
Abstract
In this article we discuss the importance of data sharing in education and psychological research, emphasizing the historical context of data sharing, the current open-science movement, and the so-called replication crisis. We additionally explore the barriers to data sharing, particularly the fear of incorrectly deidentifying data or accidentally including private information. We then highlight the importance of deidentifying data for data sharing. Finally, we present specific techniques for data deidentification, namely nonperturbative and perturbative methods, and make recommendations for which techniques are relevant for specific types of variables. To assist readers in implementing the material from this study, we have additionally created an interactive tutorial as a Shiny web application that is publicly available and free to use.
Keywords
Introduction
Data sharing has become increasingly important in the field of education research as the demand for transparency, collaboration, and rigor in scientific inquiry has grown (Borgman, 2012; Institute for Education Sciences, 2024; National Institutes of Health, 2023). Despite the growing recognition of the importance of data sharing for education research, many researchers still do not openly share their data (Fleming et al., 2024; Logan et al., 2025; Makel et al., 2021). A lack of knowledge and resources regarding how and where to share data can contribute to this reluctance, with many researchers being uncertain on the appropriate repositories, platforms, or formats for sharing their data as well as how to ensure proper documentation and metadata for effective reuse (Kim & Adler, 2015; White et al., 2024). To foster a culture of open science and support researchers in sharing their data, it is vital to provide researchers with adequate guidance, training, and support in data-sharing practices as well as addressing concerns related to privacy, intellectual property, and research integrity (Leonelli, 2014).This article aims to provide an overview of the significance of quantitative data sharing in education research, the barriers to data sharing, and the importance of deidentifying data and provide a discussion of the basic techniques used to deidentify data while preserving their usefulness and integrity. Additionally, we highlight the limitations of work currently in the field and identify several areas of future direction that are needed to create standardized recommendations for data sharing in our field. As such, this paper serves as a comprehensive guide to deidentifying data for data sharing and a tutorial for implementing these techniques in the education field. We also contribute to creating more standardized practices for data deidentification and address the need for additional research on the topic.
Open-Science Movement: Data Sharing
The history of data sharing in education and psychological research dates back to the early days of the scientific method, where researchers openly discussed their findings and exchanged data to facilitate new discoveries (David, 2008). However, as the field grew and became more competitive, a culture of secrecy emerged, with researchers often withholding data to protect their intellectual property and research funding (Nosek et al., 2012). This culture of secrecy in many cases has hampered data sharing, with reported rates of data sharing in the education and psychology fields being as low 3% (Kidwell et al., 2016). More recent work examining data-sharing practices in the education sciences specifically found that 71% of researchers rated themselves as having low or no knowledge of data sharing and finding that roughly 80–90% of respondents had never engaged in data sharing (Fleming et al., 2024; Logan et al., 2025; Makel et al., 2021). Moreover, a significant portion of collected data in general goes unused or is underused, with those being shared often going unused due to a variety of reasons. This can include a lack of discoverability, inadequate documentation, or insufficient compatibility with other data sources (Wallis et al., 2013). To address this, the open-science movement emerged, with advocates arguing that sharing data, methods, and findings can foster collaboration, accelerate the pace of scientific discovery, and increase the reliability and reproducibility of research results (Fleming et al., 2021; Munafo et al., 2017; Nielsen, 2012).
The idea of open science and public data sharing generally has gained traction in recent years (Leonelli, 2014), leading to an increase in transparency and accessibility of research data that has produced numerous replication studies and a better understanding of the robustness and generalizability of many prior research findings (Open Science Collaboration, 2015). However, the potential benefits of sharing data extend beyond just replication. Data sharing for secondary data reuse of new research questions creates more opportunities to better explore and develop evidence-based practices, increases the diversity of viewpoints and researcher expertise of who is using any given dataset, and offers an opportunity for researchers from less resourced or disadvantaged backgrounds or those who are early in their career to access and use high-quality data (Logan et al., 2021). For the field of education specifically, this also offers new opportunities for generating insights that can influence policy recommendations and future practices as well as offering opportunities for further collaboration between schools and researchers (van Dijk et al., 2020).
Deidentification as a Barrier to Data Sharing
Despite the benefits to the field, current rates of data sharing in the field of education and psychological science are currently low (Fleming et al., 2024; Makel et al., 2021). One significant barrier for researchers in the education sciences is a concern about ensuring data privacy; researchers in the field of education cite this as a major barrier to data sharing at nearly twice the rates of those in other research areas (Beaudry et al., 2022; Logan et al., 2025). Deidentifying data refers to the process of removing or modifying personally identifiable information from datasets, ensuring the protection of individual privacy (Sweeney, 2002), and is essential for ethical data sharing (Cook et al., 2022; Meyer, 2018). As researchers share data, it is essential to safeguard the privacy and confidentiality of research participants (El Emam & Dankar, 2012). From the fields of law and bioethics, we know that researchers are often worried about the risks associated with the reidentification of deidentified data, which may lead to potential breaches of confidentiality (Ohm, 2010; Rothstein, 2010). Specifically, researchers may worry that their efforts to deidentify data could be insufficient, leading to potential privacy breaches and legal or ethical consequences (El Emam & Arbuckle, 2013). This fear may be particularly pronounced in the context of education research, where data related to students, teachers, and schools are often involved (Sweeney, 2002). This fear may contribute to a reluctance to share data, even when researchers recognize the benefits of data sharing in terms of transparency, collaboration, and scientific progress. Furthermore, researchers may lack the expertise, resources, or time to properly deidentify data while maintaining their integrity, which could further deter them from openly sharing their datasets (Kim & Adler, 2015).
