
Abstract
Voice cloning is used to generate synthetic speech that mimics vocal characteristics of human talkers. This experiment used voice cloning to compare human and synthetic speech for intelligibility, human-likeness, and perceptual similarity, all tested in young adults with normal hearing. Masked-sentence recognition was evaluated using speech produced by five human talkers and their synthetically generated voice clones presented in speech-shaped noise at −6 dB signal-to-noise ratio. There were two types of sentences: semantically meaningful and nonsense. Human and automatic speech recognition scoring was used to evaluate performance. Participants were asked to rate human-likeness and determine whether pairs of sentences were produced by the same versus different people. As expected, sentence-recognition scores were worse for nonsense sentences compared to meaningful sentences, but they were similar for speech produced by human talkers and voice clones. Human-likeness scores were also similar for speech produced by human talkers and their voice clones. Participants were very good at identifying differences between voices but were less accurate at distinguishing between human/clone pairs, often leaning towards thinking they were produced by the same person. Reliability scoring by automatic speech recognition agreed with human reliability scoring for 98% of keywords and was minimally dependent on the context of the target sentences. Results provide preliminary support for the use of voice clones when evaluating the recognition of human and synthetic speech. More generally, voice synthesis and automatic speech recognition are promising tools for evaluating speech recognition in human listeners.
Introduction
Recent artificial intelligence (AI) methods support the generation of synthetic speech with unprecedented human-likeness (Hyppa-Martin et al., 2024; Nussbaum et al., 2025; Yang et al., 2025). As a result, synthetic speech is being used for an increasing number of applications, including some limited use in the assessment of speech perception for listeners with and without hearing loss (Fatehifar et al., 2024; Ibelings et al., 2022; Ibelings et al., 2024; Polspoel et al., 2025b). AI methods hold promise for revolutionizing assessment of speech perception through the ability to generate linguistically and culturally appropriate speech materials for individual listeners, and by automatic speech recognition (ASR) for scoring responses. More widespread adoption of synthetic speech in clinical audiology and hearing research requires a careful assessment of possible acoustic and psychometric differences between human and synthetic speech, and reliability of ASR scoring methods across talkers and speech materials requires additional study. Research on the validity of using synthetic speech to assess speech recognition is complicated by extensive variability across voices produced by both humans and AI (Baird et al., 2018; Calandruccio et al., 2025; Johnson & Mullennix, 1997; Kühne et al., 2020; Schweinberger et al., 2020). The present study attempts to take talker variability into account by evaluating recognition, human-likeness, and discriminability of human voices and their synthetic voice clones. The question of how predictability of speech material affects synthetic speech production and ASR scoring is also addressed by testing recognition responses for semantically meaningful and nonsense sentences.
Synthetic Speech and Voice Cloning
Human speech productions can vary tremendously over a wide range of linguistic and acoustic features (Johnson & Mullennix, 1997). Talkers can vary with respect to languages spoken, language proficiency, language mastery, idiosyncratic speech productions, speaking rate, timbre, pitch, and a multitude of sociolinguistic features. Though only a few years ago, most synthetic speech had a robotic quality, new advancements of AI technology (specifically significant advancements in Large Language Models [LLMs]) have supported the generation of synthetic speech that sounds humanlike (e.g., Khanjani et al., 2023). Reports that include comparisons between human and synthetic speech to date have compared different talkers. That is, stimuli were developed by recording a human talker(s) and generating synthetic speech of different “talker” voices (e.g., Cohn & Zellou, 2020; Herrmann, 2023; Ibelings et al., 2022; Polspoel et al., 2025b). Across these reports disparate results are observed—compared to human talkers, synthetic talkers can be more intelligible, less intelligible, or equally intelligible (Calandruccio et al., 2025; Génin et al., 2024; Yang et al., 2025); sometimes listeners can accurately identify which voices are synthetic and which are human, while other times they cannot (Calandruccio et al., 2025; Herrmann, 2023; Ibelings et al., 2022). Further, differences between human and synthetic speech productions have been observed for long-term average spectra (Calandruccio et al., 2025), speaking rate (Yang et al., 2025), and vowel space (Abeysinghe et al., 2022). These results highlight the challenge of comparing two (or more) distinct voices.
With the advent of transformer-based language models (Vaswani et al., 2017), we can now generate synthetic speech with the vocal characteristics of an individual human talker. Transformer-based language models fall under the scope of deep-learning models that use computational attention and feedforward neural networks to predict relationships between words within a sentence (Google, 2018; Wolf et al., 2020). Building on text-only language models, transformers were extended to speech by encoding audio as sequences and applying the same encoder-decoder attention machinery as an end-to-end approach (Radford et al., 2023). By using these models, text-to-speech systems can “clone” a talker's human voice based on audio samples from that talker (Zhao & Chen, 2020). Voice cloning uses synthetic speech to imitate speech productions of a human talker with respect to pitch, timbre, accent, and most importantly, vocal identity (van den Oord & Dieleman, 2016). Voice cloning can be accomplished through several different methods including, but not limited to, speaker adaptation models (e.g., Shen et al., 2018), speaker encoder models (e.g., Jia et al., 2018), neural encoder models (e.g., Kong et al., 2020), and end-to-end and large-scale models (e.g., Chen et al., 2025). In some instances, models may require more data (e.g., several hours of speech productions) to develop a specialized fine-tuned model for one specific voice (Wei et al., 2022). However, these models can also be used to produce voice clones with limited audio input, a process known as few-shot or zero-shot learning, which utilizes only a few seconds of speech recordings (Azzuni & Saddik, 2025; Brown et al., 2020; Chen et al., 2025).
