
Abstract
Speech-recognition tests are widely used in both clinical and research audiology. The purpose of this study was the development of a novel speech-recognition test that combines concepts of different speech-recognition tests to reduce training effects and allows for a large set of speech material. The new test consists of four different words per trial in a meaningful construct with a fixed structure, the so-called phrases. Various free databases were used to select the words and to determine their frequency. Highly frequent nouns were grouped into thematic categories and combined with related adjectives and infinitives. After discarding inappropriate and unnatural combinations, and eliminating duplications of (sub-)phrases, a total number of 772 phrases remained. Subsequently, the phrases were synthesized using a text-to-speech system. The synthesis significantly reduces the effort compared to recordings with a real speaker. After excluding outliers, measured speech-recognition scores for the phrases with 31 normal-hearing participants at fixed signal-to-noise ratios (SNR) revealed speech-recognition thresholds (SRT) for each phrase varying up to 4 dB. The median SRT was −9.1 dB SNR and thus comparable to existing sentence tests. The psychometric function's slope of 15 percentage points per dB is also comparable and enables efficient use in audiology. Summarizing, the principle of creating speech material in a modular system has many potential applications.
Keywords
Introduction
For the clinical diagnosis of hearing impairment and the evaluation of hearing devices, speech-recognition tests are well-established in audiology. The task of the participants in speech-recognition tests is the oral repetition or selection of recognized words or sentences. This task differs from requirements in natural, conversational speech (Beechey, 2022). However, speech-recognition tests have the advantage of being reproducible and standardizable.
Established German sentence tests are the Oldenburg sentence test (OLSA; Kollmeier et al., 2015; Wagener et al., 1999), the Göttingen sentence test (GÖSA; Kollmeier & Wesselkamp, 1997), the Hochmair–Schulz–Moser sentence test (HSM; Schmidt et al., 1997), and the Freiburg monosyllabic noun test (German: Freiburger Einsilbertest, FBE; Hahlbrock, 1953). The OLSA is a matrix sentence test with the sentence structure name–verb–number–adjective–object (Wagener et al., 1999). For other languages, the word order may be different (Kollmeier et al., 2015). Both GÖSA and HSM consist of meaningful sentences (Kollmeier & Wesselkamp, 1997; Schmidt et al., 1997). They are comparable to the hearing in noise test (HINT; Nilsson et al., 1994) or the Dutch Plomp and Mimpen sentence test (Plomp & Mimpen, 1979).
The established German speech-recognition tests not only have advantages, but also disadvantages, such as a training effect (Wagener et al., 1999b), the use of unknown or unfamiliar words (Kollmeier & Wesselkamp, 1997), or too-few test lists (Kollmeier & Wesselkamp, 1997). Therefore, this article focuses on the development of a novel principle of speech-recognition tests using phrases and synthetic speech. The phrase test can be seen as a combination of a matrix sentence test and speech-recognition tests containing meaningful sentences.
The following paragraphs describe factors that can affect speech recognition in speech-recognition tests and how the existing tests may or may not deal with them. Based on these factors, requirements for the new phrase-based speech-recognition test were set.
For most speech-recognition tests, stationary masking noise is used. The use of stationary noise instead of a fluctuating masker results in steeper psychometric functions (Festen & Plomp, 1990), which are associated with a more accurate measurement of the speech-recognition threshold (SRT; Hagerman, 1982). The SRT describes the signal-to-noise ratio (SNR) that belongs to a certain speech-recognition score, often 50%. If the spectral characteristics of the stationary masker and the speech material are similar, the effect of energetic masking is maximized (Festen & Plomp, 1990). Hence, the spectra of the new speech material and the corresponding stationary noise should be as similar as possible. This is achieved by multiple, random superimpositions of the corresponding speech material (Wagener et al., 2003; Zinner et al., 2021). While a stationary noise based on the corresponding speech material is used for OLSA and GÖSA, noise according to the Comité Consultatif International Télégraphique et Téléphonique (CCITT; ITU, 1988) is used for HSM and FBE, resulting in a shallower psychometric function (Zinner et al., 2021).
According to Zinner et al. (2021) a fixed and simple sentence structure and a limited set of familiar words, as occurs in the OLSA, have a positive effect on the SRT, as compared to sentences that differ in their sentence structure and thus in their linguistic complexity. Uslar et al. (2011) found a small effect of linguistic complexity on speech recognition for young, normal-hearing participants, but not for older, normal-hearing participants. In Uslar et al. (2011) sentences with noncanonical word order or sentences with verbs having more than one possible argument structure were considered linguistically complex, in comparison to sentences with canonical word order that were considered simple. The Oldenburg Linguistically and Audiologically Controlled Sentences corpus (OLACS; Uslar et al., 2013) includes simple sentences with subject–verb–object structure, and complex sentences with object–verb–subject structure. Carroll et al. (2016) used sentences of the OLACS corpus and showed that speech comprehension (who did what to whom) was significantly worse, and that processing times significantly increased for the complex sentences in both the older normal-hearing and the age-matched hearing-impaired listeners.
