
Abstract
Hearing devices such as hearables, personal sound amplification products, hearing aids, and active hearing protectors providing amplification in some settings are increasingly used by individuals with normal hearing. However, the benefits of providing amplification in this population remain unclear. This study investigated the effects of amplification on hearing thresholds, speech intelligibility in quiet, and experienced listening effort in normal-hearing listeners. Forty-four young adults with clinically normal hearing participated in two experiments comparing three conditions: open ear, aided with 0 dB insertion gain to approximate acoustic transparency, and aided with 15 dB flat insertion gain. Amplification was provided using a research hearing aid fitted with closed foam earplugs. Speech intelligibility was assessed with the Oldenburg Sentence Test, and experienced listening effort was measured using Adaptive CAtegorical Listening Effort Scaling (ACALES). Listening through the nominally transparent device introduced consistent disadvantages, including elevated hearing thresholds, reduced speech intelligibility, and increased listening effort. Providing 15 dB of amplification partially compensated hearing threshold elevation, fully restored speech intelligibility and reduced experienced listening effort beyond the unaided condition. Benefits of amplification at low input levels were primarily limited by the equivalent input noise of the hearing-aid microphones. These findings suggest that amplification can provide meaningful benefits for normal-hearing listeners at low speech levels, particularly when listening effort is considered alongside speech intelligibility. Future studies should examine these effects under more ecologically valid listening conditions, and potential benefits of increased amplification in hearing-impaired listeners.
Keywords
Introduction
The dynamic range of human hearing is traditionally defined as the range between the normal hearing threshold and the threshold of discomfort or pain. At 1 kHz, this range extends from approximately 0 dB SPL, corresponding to the median absolute threshold of young adults with normal hearing ISO 389-7 (2019), to roughly 100 to 120 dB SPL, where sound becomes uncomfortably loud ISO 226 (2023). In sensorineural hearing loss, the most obvious audiological consequence is an elevated hearing threshold (Moore, 2013). In addition, a variety of suprathreshold processing deficits arise, affecting loudness perception, temporal and spectral resolution, and speech processing (Oxenham, 2016; Plack et al., 2014). While elevated thresholds can be compensated by amplification that restores audibility, suprathreshold deficits typically require alternative signal processing strategies such as dynamic range compression, directional microphones, or digital noise reduction (Dillon, 2012; Metz, 2014; Schaub, 2008).
The benefits of amplification for individuals with clinically diagnosed hearing impairment are well established. Beyond this population, increasing attention has focused on listeners with normal audiometric thresholds who nevertheless report substantial listening difficulties, sometimes attributed to hidden hearing loss or other suprathreshold deficits. Several studies have examined whether mild gain amplification or specific hearing aid features may provide benefit for this group. Roup et al. (2018) concluded that mild amplification may be a viable option for a subset of listeners with self-reported hearing difficulties. Singh and Doherty (2020) reported improved speech understanding in noise with mild amplification in adults with normal audiograms. Mealings et al. (2024) observed reduced self-reported difficulties in noise and improvements in perceived understanding, participation, and mood, although no corresponding improvements were found in laboratory speech tests. Davidson et al. (2024) similarly reported benefits primarily reflected in questionnaire outcomes. Clinical considerations for this population are summarized by Beck and Danhauer (2019). Overall, these findings suggest potential benefits for selected listeners, but the evidence remains limited and heterogeneous.
A related class of amplification systems includes hearables with hear-through functionality and personal sound amplification products (PSAPs). These devices are intended for situational sound enhancement and may provide moderate amplification for individuals with mild listening difficulties who do not meet clinical criteria for hearing aid fitting, as well as for users without hearing impairment seeking enhanced listening experiences (Bothe et al., 2025; Chen et al., 2022; Kim et al., 2024; Seol & Moon, 2022). Another application involves hunters, wildlife observers, or soldiers who wish to amplify soft environmental sounds while remaining protected from hazardous impulsive noise (Gonzalez, 2022; Killion et al., 2011). Level-dependent hearing protectors address this need by amplifying low-level sounds while attenuating high-level impulses (Borg et al., 2008; Lindley et al., 1997). Despite differing use cases, these devices share common electroacoustic constraints. Systematic benefits for listeners with normal-hearing thresholds remain limited and appear more closely related to advanced processing strategies such as directionality (Amlani, 2001), noise reduction (Van Den Tillaart-Haverkate et al., 2017), or remote microphones (Husstedt et al., 2022) than to amplification alone.
One explanation for the limited benefits of amplification in normal hearing listeners is that hearing aids and related devices introduce perceptual side effects. Advanced signal processing can degrade sound quality, distort temporal cues, and impair localization (Brons et al., 2013; Picou et al., 2014; Stone & Moore, 2004). Additional effects arise from microphone placement, nonlinear distortions, and processing latency, which may alter natural pinna cues, disrupt interaural timing information, or produce comb filtering, particularly in open fit configurations (Agnew, 1998; Byrne & Noble, 1998; Cubick et al., 2018; Denk et al., 2019; Súsonnudóttir et al., 2024; Van Den Bogaert et al., 2011). Even under linear processing and in co-located speech-in-noise tasks, slight reductions in speech recognition and increases in physiological markers of listening effort have been observed (Denk et al., 2024; Dillon et al., 2003; Kemper et al., 2025), effects unlikely to be attributable to psychological factors alone (Wiederschein et al., 2025). A further limitation arises from the equivalent input noise of hearing aid microphones and preamplifiers, which can mask low level sounds (Dillon, 2012; Lewis et al., 2010; Macrae & Dillon, 1996). Because this noise is introduced at the input stage, amplification cannot compensate for its masking effect (Agnew & Block, 1997; Husstedt et al., 2025). As a result, aided thresholds may remain unchanged or even worsen relative to unaided thresholds, particularly in listeners with low unaided thresholds and devices with higher equivalent input noise.
