
Abstract
Background and aims
A substantial minority of autistic individuals score within typical ranges on standard language tests, suggesting that autism does not necessarily affect language acquisition. This idea is reflected in current diagnostic criteria for autism, wherein language impairment is no longer included. However, some work has suggested that probing autistic speakers’ language carefully may reveal subtle differences between autistic and nonautistic people's language that cannot be captured by standardized language testing. The current study aims to test this idea, by determining whether a group of autistic and nonautistic individuals who score similarly on a standardized test show differences in the number of unconventional and erroneous language features they produce in a spontaneous language sample.
Methods
Thirty-eight older children and adolescents (19 autistic; 19 nonautistic), between the ages of 10 and 18, were recruited. Both participant groups scored within normal ranges on standardized language and IQ tests. Participants engaged in a “double interview” with an experimenter, during which they were first asked questions by the experimenter about themselves, and then they switched roles, so that it was the participant's turn to ask the experimenter questions. Participants’ language during the interview was transcribed and analyzed for linguistic irregularities, including both semantic anomalies and morphosyntactic errors.
Results
Group membership accounted for significant variance in irregularity frequency; autistic participants produced more linguistic irregularities than nonautistic participants. Scores on a standardized language test did not improve model fit. Secondary analyses involving irregularity type (semantic vs. morphosyntactic) showed that group differences were primarily driven by relatively high numbers of semantic unconventionalities produced by the autistic group. While the autistic group made more morphosyntactic errors than the nonautistic group, differences in these numbers were only marginally significant.
Conclusions and implications
These findings suggest that a commonly used standardized language test does not adequately predict the number and perhaps type of language irregularities produced by some older autistic children and adolescents during spontaneous discourse. Results also suggest that differences in language use, especially semantic differences, may characterize autistic language, even the language produced by people who score within normal ranges on standardized language tests. It is debatable whether differences reflect underlying language impairments and/or a linguistic style adopted/preferred by autistic speakers. In this paper, we discuss both possibilities and offer suggestions to future research for teasing these possibilities apart.
Previous versions of the Diagnostic Statistical Manual (DSM) included language difference as inherent to autism, but the current version does not (American Psychological Association, 2013). This change was made to account for a subset of autistic children who seem to acquire language typically, while still exhibiting both the social-communication differences and repetitive behaviors associated with autism. The current DSM, the DSM-5, contends that the only area of language for which autistic people will necessarily show divergence from nonautistic people is pragmatics, whereas mastery of other components (e.g., syntax) can be similar, perhaps even identical, to neurotypical people, at least for some autistic people.
There is empirical support for this change. For example, studies suggest that about 25–50% of autistic children use fluent, phrase- or sentence-level speech by the time they are 8–11 years old (Anderson et al., 2007; Kim et al., 2014; Wodka et al., 2013). Not only has research shown that some autistic children can produce fluent sentences but there is also literature showing that a substantial minority of autistic children can score within typical ranges on standardized language tests that assess both expressive and receptive linguistic ability (e.g., Kjelgaard & Tager-Flusberg, 2001). The fact that some autistic children show language strengths despite notable difficulties in other areas in social communication has recently motivated the proposal that autism offers unique support for Chomskian, Nativist theories of language acquisition, since such cases suggest that the instinct and ability to acquire structural language (morphosyntax) can be independent of the motivation to interact socially (Kissine, 2021). While it goes beyond the scope of this paper to discuss this proposal in depth, we use this example to show that the fact that a subset of autistic individuals can score within normal ranges on standardized language tests is so well-documented that it has inspired a theoretical argument about how language can be acquired “normally” by people who show striking differences in other social behaviors from very early ages.
On the other hand, standardized language test scores offer only a limited picture of any person's language competence, and this may be especially true for autistic people. There are several reasons for this. First, the testing context does not reflect the pressures of natural language use. Test settings are quiet, and test-takers can take all the time they need to respond to a given test item. Second, the content of the tests may not effectively capture language difference for autistic speakers. Instruments like the CELF-5 (Wiig et al., 2013) assess linguistic features (e.g., tense-marking and agreement) that are vulnerable in developmental language disorder (DLD), but they were not designed to test for specific areas of language that are reported to be different for autistic language users, like pronoun referencing (Colle et al., 2008; Novogrodsky & Edelson, 2016). Accordingly, evidence has shown that for some autistic children and adults, there is a divergence between their standardized language test scores and their performance on other measures, such as psycholinguistic experiments (Canfield et al., 2016; Eigsti & Bennetto, 2009; Eigsti et al., 2007; Kelley et al., 2006) and spontaneous language production (Wittke et al., 2017).
When researchers have used qualitative and/or psycholinguistic measures to analyze language produced/understood by autistic individuals, including those with typical nonverbal IQ scores, they have identified specific features of language expression, comprehension, and acquisition that show difference for autistic users. For instance, young autistic children seem less likely to rely on object shape for lexical extension (Tek et al., 2008; Tovar et al., 2019), and they confuse semantic-pragmatic pronominal features, such as person and gender, despite mastering pronominal case-marking (Zane et al., 2021). More generally, when researchers analyze the spontaneous language produced by autistic speakers, they frequently observe speakers using language in “idiosyncratic,” but not straightforwardly ungrammatical, ways, even for individuals who score within normal ranges on standardized language measures (e.g., consider language patterns produced by the “higher autistic” group in Volden & Lord, 1991). Luyster et al. (2022) provide a review of this research, documenting how descriptions of “idiosyncratic” language use have been included in some of the earliest reports on autism spectrum conditions (Asperger, 1991). Based on such evidence, Naigles and Tek (2017) offer a hypothesis for language acquisition in autism, the “Form-Meaning Hypothesis,” whereby they argue that although some autistic children can acquire morphosyntax similarly to nonautistic children, they may still show differences with semantics. A recent study corroborates this proposal by showing that autistic children produce more lexical semantic and referencing errors than their nonautistic counterparts during a story-telling task, with no differences in morphosyntactic error rates between groups (Schroeder et al., 2023).
