
Abstract
Empirical studies on the geography of digital economic activities are currently lacking. This is due to digital economic activities remaining largely undefined in official economic statistics. This paper introduces a novel empirical pipeline to examine the spatial characteristics of the digital economy while addressing the challenges of data missingness. Firstly, we identify digital economic activities by using commercial websites and Natural Language Processing (NLP). Secondly, we study the geographical distribution of digital firms, as well as the mechanisms causing this distribution, through considering firms as the realisation of a latent spatial Poisson Point Process. In doing so, this paper enhances our understanding of urban processes by combining data created through advanced NLP techniques with spatial econometrics. Focusing on the case of London, UK, we identify digital economic activities by applying contextualized weak supervision to text scraped from firms’ websites. By doing so, we showcase how websites can complement, or even substitute official economic statistics, leading to a more complete understanding of the digital economy. Using this data, we proceed to inferring the causes of firms’ locations in space: indeed, firms can locate in space for exogenous reasons, such as the presence of infrastructure and public incentives, or endogenous reasons, such as knowledge spillovers. We base our analysis on estimating the inhomogeneous K-function, quantifying the spatial dependency between firms. Our study reveals a tendency for digital firms to cluster due to the importance of in-person interactions that cannot be explained simply by exogenous factors such as the attractiveness of the location. To our knowledge, the paper provides the first empirical evidence uncovering the persisting relevance of space and face-to-face interactions in the digital economy, prompting reflections on the geographical footprints of digitality.
Introduction
The digital economy is often portrayed by both mainstream media and senior technology figures as having the ability to empower traditionally marginalised entrepreneurial actors (Duffy and Hund 2015; Dy 2019). This is mostly due to longstanding assumptions about the neutrality and ‘placelessness’ of the digital, whereby the digital is seen as an affordable and universally accessible entrepreneurial setting (Dy et al., 2017; Leszczynski and Elwood 2015; Wahome and Graham 2020). Such ‘techno-optimistic’ claims found a recent revival during the COVID-19 pandemic, leading analysts to suggest that the rapid adoption of digital technologies, driven by their capacity to enable remote work, could bolster digital business models and reduce the significance of geographical proximity. While the clustering of economic activities is a topic of intense interest among academic circles and policy makers, the geographical distribution of digital economic activities remains surprisingly unclear. Indeed, the agglomeration of firms has been usually analysed for traditional manufacturing industries. There is one clear reason behind this enduring concentration on manufacturing industries: a substantial lack of data identifying digital firms (Nathan and Rosso 2015; Papagiannidis et al., 2018).
Gaining an understanding of whether the Internet and digitisation could counterbalance the urban ad-vantages associated with spatial proximity would play a crucial role for the economics literature, as well as for policymakers. As a matter of fact, inter-regional economic inequality in Europe has increased over the last decades (Iammarino et al., 2019). While most major cities are experiencing growth, many rural areas and smaller cities are grappling with economic stagnation or even decline. As a response to this trend, policymakers are advocating for investment in broadband infrastructure and digitisation, hoping that these measures will help offset the lack of agglomeration benefits in rural regions. The idea is that by reducing the significance of spatial proximity, digital technologies could potentially reduce inter-regional inequality. In light of these debates, discovering the spatial phenomena at work in the digital economy would provide a clear understanding of the role of cities versus the role of the Internet for entrepreneurial ecosystems. Such findings would also help demystifying discourses on the equalising power of the Internet, contributing to the ever growing literature on digital inequalities. As we previously noticed, providing such insights has been nearly impossible to date due to a substantial data missingness. Indeed, micro data on ‘digital firms’ – whatever their definition might be – is non-existent. Simply put, without better measures than current industrial classification taxonomies, researchers and policymakers lack the tools to fully understand the geography of the digital economy.
In recent years, increasing attention has been devoted to the drawbacks of existing industrial classification taxonomies for the improvement of business censuses (Dalziel et al., 2018). Most empirical proposals tapped into applying unsupervised Natural Language Processing (NLP) techniques to unstructured data sources such as commercial websites and firms’ social media profiles. Indeed, such new ways of classifying firms can provide us with a more precise identification of digital companies. This type of data can in turn be used to understand various characteristics of firms, between which they way they colocate (or not) in space. The availability of such micro-geographical data can therefore pave the way to the study of the distribution of firms and provide a quantitative base for industrial policy efforts. According to Haefner and Sternberg (2020, p. 10), this research gap ‘is a perfect arena for empirically skilled economic geographers’.
Given the above considerations, the main objective of this study is to move from theoretical intuitions about the benefits of clustering in the digital economy to a solid body of empirical evidence through the means of NLP. Specifically, we aim to answer the question: do digital firms exhibit patterns of true or apparent contagion? To achieve this, we proceed in three steps. First, we adopt a contextualized weak supervision framework to identify firms in the digital economy, addressing the data scarcity issue. In doing so, we leverage text extracted from websites as underutilized sources of urban data. Second, we explore the spatial features of the digital economy using extant methods from the spatial econometrics literature. Notably, we investigate whether digital economic activities exhibit clustering and how these patterns compare to those of ‘non-digital’ activities. Third, we contribute to discerning the motivation behind such clustering patterns. This is because firms could cluster due to both endogenous reasons, such as the need to interact closely, and exogenous reasons, such as to exploit favourable urban infrastructure. To do so, we apply an inhomogeneous transformation of Ripley’s K function allowing us to discern how digital urban production benefits from its urban context. Specifically, the distribution of firms in space can be modelled as a point pattern: the realisation of a stochastic point process within a bounded region (Diggle 2013). Within this framework, firms are considered clustered when their spatial concentration exceeds that of a benchmark distribution.
Our findings not only show that digital economic activities cluster similarly to non-digital ones but also reveal that this clustering stems from a genuine need for offline, face-to-face interaction. While these methods have been widely applied to micro-scale data in ecology, their use in analysing firm demography is more recent (Arbia et al., 2012; Duranton and Overman 2005; Marcon and Puech 2010). This analysis provides a novel perspective on economic spatial dynamics and offers data-driven policy insights, highlighting which factors may be less influential than previously assumed in driving digital economic growth and supporting entrepreneurial ecosystems. Methodologically, our approach to answer the research question, which relies on features extracted from web data, requires integrating two distinct fields: Natural Language Processing (NLP) and Spatial Econometrics. We aspire this multidisciplinary approach to encourage further expansion of the human geographers’ methodological toolkit (Fu 2024).
The remainder of the article is structured as follows. In Section 2, we provide an historical outlook on previous theoretical and empirical work on the implications of ICTs adoption for the clustering of firms in space. We highlight how, after dying down in the early 2000s, the COVID-19 pandemic revived these questions. Following the discussion of the literature, in Section 3 we describe in detail our dataset construction pipeline and the NLP methodology used for it. In Section 4, we examine the application of the inhomogeneous transformation of Ripley’s K-function to better understand the spatial dynamics of firms. Additionally, we explore how the proposed inferential framework for the inhomogeneous K-function can help disentangle whether the spatial distribution of firms is driven by exogenous or endogenous factors. In Section 5 we provide our empirical results showing that digital firms are still subjected to agglomeration forces and substantially providing the first empirical demystification of the long-standing narrative about the irrelevance of geography for digital enterprise. Section 6 summarises our results and lays out ideas for future work. In this same section we conclude with a discussion on the policy and methodological implications of our findings.
Industrial clustering and the digital economy
There is no unanimous definition of the digital economy. Among others, the most widely used concepts describing it are information economy, the knowledge economy and the weightless economy (Quah 1999). Within the literature, scholars in industrial production management and microeconomics have traditionally defined digital firms as those that trade only in intangible, electronic goods and services (Brynjolfsson and Kahin 2002). However, the digital economy has evolved significantly since then. With the pervasive integration of digital technologies across sectors, the distinction between digital and non-digital firms has become increasingly blurred. Today, digital inputs—ranging from cloud infrastructure to data analytics – are embedded in the operations of virtually all industries. As highlighted by Ash et al. (2018) and Capello and Lenzi (2021), it is now difficult to imagine any business that does not depend, in some form, on digital tools or infrastructures.
