
Abstract
This study evaluates the extent to which fully automated street network modelling can reproduce the analytical outcomes of a hybrid (automated–manual) approach for centrality and accessibility analysis across four morphologically distinct cities: Nicosia, London, Gothenburg, and Madrid. Results show that the geometry-preserving segmentation logic of the automated workflow systematically increases network granularity relative to the continuity-merging rules applied in the hybrid model, producing higher node densities and shorter street segments, particularly in cities with irregular, historically layered street patterns. Despite these geometric differences, angular integration exhibits strong to near-perfect rank correlation between hybrid and automated models across all cases, with agreement increasing at larger spatial radii. This indicates that global configurational structure is robust in automated simplification. Angular betweenness displays lower, though still moderate to high, correspondence, especially at smaller radii, reflecting its sensitivity to over-segmentation and local geometric variation. Spatial autocorrelation analysis reveals that ranking differences are strongly clustered in footpaths in open green spaces and detailed paths in residential areas. However, the differences are more locally confined and diminish at larger radii. Accessibility results further demonstrate scale-dependent divergence: short-range attraction reach and attraction distance estimates align closely between models, whereas discrepancies increase at larger thresholds due to the cumulative effects of finer-grained connectivity and additional pedestrian paths in automated networks. Overall, the findings indicate that automated street network models reliably capture large-scale integration and accessibility patterns across diverse urban contexts, while local, flow-sensitive measures remain more affected by network granularity and path representation. These results support the use of automated workflows for scalable and comparative urban analysis, with targeted manual refinement reserved for contexts requiring high local precision.
Introduction
Urban spatial models have become essential tools for understanding, planning, and managing cities across scales and disciplines (Kitchin, 2014; Miller, 2018). By providing systematic and quantitative means to analyse urban complexity, they support the evaluation of spatial structure and the assessment of impacts arising from changes in physical infrastructure (Batty, 2013; Porta et al., 2006; Røe et al., 2022). Within this domain, street network modelling is fundamental, as it captures urban morphology and spatial organisation, and underpins analyses of movement, accessibility, and spatial interaction. The growing availability of open street network data, such as OpenStreetMap and Overture Maps, together with advances in open-source analytical workflows, has significantly expanded opportunities for large-scale urban analysis and enabled the extension of syntactic approaches to metropolitan and regional contexts (Haklay, 2010).
Despite these advances, street network datasets must be transformed into analytical representations that selectively preserve properties relevant to a given theoretical framework. In space syntax research, this involves constructing segment-based models that retain angular continuity and configurational structure while abstracting away transport-operational detail and cartographic redundancy. The issue is therefore not simplification in a general sense, but the construction of theory-specific models suitable for syntactic analysis (Hillier, 2016; Hillier and Hanson, 1984; Lee, 1973; Lee, 1994). Traditionally, this process has relied on manual refinement to ensure consistency with the theoretical assumptions of syntactic analysis, with simplification choices directly influencing topological, metric, and angular properties of the resulting network. Although a range of automated tools has been developed to address this task, their outputs frequently diverge from manually refined models, which continue to be treated as the analytical reference in practice. At the same time, manual approaches are time-consuming, labour-intensive, and difficult to reproduce, limiting transparency and scalability, while fully automated methods, despite their efficiency and reproducibility, necessitate additional validation to meet analytical requirements.
This tension raises a key unresolved question: to what extent can open, automated procedures for constructing segment-based space syntax models be relied upon to produce syntactically robust representations and how sensitive are their outcomes to differences in scale and urban context? To address this question, the present study compares a hybrid street network model, combining automated processing with targeted manual refinement, with a fully automated network generated using an open-source package. The comparison is undertaken through syntactic analysis using centrality and accessibility measures, representing angular-based and shortest-path interpretations of spatial structure, respectively. The analysis is applied to four cities selected to capture diverse morphological typologies and junction configurations, enabling a systematic assessment of when and how automated simplification diverges from manually edited models and the implications of these differences for urban analytical outcomes. This provides practical guidance on the selective use of manual editing and cleaning. Specifically, it enables researchers and practitioners to determine where, spatially, and at which analytical scales manual intervention can be reduced or omitted without compromising syntactic validity. In addition, the findings contribute to more efficient, transparent, and scalable workflows for street network simplification, supporting the broader application of syntactic analysis at large-scale and across multiple urban contexts. The validity of each model must therefore be understood relative to the analytical framework of angular and metric syntactic analysis, rather than as a general representation of urban street structure.
Related work
In studies of urban form, urban morphology, and space syntax, streets are commonly conceptualised as primary spaces of movement and social interaction rather than merely as transportation infrastructure (Hillier and Hanson, 1984; Koohsari et al., 2019; Maretto et al., 2023; Stavroulaki, 2022, Xing and Guo, 2022; Yamu et al., 2021). Early syntactic approaches relied on manually drawn axial maps, representing the most simplified abstraction of urban space. Over time, this practice has shifted towards segment-based representations derived from street centrelines and transportation modelling datasets, reflecting both conceptual and technological developments in spatial analysis (Omer et al., 2017; Turner, 2007). While centreline-based models retain the spatial presence of streets and roads, they also encode substantial geometric and topological detail associated with real-world transport systems. Although this richness has facilitated the wider adoption of quantitative network-based analyses, it has simultaneously increased the need for simplification to reduce unnecessary geometric complexity and computational burden, while preserving the analytical logic of space-based representations. Consequently, a growing body of work has focused on developing automated methods to transform detailed centreline networks into simplified spatial representations suitable for syntactic analysis (Marshall et al., 2018).
A range of simplification techniques has been proposed to address this challenge, including the Douglas–Peucker algorithm, angular-based merging, and structured workflows such as SIMP. These approaches aim to reduce segment fragmentation and improve consistency with axial logic, offering scalable alternatives to manual mapping (Kolovou et al., 2017; Krenz, 2017; Stavroulaki et al., 2017). Such simplification is a prerequisite for Angular Segment Analysis (ASA), which captures directional changes at junctions and enables flexible parametric exploration through adjustable angular thresholds (Omer et al., 2017; Turner, 2007). As argued by Peponis et al. (2008), fewer direction changes correlate with easier navigation, stronger mental representation, and higher pedestrian flow. Nevertheless, raw road centreline data frequently exhibit fine-grained representation caused by excessive vertices and minor angular deviations, which can distort network structure and analytical results (Dhanani et al., 2012). Although tools such as the Space Syntax Toolkit provide functionality for preprocessing OpenStreetMap-derived networks, they often require substantial manual correction, thereby constraining scalability and reproducibility.
In parallel, a range of automated methods, implemented as coding libraries, GIS plugins, and end-to-end workflows, have been developed to process street networks sourced from open datasets such as OpenStreetMap. These approaches vary in the depth and scope of their preprocessing but commonly address geometric simplification, intersection consolidation, removal of duplicate or parallel edges, treatment of dangling or disconnected segments, and support for automation and reproducibility (Boeing, 2017; Fleischmann, 2019; Sevtsuk & Alhassan, 2025; Simons, 2023; Yap et al., 2023). Empirical studies have shown that uncorrected OSM-derived graphs, characterised by dead ends, redundant vertices, and false intersections, tend to inflate node counts and bias measures of centrality and connectivity (Venerandi et al., 2025; Zhao et al., 2025). By contrast, carefully designed simplification and consolidation strategies can produce more parsimonious networks while largely preserving the underlying distribution of centrality measures (Boeing et al., 2022; Pung et al., 2022). Collectively, this literature highlights that analytical outcomes, such as node degree, shortest-path centrality, accessibility, and gravity-based measures, are highly sensitive to preprocessing decisions, underscoring the need for transparent, well-documented, and theoretically informed network cleaning practices in urban spatial analysis.