On the other hand, other work has provided evidence that autistic children also show differences in their attainment of certain aspects of morphosyntax, such as c-command (Perovic et al., 2013), verb-argument structure (Ambridge et al., 2015), accusative clitics (in French; Durrleman & Delage, 2016), and agreement marking (Eigsti & Bennetto, 2009). Finally, measures of online processing have revealed other, subtle differences in how autistic people process language. For instance, ERP studies of narrative and sentence processing show reduced N400 responses to out-of-context words as compared to neurotypical individuals, even when comprehension appears intact (Braeutigam et al., 2008; Coderre et al., 2018), suggesting less and/or slower online sensitivity to semantic anomaly. Eye-tracking research suggests atypical processing of anaphora (Nagano et al., 2020; Schuh et al., 2016), despite—again—comprehension accuracy (Nagano et al., 2020).
In summary, when some autistic people score within normal ranges on standardized language tests, their scores may belie subtle differences in their use and understanding of language, which can be picked up in other contexts and by other measures. These differences could be attributed to subtle language deficits that are intrinsic to autism, perhaps because of early differences in social interaction and attention (Bottema-Beutel, 2016; Bottema-Beutel et al., 2020; Mundy et al., 1990; Murray et al., 2008). On the other hand, these differences, especially those that have been described as “idiosyncratic” by researchers (e.g., unusual lexical choice), could simply reflect a differing linguistic style used by some autistic speakers. For instance, one seemingly stylistic (but not erroneous) aspect of autistic speakers’ verbiage is a “pedantic” quality that has been frequently noted in autism research (review in Luyster et al., 2022). This style, which can involve the use of rarer words and surprising combinations of them, could indicate underlying differences in semantic acquisition and neural processing/connectivity (e.g., Fan et al., 2021) or a conscious choice/preference to be creative with language (Werth et al., 2001), or both. Whatever the explanation for them, because such word choices and word combinations are better described as “idiosyncratic” than “erroneous,” it is arguable that this style of speaking is just that, a style, and not a sign of a language problem.
The current study explores whether language spontaneously produced by older autistic children and adolescents contains more instances of unconventional and/or erroneous lexical items, phrasing, and phrase structure as compared to nonautistic peers, despite both groups scoring within normal ranges on a standardized language test. Importantly, we use the CELF-5 as our standardized language measure, as this test has been documented as being a valid and reliable assessment for the diagnosis of child language disorders (Denman et al., 2017). To examine a possible disparity between test scores and interactional language use, we recorded and transcribed children's language produced during a semistructured conversation with an adult. Coders identified linguistic irregularities, including both semantic unconventionalities and morphosyntactic errors, from written transcripts of interactions (therefore, stripped of prosodic and visual information). Findings have the potential to expand on previous research by determining whether language differences are apparent in the language of older autistic children and adolescents who score within and above normal ranges on an omnibus measure of structural language, rather than vocabulary and/or verbal IQ tests, which have frequently been relied upon by previous researchers to provide standardized scores of language skills for autistic participants (e.g., Schroeder et al., 2023; Volden & Lord, 1991).
Based on the existing literature, we predicted that autistic participants would produce more irregularities than nonautistic peers. Additionally, based on the Form-Meaning Hypothesis (Naigles & Tek, 2017) and other supporting research, we hypothesized that differences would be specifically driven by semantic unconventionalities. Finally, we predicted that CELF-5 scores would not correlate with the number of irregularities in the autism group, since we expected that the types of irregularities prevalent in autistic discourse would not be captured by this test.
Methods
Participants
We recruited 38 older children and adolescents, who were all native American English speakers, and who all lived within commuting distance of our lab's location in Boston, Massachusetts. Participants included 19 autistic (m age = 13.35, s.d. = 1.80) and 19 nonautistic peers (m age = 12.97, s.d. = 2.11). There were no statistically significant differences in groups’ ages (p = .56), male:female sex ratios (p = .30), racial/ethnic background (p = .25), language scores as measured by CELF-5 core language subtests (p = .86) (Wiig et al., 2013), or IQ scores as measured by the KBIT-2 (p = .18) (Kaufman & Kaufman, 2004). As predicted, autistic participants scored significantly higher on the Social Communication—Lifetime measure (p < .001), which documents developmental differences in social communication that are associated with autism (Rutter et al., 2003) (see Table 1 for participant details).
Participant demographics with comparison test statistics.

The caregivers of all participants in the autism group reported their child had received a diagnosis of autism spectrum condition, and we confirmed this diagnosis in the laboratory via administration of the ADOS-2 by a research-reliable professional (Lord et al., 2012). To be included in either group, participants could not be diagnosed with any other developmental disorder aside from autism (for the autism group), and nonautistic participants were only included if they did not have a sibling diagnosed with autism.