At the same time, recent evidence suggests that low level sounds may already be experienced as effortful by listeners with normal hearing. Husstedt et al. (2025) showed that speech in quiet elicited no perceived listening effort only at levels of approximately 40 dB SPL and above, despite ceiling intelligibility at lower levels. Many everyday communication situations involve speech at such low sound levels, particularly in environments that are otherwise quiet (Wu et al., 2018). Speech levels between 30 and 45 dB SPL correspond to quiet whispering or typical office sound levels and are commonly encountered when communicating with children, conversing across rooms, or listening from a distance (Husstedt et al., 2022; Schulte et al., 2024, 2025; Stronks et al., 2021). These findings identify soft speech in quiet as an ecologically relevant and perceptually demanding listening condition. Consequently, assessments of amplification should consider listening effort in addition to intelligibility. However, it remains unclear whether amplification can effectively reduce listening effort under near threshold conditions given its inherent side effects.
The present study therefore investigated the effects of amplification in normal hearing listeners to examine the fundamental consequences of amplification itself. Forty-four young adults with clinically normal hearing and no self-reported hearing difficulties participated. Free-field hearing thresholds, speech recognition, and experienced listening effort were assessed under three conditions: open ear, aided with approximately zero insertion gain, and aided with 15 dB flat insertion gain. We hypothesized that aided thresholds would worsen and speech recognition in quiet would be reduced due to masking by equivalent input noise, while amplification might nevertheless reduce experienced listening effort.
Methods
Study Design
For the first experiment, a total of 18 young adults with clinically normal hearing were initially recruited to assess free-field hearing thresholds, speech recognition in quiet, experienced listening effort in quiet, and pupil size as an objective marker of invested listening effort. Due to substantial data loss from the pupillometer, eight additional participants were newly recruited to replace inconsistent datasets from the original participants. This issue raised concerns about the integrity of the entire pupil-size dataset, which was therefore excluded from all subsequent analyses. Excluding the pupil data allowed all remaining measurements to be retained, resulting in a total sample size of N = 26 participants (18 original + 8 recruited as replacements). In addition, a second experiment with 18 newly recruited participants was conducted to obtain a more valid assessment of experienced listening effort. In the first experiment, incorrect instructions and potential sequence effects likely caused participants to rate speech recognition accuracy rather than perceived listening effort. For this reason, listening-effort measurements were repeated in the second sample (see Figure 1). The data from both experiments are presented in the Results section; however, the listening-effort data from the second experiment is considered more reliable.

Visualization of the study design and experimental sequence. All measurements were performed in quiet.
Participants
In summary, the analyzed dataset comprises 26 participants (21 female) aged 18 to 31 years (M = 23 years) from the first experiment, and 18 participants (14 female) aged 19–34 years (M = 23 years) from the second experiment. Participants were recruited via an online announcement at the University of Lübeck and through private contacts of employees of the German Institute of Hearing Aids. Written informed consent from all participants was obtained before the study, and participants received financial compensation for their effort. Inclusion criteria required German language proficiency comparable to that of a native speaker, no known hearing problems, no acute cold or other illnesses affecting hearing, no noise exposure within the preceding 24 hr, and no tinnitus. Pure tone hearing thresholds were assessed monaurally via headphones at frequencies between 0.25 and 8 kHz and were confirmed to be ≤30 dB HL in both ears for all participants. Moreover, the pure-tone average (PTA) across 500, 1000, 2000, and 4000 Hz was below 20 dB HL in each ear. The study was approved by the Ethics Committee of the University of Lübeck (number 2024-643).
Participants were young adults with clinically normal hearing and no self-reported hearing difficulties. This population was intentionally selected for several reasons. First, amplification technologies are increasingly used by individuals without diagnosed hearing loss, particularly through consumer hearables with hear-through functionality. Investigating amplification effects in normal-hearing listeners therefore allows assessment of potential perceptual benefits and side effects in a population representative of the majority of the general public. Second, studying listeners without reported hearing problems enables isolation of the fundamental acoustic and perceptual consequences of amplification, independent of confounding factors related to elevated thresholds or clinically significant suprathreshold deficits. This approach provides a baseline against which studies in listeners with hearing complaints can be interpreted. Third, previous work in this area has primarily focused on speech recognition or self-reported benefit. The present study additionally included experienced listening effort as an outcome measure, based on the hypothesis that amplification may influence perceptual effort even in the absence of measurable intelligibility deficits or self-reported hearing problems. This design allowed us to evaluate whether amplification produces subtle but functionally relevant effects in listeners with normal hearing.
Amplification
The study employed two aided conditions to dissociate effects related to device use from those attributable to amplification itself. A 0 dB insertion gain condition, nominally acoustically transparent, was included to quantify potential detrimental effects associated with wearing hearing aids per se and to approximate typical hear through settings used in hearables by individuals without hearing loss. The second condition applied 15 dB of flat, linear insertion gain. Flat gain was chosen to evaluate the effects of amplification without introducing frequency dependent shaping, which would confound amplification effects with spectral processing. The gain magnitude of 15 dB represents a comparatively high level of amplification for listeners with normal hearing and ensures that the equivalent input noise of the hearing aid microphones and preamplifiers constitutes a relevant limiting factor. At the same time, this gain is sufficiently low to be implemented without requiring feedback reduction algorithms, thereby minimizing additional processing artifacts. Linear amplification was selected due to simplicity and also because, at low input levels, contemporary hearing devices typically apply linear gain or expansion, whereas compression is rarely used in this range. Expansion was not implemented because, although it can attenuate microphone noise, it may also reduce potential amplification benefits. By employing linear processing with spectrally flat gain, the study was designed to examine the fundamental benefits and limitations of amplification under acoustically controlled conditions.
Experimental Sequence
Both experiments began with an interview and anamnesis phase (see Figure 1) during which participants received instructions, provided written informed consent, and answered general demographic questions (e.g., age and gender). A brief medical history was obtained, the ears were visually inspected for abnormalities, and pure-tone air-conduction thresholds were measured using headphones. Only in the first experiment, participants subsequently completed a training phase for the speech test. In both experiments, the main assessment then commenced, consisting of three listening conditions: open ear, aided 0 dB gain, and aided 15 dB gain, presented in a balanced and randomized order. In experiment 1, each condition included free-field audiometry, experienced listening-effort ratings, speech-recognition testing, and the pupil-size measurement. In experiment 2, each condition comprised only free-field audiometry and the assessment of experienced listening effort. In the first experiment, each testing session lasted approximately 2.5 hr, whereas sessions in the second experiment required about 1 hr.
