
Abstract
The use of linear mixed models (LMMs) is increasing in psychology and neuroscience research In this article, we focus on the implementation of LMMs in fully crossed experimental designs. A key aspect of LMMs is choosing a random-effects structure according to the experimental needs. To date, opposite suggestions are present in the literature, spanning from keeping all random effects (maximal models), which produces several singularity and convergence issues, to removing random effects until the best fit is found, with the risk of inflating Type I error (reduced models). However, defining the random structure to fit a nonsingular and convergent model is not straightforward. Moreover, the lack of a standard approach may lead the researcher to make decisions that potentially inflate Type I errors. After reviewing LMMs, we introduce a step-by-step approach to avoid convergence and singularity issues and control for Type I error inflation during model reduction of fully crossed experimental designs. Specifically, we propose the use of complex random intercepts (CRIs) when maximal models are overparametrized. CRIs are multiple random intercepts that represent the residual variance of categorical fixed effects within a given grouping factor. We validated CRIs and the proposed procedure by extensive simulations and a real-case application. We demonstrate that CRIs can produce reliable results and require less computational resources. Moreover, we outline a few criteria and recommendations on how and when scholars should reduce overparametrized models. Overall, the proposed procedure provides clear solutions to avoid overinflated results using LMMs in psychology and neuroscience.
Keywords
The use of linear mixed models (LMMs; Bates, 2010; Gelman & Hill, 2006; Pinheiro & Bates, 2000; Stroup, 2012) for data analysis rapidly increased in the last decade 1 and has the potential to become the standard in neuroscience and psychology research (Brauer & Curtin, 2018; DeBruine & Barr, 2021; Judd et al., 2012; Singmann & Kellen, 2020). However, LMM implementation is not always straightforward, and reviewers may not always have the necessary expertise to assess them.
In this article, we focus on the use of LMMs for hypothesis testing of fully crossed designs with categorical factors and introduce a clear approach for model selection when overparametrized models lead to convergence and singularity issues. Hence, in the first part of the article, we provide some background to the general reader about LMMs. Then, we introduce the use of complex random intercepts (CRIs; Baayen et al., 2008; Bates et al., 2015, p. 9), and test their computational performance in three separate studies. Finally, we propose a step-by-step guide for model selection using CRIs, and we validate the approach in three additional studies. We adopted the lme4 (Bates et al., 2015) and afex (Singmann et al., 2020) packages’ syntax using the free R software (R Core Team, 2018).
LMMs in Psychology and Neuroscience: Benefits and Hurdles
A typical data set for an LMM includes all observations (e.g., all single trials). This increases the power of the statistical analysis compared with analyses on aggregated data (Gelman & Hill, 2006). Another advantage of LMMs is the control of the data variability by including in the statistical model both the factors that may generalize to the whole statistical population (i.e., fixed effects; also called “population-level” effects) and the factors that may affect the generalization of the fixed effects (i.e., random effects; also called “group-level” effects; Brauer & Curtin, 2018).
Random effects are specified as “grouping terms” and usually arise from the collected sample or the experimental design. For example, consider a data set obtained from a rating task in which a sample of 30 participants rated 20 images of cars and 20 images of animals under two different stressful conditions (stress factor: low stress, high stress). Results may be affected by each participant’s variability and may differ based on the experimental condition. Hence, researchers may like to reduce the influence such variability has on the results by including “participants” as a grouping term in the LMM random-effects structure. Moreover, researchers may also specify that the participants’ variability is affected by the experimental condition (e.g., a participant may be less variable in the high-stress condition compared with the no-stress condition). Researchers may also control for the correlations among the random slopes. However, this feature often leads to complex models, 2 the fitting of which may not be reliable for data analysis. Therefore, it is clear that improving the generalization of a result requires a careful specification of the fixed effects in the statistical model and of several aspects affecting the random-effects structure for each grouping term (Brauer & Curtin, 2018).
Scholars in the fields of neuroscience and experimental psychology mostly use categorical variables and may be interested in analyzing their data using LMMs to control for covariates that may affect their results (e.g., the trial number) and generalize their findings across stimuli (e.g., by having the “stimuli” used as grouping factor). Several scholars have detailed the bases of LMMs and have provided suggestions and tools to reduce model complexity (Brysbaert & Stevens, 2018; DeBruine & Barr, 2021; Harrison et al., 2018; Luke, 2017; Matuschek et al., 2017; Singmann & Kellen 2020) and achieve the best compromise between Type I and II errors (Barr, 2013; Barr et al., 2013; Brauer & Curtin, 2018; Matuschek et al., 2017; Singmann & Kellen, 2020).
Across these proposals, we identified two main recommendations. On one side, the random-effects structure should be “maximal,” containing all the slopes of the within-subjects factors, covariates, 3 and correlations among them (Barr et al., 2013). On the other side, Bates and colleagues (2018) proposed to find the parsimonious model that best represents the data by selecting the number of random slopes following an iterative procedure that combines the removal of correlation parameters and nonsignificant variance components and a principal component analysis to remove the smallest variance components (Bates et al., 2018; Matuschek et al., 2017). However, model selection (i.e., the steps used to reduce the number of fixed and random effects of complex LMMs) is not a trivial process, 4 and peer-reviewed articles rarely report the model-selection process (Meteyard & Davies, 2020). The controversy between maximal and parsimonious models is still unresolved (Barr et al., 2013; Bates et al., 2018) and reveals two different approaches regarding the use of LMMs: One approach focuses on considering all the potential random effects that might bias the results (Barr et al., 2013), and the other focuses on obtaining the best estimates from the model given the data (Bates et al., 2018).
