
Abstract
Secondary analysis of qualitative data entails reusing data created from previous research projects for new purposes. Reuse provides an opportunity to study the raw materials of past research projects to gain methodological and substantive insights. In the past decade, use of the approach has grown rapidly in the United Kingdom to become sufficiently accepted that it must now be regarded as mainstream. Several factors explain this growth: the open data movement, research funders’ and publishers’ policies supporting data sharing, and researchers seeing benefits from sharing resources, including data. Another factor enabling qualitative data reuse has been improved services and infrastructure that facilitate access to thousands of data collections. The UK Data Service is an example of a well-established facility; more recent has been the proliferation of repositories being established within universities. This article will provide evidence of the growth of data reuse in the United Kingdom and in Finland by presenting both data and case studies of reuse that illustrate the breadth and diversity of this maturing research method. We use two distinct data sources that quantify the scale, types, and trends of reuse of qualitative data: (a) downloads of archived data collections held at data repositories and (b) publication citations. Although the focus of this article is on the United Kingdom, some discussion of the international environment is provided, together with data and examples of reuse at the Finnish Social Science Data Archive. The conclusion summarizes the major findings, including some conjectures regarding what makes qualitative data attractive for reuse and sharing.
Reusing Qualitative Data Becomes Accepted
It has now been more than two decades since the founding of the United Kingdom’s Qualidata, one of the earliest initiatives in the world to archive social science qualitative data and make them available for reuse on a national scale (Corti, 2000). Qualidata paved the way for others, eventually integrating with the UK Data Archive (UKDA), part of the larger UK Data Service, which now disseminates nearly 1,000 qualitative and mixed-methods data sets, more than half of which are available through the Service’s more recently established self-archiving system, ReShare (reshare.ukdataservice.ac.uk).
The period from 2000 has seen a boom in both the drivers of data sharing and the development of human and material capability to do so. Research funders are increasingly mandating easy or open access to research data and data management plans to ensure maximum quality, sustainability, accessibility, and openness of research data. Publishers of academic findings demand that the supporting data can be accessed for scrutiny or further exploration. Governments internationally are demanding transparency in research, and the economic climate makes it desirable for much greater reuse of data to maximize the return on science investments (Corti, Van den Eynden, Bishop, & Woollard, 2014).
In parallel with the promotion of, and support for data sharing, there are also indicators of growing acceptance of secondary analysis of qualitative data as a recognized methodology. The UK National Centre for Research Methods publishes a vocabulary of categories of research methods in the social sciences. First published in 2004, it listed the term “secondary analysis” with no sub-categories (Beissel-Durrant, 2004). By 2015, the entry for secondary analysis had numerous sub-classifications: archival research, documentary research, analysis of official statistics, analysis of existing survey data, analysis of administrative data, and last (but surely with no imputation of being least) analysis of secondary qualitative data (Luff, Byatt, & Martin, 2015).
The methodology is also appearing more frequently in methods textbooks. One of the earliest examples is by Corti and Thompson (2004) in Seale et al.’s Sage Publications compendium, Qualitative Research Practice, with an updated version that appeared in 2011. Another best-selling textbook for qualitative research, David Silverman’s Qualitative Research, first published a chapter on reuse of qualitative data by Clive Seale in 2011 (Seale, 2011). The presence of an entirely new chapter in the fourth edition gives yet more support to the claim that qualitative secondary analysis has become an established and recognized research method (Bishop, 2016).
In this article, we highlight recent changes in data sharing policies and infrastructures in the United Kingdom that have facilitated sharing of qualitative data. Then we present a variety of forms of evidence about the scale, nature, and growth in the practice of data reuse. The final sections of the article discuss recent case studies of research using secondary analysis. We conclude that, despite some limitations on the available evidence, there are strong indications of growing reuse of data.
A Brief History of Data Sharing: Policies and Infrastructure
The development of policies and infrastructure to support the reuse of qualitative data has gone hand-in-hand with the development of an ethos of data sharing; both are necessary if data are to be made available for sharing and valued as a resource for reuse.
Policies
The process of enabling data sharing has developed in a wide variety of ways when viewed comparatively across Europe. This was shown clearly by Ruusalepp (2008) who comprehensively reviewed developments across the 30 countries of the Organisation for Economic Cooperation and Development (OECD). He showed that organizations such as the OECD, UNESCO, European Strategy Forum on Research Infrastructures (ESFRI), and The Committee on Data for Science and Technology (CODATA) had policies that promoted or recommended data sharing, and that these policies influenced the development of numerous UK organizations (e.g., Office of Science and Innovation [e-Infrastructure], Jisc Strategy 2007-2009, and the Research Information Network’s Strategic Plan). These policies stopped short of recommending mandatory data sharing.
To date, there are no unified national policies across the countries of the OECD that mandate data sharing in this way, although there is an increase in requirements for “data management plans,” which ask researchers to take into account data sharing and curation, most notably in 2011 by the Research Councils UK and by the National Science Foundation in the United States. The European Commission Horizon 2020 program of funding ran a pilot project requiring data management plans to be submitted alongside applications (European Commission, 2013). The ethos of data sharing is strongly endorsed within these policies and is beginning to have a discernible impact at the organizational level.
Dating back to the 1970s, the United Kingdom’s Economic and Social Research Council or its predecessor has had a research data policy that has required all award holders to offer their quantitative data to be formally archived. In 1995, qualitative data were added to this mandate, and similar obligations continued in the 2010 and 2015 policies (Economic and Social Research Council, 2015b). The Council’s recently revised Framework for Research Ethics notes that ethical considerations apply to data archiving, sharing, linking, and reuse, as well as data collection and research publication (Economic and Social Research Council, 2015a).
Although other public research funders have published similar policies, a milestone was the adoption of the Common Principles on Data Policy adopted by all research councils in 2011 (Research Councils UK, 2011). A subsequent Policy on Access to Research Outputs (Research Councils UK, 2012) required funded peer-reviewed research papers to be published in journals that are compliant with the Policy on Open Access, and to include a statement on how the underlying research materials such as data, samples, or models can be accessed. Across UK higher education institutions, 55% of research is funded by the research councils, an annual investment of about £3 billion, and thus such policies strongly influence research practices (Higher Education Statistics Agency, 2012).
Data Sharing Infrastructure
A further important influence on data sharing has been the willingness of UK funders to underwrite projects that are fully or partially engaged in making data available for sharing. In the realm of infrastructure for qualitative data, these include continuing support for the UK Data Service, including bringing in enhanced user services such as QualiBank, a system for online searching and browsing of qualitative data (UK Data Service, 2013), and funding for a major qualitative longitudinal data repository as part of the Timescapes project, housed at the University of Leeds (Timescapes Repository, 2015). And, around the world, national funding agencies have begun to support national pilots for qualitative data sharing. However, investment is typically cautious and for fixed periods of time, thus making the long-term sustainability of an archive somewhat precarious.
