
Abstract
Scholars heavily rely on theoretical scope as a tool to challenge existing theory. We advocate that scientific discovery could be accelerated if far more effort were invested into also overtly specifying and painstakingly delineating the intended purview of any proposed new theory at the time of its inception. As a case study, we consider Tversky and Kahneman (1992). They motivated their Nobel-Prize-winning cumulative prospect theory with evidence that in each of two studies, roughly half of the participants violated independence, a property required by expected utility theory (EUT). Yet even at the time of inception, new theories may reveal signs of their own limited scope. For example, we show that Tversky and Kahneman’s findings in their own test of loss aversion provide evidence that at least half of their participants violated their theory, in turn, in that study. We highlight a combination of conflicting findings in the original article that make it ambiguous to evaluate both cumulative prospect theory’s scope and its parsimony on the authors’ own evidence. The Tversky and Kahneman article is illustrative of a social and behavioral research culture in which theoretical scope plays an extremely asymmetric role: to call existing theory into question and motivate surrogate proposals.
As Paul Meehl (1978) famously stated, theories in many “areas of Psychology lack the cumulative character of scientific knowledge. They tend neither to be refuted nor corroborated” (p. 806). Although Meehl was primarily referring to paradigms that grow in and out of fashion, we contend that the statement applies to some of the most famous and enduring scholarly contributions. In addition, whereas Meehl was primarily referring to what he called “soft” areas of psychology, his characterization can apply to high-profile and mathematically formal theories. In this article, we consider one of the most prolifically cited articles in behavioral science as a case study in both ambiguous theoretical scope and ambiguous parsimony. That article uses theoretical scope as a tool to challenge prior theories, yet a closer look at the article’s own evidence calls its own scope into question by the very same criteria. Both proponents and opponents of this theory can cherry-pick the ways in which they characterize its scope and/or its parsimony, solely on the basis of the original article, in ways that serve their goals. In some domains of science, scholars have reached broad consensus about many theories’ “edge conditions,” their actual scope, and their flexibility. Behavioral research is yet to find even minimal consensus about whom its theories describe and under what circumstances.
The article is organized as follows. We start by examining what it might mean to specify theoretical scope and parsimony, first with a simple example from the natural sciences and then with a few exemplary articles from psychology. This prepares the ground for our case study, the 1992 article by Daniel Kahneman and Amos Tversky on cumulative prospect theory (CPT). In the context of that article, we discuss the difference between theoretical scope and parsimony in more detail. In particular, we lay out how scholars can cherry-pick aspects of the same evidence on the same theory to draw diametrically opposite conclusions. Next, we dig more deeply into Tversky and Kahneman (1992) to discuss four internal inconsistencies within that single seminal article. Citing the example of such a stellar theory, we make our case that social scientists need to consider the intended scope and the parsimony of their theoretical proposals much more carefully and with less bias. We then turn to the general question of how behavioral scientists can clarify the scope and parsimony of their theories. We review symptoms that flag problems, and we sketch some ideas for better practice.
What Is Theoretical Scope? What Is Parsimony?
Physicists share virtually perfect consensus about the “theoretical scope” of Newton’s law of gravity: The law applies to all objects in all locations at all times as long as the objects in question are not “too small” and do not “move too fast.” Much of engineering is based on understanding the situations in which Newton’s laws of motion, Pascal’s law of pressure, Boyle’s law of gases, and so on either do or do not apply verbatim. There is also broad consensus on how one can cover a broader range of phenomena using more complex (i.e., less “parsimonious”) theories. 1
What is theoretical scope and parsimony in psychology? If one considers any behavioral regularity, whether it is in cognition, personality, social interaction, or another domain, is there a consensus in the field as to who displays this behavior and under what circumstances? Do the behavioral sciences strive to develop broad agreement on delineating the range of conditions in which a theory applies and the characteristics of people whose behavior it explains?
Imagine that Archimedes’s principle was subject to major exceptions: If the weight of the displaced water matched only some boats’ weight, how would that affect boat design? Psychologists take it for granted that their theories hold only with exceptions. The logic of permissible exceptions is baked into much of our statistical methodology: Whenever a statistically significant proportion of participants in a study, but nowhere close to all, show a certain behavioral regularity, say, they remember more, or take larger risks, or are more cooperative, we infer that the phenomenon or effect is ‘real.’ But what does that tell us about who actually satisfies that regularity when, how, and why? If it is too ambitious to characterize people to this level of detail, do psychologists at least estimate how large a proportion of the population obeys their hypotheses about decision-making, memory, perception, personality, reasoning, or social interaction? How does the discipline identify and interpret conditions, individuals, stimuli, or tasks in which a theoretical claim does not actually apply? In other words, how does psychology conceptualize theoretical scope, and how does it handle limitations in a theory’s scope? Going one step further, how does the field ensure the parsimony of new theories that aim to encompass phenomena not captured by earlier theories?
