
Abstract
When listening to speech under adverse conditions, listeners compensate using neurocognitive resources. A clinically relevant form of adverse listening is listening through a cochlear implant (CI), which provides a spectrally degraded signal. CI listening is often simulated through noise-vocoding. This study investigated the neurocognitive mechanisms supporting recognition of spectrally degraded speech in adult CI users and normal-hearing (NH) peers listening to noise-vocoded speech, with the hypothesis that an overlapping set of neurocognitive functions would contribute to speech recognition in both groups. Ninety-seven adults with either a CI (54 CI individuals, mean age 66.6 years, range 45–87 years) or age-normal hearing (43 NH individuals, mean age 66.8 years, range 50–81 years) participated. Listeners heard materials varying in linguistic complexity consisting of isolated words, meaningful sentences, anomalous sentences, high-variability sentences, and audiovisually (AV) presented sentences. Participants were also tested for vocabulary knowledge, nonverbal reasoning, working memory capacity, inhibition-concentration, and speed of lexical and phonological access. Linear regression analyses with robust standard errors were performed for speech recognition tasks on neurocognitive functions. Nonverbal reasoning contributed to meaningful sentence recognition in NH peers and anomalous sentence recognition in CI users. Speed of lexical access contributed to performance on most speech tasks for CI users but not for NH peers. Finally, inhibition-concentration and vocabulary knowledge contributed to AV sentence recognition in NH listeners alone. Findings suggest that the complexity of speech materials may determine the particular contributions of neurocognitive skills, and that NH processing of noise-vocoded speech may not represent how CI listeners process speech.
Keywords
Introduction
Recognizing speech in everyday life is challenging, as listeners face a large range of adverse listening conditions. These sources of adversity vary, but generally refer to factors that negatively impact the speech perception process and result in a decrease in speech intelligibility relative to when the listening task is performed under optimal listening conditions, typically generalized as a healthy individual with normal hearing listening to speech recorded clearly by a single native speaker in a quiet environment (Mattys et al., 2012). Adverse conditions can be classified in multiple ways based on their origin versus their effect on the listener, or alternatively as environmental versus source degradations (Assmann & Summerfield, 2004; Mattys et al., 2012; McLaughlin et al., 2018). Common examples of adversity employed in research labs include speech produced by a nonnative talker (McLaughlin et al., 2018; Van Engen & Peelle, 2014) or speech that is spoken in a casual/conversational (vs. clear) manner (Cohn et al., 2021; Rodman et al., 2020). Additionally, speech presented in the presence of broadband noise (Fitzhugh et al., 2021) or multi-talker babble (Phatak et al., 2019) can serve as adverse listening conditions.
Neurocognitive Compensation for Adverse Listening Conditions
Fortunately, human listeners are equipped with resources that generally enable compensation for these adverse conditions using a combination of neurocognitive mechanisms (Başkent et al., 2016a), but individuals vary substantially in their ability to apply these mechanisms to perceive speech under adverse listening conditions (Benichov et al., 2012; Bent et al., 2016; Moberly et al., 2023). For example, a prominently studied form of “top-down” neurocognitive compensation involves the use of supportive context (e.g., semantic and syntactic constraints) during speech recognition, in which listeners use their linguistic knowledge to make sense of ambiguous speech signals. Most psycholinguistic models of speech recognition share, to a greater or lesser degree, this concept of top-down compensation, in which the acoustic-phonetic features of the speech input (i.e., “bottom-up” processes) interact in some fashion with the long-term linguistic knowledge of a listener (Grossberg & Stone, 1986; Luce & Pisoni, 1998; McClelland & Elman, 1986; Morton, 1969; Norris et al., 2016; Tuennerhoff & Noppeney, 2016). Importantly, however, the neurocognitive mechanisms that support top-down compensation may differ based on the particular challenges imposed by the adverse condition, as different types of adversity place different demands on neurocognitive resources (Van Hedger & Johnsrude, 2022). For example, listening to speech in broadband noise (i.e., primarily energetic masking) poses a challenge to the listener because it interferes with target speech primarily at the periphery (i.e., the cochlea and auditory nerve), whereas speech from a single competing talker (i.e., more informational masking) poses a more central or cognitive challenge (Van Hedger & Johnsrude, 2022). The literature examining cognitive contributions to speech-in-noise performance has also revealed that lexical complexity impacts the extent to which cognitive functions are engaged (Heinrich et al., 2015; Heinrich & Knight, 2016).
