
Abstract
Understanding human behavior in the built environment is critical for designing highly-functional, human-centered urban spaces. Traditional approaches, such as manual observations, surveys, and simple simulations, often struggle to capture the complexity and nuance of real-world human behavior and experience. Here we introduce TravelAgent, a novel agentic simulation platform that models pedestrian navigation, activity, and human-like decision-making in the built environment. TravelAgent is proposed to help design teams and decision-makers understand how different users might experience diverse built environments under varying environmental conditions. TravelAgent integrates Generative Agents, multi-modal sensory inputs, and virtual environments, enabling agents to perceive, navigate, and interact with their surroundings, with tasks ranging from goal-oriented navigation to free exploration. We share analysis from 200 simulations with 3364 decision points and task completion rate of ∼80%, across diverse spatial layouts and agent archetypes. We present spatial, linguistic, and sentiment analysis, and show how agents react and experience their surroundings. Finally, we suggest TravelAgent as a new paradigm for designing, simulating, and understanding human experiences in urban environments.
Keywords
Introduction
Background
Understating human experience in the built environment is central to the design of spaces that are functional, inclusive, and responsive to their users (Gehl, 2010; Jacobs, 1961). These experiences are shaped by a complex interplay of spatial configurations, visual stimuli, social dynamics, and individual preferences (Whyte, 1980). This wide range of factors makes it challenging to assess how people will interact and experience urban spaces, especially in early urban design stages (Batty et al., 2000; Hillier and Hanson, 1984).Throughout the design process, architects, urban-planners, and other stakeholders rely on a variety of methods to evaluate the impact of design decisions on human behavior (Batty and Yang, 2022; Gehl, 2010). These include manual observations, surveys, focus groups, as well as computational simulations, models, and visualizations (Banerjee and Loukaitou-Sideris, 2011; Noyman, 2022). While these methods offer valuable insights, they often fall short of capturing the complexity of human experience in real-world settings (Perez et al., 2016). Manual observations are time-consuming and limited in scope, and surveys and focus groups represent a narrow set of user experiences, often relying on subjective interpretations (Epstein, 1999). Computational simulations, such as Agent Based Models (ABMs), provide a more scalable and controlled environment, but often rely on simplified heuristics that cannot fully capture the richness of human experience (Batty, 2021; Chopra et al., 2024; Perez et al., 2016). Recent advances in generative models offer new possibilities for simulating human-like behavior (Luca et al., 2021). Unlike traditional methods, large Language Models (LLMs) and Generative Agents (GAs) perform well in open-ended tasks and environments, exhibiting a degree of flexibility and adaptability that is often lacking in more rigid, rule-based systems (Park et al., 2023). GAs can handle non-deterministic scenarios by chaining together a series of actions guided by natural-language prompts, allowing them to reason and adapt to out-of-scope tasks (Kaiya et al., 2023; Park et al., 2023). Table S1 compares GAs with conventional agent models, highlighting their advantages in open-ended exploration, qualitative experiential feedback, and dynamic adaptation to unexpected scenarios, as well as limitations such as hallucinations and training biases (Hatalis et al., 2024). Despite these constraints, GAs represent a significant advancement in simulating human-like behavior within built environments.
TravelAgent: Generative agents simulation in urban environments
To bridge the gap between human experience and computational modeling in urban design, we introduce TravelAgent (TA). TA is a novel simulation platform leveraging Generative Agents (GA) to model human-like experiences in the built environment. TA utilizes GAs and diverse sensory inputs, enabling agents to explore, navigate, and interact with their surroundings from a human perspective. Unlike traditional simulations that rely on predefined logic or pre-trained models, TA incorporates spatial memory, visual perception, and context-based reasoning to support autonomous decision-making (Chopra et al., 2024; Wei et al., 2023). We present the TA platform, a web-based tool designed to streamline the simulation of tasks and open-ended explorations under various environmental conditions. We analyze experiments, evaluating agent behaviors, decision-making, and adaptability from 200 simulations with a ∼80% task completion rate. Finally, we offer spatial, linguistic, and sentiment analysis, providing insights into how agents navigate, respond, and experience their environments.
Related work
Understating human experience in the built environments intersects many disciplines, from urban planning and architecture, computational modeling and human–computer interaction, through spatial cognition, to social and behavioral sciences. This section reviews key research that informed the development of TA, focusing on human-centered design principles, spatial cognition, and agent-based modeling in urban simulation. We also discuss the limitations of existing methods and compare them to the potential of GAs in simulating human-like behavior.
Human experience in the built environment
Human-centered design principles, including walkability, accessibility, and the quality of public spaces, have been shown to significantly enhance the performance of built environments (Ameli et al., 2015; Banerjee and Loukaitou-Sideris, 2011; Gehl, 2010; Jacobs, 1961; Lynch, 1960). A key aspect of human-centered design involves the legibility and accessibility of places for all individuals. Research has shown that universal design principles that go beyond minimum compliance help to create environments that are usable by people with diverse abilities (Imrie, 2004; Story et al., 1998). Studies have explored how specific urban design tactics, such as predictable layouts, legible urban form, and guiding street elements, can significantly impact the mobility, independence, and social participation of individuals (Clarkson et al., 2003; Goldsmith, 2007). Furthermore, the importance of legible cityscapes and environments that minimize sensory overload is emphasized in wayfinding research (Burton and Mitchell, 2003; Passini, 1992). To assess their impact, new technologies enabled designers to better evaluate spatial interventions in immersive ways, enhancing design processes, stakeholder engagement, and decision-making (Batty et al., 2000; Billger et al., 2017; Shen et al., 2018; Yin, 2017). Computerized models, simulations, and digital visualizations can all clarify the outcomes of design choices and help with stakeholder engagement (Batty et al., 2000; Smith et al., 1998). Nevertheless, these tools are often accessible to only a few experts and even fewer stakeholders. These planning aids tend to also represent a highly-curated vision of the design—such as specific views and perspectives—leading to a limited understanding of the design’s impact on human experience (Banerjee and Loukaitou-Sideris, 2011; Lin et al., 2013; Tabrizian et al., 2020). More recent technologies, such as virtual, augmented, or mixed reality, can offer more immersive experiences (Batty and Yang, 2022). However, these methods are often limited to small groups (the design team and few stakeholders), require specialized equipment, and are less accessible for broad application. The feedback gathered, while informative, tends to be narrowly focused and may not capture diverse user demographics and their preferences (Fonseca et al., 2016; Gath-Morad et al., 2024; Perez et al., 2016).
Spatial cognition and human navigation
Spatial cognition encompasses how humans perceive, process, and navigate through physical environments (Golledge, 1999; Montello, 1993). This cognitive process is fundamental to understanding human behavior in built spaces and serves as a theoretical foundation for TravelAgent’s approach. Environmental legibility depends on key features such as landmarks, signage, and spatial configurations (Gehl, 2010; Lynch, 1960). These elements form the basis of human wayfinding strategies and significantly impact spatial experience (Epstein et al., 2017; Javadi et al., 2017). When navigating, humans employ dual representational systems: egocentric (self-to-object) frames for immediate orientation and allocentric (object-to-object) frames for broader spatial understanding (Burgess, 2006; Klatzky, 2008; Mou et al., 2004). Cognitive maps, the mental representations we construct of physical spaces, develop through accumulated experiences and enable efficient navigation and spatial memory (Burgess et al., 2017; Epstein et al., 2017). These internal maps vary in detail and accuracy depending on familiarity, environmental complexity, and individual differences in spatial ability. Recent neuroimaging advances have revealed the neural mechanisms underlying these spatial cognition processes (Epstein et al., 2017), and immersive technologies have expanded our ability to study these phenomena in controlled settings (Batty and Yang, 2022; Gath-Morad et al., 2024). For computational modeling, the challenge lies in translating these human cognitive processes into algorithms that can simulate realistic navigation behaviors (Epstein, 1999; Milivojevic and Doeller, 2013). Traditional models often reduce navigation to geometric problems, overlooking the complex perceptual and decision-making processes humans employ (Filomena and Verstegen, 2021). Here, we address these limitations by incorporating principles of spatial cognition—including landmark recognition, environmental cue processing, and cognitive map formation—into the agent architecture, enabling more human-like behaviors while maintaining computational efficiency.
