
Abstract
This paper explores the potential of Large Language Models (LLMs) for assisting with quantitative data analysis in social science research. Specifically, it introduces key concepts to help researchers effectively integrate LLMs into their workflows. For this purpose, we replicate a research paper in educational leadership on the relationship between school program coherence and student achievement. By leveraging LLMs to generate code for statistical tools like Mplus and R, researchers can streamline their data analysis, potentially saving time and effort. The quality of analytical code generated by LLMs can be influenced by the researcher’s understanding and application of concepts like context windows, LLM training data and training cut-off, model parameter settings like temperature, zero- and few-shot learning, and Retrieval-Augmented Generation (RAG). By describing and demonstrating the applications of these concepts, we aim to equip researchers with a basic toolset to leverage LLMs effectively to assist with coding for quantitative analysis.
Keywords
Introduction
Large language models (LLMs) demonstrate significant capabilities to assist researchers across disciplines with their data analysis by enhancing the efficiency of their workstreams. LLMs such as OpenAI’s ChatGPT, Anthropic’s Claude, Meta’s Llama, and Google’s Gemini and Gemma models have received a great deal of attention recently, as they show potential to achieve advances in multiple fields and applications (Bommasani et al., 2021; Bowman, 2023). LLMs are artificial intelligence (AI) models designed to generate text by predicting the next token in a sentence (Brown et al., 2020). A token refers to a small unit of data, such as parts of words, images, or videos, with each token representing about four characters in English (Kuzminykh, 2024). These models are trained on vast datasets, enabling them to capture complex statistical patterns in human language (Radford et al., 2019). They are called “large models” because they contain billions or even trillions of parameters and are trained on vast amounts of data (Brown et al., 2020; Radford et al., 2019), allowing them to generate text that is often indistinguishable from human writing (Bender et al., 2021; Chang et al., 2024). LLMs have significantly transformed natural language processing (NLP) tasks such as translation, question-answering, and reading comprehension (Brown et al., 2020). Further, an emerging Reasoning and Acting (ReAct) framework explores the potential of LLMs to implement complex, multi-step reasoning tasks (Yao et al., 2022). LLMs have shown impressive performance in extracting data from previous studies and in conducting systematic reviews (Gartlehner et al., 2024; Riaz et al., 2024). LLM applications have also been explored for programming code generation and code comprehension (Fang et al., 2024; Vaithilingam et al., 2022) and are widely used by programmers (Github, 2024).
In the context of social science research, LLMs have shown promise for applications in qualitative analysis, for example, in identifying preliminary codes, assisting in codebook development (Barany et al., 2024; J. Gao et al., 2024), and deductively coding transcripts (X. Liu, Zhang, et al., 2024; Tai et al., 2024; Xiao et al., 2023). Compared to the fair number of studies on integrating LLMs in qualitative research and systematic reviews, fewer studies have investigated their applications for quantitative reasoning and statistical analysis. X. Liu, Wu, et al. (2024) developed benchmark data to evaluate LLM capabilities in statistical reasoning, concluding that LLMs faced difficulty with these tasks. Titus (2023) explored the use of ChatGPT in guiding biostatistical analysis and validated the R code and results generated by ChatGPT by comparing them to those obtained through established statistical literature and best practices. Despite occasional errors in the code produced by ChatGPT, the study found that ChatGPT can make complex analytical procedures and advanced statistical analyses accessible, particularly for those with limited biostatistical expertise. Huang et al. (2024) compared the results from ChatGPT-4 with those obtained using established statistical programs and found that ChatGPT produced comparable results in simple analyses of medical data, including descriptive statistics, correlation, and group comparisons. However, the study noted limitations with LLMs in performing complex and advanced statistical analyses. Huang et al. (2024) and Titus (2023) emphasized the user-friendliness and efficiency of LLMs, positioning them as a tool particularly beneficial for initial data exploration and analysis, or basic analytics. Despite the speed and ease of using LLMs, both studies also showed that LLMs have considerable room to improve in terms of providing accurate results and code suggestions. However, these papers did not provide specific strategies to achieve these improvements. For example, both papers discussed the issue of hallucinations, which refers to an output produced by LLMs that includes incorrect or misleading information presented as factual (Hicks et al., 2024; Zhang et al., 2023). Both Huang et al. (2024) and Titus (2023) recommended verifying the accuracy and reliability of LLM outputs using established standards, but did not explore methods to reduce the likelihood of hallucinations.
To effectively guide statistical analysis and improve the quality of the analytic code produced by LLM tools, researchers’ own statistical proficiency and domain knowledge appear to be critical (Huang et al., 2024; Titus, 2023). LLM users can employ various strategies to obtain more accurate and relevant results, a subset of which are collectively called prompt engineering (P. Liu et al., 2023; Sahoo et al., 2024). A prompt in the context of LLMs is an input designed to guide the model’s output, effectively serving as a directive that shapes the model’s response (P. Liu et al., 2023). Prompt engineering involves the careful design and crafting of the most appropriate prompt to obtain desired results, that is, generated output that is both accurate and contextually relevant (P. Liu et al., 2023; Sahoo et al., 2024). Prompt engineering encompasses a wide spectrum of techniques and concepts, including embedding-based similarity search and RAG, temperature settings, role-play, context and training windows, and zero- and few-shot learning (P. Liu et al., 2023; Sahoo et al., 2024). These techniques and concepts are discussed in greater detail in this paper. In addition to domain knowledge, an understanding of prompting techniques can greatly enhance the accuracy and relevance of generated code from LLMs.