Speech Recognition
Speech recognition was assessed using the German matrix test, the Oldeburg Sentence Test (OLSA) (Wagener et al., 1999), and was conducted only in the first experiment. Participants first completed two training lists unaided, each consisting of 20 sentences, before performing the actual test within the three conditions. After the training phase, the adaptive procedure of the test was initiated with a starting level of 30 dB SPL to individually determine the speech reception thresholds (SRTs) for 50% and 80% intelligibility in quiet. These thresholds are referred to as SRT50 and SRT80, respectively. Based on these two points, individual and mean psychometric functions were fitted.
Subjective Listening Effort
Subjective listening effort was measured using the Adaptive CAtegorical Listening Effort Scaling (ACALES) procedure (Krüger et al., 2017), which uses the same speech material as the OLSA. In each trial, two OLSA sentences were presented, and participants were asked, “How much effort does it require for you to follow the speaker?” Responses were provided via a touchscreen using a 14-point scale expressed in Effort Scale Categorical Units (ESCU). The original scale ranges from “no effort” (ESCU 1) to “extreme effort” (ESCU 13) and includes an additional category, “only noise,” which is used within the adaptive procedure but excluded from the final analysis. For measurements conducted in quiet, several minor adjustments were made. Noise presentation was disabled, the initial speech level of the adaptive procedure was set to 40 dB SPL, and the category label “only noise” was replaced with “nothing heard.” Participants completed ACALES procedures in both experiments 1 and 2 across all three conditions. In experiment 1, OLSA training and speech recognition testing were performed within each condition prior to ACALES. Participants were instructed to rate “how effortful it is to recognize the speech.” In experiment 2, no speech recognition testing was conducted, and participants were asked to rate “how effortful it is to follow the speech,” consistent with the procedure applied in Husstedt, Husstedt et al. (2025) and the original instructions given by Krüger et al. (2017).
Facilities and Hardware
All experiments were conducted in a sound-isolated and acoustically treated auditory booth (2.6 × 3.6 × 2.5 m³, T20 = 0.1 s) that met the requirements for free-field audiometry according to ISO 8253-2 (2009). As part of the interview and anamnesis block, monaural pure-tone audiometry was performed via headphones for both ears. Additionally, within each condition, free-field hearing thresholds were assessed using wobble tones. Audiometry was implemented using a custom MATLAB script (MathWorks, USA) and conducted at frequencies of 0.125, 0.25, 0.5, 0.75, 1, 2, 4, 6, and 8 kHz, with stimulus levels adjusted in 1 dB steps. Stimuli were presented using a Fireface 802 soundcard (RME, Germany) and either DD450 headphones (Radioear, USA) or a Genelec 8351A coaxial loudspeaker (Genelec, Finland) positioned 1 m in front of the participants. OLSA and ACALES measurements were administered in the free field using the same loudspeaker and the Oldenburg Measurement Applications (OMA), Version 2.3.2.0 (Hörzentrum Oldenburg, Germany). Linear amplification was provided using the Portable Hearing Lab (Pavlovic et al., 2019) in combination with the open Master Hearing Aid software (Kayser et al., 2019). Receiver-in-the-canal (RIC) headsets with M receivers (Type RIC E-50D, Sonion), as evaluated in Denk et al. (2022), were used. Each headset includes 2 TDK ICS 40730 low noise micro-electromechanical system (MEMS) microphones, but only the frontal microphone was used. An attempt was made to quantify the research hearing aid's output noise, but it fell below the measurement system's noise floor. Moreover, no output noise was perceptible when the microphone input was muted. Coupling to the ear was achieved using closed foam earplugs incorporating short sound tubes connected to the receivers. Real-ear measurements were conducted using ER7C Series B probe tube microphones (Etymotic, USA) in combination with a custom MATLAB script (MathWorks, USA) that implemented an automated closed loop gain adjustment procedure based on a 65 dB SPL pink noise stimulus. For each participant, the script iteratively adjusted the device gain based on real-ear insertion gain measurements to approximate the target flat insertion gain of either 0 or 15 dB across frequency. The resulting individual real-ear insertion gains reflect the acoustically achievable outcome of this procedure and are shown for both experiments in Figure 2. The mean error across all participants remained within ±5 dB from 100 Hz to 10 kHz. However, although the aided configuration was designed to provide a 15 dB gain, an unintended drop of approximately 5 dB around 6 kHz appears, caused by overly restrictive limits inadvertently set in the configuration.

Real-ear insertion gain measured in the first and second experiments (N = 44) for aided configurations with intended gains of 0 or 15 dB.
Equivalent Input Noise of the Hearing Aid Microphones
The equivalent input noise (EIN) of the hearing-aid microphones in the headset used was measured in accordance with IEC 60118-0 using a 2cm3 coupler specified in IEC 60318-5. To relate the measured EIN 1/3-octave-band levels to free-field conditions, Coupler Response for Flat Insertion Gain (CORFIG) values reported by Bentler and Pavlovic (1989) were applied. In addition, direct recording of the microphones’ digital input signals was also performed in an anechoic test room, which was allowed by the platform but relied on default calibration values. To convert these recordings to free-field equivalent levels, the microphone location effect for behind-the-ear devices, as specified in IEC 60118-8, was subtracted. Because the hearing-aid microphones were not individually calibrated at low frequencies, the IEC 60118-0 coupler-based measurements were considered more reliable in this frequency range. At frequencies above 5 kHz, however, the correction to free-field levels becomes less reliable due to the low-pass characteristic of the 2cm3 coupler. Therefore, for frequencies between 5 and 8 kHz, the EIN values derived from the digital microphone recordings were used. The resulting merged EIN 1/3-octave band levels, which serve as model input in the analyses presented later in the article, are shown in gray in Figure 3.

