
Abstract
Contemporary sociological research emphasizes the need to analyze inequality beyond nominal categories. Although research has grown in this regard at the individual level, little research has pursued this approach with neighborhoods. This article explores how names can serve as a measure of the perceived typicality associated with race and how names are associated with neighborhood characteristics. Analyses on data with the names of over 300 million Americans demonstrate that name-based racial composition more fully explains socioeconomic disparities among neighborhoods than conventional survey-based racial composition metrics. Neighborhoods with the most Black-sounding names demonstrate greater socioeconomic disadvantage than neighborhoods with the most individuals self-identifying as Black. Additionally, naming patterns explain variation in socioeconomic inequality within both predominantly nominally Black neighborhoods and predominantly nominally White neighborhoods—where little nominal racial variation exists. This research suggests that infracategorical measures of race can provide additional predictive power to nominal measures of racial composition when analyzing neighborhood inequalities
Neighborhood inequality contributes to inequality in life chances in the United States (Sharkey and Faber 2014). Spatial inequality stems from decades of racial and economic segregation and even longer periods of racial disenfranchisement (Massey and Denton 1993). Black Americans, in particular, are more likely to live in the most impoverished neighborhoods (Sharkey 2008). Individuals raised in the most impoverished neighborhoods in the United States are less likely to graduate high school and tend to exhibit lower levels of cognitive ability in adulthood (Sharkey and Elwert, 2011; Wodtke et al. 2011). Growing up in the most impoverished neighborhoods in the United States substantially impacts life chances chiefly because of the resource deprivation and social isolation neighborhood residents face (Massey 1990; Wilson 2012). Systemic racism results in lower-class Black Americans being disproportionately likely to live in the poorest neighborhoods generation after generation (Sharkey 2008).
Traditionally, sociological research on neighborhood inequality has focused on the comparison of nominal “census” categories of racial identification, particularly the proportion of residents identifying as Black or White (Sampson 2009). Although such measures can provide general insights into racial inequality, scholars have recently begun to also examine race more broadly in less discrete terms (Monk 2015). Race and a broader array of stereotypes can be cued by factors other than skin color, including linguistic patterns, dress preferences, hair styling, or other cultural values (Dixon 2007; Ellis-Hervey et al. 2016; Ogbu 1999). Given the extent to which racial identity correlates with cues, it is logical to assume that racially distinctive names, which tend to be associated with racial identity (Fryer and Levitt 2004), are strongly correlated with other cues for race.
The rise of distinctively Black names in the latter half of the twentieth century was strongly associated with an earlier shift in the construction of the Black identity. Past scholars have suggested that some parents give their children distinctively Black names to signal their affinity with the Black community (Fryer and Levitt 2004). This theory is supported by observed differences between Black children who are and who are not given distinctively Black names. It is reasonable to posit that parents intending to foster a stronger identification with the Black community may be more likely to pass on other Black cultural attributes, such as linguistic expression, dressing styles, and various cultural values.
The Black middle class has grown considerably over the last 50 years (Landry and Marsh 2011), coinciding with the rise of distinctively Black names. This growth has resulted in the establishment of Black middle-class suburbs across the United States (Pattillo 2005). As socioeconomic heterogeneity between Black neighborhoods grows, the use of self-reported racial composition to identify disadvantaged neighborhoods is becoming increasingly outdated. Infracategorical measures of race may better get at these nuanced distinctions between neighborhoods where nominal categories do not. In this article, I propose that Black naming patterns might explain socioeconomic variations between neighborhoods where self-reported racial composition cannot.
Although a name-based approach should not replace a nominal approach to studying neighborhood racial composition, it can serve as a complementary approach, potentially capturing an additional dimension of inequality and providing insights into infracategorical neighborhood differences. Indeed, using a large names data set, I find that measures of racially distinct naming patterns at the neighborhood level add substantial predictive power to nominal racial composition in predicting measures of neighborhood disadvantage in residential, spatial, and mobility terms. This is in line with Monk (2022), who advocated using non-nominal categories to better understand inequality.
Literature Review
Just as Monk (2015) argued that self-reported skin color is an important measure of embodied social status, racialized naming patterns are important because names are frequently associated with individuals’ lifetime experiences. The cueing of racially distinctive names has even been found to play a role in skin tone assessment (Garcia and Abascal 2016). Names may be associated with and reinforce social and cultural identities, which may subsequently be reflected in individual anticipation of differential treatment by others. Names tend to be strongly associated with a certain set of contexts at birth and adult outcomes (Fryer and Levitt 2004). Distinctively Black names have been found to signal not only race but also social class (Crabtree et al 2022).
Black naming practices were quite similar to White naming practices up until the 1960s. Prior to the 1960s, the most common Black names aligned quite closely with the most common White names (Lieberson 2000). 1 This changed drastically in the time since, and in the early 2000s, only a quarter of Black parents chose names for their children that were common among White names (Fryer and Levitt 2004). In the 1960s and 1970s, the most popular names among Black boys and girls changed rapidly (Lieberson 2000). This period coincided with the Black Power movement and the broader affirmation of Black culture by Black Americans (Lieberson and Mikelson 1995). Fryer and Levitt (2004: 790) suggest that an “identity model” can explain the rise of distinctively Black names, where distinctively Black names can be “a benefit for those with the ‘black’ [sic] type and a cost for those with the ‘white’ [sic] type.” In support of the identity model is the fact that distinctively Black names are more common in places with larger Black populations (Fryer and Levitt 2004).