Study Purpose
In this paper, we aim to showcase prompt engineering strategies for the application of LLMs in generating statistical code for educational research. We replicated a previously published empirical paper which utilized data from the School Leadership for Student Achievement (SLSA) study that examined the association of school program coherence with student achievement (Moon et al., 2022). Program coherence is defined as “a set of interrelated programs for students and staff that are guided by a common framework for curriculum, instruction, assessment, and learning climate, and are pursued over a sustained period” (Newmann et al., 2001, p. 299). We utilized the previously analyzed SLSA data for several reasons. First, we could compare the LLM output against research results that are already published. Second, education research studies often employ complex statistical procedures to address nesting and missing data; the SLSA Coherence paper used multilevel modeling to address nesting, and multiple imputation to address missing data. With the SLSA dataset, we can evaluate whether LLMs can generate accurate statistical code for such sophisticated procedures. By applying concepts of prompt engineering that are not currently in widespread use, we hope to contribute to conversations about best practices for harnessing the full potential of these powerful tools. All code, datasets, and demonstration materials used in this study are available in the tables and supplementary materials, as well as in a publicly accessible ICPSR repository (http://doi.org/10.3886/E237744V3.). 1
A Human-Centered Framework for Integrating LLMs Into Quantitative Research
This paper positions the use of LLMs in quantitative research within a human-in-the-loop framework that focuses on enhancing code generation efficiency and accuracy while maintaining the need for critical human oversight and judgement. Our examples clearly show that while LLMs can significantly streamline the workflow of quantitative researchers, their effective use requires a guiding framework that prioritizes human evaluation. Our approach aligns with the principles of Human-Centered AI (HCAI), a framework that emphasizes three premises: (i) high levels of human control and high levels of automation; (ii) a shift from emulating humans to empowering people as “users want to be in control of technologies that support their abilities, raise their self-efficacy, respect their responsibility, and enable their creativity” (Shneiderman, 2020, p. 116); and (iii) effective governance structures that emphasize reliable systems, a culture of safety, and trustworthy certification by independent oversight. The HCAI framework serves as a lens through which we explore how educational researchers can leverage LLMs to streamline their workflow processes for quantitative analysis.
LLM Tools for Quantitative Social Science Research
Advantages of Using an API Key Over Chatbot Interface
LLMs like OpenAI’s and Anthropic’s models can be accessed through their web-based conversational chatbots (ChatGPT and Claude AI, respectively), or through an application programming interface (API) key which can then be used in a programming environment like R or Python. In this paper, we discuss the latter approach, using an API key in the Python programming environment and executed in Jupyter notebooks. These notebooks can be run locally on your desktop computer or laptop, or in cloud-based resources like Google Colab or Amazon Web Services (AWS). Table 1 shows an example of running the GPT-4o LLM model from OpenAI using an API key to generate R code to calculate basic descriptive statistics for a generic test variable. An additional example to generate SAS code for the same purpose is provided in the online supplementary materials (see Table 1S). An example to run (or invoke) LLMs to generate R statistical code in the R programming environment is also provided (see Table 2S). These examples highlight the versatility of present-day LLMs to generate code across multiple programming languages and environments.
Basic Prompt in Python to Invoke GPT-4o to Generate R Code for Descriptive Statistics

The examples shown in Table 1 and Tables 2S for generating statistical code illustrate several advantages of using an API key for response generation over web-based chatbot interfaces. First, we can use a system message to set the context or guide the behavior of the LLM for response generation to be consistent throughout our interaction (OpenAI, 2023; L. Zhu, Wang, et al., 2024). The system prompt is important for shaping LLM behavior, tone, and the type of responses (L. Zhu, Wang, et al., 2024). By specifying in the system prompt that “you are an expert in R Statistical software,” we ensure that the generated responses for the duration of that specific interaction align with our expectations and prioritize generating accurate R code. Using a system prompt to provide a role to an LLM is also known as role prompting or adopting a persona (OpenAI, 2023); it dramatically improves LLM performance with better accuracy, improved focus, and appropriate tone (Anthropic, n.d.; Sahoo et al., 2024). Incorporating personas allows LLMs to produce more contextually relevant responses, enhancing their usefulness and effectiveness for targeted applications (Tseng et al., 2024). Additional requirements such as output language (e.g., non-English), specific output styles (e.g., academic paper, presentation), and code explanation, can also be specified in the system prompt. Prior research on qualitative data coding has also shown that using an API is more efficient and yields more consistent results than a chatbot (X. Liu, Zhang, et al., 2024). This is because, once the system prompt is defined, there is no need to repeatedly clarify instructions in the input prompts (X. Liu, Zhang, et al., 2024). Further, if bulk changes are needed for previously generated code, the system prompt can be updated once to rerun the previous prompts (X. Liu, Zhang, et al., 2024).
Second, when using an API key, we can set LLM model parameters such as model temperature, which is a parameter that influences the language model’s output in determining whether the output is more random and creative versus more predictable (OpenAI, n.d.; Peeperkorn et al., 2024). Temperature controls how the model selects the next token; when temperature is set to zero, the model deterministically selects the token with the highest probability, whereas higher temperature values cause the model to sample from a broader distribution of possible tokens, introducing a degree of randomness. For purposes of generating statistical programming code, we would want temperature set close to zero to reduce randomness. However, Renze and Guven (2024) showed that changing model temperature did not have a statistically significant effect on LLM performance for problem solving tasks, whereas Peeperkorn et al. (2024) showed that temperature was only weakly correlated with novelty and moderately correlated with incoherence; overall, their results showed that LLMs generated slightly more novel outputs with higher temperatures. Y. Zhu, Li, et al. (2024) proposed an adaptive temperature sampling strategy for code generation with higher temperatures for more challenging code that allows the LLM to explore more diverse and creative choices and lower temperatures for generating standard code that is straightforward.
LLM models have a large number of model parameters that are similar to regression coefficients; for example, GPT-4 is said to have over a trillion model parameters that have been carefully adjusted to be able to correctly predict the next word, given an input text (Albergotti, 2023). The data used to adjust these parameters, known as training data, includes words from books, web texts, Wikipedia, news articles, blogs, technical documentation, and other pieces of writing from the internet. Since our simple prompts to generate R and Mplus descriptive analysis code appear to be correct in syntax and logic, we can assume that the training data for GPT-4o included statistical code in R and Mplus. All LLM models have a training data knowledge cutoff, which refers to the last date till which the model was trained. LLMs typically do not have access to any new information, events, or developments that have occurred after that date. For example, in relation to the present paper and application, LLM generated statistical code will not reflect any changes made to programming libraries after the knowledge cutoff of the underlying models. At launch, the knowledge cutoff date for GPT-4o, was October 30, 2023 (OpenAI, 2024). At the time of writing the first draft of this paper, according to GPT-4o, the latest versions of Mplus and R programming languages were 8.9 and 4.3.1, respectively, whereas the correct versions at the time were 8.11 and 4.4.1.
ChatGPT, the web chatbot interface of OpenAI, now integrates a web-search tool, improving its ability to provide up-to-date information and address knowledge-cutoff limitations. This web-search integration introduces new challenges associated with determining the reliability of web-search results. For our questions on Mplus and R versions, ChatGPT provided two answers as part of its effort to optimize and personalize output styles; one correctly identified 8.11 as the latest version of Mplus, while the other mistakenly listed 8.4.0.1. The ability to integrate tools such as web-search or a calculator is referred to as LLM tool-use and is a rapidly developing area in LLM applications. However, as demonstrated in this example, careful implementation is necessary as errors made by tools such as web-search can now be propagated through the LLM’s responses. Working with an API key in a programming environment like Python or R, allows users greater control over when and how tools are used, leading to more precise understanding of LLM generated outputs.
