
Abstract
Existing click-through rate prediction models employ both a shallow model and a deep neural model for better feature interaction. The former shallow model aims to extract explainable explicit features and the latter deep neural model aims to learn efficient implicit features. Deep neural network is a commonly used deep neural model, which can yield better performance with more neural layers. However, increasing the number of neural layers would lead to problems such as gradient vanishing, gradient explosion, and excessive parameters. In addition, the performance of a deep neural network will also decrease rapidly when it becomes too deep. In this article, we propose a novel click-through rate prediction model by improving the deep neural model part to alleviate the above problems of deep neural network-based models. This article proposes to utilize a dense deep neural network model to strengthen feature propagation, which takes the outputs of all previous layers as the input of the current layer, instead of only one previous layer being used in the deep neural network. In addition, we also utilize an advanced shallow model FmFM for better explicit features in this article, and explicit and implicit features are interacted in our model. Experiments on two data sets (Criteo and Avazu) show that the proposed click-through rate prediction model significantly outperforms existing classical models such as DeepFM, xDeepFM, and DeepLight models.
Introduction
Advertising is a very important source of income for most Internet companies. The click-through rate (CTR) is an important indicator in advertising, 1 which is used to evaluate whether the advertising is accurate and efficient. Thus, CTR prediction is becoming more important, which can bring significant benefits to Internet users, advertisers, and advertising media.2,3
A lot of traditional CTR prediction models have been proposed. Logistic regression (LR) 4 can conduct a linear combination of individual features, but lacks automatic feature interactions and leads to weak representation ability. The Poly2 model 5 can benefit from effective feature interactions, but leads to sparse features and thus increases the training complexity. The Factorization Machine (FM) 6 is different from the Poly2 model in that it models the interaction between two features as the dot product of their corresponding embedding vectors, which greatly reduces the training cost. Field-aware FMs (FFMs) 7 introduce the concept of field awareness on the basis of the FM to consider the interaction of different field features, which leads to richer representations. However, due to the large number of parameters, FFM is not desirable in real production systems. Field-weighted FMs (FwFMs) 8 use an additional weight to explicitly capture different interaction strengths of different pairs of field features with only 4% of FFM parameters. Instead of using only one scalar to weight the interaction between two different field features in FwFMs, field-matrixed FMs (FmFMs) 9 use a matrix to represent the interaction between two different field pairs for a higher degree of freedom and better feature representation.
In recent years, deep learning techniques (i.e. neural network models) has yielded great success in computer vision, speech recognition, and natural language processing with their powerful feature representation learning ability. There are also many neural CTR prediction models proposed. Instead of only using one neural model, neural CTR prediction models generally use both a shallow feature extraction model and a deep neural model to effectively capture low-order and high-order feature interactions and yield better performance while keeping the explanation ability of the model. For example, feed-forward neural network (FNN) 10 pre-trains an FM model for initial explicit features before applying a neural model for more efficient deep features. The FNN model is limited by the weak capability of the FM model and can only learn high-order feature interactions. A product-based neural network (PNN) 11 adds a product layer between the first hidden layer and the embedding layer to capture interactive patterns between inter-field categories, and further fully connected layers to explore high-order feature interactions, but its computational complexity is very high and it still can only learn high-order features. To capture low-order and high-order feature interactions at the same time, Google proposed Wide&Deep 12 in 2016, which combines a linear model and a deep neural model, but the input of the linear model still relies on expert feature engineering. In 2017, Huawei further proposed DeepFM,13,14 which changes the Wide part of the Wide&Deep model into an FM model. The advantage of DeepFM is that it does not need expert feature engineering and has higher training efficiency. In 2017, Google proposed the deep and cross network (DCN), 15 which uses a cross network to avoid expertise feature engineering. The network structure is simple and efficient, but the feature interaction is only at the bit-wise level. Later in 2018, Microsoft proposed xDeepFM, 16 whose compressed interaction network (CIN) part can automatically learn explicit high-order feature interaction, and the interaction is at the vector-wise level, but the complexity is too high to be applicable. In 2020, Google further improved DCN and proposed DCN-V2, 17 whose core is a cross layer, which inherits the simple structure of the cross network from DCN, but performs very well in learning explicit and bounded cross features. In 2021, Purdue University and Yahoo research put forward DeepLight, 18 which uses a high-quality, low-consumption, and low-latency model to increase the model’s inference speed by tens of times without any loss of the prediction accuracy.
In addition, many models introduce an attention mechanism, which can enhance the ability to represent feature information and the importance of dynamic modeling features.19,20 The earliest model is AFM, 21 which introduces an attention network between a feature cross layer and an output layer. Most recent models proposed include FiBiNET, 22 AutoInt, 23 and InterHAt. 24 Existing CTR prediction models still suffer from low performance in real application systems of advertising.
To further improve the accuracy of CTR prediction, a novel neural model DDNNFMFM (dense deep neural network with field-matrixed factorization machine) is proposed in this article. The contributions of this article are summarized as follows:
In this article, a novel dense deep neural network (DenseDNN) model is proposed, which takes the sum of the outputs of all previous layers of DNN as the input of the current layer. The DenseDNN model is constructed aiming to strengthen feature propagation and achieve better feature fusion. It can also alleviate the problem of gradient vanishing caused by increasing the number of layers of DNN, and thus improves the performance of the CTR prediction model with fewer parameters.
In this article, a novel deep learning-based feature fusion model DDNNFMFM is proposed, which employs the matrix field of a shallow feature extraction model FmFM as well as the deep feature fusion ability of a deep model DenseDNN to automatically learn explicit and implicit high-order feature interactions.
Experimental results on two classical data sets of Criteo and Avazu show that the proposed DDNNFMFM model can significantly outperform most existing classical models, such as DeepFM, xDeepFM, and DeepLight.