At an individual level, distinctively Black names are generally associated with worse outcomes among Black Americans (Fryer and Levitt 2004). Prior to the 1970s, distinctively Black names were only weakly associated with family socioeconomic status (SES), with lower-SES Black parents about as unlikely to choose a distinctively Black name for their child as higher-SES Black parents. Since then, however, it has become increasingly associated with young, impoverished, and unmarried mothers with low educational attainment (Fryer and Levitt 2004; Lieberson 2000). Distinctively Black names are much more common in racially segregated, predominantly Black neighborhoods. Although distinctively Black names are associated with worse outcomes, Fryer and Levitt (2004) found that characteristics at birth can explain any differences in the life outcomes between Black Americans with versus without a distinctively Black name. Other research has, however, suggested that individuals with distinctively Black names are more likely to be subject to discrimination. Bertrand and Mullainathan (2003) conducted a randomized resume experiment and showed that job applicants with White-sounding names receive 50 percent more interview callbacks than applicants with Black-sounding names. This suggests that names alone may pose a disadvantage—and one that is not potentially endogenous to race.
Beyond individual-level correlates, naming practices may also vary between neighborhoods because of collective dynamics. Fryer (2007) proposed that distinctive naming practices may arise from perceptions of future social interactions and what the benefit of such an investment might be. If individuals in a certain community observe a certain threshold of investment in distinctive naming practices, they may be more inclined to invest, and cooperation can be sustained. However, if the observed level of cooperation falls below this threshold, the system is no longer sustainable. Indeed, correspondence study research has found that distinctively Black names may not be subject to discrimination in majority Black neighborhoods but are subject to high levels of discrimination in predominantly White neighborhoods (Agan and Starr 2017).
Fryer’s (2007) model suggests that Black neighborhoods with more distinctive naming practices may foster greater in-group cooperation with group-specific capital investments. Rational choice theory suggests that Black individuals are more likely to make these group-specific capital investments in the face of increased discrimination and exclusion from White individuals. Additionally, Black neighborhoods, when more racially isolated, limit opportunities for interactions with non-Black racial groups, thereby reinforcing the preference for Black-specific cultural investments. The distinctive naming practices may serve as indicators of increased group-specific capital investments, potentially extending to other types of unmeasured investments. This could further exacerbate observing associations between distinctively Black naming practices and adverse outcomes across neighborhoods beyond what individual-level correlates suggest.
Beyond the correlates of Black naming practices for Black Americans, there is evidence that Black naming practices may also be relevant for White Americans. Naming patterns are partially determined by SES (Lieberson and Bell 1992), so White Americans who have names that are more common among Black Americans may be more likely to have an SES similar to the typical Black American. Beyond this, it is possible, although unlikely, that White Americans with Black names may be discriminated against in the same way as Black individuals with Black names. For example, resume-based experiments have shown that individuals with distinctively Black names suffer discrimination without race being signaled in any other way (Bertrand and Mullainathan 2003). Black naming practices additionally may be correlated with regional naming practices, which past research suggests may matter for life outcomes among White Americans (Beaudin et al. 2022).
Analyses of Mexican American naming practices suggest that Mexican-born parents are more likely to give their children more ethnically distinctive names compared to American-born parents of Mexican descent, who tend to name their children more closely to non-Hispanic White parents (Lieberson 2000). In general, the names Mexican Americans give their children are more similar to non-Hispanic White names than Black names. Unlike distinctively Black names, little research has found evidence of distinctively Hispanic names being subject to discrimination in correspondence studies (Darolia et al. 2016). It is also worth noting, however, that much less research has investigated the question and that there may be issues around certain names being broadly recognizable as distinctively Hispanic (Gaddis 2017). Given that distinctive naming practices are more common among Hispanic Americans who have spent less time in the United States, we can hypothesize that Hispanic Americans who have more distinctive names are more likely to share characteristics that are more common among recent Hispanic immigrants. This suggests that Hispanic Americans with more distinctive names may be more spatially segregated (South, Crowder, and Chavez 2005), have lower SES (Hirschman 2001), and be subject to more discrimination (Hanson and Santas 2014).
Hypotheses
Residential disadvantage is a central mediator linking racial segregation with racial inequality. Neighborhood conditions are closely associated with race, and differences in economic disadvantage between neighborhoods often explain racial disparities across various outcomes. For instance, neighborhood racial inequality in violence and fatal police shootings can be almost entirely explained by measures of neighborhood disadvantage (Levy et al. 2020; Vachuska and Levy 2022).
Neighborhood disadvantage encompasses numerous mechanisms that contribute to adverse outcomes. Two of the most commonly discussed are financial investment and collective efficacy (Galster 2011). Neighborhood disadvantage is strongly associated with limited economic investment. Because residents have fewer financial resources, outsiders may find investing in such neighborhoods unappealing. Moreover, residents may lack the social cohesion or ties that could help foster investment from outsiders (Anderson 2014). Collective efficacy theory suggests that neighborhood disadvantage produces negative outcomes, such as violence, due to a breakdown of social norms and practices (Sampson 2021). Residential stability and homeownership play crucial roles in the relationship between neighborhood advantage and neighborhood outcomes by fostering strong bonds among neighborhood residents, thus facilitating informal social control (Sampson et al. 1997). Moreover, disadvantaged neighborhoods often lack proximity to key institutions that support social control (Galster 2011).
Neighborhoods with more Black-sounding names may have greater residential disadvantage due to a combination of historical factors, racial segregation, discrimination, and socioeconomic disparities. Past research suggests distinctive naming practices among Black Americans reflect individuals’ racial identities and responses to both past and current experiences of discrimination and disadvantage (Fryer and Levitt 2004; Lieberson and Mikelson 1995). Indeed, research more broadly suggests that Black Americans respond to racist legacies and personal encounters with racial discrimination by strengthening the connection to their Black identity (Jackson 2012). This would imply that Black neighborhoods with high levels of distinctively Black names are potentially sites that have experienced greater levels of structural racism and disadvantage. On an individual level, Black Americans with distinctively Black names are more likely to come from segregated environments and have limited access to resources, education, and employment opportunities (Fryer and Levitt 2004). The isolation experienced by individuals with distinctively Black names may trigger “threshold” effects, potentially reinforcing neighborhood disadvantage. Additionally, other group-specific capital investments made by residents in these neighborhoods may further impact the socioeconomic outcomes of these individuals and their neighborhoods.