To illustrate current best practice in stating the intended purview of new theories, we briefly consider three very recent high-profile articles from cognitive psychology: Popov and Reder (2020) in long-term memory research, Schneegans et al. (2020) in working-memory research, and Lleras et al. (2020) in visual attention. These are three research paradigms in which individual differences may plausibly play a muted role compared with, say, clinical, developmental, or social psychology. Popov and Reder proposed a new theory and computational model that purports to explain a wide range of “frequency effects” on memory while also providing a process-level explanation for how working-memory capacity gives rise to these effects. Popov and Reder acknowledged: Our extensions to recall tasks could be considered lacking in some respects. For example, while our serial recall model does a good job capturing the interaction between word-frequency and serial position, it does not reproduce the one item recency effect, which has been attributed to access from a [working-memory] buffer (Anderson, et al., 1998). Furthermore, we have made no attempt to model the full specter of contiguity effects in free recall, which have been a crucial benchmark for models of free recall. (p. 38)
Schneegans et al. proposed a framework grounded on a specific neural model of visual working memory. A purported strength of this model is that it links visual working-memory limits to a concrete neural substrate. Schneegans et al. discussed limitations of their theory, stating, for example, “In keeping with most previous work on [visual working-memory] limits, we have not here attempted to reproduce the variations in bias and precision that are observed for different feature values” (pp. 8–9). Lleras et al. proposed a novel visual search model, in part to account for the specific form of “search functions.” They reported that their theory could account for a wide range of effects in visual search tasks, particularly the effects of the similarity between target and distractor items in the visual search array for simple and real-world objects. Lleras et al. acknowledged, “A . . . limitation is that TCS [Target Contrast Signal Theory] is currently mostly focused on parallel processing and efficient search. More work is needed to flesh out what happens after parallel evidence accumulation is stopped and several target likely locations need to be inspected” (p. 422).
These articles stand out in that unlike many scholarly articles in psychology, they at least acknowledge phenomena that their theories do not explain. However, although they do take the admirable step of reviewing limitations, these articles are nonetheless reflective of a research culture in which theoretical scope is usually treated like a set of moving goalposts. Often, stating that “more work is needed” can be a diplomatic way to acknowledge that the scope of a theory is inherently ambiguous. For instance, even in these cognitive tasks, the extent to which every effect holds in every individual person and across a broad range of contexts is ambiguous. Hence, it is not really clear how desirable it is to model all effects jointly in the same individuals without committing a conjunction fallacy, for instance. Even in these exemplary articles, the challenging question of how to weigh one’s own theory’s limitations against its ability to account for an enlarged range of phenomena remains unanswered. Schneegans et al. (2020) used some heuristic statistical measures of parsimony (known as Akaike information criterion [AIC] and Bayesian information criterion [BIC]) based on counting the number of free parameters in the theory. The other two articles compared their own work with other work conceptually. Ultimately, despite the authors’ best efforts, all three articles are ambiguous about both the scope and the parsimony of their theories. Our article aims to raise awareness of the asymmetric role that theoretical scope plays in the development of social and behavioral theory.
The asymmetric role of theoretical scope
Notwithstanding the higher level of nuance in the aforementioned three articles, it is common to use theoretical scope almost exclusively to motivate new theories.
Often, the scope of an existing theory is delineated through “critical tests” or “unaccounted-for effects” by selecting an empirical paradigm and carefully designing certain stimuli for which a substantial number of people generate data that conflict with the existing theory’s predictions. By focusing on critical tests or unaccounted-for effects, scholars deliberately place pressure on existing theory. Proposing a new theory that passes those same hurdles creates an inherent bias in favor of the new theory. By the design of the research paradigm, this bias is immune to detection by even the best standard statistical model selection criteria. This is because model-selection methods typically apply post hoc, only after the scholar has already selected a suitable paradigm and crafted the relevant diagnostic stimuli to stress test the old theory. Yet support for a new theory may, in fact, already be ambiguous at the time of its inception because some participants may already provide some evidence against the new theory on some of the stimuli. Indeed, because presumably no behavioral theory performs universally well for everyone on all stimuli and in all contexts, a new difficulty arises as soon as the new theory reveals some of its weaknesses. Different schools of thought may disagree on whether the cracks in the new theory represent new critical tests that create the need for yet another theory or whether these fissures are merely examples of the imperfections that are inherent to even the best behavioral theories.
In this article, we unpack these ideas for one article that proposed the most prominent theory of decision-making: CPT. Although the authors did not highlight them, the first fissures are already visible in the original article proposing the theory (Tversky and Kahneman, 1992). As for how to weigh this theory’s improvement over prior theories against its own limitations, that question, even decades later, has been neither settled nor discussed in much depth.