There are numerous potential uses for voice clones in hearing research and clinical audiology. For the present experiment, the focus is on comparing intelligibility, perception of human-likeness, and perceptual similarity of speech produced by humans and their voice clones. If voice clones are shown to produce valid estimates of speech recognition, the potential applications include quick development of speech stimuli, ability to produce new stimuli if vernacular changes (e.g., differences in vocabulary between generations), ability to modify productions with different sociolinguistic features (e.g., differences in grammar or accents), and personalization of stimuli (e.g., incorporating a child's name within testing to help keep attention). In addition, clones could be useful for producing speech that human talkers have difficulty producing (e.g., speech in different languages, nonwords, difficult to produce vocabulary, or semantically anomalous speech).
Semantically Anomalous Speech Materials—Synthetic Speech and ASR
Researchers often use speech materials that vary in the level of semantic context to help differentiate speech perception difficulties related to peripheral auditory deficits (e.g., damaged outer- and/or inner-hair cells) and those related to language mastery and/or cognition processing issues (e.g., knowledge of the target language, working memory capacity, etc.). Semantically unpredictable or nonsense sentence materials may pose a problem for AI both in terms of synthetic speech productions and ASR scoring, as LLMs rely on syntactic and semantic probability for best performance (Karlapati & Moinet, 2021).
Human talkers can find it challenging to produce semantically anomalous speech. Because of this, human speech productions of semantically meaningful and nonsense sentences often vary in terms of cadence and speaking rate (Calandruccio et al., 2018; O’Neill et al., 2020). If differences in performance are observed for meaningful and nonsense speech, it is not always clear whether to attribute this result to differences in the semantic meaning, the rate or cadence of the speech productions, or a combination of factors. Listeners tend to be better at recognizing masked sentences that are semantically meaningful compared to anomalous, and better at recognizing those that have high-semantic predictability compared to low-semantic predictability (Bradlow & Alexander, 2007; Brouwer et al., 2012), but they are also better at recognizing speech that is spoken at a slower rate, compared to a faster one (Taleb, 2020; Winn & Teece, 2021). Using synthetically generated speech could help to alleviate this confound. That is, with short, syntactically correct sentences, many speech synthesis models rely on the syntax of the sentence to infer appropriate prosody (Hodari et al., 2021; Karlapati & Moinet, 2021), and speaking rate can be controlled.
An exciting aspect of the recent advances in AI has to do with machine scoring of spoken speech recognition responses. Current state-of-the-art ASR models have extremely high rates of accuracy when recognizing meaningful sentences spoken by healthy, young adults who are native speakers of North American English (Calandruccio et al., 2025; Fatehifar et al., 2024; Graham & Roll, 2024). Word error rates of ASR transcriptions increase when speech varies from the mainstream dialect/accent (Koenecke et al., 2020), is spoken by older adults (Zolnoori et al., 2024), includes production errors (Moro-Velazquez et al., 2019), or is spoken by second-language learners of the target language (Feng et al., 2024; Vu et al., 2014). Word error rates are predicted to increase for semantically anomalous sentences, as AI-based ASR models rely on context and can be biased to map participant response onto meaningful productions (e.g., Koenecke et al., 2024; Povey et al., n.d.). It is important for audiologists and hearing scientists to understand the implications of using AI applications to score recognition responses for semantically meaningful and anomalous speech materials. In this experiment, semantically meaningful and nonsense sentences are included to assess this question.
Motivation for the Present Study
The purpose of this experiment was to evaluate speech intelligibility for five female human talkers and their synthetically generated voice clones. Intelligibility of semantically meaningful and anomalous speech was evaluated and scored using human and ASR scoring. Participants were also asked to rate the human-likeness of human and cloned stimuli for both types of sentences, and to judge whether a pair of sentences was produced by the same versus different voices. A high human-likeness score for clones would indicate naturalness of those samples and provide support for broader use in research on speech perception. Similarity ratings were carried out to better understand the relative salience of perceptual differences between individual human talkers and between human/clone pairs. Greater perceptual similarity between human/clone pairs than between human talkers would increase confidence in the use of clones to reduce effects related to talker variability when comparing performance across conditions (e.g., speech produced in different languages).
Methods
Participants and Recruitment
All participants were recruited from the Case Western Reserve University (CWRU) community, provided written informed consent to participate, and were paid $15/hour. All procedures were approved by the CWRU Institutional Review Board (IRB; #IRB-2015–1195). There were two groups of participants. Group 1 included 17 young adults (M age = 21 years, range = 18–29; 14 females, 3 males). Group 2 included 10 young adults (M age = 21 years, range = 20–22; 5 females, 5 males). None of the participants were included in both Groups. Demographic questionnaires were completed by all participants, and responses confirmed that all but one of the participants was a native speaker of American English; that participant reported Spanish as their first language, but they were comfortable using English in all four language domains (reading, writing, speaking, and listening) by early elementary school. Including the one native speaker of Spanish, three participants were proficient at speaking and listening in a language other than English (two in Spanish and one in Polish). Thirteen participants in Group 1 identified as White, two as Black, one as Asian, and one preferred not to answer. Of these participants, 14 identified as non-Hispanic, while three identified as Hispanic. Six participants in Group 2 identified as White, three as Black, and one as mixed race (Asian/White). Of these participants, nine identified as non-Hispanic and one identified as Hispanic. Participants’ hearing was tested using standard clinical procedures, TDH-39 supraaural headphones, and an Ear Scan 3 Manual audiometer (Micro Audiometrics). All participants had air conduction thresholds ≤ 20 dB HL bilaterally at and between octave frequencies of 250–8000 Hz. There were three different perceptual tasks in this experiment: masked-speech recognition (Group 1), judgements of human-likeness (Group 1), and judgements of whether pairs of sentences were produced by the same versus a different voice (Group 2).
