
Abstract
Participatory value evaluation (PVE) is a novel method aiming at the evaluation of projects from a societal perspective. It aims at establishing which investment projects or investment portfolios (with a portfolio containing multiple investment projects) are likely to be favored by the population, given a limited budget. The approach emulates the decision-making problem faced by policy-makers. The ultimate end of PVE is to evaluate and establish how individuals value attributes of public projects in order to construct social trade-offs between different attributes and investments projects. However, it is important to consider that when investment portfolios consist of more than one investment project, significant synergies (positive and negative) may exist among the projects. This paper proposes a new evaluation framework that allows addressing synergies among projects in the context of PVE, while also offering a highly flexible structure. The approach is tested making use of one synthetic and two real datasets. Results show that neglecting synergies among the utilities of the projects included in the chosen portfolio majorly reduces the model fit and biases the estimators.
Introduction
A well-established practice to address the social evaluation of government projects relies upon the principles of Cost-Benefit Analysis (CBA; van Wee, 2007). CBA, in turn, builds upon the principles of welfare economics and Kaldor–Hicks efficiency. Consequently, a given project would be implemented if its benefits outweigh its costs (including opportunity costs). However, contrasting costs and benefits is not straightforward, as their units and magnitudes are not directly comparable and, therefore, it is customary to express them on a common basis (normally monetary units) in terms of their net present value (Boardman et al., 2017). This is the point, where the evaluation of private and public goods differs: while in case of the former, costs and benefits are monetarized on the basis of private trade-offs (which are known for the decision-maker), the latter requires the use of societal values for non-monetary units. Several authors have argued that there may be major differences between both, as the goals pursued by private/commercial actors (usually maximizing the profitability of an investment project) may substantially differ from societal goals (Gálvez and Jara-Díaz, 1998; Jara-Díaz, 2007; Jara-Díaz et al., 2000; Mackie et al., 2001).
Establishing societal values to monetarize societal costs and benefits is not an easy task. For this purpose, early approaches considered the actual costs and benefits (in monetary terms) that society would experience, that is how costs and benefits would reflect upon the national accounts. Such approaches have been, however, criticized for their pure monetary utilitarianism and for not reflecting the actual preferences of the population (e.g., under this approach preserving the life of retirees has a null or negative value, while travel time only represents a cost if it translates into a loss of working hours or productivity; Bahamonde-Birke et al., 2015). The current approach to establish societal values is based upon the willingness-to-pay approach (WTP), which represents the willingness of individuals to pay an amount of money from their private income for an improvement of their current life conditions (willingness-to-pay) or to accept an amount to tolerate a deterioration (willingness-to-accept, WTA; Mishan, 1971). Hence, the costs and benefits ascribed to a given project would be based on the aggregated WTP/WTA of all individuals and, therefore, it should completely capture changes in social welfare.
One of the main criticisms raised against the former approach is based on the fact that WTP/WTA are derived from the behavior of the individuals as consumers of private or public goods (depending on the costs or benefits being monetarized). While such WTP/WTA measures would directly reflect the potential use and, eventually, the commercial profitability of a project (resembling the evaluation of private projects; Jara-Díaz, 2007), Mackie et al. (2001) postulate that no direct link can be established between the willingness to pay of a certain individual for a given feature (e.g., to reduce its travel time by 1 min) and the value that society as a whole attaches to the same improvement. In fact, Jara-Díaz (2007) shows that as the disutility of price of high-income groups is lower compared to low-income groups (i.e., low-income groups are more sensitive to price changes), the former exhibit a higher willingness-to-pay. Hence, tax money will be over-proportionally allocated to high-income groups (or public projects benefiting those groups) when social appraisal is based on WTP only. This would certainly contradict the traditional goals of taxation (Avi-Yonah, 2006; Slemrod and Bakija, 2017). Consequently, he argues that willingness to pay should not be blindly used for prioritizing public projects.
Furthermore, it is possible that the preferences that individuals exhibit at private level differ the societal level, that is, it is possible that group behavior differs from the sum of the individual decisions of the members of the group (e.g., Ackerman and Heinzerling, 2004; Sagoff, 1988; Sunstein, 2005). To exemplify this issue, let’s consider the provision of infrastructure for handicapped people. The large majority of individuals will not make use of this; however, a large share of the population is still willing to allocate resources to it even if they do not use it. This phenomenon is empirically demonstrated by the fact that such infrastructure exists (in fact, when taking only user’s preferences into account, providing such infrastructure would never be deemed socially rentable).
The existence of this dichotomy between individual’s and group’s choices has been described as early as by Buchanan (1954), but it acquires broader implications when policy-makers need to establish societal values to monetarize the costs and benefits of social projects. In this context, Mouter et al. (2018) define this dichotomy as consumer/citizen duality and present an extensive qualitative analysis on possible causes for consumers’ and citizens’ preferences differing from each other.