Additionally, the legal environment surrounding this is constantly evolving and inconsistent across institutions. For researchers in the European Union, the General Data Protection Regulation is the guiding policy related to this, but for those in the United States and elsewhere, policies are often determined at state or other locality levels. For the United States specifically, the California Consumer Privacy Act, the Virginia Consumer Data Protection Act, and other state-level policies all establish various guidance and regulations on a state-by-state basis. The presence of such policies, combined with already existing fears related to data privacy and deidentification, can more strongly position data deidentification as a barrier to data sharing, further emphasizing the need for researchers to feel confident in their own ability to deidentify data. This is further exacerbated by specific restrictions and guidelines within these policies, such as the right to erasure, where participants are able to request that their identifiable information be destroyed, that take this a step further.
Accurate deidentification of data not only complies with ethical guidelines and legal requirements but also fosters trust in the research community and encourages participation in research studies (Meyer, 2018; Ohm, 2010). As such, ensuring that participants’ data are protected and their privacy maintained can alleviate concerns about potential misuse of personal information, which may otherwise deter individuals from participating in research (Bates et al., 2016; Nebeker et al., 2015). This trust is particularly important in the fields of education and psychology, where sensitive data may be collected, and the success of research projects often depends on participants’ willingness to share personal information. Additionally, proper deidentification mitigates the possibility of reidentification of data, ensuring proper privacy and protections.
Data Deidentification Considerations
FERPA and HIPAA Regulations
When thinking about standards for deidentifying data, most U.S.-based researchers, especially in the areas of psychology and education, immediately think of data privacy as it relates to the Family Educational Rights and Privacy Act (FERPA) and the Health Insurance Portability and Accountability Act (HIPAA). These acts are two crucial regulations that govern the protection of personal information in education- and health-related research, respectively (Solove, 2013). FERPA safeguards students’ privacy by regulating the disclosure of educational records, whereas HIPAA sets standards for protecting patients’ health information. FERPA and HIPAA have been instrumental in providing a regulatory framework for protecting the privacy of students and patients, respectively, by regulating access to their personal information and setting guidelines for data handling (U.S. Department of Education, 2025; U.S. Department of Health and Human Services, 2025). These legislations have played a crucial role in raising awareness about the importance of data privacy and establishing a baseline for data-protection practices.
However, some critics argue that these regulations may not always be effective in ensuring data privacy in all situations. For example, Solove (2013) argued that FERPA might be too vague in certain areas, leading to inconsistent interpretations and applications across institutions. Similarly, Hodge et al. (2020) claimed that HIPAA, while effective in some respects, may not fully address the complexities and challenges posed by rapidly evolving health technologies and the expanding volume of health data being generated. This is additionally becoming more of an issue in the field of education, with very large datasets being used at an increasing rate that can be tied to publicly available datasets. As such, FERPA and HIPAA provide a good framework for thinking about deidentifying data but unfortunately fall short in many areas.
Direct Identifiers Versus Indirect Identifiers
The primary area where FERPA and HIPAA fall short is in the deidentification of indirect or quasi-identifiers compared with direct identifiers. Direct identifiers are pieces of information that can explicitly identify an individual, such as names, social security numbers, and addresses (El Emam et al., 2011). These are the primary types of identifying variables that are addressed in FERPA and HIPAA and even can include other information such as geographic location or date of birth. In contrast, indirect identifiers, also known as quasi-identifiers, are data points that, when combined with other information, can potentially identify an individual (Sweeney, 2002). Examples of indirect identifiers include age, gender, race/ethnicity, socioeconomic status, and ZIP code. For example, there may be publicly available data on a school with all direct identifiers already removed (e.g., a school directory or publicly available school composition data) that can be combined with a dataset containing information on that school. If there are a limited number of students identifying as a specific race/ethnicity and gender (e.g., only one student identifying as female and Asian or Pacific Islander), it is possible that that student can be reidentified using only the publicly available data and the data with all direct identifiers removed. Again, in this scenario, all directly identifying information has already been removed, but the presence of indirect identifiers combined with publicly available data makes reidentification possible. As such, effective deidentification requires careful consideration and handling of both direct and indirect identifiers to minimize the risk of reidentification.
Specific Data Deidentification Techniques
We now focus on highlighting specific data deidentification techniques as well as recommendations for when it is appropriate to use these specific techniques. These techniques can be broadly classified into two categories: nonperturbative and perturbative methods.
Nonperturbative Methods
Nonperturbative methods are a class of data deidentification methods that focus on removing or masking data points without altering their values. Nonperturbative methods offer several strengths, including ease of use and preservation of the original data’s structure (Duncan & Lambert, 1986; El Emam et al., 2011). Nonperturbative methods also have some weaknesses. One weakness is that they may not effectively address indirect identifiers, leaving the dataset still vulnerable to reidentification attacks (Sweeney, 2002), including the potential risk of indirect identifiers when combined with external information (El Emam et al., 2011). Additionally, nonperturbative methods can distort the data by reducing the level of information provided, which could impact the utility and validity of the data for subsequent analyses (Duncan & Lambert, 1986; Duncan et al., 2011; Hundepool et al., 2012).