Methods
Data
The study adopts a multiple–case study design comprising four cities (Nicosia, London, Gothenburg, and Madrid) selected to represent complex urban environments characterised by diverse morphological conditions. These cases encompass a range of historical cores, street typologies, waterfront conditions, and, in the case of Nicosia, a distinct geopolitical context (Ricchiardi et al., 2024). Together, they provide a robust basis for examining methodological performance across varied urban forms and spatial configurations.
For each case, the spatial extent of analysis was defined using the corresponding Urban Morphological Zone (UMZ). To mitigate boundary and edge effects in network-based analysis, the UMZ was expanded by a buffer of at least 20 km, following established practice in urban spatial analysis (Gil, 2017). This ensured that network metrics were not artificially distorted by truncated connectivity at the study boundaries.
Three primary datasets were assembled for each case study. First, street network models were constructed to represent non-motorised movement systems, with highways and limited-access roads excluded to maintain consistency with pedestrian-oriented syntactic analysis. For each city, official street network datasets were used as the structural base where available, as they provide authoritative coverage of primary streets and main paths. However, because this study focuses on non-motorised movement, these datasets incompletely represent fine-grained pedestrian-accessible links, such as secondary connectors and internal park routes. OpenStreetMap (OSM) was therefore used to supplement missing pedestrian paths in the hybrid workflow. Since OSM already contains the primary streets included in the official datasets, it effectively functions as a more comprehensive superset of the pedestrian network. The automated workflow relies solely on OSM, meaning that both approaches share the same primary network backbone; observed differences therefore stem primarily from procedural modelling logic and the treatment of fine-grained pedestrian links rather than from discrepancies in major street representation. Second, building footprint data were obtained from official and authoritative sources for each city whenever possible. Third, a dataset of points of interest (POIs) was compiled within QGIS through the georeferencing, harmonisation, and curation of datasets sourced from official records. Full details of data sources, preprocessing steps, and analytical workflows are provided in the supplementary materials.
Hybrid workflow
The street network modelling workflow was designed to produce syntactically suitable representations of urban space and consisted of three main stages. First, road centreline data were acquired from the most authoritative source available for each case study. Where high-quality official datasets were accessible, these were prioritised; otherwise, open volunteered geographic information, primarily OpenStreetMap (OSM), was used as a fallback source to ensure completeness and consistency across cases. Second, the raw centreline data underwent automated cleaning and preprocessing to generate a baseline network suitable for space syntax analysis. This stage involved the application of established tools within the QGIS environment, including the Space Syntax Toolkit and the Place Syntax Tool, which support geometry simplification, intersection consolidation, and network structuring in line with syntactic modelling requirements. Third, the automatically processed networks were subjected to manual review and targeted editing to produce a refined hybrid model. The manual refinement stage followed explicit rules derived from segment-based space syntax principles to produce a continuity-preserving representation for angular and metric analysis, rather than a cartographic reproduction. (1) Parallel carriageways were collapsed into single centrelines where they functioned as unified movement corridors and did not imply independent route choice. (2) Consecutive polylines were merged when angular deviation was minor and split when directional change was likely to influence route selection. (3) Complex junctions, including roundabouts, were simplified to single nodes where internal geometry did not represent distinct decision points, and redundant vertices were removed to avoid artificial fragmentation. (4) Pedestrian links were retained when they contributed to through-movement or network permeability, while purely private or non-configurational paths were excluded. (5) Publicly accessible cul-de-sacs were preserved, but spurious dangling segments were removed (Stavroulaki et al., 2020). The aim is to prioritise configurational clarity, angular continuity, and movement relevance over geometric detail, resulting in a rule-governed abstraction consistent with segment-based space syntax modelling. A detailed description of the full workflow, including decision rules and editing procedures, is provided in supplementary materials.
Automated workflow
For the automated workflow, this study prioritised the use of open-source data and methods. Given the diversity of existing packages for street network simplification, each developed for distinct analytical objectives, a set of candidate tools was first identified to select an approach capable of producing network representations that most closely approximate the hybrid model. At a conceptual level, several open-source frameworks were reviewed, including OSMnx, Parenx, Madina, Cityseer, Neatnet, and Urbanity, with particular attention to their support for segment-level angular analysis and explicit dual-graph construction. Evidence from previous comparative studies indicates that more recent frameworks tend to outperform earlier tools in terms of stability and methodological consistency in network preprocessing (Martin Fleischmann, 2026).
Within the scope of this study, three widely used and representative open-source packages were tested: OSMnx, Cityseer, and Neatnet. These tools were selected to reflect complementary strengths, with OSMnx representing a foundational and widely adopted framework for street network extraction and topological simplification, Cityseer demonstrating robust performance across multiple evaluation criteria in prior studies, and Neatnet offering a recent geometry-driven approach to network simplification. For each package, the automated workflow was executed using default parameter settings to ensure a reproducible, non-interventionist procedure. Carriageway consolidation, intersection simplification, vertex reduction, segment definition, and pedestrian inclusion were governed solely by predefined geometric and topological rules, without manual adjustment. Segment boundaries followed the original centreline geometry and embedded consolidation tolerances rather than interpretive continuity judgments, providing a parameter-driven, geometry-preserving counterpart to the continuity-based logic of the hybrid model. Then they were visually inspected to assess their correspondence with the hybrid model in terms of geometric fidelity, network continuity, and suitability for syntactic analysis (see Figure 1). Comparison between automated packages for their proxy to the hybrid model.
Based on this comparative assessment, Cityseer was selected as the primary framework for the automated preprocessing of street networks, intended for both angular (simplest path) and metric centrality analyses. It provides a methodologically consistent pipeline explicitly designed to support both primal and dual network representations. It enables the transformation of street segments into node-based dual graphs while preserving geometric fidelity and angular relationships, which are fundamental to syntactic analyses. This dual capability allows a single cleaned network to be used consistently for both angular and metric measures, thereby reducing ambiguity and methodological divergence across analytical steps.
The remaining tools were found to be less suitable for the specific requirements of this study. Neatnet performs effectively in collapsing transport-oriented artefacts, such as dual carriageways, and in resolving fine-scale geometric irregularities between building frontages, resulting in visually legible centreline networks. However, its geometry-driven simplification is less reliable in open, green, or peri-urban contexts, where generated segments may deviate spatially from their original locations, complicating direct comparison with hybrid or geometry-sensitive syntactic models. OSMnx, while highly effective for acquiring and topologically simplifying OpenStreetMap data and exporting GIS-ready networks, remains limited to primal graph representations and does not support angular or dual-graph centrality analysis. Full detailed code used to generate the network using the three packages is available in the supplementary materials.
