
Abstract
Recent discussions of the influence of publication bias and questionable research practices on psychological science have increased researchers’ interest in both bias-correcting meta-analytic techniques and preregistered replication. Both approaches have their strengths: For example, meta-analyses can quantitatively characterize the full body of work done in the field of interest, and preregistered replications can be immune to bias. Both approaches also have clear weaknesses: Decisions about which meta-analytic estimates to interpret tend to be controversial, and replications can be discounted for failing to address important methodological heterogeneity. Using the experimental literature on ego depletion as a case study, we illustrate a principled approach to combining information from meta-analysis with information from subsequently conducted high-quality replications. This approach (a) compels researchers to explicate their beliefs in meta-analytic conclusions (and also, when controversy arises, to defend the basis for those beliefs), (b) encourages consideration of practical significance, and (c) facilitates the process of planning replications by specifying the sample sizes necessary to have a reasonable chance of changing the minds of other researchers.
Valid inference in empirical psychology is threatened by data that are biased by questionable research practices (QRPs; Simmons, Nelson, & Simonsohn, 2011) and publication bias (Rothstein, Sutton, & Borenstein, 2006). To cope with these threats, researchers often use meta-analytic tools that can adjust for their distorting effects. However, many bias-correcting estimators exist, and they often yield different conclusions. There is currently no consensus as to which is most appropriate in any given circumstance (e.g., Carter, Schönbrodt, Gervais, & Hilgard, 2017; McShane, Böckenholt, & Hansen, 2016; Moreno et al., 2009; Reed, Florax, & Poot, 2015; Stanley, 2017; van Aert, Wicherts, & van Assen, 2016).
Some researchers have argued instead that inference should be based primarily on preregistered replications (van Elk et al., 2015), which are uncorrupted by QRPs or publication bias ipso facto. Any individual preregistered replication, however, requires a specific operationalization of a general claim, and as a result, replication efforts cannot easily reflect the potentially important methodological heterogeneity in studies within any given area. Moreover, discounting all nonpreregistered experiments (possibly numbering in the hundreds) from consideration during scientific inference almost surely underestimates their potential evidential value: Just because a literature is biased does not mean that it must yield hopelessly misleading conclusions (van Elk et al., 2015). How can scientists optimally combine what they believe on the basis of previous (possibly biased) findings with new and less biased findings from preregistered replications? Here, we describe a simple, principled approach to answering this question and illustrate its application to research on the topic of ego depletion. Note that this method is not designed to necessarily improve statistical estimation or hypothesis testing—instead, we intend it as a tool to make discourse more principled and thereby facilitate our field’s ability to accumulate and apply knowledge. We provide R scripts and a tutorial as online Supplemental Material so researchers can apply our method to their own areas of interest.
Our approach should be thought of as a computational process model (Lee, in press; Lee & Wagenmakers, 2013) of how real-world scientists should change their beliefs about hypothesized states of the world as new data come to light (Okasha, 2016). Broadly, this model involves using M meta-analytic estimates of an effect to specify M prior beliefs that researchers could hold regarding the effect size of a hypothesized phenomenon. Bayesian meta-analysis is then used to update these beliefs on the basis of the results from subsequent high-quality replications (Heck, Gronau, & Wagenmakers, 2017). The result is a set of M posterior beliefs, which indicate how initial beliefs formed from existing meta-analytic work have changed in the face of new evidence (i.e., the replications).
Our model assumes that researchers’ beliefs can be described as probability distributions over possible true values of some parameter, θ. When a value of θ is given higher probability, this indicates that it is more plausible—or credible—to the researcher. Additionally, our model holds that researchers change their minds in a mathematically correct fashion—that is, on the basis of Bayes rule, which in this context specifies that distributions of prior belief, p(θ), be updated in the face of data, D, to form distributions of posterior belief, p(θ|D). By using this model, researchers can study how their own beliefs should change—given the assumptions we have mentioned—in the face of new data and, therefore, what inferences they should make about the true magnitude of a given phenomenon. However, as we mentioned, our approach is not so much a statistical advance as a conceptual and discursive one inasmuch as it forces researchers to explicate and justify their beliefs and then to update them rationally (i.e., according to Bayes rule). It additionally encourages researchers to examine the practical significance of what they believe—after seeing new data from high-quality replications—to be plausible values of the effect of interest. Finally, our model provides a means of studying the beliefs of hypothetical researchers and, therefore, (a) can shed light on the impact of a particular set of replication results and (b) guide planning for preregistered replications by indicating how much data will need to be collected to change other researchers’ minds. Notably, although our approach is not designed to provide statistical advantages, the conceptual advantages are accompanied by the usual statistical advantages offered by a Bayesian approach—a topic beyond our current scope, but thoroughly covered by other authors (e.g., Kruschke, 2013; Kruschke & Liddell, 2017; Lee, in press; Lee & Wagenmakers, 2013; Wagenmakers et al., 2017).
Case Study: Ego Depletion
The method we describe is general and can be applied to any area of research in which a meta-analysis has been conducted and high-quality replication data have been collected. For illustrative purposes, here we apply the method to data that are marshaled to support the hypothesis that an act of self-control impairs people’s subsequent self-control (a state known as ego depletion; Baumeister, Bratslavsky, Muraven, & Tice, 1998).
Hagger, Wood, Stiff, and Chatzisarantis (2010) published the first meta-analysis on this effect and concluded that it was, on average, medium or large in magnitude and robust across various experimental methods. Because of our own failure to replicate the depletion effect in a large sample (Carter & McCullough, 2013), we reanalyzed their data set with an eye toward detecting and correcting for publication bias and other small-study effects (Carter & McCullough, 2014). Our analysis indicated that controlling for such effects potentially reduced the depletion effect to the point where it was indistinguishable from zero.