Suppression of Data
The first nonperturbative method, suppression, also called record suppression, involves removing specific data cases (i.e., a participant record) that have potential for reidentification (see Table 1). Suppression as a deidentification method is particularly useful when the risk of reidentification is high for specific data records, often due to unique or rare combinations of variables that could be linked to external information or in the presence of significant outliers (Willenborg & De Waal, 2001). In such instances, removing entire cases of data can help protect the privacy of the individuals involved while maintaining the overall usefulness of the dataset (El Emam et al., 2011). Suppression should be used judiciously because excessive suppression can lead to loss of valuable information and potentially introduce bias into the dataset (Duncan & Lambert, 1986). Suppression can be used when either categorical variables cause issues (when it makes sense to remove the case rather than collapsing across other categories) or when continuous data are problematic (when data can be linked with public data or in the presence of outliers). To conduct data suppression, a researcher needs only identify the cases that are at the greatest risk for reidentification and drop them from the dataset.
Data before and after deidentification via suppression


Note. Problematic cases are shaded.
Researchers can identify cases for suppression in their data by assessing the uniqueness or rarity of the attribute combinations, also called crosstabs, present across the observations in the dataset (Willenborg & De Waal, 2001). Unusual combinations of variables can make an individual more easily identifiable when comparing them with publicly available data sources, thereby increasing the risk of reidentification (Gkoulalas-Divanis & Loukides, 2013). For example, in a dataset containing information about students, a combination of variables such as age, race/ethnicity, and disability status may make a certain student easily identifiable within a school setting. Researchers can use statistical measures, such as the k-anonymity criterion, which evaluates the number of records sharing the same set of attributes (Sweeney, 2002), to ensure that there are at least k records with identical attribute combinations, suppressing cases that fall into bins not meeting the necessary k-anonymity threshold (Gkoulalas-Divanis & Loukides, 2013; Willenborg & De Waal, 2001). One specific method we recommend for assessing appropriate levels of k-anonymity is the 85/5 rule (Schatschneider et al., 2021), which takes into consideration the minimum bin sizes and the proportion of the overall population represented by the sample. The 85/5 rule establishes that for datasets where a significantly large portion of the smallest identifiable sampling frame is present (85%) or when public data are available on the predictors of interest, all crosstabs of indirect identifiers should have a minimum of five cases. That is, if the smallest identifiable sampling frame for a study consists of a specific school district (e.g., the district around a university that commonly supports research and is named in a study), researchers should ensure that the dataset contains less than 85% of the students from the identifiable schools in that district. With larger identifiable sampling frames, this is less of an issue, such as if the schools themselves are not named, allowing for any school in a given state or country to be part of the smallest identifiable sampling frame. As a brief aside, researchers should consider limiting their description, or naming, of their sampling frame in their study materials and publications because this will help protect them from this limitation of the possible sampling frame that makes their participants easier to identify.
Beyond the 85/5 rule, it is important to carefully consider the degree of recoding applied to the data because excessive generalization can lead to a loss of information and negatively impact the validity of subsequent analyses, again highlighting the importance of balancing data privacy and data integrity (Willenborg & De Waal, 2001). We recommend the use of this method in instances where a few cases provide significant reidentification issues and recommend this primarily for categorical variables but note its potential applicability for continuous variables as well and exemplify this here using the continuous measure of age. This approach is visualized in Table 1, showing the removal of the problematic case ID number 5, whose age made them a unique and potentially reidentifiable case because they are the only individual in the dataset younger than 18 years of age, posing a potential reidentification issue.
Anonymization and Dropping Variables
In contrast to suppression, which removes individual cases, anonymization techniques consider the removal of entire variables from a dataset and are particularly useful for direct identifiers (Sweeney, 2002). Direct identifiers, such as names, addresses, and social security numbers, or any of the other HIPAA 18 (Ness, 2007), can be easily linked to an individual and pose a significant risk to privacy if not removed from the dataset (El Emam et al., 2011). In cases where these variables do not hold significant value for the research analysis or when their presence could lead to reidentification, it is advisable to remove them entirely from the dataset to ensure the privacy of participants (Sweeney, 2002; Willenborg & De Waal, 2001). To do this, one needs only to drop the variables that significantly increase the likelihood of reidentification and/or are not relevant to the research at hand. We recommend this method primarily for the removal of direct identifiers, although this approach also can be taken for problematic indirect identifiers, where the prior referenced methods are not able to adequately deidentify these data and where retaining this information is unessential for the study. For example, a study may include multiple measures of socioeconomic status, reporting father and mother education. If the father’s education and its crosstabs with other indirect identifiers are unable to be deidentified appropriately, researchers may decide that the presence of the mother’s education is sufficient and rather than ensuring that crosstabs with father’s education are deidentified may instead opt to drop the father’s education in its entirety. This method is illustrated in Table 2, showing the dropping of the “Name” variable, which classifies as a direct identifier.
Data before and after deidentification via anonymization


Note. Problematic cases are shaded.