Comparing the procedural logics
A comparison between modelling rules, the hybrid, and automated approaches.

Spatial analysis
While different tools can generate/analyse street network models, the centrality and reach analysis was conducted using the Place Syntax Tool within QGIS. This tool integrates all necessary analyses in a single environment and functions as an independent platform to evaluate the two street models. For centrality measurements, we employed angular integration and angular betweenness using multiple radii: 400, 1200, and 2000 m.
For accessibility measurements, we employed two attraction-based methods: Attraction Distance
Evaluation method
To enable a direct comparison of centrality measures between the hybrid and automated network models, a spatial matching procedure was applied following the computation of centrality metrics for each model. For each street segment in the hybrid model, the centroid of the segment geometry was calculated and matched to the nearest centroid of a segment in the automated model. Nearest-neighbour matching was constrained by a maximum search distance of 30 m. This threshold was determined through iterative testing and reflects the expected positional variation between centreline representations in non-motorised street networks derived from the same underlying road data. In practice, centreline offsets between models rarely exceeded this distance, even in cases of wide streets represented by parallel carriageways or bidirectional segments. The use of a fixed distance threshold therefore ensured consistent pairing while minimising erroneous matches. Hybrid segments for which no corresponding automated centroid was identified within 30 m were excluded from subsequent analyses to avoid spurious comparisons. To statistically compare the models’ spatial rankings, we conducted a Spearman correlation test on the centroid centrality rankings, independent of absolute values, to account for differences in the number of street segments between models, which can affect the absolute centrality values. That enables a normalised and scale-independent comparison of spatial importance.
Equations used and comparison methods for each measurement (symbol’s explanation in the supplementary materials).

Results
The following results are interpreted as analytical consequences of two distinct modelling logics, continuity-preserving abstraction and parameter-driven geometry preservation, rather than as differences between more or less accurate representations.
Geometric characteristics
The geometric differences observed between models reflect the contrasting segmentation logics embedded in the two workflows: continuity-based merging in the hybrid model and geometry-preserving segmentation in the automated model. Figure 2 (left) presents the distribution of street segment lengths for hybrid and automated models using boxplots, illustrating the structural differences between the two approaches. Across all cities, hybrid models consistently produce longer median street segments and wider interquartile ranges, indicating greater continuity and reduced fragmentation. This contrast is especially pronounced in Nicosia and Madrid, where the continuity-merging rule in the hybrid workflow preserves extended street alignments by suppressing minor angular deviations that the automated logic retains as separate segments. In London, although both models display broad distributions, the hybrid model still maintains higher median values and greater variance, suggesting improved alignment with axial or continuity-based representations. In Gothenburg, differences between the two approaches are less marked, with comparable medians and overlapping distributions, reflecting the city’s relatively regular street morphology. Comparison between the geometrical characteristics, (left) average length per model, and (right) node density per km.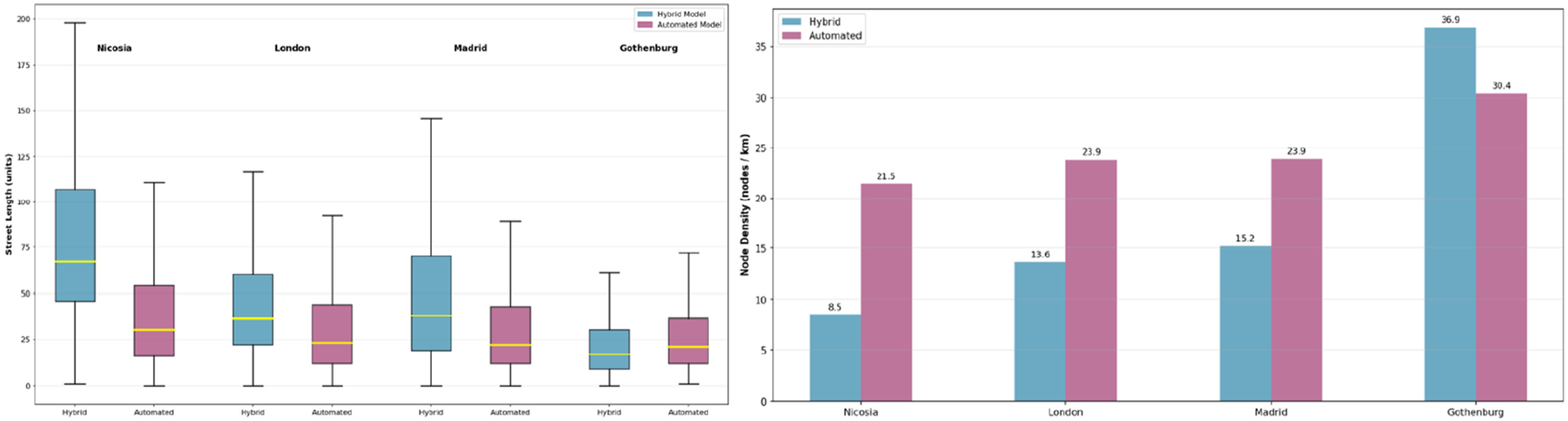