Crystallized Intelligence
A number of neurocognitive resources and linguistic abilities have been found to play a role in top-down compensation during speech recognition under some adverse listening conditions. “Crystallized intelligence,” previously acquired knowledge from education and linguistic experience (e.g., vocabulary and semantic knowledge), may be relied upon to overcome adverse conditions (Daneman et al., 2006; Mattys et al., 2005; Park, 2002; Schneider et al., 2016; Sheldon et al., 2008; Tamati et al., 2022). For example, Pichora-Fuller and colleagues (2007) examined top-down compensation in groups of older and younger adults listening to temporally jittered high- and low-context sentences. Older adults outperformed younger adults, which the authors suggested may have been a result of better use of lexical knowledge. McLaughlin and colleagues (2018) demonstrated that receptive vocabulary positively predicted speech recognition performance across multiple adverse listening conditions, including native speech in speech-shaped noise, native speech with a single-talker masker, nonnative-accented speech in quiet, and nonnative-accented speech in speech-shaped noise.
Fluid Intelligence
In contrast to crystallized intelligence, “fluid intelligence,” also known as IQ or nonverbal reasoning, generally refers to the broad ability to reason on novel tasks or solve new problems (Kaufman & Kaufman, 1993; Woodcock & Mather, 1990), without relying on explicit prior knowledge (Carpenter et al., 1990). Nonverbal reasoning tasks typically measure the ability to solve problems by using awareness of the relations among multiple items in the task, such as the Raven's Progressive Matrices Test (Raven, 1938; 2000). Yoo and Bidelman (2019) found that nonverbal reasoning contributed to better speech recognition in multi-talker babble in a group of musicians. In a study examining aging-related declines in speech-in-noise recognition, Moore and colleagues (2014) found that declines in performance on a nonverbal reasoning test were associated with declines in recognition on a Digit Triplets Test in speech-shaped noise. Nonverbal reasoning may be particularly important in highly complex listening tasks like dichotic listening (Engle, 2002; Meister et al., 2013).
Working Memory
Additional neurocognitive constructs that are related or overlapping with nonverbal reasoning include measures of working memory capacity, inhibition-concentration, and information processing speed (Salthouse & Davis, 2006). Working memory refers to the ability to store, integrate, and process new information with information that has been previously stored (Baddeley, 1992; Daneman & Carpenter, 1980). Listeners’ working memory capacity has repeatedly been reported to be associated with speech recognition performance under adverse listening conditions (Akeroyd, 2008; Arehart et al., 2013; McLaughlin et al., 2018; Moberly et al., 2017; Rönnberg et al., 2013). When it comes to adversity in the form of listening to speech spoken by unfamiliar or foreign-accented talkers, working memory may play a role in the internal calibration of the listener to a new talker (Janse & Adank, 2012). Working memory has played a central role in a prominent framework of the involvement of cognition in speech perception, the Ease of Language Understanding model, where working memory helps in the perceptual restoration of degraded speech signals (Rönnberg, 2003; Rönnberg et al., 2013). However, this relation has not always held true: Füllgrabe and Rosen (2016) performed a systematic review and meta-analysis examining working memory capacity using a Reading Span test and its relation with speech-in-noise performance (sentences in collocated noise) in young adults (<40 years old) with normal hearing. Their meta-analysis revealed an overall nonsignificant relationship. Nonetheless, working memory may play a greater role in older listeners, as the ambiguity of the speech increases, or as the strength of the context decreases (Van Hedger & Johnsrude, 2022).
Inhibition-Concentration
Regarding inhibition-concentration (or inhibitory control), this ability refers to the process by which a strongly interfering factor can be overcome to maintain focus on a particular task (Diamond, 2013). Specifically for speech-in-noise perception, poor inhibition may increase a listener's susceptibility to background noise (Janse, 2012). More broadly across adverse listening conditions, as listeners process incoming speech, lexical competitors (i.e., phonologically similar words to the target item; Luce & Pisoni, 1998) are activated and require inhibition (Sommers & Danielson, 1999). Poor inhibition may interfere with the process of selecting the correct target during lexical access (Sommers & Danielson, 1999). Additionally, Sörqvist and Rönnberg (2012) demonstrated that inhibition-concentration may help the listener to resolve semantic confusions when listening to stories masked by speech. Adapting to an unfamiliar talker may also require inhibitory control mechanisms (Banks et al., 2015). Inhibitory control may have a more general role in perceptual restoration of degraded speech signals (Janse & Jesse, 2014; Mattys et al., 2012). More recently, Stenbäck and colleagues (2021, 2022) demonstrated that inhibitory control is important for listening under adverse conditions such as in the presence of informational masking, in older adults with normal hearing (Stenbäck et al., 2021), and in older adults with hearing loss (Stenbäck et al., 2022).
