
Abstract
This exploratory mixed-methods classroom study investigated the use of ChatGPT in International English Language Testing System (IELTS) writing preparation classrooms, focusing on a) the reliability of holistic scoring, b) the actionability of feedback, and c) teacher and student acceptance. Specifically, it compared three model variants (ChatGPT 4, 4o, and 4o mini) to examine whether scoring and feedback performance were stable across commonly accessible versions within the same artificial intelligence (AI) ecosystem. Data were collected from Chinese IELTS teachers, native-English-speaking IELTS teachers, peer student raters, and IELTS essay writers in an advanced-level preparation context. Quantitative analyses examined score reliability and the frequency of actionable feedback across IELTS writing domains, while qualitative analyses of feedback and interviews identified recurring patterns in feedback characteristics and user acceptance. Five themes emerged from interview data: utility and functionality, perceived reliability of scores, actionability of feedback, concerns about over-reliance, and balancing AI with human oversight. Findings suggest that the tested ChatGPT variants generated relatively reliable and actionable feedback for surface-level features (e.g., grammar, spelling, lexical choice), but showed limitations in evaluating context-sensitive and higher-order dimensions (e.g., argument depth and creativity). Participants generally viewed ChatGPT as a useful supplementary tool rather than a replacement for teachers. Practical implications for integrating AI and human feedback in IELTS writing classrooms are discussed, and important limitations related to sample size, proficiency range, single-prompt design, and model version currency are also acknowledged.
Introduction
The integration of AI into language assessment has received growing attention in recent years, particularly with the expansion of automated essay scoring (AES) and AI-assisted feedback systems (Allagui, 2023; Barrot, 2023; Guo et al., 2024; Praphan & Praphan, 2023). Such systems can improve timeliness and efficiency by reducing grading workload, shortening feedback cycles, and supporting larger-scale writing assessments (Mizumoto & Eguchi, 2023; Nguyen & Barrot, 2024). At the same time, the reliability and validity of AI-generated scoring remain contested. Critics question whether AI can capture the full complexity of human writing and maintain fairness across diverse writers and contexts (Guo & Wang, 2023; Li et al., 2024).
Beyond scoring, AI tools are increasingly used to provide feedback on writing. The speed of AI-generated feedback is attractive, especially in test preparation settings where students need frequent revision opportunities. However, AI feedback often emphasizes surface-level issues such as grammar, spelling, and vocabulary, which are helpful but insufficient for the development of higher-level writing abilities, including argumentation, organization, and discourse coherence (Hussein et al., 2019; Ramesh & Sanampudi, 2022). This limitation is especially relevant in high-stakes assessments such as the International English Language Testing System (IELTS), where success depends on both linguistic accuracy and the effective development of ideas.
Recent advances in generative AI, especially ChatGPT, have expanded the possibilities for AI-supported writing assessment. Compared with earlier generations, newer ChatGPT variants can produce more detailed feedback and more flexible responses, which has led to increasing interest in their use in language education and high-stakes test preparation (Bui & Barrot, 2024; Dehghani & Mashhadi, 2024; Yamashita, 2024). Some studies have suggested that fine-tuning or prompt engineering may improve scoring performance (Latif & Zhai, 2024), but findings remain mixed, and performance can vary across model versions and contexts. In classroom practice, teachers and institutions may not use a single “ChatGPT” but rather whichever variant is available or affordable. For this reason, comparing model variants (ChatGPT 4, 4o, and 4o mini) can provide practical insight into the stability of scoring reliability and feedback actionability within one AI ecosystem.
The acceptance of AI tools such as ChatGPT by both teachers and students is also central to successful classroom integration. Research on technology adoption in education has consistently shown that perceived usefulness, trust, and user attitudes shape whether tools are actually used in practice (Praphan & Praphan, 2023; Teo, 2011). Emerging work on LLM use in English as a foreign language (EFL) learning similarly highlights the importance of learner engagement, perceptions, and contextual factors in adoption and sustained use (Rezai et al., 2024; Wang & Reynolds, 2024). In China, where IELTS preparation can be highly exam-oriented and teacher-led, understanding how teachers and learners perceive AI-assisted assessment is particularly important for responsible implementation (Guo & Wang, 2023; Liu & Ma, 2024).
Although this study focused on AI-assisted scoring and feedback rather than a conventional automated writing evaluation (AWE) platform, it is also informed by the AWE literature, especially research on perceived feedback source and its influence on learner uptake and writing performance (Kao & Reynolds, 2024; Reynolds et al., 2021). This broader lens helps situate ChatGPT-based feedback within ongoing debates about trust, actionability, and the pedagogical role of automated feedback in L2 writing.
Study Objectives
This study aimed to examine the use of ChatGPT in Chinese IELTS writing preparation classrooms by focusing on three interrelated issues: a) the reliability of holistic scoring across three ChatGPT variants and human rater groups, b) the actionability of feedback generated by ChatGPT and human raters across IELTS writing domains, and c) the acceptance of ChatGPT by teachers and students in this instructional context. Given the exploratory mixed-methods design and small classroom-based sample, the study was intended to generate contextualized evidence and practical insights rather than test formal hypotheses.
Literature Review
AI Tools in EFL Writing Assessment and IELTS Preparation
The integration of AI tools into EFL writing instruction has transformed many assessment practices, especially in high-stakes test preparation contexts such as IELTS. Reliable scoring and actionable feedback are especially important in such contexts because learners need both accurate estimates of performance and guidance for improvement. A growing body of work has examined AI-driven scoring and feedback systems, including ChatGPT, with mixed findings regarding reliability, validity, and pedagogical usefulness (Bui & Barrot, 2024; Lu et al., 2024; Mohamed, 2023; Su et al., 2023; Yan, 2023).
Reliability of AI Scoring Systems
One major line of inquiry concerns the reliability of AI-based scoring. AI systems are often expected to reduce inter-rater inconsistency and increase standardization (Burstein et al., 2003). Mizumoto and Eguchi (2023) reported that ChatGPT 3.5 showed a certain degree of accuracy and reliability in essay scoring, suggesting potential usefulness in classroom support. However, other studies have reported weaker reliability than human raters for some models and tasks, while noting improved performance in more advanced versions (Li et al., 2024). Bui and Barrot (2024) also noted inconsistency across assessment cycles, suggesting that model performance may vary by prompt design, context, and repeated administrations. These mixed findings indicate the need for context-specific investigations, including comparisons across model variants that teachers might use in practice.