As recently as 2011, Corti reported that only two European countries, that are part of the broader Council of European Social Science Data Archives (CESSDA), the United Kingdom and Finland, had “mature infrastructures” for qualitative data sharing. Since then, there has been progress with several other European archives that were initially established for quantitative data now accepting qualitative data as well (e.g.,Swiss Foundation for Research in Social Sciences [FORS], GESIS - Leibniz Institute for the Social Sciences in Germany, Norwegian Centre for Research Data [NSD], and Social Science Data Archives [ADP] in Slovenia). Elsewhere in Europe, specialist research centers are storing and making their data collections available. QualiService, at the University of Bremen, focuses on life course interviews and methods and has short-term support from the central German research funder, DFG (QualiService, 2016). A new facility in Poland, the Archives of Qualitative Data at the Institute of Philosophy and Sociology in the Polish Academy of Sciences, opened in 2013. Other successful infrastructure developments include the integration of the Irish Qualitative Data Archive into the national Digital Repository of Ireland, housing a whole spectrum of social and cultural Irish data. Neale and Bishop (2010-2011) provide a summary of the state of play of a selection of European qualitative archives as they were in 2010.
Developments extend beyond Europe as well. In the United States, the long-standing Henry A. Murray Centre, which holds data on the life course, is housed at Harvard University. A newly founded Qualitative Data Repository, supported by the U.S. National Science Foundation (NSF), is hosted by the Center for Qualitative and Multi-Method Inquiry, a unit of the Maxwell School of Citizenship and Public Affairs at Syracuse University. The repository’s initial emphasis is on political science, but it already has plans to cover social sciences more broadly (Qualitative Data Repository, 2015). In Australia, Research Data Australia holds a small but growing number of qualitative data sets, and the Inter-University Consortium for Political and Social Research data archive at the University of Michigan has recently begun holding some qualitative data as well.
Scale of Collections
The UK Data Service currently holds nearly 1,000 qualitative and mixed-methods collections that are accessible from the catalogue (UK Data Service, 2016). The Finnish Social Science Data Archive (FSD) began archiving qualitative data in 2003, and over the following 12 years, as many as 177 qualitative data sets have been deposited. A new longitudinal Finnish project will collect data from 100 young people over the next 10 years. Inspired by the Timescapes Project, the Finnish researchers aim to conduct their project in close cooperation with Timescapes and to deposit all the data collected during the project.
In other cases, however, the amounts of data being handled within the archives are typically quite small, some dozens of collections at the most, and the staff time available for the processing of qualitative data is often limited. In Germany, GESIS, which curates predominantly quantitative data, also holds 64 qualitative collections. QualiService, the repository for life course research located in Bremen, holds 14 collections, but each one is large, with the total number of interviews greater than 1,730. The social science data archives in Switzerland and Slovenia each holds fewer than 10 qualitative and mixed collections, although, again, a single collection may contain up to 200 qualitative interviews.
This summary of the current situation for data sharing policies and infrastructures is, inevitably, partial. There are initiatives in many other countries, albeit these are typically small-scale and very modestly funded. Although the changes may not be happening with blinding speed, there does seem to be a reasonable pace of steady growth.
Measuring Reuse of Data
It can be challenging to quantify and measure the reuse of data, but there have been many recent advances, partly driven by funders’ requirements to measure impact from research. Ball and Duke (2015) discuss many recent innovations in measuring data use as part of the effort to measure research impact. Metrics currently in use include citations of specific data collections, resolutions to a unique persistent identifier (such as a Digital Object Identifier, or DOI), page views of a web site where a data catalogue record is rendered, and downloads of the data (the user transfers a copy of the data set from a repository to another location). Additional exploratory measures are being used, such as tracking mentions on social media. Commercial metrics services are proliferating in this area as well, the best known being the Thomson–Reuters Data Citation Index, which displays the number of times a data set has been cited in the Web of Science.
Ball and Duke acknowledge limitations of such efforts: Some measurements are very noisy, duplications are not always controlled, and—as with almost any metric—the system can be gamed. This applies equally when attempting to measure use of qualitative data. At the UK Data Service, all users are asked to fully cite data they use in any publications, and every data collection record contains a block of citation text, ready to copy and paste, including a DOI. However, in practice, many authors use partial or non-standard citations, or worse, fail to cite data at all. As a result, it remains a costly manual process to obtain detailed information about reuse. In time, encouragement to cite data using DOIs that can be easily found through a web search will help automate some of this counting work (Farquhar & Brase, 2014).
In this article, we use two distinct data sources that quantify the scale, types, and trends of reuse of qualitative data: (a) downloads of data collections held at two data repositories and (b) publication citations. The first measure is the frequency and nature of downloads of qualitative data from the UK Data Service and FSD, and the second is citations of publications that have used or discussed secondary analysis of qualitative data. Although these sources have their limitations, each one provides new and useful knowledge about the reuse of qualitative data, particularly in light of the dearth of empirical information and the measurement difficulties identified above.
Measuring Data Reuse Using Information From Data Downloads
UK Data Service
The source of data for this research was based on information collected by the UK Data Service whenever a data collection from the main curated collection is downloaded. (This analysis updates and improves a previous study of similar data conducted in 2014 [Bishop, 2014].) We began by establishing the number of data collections for which information on access was available. Collections categorized as either qualitative or mixed were included across the period, 2002-2016. There were 444 curated collections in scope, which excludes more than 500 that have become more recently available (from 2011) via the ReShare self-deposit system. Of these 444, 40% (177) have never been downloaded. In a few cases, data were not accessible to users for reasons of embargo or because data had been withdrawn, but most collections were available but had just not been accessed. The remaining 60% (267) had been downloaded at least once, and these 267 collections are the source for the following analysis.
After establishing the number of collections, we then had to define and count “unique downloads” of each collection. Uniqueness in this case is defined as a specific user accessing data for a specific preregistered project. The sample that we investigated is based on 7,155 unique downloads of 267 possible data collections. For each download, additional information was available from details that users provide when they register with the UK Data Service: user affiliation, user discipline, and a brief (30-word minimum) description of the specific project for which the data were downloaded. When data are provided as open access with no user registration required, then measurement of a download is no longer possible in this manner. However, prior to 2013, almost no qualitative collections were available as open data.
The maximum number of times a single collection was downloaded was 366, with a mean of 13 and median of 27. In this analysis, and as shown in Table 1, 40% (108) of the collections were used 1 to 10 times, 54% (144) were used 11 to 100 times, and 6% (15) were used more than 100 times. It is thus the case that a modest proportion of collections received the heaviest usage; similar usage patterns have been found for use of quantitative data at the UK Data Service.
