
Abstract
In the past sixty years, network analysis has become a valuable analytic tool in the study of interpersonal relationships and also in the construction of spatial relationships within urban geographies. Researchers have applied network analysis in a wide array of spatial applications; however, the power of network analysis has yet to be applied to understanding patterns in residential mobility. Residential movement patterns take place over longer time scales and potentially greater distances than daily journeys or commutes, but equally create networks connecting places and people. This research demonstrates how applying network analysis to residential moves may lend insight to open questions in the study of residential mobility, using fine-grained data on residential moves held by the city of Zurich, Switzerland. By creating a weighted directed network linking locations on a 400 meter coordinate grid with residents moving between them, the work demonstrates that network analysis can reveal geographies that overwrite the political boundaries commonly used to categorize residential spaces in the city. The new geographies produced by this method capture a wholistic picture of moving behaviour independent of reported residential choices. By tracking completed moves rather than stated aims, the uncovered mobility geographies sidestep the common categorisation of voluntary versus structurally determined residential choices, aggregating accumulated choices to demonstrate some of the geographic specificities of residential moving behaviour.
Introduction
How or whether people make their own residential mobility choices remains a critical open question in the field of residential mobility (Rérat, 2020). These questions have broader applications to urban planning policies focused on housing, affordability, access to resources, displacement, and population segregation. Meanwhile, the analysis of spatial networks, and spatialized social networks, has ballooned as researchers seek new applications for integrating graph theory into spatial as well as social geographic analysis (Ye and Andris, 2021).
The paper has three goals. First, the paper offers a proof of concept for the application of spatial network analysis in residential mobility studies. It demonstrates how applying graph theory to residential moves between locations can reveal new patterns of urban residential mobility that supersede political boundaries or commonly perceived geographic areas. In doing so it broadens the idea of what can be used effectively as edges and vertices in spatial urban network analysis. Second, the paper shows how the patterns revealed using network analysis on residential move data demonstrate the geographically constrained nature of residential moves, even if made within a framework of choices (Ham, 2012). Third, the paper calls attention to a strategy for circumventing the participation biases of social media and technology-based data sets, such as mobile phone records, in spatial network analysis (Ye and Andris, 2021). It does this by using the detailed population registers common in several European countries, while noting that these population registers are less globally available than social media datasets and do incorporate some biases of their own.
In the following, I highlight recent advancements in spatial network analysis, describing how networks of social interactions have been spatialized, and how spatial networks have been created from diurnal and weekly urban mobilities using location-based nodes. I detail the data used and the method for constructing a residential mobility network in Zurich, along with the choice of clustering algorithms and analysis of detected clusters for significant demographic and structural characteristics. I show how the clusters detected have coherent geographic boundaries, as well as distinct housing characteristics and demographic makeup, creating new ‘neighbourhoods’ of residential mobility. Finally, I discuss how these clusters might inform our understanding of how people choose to move, and what potential applications these insights have for planners addressing housing within the city.
Urban spatial networks and applications to residential moves
Since the mid-twentieth century graph theory has been applied to transportation networks (Kansky, 1963), and been proposed as a valuable tool in the analysis of urban systems and flows (Nystuen and Dacey, 1961). Over the past several decades interest has grown rapidly in applying network analysis to urban dynamics, yielding insights in drawing new geographic territories, understanding urban vitality and lifestyle, and assessing user behaviour and transit networks.
New territories drawn by networks take different forms. Researchers have assessed the density of people moving between spatial locations on daily or weekly time scales, using network analysis to detect polycentricity or other spatial usage configurations in urban areas (Bawa-Cavia, 2011; Zhong et al., 2014). Another new type of urban territory derives from human connection and communication networks, such as remapping Great Britain through clusters where people are more likely to talk with one another (Ratti et al., 2010). Researchers have drawn networks mapping mafia interactions (Ye and Andris, 2021), new geographies of disaster response (Yang et al., 2021), gang rivalries and violence (Radil et al., 2010), and family migrations over generations (Koylu et al., 2021).
Network analysis has also been used to measure urban vitality. Places seen as nodes and people moving between them as edges on diurnal scales can flag critical properties or areas to characterize urban lifestyles (Ma et al., 2024). Mobility data can demonstrate the flow and density of people moving through urban places throughout the day (Sulis et al., 2018). Researchers also use network analysis to evaluate street networks for shortest paths between places, and how integrated or isolated specific neighbourhoods might be (Penn, 2003).
Researchers have studied daily mobility networks within the city via metro cards (Zhong et al., 2015), and how daily mobility routes can be self-segregating (Heine et al., 2021). Analysis of longer distance travel and communication networks has uncovered new social patterns (Larsen et al., 2006), and route-based similarities and route optimization analysed through graph theory applications (Agourogiannis et al., 2021). To date, no recent studies have applied network analysis methods to urban development and residential migration or mobility.