Procedure
Participants sat at a table, directly across from a researcher, and the two of them engaged in a semistructured “double interview” (Garcia Winner, 2007). In the first half of the interview, a researcher asked the participant four questions about their life. All participants were asked the same four questions, which probed for information about members of the participant's family, their hobbies, a favorite field trip or vacation, and the participant's least favorite subject in school. Although the four main interview questions were scripted, researchers were encouraged to respond to participants’ answers naturally, using spontaneous follow-up questions and comments, and they were trained to try to engage the participant enough during the interview, so that this portion of it lasted for at least 3 min. In the second half of the interview, participants were tasked with asking the researcher interview questions. Before they did so, participants were shown three photographs of the researcher. Photographs showed the researcher with different people (e.g., with the researcher's siblings in one photo and with friends in another) and engaged in different activities (e.g., on a river-rafting trip with siblings in one photograph and on a trip to another country with friends in another). These photographs were provided to help the participant create novel questions, so that they did not simply repeat the questions the researcher asked during the first half of the interview. The researcher displayed the photographs one by one, and they did not provide any verbal information about the photographs. After each photograph was shown, it was placed on the table face up. Once all three photographs were placed on the table, the researcher prompted the participant to start asking questions. If there was an early lull in the interview, researchers encouraged the interviewing participant to ask a few more questions (e.g., “Can you ask me a couple more questions?” or “You haven’t asked me about this picture”), thus maximizing the duration of this second portion. Most participants engaged in the question-asking task for at least 3 min. In total, interview durations were 10 min, on average and ranged in length from 4.5 to 17 min (SD = 2.5 min). The entire interview was video- and audio-recorded.
Transcription
Videos of interviews were imported into ELAN software (Brugman & Russel, 2004). Well-trained undergraduate and graduate student researchers who were naive to the diagnostic status of the participant in each interview watched these videos and transcribed all the language produced by both the RA and the participant. All transcribers were nonautistic and native American English speakers. All identified as White and grew up in the Northeastern United States (New York and Massachusetts). RA speech and participant speech were transcribed in separate tiers. In addition to transcribing participants’ words, transcribers included notations for false starts and nonlinguistic vocalizations like laughing. In a separate tier, participants’ nonverbal communicative signals—nodding and other gestures—were also captured. If a transcriber could not decipher a word being spoken, a phonetic transcription was provided if possible, and if not, “XXX” was used.
Each transcription underwent at least three rounds of verification. In the first round, one researcher transcribed everything. In the second round, another researcher read through this initial transcription, while watching the video of the interview. Whenever the second researcher disagreed with the initial transcription, they would indicate this by inserting an alternative transcription in brackets. If the second researcher noted no discrepancies between what was transcribed and what was in the video, the transcription was considered final. Otherwise, a third researcher went over points of disagreement between the first- and second-round transcribers and selected one of the versions as accurate, deleting the discrepant portion of transcription. This version was then considered final.
Irregularity identification
Once all transcriptions were verified, transcriptions from the speech tiers (i.e., not the gesture tiers) were exported from ELAN as text files. These text files were then converted into Excel spreadsheets (one for each participant), wherein each participant utterance occupied its own row. Each file was independently read, and language irregularities were identified by three different researchers, none of whom had been involved in transcription. To prevent order effects, each irregularity identifier was provided with a different, randomized list of all participants, and they each reviewed transcripts in their assigned order. Like the transcribers, irregularity identifiers were also nonautistic and native American English speakers. One coder was biracial and the other two were White. Two identifiers grew up in the Northeastern United States (New York and Massachusetts) and the other in Virginia. And, like transcribers, identifiers were all naive to the diagnosis of the participant whose language was transcribed. Although we did not explicitly tell coders that some participants would be autistic, coders were aware that the general focus of our research objectives are about autism. Based on that knowledge, they probably did assume that some participants would be autistic. However, they were not aware of the objectives of the current study, including the fact that we would be comparing the frequency of language irregularities between neurotypes. To further prevent irregularity identifiers from using visual (e.g., facial expressions) or auditory (e.g., prosodic) cues to “guess” whether a given participant was autistic or not, or to otherwise bias their coding, they were not provided access to the original videos of the interviews.
Researchers involved in irregularity identification read through all participant speech in each transcription. When some aspect of the participant's language stood out as being unconventional or erroneous, they would indicate this by putting an “x” in an adjacent column, in the same row as the utterance containing the irregularity. Irregularity identifiers were specifically trained to point out: (a) language that did not “sound like something a native American English speaker would say;” and/or (b) sentence structure or word choice that was not how “someone would typically put it.” Researchers were warned to avoid marking words/phrasing that are considered “slang” or informal (e.g., “Ima” or “anyways”), and they were also taught to ignore words/phrasing that are appropriate or grammatical in some dialects of American English (e.g., “ain’t” or habitual BE). If there were multiple features identified as irregular per utterance, researchers would indicate this with multiple “x”s in this column, where each “x” corresponded to one irregularity. In the utterance column, they underlined the portion(s) of speech that contained the irregular language pattern(s), and in other columns they listed the specific irregularity and then provided a description of what stood out to them as being irregular (e.g., “‘they says’ instead of ‘they say’”). Each explanation corresponded to only one irregularity, so if multiple irregularities were noted in a single utterance, there would be text in multiple columns adjacent to that utterance, one for each irregularity.
In their description, irregularity identifiers were encouraged to provide a “translation” of the utterance, either how they would expect someone to typically say it or even just how they would have phrased the same utterance, themselves. This exercise worked to provide a rationale that there was either something ungrammatical in the utterance or that there was a more conventional way to express the same idea. See Table 2 for an example of one flagger's identification and description of irregularities for a few participant utterances.
Examples of irregularity coding.