Related Work
Shallow Feature Extraction Models
FM Models
Compared with previous models, FM can model the interaction between two features by a dot product between their corresponding embedding vectors. The core equation of the FM model is introduced as follows:
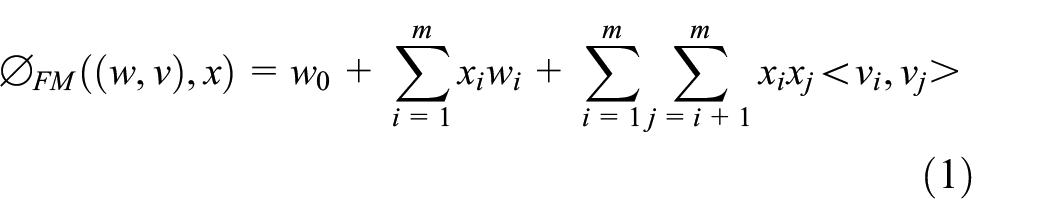
where w0 is the global bias; wi models the strength of the ith variable; xi and xj denote the ith and jth features, which are very sparse; and vi and vj are the embedding vectors corresponding to the features.
As we can see from equation (1), the equation can be generalized to unobserved cross parameters, making the FM model more robust. However, the FM model ignores the properties of features, such as different fields of features. Different fields of features may show different interaction behaviors.
FFM Models
FFM models such difference explicitly by learning n–1 embedding vectors for each feature, say i, and only using the corresponding one vi,F(j) to interact with another feature j from field F(j):
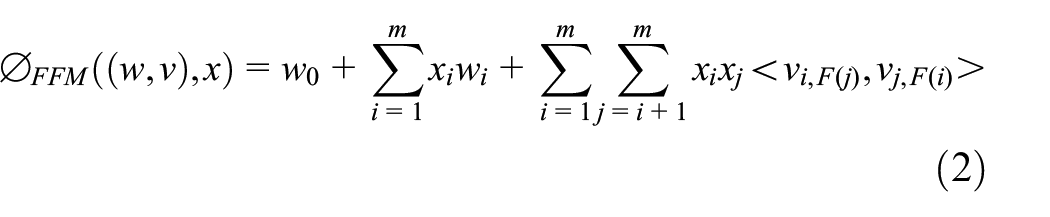
where F(i) and F(j) are the field where features i and j are located, vi and vj represent the embedding vector when feature i interacts with feature j, and vi,F(j) represents feature i interacting with another feature j from field F(j).
The advantage of FFM is that it fully considers the differences in the interaction of features between different fields. The disadvantage is that the number of parameters is too high and it is too complicated, so it is not suitable for use in actual production.
FwFM Models
Like FFM, FwFM considers the difference in the interaction of features between different fields. The difference is that FwFM uses a scalar weight r to explicitly capture different interaction strengths of different field pairs. The core equation of the FwFM model is introduced as follows:
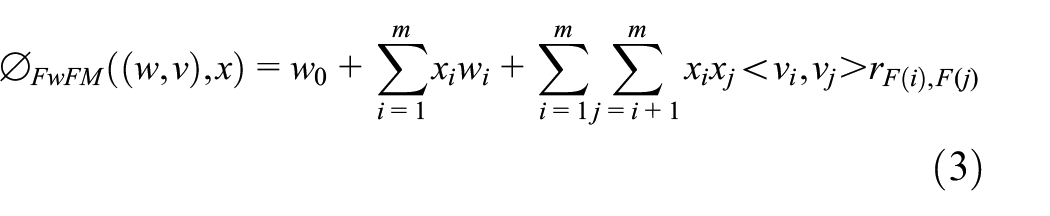
where vi and vj are the embedding vectors of feature i and feature j, F(i) and F(j) are the field to which feature i and feature j belong, and r is the weight of interaction strength of field F(i) and F(j).
The advantage of FwFM is to capture the interaction between different field features with only 4% of the parameters of FFM. The disadvantage is that only one scalar is used to express the strength of interaction between different fields, which has insufficient degrees of freedom and limited expression ability.
Deep Neural Network
DNN is an FNN, which includes an input layer, several hidden layers, and an output layer. Generally, the first layer is an input layer, which represents a low-dimensional dense vector. The last layer is called an output layer, which assigns a prediction score for each object. The middle layers between the input layer and the output layer are called hidden layers, which function as an automatic feature extractor. The DNN network takes the output of the previous layer as the input of current layer from the first hidden layer to the output layer. This process is called forward propagation. To make the calculated output fit the sample better, the method of back propagation is adopted to minimize the loss function. Forward propagation and back propagation are iterated many times until the stop criteria is reached.
Equation (4) shows the calculation of the output of the kth layer x k :

where σ represents the activation function, xk–1 represents the output of the (k–1)th layer, and W(k) and b k are parameters of the kth layer.
DDNNFMFM Model
To meet the above requirements and follow the parallel structure of some mainstream frameworks, such as DeepFM, xDeepFM, DCN, and DeepLight, the DDNNFMFM model is proposed. The deep part of DDNNFMFM uses an improved DNN network, which can perform feature fusion with fewer parameters and improve the effect of implicit feature interaction. We name it the DenseDNN network; FmFM is selected for the shallow part, which uses a field matrix to simulate the explicit interaction between different field features, so as to further improve the accuracy of the model. DDNNFMFM combines deep model DenseDNN and shallow model FmFM in parallel, which can automatically learn implicit and explicit high-order feature interaction efficiently.
This section introduces the proposed neural network-based CTR prediction model, DDNNFMFM. The architecture of the DDNNFMFM model is shown in Figure 1. The model includes (a) an input layer, which represents each user-clicked advertisement data item with designed original features, yielding a high-dimensional sparse feature vector; (b) an embedding layer, which transforms the above high-dimensional sparse feature vector into a low-dimensional dense vector; (c) a deep learning DenseDNN model, which aims to extract effective implicit features from the low-dimensional vector; (d) a traditional FmFM model, which learns explainable explicit features from the low-dimensional vector; and (e) an output layer, which combines the deep implicit features obtained from DenseDNN and the shallow explicit features obtained from FmFM, and output and user-clicked prediction score. Each module will be introduced in the following sections.