While recent network analysis has not focused on residential mobility, some of its earliest applications depict neighbourhood transformations based on residential moving behaviours. Schelling and Coleman’s foundational work on the relationship between micro-motives depicts how localized decision-making can have ripple effects through broad networks (Coleman, 1994; Schelling, 1978), and modelling these behaviours in residential preferences show their specific ramifications in increasing neighbourhood segregation. These models show how residential choices, although made individually, when aggregated can result in distinct socio-economic trends in neighbourhood evolution (Clark and Fossett, 2008).
Understanding an individual’s social ties disengages definitions of community from geospatial configurations, expanding ‘community’ to include relationships without geographic proximity (Wellman and Leighton, 1979). However, studies have also demonstrated the critical value of spatial proximity as the defining criteria of certain kinds of community ties (Connerly, 1985). Network analysis gives a structural and quantifiable approach to assessing the relevance of both geospatial ties and relationships unrelated to geographic proximity (Clauset et al., 2004; Wellman and Berkowitz, 1988) and brings both into a more nuanced and rigorous understanding of community structures.
More recently, residential mobility research has established two distinct ways of thinking: analysing individual choices and motivations for mobility decisions, or interpreting aggregated effects of residential moves through assessment of structural constraints (Rérat, 2020). Researchers have found that reasons for moving shift with the distance of the move; moving shorter distances is more affected by housing quality, while moving longer distances is more effected by changing schools or jobs (Niedomysl, 2010). In Zurich, I examine shorter distance moves within a dense and accessible public transportation network, hypothesizing that the motivation for moving might be driven by characteristics in the housing supply.
Cities around the world face housing crises; in Zurich the most pressing problem is a vacancy rate that has been stubbornly low for decades. To address the low vacancy rate, and ensure a supply of reasonably affordable housing for expected future growth, the city of Zurich has been executing an ambitious building plan, through public and privately funded channels, to increase overall housing stock and the percentage of affordable housing over the last two decades. The city added 16,266 new apartments between 2010 and 2016, for a total of 219,950 at the end of 2016. This time period therefore offers an opportunity to study how new housing supply might impact residential moving choices within the city.
I partially bridge the division between individual choices and aggregate affects by networking all completed moves within the city, to demonstrate the effects of both executed choices and structural characteristics that constrain those choices. Marrying community detection in network analysis to assessment of patterns in residential mobility counts every individual choice made to move and executing accordingly, without reference to the motivation for these choices. This method removes the biased filter of self-reporting motivation in residential relocation decisions (Coulter and Scott, 2015), instead building maps of new self-contained residential regions from documented, enacted moves, while explicitly abstracting the mobility analysis from geographic constraints. The resulting moving communities, remapped back onto geographically space, reveal the aggregate effects of individual choices, and the geographies they draw, without taking prefigured geographical bias into account.
There is ample literature on international or long-distance migration, but less that focuses on local and regional moves (Coulter et al., 2016). Between 2010 and 2016, 32%–36% of all residential moves into, out of, or within Zurich were internal to the city. As a substantial percentage of all moves, and also as moves more likely to be associated with housing supply and quality (Niedomysl, 2010), this research focuses on internal moves to assess their relationship to the geographies of the city and the new construction undertaken during this period.
Methods
Below I describe the Swiss register data used for this project, the residential mobility network structure, and the clustering algorithms used to detect mobility clusters. I map the network clusters onto Zurich geography and detail the attributes of each detected cluster. Finally, I test the significance of the difference in attribute distribution between clusters, to uncover whether the clusters detected by network analysis reveal patterns distinct from what might be randomly generated.
Data
The first dataset is from the Swiss Federal Statistics Office (FSO). In Switzerland, every resident registers their address with their local authority upon arrival or birth. When moving, a resident has 90 days to either deregister from one local authority and register with another, or update their address if they stay within the same local authority.
In 2010, the FSO replaced the decennial census, instead collecting and standardizing local authority registers quarterly. The aggregated registers are the primary source of population statistics in Switzerland, and are maintained as annual individual records that include every person’s address. The FSO also keeps a Federal Register of Buildings and Dwellings, including a building’s address, geocoordinates, and information about its construction. The data made available to this project linked the population statistics and federal building register, providing geocoordinates for every person. These geocoordinates are accurate to the metre, locating the entry door for every building. The precision of geolocation allows this study to analyse moves unconnected to the boundaries of city districts. The data available were for each year from 2010 through 2016.
The FSO population statistics data include individual attributes, including date of birth, nationality, and marital status. Because the register data includes every individual’s location at each year, it is also possible to calculate the population turnover and demographic change from year to year at a granular level by matching records for a given area from one year to the next (Cramer-Greenbaum, 2023).
Official rent data are based on surveying samples of the population aggregated by city district, and cannot provide information at the granular level of the federal population and building registers. To analyse average rent prices and apartment size with the same geographic specificity as the individual data, the second data set I used was scraped from multiple real estate listing websites across Switzerland. This data comes from Immomapper, a real estate listing aggregator website (Arndt, 2021), and was available for research purposes from 2017 to 2020. It includes the listing price, apartment size, number of rooms, and geocoordinates of the listing. Although the rental price data and the population data are from adjacent and not overlapping time periods, the rental data still give a reasonable portrait of an area’s price and housing stock profile as these attributes do not change rapidly in the context of Zurich’s rent pricing controls (Debrunner et al., 2020).