Figure 2 (right) compares node density (nodes/km) where clear and systematic differences are observed between the two modelling approaches. In Nicosia, London, and Madrid, the automated models exhibit substantially higher node densities than their hybrid counterparts. That indicates a higher level of fragmentation in the automated networks, driven by the retention of minor geometric vertices and fine-scale segmentation. Gothenburg constitutes a partial exception: while node density remains higher in the hybrid model (36.9 nodes/km) compared to the automated model (30.4 nodes/km), the gap is smaller relative to the other cases, reflecting the city’s more regular and homogeneous street structure. Overall, the magnitude of these differences varies by urban context, being strongest in cities with more complex historical cores and irregular street patterns (see Figure 3). Difference in representation between the two models across cases.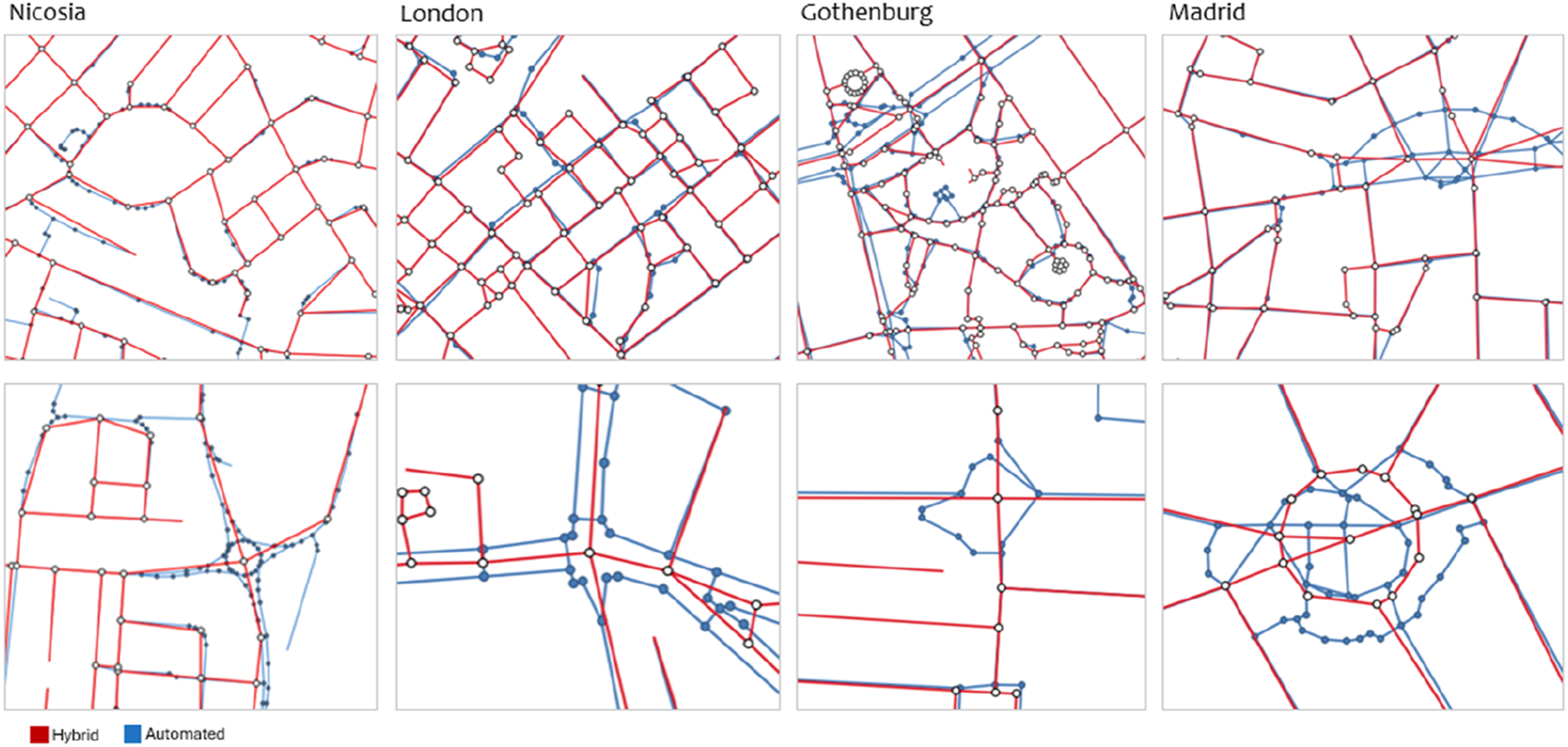
Centrality measurements
These differences in centrality correspondence can be interpreted as analytical consequences of the underlying segmentation rules governing each model. The spearman ranking correlations show that the integration in angular analysis is high and strong across contexts, and the bigger the scale the stronger the correlations. While angular betweenness is relatively lower in correlation values than integration, it is still high and also increases slightly at larger scales. For angular betweenness, correlations are moderate, ranging from 0.51 to 0.82 across cities and radii. The weakest agreement occurs at the smallest radius (ABw400), particularly in London and Madrid (ρ = 0.51, 0.55), where automated fine-grained representations most pronounced. Correlations improve modestly with increasing radius, reaching their highest values at ABw1200–ABw2k, with Nicosia showing the strongest correspondence (ρ ≈ 0.80–0.82). Across all radii, London consistently exhibits the lowest AB correlations, indicating heightened sensitivity of betweenness-based measures to segmentation and local geometric variation in complex street networks. In contrast, angular integration shows strong to very strong correspondence even at the smallest radius (AIw400H) (ρ = 0.62–0.87). For AIw1200H and above, correlations exceed 0.78 in all cases and approach near-perfect agreement in Nicosia and Gothenburg. Notably, even in London angular integration remains highly correlated (see Figure 4). Spearman correlation values between centrality measurement (right), and correlation plot per case showing the distribution across betweenness and integration (right).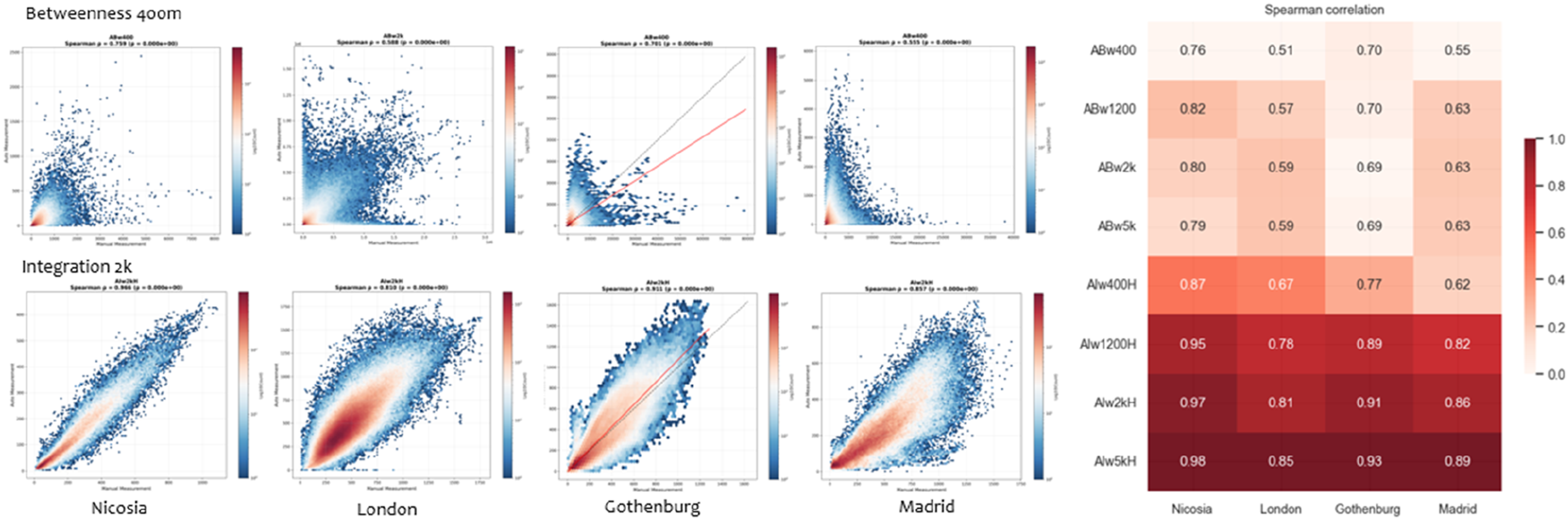
These results demonstrate a clear link between network representation and syntactic outcomes. Geometry-preserving segmentation in the automated workflow increases node density compared with the continuity-merging logic used in the hybrid model, particularly in morphologically complex cities, leading to greater divergence from the hybrid model in local, flow-sensitive measures such as angular betweenness. By contrast, angular integration, especially at larger radii, appears substantially more robust to differences in network granularity, reflecting the relative stability of global angular structure across modelling approaches. This indicates that while automated workflows can reliably capture large-scale spatial integration patterns, caution is required when interpreting local betweenness and movement-related metrics derived from highly segmented automated networks.