One could argue that Hagger et al.’s (2010) data set included inappropriate tests of the depletion effect. We found four reasons that this might be the case (Carter, Kofler, Forster, & McCullough, 2015): First, Hagger et al. included an experiment if its authors claimed it tested depletion, rather than creating an a priori definition of the depletion effect. Second, some experiments’ putative measures of self-control were so nonspecific as to provide support for the depletion effect regardless of the outcome. Third, Hagger et al. included many experiments that started with the premise that the depletion effect was real and then used the effect to test whether a given task required self-control. Finally, Hagger et al. included only published experiments in their data set. If it is true that their data set included inappropriate tests of the depletion effect, then the validity of their conclusions, as well as the conclusions we drew from our reanalysis of their data (Carter & McCullough, 2014), are undermined. Therefore, we collected a new data set following new inclusion criteria with the aim of providing a test of the depletion effect that could convince even a skeptical audience. After analyzing the resulting data set of 116 effect estimates, we again concluded that there was little convincing evidence that the true magnitude of the depletion effect differs meaningfully from zero on average (Carter et al., 2015).
Shortly thereafter, a large-scale preregistered replication corroborated our conclusions with data from 23 separate replication attempts (Hagger et al., 2016), as did one additional preregistered replication (Lurquin et al., 2016) and four experiments that Tuk, Zhang, and Sweldens (2015) claimed to constitute their laboratory’s entire “file drawer” of behavioral tests of the depletion effect. One can be fairly certain that these recent 28 results permit higher-quality inference than the data examined in Hagger et al.’s (2010) meta-analysis and our later meta-analytic effort (Carter et al., 2015), by virtue of the relatively low likelihood that they were influenced by QRPs or publication bias. Therefore, we refer to these data as the HQ28 (i.e., high-quality 28). But how should researchers integrate the previous meta-analytic data with these new findings? Should the new findings provide the final word on the depletion effect? To answer such questions, we applied our model for combining meta-analyses and replication data.
Disclosures
All analyses were conducted in R (R Core Team, 2016). Data, scripts, and a tutorial are available online as Supplemental Material (http://journals.sagepub.com/doi/suppl/10.1177/2515245918756858).
Method
Combining evidence from meta-analysis and high-quality replications
The first step in our approach is to define a set of M prior beliefs based on previous meta-analytic estimates. The published literature (Carter et al., 2015; Carter & McCullough, 2014) includes eight relevant results, which were obtained by applying each of four estimators (i.e., random-effects meta-analysis; the trim-and-fill method; the precision-effect test, or PET; and the precision-effect estimate with standard error, or PEESE) to two data sets (i.e., the original data set from Hagger et al., 2010, and our updated data set). These priors take the form of probability distributions over the average true value of the depletion effect, µ, so a prior based on the random-effects meta-analysis estimate (d = 0.43, SE = 0.05) from our updated data set would be translated to a prior of the form p(µ) = N(0.43,0.05). In principle, it is possible to add a new estimate by applying any version of any estimator to any relevant data set; however, such choices must be justified. We focus only on this set of eight estimates, not because we think these estimates are unequivocally the most valid (see, e.g., Carter et al., 2017; McShane et al., 2016; Moreno et al., 2009; Reed et al., 2015; Stanley, 2017; van Aert et al., 2016), but because of the possibility that real-world researchers may have formed their beliefs about the depletion effect on the basis of these previously published and relatively well-circulated estimates. To put it slightly differently, the M prior beliefs need not be designed to represent best practices in meta-analytic estimation—indeed, we think the use of random-effects meta-analysis and the trim-and-fill technique is naive in this case; however, there are certainly researchers who would disagree with us on this point, and the purpose of our approach is to explore the implications of such a position.
The second step in our approach is to define a set of replication data that one believes to be of appropriate quality. In other words, just as our approach allows researchers freedom to define their prior beliefs in the form of M meta-analytic estimates, it also allows researchers to define the replication studies they find to be most convincing. 1 In our view, the HQ28 are of sufficient quality, but it would have easily been possible to make a different choice. For example, Tuk et al. (2015) in fact reported a total of nine experiments. Here, we include only those experiments that made use of behavioral tasks to manipulate and measure self-control—an inclusion criterion we also used in our own meta-analysis (Carter et al., 2015). Applying this inclusion criterion resulted in the omission of data from the five experiments in which Tuk et al. measured subjects’ forecasts of their own self-control in responses to hypothetical vignettes.
In the following, we briefly describe each of the four estimators we applied to the Hagger et al. (2010) and Carter et al. (2015) data sets and compare the obtained estimates with the HQ28. We then detail how we combined information from these estimators with the HQ28 through Bayesian-model-averaged meta-analysis (Scheibehenne, Gronau, Jamil, & Wagenmakers, 2017).
Random-effects meta-analysis
This method is based on the assumption that the ith study estimates a specific true effect, δ i , which represents an observation drawn from a distribution of true effects that is centered on µ (Cooper, Hedges, & Valentine, 2009) and has a standard deviation of τ. By modeling a distribution of true effects, random-effects meta-analysis allows for the possibility that different studies will provide different results because factors such as the location of the study, the population sampled, or the study-specific operationalization may all modify the true value of the effect of interest. This approach provides an estimate of µ—the average of the distribution of true effects—without correcting for the possibility of bias.
Trim-and-fill method
Based on the logic that a scatterplot of effect size against some proxy for sample size—often called a funnel plot—will be symmetrical in the absence of publication bias (Duval & Tweedie, 2000), the trim-and-fill method begins with removing observations from the funnel plot until a criterion for symmetry is met; next, the trimmed observations are filled back into the plot along with new imputed observations of the opposite sign, which represent an informed guess at the nature of the data that may have been removed because of publication bias. Other meta-analytic methods, such as random-effects meta-analysis, can then be used to summarize this new expanded data set.