In favor of the maximal model is the fact that having all factors’ levels as random slopes allows a good control of Type I and Type II errors. Furthermore, excluding from the random-effects structure a within-subjects factor, or an interaction, inflates the risk of Type I errors (Barr, 2013; Barr et al., 2013) by overestimating degrees of freedom (i.e., pseudoreplication). Note that pseudoreplication is when dependent observations are treated as independent. This leads to an overestimation of degrees of freedom and violates the assumption of the “independence of errors” (Crawley, 2012, Chapter 19). For example, if one compares the same sample of 30 participants in two different stressful conditions but does not include the factor “stress” in the random effects, the degrees of freedom will be computed as if there are 60 independent participants, dramatically increasing the risk of Type I error. Pseudoreplication can be more harmful than expected, particularly if post hoc testing is computed on the estimated marginal means of the model with packages such as emmeans (Lenth et al., 2020) or multcomp (Hothorn et al., 2008). In addition, deflated errors of the estimates of the fitted models (Type M errors; Gelman & Carlin, 2014) may inflate Type I error.
In favor of the parsimonious model structure is the fact that fitting a maximal model leads to frequent convergence and overparameterization issues and nonreliable models (Bates et al., 2018). 5 The overparameterization issue that often arises with maximal models might affect generalizability. When data are not sufficient to robustly estimate the coefficients, estimation of variance among small numbers of groups can be numerically unstable (Harrison et al., 2018). Moreover, maximal random structures require high computational power (e.g., some models may exceed RAM memory limits during fitting), and in case of small numbers of data points, the number of random effects can be higher than the number of observations.
In addition, the lack of a standardized approach (Meteyard & Davies, 2020) to simplify the random structure of a model leads researchers to adopt solutions that vary considerably across articles and scholars. Crucially, whatever step is taken to simplify a model (e.g., by removing correlations for one or all grouping factors and checking for overparameterization with or without model comparison, removing higher-order interactions but keeping main effects or vice versa, applying a backward elimination of nonsignificant effects, or removing lowest variance parameters), once a reduced model has been selected, it may be advisable to check if the results match with the maximal (overparametrized or not) model to ensure the results are robust. 6
Introducing CRIs
A key aspect in the selection of an LMM random-effects structure is the possibility to have parameters represented as either random slopes (grouped by a grouping term, e.g., in lme4 syntax: 1 + Condition | Participants) or as random intercepts (i.e., in the context of model matrices, these are also labeled as “scalar” random effects; see Bates et al., 2015, p. 9). Random intercepts can be used to represent categorical factors by removing the correlation parameters and assuming homoskedasticity for the participants with respect to the experimental conditions (Baayen et al., 2008; e.g., in lme4 syntax: 1 | Participants:Factor). Both random-slopes and random-intercepts structures control for the within-subjects’ variability, limiting the risk of overestimating degrees of freedom.
In this article, we use the term “complex random intercepts” to refer to a categorical random slope converted into a random intercept. Note that converting a random slope into a random intercept is possible only with categorical effects, whereas it is not possible with continuous covariates. In particular, we define a CRI model as a model that uses multiple random intercepts representing the complexity of the factors within a given grouping term (for a description of the LMM matrices, see e.g., Model i1 in Table 1, and Model SM1 in the Supplemental Material available online). In other words, the random-effects structure of a full CRI model uses different random intercepts for each grouping factor (e.g., the intercept of participants only plus the intercepts of participants interacting with all nested effects). Note that although CRI covariances are assumed to be zero, the number of variances and random effects estimates varies depending on the grouping terms used in each CRI model (for details on these differences for each model, see Table 1; for its mathematical representation, see also SM1 in the Supplemental Material). This approach is different from other ways that set the correlations of the random effects to zero (i.e., zero correlation between random effects [ZCR]; e.g., “0 + Condition | Participants,” “Condition || Participants”).
Summary of the Fitted Models

Note: In the “id” column, we report the coded label used to refer to a model throughout the article. The second column specifies the model syntax. Models o1 through o3 are obtained using the buildmer package. For all models, y is the dependent variable, and Fact1 and Fact2 are the two within-subjects factors. The third and fourth columns provide a description of the model and the computed estimates, variances, and covariances in relation to Stimulation Study 1 (15 participants with Fact1 and Fact2 being two three-level factors) according to the afex package. For the mathematical representations of these models, see SM1 in the Supplemental Material available online. ANOVA = analysis of variance.
To further understand the differences between a random-slopes model, a ZCR model, and a CRI model, it is necessary to explain some features regarding random-slopes models. Random-slopes models are invariant to shifts of continuous predictors. This means that if an arbitrary value is added to a continuous predictor, the estimated beta of the fixed effect and of the random effect of the model will not change (see Bates et al., 2015, p. 7). If one does not estimate the correlations between random effects (like in the case of ZCR and CRI models), the model will lose its invariance property. However, this noninvariance of the models has an impact only when predictors are continuous and included within the random effects (Bates et al., 2015).
The key difference between ZCR and CRI models is that although random effects in the uncorrelated ZCR models are estimated from the same multinormal distribution with mean zero and as variance-covariance matrix in a diagonal matrix, the random effects in CRI models are estimated from several independent normal distributions with mean zero and a nonzero positive variance, and no variance-covariance matrix among random effects is estimated. Moreover, although in ZCR models the number of parameters for each random categorical effect is equal to the number of levels minus 1, in CRI models, the number of parameters for each random categorical effect is equal to the number of levels.
The use of CRIs in LMM specification has the potential to solve known issues around categorical random-effects-structure specification and model convergence and to be an optimal trade-off between model reliability (i.e., fitting nonsingular and convergent models while keeping low Type I and II errors) and feasibility (i.e., low computational time and resources needed). However, this approach might hide some pitfalls when random effects are highly correlated and when the variability of the fixed and random effects varies across levels. Moreover, which CRI structure better controls for Type I and Type II errors is not clear. To the best of our knowledge, a comparison between random-slopes models (correlated and ZCR) and CRI models is missing.
Henceforth, the goals of this article are (a) to provide a simulation-based comparison between the different random-effects structures by taking into account Type I and Type II errors, convergence problems, singularity issues, and the time and memory necessary for fitting the model and obtaining p values according to the Kenward-Roger degrees of freedom and (b) to propose a step-by-step approach using CRI to choose a reliable and efficient random-effects structure to be used when other solutions do not work or when there is the suspicion that pseudoreplication may increase the risk of Type I errors.