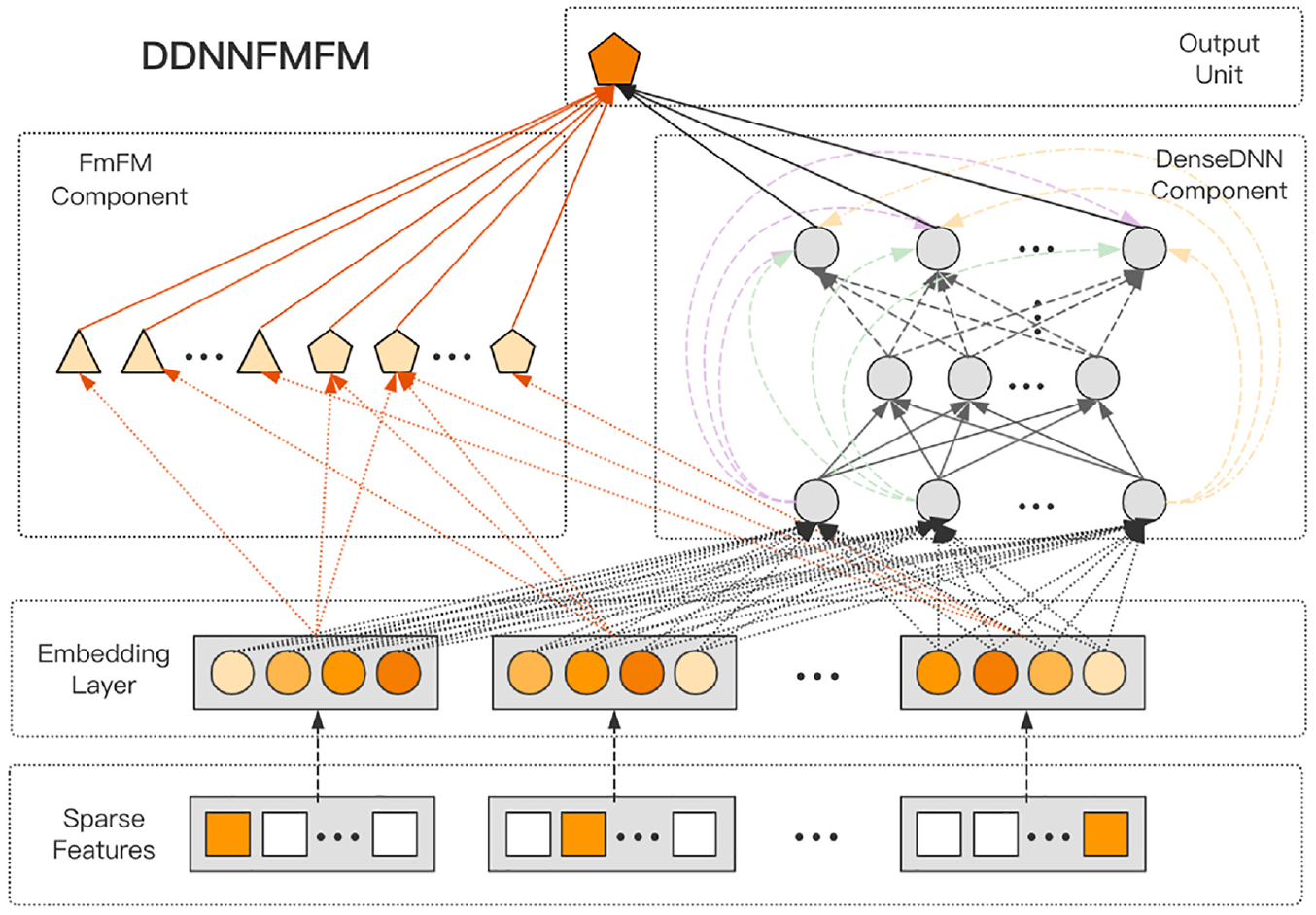
Structure of the DDNNFMFM model.
Input Layer
The input layer of the model represents a data item to a vector. In the field of advertising recommendation, the advertising data items clicked by users are usually very sparse, resulting in sparse and high-dimensional input features without temporal or spatial correlations. The original discrete features need to be one-hot encoded and converted into a one-hot vector x, where x is [ x1, x2, …, xf ], and
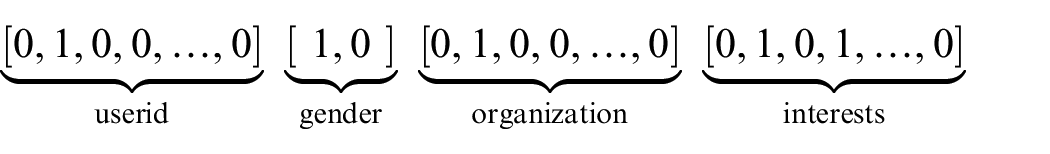
Embedding Layer
Nevertheless, the above one-hot encoding vectors often lead to high-dimensional spaces for large vocabularies; thus, we use an embedding layer to transform these binary features into dense vectors x to reduce the dimensionality (commonly called embedding vectors):

where xi denotes the binary input in the ith category, xembed,i denotes the embedding vector, and
Then, we stack multiple embedding vectors into one vector along with normalized dense features xdense
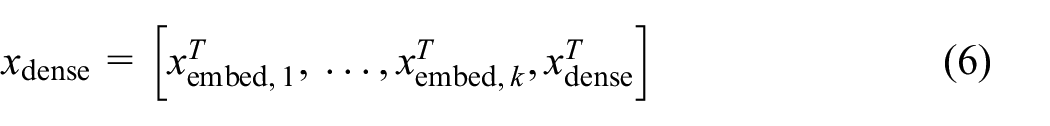
There are no combination features. We capture the interaction of a feature with a deep network and an FmFM model.
DenseDNN
Existing deep learning-based CTR prediction models can effectively capture high-order feature interactions and significantly improve the performance of the model. In recent years, the industry has proposed many CTR prediction models combined with DNNs in a parallel structure. Most of these parallel structure models improve the model performance by improving the shallow part of the model that studies explicit feature interactions. For example, the DeepFM model replaces the wide part of the Wide&Deep model with an FM model, the xDeepFM model designs a CIN network for shallow feature extraction, and the DeepLight model improves the FM model in DeepFM with an advanced FwFM model. However, the deep part usually uses DNNs in these parallel structure CTR prediction models, and there are few works focusing on improving the implicit feature interactions. To extract better implicit features, we can theoretically use more neural layers in the DNN network or use more neurons in each layer. However, practically, it will lead to problems such as gradient vanishing, gradient explosion, and excessive parameters, and the performance of DNN will decrease rapidly after reaching saturation with the increase of its layers.
