
Abstract
Obtaining an accurate understanding of group-based disparities is an important pursuit. However, unsound study designs can lead to erroneous conclusions that impede this crucial work. In this article, we highlight a critical methodological challenge to drawing valid causal inferences in disparities research: selection bias. We describe two commonly adopted study designs in the literature on group-based disparities. The first is outcome-dependent selection, when the outcome determines whether an observation is selected. The second is outcome-associated selection, when the outcome is associated with whether an observation is selected. We explain the methodological challenge each study design presents and why it can lead to selection biases when evaluating the actual disparity of interest. We urge researchers to recognize the complications that beset these study designs and to avoid the insidious impact of inappropriate selection. We offer practical suggestions on how researchers can improve the rigor and demonstrate the defensibility of their conclusions when investigating group-based disparities. Finally, we highlight the broad implications of selection mechanisms for psychological science.
Keywords
An accurate understanding of what drives inequality is an important first step toward eliminating inequality. Research from diverse disciplines has frequently shown that dimensions such as gender, race, ethnicity, and socioeconomic status are fundamental causes of inequality (Amis et al., 2021; C. C. Miller & Katz, 2024; Phelan & Link, 2015; Pickett & Wilkinson, 2015; Sbarra & Whisman, 2022). For example, scholars have sought to understand the sources of inequalities in academia by examining gender gaps in receiving recognition (Card et al., 2023), racial disparities in funding rates (Erosheva et al., 2020), and the impact of socioeconomic background on academic job placement and performance (Morgan et al., 2022). Such group-based disparities are well documented in various contexts across social, economic, and health domains. The invaluable knowledge accumulated in these scholarly works informs diversity policies and practices and is paramount in pursuing a more equitable society.
Despite the broad interest in and importance of group-based disparities research, there is a lack of methodological discussions on accurately estimating the effect of interest. In this article, we elucidate an often neglected methodological challenge of group-based disparities research by focusing on how inappropriate selection can lead to selection bias (Hernán et al., 2004). Motivated by the preceding examples, we situate our discussion of selection bias in the context of causal inquiries seeking to shed light on disparate outcomes because of differing group memberships (e.g., What is the gender gap in publishing?). Descriptive research, such as trend studies (e.g., What is the share of women among published authors over time?) or studies concerning a single group’s representation (e.g., Are women underrepresented among published authors?), is valuable, but it is outside the scope of this article.
The remainder of this article is organized into two parts. In the first part, we present two prevalent study designs used in the existing literature to answer questions about group-based disparities: “outcome-dependent” selection and “outcome-associated” selection. Leveraging the causal inference framework, we demonstrate that notwithstanding both designs being intuitive, they involve inappropriate selection of a population subset that can induce systematic (i.e., nonrandom) differences between the true disparity of interest and the empirical quantity among the subset selected. This distortion is termed “selection bias” in the epidemiological literature (Arah, 2019; Hernán et al., 2004; Hernán & Monge, 2023). Although selection bias has been well recognized in other fields, such as medicine (Hernán & Monge, 2023), public health (Smith, 2020), and sociology (Elwert & Winship, 2014), it has yet to receive much attention in psychology.
Within each study design, we organize our presentation following a “causal roadmap” (Ahern, 2018; Hernán, 2018). First, we clarify the causal effect of interest when investigating group-based disparities research. Second, we explain how each study design implies certain causal conditions by drawing on concepts from the established causal diagram framework (M. M. Glymour, 2006; J. J. Lee, 2012; Pearl et al., 2016). Causal diagrams facilitate visualizing nonparametric structural relationships between each pair of variables (Grosz et al., 2020; Pearl, 2012). Throughout this article, we assume that the causal structures depicted in the posited causal diagrams, such as the correct set of variables, the presence and ordering of directed edges, and the absence of cyclic (e.g., bidirectional) relationships, can be defensibly justified using theoretical and empirical evidence and temporal-logical constraints (Grosz et al., 2020). 1 Third, we explain the shortcomings of each design and why they are fraught with selection bias that can lead to erroneous or even entirely misleading conclusions. Throughout the article, we use a hypothetical example of a gender gap in academic recognition for expository purposes. We emphasize that the causal inference reasonings about the challenges and implications of inappropriate selection broadly apply to group-based disparities research (e.g., disparities because of race or socioeconomic status). Crucially, as we discuss toward the end of the article, selection bias is prevalent and has wide-ranging implications in psychological science beyond disparities research.
In the second part, to help researchers best address these challenges, we offer concrete suggestions that can be readily implemented in practice to circumvent these common pitfalls and strengthen the defensibility of their causal inferences. The R (R Core Team, 2023) scripts to reproduce the sensitivity analysis and simulation studies in this article are available online on OSF: https://osf.io/n6tuc/. We hope this article will equip researchers to recognize and mitigate the impact of selection bias in group-based disparities research and psychological science at large.
Running Example: Part 1
We first introduce our running hypothetical example. Suppose there is a professional organization representing psychologists—individuals who have obtained a doctoral degree in psychology—in a nation. The organization gives a prestigious leadership award to individuals who have significantly contributed to the community. The newly elected president is interested in finding out what the gender gap is between women and men in receiving this award. The president invited interested scholars in the nation to investigate this question, and two teams responded and carried out their research separately.
The first team, led by Dr. A, compiled a list of psychologists who received the award since its inception. The team inspected the list of award recipients and found that 50% of the recipients identified as women and that 45% of the recipients identified as men (5% identified as other gender identities). Dr. A’s team concluded that women were more likely to receive the award than men: Women’s chances were 1.11 times those of men (where
The second team, led by Dr. B, also compiled the same list of award recipients as their study sample. However, they adopted a different analytic strategy. They first calculated the share of women among award recipients (50%). They then compared this share of women among award recipients to a “base rate,” the proportion of women in the population of interest (i.e., all psychologists eligible for the award), which was 60%. The comparison (
Which team was correct? Neither. We explain why in the next section.
Outcome-Dependent Selection
The two teams adopted different analytic strategies, but both teams selected only award recipients as their study sample. Such a design offers limited (or possibly even no useful) information on the true gender disparity of interest. The core underlying problem is outcome-dependent selection (also termed “outcome-dependent sampling”): Observations are selected based solely on their outcome. Put differently, the outcome of interest (receiving the award) determines the selected subset of the population.
We use Figure 1 to provide a conceptual understanding of the problem. The left side depicts all eligible candidates for the award since its inception (i.e., the population of interest). The right side depicts all award recipients from this population. As Figure 1 illustrates, the chances of receiving the award among women were