Stimulus Development
Five females (ages 19–25) were recruited to record all human speech productions. Male talkers were excluded from this study to limit perceptual variability between human talkers, with the rationale that more similarity between talkers would increase attention to subtle differences that might occur for human and clone voices. Two of the talkers were born and raised near the Chicago, IL area (both identify as White and Hispanic), one near the central NJ area (identifies as Asian and non-Hispanic), one from the Tucson, AZ area (identifies as White and Hispanic), and one from the southern NH area (identifies as White and Hispanic). Three of the five talkers are bilingual speakers of English and Spanish; all three are heritage speakers of Mexican Spanish, and English is their dominant language. One of the five talkers is a bilingual speaker of English and Tamil; she is a heritage speaker of Tamil, and English is her dominant language. All human recordings were made using a Sure SM81 cardioid condenser microphone with a pop filter attached. Talkers stood 6 inches from the microphone diaphragm. All stimuli were recorded at 44.1 kHz (16 bit). Voice clones were generated for each human talker using recordings of text read from a novel (M duration = 80 s). With current implementation of zero-shot cloning, to create a high-quality voice clone, you need about 30 s of clean audio. Once you increase duration above 30 s your returns diminish rather quickly. Voice cloning was performed using ElevenLabs’ Instant Voice Cloning services (
There were two test corpora for the masked-speech recognition testing. Stimuli included (1) 250 semantically meaningful sentences from the Basic English Lexicon (BEL; Calandruccio & Smiljanić, 2012) corpus, and (2) 250 semantically anomalous versions of the BEL sentences (O’Neill et al., 2020), which we will refer to as “nonsense sentences.” The five voices produced 50 sentences of each corpus (meaningful and nonsense)—half (25 sentences) were produced by the human talker and half by their voice clone. Long-term average magnitude spectra, average fundamental frequency (f0), and speaking rate (sentence duration divided by the number of estimated syllables) are shown in Figure 1. The stimuli used in this experiment and to generate this figure can be found at GitHub (https://github.com/lxc424-lgtm/Clone_AM).

Acoustic features of speech for each talker voice, talker type, and corpus. The top row of panels shows the long-term average speech spectrum (LTASS) as a function of frequency for each talker voice and talker type. Voice is indicated by titles at the top of each panel, and type is indicated by line style (solid or dashed) and color (purple or green), as defined in the legend. The middle row of panels shows the distributions of fundamental frequency (f0), and the bottom row shows the distributions of speaking rate. Voice f0 and speaking rate were estimated for each sentence, and the results are plotted separately for the two corpora (indicated in the x-axis), talker voice (indicated in the column title), and talker types (indicated by color, following the convention defined previously). Horizontal lines show median values, boxes span the 25th to 75th percentiles, and whiskers span the 10th to 90th percentiles. M = meaningful, N = nonsense.
Perceptual Tasks and Test Environment
Masked-Speech Recognition—Intelligibility Testing and Scoring
For participants in Group 1, masked speech recognition testing was completed before human-likeness judgements. Stimulus presentation was controlled using MATLAB (MathWorks, R2023b), and stimuli were presented diotically through a sound card (M-Audio Air 192) routed to circumaural headphones (Sennheiser HD280 Pro). Testing occurred in a double-walled, sound-isolated room (ETS-LINDGREN Acoustics Systems). Sentences were blocked by corpus (meaningful or nonsense), and the order of the blocks was randomized between participants. Sentence number, talker type, and talker voice were randomized within each block. Target stimuli were presented at a fixed level of 65 dB SPL, with a fixed signal-to-noise ratio (SNR) of −6 dB. Sentences were temporally centered in a random sample of talker specific speech-shaped noise that was 1000 ms longer than each target sentence. The talker specific noise was generated based on the long-term magnitude spectra of all the sentences produced by each talker voice and type (10 different noises). Talker specific noises were used to minimize energetic masking differences that could impact speech intelligibility between talkers (see Calandruccio et al., 2025). Participants were instructed to ignore the noise and to try their best to repeat back the target sentence; they were encouraged to guess, if needed, and to repeat back every word they heard even if the sentence did not make sense. Participants were not provided any information about the types of speech productions (human or synthetic) they would hear in the experiment.
Participants’ recognition responses were scored live with a human tester who had normal hearing and was a native speaker of English. That examiner was seated in front of the participant, ensuring access to both auditory and visual cues, and scored each keyword as correct or incorrect. Results are reported as the percent correct for all keywords. Participant responses were audio recorded and saved to disk (WAV format) for offline human reliability scoring and machine scoring. Participant response WAV files are not shared in the GitHub as sharing these recordings could risk participant anonymity. Most participants (n = 13) completed testing across two days, separated by 1–14 days (M = 4 days), due to scheduling constraints. For these participants, testing for one block (speech corpus) was completed on each day of testing (meaningful or nonsense). The four participants that completed all testing on the same day were offered a break in between the test blocks. Testing for each block took approximately 48 min (IQR 45.75–49 min). Speech intelligibility scores were calculated for each participant by corpus, talker type, and voice by totaling the number of keywords correct and dividing by the total number of keywords presented (100).
Perceptual Judgement of Human-Likeness
Perceptual judgments of human-likeness were collected in a single-walled, sound-isolated room (ETS-LINDGREN Acoustics Systems). Stimuli were presented diotically over circumaural headphones (Sennheiser HD280 Pro) through a sound card (M-Track 2 × 2 C-series) using custom software (MAX 8, Cycling ‘74). Target stimuli were presented at +5 dB SNR in the speech-shaped corresponding to the target voice and type (human or clone), as described above; as in the previous task, the target was presented at 65 dB SPL. Trials were blocked by corpus (meaningful or nonsense), with the order of blocks randomized across participants. Participants heard a subset of the target stimuli included in the intelligibility testing (50 sentences per condition; 5 sentences per talker voice and talker type), but now their task was not to repeat back the sentence but rather to decide if they thought the sentence was produced by a human or a synthetic talker. Responses were entered by participants using a 5-point Likert scale ranging from 1, indicating the participant was 100% sure the talker was human, to 5, indicating they were 100% sure the talker was synthetic. Each block took about 5 min to complete (IQR 4.3–6.4 min).
