
Abstract
Cutting-edge data science techniques can shed new light on fundamental questions in educational research. We apply techniques from natural language processing (lexicons, word embeddings, topic models) to 15 U.S. history textbooks widely used in Texas between 2015 and 2017, studying their depiction of historically marginalized groups. We find that Latinx people are rarely discussed, and the most common famous figures are nearly all White men. Lexicon-based approaches show that Black people are described as performing actions associated with low agency and power. Word embeddings reveal that women tend to be discussed in the contexts of work and the home. Topic modeling highlights the higher prominence of political topics compared with social ones. We also find that more conservative counties tend to purchase textbooks with less representation of women and Black people. Building on a rich tradition of textbook analysis, we release our computational toolkit to support new research directions.
Keywords
Introduction
Recent methodological developments in a subfield of artificial intelligence—natural language processing (NLP)—offer great promise for shedding light on key questions about the social and political aspects of education. In particular, textbooks—conceptualized as artifacts of a dynamic cultural system—have long been a rich source of insight into schooling (FitzGerald, 1980; Loewen, 2008). We draw on a sample of 15 of the most widely used high school history textbooks in Texas, highlighting the insights that can be gained through the use of NLP or text data science methods. There are several potential contributions of NLP methods to curricular research. First, the methods allow us to measure complex concepts using larger sample sizes, which can shed new light on the scope and scale of trends in educational discourse. Second, there is greater capacity to analyze linguistic connections between words in the texts, which promotes attention to relational forms of meaning, allowing the discovery of topics and associations between concepts. Third, there is increased capability to systematically capture the way in which certain words are used to promote particular perspectives and frames. These measures, combined with the ability to use larger samples, allow researchers to analyze relationships between discourse and external factors in previously impractical ways.
While we see much promise in these approaches, it is important to understand computational textual analysis as a complement to, not a replacement for, more holistic analyses (e.g., ethnographic and case studies; Grimmer & Stewart, 2013; Nguyen, 2017). Indeed, we believe the flexibility of NLP tools can put greater responsibility on researchers to clearly specify the conceptual goals of research.
Our goal is to demonstrate methods for quantifying the content of textbooks that connect to the social scientific, policy, and practical aims of educational research. We do not provide a normative evaluation of textbooks, or a detailed analysis of why textbooks contain some kinds of content and not others. Instead, we use U.S. history textbooks from Texas as a case study to illustrate how NLP methods can answer research questions about depictions of historically marginalized groups that have been previously studied by textbook researchers using traditional methods. Our methodological and descriptive focus generates multiple avenues of future research that would hopefully increase interest in developing better computational tools for this domain. These methods also support social scientific explanations of content and evidence-based policy prescriptions, which we reflect on in our conclusion. We release our toolkit for computational analyses of textbook content to the research community at https://github.com/ddemszky/textbook-analysis.
Textbook Research
Textbooks are central in educational research because they represent the “intended curriculum,” sitting at the intersection between individual students and the macro forces of society, culture, and politics (Apple, 1992). Textbooks are also among the most widely used instructional technology around the world (Torney-Purta et al., 2001), and their availability and use positively influence student achievement (Fredriksen & Brar, 2015; Read & Bontoux, 2016). But, as is well known, textbooks are not neutral: their content is contested and reflects the power asymmetries and taken-for-granted beliefs of the underpinning culture (Moreau, 2010). These textbooks convey legitimated social and cultural values to students and impact students’ perspectives of people and ethnicities different from themselves (Cornbleth, 2002; Greaney, 2006). Building on ongoing work in this area, we present methods that aid the study of depictions of gender, race, and ethnicity in contemporary history textbooks.
Educational researchers’ understanding of the sources of textbook content and the mechanisms through which various discourses appear and spread have been limited by our methods. A main limitation of traditional methods is scalability. Most textbook content analyses continue to rely on a single researcher reading and hand coding textbooks (see Nicholls, 2003, or Pingel, 2010, for an overview of methods for textbook research), which is an extremely resource intensive endeavor to conduct at scale. For example, in a recent article in American Journal of Sociology, Morning (2008) hand codes 80 biology textbooks by manually searching for relevant segments of the book using index keywords. In some cases, scholars have multiple coders read books and conduct interrater reliability checks and test constructed measures for some level of statistical validity (e.g., Lerch et al., 2017). The accessibility of these constructed measures poses another limitation to hand-coding, since the annotation of subtle linguistic cues (e.g., the agency associated with certain verbs) requires training hand-coders to understand linguistic frameworks. Therefore, large textbook coding efforts may reduce their tasks to counting or identifying simple indicators. For example, Bromley et al. (2011) code a cross-national sample of over 500 social science textbooks for the presence or absence of discussions of “the environment”. Due to the limitations of human coding a large, longitudinal, cross-national sample, the authors were unable to develop more nuanced indicators of environmental education.
Computational Approaches
NLP methods are popular in computational social science (see also Nguyen, 2017; O’Connor et al., 2011), and they have yielded important insights on textual data in the field of education. For example, they have been used to analyze online and in-person class discussions (Fesler et al., 2019; Lugini et al., 2018), topics in dissertation abstracts (Munoz-Najar Galvez et al., 2019), and disciplinary differences in students’ academic writing (Crossley et al., 2017). A variety of NLP tools, such as Coh-Metrix (Graesser et al., 2014; McNamara et al., 2014), the Tool for the Automatic Analysis of Text Cohesion (TAACO; Crossley et al., 2016), and ReaderBench (Dascalu et al., 2014), have been used to characterize text cohesion, difficulty, and complexity in learning analytics and education data mining (Crossley & Kyle, 2018). These tools can enable educators to select education material suitable for students (Graesser et al., 2011) or analyze dialogue in digital learning environments at scale (Dowell et al., 2016). Other cases of NLP tools applied to educational texts include LightSIDE for automated essay evaluation (Mayfield & Rosé, 2013), TAALES for predicting lexical proficiency and word choice (Kyle et al., 2018), and Group Communication Analysis for detecting discussion participant roles (Dowell et al., 2019).
However, there has been less work on applying NLP to answer sociological questions in education. 1 Some early efforts apply machine counting of words to scanned textbooks, such as Lachmann and Mitchell (2014)’s study on depictions of war. A number of recent studies outside education have used NLP methods to study the reflection of gender and other social variables in text: Fast et al. (2016) look at gender stereotypes in online fiction; Hoyle et al. (2019) measured the association of adjectives and verbs with different genders in a million digitized books; Garg et al. (2018) quantified a century of gender and ethnic stereotypes using word representations learned from books, newspapers, and other texts; and Ash et al. (2020) examine the role of gender slant in judicial behavior using text written by judges. We build on this line of work examining depictions of social groups in texts (see also Field et al., 2019; Joseph et al., 2017; Ornaghi et al., 2019), extending NLP methods to textbooks.
Though NLP can achieve near-human performance on some linguistic tasks (Wang et al., 2019), its methods are still error-prone and subject to bias. So, its use in a field with high social impact, such as education, necessitates care when drawing conclusions (see Hovy & Spruit, 2016, or Olteanu et al., 2019 for an overview). One way to be careful is to strive for transparency and explainability when choosing methods. For example, lexicon-based approaches offer some interpretability by explicitly showing which words are counted. An overarching limitation of our work is that many machine learning models or resources are initially trained, or developed, on data from noneducational genres such as news articles, and task performance may not transfer well to a different domain. Though it would be ideal to tailor these models to history textbooks in the future, these efforts will require extensive annotation of training data. In our methods section, we further elaborate on more specific limitations of NLP.
Overall, computational approaches are not a competitor to or replacement for traditional methods when tackling complex social phenomena. We seek to unite them with shared research goals and use the strengths of one method to assist potential weaknesses of another. In particular, NLP can only describe content, rather than prescribe it, so educators, ethicists, and social scientists should interpret results and determine if they align with the intended curriculum and proper goals of schooling.
Our Contributions
Our first contribution is that we provide quantitative and scalable measurements of textbook content. These methods, when applied across books, provide a more complete picture of the discourse around historical events and people in U.S. history education. The patterned exclusion of some views from history textbooks is well documented, but our analysis sheds new light on the scope and scale of this exclusion. For example, we find Latinx people are virtually absent from discussions of racial and ethnic groups in history textbooks in Texas, and nearly all famous figures discussed are White men in politics.