In this paper, we adopt a broader definition of the digital economy, one that emphasizes the centrality of intangibles (Corrado et al., 2022; Haskel and Westlake 2017). This perspective reflects a shift in the structure of production, where value creation increasingly relies on non-physical assets such as software, design, and intellectual property. While online retail of physical goods is often seen as a key component of the digital economy, identifying all businesses involved in e-commerce, whether directly or through intermediaries, falls beyond the scope of this study. Indeed, the main technical virtue of digital goods within our definition is their unlimited tradability and versatility, making them unaffected by transportation and reproduction and increasing supply-chain efficiency (Goldfarb and Tucker 2019). Discussions on the implications of the digitisation of capital on economic geography have a long history, mainly wondering whether distance still matters in an economy where transportation costs are near zero.
The spatial implications of digitalisation
Since the dawn of the Internet, there has been no shortage of predictions that the rise of digitisation would shape-shift global economic geography. Such predictions stem from the assumption that the digital trans-formation has the potential to expand opportunities, not only in regard to who can engage in innovation or entrepreneurship but also in terms of where individuals can make valuable contributions from (Nambisan et al., 2019). Arguments from more than 20 years ago, primarily led by the works of Sassen (1994), Cairncross (2002) and Castells (1996), emphasised the power of the Internet, arguing that we should expect ICT-related firms to locate without a significant spatial structure and consequently, we should prepare for the unavoidable disruption of the traditional economic role of cities. These predictions were based on the idea that, with the increased ability to communicate in real time with any location worldwide, the exchange of knowledge and information would rely less on physical flows within geographical spaces. Within these works lie media-worthy expressions such as ‘the end of geography’, and the ‘death of distance’. In such a cyber-utopianist wave, Negroponte (1995) even predicted the ‘end of the city’. Technology writer Gilder (1995) further claimed that cities were just ‘leftover baggage from the industrial era’ and that the.
Internet revolution would strongly implied moving towards Negroponte (1995)’s predictions. Perhaps even more relevantly for the purpose of this paper, Mitchell (1996) referred to the Internet as being ‘fundamentally and profoundly anti-spatial’. Similarly, through a more philosophical lens, Michell (2002) indirectly referred to the cyber-space as something inherently belonging to metaphysics. 1 , 2
Concerning the geographical opportunities offered by the digital, if we neglect the unevenness of telecommunications access, informational goods and services may be regarded as Weber’s ubiquities (Weber 1965). These informational ubiquities encompass a diverse array of products and services that constitute a signifi-cant portion of the global economy. Such goods are readily accessible nearly anywhere on the planet, often even while travelling, as long as there is access to necessary computer equipment and broadband connectivity. Some examples include software, games, remote telephone consultations, marketing, various forms of digital design such as architectural or manufacturing projects, e-learning solutions, online retail, and a wide range of financial products. Given the ubiquity of digital economic products, it’s unsurprising that scholars have begun questioning whether those transforming and trading digitized information must also be ubiquitous in space. Building on this idea, many politicians now advocate for building better connectivity infrastructure, enhancing skills, and furthering digitization, believing these efforts could compensate for the lack of agglomeration externalities in rural areas. By reducing the importance of spatial proximity, the goal is to mitigate inter-regional inequality. In this context, Friedman (2002) argued that the expansion of trade, the internationalization of firms, and the rise of networking would create a ‘flat world’ – a level playing field where individuals are economically empowered regardless of their location.
The validity of all the arguments presented until this point was empirically disproven by a concomitant renewed interest in economic agglomeration, following the footprints of Marshall (1890). These studies demonstrated the existence of concentration phenomena in a wide range of sectors, such as information technologies (Saxenian 1996) and biotechnologies (Feldman, 2003). Echoing such findings, Florida (2002) wrote that ‘never has a myth been easier to deflate’, and that ‘not only do people remain highly concentrated, but the economy itself continues to concentrate in specific places’.
According to a consistent bulk of literature, one should expect digital firms to be spatially concentrated within big metropolitan areas. Such school of thought rejects the notion that rural regions will ‘level up’ through increased digitisation. Coherently with this line of scholarship, Rodr´ıguez-Pose & Crescenzi (2008, p. (2) stated that ‘numerous forces are coalescing in order to provoke the emergence of urban mountains where wealth, economic activity, and innovative capacity agglomerate. The interactions of these forces in the close geographical proximity of large urban areas give shape to a much more complex geography of the world economy’. Indeed, while digitisation has made it easier to transport goods and knowledge across long distances, the transmission of person-related and context-dependent tacit knowledge still relies heavily on face-to-face interaction (Morgan 2001). As a result, corporate learning predominantly takes place through trust-based personal encounters, often in locations characterised by a critical mass of human interaction, such as cities. Empirical observations seem to confirm this latter line of thought. For instance, notwithstanding the rising of the digitisation of society in the in the 1990s and 2000s, American ‘superstar cities’ like New York and San Francisco have also grew in population and economic importance (Gyourko et al., 2013). More recently, Balland et al. (2020) demonstrated that complex knowledge, and consequently complex economic activities, needs the richness of cities to thrive and do not transfer well through digital channels only. The co-occurence of centrifugal forces (which lead to reduced disparities) and centripetal forces (which result in increased disparities) in the realm of digitisation has been labelled as the ‘paradoxical geographies of the digital economy’ (Moriset and Malecki 2009).
The fact that what we could define as the ‘funeral of space’ never took place is not wildly surprising when considering existing theoretical literature on agglomeration spillovers, and more specifically knowledge ones. Indeed, knowledge spillovers are generated not only by physical space but also by what is referred to as the relational space (Sheppard 2002). Knowledge spillovers have long been recognized as crucial for studying innovation processes, with physical space playing a key role in fostering proximity, particularly through face-to-face contact. As noted by Storper and Venables (2004), this form of interaction offers several key advantages, between which enabling efficient communication, promoting socialization and fostering relationship building and knowledge sharing. Finally, it provides psychological motivation, as personal interactions often lead to greater commitment and engagement. While some of these benefits could also apply to modern video-calling technologies, face-to-face interactions have distinct advantages. They enable seamless communication through body language, and physical presence, making exchanges richer and more meaningful. As Storper and Venables (2004, p. 9) broadly describe it, face-to-face contact is akin to ‘being on stage and playing a role’.
The value of physical space has been explored in numerous empirical studies. In Audretsch and Vivarelli (1994), for instance, the effect of knowledge spillovers on innovation is measured through patents, revealing a significant effect of these spillovers on small-and medium-sized firms. The definition of spillovers used in this paper, however, is relatively narrow, focussing solely on physical proximity to universities or research centres. Autant-Bernard (2001) broaden the scope of spillovers to include proximity to a significant number of firms within the same sector. Their study also demonstrates a significant positive correlation between knowledge spillovers and the innovative performance of firms. While proximity to universities, research centres, and firms from both the same and different sectors is important, it is crucial to recognize the multifaceted nature of knowledge spillovers. The mere concentration of firms within a particular sector does not fully explain a region’s innovation. To comprehensively understand and leverage knowledge spillovers, it is essential to identify the channels through which these spillovers are transmitted and spread across a region. This is where the concept of relational space comes into play. Relational space includes all interactions among firms, institutions, and individuals, and is characterized by a strong sense of community and collaborative capabilities within the region (Capello and Faggian 2005). Despite these insights, some scholars remain skeptical about the necessity of face-to-face contact for knowledge spillovers. For example, Torre (2008, pg. 870) contended that ICTs enable ‘long-distance sharing or co-production of tacit knowledge’.