Agent-based modeling in urban simulation
Agent-Based Modeling (ABM) is foundational to urban simulation, modeling complex system dynamics through autonomous agent interactions (Bankes, 2002; Batty and Yang, 2022). ABMs are widely applied in areas such as traffic analysis (Grignard et al., 2018; Nguyen et al., 2021), pedestrian behavior (Filomena and Verstegen, 2021), and policy assessment (Perez et al., 2016). However, conventional ABMs often rely on predefined rules and deterministic heuristics (Railsback and Grimm, 2019), which may not fully capture the nuances of human decision-making and adaptability (Epstein, 1999; Zhang et al., 2024). Efforts to enhance ABMs with machine learning, including Reinforcement Learning (RL) and Neural Networks (NN) (Kobayashi et al., 2023; Li et al., 2020), aim for more adaptive behaviors. Yet, these models often require extensive data, intensive training, and significant computational power (Chopra et al., 2024). As detailed in Table S1, core challenge remains in developing agents that can robustly handle unforeseen situations and complex stimuli beyond their initial programming (Chen et al., 2019), underscoring the need for more flexible and human-like simulation paradigms.
Generative agents
Generative Agents (GAs), often powered by Large Language Models (LLMs), facilitate complex agent-environment interactions (Chopra et al., 2024; Park et al., 2023). Integrated with perception modules like computer vision, GAs can interpret diverse, real-world stimuli (Reid et al., 2024). In urban simulation, GAs provide advanced capabilities for visual processing, spatial memory, and adaptive decision-making, offering enhancements or alternatives to agents in traditional Agent-Based Models (ABMs) (Park et al., 2023; Yang et al., 2025). Typical GA architectures include a Memory Stream for recording experiences, Reflection for synthesizing knowledge, and Planning for action generation (Huang et al., 2024; Yao et al., 2023; Zhang et al., 2024). Reasoning techniques such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) enable GAs to decompose tasks and adapt to feedback dynamically (Wei et al., 2023; Yao et al). These integrated systems allow GAs to address complex tasks without predefined rules or constant human-feedback. Compared to agents in traditional ABMs, GAs adapt more effectively to novel environments and stimuli, producing more nuanced responses (Ghaffarzadegan et al., 2023; Park et al., 2023). Nevertheless, GAs also face challenges. Prompt engineering and memory management is crucial for effective task performance and for hallucination prevention (Hatalis et al., 2024). Replicating human-like reflection is challenging due to LLM context limitations and intrinsic bias in the training process (Mirzadeh et al., 2024). Despite these challenges, GAs represent a promising step for enhancing agent-based modeling in multi-modal environments, offering a more human-like approach to urban simulation.
Methodology
Agent simulation
TravelAgent (TA) is designed as an end-to-end platform allowing designers, stakeholders, and researchers, to create, simulate, and analyze Generative Agents in diverse environments. Simulation environments consist of three main components: (i) 3D environments, (ii) agent’s sensory inputs, and (iii) a Chain-of-Thought (CoT) reasoning framework, as shown in Figure 1. Each experiment is conducted as follows:
Agent Initialization
Agents are configured with parameters including starting location, orientation, environment description, simulation step limit, and task objectives. Personas can vary in complexity, from simple attributes (e.g., “student” and “researcher”) to more complex ones (e.g., “age” and “disabilities”). Memory is initialized either empty or with priors for known environments. Tasks are given as natural language objectives (e.g., reach a destination, find an object, or “Enjoy this museum gallery”). The initial prompt’s guidance lessens over time as the CoT framework updates the agent’s state using new sensory inputs and accumulated memory.
Environment
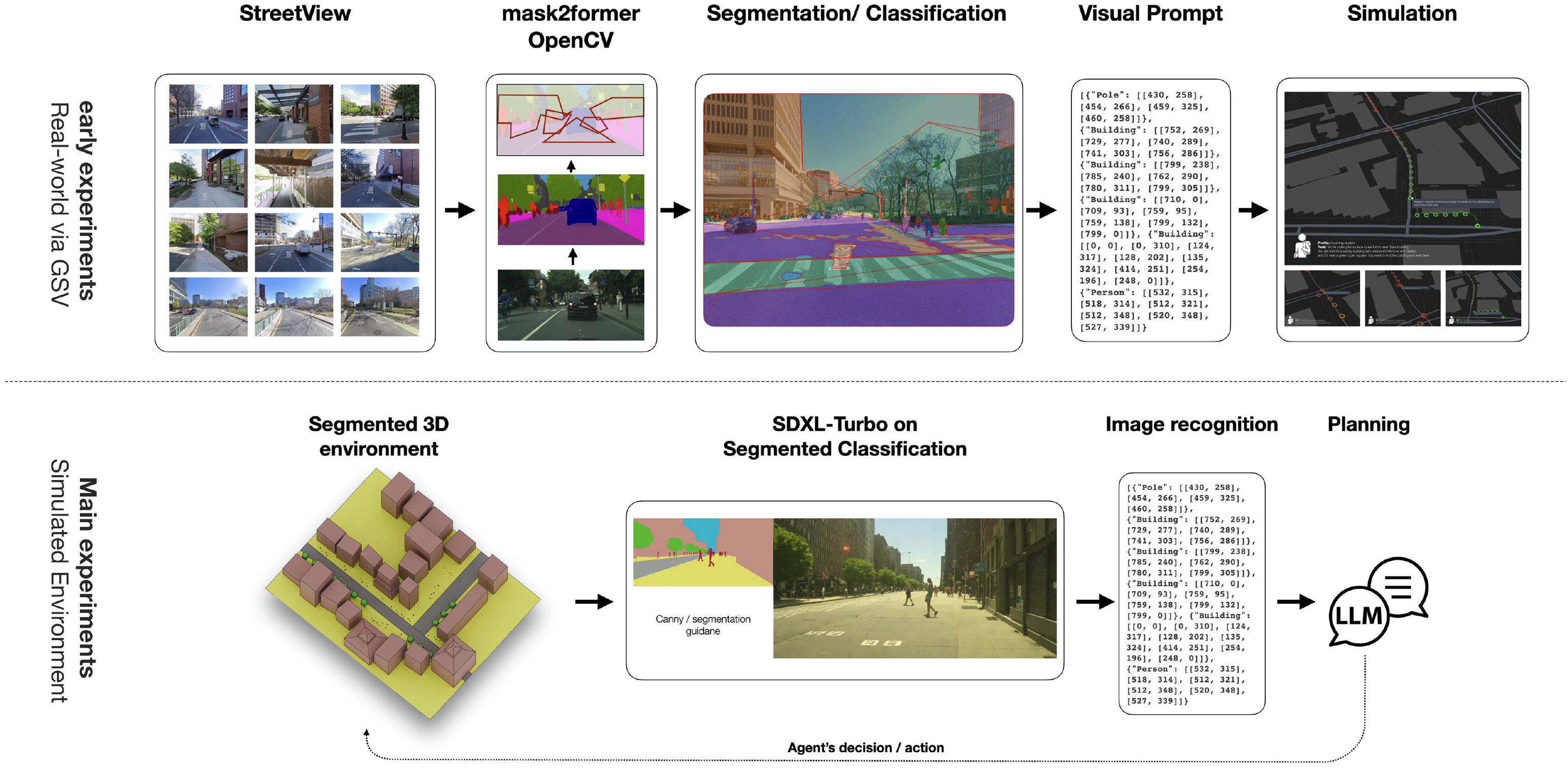
Agents navigate a rudimentary 3D environment, created using common modeling tools and generally characterized by simplified geometry. An image generation model produces realistic street-level images from this 3D model to serve as the agent’s visual input. As detailed in Figure 2, objects within the 3D model are semantically segmented, enabling the image generation model to reference these classes when creating first-person perspectives (Podell et al., 2023).