To avoid the above problems, the DenseDNN network is proposed. DenseDNN introduces the idea of DenseNet to change the input of each layer of DNN into the sum of the outputs of all previous layers. Its model diagram is shown in Figure 2. Its advantages include: (a) alleviating the vanishing-gradient problem of deep network; (b) strengthening feature propagation; (c) substantially reducing the number of parameters; and (d) reducing the problem of sample over-fitting. Equation (7) is its output, where x i represents the output of layer i, and W(n) and b n are training parameters.
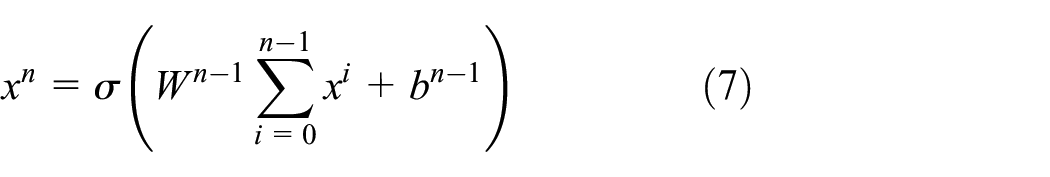
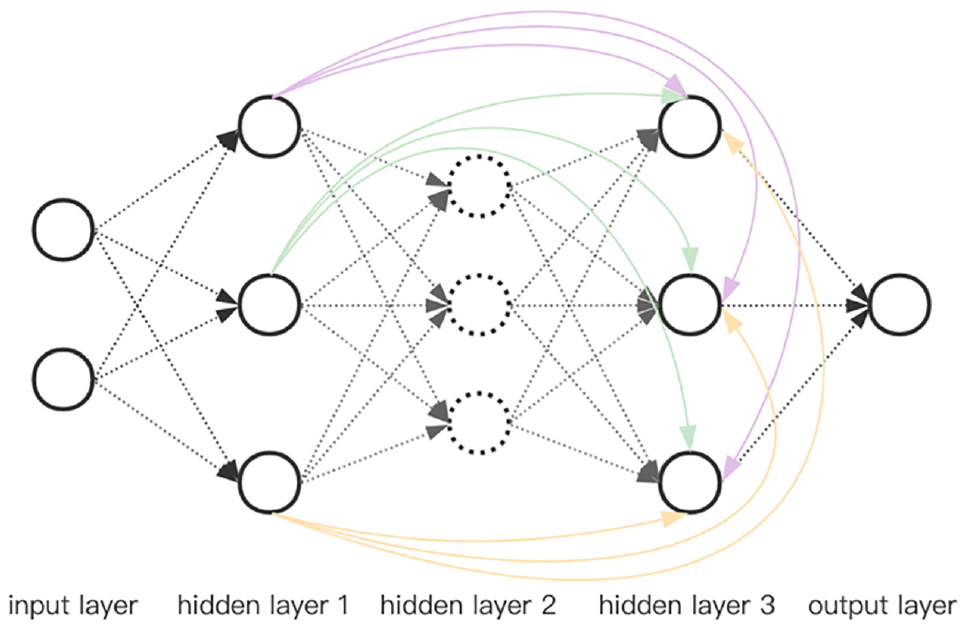
Structure of DenseDNN model.
FmFM models
The FmFM model is in line with the FM-based models, which also include the FM, FFM, and FwFM models. Similar to the FwFM model, we will learn an embedding vector for each feature. We define a matrix MF(i),F(j) to represent the interaction between field F(i) and field F(j) as follows:

where vi, vj are the embedding vectors of feature i and j, F(i) and F(j) are the fields of feature i and j, respectively,
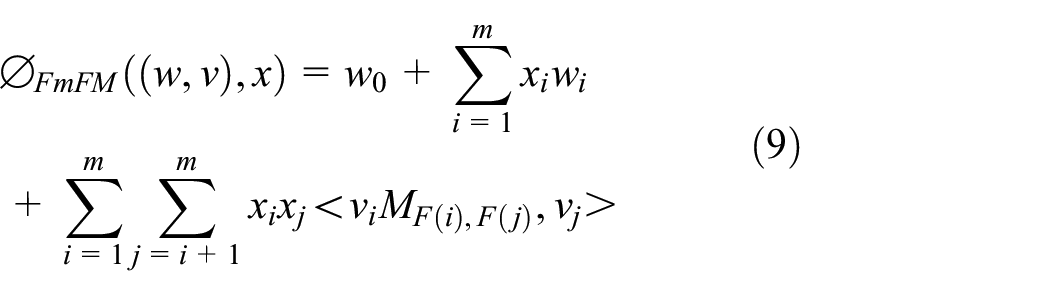
FmFM are extensions of FwFM in that it uses a two-dimensional matrix MF(i),F(j) to interact with different field pairs, instead of a scalar weight r in FwFM, which improves the degree of freedom and expression ability of the model. The interaction operation process is shown in Figure 3. The calculation of FmFM can be decomposed into three steps:
Embedding Lookup: the feature embedding vectors vi, vj, and vk are looked up from the embedding table, and vi will be shared between those two pairs.
Transformation: then vi is multiplied by the matrices MF(i),F(j) and MF(i),F(k), respectively. Here we get the intermediate vector vi, F(j)=vi×MF(i),F(j) for the field F(j), and vi,F(k)=vi×MF(i),F(kj) for the field F(k).
Dot Product: the final interaction terms will be a simple dot product between vj and vi, F(j), as well as vk and vi, F(k), which are the black dots shown in Figure 3.