Our second key contribution is that by employing NLP methods that discover patterns in the co-occurrence of terms, we enable a relational approach to meaning relevant for textbook research. These methods uncover latent structures and networks of terms and can create a rich picture of how textbooks reflect social meaning. Moreover, they can help answer questions about the substantive nature of discourse; that is, what meanings are linked to certain terms or concepts? We show evidence that despite a move toward pedagogical approaches that focus on multiple perspectives of the past, history textbooks in Texas remain dominated by topics of formal politics. Our analyses also show that Black people are discussed using terms with lower levels of agency and power than other groups—a finding that also highlights the importance of combining substantive expertise with computational methods.
Finally, we demonstrate that a quantitative analysis of larger samples allows researchers to link patterns in the text to external social, political and cultural influences on and to consequences of education, at a scale that may be less feasible through broad hand-coding of fewer textbooks. Illustratively, we link textbook content to district purchasing patterns and districts’ political leaning, which is one of many possible factors involved in the process of textbook creation and distribution. We find that although differences between textbooks are small compared with their similarities, districts in more Democratic counties tend to purchase textbooks that contain higher levels of representation of historically marginalized groups.
These contributions are motivated by our research questions, which we summarize in Table 1, along with the methods and resources used to answer each question. After outlining our data in the next section, we turn to describing each method in more detail. We then discuss the results of each question. We conclude by reflecting on the contributions and limitations of NLP methods for social science research in education.
Primary Contributions, Research Questions, Subproblems, Methods, and Resources

Data
Texas Textbooks
We focus on textbooks used in Texas, which makes its district-level textbook purchase data available online in a unified format (Texas Education Agency, n.d.). Given that it has the second largest student population in the United States, with 5.4 million students enrolled in its K–12 public school system in 2017, Texas is a major textbook market for publishers, and so the state has a significant influence on U.S. textbook content. At the same time, the Texas Board of Education has been at the center of several textbook controversies. For example, the 2015 statewide social studies textbook adoption, driven by conservative ideology, triggered controversy over possible biases within curriculum content (Goldstein, 2020; Hutchins, 2011; Rockmore, 2015). Our dataset includes U.S. history textbooks widely purchased in Texas between 2015 and 2017. We select titles that occur in at least 10 district-level transactions. The final list of fifteen textbooks, including six combined volumes, is available in Textbook Sources. Additional details are available in Appendix C. Seven volumes were PDF files, and we extracted text directly from these files. As for the other volumes, we scanned and digitized them using ABBYY FineReader, which employs optical character recognition (OCR). We perform minimal post-processing on the text (Appendix D). Our textbook data contains a total of 7.6 million tokens, defined as strings of continuous characters between spaces or punctuation marks.
Demographic Data
We use geographic and student demographic data from the 2016–2017 school year collected by the National Center for Education Statistics (n.d.) Common Core of Data for public school districts to obtain textbook distribution data. In addition, to estimate the political leaning of each county, we use the two party vote shares from the 2016 elections, broken down by county (The New York Times, 2017). 2 In our analyses, we use estimates of Democratic vote-shares as an illustration of the types of external associations that become possible with our methods. Future research designs could explore other mechanisms that might shape textbook distribution in a district, such as the demographics of a school or a school board. 3
Method
Our goal is to apply NLP methods to examine depictions of historically marginalized groups in textbooks. We illustrate the methods we found most relevant, following the order of questions listed in Table 1.
Research Question 1: How Much Space Is Allocated to Different Groups?
Our methods in this section quantify the amount of textual space that different people and groups cover, in the spirit of the frameworks used in studies of multicultural curriculum to categorize textbook diversity. Previous traditional approaches in analyzing social studies textbooks have examined the presence and discussion of everyday, generic (nonnamed) people (e.g., settler or farmer) as well as named, famous individuals (e.g., Lincoln or Washington; Gordy & Pritchard, 1995; Schmidt, 2012). Researchers have measured diversity in textbooks by considering how much a minority group is mentioned relative to a majority, by examining whether texts portray minorities’ roles as secondary or contributory, and by determining whether famous named people from a minority demographic are included (Banks, 2001; Gordy & Pritchard, 1995; Tetreault, 1986).
Identifying People-Related Terms
We identify common nouns that designate nonnamed people, such as pioneer or Mexicans, via WordNet, an English lexical database that encodes the meanings of words and relations between them (Miller, 1995), similarly to a thesaurus. We use the database to extract all hyponyms (subcategories) of human, person, people, and social group. For example, pioneer is a member of the hyponym chain person > creator > originator > pioneer in WordNet, and hence we obtain this term when we search for all hyponyms of person.
To evaluate how well this WordNet-based method performs, we also perform manual labeling. We use the spaCy package (Honnibal & Montani, 2017) to extract the heads of all noun phrases in the text that occur at least 10 times in all of our data. 4 This process yields around 12,000 unique noun heads. We manually combed through this list of heads to extract those common nouns that refer to people, resulting in 2,111 total terms. We find that our automatic WordNet-based method captures more than 95% of all manually identified nouns referring to people, and it captures 98 of the 100 most frequent nouns in our data referring to people—the exceptions being group and majority, which, in WordNet, are not hyponyms of people-referring terms, because they can refer to other entities as well. However, because in history textbooks we expect these two terms to refer to people, we still include them in our list for analyses, along with the remaining 5% of manually identified people-related terms not identified by the WordNet-based method.
Our list of people-related terms consists of 1,665 unmarked terms such as engineer or family as well as 446 terms specifying a demographic, including singular and plural forms of nouns (Appendix Table A1). To compare how different demographic groups are described, we manually categorize this list based on gender and ethnicity. Some of the nouns also have an adjectival sense (e.g., Navajo community), and therefore, when looking at specific mention of a people-term in text, we also count whether its adjectival markers are associated with a particular demographic. We also consider cases of intersectionality, such as Black women, which would be categorized as both woman and Black. For gender-based analyses we focused on women and men, because our dataset does not have many instances of other gender identities, and only three mentions of transgender.
Identifying Famous People
A textbook’s discussion of social groups also involves mentioning individuals by name. Though the inclusion of a few standout individuals alone is not enough to label a textbook as diverse, their absence is a key sign that a textbook is missing crucial parts of American history (Banks, 2001). To identify named individuals, we use spaCy’s named entity recognition (NER) tagger. A named entity is a proper noun describing a person, location, or organization, and taggers label these automatically. A manual evaluation of this NER tagger on our textbooks yielded an F1 score of .735 (Appendix D). The errors of NER and its potential biases when encountering names of different genders and backgrounds is an active area of research in NLP (Mehrabi et al., 2019), but our results indicate that, at a minimum, spaCy’s pretrained tagger is accurate enough to motivate future work on adapting this model for textbook language.
To ensure that we do not double count individuals due to aliases (e.g., Franklin D. Roosevelt and Franklin Roosevelt), we pull aliases from the free knowledge base Wikidata and standardize these variations with their official Wikidata name. One limitation is that a knowledge base such as Wikidata, like its encyclopedic sister project Wikipedia, may contain less coverage of underrepresented individuals (Wagner et al., 2015). In addition, as NER tagging is somewhat noisy and captures a long tail of phrases that are not people, we only keep the top 100 most common NER-detected names, which restricts our focus to the people textbooks repeatedly discuss. In this list, several entities are simply last names, such as Roosevelt, which are also ambiguous as to which individual (Theodore or Eleanor) they refer to. Much of this is due to errors in coreference resolution (see next subsection), such as when the coreference spans across multiple paragraphs of text. To resolve this problem, we pair last names with the most recent full name with that last name that appears beforehand in the text. We also use Wikidata to identify the gender and race of individuals, though White individuals are often missing race/ethnic group labels in this knowledge base, so we manually check these labels as well.
Measuring Space
To accurately measure how often specific people or groups occur in text, we need to also include instances when they are referred to by pronouns like he or she. To do this we perform coreference resolution, the task of linking textual expressions that refer to the same real-world person. We use the spaCy package and replace pronouns with their full referents. For example, in Washington’s wife, First Lady Martha Washington, attended social events with her husband, we substitute the pronoun her with First Lady Martha Washington.
The Clark and Manning (2016) neural coreference model in spaCy was trained on OntoNotes 5.0 (a mix of newswire, broadcasts, and web text) and since textbooks are a different genre, we manually evaluated its performance on a sample of our data (Appendix D). The coreference model achieved a F1 score of .704, with precision = .835 and recall =.618. Our estimated counts of mentions are therefore likely lower than the true number of mentions, but still closer to the true number than if we did not use coreference at all. Another limitation of coreference is that existing models, trained on imbalanced corpora, suffer from gender bias, such as attaching gendered pronouns to nouns referring to stereotypical occupations (Webster et al., 2018). Mitigating these effects is an active area of NLP research.