Spatial autocorrelation
To better understand ranking differences, especially at smaller scales like 400 m, we used Global Moran’s Index to evaluate spatial autocorrelation in the differences between the two models’ rankings (Dubé & Legros, 2014). Near-zero p-values across all variables and scales indicate statistically significant spatial clustering in the differences of Angular Integration (AI) and Angular Betweenness (AB) rankings. High Moran’s I values for AI (0.74–0.89) show that divergence in integration rankings is spatially structured and not random, with clustering evident from local (400 m) to broader scales (5000 m) (see Figure 5). Mapping disparities across models at 400 m and 5 k scale, showing the regularity from local to outer city sides.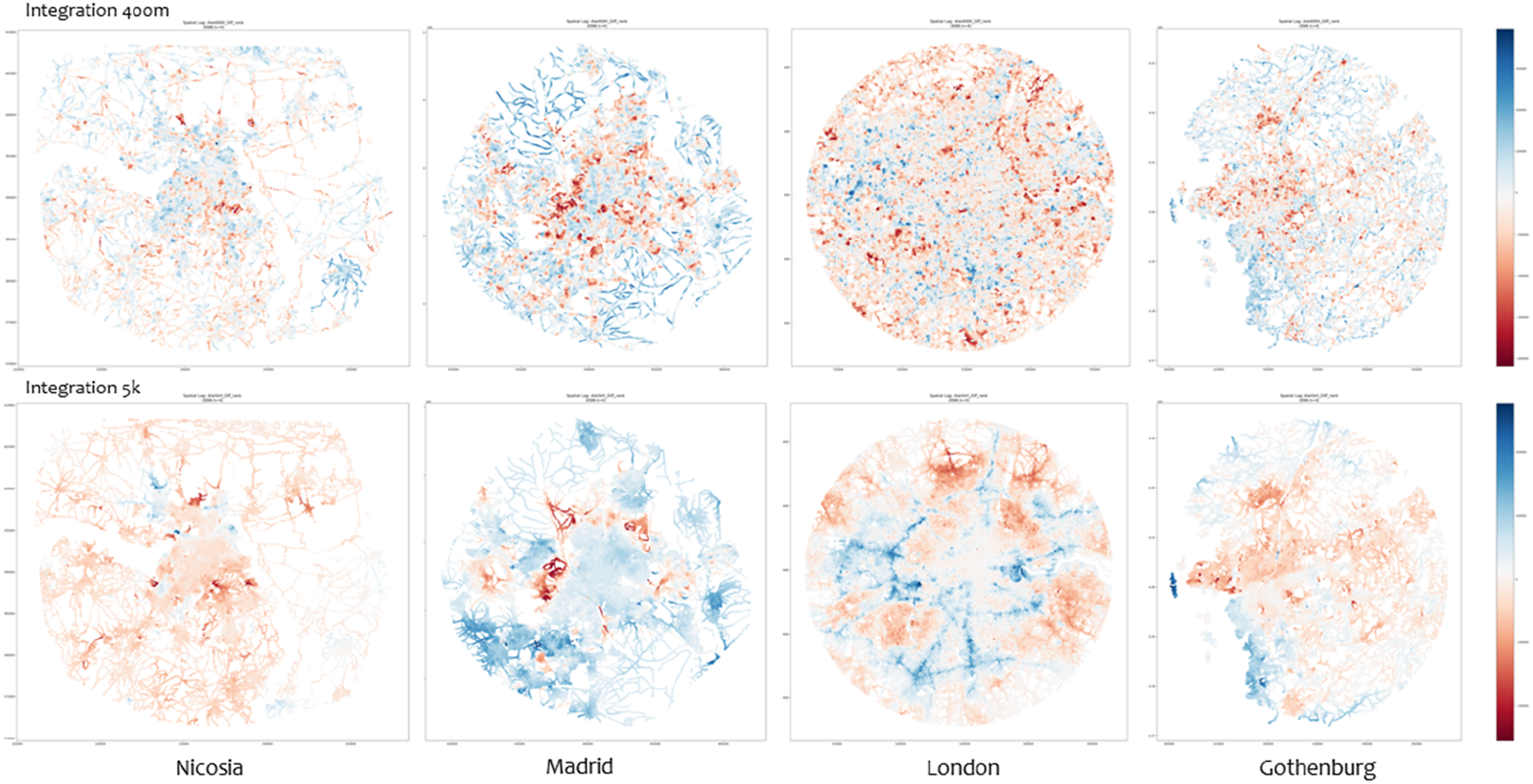
In contrast, angular betweenness exhibits only moderate spatial autocorrelation at smaller radii (400–1200 m), with Moran’s I values declining substantially at larger scales. This indicates that differences in betweenness rankings are more locally confined and less spatially persistent than those observed for integration. The reduced clustering at larger scales suggests that betweenness discrepancies are driven by fine-scale geometric and topological variations rather than by broader structural differences in the network.
The spatial clustering of ranking discrepancies corresponds to areas where the two procedural logics diverge most clearly, particularly in the treatment of fine-grained pedestrian connectors and residential dead ends. Figure 6 shows the 400 m radius, where the highest concentration of divergent locations is observed. Across all case-study contexts, two recurring spatial patterns emerge. First, pronounced discrepancies occur within large urban parks and green spaces, where variations in the representation of pedestrian paths between the two models lead to differences in local connectivity. Second, clusters of divergence are evident within residential areas, where the treatment of certain streets as connected in one model and as dead ends in the other produces contrasting local rankings. These findings highlight that ranking differences are not uniformly distributed across the network but are concentrated in specific spatial settings associated with fine-grained pedestrian connectivity and residential street structure. Close-up of the areas with the largest differences in ranking (top for integration, below for betweenness).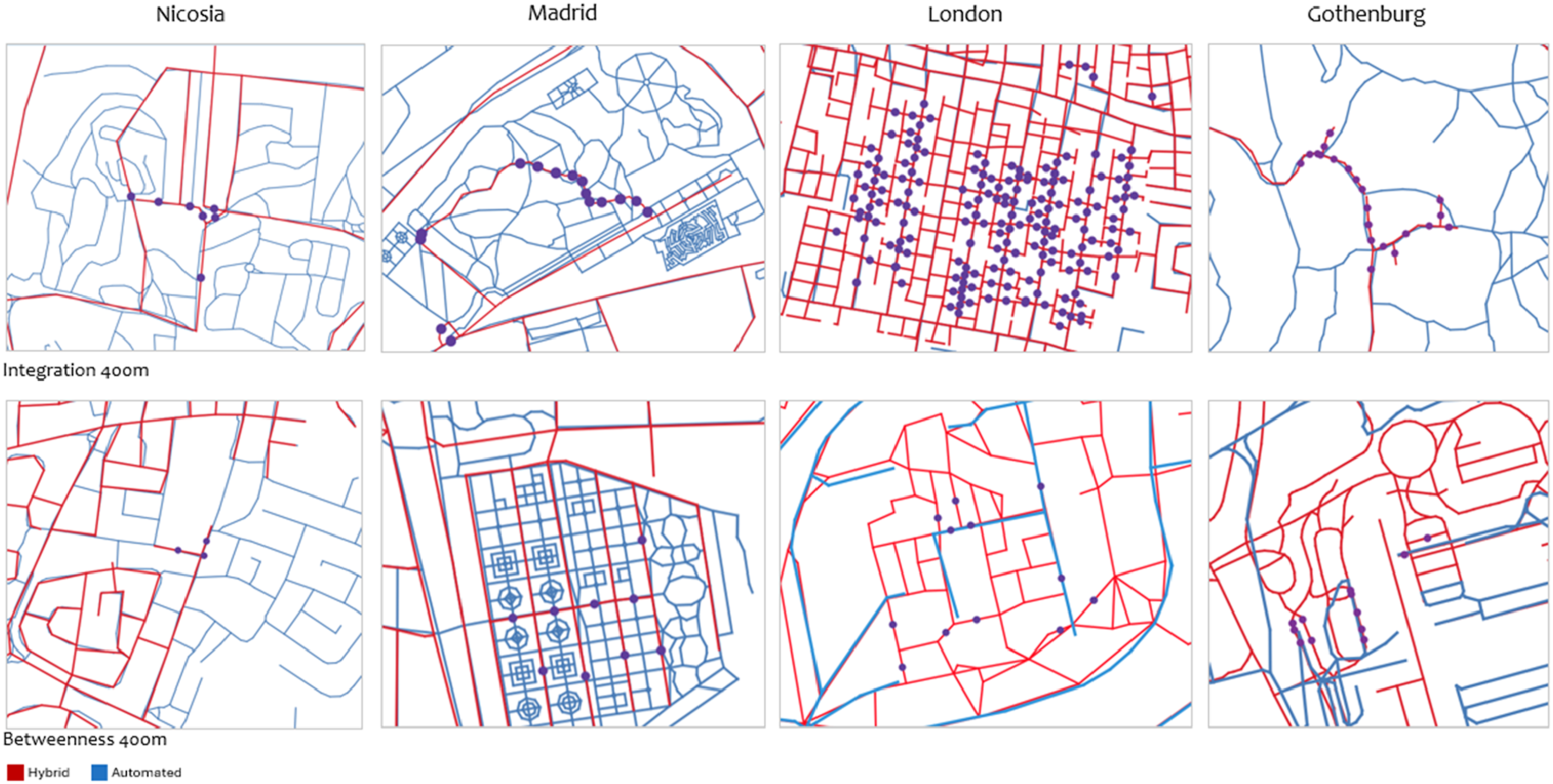