In the following sections we discuss the steps used to conduct the main analytical methods in replicating the SLSA Coherence study. The original SLSA Coherence paper used a well-established software program, Mplus, for the main analysis. Data preparation for Mplus is typically done externally using other programming tools such as SPSS, SAS, and R. In the original SLSA Coherence paper, data preparation was conducted using SAS, whereas we used R for data preparation in this study. To summarize, we used OpenAI’s GPT-4o LLM model using their API key in the Python coding environment to generate R code for data preparation and descriptive analysis, and Mplus to carry out the main data analysis steps. Similar to Titus (2023), we copied GPT-4o generated R and Mplus code and ran the code separately in their respective platforms. To simplify the coding requirements to utilize LLMs, we used LangChain, an open-source framework to simplify the creation of applications using LLMs. LangChain is a set of software tools and instructions to help people more easily work with LLM applications (Buniatyan, 2023).
Main Analysis Using LLMs
Efficiently Switching Between Programming Languages
Descriptive information about a dataset’s name, the main dependent and independent variable names, information on how missing data is coded, and a list of control variables are adequate information for an LLM to generate: (i) accurate code for data preparation using R (Table 2) and (ii) corresponding Mplus code (see Table 3) to read the dataset prepared from R output, obtain basic descriptive statistics, and estimate parameters of predictive statistical models. As noted previously, analysts may employ one software tool for data preparation and a different tool for the actual analysis. Using an LLM to generate the code for both steps can simplify and streamline the process needed to coordinate data preparation and data analysis. For example, Mplus users typically first compare output for simple descriptive statistics with those obtained from the data preparation software to confirm that data has been correctly loaded and that variables are being interpreted and matched to the raw data as expected. Using LLMs can help to streamline this process and efficiently manage various steps such as keeping track of variable names and their specific order, keeping track of variable data types (integers, floats, etc.), rules for data preparation (e.g., Mplus does not allows string variables), and handling missing data.
Basic Prompt for R Coding Instructions for Data Preparation (for Subsequent Mplus Analysis)

Mplus Coding Instructions to Obtain Descriptive Statistics

Chat History
By recording each human input and the subsequent LLM response as alternating entries in a list —called the conversation or chat history—and invoking the LLM with both new content (new prompt) and the entire previous conversational history, users can engage in a more natural conversational mode of interaction with LLMs (Paranjape & Manning, 2021; Zhang et al., 2020). For example, we first prompted the LLM to provide R code for data preparation (Table 2). The subsequent request (Table 3) simply followed on the previous prompt and asked for the “corresponding Mplus code,” without repeating previously input details about the dataset and variables. Similarly, if there are errors in the R and Mplus code suggestions, we can copy the error message as a new prompt to the LLM. The LLM will use the chat history to make sense of the error and provide corrections to its generated code. Utilizing the chat history enables LLMs to produce responses that consider the previous context and prompts, ensuring consistency through the duration of a specific task and allowing for a more conversational style of interaction (Gupta et al., 2024). Saving and utilizing prior messages in a list called chat-history to enable a conversational style of interaction is a central feature of web-based chatbots such as ChatGPT. Working with API keys allows for greater control, precise manipulation of conversation history and selective retention that can be tailored to specific research requirements.
Next, we followed up on LLM prompts to produce descriptive statistics by requesting Mplus code for regression analysis and providing information on the dependent, independent, and control variables. As the LLM had previously generated R code for data preparation, and descriptive statistics, and since that information was retained through chat history, the LLM was able to generate accurate Mplus code for conducting regression analysis (Table 4). Since the original Coherence paper reported standardized regression coefficients, we requested the LLM to include code to produce standardized betas. For certain nominal variables like grade (grade4-grade8), and location (City, Suburb, Town, and Rural), we need to provide the correct left out categories to match the specifications in the original Coherence paper, otherwise the LLM will make its own choices. All these changes and modifications can be done in an iterative manner, using a natural conversational style.