Dr. A’s and Dr. B’s study designs delimited by outcome-dependent selection. Reflecting the traditional focus of gender-gap research, the organization’s president, in our running hypothetical example, was interested in the gender gap between women and men. Hence, solely for illustrative purposes, individuals of other gender identities are not visualized in this figure.
It is straightforward to see that neither team accurately uncovered the true disparity. Despite women being less likely to receive the award than men, Dr. A’s team concluded the opposite. Although Dr. B’s team correctly reported that women were underrepresented among award recipients, they underestimated the true gender disparity (for a brief commentary, see Loh & Ren, 2023). This numerical example illustrates the perils of outcome-dependent selection: It can understate the true disparity at best or lead to opposite conclusions at worst. A formal mathematical derivation of the numerical results presented here is provided in Section A of the Supplemental Material available online.
We now formalize the methodological issue with the help of the causal diagram in Figure 2. Let the focal predictor of interest (referred to hereafter as “exposure”), for example, gender, be denoted by

Causal diagram depicting outcome-dependent selection in the hypothetical example. The dashed arrow between
We further illustrate the problem using the language of probabilities. Continuing our running example, let
Now, we turn to the descriptive quantities calculated by each team. Dr. A’s team quantified the gender disparity using a ratio of two proportions: the proportion of women among award recipients and the proportion of men among award recipients. This ratio can be written as
Could either team have improved their analytic approach (e.g., by performing a secondary data analysis of the award recipients) to get closer to the true gender disparity of
Running Example: Part 2
We continue with the running hypothetical example. After receiving two conflicting conclusions, the organization’s president sought a third opinion from another research team in the nation led by Dr. C. Knowing the perils of outcome-dependent selection, Dr. C requested access to the official records of all psychologists who would have been potentially eligible for the award—the population of