Lexical parameters such as word frequency (WF) and neighborhood density can also influence speech recognition. Winkler et al. (2020) demonstrated that a higher neighborhood density and lower word frequency can lead to a deterioration of speech recognition for FBE. Taler et al. (2010) showed the same effect for word recognition within meaningful English sentences. Like FBE, GÖSA also contains words that are today less usual (lower word frequency), which presumably have a detrimental effect on speech recognition. In contrast, matrix-sentence tests such as OLSA consist of high-frequent words (Kollmeier et al., 2015; Wagener et al., 1999). Hence, the phrases should also consist of words with high word frequency.
In addition to the above, the predictability of the speech material influences speech recognition. Studies indicate that sentences with highly predictable word combinations not only result in better speech recognition scores, but also in steeper psychometric functions (Hutcherson et al., 1979; Pichora-Fuller et al., 1995). If the words in the sentences are not, or only partly, predictable, the listeners have to rely only on sensory input and consequently, if the SNR is increased by a small extent, the impact on speech recognition is relatively small, resulting in a shallow slope of the psychometric function. If, however, the response alternatives (e.g., in matrix tests) are limited, or syntactic and semantic context is given, listeners can use this information, and even a small increase of the SNR can lead to a strong increase in speech recognition. This effect is related to the j-factor, which describes the number of independent items per sentence (Boothroyd & Nittrouer, 1988). The j-factor for the semantically unpredictable sentences of OLSA (j = 4.29) is clearly higher than for the semantically predictable sentences of GÖSA (j = 2.38).
Whether working memory capacity is related to speech recognition seems to depend on the type of speech material used to test speech recognition. For monosyllable tests, the influence of the working memory capacity, as well as the short-term memory span of the listeners, might be lower due to the presentation of single words. A meta-analysis by Bopp and Verhaeghen (2005) revealed that the word span for the elderly (on average 4.5 words, range 3.9–5.1 words) is reduced compared to the younger group (on average 5.2 words). It should be noted that the word span might be larger for words that are related, that is, words in sentences, due to syntactic and semantic information, which may lead to so-called chunking (Gilchrist et al., 2008). However, based on these findings, we assume that an average phrase length of no more than four words appears to be appropriate for the new speech-recognition test, so that the speech material can also be used reliably for elderly people.
Matrix sentences are semantically unpredictable (Wagener et al., 1999a), and therefore very difficult to remember. However, due to the matrix structure and the limited number of words, there is an initial training effect. Wagener et al. (1999b) measured six test lists in succession. The largest SRT difference occurred between the first and second test lists and is about 1 and 2 dB. After six test lists, the difference in SRT was up to 3 dB. To reduce the influence of training, two training lists are necessary before the start of data collection (Wagener et al., 1999b). After the training lists, the test lists can be repeated as often as required (Wagener et al., 1999a, 1999b). Schlueter et al. (2012) investigated the training effect of OLSA for normal-hearing participants within and between several measurement sessions, and found that the first measurement of a new session resulted in worse SRTs compared to the following measurements within that session. The training effect was the largest in the first session. After a total of five measurement sessions with six test lists each, a SRT difference of about 3 dB between the first and the last test list was observed. All of these findings may also hold for matrix tests in other languages (Kollmeier et al., 2015). The use of many different words (instead of a limited set of 50 words as used in the matrix tests) might reduce or even avoid such training effects.
Since sentence tests like GÖSA and HSM contain semantically predictable sentences, the test lists cannot be repeated indefinitely, as listeners might remember them and thus speech-recognition scores may increase (Yund & Woods, 2010). Furthermore, the speech material of these tests, as well as the number of test lists, are limited. Hence, the test cannot be repeated as often as desired. For these reasons, a large amount of speech material is needed to generate many different phrases and test lists. GÖSA consists of 10 and HSM of 30 lists of 20 sentences each (Kollmeier & Wesselkamp, 1997; Schmidt et al., 1997). The 25 lists of HINT contain 10 sentences each (Nilsson et al., 1994).
Speech recognition might also be influenced by the speech rate. According to Gebhard (2012), a speech rate of about 267 syllables per minutes is described as normal. However, the speech rate of GÖSA (279 syllables per minute; Kollmeier & Wesselkamp, 1997) was considered to be too fast especially for patients with a cochlear implant (CI). For them, the speech rate of OLSA (233 syllables per minute; Wagener et al., 1999) was considered to be appropriate by Müller-Deile (2009). This means that the new speech material should be generated with approximately the same rate as OLSA.
ISO 8253-3 (2022) describes further requirements for speech tests, which are not met by all German speech tests. Among the requirements are the perceptual equivalence of test lists, a high test–retest reliability, and a match of the speech material's phoneme distribution to that of the corresponding language. Phonemic and perceptual equivalence is met for OLSA and GÖSA. In contrast, the criteria for neither the perceptual equivalence (Winkler & Holube, 2014) nor the phonemic equivalence (Exter et al., 2016) are fulfilled by FBE.
Other aspects in which speech-recognition tests differ are the speaker and their pronunciation, whereas GÖSA is partly mumbled (Müller-Deile, 2009), HSM contains a slight Bavarian accent (Müller-Deile, 2009). Another factor that can be considered a disadvantage is that the speech tests mentioned so far were mostly recorded by a male speaker. Kollmeier et al. (2015) showed, however, that international tests, in this case matrix tests, were predominantly spoken by a female speaker. Furthermore, the fundamental frequency of female speech is between that of men and children (Kießling et al., 2008). Thus, the phrases for the new speech-recognition test should be spoken by a female speaker without a regional accent. As an alternative to recordings with a real speaker a text-to-speech (TTS) system was used.