Accessibility measurements
Figure 7 extends the comparison between hybrid and automated models by reporting agreement differences derived from Bland-Altman analyses for Attraction Reach (left) and Attraction Distance (right), disaggregated by destination type and spatial scale (400 m, 1200 m, and 2000 m). Values represent mean differences between the two models, with positive values indicating higher estimates in the automated model relative to the hybrid representation. For Attraction Reach, the results reveal a clear scale-dependent pattern. Agreement between models is high at the smallest radius (400 m), where mean differences are close to zero across most destination types and cities, indicating near-equivalent reach estimates. As the radius increases, discrepancies grow systematically, particularly at 2000 m. These findings indicate that while both models capture local accessibility in a comparable manner, the geometry-preserving inclusion rules embedded in the automated workflow expand cumulative reach at larger radii relative to the continuity-filtered hybrid model, reflecting the increasing effect of finer-grained connectivity and supplementary paths present in the automated representation. Matrices (left) and plots (right) for attraction reach and distance differences.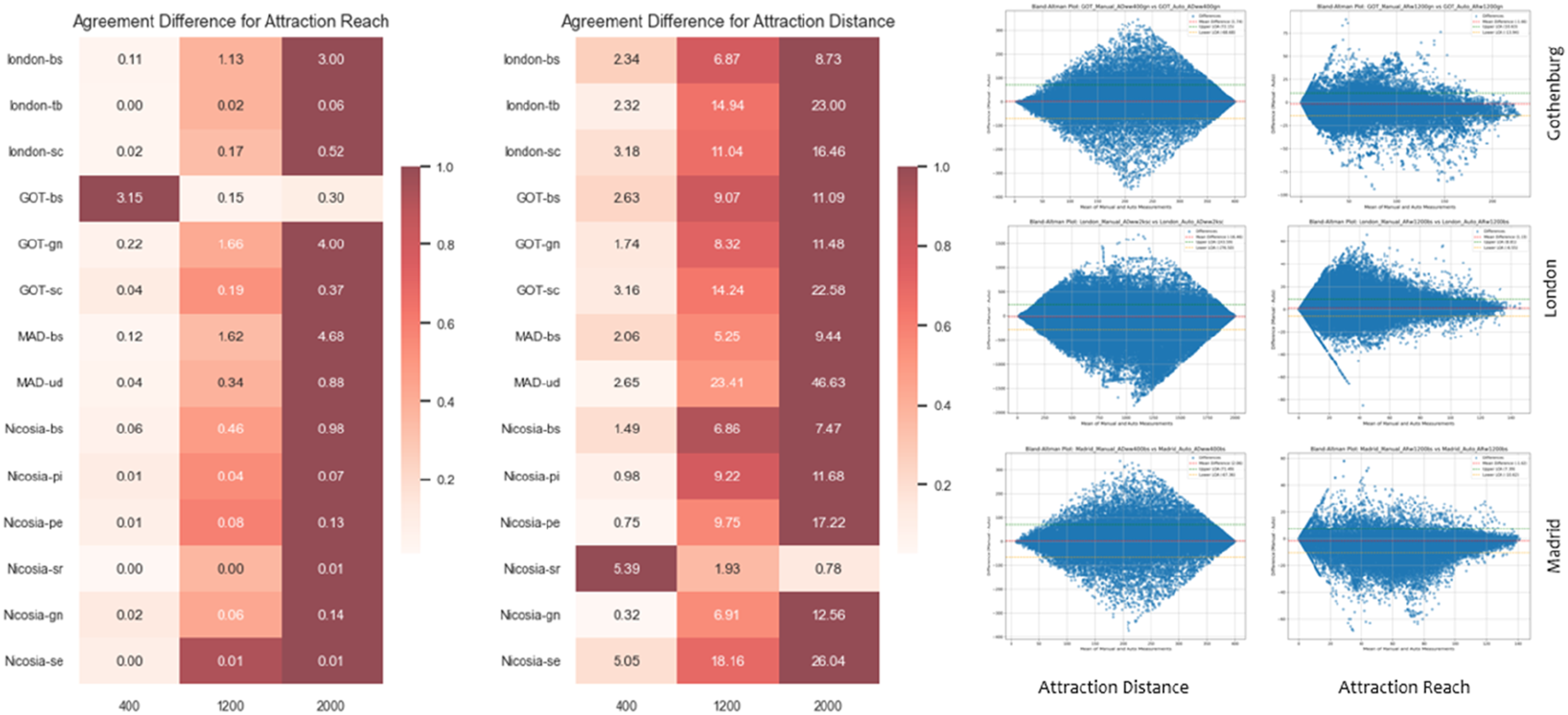
A comparable scale effect is observed for Attraction Distance. At 400 m, mean distance differences remain relatively small across all destination types, suggesting strong agreement in short-range travel distance estimation. However, divergence increases markedly at 1200 m and becomes substantial at 2000 m, with differences exceeding 20 distance units for several destination categories. In some cases, the automated model produces shorter effective distances, while in others it enables access to destinations that fall beyond the hybrid model’s reach, resulting in larger overall discrepancies. The widening spread of agreement at larger scales further indicates increased variability in how the two models represent longer-distance connectivity.