Recoding
The next nonperturbative method for deidentifying data is that of recoding data or condensing groups. This technique involves condensing or combining categories of a variable to create broader groups, reducing the granularity of the data and mitigating the risk of reidentification (Willenborg & De Waal, 2001). For example, a dataset containing race/ethnicity categories (e.g., White, Black, Asian, etc.) could be recoded simply into White and minoritized students if other selected races contain very few cases to decrease the likelihood of identifying individuals based on their unique race/ethnicity in the dataset. When deciding whether to apply recoding, it is important to consider both the univariate bin sizes (i.e., within one variable, the distribution of responses) and additionally the multivariate bin sizes, sometimes also called crosstabs (i.e., looking at the intersection of race/ethnicity, socioeconomic status, and gender). We again encourage researchers to apply this method when an appropriate level of k-anonymity fails to be reached or by using the 85/5 rule (Schatschneider et al., 2021). That is, small bin and crosstab sizes potentially can lead to reidentification, but small bin sizes do not always necessarily mean that reidentification is possible. That is, small bin sizes are problematic when the sample comprises a large percentage of the smallest identifiable sampling frame or when outside information that can be tied to the dataset is available. We recommend considering the 85/5 rule here and additionally conducting an online search for the presence of such external data (e.g., yearbooks, school rosters, etc.) that may increase the risk associated with this. It is also important, however, to consider the possibility that new external information may exist down the road, which is important to consider as well. Further, it is important to carefully consider the degree of recoding applied to the data because excessive recoding can lead to a loss of information and negatively impact the validity of subsequent analyses (Willenborg & De Waal, 2001). To apply this method, one simply needs to recode categorical variables with small bins such that the smaller bins are condensed into larger groups until a minimum crosstab of five is reached. We recommend this method for use with categorical indirect identifiers, particularly in cases where small bin sizes exist. Table 3 illustrates this, highlighting the use of recoding to increase the minimum bin size of crosstabs between parent education levels and race variables. This shows a two-step process whereby race was recoded first and education was subsequently recoded following this.
Data deidentification via recoding
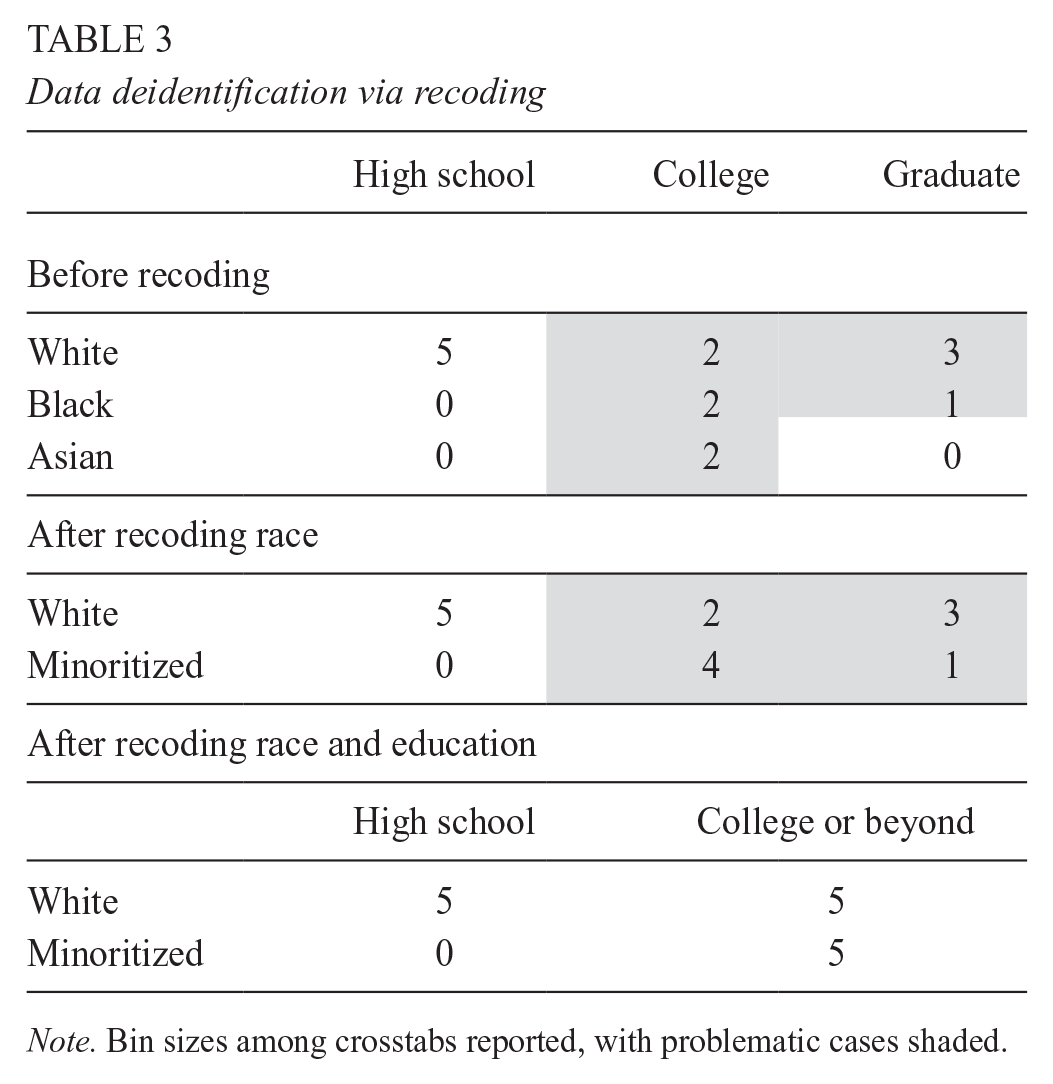

Note. Bin sizes among crosstabs reported, with problematic cases shaded.