For the purpose of capturing societal/citizen preferences, novel approaches have been developed during recent years, such as participatory budgeting (e.g., Cabannes, 2004; Capaciolli et al., 2017; Sintomer et al., 2008) and participatory value evaluation (PVE; Mouter et al., 2021a; Mouter et al., 2021b), with PVE being a more appealing approach, as it allows for more representative participation (taking advantage of technological possibilities and diminishing the bias inherent to participatory budgeting; Wilson et al., 2019) and deriving societal values that are consistent with the principles of welfare economics. 1 In principle, in PVE individuals are no longer treated as consumers of public goods and asked about their personal preferences; instead, they are treated as public resources allocators and asked to allocate limited public budgets to different social projects. This way, individuals are asked to select a portfolio of projects, consisting of one or more projects that satisfy the budget constraint.
Opposite to the classical discrete choice framework, in PVE the respondents are no longer selecting a single option, but they are allowed to select a portfolio (a bundle) consisting of different investment projects. Consequentially, the expected social utility of each portfolio is a function of the social utility of the different projects contained in the portfolio. Dekker et al. (2019) present an elaborate framework to address preferences in the context of PVE and to derive social values in accordance with the underlying principles of welfare economics. They assume that the utility of a given portfolio is given by the sum of the utility of all projects considered in the portfolio (and of the saved resources, in case the entire budget is not allocated). This depiction of utility, however, is limited, as it does not consider that different projects may exhibit important positive (or negative) synergies if they are implemented jointly. Along the same lines, it can be argued that individuals may refrain from budgeting similar projects, or favoring the same group of people, due to fairness criteria, even if, when considered independently, these are the projects exhibiting the highest social utilities in the pool. Similarly, given the fact that (social) marginal utilities are decreasing, the social utility of a given portfolio may be much lower than the sum of the parts, if they result in benefits associated with the same objectives (e.g., two highway projects reducing travel time between A and B). While it is possible to impose the restriction that similar projects cannot be selected, such an exogenous restriction does not seem to be necessary, as it seems better to let decision-makers evaluate by themselves, whether a given combination of projects is meaningful or not.
The aforementioned problem requires the development of a framework capable of capturing gains and losses in utility due to the existence of positive and negative synergies, respectively. The main contribution of the current work is to develop the aforementioned methodological framework. Note that the ability to capture positive and negative synergies among projects goes beyond the limits of the PVE, offering also powerful insights for the evaluation of projects in the context of conventional CBA by tackling one important limitation (namely, that all projects are evaluated independently). Policy-makers also perceive that this is an important problem of CBA (Mouter et al., 2013). Finally, the proposed approach is tested with the help of two illustrative examples (one synthetic database and a real dataset). An additional case study with real data is included in the supplemental material.
Methodological approaches to address PVE data
The MDCEV approach
Given that the focus of this paper is set upon the composition of the portfolios, the proposed methodological approach will substantially differ from the treatment previously suggested by Dekker et al. (2019) and applied in Mouter et al. (2021a, 2021b, 2021c), which is based upon the multiple discrete-continuous extreme value (MDCEV) model (Bhat, 2008). Under the assumptions of the MDCEV, a given discrete item will be consumed if and only if its expected utility is larger than the marginal utility of money (Lagrange multiplier of the budget constraint), or, in the context of PVE, a given project will be selected if its expected social utility is larger than the marginal utility of additional governmental budget (assuming a fixed budget) or of the private consumption (assuming a flexible budget). Therefore, the utility associated with the inclusion of a given project in the portfolio is independent of the inclusion of other projects.
While, under this approach, it would be possible to include the correlation among the utility functions of different projects, this correlation would merely refer to the way, in which the expected utility of the correlated projects is perceived by the decision-makers and not to the utility that is ascribed to their joint inclusion in a portfolio. To illustrate this situation, let us consider one individual favoring private transportation; this decision-maker may ascribe higher utility functions than the average population to road infrastructure projects, which would be captured by including correlation terms in the expected utility functions of such projects, but this correlation does not provide information on whether this decision-maker would prefer including such projects in the chosen portfolio at the same time.
Finally, it is important to note that the MDCEV framework considers that the utility occurs (is derived from) at the level of the different goods being considered (in this case, the different projects) and, consequently, the approach considers error terms at the project level only. Synergies, in turn, occur at the bundle level; thus, error terms at this level are also required. The latter is a major obstacle to the inclusion of synergies into the MDCEV approach.