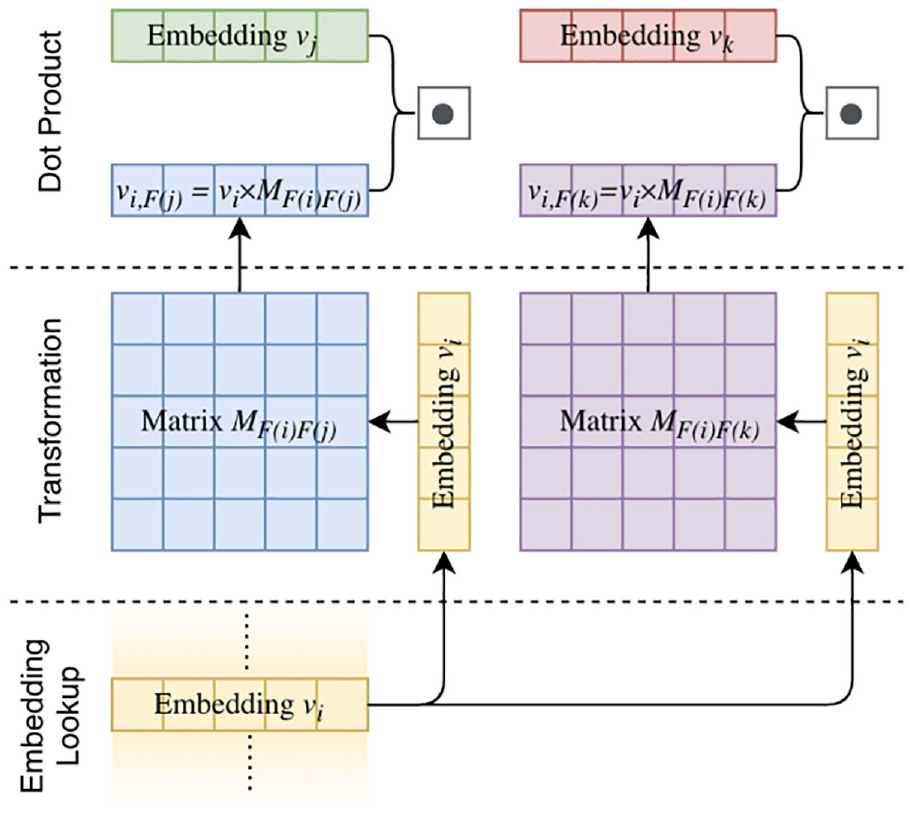
An example of FmFM interaction term calculation.
Output Layer
After splicing the results of FmFM and DenseDNN, the output results are obtained through sigmoid function:
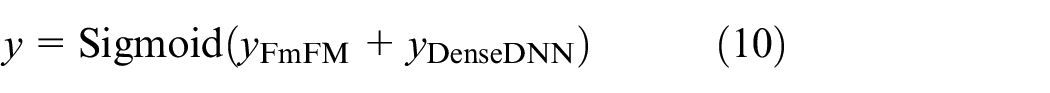
where
Experiments
The experimental environment of this experiment is Windows 10 operating system, based on the Python 3.7.0, Tensorflow 2.3.0 framework. To verify the performance of the proposed model DDNNFMFM, a large number of comparative experiments were carried out on the two data sets of Criteo and Avazu to verify the performance of the model.
Experimental Setup
Data sets
Criteo Data set
This is a well-known benchmark data set for CTR prediction. This experiment uses Sample Criteo, which is the sampling of the Kaggle Criteo data set, with a total of 1 million samples. The first column represents whether the advertisement to be predicted is clicked. Each sample also has 13 columns of digital features, mainly counting features and 26 classification features. For the purpose of anonymity, these 26 classification features have been hashed to 32 bits. 25
Avazu Data set
This is used for Avazu CTR prediction competition, which predicts whether mobile advertising will be clicked. The Avazu data set has 40 million samples, and each sample has 23 classification fields. This article makes an experiment on 1 million data randomly sampled from Avazu data set.
Evaluation Metrics
Area Under the Curve
The Area Under the Curve (AUC) is the area under the ROC (Receiver Operating Characteristics) curve and takes a value between 0 and 1. The size of the AUC is positively correlated with the performance of the CTR prediction model. The calculation steps are as follows: (a) solve the values of true positive rate (TPR) and false positive rate (FPR) through the confusion matrix to obtain the coordinate point pair; (b) the curve formed by different coordinate point pairs is the ROC curve; (c) the AUC is the area below the ROC curve. The AUC is considered to be an important index of the CTR prediction problem, and its formula is:
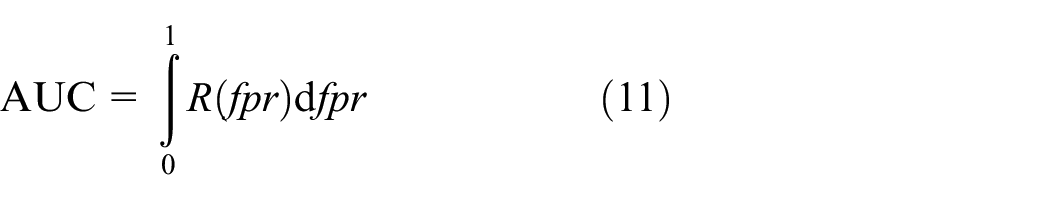
LogLoss
LogLoss is the binary cross-entropy loss function, which is used to evaluate the accuracy of the model and represent the distance between the predicted score and true label for each instance. Generally, we need to use the predicted probability to estimate the benefit of a ranking strategy. The formula is:
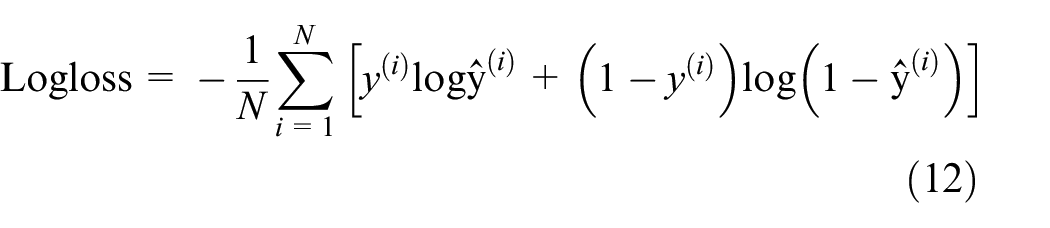
Data Processing
In the actual production activities, the data generated will be missing and abnormal. If directly used, it is easy to produce adverse results. Therefore, the missing part in the data set is filled in. To verify the performance of the model, the data set is divided into a training set, a verification set, and a test set according to the ratio of 8:1:1.
