
Abstract
Drawing on ethnographic, interview, and textual data with researchers creating machine learning solutions for health care, the author explains how researchers justify their projects while grappling with uncertainties about the benefits and harms of machine learning. Researchers differentiate between a hypothesized world of machine learning and a “real” world of clinical practice. Each world relates to distinct frameworks for describing, evaluating, and reconciling uncertainties. In the hypothesized world, impacts are hypothetical. They can be operationalized, controlled, and computed as bias and fairness. In the real world, impacts address patient outcomes in clinical settings. Real impacts are chaotic and uncontrolled and relate to complex issues of equity. To address real-world uncertainties, researchers collaborate closely with clinicians, who explain real-world implications, and participate in data generation projects to improve clinical datasets. Through these collaborations, researchers expand ethical discussions, while delegating moral responsibility to clinicians and medical infrastructure. This preserves the legitimacy of machine learning as a pure, technical domain, while allowing engagement with health care impacts. This article contributes an explanation of the interplay between technical and moral boundaries in shaping ethical dilemmas and responsibilities, and explains the significance of collaboration in artificial intelligence projects for ethical engagement.
For every complex problem there is an answer that is clear, simple, and wrong.
I step into Professor Gould’s office, standing opposite a bookshelf and long desk pushed underneath a window that stretches the length of the far wall. To the right is a gray rocking chair angled toward a gray cushioned love seat complete with a yellow throw blanket. In the center, there is a circular table with three metal chairs facing a clean whiteboard. I ask Professor Gould where the best place is for me to sit. “Well,” he begins, “are we talking data,” he points to the round table and chairs, “or are we talking life,” he motions toward the gray couch.
Professor Gould, a computer scientist, works on projects that apply machine learning techniques to health care. I spoke with him as part of research on interdisciplinary collaborations creating machine learning (a subfield of artificial intelligence [AI]) models for health care. These researchers primarily have technical backgrounds in computer science, data science, and engineering, or clinical backgrounds. They often work in interdisciplinary teams across academic and medical settings. Using large-scale clinical or patient datasets, they train algorithms that perform a range of tasks such as predicting diagnoses, assigning risk scores, autocompleting doctors’ notes, modeling biomolecular processes, and triaging patients between hospital departments.
Although such machine learning applications are promoted as promissory tools to address health care challenges, recent work documents unintended harms. For example, machine learning algorithms have been shown to perpetuate disparate treatment outcomes for marginalized groups and reinforce biased stereotypes (Obermeyer et al. 2019; Zack et al. 2023). Social science scholarship, media, and policy groups have been instrumental in uncovering and reporting adverse outcomes of AI systems (Benjamin 2019; Committee on Responsible Computing Research: Ethics and Governance of Computing Research and Its Applications et al. 2022; Eubanks 2017; Levi and Gorenstein 2023; Noble 2018). Researchers who develop models in health care express concern about potential risks such as the reproduction of biases and patient data security (Chen et al. 2021; McCradden et al. 2020; Shachar and Gerke 2023). As AI in health care is a multibillion-dollar industry that will affect millions of patients (Bohr and Memarzadeh 2020), consideration of AI systems and impacts needs to be prioritized.
In this article I address how researchers developing machine learning models for health care justify the ethical implications of their work while grappling with uncertainties between machine learning benefits and harms. Past scholarship revealed researchers and technologists to be unconcerned with ethical impacts (Burrell and Fourcade 2021; Cech 2014; Forsythe 1993) and constrained by corporate interests (Ali et al. 2023; Metcalf, Moss, and boyd 2019); more recent literature focuses on how technologists understand ethics (Avnoon, Kotliar, and Rivnai-Bahir 2023; Orr and Davis 2020; Wehrens et al. 2023). Scholarship on technical collaborations has often focused on interpersonal relationships, communication, and achieving success in corporate settings (Mao et al. 2019; Passi and Jackson 2018; Zhang, Muller, and Wang 2020), rather than project justifications, ethical engagement, and responsibilities aimed at societal benefit. In contrast, this study is focused on the relationship between ethical dilemmas, moral boundaries, and collaboration. I draw primarily on interviews with technical and clinical collaborators involved in creating machine learning models for health care, as well as participant observation of three interdisciplinary groups, observations of other meetings, conferences, workshops, and events, and textual analysis to contextualize the work of participants.
Professor Gould’s distinction between “talking data” in the metal chairs versus “talking life” on the gray couch illuminates a primary method in which researchers justify the ethical implications of machine learning projects. I find that researchers distinguish between a hypothesized world of machine learning development and a “real” world of clinical settings. Each world relates to different frameworks to describe, evaluate, and reconcile uncertainties between benefits and harms. When researchers seek to address uncertain “real” impacts, they seek to align hypothetical and applied aspects of work through two processes: (1) collaborating closely with clinicians who access and translate the real world, and (2) participating in data generation and curation projects to create more accurate and representative datasets. Alignment between the two worlds expands ethical discussions, while delegating responsibility to adjudicate between conflicting moral values to clinicians and medical infrastructure.
This study contributes to the burgeoning field of the sociology of AI by presenting a model to understand the interplay of ethics and morality in AI/machine learning research, as well as emphasizes the role of collaboration in addressing ethical considerations. I explain the relationship between technical and moral boundaries. Boundaries between the hypothetical and the “real” ultimately define the contents of ethical debate, delegate moral responsibilities, and serve as a mechanism to reconcile uncertainties. These boundaries shape the types of ethics work researchers do, the questions that they consider, the assumptions that they bring to their work, and their methods of implementing ethics. By providing a framework to identify the consequential stakes of defining what is “real” in debates about AI and applied scientific solutions, the article explains how actors come to define and prioritize technology benefits and harms. Additionally, the research highlights the significance of collaboration for AI ethics and morality in science. Collaboration bridges moral and technical boundaries to expand ethical engagement and integrate ethical responsibility into the structure of AI projects. As calls to increase stakeholders involved in AI research grows, it is necessary to understand the implications of collaboration on moral discussions, boundaries, responsibilities, and impacts.