CPT: A Case Study
Few theories from the social and behavioral sciences are as prominent across all of science, and even popular science, as CPT. Yet since its inception, CPT has also become a routine lightning rod for countless competing proposals about decision behavior. The theory enjoys extremely broad use in applied settings, in which it guides much policy development while also being the target of abundant skepticism, especially in basic research. Although some critics call it extremely narrow and easy to refute, others think it is too flexible and even irrefutable. We consider both scenarios later in this article. One possible explanation for finding both strong support and strongly mutually contradictory criticisms of one and the same theory might be that this theory may perform extremely well in accounting for some people’s behavior in some circumstances but not others. Intuitively speaking, the theory may have limited scope.
Tversky and Kahneman (1992) premised CPT on showing that many people displayed phenomena in violation of prior models, such as EUT (see also Kahneman & Tversky, 1979; Tversky & Kahneman, 1981). Specifically, Tversky and Kahneman (pp. 303–304 and their Tables 1 and 2) reported two studies in which 53% (money managers) and 46% (Stanford students) of the participants violated a core property of EUT called “independence.” Let E denote the event that the Dow Jones changes by a certain number between today and tomorrow. Suppose that two lotteries f and g both yield $25,000 if E occurs. Suppose that
Preference Patterns Among Loss Gambles of Tversky and Kahneman’s (1992) Table 3 Prospects With

Note: A “1” indicates “risk-seeking” preference in favor of a lottery over the sure amount equal to the lottery’s expected value (EV). The left side shows the predictions under Equations 1 and 3, whereas the right side shows predictions according to Equations 1 and 3 according to a “toy” theory where
Percentages of Risk-Seeking Choices Among Subjects 4, 6, and 21 and Average Percentage, Adapted From Table 4 of Tversky and Kahneman (1992)

The goal of reporting these disparities is not to take a stance about either the validity or value of CPT, or the lack thereof (recall that we focus on one article, Tversky & Kahneman, 1992, not an entire research program). In our view, every behavioral theory has limited scope. Rather, we aim to highlight the one-sidedness in much behavioral science in which theoretical scope is disproportionately used to censure a leading theory, often with little discussion of the intended or expected scope of the new theory. Building on earlier preparatory work (Davis-Stober & Regenwetter, 2019; Regenwetter & Robinson, 2017), we advocate that social and behavioral science should develop more constructive ways to reconcile, synergize, and weigh the theoretical proposals associated with different schools of thought. These recommendations reach beyond the replication crisis to more general questions, including the need to think through unintended consequences of successful replication (see also Davis-Stober & Regenwetter, 2019; Irvine, 2021; Kellen, 2020; Regenwetter & Robinson, 2017; Rotello et al., 2015; Yarkoni, 2022).
What is the difference between theoretical scope and parsimony?
Consider a prospect that leads to outcome A with probability p and outcome B otherwise in which A and B are monetary amounts. Positive values for A and/or B are monetary gains, whereas negative values are monetary losses. Table 1 shows eight such lotteries taken from Tversky and Kahneman (1992). For example, the first column shows a lottery in which the decision maker runs a 10% chance (
EUT transforms dollar amounts to subjective utilities and calculates the expected value of the subjective utilities to determine whether it is preferable to play this lottery or (in this example) to accept the sure loss. Using a utility function for losses of the form
Having established limitations in scope of a given theory, it is common, although not ubiquitous, that scholars will propose a less parsimonious revision that includes the original theory as a special case. Such is the case with CPT: It contains EUT as a special case, but CPT introduces extra flexibility that accommodates a broader range of possible preference patterns. As stated in the 1992 article (Tversky and Kahneman, 1992), CPT transforms money into subjective utilities in a fashion similar to the above version of EUT, it transforms probabilities into subjective weights, and it switches to a cumulative weighted average calculation. We omit the details of the latter because they are not important here. To keep mathematical formulas to a minimum, we restate only CPT’s core building blocks: subjective utility and probability weighting. According to Equations 5 and 6 of Tversky and Kahneman (1992), CPT invokes a value function v and probability weighting functions


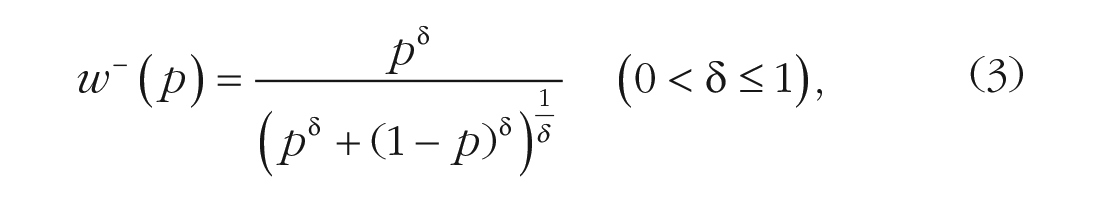
in which x are money amounts and p are probabilities. See Tversky and Kahneman for the details on how they combined these functions to derive subjective utilities of lotteries and to model preferences among lotteries.