PET
This approach assumes that the influence of small-study effects (e.g., publication bias) is revealed by the relationship between the study-level effect-size estimates and their standard errors. The intercept of a weighted least squares metaregression in which effect sizes are predicted by their standard errors provides an estimate of the effect of interest after controlling for small-study effects—that is, an effect-size estimate without the potential influence of publication bias (Stanley & Doucouliagos, 2014).
PEESE
This method is conceptually and methodologically similar to PET, but it models the influence of small-study effects as nonlinear: Rather than regressing effect sizes on their standard errors, one regresses effect sizes on their variances (i.e., standard errors squared).
Comparing the meta-analytic estimates with the HQ28 and assessing how prior beliefs should change
Figure 1 shows how the eight meta-analytic estimates compare with the HQ28. We have used blue vertical lines to highlight the area where the 95% confidence intervals from the HQ28 overlap. One might argue that this area accords best with the PEESE estimate using the updated data set; however, we cannot know which estimator is the best for these particular data sets because the performance of any estimator depends very much on the unknown processes that generated the data (Carter et al., 2017; Moreno et al., 2009; Reed et al., 2015; Stanley, 2017). Moreover, there is no objective truth regarding which meta-analytic data set more appropriately represents tests of the depletion effect: Cunningham and Baumeister (2016), for example, recently speculated that our inclusion criteria (Carter et al., 2015) systematically removed evidence for the depletion effect; specifically, they argued that by excluding experiments that did not measure self-control objectively via cognitive performance or some other behavioral measure and by actively seeking out unpublished experiments, we removed published data from expert researchers and included unpublished work by inexperienced researchers, respectively. Therefore, choosing a single estimate from a single data set as the best estimate of the true value of the depletion effect involves making many untestable assumptions. In contrast, our approach allows us to study how beliefs regarding the value of the depletion effect change in the face of the HQ28.
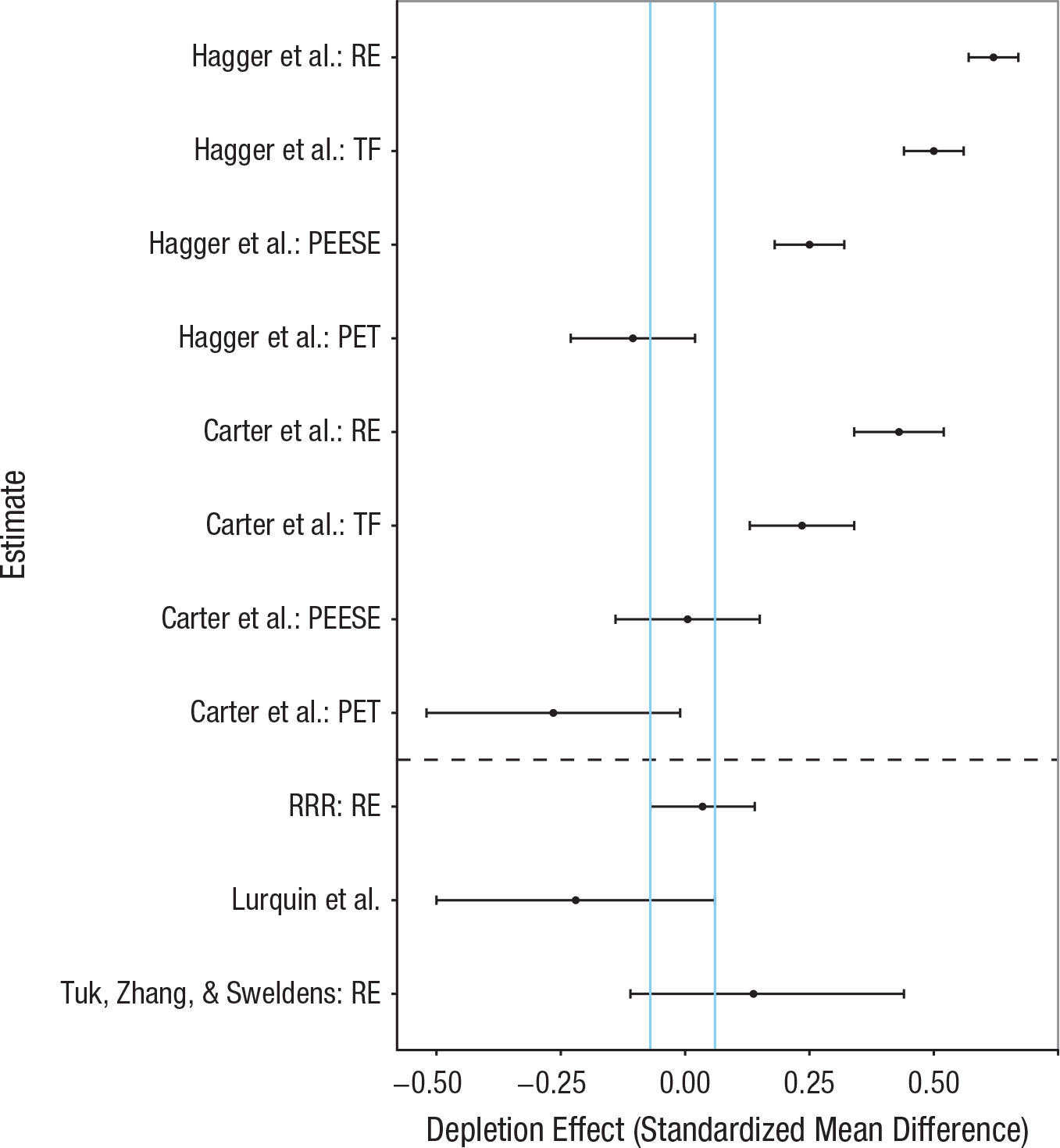
Meta-analytic estimates of the depletion effect. The estimates above the dashed line are the results of applying four different estimators to the data sets used by Hagger, Wood, Stiff, and Chatzisarantis (2010) and Carter, Kofler, Forster, and McCullough (2015). The estimates below the dashed line are from recent high-quality replications. The dots represent the point estimates, and the whiskers represent the 95% confidence intervals. The vertical blue lines demarcate the region in which the 95% confidence intervals for the high-quality replications overlapped. RE = random-effects meta-analysis; TF = trim-and-fill method; PEESE = precision-effect estimate with standard error; PET = precision-effect test; RRR = Registered Replication Report (Hagger et al., 2016).