The Sociology of AI and Ethics
Early social science scholarship on science, technology, and engineering portrayed technical researchers as agnostic or oblivious to the social and ethical implications of their work (Burrell and Fourcade 2021; Cech 2014; Forsythe 1993; Joyce et al. 2018, 2021). Case studies from across domains of science exhibited strong boundaries between science and society that upheld beliefs in the purity and objectivity of scientific pursuits (Gieryn 1995; Latour 1999; Shapin and Schaffer 1985). Similarly, computer scientists expressed discomfort with the uncontrollable nature of social interaction and excluded social concerns from their domain (Forsythe 1993). Maintaining a controllable environment to prove facts remained critical to legitimizing scientific advances (Latour 1999; Shapin and Schaffer 1985).
More recently, communities of AI and machine learning practitioners have begun to grapple explicitly with social impacts, ethics, and instances of AI harms (Bender et al. 2021; Selbst et al. 2019). For example, a group of technical researchers uncovered an AI health care algorithm that underreported the severity of risk for Black patients compared with white patients, leaving them significantly sicker and allocating fewer resources to their treatment (Obermeyer et al. 2019). Technologists have initiated efforts to lobby for what they see as more ethical standards (i.e., Collins et al. 2021; Ganapathi et al. 2022). Within both academic and corporate communities, scholars seek to encourage the evaluation of the broader impacts of new tools (Gebru et al. 2021; Mitchell et al. 2019; Wang et al. 2022). Recent reviews in top computer science and medical journals include articles such as “Governing AI Safety through Independent Audits” (Falco et al. 2021) and “Ethical Machine Learning in Healthcare” (Chen et al. 2021).
Social scientists concerned with technology impacts and ethics have studied researchers’ and developers’ interpretations of and practices to realize moral ideals. Technologists rely on a variety of frames to interpret moral aspects of their work (Avnoon et al. 2023; Sloane and Zakrzewski 2022; Wehrens et al. 2023) and perform ethics through mundane decision-making processes (Jaton 2020; Seaver 2021; Tanweer 2022; Ziewitz 2019). Through actions and interpretations, they prioritize ethical values that shape all aspects of bringing a technology into being, including topics of group conversation, model contents, and forms of sociality (Amoore 2020; Neyland 2016). However, the majority of this scholarship portrays data scientists and technologists as the “coding elite” (Burrell and Fourcade 2021), working within and constrained by corporate logics (Ali et al. 2023; Metcalf et al. 2019; Rider 2022) and decontextualized from concrete interlocuters and outcomes (Orr and Davis 2020; Widder and Nafus 2023).
In contrast, when developing machine learning solutions for health care, technologists work in interdisciplinary teams across institutional settings. Scholarship from computer-supported cooperative work centers similar collaborative, technical projects, however this scholarship often focuses on corporate teams and issues of interest alignment, communication, and success evaluation, rather than ethical justification and accountability (Hou and Wang 2017; Mao et al. 2019; Passi and Jackson 2018; Zhang et al. 2020). Increasing the stakeholders involved in technological design is purported as a method to create more beneficial technologies (Costanza-Chock 2020). However, little is known about the significance of collaboration on moral dilemmas, ethical responsibility, and project justification. Boundaries that divide and distinguish disciplinary groups and spheres have been shown to be important for professional collaboration (Farchi, Dopson, and Ferlie 2023; Weber et al. 2022), scientific legitimacy (Gieryn 1995), and moral order (Lamont and Molnár 2002). What scholarship on AI ethics misses is the relationship between moral frameworks, project justifications, and structures of work as research teams puzzle through, define, and assign responsibility for machine learning impacts.
This article focuses on AI ethics in academic and medical domains, thus outside of pure corporate settings. 1 The interpretation and practice of AI ethics for noncorporate researchers joins a large body of scholarship on morality in science. Scholarship shows how scientists respond to ethical policies and regulations in fields with clearer mandates (Evans and Silbey 2022; Hedgecoe 2014; Smith-Doerr and Vardi 2015; Stark 2012). Other scholarship highlights how scientists incorporate moral expertise as part of their jurisdiction (Evans 2021), define ethical aspects of their work (Wainwright et al. 2006), the impact of moral debates on research agendas (Dromi and Stabler 2023; Frickel et al. 2010; Thompson 2013), and the creation of new professions with ethical jurisdiction (Evans 2012). In summary, the literature on morality in science largely focuses on the cooption or projection of ethics onto regulatory structures or “ethics” professionals (Evans 2012, 2021; Evans and Silbey 2022; Jasanoff 2005). However, neither of these legitimized moral structures yet exists in the field of AI. The question remains how researchers negotiate technical and moral boundaries within the context of a collaborative, interdisciplinary domain to retain the legitimacy of science, recognize AI harms, and pursue motivations for societal benefit.
Ethics in Action
In line with dominant scholarship, I adopt a pragmatic conceptualization of ethics (Boltanski and Thevenot 1999). Ethics is found in how people negotiate among competing values, reason and make decisions, and define their goals and objectives within specific social contexts (Ananny 2016; Jaton 2021; Seaver 2017). A pragmatic ethical approach contrasts with views of ethics as fixed rules, duties, and mandates (Kant [1785] 1998), or as utilitarian focused on outcomes and maximization of action (Mill 1879). AI ethics is particularly well-suited to a pragmatic approach given the lack of centralized authority, regulations, or professional norms that substantiate “ethical AI” (Ensmenger 2010; Jobin, Ienca, and Vayena 2019). Additionally, there is a noted gap between high-level principles and on the ground practices (Morley et al. 2020). Although medicine has developed pathways for creating protocols and guidelines to realize best practices and standardize ethical prescriptions (Timmermans and Berg 1997, 2010), these steps are less clear for AI. For example, without codified guidance, it is uncertain what steps are required for a machine learning project to comply with “patient safety” or “nondiscrimination.” As a result, ethical action requires explicit deliberation as it is yet to become a normative course of action.