Network structure
From the geo-located register data, I constructed a record of every individual move within the city of Zurich from 2010 to 2016. I use moves within the city to focus solely on residential mobility, discounting moves of longer distance better categorized as migration (Rérat, 2020). I created a 400- and a 50-m grid, and assigned the start and end point of each move a label comprised of the northwest coordinates of the grid square in which they were located. The 400-m grid was chosen to approximate a 5-min walking radius as a rough neighbourhood proxy. I performed the network clustering analysis on a 50-m grid square network as well, in order to take advantage of the fine-grained data and conduct the analysis at the approximate scale of individual buildings.
I then structured a weighted and directed graph where the vertices represent each grid square, and each edge represents a move between two grid squares. In the 50 m grid, I removed moves within each grid square as they indicate people remaining in the same building. For the 400 m grid, I removed the same moves within the 50 m grid squares, while retaining moves within the 400 m grid squares as they indicate a very short distance move. Edges were directional based on the direction of the move, and weighted based on the number of moves between each grid square. The weighted network contained 43,751 edges, and 432 nodes. The diameter of the network is six. The node degree distribution is roughly normal with a spike at one, and the edge weight distribution is long-tailed (Supplemental Figure 1).
Clustering
Many different algorithms exist for detecting modularity and communities within networks (Calatayud et al., 2019). Lee et al. (2020) undertake a summary of comparative studies between different network clustering algorithms. Their findings show the Louvain clustering algorithm emerges most often as able to detect the highest modularity within reasonable processing times. In their own comparative clustering for geography keywords, they found the Louvain algorithm to function best (Lee et al., 2020).
I tested two clustering algorithms on networks created from both 400 m and 50 m grid squares: the Louvain and the Walktrap clustering algorithms. Louvain uses a two-step iterative process to create modularity partitions within hierarchical layers. It maximizes the local modularity of nodes, then each community is treated as a node and the cluster modularity is optimized again on small local communities (Blondel et al., 2008). Walktrap is also a hierarchical method using short random walks to create densely connected clusters (Pons and Latapy, 2005). Both were chosen as potentially appropriate to simulate residential moves. While Walktrap simulates flows through a network, akin to residents moving through a city, Louvain communities might offer a better approximation where connections between edges may be to some degree dependent on each other (Smith et al., 2020). As short-distance residential moves are often related – an individual’s moving behaviour may well affect another’s – the Louvain algorithm was chosen for the second half of the analysis.
Mapping
Using the coordinate labels of each grid square, I remapped the clusters detected by both algorithms with 400-m and 50-m grid squares onto the geography of Zurich (Figure 1). The 50-m grid square clusters align well with the 400-m grid square clusters for both algorithms. Both the 400 and 50-m grid square clusters for Walktrap and Louvain have a similar northeast cluster. All maps showed distinct clusters to the south, on either side of Lake Zürich. The size and arrangement of the northwest clusters show the greatest variance between the mappings. Top row from left with modularity: 400 m Louvain (0.288) and Walktrap (0.262). Bottom row from left: 50 m Louvain (0.365) and Walktrap (0.243).
To test the potential of network clustering algorithms to reveal residential mobility patterns independent from the clustering algorithm’s individual method, I compared the overlap between clusters created by each algorithm. I paired each cluster from each algorithm with each cluster from the other. For each pair, I calculated the number of grid squares overlapping (#
Given a cluster C1 from algorithm 1, and C2 from algorithm 2: The comparison matrices for the clusters generated from each algorithm on both the 400 m and 50 m grid networks.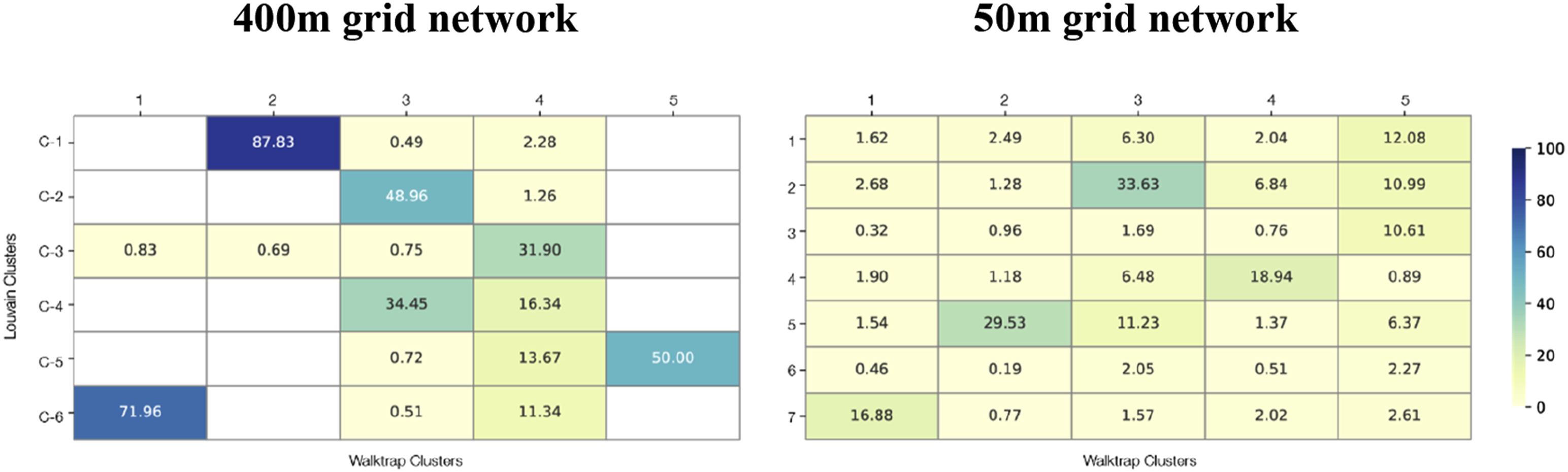
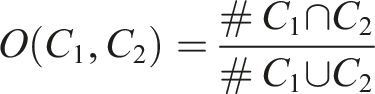
Due to the Louvain algorithm’s multi-level clustering offering the best proxy for residential moving structures, in addition to its widely documented stability and success at modularity detected (Lee et al., 2020), I move forward with the 400 m grid network Louvain clusters as a proxy for clusters detected the network. From these clusters new residential geographies emerge, and I analyse them to uncover whether the groupings display distinct characteristics.