For now, we consider only the left half of Table 1. It shows 12 different preference patterns predicted by CPT for those eight prospects. Because there are no mixed prospects (i.e., lotteries involving both gains and losses), we set
One thing is clear: Permitting more than one preference pattern is an important step toward enhancing theoretical scope. Tversky and Kahneman (1992) reported extensive individual differences in behavior, a finding that virtually all scholars agree with, at least in principle. Put differently, the theoretical scope of any theory of decision-making hinges, at least in part, on its ability to balance individual differences with theoretical parsimony. The combination of a single set of mathematical formulas (Equations 1–3) with parameters that can each vary across a continuum of permitted values creates the potential for a theory that is both parsimonious and enjoys great scope. 3
Tversky and Kahneman (1992) summarized some of their key findings as follows: The median exponent of the value function was 0.88 for both gains and losses, in accord with diminishing sensitivity. The median
Following Regenwetter and Robinson (2017), we refer to CPT with these parameter values as
We have already asserted that scholars often use theoretical scope in a one-sided fashion to establish limitations in the scope of someone else’s theory. We have also mentioned that CPT has served as a lightning rod for alternative proposals about decision-making. In fact, it is common practice to reduce CPT down to
We round out our comparison of theoretical scope and parsimony by showing that defining the latter is just as elusive as defining the former. Consider Table 1 once more. We derived preference patterns also for a hypothetical “toy” theory that satisfies Equations 1 through 3 but with parameter ranges
Four Inconsistencies
We now discuss four internal inconsistencies within Tversky and Kahneman (1992) and how they affect our understanding of CPT’s theoretical scope. As these inconsistencies reveal, Tversky and Kahneman provided evidence that their own theory suffers from limited scope almost in the same way as EUT. More generally, the inconsistencies reinforce the point that social scientists need to meticulously consider the intended scope of their own theory and how evidence stacks for or against it rather than disproportionately focus on the limited scope of contending theories.
Inconsistency 1
Tversky and Kahneman (1992) stated: The most distinctive implication of prospect theory is the fourfold pattern of risk attitudes. For the nonmixed prospects used in the present study, the shapes of the value and the weighting functions imply risk-averse and risk-seeking preferences, respectively, for gains and for losses of moderate or high probability. Furthermore, the shape of the weighting functions favors risk-seeking for small probabilities of gains and risk aversion for small probabilities of loss, provided the outcomes are not extreme. (p. 306)
Similar statements appeared in the article’s abstract (Tversky and Kahneman, 1992). The authors aimed to document this fourfold pattern in their Table 4 using four different types of prospects described in their Table 3. We provide an adapted excerpt of that table in our Table 2. All of these prospects were of the form
Test of Loss Aversion in Tversky and Kahneman (1992)

Note: For each problem, participants chose a value of x that made the prospect
According to the fourfold pattern, for these prospects, decision makers make risk-seeking choices for loss prospects with
As we saw earlier, we derived the 12 preference patterns in Table 1 by plugging 1,000 distinct values greater than zero and smaller than one for each of
This finding leads to several noteworthy insights. First, because Equations 1 through 3 can accommodate almost any conceivable data in Columns 2 and 4 of Tversky and Kahneman’s (1992) Table 4, CPT does not actually imply a fourfold pattern on the prospects that Tversky and Kahneman used in their fourfold pattern study. In particular, the theory is less parsimonious than advertised. Second, any scholar who focused only on these stimuli and on the number of predicted risk-seeking choices among them might mistakenly infer that CPT is a nearly vacuous and essentially irrefutable theory. Third, on these stimuli, the number of risk-seeking choices is a metric that obstructs a clear view of both CPT’s scope and its parsimony. Fourth, the stimuli we reproduced in Table 1 (which we took from the original article) are not diagnostic of CPT’s empirical performance when viewed through the lens of the number of risk-seeking choices.
As we show in the Proofs section, Equations 1 through 3 do, however, indeed predict 0% in Column 3 and 100% in Column 5 of Tversky and Kahneman’s (1992) Table 4 (our Table 2) almost regardless 6 of the parameter values in Equations 1 through 3. This finding also leads to several noteworthy insights. First, on these stimuli, a portion of the fourfold pattern does indeed follow from the theory. In particular, with respect to the stimuli in Tversky and Kahneman’s Columns 3 and 5, the theory is, indeed, extremely parsimonious. Second, any scholar who focused only on these stimuli and on the number of predicted risk-seeking choices among them might mistakenly infer that CPT is extremely narrow and easy to refute. Third, on these stimuli, the metric of counting risk-seeking pairwise preferences happens to be informative because a value of 0 (or 100) implies a risk-averse (or seeking) preference for every stimulus. Fourth, these stimuli are extremely diagnostic of CPT’s empirical performance, as assessed through the number of risk-seeking choices. In particular, just six out of 25 participants (including Subject 21 in our Table 2) were perfectly aligned with CPT’s prediction in that they showed 0 in Column 3 and 100 in Column 5. To label the other 19 participants as “consistent” with CPT, one needs to permit anywhere from 5% (Subject 6, Column 3) to 42% (Subject 4, Column 5) response errors. Fifth, one way to evaluate CPT’s scope on these stimuli would be to develop a model of within- and between-persons variability that allows one to infer who or how many people satisfy/violate the theory’s predictions on which stimuli after accounting, for example, for response errors.