Actionability of AI Feedback
In EFL writing pedagogy, the value of feedback depends not only on correctness but also on actionability—whether students can understand and use the feedback to revise their writing. AI tools can generate immediate feedback and thus support iterative drafting, which is especially useful in intensive preparation settings (Bucol & Sangkawong, 2025; Fathi & Rahimi, 2024). Studies frequently report strengths in feedback on grammar, spelling, and vocabulary (Liu et al., 2024; Lu et al., 2024). Some evidence also suggests that AI feedback can be comparable to human feedback in coverage across language, content, and organization in some contexts (Li et al., 2024).
However, concerns remain about depth, explanation quality, and contextual sensitivity. Bucol and Sangkawong (2025) argued that AI feedback often identifies local errors effectively but may provide limited guidance on communicative intent, argument quality, and sociocultural appropriateness. In IELTS preparation, where task response and coherence are central, such limitations are pedagogically significant. Lu et al. (2024) similarly noted that AI tools may not adequately address subtle discourse and argument development despite producing precise local corrections.
Teacher and Student Acceptance of AI Feedback Tools
The acceptance of AI tools is another critical factor in educational implementation. Teachers’ and students’ attitudes influence whether AI tools are used, how they are used, and whether they support learning meaningfully (Praphan & Praphan, 2023; Teo, 2011). In EFL contexts, emerging studies have shown that learners’ engagement with LLMs is shaped by perceived usefulness, trust, emotional factors, and contextual conditions (Rezai et al., 2024; Wang & Reynolds, 2024). In China, teacher-centered practices and exam-oriented instruction may influence both enthusiasm for and resistance to AI-assisted assessment (Guo & Wang, 2023; Liu & Ma, 2024).
The present study also intersects with AWE research on perceived feedback source. Prior studies suggest that learners may respond differently to feedback depending on whether they perceive it as teacher-generated or automated, with implications for revision behavior and writing outcomes (Kao & Reynolds, 2024; Reynolds et al., 2021). This perspective is useful for understanding why acceptance, trust, and perceived actionability matter when ChatGPT is introduced into IELTS writing classrooms.
Summary and Research Gap
Overall, prior studies suggest that AI tools may improve efficiency and consistency in writing assessment while offering fast feedback. Yet uncertainties remain regarding scoring reliability across model variants, the actionability of feedback beyond surface-level correction, and the conditions under which teachers and students accept AI-assisted assessment in specific educational contexts. These issues are especially salient in Chinese IELTS preparation classrooms, where high-stakes goals and instructional norms may shape perceptions and use.
Research Questions
This study addressed the following three research questions (RQs):
1) How reliable are the holistic scores provided to Chinese IELTS essays by the AI tool (i.e., ChatGPT versions 4, 4o, and 4o mini) when compared to those provided by human raters (i.e., native-English-speaking IELTS teacher raters, Chinese IELTS teacher raters, and peer student raters)?
2) How actionable is the qualitative feedback provided by the AI tool (i.e., ChatGPT versions 4, 4o, and 4o mini) on Chinese IELTS essays compared to that provided by human raters (i.e., native-English-speaking IELTS teacher raters, Chinese IELTS teacher raters, and peer student raters)?
3) How do teachers (i.e., native-English-speaking IELTS and Chinese IELTS teacher raters) and students (i.e., peer student raters and IELTS essay writers) perceive and accept ChatGPT as an AI-assisted assessment tool in IELTS writing preparation classrooms?
Methods
Ethical Approval
Ethical approval for conducting this study was granted by the Evidence-based Research Center for Educational Assessment (ERCEA) Research Ethical Review Board at Jiangsu University.
Research Design
This study employed an exploratory mixed-methods classroom design. Quantitative analyses were used to examine the reliability of holistic scoring (RQ1) and the distribution of actionable feedback (RQ2), while qualitative analyses of feedback and interview data were used to examine feedback characteristics and participant acceptance (RQ2 and RQ3). Because the study was conducted within a bounded classroom context with a small sample, findings are interpreted as exploratory and context-specific.
Research Context: IELTS Preparation Classrooms in Eastern China
The study was conducted in IELTS preparation classrooms in Eastern China. These classrooms are typically exam-oriented, with strong emphasis on timed writing performance, score improvement, and teacher guidance. In such settings, students often seek frequent feedback under time pressure, making AI-assisted tools potentially attractive for rapid feedback cycles. At the same time, teacher expertise remains central, particularly for task response, argument development, and exam strategy.
To examine how ChatGPT might function relative to different classroom stakeholders, the study included both teacher raters and a small group of advanced learners who served as peer student raters (i.e., students rating essays for research purposes, not formal exam raters).
Participants
The participants included eight advanced-level students (IELTS essay writers), five IELTS teacher raters (three Chinese and two native-English-speaking teachers), and three advanced-level learners who served as peer student raters. The eight essay writers were from an advanced IELTS preparation class and had advanced proficiency based on prior IELTS results. The focus on advanced-level writers reflected the immediate classroom context in which the study was conducted (i.e., an existing advanced IELTS class). This design enabled a controlled pilot comparison in one authentic instructional setting; however, it does not allow conclusions across broader proficiency bands (see Limitations).
Of the five teachers, two were native English speakers and three were Chinese teachers (average age = 34 years). One native-English-speaking teacher held a bachelor’s degree and the other held a doctoral degree, while the Chinese teachers all held graduate-level qualifications. The Chinese teachers had seven to 10 years of IELTS teaching experience, while each native-English-speaking teacher had approximately five years of IELTS teaching experience.
The three peer student raters were recruited from another advanced-level IELTS preparation class with similar English writing proficiency levels (based on prior IELTS writing performance). Two were male and one was female. Because rating required substantial effort, each human rater received a financial reward.
IELTS Essay Prompt
The IELTS essay prompt completed by the eight IELTS essay writers was: The government should control the amount of violence in films and on television in order to decrease violent crimes in society. To what extent do you agree or disagree? This prompt was selected from a prior IELTS exam. Students completed the task in class under a 30-minute time limit. The resulting eight essays were assessed by ChatGPT versions 4, 4o, and 4o mini, and by eight human raters (five teachers and three peer student raters), using the IELTS writing criteria.
Rater Training
Rater training was conducted to improve consistency in the assessment process. Teacher raters and peer student raters completed a three-hour training session informed by rater reliability literature (Furneaux & Rignall, 2007; Knoch et al., 2007; O’Connell, 2022).
During training, raters reviewed the IELTS writing rubric, covering the four domains: a) task response, b) coherence and cohesion, c) lexical resource, and d) grammatical range and accuracy. The trainer (i.e., the first author) guided raters through benchmark essays of varying quality and facilitated rubric-based discussion. Raters then independently evaluated three sample essays and discussed discrepancies to improve calibration. Following training, each rater independently evaluated the eight study essays, providing holistic scores and qualitative feedback in the four domains.