Discussion
The observed differences in geometry between the hybrid and automated models are strongly conditioned by street typology and urban morphology. Cities characterised by more regular, non-organic layouts (such as Gothenburg) exhibit a higher degree of geometric alignment between the two modelling approaches. In such contexts, the automated workflow encounters fewer conflicts in simplifying geometry, as streets tend to follow straighter alignments and junctions are more orthogonal and standardised. Although a city that has a complex transport network in functional terms, its structural regularity allows automated preprocessing to preserve continuity with relatively limited over-segmentation. As a result, discrepancies between the hybrid and automated models are smaller than in cities with more irregular spatial structures.
By contrast, cities with historically layered urban cores and heterogeneous street typologies (such as Nicosia, London, and Madrid) show substantially greater divergence between models. In these cases, nonlinear street geometries, irregular junction configurations, and frequent angular shifts lead automated workflows to introduce higher levels of segmentation, producing denser node counts and shorter street segments. These findings indicate that morphological complexity amplifies the segmentation divergence resulting from geometry-preserving rule application associated with automated simplification. Importantly, however, this pattern holds independently of the overall size or density of the network and is instead closely tied to local street form and junction geometry.
Across all cases, an additional source of divergence arises from the inclusion or exclusion of pedestrian paths that are not part of the primary street network. The presence of such paths depends both on the underlying data source and, in the case of the hybrid model, on modelling decisions made during manual refinement. These paths typically occupy a secondary or tertiary position in the urban network, often representing informal or semi-formal pedestrian connections between buildings or within open and green spaces. While they do not alter the primary structural backbone of the city, their inclusion can introduce local differences in connectivity that affect certain analytical outcomes.
Despite these structural differences, the results demonstrate that the main spatial structure of each city is generally well captured by the automated model. For angular integration, in particular, geometry-preserving segmentation appears to have limited impact on analytical outcomes. The high correlations observed between hybrid and automated models indicate that, in most cases, automated preprocessing yields results that are nearly equivalent to those obtained through manual refinement. From a practical perspective, the analytical differences attributable to continuity-based rule intervention (manual) are often disproportionate to the time and labour required, especially when integration values converge at rates approaching near-identical outcomes.
Angular betweenness, by contrast, is more sensitive to both sources of divergence. The presence or absence of specific pedestrian paths plays a secondary role, primarily affecting locations at the periphery of the network where a street may be connected in one model but treated as a dead end in the other. The dominant factor, however, remains geometry-preserving segmentation. Because betweenness is highly sensitive to small angular changes and segmentation, the increased fragmentation in automated models alters shortest-path routing and flow distribution more noticeably than integration measures. Nevertheless, even in these cases, the discrepancies observed remain within an acceptable range, suggesting that automated models still provide a reliable approximation for comparative and large-scale analyses.
For accessibility measures based on metric distance, the effects of geometry-preserving segmentation largely diminish, as these analyses depend primarily on distance rather than angular continuity. Here, the principal source of difference between models lies in the presence or absence of proximate pedestrian paths. In automated models, the availability of fine-grained segments can shift the starting point of accessibility calculations to a nearer location, resulting in shorter measured distances to destinations. Conversely, in the hybrid model, the absence of such links may increase estimated distances or exclude destinations that fall just beyond a threshold. These mechanisms can lead to systematic underestimation or overestimation of accessibility, often favouring the automated model in densely built or internally connected areas (see Figure 8). Cases where the automated model (blue lines) over- and underestimates values (the hybrid are black lines) in Nicosia.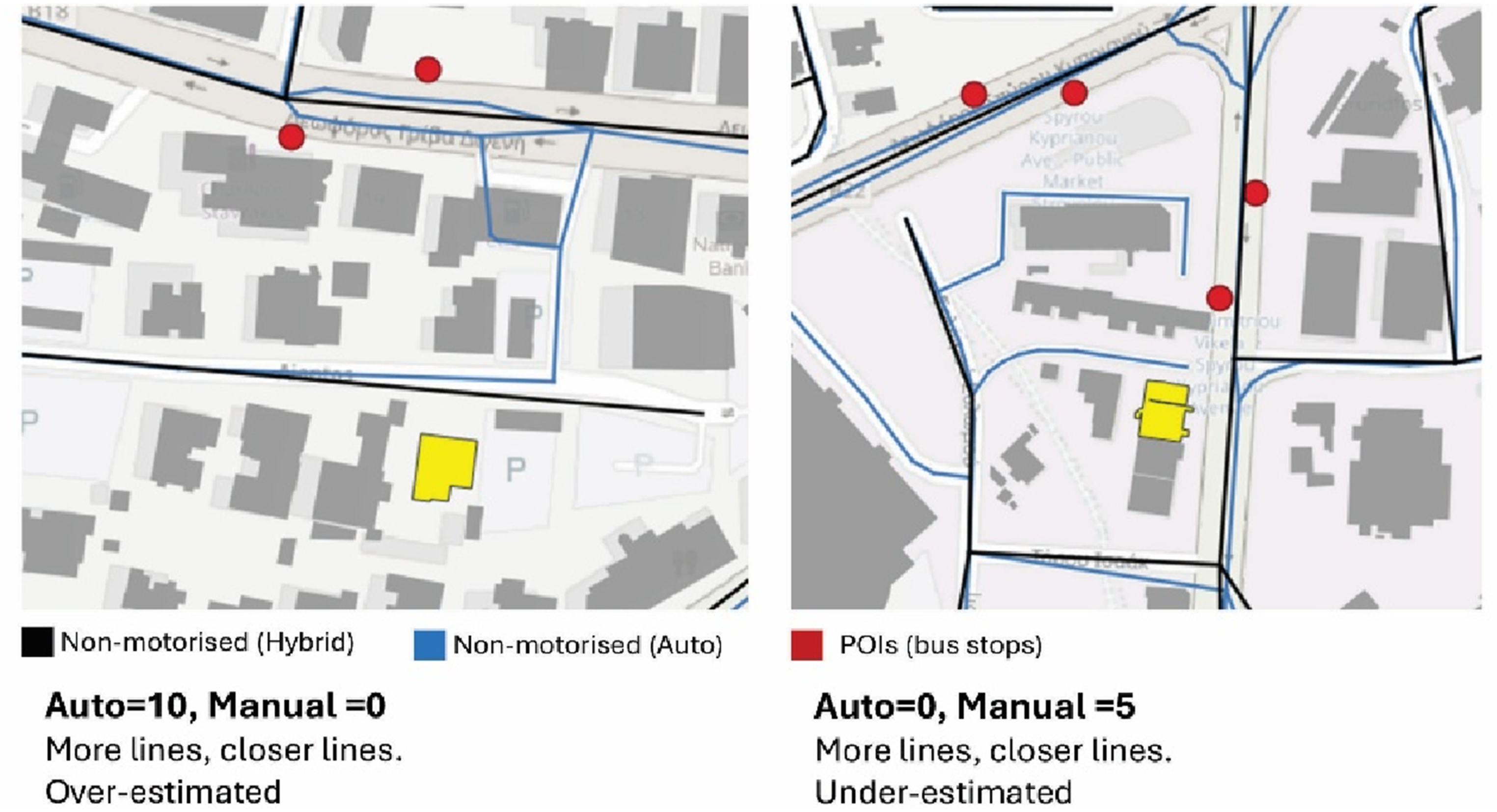
These effects are also scale-dependent. At smaller radii, only a limited number of additional paths influence accessibility outcomes, resulting in modest differences between models. As the analysis radius increases, however, a growing number of fine-scale links fall within reach, amplifying their cumulative impact and increasing divergence between hybrid and automated results. Consequently, the inclusion or omission of detailed pedestrian paths plays a significant role in shaping both local accessibility estimates and overall variance in reach-based measures. This highlights the importance of carefully considering network granularity and data completeness when interpreting accessibility results, particularly at larger spatial scales.