The scholarly evidence presented above might be enough make a reader skeptical about the ‘death of space’. Notwithstanding theoretical literature on the relational space, Florida’s arguments and Saxenian’s findings, however, the question of whether developments in Information Technology would lower the need for face-to-face interaction recently resurfaced during the COVID-19 pandemic (Budnitz and Tranos 2022; Chapple et al., 2022; Florida et al., 2023; Ramani and Bloom 2021). Indeed, the pandemic served as a massive, forced experiment in digital work, reviving predictions similar to those from the past. For example, a recent article from The Atlantic postulated ‘the decline of the coastal superstar cities’ and that ‘the next Silicon Valley is nowhere’ (Thompson 2021). The COVID-19 crisis has imposed additional challenges on businesses and their existing models. It was anticipated that this crisis would accelerate the adoption of digital technologies, primarily due to their ability to facilitate remote work. After the recovery from the pandemic, city planners are still not clear about whether urban centres are on track to return to their pre-Covid states or if they are in store for a permanent change (Ramani and Bloom 2021; Reades and Crookston 2021). Specifically, following (Florida et al., 2023, p. 1519) firms would make savings from ‘leasing less space and the efficiencies of employees using less time in meetings and chit-chat by the coffee machine or the water cooler’. Some individuals, in response to the necessity of avoiding public transportation, might be motivated to reside in neighbourhoods much closer to the city centre. This ironic outcome could potentially lead to the development of ‘live–work neighborhoods’, a concept that urban planners have advocated for decades (Florida et al., 2023).
Continuing on the same line as in Florida (2002), Florida et al. (2023) confirms that the clustering of talent and economic resources, along with face-to-face interactions, buzz, and a diverse environment found exclusively in cities, are essential for fostering innovation, creativity, and driving economic growth. In Florida et al. (2023)’s work, particular attention is devoted to the usual hyperbole of techno-optimists that emerged during the pandemic claiming that ‘everything will change’, or that everything will be better because of the latest technological advancements in video communications. Such claims relied on the assumption that ‘this time is different’, because this is the first pandemic to occur together with a widely available alternative to face-to-face work. As the authors notice, however, there is a long history of failed forecasts that ‘this time, distance is dead’. Indeed, over the past two centuries, urbanisation has surged in tandem with significant advancements in transportation and telecommunications capabilities (Leamer and Storper 2001). Yet, as summarised in Busch et al. (2021), urban areas persist in their ability to draw knowledge-intensive (digital) production by offering skilled labour, favourable ecosystems, and a consumer base. All in all, a thread pulls consistently in objections to the placelessness of the digital economy, that is, the increase in urbanisation.
Industrial clustering in the digital and previous empirical efforts
In the previous section, we discussed how (more or less utopistic) reflections over the ‘death of space’ managed to retain scholarly interest to this day. All these reflections are behind a growing body of scholarship, predominantly disagreeing with the space-flattening properties that continue to be attributed to the Internet. The gist of these works revolves around the concept of knowledge spillovers and emphasises the importance of physical proximity for economic development. Notwithstanding the importance of this literature, we note that it never specifically addresses the digital economy, or when it does, it tends to offer context-dependent definitions.
To our knowledge, one of the first empirical evidence of the relevance of spatial proximity in innovative high tech firm can be found in Anselin et al. (1997). While this work does not specifically focus on the digital economy per se, it still provides an account of the mechanisms through which agglomeration forces contribute to a higher equilibrium growth rate for both cities and regions, and it is often cited as a motivation for further work. The investigation found a significant causal relation between university research and R&D activity when geographical proximity is observed. Thus, the presence of universities is an endogenous factor causing the agglomeration of high technology firms. Furthermore, the authors contribute to the argument at the centre of this article over the difficulties posed by data missingness on innovative economic activities.
Looking at online content production, Sinai and Waldfogel (2004) found that densely populated areas contribute more to the Internet than their less populated counterparts. Furthermore, since people’s preferences are often regionally clustered and there is a higher likelihood of consuming local media, individuals in densely populated regions are more likely to access the Internet. On a related note, Blum and Goldfarb (2006) investigated the online behaviour of approximately 2,600 American Internet users on international websites. Their findings align with a well-established observation in trade literature: bilateral trade decreases with increasing distance (Disdier and Head, 2008; Overman et al., 2003). This principle extends to online behaviour, implying that, even for products or services with zero shipping costs people are more inclined to access websites from neighbouring countries rather than distant ones (Goldfarb and Prince 2008).
Focussing on firms classified at the 2-digit level, Caragliu et al. (2016) tested for the relevance of different types of externalities, namely spatial proximity, labour market pooling, specialisation, diversity and learning advantages for agglomeration. Their work finds that agglomeration externalities are stronger for technology intensive industry. For as much as their results are indicative of the persisting power of agglomeration externalities for potentially ‘spaceless’ industries, similarly to Anselin et al. (1997) the authors suggest that the availability of more granularly classified firm level microdata would benefit their findings.
Examining online crowdfunding within the music industry, Agrawal et al. (2015) presented additional evidence underscoring the significance of local social networks. The study demonstrated that musicians typically receive initial funding from local supporters whom they were acquainted with before joining the crowdfunding platform. Always relating to (urban) agglomeration externalities, Busch et al. (2021) investigated how production of digital goods in cities is supported by urban context factors. The study employs a qualitative interview approach on 10 firms in Germany, discovering that urban advantages are still crucial in the production of digital goods, eventually arguing that a decoupling between such firms and cities is ‘fairly unlikely’.
Concerning inner-city firm demography, and differently from all previously presented evidence, Ramani and Bloom (2021) recently showed how COVID-19 has induced substantial change to the organisation of work and economic activity. Specifically, the study reveals that in large U.S. metropolitan regions, the pandemic caused a noticeable shift in household preferences, business locations, and real estate demand away from central business districts towards lower-density suburbs and exurban areas. This pattern suggests that the largest metropolitan areas, which tend to be the most agglomerated, have experienced the most pronounced movement of economic activities out of their city centre. Ramani and Bloom (2021)’s findings are particularly interesting in the context of this paper, as a by-product of our findings will be the inner-city locational preferences of firms.
To our knowledge, the only study yet that has addressed the reasons behind the clustering of potentially intangible firms with a robust statistical methodology and using micro-data is Arbia et al. (2012). The paper investigates the spatial distribution of high-tech firms in Milan. While the methodology used in this study, particularly the inhomogeneous K-function, will form the basis of our analysis, we note that the authors categorize high-tech manufacturing firms as representative of potentially ‘placeless’ firms, a view with which we substantially disagree. Additionally, the study’s sample size is relatively limited. Nonetheless, akin to the findings of this paper, we anticipate that if the arguments about the death of distance were to hold true, companies should cluster due to exogenous factors rather than endogenous ones.
Dataset construction
For our empirical analysis, we build a dataset of geo-located digital firms in the Greater London area (UK) by classifying text from firms’ websites into two groups: digital and non-digital. We chose Greater London as an example for the study as this allows us to focus on where economic activity is most clearly concentrated in the UK. London is at the centre of the UK tech economy, and the largest and most dynamic agglomeration in the UK. To create our dataset, we rely on the FAME enterprise dataset (Van Dijk 2020). FAME is a proprietary data source widely used in business studies (see, for instance, its use in Afrifa et al., 2022; Rizov et al., 2022; Shapira et al., 2014), and it relies on information reported by the UK registrar of companies (Companies House), while also providing the URL to companies’ websites. While we acknowledge that FAME has been criticized for undersampling smaller firms, it remains the only academically accessible source that includes firm websites. To address these concerns, we provide more general information on FAME and comprehensive validations of the dataset within the Appendix.
Dataset preprocessing
Digital economy activities selected for analysis list of 2007 SIC codes.