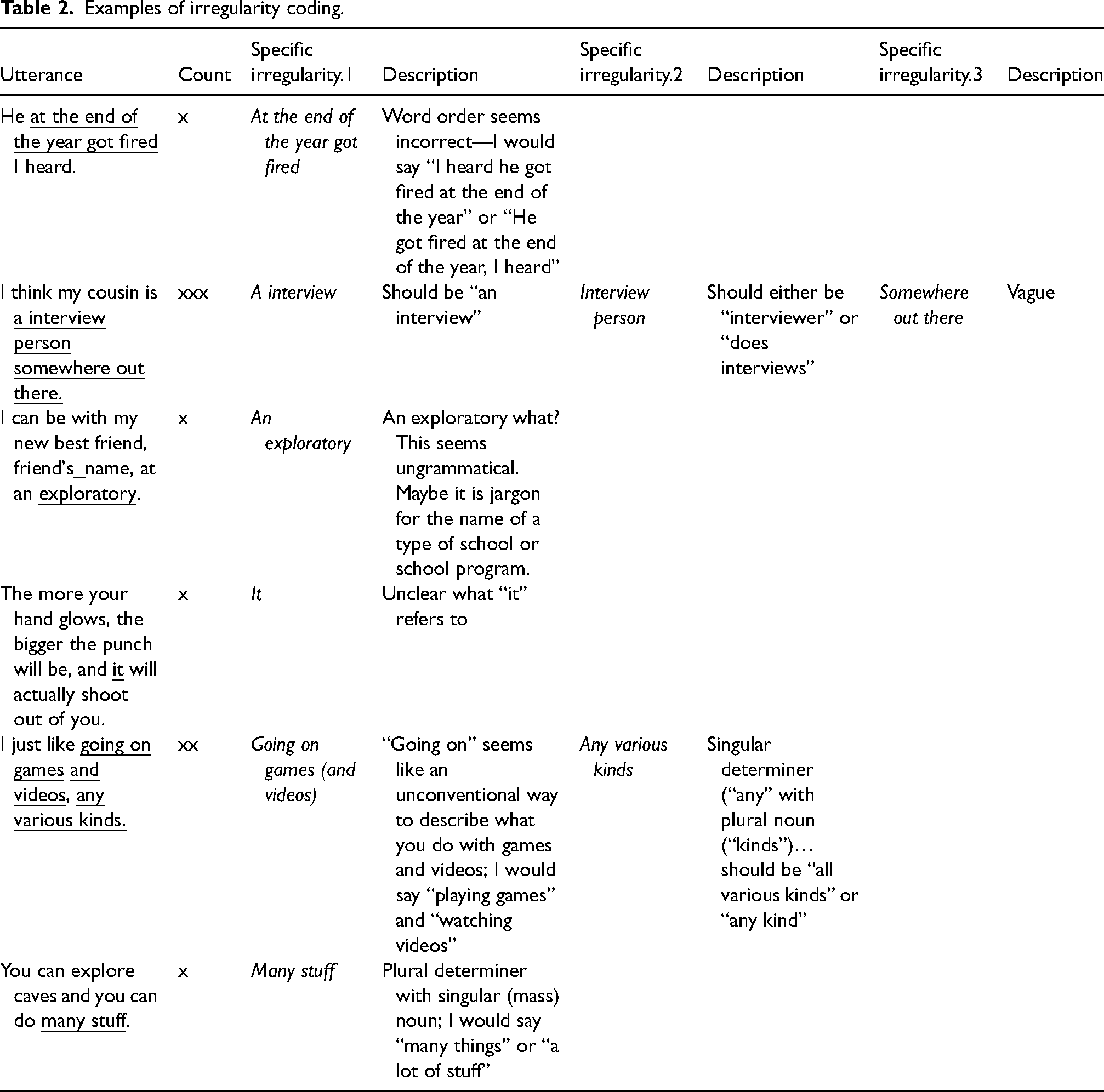
To ensure validity of the final dataset, each transcription underwent independent irregularity flagging by three different people, in three separate Excel documents. The first author then merged these three documents together, and with the assistance of a master's student, identified irregularities that had been agreed upon by at least two of the RAs. Only these agreed-upon irregularities were analyzed further.
Irregularity categorization
Our second research question pertained to the types of irregularities produced by each group. Specifically, we hypothesized that a higher rate of irregularities by autistic participants (if found) would be due specifically to semantic unconventionalities, rather than morphosyntactic errors. To determine this, the first author categorized each irregularity that had been identified by at least two researchers as either morphosyntactic or semantic. Morphosyntactic errors typically involved number/person disagreement (e.g., “Is they…”), missing function words, including determiners, linking verbs and/or particles (e.g., “…you in woods”), and/or word-order errors, including lacking subject-auxiliary inversion in questions (e.g., “Where you went to high school?”). Semantic unconventionalities most often included surprising word choice (e.g., “Which cultural food is your best” instead of “…favorite”; “a mosquito nicked me on the foot,” instead of “bit”), unusual phrasing within an idiom (e.g., “all in its own”), inappropriate use of tense or aspect (“Did you go on any cool vacations in your life?” instead of “Have you gone…”), and redundancies (e.g., “do you have a professional job?”).
Analysis
To answer our primary research question—whether group membership can predict the frequency of language irregularities as well as or better than standardized language test scores—we used the lmer() function from the lme4 package in RStudio to model data using linear mixed-effects modeling (Bates et al., 2015), with frequency of linguistic irregularities as the dependent variable. All models included by-participant random intercepts, as well as a covariate of utterance number, as participants who produced more utterances had a higher chance of producing more irregularities, simply because they produced more language. The models differed in the additional independent variables added. One model included participant group (autistic vs. nonautistic) as the only other independent factor (in addition to utterance number), another included CELF scores as the only other predictor, a third included both variables, and a fourth included both variables and interactions. We used analysis of variances to compare the fit of these models.