The use of a TTS system, instead of real speakers, can simplify the process of development. For recordings with real speakers, not only is a lot of time needed, but also professional equipment. Also, different optimization steps of the recorded speech material are necessary to ensure comparable SRTs. To reach this goal, psychometric functions must be measured for each sentence. Synthetic speech has already been used for FBE (Schwarz et al., 2022), OLSA (Nuesse et al., 2019), and GÖSA (Ibelings et al., 2022). Those studies showed that optimization steps are not mandatory when using a TTS system, although this may depend on the TTS system used. Nuesse et al. (2019), as well as Schwarz et al. (2022), used a TTS system based on unit selection, and Ibelings et al. (2022) used a TTS system based on deep neural networks (DNN). For the female OLSA, the SRT for the synthetic speech (−8.6 dB SNR) was significantly poorer than for the natural speech (−9.1 dB SNR); the slopes were, however, not significantly different (Nuesse et al., 2019). The synthetic FBE resulted in an SRT comparable to that of natural speech. However, the slope showed a significant difference of about 0.3 percentage-points per dB (pp/dB; Schwarz et al., 2022). For GÖSA, the SRTs differed significantly by 1.2 dB, with synthetic speech showing a better SRT (−7.7 dB SNR) compared to natural speech. The slopes differed by 2 pp/dB (Ibelings et al., 2022). Table 1 gives an overview of the SRT and slopes for natural (original) and synthetic speech. In none of the mentioned articles was the synthetic speech material optimized. In addition, the differences found were regarded to be practically irrelevant, so that the TTS systems used can be applied quite successfully in audiology (Ibelings et al., 2022; Nuesse et al., 2019; Schwarz et al., 2022). Nevertheless, it should be noted that the use of other TTS systems might lead to deviating results (King, 2014).
Comparison of the Average SRTs and Slopes for Established German Speech-Recognition Tests and the Phrases.

The following list summarizes the requirements for the new phrase-based test:
A stationary noise based on the speech material, constructed in the same way as the speech-adjusted noises (SAN; Zinner et al., 2021), is required to obtain a steep psychometric function for efficient measurement. A fixed and simple structure is recommended, to reduce the influence of linguistic complexity. To reduce the influence of word frequency on speech recognition, the test items should be composed of known words of different word types. Four words should be connected to form meaningful constructs. Too many words would increase the impact of working memory. Fewer words would lead to a lower test–retest reliability and to shallower slopes of the psychometric function. As a compromise, an average length of no more than four words appears appropriate. Many combinations and test lists are necessary to reduce or eliminate a possible training effect. A large number of different words as well as phrases allows many measurement repetitions. The speech rate should be comparable to the speech rate for the German language. To allow measurements with normal-hearing, hearing-impaired, and CI participants, a speech rate of about 233 syllables per minute appears appropriate. The phoneme distribution of the new speech material should match that of the German language according to ISO 8253-3 (2022). A female speaker without a regional accent should be used, because international speech-recognition tests were predominantly spoken by a female speaker.
The first part of this contribution describes how the phrases are created and the second part focuses on the characteristics of the new synthetic speech material, including the number of syllables and phonetics. The last part deals with the measurement of the “phrases” speech recognition.
Methods
Composition of the Speech Material
The new speech-recognition test is composed of phrases of the structure article–adjective–noun–infinitive, for example, “den grünen Apfel essen.” In English, the word order would be different “infinitive–article–adjective–noun,” for example, “to eat the green apple.” To select a large amount of different words, annotated German corpora were used. The German newspaper corpus based on material from 2021 (Leipzig Corpora Collection, 2021) was filtered by the tags for the needed word types using Matlab 2020a (MathWorks, Natick, MA). Another corpus, the Tagged C2 Corpus, which is included in the German Reference Corpus (Leibniz-Institut für Deutsche Sprache, 2021), and was directly filtered online using COSMAS II (Corpus Search, Management and Analysis System, http://www.ids-mannheim.de/cosmas2/, Leibniz-Institut für Deutsche Sprache, Mannheim). Since the words should be quite frequent, their frequency was analyzed using the dlexDB database (Heister et al., 2011). The words from the corpora served as input, and the output were the words in their basic form and the corresponding logarithmized and normalized word frequencies (log10(WFnorm)). For each word type, the words were sorted by frequency. From the high-frequent words (log10(WFnorm) > 1; Gmoser, 2013), thematic noun categories were formed. The final noun groups were people, animals, clothes, house items, objects, writings, games, body parts, food and drinks, vehicles, buildings, places, celestial bodies, emotions, and number words. Adjective and infinitives which are related to the nouns within a category (e.g., “fast” for animals, but not for clothes) were added. This procedure initially eliminated many meaningless combinations, so that the subsequent sorting out was considerably shortened. In addition, the thematic categorization allowed the creation of thematically balanced test lists in the future.