Even when controlling for residential disadvantage, I hypothesize neighborhoods with higher rates of Black naming patterns will tend to be more spatially isolated. I posit this may occur due to the link between Black naming practices and heightened racial segregation, in line with past research (Fryer and Levitt 2004). Being in a more segregated community and having more segregated social ties might enhance recognition of distinctively Black names, potentially increasing the perceived value of having such a name and the overall chance that parents choose them (Fryer 2007; Fryer and Levitt 2004). Theoretically, isolation in White communities would limit one’s recognition of distinctively Black names because Black individuals in these places would hypothetically have fewer examples to draw from and potentially a lower perceived value of having such a name.
Studying adjacent neighborhoods provides valuable insights into neighborhood sorting. Given that Black Americans typically prefer neighborhoods that are at least half Black and White Americans prefer predominantly White neighborhoods (Krysan and Farley 2002), similar preferences for proximal neighborhoods that align with their racial preferences are expected. Consequently, I expect that if Black Americans have a stronger affinity with Black neighborhoods, they may prefer residing in neighborhoods that are near other Black neighborhoods. In contrast, White Americans may prefer not to live in neighborhoods that are near Black neighborhoods.
In addition to spatial indicators of neighborhood disadvantage, mobility-based measures have gained popularity in recent scholarship. These measures are more aligned with the conceptual understanding of neighborhoods and their significance. Recent studies have demonstrated that mobility-based measures of disadvantage outperform traditional residential measures in predicting a wide range of outcomes, including homicide, police violence, COVID-19 incidence, and adverse birth outcomes (Levy et al. 2020, 2022; Vachuska and Levy 2022). Theory suggests that mobility-disadvantaged neighborhoods experience challenges similar to those of residentially disadvantaged neighborhoods, such as lower levels of collective efficacy and limited investment, but to a greater extent. Intensified negative outcomes for mobility-disadvantaged neighborhoods may be attributed to weakened social cohesion and a lack of connection to important stakeholders, which may limit neighborhood investment (Levy et al. 2020).
Even net of spatial isolation, mobility-based isolation should also be associated with higher rates of Black naming patterns in certain neighborhoods. Everyday mobility patterns ultimately shape everyday life, so the extent to which the everyday contexts of a neighborhood’s residents are highly segregated and isolated will be better represented in terms of everyday mobility patterns than through a residential or spatial measure. The racial segregation experienced in everyday life is expected to be more strongly associated with racially distinctive names than residential or spatial exposures alone.
Method
Data
Three publicly available data sources were used in this study. First, demographic data for this project were obtained from the 2015–2019 American Community Survey (ACS). Notably, although this survey’s estimates were based on only a 5 percent sample, I was also able to replicate the main results using racial composition data from the 2020 census, mitigating concerns that the findings are sensitive to sampling limitations. Second, names and addresses were obtained from clustrmaps.com. The publicly available website uses automated methods to consolidate public records, linking names with addresses, and subsequently publishes the compiled data. The resulting data set listed the names of approximately 320 million Americans, with an attached census block for each person.
Third, mobility data were obtained from SafeGraph, an American firm specializing in mobility and traffic data. SafeGraph aggregates anonymized everyday location data from a nationally representative sample of 45 million smartphone devices managed by Veraset. SafeGraph’s Social Distance Metrics data set provides daily information on individuals’ visits to and from each census block group in the United States for every day in 2019. The home location of a device is determined by SafeGraph based on the common nighttime (6:00 p.m. to 7:00 a.m.) location of the device.
Neighborhood measures
The goal of creating name-based racial composition measures is to quantify the extent to which the first names of residents of a neighborhood are associated with a given racial group. To do so, I draw on the predict_race function in the R package predictrace to calculate an individual-level association (Kaplan 2023). The function works by identifying the racial composition of Americans who have a given first name based on mortgage application data that were validated using census data (Tzioumis 2018). As an example, if I enter the name “Robert” into the function, I am returned with a non-Hispanic White probability (94.51 percent), a non-Hispanic Black probability (2.16 percent), and a Hispanic probability (2.14 percent). These probabilities indicate that if a person in the United States is named Robert, there is a 94.51 percent probability they are non-Hispanic White, a 2.16 percent probability they are non-Hispanic Black, and a 2.14 percent probability they are Hispanic. By averaging these probabilities over all names in a neighborhood, I obtain aggregate measures of how the first names in a given neighborhood are associated with a particular racial group.
Four name-based racial composition measures were calculated for all census block groups in the United States.
For a neighborhood i, I calculated the Black name-based racial composition measure as follows:

where
Similar measures were estimated for non-Hispanic White names and Hispanic (of any race) names. Subsequently, other names were calculated as follows:

Neighborhood disadvantage is central to how neighborhoods shape the educational, economic, and health outcomes of their residents. Non-White Americans, particularly Black Americans, are disproportionately exposed to concentrated neighborhood disadvantage (Sharkey 2008) and experience higher degrees of exposure to the harmful correlates of disadvantage, such as air pollution and violence (Galster 2011). In line with past research (Levy et al. 2020), I calculated residential neighborhood disadvantage (RND) using principal factor analysis on seven variables. These variables comprised proportions of poverty, unemployment, single-headed households, public assistance receipt, adults without a high school diploma, workers who are managers or professionals, and adults with a bachelor’s degree or higher. The first five variables load positively, and the last two load negatively.
I also consider spatial disadvantage as an additional measure of neighborhood disadvantage. Neighborhood residents interact with other individuals and institutions outside their neighborhoods, which can impact their life outcomes. The level of disadvantage in spatially proximal neighborhoods has been found to play a role in residents’ life outcomes (Crowder and South 2011). Given the relevance of spatial disadvantage, measuring the extent to which residents are exposed to disadvantage in broader spatial terms is crucial for understanding neighborhood inequality. In line with past research (Levy et al. 2020), I operationalized spatial disadvantage as the average RND score of all adjacent neighborhoods using a queen contiguity matrix based on spatial adjacency.