A new methodological approach at the portfolio level
Because of the aforementioned issues, addressing positive and negative synergies between projects requires treating the chosen portfolios as a whole. Therefore, it is convenient to consider the choice probabilities of the entire portfolios and not of the independent projects and, consequently, to frame the decision as a choice between portfolios, which, in turn, consist of potentially interdependent projects (opposite to the probability of including a given project in a portfolio, as done in the MDCEV approach). This framing, however, may be expensive in terms of statistical and computational efficiency, as it would require considering the entire set of feasible portfolios A
P
(combinations of projects k satisfying the budget constraint B). Under these circumstances, the decision-maker i would opt for the portfolio p providing the highest expected social utility SU so that the choice probability of the portfolio p is given by
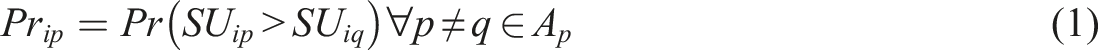
The social utility of a given portfolio, in turn, will be given by a function of the social utility of the different projects k contained in p.

Then, assuming additive linearity, the social utility of a given portfolio can be expressed as
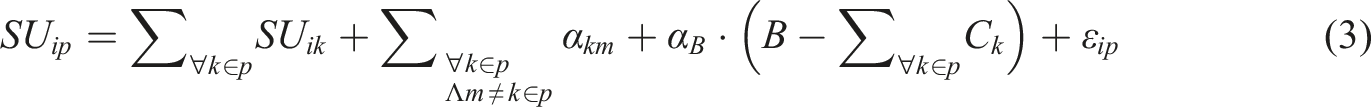
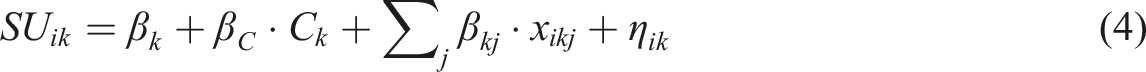
Note that η ik can eventually be ignored, as it is not necessarily required for the model’s estimation; however, from a theoretical perspective, its inclusion is meaningful as it reflects any distortion between the representative (modeled) and the actual social utility of a project. Moreover, all portfolios containing the same projects are likely to be stochastically correlated, as differences between the actual social utility ascribed to a project by a given individual and the modeled social utility should affect all portfolios including the aforementioned project. Consequentially, neglecting η ik would create a very dense cross-correlation structure among alternatives at portfolio level.
The joint treatment of ε
i
and η
ik
can be approached by means of a cross-correlated logit model (Williams, 1977; Williams and Ortúzar, 1982) or a cross-nested logit model (Ben-Akiva and Bierlaire, 1999). However, both require assuming homoscedasticity, which is very unlikely to hold, when the number of error sources (and consequently the magnitude of the error at portfolio level) depends on the number of projects considered in each portfolio. Hence, the Mixed Logit model considering an MNL probability kernel (ε
i
is EV1 distributed; Boyd and Mellman, 1980; Cardell and Dunbar, 1980) seems to be a more adequate alternative. Then, η
ik
can follow any desired distribution and it is usually considered via simulation (as the likelihood function does not exhibit a closed-form expression). Note also that this allows to easily introduce correlation among the utility functions of different projects. Under these circumstances, the likelihood function associated with the answers at the portfolio level takes the following shape:
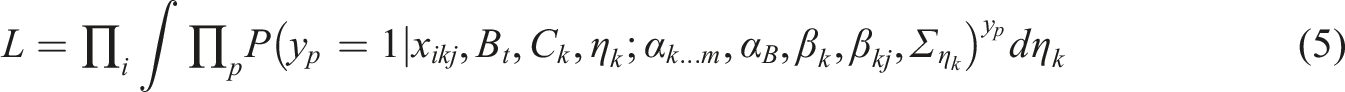
Opposite to classical discrete choice models, in which one ASC has to be fixed for identification purposes, in the proposed framework is not always necessary to fix a PSC. It holds, however, that the maximum number of PSCs and synergy parameters that can be identified equals P − 1, where P represents the total amount of feasible portfolios. However, the actual identification conditions have to be established on case-by-case basis, given the number of projects, the number of feasible portfolios, the possible combinations of projects leading to feasibility, and the answers collected in the experiment (empirical identifiability; at least one PSC would have to fixed if no individual selects the empty portfolio).
Illustrative examples
For illustrative purposes, the framework has been tested with help of real and synthetic datasets. The goal of the synthetic dataset is to be able to control the conditions and to analyze whether the model is capable of dealing with synergies if they actually exist. The real datasets aim at analyzing whether synergies exist in real life and what are the effects of neglecting them. Due to space constraints, only one of the real datasets is presented here while the other can be found in the Supplemental Material.
In the following, we present the results of the illustrative examples.
Synthetic dataset
Values used in the generation of the synthetic dataset.