To model how prior beliefs change in the face of the HQ28, we implemented the Bayesian-model-averaged meta-analytic approach proposed by Scheibehenne et al. (2017). In this approach, two Bayesian implementations of standard meta-analytic models are applied to the data. The first is the random-effects model as described earlier. The second is the fixed-effect model, which differs from the random-effects model in that it assumes there is only one true effect, µ, and each study-specific estimate differs from this value only because of sampling error (i.e., the model does not allow for the influence of moderators). Both models are realistic for a meta-analysis of high-quality replications: On one hand, one might assume that the fixed-effect model is more appropriate for a set of estimates from exact replications, such as those reported by Hagger et al. (2016). On the other hand, there are good reasons to think that even carefully conducted exact replications may measure different true effects (Hagger et al., 2016; Klein et al., 2014) and, therefore, that one should prefer the random-effects model. The choice between these two models is further complicated by other issues (e.g., Rice, Higgins, & Lumley, 2017), and for these reasons, Scheibehenne et al. proposed a Bayesian-model-averaged approach that creates a combined estimate that is influenced by both models in proportion to how likely they are given the observed data. 2
Applying both the random-effects and the fixed-effect models requires first describing distributions of prior beliefs over the parameters in the models. For both models, we set p(µ) as normal distributions with means and standard deviations equal to the point estimates and standard errors shown in Figure 1. For example, the distribution for p(µ) when based on the PEESE estimate (d = 0.00, SE = 0.07) from our data set (Carter et al., 2015) is N(0.00,0.07). The random-effects model includes a second parameter, τ, for which we set a prior, p(τ), as following a half-Student-t distribution with scale and degrees of freedom set to 1. The prior over τ, therefore, allows for positive values only and is right skewed, much as appears to be the case in psychology in general (van Erp, Verhagen, Grasman, & Wagenmakers, 2017).
Our goal is to derive a posterior distribution, p(θ|D), where θ represents an arbitrary set of parameters of interest (e.g., µ and τ) and D represents the data. From Bayes rule, we know that
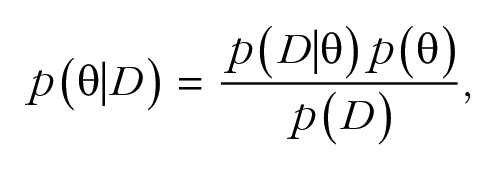
where p(θ) is the prior based on previous meta-analytic results, p(D|θ) is the likelihood (the standard normal likelihood in this case), and p(D) is the marginal likelihood of the data. Instead of deriving the posterior distribution analytically, which can be problematic in many cases, we rely on recent advances in Markov chain Monte Carlo techniques to approximate it through Gibbs sampling as implemented with JAGS software (Plummer, 2015) through R (R Core Team, 2016) with the r2jags package (Su & Yajima, 2015).
In the case of Bayesian-model-averaged meta-analysis, p(θ|D) is the weighted sum of the posteriors from each of the L models considered, and the weight of each model is given as its posterior probability, p(M|D) (i.e., the relative plausibility of model M given the data):
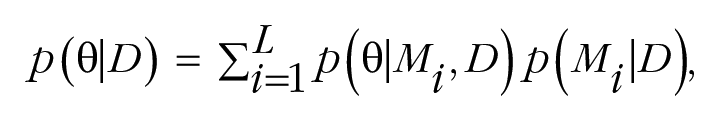
where
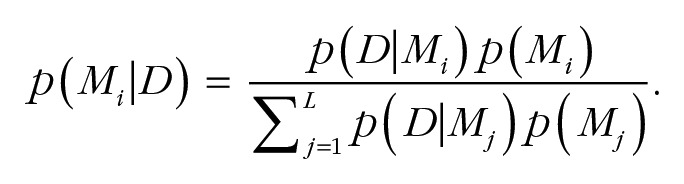
In this last equation, p(D|Mi) and p(Mi) are the marginal likelihood and the prior probability of the ith model, respectively. In our application, L = 2 (the random-effects and fixed-effect meta-analysis models with priors, as described earlier), and the two models are taken to be equally likely a priori. We derived the marginal likelihoods using bridge-sampling techniques (Gronau et al., 2017; Meng & Wong, 1996) as implemented with the bridgesampling package in R (Gronau & Singmann, 2017). Furthermore, the Bayesian-model-averaged marginal posterior—p(µ|D)—is of primary interest, as it represents how, in the face of the HQ28 and for a given set of prior beliefs, one ought to distribute belief over a range of candidate values for the average true magnitude of the depletion effect, µ.