Mobility-based disadvantage serves as a crucial measure of the extralocal conditions that residents encounter in their everyday travels, which may or may not include neighborhoods that are spatially proximal to one’s home neighborhood. Although research on concentrated disadvantage and neighborhood effects has historically focused on residential neighborhoods or spatially adjacent neighborhoods, these approaches ignore the interneighborhood exposures that arise from everyday mobility patterns. Urban sociologists have increasingly conceptualized a city’s neighborhoods from a network perspective, recognizing the importance of these interneighborhood ties for neighborhood outcomes (Levy et al. 2020).
To calculate mobility-based disadvantage, I constructed a nationwide mobility network of neighborhoods using SafeGraph’s Social Distance Metrics data set. This constructed mobility network had values indicating the extent of mobility of residents of block group i to block group j over all days (a) in the sample.

In the formula,
I then used the mobility network matrix to calculate the weighted average of residential disadvantage among neighborhoods to which any neighborhood
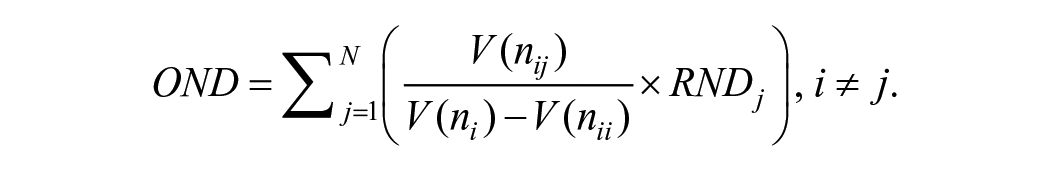
In this formula,
To calculate a neighborhood’s indegree neighborhood disadvantage (IND) score, I combined directed neighborhood networks with the study’s RND measure, averaging the weighted RND scores of the other neighborhoods in the commuting zone that receive visits. For counties located on the edge of a commuting zone, I included adjacent counties in other commuting zones in the neighborhoods’ mobility networks. Commuting zone boundaries were determined using the most recent (2000) available version of the USDA Economic Research Service commuting zone classifications. To account for the fact that sizes and visit probabilities of sending neighborhoods vary, I included adjustments in the formulate for calculating IND. This formula follows exactly from Levy et al.’s (2022) method.

where
I combined these two measures into a single measure of mobility-based disadvantage by simply averaging these two measures:

Data Analysis
The analysis was conducted using R. In my analyses, I examine how name-based infracategorical measures of race can contribute additional explanatory power to nominal measures in predicting neighborhood inequality in terms of residential disadvantage, spatial disadvantage, and mobility-based disadvantage. For the three outcomes, I used ordinary least squares (OLS) models with neighborhood as the unit of analysis. The key racial variables are proportion non-Hispanic Black, proportion Hispanic (of any race), and proportion other, with proportion non-Hispanic White as the omitted reference group; the key name-based racial variable are proportion non-Hispanic Black names, proportion Hispanic names, and proportion non-White other names, with proportion non-Hispanic White names as the omitted reference group.
My general main model can be written as follows:

where
These models employ variable controls depending on the outcome. Commuting zone fixed effects accounted for the fact that regional location may confound the association between naming patterns and SES. For predicting spatial disadvantage, I conditioned on residential disadvantage to test whether the effect of racial composition on spatial disadvantage operated outside that central pathway. Similarly, to predict mobility-based disadvantage, I conditioned on residential and spatial disadvantage to test whether the effect of racial composition on mobility-based disadvantage operated outside those central pathways.
Table 1 presents summary statistics on the variables, and Table S1 (in the appendix) presents the correlation matrix. As one would expect, across a variety of groups, name racial proportion is strongly correlated with ACS racial composition. Although strongly correlated, however, the measures are not duplicative.
Summary Statistics.

Note: ACS = American Community Survey; Q1 = 25th percentile; Q3 = 75th percentile.
As stated earlier, even though they are strongly correlated, there are several reasons to consider name-based measures of racial composition in addition to nominal measures. Because individuals with Black-sounding names are often more discriminated against (Bertrand and Mullainathan 2004) and may be more disadvantaged from birth (Fryer and Levitt 2004), a neighborhood-based measure of Black names has substantial conceptual value. The mechanisms of neighborhood effects and the social processes that drive neighborhood effects include (but are not limited to) the following: social isolation, stigma, discrimination and collective socialization, social cohesion, and control (Galster 2011). These factors should all be related to name-based racial composition net of true racial composition because individuals with Black-sounding names suffer more discrimination and are more disadvantaged to begin with, creating neighborhood-based social processes through segregation. In addition, the neighborhoods where distinctively Black naming patterns are likely to be the most common may have potentially suffered more isolation and systemic racism historically. Ultimately, understanding the unique segregation and residential disadvantages faced by individuals with Black-sounding names is crucial for comprehending the specific challenges and inequalities experienced by this group and for better understanding infracategorical inequality more broadly.
Results
Residential Disadvantage
Residential disadvantage is a primary driving force behind a multitude of neighborhood social processes paramount to understanding neighborhood inequality, including financial investment, collective efficacy, and social disorder. It is one of the most historically popular measures of neighborhood SES. Residential disadvantage has been strongly associated with a variety of adverse outcomes for youth and is central to explaining how neighborhoods causally affect children (Wodtke et al. 2011). Past studies have suggested that racialized naming practices are strongly linked with individual SES (Fryer 2004). This suggests that if racially distinctive naming patterns vary substantially between neighborhoods (conditional on nominal racial composition), it is reasonable to expect that neighborhoods with a higher prevalence of Black and Hispanic names might experience greater residential disadvantage even after controlling for nominal racial composition.
Table 2 estimates residential disadvantage across all census block groups in the United States. Model 1 estimates the residential disadvantage score of a census block group based solely on ACS racial demographics, where proportion non-Hispanic White is the omitted reference group. This model reveals that proportion Black and Hispanic is positively and significantly (p < .001) associated with a higher residential disadvantage score, whereas proportion other is negatively associated. This model suggests that a 100 percent Black neighborhood should have a residential disadvantage score 1.60 SD higher than a 100 percent White neighborhood. That is, a 1 SD increase in Black names is associated with a 0.36 SD increase in residential disadvantage. This descriptive model can explain 32 of the variance in residential disadvantage scores.