EIN of the hearing-aid microphones expressed as 1/3-octave-band levels and referred to free-field conditions. Dashed curves show EIN measured according to IEC 60118-0 and converted to free-field levels using the CORFIG values of Bentler and Pavlovic (1989). Solid curves represent EIN derived from digital recordings of the microphone input signals obtained in a quiet anechoic test room and converted to free-field levels using the MLE for behind-the-ear devices specified in IEC 60118-8. CORFIG= Coupler Response for Flat Insertion Gain; EIN= equivalent input noise; MLE= microphone location effect.
Simplified Model of Aided Hearing Thresholds
In an idealized scenario, a hearing aid would simply apply gain to the acoustic input, thereby shifting the hearing threshold by the amount of gain provided. In practice, however, hearing aid microphones introduce input noise (

Simplified model of hearing aid amplification including noise at the input and output. Moreover, the recognition of a sound is assumed to be limited by an internal noise source.
We assume that all noise sources add in level. By referring the output noise and internal noise back to the input, that is, by subtracting the applied gain G, the overall noise level can be expressed as

Next, the relationship between masking noise level and hearing threshold is considered based on the data reported by Fletcher (1940). Fletcher defined the factor K as the difference in decibels between the noise power spectral density (which he termed a noise spectrogram) and the resulting noise-masked hearing threshold. In the present work, we adapt this concept to noise levels expressed in 1/3-octave bands. To this end, the data from Figure 13 in Fletcher (1940) were digitized, and the corresponding noise power spectral density was converted to 1/3-octave-band levels, yielding the factor

Upper panel shows the digitalized data of Figure 13 of Fletcher (1940). The lower curve represents the threshold of hearing, and the upper curve represents the “threshold of feeling,” that is, the threshold of tolerable sound pressure levels. Note that these curves do not exactly correspond to the current reference data defined in ISO 389-7 (2019) or ISO 226 (2023). The lower panel visualizes
We use the factor K in two ways. First, it is employed to estimate the internal noise level from the unaided hearing threshold (

Figure 6 illustrates four example scenarios based on equation (2). In all cases, the unaided hearing threshold and K are assumed to be zero (i.e.,

Four examples for the application of the simplified model defined in equation (2), where the hearing threshold and K are always assumed to be zero (i.e.,
In panel (a), the output noise is well below the unaided hearing threshold (
Statistics
Normality of the data was initially assessed using the Shapiro–Wilk test. Comparisons were performed using paired t-tests or the Wilcoxon signed-rank test, as appropriate. For multiple tests, Bonferroni's correction was utilized.

The upper panel shows the aided minus unaided hearing threshold measured in a free field of both experiments (N = 44). Statistically significant difference from zero and between the conditions aided 0 dB and aided 15 dB are indicated at each test frequency (0.125, 0.25, 0.5, 0.75, 1, 2, 4, 6, and 8 kHz). The lower panel depicts the standard error of the aided minus unaided hearing thresholds.
Results
Free-Field Hearing Thresholds
In addition to the monaural headphone screening of both ears, binaural hearing thresholds were assessed in the free field via loudspeaker for all three configurations. Figure 7 shows the difference from the open-ear condition for the aided configurations with 0 and 15 dB gain, averaged across all participants from both experiments (N = 44). A post hoc sensitivity analysis assuming a statistical power of 0.80 and an alpha level of 0.05 indicated that differences in relative hearing thresholds could be detected if they were at least 1.9 dB in magnitude. Statistically significant deviations from zero, as well as significant differences between the 0 and 15 dB aided conditions, are indicated for each test frequency. For the nominally acoustic transparent condition (0 dB gain), hearing thresholds increased (i.e., worsened) at nearly all frequencies, except at 250 Hz and 8 kHz. The largest elevation in threshold, approximately 9 dB, occurred at 4 kHz. In the 15 dB gain condition, threshold changes varied across frequency. Compared to the unaided condition, thresholds were lower, indicating improved sensitivity, at the three lowest frequencies between 125 and 500 Hz and at 8 kHz, with improvements of up to 5 dB. In contrast, between 1 and 6 kHz thresholds were elevated, with the largest increase of approximately 9 dB observed at 4 kHz. When compared to the nominally transparent condition, the 15 dB gain condition resulted in significantly lower thresholds at most frequencies. Exceptions were 4 and 6 kHz, where no significant differences were observed between conditions.
Figure 7 also shows in gray the estimated hearing-threshold shift predicted by the model described in equation (2). For this calculation, the output noise (
Speech Recognition
Speech levels corresponding to 50% and 80% speech intelligibility (SRT50 and SRT80) were adaptively measured in the first experiment (N = 26) for all three configurations (see Table 1). A post hoc sensitivity analysis, assuming a statistical power of 0.80 and an alpha level of 0.05, indicated that differences in speech level could be detected if they were at least 0.75 dB for SRT50 and 0.87 dB for SRT80. For comparison, Table 1 also includes values from Husstedt et al. (2025), which do not differ significantly from the present results in the unaided condition. As illustrated in Figure 8, the unaided condition required speech levels of approximately 14.9 and 18.2 dB to reach 50% and 80% intelligibility, respectively. At both SRTs, the nominally transparent hearing-aid condition resulted in poorer performance, with increases on average of 3.6 dB at SRT50 and 4.6 dB at SRT80 compared with the unaided condition. This disadvantage was fully compensated by the application of amplification, such that no statistically significant differences were observed between the unaided condition and the aided condition with 15 dB gain. Consequently, amplification improved performance relative to the nominally transparent hearing-aid condition and restored speech recognition to the unaided level. No additional improvement beyond unaided performance was observed.

Boxplot and individual results of SRT50 and SRT80 for all conditions measured in experiment 1 (N = 26). Gray lines show results of individual participants. SRT=speech reception threshold.
Mean Speech Levels for SRT50 and SRT80 in Experiment 1 (Free Field) and in Husstedt et al. (2025) (headphone presentation).