Research Question 2: How Are Different Groups Described?
After identifying the people discussed in these textbooks, we investigate how they are characterized. Multiple studies using traditional methods have focused on the characterization of women or racial groups in textbooks (Anderson & Metzger, 2011; Blumberg, 2007; Brown & Brown, 2010; Schmidt, 2012). For example, Sarvarzade and Wotipka (2017) looked at the stereotypicality of the women’s actions depicted through verbs and visuals in Afghanistan primary school textbooks, and they found that women are often represented as caregivers and mothers.
Here, we demonstrate how relational forms of meaning–associations between words and groups of people–can be identified and extracted using computational methods. The relationships between these words and terms denoting people reveal textbooks’ depictions of who people are and what they do.
Identifying Descriptor Words
To extract verbs and adjectives associated with people, we used a part-of-speech tagger and dependency parser, a tool that annotates dependency relations between words (we used a parser by Dozat et al., 2017). This approach is similar to those used by previous work for gathering descriptive attributes of entities in movie plot summaries, books, and news (Bamman et al., 2013; Card et al., 2016; Hoyle et al., 2019). We perform dependency parsing to extract verbs and adjectives associated with people-related terms. Figure 1 illustrates the dependency relations we focus on: adjectival modifier, subject of verbs and object of verbs. In this example, we would extract individual and managed, since those are two terms associated with women.

Dependency parsing example.
Comparing Descriptors of Different Groups
To compare the descriptors (adjectives or verbs) of two different groups of people A and B, we calculate the weighted log-odds-ratio with informative Dirichlet prior of the words associated with them, as described in Section 3.5.1 of Monroe et al. (2008). This method estimates the association of words and groups, building on word frequency counts and an estimate of prior word probability. We chose this method over other, frequentist methods (e.g., difference of proportions, tf-idf), because it makes use of the prior probability of a word occurring based on counts in a large corpus (in our case, all descriptor words in textbooks), which helps get more accurate signals from words with both very low and very high frequencies. As for the output scores, words with a high positive score are closely associated with Group A, while words with a low negative score are associated with Group B.
Measuring Connotations of Descriptors
Lexicon-based approaches illuminate the affective and social connotations of words, an area of great importance for the social sciences (Nguyen et al., 2019). This method counts the number of words occurring in a text that are defined in a lexicon as denoting a particular meaning, such as words of positive sentiment. Lexicons have been used since early work in computational content analysis (Stone et al., 1966), and usually have human-generated ratings or labels. Lexicon-based methods are interpretable and computationally inexpensive, but they also have several limitations. They operate under the assumption that the context for which a lexicon is created is similar to the one in which it is applied, which may not hold when a word’s meaning varies across contexts (Grimmer & Stewart, 2013). In addition, lexicons contain a fixed number of words and may not always provide good coverage of all relevant words in the corpus (Field et al., 2019).
We apply two families of lexicons: for adjectives, National Research Council (NRC)’s Valence, Arousal, and Dominance (VAD) lexicon (Mohammad, 2018), and for lemmatized verbs (that is, all forms of a verb), the Connotation Frames lexicons of sentiment, power, and agency (Rashkin et al., 2016; Sap et al., 2017). These six metrics we chose to highlight are related to three primary affective dimensions identified in social psychology: power/dominance (strong vs. weak), sentiment/valence (positive vs. negative), and agency/arousal (active vs. passive; Field et al. 2019; Osgood et al., 1957; Russell, 1980). As examples of labeled words in the NRC VAD lexicon, a high valence adjective is amazing, a low arousal one is asleep, and a dominant one is competitive. In the lexicons for connotation frames, X has low agency in the phrase X obeys, and for the phrases X affects Y and Y applauds X, X has power while Y does not. In the phrase X suffered, the verb suffered implies the writer may have positive sentiment toward X because it suggests sympathy.
We calculate lexicon scores for social groups following Field et al. (2019), who applied these two lexicon families on online media articles to study portrayals of people in the #MeToo movement (Appendix D). The score for a group of people-related nouns is determined by the average rating of adjectives or verbs describing nouns in that group. We calculate these scores for non-named terms related to different social groups (Appendix Table A1), as well as the top 100 named individuals. We only consider words that have labels in each lexicon, and we use the z-score of the calculated values for each lexicon.
Comparing the Association of Words to Different Groups
Similar to previous work looking at gender and ethnic stereotypes (Garg et al., 2018), we also estimate the degree to which certain words are associated with a group by calculating their distance in a latent vector space. We obtain these vector representations, or embeddings, of words and frequent phrases by using a machine learning algorithm that generates them from co-occurrence patterns in corpora. The goal of learning embeddings is to create similar representations for words that occur in similar contexts and different representations for words that occur in different contexts. For example, in history textbooks, the words women and rights are expected to occur in contexts that are more similar to each other than are the words women and army, and thus the embedding of women should be closer to the embedding of rights in the latent space than to the embedding of army.
We use the publicly available word2vec skip-gram model (Mikolov et al., 2013) to train our own embedding model on our textbook data. We train our own model instead of using available pre-trained embeddings, in order to capture word co-occurrence patterns present in our textbook data rather than patterns in the dataset (e.g., Wikipedia or the web) used for training the pre-trained model. We use word2vec since it has been shown to be more robust to changes in the data for small datasets (Antoniak & Mimno, 2018) than alternatives (e.g., GloVe; Pennington et al., 2014). We describe the vocabulary and parameter settings in Appendix D.
Semantic similarity between words in the vector space is usually estimated via cosine similarity, which is a measure of how similar the values of a vector are on each dimension. Since word embeddings can be unstable in the case of small corpora, we perform bootstrapping, following Antoniak and Mimno (2018), to ensure that we have robust estimations of word similarity (Appendix D).
To identify words for our analyses, we select themes that are relevant to previous studies on the representation of gender in history textbooks, such as the home, the workplace and politics (Sarvarzade & Wotipka, 2017; Schmidt, 2012). We match these three themes with the home, work and achievement word categories in the Linguistic Inquiry and Word Count (LIWC) lexicon (Pennebaker et al., 2015), respectively. For each category, we select the words in LIWC that are the most frequent in our data and filter out words that, in our domain, are unlikely to be used in a sense that fits their LIWC category (e.g., house in the context of history books is usually used to refer to a political institution rather than a synonym of home). Then, for each term (e.g., household) we calculate the mean cosine similarity between that term and all the terms referring to a particular gender (e.g., she, her, woman, etc.).
Research Question 3: What Are Prominent Topics and How Are They Related to Groups of People?
Next, we move from methods that draw out word-to-word relationships in text to methods that enable the study of word-to-topic and topic-to-topic ones. Textbook researchers often study the prevalence of topics and the relationship among them, as they can shed light on the perspective and framing that a particular textbook promotes. The words associated with each topic and the way in which the topics are related, however, is usually left to the coder to define (see Lachmann & Mitchell, 2014, for an example where the authors use hand-curated word categories). This may lead to low interrater reliability due to annotation bias or coding error from overlooking relevant items. Computational methods built on word co-occurrence patterns allow for the automatic grouping of words into topics, thereby potentially uncovering relational meanings with greater efficiency than manual coding when attempting to analyze large amounts of text. Subject area expertise remains of central importance, as researchers must thoughtfully attribute meaning to the automatic groupings.
Identifying Topics
Topic modeling is a central approach for automatically discovering topics in a collection of documents. There are several different kinds of topic models, the most commonly used being Latent Dirichlet Allocation (LDA; Blei et al., 2003). LDA represents the distribution of topics within documents and the distribution of words within each topic. Such LDA models have been previously applied to an enormous variety of texts and genres (Boyd-Graber et al., 2017). In educational contexts, LDA models have been used to analyze student writing (Chen et al., 2016) and MOOC (Massive Open Online Courses) discussion forums (Ramesh et al., 2014; Reich et al., 2015; Vytasek et al., 2017). We employ LDA to study the prominence of different topics within and across textbooks and the prominence of words related to different groups of people within and across topics.
Topic models require a collection of documents as input. We perform topic modeling at the sentence level, which provides us with a large number of similarly sized documents (17 tokens on average) that are suitable for inducing stable estimates of a wide range of topics. To build our vocabulary for the model, we first remove function words (e.g., the, it, have) based on a list of stopwords included in MALLET, an off-the-shelf tool for topic modeling (McCallum, 2002). We also perform stemming 5 via the SnowballStemmer (Porter, 2001). We use our resulting set of tokens (unigrams and bigrams) to compile document-to-token counts, which serve as an input to MALLET. We build a topic model with k = 50 topics. We expect there to be a large number of different topics in the textbooks, but we limit the number of topics to 50 because in experiments with more topics (k = 75, k = 100, k = 300), we found that the topics were too fine-grained for our analyses (e.g., multiple topics representing multiple wars). Depending on the research focus, a lower or higher number of topics may prove necessary. We explain other parameter settings and decisions in Appendix D.