We conducted six separate studies using a limited set of well-known and supported R packages (afex, Singmann et al., 2020; lme4, Bates et al., 2015; car, Fox & Weisberg, 2019; performance, Lüdecke et al., 2020; emmeans, Lenth, 2023). In Simulation Study 1, we simulated data of a 3 × 3 repeated-measures (RM) design and compared analysis of variance (ANOVA)-like tables obtained from CRI models, random-slopes models, and models fitted with a package that automatically applies the most common random-effects reduction strategies (buildmer, Voeten, 2022). In Simulation Study 2, we then ensured that CRIs were not affected by the number of participants and the degrees-of-freedom calculation. In Simulation Study 3, we then tested their reliability for post hoc analyses.
In Simulation Study 4, we report the application of the proposed approach to data simulated using our scripts. In Simulation Study 5 and in Study 6, we tested our approach using scripts from Matuschek et al., 2017 (http://read.psych.uni-potsdam.de) and real data, respectively. Finally, we provide clear recommendations for when and how model reduction may be performed.
Simulation Study 1: CRI-Model Evaluations
We simulated data of a 3 × 3 RM design. In particular, the fixed effects were characterized by two within-subjects factors (Factor 1 and Factor 2) with three levels each. We simulated 15 participants, and the random-effects structure included “participant” as grouping factor.
Moreover, data were simulated using a factorial design with three binary factors, yielding eight different scenarios:
variance within the levels of the fixed effects, which could be homogeneous (the standard deviation was identical for each level of Factor 1 and Factor 2, set to 20 for the nine coefficients) or heterogeneous (the standard deviation was different for each level of Factor 1 and Factor 2, set to [16, 24, 21, 26, 25, 20, 19, 15, 14]);
variance of the random effects, which could be homogeneous (all standard deviations set to 10) or heterogeneous (standard deviations set to [15, 10, 5, 4, 9, 14, 16, 11, 6]);
correlation of the random effects, which could be highly correlated (ρ = .8) or lowly correlated (ρ = .2).
For each scenario, the simulated dependent variables
We compared the performance of different model-fitting approaches (random slopes: Models s1–s4; CRI: Models i1–i4; models obtained from the buildmer package: Models o1–o3; see Table 1) using several indexes: (a) Type I and II errors, (b) convergence and singularity issues, (c) Type I and II errors of post hoc tests computed on the estimated marginal means, and (d) computational time and maximal memory used during the fitting procedure. Below, we provide a discussion for each index. For the errors of the estimates of each coefficient for the fixed effects of each model (Type M errors; Gelman & Carlin, 2014), see Table SM2 in the Supplemental Material.
Type I and Type II errors
Type I and Type II errors were obtained from the proportion of significant results excluding the intercept. In particular, we used the proportion of p values computed from
Type I Error and Power for Each Model in Simulation Study 1

Note: For a description of the models (Models s1–s4 i1–i4), see Table 1. For the eight different scenarios, see the main text and Supplemental Material available online. (Upper) For each scenario, we report the percentage of Type I error for each fixed effect of models. The last two columns represent the Type I error mean for each fixed effect and the Type I error mean for each model (“Mean Type I Error Per Effect” and “Mean Type I Error Per Model,” respectively). (Middle) For each scenario and model we report the power. The last two columns represent the mean per model and the power/Type I error ratio. The latter may represent a qualitative index of the overall performance of the model (the higher the better). However, this index should never be considered alone, but always in relation to the other type of errors and singularity and convergence issues. (Bottom) We report the results from the models obtained using the buildmer package (Models o1–o3; for details, see the main text and the Supplemental Material). We report the Type I error for each fixed effect. The last two columns represent the mean per model and the power/Type I error ratio. Fact1 and Fact2 are the two within-subjects factors. RE = random effects.
The model with the greatest resilience to Type I error is the full-slope maximal model (Model s1; see Table 2). This model also shows more conservative results in terms of power. We also observe a higher power, at the cost of a slightly higher rate of Type I errors, for Models i1, i2, s2, and s3. Contrary, those models that uniquely control for the interaction (Models s4 and i4) show the worst combination of Type I and Type II errors. Finally, the models automatically generated by the buildmer package (Models o1–o3) show a very good power but an excessive Type I error.
Convergence and singularity
The percentage of singularity and convergence issues are reported in Table 3. Random-slopes models (Models s1–s4) in almost all cases showed high convergence or singularity issues (singularity averages: 90.18%, 15.62%, 0.00%, 31.58%; nonconvergence averages: 49.60%, 6.01%, 3.30%, 6.45%, respectively). Contrary, CRI Models i1 through i4 showed convergence and singularity issues with an average below 2% (except Model i3, which had an average of convergence issues of 2.03%). Overall, the random-slopes models had a worse performance than CRI models in relation to convergence and singularity issues.
Statistics in Simulation Study 1

Note: For each model and simulation scenario, we report (upper) the percentage of singularity issues and (middle) the percentage of convergence issues. (Bottom) We report the time to fit the model and obtain the ANOVA-like table and the maximum RAM use during model and ANOVA table computation (the lower, the better). RE = random effect; ANOVA = analysis of variance.
Computational time and maximum memory usage
Table 3 reports the time and maximal memory used to fit the model and compute the ANOVA table. Computing the slope models (Models s1–s4) rather than CRI models took more time and required greater RAM memory usage. Note that the times shown in Table e are specific to the high-performance facility VIPER (28 separate cores) Broadwell E5-2680v4 processors (2.4–3.3 GHz, each core with 128 GB DDR4 RAM).
Simulation Study 2: Increasing Sample Size
So far, we observed that CRI models have low Type I error and greater power compared with other models. However, a greater sample might favor random-slopes models. We simulated new data sets with 50 participants, homogeneous variability of the standard deviations of fixed effects, and lowly correlated random effects. We compared a maximal model with correlation (Model s1), a maximal model without correlation (Model s2), and a full CRI model (Model i1) using the Satterthwaite degrees-of-freedom approximation to reduce the time to perform the ANOVA with the lmerTest package (Version 3.1-3; Kuznetsova et al., 2017).