In all, Tversky and Kahneman’s (1992) discussion of fourfold patterns creates an internal tension in that (a) in contrast to their claim, their theory does not actually imply a fourfold pattern on the stimuli they used to document that pattern; (b) their theory is virtually immune to rejection on two columns in their Table 4 because of undiagnostic stimuli (or an undiagnostic performance statistic); and at the opposite extreme, (c) the other two columns can be viewed as supporting CPT only if one is willing to permit substantial error rates in responses in many participants. In all, Tversky and Kahneman’s own study of fourfold patterns paints an ambiguous picture about both the parsimony and the theoretical scope of their theory.
This leads us back to considering the inherent difficulty, in current-day psychology, to properly define what we mean by either “parsimony” or “scope” of a theory and how we can go about assessing either of these concepts. One way of looking at this challenge is to consider the substantial ambiguity associated with asking what constitutes a suitable study design to either reject or support a theory: Tversky and Kahneman (1992) used two studies, each with just two decision problems, but a large number of participants, to challenge EUT’s scope in their test of independence. In contrast, their assessment of CPT involved far fewer participants but many more stimuli for each study. How do these experimental design choices affect the balance of evidence between competing theories? A contemporary statistical analysis could evaluate the parsimony and statistical power of each approach, given a suitable probabilistic specification of the theory, for given stimuli. It is far less clear how it would evaluate and take into account the very design of the tasks, studies, and stimuli themselves (for important related challenges, see also Broomell & Bhatia, 2014). The perplexing trade-off between ‘diagnostic’ and ‘undiagnostic’ stimuli is particularly striking in the fourfold pattern study.
In this context, it is useful to return to the toy theory we discussed earlier. We mentioned earlier that both theories use the same mathematical formula, the same number of parameters, and two different but equally sized (unit interval) domains for their parameters. Yet we also saw that CPT permits almost twice as many binary preference patterns on these stimuli. We omit a proof, but when concentrating only on the number of risk-seeking choices, the toy theory can accommodate almost any imaginable data in Tversky and Kahneman’s (1992) Table 4 with little or no reliance on response errors. This makes the toy theory almost irrefutable by that particular statistic on those stimuli. In contrast, as we have seen, through the lens of the same statistic, CPT is more parsimonious in that it predicts values of 0 in Column 3 and 100 in Column 5. This creates a tension: CPT can be viewed as equally parsimonious, more parsimonious, or less parsimonious than the toy theory depending on the viewpoint. At the same time, by almost any measure of fit, CPT does not fit the data nearly as well as the toy theory in two columns. Comparing both the scope and the parsimony of CPT versus the toy theory would only become more complicated if we were to expand from these stimuli to include other stimuli, from binary choices and lotteries to include other tasks, or from these participants in this lab to include other participants in other labs. All in all, we face an inherent ambiguity as to which theory performs better and at what cost. Psychology is yet to develop agreed-on ways to weigh experimental task, study design, stimulus design, parsimony, and goodness of fit. Many aspects of this trade-off reach beyond model-selection methods in statistics largely because the concept of degrees of freedom is ill-defined without a specified data structure. For related points, see Yarkoni (2022), who warned that sampling individuals from a population, sampling stimuli from a universe of possible stimuli, and sampling tasks or other study features from a design space creates many additional and unaccounted for sources of variance: Failing to model such factors appropriately (or at all) means that a researcher will end up either (a) running studies with substantially higher-than-nominal false positive rates, or (b) drawing inferences that technically apply only to very narrow, and usually uninteresting, slices of the universe the researcher claims to be interested in. (Yarkoni, 2022, p. 5)
Returning to Tversky and Kahneman (1992), besides the fourfold pattern, they also discussed a phenomenon called “loss aversion,” according to which decision makers may go to great lengths to avoid losing something. Tversky and Kahneman asked decision makers to determine the value of x that makes a 50/50 chance of receiving either
Inconsistency Part 2
We first reevaluate Tversky and Kahneman’s (1992) findings for their Problem 7 (in which
Alas, it is impossible, according to CPT, to be indifferent between ($50,
Inconsistency 3
We now consider Problem 8, in which
Inconsistency 4
Table 3 summarizes some information of Tversky and Kahneman’s (1992) direct test of loss aversion (see their Table 6). Besides providing median x values, they also reported that the median value of
As we quoted earlier, Tversky and Kahneman reported (1992, p. 312), without giving any details, that the “parameters estimated from the median data were essentially the same” as
How Can Scope and Parsimony Be Clarified?
Recently, there has been much activity to protect psychology from fraud, improve the quality of research, and strengthen theory. This work has led to prominent recommendations for good practice with respect to a variety of goals. We now review and comment on some of these from our perspective of theoretical scope and parsimony.