Qualitative and Mixed-Methods Collections by Number of Times Downloaded, 2002-2016, UK Data Service.

Figure 1 presents the breakdown of who uses data. Overall, 42% of the downloads were by postgraduate students, 25% by undergraduates, and 27% by staff members at institutions of higher education. The remaining 6% comprised other staff, other students, people using data for personal or genealogical research, and commercial users.

Downloaded data by type of user, 2002-2016, UK Data Service.
Next, the reuse projects were classified into several broad categories of depending on the purposes for which the data were being used: research, teaching, and learning. To qualify as research, the project description had to include sufficient detail to suggest a plausible research project. PhD projects were automatically included in research unless the description specified that the data were being used only for exploratory purposes, that is, for learning. “Learning” projects typically mentioned that the data were being used to complete an assignment; all master’s and undergraduate projects were classified as learning. A project was categorized as teaching if that purpose was mentioned. The majority of the teaching projects involved the teaching of qualitative research methods. In the cases where we were not able to differentiate, we used the category Teaching/Learning and assigned the category partly based on the type of user (educational staff or student).
Figure 2 shows that 15% (1,073) of the downloads were used for research, 13% (957) for teaching, and the significant majority, 64% (4,559) were for learning. The remaining 8% were either miscellaneous uses or unclassifiable due to insufficient information in the project descriptions.
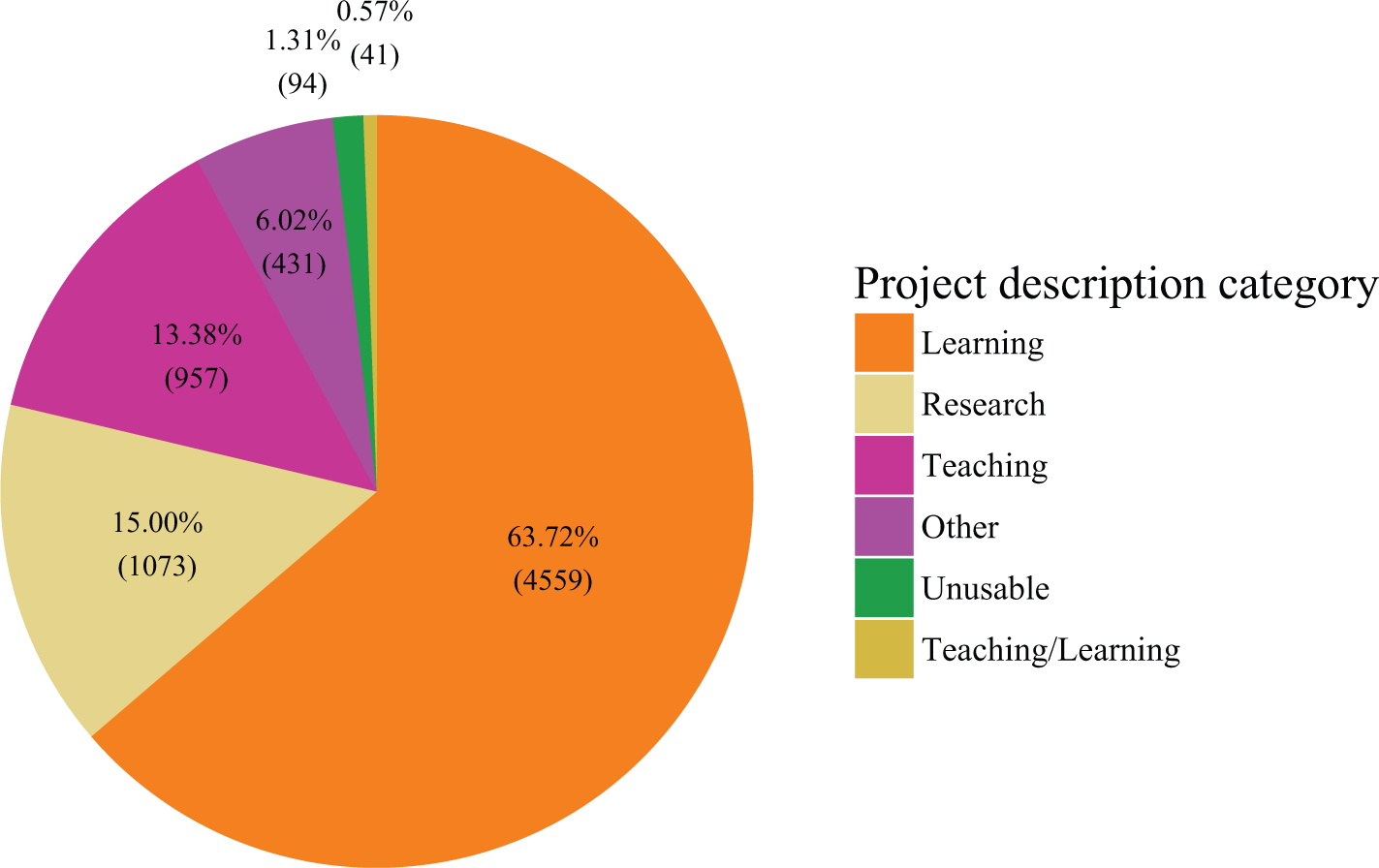
Reuse purposes of qualitative data downloaded from UK Data Service during the period 2002-2016.
In addition to the broad pattern of teaching and learning use, we are also able to say a bit more about the breakdown between undergraduates and postgraduates within each group (see Tables 2 and 3). For teaching, the share of postgraduate-level teaching was somewhat higher than for undergraduate teaching (32% vs. 23%). Nearly half of the observations could not be classified into either category. However, for learning, a quite substantial majority (58%) were postgraduates compared with 39% of the learning uses reported by undergraduates. Given that much of the teaching use was for courses in research methods, and these are more common at the postgraduate level, this finding is not surprising, but does add useful detail as well as suggest possible opportunities to expand the reuse of data for undergraduate teaching.
Learning Use—Breakdown by Undergraduates and Postgraduates.

Teaching Use—Breakdown by Undergraduates and Postgraduates.

For any archive, it is important to understand what it is that makes a collection a good candidate for reuse. This study looked for patterns in the characteristics of the collections that are being reused most often. The list of most used collections (see Table 4) is highly varied, making patterns hard to ascertain, but some features clearly stood out. Mixed-methods collections and collections with multiple types of data are used, perhaps because of the convenience of learning about several genres of data within one study. Topics tended to be current and to be relevant for policy debates, for example, crime, gender, social exclusion, and food. In addition, some collections not in the top five but still highly ranked might be seen to appeal to a younger generation of students: youth into adult transitions, youth crime, and cannabis use. However, in addition to specific focused studies, oral histories covering a breadth of topics are also used heavily.