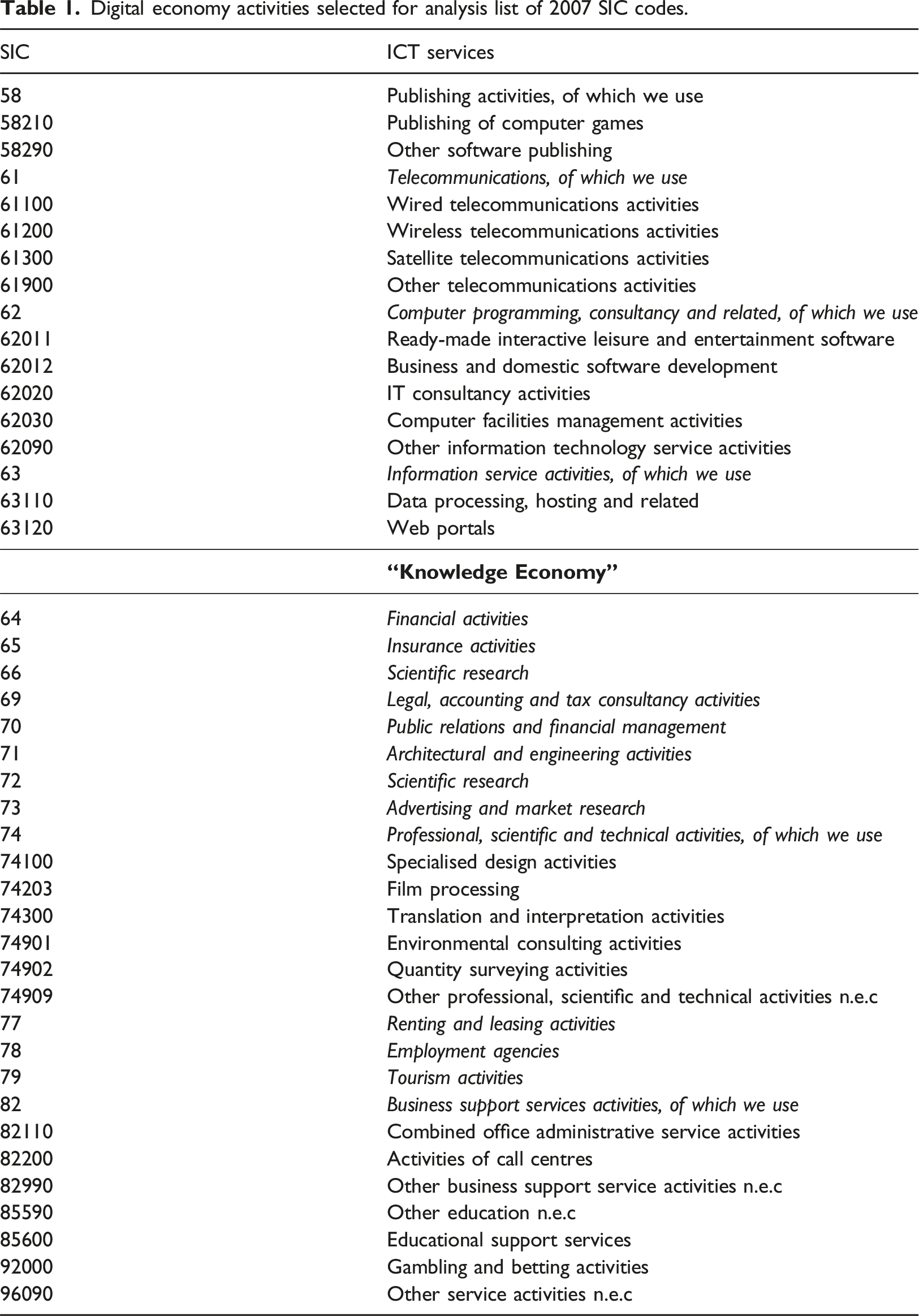
The second dataset builds on the first by including all of its firms, plus those under SIC sections C: Manufacturing, F: Construction, G: Wholesale, and I: Accommodation and Food Service Activities. We exclude sections A (Agriculture, Forestry, and Fishing) and B (Mining and Quarrying), as these sectors are geographically constrained by natural resource availability. The complete list of digital and non-digital SIC codes is provided in the supplementary materials.
To ensure a one-to-one mapping between firms and websites, we exclude websites linked to multiple companies. Most of these are owned by legal entities – often subsidiaries sharing a single parent company and website – whose inclusion would artificially inflate firm concentration in a given area. We also remove all dormant, non-trading, or dissolved companies, as well as firms with a majority shareholder (>50%) that is not a natural person (e.g. legal entities). This helps ensure we capture firms genuinely operating in the UK, rather than shell entities registered for legal or tax purposes.
To study the spatial distribution of digital and non-digital firms, we focus on their trading addresses.
FAME provides both registration and trading addresses: the former is a legal requirement for incorporation, while the latter reflects where business activities are primarily conducted. However, as firms often list the same address for both fields, we validate trading addresses using location data extracted from firm websites. We scrape the HTML content of each firm’s landing page and extract postcodes using a regular expression based on the UK Government Data Standard 3 . If the postcode found on the website matches the one reported in FAME, we treat the trading address as valid. If it differs, we exclude the firm from the dataset. In cases where no postcode is found on the website, we assume the FAME entry is correct. Using this procedure, we identify and remove 6% of firms due to inconsistent postcodes.
We successively remove all postcodes associated with more than 100 firms, following the reasoning that it is highly unlikely for a single postcode to physically accommodate such a large number of companies (Stich et al., 2023). This results in the exclusion of 14 postcodes, covering a total of 2,245 firms. 4 According to the ONS (Watkins 2020), this concentration may result from factors such as the rise of management and personal service companies, or firms registering addresses in prestigious locations. However, investigating the nature of companies in these postcodes lies beyond the scope of this study.
Websites’ classification
After this first round of data pruning, our next step is building a classifier in order to understand which, between the companies we selected as being potentially digital in nature, actually trades digital goods and services. To do so, we use a contextualised weak supervision framework (Mekala and Shang 2020). Said simply, weakly supervised learning aims at building predictive models by instilling domain knowledge on the data, in this case, through the use of seed words. Unlike previous research efforts that used fully unsupervised methods like topic modelling for firm classification (e.g. Bishop et al., 2022), weakly supervised learning offers the advantage of allowing the user to define both the number of classes and their semantics, rather than relying on the model to do so. In contrast to supervised techniques, weakly supervised classification techniques only require seeds in various forms, which alleviate the burden of human experts on annotating massive documents, especially in specific domains We find this classification method to be particularly suited for the industrial classification problem at hand, as researchers and policy makers alike might wish to define their own taxonomy of firms according to their research purposes. Moreover, while other studies might use self-collected datasets to train and test their web page classifiers, in the case at hand, a lack of a comprehensive test-bed makes it challenging to compare the accuracy of different web page classifiers (Hashemi 2020).
In this context, weak supervision is formulated by generating pseudo-labels for each class to predict, composed by indicative seed words. This process is complemented by contextualised embeddings, assigning to each token in the text a different interpretation according to its context. Despite individual word embeddings models such as word2vec (Mikolov et al., 2013) having been highly effective in previous applications, these word representations remain static, meaning that they lack contextual adaptability. Since 2018, Transformer-based text contextualization models, such as BERT, have revolutionized the NLP landscape. These models are highly effective for creating meaningful, computer-readable text representations, as they can disambiguate between different interpretations of the same word and provide a more holistic under-standing of text compared to traditional bag-of-words approaches (Devlin et al., 2019). We hereby present a simple example of contextualisation: suppose, in our experiment we want to differentiate between the word ‘cloud’ in ‘cloud computing infrastructure’ versus the word ‘cloud’ in ‘having your head in the clouds’.
Table showing the seedword expansion of the software.development.services class evolution through iterations.