Simulation Steps
In each simulation step, the agent gathers sensory inputs (e.g., street-level images, segmentation maps, discovery map, and memory, as detailed in Sec. Sensory Inputs). These inputs are processed using a CoT framework, progressing through observation, planning, and action phases. The agent executes its decision by selecting an action (e.g., “move forward,”“turn right,” or “finish”) and an associated parameter (e.g., “1 m”). Supp Section ‘Simulation Log’ provides an example of such CoT stream. Simulation steps and non-uniform actions are determined by the agent’s persona and task. As shown in Figure 7, a simulation step may include a major advancement or only minor exploratory turns. Each step concludes when the agent updates and condenses its memory; this cycle repeats until the agent reaches its task objective or exhausts its step limit. Schematic representation of TravelAgent (left). TAs are initialized with various parameters defining the agent persona, environment, contextual priors, and initial planning (center). At each step, the agent employs Chain-of-Thought (CoT) to process sensory inputs, plan actions, and make decisions, based on its memory and observations. The agent’s memory updates and accumulates with each step, allowing it to learn from its experiences and adapt to new information (right). The agent executes actions within the TA environment and updates its internal memory based on its experiences. The updated environmental cues then feed back into the CoT framework for the next step. Street-level image generation for agent perception. (Top) Visual input from google street view (GSV) images. Objects (e.g., buildings and trees) are segmented using a Mask2Former model; an OpenCV convex hull algorithm then outlines and clusters these segments for semantic identification. (Top-right) Example of an agent’s path mapped in a GSV-based environment, with decision points highlighted. (Bottom) Synthetic pedestrian-level images generated from a 3D model using an SDXL-Turbo guided diffusion model (Podell et al., 2023). These images are analyzed by a Large Language Model (LLM) for environmental inference, object recognition, and layout assessment. Depth data and collision warnings, derived from the 3D model, supplement visual inputs to aid agent decision-making.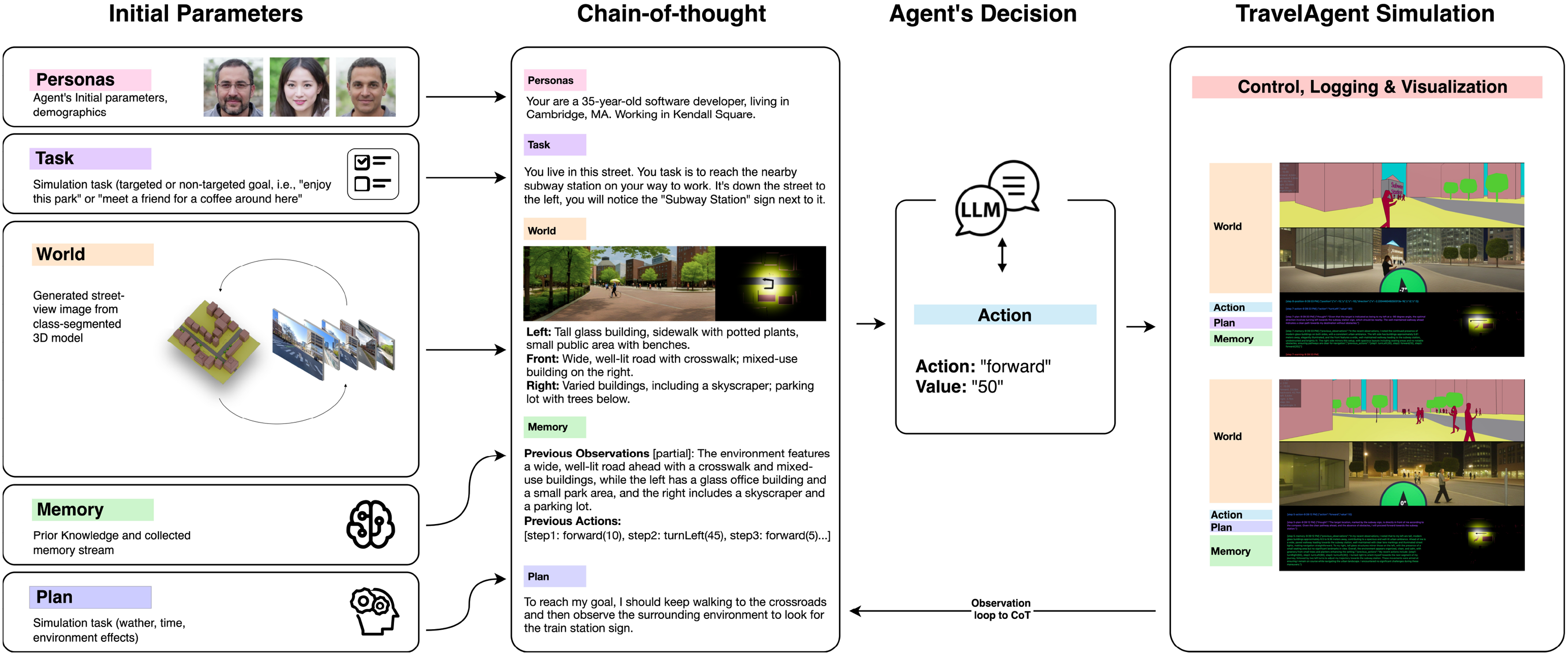
Sensory inputs
TravelAgents interact with the environment through a variety of sensory inputs, designed to mimic pedestrian eye-level perception, without restrictive navigation algorithms or predefined paths. Deciding which sensory inputs to include in the agent’s Chain-of-Thought (CoT) framework was driven by trial-and-error experimentation, as well as the need to balance realism and computational efficiency. The following sensory inputs are provided at each step of the simulation:
Visual Perception
TA employs computer vision techniques for processing visual information, including object detection, scene segmentation, and depth estimation. Various image recognition models, such as YOLO, Mask2Former, and OpenAI’s GPT, were explored (Achiam et al., 2023; Cheng et al., 2021; Redmon et al., 2015). To compensate for some visual inference shortcomings, depth and collision information is provided via ray-casting from the agent’s viewpoint to nearby objects in the 3D scene. This information is returned as class labels (e.g., “a wall” and “a tree”) and distance values (e.g., “front: 2 m”). A notable limitation in the current image generation pipeline is the difficulty in consistently producing readable text (e.g., on street signs), which restricts the agent’s use of textual cues common in human wayfinding. The current pipeline prioritizes simulation speed and iterative design flexibility using segmented 3D models; however, future iterations should explore more advanced image generation models that can produce consistent images with readable text.
Discovery Map
To mitigate unintentional revisits to previously explored locations (see Early Experiments), a “Discovery Map” was introduced. This map provides a top-down schematic of the environment, displaying the agent’s current location, orientation, and explored areas. The Discovery Map is dynamically updated with each agent movement and integrated into the CoT framework as a sensory input. It serves as a visual record of traversed paths, rather than an explicit pathfinding tool, allowing agents to maintain awareness of previously visited locations while retaining exploratory freedom, as shown in Figure Spatial Analysis.
Compass
In scenarios where the agent is assumed to have prior familiarity with the environment or possesses some navigational aid (such as a GPS enabled cellphone), a compass-like navigation cue provides general guidance. As shown in Figure 3, this compass is displayed on the agent’s field of view and is provided to the agent’s Chain-of-Thought (CoT) framework as part of the image inference process. The compass can be omitted to simulate activity in unfamiliar environments, such as visiting a place for the first time, compelling the agent to rely solely on visual cues and spatial memory for navigation. As with the Discovery Map, the agent is not forced to navigate using the compass, and can alter its path as needed, as shown in Section Spatial Analysis.