Note. SRT=speech reception threshold.
Experienced Listening Effort
The adaptive ratings of experienced listening effort are shown in Figure 9 for both experiments, all three conditions, and the rating categories “no effort” (ESCU1), “moderate effort” (ESCU7), and “extreme effort” (ESCU13). These data were compared to results from Husstedt et al. (2025), which previously characterized the relationship between listening effort and speech level for soft speech in quiet and demonstrated that this relationship differs from that observed in typical speech in noise paradigms. Replicating this pattern was therefore important for validating the present experimental approach. A post hoc sensitivity analysis, assuming a statistical power of 0.80 and an alpha level of 0.05, indicated that differences in speech level could be detected if they were at least 1.0 dB for ESCU1, 0.8 dB for ESCU7, and 1.1 dB for ESCU13. Comparing the highest and lowest ratings in the unaided condition with those from Husstedt et al. (2025) revealed statistically significant differences in experiment 1 (see Table 2), manifested as a steeper slope and a shift toward lower speech levels. Because participant instructions differed slightly (see Methods section) and a speech recognition task always preceded the listening effort ratings, experiment 2 was conducted to better replicate the conditions of the earlier study by including listening effort ratings without a preceding speech recognition task. In experiment 2, no statistically significant differences relative to Husstedt et al. (2025) were observed for either ESCU1 or ESCU13 (see Table 2). Consequently, the listening effort data from experiment 2 are considered more reliable and are therefore discussed in more detail below.
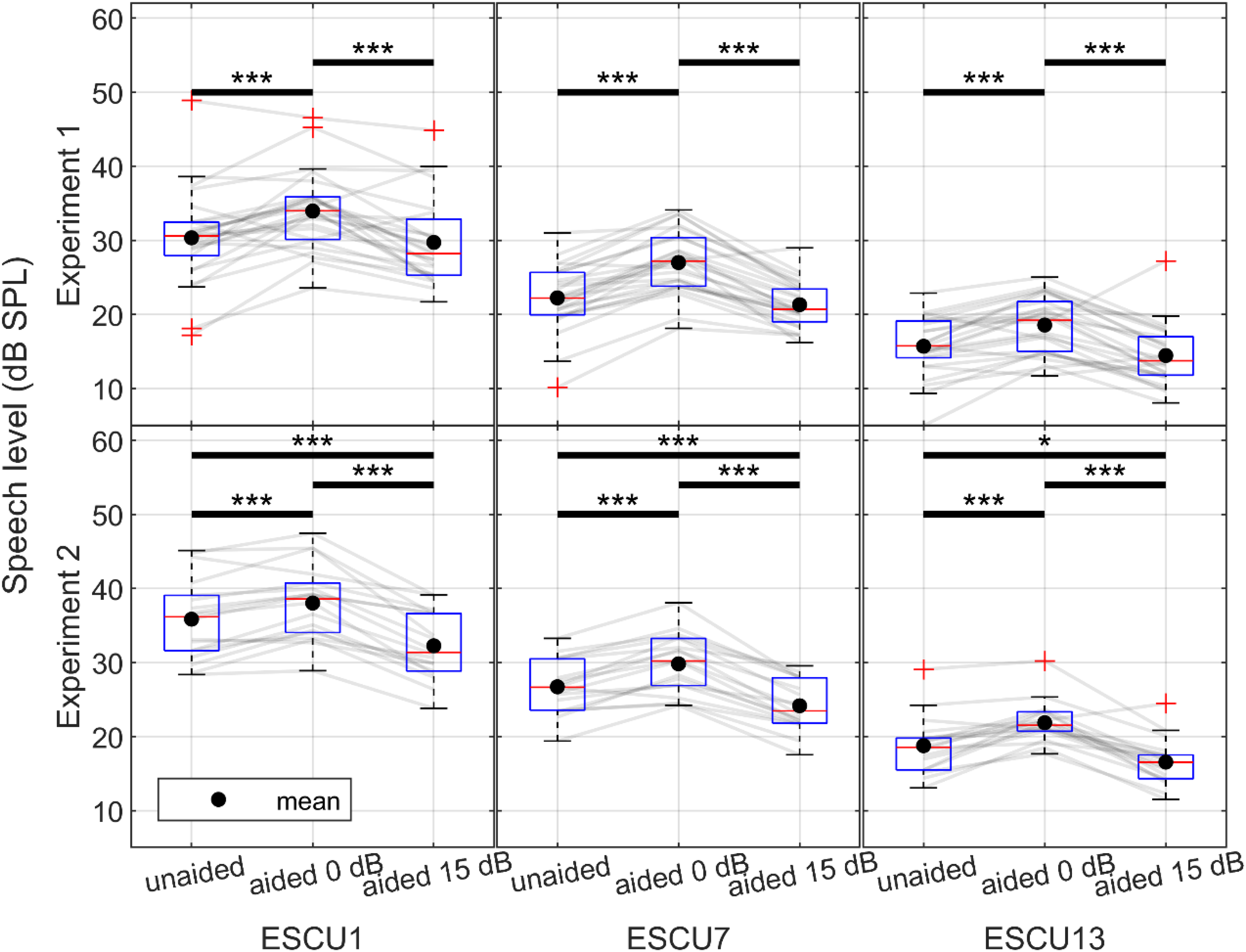
Adaptive ratings on experienced listening effort for experiment 1 (N = 26) and experiment 2 (N = 18) in all three conditions, and for the ratings “no effort” (ESCU1), “moderate effort” (ESCU7), and “extreme effort” (ESCU13). ESCU= Effort Scale Categorical Units.
Mean Ratings for “No Effort” (ESCU1) and “Extreme Effort” (ESCU13) in the Unaided Condition Across Experiment 1, Experiment 2, and the Previous Study by Husstedt et al. (2025).

Note. ESCU= Effort Scale Categorical Units.
As shown in the threshold data, the 0 dB insertion gain condition was associated with elevated aided thresholds relative to the unaided condition, indicating incomplete acoustic transparency. This reduced effective audibility likely contributed to the increased listening effort observed across ESCU levels.