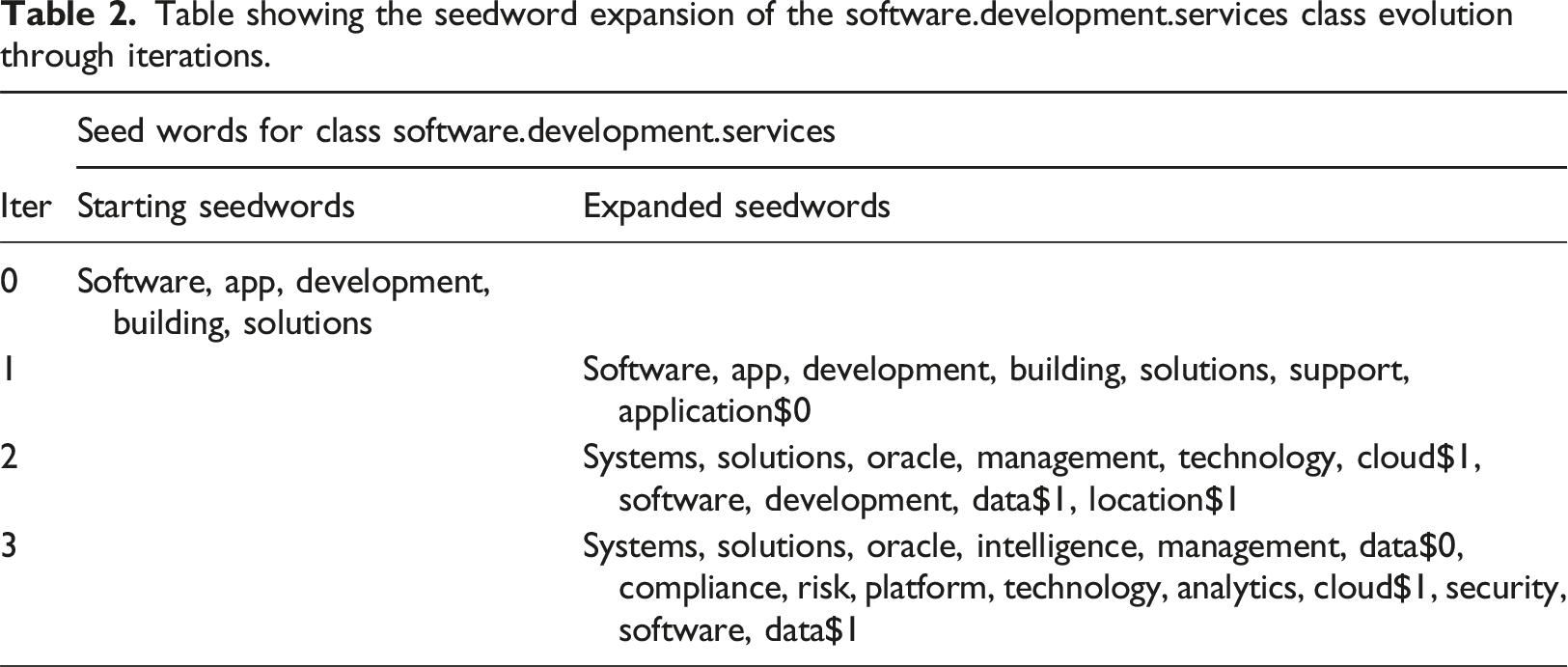
Following the extensive dataset construction procedures described above, composed of data collection, text scraping, postcode validation and text classification, we obtain a sample of 18,399 digital firms and a sample of 68,358 non-digital firms. Considering this as a further preprocessing steps, we check whether all the steps mentioned above introduced any industrial and geographical bias into our sample. The results of the validation are presented in the supplementary materials.
Methodological pipeline
Following the creation of the digital and non-digital firms microdata, we need to adopt an appropriate statistical framework in order to understand the distribution of firms in an inhomogeneous space. To account for this inhomogeneity, we rely on methods developed in the spatial point patterns literature. The analysis of point pattern has a long tradition of being used in ecology and epidemiology, explaining the spatial distributions of species and diseases (Baddeley et al., 2015; Bivand et al., 2008). The method we utilise here is based on the Inhomogeneous K function (Baddeley et al., 2000).
First of all, by inhomogeneous space we mean that the probability of observing a firm is not constant in space. This practically implies that the probability of a firm to locate at a given location is not constant, but instead varies systematically with both observable traits, such as land price or transport proximity, and unobservable traits, like ‘buzz’, indicating the chatter and interactions in offices, bars, and restaurants within urban areas serve as a form of information transmission, a group-based, self-generating ex-change of knowledge and information that occurs outside of formal collaboration.
Specifically, a spatially heterogeneous context gives rise to the phenomenon of apparent contagion, whereby firms will tend to cluster in a specific location. For instance, firms might cluster around useful infrastructure such as train stations, or around amenities such as restaurants and cafes. In other words, the contagion is only ‘apparent’ because firms are not influencing one another to make similar choices, that is, location preferences are not contagious. In the economics jargon, these can also be referred as ‘exogenous causes’. Statistically, spatial heterogeneity is captured through the first order intensity function of a spatial point pattern λ(x), where in this context x denotes the geographical coordinates of a point. As a consequence, λ(x)dx denotes the probability that an event locates in an infinitesimal region centred on x and with a surface area dx.
On the other hand, in a scenario of true contagion the presence of one specific point x in an area would be the main attraction for firms. An instance of this phenomenon is triggered by knowledge spillovers, and the relational space discussed in in paragraph 2.1. In the economics jargon, we call these ‘endogenous effects’. Statistically, true contagion is formalized by the second-order intensity function λ2(x, y)dxdy, expressing the probability that two events locate in two infinitesimal regions centred in x and y and with surface areas dx and dy, respectively (Diggle et al., 2007). Hence, λ2(x, y) serves as an indicator for the anticipated extra events situated in location y in comparison to a specific event situated in location x, thereby offering a measure of spatial dependence.
In its natural environment, the clustering of firms could arise from a combination of apparent and true contagion. As our research aim is to disentangle these two effects, we will need to adopt a method capable of achieving this distinction. In the next section, we discuss the inhomogeneous K functions and its usage in the analysis of firm demography.
Descriptive statistics
To the best of our knowledge, the Inhomogeneous K function has been rarely utilised in evaluating the spatial concentration of economic activities. The inhomogeneous K-function is a cumulative distance-based measure that adheres to most of the characteristics of a ‘good concentration index’, as defined by Marcon and Puech (2010, p. 2). Specifically, there are several advantages to adopting this function: it does not rely on arbitrary definitions of spatial units (such as provinces, regions, or states); it enables the assessment of statistical significance; it facilitates comparisons across different industries, and it assesses spatial heterogeneity.
The inhomogeneous K-function is a generalisation of Ripley’s K-function (Ripley 1976, 1977) to in-stances of non-stationary point processes. Practically, in a non-stationary point-process inhomogeneity is operationalised by replacing the constant intensity λ with an intensity function varying over space λ(x). This variation is used to assess the endogenous effects of the interaction among events while adjusting for the exogenous effects of the attributes of the study area. The function follows equation (1) below, where the term d
ij
is calculated as a Euclidean distance
5
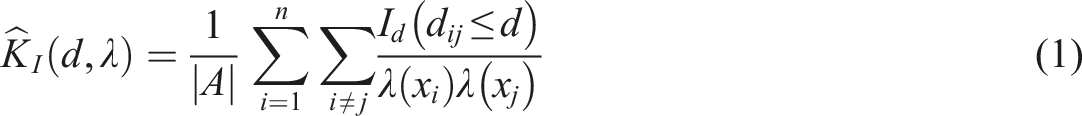
The functional form of the first-order intensity λ(x) is estimated non-parametrically through kernel smoothing, following equation (2) below. In equation (2), h representes the bandwidth, K(x) the Kernel function and x
j
− x
i
the Euclidean distance between each point. In practice, the values of the function were computed using the Gaussian kde function in SciPy (Virtanen et al., 2020)
In order to disentangle the contribution due to spatial heterogeneity or spatial dependence, we tackle the problem following Arbia et al. (2012), Krugman (1991) and Duranton and Overman (2005). Specifically, we formally assess the validity of the empirically observed inhomogeneous K-function value via building the confidence intervals for the null hypothesis of absence of endogenous effects. We estimate λ(x), the first order intensity function, on a different point pattern in which the locations represent the heterogeneity of the study area, in this case the ‘non-digital’ firms described in Section 3. Hence, in the analysis of the spatial interaction between digital firms, we estimate λ(x) on the spatial locations of all selected firms (digital and non-digital). As in a case-control study, in this approach the location of all firms constitutes the control data, while the location of digital firms constitute the case data, used for the estimation of the inhomogeneous K function. Following the epidemiological literature (specifically, see Schulz and Grimes (2002)) the control group contains instances of cases as it should be representative of the population at risk of developing an illness and being cases, or, in this context, ‘at risk’ of being digital. This design will allow us to measure the extra-concentration of digital firms with respect to all firms.
