores tending to be biased upward and low scores downward” (p. 259). These recommendations imply, incorrectly, that the equation below should be used to construct an interval that captures a test taker’s true score at the specified probability:

Using the estimated true score in this context results in an interval that does not capture a test taker’s true score at the specified probability. A Standard Error of Measurement interval that captures a test taker’s true score as the specified probability must be centered on the test taker’s observed score. Using an estimated true score as the center for the Standard Error of Measurement interval will not result in an interval that captures the test taker’s true score at the specified probability.
Myths summary
Overall, the myths we have reviewed can be understood as conflating correct interpretations from different models to produce a number of incorrect interpretations. Previously, we provided a ground-up, detailed, but accessible foundation for Standard Error of Estimation and Standard Error of Measurement intervals. Our hope is that this foundation makes it possible to understand why these myths are incorrect. To further aid in understanding these myths, we remind readers of the activities in our supplemental materials (https://dstanley4.github.io/comedyerrors/) that walk readers through several simulations demonstrating that Myths 1 to 4 are, in fact, myths.
Which Interval Should I Use?
Now that we have outlined the statistical foundation for the three intervals, a natural question for readers may be the following: Which interval should I use? As with many situations, the answer to this question is that it depends on what you want to know. Correspondingly, what you may want to know could depend on whether you are the test taker or if you are using test scores in an administrative manner to make decisions.
Consider the scenario of a test taker named William who completes the HEXACO Conscientiousness Scale and receives a score of 4.00. The HEXACO Conscientiousness Scale is known to have M = 3.45, SD = 0.58, and a reliability of .84 (Lee & Ashton, 2018). It is likely that William is interested in knowing what his “true” conscientious score may be. Thus, if William would like an interval estimate of his personal conscientiousness true score, then he would be interested in the Single-Test-Taker SEM Confidence Interval. In this case, William’s Single-Test-Taker SEM Confidence Interval would be 95% = [3.55, 4.45]. If William took the IQ test 100 times, he would likely obtain 100 different observed conscientiousness scores—each with a different confidence interval. Of those 100 confidence intervals, on average, 95 of them will overlap with William’s true conscientiousness score. Thus, 95% = [3.55, 4.45] is an interval estimate of William’s true conscientiousness score. The specific interval [3.55, 4.55] received by William after this single test administration should be viewed as merely one of many intervals that could have been obtained in the imaginary multiple-testing scenario described. The specific interval William obtained may be, with repeated testing, one of the five intervals that does not overlap with his true conscientiousness score. Alternatively, the specific interval William obtained may be, with repeated testing, one of the 95 intervals that does overlap with his true conscientiousness score. Because 95% of constructed intervals will, on average with repeated testing, overlap with his true score, it is reasonable for William to suspect that his true conscientiousness score falls within the bounds of his specific interval:

Alternatively, imagine a scenario in which an employer uses the HEXACO Conscientiousness Scale as part their selection process for hiring new employees. In this fictitious example, the employer is considering using a conscientiousness cut score of 4.00 as part of the selection process such that to be hired, job applicants must have an observed conscientiousness score of 4.00 or higher. The employer recognizes that the observed conscientiousness scores obtained from applicants are all contaminated with random measurement error. Consequently, the employer would want to know for all those people with an observed conscientiousness score of exactly 4.00, what the range is of their true conscientiousness scores. To obtain this range, the employer calculates an SEE Interval. This process involves estimating the mean true score for individuals with an observed score of 4.00. Recall the HEXACO Conscientiousness Scale is known to have M = 3.45, SD = 0.58, and a reliability of .84 (Lee & Ashton, 2018):
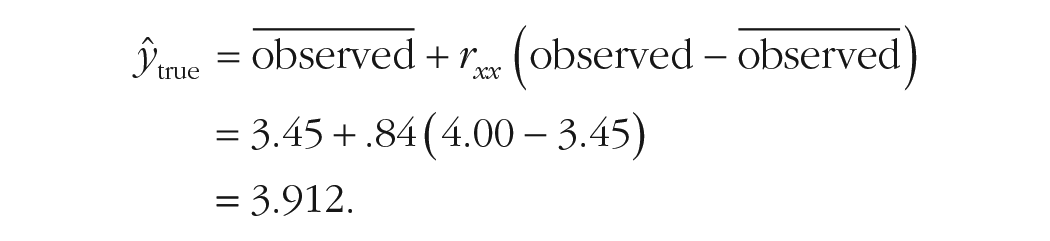
Then, this information is used to calculate the SEE interval:

The SEE interval provides a range that captures 95% of the true scores for those individuals with an observed conscientiousness score of 4.00. In the context of our employment example, this indicates that if an employer were to hire only employees with an observed conscientiousness score of 4.00, many of those employees would have a true conscientiousness score below 4.00. Specifically, for those job applicants with an observed conscientiousness score of exactly 4.00, 95% of them would have a true conscientiousness score between 3.50 and 4.33. This type of interval could also be created for any conscientiousness score above 4.00. Clearly, when selecting only employees with an observed conscientiousness score of 4.00 or higher, the organization would end up employing a large number of people with a true conscientiousness score below 4.00. This type of information could be very useful for a company considering setting a cut score based on observed score for any type of preemployment test.
In addition, we note that William might be interested in reflecting on the SEE interval after obtaining his observed score of 4.00. For William, this would inform him that for individuals with an observed conscientiousness score of 4.00 (his score), 95% of them will have true scores between 3.50 and 4.33. This interval tells William about the range of conscientiousness scores for others with his observed score of 4.00 but does not provide information specific to him. To obtain an interval estimate for his personal conscientiousness true score, William needs to examine the Single-Test-Taker SEM Confidence Interval calculated previously: 95% = [3.55, 4.55].
Finally, we note that although we reviewed and explained the Many-Test-Takers SEM Interval, in our view, this interval is of no practical value. We provided the in-depth explanation of this interval, however, because of the tendency of some stakeholders to incorrectly report the definition of the Many-Test-Takers SEM Interval when providing test takers with a Single-Test-Taker SEM Interval. We suspect that this type of error is made because the stakeholder may find the correct interpretation of Single-Test-Taker SEM confidence interval somewhat difficult to explain.
Conclusion
Test scores are an unavoidable part of everyday life in contemporary society. Moreover, they form a critical foundation for key aspects of society. Intervals are often constructed around test scores to provide an indication of the uncertainty associated with scores. Unfortunately, over several decades, a number of conflicting interpretations have been described for both Standard Error of Measurement and Standard Error of Estimation. Even more problematically, these descriptions and critiques are sometimes in error. Often, those errors are merely the result of applying the correct description of one interval to another interval. We have presented detailed expositions of the statistical models on which Standard Error of Estimation and Standard Error of Measurement are constructed to illustrate the correct meaning and interpretation of these terms (see Table 2). We used algebra to illustrate the link between classical test theory and bivariate regression that is essential for understanding these intervals. It is our hope that the current article will be used to avoid the unfortunate pitfalls of misinterpreting test-score intervals and increase their effective use in both research and practice.
Footnotes
Appendix A1
Researchers previously familiar with the use of prediction intervals for criterion scores may be surprised to see the simplicity of the prediction intervals used in the Standard Error of Measurement and Standard Error of the Estimate intervals. Indeed, in an applied (nonmeasurement) context, the formula for predicting the range of responses on the y-axis for a specific value of
We explain here why this less complex version of the prediction interval formula is used in a measurement context. The basis for the difference is the number of test takers involved in the scenario modeled by classical test theory and measurement intervals. More specifically, classical test theory is a population-level theory that assumes an extraordinarily large number of test takers. In contrast, in the typically substantive research scenario, the number of participants is often quite small in comparison. These smaller sample sizes in substantive research necessitate a different approach for the error term for
In applied research, with a finite sample size, a researcher might desire to make obtain a predicted value on
We can combine these into one equation:
This produces the equation below:
But this is typically rearranged as per the following:
Taking the square root, we obtain the following:
Recall in classical test theory that the
Thus, in a classical-test-theory context, we can make a prediction interval using
Appendix A2
The Standard Error of Measurement error term can also be obtained by rearranging the classical-test-theory formula for reliability:
Transparency
Action Editor: Katie Corker
Editor: David A. Sbarra
Author Contributions