Cluster attributes
From the FSO data, I calculated the average resident age, percentage of Swiss residents, percentage of married residents, and average turnover per 100 people for each cluster from 2010 to 2016. For the same time frame, I calculated the average building age by cluster for residential buildings from the Federal Building Register, and the count of buildings completed between 2010 and 2016. From scraped rental listing data, I calculated the average number of rooms, size in metres squared (sm), price in Swiss francs (CHF), and price/square metre of listed rentals from 2017 to 2020. The analysis shows distinct average attributes from each cluster, implying that the detected clusters might indicate areas with substantially different populations or housing stock.
I tested whether the differences between the cluster averages were significantly distinct, or whether randomly assigned clusters created with an adjacency constraint would produce a similar spread of cluster values. To do this, I took the empirical grid squares representing each node of the network, with their attendant attributes, and randomly assigned them 500 times to clusters of the same size as those detected by the Louvain algorithm, with comparable cluster contiguity. I took the demographic and structural indicators tested on the real groupings, found their average values for all random groupings, and for each attribute and each cluster measured the spread between the highest and lowest cluster value. Finally, I calculated the mean and standard deviation for the 500 randomly generated spreads in each attribute. Figure 3 shows, for each attribute, the mean spread of the random groupings, the standard deviation of the randomly generated spreads, and the spread between the highest and lowest group values in the empirical communities detected by the Louvain algorithm. The last column shows how many standard deviations outside the mean the empirical data is from the attributes spreads in randomly generated groups. For the Louvain clusters, random spreads and empirical standard deviations from the mean.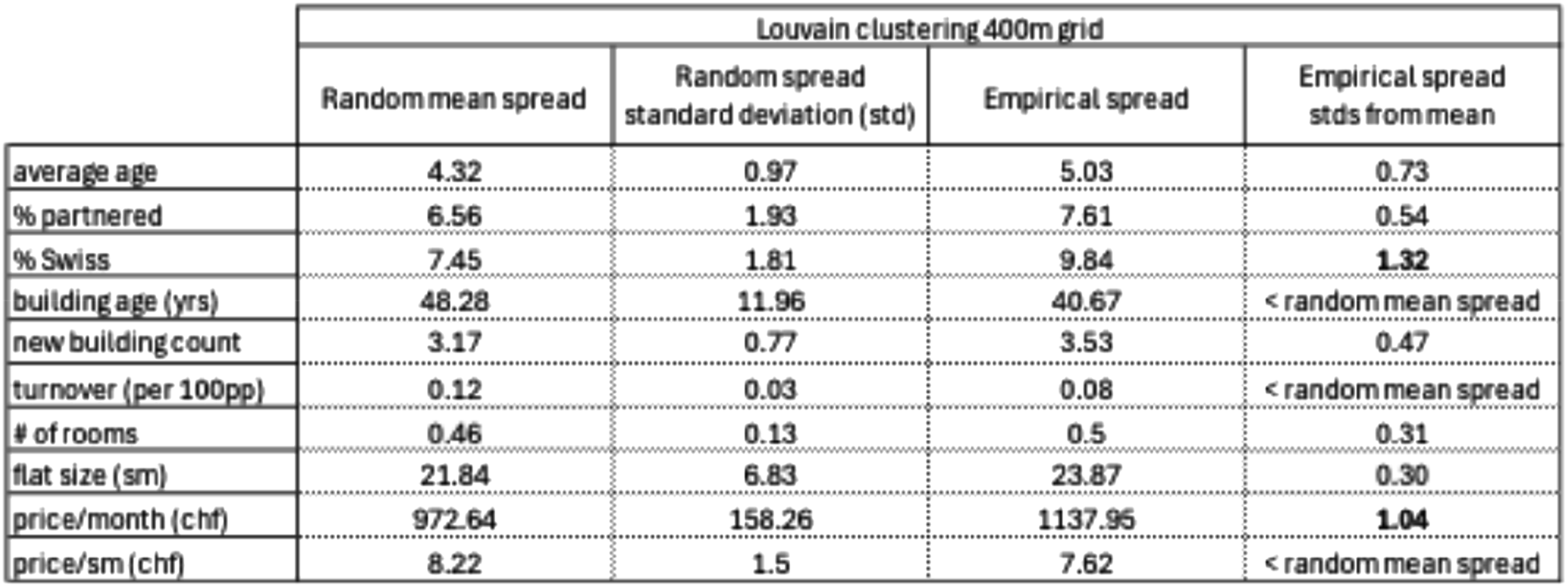
Two of the empirically detected attribute spreads fall more than one standard deviation outside the mean, suggesting that the clustering methods detected clusters with significantly distinct attributes for both citizen status of the population and cost of the housing. The three attributes for which the empirical attribute spread was less than the generated mean spread were building age, population turnover, and the value of housing (chf/sm).