To make associations within points more easier to inspect, especially in instances with high estimator variance, Baddeley et al. (2000) suggests transforming the K-function to the L-function, as proposed in Besag (1977). The transformation is shown in equation (3) below
In order to evaluate the statistical significance of the values of Kˆ I (d) (or Lˆ I (d)), we follow the inferential framework proposed in Arbia et al. (2012) and Baddeley et al. (2014). Specifically, as we do not know the exact distribution of Kˆ I (d), we cannot theoretically evaluate its variance. Consequently, we construct the confidence interval for the null hypothesis of absence of spatial interactions based on Monte Carlo simulations. To adjust for potential edge effect, we get a bigger hull (overscan) for simulations following Haase (1995). We provide more technical detail on the computational implementation of Baddeley’s Inhomogeneous K function in the Technical Appendix.
Inference
To attain inferential evaluation of the findings, we follow the framework proposed in Arbia et al. (2012). In practice, we simulate 999 inhomogeneous Poisson processes with the same number of points as the observed pattern. These simulations follow a probability density function that is proportional to the first-order intensity, denoted as λ(x), which we estimate within the study area. We estimate the function λ(x) using the spatial locations of all non-digital firms. Under this approach, all firm locations are part of the control data, while the functionals denoted as Kˆ I (d), estimated on the identified digital firms, constitute the case data. In essence, similar to a case-control design, we evaluate the excess concentration of digital firms over the overall distribution of all firms. This methodology is commonly employed in spatial epidemiology, where cases represent points related to a specific disease, and controls reflect the spatial distribution of the population, as discussed in Diggle and Rowlingson (1994).
Subsequently, we calculate an Lˆ I (d) function for each simulation. This process allows us to derive ap-proximate n/(n + 1)×100% confidence envelopes based on the highest and lowest values of the LˆI (d) functions obtained from the 999 simulations under the null hypothesis. Hence, these envelopes correspond to 99.9% confidence under the null hypothesis. Consequently, if the empirical LˆI (d), at a particular distance d, falls outside these envelopes, it indicates a significant deviation from the null hypothesis.
We employ a thinning sampler, which involves accepting or rejecting a Bernoulli variable based on the probability density calculated from λˆ(x)/λ0, where λ0 corresponds to the maximum value of the estimated first-order intensity function λˆ(x). In Figure 1, we present a schematic view of our working pipeline combining our data collection, classification and analysis. For more information on how to implement a thinning sampler, please refer to the technical Appendix. Our proposed framework of data preprocessing, classification, and analysis. We start by collecting firms’ websites’ urls, scraping their landing page, cleaning their text and geo-referencing the text. We then classify firms in digital and non-digital ones through applying a weak supervision algorithm to contextualised embeddings of websites’ text. Once we obtained our two distinct datasets of firms, we analyse the data through the simulating companies location patterns.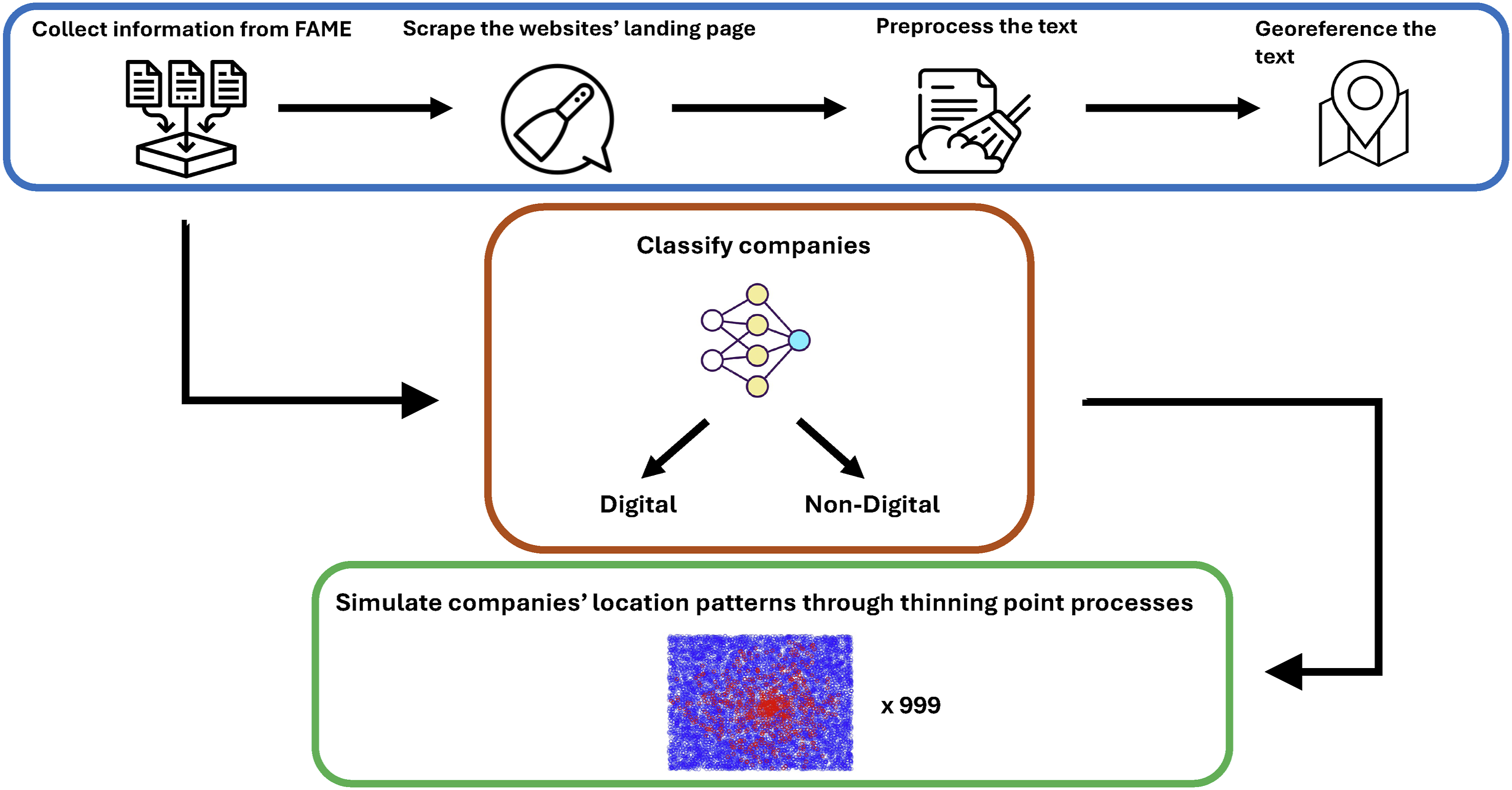
Results and discussion
The Gaussian kernel density estimates for the point processes of digital and non-digital firms are shown in Figure 2. The Gaussian KDE is computed with SciPy using Scott’s Rule for optimal bandwidth estimation.