Similarity Judgements
Group 2 participants judged the similarity of speech produced by different talker voices and talker types. Similarity judgement took place in either the single-walled or double-walled booth, with the same hardware as described above (Sennheiser HD280 Pro; M-Track 2 × 2 C-series or M-Audio Air 192). On each trial, two different sentences were presented diotically over circumaural headphones (Sennheiser HD280 Pro) using custom software (MAX 8, Cycling ‘74). These sentences were presented in quiet at a fixed level of 65 dB SPL. Participants were asked to decide if they thought the two sentences were produced by the same person or different people. Participants were specifically instructed to focus on vocal characteristics of the talkers and not on what they said or their speaking rate. Participants were not told that they would hear synthetically generated speech. There were 120 sentences per test corpus (meaningful and nonsense). Of those, 40 trials included pairs of sentences that were matched for both talker voice and type (e.g., V1 human & V1 human), 40 that were matched for talker voice and mismatched for talker type (e.g., V1 human & V1 clone), and 40 that were matched for talker type (e.g., always human) and mismatched for talker voice (e.g., V1 human & V4 human). The sentences used for each combination of parameters were selected at random. Responses were recorded using a 5-point Likert scale ranging from 1, indicating the participant was 100% sure the same person produced the two sentences, to 5, indicating they were 100% sure the sentences were produced by different people. Test corpus (meaningful or nonsense) was blocked and was randomized across participants. Each condition took about 22 min to complete (IQR 18–25 min).
Data Analyses and Off-Line Scoring of Speech Recognition Data by Humans and ASR
The first set of scores for masked-speech recognition testing were assigned real-time by the live examiner. After testing, one of three off-line examiners was assigned to listen to recorded responses over headphones and re-score the participant responses; all three off-line examiners had normal hearing, were native speakers of English, and spoke a second language.
In addition to human examiners, OpenAI's Whisper model (whisper-large-v3, with 1.54B parameters, https://huggingface.co/openai/whisper-large-v3; Radford et al., 2023), a sequence-to-sequence transformer, was used to score the offline, recorded responses. Participant responses were fed into the encoder, and the decoder generated a transcription for each trial. Transcriptions were then passed to the custom scoring code to determine keyword accuracy. To begin, transcriptions are normalized to eliminate case sensitivity (i.e., all words are converted to lowercase). Following normalization, a predefined homophone lexicon is applied to allow for correct responses for words with equivalent pronunciations during scoring. Pronunciations were obtained from the CMU Pronouncing Dictionary as distributed through Natural Language Toolkit (NLTk)'s cmudict corpus interface (http://www.speech.cs.cmu.edu/cgi-bin/cmudict). Similar to human scoring procedures, incorrect word order was allowed, to accommodate cases when a participant skips one or more words early in their response and then goes back to correct that omission. This model was run nine times. Final scores were determined based on majority vote of the nine runs.
Acoustic data were modeled using linear mixed effects models, and speech intelligibility scores by keyword were evaluated using general linear mixed effects models with a binomial link function using the lme4 package in R (Bates et al., 2015). For models of participant data, there was a random intercept for each individual participant. When the corpus and talker type were included in a model, they were dummy coded (Talker type: −0.5 = clone, 0.5 = human; Corpus: −0.5 = nonsense, 0.5 = meaningful). Perceptual rating data were analyzed with cumulative link mixed effects models implemented using the ordinal package in R (Christensen, 2023). Talker voice was treated as a random effect for most models because the primary focus of the present experiment was to understand the relationship between performance for human talkers and their voice clones generally.
Results
Acoustic Features of Speech Stimuli
Boxplots in the bottom row of Figure 1 show that human talkers spoke more slowly than their clones. This observation was evaluated with a linear model with fixed effects of talker type and corpus; there was a random intercept for each talker voice. This model indicated significant main effects of talker type (coef = −1.04, t = −17.8, p < .001) and corpus (coef = 0.15, t = 2.56, p = .011), and a non-significant interaction between these factors (coef = 0.18, t = 1.54, p = .125). Averaged across talker voices and corpora, the speaking rate was 3.6 syllables per second for humans and 4.6 syllables per second for clones. Averaged across talker voices and types, speaking rate was 4.2 syllables per second for meaningful sentences, and 4.0 syllables per second for nonsense sentences.
Boxplots in the middle row of Figure 1 show the distributions of voice f0 values. Values differed between talkers, with mean values ranging between 189 Hz (V5 clone) and 234 Hz (V4 clone). There was also evidence of differences in f0 between talker types, with clones having lower mean f0 than humans for some voices (e.g., V1) and higher f0 than humans for others (e.g., V4). A linear model was run with fixed effects of talker type and corpus; there was a random intercept for each talker voice. This model indicated a significant effect of talker type (coef = −2.68, t = −2.41, p = .016), reflecting a modestly higher mean f0 for clones (M = 211 Hz) than humans (M = 208 Hz). Neither the effect of corpus (coef = 1.41, t = 1.26, p = .207) nor the interaction between talker type and corpus (coef = 2.28, t = 1.02, p = .307) reached significance.
Masked-Speech Recognition—Intelligibility Testing and Scoring
Figure 2 shows speech recognition scores for each talker voice and type, plotted separately for the two corpora. As expected, scores tended to be higher for meaningful than nonsense sentences, with means of 57% and 36% correct, respectively. Combining data for the two corpora, scores were very similar for the two talker types, with means of 47% (human) and 46% (clone) correct. There was some evidence of variability in intelligibility across talkers. For example, among human talkers producing meaningful sentences, mean scores ranged from 44% (V4) to 63% (V5).

The distributions of percent correct scores for each talker voice. Symbol shading and color indicates human and clone stimuli for each voice, as defined in the legend. Results are plotted separately for meaningful sentences (left) and nonsense sentences (right).
Results were evaluated using a general linear mixed model with fixed effects of talker type (human, clone) and corpus (meaningful, nonsense), along with random effects of talker voice, participant, sentence, and keyword. Results are shown in Table 1. There was a significant effect of corpus, no significant effect of talker type, and a significant interaction between talker type and corpus. For meaningful sentences, clones tended to be more intelligible than human talkers (57.6% vs. 56.3%), but for nonsense sentences, clones tended to be less intelligible than human talkers (35.2% vs. 37.3%). Neither of these trends reached significance on their own.