LLM Prompt to Obtain Mplus Coding Instructions for Regression Analysis
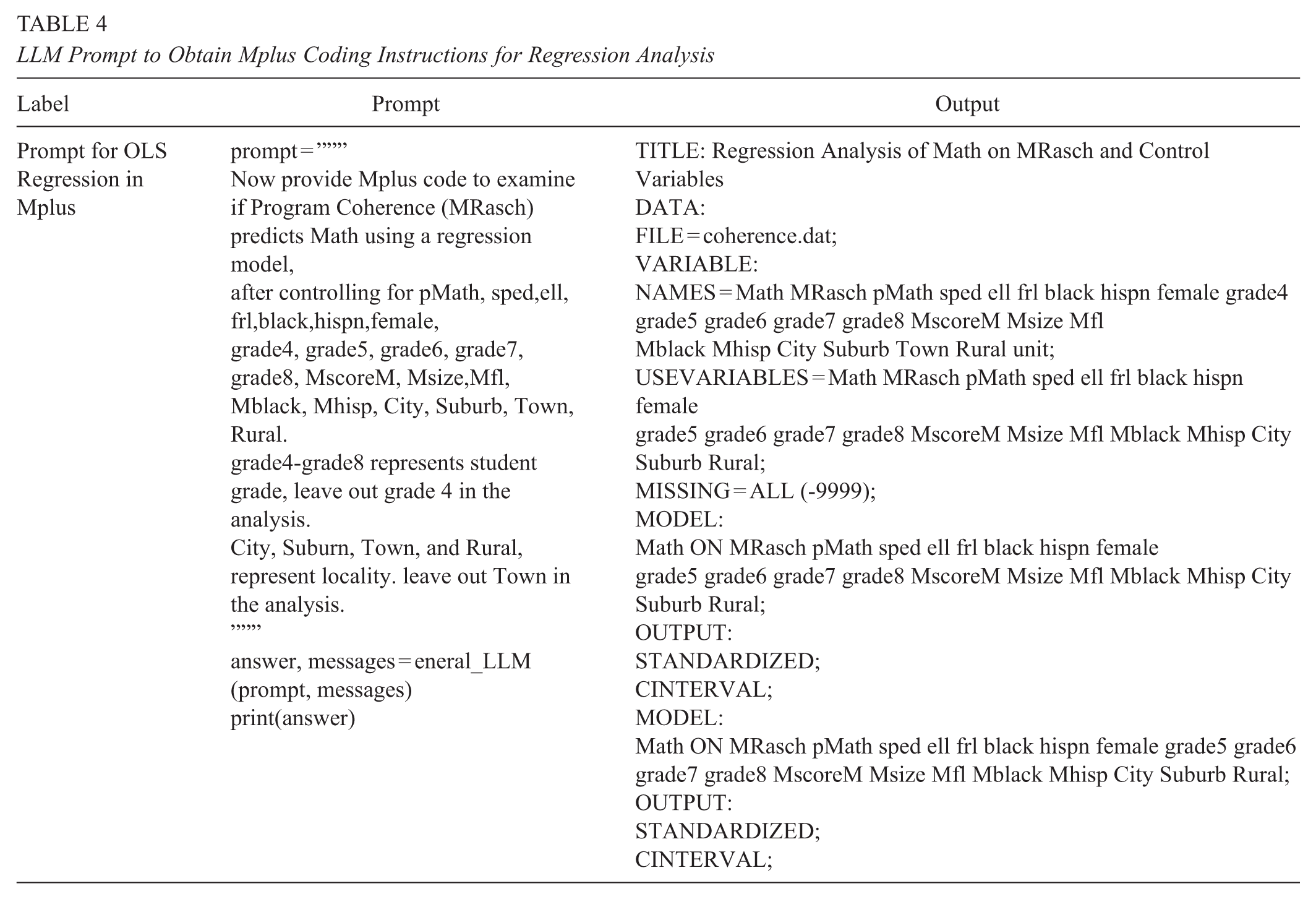
Prior research on LLM prompt engineering also provide a few additional guidelines for optimizing LLM performance for generating code. These include providing the LLM with information about: (i) dataset structure which includes a list of the variable names and their type (categorical, numeric); (ii) whether they contain missing values; and (iii) the first few rows of the dataset (Rajkumar et al., 2022). When providing examples of a few rows to the LLM, researchers should be careful about permissions, privacy concerns, and confidentiality requirements. Since LLM response accuracy for code generation is not contingent on providing actual data, we can provide simulated data that follows the same data structure. The code for obtaining this additional information can itself be derived from LLM prompts. In our case, this extra contextual information was not needed for the LLM to generate accurate Mplus code for OLS regression. However, we include these steps in the example code provided in the ICPSR repository.
Iterative Code Development: From Simple to Complex
The regression results from LLM generated code shown in Table 4 do not match the results in the original SLSA Coherence paper. This is because the regression analysis in the original paper used multilevel modeling. To illustrate how incomplete contextual information and lack of domain expertise can lead to faulty output, we did not include information about the clustered nature of the SLSA dataset in our prompts. The nested structure of the SLSA dataset introduces the issue of the non-independence of observations, which can lead to the incorrect estimation of standard errors. Multilevel modeling is commonly used to address non-independence between observations due to nesting (Hayes, 2006). The original SLSA Coherence paper additionally used multiple imputation to account for missing data, by generating 10 imputed datasets with Mplus and combining information from all 10 datasets for final analysis.
The multilevel modeling extension for OLS regression was easily addressed with a follow-up prompt to the LLM to account for nesting by conducting multilevel modeling and providing the LLM information about the clustering variable, school ID (see Table 5). However, since we had deliberately not included information about the school identification variable in our previous LLM prompts, we needed to go back to the data preparation stage, repeating all the steps with the school ID information included. In a traditional workflow, this might have been painstaking to implement. With LLMs, a simple prompt in natural conversational language quickly provides the necessary code correction for the previous steps. A simple prompt in this instance could be “I forgot to note that the dataset has a nested structure, the clustering variable is schoolID. Redo all the steps starting with data preparation step in R.” The simplicity of this approach, making all the required changes with a single prompt, illustrates the advantage mentioned earlier about using LLMs to coordinate the steps between data preparation and final analysis. LLMs can replace custom layers and specialized programs that researchers needed to develop independently in the past to make their workflows more efficient.
Prompt for Mplus Coding Instruction for Multilevel Regression Analysis

Addressing Hallucinations
The results from the Mplus input code that estimated multilevel models were close to the results provided in the original paper. The last source of discrepancy came from a final step in the original paper that involved conducting multiple imputations after generating 10 imputed datasets. Unlike the multilevel example, providing the LLM with more conversational guidance and contextual information did not produce correct code (see Table 6). When we asked the LLM to generate Mplus code to conduct multiple imputation with 10 imputed datasets, the generated code did not run in Mplus because of syntax errors that were flagged when the program did not execute. This example highlights a risk in using LLMs for code generation; the models can generate code that appears correct and well-structured while containing fundamental flaws. While in this case the errors prevented execution, a greater concern would be code that successfully runs but incorrectly implements the researcher’s intent.