interest (as shown in the left side of Fig. 1). The president sighed, “Alas, I’m afraid our organization did not maintain consistent records over the years.” Without these records, Dr. C’s team decided to construct a proxy for the population. They scraped the web pages of all psychology departments at research institutions nationwide and compiled a list of faculty members as their selected study sample; see the left side of Figure 3. They then checked the list of award recipients and recorded whether each faculty member in their selected sample received an award. They calculated the proportions of women versus men in their selected sample who received the award (Fig. 3, right side vs. left side). The proportions were
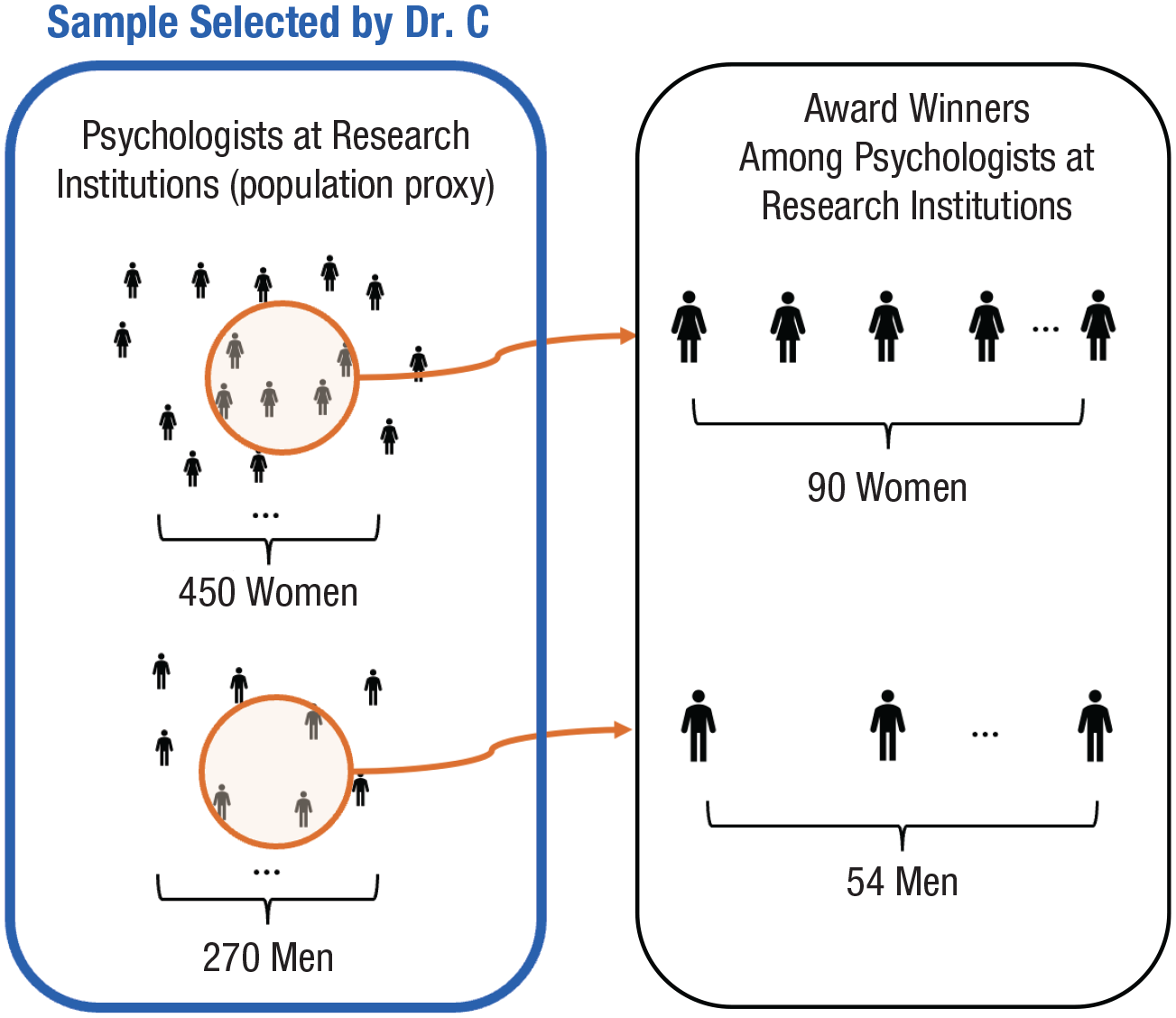
Dr. C’s study design showing susceptiblity to outcome-associated selection. Reflecting the traditional focus of gender-gap research, the organization’s president, in our running hypothetical example, was interested in the gender gap between women and men. Hence, solely for illustrative purposes, individuals of other gender identities are not visualized in this figure.
The approach by Dr. C’s team is predicated on selecting faculty members at research institutions as a proxy for the population. This selected subset was not representative of the true population of all psychologists in the nation. The key issue is that securing a faculty position at a research institution (i.e., selection) and receiving the award (i.e., outcome) share several common causes. Possible common causes include the prestige of the doctoral-degree-granting program, research area, academic record, and professional-network ties. These common causes of the outcome and selection lead to systematic differences in outcomes between individuals selected and individuals unselected that are not due to gender. As a result, the calculated gender gap among the selected subset is tainted with selection bias.
So, how did Dr. C’s team reach the conclusion that there was no gender disparity? We offer a numerical illustration in Table 1. As a simple probative example, we assumed that being a faculty membeer at a research institution and receiving the award shared a single common cause: whether the psychologist’s PhD was from an elite university
Population (Top) and Subset Selected by Dr. C (