Based on the account offered by Naigles and Tek (2017), our second hypothesis was that group differences in irregularity rates would be driven by higher relative rates of semantic unconventionalities in the autism group. Testing this hypothesis depended on the results of the analyses used to test Research Question 1, where we planned only to compare differences in the type of unconventionality (syntactic vs. semantic) if modeling suggested that group (autistic vs. nonautistic) did have a significant effect on frequency of irregularities. If so, we planned to follow up our primary analyses by adding language component (morphosyntax vs. semantics) as an additional factor to whichever model was determined to best fit the data for Research Question 1, and then we would examine how the interaction between group and semantic component affected differences in rates of irregularities.
Results
Table 3 presents the number of total irregularities produced for each group, along with the number of semantic unconventionalities and syntactic errors, and corresponding proportions.
Mean raw frequencies and mean percentage of utterance counts of syntactic errors, semantic unconventionalities, and totals for each group.

Mean utterance counts are included in the final row. Values in parentheses represent standard deviation.
Summary of output from best-fitting statistical model for research question 1 (irregularity ∼ group + utterance count + (1|participant)).

Total irregularities
Model comparisons showed that the model including Group (autistic vs nonautistic) and Utterance Number as the only independent predictors fit the data best. Table 4 includes a summary of this model's output, and Figure 1 displays average overall irregularity counts by group.

Bar and point plot displaying group means of proportions and individual proportions of linguistic irregularities. Error bars represent standard error of the mean.
Adding Group as an independent variable significantly improved the fit of the data as compared to a “null” model, which included Utterance Number as the only independent variable (χ2 = 15.09, df = 1, p < .001). Adding CELF-5 scores did not significantly improve model fit compared to the null model (χ2 = 0.84, df = 1, p = .36). The model including both CELF-5 scores and Group as independent variables did not fit the data significantly better than the model including Group alone (χ2 = 2.26, df = 1, p = .13), nor did the model that included both variables and the interaction between the two (χ2 = 2.27, df = 2, p = .32) (see Figure 2).
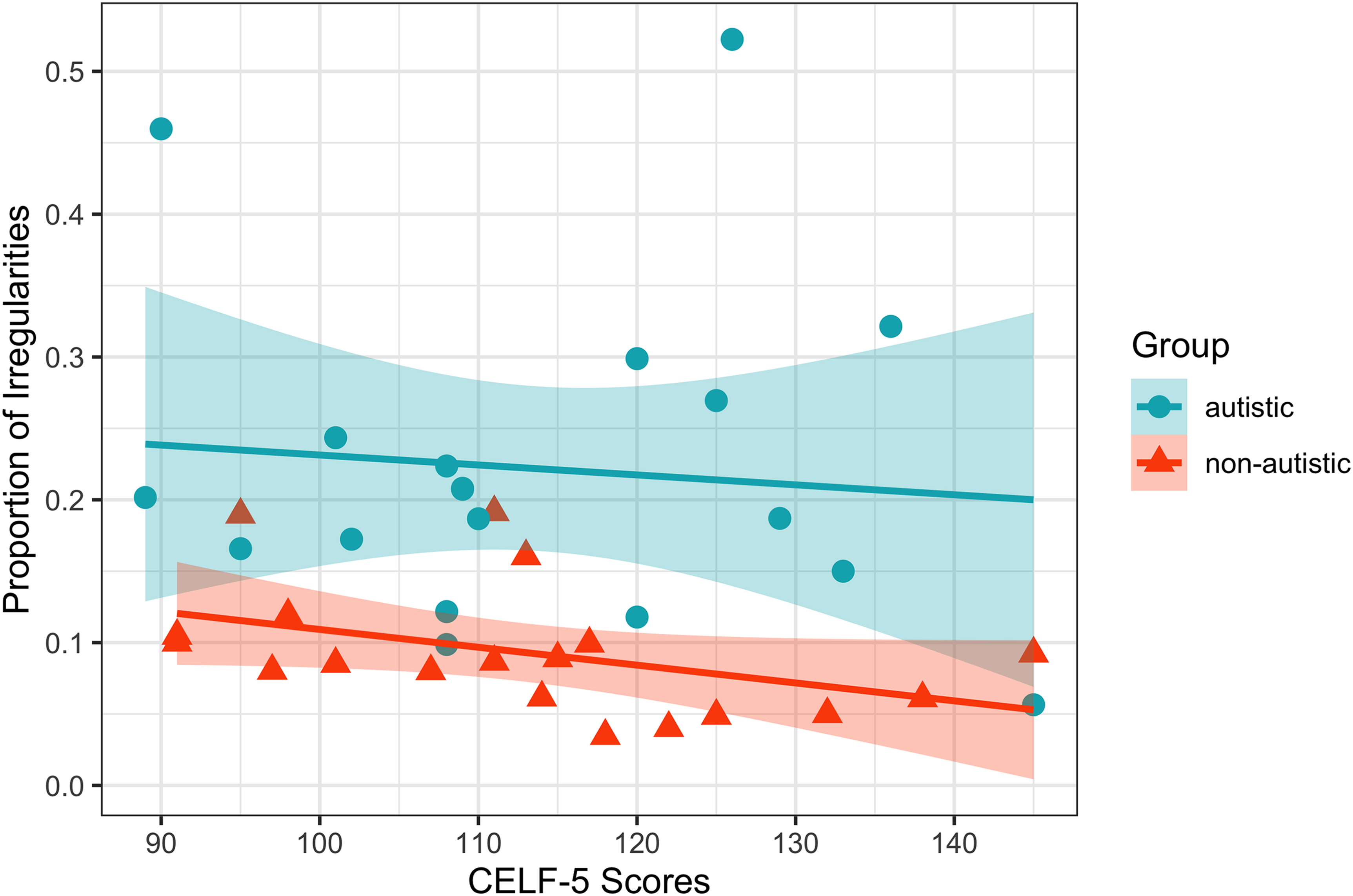
Scatter plot displaying the relationship between proportions of irregularities and CELF-5 scores for participants in both groups. Ribbons represent standard error of the mean.