Practical significance
Bayesian inference, as we have described it, lends itself easily to the consideration of the practical significance of an effect through a focus on effect-size estimates rather than, for example, statistical significance. Practical significance can be operationalized in this context by setting a region of practical equivalence (ROPE) in the posterior distribution, that is, a region where the true effect is considered practically equivalent to zero. Furthermore, our approach allows researchers to assess how any idiosyncratic definition of a ROPE compares with the most credible estimates of the effect of interest as represented by the posterior distributions. Just as setting prior beliefs is subjective, so too is defining a ROPE, and just as when one sets prior beliefs, it is necessary to explain one’s reasoning behind a given ROPE. To us, a true depletion effect, µ, of 0.15 (approximately the highest point estimate in the HQ28; see Fig. 1) can reasonably be considered practically nonsignificant. Furthermore, theory regarding ego depletion clearly involves a directional hypothesis, so we set our ROPE as µ < 0.15.
Our assessment of why effects below this value of 0.15 are practically nonsignificant is based in part on translating this standardized mean difference into more interpretable metrics. For example, in their third experiment, Vohs and Heatherton (2000) tested whether ego depletion increased ice-cream consumption. Given the pooled standard deviation in that experiment, a µ value of 0.15 would imply that depleted subjects, compared with nondepleted subjects, consume 15 g more ice cream—something like one to two more bites. Similarly, Muraven, Collins, and Neinhaus (2002) studied whether depletion increased beer consumption. In that study, a µ of 0.15 would correspond to consumption of an additional 38.4 ml of beer—about 2.6 tablespoons. If the depletion effect were concretely related to more devastating outcomes, such as death or disease, instead of consumption of ice cream and beer, our analysis would need to account for that by modifying the definition of practical significance; however, we judge that effects such as eating 15 g more ice cream or drinking 38.4 ml more beer following a depleting episode would ultimately be of little consequence in the real world.
An additional reason to consider µ of 0.15 as practically nonsignificant is that achieving 80% power to detect such an effect in a simple two-group comparison requires 699 subjects per experimental condition—about 5 times the total number of subjects in the largest experiment we included in our meta-analysis (Carter et al., 2015). Note that research on the depletion effect frequently takes the form of testing whether the effect is reduced by some moderator, such as glucose ingestion (Gailliot et al., 2007) or subjects’ belief in the nature of willpower (Job, Dweck, & Walton, 2010). For such attenuated interactions, achieving 80% power requires twice the number of subjects per experimental condition compared with the simple two-group design (Simonsohn, 2011). Therefore, if the true magnitude of the depletion effect is 0.15, a total sample size of 5,592 (i.e., 699 × 4 × 2) would be required to achieve 80% power in testing whether drinking lemonade, for example, replenishes self-control following a depletion manipulation. This sample size, which is for a single study, is fully 85% of the total number of subjects in our meta-analytic sample (Carter et al., 2015). Moreover, 5,592 is about 92 times the sample size in one of the original, iconic experiments testing whether ingestion of glucose attenuates the depletion effect (Experiment 7 in Gailliot et al., 2007). We believe such sample sizes are prohibitively large: If the true magnitude of the depletion effect were 0.15, researchers would only very rarely have the resources to achieve an acceptable level of statistical power to detect the phenomenon, a fact that should raise doubts about the practicality of studying the depletion effect.
Planning replication efforts that can change partisans’ minds
Researchers can also use the approach we describe here to estimate the amount of data necessary to have a reasonable chance of shifting hypothetical skeptics’ or proponents’ prior beliefs. To do so, one would simulate registered replications in which k simulated teams each produce an experiment with the target sample size of n subjects per cell in a standard two-group design. By applying our approach to these simulated data, one can track the proportion of times that the posterior distribution falls in a given area relative to the ROPE (Kruschke, 2015). This proportion is akin to statistical power, but instead of indicating the probability of rejecting a false null hypothesis, it represents the probability that a simulated researcher, after updating his or her prior beliefs on the basis of the simulated replications, either correctly believes only practically significant values of the effect to be plausible (i.e., the posterior distribution remains outside of the ROPE) or correctly believes practically nonsignificant values to be plausible (i.e., the posterior distribution overlaps with the ROPE).
Imagine that the beliefs of proponents of ego depletion can be modeled as p(µ) = N(0.43,0.05) on the basis of the random-effects estimate from our updated data set (Carter et al., 2015) and that the beliefs of skeptics can be specified as p(µ) = N(0.00,0.07) on the basis of the PEESE estimate from that data set. Imagine further that both skeptics and proponents can agree on µ < 0.15 as the range in which the depletion effect could be called practically nonsignificant (i.e., the ROPE) and that both groups are willing to have their minds changed by the data from the replication effort being planned (a crucial assumption that cannot necessarily be taken for granted). One can then map the probability of correctly changing a proponent’s mind given the possible reality that the true magnitude of the effect is 0 and the probability of correctly changing a skeptic’s mind given the possible reality that the true magnitude of the effect is 0.43. Here, we define changing a simulated proponent’s or skeptic’s mind as observing that the inner 95% of the posterior distribution (sometimes called the highest density interval, HDI) either overlaps with the ROPE or does not overlap with the ROPE, respectively. We conducted a simulation of this example across a range of numbers of research teams conducting replication studies (k = {6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36}) and a range of number of subjects per study (n = {20, 50, 80, 110, 140, 170, 200, 230, 260, 320}). Each unique combination of k and n was simulated 100 times, and for each combination we assessed the number of times out of 100 that (a) a proponent—p(µ) = N(0.43,0.05)—changed his or her mind when the true value of µ was 0 and (b) a skeptic—p(µ) = N(0.00,0.07)—changed his or her mind when the true value of µ was 0.43.