Findings and discussion
The analysis yielded two results. First, the clusters detected by the Louvain algorithm, as well as the Walktrap algorithm, demonstrated a high level of geographic coherence. Second, the clusters had distinct profiles across demographic and structural attributes, some significantly more distinct than might be expected in comparably contiguous clusters generated at random.
Geographies
The high level of geographic coherence among clusters supports Tobler’s First Law that closer distances contain more densely connected relationships, and demonstrates that this law holds true for intra-city residential mobility. These adjacencies are striking given that applying network community detection to residential moves explicitly removes spatial adjacencies from the analysis. The adjacencies that then re-emerge in the groupings delineate clear ‘neighbourhoods’ of residential mobility not aligned with administrative districts. The adjacencies show that city-wide moves are not as common as moves within one’s current area, also demonstrated by assessing pairs with high edge weight and high directionality, indicating some of the more popular moving trajectories in the city. For the pairs with edge weights 10 or higher, representing 25% of moves, both source and destination were all within the same district, with an average move distance of 1124 m, less than half the city-wide average of 2292 m.
Several physical features play a role in the adjacency of the clusters. Both the 400 and 50-m grid clusters had a northeast cluster encompassing everything passed the saddle of the Käferberg and Züriberg hills (Figure 4), indicating the hills as a key dividing point in residential mobility communities. Likewise, the maps showed distinct clusters to the south, on either side of Lake Zürich. The river Limmat also functions as a dividing line between clusters. Louvain moving clusters with geographic features of Zurich and administrative districts.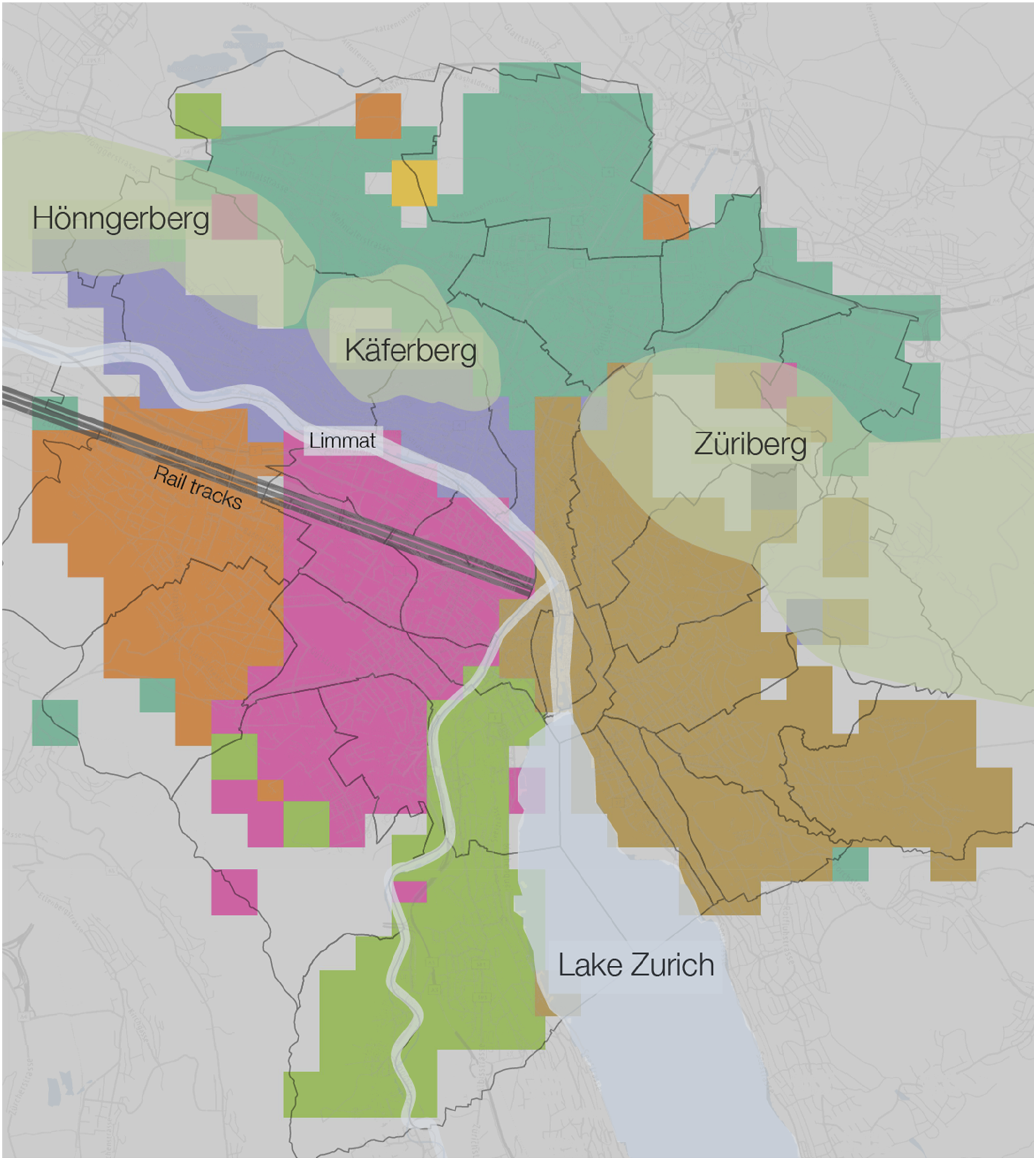