To support consistency, raters also discussed notable scoring discrepancies during the rating process. It is important to acknowledge that this may have influenced independence and should be interpreted as a classroom-oriented calibration procedure rather than a fully controlled large-scale rating design.
ChatGPT Prompting and Model Comparison Rationale
For consistency, each ChatGPT variant (4, 4o, and 4o mini) received the same IELTS prompt and the same essay texts. The prompting procedure required the model to produce a holistic score and feedback in the four IELTS domains (task response, coherence and cohesion, lexical resource, and grammatical range and accuracy).
The purpose of comparing ChatGPT 4, 4o, and 4o mini was to examine within-platform variation across model variants that educators may realistically use in practice (e.g., depending on access, cost, or platform defaults). This comparison was intended to assess whether scoring reliability and feedback actionability remain stable across variants, rather than to establish a definitive ranking of all present or future AI models.
Each ChatGPT variant assessed the same set of eight essays across three sessions, each spaced three days apart. This repeated administration was used to explore consistency across sessions and potential variation by model version under the same task conditions.
Data Collection
Human raters assessed essays in two phases: a) assigning a holistic score based on the IELTS rubric and b) providing detailed feedback in the four IELTS domains. To reduce fatigue, human raters reviewed no more than four essays per day and completed the work in two batches. ChatGPT variants evaluated the essays across three sessions (three days apart), with each variant producing holistic scores and domain-specific feedback in each session.
After rating and feedback were completed, interviews were conducted with all participants (teacher raters, peer student raters, and essay writers) to examine their perceptions and acceptance of ChatGPT as an AI-assisted assessment tool in IELTS writing classrooms.
Data Analysis
Data analysis for RQ1
To address RQ1, the researchers examined the reliability of holistic scores assigned by ChatGPT and human raters using generalizability theory (G-theory) (Cronbach et al., 1972). Variance components were estimated and reliability was examined using the GENOVA software (Crick & Brennan, 1983). This enabled comparison of score reliability across AI raters and human rater groups in this dataset.
Given the small sample size (eight essays), the researchers interpreted these estimates cautiously and emphasized comparative patterns within this dataset rather than broad generalizations.
Data analysis for RQ2
To address RQ2, the researchers used a two-stage analysis of feedback. First, feedback from human and AI raters was categorized into the four IELTS domains using a color-coded coding system (Creswell & Creswell, 2023; IELTS, 2024). Second, feedback was evaluated for
Because this analysis included frequency counts of coded feedback units, the results should be interpreted as comparative indicators of feedback patterns rather than definitive measures of pedagogical quality.
Data analysis for RQ3
To address RQ3, interview data were analyzed using thematic analysis. Responses were coded, categorized, and organized into themes reflecting perceived usefulness, reliability, limitations, and acceptance of ChatGPT in IELTS writing preparation classrooms.
Results
Findings for RQ1