Zero-Shot Prompt to Conduct Multiple Imputation (Generated Incorrect Code)
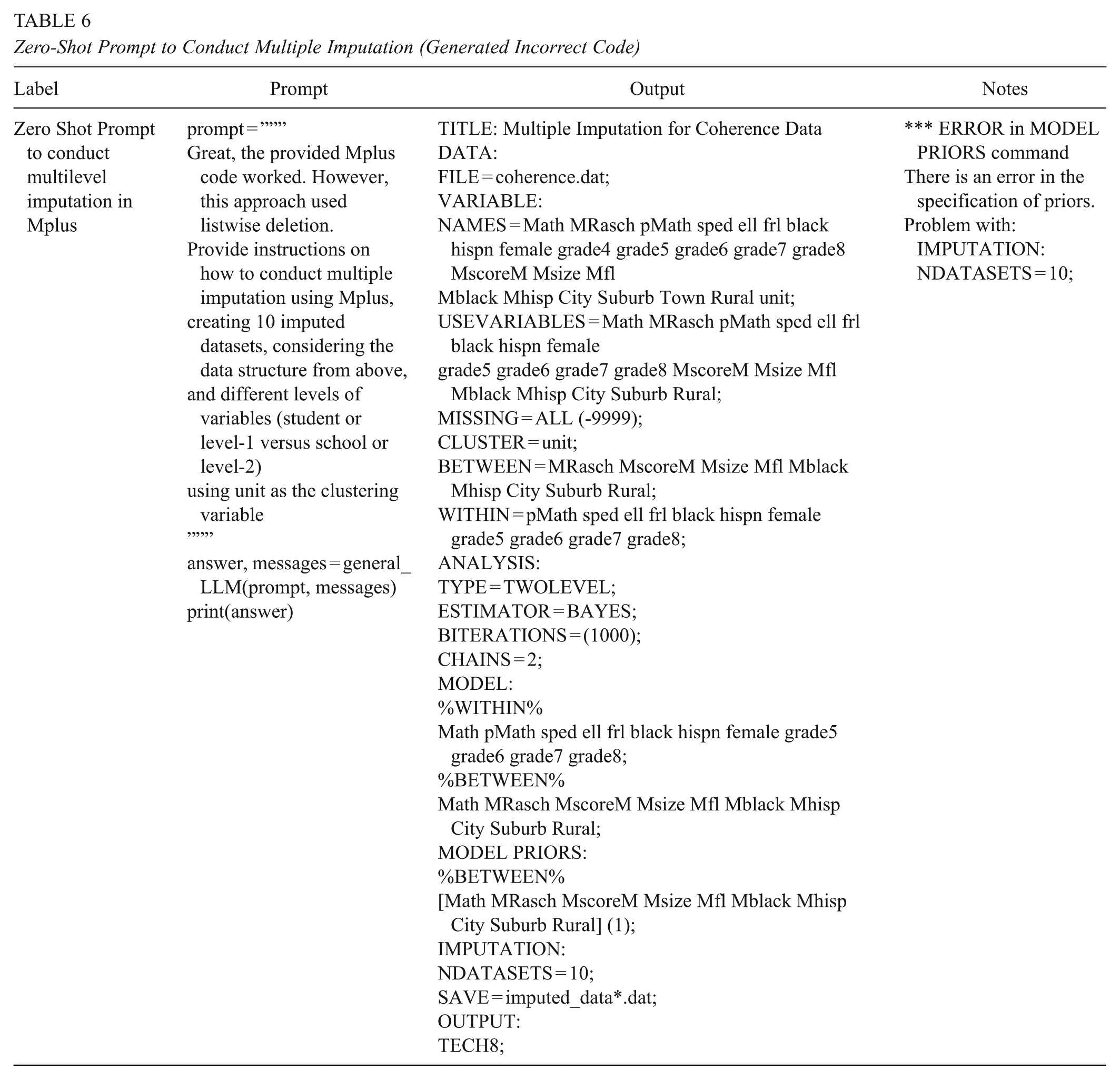
The incorrect code generated for missing data imputation is an example of LLM hallucination which might have been a result of Mplus program updates since the knowledge cut-off date for ChatGPT-4o or due to several other reasons. Hallucinations—as described earlier, in the introduction—refer to the generation of content that is irrelevant, made-up, or inconsistent with the input data (Zhang et al., 2023). Since LLMs are pre-trained using extensive data sourced from the internet, the training data itself may contain fabricated or outdated information, leading LLMs to reproduce inaccurate information (Zhang et al., 2023). LLMs might misinterpret user prompts, resulting in irrelevant outputs (Zhang et al., 2023). Due to limitations in maintaining long-term memory, LLMs may lose track of the specific task’s context and generate inconsistent information (Zhang et al., 2023; Zhong et al., 2024). Some scholars have argued that because LLMs are fundamentally designed to generate plausible text without concern for the truth of the content, it is prone to generating made-up or false information, even with fabricated references and evidence (Hicks et al., 2024). This tendency to generate false information, they argue, should be called “bullshit,” rather than hallucinations, to more clearly represent its nature (Hicks et al., 2024).
For the end user, as shown in this example, the experience is an instance of non-optimal interaction and can result in decreased trust in the output of LLMs. Sometimes, errors can be corrected by simply copying and pasting the error itself as a follow-up prompt. This did not work in our case, which meant that, very likely, the original training data for GPT-4o (at launch) had not included the correct Mplus code for handling missing data with imputed datasets (Table 6). In such cases, we need to provide the correct context information to the LLM. This can be done in two ways. In the first approach, known as LLM fine tuning, the correct or updated contextual information can be provided as additional data in retraining the model, or continuing its training. This requires access to the model architecture and parameters and is only possible if the LLM provider makes the model publicly available. It involves re-adjusting the large number of model parameters (typically numbering in several hundred-billions or trillions), a process which is currently costly and not practical in most instances. Fine tuning methods are rapidly evolving with innovations in parameter-efficient fine-tuning techniques, and methods like transfer learning and knowledge distillation, which are making model customization increasingly accessible. At present they are practically restricted to relatively smaller models due to the substantial computational resources required for larger architectures.
The other approach is to simply include the relevant information in the prompt itself. For example, for the present application, the Mplus user guide (Version 8) is publicly available online, and includes the correct code and detailed explanations for generating multiple imputed datasets for missing data (Chapter 11) and then using those imputed datasets for subsequent modeling (Chapter 13; see Muthén & Muthén, 1998-2017).
Prompt Augmentation
If we know the precise information that should be included in the prompt, we can simply copy and paste the relevant information and append it to our instructions. This can be done manually, or with more efficient document loaders that are available for a wide variety of sources, such as pdf, word documents, web pages, YouTube transcripts, and Wikipedia pages. These tools convert the content in those sources to a text-based format suitable for LLM models (LangChain, 2024); we can then add the relevant information as additional context information to our prompt (see Tables 7 and 8). Our results show that by copying content from the relevant Mplus user guide chapters directly in our prompt, we can get the correct model specifications with results that fully match those in the original paper. However, when augmenting prompts with external content, it is important to exercise caution regarding copyright considerations as the data we input may be retained and potentially used for training purposes, which could inadvertently lead to copyright infringement.
Few-Shot Prompt to Create Imputed Datasets

Note. This code worked to create 10 imputed datasets.
Few-Shot Prompt to Conduct Multilevel Modeling with Imputed Datasets

Retrieval-Augmented Generation
An alternative to locating the precise relevant materials and copying or attaching them to LLM prompts directly is to use a computational process known as RAG. RAG is the process of optimizing the output of a large language model, so that it references an authoritative knowledge base outside of its training data sources before generating a response (Y. Gao et al., 2023; Sahoo et al., 2024). In simpler terms, RAG functions as an automated information retrieval system that identifies relevant contextual material for a prompt from a vast array of data or information sources. RAG can extend the already powerful capabilities of LLMs to specific knowledge domains or an organization’s internal knowledge base, all without the need to retrain the model (Y. Gao et al., 2023). It is a cost-effective approach to improving LLM output so that it remains relevant, accurate, and useful in various contexts.