Results
The eight prior distributions of beliefs calculated by applying the four estimators to the two data sets (Hagger et al., 2010; Carter et al., 2015) and the eight corresponding posterior distributions of beliefs are displayed in Figure 2. As is evident from the figure, prior beliefs about the magnitude of the depletion effect play a powerful role in how those beliefs are changed in the face of the HQ28. For example, if one believed that Hagger et al.’s (2010) data were the most valid and that no correction for publication bias was necessary—and one therefore preferred the estimate d = 0.68 (SE = 0.03)—the 28 recent high-quality replications that yielded an average d of roughly 0 would come nowhere near dissuading one from believing in the reality of ego depletion (see the dashed lines in the top panel of the figure). This conclusion is clear from the fact that a value of zero (or any value in the ROPE) is far from the 95% HDI. Moreover, examining this 95% HDI, one can see that a hypothetical researcher who holds these prior beliefs would find a d value of 0.65 to be the most credible estimate of the true magnitude of the depletion effect, and that the range of the most credible estimates for this researcher would span 0.59 to 0.71. A similar conclusion is reached if one bases one’s prior beliefs on the trim-and-fill estimate from the Hagger et al. (2010) data or the random-effects estimate from our updated data set (Carter et al., 2015). Alternatively, if one’s prior beliefs accord with any of the five other prior distributions we specified, then the 28 subsequent replications compel one to believe that the true magnitude of the depletion effect is very likely either 0 or practically equivalent to 0 (as we have defined it). This is indicated by the fact that the 95% HDIs of these posterior distributions contain values from the ROPE (Fig. 2).
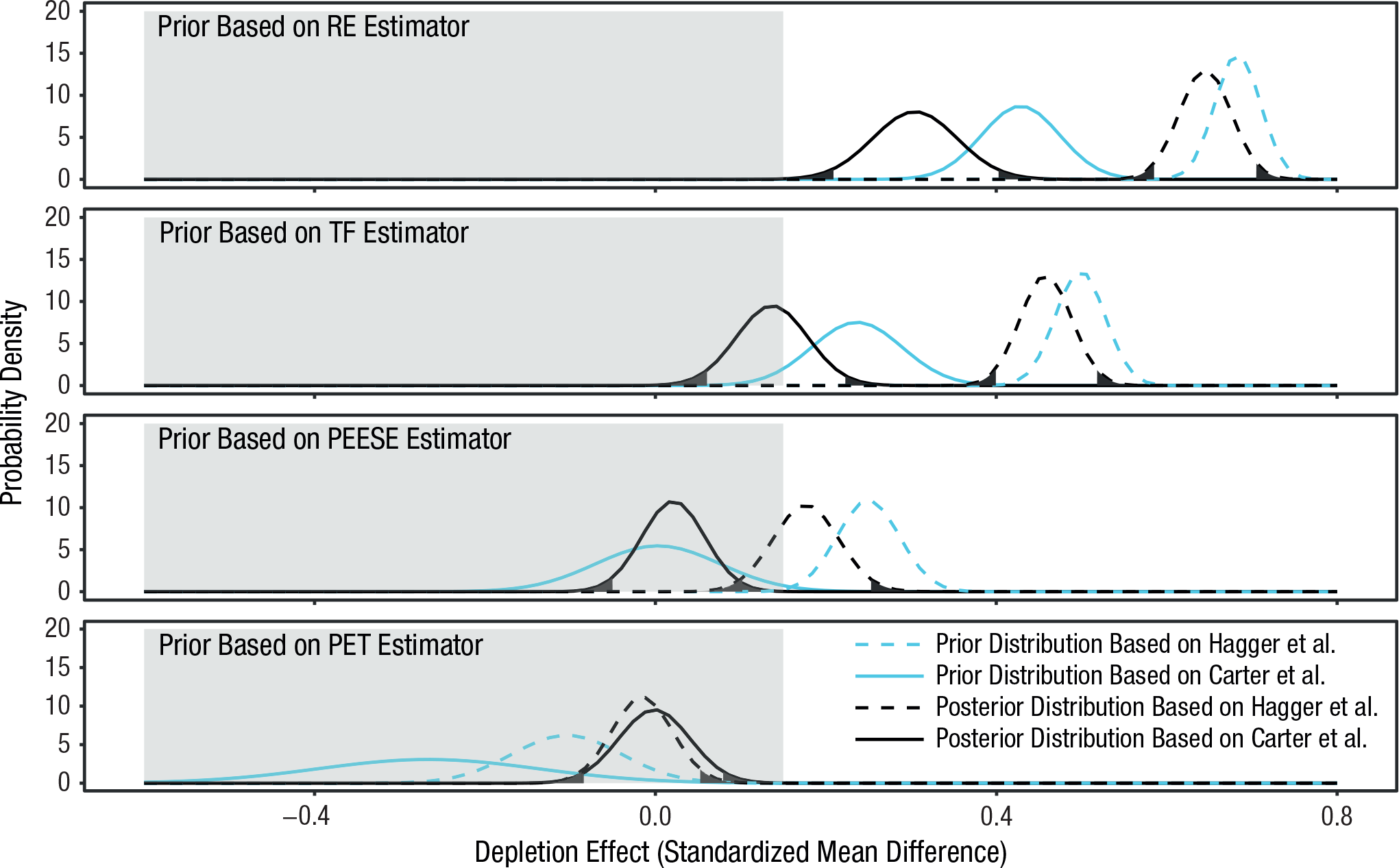
Results showing how prior beliefs based on previous meta-analytic estimates should change in response to the HQ28 data. For each of the four estimators, distributions of prior belief are shown separately for the meta-analytic estimates from Hagger, Wood, Stiff, and Chatzisarantis’s (2010) data and Carter, Kofler, Forster, and McCullough’s (2015) data. The posterior distributions are based on a Bayesian-model-averaged meta-analysis applied to the HQ28 data given the corresponding distributions of prior belief. Unshaded areas of the posterior distributions indicate the 95% highest density intervals. RE = random-effects meta-analysis; TF = trim-and-fill method; PEESE = precision-effect estimate with standard error; PET = precision-effect test.