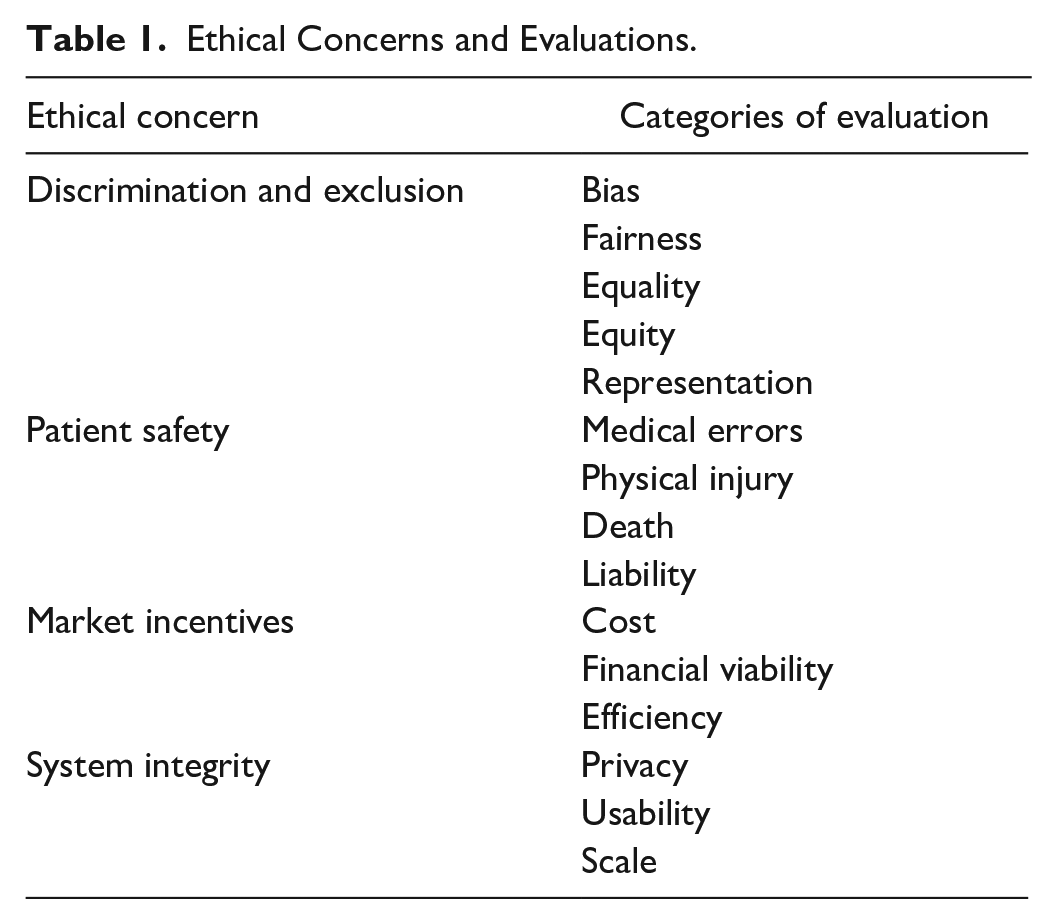
In a pragmatic ethical approach, people mobilize evaluative categories that define “the good” to deliberate courses of action and realize a version of this ideal (Boltanski and Thevenot 1999). In this article, I focus on the categories that actors mobilize to discuss beneficial machine learning projects and strategies to reconcile trade-offs between multiple categories of evaluation in hopes of realizing an understanding of the good. Table 1 presents a nonexhaustive sample of ethical concerns and categories of evaluation that actors mobilize to deliberate courses of action in the field of machine learning for health care. Within this framework, ethics constitutes the categories used to make evaluations, as well as the results of evaluations on social action and arrangements. Oftentimes, scholarship on ethical evaluations focuses on “hot” moments or conflict between incommensurable evaluative criteria (Boltanski and Thevenot 1999; Dromi and Stabler 2023; Stark 2011; Tavory, Prelat, and Ronen 2022). Instead, I focus on strategies used to avoid conflict, manage uncertainty, retain the “purity” of evaluative criteria, and distribute responsibility for ethical judgement.
Ethical Concerns and Evaluations.
Data and Methods
This research focuses on interdisciplinary teams creating machine learning models for health care as a subfield of AI research and development. AI encompasses the development and deployment of computing infrastructures that seek to mimic or incorporate elements of human reasoning. Machine learning is a subfield of AI that constitutes the training of computer systems to analyze and draw inferences from patterns in data. AI is increasingly consequential for health care, assisting tasks such as predicting treatment outcomes, diagnosing diseases, automating documentation and billing, assisting in surgeries, and discovering drugs. Machine learning is often used for optimization, prediction, object recognition, natural language processing, and text comprehension. For example, machine learning models are being used to predict risk for breast cancer by automatically analyzing mammograms (Yala et al. 2022). Risk predictions then inform diagnosis and treatment decisions.
Data for this project include (1) interviews with participants in interdisciplinary groups engaged in machine learning for health care research (see Appendix A for descriptive statistics); (2) in-depth participant observation with three project groups; (3) observations from other meetings, workshops, conferences, and events; and (4) textual analysis of materials related to each participant (see Appendix B). Table 2 presents a summary of data modalities.
Data Modalities.

Note: AI = artificial intelligence; CV = curriculum vitae; ML = machine learning.
Respondents were identified using a multipronged approach. One method of recruitment sampled researchers engaged with any of three prominent conferences on machine learning and health that target stakeholders from technical and clinical fields. Another method relied on digests and news updates from medical and research institutions that work in the area of AI and health care. Third, respondents were recruited through department and web specific Google searches. Last, respondents were recruited through snowball sampling, particularly collaborators on the same project. Respondents and labs qualified for the study if they described their work as using machine learning methods for health care application, worked on at least one machine learning and health care project, or published papers on a similar theme. For example, a lab that publishes research on creating an algorithm to predict cardiac arrest among intensive care unit (ICU) patients qualifies for the study. Similarly, a lab that describes its work as “augmenting medical decision making through machine learning” also qualifies for the study. Respondents were recruited through e-mail and confirmed qualification. 2 All members of a collaboration or lab were invited to participate including principal investigators, research associates, postdocs, graduate students, medical fellows, physicians, interns, and administrative staff members (Appendix A). 3
Interviews lasted between 30 and 90 minutes and focused on professionals’ career trajectories, goals, project workflows, roles in relation to collaborators, views on ideal collaboration, and prominent topics under the banner of ethical AI (i.e., bias, fairness, privacy, regulation, risks). To gain further insights about the composition of labs and the professional background of members and contextualize projects and discussions, a corpus of textual data was collected from the web (see Appendix B for details). Together, interview transcripts and textual data compose a profile for each individual and group that represents the structure of labs and collaborators, project details, and broader participation and views on the field of machine learning and health care.