Top/Bottom Coding and Rounding
The next two sets of nonperturbative techniques are highly related to one another, with top/bottom coding applying primarily to outlier data and rounding applying to data throughout the distribution. Both methods work by directly altering the scale on which the data are transformed, with top/bottom coding establishing a new floor and/or ceiling value and rounding changing the level of unit at which the variable is assessed. For example, income data, especially when considering parents/families who may have jobs with posted salaries (e.g., government and university employees), can be a potentially identifiable variable. Using top/bottom coding (see Table 4), one can control for any outliers that may have significantly high or low incomes by setting those outlier values to an established ceiling or floor value. The specific ceiling and floor values used can be derived in a variety of ways, applying the same methods commonly used to treat outliers, such as “bringing of data to the fence” (i.e., setting outliers equal to the specific upper or lower threshold for outliers) or using theoretical values as established ceilings/floors. This restriction of the range of possible values removes the possibility that outliers are reidentified. Carrying the same example forward, if data on salaries are publicly available, then having income data with a high level of granularity significantly increases the likelihood of reidentification. To counter this, one can recode the data to present granularity only down to the thousands place (e.g. transforming an income of $11,257 to $11,000), thereby removing the direct link between the income and the publicly available data. That is, with access to a public salary database, we can directly link an individual when a high level of granularity exists, but removing this granularity through rounding removes the one-to-one correspondence between the values in the dataset and the values in the publicly available database. We recommend using this method for continuous indirect identifiers when either a significant portion of the population is represented or when public data are available.
Data deidentification via top/bottom coding


Note. Problematic cases shaded. Minimum value of $50,000 and maximum value of $150,000 used.
Aggregation
The final nonperturbative method we discuss is aggregation. Aggregation is a technique where individual data points are amalgamated to generate summary statistics (Dalenius, 1977). This is beneficial when the individual data points are sensitive but the summary statistics are not. For instance, aggregating test scores to derive an average score for a group of students is a common practice. Moreover, aggregation can be employed to formulate totals, ranges, and other summary metrics that furnish valuable insights into the data while preserving privacy. This method can be applied to either categorical variables (when it is plausible to aggregate data across different categories) or continuous data (when data can be summarized without a risk of reidentification). Through data aggregation, researchers can disseminate the outcomes of their analyses without revealing sensitive information concerning individual participants (Dwork et al., 2006). This is paramount in education research, where data often encapsulate sensitive details about students, such as their academic achievements, socioeconomic status, and other personal information. Caution is noted, though, because excessive aggregation can lead to a loss of valuable information and potentially introduce bias into the dataset.
Researchers should aim to employ data aggregation when the sharing of individual data cannot be done without posing a risk to reidentification and should aim to provide as much information as possible related to the dataset while minimizing the potential risk of reidentification associated with the individual data points (Duncan & Lambert, 1986). For example, in a dataset containing information about students, aggregating variables such as test scores by class or grade level can help prevent the identification of individual students. This example may be useful when publicly available data exist that can be used to link to the individual participant data but researchers are still interested in exploring subgroup associations and trends across classrooms. Although not as useful as sharing the individual data themselves, the shared aggregated data still can be used to generate useful insights about the data and still can be analyzed using a variety of techniques such a summary statistics–based structural equation modeling.
Perturbative Methods
Perturbative methods represent the other class of data deidentification methods that involve modifying the original data to protect privacy and include data swapping, adding noise, and microaggregation, among others (Domingo-Ferrer & Torra, 2001; Dwork, 2006; El Emam et al., 2011). Perturbative methods offer several strengths, providing an alternative to the nonperturbative methods that may reduce the level of information available. Instead, perturbative methods aim to maintain as much information and granularity as possible while still ensuring that cases are not identifiable. These methods come with their own weaknesses, however, the primary one being that perturbing the data changes the values of the data themselves and may alter the observed associations and downstream results of analyses. These methods involve modifying the original data to create plausible uncertainty while preserving overall data utility (El Emam et al., 2011; Hundepool et al., 2012) and are useful for both categorical and continuous data and can be applied to both direct and indirect identifiers. That is, one distinction between the nonperturbative and perturbative methods is that whereas nonperturbative approaches aim to make reidentification impossible, perturbative methods may allow for reidentification but do so in a way that any reidentification of individuals results in the incorrect individuals being reidentified. The exception to this is jitter/adding noise, which through altering the values themselves makes reidentification via said variables theoretically impossible. Again, given the perturbative nature of altering the data themselves, these methods are recommended only after attempts to deidentify data via nonperturbative methods have already occurred. For most situations, the nonperturbative approaches already covered will be more appropriate and relevant.
Adding Noise or Jittering
Adding noise or jittering variables works by introducing small amounts of random variations to the original values in the dataset (Dwork, 2006; El Emam et al., 2011). This perturbative technique preserves the overall structure and patterns of the data while reducing the risk of reidentification by preventing an exact match with the original values (Drechsler, 2011). For example, using our example of income or another sensitive variable, age, adding small amounts of random noise can help obscure the true values while maintaining the overall distribution and relationships between variables (Dwork, 2006). That is, adding a small amount of noise to our hypothetical case with an income of $11,527 may result in a new value of $11,613. The value is still like the original value, preserves rank order to a large degree, and does so without drastically altering the interrelations among variables. To do this, there are several existing functions within statistical software programs that can be used to add random amounts of noise or jitter the data. In contrast, researchers also can opt to simulate random errors by hand and then adding these errors to their datapoints, giving the researcher more control over the level of noise/jitter that takes place. Although these techniques can effectively protect participant privacy, it is important to carefully balance the amount of noise or jitter added to minimize the impact it has on the data and to ensure that the utility of the data for analysis is preserved (Drechsler, 2011). We recommend applying this method to continuous indirect identifiers.