Models Predicting Residential Disadvantage.

p < .05. ***p < .001.
Standard errors are in parentheses.
Model 2 estimates the residential disadvantage score of a census block group based solely on the races associated with resident names. The general pattern of the coefficients for Model 2 aligns with those of Model 1. Specifically, the proportion Black and proportion Hispanic are strongly positively associated with residential disadvantage, whereas the proportion of other is strongly negatively associated with this disadvantage. An increase from the 1st percentile 2 of Black names to the 99th percentile 3 of Black names represents an increase of 2.17 SD in residential disadvantage. That is, a 1 SD increase in Black names is associated with a 0.44 SD increase in residential disadvantage. Notably, this model can also explain 38 percent of variance in the outcome—substantially more than the 32 percent of Model 1.
Model 3 combines the variables of Models 1 and 2. This model tests which set of variables is the dominant predictor of residential disadvantage. Notably, the coefficient for the proportion of Black residents becomes negative in Model 3, whereas the coefficient for the proportion of Black names remains positive and actually increases in size relative to Model 2. This finding suggests that the name-based measure of proportion Black may be the dominant predictor rather than the nominal Black measure. Thus, Black names can better explain variation between neighborhoods in terms of residential disadvantage than the actual number of Black residents.
In terms of the Hispanic coefficients, names and self-reported ethnicity appear evenly split in predicting residential disadvantage. The proportion Hispanic coefficient in Model 3 is approximately half of what it was in Model 1, and the proportion Hispanic name coefficient is also approximately half of what it was in Model 2.
Models 4, 5, and 6 replicate Models 1, 2, and 3 with commuting zone fixed effects. Generally, these models align closely with the first set of three models. Model 5 appears superior to Model 4 in terms of Akaike information criterion, Bayesian information criterion, and R2, again highlighting the importance of name-based measures of race over self-reported race in predicting neighborhood disparities.
Notably, in Model 3, the proportion Black coefficient is negative and highly significant (p < .001), but this coefficient is positive and slightly significant (p < .05) in Model 6. Additionally, the proportion of Black names is positive and highly significant in Model 6, similar to Model 3.
Figure 1 demonstrates that neighborhoods vary socioeconomically more in the degree of race in terms of names than in self-reported race. The figure presents the mean residential disadvantage score of neighborhoods binned by ventile in terms of ACS racial composition compared to Black name proportion. As the figure shows, the neighborhoods with the least Black names have lower residential disadvantage scores than neighborhoods with the fewest Black individuals, and the neighborhoods with the most Black names have greater residential disadvantage scores than neighborhoods with the most Black individuals. Figure 2 presents a similar figure except examining strictly neighborhoods that are predominantly Black (based on the ACS).

Residential disadvantage by Black name mean proportion versus proportion Black residents.

Residential disadvantage by Black name mean proportion versus proportion Black residents (predominantly Black neighborhoods).
In summary, these results indicated that neighborhoods with higher concentrations of Black and Hispanic names exhibit greater residential disadvantage even after accounting for the true racial composition. Models using name-based measures of race were superior to models using self-reported race in predicting neighborhood disparities. Additionally, the proportion of Black names was a stronger predictor of residential disadvantage than the proportion of Black residents. At the extremes, the neighborhoods with the least Black names have lower residential disadvantage scores than neighborhoods with the fewest Black individuals. Beyond this, the neighborhoods with the most Black names have greater residential disadvantage scores than neighborhoods with the most Black individuals.
Spatial Disadvantage
Residential disadvantage is a focal measure for explaining neighborhood effects, but this factor only partially explains neighborhood effects and other adverse outcomes. Research has emphasized spatially proximal neighborhoods’ contributions to neighborhood effects (Crowder and South 2011). The association between name-based racial composition and residential disadvantage follows from the individual-level association. Distinctly, an association between name-based racial composition and spatial disadvantage implies that neighborhoods with higher concentrations of certain names are spatially situated in a broader context of disadvantaged neighborhoods.
Table 3 presents models estimating spatial disadvantage. In Model 1, predictions are made based solely on racial composition data from the ACS. The results show a positive association between the proportion of Black and Hispanic residents and spatial disadvantage, whereas the proportion of residents categorized as other is negatively associated with spatial disadvantage. Specifically, a 1 SD increase in the proportion Black is associated with a 0.16 SD increase in spatial disadvantage. In Model 2, predictions are based solely on name-based measures of race, with results mirroring those of Model 1. However, the predictive power of Model 2 is significantly greater than that of Model 1, with respective R2 values of .40 and .29. The coefficient size of proportion Black names indicates that a 1 SD increase in proportion Black names is associated with a 0.23 SD increase in spatial disadvantage.
Models Predicting Spatial Disadvantage.

p < .01. ***p < .001.
Standard errors are in parentheses.
Model 3 replicates Model 1 but includes residential disadvantage as a control. The coefficients for proportion Black and Hispanic attenuate substantially from Model 1 to Model 3. These results suggest that after accounting for residential SES, Black and Hispanic neighborhoods are only somewhat more likely to experience spatial disadvantage relative to White neighborhoods. Model 4 replicates Model 2 but, similarly, also includes a residential disadvantage measure. The coefficients of the name-based variables differ significantly from Model 2, but to a lesser extent compared to the difference in aligning nominal coefficients from Model 1 to Model 3. The coefficient for the name-based measure of proportion Black is about a third of what it was in Model 2 compared to Model 4. Distinctly, the coefficient for proportion Black in Model 1 was less than a quarter of what it was in Model 3. The same pattern is observed for the proportion Hispanic coefficient.