Model Comparison
In the individual model comparison experiment, LR, FM, CIN, and FwFM are selected as the models for learning explicit feature interaction to compare with FmFM used in DDNNFMFM, because FmFM is developed from LR, FM, and FwFM, and CIN is also used as a comparison model because it is a very classic and efficient model for learning high-order explicit feature interactions; the DNN model is compared with the DenseDNN proposed in this article, because DenseDNN is developed from the DNN model.
In the comprehensive model comparison experiment, shallow models LR, FM, FwFM, and FmFM are selected as the comparison models; the deep model DeepFM, xDeepFM, and DeepLight are selected as the comparison model, because they have similar architectures to DDNNFMFM and they are also the state-of-the-art models for CTR prediction.
Performance Evaluation
Individual Model
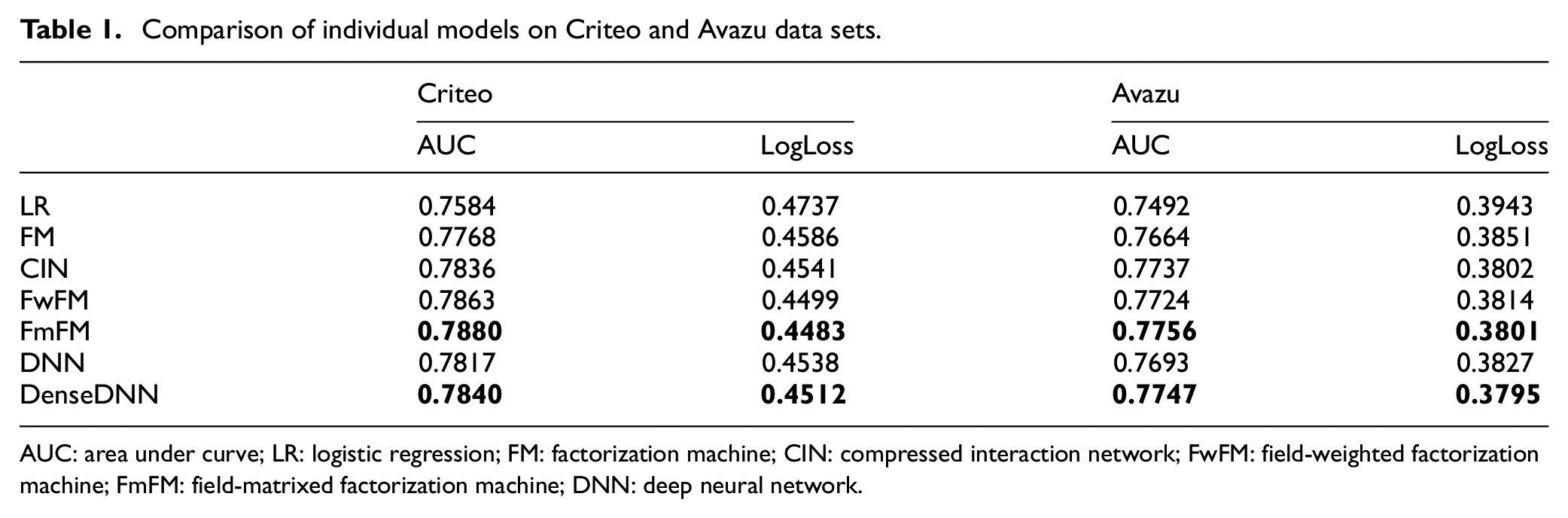
To verify the performance of DenseDNN and FwFM in DDNNFMFM, it can be seen from the comparison results of individual models in Table 1 that:
Learning feature interactions can improve the prediction results of the model. LR, as the only model without learning feature interaction, performs at least 1.1% on Criteo data set and 2.3% on Avazu data set worse than other methods in terms of the AUC, which shows that feature interactions are critical to improving the CTR prediction.
Compared with the individual model of explicit feature interaction, FmFM has the best performance on the Criteo data set and Avazu data set. It is proved that modeling the interaction of different field features as a matrix is conducive to the improvement of model performance.
Compared with DNN, the accuracy of DenseDNN proposed in this article improves by 0.29% on the Criteo data set and 0.70% on the Avazu data set in terms of the AUC, and reduces by 0.57% on the Criteo data set and 0.84% on the Avazu data set in terms of LogLoss, which proves that DNN has better performance after feature fusion.
Comparison of individual models on Criteo and Avazu data sets.
AUC: area under curve; LR: logistic regression; FM: factorization machine; CIN: compressed interaction network; FwFM: field-weighted factorization machine; FmFM: field-matrixed factorization machine; DNN: deep neural network.