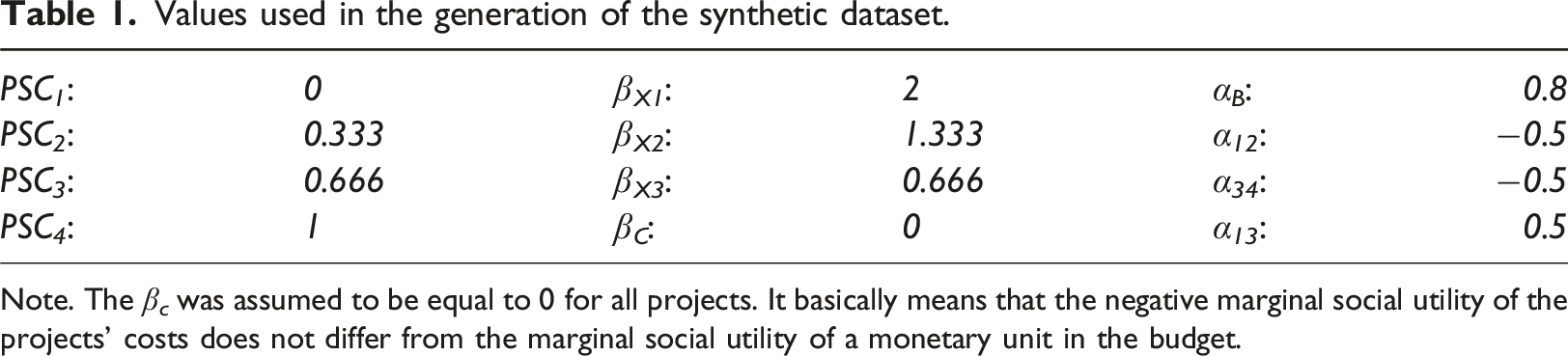
Note. The β c was assumed to be equal to 0 for all projects. It basically means that the negative marginal social utility of the projects’ costs does not differ from the marginal social utility of a monetary unit in the budget.
Estimated parameters. Synthetic dataset.
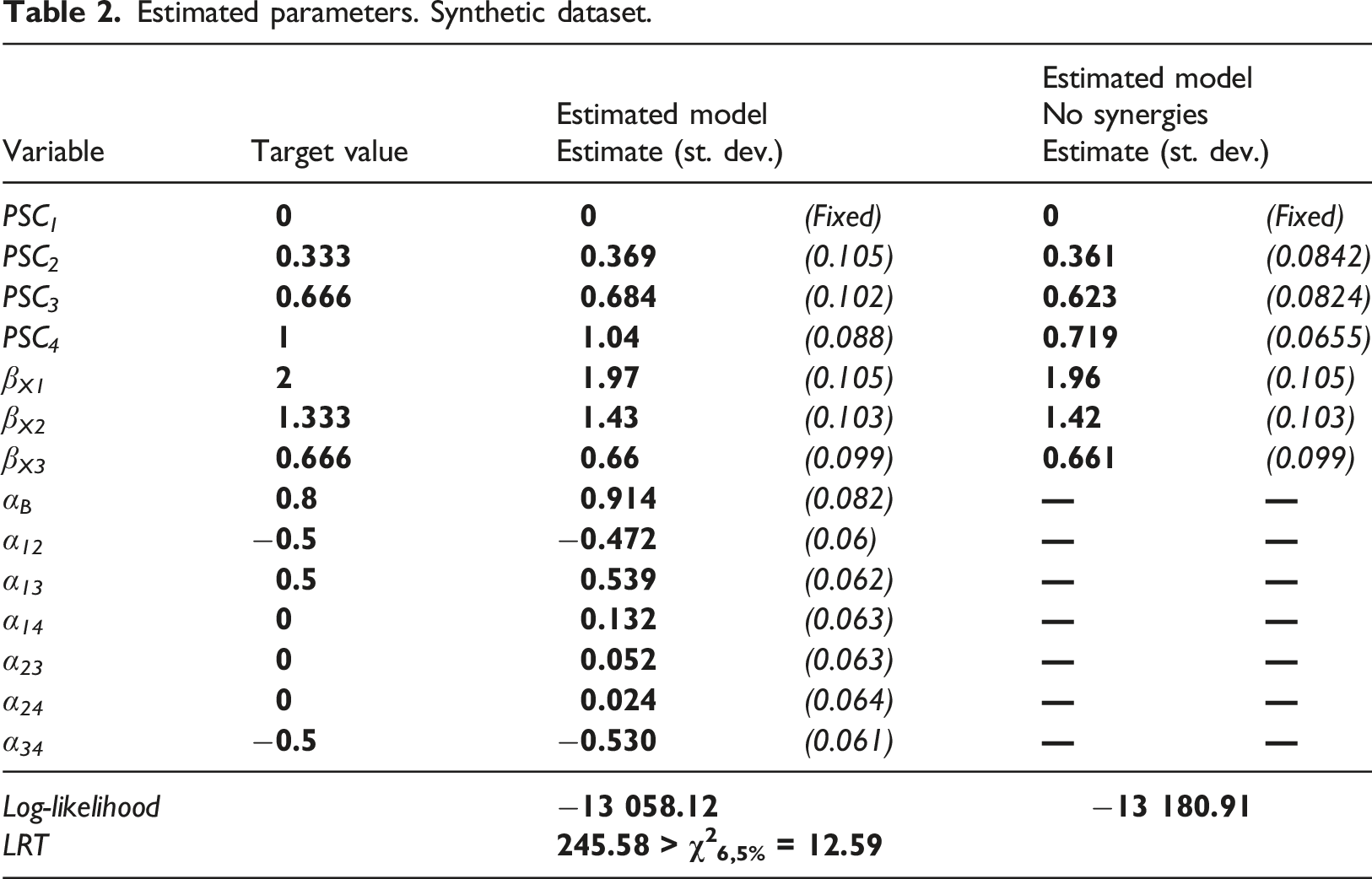
As it can be observed, it is possible to recover the parameters used in the generation of the dataset without major problems, as it is not possible to reject the hypothesis of equality between the estimated parameters and the target values. The only surprise relates to the synergy between projects 1 and 4, which was not considered in the generation of the dataset and was found to be slightly statistically significant in the estimation; however, its effect is neglectable compared with the other estimated parameters. At the same time, the model considering no synergies obtained substantially biased results for PSC 4 (note, that as the model is based on differences, it affects all comparisons including project 4); however, the estimates associated with the projects’ features are recovered without major troubles. Neglecting the synergy parameters majorly deteriorates the goodness-of-fit, as it is shown by the likelihood ratio test (LRT).
Consequently, the synthetic dataset reveals that if the population indeed behaves as assumed in the previous section, the proposed framework is capable of capturing positive and negative synergies between projects. Hence, it provides evidence sustaining the validity of the approach to evaluate the social utility individuals assign to different social investment projects as well as to capture positive and negative synergies among projects in the construction of investment portfolios. Similarly, neglecting the synergies among projects leads to an incorrect assessment of the PSCs (but not of the projects’ features) which is to be expected as the synergies occur at the level of the entire project (same as the PSCs).
Real dataset
The real dataset arises from a PVE experiment conducted by Bahamonde-Birke et al. (2024). It was carried out in the second semester of 2021, in the city of Rotterdam, NL. In total, more than 500 individuals conducted the PVE experiment, which led to more than 1500 observations (each individual stated their preferences under 3 different budgets). 1230 were considered valid for modeling purposes. In the following, we will briefly describe the main characteristics of the PVE. 4
In short, each individual was confronted with a pool of investment projects consisting of 3 Mobility-as-a-Service (MaaS) projects, 2 biking infrastructure projects and 2 public transport projects to be possibly implemented in the city of Rotterdam.