To understand which topics relate to which social groups, we can look at the topics in which non-named people-related terms have a high probability. We consider a topic to be associated with a term if the term is among the top ten highest probability terms for that topic. Since we remove function words, we expect high probability words in each topic to represent a collection of semantically related words, also known as a semantic field. Thus, the more topics a term is associated with, the more semantically diverse we expect the discussion around that term to be–henceforth, we refer to this phenomenon as topical diversity.
Comparing the Prominence of Topics Across Books
We estimate the prominence of a given topic within a textbook by taking the mean probability of the topic across sentences in that book. We measure the prominence of multiple topics (henceforth, a topic group) associated with a term by summing their average probabilities. We calculate relative topic prominence of a topic group pair by calculating the ratio of their prominence within a book. We compare the relative prominence of topic group pairs across books instead of the prominence of a single topic group because the former method is more robust to noise arising from different textbooks having different lexical distributions and hence, topic probabilities. We remove three books that only cover half of U.S. history from topic-related analyses.
Results and Discussion
Research Question 1: How Much Space Is Allocated to Different Groups?
Identifying People-Related Terms
The three most common nonnamed people terms overall are people, women, and his. The high frequency of his suggests that some pronouns were not resolved with the noun they refer to during coreference resolution. Most terms are unmarked by gender or race/ethnicity, though from the percentage of those that are, men are mentioned more often than women (Figure 2). Black people are the most common nonwhite racial/ethnic group discussed (Figure 2). Though a slight majority of people marked by race/ethnicity are nonwhite, it does not mean these textbooks do not focus on the history of White Americans; rather, many terms (e.g., pioneer, farmer, priest) seem to implicitly convey or assume Whiteness. This is a common kind of “reporting bias,” in which people are less likely to state the most common properties of an entity, since they believe the audience will assume the majority demographic as the default (Gordon & Van Durme, 2013).
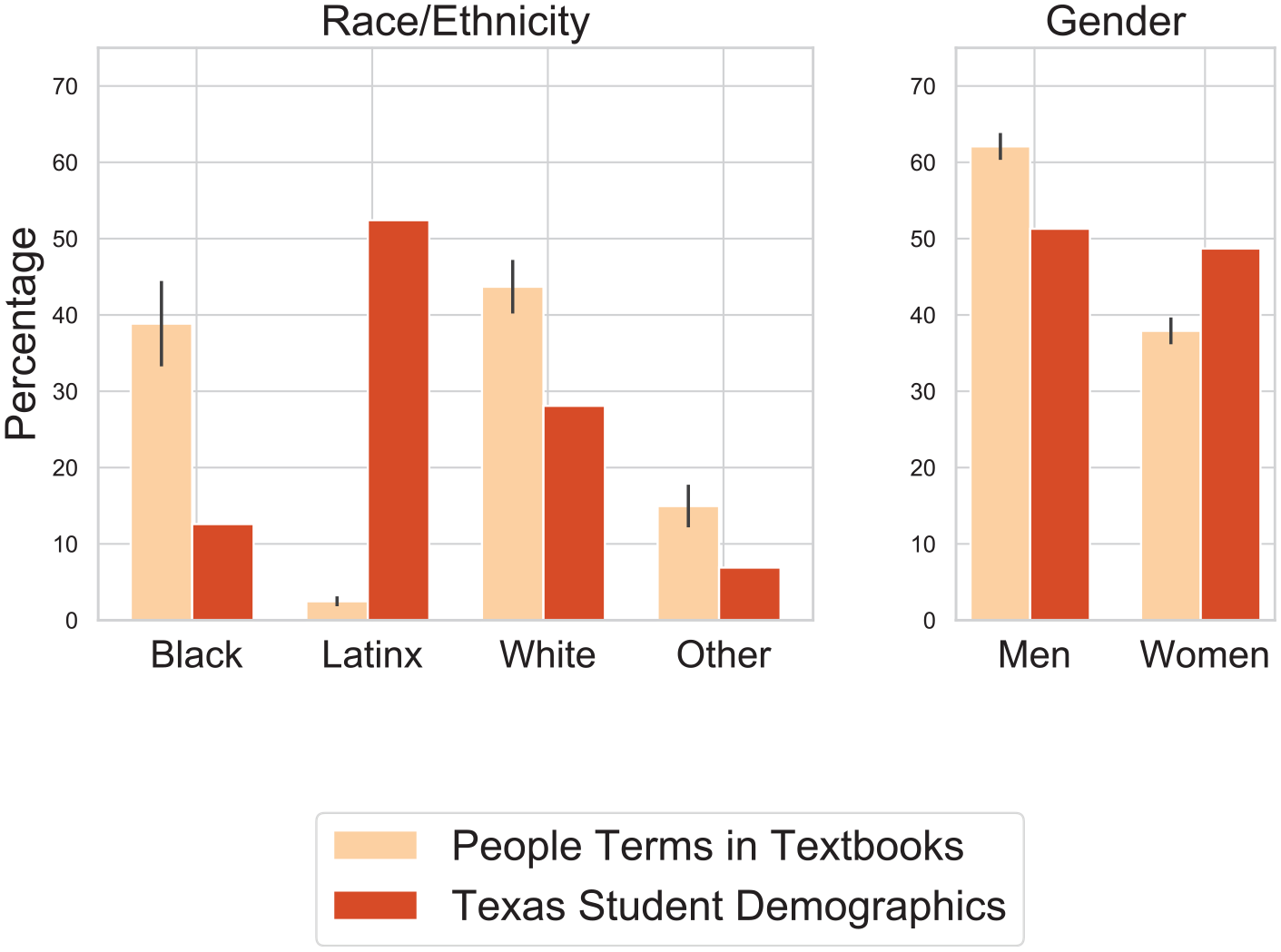
Percentage of people of different demographics in Texas textbooks and schools.
Perhaps the most striking finding with regards to the ethnicities of people mentioned in textbooks is the scarcity of Latinx groups (Figure 2). Previous work has shown the importance of culturally relevant education, such as students seeing their personal identities represented in school curriculum, in improving students’ learning outcomes (Aronson & Laughter, 2016; Dee & Penner, 2017). However, despite the fact that demographic data shows 52.42% of students in Texas are Latinx, they are only mentioned 961 times across all textbooks, which accounts for only 0.248% of people terms and 2.23% of people terms marked by ethnicity/race. Latinx groups tend to be discussed in coverage of the Mexican-American War, as well as in contrast to incoming White settlers: [Early pioneers] left the Oregon Trail . . . and mostly settled in the interior along the Sacramento River, where there were few Mexicans (Bedford America’s History, Henretta et al., 2014, p. 413). Indigenous peoples and Asian Americans are also scarce in the texts. We do not expect to see representation that is directly proportional to population demographics, but the distinctions we find provide empirical information for future research on how and why curricula shape students. Given most research in this field relies on hiring human coders for the task of identifying social groups in text (e.g., Bromley et al., 2011), we examined how our NLP results compare with the traditional approach (Appendix E).
Identifying Famous People
The most frequently mentioned named people across textbooks are almost entirely White men in politics (Table 2). Our books place a significant amount of focus on these named individuals; one fifth of sentences mention at least one of the top 50 named people. The only woman in the top 50 is First Lady Eleanor Roosevelt, who is the 28th most common person discussed. This finding agrees with prior work, which also found that Eleanor Roosevelt is the most mentioned woman in U.S. history textbooks (Tetreault, 1986). In our textbooks, the next most common woman is American activist Jane Addams, ranked 54th. The limited number of people of color within the top 50 include President Barack Obama (29th), activist Martin Luther King, Jr. (30th), slave Dred Scott (42th), and abolitionist Frederick Douglass (44th), who are all Black. Thus, the amount of space allotted for famous people featured in history textbooks is dominated by a single demographic, with a few exceptions. This result may be a consequence of the textbooks’ focus on politics rather than everyday life and sociocultural movements–a phenomenon that we return to in our later results.