In the framework of G-theory, G-studies were conducted to examine the variability of holistic scores, specifically to determine the percentage of total score variance explained by each variance component. The obtained variance components were further analyzed through D-studies to assess the reliability of scoring (Brennan, 2001). Therefore, results from both the G- and D-studies are presented in Tables 1 and 2, respectively.
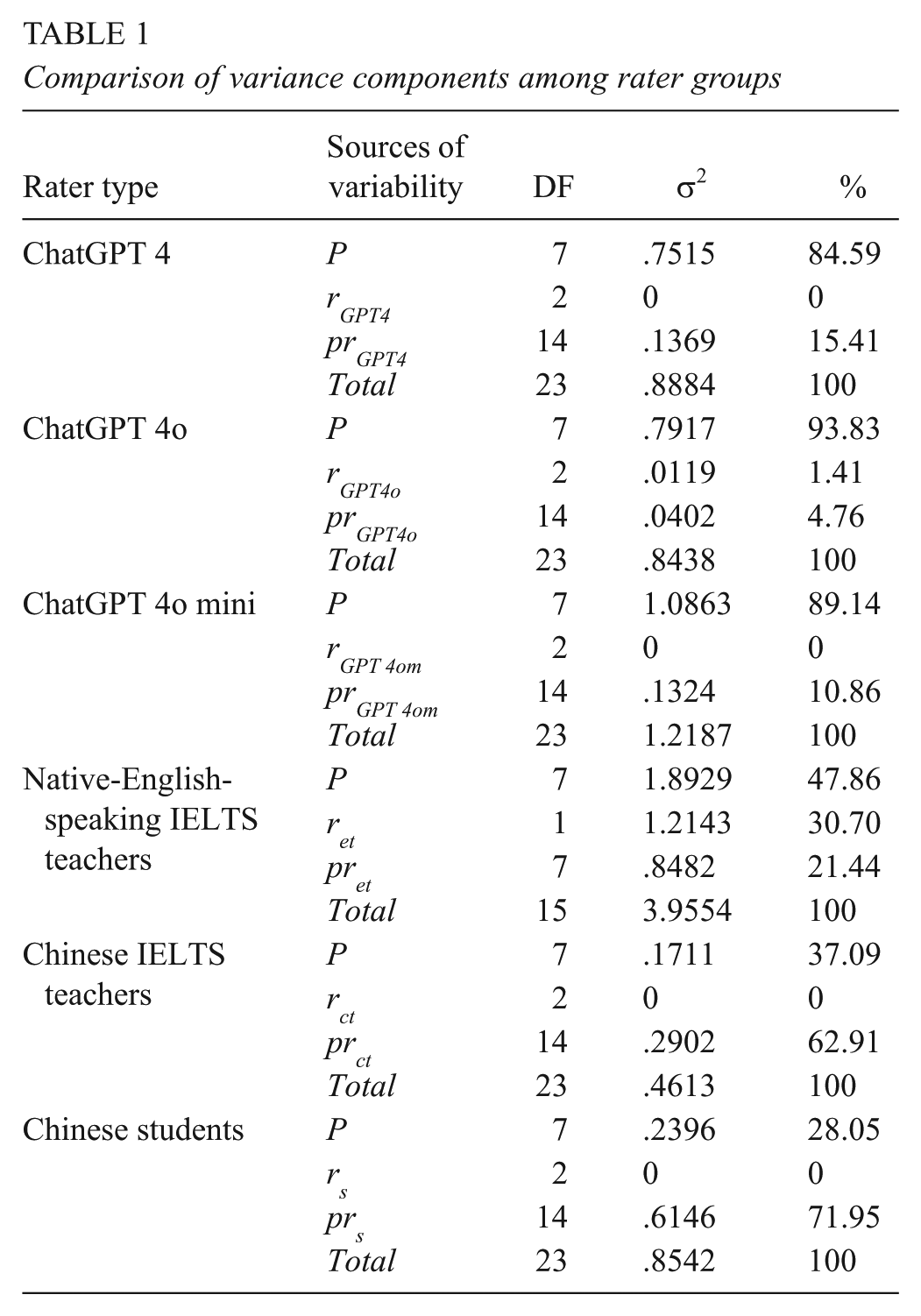
Comparison of variance components among rater groups
Comparison of G-coefficients among rater groups
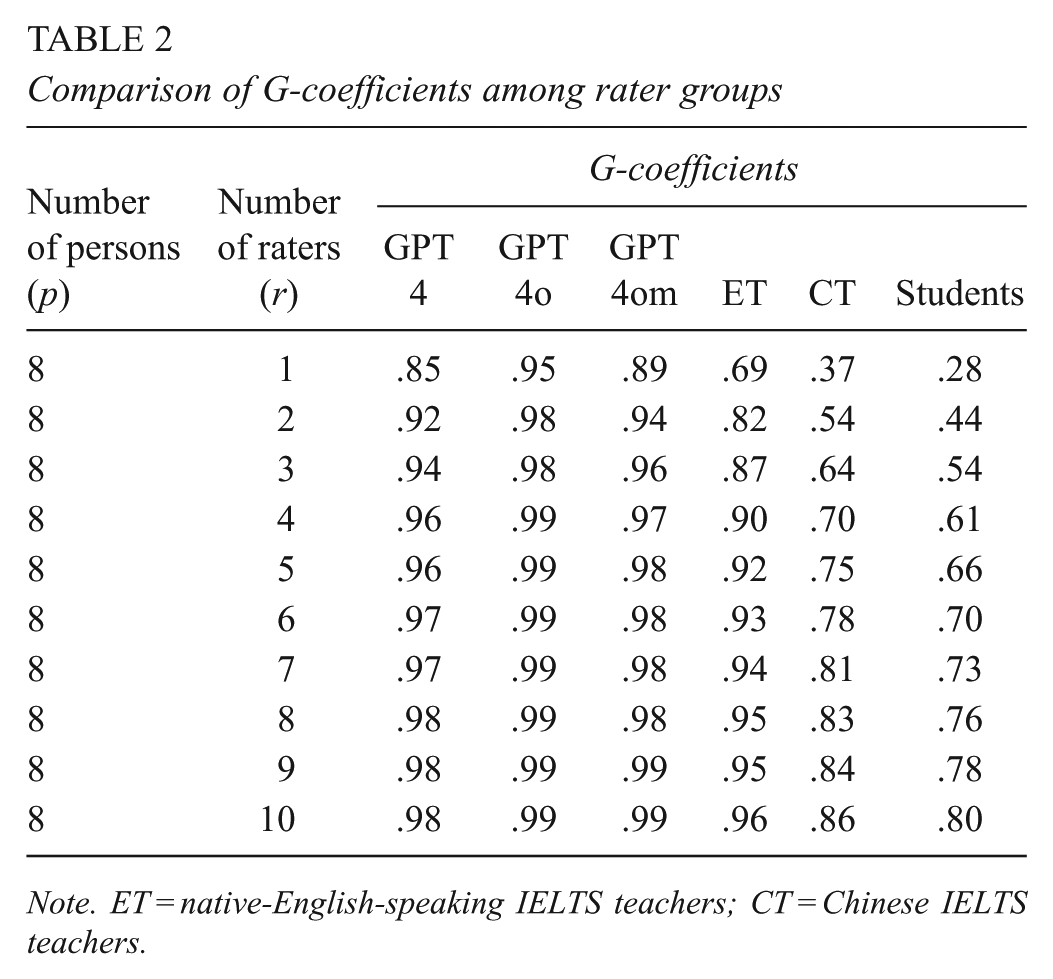
Note. ET = native-English-speaking IELTS teachers; CT = Chinese IELTS teachers.
Table 1 presents the outcomes from six G-studies conducted on the scoring of ChatGPT versions 4, 4o, 4o mini, and human raters (i.e., native-English-speaking IELTS teachers, Chinese IELTS teachers, and Chinese students). In all cases involving ChatGPT and native-English-speaking IELTS teachers, the largest variance component was associated with the “person” factor (i.e., the students’ writing abilities). Specifically, the variance component related to person accounted for 84.59%, 93.83%, 89.14%, and 47.86% of the total variance in the scoring of ChatGPT versions 4, 4o, 4o mini, and native-English-speaking IELTS teachers, respectively. However, for the scoring by Chinese IELTS teachers and Chinese students, the same variance component explained only 37.09% and 28.05% of the total variance, respectively. This person variance component is desirable, as it reflects the natural variation in students’ writing abilities (Brennan, 2001; Huang, 2008, 2012).
A similar pattern was observed for the residual variance component, which represents variability due to interactions between facets and other unmeasured errors. In cases involving ChatGPT and native-English-speaking IELTS teachers, the residual variance component was the second-largest source of variability. Specifically, the residual variance explained 15.41%, 4.76%, 10.86%, and 21.44% of the total variance in the scoring of ChatGPT versions 4, 4o, 4o mini, and native-English-speaking IELTS teachers, respectively. For Chinese IELTS teachers and Chinese students, the residual variance component accounted for 62.91% and 71.95% of the total variance, respectively. These results suggest that hidden factors, such as raters’ gender and experience, were not considered in the G-studies (Brennan, 2001; Huang, 2008, 2012).
Finally, the rater variance component, which reflects differences in scoring leniency or stringency among raters, was the least significant source of variance, explaining less than 2% of the total variance in all cases except for native-English-speaking IELTS teachers. Notably, the rater variance component accounted for 30.7% of the total variance in the scoring by native-English-speaking IELTS teachers, indicating a high level of inconsistency in their scoring. For Chinese IELTS teachers and Chinese students, the rater variance component explained no variance but was confounded in the residual variance component, which explained 62.91% and 71.95% of the total variance for Chinese IELTS teachers and Chinese students, respectively.
Results from the six D-studies highlight an overall increase in the reliability of holistic scores across raters, including Chinese students, Chinese IELTS teachers, native-English-speaking IELTS teachers, and ChatGPT versions 4, 4o mini, and 4o (see Table 2 and Figure 1). Table 2 details the reliability measures for the six types of raters, calculated using G-coefficients (for norm-referenced interpretations in IELTS large-scale standardized testing contexts). These coefficients were computed under conditions ranging from a single rater to 10 raters, with a sample size of eight.