Phrase Generation and Selection
Matlab 2020a was used for the phrase generation combining nouns and adjectives, as well as nouns and infinitives, for each category (see Figure 1A) and selection process. Subsequently, meaningless, discriminatory, or too-negative noun-adjective- or noun-infinitive-combinations were removed. The remaining combinations were merged (Figure 1B), and the selection process was applied again, resulting in 583,876 phrases. Next, phrases that were too similar were discarded to avoid repeating noun-adjective, noun-infinitive, or adjective-infinitive combinations. This was achieved by selecting a random phrase and splitting it into its single words. This phrase was the first phrase in the final corpus. In the next step, a second phrase was selected and then split into its words, checking whether the words were already included. If only one word was included in the corpus, the second phrase was added to the final corpus. If two words were already in the corpus and occurred in combination, the phrase was discarded. The process was repeated until there were no more phrases to choose from. Following this procedure, the corresponding definite article (“den,” “die,” or “das”) was inserted for each of the 891 remaining phrases (see Figure 1C). These phrases were then rated regarding naturalness by two different experts (of five possible experts) with a linguistic background on a 5-point scale. Naturalness is related to meaningfulness and usability in conversational speech. Phrases with an average rating below 3 (unnatural and very unnatural) were discarded, thus reducing the number of phrases to 772. In total, these phrases consisted of 142 different adjectives, 208 different nouns, and 193 different infinitives.

Schematic illustration of phrase generation. (A) Each noun per category was combined with each adjective and infinitive per category. (B) Adjective–noun and noun–infinitive combinations were merged to phrases. (C) Resulting phrase with corresponding article.
Procedure for Synthesis
All 772 phrases were synthesized using the German voice Claudia of Acapela Cloud Service (Acapela Group, Solna, Sweden, https://www.acapela-cloud.com, accessed 30 July 2022). This system is based on a DNN and in a previous study was rated as the best regarding naturalness, prosody, and speech flow (Ibelings et al., 2022). A text file containing all 772 phrases served as the input to the online software. The sampling frequency was set to 44.1kHz. The synthesized phrases are openly available at Zenodo (Ibelings et al., 2023).
Noise
A stationary masker was generated, which had the spectral characteristics of the corresponding speech material. For noise generation, all phrases were superimposed 30 times (Wagener et al., 2003). The power-density spectra of the speech-simulating noise and of all the phrases differed by up to 0.1 dB in the frequency range from 100 Hz to 12 kHz. Due to this close match, a very strong spectral masking effect was expected. Both masker and the sentences were digitally calibrated to the same overall root mean square value.
Characteristics of Speech Material
Speech Characteristics
Figure 2A shows the speech rates of all 772 phrases, the average rate was 238 ± 21 syllables per minute. The distribution of the fundamental frequency is depicted in Figure 2B. Its average frequency was about 195 Hz. The long-term average speech spectrum is shown in Figure 2C.

Distributions of (A) speech rate, (B) fundamental frequency, and (C) long-term average spectrum of the 772 phrases.
Syllables
Figure 3 shows the number of syllables per phrase of each noun category. Most of the categories consisted of phrases of 7–8 syllables in the median. Some categories, such as people, writings, games, and buildings, included phrases of up to 13 syllables.

Number of syllables per phrase of each noun category.
Phonetics
According to ISO 8253-3 (2022), the phrases should have a phoneme distribution comparable to that of the German language. Figure 4 depicts the phoneme distribution for the German reference (Kohler, 1995) as well as for the 772 phrases. For this, based on writing and audio files, the phrases were transcribed by a phonetician into the International Phonetic Alphabet (IPA). In general, there is a good agreement to the reference, although some differences were noticeable. For the vowels, the /a/ is slightly overrepresented. This is due to the more frequent use of the article das and the prefixes an- and aus-. Also, the /e/ is somewhat overrepresented, which might be due to the use of the German accusative, which always ends with an en for the male gender, and due to the use of the infinitives that also end with -en. This is also an explanation for the increased frequency of the consonant /n/. The /d/ is overrepresented because of the use of definite articles den, die, and das. The same trend can also be seen at the phoneme groups required by ISO 8253-3 for the different categories. The proportion of voiced plosives (e.g., /d/) in the phrase corpus is almost 8% higher than in Kohler's German phoneme distribution. Also, the nasals (e.g., /n/) occur more often. While the German reference quantifies a proportion of 18.5%, it is 25% for the phrases. For all other phoneme groups, the deviations from the reference are not more than 5%.

Distribution of phonemes (A) vowels and (B) consonants for all phrases in comparison to a reference set for the German language (Kohler, 1995).
Speech Recognition
Methods
Participants
In total, 31 participants (21 female, 10 male) took part in the speech-recognition measurements. They were between 18 and 25 years old (average: 22.9 years, standard deviation: 1.9 years) and had normal hearing: Their pure-tone hearing thresholds were 10 dB HL or lower for the frequencies 250, 500, 750, 1000, 1500, 2000, 3000, 4000, 6000, and 8000 Hz, except for a maximum of two frequencies for which a hearing threshold up to 15 dB HL was accepted. Most of the participants were students at the Jade University of Applied Sciences or the Carl von Ossietzky University, both in Oldenburg, Germany, and already had some experience with speech-recognition tests. They received 10 Euros per hour for reimbursement. The experiment was approved by the ethics committee (Kommission für Forschungsfolgenabschätzung und Ethik) of the Carl von Ossietzky University in Oldenburg, Germany (Drs. EK/2021/063).