The lower panel of Figure 9 shows that the ratings for ESCU1, ESCU7, and ESCU13 differed significantly across conditions. Wearing nominally transparent hearing aids increased experienced listening effort at all ESCU levels, indicating that higher speech levels were required to achieve the same listening-effort rating. On average, this increase amounted to 2.2 dB for ESCU1, 3.1 dB for ESCU7, and 3.1 dB for ESCU13. In contrast, providing 15 dB of amplification in the aided condition fully compensated for this disadvantage and even improved performance relative to the unaided condition. In this case, lower speech levels were sufficient to achieve the same listening-effort ratings, with average reductions of 3.6 dB for ESCU1, 2.6 dB for ESCU7, and 2.2 dB for ESCU13. Although a trend toward slightly greater benefit at lower effort levels was observed, this effect was not statistically significant. Overall, the aided configuration with 15 dB gain demonstrated a clear advantage of hearing aid use in terms of experienced listening effort, yielding an improvement of approximately 3 dB. However, a full 15 dB shift, as would be expected with ideal broadband amplification, was not observed.
Speech Intelligibility and Experienced Listening Effort
Figure 10 shows the speech recognition results as psychometric functions fitted to the individual and mean SRT50 and SRT80 data. In addition, the individual and mean ACALES curves are overlaid in the same plot. On average, the maximum listening-effort rating (ESCU13, “extreme effort”) was reached at speech recognition scores of 84% in the unaided condition, 75% in the aided condition with 0 dB gain, and 66% in the aided condition with 15 dB gain. The dynamic range between SRT50 and the “no effort” rating (ESCU1) amounted to 20.9 dB for the unaided condition, 19.4 dB for the aided condition with 0 dB gain, and 17.8 dB for the aided condition with 15 dB gain.

Speech recognition results shown as psychometric functions fitted to the individual and mean SRT50 and SRT80 data from experiment 1 (N = 26) across all configurations. In addition, the individual and mean ACALES curves from experiment 2 (N = 18), also across all configurations, are overlaid. ACALES= Adaptive CAtegorical Listening Effort Scaling; SRT=speech reception threshold.
Influence of Individual Hearing Thresholds
To examine whether individual hearing thresholds predict aided outcomes, we analyzed correlations between unaided pure-tone thresholds and the respective outcome measures. Thresholds were averaged either across all test frequencies or across the speech-relevant frequency range between 750 Hz and 4 kHz. Unaided thresholds were significantly correlated with changes in aided hearing thresholds in both gain conditions and for both frequency averages. The strongest associations were observed for the average across all frequencies, with
Discussion
The present study investigated the benefits of amplification in terms of aided hearing thresholds, speech intelligibility, and experienced listening effort using a research hearing aid with 0 and 15 dB insertion gain. We hypothesized that although aided thresholds would increase (i.e., worsen) and speech recognition in quiet would be reduced due to masking by the microphones’ input noise, amplification might nonetheless yield a measurable reduction in experienced listening effort. Our results partly confirm this hypothesis. While aided hearing thresholds were worsened at some frequencies and improved at others, speech intelligibility in quiet was reduced only in 0 dB gain condition; with 15 dB gain, it did not differ significantly from the unaided condition. Importantly, these findings demonstrate that state-of-the-art hearing-aid technology can reduce experienced listening effort relative to the unaided condition even in normal-hearing participants.
Aided Hearing Thresholds
To better interpret the results shown in Figure 7, we refer to the model described by equation (2) and the four illustrative examples in Figure 6. Overall, the model provides a good approximation of the observed effects across frequencies, capturing the main trends in aided hearing-threshold shifts. Deviations between model predictions and measured data were generally small; larger differences in the range of approximately 2 to 4 dB were observed only at the lowest frequency of 125 Hz and in the region of the ear-canal resonance between about 4 and 6 kHz. We first consider example (c) in Figure 6, in which increasing gain has no effect on the aided hearing threshold. A comparable pattern is observed in our data at 4 and 6 kHz, where the aided thresholds obtained with 0 and 15 dB gain do not differ significantly. This indicates that input noise constitutes the dominant limiting factor in this frequency region. The most likely explanation is the ear canal resonance, which provides an amplification of incoming sound and leads to the lowest unaided hearing thresholds expressed in sound pressure level between approximately 2 and 5 kHz (see ISO 389-7, 2019). In this frequency range, the natural acoustic gain of the ear canal effectively lowers the hearing threshold relative to the equivalent input noise of the hearing aid microphone. As a result, additional electronic amplification cannot further improve thresholds because they are limited by the input noise. If the hearing aid microphone were positioned deeper in the ear canal, as in completely in canal or invisible in canal devices, this natural amplification would also act on the microphone signal and could potentially reduce noise limitations or even lead to improved aided thresholds in this frequency range.
Next, we consider frequencies at which no threshold shift relative to the unaided condition is observed at 0 dB gain, namely 250 Hz and 8 kHz. We additionally included 125 Hz, since the observed threshold shift of approximately 2 dB can likely be attributed to a notch in the actual insertion gain at 0 dB, as shown in Figure 2. Thus, at both low and high frequencies, neither input noise nor output noise appears to limit the aided hearing threshold, as illustrated in example (a) in Figure 6. This behavior can be explained by the fact that absolute hearing thresholds in sound pressure level increase substantially at these frequencies (see ISO 389-7, 2019), reducing the effect of EIN. Moreover, amplification in these frequency regions improved hearing thresholds by up to 4 dB compared to the unaided condition. Frequencies between 500 Hz and 2 kHz, are assumed to correspond primarily to the situation depicted in panel (d) of Figure 6. At 0 dB gain, aided thresholds show a small elevation relative to the unaided condition, and increasing the gain to 15 dB improves thresholds by no more than about 3 dB. Across this range, the relationship between input noise and the hearing threshold varies slightly. At 500 Hz the input noise appears somewhat below threshold, at 1 kHz it is approximately equal to threshold, and at 2 kHz it is slightly above threshold. Accordingly, aided thresholds at 15 dB gain are slightly lower than, similar to, or slightly higher than the unaided thresholds at the respective frequencies.