Table 4 shows that all models were comparable in terms of Type I error and power (given that an increased sample size increases the chance to find a difference). However, correlated maximal models had a greater number of singularities and convergence issues compared with uncorrelated maximal models and CRI models. Uncorrelated models reduced the number of singularity issues but presented a greater number of convergence problems compared with CRI models. We also confirmed a previous report (Kuznetsova et al., 2017) that the Satterthwaite method successfully reduced the processing time and memory usage.
Type I Error, Power, and Statistics for Each Model in Simulation Study 2

Note: We report the results for the maximum full random-slopes model (Model s1), the full random-slopes model with the correlation matrix between random effects constrained to zero (Model s2), and the full CRI model (Model i1). For each model, we report the Type I error for each fixed effect, the power for the interaction, the power/Type I error ratio as a qualitative index, and the percentages of singularity and nonconvergence issues. We also report the time to fit the model in seconds, the time to fit the ANOVA-like table in minutes, and the megabytes of the maximum RAM memory used during model computation. Fact1 and Fact2 are the two within-subjects factors. ANOVA = analysis of variance; CRI = complex random intercept.
Overall, CRI models were affected by neither sample size nor the method used to compute the degrees of freedom (i.e., Type I error was comparable across Simulation Studies 1 and 2 with 15 and 50 participants, respectively).
Simulation Study 3: Post Hoc Testing
We tested whether reduced models inflate Type I errors also in post hoc tests based on estimated marginal means (for details about these differences for each model, see Table 1). Therefore, we simulated new data. The formula used to obtain the
Type I and Type II errors of post hoc tests
Post hoc comparisons through estimated marginal means (i.e., using emmeans or similar packages) depends on the degrees of freedom that are estimated by the model structure. Removing factors from the random effects causes pseudoreplication and overestimation of degrees of freedom. All pairwise comparisons between all levels of Factor 1 within each level of Factor 2 were computed by using the emmeans syntax “emmeans(model, pairwise ~ Fact1 | Fact2)” and applying the Tukey honestly significant difference correction for multiple comparisons. It is expected that under
Results in Table 5 show that the models with all within-subjects factors and interactions (or at least their interaction only; Models Ph_s1, Ph_s2, Ph_i1, and Ph_i3) specified as random effects had the lowest risk of committing Type I error (for the lme4 syntax for each model, see the bottom part of Table 1). Hence, computing post hoc analysis when the effect of interest is missing in the random structure may increase the Type I error (e.g., Model Ph_i2 performed worse than Models Ph_i1 and Ph_i3).
Type I and II Errors of Post Hoc Tests in Simulation Study 3
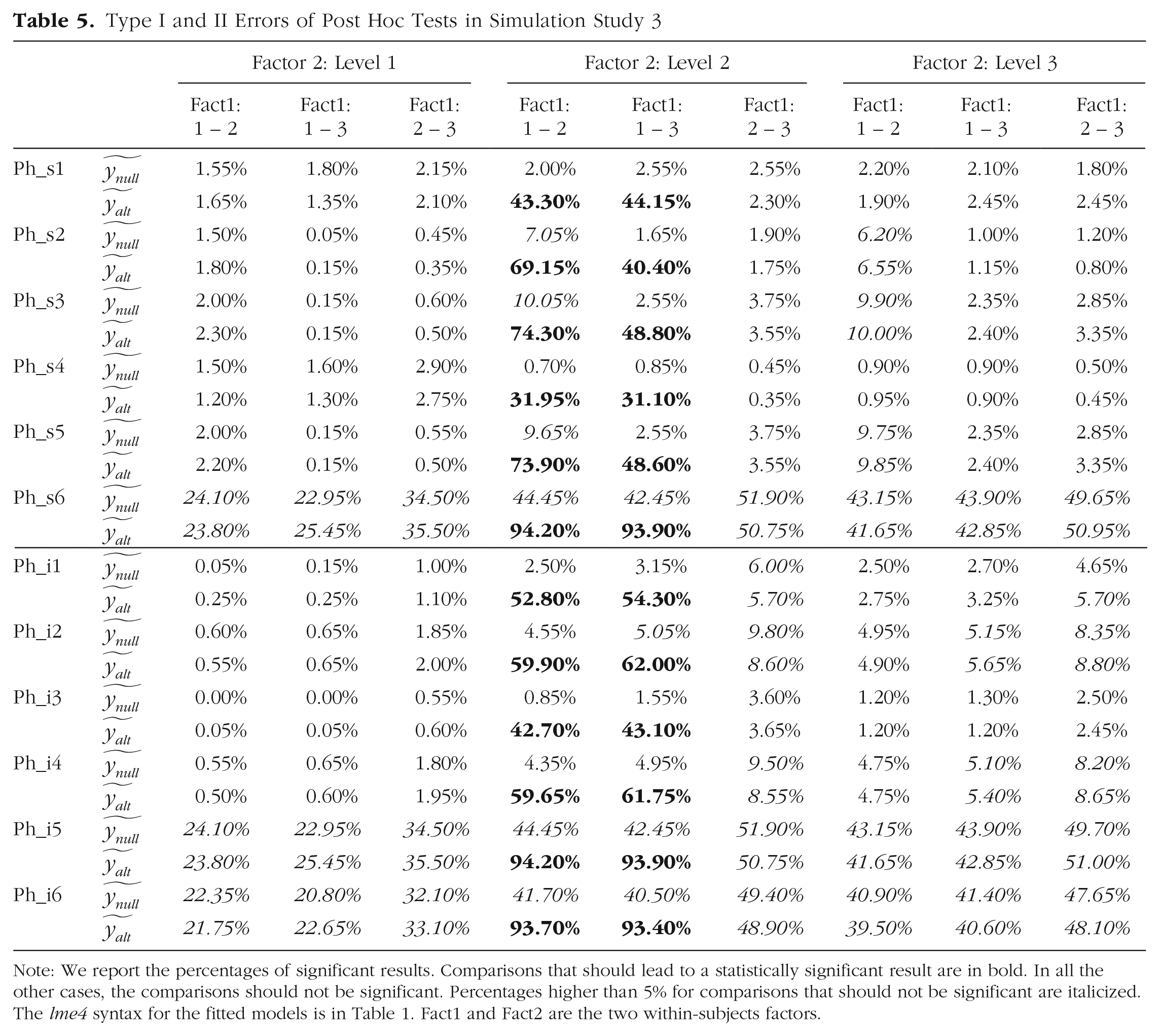
Note: We report the percentages of significant results. Comparisons that should lead to a statistically significant result are in bold. In all the other cases, the comparisons should not be significant. Percentages higher than 5% for comparisons that should not be significant are italicized. The lme4 syntax for the fitted models is in Table 1. Fact1 and Fact2 are the two within-subjects factors.