Equipment
The measurements took place in a sound-attenuating booth at Jade University Oldenburg. The pure-tone audiogram was measured using a Siemens Unity 2 audiometer (Signia GmbH, Erlangen, Germany) and Sennheiser HDA 300 headphones (Sennheiser, Wedemark, Germany). For speech-recognition measurements, a computer with a Matlab-based implementation was used. The stimuli were presented diotically via Sennheiser HDA 200 headphones (Sennheiser, Wedemark, Germany) driven by a sound card (RME Fireface UC, Audio AG, Heimhausen, Germany) and a headphone amplifier HB7 (Tucker-Davis Technologies, Alachua, USA). Participants’ repeated phrases were entered on the screen by the investigator.
Measurement Procedure
To conduct the study, the 772 phrases were divided into 25 test lists of 30 phrases each, and one list of 22 phrases. The study was divided into two sessions that were never held more than 2 weeks apart. During the first session, after information was given, consent received, and otoscopy, the air-conduction hearing thresholds were measured. This step was not necessary if a participant’s existing audiogram was not older than 12 months, and the participants did not indicate any special issues, for example, middle ear infections, subjective changes of the hearing threshold. Subsequently, the written instructions were handed to the participants, in which both the procedure of measurement and the phrase structure on the basis of an example phrase were explained. Afterward, 11 of the 26 test lists were measured at fixed SNR. The 15 remaining test lists were presented in the second session. The SNR were chosen based on pilot measurements, so that on average 20, 50, and 80% of the phrases were correctly recognized. This led to the SNRs −11, −8.5, and −6 dB. For both sessions, the noise level was kept constant at 65 dB SPL and the speech level constant within a test list according to the chosen SNR. The order of the SNR and the test list number were randomized. Within a test list, the phrases were presented in randomized order. A 10-min break was taken at the latest after five lists, but earlier in case of signs of tiredness, or if the participants asked for it. The two sessions together took about 3 h.
Analysis and Statistics
Matlab 2020a and SPSS 27 (IBM Corp., Armonk, New York) were used for analysis and statistics. For each measurement, a file was generated that contained the phrases presented, the SNR, and the number of correctly recognized words per phrase. The analysis was divided into two parts.
For the analysis of speech recognition per participant, the speech-recognition scores were averaged per SNR for each participant. The resulting speech-recognition scores were normally distributed according to the Kolmogorov–Smirnov test (p > 0.05). Based on these individual speech-recognition scores per SNR, an individual psychometric function according to Brand and Kollmeier (2002) of the form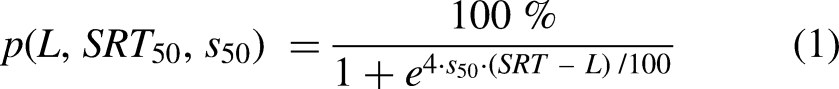
Each phrase was measured 10 times per SNR with different participants. For the speech-recognition analysis of each phrase, a psychometric function was fitted according to equation (1) based on the 10 speech-recognition scores for each phrase for each SNR. Due to an error in the measurement setup, two phrases were excluded from the analysis.
For the analysis of training effects, the speech-recognition scores for the different SNRs were grouped according to the order of presentation. For example, to determine the SRT for the first measured test list (first measurement), the speech-recognition scores for the different SNR of the first test list of all participants were used for the fitting. This procedure was also used for subsequent test lists.
In the results section, speech-recognition scores, as well as SRTs and slopes, are presented as boxplots. The line in the middle indicates the median, and the lower and upper limits of the box show the 25th and 75th percentiles, so that the length of the box is the interquartile range; whiskers were drawn from the lowest to the highest value within 1.5 times the interquartile range, the symbol + represents outliers.
Results
Speech-Recognition per Participant
Neither speech-recognition scores for the three different SNRs (p > 0.05) nor SRTs for the participants (p > 0.05) showed a significant deviation from a normal distribution according to the Kolmogorov–Smirnov test. The slopes were not normally distributed (p < 0.001).
Lower SNRs led to poorer speech-recognition scores (see Figure 5). At an SNR of −6 dB, the median speech-recognition score was 85%, whereas at an SNR of −11 dB it was only 25%. An repeated-measures analysis of variance (ANOVA) with the within-subject factor SNR confirmed a significant effect of the SNR on the participants’ speech-recognition scores (F(2, 60) = 3309.0 p < 0.001). Post hoc t-tests for paired samples with Bonferroni correction (α = 0.0167) revealed significant differences for all SNR values (p < 0.001). Fitting individual psychometric functions according to equation (1) resulted in individual SRTs and slopes for each participant (see Figure 6). The individual SRTs differed from each other by up to 2 dB (average SRT −9.1 dB SNR), and the slope showed differences of up to 5 pp/dB (median slope 15.0 pp/dB).

Speech-recognition scores averaged over the presented phrases per SNR for each participant (unfilled boxes) and averaged over participants per SNR for each phrase (filled boxes).

SRTs and slopes of the psychometric functions fitted to the speech-recognition scores of individual participants (unfilled boxes) and the speech-recognition scores of single phrases (filled boxes).
Speech-Recognition for Single Phrases
The speech-recognition scores of the phrases for the three different SNRs (p < 0.001), the phrase-SRTs (p = 0.007), and the slopes (p < 0.001) showed a significant deviation from a normal distribution according to Kolmogorov–Smirnov-test. Phrases whose SRT or slope is both outside of 1.5 times the interquartile range and whose distribution of data points was poor were classified as outliers. Poor distribution of data points means, for example, that speech-recognition scores at −11 dB SNR were higher than for −6 dB SNR. Thus, the fitting did not yield reliable results. In total, the data of 13 phrases were excluded as outliers from further analysis.