Information Processing Speed
Information processing speed refers to the rate at which information is processed in order to carry out a task (Salthouse, 1996). Processing speed has been found to be related to performance on complex cognitive tasks including reasoning and language comprehension (Salthouse, 1996; Verhaeghen & Salthouse, 1997; Wingfield, 1996). Because recognition of a running speech stream requires rapid processing of sequential information from the speech signal and repeated recruitment of linguistic knowledge, processing speed plays a key role in speech-in-noise perception (Pichora-Fuller, 2003; Wingfield, 1996). More specifically, information processing speed for linguistic information—speed of lexical and phonological access—is a likely contributor to successful speech recognition (Marslen-Wilson, 1993; McClelland & Elman, 1986). These forms of linguistic information (lexical and phonological) are stored as representations in long-term memory, and the quality of these representations may impact how effectively and rapidly a listener can compensate for adverse listening conditions (Rönnberg et al., 2013; Tamati et al., 2022). Faster lexical access speed, through stronger phonological representations, may promote better speech recognition abilities because the listener has more cognitive resources available for additional speech processing.
In addition to the behavioral studies above, support for differential contributions of cognition to speech recognition in adverse listening conditions comes from the neuroimaging literature. In a study of individuals with progressive aphasia, impairment in auditory word comprehension was found to correlate with atrophy in certain brain regions (i.e., the anterior temporal regions), whereas impairment in sentence comprehension correlated with atrophy in other regions (i.e., the orbitofrontal and lateral frontal regions), even in quiet listening conditions (Mesulam et al., 2012). It is reasonable to expect differential cortical involvement in recognizing speech that varies at a linguistic level (e.g., varying in degree of semantic context) (Scott & McGettigan, 2013). Similarly, in a language comprehension fMRI study, Xu and colleagues (2005) compared brain activation in tasks of word versus sentence comprehension and found differential activation in regions including Broca's area and the left middle temporal gyri for sentence comprehension compared to single word comprehension, indicating a differing network of activation for these types of stimuli. Additional work supports the role of activity in a particular brain region, the cinguloopercular (CO) network, whenever cognitive control demands are high (Dosenbach et al., 2006; Duncan, 2010).
Cochlear Implant Listening as an Adverse Listening Condition
A form of adverse listening condition that has received less extensive examination in the literature, but is relevant to a growing clinical population, is the perception of speech that is spectrally degraded through a cochlear implant (CI). CIs are surgically implanted devices that restore a sensation of sound to individuals with moderate-to-profound sensorineural hearing loss. These devices bypass a poorly functioning cochlea to stimulate the auditory nerve directly through multiple electrodes placed into the cochlea (Wilson & Dorman, 2008). The CI electrodes produce amplitude-modulated electrical pulses to stimulate the auditory nerve. Although current multi-channel CIs attempt to capitalize on the frequency-specific tonotopic organization of the cochlea (i.e., delivering high-frequency signals to the basal region of the cochlea and auditory nerve and low-frequency signals to the more apical region), a major source of adversity for the CI listener is that the signal delivered remains highly spectrally degraded. This degradation is a result of multiple factors, including the limited number of electrodes implanted, detrimental changes to the auditory nerve related to hearing loss, and the relatively broad electrical stimulation of the auditory nerve (Başkent et al., 2016b). As a result, even listening to “optimal” clear speech by a native talker under quiet conditions should be considered an adverse listening condition for a CI user. In the current study, the first aim was to examine the neurocognitive factors that would help explain individual CI listeners’ speech recognition abilities, with the broad hypothesis that neurocognitive functions would contribute to speech recognition in adult CI users.
Some prior work provides general support for this overarching hypothesis in adult CI users. Early work by Knutson and colleagues (1991) demonstrated a moderate association between nonverbal reasoning and speech recognition in adult CI users. More recently, Tamati and colleagues (2021) found that speed of lexical access on a visual reading measure correlated with speech recognition performance in adult CI users. In a study using discriminant analysis to differentiate a group of CI high-performers on a high talker-variability sentence recognition task versus a group of low-performers, Tamati et al. (2020) found that a visual measure of nonverbal reasoning contributed to the discriminant function. Similarly, O’Neill et al. (2019) found that performance on a reading span measure of working memory correlated moderately with sentence recognition in adult CI users. Kaandorp and colleagues (2017) demonstrated that lexical access ability on a lexical decision task and reading span performance contributed to adult CI users’ speech-in-noise recognition abilities. Moberly and colleagues (2021) demonstrated that a composite score of neurocognitive functions was associated with speech recognition in adult CI users, but that these associations depended on individual auditory resolution abilities, with the strongest associations in listeners with the best auditory resolution. Tamati et al. (2023) found that measures of auditory working memory capacity were moderately to strongly correlated with speech recognition performance on high- and relatively lower-variability sentence recognition tasks. Interestingly, Mosnier and colleagues (2015) found that preoperative performance on a test of phonemic verbal fluency predicted improvements in speech perception in white noise for adults 12 months after implantation. In contrast, Bosen and colleagues (2021) found that working memory capacity assessed using a digit span measure and vocabulary size using a Word Familiarity measure did not correlate with sentence recognition ability in adult CI users, after controlling for individual auditory resolution.