Rank Swapping or the Post-Randomization Method
The next set of perturbative methods that can be used consists of rank swapping and the post-randomization method, two techniques used to deidentify data by altering the original values of continuous and categorical predictors, respectively. Rank swapping is a perturbation method used to protect the privacy of continuous data by swapping the values of cases within a predefined range (Dalenius & Reiss, 1982; Willenborg & De Waal, 2001). In this technique, records are first sorted based on the variable of interest, and then the values are swapped between pairs of records that closely match one another based on this ranking. This method preserves the overall distribution and relationships between variables but drastically reduces the risk of reidentification by making it so that if there is any reidentification based on a variable value, it is not tied to the correct participant. In other words, reidentifying data will appear to be successful but in reality will have incorrectly identified the cases (Dalenius & Reiss, 1982).
The post-randomization method (PRaM) is a technique applied to categorical variables that involves perturbing the original values by replacing them with new values based on a specified probability matrix (Kooiman et al., 1997; Templ et al., 2011). In PRaM, each category of a variable is replaced by another category according to the probabilities in the matrix, which introduces a controlled level of uncertainty while preserving the overall structure of the data. This approach is like rank swapping, with the primary difference being that PRaM can be used to swap or replace cases for categorical variables instead of continuous variables. For both methods, it is important to consider the necessity and level of swapping that occurs, again considering the risk of reidentification by specific variables.
Shuffling
The next technique is shuffling, which is similar to rank swapping for continuous variables, but rather than using the variable ranks to conduct the swapping, the researcher uses a regression model. That is, researchers can specify the relations they wish to prioritize in their dataset by specifying a regression model and then applying shuffling to swap cases with similar predicted values. Doing so preserves the integrity of the data, with particular attention paid to preserving the given set of relations specified in the regression model. As such, this method may be preferred over rank swapping, although it is very important to consider the variables selected in the underlying regression model. In many ways, this process is similar to data imputation for missing data, where auxiliary variables are selected on which we want our imputation based, and the associations that we would like to ensure are preserved following the imputation. In the same way, selecting the appropriate variables that will allow for this process to be done reliably while maintaining the associations we care most about is an important component of using this approach. As such, employing intentional and well-informed variable selection is very important if these methods are to be conducted appropriately. Selecting an inappropriate set of variables or overperturbing the data may lead to excessive distortion, causing biased estimates and loss of information, which could change the entire structure of the data and affect the validity of subsequent analyses (Domingo-Ferrer & Torra, 2001; El Emam et al., 2011; Templ et al., 2014; Willenborg & De Waal, 2001).
Microaggregation
The final method is microaggregating, or blurring the data. This approach works by ranking the cases for a given variable, followed by partitioning those cases into small groups based on rank, and finally replacing the values falling into each group with an aggregate value for said group (Domínguez & Torra, 2001; Morehouse et al., 2023). By doing this, microaggregating the data ensures that an individual’s data are indistinguishable from the data in their smaller group and removes the level of granularity necessary for reidentifying the data (Nin et al., 2008). The group size used for microaggregation can specified as long as the group has two or more individuals. This technique is very useful for deidentifying data where publicly available data that can be linked exist. Returning to our income example, microaggregation can help reduce the likelihood of reidentification by removing the granularity of the income levels and by ensuring that the reidentification at best can occur at a group level. In terms of perturbative methods, this method tends to distort the data less than rank swapping, PRaM, and shuffling and is encouraged for deidentification of continuous indirect identifiers after attempts at applying less perturbative methods failed to adequately deidentify the data.
A summary table describing all the included methods and the level of caution to be had when employing those methods is presented in Table 5. Specifically, we recommend that researchers begin with the nonperturbative approaches when deidentifying their data because these approaches focus on using recoding and varying versions of the same data rather than altering the data themselves, which can help to better ensure that the accuracy and integrity of the data are preserved. We recommend the perturbative measures as a last-ditch approach or to be used when prioritizing important aspects such as replication efforts may not be possible using the less invasive nonperturbative approaches. Beyond this paper, we provide a tutorial where researchers can learn and practice applying these techniques using an R statistical environment (https://jeffreyshero.shinyapps.io/DataDeidentificationTutorial/) . We also recommend reading a recent study that describes reidentification risk and anonymity thresholds and provides a decision tree for assessing said risk (Morehouse et al., 2023). In contrast to their study and materials, which focus largely on assessing risk and applying blurring techniques, we instead focus on a more expansive set of techniques available to researchers. With that said, we recommend that researchers draw from both studies to get a more comprehensive understanding of the risk associated with their data and the many techniques and approaches available to handle those risks. Lastly, we would like to highlight the book, Statistical disclosure control for microdata (Benschop & Welch, 2023), which contains a plethora of information and code on these topics that were useful in developing this paper.