A Step-by-Step Procedure for Efficient and Reliable Random-Effects Structures
Preliminary considerations
In the previous simulations, we showed that full CRI models can lead to the presence of nonidentifiable random intercepts (i.e., a random intercept with zero variance). Nonetheless, the presence of nonidentifiable random intercepts did not affect (a) the estimation of fixed effects (see Supplementary Table in SM2 in the Supplemental Material, in which the range of the standard deviation in the estimation error is between 5.68E-15 and 3.32E-10), (b) the power of the model (see Table 2, in which the full CRI and full random-slopes models have a mean power of 88% and 66%, respectively), (c) the Type I error (see Table 2, in which the full CRI and the full random-slopes models have a Type I error mean of 6.26% and 3.58%, respectively), or (d) the Type I error on post hoc tests based on estimated marginal means (the full CRI model has only three comparisons in which the error is greater than 5% and the magnitude is equal or lower than 6%). Moreover, full CRI models showed lower singularity or convergence issues, reduced time to fit and estimate the ANOVA-like tables with Kenward-Roger degrees of freedom, and lower RAM usage than either the full random-slopes models or full random-slopes models with the correlation matrix of random effects constrained to zero (see Table 3).
Nonetheless, starting with a maximal random-slopes structure is recommended because it has the best trade-off between Type I and Type II errors. Main effects and interactions of interest varying within subjects and stimuli should be considered as fixed and random effects (Brauer & Curtin, 2018). LMM users should start with a maximal random-slopes model (Barr et al., 2013), following the best practice guidelines of these approaches, avoiding pseudoreplication and overestimation of degrees of freedom (Barr et al., 2013; Brown, 2021; Matuschek et al., 2017).
However, scholars who may obtain singularity or convergence issues after fitting an uncorrelated maximal model may be tempted to remove the highest-order random effect with the lowest estimated variance. We showed that such models dramatically increase Type I error. In other words, removing within-subjects random slopes increases the risk of overestimating the degrees of freedom and the risk of deflated errors of the fixed-effects estimates.
Here, we make a step forward to avoid the inflation of Type I errors when singularity and convergence issues may arise and propose a step-by-step rationale to select the LMM random-effects structure using CRI (Fig. 1).

The procedure to use linear mixed models and complex random intercepts. Process and decision boxes are for explanatory purposes. See the main text for full details on how to implement model reduction.
Model reduction from full CRI models
This pipeline can be applied when full random-slopes models are not feasible or when the access to adequate computational resources is not possible. Other elements of great importance, such as controlling for the normality of both model residuals and random-effects distributions, are not among the present work’s purposes. However, the scripts available online (https://osf.io/zbkdv/) provide the necessary functions to check the selected model’s appropriateness successfully.
Step 1: defining full CRI models
When random-slopes techniques fail in fitting a maximal model, a full CRI model should be considered and defined. CRIs should cover all main effects and interaction, varying within subjects and stimuli. Note that relevant covariates that may not be equally distributed among groups or participants (e.g., the scaled trial number for each observed case) may be considered as fixed effects. Although we did not simulate models with continuous covariates that change across the data, researchers may consider including covariates as random slopes of the CRI that they find the most appropriate. For example, scaled trial number may affect any experimental condition; in our examples, “1 + Trial_Number | Participants:Fact1:Fact2” if the number of the trials restarts each level of Factor 1 and Factor 2 or “1 + Trial_Number | Participant” if the number of the trials does not restart along the experiment. Obviously, it is not possible to use a continuous covariate as random intercept or grouping variable. The model should then be checked for singularity (Step 2) and convergence (Step 3).
Step 2: model singularity
The model can now be run to test for singularity. In case the model is not singular, no action is required, and you can move to Step 3. Otherwise, CRIs with the lowest variance can be removed. We suggest removing one CRI at a time. This step is executed iteratively until a nonsingular model is fitted (for further details, see the Recommendations section).
Step 3: model convergence
At this stage, you should check model convergence. If the model converges, no action is required, and you can move to Step 4. If it does not converge, an appropriate optimization algorithm should be added to the model specification (for a list of other remedies for convergence issues, see Brauer & Curtin, 2018), and the optimized model should be checked again for singularity (i.e., go back to Step 2). If convergence is not reached after the optimization procedures, a simplification of the random structure of the model may be required as outlined in Step 2, and the reduced model should be checked again for singularity (i.e., go back to Step 2).
Step 4: checking the final model
At this stage, with a nonsingular and convergent model, you need to check the distribution of the residuals of the random effects and of the final model. If residuals appear normally distributed, no action is required, and you can move to Step 5. If residuals are not normally distributed, scholars can transform their data and start the pipeline again (i.e., go back to Step 1) or achieve a normal distribution of the residuals by removing influential cases before moving to Step 5.
Step 5: computing ANOVA tables for LMMs
Now that you have the final model, you can compute the F and p values using the Kenward-Roger degrees-of-freedom approximation (especially for small sample sizes). Assuming that you had to simplify the model and given that simplifications may increase Type I error, if an effect is found to be significant but its CRI is not specified in the random structure, the scholar discussing such result should support the analyses by fitting a new LMM with the observed significant effect as CRI in the random structure. In the rare event the new LMM presents some singularity or convergence issues, we advise scholars to report both analyses and discuss discordant results. This should control for the risk of pseudoreplication because CRIs of main effects do not correct for Type I error inflation of interactions (see Models s3 and i2, in which only main effects were part of the random structure and had higher Type I error than Models s1, i1, and i3 models in Simulation Study 1).