First, three projects consider possible subsidies for Mobility-as-a-Service (MaaS) were considered. Their focus was either set on the general population, on the elderly and socially disadvantaged individuals, or on sustainability, respectively. All possible MaaS investment projects considered different monthly subscription packages to be offered to the users (described in terms of price, number of trips by public transport, number of trips by bike-sharing, free hours of car-sharing, number of trips by taxi as well as the number of users that would use such services) as well as a subsidy that would affect the subscriptions’ monthly costs as well as some of their key attributes. Maas subsidy projects targeting the general population would simply reduce the monthly fee paid by all individuals, while projects aiming at the elderly and socially disadvantaged would only reduce the monthly fee paid by these social groups while also focusing on features to be likely used by them. Finally, MaaS subsidies aiming at sustainability would focus on features such as the integration of MaaS with public transport and bike-sharing. The social costs of the MaaS investment projects were presented as the cost of the subsidies for a period of 5 years.
Investments in MaaS were contrasted with two possible investments in biking infrastructure and two possible investments in public transport (in total all individuals faced seven different investment projects with different characteristics). The biking infrastructure projects were defined in terms of the expansion of the current infrastructure focusing on six key aspects: kilometers of non-segregated on-street bike lanes, kilometers of fully segregated bike lanes at street level, kilometers of fully segregated bike lanes at sidewalk level, kilometers of bike-freeways, number of improved bike-crossings in the city center, the number of available spots in public bicycle parking stations, and costs. Public transport projects, in turn, were presented in terms of the reduction of the average access distance to busses, the number and frequency of shuttle lines connecting suburbs with the subway system, the number of public transport mobility hubs (understood as multimodal stations oriented towards the integration of public transport and other mobility options), and costs. To preserve the comparability with the MaaS projects, all societal costs were expressed in costs for a period of 5 years.
Opposite to most PVEs conducted up to date (as well as the experiment presented in the supplemental material), in which all respondents faced the exact same projects (in terms of attributes), in this study case the projects’ attributes were varied and the choice situations were constructed by selecting one out of six possible implementations (in terms of the projects’ attributes) for each of the MaaS projects and two out of nine possible implementations for each of the bike infrastructure and public transport projects (bike infrastructure and public transport projects rather generic, so the only difference among them is given by their attributes). As a consequence, it was possible to identify not only project-specific constants, but the effect of the different variables.