Noise-Vocoded Speech as an Adverse Listening Condition
A research model of CI processing that is frequently used as a tool for investigating the effects of spectral degradation on speech perception in normal-hearing (NH) listeners is noise-vocoding (Shannon et al., 1995). In noise-vocoding, temporal envelopes are extracted from broad frequency bands of speech, and these envelopes are used to modulate noises of those same bandwidths, resulting in spectrally degraded speech signals. A few studies have examined the neurocognitive functions that contribute to speech recognition in NH adults listening to noise-vocoded speech. Lewis and colleagues (2021) found that inhibition-concentration skills measured on a visual Flanker task correlated with sentence recognition scores for young NH participants listening to 8-channel noise-vocoded speech. In a study by Bosen and Barry (2020), a correlation was found between a working memory measure of auditory word recall (of vocoded words) and vocoded sentence recognition in young NH adults. Similarly, Schvartz and colleagues (2008) demonstrated a correlation between verbal working memory capacity and noise-vocoded speech recognition skills in NH listeners. In contrast, Shader and colleagues (2020) failed to demonstrate any relation between working memory capacity and vocoded speech recognition performance in young NH adults.
Although recent studies have demonstrated that noise-vocoded speech does not correspond well to the sound quality of CIs (Dorman et al., 2017), it has still been assumed that noise-vocoding serves as an overall valid model for CI signal processing of speech, such that testing NH listeners with noise-vocoded speech provides results that are reasonably representative of how CI users process speech. If so, it would be predicted that noise-vocoding should result in a degraded speech signal for which a NH listener should tap into similar neurocognitive functions as those that allow top-down compensation by actual CI users. However, to our knowledge, that prediction has not been tested in a direct comparison between CI users and NH peers listening to noise-vocoded speech. Moreover, studies of listeners hearing noise-vocoded speech typically enroll groups of younger NH adults who may differ substantially from typical adult CI users in age, socioeconomic status, and neurocognitive functioning (e.g., Goldsworthy, 2019; Iverson et al., 2006; Koelewijn et al., 2023). Additionally, in those studies of NH listeners, participants are listening to processed signals with which they are not previously accustomed, as compared with CI users who have acclimated to hearing speech as processed through their devices. Thus, a second goal of the current study was to test the hypothesis that an overlapping set of neurocognitive functions would contribute to recognizing spectrally degraded speech in NH adults listening to noise-vocoded speech as in actual adult CI users.
For both NH adults listening to noise-vocoded speech as well as CI users, details of the neurocognitive mechanisms supporting speech recognition for measures of varying linguistic complexity have not been defined in detail. The third hypothesis tested was that specific neurocognitive functions would contribute differentially to performance on speech recognition across a range of linguistic materials: isolated words, words in meaningful sentences, words in anomalous (syntactically appropriate but semantically meaningless) sentences, words in high talker-variability sentences spoken by multiple talkers, and words presented in a combined audiovisual (AV) fashion. These measures were selected to represent a range of linguistic complexity (e.g., isolated words and words in sentences) as well as a range of real-world types of listening adversity (e.g., high-variability speech and AV speech). Moreover, we predicted that the same pattern of relations of neurocognitive functions to speech recognition across these materials would be revealed when comparing CI users to NH adults listening to noise-vocoded speech.
It should be noted, when studying an adult population of listeners, that aging impacts speech recognition abilities through declines in both sensory and cognitive processes. Even in older NH adults, sensory changes may result in greater demands on cognitive processes to understand speech (Wayne & Johnsrude, 2015). However, older adults are also at risk for declines in these particular cognitive functions, especially those related to processing speed (Pichora-Fuller, 2003; Salthouse, 1996). Thus, in this study, we enrolled age-matched groups of CI users and NH control participants.