The Top 30 Most Common Named People Across All Textbooks
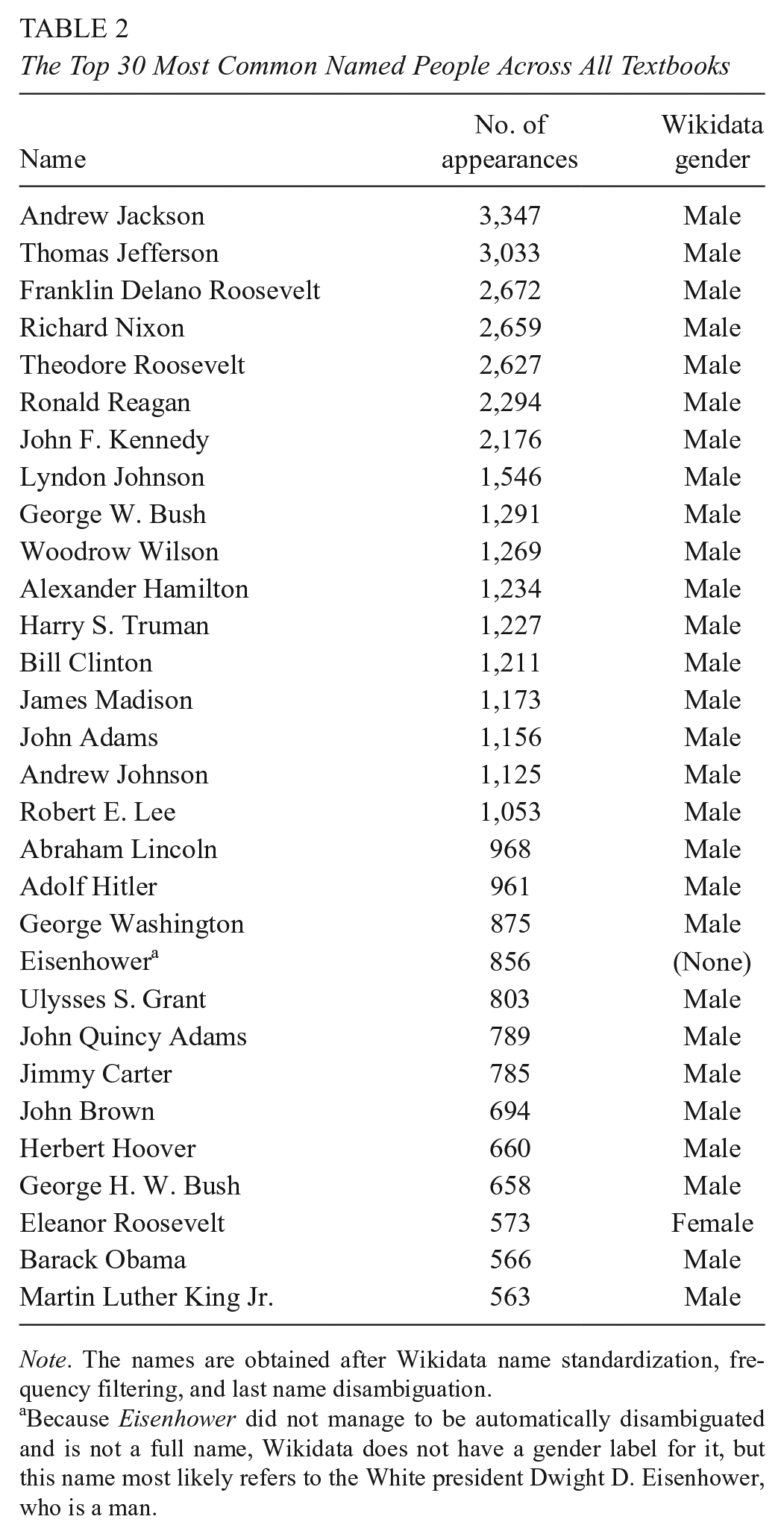
Note. The names are obtained after Wikidata name standardization, frequency filtering, and last name disambiguation.
Because Eisenhower did not manage to be automatically disambiguated and is not a full name, Wikidata does not have a gender label for it, but this name most likely refers to the White president Dwight D. Eisenhower, who is a man.
Link to External Factors
It is well established that the creation of textbooks is deeply political (Apple, 1992; Apple & Christian-Smith, 2017; Foster, 1999). We found that percentages of nonnamed women and Black people in textbooks are positively correlated with the median percentage of Democratic votes in counties that purchased each textbook (Figure 3). The Pearson correlation r between the percentage of mentions of Black people and the percentage of democratic votes during the 2016 presidential election is .519 (p < .05) and between the percentage of women mentions and Democratic votes is .583 (p < .03). In Pearson’s U.S. History, which was purchased in the most Republican counties, 1.82% of nonnamed people mentions are Black and 4.87% are women, while in Give Me Liberty, which was purchased in the most Democratic counties, these values are 8.58% and 6.82%, respectively. State-adopted textbooks or textbooks such as Jarrett’s Mastering the TEKS that adhere to Texas-specific standards in particular have less representation of Blacks and women and are used in more conservative counties (Figure 3). The percentage of Latinx mentions did not show any significant trend (Pearson r = −.107, p = .703), likely due to the low prevalence across all textbooks (variance σ2 = .01). While emphases on diversity are quite low across all districts, there are significant differences in district purchasing, with districts in more conservative counties using less diverse books.

Political factors and textbook distribution versus percentage of mentions.
Research Question 2: How Are Different Groups Described?
Comparing Descriptors of Different Groups
A log odds comparison of the words associated with Black people with those associated with Whites and people terms unmarked for ethnicity reveals that Black people tend to be described with words related to slavery, such as free and runaway, and not words related to politics such as political and federal (Figure 4). We also compared the words associated with women with those associated with men and terms unmarked for gender. Women tend to be described with words related to their marital status, and not with words related to the military or government, which is consistent with other stereotypical portrayals of women in media (Collins, 2011). These results are also consistent with the historical exclusion of nonmen and non-White people from politics, and further illustrate the kinds of contexts in which these social groups are portrayed.

Log-odds-ratio of words associated with Black people and women.
Measuring Connotations of Descriptors
We used lexicons to categorize descriptors associated with different groups of people and famous individuals. Though the concepts labeled in these lexicons, such as dominance in NRC VAD, could be interpreted as positive attributes for people to have, these labels do not advocate for how people should be described in textbooks. In the first lexicon for connotation frames, 85.0% of a total of 165,386 non-unique verbs (3,983 are unique) attached to people in these textbooks had sentiment labels, 92.4% had power labels, and 61.1% had agency labels. Our second lexicon, NRC VAD, contains 68.8% of the 108,033 nonunique adjectives (7,563 are unique) describing people. A line of future work would be to induce scores for words not labeled in these lexicons and customize their scores for history textbooks.
Our analysis of verbs using the lexicon for connotation frames showed that Black people are depicted with less power and agency than other social groups (Figure 5). These differences are largely due to their appearance in the context of slavery and racial oppression, and they are the object of high-power verbs such as owned and barred. This finding contrasts with new historical research that emphasizes the power and agency of Black people in freeing themselves from enslavement and oppression (Devlin, 2018; Hines, 2016). Named individuals have the highest agency and power, performing political actions such as veto and initiate (Figure 5). Additionally, the sentiment of a writer toward a subject or object is most positive for women (Figure 5). Examples of common verbs associated with women that have high positive sentiment scores include marry and help. This result illustrates the importance of examining the actual words involved in the calculation of a lexicon-based score, as lexicons may have labels that gloss over words’ complex and context-dependent connotations. Due to the small amount of Latinx representation in textbooks, the confidence intervals for their words’ lexicon scores are large, and no clear conclusions can be drawn about the words associated with them.