Note: Reflecting the traditional focus of gender-gap research, the organization’s president, in our running hypothetical example, was interested in the gender gap between women and men. Hence, solely for illustrative purposes, individuals of other gender identities are not visualized in this table.
Outcome-Associated Selection
We formalize the problem by visualizing the study design Dr. C’s team used with the causal diagram in Figure 4. Here, the causal estimand remains the causal effect of

Causal diagram depicting outcome-associated selection in the hypothetical example. Reflecting the traditional focus of gender-gap research, the organization’s president, in our running hypothetical example, was interested in the gender gap between women and men. Hence, solely for illustrative purposes, individuals of other gender identities are not visualized in this figure.
This is an example of outcome-associated selection. Under such a scenario, selection
Note that

Causal diagram depicting outcome-associated selection in which selection
Under the causal diagrams depicted in Figures 4 and 5, the structural bias induced by outcome-associated selection can be mitigated or eliminated by carefully recording and adjusting for
Recommendations to Mitigate Selection Bias
We offer three practical suggestions researchers can readily adopt to mitigate selection bias and strengthen their causal conclusions in group-based disparities research. These suggested strategies are complementary, and we encourage researchers to practice all three.
Avoid outcome-dependent selection
As a first step, researchers should avoid study designs that beget outcome-dependent selection designs. Researchers should ensure that their inclusion or selection criteria can be justifiably unaffected by—and, if feasible, blinded to—the outcome. Achieving this objective may not be straightforward. A unique challenge in disparities research is that outcomes of interest are often those that have occurred before the time of investigation (e.g., receiving the award in years past). Thus, researchers often work with historical data (e.g., from employment or administrative records or archived websites), leaving it possible that sample selection is influenced by the outcome of interest.
How to select a study sample to avoid outcome-dependent selection? Continuing our running hypothetical example of examining the gender gap in academic recognition, one could construct a “risk set” of psychologists nationwide to enumerate the population, such as procuring graduation records of all psychology PhDs from the department of education. Here, selection into the risk set
We briefly describe three other examples from the field of gender-disparities research. Card et al. (2023) investigated whether there was a gender gap in researchers being inducted into the National Academy of Science or the American Academy of Arts and Science (outcome
Covariate adjustment to mitigate outcome-associated selection bias
Next, we recommend researchers incorporate covariate adjustment as a crucial part of their analytic strategy. Selection is inevitably conditioned upon as part of a study design and is unavoidable in the subsequent data analysis. Researchers should thus strive to record variables that suffice to block the paths between
Sensitivity analysis to assess the impact of selection bias
Covariate adjustment alone may be insufficient to mitigate selection bias. Researchers should conduct a sensitivity analysis to empirically evaluate how selection can affect the reported results.
5
We describe an approach developed in the epidemiological literature (Thompson & Arah, 2014). This approach employs inverse probability of selection weights (IPSW) to remove the impact of selection. IPSW eliminates selection by weighting individuals selected to represent a pseudopopulation comprising a mixture of selected and unselected individuals. For example, if a selected individual has a weight of 4, that individual accounts for four individuals (one selected and three unselected) in the pseudopopulation. In this pseudopopulation, the distributions of the predictors of selection (e.g.,
We describe how to conduct a sensitivity analysis using IPSW in the following steps:
Determine the observed predictors of selection
Specify a statistical model for the selection mechanism (i.e., “selection model”) based on the determined predictors. For example, suppose that the probability of being selected
Posit a numerical (vector) value for the selection parameters β; this is held fixed for the rest of these steps. Calculate each individual’s predicted probability of being selected. For example, given a value of
With the predicted selection probabilities in hand, assign each individual in the selected subset (