The alignment of physical geographic features with cluster borders shows that physical geography plays a role in the makeup of the city, although the reason why could be many factors. Construction, zoning, and planning permission occur in different phases and at different paces based on the different physical geographies. For example, the cluster beyond the hill saddle covers an area more recently developed, with some of the newest buildings, youngest residents, and least expensive and best value for space rental pricing (cluster C-1, Figure 5). This later development coincides with a significantly different housing stock than other areas of the city more constrained by earlier developments and historic infrastructure. Map and chart of Louvain empirical cluster attributes.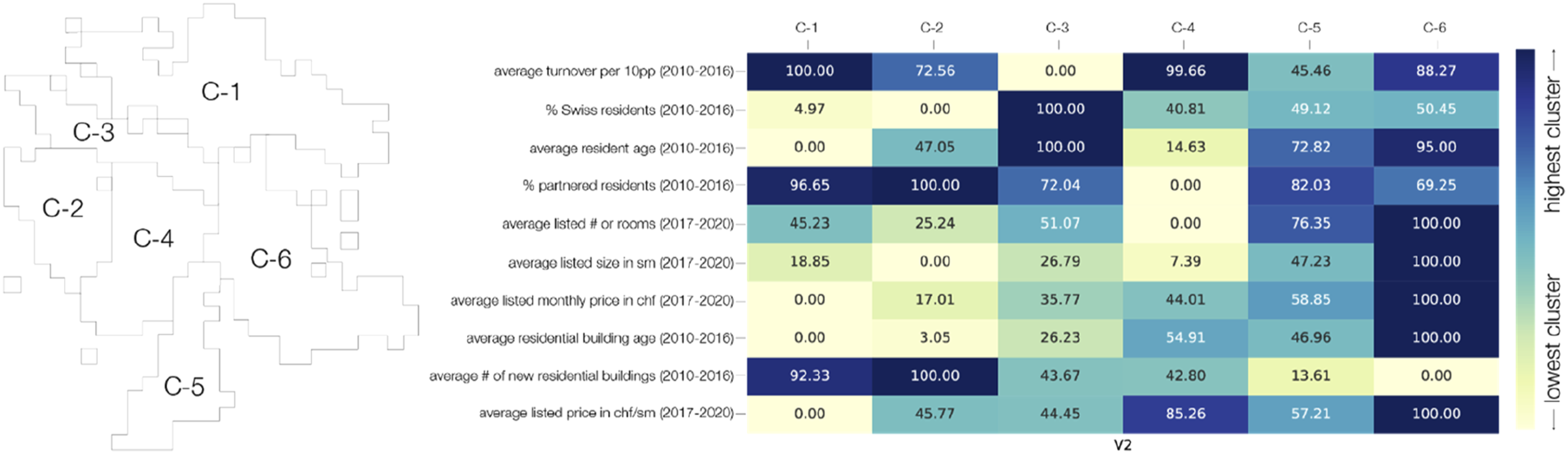
Cluster C-6 along the east side of Lake Zurich is known colloquially as the ‘Gold Coast’, both for its better sun exposure than other areas of the city, and for the perceived wealth of its inhabitants. The cluster has the fewest new buildings, with the most expensive flats both by price and price per area, and flats with the largest average number of rooms (Figure 5). It also has the second oldest average resident age. Cluster C-3 sits between the river Limmat and the hills, off the beaten path and less well connected to the rest of Zurich, with an older, more Swiss, and more stable population. Cluster C-4 and C-2 are distinct but adjacent with no obvious geographic break.