The speech-recognition scores for the phrases showed a larger variation than for the participants, especially for −8.5 dB SNR (see Figure 5). The Friedman test with the factor SNR revealed a significant effect of the SNR on the phrases’ speech-recognition scores (χ²(2) = 1452.2, p < 0.001). Post hoc Wilcoxon-tests with Bonferroni correction (α = 0.0167) found significant differences for all SNR values (p < 0.001).
With the outliers excluded, the SRTs of the 757 remaining phrases were normally distributed (p > 0.05). Figure 6 depicts the SRTs and slopes; the median is −9.0 dB SNR, the range of SRT difference is 4.1 dB (lowest SRT: −10.9 dB SNR, highest SRT: −6.8 dB SNR). The slopes vary by up to 29 pp/dB, with a median of 15 pp/dB.
Training Effect
The SRTs as a function of the measurement number are shown in Figure 7. For the first measurement, the SRT was −7.9 dB. The second measurement revealed an improvement of 0.5 dB. In the following five measurements, the SRT decreased by a maximum of 0.3 dB, and after the 7th measurement, the SRT was −9.3 dB. This led to an SRT difference of about 1.4 dB. The SRT for the twelfth measurement, which was the first measurement of the second session, was −8.8 dB and settled to be around −9.3 dB in the following measurements. After 26 measurements, the overall SRT difference to the first measurement was about 1.5 dB.

SRTs as a function of the number of measurements.
Discussion
Construction
The novel synthesized speech-recognition test consists of phrases that fulfill almost all our requirements for a new speech-recognition test. The phrases have a fixed structure of article, noun, adjective, and infinitive, consisting of highly frequent words combined into semantically meaningful constructs. Thus, the novel test shows features of matrix sentence tests as described by Kollmeier et al. (2015), but with higher semantic predictability. Many different phrases were created, and 757 of them survived the selection following the speech-recognition measurements. Furthermore, with a few exceptions, the phoneme distribution matches that of the German language, which is due to the structure of the phrases (accusative, infinitives, and definite articles). The speech rate is comparable to that for the OLSA, and thus is expected to also be appropriate for listeners with impaired hearing. The stationary masking noise, which was mixed from the speech material of the phrases maximized the effect of energetic masking, resulted in a median slope of 15 pp/dB.
All materials used for creating the phrases are freely available. Both the annotated corpora to obtain many different words, and the dlexDB database for querying the WF may be openly accessed and easily used. The manual selection of unusual word combinations and phrases was time-intensive and prone to errors due to the large numbers involved. Therefore, an automated analysis of combinations and phrases for various aspects such as discrimination, racism, negativity, and the subsequent removal of this material is recommended when creating additional speech material. Although the TTS system is not free of charge, it not only saves a lot of time, but also a lot of effort, which would have been associated with higher costs (Ibelings et al., 2022). The use of a TTS system facilitates the extension of the phrase corpus, or replacing phrases.
The phrase-test development may be applicable to other languages as well. Since international tests also have comparable advantages and disadvantages to those of the German tests, the development of a new test for these languages may also be appropriate. The application to other languages would require more than just translating the phrases, as this would probably result in a different phoneme distribution and word order than in the target language. Instead, phrases in other languages should be generated using a similar procedure as presented in this contribution.
SRT Differences Between Participants
Individual SRTs differed by up to 2 dB. This small difference can be explained on the one hand by the quite homogeneous group of participants, not only in their age (18–25 years), but also in their hearing thresholds. Also, instruction and measurement procedures were the same for all participants. Furthermore, it should be noted that most of the participants already had some experience with speech-recognition tests. Thus, a less homogeneous group would probably have resulted in more varied SRTs.
SRT Differences Between Phrases
SRTs of the 757 phrases varied by up to 4 dB. This range is comparable to the SRT differences of the 200 sentences of the GÖSA (Kollmeier & Wesselkamp, 1997). The standard deviation of the SRTs for the phrases was 0.7 dB. To estimate whether these deviations were systematic or random, the experiment was simulated using a Monte-Carlo simulation. For this purpose, the number of participants in the Monte-Carlo simulation was set to 10, as this number equals the number of data points per phrase and SNR in the presented work. For the simulation, a fictitious psychometric function with SRT = −8.5 dB SNR and slope = 15 pp/dB was assumed. The SNRs used were equal to the SNR of the study (−6, −8.5, and −11 dB). The speech-recognition scores for the 772 phrases for each SNR were then measured with the probability specified by the assumed psychometric function. Then, psychometric functions were fitted based on the simulated scores per SNR. The simulation was run for 10,000 trials, resulting in a standard deviation for the SRT of 0.4 dB SNR. This is about half of the measured standard deviation. Thus, half the standard deviation in the phrase SRTs might be nonsystematic. The other half, which can be considered to be very small, is due to systematic differences between the phrases. However, it should still be examined how factors such as loudness, number of syllables, or WF influence the SRTs, so that perceptually equivalent test lists can be created according to ISO 8253-3 (2022).