Figure 3 indicates the amount of data required to change the minds of proponents and skeptics when the beliefs they hold are incorrect, as indicated by our simulations. For example, proponents could aim for 24 replications with a target of 110 subjects per cell (total N = 5,280) to reach 80% power for convincing skeptics—defined as holding prior beliefs such that p(µ) = N(0.00, 0.07)—when the true magnitude of the effect is 0.43. Alternatively, if proponents who believed the true magnitude of the effect is 0.43 wished to reach 80% power to be able to change their own minds, Figure 3 indicates that they could aim to conduct, for example, 15 replications with a target of 170 subjects per cell (total N = 5,100). By comparison, Hagger et al.’s (2016) registered replication study included data from 23 labs that tested about 47 subjects per cell (total N = 2,141); this sample size although impressive, falls below our estimate of the sample size required to change the mind of a proponent.
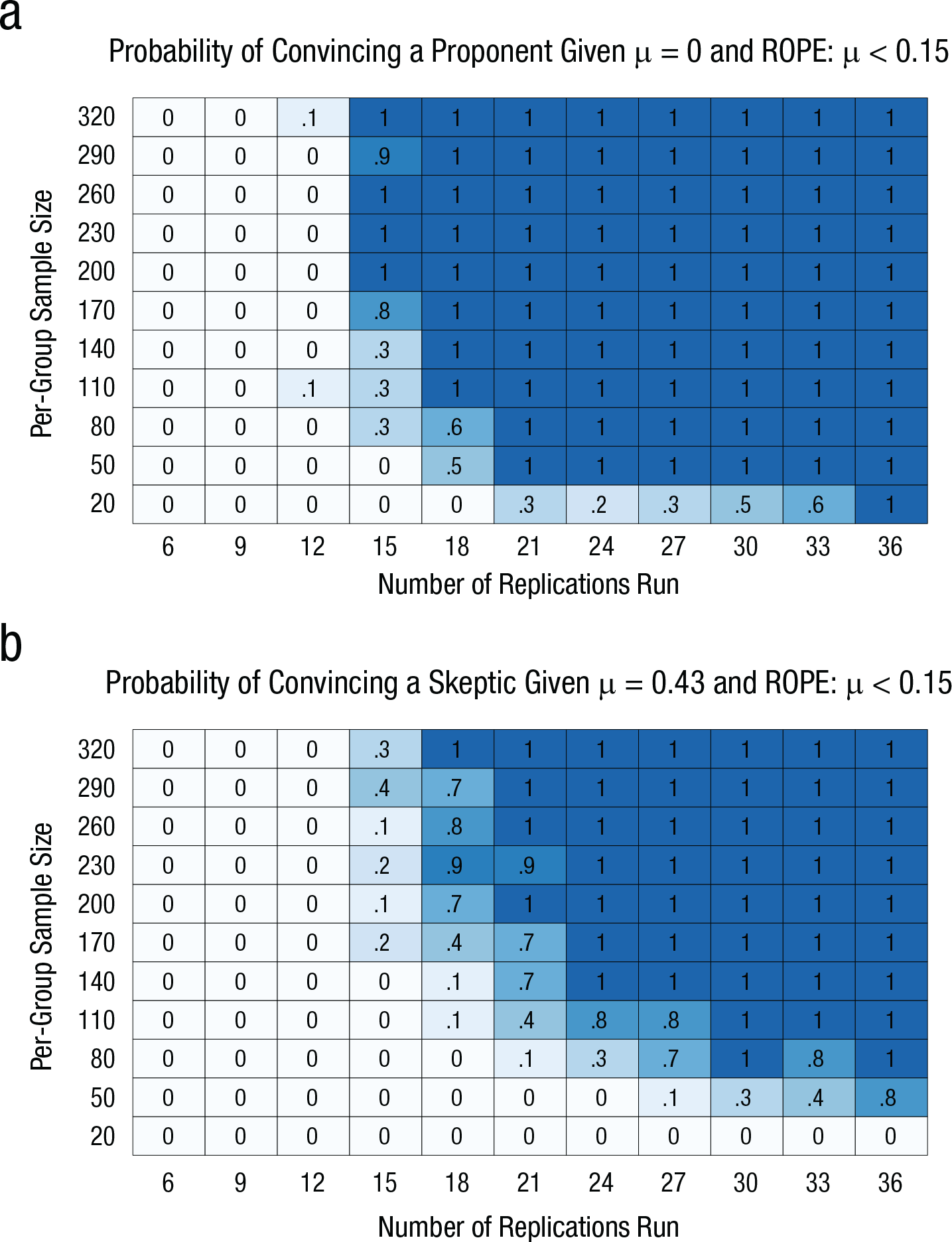
Results of the simulations testing the amount of data necessary to change proponents’ and skeptics’ minds about the depletion effect. The graph in (a) shows the probability of convincing a proponent that he or she is wrong—that is, the probability of observing overlap between the 95% highest density interval (HDI) and the region of practical equivalence (ROPE), µ < 0.15—given that µ = 0.00 and that the proponent’s prior belief is represented by p(µ) = N(0.43,0.05). The graph in (b) shows the probability of convincing a skeptic that he or she is wrong—that is, the probability of observing overlap between the 95% HDI and the ROPE—given that µ = 0.43 and that the skeptic’s prior belief is represented by p(µ) = N(0.00,0.07). In each panel, probabilities are given for all simulated combinations of number of replications conducted and per-group sample size.