Spatial Memory
TA records CoT outputs at each simulation step. This memory encapsulates the agent’s past experiences, including visited locations, observed objects, and navigational cues. The memory is stored in a compressed textual format, representing the agent’s accumulated knowledge and experiences. This memory can also be used to initialize new agents to mimic an ongoing simulation. As discussed in Section Results, at the end of each simulation, the memory is analyzed to infer the agent’s behavior, experiences, and decision-making processes. TravelAgent web interface (top-left). Agent initialization settings; (bottom) chain-of-thought log: [orange] observations, [green] memories, [purple] plans, [blue] actions (top). Panoramic street-level view generated from a 3D environment, providing visual, depth, and collision cues. Visitation history is shown in the discovery map (bottom-right). The agent’s compass is displayed at the bottom of the field of view.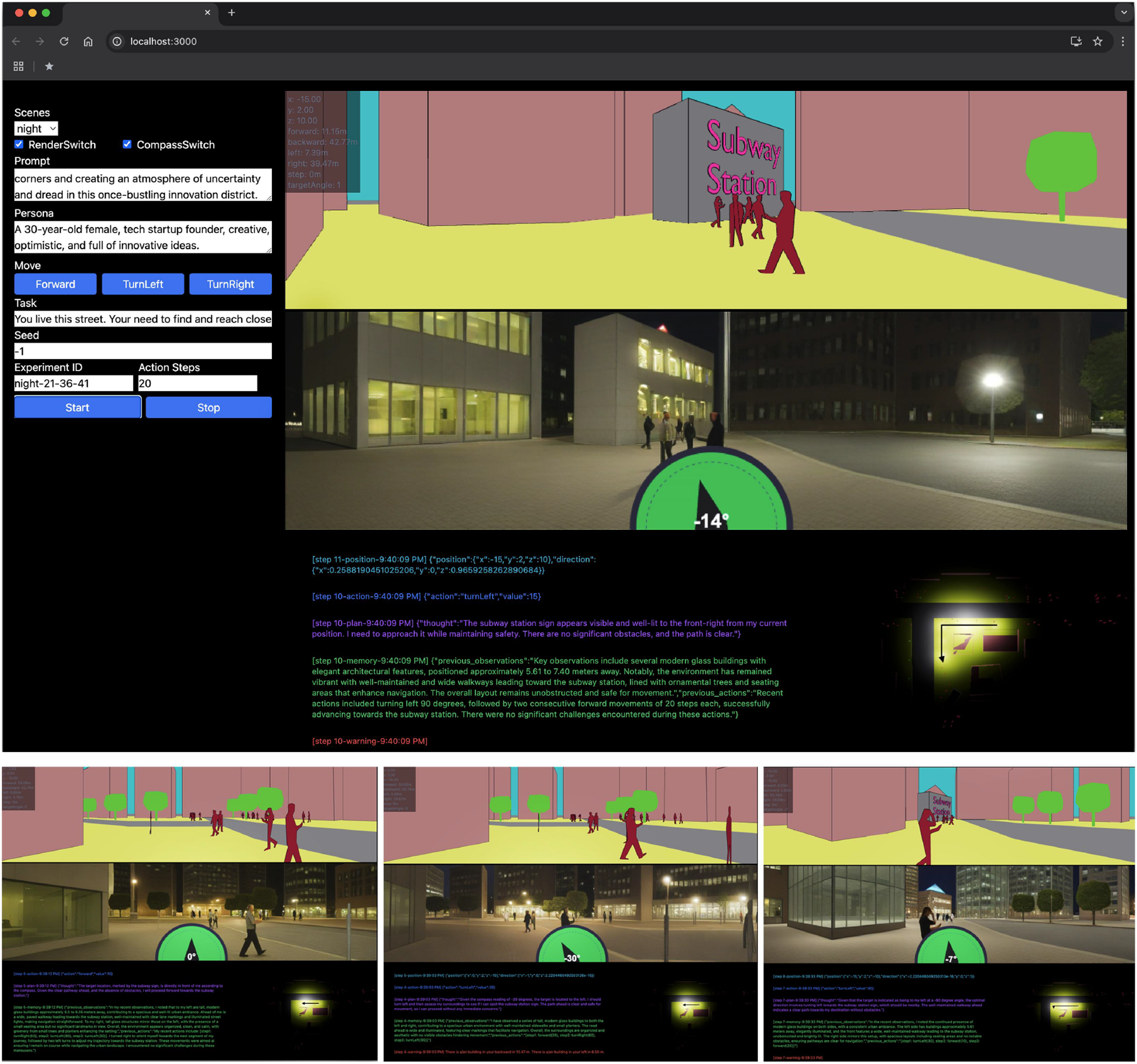
Despite this variety of sensory inputs, human perception of physical environments is complex and multifaceted (Burgess, 2006; Kim, 1999), and the agent’s ability to interpret and respond to these inputs is limited by its current inference capabilities. With the advancement of multi-modal models (Reid et al., 2024), future iterations of TA should explore wider range of sensory inputs, including textual information from signs via OCR, and complex social interactions (i.e., agent-to-agent, agent-to-object, and agent-to-multiple agents (Park et al., 2023)) to enhance the realism and complexity of the agent’s experiences.
Case studies
To facilitate scalable experimentation, we developed a web-based platform for the creation, simulation, and evaluation of TAs. We conducted experiments in both interior and exterior spaces, existing, as well as simulated environments. This section outlines the experiments and the evolution of the platform, from initial tests in real-world settings to controlled experiments in simulated environments. We detail the platform’s development and the iterative refinement of the agent’s capabilities.
Early experiments
Exterior—“Lunch Break in Kendall Square”
Initial experiments explored navigation and decision-making in Kendall Square, Cambridge, MA, where agents sought a “shaded lunch spot” using Google Street View (GSV) images. Each step provided a new GSV image, enabling decisions based on visual data, LLM context, and task objectives. While GSV offered realistic streetscapes, it lacked depth and collision information and prevented scenario modifications (e.g., seasonal or weather variations), limiting experimental flexibility.
Interior—“Laboratory Exploration”
To address these constraints, subsequent experiments employed a 3D laboratory model containing rooms, elevators, and staircases. Agents were tasked with finding “a meeting location with a faculty member” in a familiar environment. Although agents frequently reached target locations, they exhibited decision loops due to over-reliance on immediate visual stimuli rather than sustained reasoning. These early experiments revealed that agent decisions were predominantly driven by immediate visual recognition rather than long-term cognitive processes. Agent paths were largely determined by initial choices, such as arbitrary starting directions or crossroad decisions, suggesting behavioral patterns lacking sustained memory integration. These observations motivated the development of the Chain-of-Thought (CoT) framework, memory module integration, and expanded sensory inputs detailed in Section Sensory Inputs.
Main experiment: “Subway station”
Building on early experiments, we designed a controlled environment to assess how the agent uses Chain-of-Thought (CoT) reasoning and sensory inputs to navigate a daily commute to a subway station. Here, agents rely on evolving observations and memory, navigating without maps or shortest-path algorithms, in order to examine how different environmental conditions and agent personas affect decision-making and experience.
Experiment design
This experiment utilized an urban environment and a uniform task of reaching a nearby subway station, while varying scenarios, agent personas, and physical conditions. The scene included a mix of buildings, streets, urban design elements, and pedestrians. In this experiment, all agents are assumed to be familiar with the environment, as their initiation prompt states: “You reside on this street and you are on your way to work. Your objective is to reach the nearby subway station. To do so, you proceed down the street, turn left, and look for a large ‘Subway’ sign on your left.” Scenarios and personas were combined to form an agent-environment matrix of seasons, location, time, persona, and scene as detailed in Supp Section ‘Scenario Descriptions’ and Supplemental Table S1. Upon reaching the subway station, the agents are informed that trains were unavailable and then randomly assigned one of these sub-tasks: “If the train is unavailable, find an alternative way to get to work.”, “Buy coffee before work if there’s time.”, or “Interact with a friend across the street if encountered.” These sub-tasks examined the agent’s adaptability to unexpected conditions and ambiguous goals. Dotted lines in Figure 5 illustrate the agent’s actions in these sub-tasks.
Diabetic Retinopathy Vision (DRV) Conditions
To examine navigation behavior under visual impairment, we implemented a Diabetic Retinopathy Vision (DRV) filter that simulates reduced contrast sensitivity and blurred vision characteristic (Lee and Afshari, 2017; Kleck). In addition, challenging environmental conditions were prompting the streetscape generation, such as a foggy and dark winter night, lack of proper street lighting, and long shadows and reflections, as shown in Figure 4. The agent persona was modified accordingly: “You are a visually impaired person with Diabetic Retinopathy. You have a cane and are familiar with the environment. Your task is to reach the subway station.” Comparative analysis of the agent’s vision in “Base” and “visually impaired” (DRV). DRV agents’ vision is blurred and has reduced contrast sensitivity, simulating the effects of Diabetic Retinopathy (Lee and Afshari, 2017; Kleck). This filter affects the agent’s ability to perceive environmental cues, leading to more erratic paths and decision-making. The DRV filter is applied to the agent’s visual inputs, affecting its perception of the environment and decision-making process.