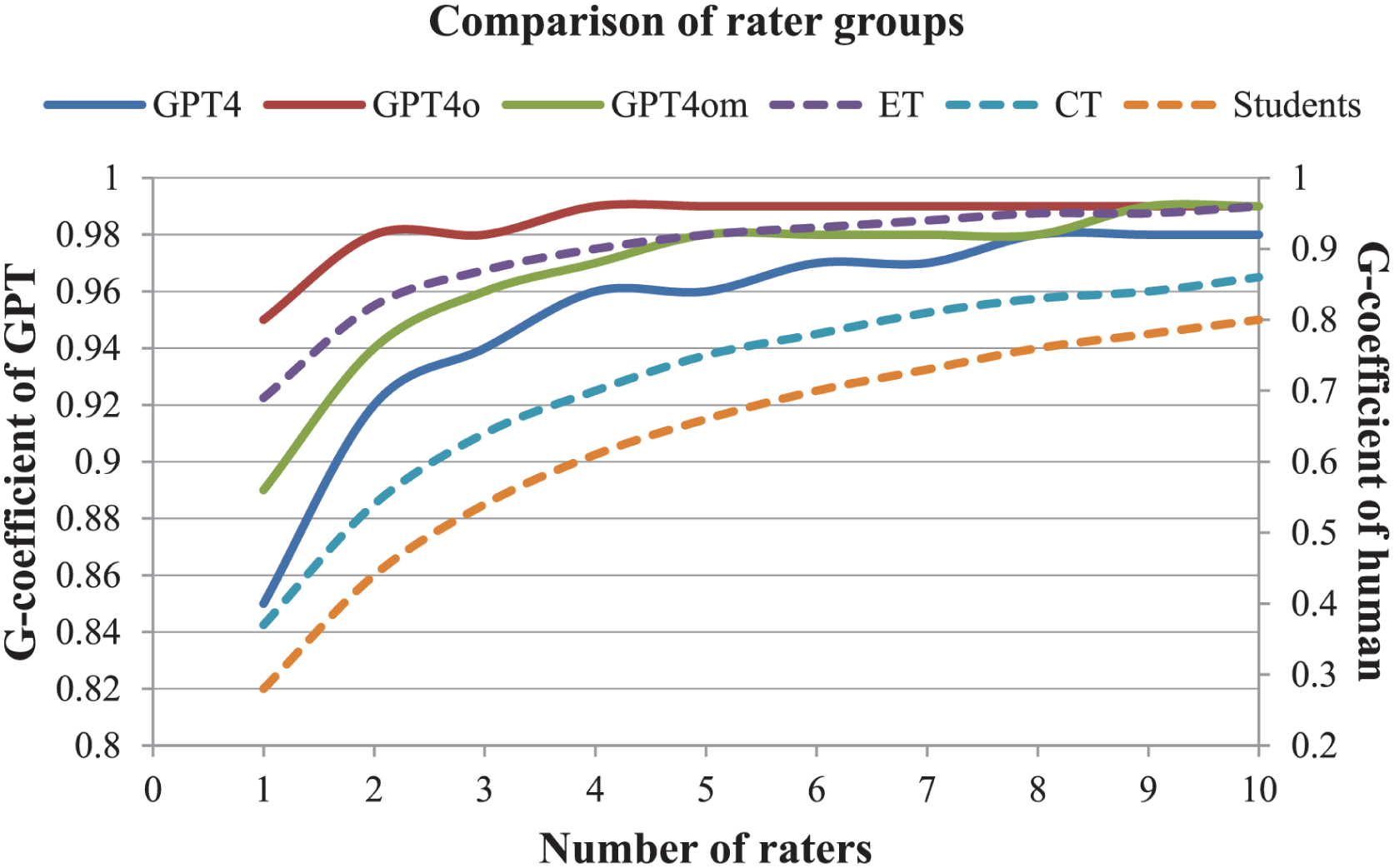
Comparison of G-coefficients among rater groups
For the IELTS essays assessed by a single rater, the G-coefficients for Chinese students, Chinese IELTS teachers, native-English-speaking IELTS teachers, and ChatGPT versions 4, 4o mini, and 4o were .28, .37, .69, .85, .89, and .95, respectively. With two raters, reliability improved considerably for all rater types, with G-coefficients increasing to .44, .54, .82, .92, .94, and .98, respectively. Additionally, the reliability of ChatGPT versions, when rated once (>.85), met the minimum threshold of ≥.80, which is acceptable in large-scale standardized testing settings such as IELTS (Huang & Whipple, 2023). This reliability was comparable to that of three native-English-speaking IELTS teachers (.87), 10 Chinese IELTS teachers (.86), and more than 10 Chinese students (>.80).
Figure 1 illustrates the reliability of different rater groups using the holistic scoring method for evaluating the IELTS essays. The reliability coefficients for all versions of ChatGPT were consistently higher than those for the three human rater groups. These findings suggest the potential of ChatGPT to contribute to IELTS writing assessments, highlighting its effectiveness as a valuable tool for augmenting essay scoring. ChatGPT could potentially assist teachers and students in the assessment process and even be considered as a replacement for human raters in classroom settings, thereby improving the scoring process while maintaining high standards of accuracy.
Findings for RQ2
The descriptive statistical results for the average number of actionable feedback provided by Chinese IELTS teachers, native-English-speaking IELTS teachers, Chinese students, and ChatGPT versions 4, 4o, and 4o mini across different domains of task response, coherence and cohesion, lexical resources, and grammatical range and accuracy are displayed in Table 3. Actionable feedback refers to the degree to which the feedback is clear, understandable, and supportive, enabling students to effectively take specific, constructive actions toward improving their IELTS writing (Black & Wiliam, 1998; Carless et al., 2011; Hattie & Timperley, 2007).