Definition of the estimators considered in the model.
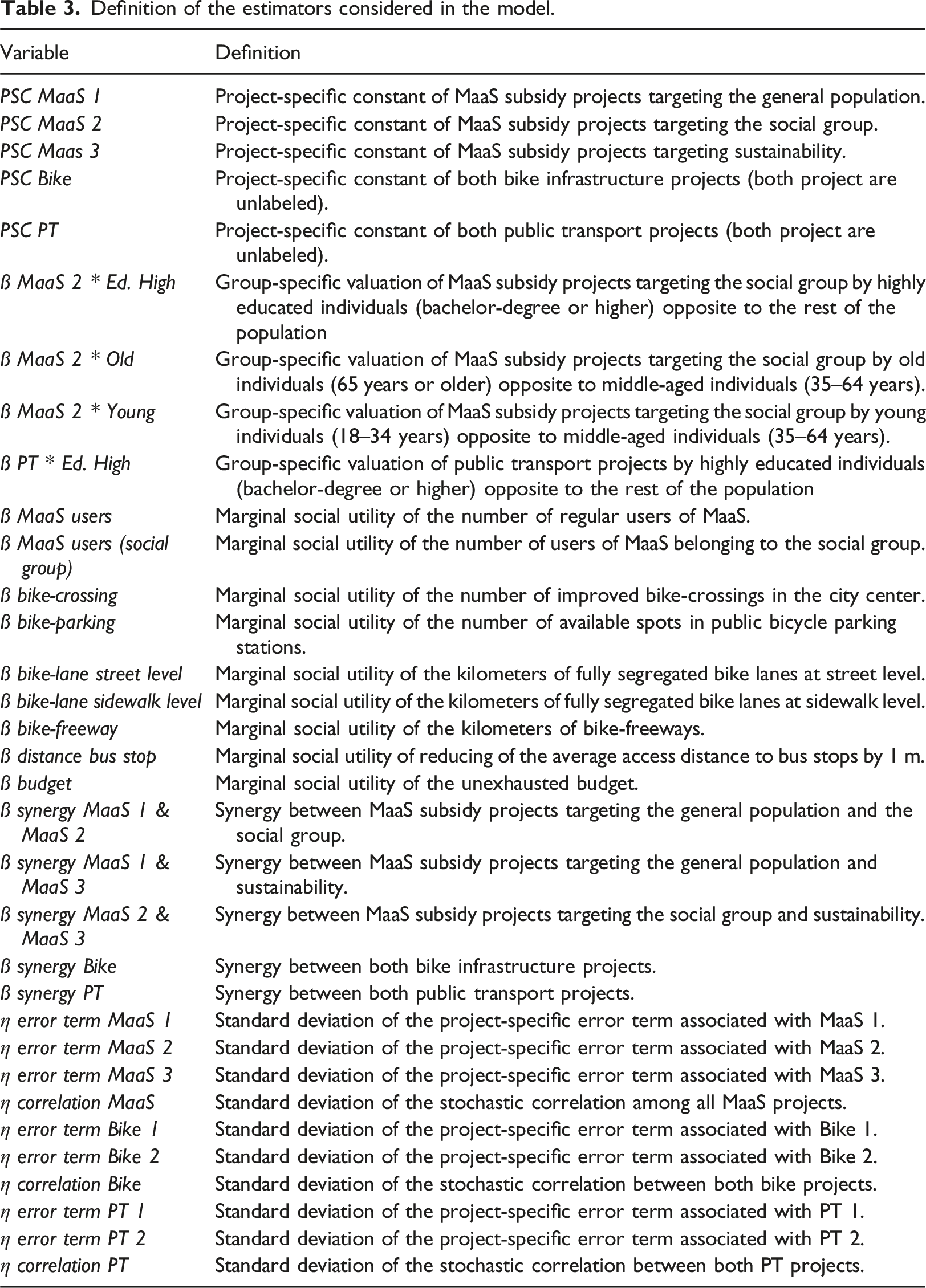
The supplemental material presents examples of some of the projects that may have been faced by the respondents.
Estimated parameters. Real dataset.