Comprehensive Model
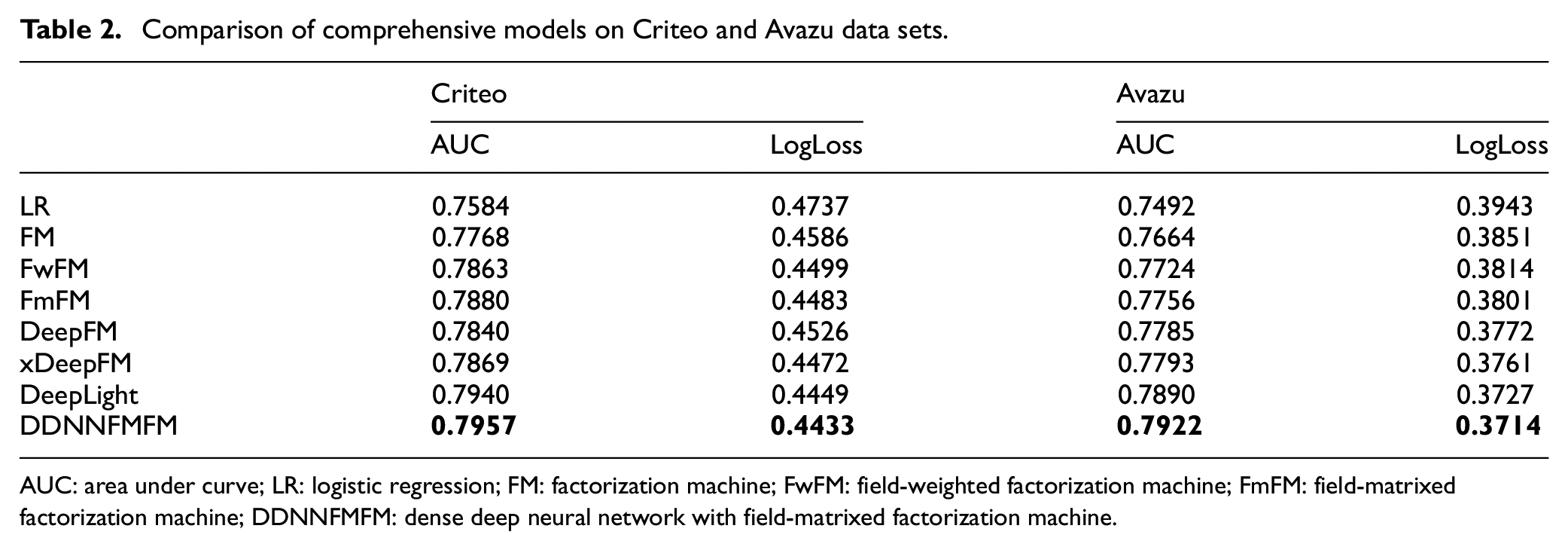
To verify the accuracy of DDNNFMFM, it can be seen from the comprehensive model comparison results in Table 2 that:
FmFM is not only a shallow model with the best performance, even in the Criteo data set, but also its performance is better than the classic deep learning models DeepFM and xDeepFM. This once again proves the advantage of the field matrix in the FmFM, which is lighter and faster than the two parallel models DeepFM and xDeepFM.
DDNNFMFM has the best effect among all models based on embedded neural network. As shown in Table 1, in the Criteo data set and the Avazu data set, compared with the classical suboptimal model DeepLight, the AUC of DDNNFMFM proposed in this article is increased by 0.21% and 0.41%, respectively, and the LogLoss is reduced by 0.36% and 0.35%, respectively.
Comparison of comprehensive models on Criteo and Avazu data sets.
AUC: area under curve; LR: logistic regression; FM: factorization machine; FwFM: field-weighted factorization machine; FmFM: field-matrixed factorization machine; DDNNFMFM: dense deep neural network with field-matrixed factorization machine.
Hyper-Parameter Study
Number of Neurons Per Layer
Figure 4 shows the influence of the number of hidden layers in the Criteo data set on the experimental results. It can be seen that the DDNNFMFM model’s performance increases with the increase in network depth at the beginning, but when the network depth is greater than 5, the model performance declines, which is the result of over-fitting. The comparison models DeepFM, xDeepFM, and DeepLight perform best when the network depth is 3, because DDNNFMFM improves DNN, and feature fusion occurs only when the network depth is three layers and above. As a result, DDNNFMFM has the best result when the network depth of the hidden layer is 5.
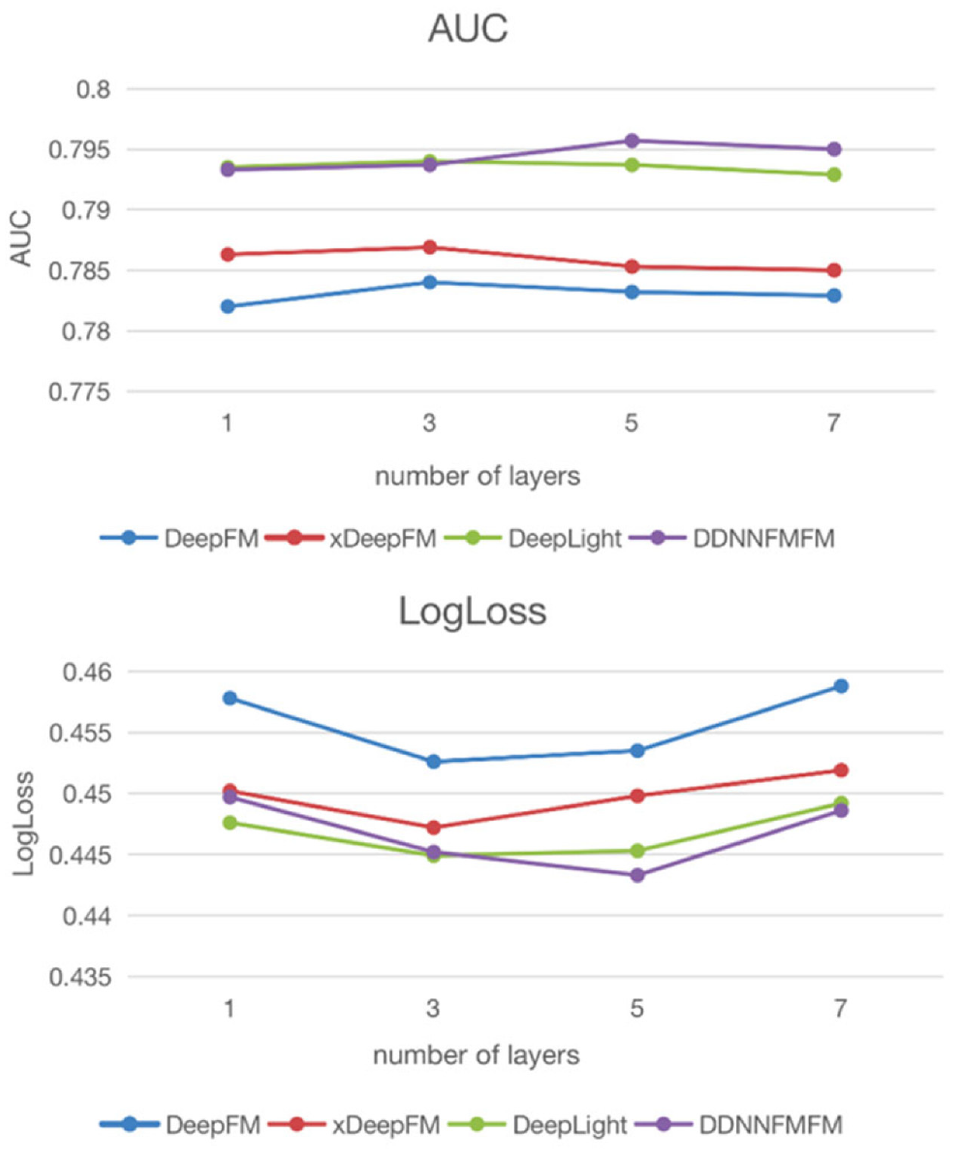
AUC and LogLoss comparison of number of layers.