In summary, the current study enrolled experienced adult CI users and a group of age-matched NH adults listening to noise-vocoded speech to better understand the contributions of neurocognitive functions to speech recognition under conditions of spectral degradation. We tested listeners using a variety of speech materials that differed in complexity to determine which neurocognitive functions contribute most to performance on each measure. Lastly, we aimed to determine whether noise-vocoding serves as a reasonable simulation of CI speech from the standpoint of the underlying neurocognitive functions that contribute to spectrally degraded speech.
Methods
Participants
A total of 97 adults participated in the study. Of note, these participants partially overlap with participants from previous publications (Moberly et al., 2021; Moberly et al., 2023). Participants included 54 adults with CIs for moderate-to-profound sensorineural hearing loss between the ages of 45 and 87 years (mean = 66.6, SD = 9.4), and 43 adults between the ages of 50 and 81 years (mean = 66.8, SD = 6.6) with “near-normal” hearing. Because enrolling older adults with normal pure-tone thresholds was challenging, the “near-normal” pure-tone average (PTA) criterion for frequencies 0.5, 1, 2, and 4 kHz was relaxed to 30 dB HL or better in both ears, as was done by Moberly et al. (2023). Three NH participants did not meet the near-normal PTA criterion, so their data were excluded prior to analysis. Lastly, one CI participant demonstrated Stroop response times that were >3 SD longer than the mean, so this participant's data were excluded from analyses. Thus, 53 CI participants and 40 NH participants were included in analyses. All participants were recruited from the Otolaryngology department at The Ohio State University or using Research Match, a national research recruitment service. All participants passed a combined audiovisually presented version of the Mini-Mental State Examination (MMSE), which is a validated cognitive screening assessment tool (Folstein et al., 1975), all with a score of ≥ 26 on the MMSE. All participants were also assessed for basic word-reading ability to ensure general language proficiency, using the Word Reading subtest of the Wide Range Achievement Test, 4th edition (WRAT; Wilkinson & Robertson, 2006). All participants whose data were included in analyses demonstrated WRAT standard scores of ≥ 75, suggesting reasonably good general language proficiency. Because some tasks required the participants to look at a computer monitor or complete paper forms, a final screening test of near-vision was done, and all but 1 participant had corrected near-vision of better than or equal to 20/40. The participant who demonstrated near-vision worse than 20/40 had a reading standard score on the WRAT of 103, suggesting sufficient vision abilities to be included in data analyses. All participants spoke American English as their native language and had at least a high school diploma. Socioeconomic status (SES) was measured for each participant using a metric defined by Nittrouer and Burton (2005), which quantifies occupation and education levels between 1 (lowest) and 8 (highest). The two scores were multiplied, giving scores between 1 and 64. CI users had a range of self-reported durations of hearing loss (mean = 39.3 years, SD = 18.6 years, range = 4–76 years) and all had at least 12 months of experience with their CIs (mean duration of CI use 6.6 years, SD = 5.4 years, range = 1–27 years). Fifteen CI participants had bilateral CIs, while the remaining 38 had unilateral CIs. Of the unilateral CI users, 23 also continued to wear a contralateral hearing aid. Average demographic, audiologic, and screening data for the 93 participants included in analyses are shown in Table 1, along with results of tests comparing the two groups. These tests demonstrated no statistically significant group differences in age and gender, whereas SES, MMSE, and WRAT were significantly lower in CI users than NH peers, and unaided PTA was significantly worse in CI users than NH peers.