In analyses of global configurational structure (e.g., angular integration or large-scale accessibility), automated workflows closely approximate manually refined models, rendering additional manual editing of limited benefit. In contrast, local flow-sensitive measures, particularly angular betweenness, are more sensitive to segmentation and pedestrian path representation; targeted hybrid refinement may therefore improve reliability in such cases. Differences are most pronounced at smaller radii (e.g. 400 m), supporting hybrid modelling for neighbourhood-scale or site-specific studies. At larger radii (≥1200 m), divergence diminishes, and automated preprocessing is generally sufficient for metropolitan or comparative analyses. Morphological context also matters in regular, grid-based cities; automated segmentation aligns closely with hybrid models, whereas in complex or historically layered environments, selective manual intervention may be warranted for locally sensitive metrics. The two approaches should be understood conditionally rather than hierarchically: automated workflows are appropriate for scalable and comparative research, while hybrid review/refinement remains valuable where fine-grained local precision is required.
Limitations
While this study provides a systematic comparison between hybrid and fully automated street network models, several limitations should be acknowledged. First, the analyses are limited to angular centrality measurements, and selected metric accessibility measures; since alternative syntactic, flow-based, or behavioural metrics may respond differently to variations in network preprocessing and could yield additional insights. Second, the results are inherently dependent on the quality, completeness, and consistency of the underlying street and pedestrian datasets. Differences in data sources, particularly regarding the representation of fine-grained pedestrian paths, may introduce biases that are independent of the modelling approach itself. Third, the study focuses on segment-based network representations and does not evaluate alternative abstractions, such as axial or hybrid representations, which may interact differently with automated simplification workflows. Finally, although the selected case studies capture a range of urban morphologies, the limited number of cities restricts the generalisability of findings to other contexts, including informal, rapidly evolving, or non-European urban environments. Future research could address these limitations by extending the range of analytical measures, testing additional urban contexts, incorporating sensitivity analyses of preprocessing parameters, and validating results against empirical mobility data.
Conclusion
Overall, the findings demonstrate that fully automated street network models provide a robust and generally reliable basis for syntactic analysis across a range of urban contexts. The strongest alignment between automated and manually refined models is observed in cities characterised by grid-based or predominantly linear street patterns, where geometric regularity limits over-segmentation and ensures close correspondence in network structure. In more organic and historically evolved urban fabrics, automated models still exhibit strong positive agreement with hybrid representations, particularly for angular integration at larger spatial scales, indicating that global configurational properties are captured effectively despite local geometric discrepancies. While angular betweenness consistently shows lower correspondence than integration, this reduction must be interpreted in light of the substantial time and labour required for manual refinement: at local scales, the analytical gains achieved through manual editing are relatively modest compared to the effort involved. Nevertheless, the results also indicate that caution is warranted when applying automated workflows to fine-grained, local-scale analyses, where geometric simplification and the inclusion or omission of pedestrian paths can have a disproportionate influence on flow-based measures. Taken together, these conclusions support the use of automated preprocessing as a valid and efficient alternative to manual network refinement for large-scale and comparative studies, while highlighting the continued value of targeted manual review in highly complex or locally sensitive urban environments.
Data statement
All datasets used in this study were derived from open-source sources, as detailed in the Supplementary Materials. The street network, building footprints, and points of interest employed in the automated workflows are fully open and publicly accessible. The hybrid (manually edited) street network models for London and Madrid constitute the only exceptions; these were developed through manual refinement for research purposes and are not fully open due to reuse constraints. These datasets can be made available upon reasonable request for non-commercial academic use.
Supplemental material
Supplemental material - Automated versus hybrid street network modelling for centrality and accessibility analysis
Supplemental material for Automated versus hybrid street network modelling for centrality and accessibility analysis by Walid Samir Abdeldayem, Ilaria Geddes, Ahmed Hazem Eldesoky, Ioanna Stavroulaki, Gareth Simons, Meta Berghauser Pont, and Nadia Charalambous in Environment and Planning B: Urban Analytics and City Science
Footnotes
Acknowledgement
The author gratefully acknowledges Kayvan Karimi, Ed Parham, Valentina Marin, and Nick Bristow of Space Syntax Limited for their insightful discussions and generous support throughout the development and application of the London Model. Their expertise and engagement significantly enriched the analytical framework and interpretation of the findings.
ORCID iDs
Author contributions
W.S.A., I.G., N.C., A.H.E., M.B.P., and I.S., conceptualised the study. W.S.A., A.H.E., I.S., and I.G. designed and developed the methodology. W.S.A. conducted formal analysis with assistance from A.H.E. W.S.A. created the visualisations. W.S.A. conducted the investigation process. G.S. provided the supporting algorithms. I.G. and G.S. provided the study models. W.S.A. and I.G. wrote the original draft. W.S.A., I.G., I.S., A.H.E., M.B.P., N.C., and G.S. reviewed and edited the manuscript. N.C. acquired the funding and supervised the entire project.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was produced within the project ‘Twin2Expand: Twinning towards research excellence in evidence based planning and urban design’, which has received funding from the European Union’s Horizon Europe Research and Innovation Programme under grant agreement number 101078890 and from the UK Research and Innovation (UKRI) under the UK government’s Horizon Europe funding guarantee under grant numbers 10052856 and 10050784.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article
Data Availability Statement

| Dataset | DOI |
|---|---|
| Nicosia’s non-motorised segmented street network – manually edited | 10.5281/zenodo.16406543 |
| Nicosia’s motorised segmented street network – manually edited | 10.5281/zenodo.16410668 |
| Nicosia schools | 10.5281/zenodo.16410567 |
| Cyprus citizen and service centres, and post offices | 10.5281/zenodo.16409080 |
| Cyprus bus stops and bus routes | 10.5281/zenodo.16599000 |
| Nicosia’s non-motorised segmented street network – automated | 10.5281/zenodo.16411132 |
| Nicosia’s motorised segmented street network – automated | 10.5281/zenodo.16411188 |
| Cyprus buildings | 10.5281/zenodo.16600733 |
Additional information
Supplementary material: The online version contains supplementary material.
Supplemental material
Supplemental Material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.