Model Coefficients for Recognition by Keyword.

Contrast coding was used to represent the fixed effects of talker type (−0.5 = clone, 0.5 = human) and corpus (−0.5 = nonsense, 0.5 = meaningful). Random effects included talker, participant, sentence, and keyword position.
Whereas the mean differences between scores for human and clone talkers was small (<2 percentage points on average), the difference exceeded 10 percentage points (pp) for some voices. The significance of these differences was evaluated with a series of 10 paired t-tests. Of these, 6 were significant at α < 0.05 after Bonferroni adjustment for multiple comparisons. Higher scores for clones than human talkers were observed for V4/Meaningful (17.1 pp) and V2/Nonsense (14.4 pp). Lower scores for clones than human talkers were observed for V3/Meaningful (8.5 pp), V5/Meaningful (10.0 pp), V3/Nonsense (8.2 pp), and V5/Nonsense (10.6 pp). These correlations were repeated on logit-transformed scores. In this second analysis, the 8.2 percentage point difference for V3/Nonsense failed to reach significance (p = .066). The other five differences were significant after Bonferroni correction.
Scores produced using the three scoring procedures were in high agreement. Out of the 34,000 potential scoreable keywords, 323 keywords were cut off at the end of the participant response recordings (0.95% of scoreable keywords). This happened for five participants. Of the cut-off words, 231 and 86 (98% of the total cut-off words) were for two participants who were particularly slow to respond. Live scores were compared to the off-line examiner scores for all scoreable keywords in which responses were recorded. There were 358 discrepancies between those two sets of scores, resulting in 98.9% agreement. It took approximately 34 h to complete reliability scoring for this data set using human scorers. Live scores were correct 71% of the time (254/358), as determined offline by a third examiner. Scores provided by the live human examiner and the ASR agreed 98.6% of the time, with 459 discrepancies between scoring methods. Of these discrepancies, human scoring was accurate 58% of the time (266/459). Human errors fell into three categories: wrong word (the participant said the word, we can hear the word on the audio recording, ASR transcribed it correctly, but the human scorer marks it incorrectly), inaccurate morphology (e.g., asked not asks), and inaccurate phonology (one morpheme within the word varies, e.g., flyer instead of fire). Errors made by machine scoring included transcription errors for morphological endings (e.g., inaccurate pluralization), inaccurate word (e.g., salmon vs. sounded), phonological errors (e.g., buck instead of book), inaccurate timing of production (e.g., sunsets instead of sun sets), different lexical transcription than what occurs in text (e.g., grandparent's vs. grandparents) and transcription spelling error not caught by a traditional homophone library (i.e., Sirius instead of serious). Wrong word transcriptions accounted for the largest number of ASR errors (135/193 total inaccuracies, 70%). A comparison between the initial model run and the majority vote indicated a difference in only one keyword; the majority vote analysis corrected an inaccurate transcription of the word “mouth” for the accurate transcription of the word “mouse.” The code used for machine scoring is provided in the GitHub.
Perceptual Judgements of Human-Likeness
Figure 3 shows the distributions of perceptual judgements of human-likeness. Each panel in this figure presents results for human or clone talkers, as specified in the column titles, and features either meaningful or nonsense sentences, as labeled on the left side of each panel. The length of each bar indicates the proportion of responses associated with each score, indicated by bar shading. The dominant impression looking at this figure is that there is variability in distributions of scores given for each talker voice, but that the pattern of scores is similar for the two talker types and corpora. The mean score across voice and corpus ranged from 2.56 (human talkers producing meaningful sentences) to 2.80 (clones producing meaningful sentences). Averaging scores across talker type and corpus, the mean score for each voice ranged from 1.85 (V2; more human than synthetic) to 3.52 (V4; more synthetic than human).

Distributions of perceptual ratings applied to speech from human (left column) or clone (right column) talkers. The top row shows results for meaningful sentences, and the bottom row shows results for the nonsense sentences. The legend at the bottom of the figure defines the color scale.
A cumulative link mixed effects model was used to evaluate the fixed effects of talker type and corpus, along with random effects of talker voice and participant. We found a significant effect of talker type (coef = −0.25, z = −2.80, p = .005), no significant effect of corpus (coef = −0.05, z = −0.59, p = .555), and a non-significant interaction between talker type and corpus (coef = −0.24, z = −1.34, p = .180). The significant effect of talker type reflects slightly more human-likeness for human talkers than clones, with mean scores of 2.61 and 2.77, respectively. This 0.16-point difference is small compared to the 1.67-point spread of scores between voices. The possible association between human-likeness and speech intelligibility was evaluated by computing the correlation between mean scores for each voice and talker type (n = 10); the result did not approach significance (r = −.05, p = .836).
Perceptual Similarity Judgements
Figure 4 shows the scores for the similarity rating task. The mean score varied widely for the three trial types. When both sentences were produced by the same talker voice and type, the mean score was 1.3, with a score of 1 (“100% same”) assigned on 80% of trials. When they were produced by two different human talkers, the mean score was 4.7, with a score of 5 (“100% different”) assigned on 83% of trials. When sentences were produced by the same voice but different talker types (one human and one clone), the mean score was 2.5. For this trial type, participants assigned scores of 1 or 2 (more likely same than different) on 62% of trials (95% CI: 59–65%), and they assigned scores of 4 or 5 (more likely different than same) on 33% of trials (95% CI: 30–36%). Bootstrapping procedures were used to construct confidence intervals around these estimates and to establish the significance of this difference. Data for trials with a human and their voice clone were resampled by participant with replacement 10,000 times. Results indicate significantly more scores of 1 or 2 than scores of 4 or 5 (p < .001). The same pattern of results was observed when evaluating the probability of assigning a score of 1 or 5 on trials containing human/clone pairs.