Model 5 combines Models 3 and 4 to further evaluate the predictive power of true racial demographics and name-based measures. All three racial composition measures are negative and highly significant predictors in Model 5. However, the coefficients for the proportion Black names and the proportion Hispanic names remain positive and highly significant. These results suggest that neighborhoods where more residents have Black- or Hispanic-sounding names tend to have greater spatial connections with disadvantaged neighborhoods even after accounting for true racial composition and residential disadvantage. Model 6 replicates Model 5 but adds commuting zone fixed effects.
Mobility-Based Disadvantage
Mobility-based disadvantage is an especially powerful measure of neighborhood disadvantage. Recent research has suggested that mobility-based disadvantage is significantly associated with an array of adverse neighborhood outcomes (Levy et al. 2020, 2022; Vachuska 2023a and 2023b; Vachuska and Levy 2022). Conventional measures of disadvantage based solely on residential factors may not fully explain neighborhoods’ everyday contexts, whereas mobility-based measures represent the everyday exposures residents encounter. This is particularly relevant given that recent research has demonstrated that most Americans spend their waking hours outside of their residence in neighborhoods other than their own (Browning et al. 2021).
Mobility-based disadvantage is a consequence of certain mechanisms. First, there is strong socioeconomic homophily between neighborhoods in terms of mobility patterns. Individuals from disadvantaged neighborhoods often visit and receive visits from residents of other disadvantaged neighborhoods. (Levy et al. 2020). Moreover, neighborhood residents primarily receive visits and make visits to individuals from spatially proximal neighborhoods (Vachuska 2023). Consequently, neighborhoods near disadvantaged neighborhoods will likely have higher levels of mobility-based disadvantage. I also hypothesize that neighborhoods with a high proportion of non-White names are more likely to experience greater mobility-based disadvantage due to the lasting impacts of systemic racism, disenfranchisement, and isolation. Recent research has documented that Black and White neighborhoods are markedly disconnected from one another in mobility patterns (Vachuska 2023). Because racially distinctive names are expected to be associated with racially isolated communities, I hypothesize that neighborhoods with more non-White names will likely face greater mobility-based isolation.
Table 4 presents models estimating neighborhood mobility-based disadvantage. Model 1 predicts mobility-based disadvantage based solely on estimates of nominal racial composition from the ACS. Predictably, the proportions of Black and Hispanic residents are positively associated with mobility-based disadvantage, whereas proportion other is negatively associated with this measure. The coefficient size of proportion Black suggests that a 1 SD increase in proportion Black is associated with a 0.16 SD increase in mobility-based disadvantage. On the other hand, Model 2 predicts mobility-based disadvantage based solely on name-based measures of race. The results mirror those of Model 1. The coefficient size of proportion Black names suggests that a 1 SD increase in proportion Black names is associated with a 0.23 SD increase in mobility-based disadvantage. Notably, the predictive power of Model 2 is much greater than that of Model 1, with respective R2 values of .39 and .28.
Models Predicting Mobility-Based Disadvantage.

p < .01. ***p < .001.
Standard errors are in parentheses.
Model 3 replicates Model 1 but adds residential disadvantage and a residential disadvantage spatial lag term (spatial disadvantage). Past research has documented substantial socioeconomic homophily in mobility patterns, suggesting that a measure of residential disadvantage would be an important control. Furthermore, past research has documented that mobility patterns tend to be strongest between spatially proximal neighborhoods, necessitating the inclusion of a spatial lag term for residential disadvantage in the model. Net of these two variables, the coefficients of the racial composition variables are substantially different from those of Model 1. Although the coefficient for proportion Black is positive and fairly large in Model 1, the coefficient for proportion Black is small and negative in Model 2. The coefficient for proportion Hispanic remains positive in Model 3 but is highly attenuated. The coefficient for the proportion other remains negative and significant in Model 3 but is also attenuated. Ultimately, the results of Model 3 suggest that after accounting for the residential SES and spatial placement, nominally Black neighborhoods are not more likely than White neighborhoods to experience mobility-based disadvantage.
Model 4 replicates Model 2 but adds a residential disadvantage and a residential disadvantage spatial lag term. After accounting for these two variables, the coefficients of the name-based variables are substantially different than those of Model 2, but notably, not in the same manner that the results of Model 3 varied from Model 1. Although the coefficient for proportion Black is entirely attenuated from Model 1 to Model 3, the coefficient for the proportion of Black names remains positive and highly significant in Model 4 (p < .001). The coefficient for the proportion of Hispanic names also remains positive but is attenuated in Model 4. The coefficient for the proportion other names remains negative and significant but is attenuated in Model 3. Ultimately, whereas Model 3 suggests that the relationship between nominal racial composition and mobility-based disadvantage can be largely explained by residential disadvantage and spatial proximity to other disadvantaged neighborhoods, Model 4 suggests that the same is not true for name-based measures of racial composition.
Model 5 combines Models 3 and 4 to further evaluate the predictive power of nominal racial demographics compared to name-based measures. Notably, all three racial composition measures are negative and highly significant in Model 5, and the coefficients of the proportion Black names and the proportion Hispanic names remain positive and significant. These results suggest that neighborhoods with more residents with Black- or Hispanic-sounding names tend to have greater mobility connections with disadvantaged neighborhoods after accounting for true racial composition, residential disadvantage, and spatial proximity to disadvantaged neighborhoods. Model 6 replicates Model 5 but adds the fixed effects for commuting zone.
This sequence of models reveals a strong association between racialized naming patterns and mobility-based disadvantage. Particularly, neighborhoods with high rates of Black-sounding names have high levels of mobility-based disadvantage, especially because these neighborhoods tend to be residentially disadvantaged and spatially isolated. However, these mechanisms alone do not entirely explain the observed association. Neighborhoods with greater rates of Black and Hispanic naming patterns appear highly disadvantaged in terms of everyday mobility patterns even after accounting for these two factors, indicating the additional value that race, in terms of naming conventions, has in predicting isolation in terms of everyday mobility patterns.