Step 6: final model fit and post hoc analyses
After computing p values, you should compute the marginal and conditional coefficients of determination (R2) of the final model (Johnson, 2014; Nakagawa et al., 2017; Nakagawa & Schielzeth, 2013). Marginal and conditional R2 values range between 0 and 1 and represent a measure of the proportion of variance accounted by the final model. Whereas the marginal R2 values are associated with fixed effects, the conditional R2 is associated with fixed and random effects. R2 values can be computed via the MuMIn (Barton, 2020) or the performance (Lüdecke et al., 2020) packages, among others. Having a model representing the data, without exceeding in overfitting, is always important, and it becomes critical if the researcher plans to compute post hoc analysis on the model’s estimated marginal means. In other words, if the goodness of fitness is poor, then the mathematical model fitted by the LMM cannot be a good representation of the actual data. This might cause misleading results in the post hoc analysis based on estimated marginal means. Therefore, having a conditional R2 greater than .6 (Faraway, 2002) might indicate a model representative of the dependent variable without overfitting and be viable for post hoc analyses on estimated model effects. If the conditional R2 is low (e.g., < .6; Faraway, 2002), we advise the scholar to support further the results by performing pairwise comparisons on aggregated data and not to rely exclusively on estimated-marginal-means techniques. In both cases, multiple comparisons should be adequately corrected to reduce the risk of Type I error inflation because of multiple comparisons. Note that although we propose a range of R2 values to assess model goodness, this range needs to be taken with caution. The same R2 value can be interpreted as adequate or inadequate depending on the nature of the experiment, the variability of the dependent variable, and the purposes of the analysis. For example, if the dependent variable is very noisy and the number of observations is high, a low R2 might be considered adequate.
Simulation Study 4: Testing the Proposed Pipeline
To test the efficacy of our proposed pipeline, we simulated data of a 3 × 3 RM design with 30 participants, a homogeneous residual standard deviation of the fixed and random effects (SDs = 60 and 7, respectively), and lowly correlated random effects (r = .2). This was necessary to increase the number of singularity or convergency issues for full CRI models (for further details about model specification, see the Supplemental Material). Each simulated data set was analyzed with a full CRI model, a minimal model with participant-only random intercept, and the reduced full CRI model following Step 2 and Step 3 of the proposed pipeline.
Table 6 shows that our setting created singularity issues (> 15%) in the full CRI model, although in both the minimal and the reduced CRI models, there were no convergence or singularity issues. Crucially, although the minimal model showed extremely large Type I error, the reduced and the full CRI models did not show Type I error inflation for main effects or the interaction.
Type I Error, Power, and Statistics for Each Model in Simulation Study 4

Note: We report the statistics for the maximum full CRI model (Model i1), the reduced full CRI model using the proposed pipeline, and the minimal model (Model Ph_i6). For each model, we report the Type I error for each fixed effect, the power for the interaction, and the percentages of singular and nonconvergent models. Fact1 and Fact2 are the two within-subjects factors. CRI = complex random intercept.
Simulation Study 5: Simulations From Matuschek et al. (2017) Scripts
To ensure that the low Type I error observed above was not a specific case of our simulated data sets, we used the scripts from Matuschek et al. (2017) and specified a two-level categorical fixed effect C with S and I as participants and items grouping factors, respectively (50 participants, 20 items). Further details concerning the simulations are available in Matuschek et al.
We simulated 2,000 data sets with the beta for the null-hypothesis and the alternative-hypothesis populations identical to the original article (
Type I Error, Power, Statistics for Each Model in Simulation Study 5
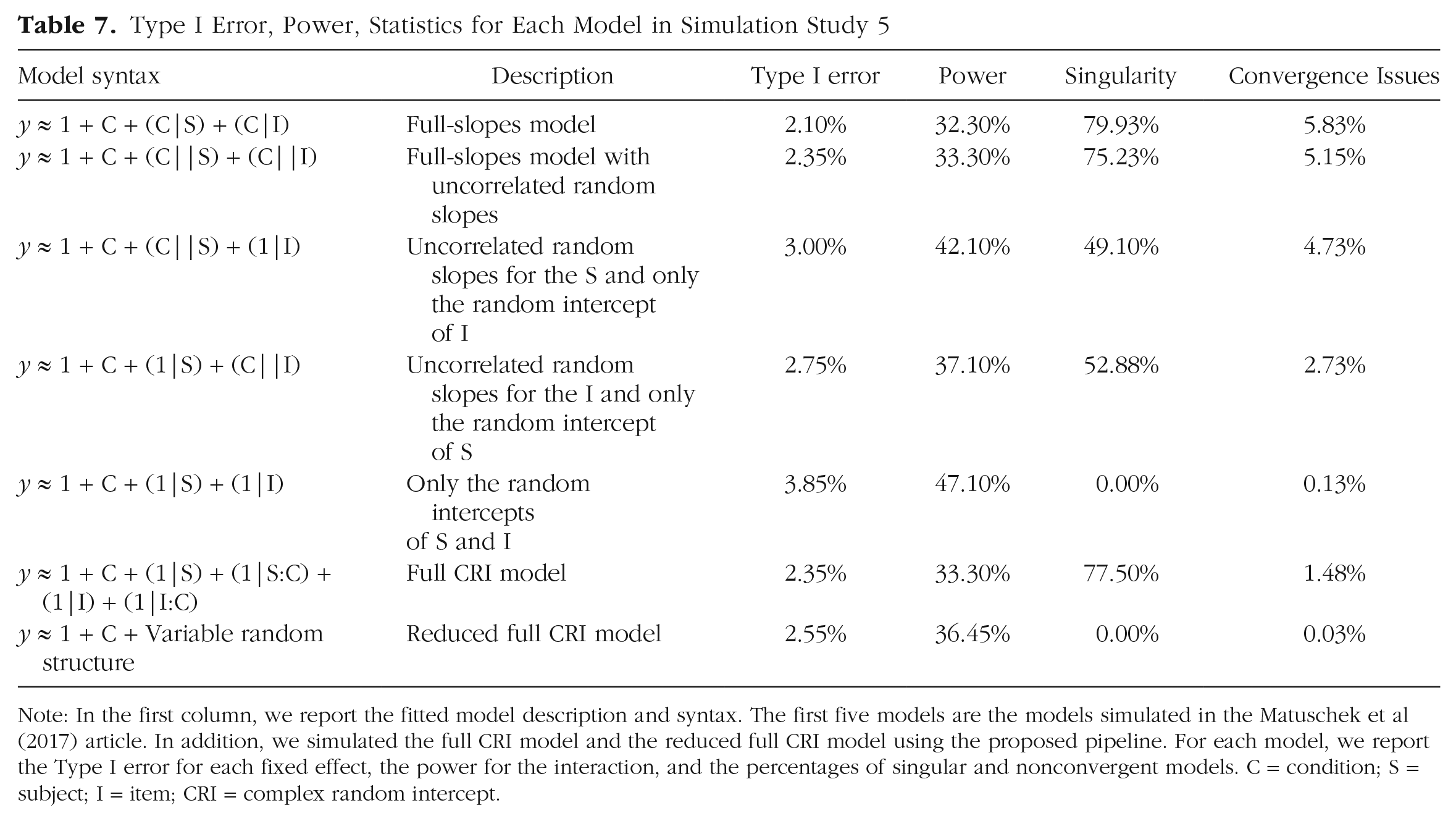
Note: In the first column, we report the fitted model description and syntax. The first five models are the models simulated in the Matuschek et al (2017) article. In addition, we simulated the full CRI model and the reduced full CRI model using the proposed pipeline. For each model, we report the Type I error for each fixed effect, the power for the interaction, and the percentages of singular and nonconvergent models. C = condition; S = subject; I = item; CRI = complex random intercept.