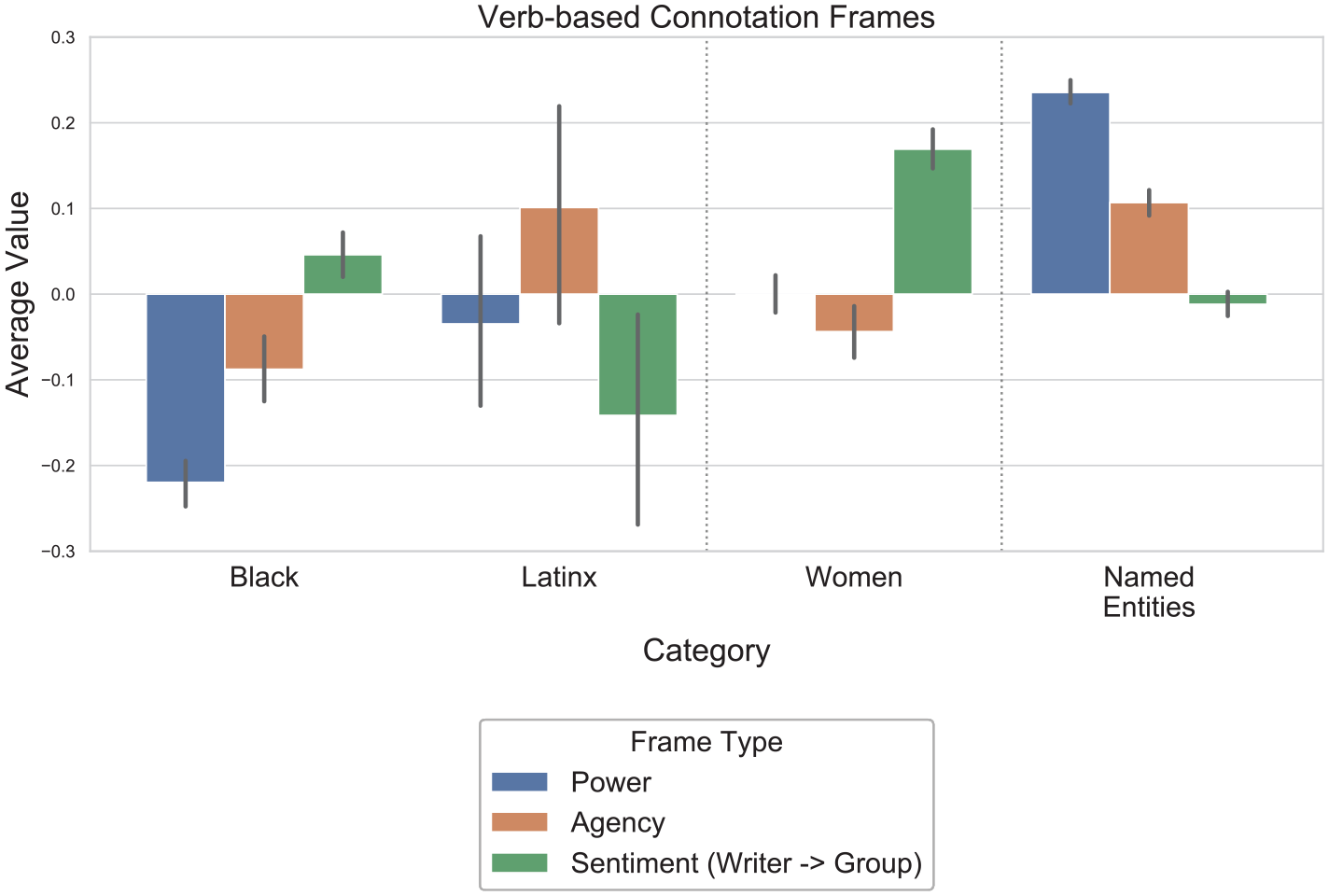
Verb-based connotation frames of power, agency, and sentiment for social groups.
Our analysis of adjectives using the second lexicon, NRC VAD, reveals a few trends that complement our verb-based findings. For example, the adjectives describing Black people, such as slave and inferior, have lower dominance ratings than those describing other groups. Additionally, named entities tend to be described with high arousal adjectives, such as worried, victorious, and furious.
Comparing the Association of Words With Different Groups
Another indicator that women are associated with domestic activities in textbooks can be seen in our word embedding results. First, the most similar tokens in the textbook embedding space to words denoting women (woman, women, female, she, her, hers), as measured by cosine similarity, are words and phrases related to the domestic sphere. These tokens are woman’s husband (.58), wife and mother (.57), housewife (.56), breadwinner (.56), husband (.54), where parenthetical values indicate cosine similarity estimated via bootstrapping. Second, by using terms within LIWC categories, we find that men (man, men, male, he, him, his) are less closely associated with the home and more closely associated with achievement than women (Figure 6).
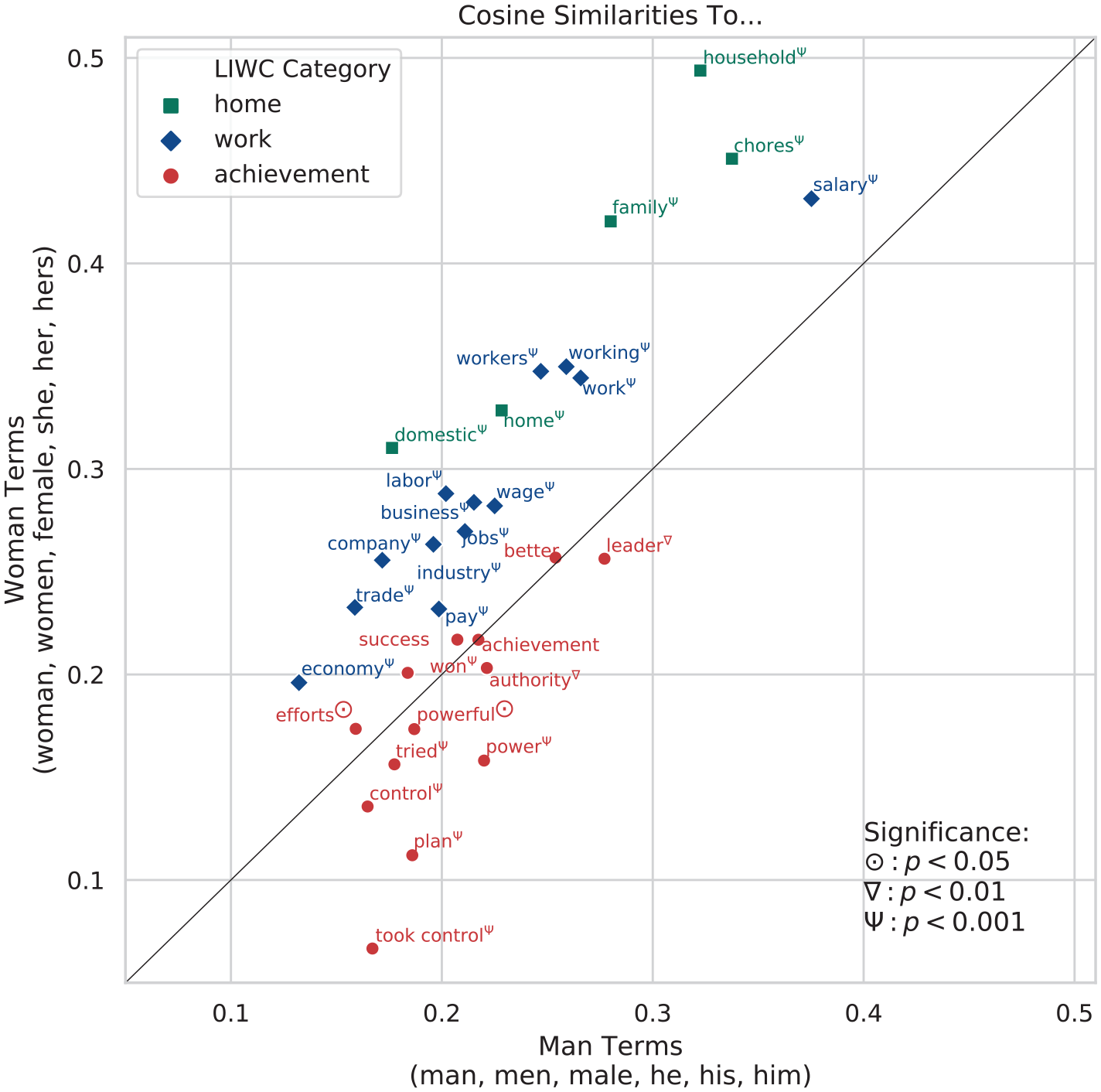
Cosine similarity of gendered terms and words related to home, work, and achievement.
Women are also more closely associated with work-related terms than men. This result is consistent with that of Schmidt (2012) who found that the greatest number of references to women occur in the context of the workplace in recent U.S. history curricula. However, again following Schmidt (2012), the strong association between women and the workplace does not imply the textbooks take a feminist view. The degree to which women’s agency and their choice (rather than need) to work is emphasized, and the type of jobs that they are associated with is also an important part of this framing. Exploring these aspects could be a useful contribution of future work.
Research Question 3: What Are Prominent Topics and How Are They Related?
Identifying Topics
Table 3 shows the highest probability terms for the 10 most prominent topics that emerge from the texts. Topics are ordered by their average probability across all books (see all 50 topics in Appendix Table B1). Note that the topic probabilities are similar, which is expected given that we keep the prior probabilities of the topics and the words fixed (Appendix D).