Predominantly Black Neighborhoods
Table 5 examines only neighborhoods where at least 80 percent of residents identify as non-Hispanic Black. Black neighborhoods are frequently stereotyped as being impoverished, disadvantaged, and violent, but substantial variation exists across Black neighborhoods, with Black middle-class suburbs developing in many metropolitan areas (Pattillo 2005). Thus, naming conventions may distinguish disadvantaged and advantaged Black neighborhoods. Table 5 predicts four different neighborhood outcomes: residential disadvantage, spatial disadvantage, mobility-based disadvantage, and gun violence incidents.
Models Predicting Outcomes for Predominantly Black Neighborhoods.

p < .05. ***p < .001.
Standard errors are in parentheses.
Model 1 considers residential disadvantage, a variable central to many adverse neighborhood outcomes. The results reveal that Black names, Hispanic names, and other non-White names are all strongly positively associated with residential disadvantage. Of these groups, Black names have the greatest effect. A 1 SD increase in Black names among Black neighborhoods is marginally associated with a 0.32 SD increase in residential disadvantage (0.38 SD increase in terms of the variance among only Black neighborhoods).
Model 1 also suggests that Hispanic names are associated with increased residential disadvantage among Black neighborhoods. This finding supports the broader notion that non-White naming patterns may be associated with greater disadvantage. For instance, a 1 SD increase in Hispanic names among Black neighborhoods is marginally associated with a 0.15 SD increase in residential disadvantage (0.18 SD increase among only Black neighborhoods).
Model 2 examines spatial disadvantage. Generally, non-White names, Black names, Hispanic names, and other non-White names are all strongly positively associated with spatial disadvantage, but Black names have the strongest effect. A 1 SD increase in Black names among Black neighborhoods is marginally associated with a 0.37 SD increase in spatial disadvantage (0.47 SD increase among only Black neighborhoods).
Model 3 explores mobility-based disadvantage. Ultimately, non-White names, Black names, Hispanic names, and other non-White names are all positively associated with mobility-based disadvantage, with Black names having the greatest effect. A 1 SD increase in Black names among Black neighborhoods is marginally associated with a 0.25 SD increase in mobility-based disadvantage (0.38 SD increase among only Black neighborhoods).
Model 4 demonstrates the incidence of gun violence incidents using Poisson models, revealing that non-White names, Black names, Hispanic names, and other non-White names are all positively associated with gun violence incidents. Specifically, a 1 SD increase in Black names among Black neighborhoods is marginally associated with a 55 percent increase in the incidence of gun violence.
Predominantly White Neighborhoods
The scale of Black names can explain outcome variations in Black neighborhoods, but this measure may also be important for explaining neighborhood outcomes in White neighborhoods (neighborhoods that are at least 80 percent non-Hispanic White). Table 6 analyzes neighborhoods where at least 80 percent of residents identify as non-Hispanic White. Despite common stereotypes of White neighborhoods as affluent and advantaged, significant variation exists in White neighborhoods. Thus, naming conventions may help distinguish between disadvantaged and advantaged White neighborhoods. Table 6 predicts four different neighborhood outcomes: residential disadvantage, spatial disadvantage, mobility-based disadvantage, and gun violence incidents.
Models Predicting Outcomes for Predominantly White Neighborhoods.

p < .05. ***p < .001.
Standard errors are in parentheses.
Model 1 look at residential disadvantage. Overall, Black names, Hispanic names, and other non-White names are all positively associated with residential disadvantage. Black names have the most significant impact, with a 1 SD increase among White neighborhoods being marginally associated with a 0.40 SD increase in residential disadvantage (0.60 SD increase in terms of the variance among only White neighborhoods).
Additionally, Model 1 suggests that Hispanic names are associated with increased residential disadvantage among White neighborhoods, supporting the notion that non-White naming patterns more broadly are associated with increased disadvantage. Specifically, a 1 SD increase in Hispanic names among White neighborhoods is marginally associated with a 0.15 SD increase in residential disadvantage (0.18 SD increase among only White neighborhoods).
Next, Model 2 examines spatial disadvantage. In this model, Black names, Hispanic names, and other non-White names are all positively associated with spatial disadvantage, with Black names having the most significant effect. A 1 SD increase in Black names among White neighborhoods is marginally associated with a 0.28 SD increase in spatial disadvantage (0.54 SD increase among only White neighborhoods).
Model 3 looks at mobility-based disadvantage. Overall, non-White names, Black names, Hispanic names, and other non-White names are all positively associated with mobility-based disadvantage, with Black names having the most significant effect. A 1 SD increase in Black names in White neighborhoods is marginally associated with a 0.18 SD increase in mobility-based disadvantage (0.49 SD increase among only White neighborhoods).
Finally, Model 4 illustrates gun violence using Poisson models. Generally, non-White names, Black names, Hispanic names, and other non-White names are all positively associated with gun violence, with both Black and Hispanic names having large significant effects. Specifically, a 1 SD increase in Black names in White neighborhoods is marginally associated with a 17 percent increase in gun violence incidents, whereas a 1 SD increase in Hispanic names is associated with a 4 percent increase.
Discussion
This study examined the relationship between race and neighborhood outcomes using both nominal self-reported race and name-based measures of race. Overall, name-based measures of race were shown to be relatively stronger predictors of residential disadvantage compared to self-reported race. Specifically, neighborhoods with higher proportions of Black and Hispanic names were strongly associated with higher levels of residential disadvantage, whereas Black and Hispanic nominal proportions had only small effects net of names. Additionally, neighborhoods with the least Black names had lower residential disadvantage scores than neighborhoods with the fewest Black residents, and neighborhoods with the most Black names had greater residential disadvantage than the neighborhoods with the most residents who self-identified as Black.
This study additionally examined spatial disadvantage in neighborhoods, assessing which neighborhoods were spatially isolated from advantaged areas. Past research has documented that spatial disadvantage often better predicts adverse neighborhood outcomes compared to residential disadvantage and that nominally Black neighborhoods are more likely to be spatially isolated. My results suggested that both nominal and name-based racial composition are jointly associated with spatial disadvantage. However, when residential disadvantage was considered, nominal racial composition was not found to have any association with spatial disadvantage, but name-based racial composition was.