Slope Differences
The values for the slopes showed large differences of up to 29 pp/dB. Using the Monte-Carlo simulation, a range of 25 pp/dB was obtained. Thus, the values differ only slightly from each other. Nevertheless, it cannot be ruled out that the naturalness, which is associated with meaningfulness and usability of the phrases in conversational speech, had an impact on the slopes. All phrases were checked for naturalness by persons with a background in linguistics. Their ratings ranged from “natural” to “very natural.” However, persons without a linguistics background might rate some phrases as less natural. Five participants remarked that a few phrases appeared surprising to them. This might be because these people were familiar with other speech-recognition tests such as OLSA and GÖSA, which consist of complete sentences. Thus, it cannot be ruled out that single phrases led to uncertainties, due to the unfamiliar structure. Another reason could be that, especially in difficult acoustic conditions, words might be misunderstood or guessed in such a way that the phrases no longer make any sense. This is in line with Bronkhorst et al. (1993), who claimed that sentences with less predictability led to a shallower slope, since in this case participants are dependent on bottom-up processes. Even if the SNR is improved a little, top-down processes do not add any benefit, and speech recognition changes only slightly, resulting in a shallower slope than for phrases with more predictability. In addition to the written instructions, we recommend presenting a few example phrases acoustically before the actual measurement phase begins. In this way, the participants would not only get to know the task, but would also register the possibly unfamiliar structure both acoustically and visually in the form of a written example in the instructions.
Comparison to Other Speech-Recognition Tests
Compared to existing matrix sentence tests, the words within a word category are not limited to 10 in the phrase-based test, but include 208 nouns, 142 adjectives, and 193 infinitives. The number of articles is limited to three. Due to the large number of different words per word category, it was assumed that compared to matrix sentence tests such as the OLSA, the phrases could lead to a reduction or exclusion of the training effect. Both Wagener et al. (1999b) and Schlueter et al. (2012) investigated the training effect of the OLSA. In Wagener et al. (1999b) six measurement repetitions were carried out. The largest difference in SRT was found between the first and second measurements (about 1 dB). The subsequent changes from one list to the next were each less than 0.5 dB. After six lists, there was a difference of up to 3 dB in the SRT compared to the first measurement (Wagener et al., 1999b). Schlueter et al. (2012) extended the investigation of the training effect from OLSA to five sessions with six lists each. The difference between the first and second measurements agreed with Wagener et al. (1999b). After 26 lists, the difference to the first amounted to 3 dB (Schlueter et al. 2012). In contrast, the results for the phrases showed a SRT difference of about 1.2 dB after 6 lists, and about 1.5 dB after 26 lists. The largest difference was found between the first and second measurement, and was up to 0.5 dB. Therefore, so far, at least one training list is recommended, less than for OLSA with two training lists.
Additionally, Schlueter et al. (2012) found an effect of the sessions. The first measurement of each session resulted in slightly higher SRTs than the following measurements within a session. This effect was also found for the phrases. Measurement 12 was the first measurement of the second session and showed a poorer SRT than both the previous and following measurements. Furthermore, there was also a slight increase in the SRT after measurement 7 and 21. This could be explained by the breaks that took place. The comparisons with Wagener et al. (1999b) and Schlueter et al. (2012) show that there is a training effect from the phrases, but it appears to be smaller than for OLSA. On the one hand, the training effect consists of a component based on habituation with the measurement procedure, the voice, and the noise. On the other hand, there is familiarization with the speech material, its structure, and the possible responses. Due to the smaller number of items per word category, the latter factor appears to be more important for the OLSA than for the phrases. Nevertheless, it should be noted that perceptually equivalent test lists, as well as an adaptive measurement procedure, were used for OLSA (Wagener et al., 1999b). In contrast, SRTs in the present study were established by fitting a psychometric function based on the speech-recognition scores, and the lists were compiled randomly, which is why perceptual equivalence cannot be assumed. In a future study, adaptive measurements will be conducted to determine the SRT after equivalent test lists have been created.
Furthermore, according to Uslar et al. (2011), the fixed sentence structure probably reduces the influence of linguistic complexity. Further studies should examine whether this intended objectives was also achieved.
The calculation of the current phrases’ j-factor according to Boothroyd and Nittrouer (1988) led to j = 2.1 for −11 dB SNR and increased to j = 3.1 for −6 dB SNR. This result appears plausible, since adjectives and nouns, with their specific word endings, can already give cues to the article, as well as the other way round. In addition, the individual words of the phrases also belong together thematically, which also affects the j-factor.
The phrases’ speech rate (238 syllables per minute) is comparable to the speech rate of the OLSA (233 syllables per minute), and lower than the average speech rate for the German language of 267 syllables per minute (Gebhard, 2012). Müller-Deile (2009) considered the OLSA and its speech rate to be appropriate for hearing-impaired persons, and described the speech rate of the GÖSA, with 279 syllables per minute, as too fast for CI patients. Hence, the speech rate of the phrases is applicable for measurements with normal-hearing, hearing-impaired, and CI patients.