To test whether the frequency of irregularities decreased with age, we constructed a model with Age, Group, and the interaction between them as predictors of irregularity frequency (in addition to a covariate for Utterance Count and a random intercept for Participant). Comparisons between this model and the one containing Group alone suggested that adding Age or the interaction between Age and Group did not significantly improve model fit (χ2 = 3.77, df = 2, p = .15). A summary of model output confirmed this. Neither Age (Estimate = −0.01, SE = 0.04, t-value = −0.22, p = .82) nor the interaction between Age and Group (Estimate = −0.11, SE = 0.03, t-value = −1.34, p = .19) significantly predicted the number of linguistic irregularities produced.
Irregularity types
Adding Irregularity Type (syntactic errors vs. semantic unconventionalities) as an independent variable (in addition to Group and Utterance Count), along with the interaction between Group and Irregularity Type, significantly improved model fit, compared to the model with Group alone (χ2 = 7.70, df = 2, p = .02). The model including the interaction between Group and Irregularity Type also showed a significant improvement in fit compared to the model including Group and Irregularity Type as main effects only (χ2 = 5.04, df = 1, p = .03). Table 5 includes a summary of this model output and Figure 3 displays proportions of semantic and morphosyntactic irregularities (out of utterance counts) for each group.

Bar and point plot displaying group means of proportions and individual proportions of semantic unconventionalities and morphosyntactic errors. Error bars represent standard error of the mean.
Model summary for statistical model for research question 2 (irregularity ∼ group + type + (group x type) + utterance count + (1|participant)).

To better understand the interaction between Group and Irregularity Type, we calculated post hoc pairwise comparisons for this model using the “emmeans” package in R (Lenth et al., 2021). Comparisons showed significantly higher numbers of semantic unconventionalities for autistic participants, both as compared to their own frequencies of morphosyntactic errors (p = .04) and as compared to the number of semantic unconventionalities produced by nonautistic participants (p < .001). The number of morphosyntactic errors produced by autistic participants was not significantly larger than nonautistic participants (p = .06). The number of morphosyntactic and semantic irregularities produced by nonautistic participants were not significantly different (p = .98) (see Table 6 for details).
Pairwise comparisons of irregularity type frequencies between groups.

Discussion
During a spontaneous, dyadic interaction, older autistic children and adolescents produced significantly more linguistic irregularities, including straightforward morphosyntactic errors, like person-number disagreement, than their nonautistic peers did, despite groups showing nonsignificant differences in their language scores on a standardized test (the CELF-5). In fact, standardized language scores showed limited ability to predict the number of irregularities participants produced in either group suggesting that standardized language testing is not sensitive to these differences, at least not this standardized language test, and at least not for older autistic children and autistic adolescents who are prone to making these kinds of irregularities.
Secondary analyses involving irregularity type (semantics vs. morphosyntax) resulted in two main findings. First, autistic participants produced significantly more semantic unconventionalities than nonautistic participants, while group differences between rates of morphosyntactic errors were not significant. Second, older autistic children and adolescents produced more semantic unconventionalities than morphosyntactic errors, while there were no such differences in the number of semantic vs. morphosyntactic irregularities for the nonautistic peer group. Together, findings have several implications about language in autism, generally, at least for older children and adolescents, and the limitations of using standardized tests to document language differences for this population.
As predicted by the form-meaning hypothesis (Naigles & Tek, 2017), autistic participants produced a relatively higher proportion of semantic irregularities, suggesting that autistic language-acquirers may show greater differences in their development of lexical and phrasal meaning than in the acquisition of grammar and morphology. Interestingly, there were certain subcategories of semantic unconventionalities that seemed much more common among the autistic group and maybe even unique to them. For example, autistic participants produced neologisms (e.g., “electroid” instead of “electrode” and “compies” as shorthand for “compsognathus,” a type of dinosaur), and nonautistic participants did not. Although neologisms have frequently been identified as features of autistic language (Luyster et al., 2022), we discovered other semantic unconventionalities that have either not been previously associated with autistic language or have only been identified in a few papers. For instance, we found that autistic participants used seemingly redundant adjectives (e.g., “big and large”; “professional job”) with relative frequency.
Among this group of autistic participants, we also noted frequent unconventional uses of function words, such as prepositions, classifiers, deictics, and auxiliaries. In contrast to the known role function words play in structuring grammar, we discovered numerous instances when autistic participants used a function word in a way that was semantically inappropriate. For instance, one adolescent asks, “Do you bike, or do you not
It is important to point out that there was substantial heterogeneity in the autism group (see Figure 2). This is consistent with lots of research on expressive language in autism, and it could be indicative of language “subprofiles” among otherwise seemingly homogenous groups of autistic individuals, like those in the current study, who all scored similarly on language and cognitive tests (review of heterogeneity in Schaeffer et al., 2023, along with a proposal for “subprofiles”). Future work with a larger dataset could determine whether “clusters” of different language-use patterns emerge among autistic individuals who score within normal ranges on standardized tests of structural language, possibly indicating subprofiles. On the other hand, despite relativity heterogeneity in irregularity proportions among autistic participants in the current study, there were other aspects of the data that unified them. For example, 14 nonautistic participants (70%) produced five or fewer semantic unconventionalities, while all 19 (100%) autistic participants produced five or more. Similarly, all autistic participants produced 10 or more irregularities overall, while nine nonautistic participants produced 10 or fewer. Thus, even with heterogeneity among the autism group, the binary groupings (autistic vs. nonautistic) used in analyses do seem to predict real patterns in participants’ language use.