Summary of data deidentification methods

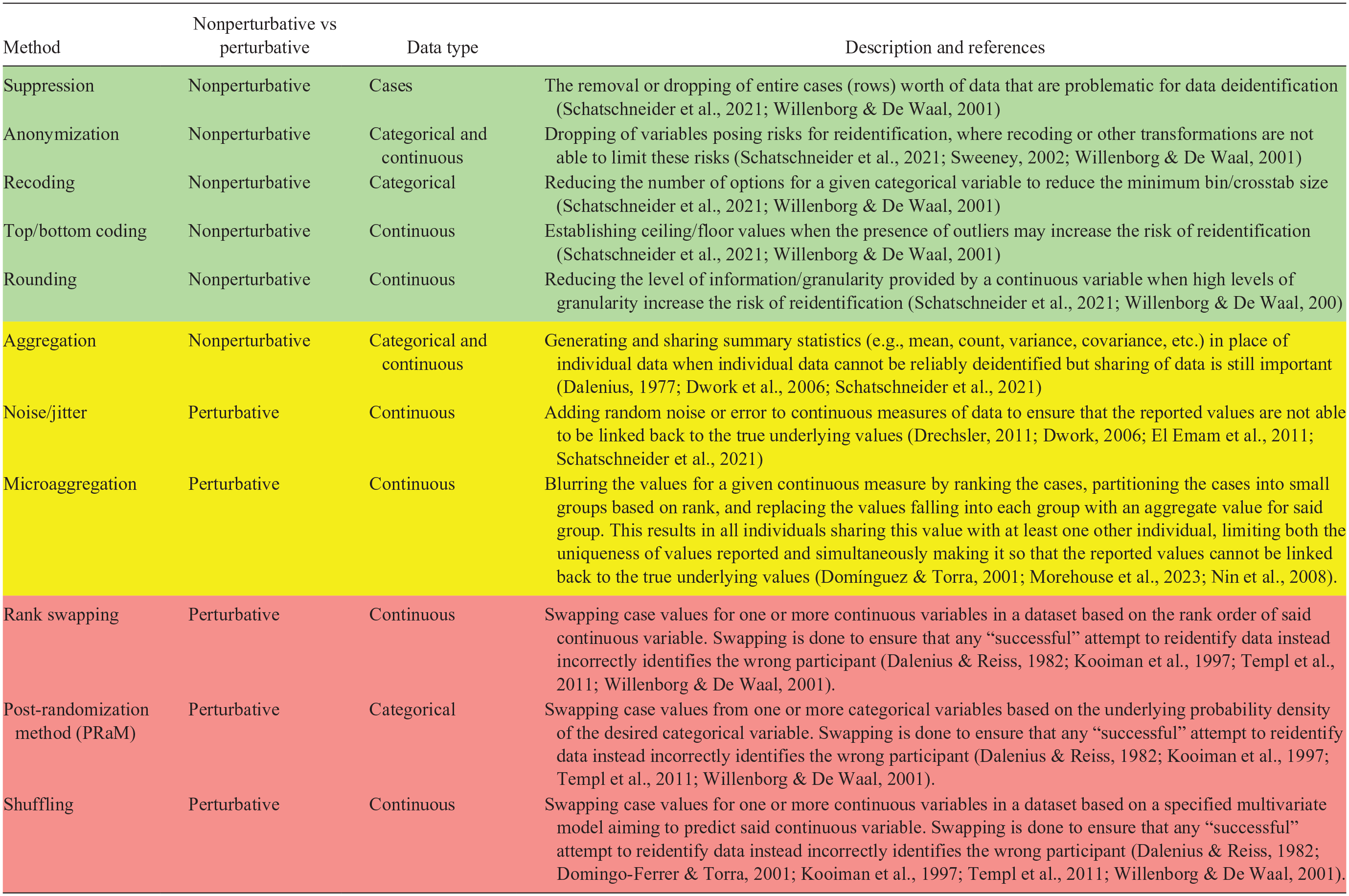
Note. Methods are presented in order related to the level of caution that should be employed when using them and the potential tradeoff in information loss and decrease in accuracy with ensuring privacy. These are additionally color-coded to highlight methods requiring low (green), medium (yellow), or high (red) levels of caution when employed.
Discussion
The primary purpose of this article and the accompanying tutorial was to provide education researchers with an overview of deidentification techniques, providing some guidance on how and when to implement these techniques. However, given the recency in changes to data-sharing requirements and practices broadly, there are still many questions about data deidentification that remain. We conclude with a discussion on the current limitations of best practices of data identification and lay out future studies that are necessary to create more evidence-based standardized recommendations.
Remaining Questions and Future Directions
Despite data sharing being required by many granting agencies, there is a distinct lack of recommended or standardized practices for conducting deidentification of data prior to public sharing. Although this paper attempts to address this gap, we are limited in the extent to which we can do so given the limited body of work currently available. One significant limitation is the lack of work on the impact of various deidentification techniques as it relates to data reuse for replication. One challenge for deidentifying and sharing data is in striking a balance between data deidentification and preserving data integrity. This is a complex task that researchers must navigate to ensure both participant privacy and the utility of the shared data (El Emam & Dankar, 2008; Ohm, 2010). Robust data deidentification techniques may remove or transform data in ways that can affect the accuracy, generalizability, and interpretability of the dataset (Duncan et al., 2011). For instance, data aggregation or blurring may reduce the level of information in the data, in turn limiting the potential for detailed analyses. Excessive deidentification also could hinder the discovery of meaningful patterns or relationships within the data, ultimately diminishing the value of the shared dataset for future research and limiting its potential for replicability (El Emam & Dankar, 2008; Rothstein, 2010). Beyond preserving the integrity of the data, balancing data deidentification and the beneficence of the work is equally important because researchers must consider the potential benefits of their study against potential risks to participants’ privacy (Loukides et al., 2010; Vayena et al., 2015). Researchers should assess the sensitivity of the data, the potential harm that may arise from reidentification, and the likelihood of such an event occurring when determining the appropriate level of deidentification (McDonald, 2019). Further, researchers should take into consideration the purpose of data sharing and the simultaneous reuse of data for strict replication efforts versus reusing data to generate new insights. As of now, there is no clear guidance on which of these is more important, and in turn, the value placed on replication versus reuse is largely up to the researcher sharing the data themselves. Future research is needed to explore this idea more directly.
