
Abstract
In this perspective, the authors paint a vision for industrializing drug discovery with an “atoms and bits” approach. This approach leverages advancements in machine learning, automation, and biological tools to create a platform for drug discovery that de-specializes the output of insights and generates feedback loops to iterate on each success and failure. Recursion Pharmaceuticals, where the authors work, is provided as an example of how one company is attempting to achieve this vision.
The digital revolution marches onward at an incredible pace. Cryptocurrency, self-driving cars, and reusable rockets felt unrealistic not too long ago and are now creating entire industries. Smartphones are the norm. Much of human knowledge is only a few thumb taps away. Yet, this digital revolution has failed to live up to its hype in reducing drug discovery research and development (R&D) costs, timelines, or failure rates.
One fundamental part of the problem is that novel advancements in science and technology cannot be simply tacked onto existing historical processes. Instead, we propose here that the drug discovery process needs to be reconceived as a new era of flexible technology industrialization.
Industrialization is the transformation of a field to large-scale production and superlinear growth. Manual labor is replaced by standardized processes and automation. When this is implemented successfully, the output is bolstered by improved reproducibility, reduced cost per unit, and massively increased throughput.
In drug discovery, the desired output is a drug that improves lives—or, to focus further upstream, a unit of useful scientific insight. And more insights are sorely needed: In the decade ending in 2018, fewer than 40 drugs were approved each year by the US Food and Drug Administration (FDA) despite pharmaceutical companies investing a mean of more than $1 billion per drug. 1 In short: Change is needed.
Many Parts of Pharma Are Already Industrialized: Why Not Drug Discovery?
In the late 1800s, new insights in chemistry and engineering led to the industrialization of the preparation of drugs. The results were massive increases in scale, quality control, and—ultimately—societal access to drug treatments. It was the dawn of the modern pharmaceutical industry, 2 with a transition from local drug preparation at apothecaries to industrial manufacturing and global behemoths that we still recognize today, like Eli Lilly and Merck. At the same time, companies in other industries—in particular, the fine chemical and dye industries, with entrants including Pfizer and Roche—realized how their skills in large-scale production could be applied to drug manufacturing.
But even 150 years later, industrialization has still not fully arrived for the drug discovery process. R&D units at pharmaceutical companies are generally structured around lead scientists, in verticals of specific and narrow disease focus. Team expertise and scientific tools grow to serve these foci, resulting in data silos and tribal knowledge that can be difficult to transfer efficiently between efforts. While these teams often have many of the hallmarks of industrialization, including various high-throughput discovery platforms, 3 they lack one of the key ingredients of the digital revolution: de-specialization of outputs.
In the first industrial revolution, industrialization was achieved by uniformity in output: A textile factory made a specific type of fabric, or a farm specialized in a certain crop. The digital industrial revolution brought a change to this, in which companies standardize processes while allowing for de-specialization, complexity, and diversity in output. For example, it is estimated that Google’s search capability infrastructure enables some 5.6 billion personalized queries per day, while 4.7 billion unique updates are shared by users on Facebook’s platform. We propose that in the pharmaceutical industry, R&D industrialization will be reached by embracing analogous forms of standardized technology processes that allow for data relatability among diseases, programs, and biology (de-specialization of outputs). Standardized experimental platforms that can rapidly process and compare a broad diversity of biological information will allow drug engineers to explore at an unprecedented scale.
Enter Modern Industrialized Drug Discovery
Today, drug discovery is standardized high-throughput lab processes applied among broad scientific applications and disease areas. It is industrial rigor and analytical relatability that combine FAIR (findable, accessible, interoperable, and reusable) data principles 4 with modern data processing. It is drug discovery that spans both “atoms and bits.”
You can see this vision for the future of drug discovery unfold at companies across the globe—from multinational pharmaceutical giants to startups like LabGenius in London and BioAge in California—and hear the hum of both biology-handling robots and data science computing.