6
This first descriptive set of results shows that firms intensities for digital and non-digital firms in London are almost equal, with a higher concentration in the central boroughs (Camden, City of Westminster, City of London). For both types of firms, we find pockets of significant concentration more peripheral boroughs such as Kingston and Richmond upon Thames (South-West), Harrow and Barnet (North-West), Enfield, Waltham Forest and Redbridge (North/North-East) and Croydon (South). Oppositely, we also observe lower densities in East London boroughs such as Havering and Barking and Dagenham. A reader who is informed about the socio-economics of London, will not find these results particularly surprising. Indeed, East London boroughs are some of the most deprived of the whole UK (Smith et al., 2015). Turning back to our research question, the observed densities are coherent with our literature informed theoretical expectations, in that we do not find striking differences when comparing the distribution in space of digital and non-digital companies. These results serve as a first indication of the exaggerated ‘space-flattening’ properties attributed to the digital: if space was so irrelevant to entrepreneurship in the digital, we would expect a smoother distribution across London. Non-parametric Gaussian kernel smoothing estimate of the intensity of our two datasets of firms within the boundaries of the NUTS 2 Greater London region. The bandwidth parameter is set to h = 1 km. (a) KDE of digital firms. (b) KDE of non-digital firms.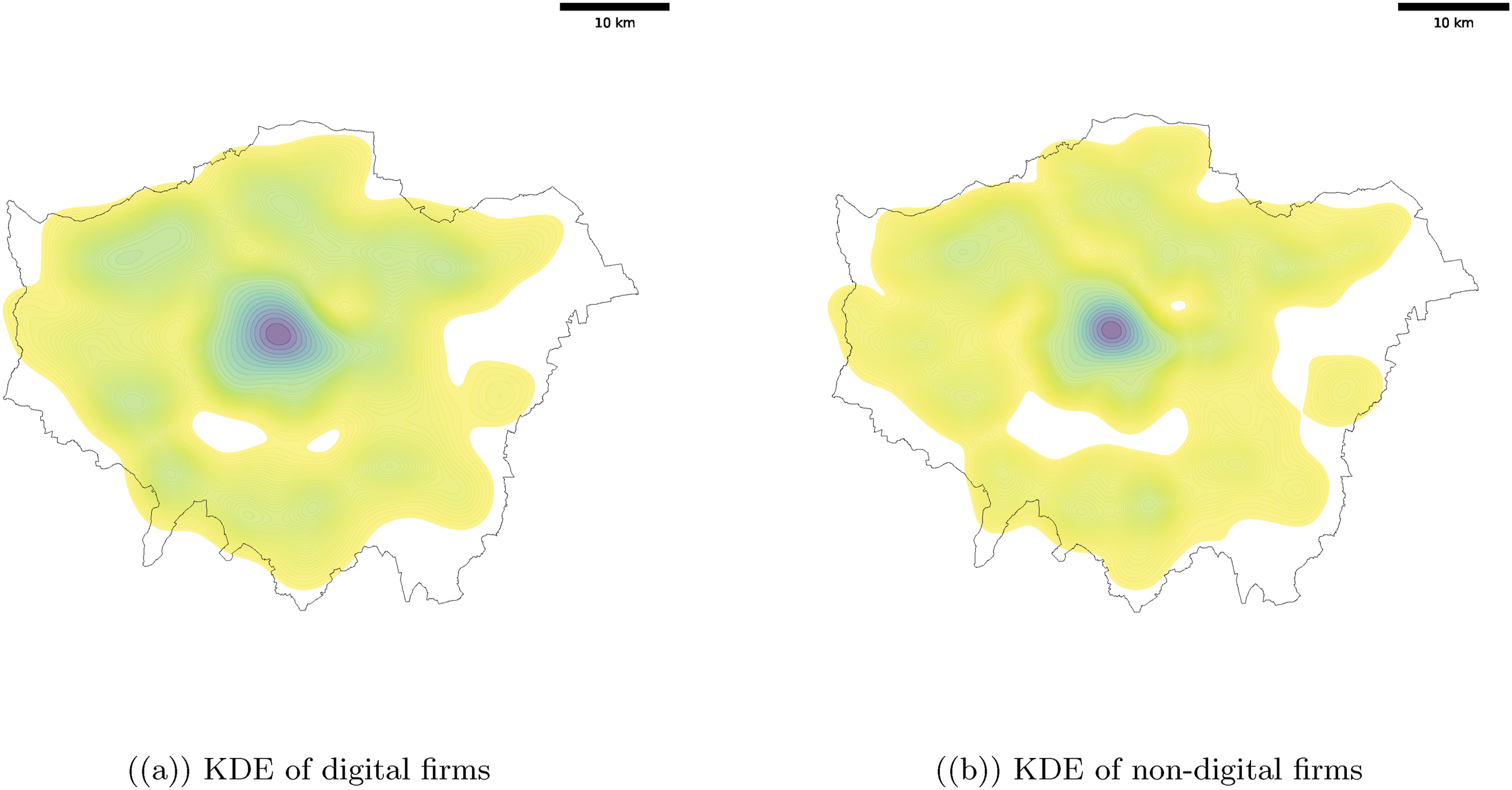
Figure 3 showcases our second set of results, and one of our main contributions to the literature. The figure displays the behaviour of the Lˆ
I
(d) function at various distances d for firms producing digital goods. Within the figures we also display as dashed lines the confidence envelopes referred to the null hypothesis of absence of interaction at a significance level α = 0.01. As explained while discussing our methodology in Section 4, the values of Lˆ
I
(d) transformation are essentially interpretable in graphical terms. This means that when the value of function Lˆ
I
at distance d is above the confidence envelopes, we observe a significant level of spatial concentration. Conversely, if the values assumed by Lˆ
I
were to be under the envelopes, we would observe significant spatial dispersion. The function clearly indicates spatial interaction for digital firms. Specifically, the results show the presence of non-statistically significant clustering at lower distances (<5 km), and of highly statistically significant clustering at higher distances (>10 km). In practice, this means that digital firms don’t really cluster along a street or in a single city block, but cluster within specific districts or areas, or in this case boroughs. Behaviour of the estimated inhomogeneous L-functions (solid line) and of the corresponding 99.9% confidence envelopes under the null hypothesis (dashed lines) of our identified digital firms.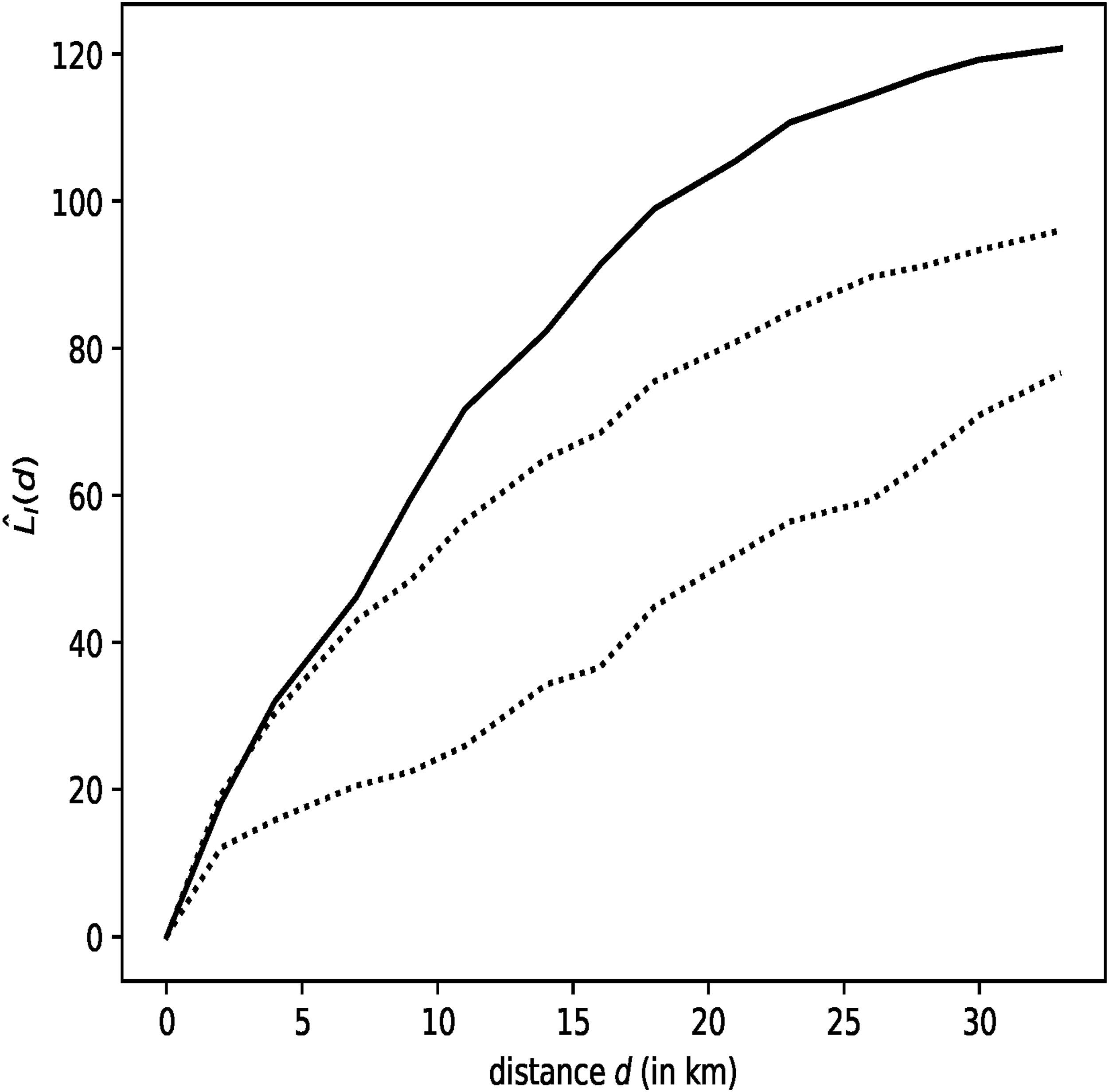
Reflecting on the results presented in Figure 3 allows us to disentangle the whether the clustering of digital firms observed in Figure 2 is motivated by firms need for physical interaction or by specific characteristics of the area they are located in. As the Lˆ I function quantifies the amount of spatial concentration that cannot be explained by exogenous factors such as presence of infrastructure, cultural amenities or regulatory incentives, we can infer that digital firms cluster due to a genuine need to interact between each other. These findings are coherent with our working hypothesis, motivated by advancements in the literature demonstrating that the digital would have not meant the abandonment of physical interactions between firms. In other words, our empirical findings confirm that agglomeration externalities might still play a role in the distribution of potentially ‘placeless’ industries, suggesting that the Internet and digitisation are yet to counterbalance the urban advantages associated with spatial proximity.