Descriptive statistical results
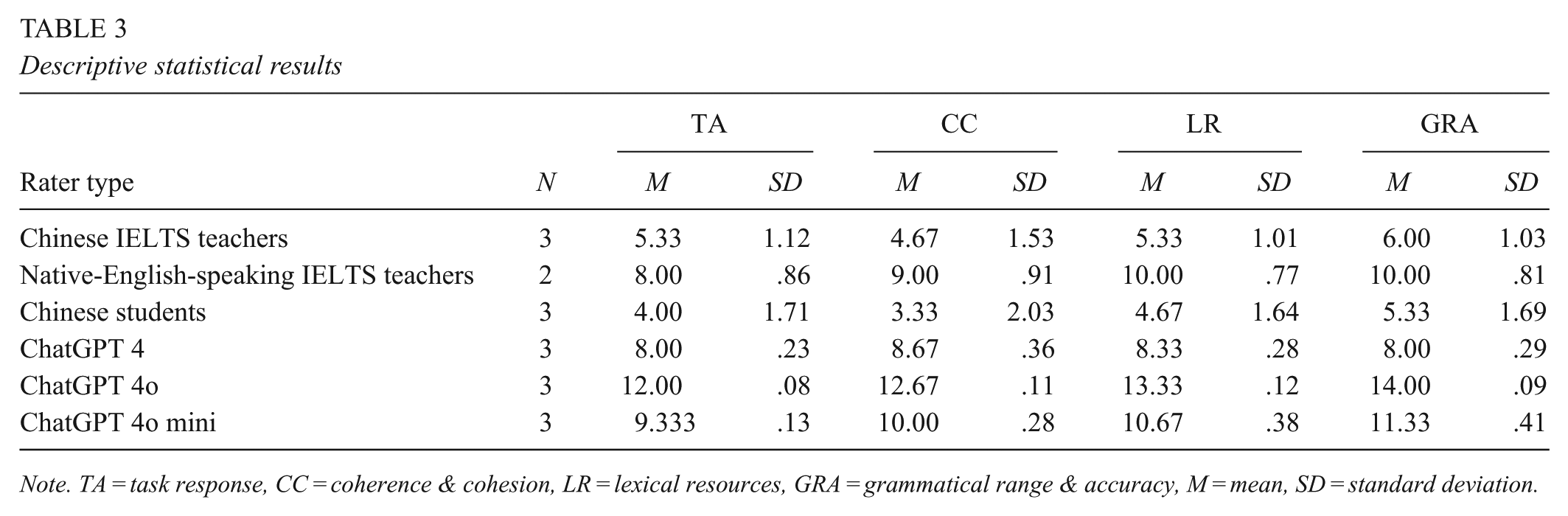
Note. TA = task response, CC = coherence & cohesion, LR = lexical resources, GRA = grammatical range & accuracy, M = mean, SD = standard deviation.
From Table 3, it is evident that ChatGPT 4o provided the highest mean number of actionable feedback across all four domains, particularly in lexical resources and grammatical range and accuracy. ChatGPT 4o mini ranked second in providing actionable feedback across all domains. Chinese students tended to provide the lowest mean number of actionable feedback in all areas. Both native-English-speaking IELTS teachers and ChatGPT 4 provided relatively similar mean numbers of feedback across the four domains, although native-English-speaking IELTS teachers were slightly more generous in their assessments, particularly in lexical resources and grammatical range and accuracy.
Additionally, the standard deviation values for the ChatGPT versions were much smaller (less than .5) than for all human raters, although the standard deviation values for native-English-speaking IELTS teachers were less than 1.0. The standard deviation values for Chinese IELTS teachers and Chinese students were larger than 1.0, indicating that they were considerably more inconsistent in providing actionable feedback compared to the other rater groups.
The qualitative feedback analysis from human raters (Chinese IELTS teachers, native-English-speaking IELTS teachers, and Chinese students) and AI raters (ChatGPT versions 4, 4o, 4o mini) identified key themes across the four domains. In each domain, three primary themes emerged, with both human and AI raters providing feedback on similar issues but differing in their focus and specificity.
Task response
In the task response domain, both human and AI raters emphasized the importance of clarity and supporting arguments with examples. Human raters, particularly Chinese IELTS teachers, focused on the depth and development of arguments, often recommending more detailed explanations. For example, one teacher suggested, “You should provide more detailed examples to support your argument.” Native-English-speaking IELTS teachers also stressed clarity, urging students to elaborate on how examples relate to their points. Chinese students, on the other hand, emphasized staying on topic and avoiding irrelevant points, with one student advising, “Stick to the topic.”
AI raters, especially ChatGPT 4 and 4o, also prioritized clarity and the inclusion of examples. ChatGPT 4o mini suggested presenting both sides of the argument before concluding, a feedback style less commonly found in human raters’ responses. While both human and AI raters agreed on the importance of clarity, human raters were more concerned with task relevance and logical flow, whereas AI raters focused more on structural advice.
Coherence and cohesion
For coherence and cohesion, both human and AI raters stressed the need for logical flow and clear transitions. Chinese IELTS teachers pointed out issues with the logical organization of ideas, recommending that students structure their essays more clearly. Native-English-speaking IELTS teachers highlighted the importance of smooth transitions, advising students to ensure each paragraph builds on the previous one. Chinese students similarly noted disjointed ideas, urging writers to stay focused.
AI raters raised these concerns, with ChatGPT 4 suggesting smoother transitions between paragraphs, and ChatGPT 4o offering more specific language recommendations, such as using transitional words like “Moreover” or “However.” ChatGPT 4o mini focused on structural organization, advising students to break up ideas into clearer paragraphs. While both human and AI raters emphasized logical flow, AI raters provided more actionable language suggestions to improve cohesion, whereas human raters offered broader advice on essay structure.
Lexical resources
In the lexical resources domain, both human and AI raters focused on improving vocabulary variety and avoiding repetition. Chinese IELTS teachers encouraged students to use more specific and advanced vocabulary, with one teacher suggesting, “Instead of saying ‘big problems,’ use ‘serious issues.’” Native-English-speaking IELTS teachers also recommended synonyms to avoid repetition, such as replacing “violence” with “aggression” or “hostility.” Chinese students similarly pointed out the use of basic vocabulary and advised using more sophisticated terms.
AI raters, particularly ChatGPT 4 and 4o, also suggested avoiding repetition and recommended synonyms for clarity. For example, ChatGPT 4 advised, “Try replacing ‘violent’ with ‘aggressive’ or ‘harmful’ to avoid repetition,” while ChatGPT 4o suggested more specific alternatives, such as rephrasing “violent films” to “films featuring intense action scenes or aggressive behavior.” ChatGPT 4o mini focused on contextually appropriate word choices, recommending a replacement like “impact” with “contribution.”
Both human and AI raters emphasized vocabulary variety and avoiding repetition, but AI raters, particularly ChatGPT 4o, provided more actionable recommendations for rephrasing phrases and making vocabulary contextually appropriate, while human raters focused on using advanced vocabulary.
Grammatical range and accuracy
Both human and AI raters identified grammatical errors and provided suggestions for improvement. Chinese IELTS teachers often pointed out subject-verb agreement and tense errors, advising students to simplify sentence structures for clarity. Native-English-speaking IELTS teachers similarly addressed tense inconsistencies and sentence structure issues. Chinese students also focused on basic grammatical errors, often suggesting sentence simplification.
AI raters, such as ChatGPT 4, identified subject-verb agreement and tense errors, offering specific corrections. ChatGPT 4o also focused on sentence simplification, while ChatGPT 4o mini emphasized punctuation and sentence clarity. For example, ChatGPT 4o mini suggested, “Consider breaking this long sentence into two for better clarity.”