The 10 Most Prominent Topics in Our Data

Note. Topics are ordered by their average probability across textbooks.
In topic modeling, careful interpretive sense-making is required as the researcher determines the label or meaning of word groupings. Examining the 10 highest probability words for all 50 topics manually, we find that seventeen topics are associated with formal politics (including stems such as govern, presid, polit, federal), two with social movements (movement, protest, civil), and three with everyday workers (farmer, worker, soldier). Since each topic occurs with a relatively similar probability (1.8%–2.2%), the greater number of topics provides evidence that formal politics are emphasized more than topics that focus on the voices of the citizens, in contrast to recommendations by some scholars (e.g., Loewen, 2008; Zinn, 1984).
To dig deeper into our topics, we consider how they are distributed across the different non-named people groups we identified earlier. We study the topical diversity of groups by looking at the number of topics they are associated with (Table 4). As for gender, we find that woman/women are associated with two topics–one related to social movements (women’s rights) and the other to family. Man/men are also associated with the family topic, as well as with three others: one related to the military, another to decision making/morality, and another to mentions in quotes (Appendix F). As for ethnic groups, we find that white only occurs in the context of other ethnicities, suggesting that Whiteness is unmarked unless it is contrasted with minority ethnicities. Black people are associated with two topics, one related to slavery and the other to civil rights, Native Americans are discussed in the context of settlers, and Latinx people in the context of territorial claims. These topics suggest that the discussion of minority ethnicities is dominated by topics where the relationship of the minorities to the majority group is highlighted in some way. These topics, combined with further qualitative analyses, could allow for a better understanding of textbooks’ degree of multifocality (Gordy & Pritchard, 1995).
Topics Associated With Different Groups of People

Note. We define association between a term and a topic as the term occurring in the 10 highest probability words for the topic. Note that the same topic can represent multiple groups.
Comparing the Prominence of Topics Across Books
We also take a closer look at the relative prominence of topics that have been studied in previous research on U.S. history textbooks due to their relevance to the representation of people and events (Anderson & Metzger, 2011; Schmidt, 2012). For example, we compare the prevalence of discussions of slavery with the military in textbooks, and the prevalence of discussions of women relative to discussions of presidents. As Figure 7 illustrates, we find that books that are purchased in more Republican counties tend to talk more about the military (topics associated with armi, militari) than about slavery (slave, slaveri; r = .56, p ≈ .06). We also find a positive correlation between the median percentage of Democrats where books are purchased and the relative prominence of topics associated with women (women, woman) versus ones related to presidents (r = .58, p < .05). Nonetheless, despite differences across books, all books talk more about presidents than women. In fact, both of our results on between-book differences in their representation of people (Figures 3 and 7) suggest that the between-book variation is small compared with pervasive similarities reflecting a deeper, shared historical narrative that is conveyed in these books.

Correlation of topic ratios with political orientation of counties where books are purchased.
Conclusion
Textbook research, and other fields where traditional content analysis methods have dominated, are particularly fruitful settings for the application of NLP methods. Computational tools not only allow for faster, more comprehensive, and bigger studies than prior research but can also enable different insights. They can illuminate the scope and scale of discursive trends in new ways and deepen understandings about the meaning of concepts through the co-occurrence of words, people, and topics. Furthermore, these quantitative measures combined with larger sample sizes facilitates analyzing links between the text and external influences.
In our work on U.S. history textbooks used in Texas, NLP methods for identifying people reveal that Latinx people are virtually absent from textbooks and named individuals are mostly white men. Measured associations between words show that women are mentioned in the contexts of marriage, home, and work, and Black people are involved in actions with low agency and power. Topic modeling demonstrates that books focus more on political history than social history, and discussions of minority ethnicities center on their relationships with White people. We also find that more conservative counties tend to purchase textbooks with less representation of marginalized groups, but that the systematic variation across textbooks is small relative to their pervasive similarities.
Future methodological work would be to develop novel algorithms, models, and lexicons specifically for the domain of social science textbooks, as many of the methods we demonstrate were previously applied to other domains such as news, social media, or fiction. In addition, echoing our introduction, this type of work is inherently interdisciplinary, which means computational approaches cannot operate alone. In-depth qualitative analyses based on the expertise of education researchers and other social scientists still remain crucial not only for a thorough understanding of textbook content but also for interpreting and contextualizing the computational results themselves. The methods are also still under constant development, including efforts to improve fairness (Hovy & Spruit, 2016).
Our contribution centers on methods for describing what textbooks contain. We hope that our approaches can support further research, such as that of Apple and Christian-Smith (2017), on explaining the mechanisms that lead books to contain certain content. For example, one could delve deeper into our preliminary association between political environment and content, by looking at the composition of a state’s board of education or other factors. We hope more nuanced measures will inform discussions about how textbooks can be improved, understanding that norms are constantly evolving and there may not be a single correct answer to what should be in a book. Used thoughtfully, NLP and other methods linked to the rise of artificial intelligence and data science have the potential to generate novel conceptual insights for education research, policy, and practice.
Footnotes
Appendix A
List of Categorized People-Related Terms in Their Singular Noun Form

| Black | Latinx | Other minority | White | Women | Men |
|---|---|---|---|---|---|
| slave (9,339) | mexican (523) | immigrant (3,993) | white (6,350) | woman (14,718) | man (11,558) |
| black (5,673) | latino (136) | tribe (1,657) | colonist (3,172) | her (2,181) | his (9,902) |
| african (476) | hispanic (98) | indian (1,394) | british (2,224) | wife (1,502) | he (6,536) |
| enslaved (437) | mexican-american (46) | minority (897) | english (1,350) | mother (1,132) | king (1,181) |
| freedman (336) | bracero (44) | native (871) | european (1,038) | she (954) | husband (1,044) |
| negro (330) | [puerto] rican (33) | japanese (372) | spanish (856) | girl (746) | him (980) |
| fugitive (311) | chicano (30) | refugee (289) | french (818) | female (547) | son (964) |
| african-american (278) | mexicano (25) | jewish (246) | german (652) | daughter (436) | father (881) |
| runaway (275) | tejano (18) | vietnamese (209) | slaveholder (407) | feminist (308) | himself (847) |
| ex-slave (101) | panamanian (6) | foreigner (158) | puritan (206) | sister (298) | male (774) |
| freeman (71) | latina (2) | savage (156) | italian (196) | lady (263) | boy (680) |
| n*gger (55) | asian (105) | portuguese (104) | widow (171) | brother (585) | |
| freedperson (47) | filipino (102) | slaveowner (90) | queen (159) | congressman (400) | |
| mulatto (46) | iraqi (87) | minstrel (89) | witch (154) | uncle (387) | |
| creole (30) | korean (86) | secessionist (64) | lesbian (134) | businessman (332) | |
| freedwoman (10) | cherokee (85) | nazi (57) | mistress (130) | cowboy (275) | |
| africanamerican (2) | iroquois (82) | yankee (50) | flapper (91) | gentleman (206) | |
| tribal (78) | conqueror (46) | herself (78) | militiaman (168) | ||
| outsider (76) | ex-confederate (43) | housewife (65) | lord (146) | ||
| ethnicity (71) | anglo (38) | grandmother (61) | spokesman (134) | ||
| muslim (65) | vice-president (36) | bride (57) | emperor (130) | ||
| Taztec (60) | anglo-american (30) | midwife (55) | policeman (112) | ||
| pueblo (60) | greek (27) | seamstress (52) | statesman (107) | ||
| sioux (59) | jesuit (23) | heroine (44) | clergyman (106) | ||
| non-white (47) | roman (23) | aunt (32) | grandfather (85) | ||
| nonwhite (45) | hungarian (17) | princess (30) | chairman (77) | ||
| iranian (45) | austrian (15) | waitress (28) | serviceman (73) | ||
| caribbean (40) | anglo-saxon (13) | laundress (27) | frontiersman (71) | ||
| shawnee (34) | czech (13) | goddess (23) | brethren (67) | ||
| cheyenne (29) | tory (12) | niece (19) | seaman (62) | ||
| inca (29) | klansman (10) | nun (18) | countryman (62) | ||
| jew (25) | irishman (8) | hers (13) | minuteman (50) | ||
| subculture (24) | englishman (8) | cowgirl (0) | grandson (46) | ||
| apache (24) | australian (7) | bridesmaid (0) | guy (45) | ||
| navajo (22) | amish (6) | workingman (45) | |||
| anasazi (22) | scandinavian (5) | foreman (45) | |||
| israeli (21) | moravian (4) | workman (39) | |||
| japanese-american (21) | latin (3) | salesman (38) | |||
| mohawk (19) | victorian (3) | horseman (35) | |||
| algonquian (19) | georgian (3) | nobleman (32) | |||
| seminole (19) | bolshevik (2) | cattleman (32) | |||
| palestinian (18) | slav (2) | friar (32) | |||
| gypsy (18) | spaniard (2) | fisherman (27) | |||
| jamaican (15) | anglo-texan (2) | widower (26) | |||
| huron (13) | briton (2) | forefather (25) | |||
| powhatan (13) | englander (1) | journeyman (25) | |||
| perce (12) | patriarch (23) | ||||
| comanche (12) | tradesman (21) | ||||
| dakota (12) | fireman (21) | ||||
| marginalized (10) | gunman (20) | ||||
| arapaho (10) | prince (20) | ||||
| choctaw (8) | nephew (19) | ||||
| haitian (7) | rifleman (14) | ||||
| chickasaw (7) | guardsman (13) | ||||
| barbadian (6) | pope (9) | ||||
| lakota (6) | duke (5) | ||||
| sauk (6) | groom (4) | ||||
| hebrew (5) | dairyman (1) | ||||
| mandan (4) | |||||
| mexica (4) | |||||
| asian-american (2) | |||||
| hopi (2) | |||||
| puebloan (1) |
Note. These nouns were manually filtered from all heads of noun phrases across textbooks, and the frequency in brackets also includes occurrences where they are used as adjectives to mark other people-related nouns, e.g., Black man. Our analyses included an additional 1,665 terms, such as worker and village, that were not categorized into a demographic group.