Demographics, Audiologic, and Screening Characteristics of Cochlear Implant (CI) Participants and Normal-Hearing (NH) Peers
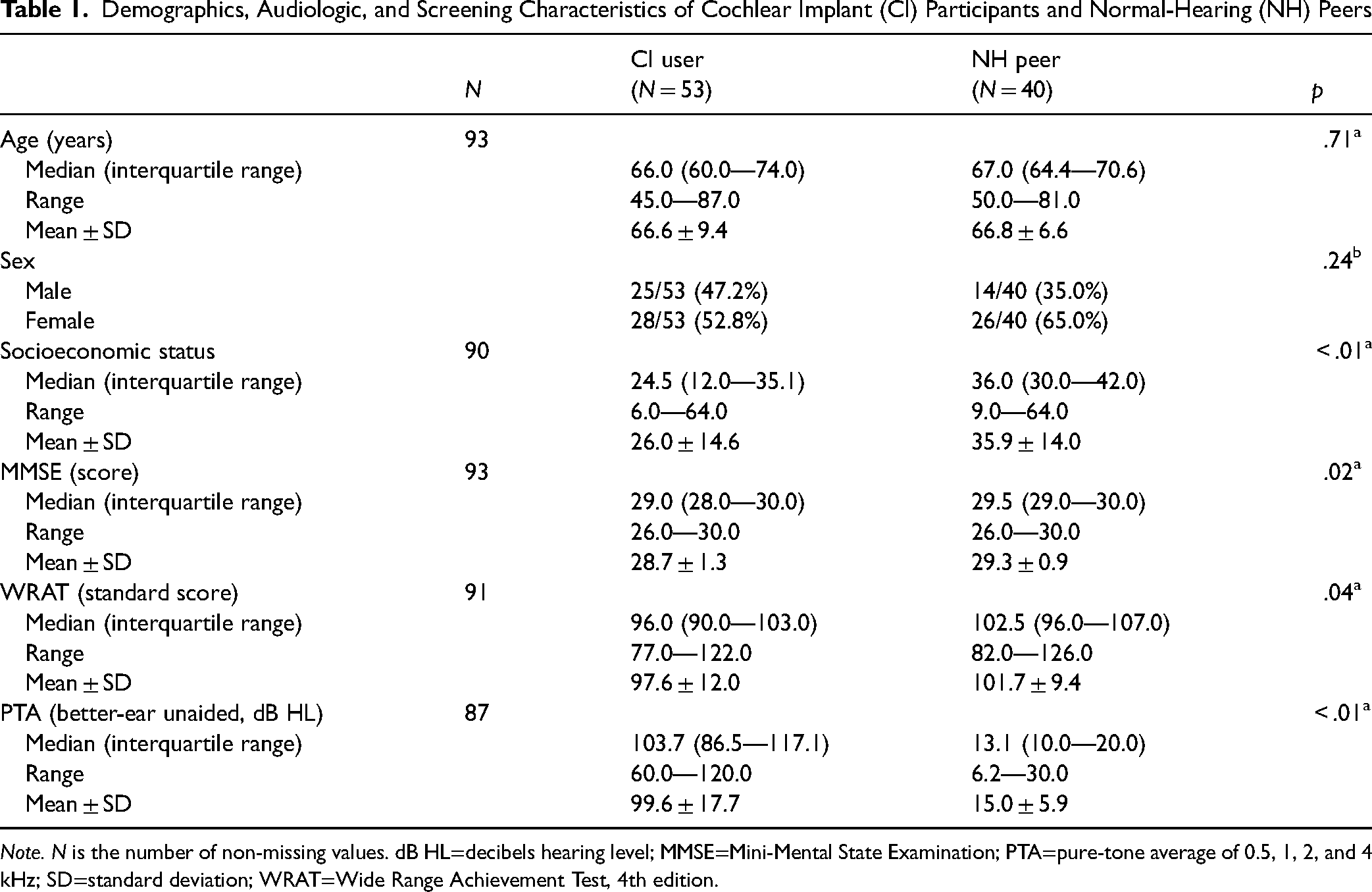
Note. N is the number of non-missing values. dB HL=decibels hearing level; MMSE=Mini-Mental State Examination; PTA=pure-tone average of 0.5, 1, 2, and 4 kHz; SD=standard deviation; WRAT=Wide Range Achievement Test, 4th edition.
General Approach and Measures
Participants were tested in one session lasting approximately 3 hr. All tasks were performed in a soundproof booth or sound-treated testing room. Participants completed speech recognition tasks and a battery of non-auditory neurocognitive measures. To ensure audibility, all participants underwent audiometric screening. For NH participants, audiometric thresholds were tested to confirm hearing within normal limits across key frequencies. For CI users, warble tone thresholds were measured to ensure their devices were appropriately adjusted and that they could detect sounds across key frequencies. Additionally, all participants confirmed they could hear the stimuli before testing began. Auditory speech stimuli were presented soundfield in quiet at 68 dB SPL via a Roland MA-12C speaker (Roland Corp., Los Angeles, CA, USA) placed one meter in front of the speaker at 0° azimuth. For AV speech recognition testing, visual stimuli consisted of simultaneous presentation of the talker's face presented on a computer monitor placed 2 ft in front of the participant. CI participants were tested in their own best-aided everyday listening configuration. Neurocognitive tasks included measures of vocabulary knowledge (crystallized intelligence), nonverbal reasoning (fluid intelligence), working memory capacity, inhibition-concentration, and speed of lexical and phonological access. For speech recognition tasks and the measure of speed of lexical and phonological access, participant responses were video- and audio-recorded to allow later scoring. Participants wore vests with FM transmitters that sent signals to receivers connected to a video camera. Responses for these tasks were scored offline. Two experimenters independently scored 25% of responses to assess reliability. For the computerized tasks of working memory capacity, inhibition-concentration, and fluid intelligence, participants entered responses directly into the computer, which generated output scores. Audiometry was performed using a Welch Allyn TN262 audiometer with TDH-39 headphones. The measure of vocabulary knowledge (WordFAM) was completed in written fashion on paper and scored later. All participants provided informed written consent prior to participation and received $15 per hour for their time. Institutional Review Board (IRB) approval was obtained by the Biomedical Sciences IRB of The Ohio State University.