Most Frequently Downloaded Qualitative and Mixed-Methods Data Collections, 2002-2016, UK Data Service.

Note: SN indicates “Study Number” at the UK Data Service.
We believe the key finding from this research is the scale and significance of the reuse of data for teaching and learning. Although there is sometimes a tendency to privilege data reuse for research, the widespread use across several levels of education is clearly enriching teaching by the use of real data. This is certainly consistent with recommendations from several higher education authorities regarding the importance and value to learners of research-led teaching (Blair, 2015). In some project descriptions, methods teachers noted that their students learned qualitative methods best if they were able to use actual data that matched their interests. In her project description, one instructor wrote, “Real interview data is effective in engaging student interest.” It would seem that being engaged with the specific topics the data describe is more effective at motivating students to learn methodology than working with generic or artificial data. Our analysis revealed another finding: Active promotion of a study, by either a particular faculty member or by the UK Data Service, dramatically increases the use of its data. We can see this effect when teachers repeatedly assign students to use data they have generated for teaching, which we know has happened for several of the most frequently used collections, notably the highest ranked collection on gender and crime (Hollway & Jefferson, 2003).
Teachers, especially recent PhDs, have the benefit of expertise in their subject area, but often, they will not have had the time or opportunity to build a broad repertoire of materials with which they are well acquainted and make them available for teaching. Archives are perfectly suited to filling that gap. (See Haaker & Morgan Brett, 2016, in this issue, for a more extensive treatment of reusing data for teaching.) This is a need that data centers are ideally positioned to meet. Archives can offer a wide range of types of data from diverse methods of qualitative research. In addition, archives are able to promote their distinctive holdings through teaching resources.
The challenge in developing appealing teaching resources is, as always, the time, effort, and cost to produce them. However, even smaller data centers have used this strategy successfully, and often, a strategy of co-production with data creators can be deployed. The Irish Qualitative Data Archive (2015) produced a series of learning resources based on archived data from the Life Histories and Social Change Project. The resources consist of guided introductions to key sociological concepts, such as social class, using audio and text extracts from life history interviews. In a second example, Mass Observation is a key historical resource of popular accounts of everyday life in the United Kingdom produced by a panel of recorders who respond to thematic directives (e.g., life under austerity). A variety of learning activities are supported, for example, English teachers in higher and further education use its resources for inspiration for creative writing or performance (Mass Observation Archive, 2015). All these examples demonstrate that providing archived data to teachers enables innovations in substantive and methods instruction. Although requiring an investment, there are two obvious benefits for archives: Usage numbers for the promoted data will rise, and a next generation of researchers will learn to see reuse of qualitative data as a routine and normal part of their methods training. This would be a significant accomplishment.
Finnish Data Service
The FDS is usefully compared with the UK Data Service because it has held qualitative data for more than a decade and collects similar usage statistics. Since 2007, there have been between 70 and 95 requests for qualitative data sets annually from FSD, and after launching the online data service “Aila” in mid-2014, the number of reusers of qualitative data sets increased (Finnish Social Science Data Archive, 2016). In 2015, there were 323 downloads of qualitative data sets, and over the 18 months period since the launch, 550 unique reuse projects were identified: 41% (224) for undergraduate study, 28% (155) for master’s theses, 20% (108) for teaching, and 11% (63) for research, as shown in Figure 3. The categories used are somewhat different from those used by the UK Data Service; however, the pattern of a significant majority of reuse for teaching and learning holds in both countries. The higher figure for research in the United Kingdom (15% vs. 11% in Finland) may be due to including PhD work in research in the United Kingdom.
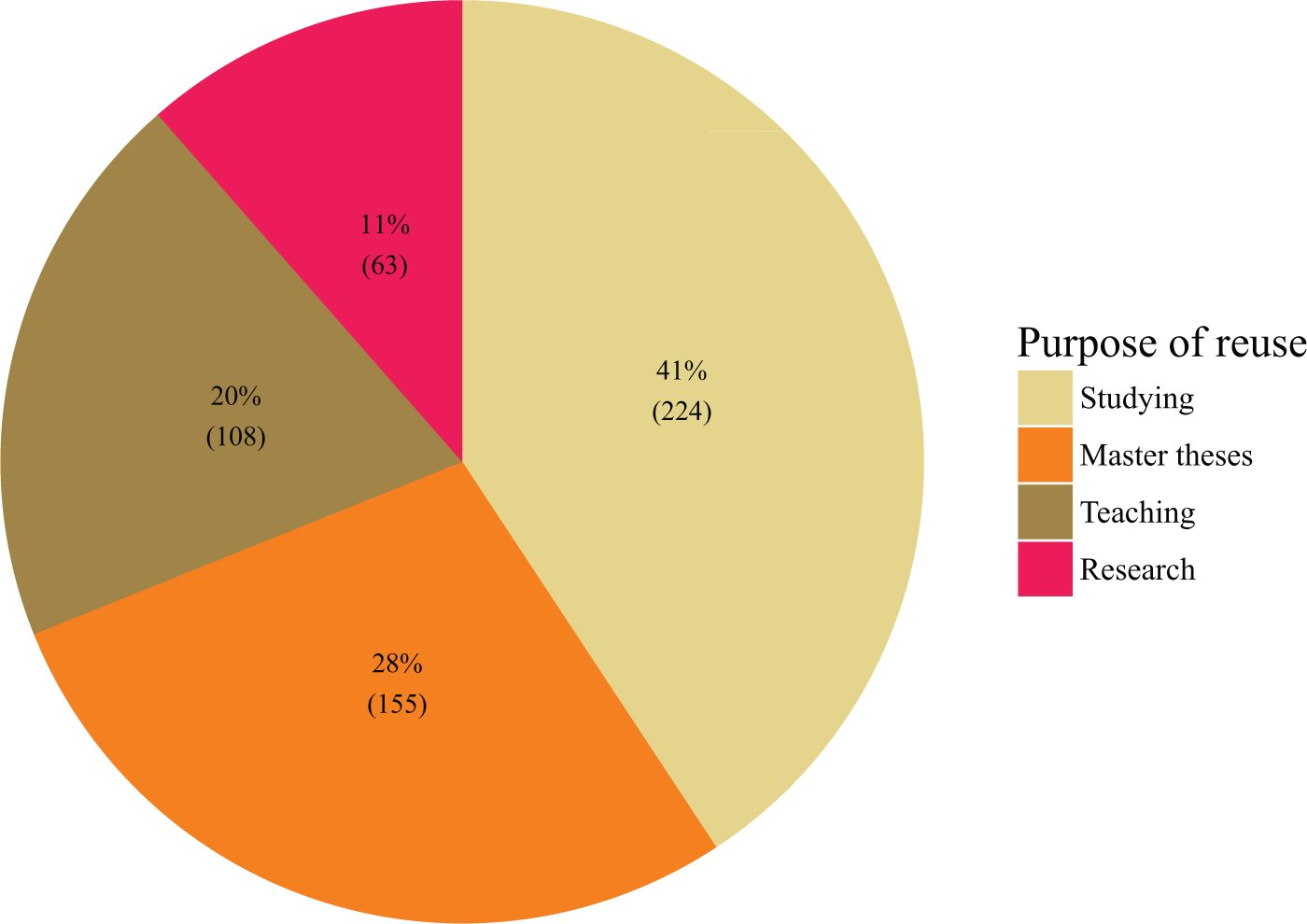
Reuse purposes of qualitative data downloaded during the period May 2014 to February 2016, FSD Aila data portal.