Ethnographic observations occurred in labs located in one metropolitan area and recruited through the methods previously described in which the principal investigator invited me to attend a group meeting. Three core groups were selected for extended observation. A comparison of each group is not the subject of this article. With each group, I spent one day a week attending project meetings, as well as attended special events and socials. Observations at other events, including data hackathons, 4 conferences, lectures, and webinars provided further opportunities to observe interactions between collaborators, discussions about roles and responsibilities, and the potentials and risks of machine learning.
Data were analyzed inductively. After each interview or event, I wrote a memo outlining major themes and reactions. Through the memos, I identified consistent distinctions between the world of technological development and the “real” world of clinical practice. I was often struck by the addition of the word real to describe entities such as “real-world hospital data.” From this observation, I conducted word searches to isolate data segments that related to “real” aspects of work compared with “imagined” or “hypothetical” aspects. I read and annotated isolated segments to understand the meanings of reality compared with imagined or hypothetical work. Last, I mapped identified segments to professional profiles, research focuses, and project structures. Conclusions are drawn from the ways in researchers use themes of reality in connection to specific research agendas, workflows, and role definitions. 5
Results
Researchers distinguish between a hypothesized world of machine learning and a “real” world of clinical practice, each with different frameworks to describe, evaluate, and reconcile ethical uncertainties (Figure 1). In the hypothesized machine learning world, solutions are hypothetical. Within this framework, researchers are content with imagining future impacts. They can control and compute hypothetical impacts as definitive metrics that represent algorithmic bias and fairness. In contrast, in the real world, solutions relate to concrete patient outcomes in clinical settings. When considering real impacts, researchers are concerned with how AI tools will integrate within health systems and affect patient well-being and clinical workflows. Impacts within clinical settings are chaotic and uncontrolled and cannot be computed as summary metrics. Instead, these impacts relate to complex issues of equity.

Social impacts in the hypothesized world of machine learning and the real world of clinical practice.
To address more uncertain “real” impacts, researchers seek to align the two worlds by collaborating with clinicians and participating in patient data generation and curation projects geared toward representation. Through collaboration, researchers bridge technical and moral boundaries, which concretizes and assigns clinicians the responsibility of defining the impacts of machine learning. Distinctions between the hypothesized and the real help resolve ethical uncertainties between benefits and risks by defining relevant ethical frameworks that maintain a controllable world to legitimate machine learning while relying on collaboration to make ethical judgements in an uncertain world outside of machine learning researchers’ full responsibility.
Distinctions between the Hypothesized World of Machine Learning and the “Real” World of Clinical Practice
A research group based in a large medical facility had been working on building a machine learning large language model for a few months. The model is intended to help with a variety of clinical tasks, such as answering medical questions, searching for diagnosis, and summarizing labs. In a group check-in, the lead researcher, Dr. Ryder, began the meeting with an update. He explained, “[The computer science intern] has been working with the server and we’ve got a real, I shouldn’t say real, but we’ve got, you know, some forward progress in terms of the approach to what we’re building.” The team, excited about the progress, focuses on organizing the next phase of the project for the remainder of the meeting. They create an agenda and assign programming tasks but postpone questions about “end users” for when the product is ready to be implemented into the hospital setting. Although Dr. Ryder initially describes progress on the model as “real,” he had redacted the statement. The model still exists in the realm of creation. Dr. Ryder does not have any concrete or tangible impacts to share, and the model is not integrated within the hospital infrastructure or used by clinicians. The model is progressing, but it is not yet real. Similar common phrases used in interviews, papers, and conference sessions include “real-world hospital data,” “real-world impacts of AI in health,” “running models in real-time clinical settings,” and the “reality of the hospital.” The “real” world associates with medical infrastructure, personnel, and settings.
In contrast, machine learning models associate with the realm of the imagined. Mr. Long, a senior health executive, describes as follows: We understand that tech improvements are there, but the speed at which they are evolving, stretches human imagination. We have to get to an area that says what types of use cases are relevant today. Is [the technology] something that we should actually pull into the [health] system or not? . . . when [the technology] gets closer to an area that we are intimately familiar with, our own health and decisions that are made with a physician in an exam room, a clinical decision, maybe we get a little bit more uncomfortable.
As Mr. Long explains, machine learning models exist “there,” separate from health systems. The “there” of machine learning keeps evolving, in the realm of imagination. In contrast, the health system is “an area that we are intimately familiar with” such as “a physician in an exam room.” Machine learning models could be pulled into these familiar settings, but function as distinct entities in their own realm coming from “there.” Given the current state of research and development, the difference between imagined machine learning solutions and clinical settings makes Mr. Long uncomfortable about their prospect of integration. Continual discrepancies separate the real world of clinical settings and the hypothesized world of machine learning.
Impacts in the Hypothesized and “Real” World
Hypothesized Machine Learning Impacts
Distinctions between the real and hypothetical worlds uphold technical and moral boundaries that narrow relevant contingencies and uncertainties to consider when describing and justifying machine learning impacts. In the hypothesized world of machine learning, respondents define impacts as hypothetical. Participants describe “imagining” the benefits of solutions. Carly, a research associate in a biomedical informatics lab, works on projects such as creating models to interpret radiographs and combine data modalities (i.e., radiographs and genomics data) to aid clinical decision making. She connects her work to outcomes such as “improving diagnosis and prognosis,” “the responsible use of AI,” and “validation and bias detection” but does not work on projects at the “implementation stage” in clinical settings. She explains, “My overall goal is to be working on problems that I can at least imagine what the impact would be. . . . I’m comfortable with being a couple of degrees removed from the final impact.” By justifying her impacts hypothetically outside of clinical settings, Carly can imagine the benefits of her tools without considering additional questions that arise during use or application.