Net of spatial disadvantage, mobility-based disadvantage is an additional measure that was more predictive of adverse outcomes than residential disadvantage. When considering residential and spatial disadvantage, nominal racial composition was not found to be predictive of mobility-based disadvantage. However, name-based measures of race were positively associated with mobility-based disadvantage, indicating that neighborhoods with more residents with Black-sounding or Hispanic-sounding names frequently have greater mobility connections with disadvantaged neighborhoods. This finding is notable because mobility-based disadvantage is highly associated with a wide array of adverse outcomes (Levy et al. 2020, 2022; Vachuska 2023; Vachuska and Levy 2022).
Generally, these findings suggest naming conventions may be extremely useful for distinguishing disadvantaged and advantaged neighborhoods from each other. It is important to note, however, that these results do not imply any form of a causal relationship between naming practices and increased disadvantage. Past research has found no evidence of a causal effect of naming practices (Fryer and Levitt 2004). Rather, the results of this article descriptively highlight broader socioeconomic and structural patterns that are associated with racially distinctive naming patterns. Whereas previous research has demonstrated a strong link between racialized naming patterns and individual outcomes, this study extends that understanding by showing that these names also serve as markers of neighborhood-level disadvantage. The clustering of racially distinctive names in certain neighborhoods may signal broader patterns of racial segregation, discrimination, and isolation that go beyond individual-level effects. These results suggest that name-based measures of race may provide insights into the collective social and economic dynamics in neighborhoods that are not fully captured by individual-level analyses. My analyses across racially homogeneous neighborhoods suggest that naming patterns can be helpful in explaining neighborhood outcomes in both Black and White neighborhoods where little apparent nominal racial variation exists.
These findings suggest that in terms of cues and perceived typicality, neighborhood disadvantage (residentially, spatially, and in terms of mobility) is worse for Black Americans than nominal examinations may suggest. Although research highlights the growth of middle-class Black neighborhoods (Pattillo 2005), these findings suggest that the residents of more affluent Black neighborhoods may have lower degrees of Black cues and perceived typicality compared to other Black neighborhoods. These findings suggest a potentially important spatial bifurcation of Black Americans and suggest what neighborhoods may or may not be accessible to what subgroups of Black Americans. That is, Black neighborhoods where residents have less Black-sounding names tend to be much more affluent than Black neighborhoods with more Black-sounding names. Broadly, a major implication of this research for broader ethno-racial inequality is that just as nominal racial composition can reveal inequality between White and non-White neighborhoods, names can reveal substantial inequality in nominally homogeneous neighborhoods,
Although this study provided valuable insights into the relationship between race and residential disadvantage, there are certain limitations to bear in mind when interpreting the results. For one, the underlying data to this analysis were aggregated public records data. It would be beneficial for these results to be replicated with other data sets. Furthermore, this article is framed in the context of the infracategorical model of inequality (ICMI) model, but name-based measures of race may not accurately reflect individuals’ racial identities or their broader perceived typicality/cues for race. Additionally, these models do not examine the historical and structural factors affecting the observed patterns of racial segregation and inequality, which are paramount to better interpreting and understanding the observed descriptive findings.
This research lays the groundwork for future studies. First, although some have already (Agan and Starr, 2017), correspondence studies could better explore the role that neighborhoods play in discrimination. Future research could also enhance the findings of this work by examining the mechanisms underlying the relationship between name-based measures of race and residential disadvantage. Although I posit that naming patterns are associated with other forms of perceived typicality and racial cues, there is no empirical evidence to date to support this. Better investigating how naming patterns at the neighborhood level are associated with these factors is central to understanding and interpreting these findings. Additionally, future studies could investigate how different naming conventions interact with other demographic and socioeconomic factors to shape neighborhood outcomes. Much of the literature on racially distinctive naming practices focuses on distinctively Black names, but more research is needed to explore distinctive naming practices among other ethno-racial groups (Gaddis 2017). Furthermore, it may be worthwhile to investigate this research in terms of other nonracial historical naming practices, potentially building on the work of Beaudin et al. (2022), which documented the penalty of Southern-sounding names in the twentieth century.
Beyond this, research could also explore the impact of name-based neighborhood measures of race on other individual-level social outcomes. For example, studies could investigate whether name-based measures of race at the neighborhood level are associated with neighborhood effects in terms of educational attainment, health outcomes, or employment opportunities. Recent data have revealed important variation in the types of neighborhoods that promote upward mobility among Black adolescents (Chetty et al. 2020, 2022), and examining how the naming patterns of neighborhoods are associated with intergenerational mobility patterns would be an important contribution. Broadly, given the strong axis in terms of race along which such naming disadvantages exist, further understanding these inequalities is of great importance.
Supplemental Material
sj-docx-1-srd-10.1177_23780231241286366 – Supplemental material for The Significance of Name-Based Racial Composition in Analyzing Neighborhood Disparities
Supplemental material, sj-docx-1-srd-10.1177_23780231241286366 for The Significance of Name-Based Racial Composition in Analyzing Neighborhood Disparities by Karl Vachuska in Socius
Footnotes
Acknowledgements
I would like to gratefully acknowledge and thank Max Besbris, Rob Warren, Brian Levy, and Leila Moustafa for their helpful comments on this work. This research was carried out using the facilities of the Center for Demography and Ecology at the University of Wisconsin–Madison, which is supported by Eunice Kennedy Shriver National Institute of Child Health and Human Development grant P2C HD047873, and was supported in part by training grant T32 HD007014.
Supplemental Material
Supplemental material for this article is available online.
1
Other research has documented distinctively Black naming practices in the late nineteenth and early twentieth century as well (Cook, Logan, and Parman 2014).
2
In the first percentile of Black name neighborhoods, the average resident has a first name that is 2.967 percent Black.
3
In the 99th percentile of Black name neighborhoods, the average resident has a first name that is 12.665 percent Black.
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.