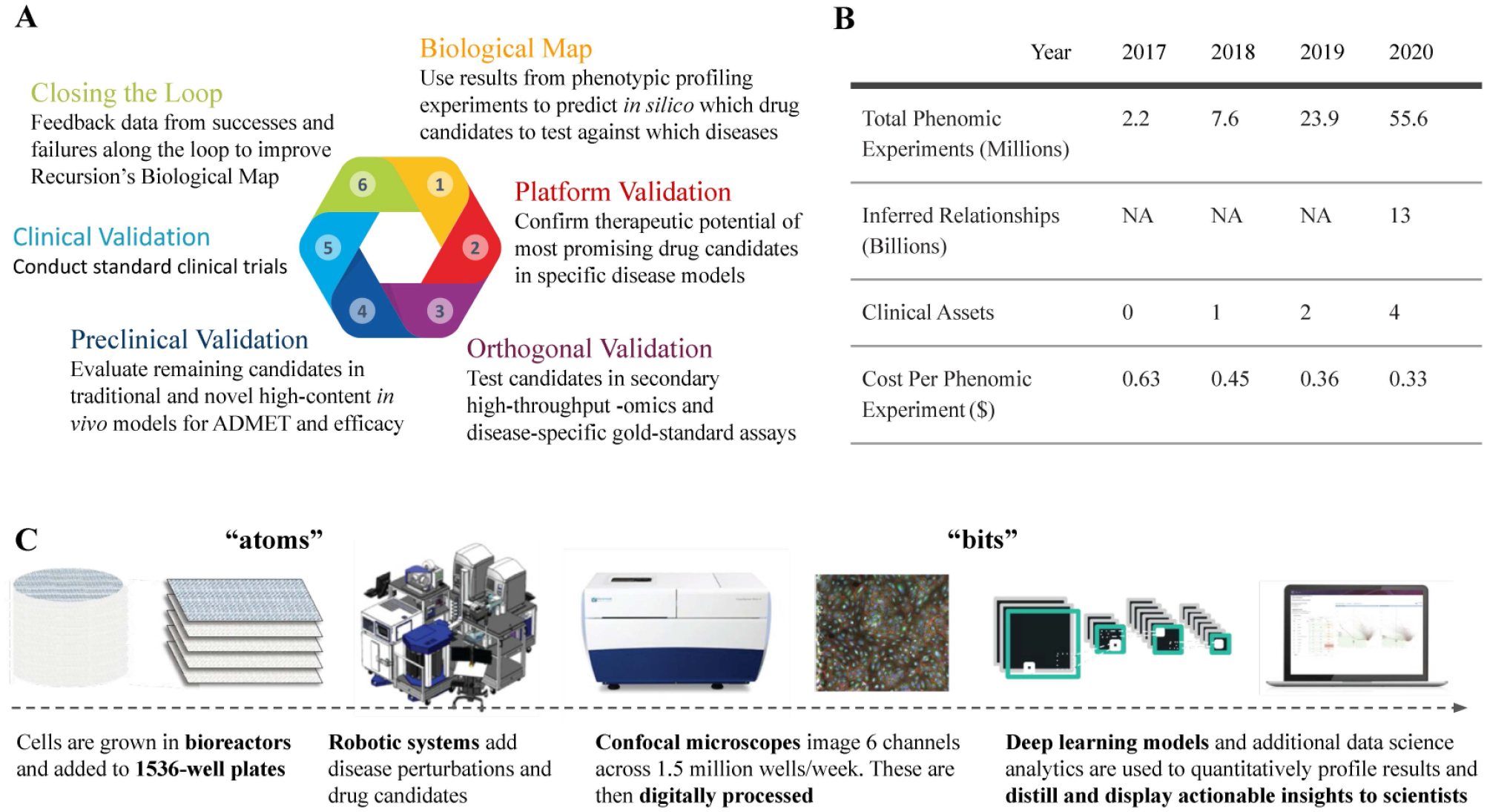
At Recursion, where the authors work, we are also embracing this new “atoms and bits” approach. We run more than 1000 1536-well tissue culture plates every week through a standard, high-content screening assay
5
(
(
This focus on industrial repeatability and large-scale production among both atoms and bits means that a single biological map can inform throughout R&D efforts and incorporate data that are added throughout time to enable a superlinear growth of insights. We use our growing map to predict relationships and interactions among various elements of biology and chemistry at scale and speed. Furthermore, we have focused on controlling our own vertical; our predictions can be validated experimentally in our own labs, translated through animal models in our own vivarium, and developed through the clinic by our own team (
We currently have four drug candidates at the human clinical trial stage that were identified because they reverse the features of specific disease cell phenotypes in our high-dimensional biological map. For each of these four drug candidates, we expect to initiate a Phase 2 clinical trial within the next four to five quarters. Rather than zeroing in up front on specific scientific hypotheses around individual protein targets, we deployed a brute-force approach throughout broad biology and let the data inform what diseases and therapeutics to pursue. These first clinical-trial-stage candidates are repurposed compounds intended to treat genetic diseases, but today we also evaluate new chemical entities and more diverse disease states using the same approach.
What Will It Take to Get to Successful, Established Industrialization?
On an immediately practical level, many pieces have to come together to truly achieve modern industrialization of drug discovery. You need standardization of processes. You need to build on advancements in biology that enable scale (e.g., gene-editing tools like CRISPR). You need to integrate advancements in both physical processes (lab robotics) and digital analysis pipelines (e.g., cloud computing and machine learning). You need industrialized feedback processes to continually validate and iteratively optimize your data collection and analysis for long-term clinical success, such as information on preclinical efficacy, pharmacokinetics, and toxicity.
In short, you need to replace early-stage manual work by scientists with automated drug discovery loops of atoms and bits, freeing up the hero scientists’ time for focused, deep investigations. Done successfully, the result is a reduction in cost and—most importantly—an ability for the drug discovery field to act more nimbly to address new challenges at scale.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.