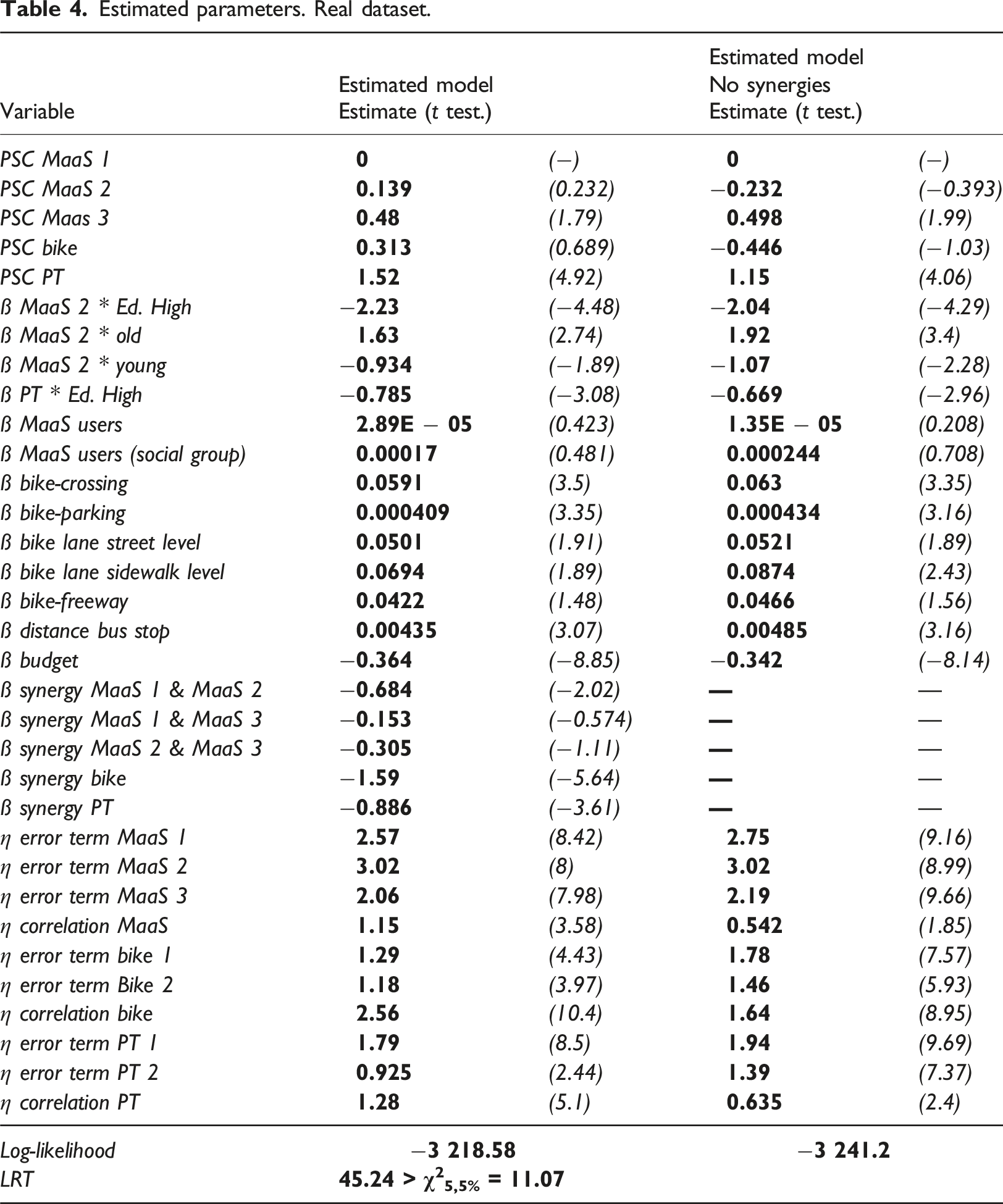
As can be observed, the results fully align with the previous findings. Three of the synergy elements are statistically significant (ß synergy MaaS 1 & MaaS 2, ß synergy Bike, and ß synergy PT). The negative sign of the parameters indicates showing that similar projects are associated with negative synergies. Or in other words, MaaS projects targeting the general population and the social group exhibit each a smaller social utility if both are implemented at the same time. The same occurs if two different bike infrastructure projects or if two different public transport projects are implemented together. This phenomenon aligns with the findings by Bondemark et al. (2022) indicating that individuals strongly prefer to distribute the budget among different kinds of investment projects (variety-seeking behavior). Similarly, neglecting the synergy elements has a significant impact on some of the estimated PSCs, while the estimators associated with the projects’ features do not appear to be majorly affected by it. The goodness-of-fit also exhibits a substantial and statistically significant deterioration.
Additionally, in this case, it is possible to observe that neglecting the synergy elements also impacts the distribution of the random elements. This is not surprising, as the random elements have been specified as error components (Ortúzar and Willumsen, 2011). Hence, the random elements are directly linked to the PSCs and to the synergy elements; consequently, neglecting the latter should necessarily impact the error components.