Hidden impairment or “linguatypic” style
One interpretation of the relatively frequent irregularities discovered among the spontaneous language of these autistic participants is that they reflect an underlying, “hidden” language impairment that was not previously identified. Such an argument has been used to explain subtle differences in language use and comprehension by individuals who were previously diagnosed with autism, but who have since “lost” their diagnosis, meaning that their current behavior no longer meets diagnostic criteria. These individuals use certain language features, like idiosyncratic phrasing, more often than neurotypical peers, despite scoring equivalently on standardized language measures (see review in Suh et al., 2017). Authors often describe such differences as indicating residual language deficits, resulting from the early developmental divergences that led to their previous autism diagnosis (Kelley et al., 2006). Such an argument implies that language impairment, albeit sometimes a very subtle impairment, is inherent to autism; the same early differences in social-communicative attention and processing that contribute to an autism diagnosis also prohibit typical acquisition of language. This argument, along with evidence that standardized language tests cannot effectively capture autistic language differences, has been nicely laid out in a chapter by Eigsti and Schuh (2017).
Following this logic, autistic participants in the current study have a subtle language impairment resulting from their being autistic, and our vigilant, in-depth analysis of their spontaneous conversational language use uncovered this impairment, when standardized testing could not. Thus, the fact that autistic participants in the current study produced so many irregularities is to be expected by virtue of their being autistic, and the fact that they do not have a documented language disorder can be explained by the inability of current standardized language tests to pick up on their particular type of impairment. Accordingly, our own results showed that standardized language scores, at least from the CELF-5 core language subtests, do not identify these participants as having language impairments. Their scores not only fell within average ranges, with some falling well above average, but their scores also did not predict irregularity frequency. Thus, if these participants had received testing to check for a language disorder, their standardized language test scores likely would not have revealed any reason for concern.
In contrast to their standardized language test scores, rates of language irregularities among the autism group were quite high. On average, 20% of autistic participants’ utterances contained an irregularity, and some participants showed rates as high as 50%. It seems difficult to understand how a child's tendency to use an unconventional word or phrase in every other utterance would not qualify them as having language impairment or be recognized as a sign of a language problem by professionals who have interacted with these participants. However, none of the participants in the current study were diagnosed as having language impairment at the time of data collection.
This becomes easier to understand when we emphasize the subtlety of errors. For example, semantic unconventionalities almost never involved using a word that was straightforwardly wrong, such as calling a horse a potato. Instead, most involved using a word in a way that was simply surprising, and it is for this reason that we maintain our use of the word “unconventionality” rather than “error.” Consider the following utterance produced by one autistic participant: Of all the things I
An irregularity identifier recognized four aspects of this sentence as unconventional: (1) the use of present perfect aspect (“have eaten”) instead of simple past (“ate”); (2) the use of “in” (instead of “during”) to refer to this span of time; (3) the use of the singular noun “egg” to represent the mass concept, rather than “eggs”; and (4) the use of the verb “denied” instead of “refused.” Importantly, while the coder identified four irregularities, the sentence itself is not ungrammatical, and the listener/reader can certainly understand the speaker's message: When they were very young, they refused to eat eggs. Someone listening to this sentence, even someone trained to recognize language disorders, might perceive the language therein as odd but not as obviously wrong or disordered.
In fact, not only are the irregularities contained in this utterance unconventional rather than straightforwardly erroneous but there are also certain aspects of this sentence that are unexpected for what is generally indicative of developmental language conditions, like DLD. First, the sentence is grammatically complex, involving multiple clauses; such phrasing would certainly not indicate DLD (Paradis et al., 2022). Similarly, although the use of present perfect aspect is arguably incorrect in this context, its morphological form is correct, again making it an unlikely indicator of DLD (Leonard, 2015). Finally, the participant demonstrates use of advanced vocabulary (e.g., “adamantly denied”), when one common indicator of DLD is slow vocabulary acquisition and smaller vocabulary size than age-matched peers (Gray, 2004; Nash & Donaldson, 2005; Rice, 2004).
In summary, three factors could explain why these participants have not been diagnosed with language impairment, despite producing relatively frequent irregularities. First, standardized language testing scores are unlikely to have indicated an impairment. Second, the irregularities they most frequently produced are not typical of DLD. Finally, most irregularities are so subtle that someone may not recognize them as “errors” and instead perceive them as slightly unusual or “awkward,” if they were recognized at all.
This last point brings us to a question: How subtle must language differences be to be considered stylistic rather than disordered? It seems defensible that morphosyntactic errors, no matter how subtle, would point to an underlying language impairment, if they are made regularly and systematically. However, the semantic irregularities we noted as particularly prevalent among autistic participants’ samples are harder to attribute to disorder, especially when they are compared to what is characteristic of other DLDs. While DLD, for instance, often involves challenges with vocabulary, these challenges usually manifest as a more limited repertoire of vocabulary (Gray, 2004, 2005; McGregor et al., 2013; Nash & Donaldson, 2005), with a substantial proportion of children with DLD evidencing word-finding challenges, by replacing targeted words with generic and/or semantically vacuous words (e.g., “thing”), or phrases suggesting challenges with lexical access (e.g., “you know what I mean”) (Dockrell et al., 1998). Such patterns are not at all characteristic of the language produced by the autistic participants in the current study. Instead, word choice irregularities involved the use of surprising (and sometimes surprisingly specific) words, rather than by incorrect or more vague ones. For example, consider the participant who says he was “nicked” by a mosquito. The verb “nick” typically refers to getting a small cut; when a mosquito bites a person, they do, technically, cause a tiny (microscopic) cut. Thus, it is unclear whether the participant made an error, misunderstanding what “nick” means or accessing this verb by mistake, or if they instead very carefully and purposefully selected this verb to highlight the fact that mosquitos must cut through a person's skin to draw blood. It is perhaps enlightening to learn that this phrase was used during a conversation about how much the participant hated and feared any insect that could sting or bite. Thus, it is at least possible that the participant's selection of “nick” does not reflect a mistake at all, and it instead reflects the conscious selection of a verb that is not conventionally used to describe what a mosquito does.