Speech Recognition Measures
Participants completed five speech recognition tasks. Each type of speech material was presented within a single block, and order of blocks was counterbalanced among participants. Within a block, stimulus items were presented in the same order for each participant.
Isolated Words
The recognition of isolated words was assessed using fifty Central Institute of the Deaf (CID)-W22 words (Hirsh et al., 1952). The participants were instructed to repeat the last word that was said after the prompt, “Say the word __.” CID W-22 words are phonetically balanced and spoken and recorded by a single male speaker with a general American dialect. Because these are words presented without sentential context, performance should more closely represent sensitivity of the listener to acoustic-phonetic details of speech, as compared with the sentence recognition tasks below. List 1A, which consisted of 50 words, was used for testing. Scores were number of whole words correct, out of 50 words.
Meaningful Sentences
The recognition of semantically meaningful sentences was assessed using sentences from the Institute of Electrical and Electronics Engineers (IEEE) corpus (IEEE, 1969). Each sentence consisted of five keywords in a semantically rich context (e.g., “The boy was there when the sun rose.”). Participants were presented with a single sentence and were asked to repeat what they understood, without stimulus repetition. Listeners were presented with 2 training sentences without feedback and then 28 test sentences spoken by the same male talker. Scores were computed as number of correct words for all words in sentences, out of 224 words.
Anomalous Sentences
The recognition of semantically anomalous sentences was assessed using modified versions of sentences from the IEEE corpus (Herman & Pisoni, 2000; Loebach & Pisoni, 2008). Sentences were phonetically balanced, syntactically correct, and semantically meaningless (e.g., “The deep buckle walked the old crowd.”). As was done for the meaningful sentences, listeners were presented with two training sentences without feedback and then 28 test sentences spoken by the same male talker. Scores were computed as number of correct words for all words in sentences, out of 215 words.
High-Variability Sentences
Perceptually Robust English Sentence Test Open-set (PRESTO) sentences are high-variability, complex sentences, chosen from the Texas Instruments/Massachusetts Institute of Technology speech collection, and were created to balance talker gender, key words, frequency, and familiarity, with sentences varying broadly in speaker dialect and accent (Gilbert et al., 2013). An example of a sentence is, “A flame would use up air.” Participants were asked to repeat 32 sentences. Scores were again the number of words correct for all words in sentences, out of 224 words, excluding the first two sentences as practice.
AV Sentences
City University of New York (CUNY) sentences were administered (Boothroyd et al., 1985). One list of twelve CUNY sentences was presented, containing 102 words, presented in combined AV fashion. The sentences were spoken by a single female talker, and they varied in length and subject matter. Visual stimuli consisted of simultaneous presentation of the female talker's face on the computer monitor. An example sentence is, “The forecast for tomorrow is clear skies, low humidity, and mild temperatures.” Scores were number of words repeated correctly for all sentences, out of 102 words.
Noise-Vocoding
A MatLab script that was created for an overlapping study (Moberly et al., 2023) was used to vocode sentences. Using this script, a white noise-vocoder was implemented with 8 spectral bands to create each degraded condition. A frequency range with a lower edge of 250 Hz to an upper edge of 8000 Hz was used, with center frequencies evenly spaced on an octave scale, along with a low-frequency cutoff of 300 Hz to mimic the typical upper limit of pitch perception in actual CI users. The temporal envelopes were extracted using half-wave rectification and a fourth-order, zero-phase, low-pass filter.
Neurocognitive Measures
Participants completed five visual neurocognitive tasks, with order of measures counterbalanced among participants. Measures were selected to cover important neurocognitive domains that have been demonstrated to relate to speech recognition abilities in adverse listening conditions, as described above. Visual neurocognitive tasks (instead of auditory tasks) were used to avoid the direct impact of auditory abilities on neurocognitive performance.
Vocabulary Size
To serve as a proxy for vocabulary knowledge and crystallized intelligence, participants completed a self-report written word familiarity task, the WordFAM test (Pisoni, 2007). In the WordFAM test, participants rated 50 low-, medium-, and high-frequency English words (150 total words) from 1 (“have never seen the word before”) to 7 (“recognize word and are confident of its meaning”). A mean familiarity score across all words was computed and used in analyses.