Results
In this experiment, we conducted 200 simulations with 3364 decision points (DP), of which 100 (1898 DP) explored the agent-environment matrix, and 100 (1466 DP) compared agents’ performance across “Base” and “visually impaired (DRV)” scenarios. Overall, nearly 80% of the agents completed their tasks within the steps limit, while others failed due to confusion, decision loops, or disorientation. For both successful and failed simulations, we evaluated the agents’ behaviors and decision-making through spatial analysis, thematic and topical modeling, and sentiment analysis (see Supp Section “Simulation Log” for an example). The main objective of these results was not simply to reach the goal, but rather to suggest a way to inspect and refine spatial layouts based on agents’ observations, decisions, and experiences, potentially leading to more human-centered designs. In some cases, “failed” experiments provided more valuable insights into potential shortcomings in the environment, such as insufficient navigational cues or unintuitive layout.
Spatial analysis
An evaluation of agent paths across different scenarios revealed how environmental conditions and urban form shaped the agents’ decisions and overall experiences. As shown in Figure 5, agents operating under the “Night” scenario showed the highest failure rates and most erratic trajectories. Their logs indicated hallucinations and confusion when interpreting the environment (e.g., citing “ancient trees” or a potential “winding river”), suggesting that reduced visibility obscured building edges, signs, and other landmarks. The agent repeatedly attempted to reorient itself, stating that “..I need to reassess my surroundings to determine the best route.” By contrast, agents in the “Winter” scenario followed more consistent, direct paths, with decision points closely clustered early along their routes. The top-terms analysis (Sec. Term Frequency Analysis) points to a focus on weather conditions (snow, ice) and clear urban forms (distinct station entrance, straightforward road). These patterns highlight how variations in environmental cues and conditions substantially influence navigation strategies. As outlined in Sec. Experiment Design, if agents reach their goal (Subway station), they receive an additional sub-task to explore their adaptability to unknown scenarios. Simulation logs show that sub-task behavior involved more open-ended exploration; agents relied on prior observations, memory, and “imagination” to make decisions. For instance, an agent recognized a public plaza beyond the station entrance, inferred potential commercial offerings (e.g., cafes), and reasoned it could be a suitable place to find a coffee shop. These reactions demonstrate the agents’ capacity to associate and extrapolate new possibilities beyond their immediate environment and goals. Spatial analysis of the “Subway” experiment. Each scenario compares successful and failed paths. A path is deemed successful if the agent reaches and identifies the station by declaring “stop”; it is then presented with a sub-task. The top-left figure contrasts a successful and a failed path in the “Base” scenario. The top row in the bottom figure shows the paths of all agents in the remaining scenarios, while the bottom row depicts the aggregated decision points. Agents in the “Night” scenario exhibit higher failure rates and dispersed decision points, whereas those in the “Winter” scenario produce more consistent paths with clustering of decisions early in the simulation.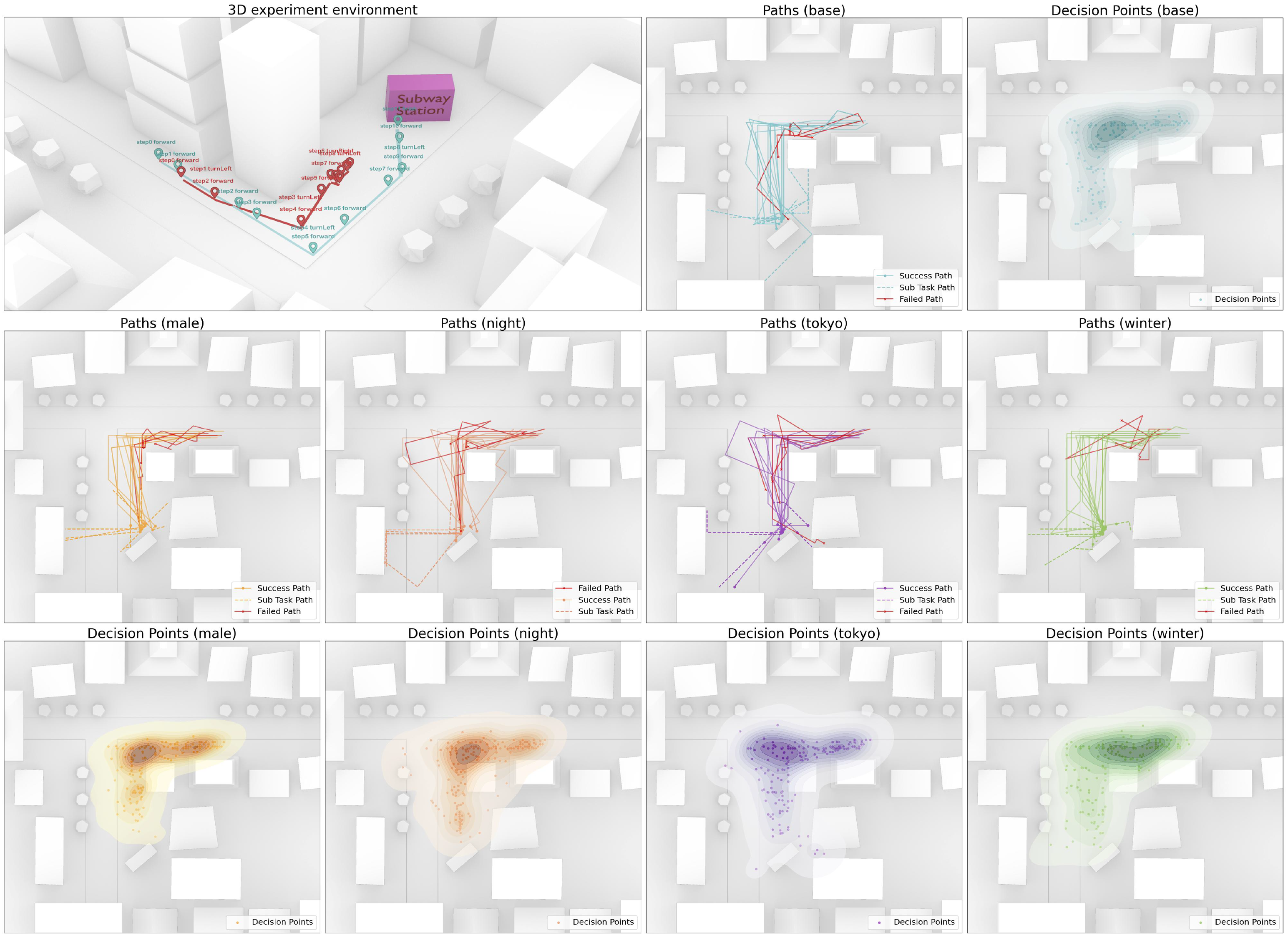
Term frequency analysis
To further understand its cognitive process, we conducted a thematic analysis of the agent’s environmental observations. Across 1898 sim-steps, we recorded 91,340 words in the Planning stream, 156,663 in the Memory stream, and 219,742 in the Observations stream. We extracted these from the simulation steps logs and applied tokenization, lemmatization, and n-gram analysis (Jianqiang and Xiaolin, 2017). Subsequently, we used term frequency-inverse document frequency (TF-IDF) vectorization to identify the most prevalent features (Kantardzic, 2011). These features were then clustered into key topics using an LLM (Achiam et al., 2023). Figure 6 highlights the most