Geographic and other features might represent a psychological barrier effecting neighbourhood delineation in residential mobility choices. In a city as small and compact as Zurich, with an efficient and comprehensive public transit network, the adjacencies of these moving clusters suggest a tantalizing psychology lurking behind residential moves. Physical geography clearly plays a role, but the general adjacencies of the clusters, not always dictated by physical boundaries, indicates a strong prevalence of the population moving within an area circumscribed less by physical geographic factors than by structural or psychological factors.
Profiles and cluster comparison
The mostly contiguous clusters also demonstrated differentiated demographic and housing stock attributes (Figure 5). A principal component analysis of the attributes yields a map showing the distinct characteristics (Figure 6). The map shows the arrangement of principal component analysis attributes in geographic space. The chart and graph explain the overall variance ratio and component relationships.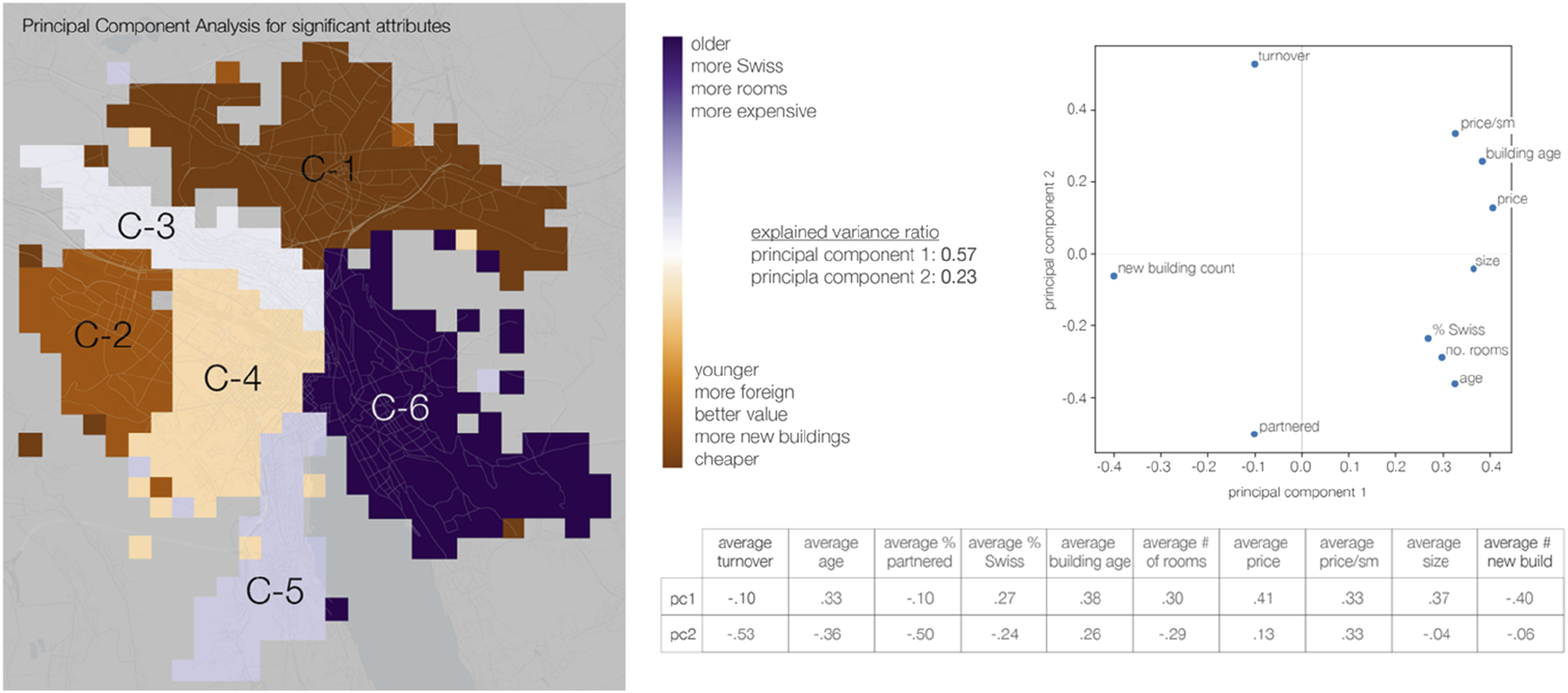
Areas that are older and more Swiss, where the flats have more rooms and are more expensive are shown in purple, and areas that are younger, more foreign, and where the flats are both cheaper and better value show in brown. The count of new buildings per area works counter to almost all other attributes, both demographic and relating to housing stock type and cost. Clusters C-4, C-1, and C-2, areas where flats are cheaper and the population is younger and more foreign, are also the most likely landing spot for people moving into Zurich from outside the city (Supplemental Figure 2).
