
Abstract
In psychological research, longitudinal study designs are often used to examine the effects of a naturally observed predictor (i.e., treatment) on an outcome over time. But causal inference of longitudinal data in the presence of time-varying confounding is notoriously challenging. In this tutorial, we introduce g-estimation, a well-established estimation strategy from the causal inference literature. G-estimation is a powerful analytic tool designed to handle time-varying confounding variables affected by treatment. We offer step-by-step guidance on implementing the g-estimation method using standard parametric regression functions familiar to psychological researchers and commonly available in statistical software. To facilitate hands-on usage, we provide software code at each step using the open-source statistical software R. All the R code presented in this tutorial are publicly available online.
Keywords
Longitudinal studies are often used to investigate causal questions. In psychological research, many naturally observed predictors of interest (referred to hereafter as “treatments”) are time-varying. For example, researchers might be interested in examining how consuming coffee at various times of the day influences sleep quality at night, how repeatedly being ostracized at work affects job performance, or how social media use over time can contribute to depression. Questions such as these share the commonality that the treatments change over time. As discussed in depth in the existing public health and medical sciences literature, a central challenge of causal inferences about time-varying treatments is “time-varying confounding” (Daniel et al., 2013; Hernán & Robins, 2008; Keogh et al., 2017; Mansournia et al., 2017). It is well recognized that routine methods for handling confounding are inadequate under such settings and lead to incorrect causal conclusions (Bray et al., 2006; Moodie & Stephens, 2010; Rosenbaum, 1984b). 1
How should researchers handle time-varying confounding? G-estimation offers a solution. G-estimation is a powerful statistical tool designed to deal with time-varying confounding (Robins, 1997; Vansteelandt & Joffe, 2014; Vansteelandt & Sjölander, 2016). Despite being a well-established and widely implemented analytic technique in public health and medical sciences, it has only recently been introduced to the psychological literature (Loh & Ren, 2023). In this tutorial, we provide concrete guidance on g-estimation to make this method accessible to psychological researchers. We provide software code at each step using the open-source statistical software R (R Core Team, 2021) to facilitate hands-on usage. All the steps implemented in this tutorial are publicly available online. 2 Additional references for interested readers are provided throughout the tutorial.
A Brief Introduction of G-Estimation
G-estimation is a well-established causal inferential-based technique for evaluating the effects of a time-varying treatment in the presence of time-varying or treatment-dependent confounding. It is among a broad class of so-called g-methods (where the “g” stands for “generalized”) developed by James Robins, with deep roots in causal inference research, and is widely used in biostatistics, epidemiology, and medical sciences to assess time-varying treatment effects in longitudinal data (for introductions to g-methods, see, e.g., Hernán and Robins, 2020, Part III; Naimi et al., 2016).
Three desirable features motivate the use of g-estimation. First, no models for the (distribution of the) covariates are required, so covariates can be either continuous or noncontinuous and be either time-invariant or time-varying (and thus possibly affected by treatment). Second, unbiased estimation requires correctly specifying a model for the treatment or the outcome but not necessarily both. Finally, it is relatively easy to implement using standard parametric regression functions; these are familiar to psychological researchers and commonly available in statistical software. We exploit these advantageous features to present a tutorial on g-estimation.
Establishing the Causal Effects of Interest
Minimal illustrating example
To illustrate the steps of the g-estimation method, we use a hypothetical example investigating coffee consumption on mood over the course of a day. Researchers may posit fatigue as a confounder of the causal effect of coffee consumption because fatigue affects the decision to consume coffee, and fatigue is likely to be correlated with mood because of hidden common causes. Crucially, fatigue fluctuates over the course of a day, making it a time-varying confounder that should be recorded at each time point.
Now, suppose that researchers prompted participants to take a short survey at three time points during the day: 10 a.m. (t = 1), 1 p.m. (t = 2), and 4 p.m. (t = 3). At each time point t, participants reported whether they were drinking coffee (binary treatment X) and their mood (continuous outcome Y) and fatigue (time-varying confounder L) during the past 3 hr since the previous survey at t−1. Therefore, coffee drinking (treatment) recorded at each survey t was causally and temporally preceded by mood (outcome) and fatigue (confounder) during the previous survey at t−1.
The underlying data-generating process for this example is readily visualized using a “causal diagram” (C. Glymour, 2001; Greenland et al., 1999; Pearl, 2009), such as the one depicted in Figure 1.
3
Subscripts index the time t that a variable is recorded.
4
The treatment (coffee), outcome (mood), and time-varying confounder (fatigue) at each time t is denoted by

Causal diagram for example with three time points. A circular node denotes the (set of) unmeasured variable(s) U. For visual clarity, arrows emanating from U are drawn in gray, and the causal paths corresponding to the treatment effects are drawn as dashed arrows. Descriptions of the treatment effects are provided in the main text. Note that the treatment at Time 3 (
Defining the causal effects of interest
In this example, we focus on three causal effects of interest: the Lag 1 effect of
Continuing our example, our focus is on the causal parameters: (a)
For illustration, the true parameter values are
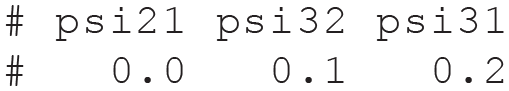
We generate a data set and display the first few rows of the data set below 8 :