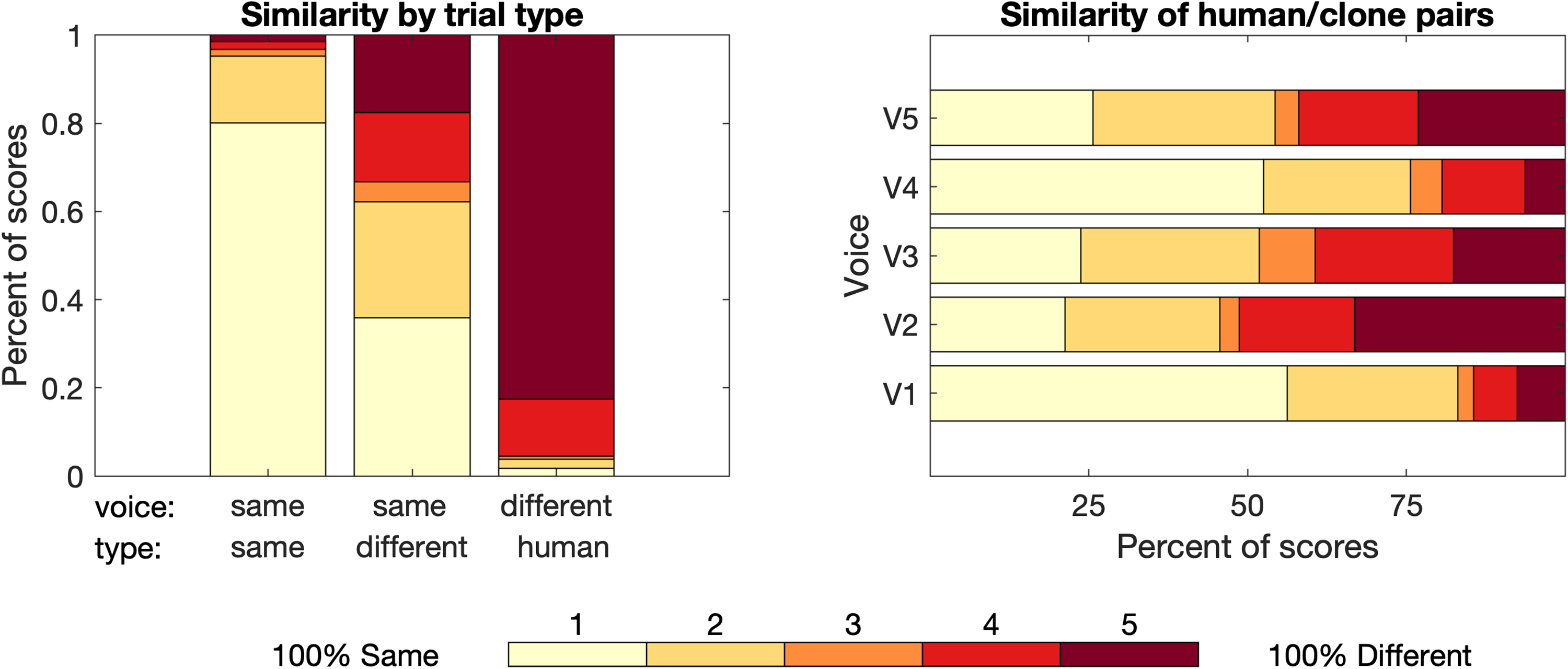
Distributions of perceptual similarity ratings across participants. The left panel shows results plotted separately for the three trial types, defined based on the match between talker voice and type for the two sentences on each trial. The right panel shows the distributions of scores by talker voice for trials with sentences produced by a human talker and their clone (i.e., talker voice was the same and talker type was different). For both panels, bar shading indicates the numeric score, as defined in the legend.
For all three of these trial types, the distributions of scores were very similar for meaningful and nonsense sentences with mean scores differing by < 0.1. This pattern of results was confirmed by results of a cumulative link mixed effects model. This model included fixed effects of trial type and corpus, along with random effects of talker voice and participant. For this model, the reference condition for trial type was the same talker voice and different talker type (i.e., human/clone pairs). This model resulted in a significant effect of trial type, indicating a difference in the scores assigned to human/clone pairs and those assigned in the other two trial types (same voice and type, coef = −2.23, z = −19.13, p < .001; different voice and human type, coef = 3.54, z = 26.75, p < .001). None of the other factors approached significance (p = .243).
The similarity of human/clone pairs was of particular interest in the present study. Whereas the middle bar in the left panel of Figure 4 shows the distribution of scores for all trials with human/clone pairs produced with the same voice, the right panel shows the scores for the five human/clone pairs plotted separately. For these human/clone pairs, mean similarity scores ranged from 1.8 (V1) to 3.2 (V2) across the five voices. The significance of differences in similarity ratings across voices was evaluated with a cumulative link mixed effects model for this subset of the data, with a fixed effect of voice and a random intercept for each participant. The reference condition for this model was voice V1. This model fit indicates a significant effect of voice, which was evaluated post-hoc with Tukey contrasts. There were two groupings of scores: Group A (V1 and V4) and Group B (V2, V3 and V5), indicating that participants found it significantly harder to distinguish human and clone productions for V1 and V4 compared to the productions for V2, V3, and V5.
Discussion
This experiment evaluated the use of synthetic voice clones for masked-speech recognition, with meaningful and nonsense sentences. Reliability of open-set speech recognition scoring was evaluated using both human examiners and AI methods. Perceptual judgments of human-likeness and similarity between voices were also evaluated. Masked-speech recognition was better for meaningful sentences than nonsense sentences (by about 20%), but no effect of talker type (human or clone) was observed. Some voices were more consistently judged as sounding synthetic, while others were more consistently judged as sounding human; the pattern of scores across the five voices was similar for human talkers and their clones. Whereas clones were judged as more synthetic sounding than human talkers, this effect was an order of magnitude smaller than differences in mean scores of human-likeness across voices. Participants were very good at identifying when a pair of sentences was produced by the same talker voice and type, and when they were produced by different human talkers. They were much less accurate at discriminating between human and clone productions produced by the same voice, rating these sentence pairs as being produced by the same person more than half the time.