One prominent recommendation is to preregister studies. Preregistration is often promoted as a way to decrease post hoc analyses and theorizing because it forces researchers to identify key hypotheses before data collection (e.g., Mistler, 2012; Moore, 2016; Simmons et al., 2021; Wagenmakers et al., 2012). However, as noted by others, preregistration is not a panacea for poor theory development, mediocre methods, or undiagnostic data (see e.g., Lakens & DeBruine, 2021; Szollosi & Donkin, 2021; Szollosi et al., 2020). It is unclear how preregistration guards against the problems and errors we have discussed here. Preregistered studies can engage in the same logical fallacies, use the same stylized statistics, perpetuate the same double standards, repeat the same asymmetric philosophies of science, and be as internally inconsistent as nonpreregistered studies. Preregistering a design that perpetuates ambiguous scope and ambiguous parsimony merely documents study flaws in advance. On the upside, preregistration provides an opportunity for scholars to discuss issues of scope, parsimony, diagnosticity of stimuli, fairness of model selection, and so on ahead of running a study if they so choose.
A second prominent recommendation is increased emphasis on replication (see e.g., Pashler & Harris, 2012; Simons, 2014). Replication helps to improve measurement precision and asses the reliability of an effect of interest. This is inherently useful and can also be leveraged to compute lower and upper bounds on the number of people who satisfy a theoretical claim or display a phenomenon (see e.g., Bogdan et al., n.d.; Davis-Stober & Regenwetter, 2019; Heck, 2021). Thus, replication can help assess scope. However, along with others, we advocate that replicability is far from a panacea: For one thing, efforts invested into reproducing and replicating a prior study as identically as possible are efforts not invested into exploring how the finding extends to other people, novel stimuli, different tasks, or new contexts. Relatedly, for arguments on the relative merits (e.g., of direct and conceptual replication), see also Carpenter (2012), Nosek et al. (2012), Pashler and Harris (2012), Schmidt (2009), and Simons (2014). In other words, replication can be orthogonal to explorations of theoretical scope. Just as importantly, like preregistration, successful replications of a phenomenon would not guard against most of the errors we identify here, such as fallacies of sweeping generalization, conjunction fallacies, and other problems associated with stylized statistics. To the contrary, it can repeat, reinforce, and even perpetuate reasoning errors and scientific biases (Davis-Stober & Regenwetter, 2019; Irvine, 2021; Regenwetter & Robinson, 2017, 2019a, 2019b; Rotello et al., 2015; Yarkoni, 2022). On the upside, we can envision situations in which scholars could both reproduce a prior study and enhance it with additional features that aim to bring theoretical scope and parsimony into better focus. We also advocate that scholars preface replication with a discussion of its impact on understanding scope.
A third recommendation, which is gaining traction especially in cognitive psychology, is to replace or supplement verbal theories with formal computational or mathematical models (e.g., Borsboom et al., 2021; Grahek et al., 2021; Guest & Martin, 2021; Navarro, 2021; Oberauer & Lewandowsky, 2019; Robinaugh et al., 2021; van Rooij & Baggio, 2020). We agree that formal modeling can force researchers to think more explicitly about both the intended scope and the flexibility of their theories. However, formal modeling on its own is not sufficient for addressing many of the double standards and ambiguity problems that we have identified. Clearly, CPT is a formal model. Yet our discussion above demonstrates that the value of formal modeling hinges on how it is implemented (and this point is reinforced by all of the references in this paragraph). Formal modeling can give the appearance of rigor and mask systemic errors (Chen et al., 2021). Formally precise models often force simplifying assumptions or omit hidden variables. These can become counterproductive (for related general points, see also Kellen et al., 2021; Yarkoni, 2022). To keep formal models tractable, scholars may limit themselves to overly simple tasks or simple stimuli (for a discussion, see e.g., Navarro, 2021). On the upside, in contrast to verbal theories, which we would consider inherently ambiguous, formal modeling does provide a common language (logic, computer code, mathematics, and/or statistics) through which to discuss theoretical scope, parsimony, and standards of scientific discourse openly and rigorously. However, as we show when we review the fifth recommendation, although mathematical formulas ostensibly eschew rhetoric, the connection between the mathematics and the substantive questions of interest can also be ambiguous. Our discussion of CPT in this article highlights an example of that broad problem.
A fourth prominent recommendation is to supplement or replace data fitting with prediction to other tasks or unseen data (e.g., Busemeyer & Wang, 2000; Erev et al., 2010, 2017; Pitt et al., 2003; Yarkoni & Westfall, 2017). This has been advocated as a tool for addressing overfitting and for developing theories that generalize. We agree that prediction is an important step toward recognizing and avoiding heuristic approaches to parsimony. However, to avoid asymmetries and double standards, scholars should provide a clear explanation why the participants, tasks, stimuli, and contexts are designed in such a way as not to provide an unfair advantage to some theories over others. Notice that searching a parameter space for best fitting parameters need not make a theory unparsimonious or cause overfitting. The number of parameters is no more than a heuristic measure parsimony.