While both human and AI raters identified grammatical errors, AI raters were more specific in providing grammatical corrections, particularly related to subject-verb agreement and sentence structure. Human raters often provided broader and less actionable advice on improving overall clarity and consistency.
Comparison of human and AI raters
The comparison between human and AI raters highlights both similarities and differences in their approaches to IELTS essay feedback. Both human and AI raters emphasized clarity, logical flow, and accuracy across all domains. However, human raters were more likely to provide context-specific feedback on task relevance, organization, and the depth of explanations, while AI raters offered more precise linguistic suggestions, such as rephrasing sentences and correcting grammatical errors. AI raters, especially ChatGPT 4o, provided detailed and actionable recommendations on vocabulary, syntax, and cohesion, whereas human raters offered more general but less actionable advice on overall structure and relevance. By combining the strengths of both human and AI raters, a more comprehensive approach to improving IELTS writing can be achieved.
Findings for RQ3
The final research question explored human raters’ acceptance of ChatGPT in IELTS writing preparation classrooms. Data from native-English-speaking IELTS teachers, Chinese IELTS teachers, peer student raters, and IELTS writers revealed diverse views on using ChatGPT for writing assessment. Five key themes emerged: (a) utility and functionality, (b) perceived reliability of scores, (c) actionability of feedback, (d) concerns about over-reliance and limitations, and (e) balancing AI with human oversight. Below is a summary of these findings.
Theme 1: Utility and functionality of ChatGPT in IELTS writing assessment
Participants acknowledged ChatGPT’s usefulness in automating assessment, especially for handling large volumes of student writing. Teachers appreciated its expandability, with Teacher A (China) noting that “ChatGPT can effectively handle large volumes of writing” and suggesting it could assist in pre-assessment. However, concerns arose about ChatGPT’s ability to evaluate complex writing tasks, such as argumentation or creativity. Student Writer B emphasized, “It’s useful for fixing small mistakes, but it can’t help me refine my argument.” Despite this, ChatGPT was seen as a helpful supplementary tool for addressing basic language issues like grammar and vocabulary.
Theme 2: Perceived reliability of ChatGPT-generated scores
ChatGPT was praised for providing consistent evaluations, which were valuable in large-scale settings. Teacher A (native) observed that “ChatGPT gives reliable, repeatable scores,” while Peer Student Rater A noted the fairness of stable scores. However, some participants questioned ChatGPT’s ability to assess more subjective aspects of writing, such as rhetorical techniques or the depth of an argument. Teacher B (China) pointed out that “ChatGPT may miss out on assessing things like rhetorical or persuasive techniques,” and Student Writer A expressed dissatisfaction with scores that did not align with her perceived writing quality. This highlighted the tension between consistency and depth in ChatGPT-generated assessments.
Theme 3: Actionability of ChatGPT-generated feedback
ChatGPT was praised for providing clear, actionable feedback on surface-level errors like grammar and coherence. Teacher A (China) noted, “The feedback on sentence structure and word choice is excellent,” and Peer Student Rater A appreciated its help with recurring grammar mistakes. However, some questioned the depth of the feedback. Teacher B (China) criticized it as “mechanical,” with limited explanations for errors. Similarly, Student Writer B noted that “ChatGPT doesn’t explain the reasoning behind suggestions,” pointing to its inability to offer specific guidance for improving more complex writing issues, such as argument structure or logic.
Theme 4: Concerns about over-reliance and limitations of ChatGPT
Several participants expressed concerns about students becoming over-reliant on ChatGPT, potentially hindering their critical thinking and writing development. Peer Student Rater C commented, “I sometimes feel like I rely on it too much,” while Teacher B (China) warned, “If students only listen to ChatGPT’s suggestions, they may not develop their skills independently.” Furthermore, concerns were raised about ChatGPT’s inability to assess more subtle aspects of writing, like creativity. Teacher A (China) stated, “ChatGPT is good for grammar but misses out on more subtle aspects,” and Student Writer A added, “It doesn’t help me think about the bigger picture of what I want to communicate.” Despite these concerns, participants acknowledged that ChatGPT could still be useful in moderation, as long as it did not replace the broader learning process.
Theme 5: Balancing AI tools with human oversight
The final theme emphasized the importance of balancing AI tools with human oversight. While participants recognized ChatGPT’s usefulness, they stressed the need for teachers to offer personalized feedback. Teacher B (native) stated, “ChatGPT can be used as a first step, but teachers should offer detailed feedback.” Student Writer C echoed this, saying, “My teacher’s feedback is still what helps me improve overall.” Human oversight was also seen as essential for preventing over-reliance on AI and ensuring that students receive contextualized, personalized guidance. Teacher C (China) stated, “AI can assist, but it cannot replace the teacher’s ability to understand the broader context of a student’s progress.”
In conclusion, while participants acknowledged the benefits of ChatGPT in IELTS writing assessment, they emphasized that AI should complement, not replace, human feedback. The balanced use of AI tools and human oversight was deemed essential to provide students with the most effective and personalized learning experience.
Discussion and Conclusion
Discussion of Findings
This exploratory mixed-methods classroom study examined the reliability of holistic scoring, the actionability of feedback, and teacher/student acceptance of ChatGPT in IELTS writing preparation classrooms in China. The results suggest a pattern of complementary strengths between AI and human raters in this context.
First, the quantitative findings for RQ1 indicate comparatively high reliability estimates for the tested ChatGPT variants under the specific prompting conditions used in this study. This aligns with research highlighting the consistency advantages of AI-assisted assessment (Guo & Wang, 2023; Li et al., 2024; Lu et al., 2024). At the same time, these findings should be interpreted cautiously because the dataset was small, limited to advanced writers, and based on a single IELTS prompt. Rather than demonstrating that ChatGPT can replace human raters, the present findings suggest that, in a bounded classroom setting, the tested models can produce stable scoring patterns that may support instructional assessment.
Second, regarding RQ2, both the descriptive and qualitative analyses indicate that ChatGPT feedback—especially from some variants—was frequently actionable for surface-level revision, including grammar, vocabulary, and local cohesion. This is consistent with prior findings that AI tools are effective at identifying and correcting language-level issues (Bucol & Sangkawong, 2025; Liu et al., 2024; Lu et al., 2024). However, participants also identified limits in the depth of explanations and in support for higher-order writing concerns. This pattern echoes research suggesting that corrective feedback is useful when clear and specific, but that deeper learning often requires more explanatory and contextualized guidance (Bucol & Sangkawong, 2025; Link et al., 2022).