Building on this, many of the semantic unconventionalities produced by autistic participants similarly allow for the possibility that they are using words differently, maybe to be creative or specific, rather than using words incorrectly. We therefore offer a proposal that at least some of the semantic irregularities noted by our neurotypical coders evidences an autistic style of speaking, something like an idiolect or register. We refer to this style as a “linguatype 1 ,” to highlight the fact that this manner of speaking may be attributable to a person's neurotype, perhaps due to conscious choices about word selection and phrasing, or due to underlying differences in semantic connectivity, or both. Based on our findings, the autistic linguatype might entail features such as the selection of specific words (e.g., “duplicate” instead of “remake”), the use of interesting phrasing (e.g., “what's a big question starter” instead of “what's a good first question”), modifiers that seem redundant but may be used for emphasis (e.g., “the Basilica is very large and huge” and “me neither too”), and unconventional uses of prepositions, perhaps especially in nonspatial contexts (e.g., “on your free time” and “we do random things for math class”). We are not the first to suggest that there may be a linguatypic style associated with autism. With respect to written texts, Rodas (2018) proposes that certain novelists and poets (e.g., Charlotte Brontë, Daniel Defoe, and Gertrude Stein) make use of an “autism aesthetic” in their writings, and the suggested features of this proposed aesthetic are strikingly reminiscent of some of the linguatypic attributes we list above. For example, Rodas describes Robinson Crusoe as involving repetitive (even seemingly redundant) information that is often surprisingly specific.
Of course, it is important to point out that in the case of the current study, participants were older children and adolescents, so it is possible that the patterns we observed here do not generalize to a style used by many highly verbal autistic people, and instead reflect developmental patterns that may disappear in adulthood. Although post hoc tests did not demonstrate a significant decrease in irregularities with age, even our oldest participants were still adolescents, allowing for the possibility that these irregularities could yet dissipate. Therefore, future research should analyze the spontaneous language produced by autistic adults to determine whether the features we describe remain observable patterns in their language use.
We would like to end our discussion by highlighting an important consideration for the current dataset: Researchers charged with identifying irregularities for the current study were neurotypical. These researchers indicated that about 20% of utterances produced by autistic older children and adolescents in this sample “stood out” to them as being odd or surprising or erroneous in some way. Autistic coders may have reacted differently. The Double Empathy proposal (Milton, 2012), for example, might predict that autistic coders (and listeners) would be less surprised by the irregularities—perhaps, especially the semantic unconventionalities—that were identified by nonautistic coders. Future work could explore this by determining whether autistic coders would pick out the same, different, or fewer language features of autistic speech as “standing out.” They could also test how these features predict various outcome measures related to discourse success for within and cross-neurotype interactions.
The implications of current findings are limited by several factors, which can be addressed by future research. First, by including older children and adolescents in the current research (rather than adults), it is difficult to determine whether findings merely reflect differing developmental trends between groups that could disappear once participants reach adulthood. Second, we only tested participants’ language with the core subtests of the CELF-5, rather than the entire assessment, and we did not use additional language tests. It is possible that scores from a different assessment or a more comprehensive version of the CELF would have correlated with irregularity frequencies. Other limitations deal with the context within which language was recorded. Participants engaged in a social interaction with a neurotypical adult in a laboratory setting, when participants knew they were being observed and evaluated. Any or all of these factors may have led autistic participants to camouflage certain behaviors indicative of their neurotype (Cage & Troxell-Whitman, 2019), a process that is described by autistic people as cognitively taxing (Cook et al., 2021). Such demands may have inflated the frequencies of linguistic irregularities in this context. Relatedly, socially interacting with anyone, but perhaps especially a nonautistic adult, could have led to relatively high levels of anxiety for autistic participants, which may also have increased their rates of linguistic irregularities. Future research should strive to capture samples of autistic individuals’ language during natural interactions, including with other autistic people. Finally, all language coding (including both irregularity identification and categorization) was performed by neurotypical people. If, as we have suggested, some linguistic irregularities produced by autistic speakers are attributable to a specific style of speaking, a linguatype, then our choice of coders made it inevitable that autistic participants would be identified as producing more irregularities than nonautistic participants. We encourage researchers to explore this possibility by having both autistic and nonautistic people participate in identifying and coding language for features that stand out. Differences in their selections, if found, could help tease apart irregularities that signal style versus struggle.
Conclusion
In the current study, we find that language samples from autistic participants contained significantly more irregularities, overall, and specifically more semantic unconventionalities, than nonautistic participants, despite both groups of participants earning similar scores on a commonly used standardized language test, the CELF-5. These results may suggest that differences in language use, especially semantic differences, may be characteristic of autistic people, even those who score within normal ranges on standardized language tests. In addition, these results suggest that a commonly used standardized language test cannot effectively capture the different ways that some autistic people use language. Whether these differences are due to underlying impairment or difference, akin to dialect or register variation, is up for exploration in future research.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Institute on Deafness and Other Communication Disorders, (grant number NIH-NIDCD R01 DC012774-01).