The percentage of Swiss residents and the cost per month of housing were the two cluster attributes for which the empirical spread between clusters was outside the standard deviation (Figure 3), and they offer some clues to why these distinctive residential mobility groupings might exist. The number of rooms per flat, often seen as a metric indicating where and how families are able to move within urban trajectories, was not a significant differentiator, and did not align with where higher a percentage of residents were married or partnered. The significance of price point, and not the number of rooms, suggests that varying the type of housing stock might matter less for equalizing access to housing than ensuring a mix of housing prices. If equalizing access to housing for varied socio-economic situations is desirable, the primacy of price point over room count indicates a need for some kind of governmental control or intervention in prices rather than initiatives to build flats of varied sizes such as those currently underway in Zurich (Cramer-Greenbaum, 2022). While Zurich has relatively effective soft rent control that tamps down rent inflation across the city, rent control alone does not ensure an even mix of rental prices in all areas.
Population makeup with respect to being Swiss or foreign was another significant distinction between clusters. This distinction might offer evidence that people move, intentionally or not, in ways that create self-selecting groups of segregated sameness regarding immigration status. In identifying grid square pairs with predominantly one-directional moves, I found the most popular moves were likely to be to a destination area with similar demographic and socio-economic characteristics to the area of origin, aligning with the most popular moves typically being within individual city districts. There is an interesting Zurich specific discussion here about cultural allegiance to home territory and highly devolved administrative frameworks within very small local units. It is also notoriously difficult to find an apartment in Zurich, with many leases turning over through word-of-mouth and social networks, which may in turn lead to the evident self-segregation along immigration status lines.
Population turnover fell within the standard deviation of the randomly generated spreads. The lack of turnover’s significance as a differentiator between clusters implies that the stability of an area’s population doesn’t play a role in determining the geographic bounding of people’s residential moving choices, even though perceptions of and concerns about neighbourhood changes such as displacement and gentrification in Zurich abound (Cramer-Greenbaum, 2023).
That straightforward flat size was not a significant differentiator also has interesting implications for planning purposes. Cost mattered in the geographies of residential moving, but overall flat size did not. In a city as compact as Zurich, and one aiming to achieve significant density for its myriad touted benefits (Cramer-Greenbaum, 2024), this finding supports the idea that accommodation for multiple constituencies need not require extensive space.
Limitations
The population register data is highly effective at circumventing the participation bias of network analysis that uses social media or cellular networks. However, while it captures almost the entire population of Zurich, a group likely to be underrepresented is young adults, who might move to Zurich from a family home elsewhere but stay registered in the local authority of their family (Rérat and Lees, 2011). Some residents of Zurich are not registered at all, either in Zurich or elsewhere, although this kind of irregular residential status is uncommon, as local authority registration is critical for accessing most public and financial services. In this author’s personal experience, the Zurich authorities are very good at tracking down someone who doesn’t properly register a change of address when moving within the city.
That the rental listings are from the three years following the population movement data are another limitation, although as mentioned before the Zurich rent controls create limited variability in rental pricing over short time spans. The rental data also only includes those rentals that are advertised on any of Switzerland’s real estate websites. While these websites are the main source for residents to find flats in Switzerland, off the record rental markets exist, where a resident, with landlord approval, can sign over a lease to someone they know. Additionally, rent controls make subletting a profitable option for some leaseholders, and some percentage of Zurich rentals are re-let through official or at times unofficial subletting transactions. Finally, a significant percentage of Zurich renters live in housing cooperatives, where flats are not always listed through rental websites but rather allocated through cooperative policies to co-op members. The above factors have the potential to introduce bias into the rental data set. What the research can claim is that the housing stock attributes discussed above accurately depict the characteristics of official leases in the private rental sector.
Finally, this paper does not focus on regional cohesion outside the limits of city Zurich, which like many cities has a greater metropolitan area surrounding it. Studying regional residential mobility patterns around Zurich, in other cities, or even at a national level would be fascinating research direction outside the scope of this work. While this analysis uses economic information specifically about housing stock only, layering additional person based socio-economic information onto this sort of analysis would also potentially yield interesting results in future research.
Conclusion
This article demonstrates the potential value of network analysis in residential mobility studies to capture a wholistic picture of executed residential choices and the patterns this network of choices reveals. The findings show how clustering algorithms could detect geographically coherent clusters of moves, invisible to more standard analysis methods and independent of political boundaries within the city of Zurich. The clusters also demonstrated distinct demographic characteristics and housing stock profiles, yielding insights on what criteria might govern how people move within Zurich. These criteria could inform planning approaches with targeted aims of residential accessibility and heterogeneity. The article presents this novel approach to demonstrate its potential use and application, as city planning attempts to direct or shape how and where people choose and can move.
Supplemental Material
Supplemental Material - Clustering moves: Spatial network analysis in residential mobility
Supplemental Material for Clustering moves: Spatial network analysis in residential mobility by Susannah Cramer-Greenbaum in Journal of Environment and Planning B: Urban Analytics and City Science.
Supplemental Material
Supplemental Material - Clustering moves: Spatial network analysis in residential mobility
Supplemental Material for Clustering moves: Spatial network analysis in residential mobility by Susannah Cramer-Greenbaum in Journal of Environment and Planning B: Urban Analytics and City Science.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the ETH Institute for Technology and Architecture Fellowship.
Data availability statement
The data used may be provided upon request in anonymized and aggregated form. The individual data records are property of the Swiss Federal Statistics Office and cannot be provided by the author.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.