Further, questions of when to deidentify data, such as deidentifying data prior to the main analyses versus after the analyses but before the data are shared, are also important to consider but lack empirical work. On the one hand, deidentifying data prior to the original analyses can help ensure that the data shared and used for analyses are consistent, allowing for more accurate replication of the original analyses. On the other hand, this limits the amount of information available and could be viewed as unnecessarily reducing the data prior to analysis. This further calls into question what the true purpose of data sharing is, whether it is for ensuring data replication, allowing new insights into the data, or simply making data that were collected using tax dollars available to the public. More direct work on these questions and implications is necessary before research can provide more standardized practices and recommendations.
Similarly, another issue with limited empirical work is the implications of partially shared data as they relates to data reuse and replication efforts. That is, as data are suppressed or altered in the name of privacy prior to sharing, it results in a dataset that is only shared in part. A similar concern could arise if study participants are included in a primary study but choose to opt out of data sharing (e.g., de Man et al., 2023). This leads to different sets of data being used for the original published analyses compared with what will be shared. We have been internally referring to this concept as postanalytic attrition. At this stage, given the lack of empirical research, we recommend clear and transparent reporting of the practices used when deidentifying data and the decisions made surrounding the timing and specific techniques for doing so. That is, highlighting any changes in the supporting data documentation (e.g., data dictionaries, codebooks, data guides, etc.) will help outside researchers using the data best understand the data themselves and why discrepancies may arise between original analyses and attempts at analytic replication. Further, this will best equip researchers reusing the data with the knowledge needed as they attempt to reuse the data in other ways and the limitations in the data that may result because of data deidentification procedures. However, we reiterate that empirical work exploring this and higher-level conversations surrounding the true purpose of data sharing are still greatly needed.
Although this study focused on supporting researchers in sharing their more traditionally collected data in a public format via data repositories, we also would like to mention the existence of other processes and work focused on data privacy and reuse, such as data-enclave and data-mining approaches. Unlike sharing data via an open repository, data enclaves leverage secure and controlled environments where sensitive or confidential data can be accessed and analyzed by researchers, typically without the data ever being directly accessible to the researchers themselves (Baker & Hutt, 2025; Plale et al., 2019). Another distinct difference here is that rather than being open to the public, data enclaves typically require researchers aiming to use the data to be vetted or undergo a screening process, whereas open data sharing does not (Plale et al., 2019). Whether researchers choose to share their data via an open repository or leverage an existing data enclave is largely up to the researchers themselves and their institution as well as the granting agency from which the funds for data collection were obtained. We recommend that researchers who are interested can explore this option further. SafeInsights is a National Science Foundation–funded education-specific option (National Science Foundation, 2023).
The final area for future research that we address here is the need for treating qualitative and free-text response data differently from quantitative data because sharing qualitative data comes with its own barriers and techniques for data deidentification (Campbell et al., 2023; Makel et al., 2025; Mannheimer et al., 2018; Mozersky et al., 2021). Understanding how to deidentify qualitative data alongside quantitative data is a question that we believe warrants its own future studies. Very often researchers in education collect both quantitative and qualitative data, and balancing these two distinct types of data, their privacy, and their reuse is extremely important.
Conclusion
Data sharing in the education and psychological research fields is critical for promoting transparency and collaboration and is essential for moving the open-science movement forward. Ensuring the protection of individual privacy through deidentification is an essential aspect of ethical and responsible data sharing and is an area that requires better training in research programs to ensure that it is adequately and consistently conducted. This paper and its associated supplemental materials serve as guides for helping researchers deidentify data, with specific examples of code available to apply the data deidentification techniques discussed within. Overall, researchers must be thoughtful about the approaches they take to deidentify data and must balance concerns of data integrity and utility. We hope that this paper and guide not only will encourage researchers to engage in open-science and data-sharing practices but also will further increase their ability and comfort level in doing so.
Footnotes
Declaration of Conflicting Interests
The authors declare no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work was supported by Eunice Kennedy Shriver National Institute of Child Health and Human Development Grants R01HD095193, P50HD052120, R01HD11053, and R25HD114368; by the Office of Special Education Programs (Grant H325D180086) at the U.S. Department of Education, and, in part, by the Canada Excellence Research Chairs Program. Views expressed herein are those of the authors and have neither been reviewed nor approved by the granting agencies.
Note: This manuscript was accepted under the editorial team of Kara S. Finnigan, Editor in Chief.
Authors
JEFFREY. A. SHERO is a postdoctoral scholar at Vanderbilt University. His research focuses on the development and application of advanced quantitative research methodologies and designs to explore inequities and the etiology of developmental outcomes such as academic, cognitive, and mental health outcomes. His research also focuses on topics related to data sharing and open science more broadly.
ALEXIS E. SWANZ is a doctoral student at Vanderbilt University. Her research focuses on how children develop mathematical skills and the cognitive factors that support math achievement as well as research design, measurement, and quantitative methods for improving the rigor and reproducibility of research in education and developmental science.
ALLYSON L. HANSON is a PhD student at Vanderbilt University. Her work focuses on how to better identify children with and at risk for reading disabilities using innovative quantitative methods and engaging with the meta-scientific foundations of reading research.
SARA A. HART is a professor at the University of Waterloo. Her research focuses on using twin methodologies to explore the etiology of individual differences in cognitive development. She also focuses largely on topics related to data sharing and open science more broadly.
JESSICA A. R. LOGAN is a professor at Vanderbilt University. Her research focuses on the development and application of advanced quantitative research methodologies and designs to explore topics in special education. Her research also focuses on topics related to data sharing and open science more broadly.