Results in Table 7 show that full-slope, full-slope with uncorrelated random effects, and full CRI models had the highest number of singularities and the lowest Type I error. In this case, the minimal models showed a good Type I error and power, as already shown in Matuschek et al. (2017). This is probably caused by the fact that the simulated experimental design is relatively simple (only one independent variable with two levels: a situation that barely occurs in experimental psychology and neuroscience) and that this minimal model also contains the intercept for each stimulus, an aspect that might limit the pseudoreplication effect by explaining more variability of the data.
Note that the reduced CRI model performed very well and had Type I error and power comparable with the other models and lower converge and singularity issues.
Reanalysis of Singmann and Klauer (2011, Experiment 2)
To further assess the reliability of CRIs, we reanalyzed the sk2011.2 data set available in the afex package (Singmann et al., 2020). The study was a mixed design with one between-subjects factor (instruction) and two within-subject factors (inference, type). Here, we analyzed the dependent variable response with LMM ANOVA tables (see Table 8a), and we tested models that differed in their random structure but not their fixed effects (the scripts are available in the OSF (https://osf.io/zbkdv/) “Reanalyses” folder). Specifically, we compared the results obtained by (a) the maximal model (Model s1), (b) the maximal model without correlations among random effects (Model s2), (c) the model obtained from buildmer (using the method described for Model o1), (d) a full CRI model (Model i1), (e) the model reduced using the proposed pipeline starting from the full CRI model, and (f) a participants’ random-intercept-only model.
ANOVA Tables and Post Hoc Analysis on Real Data

Note (a) Each column represents a model and whether it was a nonsingular and convergent model. Each row represents a predictor of the model, and we report the degrees of freedom and p values obtained from the different linear mixed models. For simplicity, each model’s label indicates how the random-effects structure has been adapted based on Models s1, s2, o1, and i1; a reduced model using the proposed pipeline; and an intercept-only model. (b) We report a descriptive evaluation of the triple instruction:inference:type interaction for each model. We show the average of the estimates (±SD), the average standard error of the estimates (±SD), and the total number of significant Bonferroni-corrected comparisons for that model. ANOVA = analysis of variance.
p < .05.
We collected convergence and singularity issues, degree of freedom, and p-value estimates for each model. Models were fitted using afex (Version 1.1-1; Singmann et al., 2020), lme4 (Version 1.1-29; Bates et al., 2015), and buildmer (Version 2.4; Voeten, 2022). The p values were computed using Kenward-Roger degrees of freedom with the R package car (Version 3.0-13; Fox & Weisberg, 2019). All these analyses were carried out in R (Version 4.1.2; R Core Team, 2018).
All models produced similar results with few exceptions (see Table 8a). In particular, p values of the double instruction:type interaction was significant for the model without correlations and the model obtained from buildmer. Moreover, the triple interaction instruction:inference:type was significant in all models. Thus, we explored whether multiple comparisons of this interaction were affected by different random structures (see Table 8b). Results indicate that the model with the participants’ intercept only was the most anticonservative with 42 out of 66 Bonferroni-corrected paired comparisons showing a p value lower than .05, followed by the model obtained by buildmer. Note that the reduced model following our suggested pipeline had no convergence and singularity issues, and both ANOVAs and Bonferroni-corrected paired comparisons were highly similar to the full random-slopes model. Overall, these reanalyses support the importance of including significant effects as CRIs or random slopes and indirectly confirm the findings from the simulation studies.
Discussion
In a series of studies, we tested the reliability of different methods used to reduce overfitted LMMs in fully crossed experimental designs. We showed that removing correlations or random slopes to achieve nonsingular and convergent models may dramatically inflate Type I errors. We also introduced a new method for model reduction using CRI and tested its reliability for hypothesis testing using simulated and real data. Finally, we proposed and tested a pipeline to reduce arbitrary decisions when reducing an overparametrized model and to achieve nonsingular and convergent models without inflating Type I errors.
To the best of our knowledge, our work for the first to show that using CRIs can play an important role in reducing pseudoreplication and obtaining models with few convergence problems. Moreover, it also demonstrates the importance of adding CRIs of significant effects. Our pipeline can be successfully applied following six steps and a few simple criteria to obtain conservative reduced LMMs (see Fig. 1 and A Step-by-Step Procedure for Efficient and Reliable Random-Effects Structures). We combined into a single procedure many suggestions (e.g., use of maximal model, the possibility of simplifying overparametrized models by removing random slope or correlations) put forward by different scholars (Barr, 2013; Barr et al., 2013; Bates et al., 2018; Brauer & Curtin, 2018; Singmann & Kellen, 2020) and extended them by using CRIs.