8
CPT is a prominent example in which prediction has gone awry: ‘Refuting’ CPT by testing predictions from
A final major recommendation is increased attention to the problem of “coordination” in psychological research: Theory simultaneously presumes and guides measurement of latent constructs (Irvine, 2021; Kellen et al., 2021; Singmann et al., 2021; van Frassen, 2008). Some of these articles warn that heated debates about the relative merit of competing theories often heed no attention to the pivotal role of technical and auxiliary assumptions, such as analysis of variance or other off-the-shelf models. Attending to the circular connection between theory and measurement (e.g., attending to auxiliary assumptions) forces researchers to consider both jointly. For a related literature, see the extensive work on meaningfulness in psychological measurement and theory (Falmagne & Doble, 2016; Falmagne & Narens, 1983; Narens, 2002, 2007; Roberts, 1985; Roberts & Rosenbaum, 1986). Attention to the coordination problem and to meaningfulness may lead to a more nuanced understanding of both theoretical scope and theoretical parsimony.
Flagging symptoms of ambiguous scope or parsimony
We have touched on a number of features of Tversky and Kahneman (1992) whose parallels and analogues in other paradigms can flag ambiguous scope or ambiguous parsimony in psychological theory more broadly. First, the most prominent flags are all forms of asymmetric reasoning in which scholars point out shortcomings of others’ theories or evidence without discussing the possible shortcomings of the replacements they propose. Double standards, such as using many more or many fewer stimuli to test the old theory than the new one, using stimuli (even if picked ‘randomly’) that pressure the old theory but not the new one, pushing a novel theory merely on the basis of its ability to accommodate some ‘anomalies‘ that the old theory does not explain, may all create systematic biases against existing theory and in favor of the proposed new theory. When the latter is custom designed to handle certain phenomena, it is important to also understand the associated cost in parsimony. Extreme forms of asymmetric reasoning occur when scholars provide evidence only against special cases of a theory (e.g.,
How parsimonious is CPT?
We end with an illustration of Bayes’s factors as a quantitative measure of parsimony for CPT. We concentrate on the 8 + 8 + 17 + 17 = 50 stimuli from Tversky and Kahneman’s (1992) fourfold pattern study used in their Table 4 (we show and label some of them in our Table 2). As we have already seen, there are 12 possible preference patterns for the 25 gains prospects and 12 possible preference patterns for the 25 loss prospects. We briefly consider two “probabilistic specifications” of CPT (with Equations 1–3) from Regenwetter et al. (2014) and Zwilling et al. (2019). According to the “aggregation-based” model, each individual has one of the

The remaining choice probabilities for the other 17 loss prospects are 1. Similar constraints hold among the choice probabilities for the 25 gain prospects.
Regenwetter et al. (2018) and Zwilling et al. (2019) reviewed how to calculate the range of possible Bayes’s factors between such a given model and an unconstrained “encompassing” model. The aggregation-based model can generate a Bayes’s factor anywhere between 0 and
Conclusion and Discussion
Since the publication of prospect theory some 40 years ago (Kahneman & Tversky, 1979), scholars have prolifically cited Tversky and Kahneman’s (and others’) findings that EUT suffers from limited scope. Yet for nearly 30 years, it has gone unnoticed that Tversky and Kahneman (1992) provided evidence for the exact same limitation in CPT’s scope: Just like half their participants violated EUT early in their article, so did ostensibly half the respondents violate CPT in Problem 7 of their loss aversion study later in the same article. In addition, some aggregate measures do not align with each other, and the exact role of fourfold patterns is ambiguous. All in all, this raises the question about the overall balance of evidence that the original CPT article ultimately provided in favor of or against its own theory. Likewise, moving beyond the 1992 article and considering CPT’s entire “functional menagerie” (Stott, 2006) of potential utility and weighting functions, it is unclear to us whether these modifications make the theory’s scope or parsimony any less ambiguous and in what way. We are not aware of any consensus in the field as to how to weigh the many versions of the theory against each other and against competing theories or how to determine which version of the theory provides unambiguously the best trade-off between scope and parsimony across all possible stimuli and tasks.