Third, the interview findings for RQ3 highlight that acceptance is conditional rather than unconditional. Teachers and students recognized efficiency and consistency benefits, but expressed concerns about over-reliance, reduced independent thinking, and the AI’s limited ability to evaluate creativity and rhetorical nuance. These concerns align with prior work on AI in writing education and technology adoption, which emphasizes trust, perceived usefulness, and pedagogical fit (Barrot, 2023; Praphan & Praphan, 2023; Rezai et al., 2024; Wang & Reynolds, 2024). The findings also resonate with AWE-related research on perceived feedback source, suggesting that how learners interpret AI-generated feedback may shape their uptake and revision behavior (Kao & Reynolds, 2024; Reynolds et al., 2021).
A further contribution of this study is the comparison across ChatGPT 4, 4o, and 4o mini. Although not intended as a definitive ranking of models, this within-platform comparison shows that performance can vary across variants commonly available to teachers and learners. This is practically relevant because classroom implementation often depends on access and platform defaults rather than research-grade model standardization. At the same time, rapid model updates make all such findings time-bound.
Overall, the study supports a blended instructional approach: AI tools can efficiently support local revision and repeated practice, while human teachers remain essential for evaluating task response, argument quality, discourse organization, and individualized development.
Implications for Practice
The educational implications of this study are most useful when translated into specific classroom routines. Based on the findings, the researchers propose the following concrete implementation strategies for IELTS writing preparation classrooms:
Use a staged feedback workflow (AI first, teacher second)
Teachers can structure revision into two stages:
Stage 1 (AI-assisted revision): Students submit a draft to ChatGPT for feedback on grammar, vocabulary repetition, sentence clarity, and basic cohesion.
Stage 2 (teacher-guided revision): Teachers review the revised draft and focus on task response, argument depth, paragraph logic, and score-relevant rhetorical effectiveness.
This division of labor allows teachers to spend less time on repetitive sentence-level corrections and more time on higher-order writing development.
2. Require student verification of AI suggestions
To reduce over-reliance, teachers can require students to label each AI suggestion as: Accepted, Rejected, or Modified and provide a short reason (e.g., “accepted—improves tense consistency” or “rejected—changes intended meaning”). This practice encourages critical evaluation rather than passive adoption of AI feedback.
3. Use rubric-aligned prompt templates
Teachers can provide students with standardized prompts aligned to the IELTS rubric (task response, coherence and cohesion, lexical resource, grammatical range, and accuracy). This can improve consistency in AI outputs and help students interpret feedback in exam-relevant categories. For example, teachers might require students to ask ChatGPT to:
identify two strengths and two weaknesses in each IELTS domain,
provide specific revision suggestions, and
explain why the suggestion improves the response.
4. Create “teacher checkpoint” rules
Teachers can establish clear rules for when AI feedback is insufficient and human guidance is required. For instance, students must consult the teacher when feedback concerns: a) argument logic, b) task interpretation, c) examples/evidence quality, d) paragraph development, or e) conflicting feedback across revisions. This helps preserve teacher authority and ensures that higher-order writing problems are addressed pedagogically.
5. Incorporate peer review after AI use
Because AI may generate plausible but contextually weak suggestions, teachers can add a peer-review step in which students evaluate whether AI feedback actually improves meaning, coherence, and persuasiveness. This may strengthen learner metacognition and reduce over-trust.
6. Train students in AI literacy for writing classrooms
Teachers should explicitly discuss:
what AI tools do well (e.g., local language correction),
what they do less well (e.g., nuance, rhetorical intent, audience awareness),
and how to use AI ethically and strategically in test preparation.
Such training can help students use AI as a support tool rather than a replacement for learning.
Summary of Main Findings
This exploratory study found that, within a small advanced-level IELTS classroom dataset, the tested ChatGPT variants (4, 4o, 4o mini) produced comparatively high reliability estimates for holistic scoring and generated frequent actionable feedback for surface-level writing issues such as grammar, vocabulary, and local cohesion. However, both the qualitative feedback analysis and interview data indicated limitations in addressing higher-order and context-sensitive dimensions of writing, including argument depth, rhetorical nuance, and creativity. Teachers and students generally accepted ChatGPT as a useful supplementary tool but emphasized that human oversight remains essential.
Limitations
This study has several important limitations. First, the study used a small sample of eight essays, which limits the statistical robustness and generalizability of the quantitative findings. The reliability estimates should therefore be interpreted as exploratory and context-bound.
Second, all essay writers were advanced-level IELTS learners. This proficiency-restricted sample does not allow conclusions about how AI and human raters perform across lower or mid-level writing proficiency, where error patterns and feedback needs may differ substantially.
Third, the study used a single IELTS essay prompt, which limits task coverage. Different prompts may elicit different discourse structures, lexical demands, and argumentation patterns, which could affect both scoring and feedback actionability.
Fourth, the study was conducted in one classroom context in Eastern China, and participant perceptions may reflect local instructional practices and exam-preparation norms. Findings may not transfer directly to other regions or educational systems.
Fifth, the comparison of ChatGPT variants is time-bound to the specific model versions and prompting conditions used. Given the rapid pace of AI model updates, these findings should not be generalized to later versions of ChatGPT or other LLMs without replication.
Finally, while this study included qualitative analysis of feedback and interviews, future work would benefit from richer text-level analyses linking specific essay excerpts to AI/human feedback and subsequent revisions.
Future Research Directions
Future research should address the limitations by: a) using a larger and more diverse corpus of IELTS essays; b) sampling writers across multiple proficiency levels (low, mid, high); c) including multiple prompts and task types; d) conducting longitudinal studies to examine how AI feedback affects writing development and learner autonomy over time; e) comparing student uptake and revision outcomes after AI vs. teacher vs. blended feedback (drawing on AWE and perceived feedback source research); and f) replicating the study with newer AI model versions using version-locked reporting, standardized prompts, and transparent prompting protocols and comparing ChatGPT with other writing support tools (e.g., Grammarly, Write & Improve, or other LLM-based systems) in IELTS and broader EFL contexts.
Footnotes
Author’s Note
Ying Liu is now affiliated with the Chinese University of Hong Kong.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the research on artificial intelligence and human expert assessment of Chinese graduate theses, Jiangsu University Key Project (G202502).
Authors
HUI ZHAO is an English teacher at Zhenjiang Juvenile Growth Guidance Center, Zhenjiang, China. Her research interests include EFL assessment and language policy issues.
JINYAN HUANG is a professor at the School of Teacher Education of Jiangsu University, China. His research interests are assessment, research methods, and AI-assisted language education.
YING LIU is a Ph.D. student at the Faculty of Education of the Chineses University of Hong Kong, China. Her research interests are educational assessment and research methods.
PATRICK B. WHIPPLE is a director at the Genesee Valley Board of Cooperative Educational Services in New York. His research interests are related to educational assessment fairness issues.