prevalent terms in the agent’s “plan” stream, organized by scenario. This analysis shows that the agent focuses more on urban and spatial features rather than movement or navigation. Under “winter” conditions, visibility is most prominent, whereas at “night,” navigation takes precedence. The most frequent terms highlight physical and spatial elements (e.g., bricks, glass, and building) alongside navigational cues (e.g., front, clear, and compass). (Top-left) Analysis of the 100 most frequent terms in the agents’ planning stream, grouped by scenario. (Top-right) 20 most dominant terms reflect environmental descriptors (bricks, glass, building), alongside navigational cues (front, clear, compass). (Bottom) Topical clustering performed on observations and planning, clustered into major themes: navigation, visibility, movement, obstacles, and environment. The NLP model extracts key topics, assigning terms based on semantic content and shows their distribution across scenarios. (Bottom-right) Overall, the agent’s focus is primarily on navigation and urban features, with less emphasis on movement. At “winter,” the agent’s focus is on visibility, while at “night,” the agent’s focus is on navigation.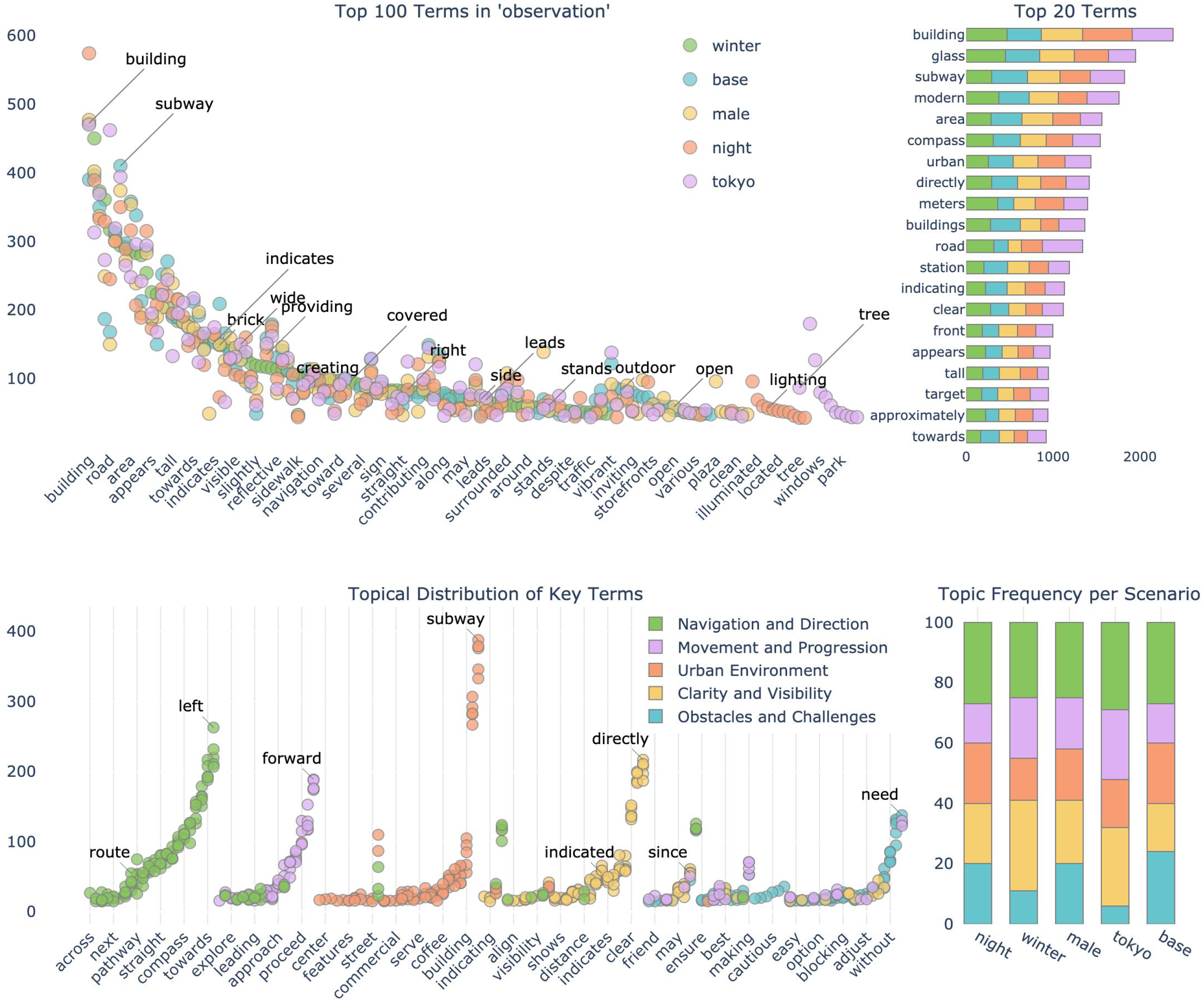
Topical modeling
To better understand the decision-making processes underlying the agent’s behavior, we performed topic modeling on both observation and planning streams. Key topics were extracted using LLM clustering and semantic analysis (Petukhova et al., 2024), categorizing the terms into navigation, visibility, movement, obstacles, and urban environment. Latent Dirichlet allocation (LDA) (Blei et al., 2003) was then applied to the agent’s logs to identify semantic themes. We used the Natural Language Toolkit (NLTK) and GPT-4 for textual analysis and initial semantic categorization (Achiam et al., 2023; Hutto and Gilbert, 2014). As shown in Figure 6, terms related to urban features and navigation predominated, while fewer references pertained to movement, obstacles, and visibility. As indicated in Figure 5, the 3D environment included shortcuts and detours to allow variability in the agent’s choices. Despite these alternatives, the agent consistently selected the main road. Its behavior may reflect its initial conditions, prior knowledge, or reliance on navigational aids (discovery map and compass). As discussed in Sec. Discussion, further research should explore the agent’s adaptability to dynamic and open-ended environments, including variations in pedestrian flows, weather, unexpected obstacles, or interaction with other agents.
Sentiment analysis
To evaluate the agent’s inferred emotional state, sentiment analysis was performed on its thought and observation streams using the Natural Language Toolkit’s (NLTK) VADER sentiment analyzer (Burgess, 2006; Hutto and Gilbert, 2014). Sentiments were classified as positive, neutral, or negative. The results (Figure 7) reveal differences between successful and failed navigational paths. Although overall sentiment was predominantly positive across simulations, failed paths distinctively exhibited clusters of negative sentiment co-occurring with repetitive “search” actions. This pattern suggests agent “frustration” or “confusion” when unable to find a path. In contrast, successful paths generally showed more consistently positive sentiment and fewer “search” steps, correlating with more confident navigation. Following primary task completion, agents received a sub-task (see Experiment Design), during which sentiment frequently became more negative, and “search” behaviors increased, likely reflecting uncertainty due to less defined objectives. Correspondingly, agent paths during sub-tasks were typically more exploratory (Figure 5). Notably, for the sub-task “Interact with a friend across the street,” sentiment was more positive and actions more deliberate. This may indicate increased agent engagement with less ambiguous objectives, even without explicit navigational cues. Since this analysis is based directly on the agent’s thought and observation streams, the captured sentiment primarily reflects immediate reactions to the environment and task, rather than complex emotional states. Future work could integrate explicit emotional