The primary purpose of this article is not to question the validity of CPT as a theory or to provide further grounds to endorse it but, rather, to call attention to the ambiguity of the evidence provided by the authors in support of their own theory. Nor is our goal to single out Tversky and Kahneman for a practice that appears rather widespread. Our goal is conceptual: How should one really think of theoretical scope in psychology? History has been repeating itself in that much behavioral decision research turns CPT’s limitations against it. Scientific cost-benefit analysis in decision science all too often appears to focus on highlighting the cost of others’ theories and the benefits of one’s own proposals. The resulting fault lines have left us with various ‘camps:’ Some endorse EUT as their preferred theoretical idealization. Others consider CPT as their sweet spot for a theory of risky choice. Meanwhile, countless articles expand or modify prior theories to accommodate behavioral regularities or irregularities that have been reported as evidence against those theories. Over time, each new generation has tended to develop its new proposals by calling out limitations in previous ideas 12 with little attention to the limitations of the new theses (for examples of notable exceptions, see Brandstätter et al., 2006, 2008; Loomes, 2010, who acknowledged and specified limitations of their own models) and, perhaps more importantly, with little discussion about what limitations are acceptable or inacceptable. The literature in risky choice often appears to follow a three-pronged research strategy: (a) Scrutinize the old theory by showing certain weaknesses and promote the new theory by showing that it overcomes that particular set of weaknesses, (b) leave it to others to explore the new proposed theory’s weaknesses, and (c) either ignore the other camps or defend the new theory vigorously against their challenges. We see little effort toward reconciliation among schools of thought that highlight different aspects of and approaches to decision-making. We also detect little effort to weigh strengths and weaknesses of competing theories in a comprehensive manner.
Although our discussion centered around decision-making, our conclusions apply to the discipline more widely. In our view, psychology should move from using theoretical scope primarily as a bludgeon to attack others’ theories and proceed toward pursuing more constructive goals. Every scientific theory has some limitations, especially in psychology. When proposing a new idea, behavioral scientists should make every effort to spell out the intended scope of this new theory. Proposals for new theories are far more interesting when they also delineate what would constitute critical tests, what would qualify as refutation of a new proposal, what is considered beyond a theory’s intended scope, and who the theory applies to when, where, and why. Likewise, more adversarial collaborations between camps would help bring sense to the balkanized landscape of entrenched schools of thought (for useful guidelines on how to run such projects, see e.g., Mellers et al., 2001, Table 1).
So, what is one to make of the fact that half of Tversky and Kahneman’s (1992) participants in one of their studies appear to have violated their own theory on one stimulus? What is one to make of the internal inconsistencies among reported findings within one article? It is unclear how to weigh the evidence in favor of CPT on the one hand and the limitations of CPT on the other hand against the corresponding strengths and weaknesses of competing theories. Statistical science actively researches and studies the trade-off in complexity and parsimony in statistical models by counting parameters and degrees of freedom, computing heuristic model selection indices such as AIC and BIC, and applying quantitative model selection tools such as Bayes’s factors. As Yarkoni (2022) argued in somewhat different words, the ‘sampling’ of stimuli, participants, and design features of psychological research effectively hides uncounted degrees of freedom in the data. Psychology still needs to properly define theoretical scope and theoretical parsimony beyond post hoc statistical models. The discipline should move beyond weighing, say, ‘good’ and ‘bad’ stimuli or study designs heuristically and develop methods, concepts, and standards for weighing theoretical scope against scientific simplicity. A first step is for scholars of different schools of thought to cooperate more systematically in synergizing the strengths of different theories. A second and easy-to-implement step is for scholars to specify what they mean by “diagnostic stimuli” and/or “critical tests” not only for existing theory but also for their own proposed new theory. A third step is for scholars to be more cognizant that every behavioral theory has limitations and therefore spell out, as explicitly as they can, what scope they envision for their proposed theory.
Footnotes
Appendix
Acknowledgements
We thank Meichai Chen, Brittney Currie, Yu Huang, Emily Line, Xiaozhi Yang, and our referees for comments on earlier drafts. We are grateful to Lyle Regenwetter for providing an elegant mathematical proof of Claim I in the ![]() . The National Science Foundation (NSF) and Army Research Office (ARO) had no other role besides financial support. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the ARO or the U.S. Government, the NSF, colleagues, or the authors’ home institutions. The U.S. Government is authorized to reproduce and distribute reprints for government purposes notwithstanding any copyright notation herein. Part of this article was previously presented orally at the annual Society for Mathematical Psychology satellite meeting of Psychonomics in 2019 and at the 57th Annual Edwards Bayesian Research Conference in 2020.
. The National Science Foundation (NSF) and Army Research Office (ARO) had no other role besides financial support. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the ARO or the U.S. Government, the NSF, colleagues, or the authors’ home institutions. The U.S. Government is authorized to reproduce and distribute reprints for government purposes notwithstanding any copyright notation herein. Part of this article was previously presented orally at the annual Society for Mathematical Psychology satellite meeting of Psychonomics in 2019 and at the 57th Annual Edwards Bayesian Research Conference in 2020.
Transparency
Action Editor: Frederick L. Oswald
Editor: Frederick L. Oswald
Author Contributions
M. Regenwetter guided and supervised the project and contributed most of the writing. M. M. Robinson and C. Wang discovered the inconsistencies when exploring how much preference heterogeneity cumulative prospect theory permits. They provided most of the mathematical proofs in joint work while M. M. Robinson was a PhD student in psychology at University of Illinois at Urbana-Champaign and C. Wang was an undergraduate mathematics/economics double major at University of Illinois at Urbana-Champaign. All of the authors approved the final manuscript for submission.