It has been reported that TTS models are “worse” at producing semantically anomalous speech as compared to meaningful speech (Hodari et al., 2021; Milvus, n.d.). The human-like prosody of synthetic speech productions is directly correlated with the machine's ability to capture the relationship between words in context and syntactic context of the sentence. Anomalous sentences are also harder to produce for human talkers. It isn’t natural to produce nonsensical sentences. For both types of talkers, speaking rate slowed, albeit by a small but significant amount. This was expected for humans, but not necessarily for their clones.
Intelligibility of Synthetic Speech
In the past couple of years, with the advent of the first modern LLM (Brown et al., 2020), published data are consistently showing synthetic speech to have similar or greater intelligibility as compared to human speech (Calandruccio et al., 2025; Herrmann, 2023; Ibelings et al., 2022; Ma & Tang, 2024). These comparisons of intelligibility have been made across different talker voices, often using one spectrally matched noise or competing speech signal (e.g., a multi-talker babble) to evaluate masked recognition of all talkers. In the present dataset, there was not a main effect of talker type, meaning that there was no consistent difference in scores for human talkers and their clones. However, there was a small but significant interaction between talker type and corpus, with poorer scores for clones than human speech for nonsense sentences (35.2% vs. 37.3%, respectively), and the opposite trend for meaningful sentences (57.6% vs. 56.3%). Despite the very similar performance for human talkers and clones in the full dataset, there was also evidence of more consequential differences for some voices—up to 17 percentage points for V4's productions of meaningful sentences. This variability in results across voices could represent differences in the extent to which the clone captured vocal characteristics of the human talker or to the fact that different sentences were produced by the human/clone pairs. In either case, this result highlights the need to evaluate multiple talkers in experiments like these and indicates that further research is needed to understand the acoustic and perceptual features that may predict when clones diverge from human performance. Closely examining fine-grained acoustic phonetic talker characteristics for clones and humans are logical next steps (e.g., Bradlow et al., 1996).
One primary motivation for this study was to address the problem of comparing intelligibility across talker conditions in the face of marked variability in intelligibility across talkers. For example, Calandruccio et al. (2025) compared speech-in-noise for five human talkers and five unrelated synthetic talkers, all producing meaningful BEL sentences. Those targets were presented at −6 dB SNR in a speech-shaped noise that matched the average long-term speech spectrum of all talkers (human and synthetic). Scores for human listeners in that study spanned a range of 41 percentage points, from 32% to 73% correct. In contrast, scores in the present study spanned a range of only 19 percentage points, from 44% to 63% correct. There are several aspects of the present study that may have reduced the magnitude of talker variability that is typically observed in natural speech. As in Calandruccio et al., all talkers in the present study were healthy young females who were speakers of American English with no obvious regional dialects, recorded using uniform procedures in highly controlled conditions. In contrast to the methods of Calandruccio et al., energetic masking differences were minimized in the speech intelligibility task of the present study by using a different spectrally matched speech-shaped noise for each talker voice and type.
Calandruccio et al. (2025) also observed less variability between intelligibility scores for synthetic talkers as compared to human talkers, with scores spanning a range of 18 and 41 percentage points, respectively. More consistency in intelligibility across synthetic talkers as compared to human talkers has also been observed by Ibelings et al. (2022) and Polspoel et al. (2025a). The current study showed a trend for less variability among clones compared to human talkers, with differences of 13 versus 19 percentage points for meaningful sentences and 12 versus 17 percentage points for nonsense sentences.
Scoring Meaningful Versus Nonsense Sentence
We originally hypothesized that ASR would perform worse when transcribing nonsense sentences than meaningful sentences. This hypothesis was based on the fact that ASR models use both syntactic and semantic meaning for speech-to-text transcription (Karlapati & Moinet, 2021). What we observed was that ASR made only 11 more errors for nonsense than meaningful sentences. This can be compared to the effect observed with human scorers, with 30 more errors for nonsense than meaningful sentences. In both cases, the difference in accuracy of scores for nonsense versus meaningful sentences was very small, affecting < 0.2% of trials. While this difference is negligible, it is possible that larger effects would be observed for nonsense stimuli that were more unpredictable (i.e., more nonsensical).
Development of the anomalous version of the BEL sentences—the corpus we refer to as “nonsense”—included procedures to equate the new version with the format of the original BEL sentences. Each BEL sentence list included 25 sentences with 4 keywords per sentence (100 keywords per list). O’Neill and colleagues (2020) kept the syntactic structures of the 25 sentences and the keywords fixed for each list. They scrambled the keywords by word category to remove the semantic meaning of the sentences. However, due to the constraints of this process, some of the nonsense sentences are more meaningful than others. For example, the sentence, The waiter lasted two keys, is not clearly nonsensical until the final keyword. In contrast, the sentence, The brown bar lost questions, is more consistently anomalous. Further, since all the sentences are short (between 5–7 words), missing only one word can significantly change the meaningfulness of the sentence (for both sentence types). Since participants were listening at −6 dB SNR, a large proportion of sentences were heard incompletely. In fact, across participants, only 13% of sentences were repeated back correctly in their entirety, potentially further limiting the functional differences between the meaningful and nonsense sentences with respect to scoring.
It is important to note that both our human reliability scorers and the AI-powered ASR scoring program had access to recordings of well-enunciated speech in quiet. No participants had a reported history of speech sound disorders or any noticeable speech production errors. Further, our participants had normal hearing, were young adults, and were native speakers of American English. There is a possibility that a consequential discrepancy in ASR accuracy between meaningful and nonsense sentences may arise if the ASR or human examiner also had to contend with different types of speech productions (e.g., child speech, Deaf speech, a different English dialect or foreign-accented English; Graham & Roll, 2024).