reflection within the agent’s CoT framework; For instance, by prompting the agent to articulate its “emotions” or “motivations”—to achieve a more nuanced understanding of its cognitive and affective processes. Sentiment analysis of the agent’s “thought” and “observation” streams. Each row visualizes an experiment, where decision points are color-coded by sentiment classified using NLTK’s VADER (Hutto and Gilbert, 2014): positive (blue), neutral (gray), or negative (light pink). The spacing between points visualizes the distance traveled after each decision, if any. In successful experiments, dark-pink dots denote “Finish” steps, later triggering a randomized sub-task, as described in Sec. Experiment Design. Failed paths frequently display clusters of “search” actions—indicative of reorientation efforts—correlated with negative sentiment. Successful paths, in contrast, typically exhibit predominantly positive sentiment and fewer “search” steps. During sub-tasks, sentiments are mixed, and “search” clusters may also appear, as the agent holds less information about the environment and task.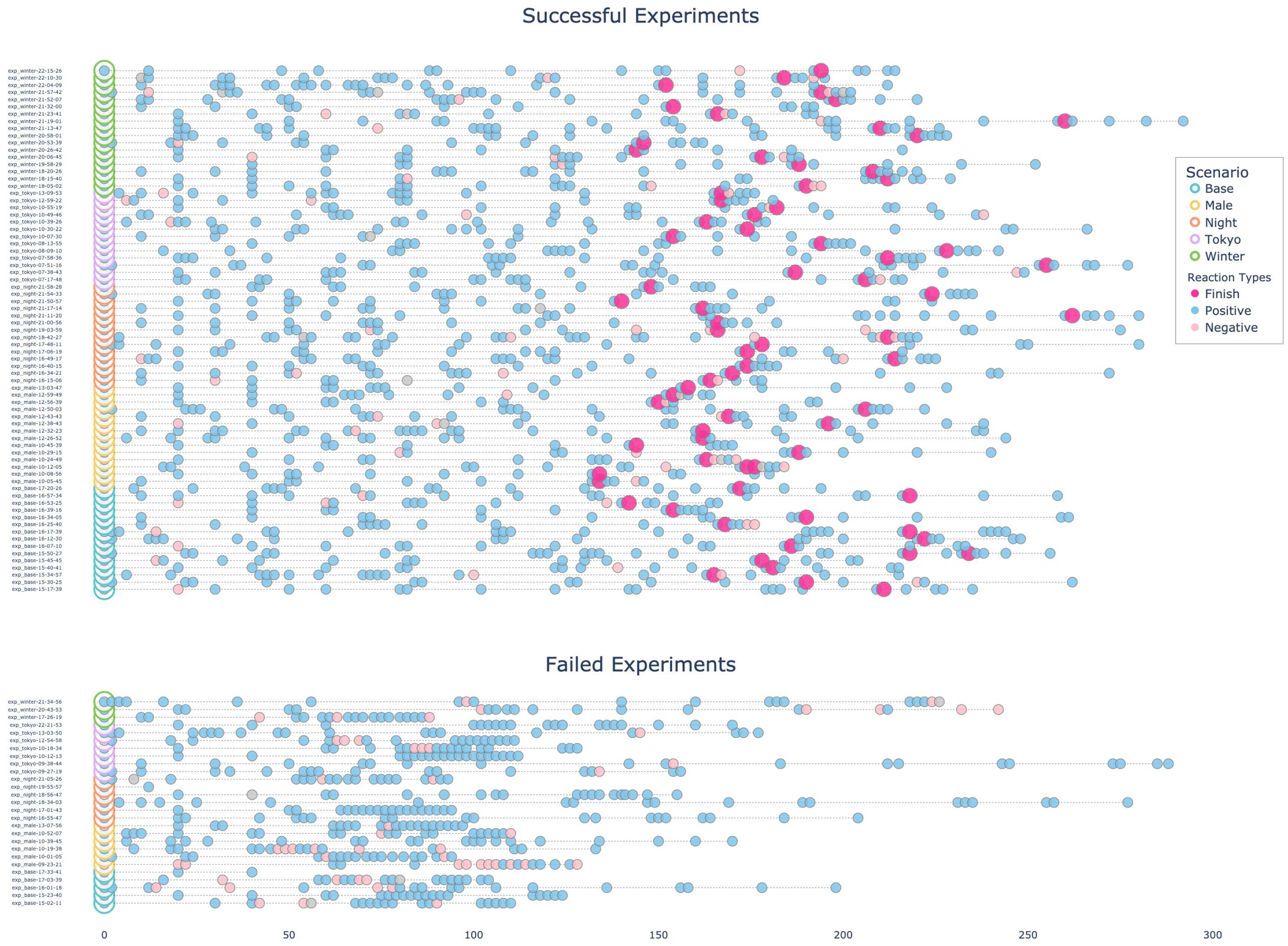
Comparative analysis of “base” and “DRV”
To examine behavior and experience under visual impairment, we conducted an additional 100 simulations (1466 DP) between agents with normal vision (“Base”) and those with simulated Diabetic Retinopathy Vision (“DRV”). Figure 8 shows that DRV agents exhibited distinct behavioral patterns: while successful DRV agents followed more consistent paths, failed attempts were notably more erratic compared to base conditions. Critically, DRV agents rarely corrected their trajectories mid-navigation, suggesting greater reliance on memory and prior knowledge rather than real-time visual feedback and spatial understanding. Behavioral analysis showed DRV agents employed simplified navigation strategies, with 73.5% forward movements versus 65.8% in base conditions, indicating preference for straight-line over complex maneuvers. Task completion rates were reduced by 20% under DRV conditions (60% vs 80%), consistent with the challenges of impaired visual navigation. Linguistic analysis revealed systematic differences in environmental perception and decision-making strategies, as detailed in Figure 9. Term frequency analysis of observation streams showed that while both conditions shared some high-frequency spatial terms (e.g., “building” and “navigation”), DRV agents used fewer diverse descriptors, indicating reduced perceptual richness. Topical modeling demonstrated that DRV agents focused disproportionately on “Obstacles and Challenges” and “Clarity and Visibility” themes, with increased usage of cautionary terms such as “need,” “immediate,” and “carefully,” suggesting heightened risk assessment. Sentiment analysis revealed that DRV agents exhibited more negative affect in both successful and failed simulations, reflecting the increased cognitive load and uncertainty associated with navigating under visual constraints. Comparative analysis of the agent’s paths in “Base” and “visually impaired” (DRV). DRV agent paths are more erratic when failed, but more consistent when successful. DRV agents rarely “correct” their paths, while agents with normal vision adjust more frequently. This suggests that the DRV agent relies heavily on its memory and prior knowledge to navigate the environment, while the agent with normal vision can rely more on its visual inputs and spatial cues.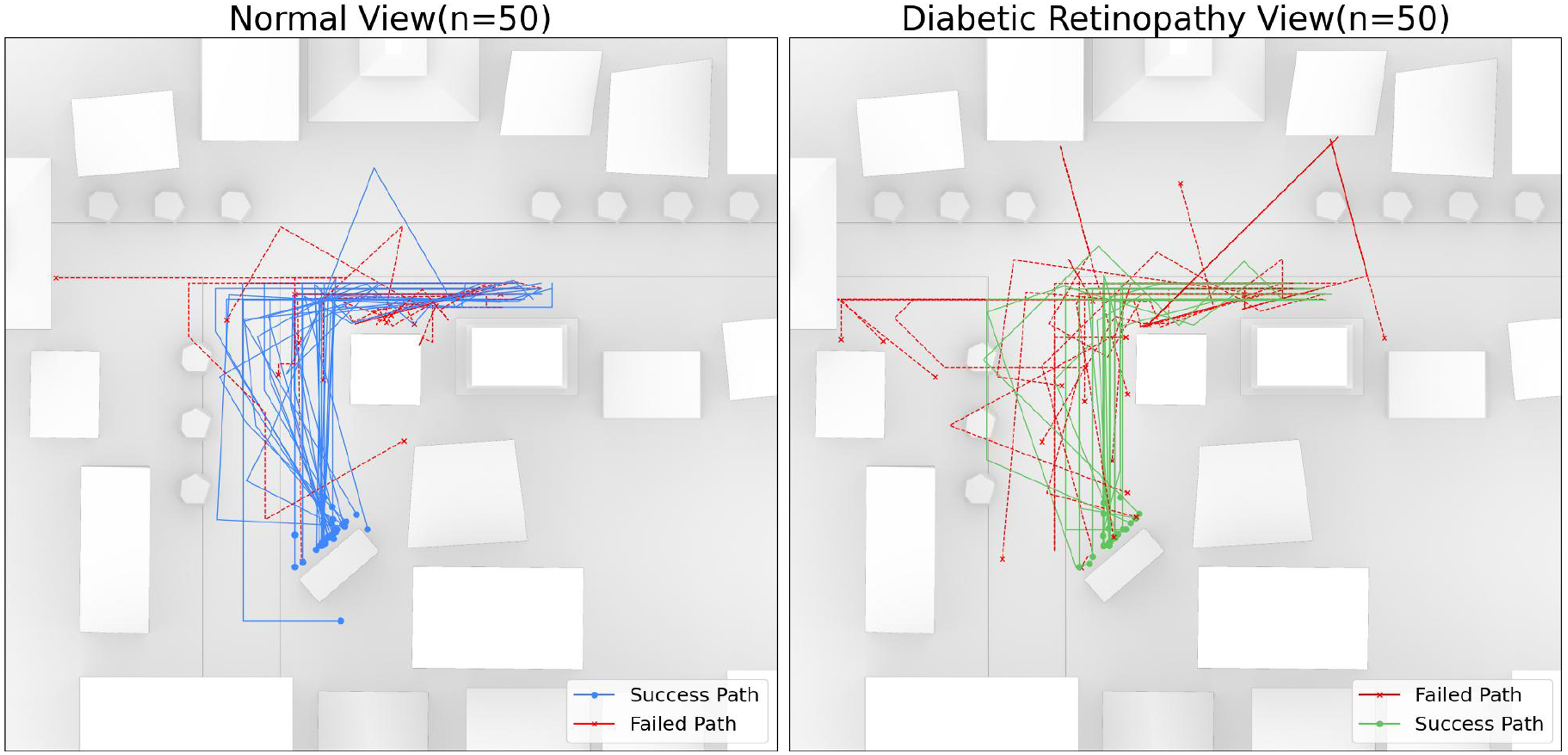
Discussion
We have presented TravelAgent (TA), a novel platform that integrates generative agents with a Chain-of-Thought (CoT) framework to simulate human behavior and experience within built environments. TA models agent decision-making in virtual settings, thereby offering urban-designers, planners, and decision-makers a new methodology to evaluate spatial designs. The experiments demonstrated TA’s capacity for simulating complex agent profiles, behaviors, and interactions and provided insights into the agent’s decision-making, experience, and emotional responses. This section discusses the potential implications of TA for spatial design, alongside the opportunities and challenges inherent in utilizing generative agents for behavioral simulation.