Reuse of archived qualitative data in Finland for teaching and studying makes up more than 60% of all applications for data. Finnish methods teachers usually want to demonstrate different kinds of analytical methods and a variety of research questions to students by using a single data collection, with teachers themselves often selecting a sample from an archived data set. Students using the data archive’s resources often write their masters theses based solely on archived qualitative data sets. Compared with collecting their own data for the theses, using archived data has the advantage of allowing students to spend significantly more time on thinking, analysis, and interpretation rather than on data collection (Haynes & Jones, 2012).
Measuring Trends in Data Reuse
Having looked at the overall picture of qualitative data reuse by purpose and user type, with comparative data from the United Kingdom and Finland, we next investigated the pattern of data reuse over time. In this section, two data sources are presented: the UK Data Service downloads analyzed above, and data from a citation search on Web of Science.
In Figure 4, we show the number of qualitative and mixed data downloads from the UK Data Service per year from 2002 to 2016. The first 10 years show a fairly steady rate of increase, rising to a peak of just more than 900 downloads in 2011. This is followed by a decline, then leveling out at about 700 per year from 2013 to 2015. The shaded area for the year 2016 is the extrapolation if the rate for the first 2 months of the year continues. We do not know of any factors that would have contributed to the peak in 2011, but the overall pattern is broadly consistent with the use of all data types from the UK Data Service (Economic and Social Research Council, 2012 and other years).
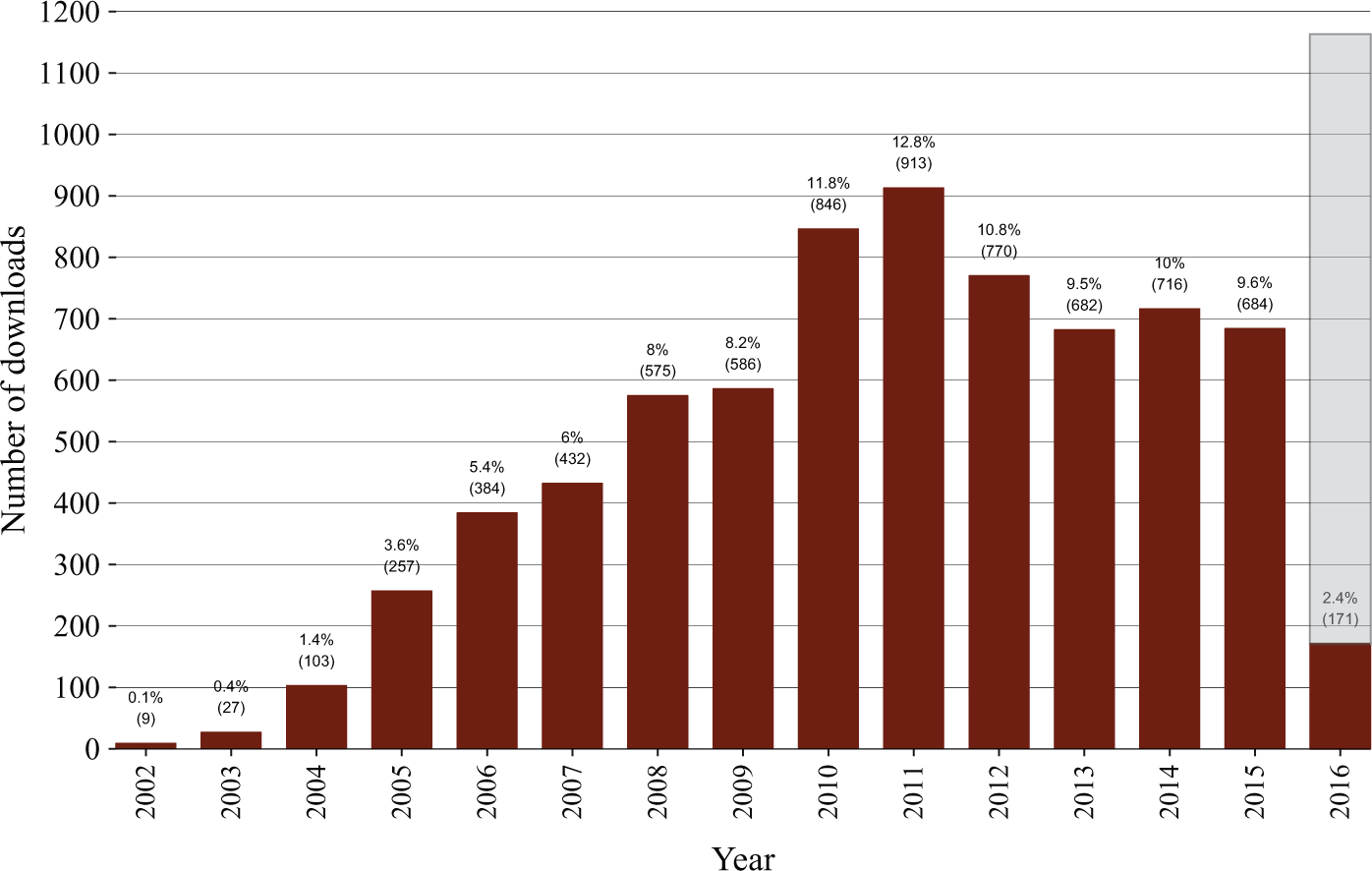
Number of data downloads per year, 2002-2016, UK Data Service.
The second measure of reuse over time used in this article involved a web-based search for articles that had reused qualitative data in their analyses or discussed the technique. The Thomson–Reuters Web of Science (webofknowledge.com) citation metrics portal was used to extract information, and we chose a 25-year period, 1990-2015. We defined search criteria that would return articles that had reused qualitative data, specifying either of the two phrases: “qualitative research” or “qualitative study(ies).” A second component was added using the AND Boolean using “secondary analysis” or “reuse” as both terms are applied to repurposing of data. We placed no restrictions on the disciplines of the publications.