Imagined impacts can be controlled and neatly and definitively evaluated and presented. This allows machine learning projects to be summarized as technical papers and contribute to a scientific discipline, justifying impacts as valuable, even if hypothetical. Jim, a graduate student, describes the publication process in relation to releasing code and software which would make the research more accessible and practical for medical personnel: What we typically do is examine the currently existing methods to see what is still lacking, and then try to solve the problem. We find a test [data]set to test on that, find a metric to evaluate if [our model is] better. We will evaluate the algorithm on [a], [b] and [c]. And if all of that works, then it’s already a publishable paper . . . but we still need to engineer the software to make it more user friendly to solve the bugs people are reporting . . . there’s typically a lot of new problems that come up . . . for research, you don’t have to be like 100% robust, you just need it to work enough so that you can test it yourself and get some results for a paper. But to release it for other people there are going to be a lot of other problems.
As Jim explains, publishing solutions as a technical paper is simpler than making software and data available for use. He admits that for publication, research does not need to be “100% robust.” It just has to work well enough to compute a result framed as significant. Clear, controlled steps, such as evaluating the algorithm against existing benchmarks, create a stable pathway to publication and justification of value. However, making the code usable to implement or test requires further work. By differentiating hypothetical research for publication from the necessary steps for application, Jim upholds technical boundaries, limiting the relevance of additional ethical questions as long as he remains in the hypothetical machine learning world.
Last, machine learning impacts can be computed, often as a metric for bias or fairness. Although participants’ colloquial and formulaic definitions of bias and fairness vary, and the two are often used interchangeably, typically bias refers to instances when some subgroups receive less optimal outcomes compared with others, and fairness refers to equalizing optimization for all subgroups. At a computer science and health care conference, the top paper in the tract “Impact and Society” was a paper on “fair risk prediction.” When presenting the paper, Dr. Frise, the lead author, provided background: Just to give an overview of fair machine learning there are two steps, first we want to define some measure of fairness and . . . then we are going to use an algorithm to try to optimize the model to satisfy that measure.
As the paper demonstrated, fairness within the bounds of the hypothesized machine learning world is measured as a metric that can be optimized through calculation.
Similarly, bias can be statistically evaluated. Dr. Volger, an MD with a background in biomedical engineering, works on a variety of machine learning projects such as creating models to customize and optimize patient postoperative treatment plans. He advises evaluating models to check for bias by comparing the statistical distribution of patient demographics and outcomes. Some of the factors he would use to evaluate a model include ensuring that the model is “actually relevant across multiple groups” on the basis of the “demographic of the setting” and “looking whether our prediction actually was consistent with what actually was happening over time.” In this instance, model bias is calculated as disparities in accuracy between demographic groups in different settings and over time. Bias exists as a computable metric that represents an aspect of model performance between discrete population groups that can be neatly summarized. Differentiating hypothetical impacts creates an imagined scenario in which outcomes can be statistically evaluated, computed, and neatly presented, reducing uncertainties, and justifying machine learning benefits. Within the hypothetical world, boundaries between the technical and the moral limit the relevance of additional risks or ethical questions.
Real-World Impacts
In contrast to the hypothetical, controllable, and calculable nature of machine learning impacts, real-world impacts consider clinical use and integration and grapple with the uncontrollability of health care settings and complex issues of equity. Thus, real impacts require an expanded moral framework.
Dr. Smith, a lead researcher in a hospital group, gave a presentation about his work on machine learning language models to clinicians at his institution. He shows examples about how the model can help summarize labs and suggest treatment options. In discussing his goals to “get [the machine learning model] to the bedside,” Dr. Smith elaborates, this is an exact sort of rubber meets the road example of where these language models can affect real impact at the bedside. . . . What we’re trying to build here is not just a research tool. We are trying to make it as valuable as possible in the clinical standpoint.
Dr. Smith defines project value on the basis of “real impact,” which occurs “at the bedside,” meaning at the point of clinical care used by medical professionals. Impacts must be tangible in the hospital environment and the tool must be in the hands of clinicians.
However, real hospital and clinical settings are chaotic and difficult to evaluate, requiring more uncertain moral deliberation in contrast to controllable machine learning impacts. Speaking at a conference Professor Bennett, a prominent entrepreneur and professor of machine learning and health care, admits that “papers always look nicer than the reality of the real world. The reality of the real world is really complicated.” Similarly, Dr. Carlyle, a researcher with an MD and PhD in computer science, compares the complexity of impacts in clinical settings versus publishing in machine learning outlets: I often saw machine learning researchers that started out with a nice goal, but then . . . I had the situation of explaining to them the complexity of a real medical problem . . . people don’t really know about the complexity of problems that can occur. Medicine and machine learning often boils down to some predefined tasks that people work on and optimize and then after a couple of years, they realize oh, we optimized this task, I want to translate it, but it doesn’t work.
“Real medical problems” and the “reality of the real world” are “complicated” and “complex.” As a result, controlled and computed machine learning solutions currently do not adequately grapple with this complexity, and thus they do not translate between the two worlds. The “real” world requires asking a less defined and more uncertain set of ethical questions that transcend technical boundaries.
The complexity of the real world leads to consideration of equity issues that pervade calculation and directly contrast with the computable nature of bias and fairness metrics. Although equity can be variably defined, respondents typically use it to refer to goals of eliminating disparities and improving health for all groups by considering health and social system outcomes in which machine learning models play a part. Professor Nittle in biomedical informatics describes tensions between fairness and equity: the question is always going to be a tradeoff between pure model performance and equity . . . is it actually fair to potentially penalize a group that the model works well on for the sake of equity and another group? It’s like, we just won’t run this model in this group because it doesn’t work well for them. Is that a fair thing to do?