RAG applications are often necessary because of limitations in LLM context windows, which limit the amount of information we can directly include in our prompts. Context windows refer to the amount of information (words or tokens) that an LLM model can receive as input when generating responses (Gartenberg, 2024). Context windows vary between LLM models; GPT-4o has a context window of 128k tokens, Anthropic Claude models have a context window of 200k tokens, and Google’s Gemini 1.5 Pro AI model has the largest context window with up to 2 million tokens (Kilpatrick et al., 2024). Context windows have generally been increasing over time; for example, the first GPT models had a context window of 2048 tokens.
Despite the relatively large and increasing context windows sizes, there still could be instances where the information we have to provide as context for an LLM is larger than the context window. For example, in the present example, we wanted to use the entire Mplus User Guide (Version 8) as the authoritative knowledge base for augmenting our prompts. The Mplus user guide has 23 sections and 950 pages. Even if an LLM’s context window is large, since there is a per-token cost to use LLMs, it is not cost-efficient to add large amounts of contextual information to improve prompts. Further, non-relevant content can distract the LLM from prioritizing the information that is needed to generate accurate responses. Therefore, it is important to retrieve only the most relevant pieces of contextual information through RAG to add to LLM prompts.
When conducting RAG, we first break up our data into chunks or smaller pieces of information. Next, these chunks are converted into vectors or mathematical representations called embeddings (Y. Gao et al., 2023). Embeddings are number sequences or vectors that represent concepts, making it easier for computers to understand the relationships between those concepts (OpenAI, 2022). For example, “cat” and “feline” have embeddings that are closer to each other whereas embeddings for dissimilar words such as “cat” and “skyscraper” are further apart. When it is time to provide a prompt to an LLM with RAG, the relevant context is retrieved dynamically from the data chunks, so that only relevant information that is most similar in their mathematical representations (or embeddings) to the user prompt is provided (Y. Gao et al., 2023). To achieve this, the user’s prompt is also converted to a vector embedding. Then, a few embedding vectors from the original content (e.g., the embedded Mplus user guide) that are most similar to the user’s query, are retrieved using a similarity calculation such as cosine similarity. Finally, these embedding matches are used to retrieve the original text which is added to the LLM prompt as additional contextual information. In our example, since our final prompt included phrases such as “multiple imputation,” “missing,” and “imputed datasets,” the similarity search process will retrieve embeddings (data chunks) of the Mplus User Guide that are most similar to sections that also contain semantically similar phrases.
To recap, the RAG process applied to our Mplus User guide example included the following steps: (i) the whole Mplus user guide document was first broken up into smaller chunks. Chunking level or size can be chosen by the user; for example, the user guide can be divided by chapter, or typically, by smaller units. (ii) These chunks were then converted to vector embeddings, or mathematical representations of text using an open-source Huggingface embedding model. The embedding process for the authoritative knowledge base is only done once and the embeddings are stored locally. (iii) Our final prompt that includes instructions on generating multiple imputed datasets and conducting analysis with those datasets is also converted to vector embeddings. (iv) This final-prompt embedding is compared with the entire set of Mplus user guide embeddings to retrieve a few most similar embeddings. (v) The retrieved embeddings are linked back to their original text content which is included with the final prompt.
In our example, we would expect this retrieval process to correctly retrieve instructions and coding examples from the Mplus user guide on conducting multiple imputation for missing data. As shown in Table 3S in the online supplementary materials, the retrieved chapters did include the relevant content, and the subsequent LLM generated Mplus code was accurate. Note that we used the simplest RAG implementation as an illustrative example; there are a variety of procedures available to improve RAG performance that are commonly used by programmers working with LLMs. With this example, we demonstrated that we could use RAG to augment prompts with relevant contextual information, even if we do not know the precise location of that information in an authoritative knowledge base.
Zero-Shot and Few-Shot Prompting
Another concept that is important in prompt engineering is the application of zero-shot prompting and few-shot prompting. Until we included information from the Mplus user guide, we were implementing zero-shot prompting. Zero-shot prompting refers to using a prompt that does not include any examples or demonstrations when interacting with an LLM model (DAIR.AI, 2024). The prompt gives the model a direct instruction to carry out a task without providing extra examples to guide the LLM model (DAIR.AI, 2024). After we introduced relevant context from the Mplus user guide either through RAG or direct prompt augmentation, we were implementing few-shot prompting. Few-shot prompting refers to the inclusion of one or more examples within the prompt to guide the model towards improved performance (DAIR.AI, 2024). These examples help condition the model, making it more likely to produce accurate responses in the subsequent tasks (DAIR.AI, 2024). The Mplus guide contained examples of code to implement our analytical objectives. Alternately, we could include our own examples, perhaps from previous projects and similar analytical models to implement few-shot prompting and improve LLM performance.
Data Privacy and Security Considerations
A critical concern for researchers is the protection of their research data and compliance with the regulations of their institutions and grant funding agencies around data use, storage, and protection. When using web-based chatbots, the risk of accidentally sharing confidential data and information is substantial. While this risk is mitigated with using API-based approaches through greater control over content submission and conversation management, it is not eliminated. Policies around using customer submitted data for model training vary between LLM providers. OpenAI notes that user content submitted via the web interface ChatGPT can be used for further model training and improvements, unless customers opt out (OpenAI, n.d.). User content submitted via OpenAI API keys is not used for model training by default, and customers have to opt-in. User submitted data is also retained by OpenAI for customers using the free-tier ChatGPT plan, whereas it is retained for 30 days if they are using the paid tier plans or the API key. Anthropic’s data policy notes that they do not use customer data to train their models for both API and web-based interfaces, unless customers opt in (Anthropic, n.d.). We should assume that any data shared through prompts—even when using API keys—could become immediately visible to LLM providers. Furthermore, sharing sensitive information or research data with these providers would likely not be permitted by researchers’ own institutions or by granting agencies unless there are specific agreements in place. Therefore, researchers need to be careful to avoid including actual data or protected information in their prompts. In the examples presented in this paper, we showed that researchers do not need to share actual data with LLMs to generate statistical code.