Note that although we mainly based our results on simulated data for statistical inference, pseudoreplication problems might inflate Type I error also in other statistics influenced by degrees of freedom, such as the Akaike information criterion, or even in statistical procedures that can be independent from degrees of freedom, such as bootstrap techniques. The procedure set out in this article does not have the ambition to be perfect in terms of Type I error and power but, rather, to be a pragmatic approach with a clear and concise step-by-step procedure that can be used by any scholar who wants to use a method validated by simulations with clear recommendations.
Recommendations for model reduction
Scholars usually reduce maximal models to increase the power of LMMs. It is known—and shown also by our simulations—that removing random effects from the random-effects structure can dramatically increase Type I error. Henceforth, scholars who have access to adequate computational resources are recommended to start from a maximal model. In case limited computational resources do not allow computing the model, the p values, or multiple comparisons or unforeseen system errors preclude statical analyses, our pipeline provides the possibility to start from full CRI models. Using CRIs to avoid Type I error inflation also extends other approaches when these may fail to solve singularity and convergence issues (Brauer & Curtin, 2018; Singmann & Kellen, 2020). This may be crucial if the scholar cannot compute the maximal model in the first instance, precluding the possibility to assess which random effects have the lowest variance or whether the model has any singularity/convergence issue. Moreover, our pipeline suggests few clear steps (i.e., starting from a full CRI model and removing CRIs with the lowest variance one at a time) to avoid anticonservative results (e.g., by supporting main findings by also analyzing aggregated data).
Practical implications for statistical inference
In terms of Type I errors and power, the full-random-slopes models (Model s1) have the best performance. However, full CRI models (Model i1) may be a valid alternative to (non)correlated full random-slopes models. That is, scholars may start directly with a full CRI model when there is limited computing power or a small number of data points or when singularity or convergence issues arise. Conversely, the resulting models from automatic packages, such as buildmer, have the advantage to always avoid convergence and singularity issues, but unfortunately, they tend to show higher Type I error.
In this article, we presented a practical step-by-step procedure to simplify the random-effects structure of an LMM while controlling for pseudoreplication. Our approach differs from other approaches because we provide a single criterion to remove random effects (i.e., the CRI with the lowest variance), reducing the risk of arbitrary decisions (e.g., removing the highest-order effect or keeping it) and spurious results.
We tested our pipeline in three different ways: two based on data simulations and one using real data. In all cases, the reduced model never inflated Type I error. We also checked the models’ performance in post hoc analyses based on estimated marginal means by using the emmeans package, one of the most used among researchers. We showed that models with a highly reduced random-effects structure will likely increase Type I errors even after applying conservative corrections. Conversely, post hoc tests computed on the estimates of the simplified models following the suggested pipeline did not inflate Type I error and were more conservative.
However, based on our simulations, any model reduction of the random-slopes structure may increase the Type I error compared with a full-slopes maximal model. Thus, scholars should carefully discuss a fixed effect with a significant p value obtained from a reduced model and may also try to validate their findings by analyzing the data in other supportive way (e.g., adding effect sizes and/or confidence intervals). Moreover, note that post hoc testing on the estimated effects of a model with a poor conditional R2 may lead to greater Type I errors and biased results. In these cases, it is recommended to compute post hoc testing with pairwise t tests, or pairwise regressions when necessary, on aggregated data and apply family-wise error corrections.
Simulation differences between this work and other studies
Our simulations adopted a frequentist approach and lead to more Type I errors and singularity and convergence issues than the reader can find in other articles based on data simulations. This is because the seminal and traditional simulative approach to validate statistical procedures is to simulate data that perfectly follow all model assumptions and to simulate simple experimental designs to have clearer insights concerning the validity of the proposed approach.
Notwithstanding these methodologies are of the utmost importance and a validation has to use one of such approaches (in this work, we used the simulation scripts from the seminal work of Matuschek et al., 2017), sometimes simulated data are different from the data obtained in real experiments. Moreover, at least from our and other colleagues’ experience, (un)correlated full random-slopes models often lead to nonconvergence or singularity issues, and traditional model-reduction methods lead to pseudoreplication issues.
For all these reasons, we lowered the number of simulated participants under the recommended level (note that we also simulated data with 50 and 30 participants in Simulation Studies 2 and 4, respectively), and we used two categorical independent variables with three levels each. We believe this approach allowed us to simulate more closely a psychology or neuroscience experimental design and allowed us to stress the difficulties in obtaining models with no singularities and convergence issues.
Conclusions
In this article, we proposed transforming random slopes into CRIs to control for Type I error inflation following model reduction. We also proposed a new and concise iterative decision process to determine the random-effects structure starting from a full CRI LMM. We demonstrated that our approach successfully reduces the risk of Type I error inflation by providing a few criteria to interpret results from reduced models. We believe this step-by-step approach can be easily implemented also by scholars and reviewers who are new to LMMs. Moreover, scholars who have not enough computational power or enough observations to start with a full random-slopes model can directly start with a full CRI model. Our step-by-step approach, together with other seminal approaches (Barr et al., 2013; Matuschek et al., 2017), may positively contribute to reduce study replication failure, and although we applied this approach to LMMs and behavioral data, we believe our pipeline may also be applied to generalized LMMs and neural data.
Supplemental Material
sj-docx-1-amp-10.1177_25152459231214454 – Supplemental material for Reliability and Feasibility of Linear Mixed Models in Fully Crossed Experimental Designs
Supplemental material, sj-docx-1-amp-10.1177_25152459231214454 for Reliability and Feasibility of Linear Mixed Models in Fully Crossed Experimental Designs by Michele Scandola and Emmanuele Tidoni in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
We acknowledge the Viper High Performance Computing facility of the University of Hull and its support team (http://hpc.wordpress.hull.ac.uk/home/). We thank Richard O’Connor for his helpful insights on an earlier version of the article. The codes used for the simulations are available online (![]() ).
).
Transparency
Action Editor: Rogier Kievit
Editor: David A. Sbarra
Author Contributions
Authors are listed in alphabetical order. Both authors contributed equally.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.