Professor Nittle feels unsure about how to achieve equity given the uncertainty and complexity of impacts on different populations. Similarly, Professor Jefferies, also in biomedical informatics, critiques the use of performance metrics in contrast to a focus on equity: I think of challenges of mostly equity. . . . I think of it as will this tool even work for certain kinds of people? Should I even bother to build such a tool? . . . I have these conversations a lot with people in machine learning who operationalize all of these values specifically through performance metrics, but then end up realizing that that doesn’t actually translate to a real health outcome.
Achieving a “real health outcome” requires considerations beyond narrow and neat metrics that extend beyond the technical boundaries of the hypothetical machine learning world, including scrutinizing the entire research and development process from first steps of project conception. A focus on equity entails expanding relevant ethical questions to consider holistic processes of health care and model development; however, this leaves machine learning researchers with less certain outcomes and answers.
Alignment between the Hypothesized World of Machine Learning and the “Real” World of Clinical Practice
When faced with uncertainty in “real” world benefits and harms, researchers seek to structure projects and collaborations to align the two worlds and resolve uncertainties. This occurs through two processes: working closely with practicing clinicians and participating in patient data generation projects that seek to promote representation. Through these processes, collaboration and clinical consideration bridge technical and moral boundaries and come to stand in for and define “real” world ethical engagement.
Clinical Collaboration
Researchers seek to align the hypothetical and “real” world by closely working with practicing clinicians. Clinicians serve as gatekeepers of health care settings and resources and are seen as responsible for health care outcomes. As Lucas, a computer science PhD student, says, “what’s really important if you want to actually take it to the real world is . . . doctors.” Practicing doctors directly interact with patients in medical settings. They are critical for implementing tools in clinical practice. Furthermore, the association of their expertise with the clinical setting makes them responsible and accountable for patient outcomes within health care. Making machine learning models “real” requires clinical collaboration.
Clinicians privileged access to the real-world tasks them with discretion over judgements about the benefits and value of machine learning technologies. Research teams consistently describe instances of deferring to the perspective of clinicians when making ambiguous “real” world value decisions. Carl, a joint MD-PhD student, describes trade-offs in his work on developing diagnostic and prognostic algorithms: What is really challenging is the fact that there is no perfect [model] outcome that captures everything that we want . . . people will define the outcome in different ways and reach different conclusions . . . especially for topics around race and around bias and around equity.
The lack of clear ways to make value judgements about what constitutes an acceptable machine learning outcome leads to uncertainty. When asked how he manages trade-offs between value frames or definitions of success, Carl explains, We have generally talked with clinicians about which [outcome] they end up relying on most, and then using that as the basis. For example, with heart function, you can measure the accuracy of the equation itself, how well it predicts, you know, just like mean squared error or something like that. You could measure whether it’s within a certain range of outcomes, like the differences and how many people get diagnoses or how much people get paid, or where they end up on the transplant waiting list. Generally, clinicians will tell you that they care very little about the first one and they care very much about the last ones, who gets what thing and how resources are allocated. How do clinical thresholds change? So, we’ve been [leaning] towards that.
Carl relies on the outcomes that clinicians deem most valuable to structure his projects. Machine learning models are valuable if they provide “clinical utility” as determined by collaborating doctors. What doctors declare most useful maximizes real-world impact. Through collaborations, machine learning perspectives remain isolated from responsibility for ethical judgements while engaging with broader ethical questions.
Practicing clinicians also translate the meaning of data to provide clinical context, better align the hypothesized and “real” worlds, and explain implications for patients and clinical settings. Liam, a PhD student in computer science, explains that doctors, as domain experts, “understand the data that they have, where it comes from, how its measured.” Observations of interdisciplinary project meetings clarify the role of clinicians in translating the meaning of data as a method of bridging technical and moral problem solving. At a lab meeting in a medical engineering program, Matt, a visiting student in bioengineering, presented research on predicting treatment outcomes in an ICU using a local hospital database. Matt showed a list of variables used in the models. Dr. Crofter, a senior researcher in the group and an ICU doctor, interrupted the presentation. He stated that red blood cell count, one of the variables listed, is not a good variable because it can be correlated with some of the treatment outcomes the model intends to predict, such as being put on a ventilator. Dr. Crofter goes on to explain that often, being prescribed a stool softener is used in similar models as a random effect. 6 However, stool softeners are actually not good random-effects variables because they can be correlated with outcomes of interest. Oftentimes in the ICU doctors give people fentanyl, which makes patients constipated and require a stool softener. Doctors then put in a standing order for stool softeners, but it does not mean that the patient is actually taking them and, because it is associated with being given fentanyl, correlates with a lot of serious clinical outcomes. As the most senior practicing clinician in the lab, one of Dr. Crofter’s main roles is to explain the context and meaning of data inputs and variables for technical researchers with less access to and knowledge about clinical practice. Through direct clinical input, groups more closely align machine learning projects with the reality of clinical settings in an effort to understand how data and models more definitively relate to practices, patients, and outcomes.
Last, accessing the real world through clinicians includes embodied exposure to the clinical setting, which provides context to understand the implications of and potential harmful blind spots in machine learning work. Professor Troy, in computer science, recounts the insights she gained by shadowing a physician in her subfield of pediatric neurology: I shadowed one of my physicians I was working with in [neurology]. It was shocking to me, because I’ve been working with [neurology] data for a while, and I just had this thought of, “Oh, I’ve never actually seen an EEG (electroencephalogram)
7
being taken. I’ve been looking at EEG data all day, I should go look at it.” I saw a nurse deleting part of the data and I said, “whoa, whoa, whoa, what’s going on there.” I also saw the system saved, it just connected the two parts. So, if someone is looking at the data later, I was like, “Okay, this is a problem when we’re not looking at the data in the software that they’re using. We’re looking at it from our end, we’re only reading it in as a continuous data stream.”