This method has significant limitations. Other genres of qualitative research, such as ethnography, content analysis, and case studies, all could have involved secondary analysis without containing any of the keywords we chose. However, to use additional keywords would have required far more extensive content analysis of each article, which we were not in a position to undertake. Also, we were not able to be certain if each article used the method, although a review of abstracts and selected content indicated that most did. This analysis, then, may overcount by including some articles that did not actually use secondary analysis, but it also undercounts by omitting reuse research that did not use our chosen search terms.
The search results produced the number of articles published that, by our definition, were likely to have conducted secondary analysis of qualitative data.
The number of publications identified was almost zero until 1997 when five items were published (Figure 5). The number then increased to almost 50 per year by 2014, dropping to 36 in 2015 to reach a total of 347 over 25 years. The increase has been somewhat uneven, with fluctuations in several years.

Publications likely to have used qualitative data for secondary analysis—Web of Science—1990-2015.
A similar, but more narrowly circumscribed, search was conducted by Yardley, Watts, Pearson, and Richardson (2014). They searched for all articles that mentioned use of secondary analysis of qualitative data with a focus on ethical issues, especially consent, over the period 1994 to 2010. Their goal was to “identify and critique the ‘state of the science’ related to secondary analysis with particular focus on issues of consent” (p. 104). The search terms they used were “qualitative and ethics” and “consent and secondary analysis.” Using these more restrictive criteria, they found 154 references. With the differences in search terms and time periods between our own search and Yardley’s, an exact comparison of results is not possible. Nonetheless, given that ethical concerns have been prominent in debates about reusing qualitative data, it is not implausible that articles that address ethical issues could comprise roughly half of all articles about secondary analysis of qualitative data.
Summary of Data About Qualitative Data Reuse
Here, we summarize a few key findings about data reuse from the UK Data Service, FSD, and the analysis of publications. Significantly, the majority of the data collections have been used at least once. The concern that vast quantities of data are being archived but never touched is demonstrably not the case. And it is clear in both the United Kingdom and Finland that the main purposes are for education: Students and staff in educational institutions make up most users, and learning is nearly twice as frequent as all other uses combined in the United Kingdom. In terms of understanding trends of reuse over time, the evidence suggests a fairly rapid rate of growth in early years. This is not surprising, given the low initial base. The most recent data have suggested the growth may have stabilized, but it is not possible to tell whether the previously rapid growth will resume.
To our knowledge, this is the most robust and detailed data available on the actual practices of reusing qualitative data. That said, these data have significant limitations and the inferences need to be modest. We know we are overcounting usage of qualitative data by including mixed-methods studies. However, there is also substantial undercounting as these data did not include usages from the UK Data Service self-archiving system, ReShare, which hosts more than 500 collections of qualitative data (excluded for reasons of not being able to obtain comparable metrics at this time). It is also the case that high variability of the descriptions reusers is a constraint. There is an inevitable tension at work: Demanding more information from reusers would certainly reduce actual reuse, but minimal information limits the potential scope of any analysis. Improved integration in internal systems at the UK Data Service may be able to address some of these issues.
Later in this article, we will return to the question of what seems to make some topics and disciplines more inclined to use secondary analysis of qualitative data.
Diverse Approaches to Reusing Qualitative Data for Research
The first half of this article has addressed the following questions: How often are archived qualitative data reused, for what purposes, and by whom? In the second half, we look in more detail at how have data been reused in several research projects and consider these usages in light of the debate about the role of context when reusing qualitative data. This assessment also contributes some better understanding of what makes a data collection a good candidate for reuse.
The examples of reuse presented below have been selected to capture the variety of research using secondary analysis of qualitative data across dimensions of method, subject, data sources, and the connections, if any, between primary and secondary researchers. Another dimension of interest is the extent to which the reuse project drew upon extensive context of the primary research project. At the time when reusing data was less common, this “context debate” was quite pronounced, and has been usefully summarized by Hammersley (2010). In this section, we hope to advance the debate beyond what has been, at times, often speculative discussion by looking at actual research practice and the role context has played in successful research projects that have reused qualitative data.
Ten years ago, Jennifer Mason (2007) had already observed the progress made when researchers moved beyond overly moralist debates about reuse to “get on and do it” (par.1.3). The diversity and quality of these cases suggest that, over the past decade, researchers have continued to do just that. Moreover, these cases demonstrate that a kind of pluralism of approaches to secondary analysis has emerged and expanded. For some approaches, deep knowledge of the original context is highly beneficial, perhaps even essential. In others, usage of data seems to proceed with equally good outcomes with little need for it.
Before turning in more detail to several UK cases, it is helpful to consider the rather different environment for data sharing that exists in Finland. There are valuable insights from recent evidence from Finnish users as to how much context they actually require to proceed with analyzing another’s data. The non-binding policy and funding framework in Finland, which recommends archiving data rather than requiring it, has framed the FSD’s expectations of depositors regarding what they need to do as part of their data sharing activities. FSD has fairly modest expectations for depositors because it was felt that demanding comprehensive descriptions of the methodology and analyses used in primary research would have decreased the willingness of researchers to archive their data and resulted in far less data being made available. Instead, archivists have been able to reassure researchers that the workload required by the archiving process will not be onerous.
As a result, the FSD focuses on ensuring that the data are fully documented, but do not seek extensive documentation of the primary project. In practice, this means providing information about fieldwork and data collection methods (e.g., questionnaire, interview instructions, sample design) together with background information about participants for each data file (e.g., an interview), but little or no detail about the primary project itself, why it was done, and so on. This level of documentation seems to be sufficient for many users’ requirements, as most of them do not seem to have an interest in replicating the original research. For teaching research methods, samples of qualitative data sets are used in Finland much more often than whole data sets. And for more substantive research, archived qualitative data are often used to supplement the researcher’s own data or intended data. This type of reuse is demonstrated in the query below from a Finnish researcher seeking data:
I am writing a research plan. My research concentrates on the meaningful life and happiness of elderly women living alone. To get new ideas and insights, I would like to order any interviews of women aged 70 and over living alone. The topics of the interviews are irrelevant.
This is, we suggest, a pragmatic approach that acknowledges the need to balance burdens on depositors with demands for exhaustive details of their primary research with making more research data available in a timely manner.