Hearing Aid Disadvantage for Speech Recognition in Quiet
Several disadvantageous effects of listening through hearing aids have been reported, for example (Cubick et al., 2018; Denk et al., 2024; Kemper et al., 2025; Schepker et al., 2020), which limit their benefit, particularly for individuals with normal hearing. One important factor is impaired directional hearing caused by microphone location effects, which can reduce speech intelligibility in spatially separated listening scenarios. However, even when the effects of impaired spatial hearing are minimized, by measuring speech-in-noise performance in a collocated, frontal presentation, a residual hearing-aid disadvantage of approximately 0.5 to 1 dB at SRT50 remains (Cubick et al., 2018; Denk et al., 2024). In these suprathreshold speech-in-noise experiments, the influence of microphone input noise is typically negligible. In contrast, our results obtained in quiet conditions reveal a substantially larger hearing-aid disadvantage, amounting to 3.6 dB at SRT50 and 4.6 dB at SRT80 in the 0 dB gain setting. This disadvantage is considerably greater than that typically reported in noise. Importantly, although aided hearing thresholds are partly limited by microphone input noise, amplification improved aided thresholds by up to 4 dB at low and high frequencies. Speech recognition in quiet with 15 dB gain does not differ from the unaided condition, neither at SRT50 nor at SRT80. It appears that the improved aided thresholds compensate for the hearing-aid disadvantage in the speech-in-quiet task, such that it is no longer present in the 15 dB gain condition. These findings indicate that amplification plays a crucial role in mitigating the hearing-aid disadvantage in quiet listening conditions. However, amplification does not improve speech recognition in quiet beyond unaided performance.
Experienced Listening Effort as a Dimension of Amplification Benefit
When someone speaks too softly, we intuitively ask them to speak up or to move closer to increase the speech level. At first glance, one might assume that this request aims to improve speech intelligibility because parts of the speech signal are too quiet to be audible. However, a range of speech levels exists in which speech is fully intelligible while listening effort remains elevated. The second experiment successfully replicated the findings of our previous work, demonstrating that listening to speech in quiet is effortless only at speech levels of approximately 36 to 40 dB SPL and above (Husstedt et al., 2025) while full intelligibility is reached at approximately 25 dB SPL.
For the evaluation of experienced listening effort, it is crucial that participants rate listening effort rather than speech recognition itself. Ratings of listening effort may be biased if speech recognition is assessed prior to the effort evaluation or if participants are incorrectly instructed to judge speech intelligibility instead of the effort required to follow the speech. This was unintentionally done in experiment 1, and corrected in experiment 2, where no speech recognition measures were obtained at all. In Figure 9 it is well evident that these procedural differences shifted the effort ratings significantly, and also changed some relative differences between conditions.
Highest listening effort was observed at around 90% speech intelligibility in quiet and extends well into the ceiling range of speech intelligibility, well replicating our previous findings (Husstedt et al., 2025). Consequently, the dynamic range of ACALES ratings covers higher speech levels than the range captured by speech recognition measures. We therefore assumed that input noise would have a smaller impact on ratings of experienced listening effort than on speech recognition performance in quiet. Based on this assumption, we hypothesized that amplifying speech in quiet within this range, where speech is fully intelligible yet effortful, would reduce experienced listening effort, even if speech intelligibility was slightly degraded. When comparing the hearing aid disadvantage in the 0 dB gain condition, speech recognition showed disadvantages of 3.6 dB at SRT50 and 4.6 dB at SRT80. These values are larger than those observed for experienced listening effort, which amounted to 2.2 dB for ESCU1, 3.1 dB for ESCU7, and 3.1 dB for ESCU13. In addition, although not statistically significant, a trend toward slightly greater benefits at higher speech levels (i.e., lower ESCUs) was observed, further supporting our assumption. In the aided condition with 15 dB of gain, our hypothesis that amplification reduces listening effort compared to the unaided case was confirmed. Average reductions in experienced listening effort amounted to 3.6 dB for ESCU1, 2.6 dB for ESCU7, and 2.2 dB for ESCU13. Again, greater benefits were observed at higher speech levels, corresponding to lower ESCUs.
Taken together, these findings indicate that experienced listening effort constitutes an important dimension in the evaluation of amplification benefit and is frequently overlooked when benefit is assessed solely on the basis of speech intelligibility.
Individual Hearing Thresholds as Predictor for Aided Outcomes
Although all participants had a PTA better than 20 dB HL, variability within the normal-hearing range could influence susceptibility to microphone input noise and the benefit of amplification for soft speech. Listeners with thresholds closer to a PTA of 20 dB HL might be expected to show larger aided threshold shifts and greater difficulty with quiet speech than those with thresholds near or below 0 dB HL. Consistent with this assumption, unaided thresholds were significantly correlated with changes in aided hearing thresholds in both gain conditions, indicating that participants with higher baseline thresholds experienced larger threshold shifts. This pattern accords with the proposed framework, as the relative impact of equivalent input noise depends on baseline sensitivity. In contrast, unaided thresholds were not related to speech intelligibility or experienced listening effort. Thus, small variations in hearing sensitivity within the normal range did not systematically influence suprathreshold performance or perceived effort. The observed effects of amplification therefore appear robust across the range of normal hearing included in this study and cannot be attributed to a subgroup with comparatively elevated but still normal thresholds.
Implications
The present findings have several important implications for the design and evaluation of amplification systems intended for normal-hearing listeners. First, the observed hearing-aid disadvantage in speech recognition in quiet could be fully compensated by the provision of amplification. This suggests that a compressive gain strategy characterized by high amplification at low input levels combined with transparent or even attenuating behavior at higher levels may be beneficial for a broad range of amplifying devices, including hearables, PSAPs, and level-dependent sound protectors. Notably, this approach differs fundamentally from commonly implemented concepts such as expansion or noise-guard algorithms, which typically reduce gain at low input levels to minimize the audibility of input noise (Zakis & Wise, 2007). Our results instead indicate that low-level amplification can be advantageous, particularly when speech is present. Consequently, smart gain-control algorithms that selectively increase gain at low levels only during speech activity may represent a more effective solution than globally increasing low-level amplification.