We also examined the sensitivity of our results to the definition of prior belief (see Fig. S1 in the Supplemental Material). Specifically, there is reason to think that our definition of a proponent’s beliefs is too close to 0: For example, Cunningham and Baumeister (2016) clearly rejected the inclusion criteria used to assemble our updated data set (Carter et al., 2015). If, instead, proponents’ beliefs are modeled as based on the random-effects analysis of Hagger et al.’s (2010) data—p(µ) = N(0.68,0.03)—it becomes essentially impossible to change proponents’ minds when they are incorrect. Our simulation of this possibility (see Fig. S1 in the Supplemental Material) indicated that having 36 research teams run experiments with a target of 320 subjects per group (total N = 23,040) resulted in 0% chance of a proponent correctly accepting the null hypothesis. This result likely stems from the fact that this random-effects estimate is relatively precise (i.e., has a small standard deviation). A prior distribution with high precision represents fairly certain beliefs in that credibility is concentrated over a small range of candidate values. Significantly shifting such a distribution will require much more contrary data than we simulated. This result, therefore, illustrates how difficult it can be to change strongly held beliefs.
Discussion
For psychology’s foreseeable future, scientific inference will likely be stuck between controversial meta-analyses and preregistered replications that can realize only some of the conditions under which a phenomenon has been hypothesized to occur. The approach outlined here makes the best of this tricky situation by modeling how researchers combine their prior beliefs (perhaps formed on the basis of meta-analytic conclusions about literature that may be biased) with higher-quality evidence from subsequent preregistered replications. Our approach forces both the proponents and the critics of an idea to make their initial beliefs explicit and to defend the basis for formulating those beliefs. Then it shows them how their beliefs should change when they are confronted by new data. It also provides guidance about the amount of new data that would need to be collected for a planned replication effort to have the potential to change those beliefs.
The case of ego depletion illustrates how difficult it can be to resolve the difference between a skeptic’s view and a proponent’s view of a phenomenon. As a first step, such a resolution requires that researchers clearly specify their beliefs as well as the conditions under which they are willing to change those beliefs. Our meta-analysis (Carter et al., 2015) was designed to provide a test that would be stringent enough to convince a skeptical audience, so it is not surprising that it seemed overly strict to proponents of the ego-depletion effect and may have done little to change their minds (e.g., Cunningham & Baumeister, 2016). However, if one were willing to entertain some skepticism—for example, by basing one’s prior beliefs on estimates obtained by applying the trim-and-fill method, PET, or PEESE to the same data set—then the HQ28 replication data would lead one to conclude that the true value of the depletion effect very plausibly is no greater than 0.15, which we argue means that the effect is practically nonsignificant. Of course, if a researcher believed that the HQ28 includes inappropriate replications, then he or she would be justified in maintaining his or her beliefs—until a new massive replication effort was produced. Thus, the way forward for ego-depletion research, as for all research generally when inferences must be made on the basis of meta-analytic data and preregistered replications, will involve carefully considering what it will take to change the minds of researchers on both sides of this issue and then applying adequate effort to do so.
Our approach highlights that rational people can remain unconvinced by dozens of preregistered experiments that question the reality of a highly studied phenomenon, although maintaining such a belief could (depending on the meta-analytic data set and estimator it is based on) require them to defend rather optimistic assumptions about the amount of bias in the literature. Along similar lines, our approach can highlight when researchers’ beliefs regarding an effect are so strong that it is practically impossible to collect enough data to change their minds. We are not sure if the debate about the depletion effect is at such an impasse, but it might be: If proponents’ prior beliefs can be described in terms of the original estimate reported by Hagger et al. (2010)—p(µ) = N(0.68,0.03)—but the true effect is actually described by our bias-corrected estimate (i.e., µ = 0.00), then a replication effort on the order of 36 teams each collecting data on approximately 320 people per group (total N = 23,040) will have no chance of correctly changing these confident proponents’ minds (Fig. S1). To our knowledge, this interesting problem facing psychological science has received little discussion. Indeed, it may be that becoming more explicit about what we each believe and how strongly we believe it—and what those beliefs imply about how a rational person should react to subsequent empirical evidence—could be extremely beneficial as we move forward from science’s current crisis in confidence.
Supplemental Material
CarterMcCullough_Analysis_BMA – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, CarterMcCullough_Analysis_BMA for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
CarterMcCullough_DataOrg – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, CarterMcCullough_DataOrg for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
CarterMcCullough_FigureS1 – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, CarterMcCullough_FigureS1 for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
CarterMcCullough_Fig_S1_Caption – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, CarterMcCullough_Fig_S1_Caption for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
CarterMcCullough_Functions – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, CarterMcCullough_Functions for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
CarterMcCullough_PowerFigures – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, CarterMcCullough_PowerFigures for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
CarterMcCullough_PracticalSignificance – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, CarterMcCullough_PracticalSignificance for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
CarterMcCullough_Simulation_BMA – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, CarterMcCullough_Simulation_BMA for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
CarterMcCullough_Tutorial – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, CarterMcCullough_Tutorial for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
model_fixed_H1 – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, model_fixed_H1 for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Supplemental Material
model_random_H1 – Supplemental material for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications
Supplemental material, model_random_H1 for A Simple, Principled Approach to Combining Evidence From Meta-Analysis and High-Quality Replications by Evan C. Carter and Michael E. McCullough in Advances in Methods and Practices in Psychological Science
Footnotes
Action Editor
Alex O. Holcombe served as action editor for this article.
Author Contributions
E. C. Carter and M. E. McCullough developed the ideas for this project, ran the analyses, and wrote the manuscript.
Declaration of Conflicting Interests
The author(s) declared that there were no conflicts of interest with respect to the authorship or the publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.