The cases of reuse below, then, present a range of genres of reuse. Some of the examples presented tend toward the “context-rich” end of the continuum, with the secondary researchers availing themselves of detailed knowledge of the original data and project as well. However, other examples show that even when relatively little contextual information is available, secondary analysis can proceed with positive results. To be absolutely clear, we do not want to overly exaggerate this point—these cases vary on many dimensions, not only context. And we would still encourage depositors to include rich project descriptions, and those reusing data to make use of any available materials. Our point is that secondary analysis is, or should be, a broad church, and these cases are useful for moving beyond abstract debate by showcasing actual secondary research projects that can be assessed on their own merits.
Connecting Qualitative and Quantitative Data
A number of qualitative reuse projects have drawn upon related quantitative data. The studies below demonstrate different approaches to connecting qualitative secondary analysis with survey data. Jane Gray’s (2014) research examined children in rural Irish communities during the first half of the 20th century. Children’s movement to and from school, and to non-parental residences, was investigated using the Life Histories and Social Change database held at the Irish Qualitative Data Archive, which comprises 113 life stories, sampled from participants in the nationally representative survey, Living in Ireland. Because the interviews were selected from this larger, quantitative survey, it permitted robust sampling by age (three cohorts) and geography (urban/rural). Moreover, the in-depth qualitative data made it possible to probe previous research themes that claimed to have found evidence of “rural decay” with young people leaving the countryside (Brody 1973). By drawing upon the qualitative interview data, Gray found more and stronger interconnections between households centered on children. These ties worked to strengthen extended families and promote social mobility of young people, moderating earlier findings of rural decay.
Using a mixed-methods approach, Sarah Irwin (2011) worked across qualitative and quantitative data by drawing on data from the Longitudinal Study of Young People in England and the Young Lives and Times study, qualitative longitudinal data that are part of the Timescapes Study, to address both methodological and substantive research questions. She used qualitative interview data to inform the design of Young Lives and Times survey questions, and findings from the Longitudinal Study of Young People in England helped to shape interview questions asked in later phases of qualitative longitudinal work. Finally, she situated participants in the qualitative sample in relation to characteristics of the nationally representative sample. These strategies have been highly successful in combining qualitative depth with quantitative breadth.
Health
Broad topics with general appeal seem open to secondary research; the field of health is an especially fertile domain. An exemplary project was done by Stajduhar, Martin, and Cairns (2010) on bereaved family caregivers and health care providers supporting cancer patients. They reused data taken from a larger mixed-methods study and conducted secondary analysis on the focus group data: three with bereaved family caregivers, and two with health professionals. One author had been involved with collecting the original data, but the team also included new investigators who had not been involved in the primary project. The team of secondary researchers addressed new research questions, quite different from those of the original study. Existing data were used to identify factors that made grieving difficult for carers, for example, carers may conceal the emotional toll of caregiving, and after a patient’s death, and they lack the ability to sustain social networks that could be supportive. The research also revealed an ambivalent role for paid employment for carers: It could provide some support and structure, but often, the stress of work simply compounded the burden of caring responsibilities. Another study on bereavement by Ribbens McCarthy (2006) drew on many sources such as historical literature and also reused data from the Inventing Adulthoods data collection (Henderson, Holland, Thomson, McGrellis, & Sharpe, 2011).
One factor accounting for the abundance of secondary analysis research in health is the availability of data. The Health Experiences Research Group (2014) is located in the Primary Care Health Sciences at University of Oxford and has amassed one of the largest and best known repositories of qualitative data about medical conditions at healthtalk.org. It was established to conduct multi-disciplinary research on health experiences and has compiled interviews with more than 3,500 people about their experiences of more than 85 health-related issues. These data are being reused extensively.
The substantial collection of data and the extensive network of interested researchers have yielded diverse approaches for primary and secondary analysts to work together. For example, in Locock and Brown’s (2010) work on attitudes about support in motor neuron disease, the two researchers pooled their data, in effect, both becoming secondary analysts of each other’s data. Their method also included joint development of coding categories for thematic analysis. Ryan and Ziebland (2015) used data selected from the collection to study the role of pets in peoples’ experiences of chronic illness, but neither had been involved in conducting the original interviews. Not only has this significant repository supported diverse forms of collaboration, it has also produced both theoretical and applied outputs. Published articles cover a wide range of subjects and have appeared in core medical journals, and other outputs and reports have had direct policy relevance, such as improving understanding of how people use the experiences of others to make their own medical decisions and advice on end-of-life decision making (General Medical Council, 2010).
Food
Food research is also well represented in qualitative secondary analysis. Knight, Brannen, and O’Connell (2015) studied food and domestic life in England during 1950 by analyzing three diaries written for the Mass Observation Archive. These narrative archival sources offered a methodological alternative to traditional research formats, such as interviews. In their case, the nature of diaries offered not a “second-best” data source, but possibly one preferable to direct interviews. The subject of food is sufficiently morally freighted that direct questions often elicit normatively correct answers: “of course I eat five a day.” It was thought the more personal reflective diary format might reveal more authentic practices. In addition, the Mass Observation Archive provided an ample supply of diaries from which to sample.
We decided to focus on the year 1950, for a number of reasons: first, material from Mass Observation during the period of the Second World War had already been extensively studied by other researchers but the post-war period less so. Second, the year 1950 was a particularly difficult time for ordinary people with rising prices, including food, and the continuation of rationing. Third, the Mass Observation Archive includes directives from 1950, in which correspondents were asked for their views on topics relevant to food, for example, on standards of living, food costs, attitudes to continuing rationing and housework tasks. We thought that this information could usefully supplement and facilitate contextualisation of the diary data. (Knight et al., 2015, par. 2.7)
Family Practices
The particular suitability of existing data is also a feature of research on family practices. As with food, everyday family practices can go unremarked, and are often not recalled because they are—consciously or not—regarded as insignificant. Phoenix and Brannen (2014) each revisited their own data that had originally been collected for different purposes. They then collaborated to use the narrative data that had been produced in the original projects to investigate family experiences of fatherhood and of children as language brokers for their families.
Motherhood as well as fatherhood has proved a rich object for reuse studies. In Thomson, Moe, Thorne, and Bjerrum-Nielsen (2012), the original empirical materials were produced in an earlier study about motherhood. A researcher made weekly visits to observe interactions between one young mother and her baby, with highly detailed notes made after each visit, ranging from bodily movements and vocalizations to notes about the home environment. More than five years later, a new team assembled, including the original observer and others from the primary team, with several new researchers to embark on an intensive study of this single case using psycho-social techniques of close reading of these texts. In intensive group sessions, which included reading the original notes aloud, the team concurred that key passages conveyed strong affect (e.g., the baby described as very “demanding” about feeding), and these corresponded with passages that had been noted by the original observers, suggesting that even something as subtle as “affect” can be captured in transcribed notes. The highly detailed original observational notes, the presence of the original observer in the new team, and the psycho-social method that focused on both manifest and latent meanings in the data as well as the (relatively) slow pace of the reanalysis all combined to help mitigate one of the most frequent criticisms of secondary analysis: absence of the context of the original study.