Second, amplification was not only able to compensate for the hearing-aid disadvantage in speech intelligibility but also led to a reduction in experienced listening effort compared to the unaided condition. This finding suggests that the benefit of amplification may be greater than commonly assumed and that even individuals with normal hearing can benefit from amplification under certain listening conditions. More importantly, these results highlight the relevance of listening effort as an outcome measure and raise the question of whether this dimension should be routinely considered when evaluating amplification benefit. Extending the present evaluation to hearing-impaired listeners therefore appears warranted. If similar reductions in listening effort were observed in this population as suggested by Schulte et al. (2025), it would prompt a critical reassessment of whether current hearing-aid prescription rules adequately account for listening effort, particularly for soft sounds.
Finally, the results clearly demonstrate that the benefit of amplification at low input levels is primarily limited by the input noise of the hearing-aid microphones. This observation raises important questions regarding potential improvements in microphone technology. While low-noise microphones of practical size are available, they are typically more expensive and often larger in size, which can limit their applicability in hearing aids. An alternative approach could involve averaging the sound pressure levels of multiple microphones. Most behind-the-ear devices are equipped with two microphones that are commonly used for directional processing. In an omnidirectional setting, averaging the microphone signals could reduce input noise by approximately 3 dB. This approach would have been feasible in the present experiment and would likely have further increased the benefit of amplification for normal-hearing listeners.
Real-Life Benefit
Many real life communication situations involve speech presented at low sound levels, particularly in otherwise quiet environments, as described by Wu et al. (2018). However, it is important to note that the data reported by Wu et al. were obtained from adults over 65 years of age with mild to moderate hearing loss who were wearing hearing aids. This population differs substantially from the young adults with normal hearing and a mean age of 23 years examined in the present study. In addition, Wu et al. acknowledged that very noisy situations may have been underrepresented in their real world sampling, which may have influenced their findings.
Stronks et al. (2021) reported that soft speech levels between 30 and 45 dB SPL correspond to quiet whispering or typical office noise levels, conditions commonly encountered when conversing with children, speaking across rooms, or listening from a distance (Husstedt et al., 2022; Schulte et al., 2024). However, it remains unclear how the present results translate into perceptible benefits in everyday listening situations. From a practical perspective, providing gains on the order of 15 dB for low level sounds typically requires some form of level dependent processing to prevent excessive output for higher level inputs. The introduction of compression, particularly if fast acting, may introduce distortions or alter speech and noise cues, potentially offsetting some of the benefits observed under controlled linear amplification. Although slow acting compression or hybrid input output strategies may better preserve speech dynamics at low levels, their effectiveness in this context remains to be evaluated.
In addition, real-world environments introduce acoustic factors that were not addressed in the present laboratory setting. Environmental influences such as wind noise may elevate the effective input noise floor of a hearing aid more strongly than in the open ear, thereby limiting the potential benefit of amplification for soft speech. Although modern devices often incorporate dedicated wind noise reduction algorithms, their effectiveness varies across listening situations and may not fully restore the signal to noise conditions of the open ear. Amplification may also interact with auditory nonlinearities, such as upward spread of masking, whereby amplified low frequency sounds increase masking of higher frequency speech cues. At higher overall levels, negative level effects or rollover phenomena could further degrade speech perception. While appropriate compression strategies can help limit excessive output levels and potentially reduce rollover-related effects, they may introduce other tradeoffs, as discussed above. Together, these mechanisms suggest that amplification could have complex and potentially detrimental effects on speech perception in noise, which were beyond the scope of the present study.
In real-world contexts, potential advantages of amplification may therefore be reduced by additional disadvantages associated with hearing aid use, including limited wearing comfort, impaired spatial hearing, occlusion effects, processing related artifacts, and noise-related limitations. Consequently, future studies should examine whether the benefits observed here can be maintained under more realistic signal processing configurations and ecologically valid listening conditions, particularly in dynamic and noisy environments.
The present study employed closed couplings to ensure controlled acoustic conditions and effective low-frequency amplification. Although such fittings are less common in individuals with normal hearing, similar closed designs are widely used in contemporary hearables, often in combination with active occlusion cancelation. We therefore consider the coupling approach both technically appropriate for the experimental aims and not unrealistic for potential real-world applications in users without hearing loss.
Further research is required to determine whether normal hearing individuals experience sufficient benefit in low level listening situations to prefer amplification over open ear listening, and to evaluate its practical relevance in daily life.
Conclusion
The present study demonstrates that hearing aids providing gain can reduce listening effort for soft speech in normal-hearing listeners, despite measurable disadvantages of a 0 dB gain setting that affect hearing thresholds, speech intelligibility in quiet, and experienced listening effort. Amplification compensated for these disadvantages to varying degrees. While the elevation in hearing thresholds was only partially offset, speech intelligibility in quiet was fully restored to the unaided level. Moreover, amplification reduced experienced listening effort beyond the unaided condition, highlighting an additional dimension of benefit that is not captured by speech intelligibility measures alone. The limitations observed at low input levels were most likely driven by hearing-aid microphone input noise, suggesting that improvements in microphone performance could substantially increase the benefits of amplification.
Taken together, these findings indicate that the potential benefit of sound amplification devices for individuals with normal hearing in low-level listening situations may be greater than previously assumed when listening effort is considered alongside traditional outcome measures. Future work should examine whether similar benefits are observed in hearing-impaired listeners and whether current hearing-aid gain prescriptions for soft sounds adequately account for listening effort.
Footnotes
Acknowledgments
The authors thank the participants for their valuable time. English language corrections were assisted by ChatGPT (OpenAI, Inc.). The authors take full responsibility for the content.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data obtained within this work are available at https://doi.org/10.5281/zenodo.19555136 (Husstedt et al., 2026).