Regardless of the structural differences between the speech tests, the SRTs for the phrases and the established sentences tests are similar (see Table 1). The average SRT of the phrases used is −9.1 dB SNR. Ibelings et al. (2022) showed that synthetic speech resulted in significantly lower thresholds than natural speech using the GÖSA (−7.7 dB SNR for synthetic speech). In contrast, Nuesse et al. (2019) found that synthetic speech resulted in a poorer threshold by 0.5 dB compared to the OLSA recorded by a real speaker (−8.6 dB SNR for synthetic speech). Both Nuesse et al. (2019) and Ibelings et al. (2022) presented the stimuli monaurally via headphones. In contrast, the current phrases were presented diotically with headphones. According to Brinkmann and Diestel (1970), diotic measurements can result in up to 2.5 dB better SRTs than a monaural presentation. This means that the SRT for the phrases is comparable or somewhat lower than for synthetic OLSA and GÖSA. Comparing with the SRTs for sentence tests with natural speakers using the corresponding stationary noise in free field shows that the SRT for the phrases is closer to the SRT for the OLSA (−8.5 dB SNR) and the HSM (−8.9 dB SNR) than to the GÖSA (−6.2 dB SNR; Zinner et al., 2021). The reason for the large difference between GÖSA and HSM, despite the similar sentence types, is not known, but might be related to the articulation of the different speakers. Even matrix tests of different languages, which are structurally similar, show differences of up to 4 dB SNR in SRT (Kollmeier et al., 2015). This might also be due to different speakers and their articulations (Hochmuth et al., 2015). All in all, it can be assumed that the fixed sentence structure, in combination with the meaningfulness of the phrases, complement each other and therefore might lead to slightly lower SRTs than for other German speech-recognition tests. It is unclear whether the TTS system has influenced the SRTs, or whether it is simply due to a different articulation. It should be noted, however, that a different TTS system could result in different speech-recognition scores (King, 2014).
The median slope for the phrases was 15 pp/dB. Ibelings et al. (2022) used the same TTS system and the same voice for the female GÖSA, which resulted in a slope of 16 pp/dB. For the synthetic OLSA, the slope is 13 pp/dB. After Miller (1951), it can be assumed that the phrases’ length of four items leads to a shallower slope than for the sentences of GÖSA (up to seven words). Nevertheless, the slopes are still very similar to each other. This might be explained by the use of stationary noise based on the corresponding speech material for the synthetic OLSA, synthetic GÖSA, and the current phrases (Zinner et al., 2021). Overall, although no optimization steps were applied, the observed slopes for the synthesized phrases almost match the literature values for natural speakers. This suggests that optimization steps may not be necessary in the production of speech tests with TTS systems.
Clinical Practice
The phrases could be used instead of existing speech-recognition tests, for example, as an alternative to the OLSA, as they have a lower training effect and avoid possible irritation in patients due to the meaningful word combinations. Furthermore, its use as an alternative to HSM and GÖSA appears appropriate if more measurement conditions are to be tested. Since the speech rate is lower than that of the GÖSA, the use of the phrases also seems appropriate for diagnostic purposes and validation of hearing aid or CI fittings. Additionally, it should be noted that the phrase-based test is intended for the evaluation of the hearing ability and is not designed for listening under dynamic, natural conditions where, for example, noise, speaker, predictability, and sentence structure vary.
Conclusion
As a novelty, the new speech-recognition test presented combines the matrix structure of matrix-sentence tests with the meaningfulness of GÖSA or HINT sentences. The synthesis of phrases, which were created with a fixed structure, can be used to generate further speech material. The process is especially facilitated by the use of freely accessible databases. Moreover, the use of a TTS system can simplify the production of speech material for a speech-recognition test by reducing the time required both for recording and subsequent optimization. The phrases result in an overall SRT that is comparable to other speech-recognition tests. Also, the slope is comparable. The training effect appears to be smaller than for matrix sentence tests. In general, not least because of its composition, speech rate and high slope, we expect that the phrases will be useful for a variety of applications, such as clinical audiology and hearing-aid fitting.
Future Applications
This study presents the requisite data about characteristics (WF, SRT, slope, and phonetics) that are needed to construct future equivalent test lists according to ISO 8253-3 (2022). It can be assumed that the principle of creating speech material in the modular system used here offers a variety of possible applications in the future. This allows the analysis of speech recognition of individual components within a phrase. Whether there should be context or not can be decided individually, thus the phrases can consist of semantically unpredictable or predictable combinations. The corpus could also be changed, so that on the one hand only monosyllabic nouns, and on the other hand only nouns with more than one syllable appear within the phrases. This enables adjusting the test according to the expected performance of the participants, a possibility that will be especially useful in the field of CI adaptation.
Footnotes
Acknowledgments
English-language services were provided by stels-ol.de. Special thanks to Matthias Hey, Ulrich Hoppe, Hendrik Husstedt, and Theresa Nuesse for constructive discussions on the possibilities and requirements for a new speech-recognition test, and to Patricia Fürstenberg for her help with data collection. The authors would also like to thank the five linguists for checking the naturalness of the phrases, and Kathrin Kliem for the phonemic transcription.
Authors’ Note
Part of the results were presented as a poster at the International Hearing Aid Conference (IHCON), Lake Tahoe, CA in 2022, as a presentation at the annual meeting of the German Audiological Society (DGA) 2022 in Cologne, Germany, and as a poster at the International Symposium on Auditory and Audiological Research (ISAAR), Nyborg, Denmark, in 2023.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by a PhD scholarship Jade2Pro of Jade University of Applied Sciences. The research of author Esther Ruigendijk is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy—EXC 2177/1 - Project ID 390895286.