5. Estimate the effect of
We make a few remarks about the sensitivity analysis procedure. First, we formally demonstrate the unbiasedness of using IPSW in Section D in the Supplemental Material. Monte Carlo simulation studies empirically demonstrating the unbiasedness are also provided in Sections B.2 and E (see rightmost column of Table S1) in the Supplemental Material.
Second, the selected study sample consists only of observations with
Third, we suggest adopting a functional form for the selection model that ensures the probability of being selected is bounded between 0 and 1 to avoid negative weights. As a probative example, a logistic model with main effects only would be:

where
Fourth, it is rarely straightforward or desirable to posit a single value for the selection parameters in practice. Therefore, we recommend systematically varying the values of β and repeating Steps 3 to 5. The resulting estimates given each posited value of β can then be plotted. We demonstrate this using a single simulated example described in Section B.2 in the Supplemental Material. We specified the selection model in Equation 2 and considered a discrete grid of values for

Sensitivity analysis showing the estimated effect of
Fifth, when

Discussion
In this article, we sought to raise scholars’ awareness of selection bias in group-based disparities research and offered suggestions for mitigating selection bias. We emphasize that selection bias is only one methodological issue in disparities research. There are other methodological challenges we did not unpack here. For example, in the current material, we did not consider other threats to causal inference. A long-standing debate in the formal counterfactual literature that is especially relevant to disparities research is whether an exposure must be realistically (or hypothetically) manipulable to be regarded as a cause. We offer further context of this debate in Box 1 for interested readers.
Is Manipulability Strictly Necessary for Causation?

We acknowledge that causes of interest in disparities research, such as race (Howe et al., 2022; Sen & Wasow, 2016; VanderWeele & Robinson, 2014), are inherently complex and multifaceted. These are undeniably established and fundamental causes of inequality (Amis et al., 2021; Phelan & Link, 2015; Pickett & Wilkinson, 2015). But the extent to which they can be unambiguously and meaningfully defined depends on the unique context in which they are applied. For example, perceived gender, race, or social class are well-defined and experimentally manipulable causes (Goldin & Rouse, 2000; C. C. Miller & Katz, 2024; Quillian & Midtbøen, 2021). Therefore, we encourage researchers to explicate whether their research question is causal or associational (Hernán, 2018). If interest is in addressing a causal question, researchers may find it useful to follow the causal roadmap (Ahern, 2018; Hernán, 2018), starting with clarifying the population of interest (Lu et al., 2022) and precisely specifying the hypothetical counterfactual scenarios used to define the causal estimands (VanderWeele, 2016; VanderWeele & Robinson, 2014).
Throughout the article, we used a hypothetical example concerning the gender gap between women and men. We reiterate that this is an expository example from the mainstream literature, and the causal reasonings we present in the article apply broadly to group-based disparities research. For example, when investigating the effect of gender, scholars are increasingly adopting a more inclusive approach by examining different gender groups beyond the “gender binary” (Aghi et al., 2024; Hyde et al., 2019; Ledgerwood et al., 2023). Scholars also frequently examine other forms of inequality because of dimensions or a combination of dimensions, such as race, sexual orientation, disability, migration background, marital status, socioeconomic positions, and neighborhood (Gaskin et al., 2013; Slaughter-Acey et al., 2023; Turney & Wildeman, 2015). Regardless of the specific groups being compared, scholars engaging in disparities research face similar challenges of minimizing the impact of selection bias.
Finally, we emphasize that the issue of selection bias applies broadly across various research areas in psychological science. In Box 2, we briefly present putative examples from psychological science beyond the context of disparities research to illustrate the importance of carefully considering selection mechanisms. Of these, Examples
Examples Illustrating Broader Implications of Selection Bias in Psychological Science

Conclusion
Group-based disparities research is critical to achieving a more equitable society. But inappropriate selection of a population subset impedes or undermines this essential scientific pursuit (Arah, 2019; Hernán et al., 2004; Smith, 2020). With this article, we sought to raise researchers’ awareness of the threat selection bias poses and provide guidance on mitigating it. Note that selection bias is not unique to group-based disparities research but is prevalent in causal pursuits across the psychological sciences. We hope that this article aids researchers in minimizing the potential for inaccuracies because of selection biases toward a stronger psychological science.
Supplemental Material
sj-pdf-1-amp-10.1177_25152459241260256 – Supplemental material for Advancing Group-Based Disparities Research and Beyond: A Cautionary Note on Selection Bias
Supplemental material, sj-pdf-1-amp-10.1177_25152459241260256 for Advancing Group-Based Disparities Research and Beyond: A Cautionary Note on Selection Bias by Dongning Ren and Wen Wei Loh in Advances in Methods and Practices in Psychological Science
Footnotes
Transparency
Action Editor: David A. Sbarra
Editor: David A. Sbarra
Author Contributions
Both authors contributed equally to this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.