Another concern involves copyright considerations when using RAG approaches. Several high-profile copyright infringement cases against LLM developers have drawn attention to debates around copyright law and generative AI development, especially around what constitutes fair use (Buick, 2025; Lucchi, 2024; Madigan, 2025). For example, the New York Times (NYT) claims that OpenAI and Microsoft infringed on copyrights when they trained their LLMs with material owned by the NYT (Pope, 2024). AI companies, on the other hand, claim exceptions to copyright law, arguing that generative AI is for a transformative purpose which constitutes fair use (Madigan, 2025). They also claim that web scrapping of publicly available information is based on well-established precedent (Klosek & Blumenthal, 2024). Debates around generative AI development and copyright infringement are complicated by an increasing lack of transparency from LLM developers on their training sources (Buick, 2025). In their lawsuit, the NYT casts OpenAI as a “multibillion for-profit business built on large part on the unlicensed exploitation of copyrighted works” (Pope, 2024, para. 5). On the other hand, if LLM training were restricted to works solely in the public domain, they would be outdated and not representative of current culture and society, making them less relevant and useful (Buick, 2025; Klosek & Blumenthal, 2024). Restricting LLM development on the basis of copyright protection would also limit LLM development to a few large companies that can afford licencing fees (Lucchi, 2024).
While the outcomes of these lawsuits will have enormous ramifications for generative AI and copyright law (Buick, 2025), they are largely centered on initial model training and development. There is less clarity and awareness on the legal and ethical boundaries around user-submitted copyrighted materials via chat interfaces or through RAG. The use of copyrighted material in RAG without explicit permission from the copyright holder raises the question of whether it constitutes fair use (U.S. Copyright Office, n.d.). While transformative use and non-commercial, scholarly research are highly favorable criteria, fair use is a nuanced topic involving case-by-case ethical and legal judgements (Stim, 2019; Zirpoli, 2025). It is the responsibility of researchers to respect and be cautious about copyright law; researchers should implement necessary safeguards to ensure that copyrighted materials uploaded for RAG are not used for unauthorized purposes.
Working with API Keys and integrating RAG systems into their workflows can help researchers safeguard against directly uploading copyrighted material, which may then be used for further model training. As noted earlier, OpenAI and Anthropic data-use policies offer some safeguards for user uploaded content through API keys; however, the data might still be retained for a certain period. In this paper, we showed an example of conducting RAG with the Mplus user guide, which is a copyrighted work. We want to emphasize that this example was for demonstration purposes only and we obtained permission from the authors for using their content for this specific use case.
A safer alternative is using open-source, locally downloaded LLMs that can run on researchers’ own computers or using secure computing resources provided by their institutions. While these models tend to be much smaller (tens of billions versus hundreds of billions of parameters) with correspondingly lower performance compared to commercial alternatives, techniques like RAG can enhance their capabilities. We include a demonstration in our ICPSR repository materials to show how a locally downloaded, open-source LLM can replicate the results we achieved with GPT-4o for generating statistical code. With this approach, researchers can safely input protected data and copyrighted information that they already have legitimate access to, provided the model remains securely hosted. Another advantage with using local LLM models is that they can be trained further or fine-tuned using parameter efficient methods that train only a subset of all the parameters. For example, a model could be fine-tuned on the Mplus user guide to become highly specialized in that knowledge domain and function as a researcher’s Mplus code guide or assistant. While these smaller models may struggle with broad, general-purpose tasks, they can perform remarkably well on narrowly defined, specialized tasks (Hu et al., 2021; Zhou et al., 2023).
Discussion
In this paper, we sought to showcase LLM capabilities for generating statistical code to assist with quantitative research in education research. We also presented prompt engineering strategies focusing on few-shot learning and RAG to reduce LLM hallucinations and generate accurate statistical code. More broadly, we introduced several fundamental concepts in applied LLM research that can assist end users to have more productive interactions with LLMs to act as a useful assistant or collaborative partner to conduct quantitative research. As an illustrative example, we replicated the statistical procedures from a previously published study on school organization (Moon et al., 2022). This replication shows that a user’s statistical proficiency and domain knowledge are crucial to work with LLMs, consistent with observations from previous work (Huang et al., 2024; Titus, 2023). They are important for correctly guiding LLMs with appropriate contextual knowledge and assessing the quality of LLM output.
Our findings that demonstrate that LLMs can enhance the efficiency of quantitative analysis workflows, but ultimately rely on human judgement and evaluation, align with the HCAI framework’s first premise, which balances high levels of human control and automation (Shneiderman, 2020). The process we’ve outlined here—where the researcher maintains final authority over evaluating the quality of LLM output—emphasizes efficiency gains that can be achieved without sacrificing critical oversight. This approach also supports the HCAI framework’s second premise: empowering people by providing them with technologies that support their abilities and raise their self-efficacy (Shneiderman, 2020). Our focus is deliberately narrow; we do not explore scenarios where LLMs might be used without expert human oversight. Indeed, the third premise of the HCAI framework specifically calls for robust governance structures with more human involvement. For educational research, this might involve professional organizations like the American Educational Research Association developing specific tenets, guidelines, and policies around LLM use for generating code, analyzing data, and other aspects of the research process. Another governance component could involve more stringent requirements for researchers to make their data, code, analytical procedures, and results publicly available for peer verification and oversight.
Overall, LLMs can be an effective tool for researchers to analyze quantitative data more efficiently compared to using traditional software alone. LLMs facilitate this process in several ways: (i) They generate syntactically correct analytical code based on their training data, thus providing a useful starting point for statistical programming that can be especially helpful for novice researchers and analysts; (ii) they use a natural conversation style of interaction to iteratively develop and implement simple to sophisticated analytical models; (iii) they allow switching between programming languages and different statistical methods as needed and enabling the efficient organization of research workflows; (iv) they easily accommodate code modifications and corrections, for example, including, or excluding variables and adapting to new information (e.g., data clustering); (v) they can generate suggestions for applying sophisticated analytical procedures while explaining the procedures and interpreting the model results correctly; and (vi) they can accommodate updated contextual information through augmented prompts, or RAG.
We stressed here the advantages of working with API keys in a programming environment instead of using web-based chatbots that have been developed for the general public. It is possible that many of the strategies shown here could also work with web chatbots. For example, at the time of writing the first draft of the paper, it was not possible to upload files to ChatGPT. RAG has now been integrated into ChatGPT, enhancing the model’s ability to interact with user-provided documents. However, despite these advancements, working with API keys offers several advantages including: (i) finer-grain control over LLM behavior and outputs; (ii) ability to develop more complex workflows including the flexibility to work with a variety of LLM models; and (iii) greater customization and finer-grain control in integrating RAG, using various document loaders and embeddings models to enhance prompts. Further, they permit easier integration with the emerging Reasoning and Acting (ReAct) framework that constructs agents out of LLMs that are prompted to generate a thought/output, reflect on its output, think out loud, and use available tools or functions to interact with the external world. For example, the ReAct framework applied to our case study would not only generate statistical code but also reflect on the generated code, implement dynamic RAG using tools such as web searches, conduct self-corrections, and also execute the code if it has access to the data and has code execution permissions. While tool-use and agent-based applications are continually being developed and integrated into web-based interfaces, they remain more limited and less customizable compared to the extensive capabilities available through programming environments and API keys.