Implications for urban design and architecture
TravelAgent (TA) can augment urban planning and architectural design processes with insights into human-like behavior and experience, particularly concerning wayfinding, spatial legibility, and user experience in yet-to-be built environments.
Wayfinding and Navigation
TA’s capacity to simulate human-like navigation provides insights into the interplay between urban form and pedestrian activity. Analysis of agent paths and decision points enables designers to identify wayfinding challenges and optimize spatial layouts for improved navigability. For example, the observed clustering of decision points in the “Winter” scenario underscores the importance of clear sightlines and distinctive landmarks for effective navigation. Conversely, dispersed decision points in the “Night” scenario may indicate a need for enhanced signage, lighting, and visibility. Incorporating such design considerations can improve wayfinding and reduce cognitive load for pedestrians.
Environmental Legibility
TA simulations highlight the critical role of visual cues and spatial memory in navigation. By examining agents’ observations and planning processes, designers can assess the legibility of different design proposals. The agents’ cognitive outputs, especially in the DRV scenario, suggest that clear landmarks, lighting, and visual cues are crucial for enhancing the clarity and coherence of urban spaces. Beyond DRV analysis, future research could incorporate additional factors impacting human cognitive capacity and states. These may include individual differences in creating accurate discovery maps-akin to Kevin Lynch’s concept of mental maps (Lynch, 1960); the temporal decay of spatial memory (Barnes, 1988); “mental noise” from competing thoughts and distractions, and varying speeds of cognitive processing (Garrett et al., 2013). Modeling these variables would allow for a more granular analysis of how different cognitive profiles interact with the built environment. Furthermore, as indicated in Section Term Frequency Analysis, material properties, opacities, and textures can significantly influence navigation and spatial orientation.
User Experience and Safety
Sentiment analysis of agent logs can identify urban areas where agents exhibit frustration or confusion, thereby helping to address safety concerns and improve overall user experience. For instance, negative sentiments and frequent “search” actions in failed navigational paths often correspond to confusing areas characterized by inadequate signage, obstructed views, or ambiguous pathways, which can cause user discomfort and disorientation. Simulating agents with diverse demographic profiles and personas allow designers to evaluate inclusivity and accessibility, contributing to the creation of more user-friendly and safer urban environments.
Policy Planning
TA has the potential to aid in evaluating urban safety through the simulation of emergency scenarios and disaster responses. Moreover, integrating TA with traditional ABMs could enhance urban planning processes, offering policymakers a tool to assess the impact of interventions such as zoning regulations, transportation infrastructure development, and public space design.
Limitations and future work
TA shows promise in simulating human-like behavior in urban settings but has notable limitations. This section outlines key constraints and future research directions.
Validation and Real-World Evaluation
Despite seeming “human,” distinguishing TA’s simulated actions from actual human behavior is necessary, as TA decisions are contingent upon LLM training data and initial conditions. LLM’s inherent limitations, including accuracy, bias, and potential for hallucinations, may affect reasoning (Ferrara, 2023; Kotek et al., 2023). This is particularly pronounced in 3D environment inference due to the added complexity of translating visual scenes into text-based inputs (Manvi et al., 2024). Consequently, extensive validation is essential, involving human-subject studies, comparisons with real-world data, and benchmarking against traditional ABMs. Future work should compare agent behavior with that of human participants utilizing immersive technologies like VR headsets in analogous environments to assess simulation accuracy and the reliability of the agent’s decision-making processes (Gath-Morad et al., 2024; Langevin et al., 2015).
Prompt Sensitivity and Behavioral Consistency
Agent decision-making is heavily reliant on LLM-based generation guided by prompts. The sensitivity of agent behavior to variations in prompt wording or structure was not systematically explored in this study. Although the CoT framework demonstrated some mitigation of initial prompt variations, future work should incorporate controlled experiments to systematically assess prompt-induced biases and ensure behavioral consistency across diverse prompts.
Agent Diversity and Personalization
TA can benefit from more comprehensive representation of diverse demographic profiles. Beyond the agent-environment matrix and the DRV scenario (see Experiment Design), future work should systemically incorporate attributes such as age, mobility limitations, and cultural backgrounds. Simulating specific user groups, including elderly individuals, children, or persons with disabilities, could significantly improve the assessment of design impact on these demographics.
Environmental Complexity and Dynamics
The environments currently simulated in TA are relatively simplistic, supporting basic agent behaviors like movement and observation. Future research should focus on introducing dynamic environmental elements (e.g., changing weather conditions, variable traffic, or pedestrians) and more advanced agent behaviors, including object interaction and three-dimensional movement. Additionally, multi-agent simulations via TA-to-ABM interaction should be developed to model complex social behaviors.
Perceptual Realism and Text Recognition
The current agent model lacks Optical Character Recognition (OCR) capabilities, preventing it from reading textual information such as signs or street names, which are crucial for human wayfinding. This limitation arises from the existing image generation pipeline, which prioritizes simulation speed and iterative design flexibility above the consistent generation of readable text. Future work should focus on incorporating more robust image generation and visual perception modules that produce and infer consistent and detailed environmental cues (Hurst et al., 2024).
Computational Efficiency
TA simulations are computationally intensive due to the demands of sensory processing and CoT analysis; A single step may take up to a minute to process, including image generation, segmentation, and multiple LLM inferences. Performance optimization, through methods such as parallelization or the integration of hybrid ABM logic, could alleviate these resource requirements.
Conclusion
TravelAgent (TA) is a novel platform designed to simulate human behavior and experience in built environments by integrating pedestrian-level generative agents and a Chain-of-Thought (CoT) framework. TA enables designers, planners, and architects to evaluate spatial configurations, assess user interactions, and enhance the performance and functionality of their designed spaces. Experimental results demonstrate TA’s potential to provide valuable insights into wayfinding, environmental legibility, and user experience. Despite its promise, TA’s current implementation requires further validation, increased environmental complexity, improved computational efficiency, and greater agent diversity. Addressing these challenges will enable future iterations of TA to become an integral part of the designers’ toolbox, allowing the evaluation and optimization of designs based on human-centric criteria and feedback.
Supplemental Material
Supplemental Material - TravelAgent: Generative agents in the built environment
Supplemental Material for TravelAgent: Generative agents in the built environment by Ariel Noyman, Kai Hu and Kent Larson in Environment and Planning B: Urban Analytics and City Science.
Footnotes
Correction (July 2025):
The article has been updated with grammatical errors since its original publication.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.