Perceptual Judgements of Human-Likeness
Perceptual judgements of human-likeness were remarkably similar for pairs of human talkers and their clones. For example, both human and clone productions from talker voice V2 were perceived to be very human-like. In fact, her human recordings were never rated with a score of 5 (100% synthetic). Even for her synthetic productions, participants assigned a score of 5 less than 2% of the time. Interestingly, human talker V2 has a slight idiosyncrasy in her natural speech production. Her speech productions sound as if she has a compensated frontal lisp that results in a soft /s/ (as opposed to a full lisp) for final word positions and a stopped voiced /th/ for some initial word position productions. This idiosyncrasy was captured by her voice clone. It is likely that participants were not expecting such an idiosyncrasy from synthesized speech, and therefore tended to rate these productions as human. In fact, one participant reported after the experiment that when he was making judgements about whether two talkers were the same or different, he listened for these small idiosyncrasies between voices to help him make his decisions.
This result is in contrast to talker V4. Participants tended to rate this talker as synthetic, with scores of 5 (100% synthetic) for 26% of trials with the human productions and 19% of trials with the synthetic productions. In fact, participants rated V4 productions with a 4 or 5 (more likely synthetic than human) for 58% of trials for both human and synthetic productions. Human productions for V4 were somewhat monotonic, and the cadence of some recordings sounded slightly unnatural. There is precedent for variability in the human-likeness across human talkers (Calandruccio et al., 2025), but it isn’t clear what cues participants use to perform this task. More work is needed to better understand the cues that listeners use when rating the human-likeness of modern voice clones, such as prosody or naturalness (Ibelings et al., 2022; Lewis, 2018).
Perceptual Similarity Judgements
A goal of the present experiment was to evaluate the use of voice clones for controlling variability in speech intelligibility of different voices. Here we measured variability by asking participants to determine whether two samples of speech were produced by the same person or different people. Participants were good at identifying sentences produced by the same talker voice and type (human or clone), with 80% of trials receiving a score of 1 (same). They were also very accurate at identifying pairs of sentences that were produced by different human talkers, with 83% of trials receiving a score of 5 (different). Participants were significantly less accurate at identifying differences between pairs of sentences produced by a human talker and their clone. For these trials, participants were significantly more likely to rate the human/clone pairs as being produced by the same person as compared to different people. In fact, they were approximately twice as likely to rate these productions as being produced by the same (vs. different) people, although the preponderance of scores fell in the range of 2–4, between the endpoints of the scale, indicating that participants were aware of uncertainty in these judgements. The finding that participants were more likely to rate human/clone pairs as the same talker is consistent with published data, with some indication of reduced similarity for female talkers compared to male talkers (Barrington et al., 2025).
Relationship Between Measures
At the outset of this study, we thought there would be an association between intelligibility of clones and their perceptual human-likeness and similarity to corresponding human talkers; clones that were more consistently rated as sounding human-like and more similar to their human counterparts might be associated with speech scores that were likewise similar to those of their human counterparts. The results do not support that general expectation. Human/clone pairs tended to receive similar scores of human-likeness, and participants did not reliably score sentences produced by human/clone pairs as productions from different people. When considered together, these results show that participants were poor at discriminating humans from their clones, whether comparing clones to familiar features of human speech (human-likeness) or to features of the corresponding human talker specifically (similarity). These high levels of human-likeness and similarity could allow us to use human and synthetic speech interchangeably in future experiments.
Further, differences in human-likeness and human/clone similarity were not obviously related to intelligibility. For example, perceptual judgments of human-likeness showed that both the human talker and clone productions of V2 tended to be rated as human, and those of V4 tended to be rated as synthetic. Similarity judgements for the same talkers indicated that productions from human/clone pairs were less likely to be rated as being produced by the same talker for V2 than V4. Further, whereas speech recognition scores for meaningful sentences were more similar for human-clone pairs produced by V2 than V4, the opposite pattern of results was observed for nonsense sentences. This example illustrates the general dissociation between intelligibility scores and perceptual ratings in the present dataset. This dissociation is also evident in the absence of a correlation between mean intelligibility and human-likeness scores. However, this result does not rule out the possibility that an association would be observed with a more heterogeneous sample of voices or for recognition evaluated with a generic speech-shaped noise masker.
Conclusions
While some recent research has evaluated the use of synthetic speech for masked speech recognition testing, little is known about the functional equivalence of speech produced by human talkers and their voice clones. One potential benefit of using synthetic clones is as a means of comparing perception of synthetic and human speech, while holding constant vocal features of a particular talker. Preliminary data using this approach with female talkers suggests no significant difference in intelligibility between human talkers and their voice clones, although there may be differences for specific voices, and results should be examined for male speech. Participants tended to rate human/clone pairs as similarly human-like and often rated them as being produced by the same person. There was no association between intelligibility and perceptual rating, although this could be due to heterogeneity of the voices and the use of masking noise matched to each target talker. Reliability of ASR scoring was similar to that of human scoring, even with nonsense sentences. Modern AI methods for speech synthesis and recognition could greatly improve accessibility, inclusivity, and personalization of speech perception testing. By using voice clones, we can pay particular attention to acoustic and psychometric validation of synthetic speech by using human talker counterparts.
Footnotes
Acknowledgments
Portions of this work were presented by the first author at the International Symposium on Hearing 2025, Vienna Austria. We are thankful for the hard work of our research assistants: Grace Capretta, Berenice Grijalva Arvizu, Pablo Rodríguez Rivera, and Nandini Venkiteswaran.
Ethical Approval and Informed Consent
All research participants provided written informed consent prior to participating. All procedures were approved by the Institutional Review Board at Case Western Reserve University. The people who produced the speech (human and cloned) used in this experiment have provided oral consent to share the stimuli used in the experiment.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the College of Arts and Sciences and the Office of Faculty Advancement at Case Western Reserve University.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
Speech recognition data, perceptual judgment data, similarity data, code for machine scoring, and speech stimuli WAV files are available through GitHub.