Last, we also discussed the advantages of working with local open-source LLM models that can allow researchers to work safely with protected data and copyrighted materials. However, these benefits come with some trade-offs in terms of increased computational requirements, lower model performance, and additional technical expertise for model deployment and maintenance.
Limitations and Future Research
This paper demonstrated the use of LLMs in the later stages of quantitative data analysis, thereby limiting the illustration of a wider range of LLM applications, such as in the preliminary data cleaning, data organization, and preparation processes, which are often time-consuming. The SLSA datasets used in this paper had already undergone data cleaning and pre-processing. Researchers often devote much effort in initial data preparation; for example, preparation of the SLSA datasets required merging of several datasets on schools, students, and teachers, and cleaning and restructuring the data. These processes are often complex and require a deep understanding of specific dataset structures and keen analytical proficiency. A follow-up or companion paper can focus on using LLMs for the entire analytical process, including the data preparation stage, such as the merging and organization of multiple data sources.
Next, we only explored a few important prompt engineering methods. Prompt engineering is a rapidly evolving field, and additional methods such as chain-of-thought prompting, self-consistency, prompt chaining, and tree of thoughts (see DAIR.AI, 2024) could be explored in the context of generating statistical code in future papers.
While our approach relies on expert review as the final arbiter of code quality and accuracy, there are opportunities to enhance upstream processes. For instance, researchers could task different LLM models with generating parallel code implementations with different statistical software packages (e.g., in Mplus, R, and SAS) to verify consistency of results across platforms before human review. Additionally, LLMs could be prompted to self-critique their code, identify potential weaknesses, and suggest improvements, prior to human evaluation. These intermediate verification steps could potentially streamline the human review process while maintaining the essential role of expert oversight.
We acknowledge that LLM use and AI development are associated with a much broader range of ethical, legal, and privacy issues that extend well beyond the scope of this paper. However, it is important to briefly introduce some of the emerging concerns for researchers that highlight the importance of adopting an HCAI framework. First, when programming tasks are repeatedly delegated to LLMs, there is a risk of metacognitive laziness or skill atrophy, as observed in prior writing experiments (Fan et al., 2025; Niloy et al., 2024). While LLM use may improve short-term performance, prior research suggests that underlying competencies can stagnate or even deteriorate (Fan et al., 2025; Niloy et al., 2024). Thus, it is crucial for even experienced researchers to intentionally adopt metacognitive strategies such as evaluating LLM outputs, monitoring LLM workflows, understanding tool use and outputs, and adopting deliberate strategies to maintain and advance their coding skills. Second, viewing programming as a mundane task and routinely offloading it to LLMs may, in the long run, negatively affect the development pipeline of emerging researchers (Bechky & Davis, 2025). Like other research skills, programming often involves an apprenticeship model, where students or novice researchers work closely under the mentorship of experienced researchers. Delegating this developmental stage completely to LLMs risks weakening the formation of technical expertise within the academic community (Bechky & Davis, 2025). Finally, while this paper is limited to the application of code generation within the HCAI framework, there are alternate approaches that favor more autonomy or delegate the entire research process to LLMs (Ifargan et al., 2025). LLMs have been shown capable of producing reliable research papers, even for complex problems with minimal human input (Ifargan et al., 2025). These developments raise critical questions related to the possibility of exponentially increasing volumes of LLM generated research, the cultivation of research skills, and the nature of scientific inquiry itself (Bechky & Davis, 2025; Messeri & Crockett, 2024). Another concern is epistemic drift (Bender et al., 2021; Obiefuna, 2025), wherein systems of AI-generated research also reviewed by AI systems may gradually become increasingly untethered from experiential reality. The human-in-the-loop approach serves as a critical safeguard ensuring that AI-assisted research remains grounded in human experience and subject to human verification.
The responsible development and deployment of AI in research contexts is a substantial topic that falls outside our current focus; it is worth briefly noting that frameworks such as Bowers’ (2021) Four As provide valuable guidance for researchers utilizing advanced technologies. This framework emphasizes that AI-assisted research outputs should be Accurate, the algorithms should be Accessible and understandable, findings should be Actionable, and the entire process should be Accountable with careful consideration of potential biases. These principles offer a starting point for researchers seeking to integrate LLMs into their workflows while maintaining research integrity and ethical standards.
The use of LLMs in academic analysis is still in its infancy, not only for quantitative data but also for qualitative data and systematic reviews. In an academy that values analytical rigor, it is understandable to be cautious about using LLMs when accuracy, validity, and appropriateness are not yet assured. As this paper shows, researchers can use LLMs as a supplement to their own expertise, and as a coding partner or assistant. As more advanced models become available in the future, LLMs are likely to further cement their position as important partners to researchers in the entire research process. We hope that this paper has contributed an initial discussion on the use of LLMs for supporting quantitative analysis for social science research.
Supplemental Material
sj-docx-1-ero-10.1177_23328584251389621 – Supplemental material for Enhancing Quantitative Analysis in Social Sciences With Large Language Models (LLMs): A Methodological Case Study in Educational Research
Supplemental material, sj-docx-1-ero-10.1177_23328584251389621 for Enhancing Quantitative Analysis in Social Sciences With Large Language Models (LLMs): A Methodological Case Study in Educational Research by James Sebastian, Jeong-Mi Moon and Eric Camburn in AERA Open
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Open Practices
The data and analysis files for this article can be found at http://doi.org/10.3886/E237744V3.
Notes
Authors
JAMES SEBASTIAN is a researcher in the College of Education & Human Development at the University of Missouri-Columbia, 118 Hill Hall, Columbia, MO, United States, 65211; email:
JEONG-MI MOON is a collegiate professor in the Department of Energy Engineering at the Korea Institute of Energy Technology, 21 Kentech-gil, Naju-si, Jeollanam-do, South Korea, 58330; email:
ERIC CAMBURN is the Sherman Family Foundation Endowed Chair and Director of the Urban Education Research Center, and a professor in the School of Education, Social Work and Psychological Sciences at the University of Missouri-Kansas City, Volker Campus 615 E. 52nd Street, Kansas City, MO, United States, 64110; email:
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.