Appendix B
All 50 Topics Used in Our Topic Modeling Analysis

| Topic probability | Top 10 topic terms |
|---|---|
| .022 | armi, general, confeder, troop, union, forc, command, battl, british, victori |
| .0218 | democrat, parti, republican, elect, vote, candid, won, voter, major, popular |
| .0213 | read, inform, sourc, newspap, write, book, chapter, map, publish, learn |
| .0213 | man, hand, boy, thing, back, day, eye, told, cloth, dress |
| .0211 | centuri, industri, chang, growth, develop, economi, econom, revolut, region, increas |
| .021 | european, north, america, spanish, explor, empir, europ, trade, spain, africa |
| .021 | water, river, cattl, miner, mountain, gold, mine, food, west, forest |
| .0209 | unit, war, world, state, nation, civil, end, power, america, year |
| .0208 | explain, identifi, role, describ, effect, event, analyz, play, import, impact |
| .0206 | german, germani, soviet, alli, franc, soviet union, europ, hitler, russia, unit |
| .0204 | cultur, societi, american, tradit, life, group, immigr, distinct, valu, reflect |
| .0204 | presid, kennedi, johnson, reagan, nixon, administr, truman, polici, eisenhow, bush |
| .0203 | popular, show, imag, paint, artist, photograph, depict, music, televis, audienc |
| .0202 | human, natur, man, person, thing, moral, reason, believ, good, individu |
| .0202 | african, black, slave, white, southern, free, south, american, slaveri, northern |
| .0202 | indian, nativ, land, tribe, west, settler, american, white, western, frontier |
| .0201 | social, reform, polit, progress, econom, societi, interest, class, effort, system |
| .0201 | peopl, freedom, liberti, equal, american, countri, free, democraci, idea, great |
| .0201 | slaveri, southern, lincoln, northern, union, south, territori, free, north, compromis |
| .0201 | debat, conflict, tension, polit, issu, continu, divis, cold war, era, controversi |
| .0201 | movement, women, organ, group, civil right, right, leader, african, polit, equal |
| .0201 | percent, million, number, popul, year, immigr, increas, half, larg, total |
| .02 | constitut, right, amend, vote, citizen, convent, deleg, state, bill, congress |
| .02 | face, problem, depress, econom, suffer, economi, caus, great depress, crisi, prosper |
| .0198 | bank, money, tax, pay, debt, loan, rais, fund, paid, govern |
| .0198 | worker, labor, work, union, job, employ, strike, factori, industri, wage |
| .0198 | govern, power, feder, nation, peopl, author, constitut, state, system, unit |
| .0198 | roosevelt, wilson, peac, presid, treati, negoti, theodor roosevelt, taft, leagu, agreement |
| .0197 | men, women, famili, children, young, work, woman, home, mother, husband |
| .0197 | citi, york, urban, hous, live, town, center, communiti, move, chicago |
| .0197 | railroad, build, line, technolog, transport, road, develop, travel, invent, canal |
| .0197 | good, trade, product, manufactur, market, import, produc, economi, consum, tariff |
| .0196 | farmer, farm, planter, small, land, cotton, plantat, crop, famili, larg |
| .0196 | jackson, jefferson, adam, federalist, support, presid, hamilton, andrew jackson, whig, republican |
| .0196 | soldier, thousand, die, kill, hundr, death, year, day, men, fight |
| .0196 | king, march, day, protest, washington, demonstr, polic, martin luther, mob, black |
| .0196 | vietnam, forc, militari, troop, south, unit, war, attack, iraq, communist |
| .0195 | ship, japanes, japan, island, china, navi, british, sea, chines, attack |
| .0195 | mexican, mexico, unit, texa, california, territori, spanish, florida, spain, claim |
| .0194 | crime, charg, prison, accus, trial, critic, convict, public, communist, murder |
| .0194 | religi, church, christian, protest, god, minist, cathol, religion, puritan, communiti |
| .0193 | program, deal, feder, provid, public, creat, administr, aid, roosevelt, work |
| .0193 | english, england, virginia, coloni, pennsylvania, settler, governor, establish, york, dutch |
| .0193 | british, colonist, coloni, french, britain, independ, king, revolut, parliament, patriot |
| .0192 | suprem court, court, decis, law, rule, case, justic, legal, constitut, separ |
| .0192 | compani, busi, railroad, corpor, industri, steel, product, manag, oil, trust |
| .0191 | offic, presid, hous, senat, elect, member, repres, appoint, congress, serv |
| .0191 | act, pass, law, congress, legisl, bill, immigr, feder, reconstruct, prohibit |
| .0191 | john, william, wrote, jame, son, henri, georg, name, smith, brown |
| .0186 | school, educ, public, student, univers, colleg, servic, high, children, train |
Note. Topics are sorted by their average probability across books.
Appendix C
Appendix D
Appendix E
Appendix F
The topics associated with men are more difficult to interpret in relation to topics associated with other groups, as it is possible man or men is used in an ungendered manner, such as in historical quotes. Here, for each topic associated with man/men, we include a random sample of 20 sentences where the corresponding topic has a high probability (>.3). The sentences are uniformly sampled across all books. Topic 3, as we mention in the paper, consists predominantly of quotes. We do not treat quotes differently from the main text in our analyses, as we believe that the choice of quotes is a core part of a textbook’s framing of people as well.
Acknowledgements
We would like to thank the following individuals for helpful conversations, feedback, and ideas: Noah Smith, Sebastian Munoz-Najar Galvez, Lily Fesler, Julia Lerch, Dallas Card, Ramón Antonio Martínez, Hannah D’Apice, Arya McCarthy, Bonnie Krejci, Mark Algee-Hewitt, AJ Alvero, Julia Perlmutter, Christine Wotipka, and Morgan Polikoff. We are grateful for the support of the Melvin and Joan Lane Stanford Graduate Fellowship (to D.D.) and NSF Graduate Research Fellowship Grant No. DGE 1752814 (to L.L.).
Authors’ Note
The first two authors are equal contributors.
Notes
Authors
LI LUCY is a PhD student in the School of Information at the University of California, Berkeley. Her research uses natural language processing and data mining to shed light on social behavior and interactions.
DOROTTYA DEMSZKY is a PhD student in linguistics at Stanford University, advised by Dan Jurafsky. Her research focuses on developing natural language processing methods to study semantics and social phenomena mediated through language, with applications to the domain of education.
PATRICIA BROMLEY is an assistant professor of education and (by courtesy) sociology at Stanford University. Her research focuses on the rise and globalization of a culture emphasizing rational, scientific thinking and expansive forms of rights, and spans a range of fields including comparative education, the sociology of education, organization theory, and public administration and policy.
DAN JURAFSKY is professor and chair of linguistics and professor of computer science at Stanford University. His research focuses on natural language processing as well as its application to the behavioral and social sciences.