Selecting pretreatment covariates for confounding adjustment
Before attempting to estimate each causal effect of interest, researchers must first consider putative confounding variables. This warrants selecting a set of pretreatment covariates that suffice to eliminate all noncausal associations when adjusted or statistically controlled for (Imbens & Rubin, 2015; Rosenbaum, 1984a). Extensive discussions of pretreatment confounding adjustment for causal inference have been presented elsewhere (Hernán & Robins, 2020; Morgan & Winship, 2015; Pearl, 2009; Steiner et al., 2010).
In our motivating example, an adjustment set that is sufficient to block all noncausal paths with
A simplified g-estimation procedure
For ease of understanding, we first present a simplified version of the g-estimation procedure. It uses only regression models for the outcome given treatment and the pretreatment confounders. In a later section, we describe an enhanced version of g-estimation that is robust to biases from certain forms of incorrectly specified models and likely to be better applied in practice. Estimation proceeds by focusing on each outcome measurement in turn and sequentially estimating the treatment effects on that outcome. In particular, estimation follows a sequence starting with the latest treatment and working backward in time to the earliest treatment.
We briefly explain the motivation for such a reverse temporal ordering. The outcome
To achieve this, rather than consider the observed outcome
Now we describe each step of the estimation procedure below:
1. First, we estimate the Lag 1 effect of

2. We can thus use the estimate of


Now let’s inspect the first few rows of the data set to ensure the new counterfactual quantity has been successfully created.

We can now use
3. Fit a linear regression model for

Finally, we estimate the Lag 1 effect of
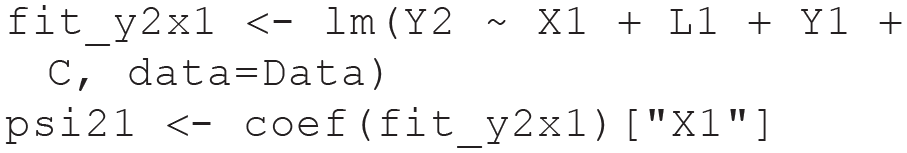
Having carried out all the steps above, we can now inspect the estimates of the three causal effects below. The estimates were almost identical to the true values, with differences only at the second decimal place.

Finally, note that if we merely used the coefficient of

G-Estimation Using Lavaan
We illustrated the steps of a simplified g-estimation procedure using the linear regression functionality (lm) in R. We now describe how to carry out the above procedure using the R package lavaan (Rosseel, 2012). There are two critical advantages conferred by using lavaan for g-estimation. First, regression models for outcomes at multiple times can be evaluated simultaneously within the same lavaan model. This renders a more compact and coherent presentation of the estimation procedure. Second, equality constraints on the (regression) model parameters can be easily implemented during estimation. We provide examples of why such constraints are advantageous later.
1. First, we estimate both Lag 1 effects

The g-estimators of

2. Similar to Step 2 above, remove the Lag 1 effect of


3. Similar to Step 3 above, fit a model for

Having carried out all the steps above, we can now inspect the estimates of the three causal effects below. The estimates were almost identical to the true values, with differences only at the second decimal place.

Standard errors and confidence intervals can be estimated using a nonparametric percentile bootstrap procedure (Efron & Tibshirani, 1994) that randomly resamples individuals with replacement and then repeats all the above steps for each bootstrap sample. We advise against merely using the standard errors for
Benefits of using constraints in lavaan
A major advantage of using lavaan for g-estimation is the ease with which parameter constraints can be introduced in the lavaan model syntax. We describe two examples relevant to g-estimation. Suppose researchers postulate a constant Lag 1 (i.e., stationary or time-invariant) effect that is equal across all treatment time points (i.e.,

A fundamental yet empirically untestable assumption for valid causal inference is the absence of unmeasured treatment-outcome confounding. This assumption can be challenging to justify defensibly in practice, thus warranting a sensitivity analysis. Because unmeasured confounding can manifest in correlated treatment and outcome residual errors, we propose a sensitivity analysis for unmeasured confounding. We briefly summarize the steps. First, we fix the residual correlations at a given value. Next, we estimate the treatment effects under this fixed constraint. Both steps are then repeated using different fixed values of the residual correlations. This lets us systematically investigate how the effect estimates change depending on the given strength of unmeasured confounding. 12 Stronger correlations indicate more severe violations of the unconfoundedness assumptions, whereas a zero correlation corresponds to the assumption of no unmeasured confounding.
The correlations can be readily parametrized in lavaan as follows:

A sensitivity analysis then entails fixing the residual correlations to different (nonzero) values in turn (e.g., by replacing
Doubly Robust G-Estimation
In the simplified version presented in the preceding sections, estimation was carried out using only outcome models given treatment and the pretreatment confounders. A crucial shortcoming of such an approach is that unbiased estimation is predicated on correctly specifying the statistical relations between the outcome and the covariates. 14 Hence, the estimators can be (severely) biased because of incorrectly specified outcome models. To illustrate the biases, we generated a new data set with the same values of the treatment effects but with outcomes that depended on nonlinear functions of the covariates. Using the simplified estimation procedure (i.e., with outcome models that depended linearly on main effects of the covariates) thus yielded biased estimates, as shown below:

To offer protection from this shortcoming, the estimation procedure can be supplemented with a model for the distribution of treatment to endow the g-estimators with a doubly robust property (Hernán & Robins, 2020; Kang & Schafer, 2007; Robins, 2000; Vansteelandt & Daniel, 2014). The g-estimators are unbiased when both the treatment model and the outcome model are correctly specified and consistent when either model is correctly specified (in addition to a correctly specified SNMM and unconfoundedness being satisfied). No knowledge of which model is correctly specified is required. For example (as we have done here), suppose that the outcome was generated, unbeknownst to the researcher, based on nonlinear or complex functions of the covariates. But an incorrectly specified outcome model with only main effects of the covariates is assumed for estimation. A correctly specified treatment model can ensure that the probability of the empirical estimate getting closer to the true value converges to 1 as sample size increases, thus reducing the reliance on correctly specifying the outcome model for valid statistical inference (Vansteelandt & Joffe, 2014). 15 We now describe how to carry out the doubly robust g-estimation procedure:
1. Fit a model for
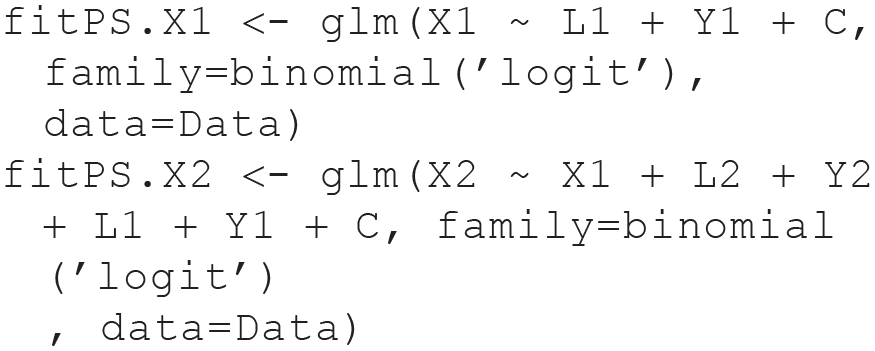
2. Calculate the predicted treatment or PS given the fitted models above.

Now let’s inspect the data set’s first few rows to ensure the predicted treatments have been successfully created.

3. Carry out the steps in the previous section but now include the predicted treatment or PS as an additional predictor in each outcome model. For example, the model for estimating the Lag 1 effects is:

Likewise, the model for the Lag 2 effect is
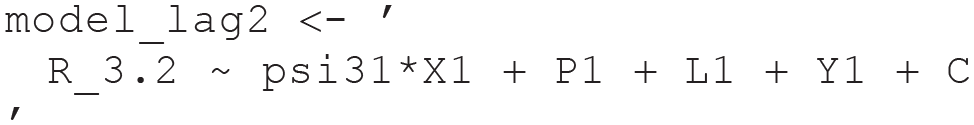
Having carried out all the steps above, we can now inspect the estimates of the three causal effects below. The estimates were almost identical to the true values, with differences only at the second decimal place.

In this article, we presented a simple example of g-estimation as described in Hernán and Robins (2020, Section 21.3) and Vansteelandt and Sjölander (2016). We focused on leveraging lavaan (Rosseel, 2012) to implement g-estimation. In doing so, we hope to make g-estimation more accessible to psychology researchers who are already familiar with the features and functionalities of the widely used lavaan platform. Readers interested in alternative g-estimation procedures designed to deal with a broad variety of research settings and using other software packages or platforms as further points of investigation are referred to Picciotto and Neophytou (2016), Sterne and Tilling (2002), Tompsett et al. (2022), and Wodtke (2018); for closely related approaches, although framed slightly differently, see Ertefaie et al. (2021) and Simoneau et al. (2018). For example, g-estimation has been extended to noncontinuous outcomes, such as binary outcomes (Dukes & Vansteelandt, 2018) and time-to-event data with censored outcomes (Seaman et al., 2021; Vansteelandt and Sjölander, 2016).
Summary
Time-varying (or treatment-dependent) confounding poses unique challenges to valid causal inferences using longitudinal data. G-estimation of linear SNMMs provides a well-established solution to this problem. In this tutorial, using a linear and simple SNMM, we demonstrated how to implement g-estimation using standard parametric regression functions familiar to psychological researchers. The resulting g-estimators have a double robustness property that ensures valid inferences even under certain model misspecifications. In summary, g-estimation is flexible, practical, robust, and relatively straightforward. We encourage psychology researchers to employ g-estimation when testing the causal effects of a time-varying treatment in longitudinal studies.
Footnotes
Transparency
Action Editor: Yasemin Kisbu-Sakarya
Editor: David A. Sbarra
Author Contribution(s)