In a final example, Meg Wiggins followed up with some of the mothers from Ann Oakley’s (1979) Becoming a Mother project to interview them about their reflections on motherhood 35 years after they had given birth. It is a methodologically impressive project, both for successfully locating the mothers after so long a time period and the innovative blending of expertise, with Oakley assisting in the research, and Wiggins in the leading role in the secondary project. Wiggins was able to secure consent from many participants and successfully archived interviews from the follow-up study (Wiggins, 2015).
At the UK Data Service, the largest qualitative data set, almost 500 long interview transcripts and audio from the study, Family Life and Work Experience Before 1918, 1870-1973, known as The Edwardians have been available to users since 1972, and in a digital version from 2009 (Thompson & Lummis, 2009). The study is unique, not only as it enabled Thompson to pioneer his Life History method, but also in its extensive coverage of content providing researchers with a wide range of topics to investigate about working class life in the Edwardian period: issues on domestic routine, household roles, meals, the upbringing of children, emotional relationships and values in the family, leisure, religion, politics, school, courtship and marriage, extended family, relationships with neighbors, experience of work, and occupational history of the whole family. The available data have resulted in hundreds of reuse publications written predominantly by social historians and sociologists.
Work
Sometimes, the discovery of data from an earlier research study borders on the marvelous. In 2000, data from a study about young workers in Leicester conducted by Norbert Elias in the early 1960s were discovered in boxes stored in an attic. In the boxes were 894 original interview schedules, along with letters, memos, and other notes and supporting materials. In the world of data archiving, this constitutes pure gold. Two researchers, O’Connor and Goodwin (2010), began a project of two phases, first to examine the recovered data, and second to retrace and reinterview a sub-sample of the original respondents. About 500 respondents had indicated on the original questionnaire that they were willing to be contacted for subsequent research. Using many search strategies, 157 were located and 97 agreed to be reinterviewed, an extraordinary success given that nearly four decades had elapsed. This case illustrates the immense potential of qualitative longitudinal research, and importantly, it represents the genre of research where the analysts of secondary data proceed without assistance from, or even contact with, the original investigator. The prevalence of diverse configurations of teams composed of primary and secondary collaborators should not detract from the demonstrated viability of researchers coming fresh to newly discovered data.
In Finland, work has also been a frequent topic of secondary analysis. Finns love to write, and as such, humanities and social science researchers collect written contributions by organizing writing competitions or by publishing requests in the press asking people to write about certain issues and experiences. One example of data collected in this in way is the data set now archived at FSD titled, Stories about Fear and Intimidation at Work 2008-2009, that consists of 102 written stories of approximately 500 pages (Eriksson, Koski, Luomanen, & Parviainen, 2011). The data were collected as part of the Leadership, Power and Fear (LEAR) research project at the University of Tampere via an online research platform in June 2008 that invited volunteers to write narratives about their experiences following a set of guidelines (Luomanen, 2009). Respondents provided essential background variables such as gender, education, age, the branch and size of their organization, and position at work at the time. They were asked to describe intimidation events, what they had been afraid of and why, what had led to the situation, and how they had been intimidated. The writers were also invited to describe situations where they themselves had resorted to intimidation at work and what the consequences had been.
The final LEAR project data set did not need to be anonymized by archivists. Not only was the background information collected using predefined codes, the writers were instructed to tell the story without mentioning the proper names of people or organizations they referred to. This “self-anonymising” aspect suggests that projects are increasingly planned with reuse in mind and that respondents can be asked and trusted to take on some of these responsibilities for ethical data sharing. The resulting stories can still be told in a vivid and captivating way.
This data set has been reused for 29 different reuse purposes, including seven published masters’ theses. Researchers are studying various aspects of working life, and they use the data set to get ideas for refining their research questions, to plan new data collection, or to compare with their own data.
Summary of Reuse Case Studies
It has proven challenging to determine what features make data collections amenable to reuse, but the cases presented here present some clues. For teaching, some features have been noted above: collections with multiple types of data, data relevant to current policy debates, and topics of interest to young people. The research cases presented display some of these same features and also suggest that detailed data on broad topics such as health, family, food, work, and poverty make qualitative data appealing for secondary analysis. Intriguingly, it may be that when the topic of interest for reuse was not central in the original research that the primary data may have the greatest reuse potential. This is particularly true when it may be difficult to elicit direct responses because the topic is sensitive (health), morally laden (food), or taken for granted (family practices).
Conclusion
Are we in any better position in 2016 to assess the state of secondary analysis of qualitative data? In some regards, we believe the answer is yes. Data policy requirements are diverse, and infrastructures are varied; however, expectations in the United Kingdom are shifting: Twenty years ago, most researchers would not have even considered sharing qualitative data; now, at least in the United Kingdom, there is a growing belief that much data can be shared and reused, and exceptions need to be well justified. Significantly, there is institutional support and funding for reusing qualitative data: the Economic and Social Research Council’s (2016) Secondary Data Analysis Initiative includes qualitative data in its list of eligible resources. Whereas this is the case in the United Kingdom, it is still far from the situation elsewhere, even in countries such as Finland.
Although evidence presented here is partial, there are multiple indicators of growing reuse and the presence of the approach in highly regarded research methods events and publications further confirms that finding. We also know that three-fifths of the data collections (in scope and analyzed in this work) at the UK Data Service are used, that teaching and learning are the primary purposes of reuse, and that usage is increasing reasonably steadily. In addition, the cases presented above on health, food, family, work, and poverty are just that, selected exemplary cases. There is further evidence of expanding reuse of qualitative data, sometimes across entire disciplines. In the United States, Elman et al. (2010) describe what they call a “renaissance” in qualitative research methods in political science, citing a proliferation of articles, books, and courses.
What we find most exciting, and encouraging, is the diversity of models developing even within the genre of secondary analysis. In so many instances, data reuse practices are emerging to enhance methodological robustness, for example, by combining the breadth of quantitative scope with the depth of qualitative insight. The reuse of data from especially hard-to-reach or vulnerable respondents—notably for teaching in the health area—gives students opportunities to work with rare data while minimizing patient burden. As for the context debate, more may be good, but there is no doubt that researchers find ways (as historians have long done) to use rich sources when available, yet still proceed carefully and creatively when they are absent. And finally, examples of data from studies done decades ago prove that even when collaborations with the primary researchers are impossible, data from the past can still yield rich, relevant research outcomes.
Footnotes
Acknowledgements
We would like to thank Ausra Suboniene for her expert research and editorial assistance for this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research and/or authorship of this article.