Discussion and conclusions
The literature on consumer research has well established that when considering bundles of goods, the value of a bundle is not equal to the sum of the parts (Shaddy and Fishbach, 2017). A possible explanation for phenomenon (leading to a larger valuation of the bundle) is given by the complementarity of the goods that compose it (Saini et al., 2019; Yan et al., 2014;). On the other hand, if two goods could be considered to be (imperfect) substitutes, it is possible that the valuation of the bundle be reduced. This negative impact can be explained by decreasing marginal utilities (two or more goods satisfy the same needs and each additional unit of gain leads to an smaller increase in the valuation; Garg et al., 2018) or variety-seeking (O’Donell et al., 2023), although both explanations can be considered to be merely two “flavors” of the same phenomenon (substitutability of goods). When considering public policy and the implementation of public projects, complementarity and substitutability also exist (think, for instance, of building multiple high-speed rails connecting the same cities—substitutability—or a short high-speed rail connecting two parts of a pre-existent network—complementarity). Hence, when considering the selection of public project packages or the design of policies involving multiple decisions, positive and negative synergies cannot be neglected. This issue impacts directly methods to evaluate the valuation of public policies such as Participatory Value Evaluation (PVE).
The present work proposes a new framework to evaluate results from participatory value evaluation experiments, considering error terms both at the levels of the projects and at the level of the portfolios, with the probability being computed at portfolio level. While the main objective of this specification is to capture (positive and negative) synergies among projects, the simplicity of the specification also facilitates the treatment of stochastic correlation among projects and other straightforward extensions: for instance, the framework could be used to capture framing effects or non-compensatory behavior, such as regret minimization (Chorus, 2010), or reference dependence (Bahamonde-Birke, 2018), among many others. Hence, the framework enables the possibility of exploring behavioral aspects departing from the usual homo economicus assumptions, which may prove eventually essential in the context of many PVE experiments. However, the gains in simplicity come at the expenses of computing the probabilities at the portfolio level, which necessarily implies the requirement of specifying the entire set of feasible portfolios, which, in turn, may lead to longer estimation times and losses in efficiency (as the probability function becomes flatter). Along these lines, specifying the entire set of feasible portfolios may become highly complex as the number of projects increases. Furthermore, the fact that the error terms associated with the probability kernel be at portfolio level only necessarily implies that any error term at project level (whose consideration may be crucial, as portfolios comprising the same projects are likely to be stochastically correlated) should be considered via simulation, which would further impact the estimation times.
Hence, the analyst has to ponder whether their purposes and the nature of the projects being considered (which may require considering synergies, non-compensatory behavior, or other behavioral aspects) justify departing from the MDCEV, in order to consider error terms at portfolio level. Nevertheless, it is important to keep in mind that PVE data arises from social experiments; hence, if the analysis aims at considering the data on the basis of the proposed framework, it would be highly advisable to take this into account when designing the experiment, in order to keep the number of feasible portfolios manageable.
In the present paper, the approach has been tested by making use of simulated and real databases. The results from the simulated database illustrate the framework’s capacity of recovering the real parameters used in the generation of the pseudo-population. Furthermore, it shows that neglecting the synergy elements leads to biased results in association with the PSCs, while the estimators associated with the projects’ features do not seem to be majorly affected. The analysis of the real datasets shows that in both study cases (see supplemental material), correlation and synergies in the valuation of social projects do exist, and therefore, it is necessary to take them into account when evaluating the PVE data. Akin to the results obtained with the synthetic dataset, the real data also shows that neglecting the synergy elements has a major impact on the PSCs, but not on the valuation of the projects’ features. It was also observed that neglecting the synergies also impacts the distribution of the random elements when specified as error components.
Summarizing, as shown in all three study cases, neglecting the synergy elements may significantly impact the utility ascribed to the different projects and, consequently, the choice probabilities of the different portfolios. The consequences of the latter are particularly important when using PVE to provide direct policy advice about the projects being evaluated. When aiming at deriving societal trade-offs among different features, the consequences are less important, as they do not seem to be majorly affected by considering/neglecting the synergy elements.
Supplemental Material
Supplemental Material - About positive and negative synergies of social projects: Treating correlation in participatory value evaluation
Supplemental Material for About positive and negative synergies of social projects: Treating correlation in participatory value evaluation by Francisco J Bahamonde-Birke and Niek Mouter in Journal of Environment and Planning B: Urban Analytics and City Science.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data availability statement
This paper postulates a novel method to consider PVE data. The methods is considered by means of 3 study cases: Study case 1: Synthetic data. The data generation process is described in full in the paper. Consequently, there is no added value in the dataset (however, if required, it can still be uploaded). Study case 2: Real data. We do not have ownership of the data and it was shared with us by de Geus. More information can be found under: ![]() . Decision-Making in Participatory Value Evaluation. Master Thesis, TU-Delft. Study case 3: Real data. We have ownership of the data, but it is currently still subject to an embargo period. It will be made available as soon as possible.
. Decision-Making in Participatory Value Evaluation. Master Thesis, TU-Delft. Study case 3: Real data. We have ownership of the data, but it is currently still subject to an embargo period. It will be made available as soon as possible.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.