By witnessing clinical practice, Professor Troy learned that what appears to her to be a continuous process actually is produced by the conjoining of two separate processes of data collection. Discrepancies between how the data were created and how it is viewed in the lab could produce issues by discounting contextual features, such as the temporal structure of a clinical practice. Professor Troy describes the value of her clinical encounters which inform “what’s the big picture” to ask “the right questions.” She bridges her technical research and moral engagement by collaborating closely with clinicians to understand the full context of her work, such as the data and its limitations, and relevant questions for clinical impact. The collaborative context raises questions about the accuracy, benefits, and limits of a model not considered in the “hypothetical” world of machine learning.
Patient Data
A second method to align the two worlds is to move closer to the stage of collection and curation of identifiable patient data in the clinic. Dr. Oliver, a postdoc in computer science, discusses issues in data representation when interviewed on a machine learning podcast. She explains that when you develop a health care algorithm “questions about fairness and bias” can be “baked in” to the dataset because of “systematic health disparities.” These systemic disparities influence who accesses health care, and thus the population of people represented in clinical datasets, and then the population of people for which machine learning tools become optimized. Olivia uses an “equity” lens, which requires scrutinizing clinical resources and datasets used in her work.
Researchers shift their focus from model creation to resource generation, bridging technical and moral boundaries with the goal of creating “better data” in support of beneficial health care solutions. As Carl, the MD-PhD student, remarks, “if you just collected more data from underrepresented groups, you could improve [equity] very quickly.” Brian, a senior researcher in computational biomedicine, expresses a similar sentiment: “I think the only real way you can fix all these biases is to have better, more sensitive data.” One way in which he works toward this goal is “trying to make sure that we’re getting datasets, pretty good shared by other organizations around the world.” Part of Brian’s job includes helping run a repository of reviewed clinical datasets submitted by research groups and hospitals. Working on the repository helps achieve the goal of curating more representative patient data to build models that better reflect “real” patient populations while bridging hypothetical machine learning work and real world considerations.
Dr. Crofter, the researcher and ICU clinician previously mentioned, explains how he now devotes the majority of his work to understanding data and improving data collection to be more representative. He shifted the focus of a course that he teaches to work toward health equity: our course on data science is now primarily, “let’s start off with understanding where is the selection bias, who did not make it to your database? And what is the implication of building an algorithm only on the people who made it to your database?”
By first asking questions about resources, medical infrastructure, and data content in the real world, Dr. Crofter hopes to help machine learning work toward health equity.
Researchers also work to generate more representative and higher quality data by working directly in clinical settings, rather than relying on preprocessed databases. Professor Bentley, who works in a public health department on machine learning problems from prediction to diagnosis and natural language processing, describes a new project in which he is collaborating to build a camera that will provide information about a patient’s blood through reflected light. Patients will be able to use the camera through a personal device. Professor Bentley discusses the importance of directly working with patients to collect these data: “I could try to post hoc fix the data that we have in the EHR (electronic health record), or I could just try and go in directly to measure physiology (bodily functions) to learn directly from that.”
Similarly, Dr. Troy, previously mentioned, expressed interest in wearable devices, such as sensors, that generate abundant individual level data directly from patients. She describes how this can address concerns about bias and representation because the model will learn from your own data. She explains, if you’re wearing a wearable device . . . it should replace cohort level data with your own individual data, because you’ve got so much. That is really what I think is central to these ethical issues of data being trained, models being trained on people who are not like you.
To better align machine learning with the “real” world of patients served by health systems and to address systemic disparities, researchers advocate considering alternative methods to acquire patient data. These methods require accessing patients and/or clinical settings directly and devoting attention to medical infrastructure and resources. As such, they bridge technical and moral boundaries as researchers engage in hypothetical machine learning work, while expanding relevant ethical frameworks to carry out beneficial projects.
Ethical Trade-Offs between the Hypothetical and the “Real”
Researchers who separate their work from clinical practice and identifiable patient data uphold technical and moral boundaries, defining “real” impacts and ethical questions as less relevant to their research. They emphasize distinction between the two worlds, drawing on frameworks from the “hypothetical” world to describe and justify projects. Gavin, a graduate researcher in biochemical engineering, works on drug discovery in machine learning. He explains that “one advantage of working on the preclinical side is, you don’t have to worry too much about that . . . working with cell level data, there’s not too much ethical concern.”
Similarly, Dr. Lester, a principal investigator of a neurobiology lab studying brain processes explains how he does not think issues of ethics, bias, and social impact relate much to his work: There’s a big open question about the ethics of things like AI, and how that impacts society. For us, what we do might be a little bit more granular, directed at particular questions, and applying the tools to derive more information out of big data sets that we couldn’t have otherwise. It’s kind of more towards foundational understanding . . . it could have social impact, but many steps away.
Dr. Lester goes on to describe how he started using computational tools to leverage neurological datasets too big to analyze any other way. In the future, he notes this will prove challenging: “we’re consuming so much power from the power grid to be able to analyze these data sets, they need to become more efficient.” Although access to expensive data and compute resources could be seen as part of ethical trade-offs inherent to AI projects, the divide between the hypothetical and “real” world limits considerations of other dilemmas as part of the moral justification of machine learning work. As these examples show, understandings of “real” ethical concerns in machine learning associate with evaluations based on “bias,” “fairness,” “representation,” and “subgroup disparities” in the “real” world of clinical practice working with identifiable patient characteristics. When researchers perform machine learning and health research, but do not directly work with “real” world patient data or engage with clinicians and outcomes in medical settings, they do not define ethics and “real”-world impacts as relevant. Boundaries between the technical and the moral come to define ethical content and frameworks.
Discussion and Conclusion
When developing machine learning models for health care, researchers and developers distinguish between a hypothesized world of machine learning and a “real” world of clinical practice. Distinctions between the hypothetical and the “real” determine relevant frameworks to describe, evaluate, and reconcile ethical uncertainties. In the machine learning world, impacts remain hypothetical, controllable, and computable. In the “real” world, impacts relate to patients and outcomes in clinical settings. Real impacts are uncontrollable, incomputable, and complex. To resolve uncertainties in determining “real” machine learning impacts, researchers seek to align hypothesized and “real” aspects of work. Alignment between the two worlds occurs by centering patient data representation and leaning on clinical collaborators to explain the value of results, the meaning of data, and access clinical resources. Consequently, clinicians become responsible for defining and concretizing beneficial impacts while machine learning development remains a distinct arena of scientific practice. In the real world, questions about clinical access, data representation, and health system resource allocation come to define ethical engagement in place of questions about machine learning development, harm, and equity.