Number of Hidden Layers
Figure 5 shows the influence of the number of neurons at each layer in the Criteo data set on the experimental results. In this comparative experiment, DDNNFMFM chooses the five layers with the best network depth. It can be seen that when the number of neurons is increased from 200 to 500, the performance of the model gradually improves and then declines, because the overly complex model is easy to overfit. The DDNNFMFM model performs best when the number of neurons is set to around 400.
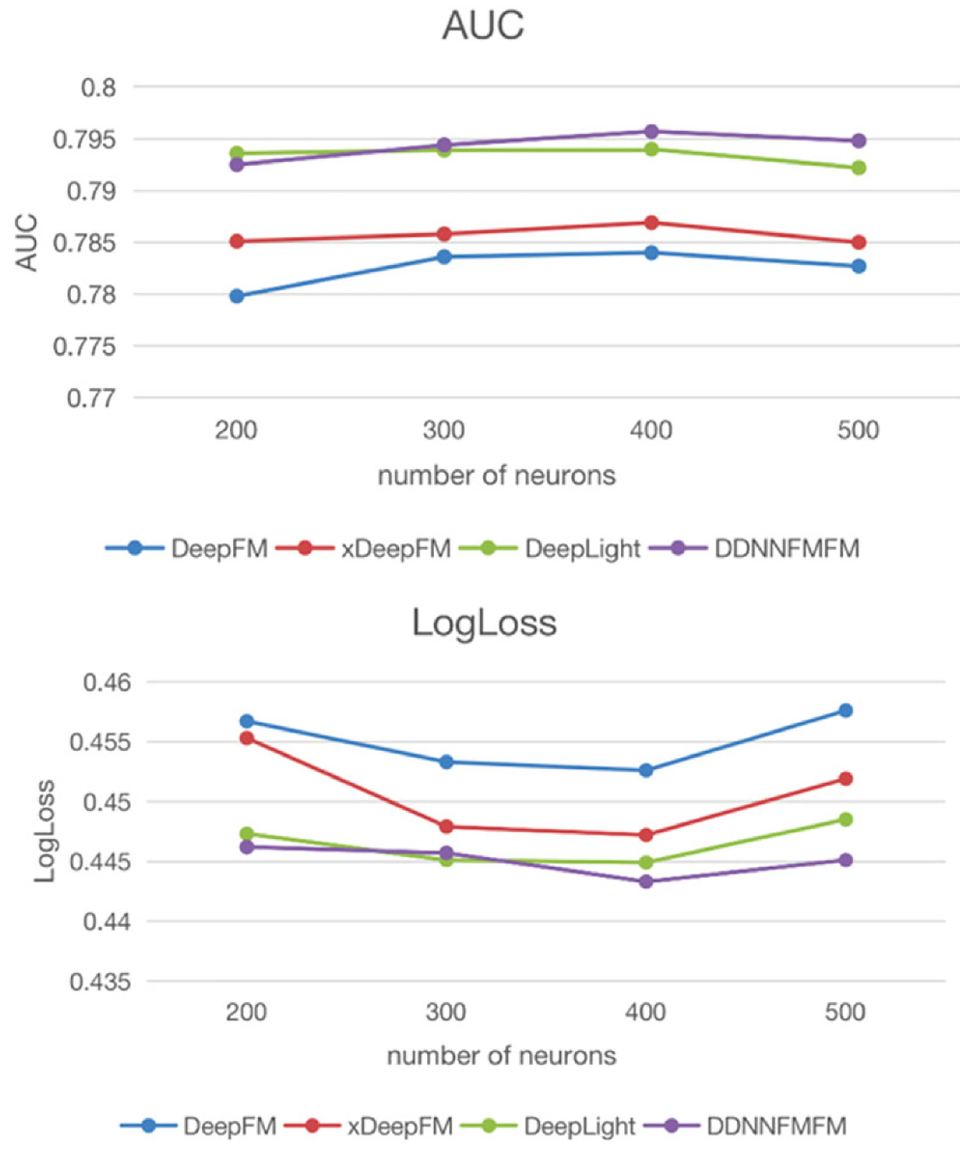
AUC and LogLoss comparison of number of neurons.
Conclusion
This article constructs a deep fusion network, DenseDNN, whose purpose is to deeply fuse features without deepening too many network layers or too many parameters to improve the performance of the model. To further improve the accuracy of CTR prediction model, following the parallel structure of some mainstream frameworks, the shallow model FmFM is combined with the deep model DenseDNN proposed in this article, and it is named DDNNFMFM. DDNNFMFM can automatically learn high-order feature interactions in both explicit and implicit ways, and carry out deep feature fusion while implicitly learning feature interactions, thus improving the accuracy of implicit learning feature interactions with a small cost. In this article, comprehensive comparative experiments are carried out on the Criteo data set and the Avazu data set to prove the effectiveness of DDNNFMFM. Compared with current mainstream deep learning-based models, such as DeepFM, xDeepFM, and DeepLight, DDNNFMFM has a great improvement in performance. In the practical application of advertising recommendation systems with huge data, a small increase in prediction accuracy may significantly increase the online CTR, which verifies the validity of DDNNFMFM in this article. In the future, further research will be done to reduce the complexity of DDNNFMFM by optimizing redundant parameters and network pruning, so as to better apply it to online advertising services.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.