Overall, our results provide a strong empirical contribution to the demystification of discourse portraying the digital economy as providing opportunities notwithstanding geography. In doing so, it empirically confirms narratives on the extant value of the ‘relational space’ in the digital, confirming the role of urban areas in the attraction of knowledge-intensive production (Busch et al., 2021; Capello and Faggian 2005; Florida et al., 2023). While our results are in line with recent findings by Balland et al. (2020), we wish to highlight how our study proposes a causal and more granular, within-city approach. Although our results highlight the importance of endogenous agglomeration externalities for digital industries, we cannot make overly strong claims about the phenomenon. This is because our data could have been processed at a higher level of granularity, that is, we are yet to test our claims for different types of digital firms. Indeed, different types of firms produce different typologies of knowledge, and might consequently exhibit different patterns of agglomeration (Asheim et al., 2007; Storper and Venables 2004). We hence consider this paper and its result as a starting point for researchers to analyse the clustering of different types of digital firms and further contribute to the literature on the ‘paradoxical geographies of the digital’ (Moriset and Malecki 2009). We believe that adopting this approach contributes to clarifying the need for cluster policy in digital industries, as well as demonstrating how spatial microdata can help with the analysis firm demography, their location, and the impact that this has on their survival in the longterm. Considering the TechCity cluster in Shoreditch as a case study, Nathan (2022) proposed a causal interpretation of whether cluster policy has an impact, highlighting that although such policies are popular among policymakers, we know surprisingly little about their effectiveness. The study finds that digital content firms experienced higher revenue and more high-growth activity in the post-policy period than firms in comparable areas. Taken together with our own findings, this suggests that clustering effects remain significant even in sectors characterized by intangible outputs.
Accordingly, we argue that targeted policies to support urban clusters – such as investment in co-working infrastructure, support for local knowledge-sharing ecosystems, and place-based innovation incentives – can be effective tools for fostering digital and knowledge-intensive industries. In addition, our methodological pipeline provides a scalable way to monitor and detect emerging clusters in near real-time, particularly where traditional economic statistics fall short. These findings offer policymakers both empirical grounding and actionable insights for designing more responsive, spatially aware strategies in the digital economy.
Finally, the results obtained in this experiment emphasize the value of adopting multidisciplinary research pipelines in geography. Indeed, while our experiments are heavily influenced by the work of Arbia et al. (2012), had we not adopted an NLP framework to identify digital firms, we would have not been able to provide an analysis of the digital economy effectively. Contrarily to our work, Arbia et al. (2012) equates placeless industries are equated to ‘high tech’ manufacturing ones. In proposing such multidisciplinary working framework we also answer Anselin et al. (1997)’s call advocating for the usage of micro-data in the investigation of economic clustering. Moreover, we believe to have practically confirmed Haefner and Sternberg (2020, p. 10)’s claims on how this field of research is ‘a perfect arena for empirically skilled economic geographers’. By doing so, our hope is to further motivate geographers to engage in problems spanning over diverse methodological areas.
Conclusions and suggestions for further research
In this paper, we tackled two main objectives. First, we clearly demonstrated that digital and non-digital firms in the Greater London area showcase similar patterns of agglomeration. Second, we found that such clustering is motivated by true contagion, that is, firms need to interact with each other. As discussed within the literature review, this might be motivated by the power of knowledge externalities. By investigating these phenomena, our aim was to further demystify digital transformation narrative suggesting that digital technologies will contribute to the spreading of firms regions. Further, this work contributes to governmental and wider policy work towards the understanding of the benefits of clustering policies for levelling up. Our findings strengthen the case for policies that support clustering as a driver of innovation and regional development, even in the digital economy. We situate our work in an extensive theoretical framework touching upon the main reasons causing industrial clustering. We notice how most of the previous empirical literature on the spatial footprints of the digital economy did not approach the problem with microdata, and when it did, it equated digital firms with tech-manufacturing ones. To solve this problem, we based our analysis on digital economic microdata identified through contextualised weak supervision applied to firms website data. By doing so, we demonstrate the potential of internet trace data (in this case, websites) can expand our understanding of firm demographies. To analyse such data, in this paper we have utilised a set of tools proposed in spatial statistical literature, ultimately allowing us to disentangle the motivations behind firms clustering in a city. These tools belong to the family of K-functions and fall within the domain of Point Pattern Analysis. They were first introduced in the epidemiological context in the seminal work of Diggle et al. (1995) and, to the best of our knowledge, this is the second time (after the work of Arbia et al., 2012) that they have been used in economic geography.
While the study is focused on London, leveraging the availability of rich administrative data and firm-level website information, the framework and methods we propose are broadly transferable to other urban contexts. Importantly, the proposed classification approach relying on firm website content and weak super-vision via seed words, is adaptable to different regional settings where similar data is available. However, we acknowledge that the patterns of digital firm formation and spatial clustering may vary with local institutional, economic, and infrastructural conditions. Specifically, our classification deliberately excludes firms that offer both digital and non-digital outputs, as these ‘mixed’ firms pose challenges both conceptually and empirically. Thus, this study should be seen as a first step, one that opens the way to deeper investigations into the structure, dynamics, and spatial footprints of the digital economy across geographies. Much remains to be uncovered about its full structure, dynamics, and spatial footprints, particularly across different geographic contexts. It is crucial to note that this work was conducted prior to the emergence of open-source, commercially available large language models. Since then, new methods have been proposed holding the promise to improve large-scale unsupervised text mining with minimal human effort (see, e.g. Wan et al., 2024). We believe that applying such approaches to firm-level text data has the potential to generate more accurate and granular taxonomies, thereby enabling a finer understanding of firm localization processes at the micro-scale. Such advances would also provide policymakers with more precise insights to design place-based industrial and innovation policies.
Supplemental Material
Supplemental Material - Not so ‘placeless’ after all. Understanding the spatial implications of the digital economy
Supplemental Material for Not so ‘placeless’ after all. Understanding the spatial implications of the digital economy by Giulia Occhini, Levi John Wolf, Emmanouil Tranos in Environment and Planning B: Urban Analytics and City Science.
Footnotes
Funding
Giulia Occhini’s Doctoral Studentship is funded by The Alan Turing Institute via EPSRC grant EP/N510129/1.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.