These results bear implications for considering multidimensional aspects of equity and harm in debates about technology ethics, explaining the relationship between technical and moral boundaries, and the significance of collaboration and expanding project stakeholders for AI and machine learning. Rather than study what algorithms obscure (Burrell 2016; Kiviat 2023; Pasquale 2016), in this article I focus on collaborative and cultural processes that concretize “real” technology impacts. In the case of machine learning and health care, associating the “real” with the realm of clinical practice and medical infrastructure essentializes tangible patient outcomes and clinical resources as the most impactful and beneficial goals of machine learning work. These definitions of the “real” open and forecloses ethical discussion (Jasanoff 2005). For example, definitions of the “real” exclude considerations such as project funding allocation as part of “real” impacts and ethical machine learning (Crawford 2021). Furthermore, privileging clinical resources and outcomes as “real” precludes consideration of cultural processes as fundamental parts of inequity (Lamont and Pierson 2019), such as who is included and able to imagine and evaluate technological solutions,. Through an explanation of what is “real” in the context of machine learning collaborations, the article lends a framework to substantiate statements such as “AI for good,” “just data,” or “AI for health equity” by illuminating how people purporting these goals define and access the worlds they seek to benefit.
The paper also contributes an explanation of the relationship between technical and moral boundaries. Boundaries not only separate “science” from “nonscience” (Gieryn 1995), but define the ways in which actors mobilize ethical categories to connect their actions to outcomes and describe project impacts. In the case of machine learning and health care, boundaries between the technical and the clinical preserve machine learning as an abstracted, controllable, and legitimate arena of scientific practice (Gieryn 1995; Latour 1999; Shapin and Schaffer 1985), while allowing recognition of broader impact in a domain outside of researchers’ responsibility. Machine learning remains a “pure” domain by creating categorical and role distinctions between the hypothesized world of machine learning and the real world of clinical practice.
Last, studying machine learning development within the context of collaboration contributes a model of how interactions and structures of work support ethical justifications and the distribution of moral responsibilities. Collaboration serves as a mechanism that bridges technical and moral boundaries while delegating ethical responsibilities. Within the collaborative context, clinical expertise and experience include defining optimal machine learning outcomes. 8 Clinicians renarrativize abstracted data elements and model outputs (Kiviat 2023). Although clinicians do not become “ethics experts” (Evans 2012), they do become responsible for defining ethical impacts and benefits. Rather than knowledge being translated across domains and responsibilities shared, expertise is differentiated and accountability delegated (Hou and Wang 2017; Mao et al. 2019; Zhang et al. 2020). As a result, clinical expertise is seen as more “social,” reinforcing distinctions between “the social” and “the technical” even as technologists recognize considerations of the risks and impacts of their tools (Bowker and Star 2000). The “technical” can be contextualized within a broader system of practice, allowing researchers to express moral concern and recognize ambitions for broader impact, without shifting moral boundaries or responsibilities. Collaboration comes to stand in for ethical engagement focused on questions of clinical practice and medical infrastructure.
As suggestions to include more stakeholders in AI design, development, and deployment become prominent (i.e., Committee on Responsible Computing Research: Ethics and Governance of Computing Research and Its Applications et al. 2022; U.S. Department of Health and Human Services 2021), future research can adopt a framework of collaborative ethics to explain the responsibilities assumed of each actor and the implications on defining categories of ethical justification. In particular, research can focus on the role of community and patient representatives and social scientists as stakeholders being brought into AI projects, as well as the effects of stakeholder inclusion on model impacts and project trajectories. Future research must consider how the reconfiguration of collaborative teams and stakeholder perspectives may center different pathways for addressing equity and harm, as well as how groups define, evaluate, and imagine problems and solutions. Working toward ethical AI will require more than uncovering AI impacts and harms, but understanding the definitions of impact, harm, and benefit promoted throughout AI projects and collaborations.
Footnotes
Appendix A
Participant Demographics.

| BA | MA | MPH | MBA | JD | PhD | MD | MD-PhD | Total | |
|---|---|---|---|---|---|---|---|---|---|
| Gender | |||||||||
| Male | 2 | 3 | 0 | 2 | 1 | 19 | 9 | 5 | 41 |
| Female | 1 | 2 | 2 | 2 | 0 | 9 | 3 | 1 | 20 |
| Race | |||||||||
| White | 2 | 0 | 2 | 2 | 1 | 14 | 4 | 5 | 30 |
| Asian | 1 | 4 | 0 | 1 | 0 | 13 | 5 | 1 | 25 |
| Other a | 0 | 1 | 0 | 1 | 0 | 1 | 3 | 0 | 6 |
| Work experience | |||||||||
| 0–10 y | 1 | 5 | 2 | 3 | 0 | 13 | 3 | 1 | 28 |
| 11–20 y | 1 | 0 | 0 | 0 | 1 | 8 | 7 | 0 | 17 |
| 21–30 y | 1 | 0 | 0 | 1 | 0 | 7 | 1 | 2 | 12 |
| ≥31 y | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 3 | 4 |
| Additional degrees | |||||||||
| MA b | 0 | 1 | 0 | 2 | 0 | 1 | 7 | 1 | 12 |
| MPH | 0 | 0 | 0 | 1 | 0 | 1 | 6 | 0 | 8 |
Other category includes Black, Hispanic, and Middle Eastern/North African.
MA is marked if the participant has an MA that is in a different field than their highest degree.
Appendix B
Textual data include the following:
Acknowledgements
I would like to thank Michele Lamont, Ya-Wen Lei, Michael Zangler-Tischler, Mira Vale, members of the Inside the Sausage Factory working group at Harvard University, Kelly Joyce, Taylor Cruz, and two reviewers for their thoughtful feedback.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Horowitz Foundation and the Graduate School of Arts and Sciences, the Weatherhead Center, and the Institute of Quantitative Social Science at Harvard University.