Nonverbal Reasoning
A computerized version of the Raven's Progressive Matrices was used (Raven, 2000). This task presented geometric designs in a matrix where each design contained a missing piece, and participants were asked to complete the pattern by selecting a response box that completed the design. Participants were encouraged to guess if they were unable to determine the correct response. An abbreviated version of the Raven's test was conducted over 10 min, with a maximum number of 48 test items. Raw score (items correct) was used as the measure of nonverbal reasoning.
Working Memory Capacity
A computerized Visual Digit Span task was used to measure working memory capacity, based on the original auditory digit span from the Wechsler Intelligence Scale for Children, Fourth Edition (WISC-IV-I, Wechsler, 2004) and previously used in adults with CIs (Moberly & Reed, 2019). Visual stimuli were used to eliminate potential effects of audibility on performance. Sequences of digits were presented visually on a computer screen, one at a time, and participants were asked to reproduce the lists of digits in correct serial order by touching the screen. Span length started at two items per list and could increase up to thirteen items per list. An up-down adaptive testing algorithm was used to increase the list length if the participant correctly reproduced the sequence. Two sequences were presented at each list length. If the participant correctly reproduced both sequences at a given list length, the algorithm increased the list length on the next trial. If the participant made an error, the algorithm decreased the length of the next test list. The stopping rule for the test was two incorrect responses in a row. Total number of correct digits in correct serial order was used in analyses.
Inhibition-Concentration
A computerized visual version of a verbal Stroop task was used, which is publicly available (http://www.millisecond.com). Participants were presented with color words one at a time on a computer screen and were asked to push a keyboard button identifying the color of the text of the word shown. Scoring was automatically performed by the computer at the time of testing after the participant directly entered responses. Response times were computed for correct responses to congruent words (automatic word reading; e.g., the word “Green” was shown in green text) and to incongruent words (inhibition of word reading to concentrate on text color; e.g., the word “Red” was shown in green text), as well as for control items (a colored rectangle), with 28 items for each condition (congruent, incongruent, or control). An interference score was computed as the response time to incongruent words minus the response time to congruent words, with response times computed only for correct responses, with larger scores representing greater interference (i.e., poorer inhibition-concentration), and this interference score was used in analyses. Note that a negative interference score represents better inhibition-concentration ability.
Speed of Lexical and Phonological Access
The Test of Word Reading Efficiency, version 2 (TOWRE-2), was used to assess participants’ speed of verbal processing for written materials (Torgesen et al., 1999). Participants were asked to read as many words and nonwords as accurately as possible from a list of 108 words and 66 nonwords within 45 s. Percent correct words and percent correct nonwords served as the measures used in analyses.
Data Analyses
Inter-scorer reliability was assessed for tests that involved AV recording and offline scoring of responses. All responses were scored by one trained scorer and then scored again by a second scorer for 25% of all participants (n = 24). With inter-scorer reliability greater than 90% (range: 94%–100%) based on percent agreement among scorers for the MMSE, word reading, sentence recognition, and neurocognitive tests, the scores from the initial scorer were used in all analyses.
Statistical analyses were performed using R software version 4.4.0. For all comparisons, a two-sided test with a p-value of .05 or less was set for statistical significance. For univariate comparisons, Pearson chi-squared test for categorical variables and Wilcoxon rank sum test for continuous variables were used. To test our hypothesis that recognition performance on speech materials would be associated with specific neurocognitive skills, separate linear regression analyses with robust standard errors were performed for each of the five speech recognition task conditions as a dependent variable and each of the neurocognitive skills as an independent variable. In addition, in each regression model, the group (CI vs. NH) and its interaction with the neurocognitive skill were included to test whether the effect of the skill would differ between the two groups. All models were adjusted for age, SES, MMSE, and standardized WRAT linearly. All analyses were based on complete data for the 93 participants defined above in “Participants.”
Results
Summaries for all neurocognitive assessments and speech recognition measures in CI users and the NH group are provided in Table 2. These comparisons showed some differences between the two groups in neurocognitive skills including working memory capacity, speed of lexical access, nonverbal reasoning, and vocabulary size, with NH participants tending to outperform the CI users. All the speech recognition measures, except for the high-variability sentences, also demonstrated differences between the two groups. For these measures, CI users tended to outperform NH participants, but testing conditions were not equivalent between groups: NH listened to noise-vocoded speech, while CI users heard unprocessed speech.
Neurocognitive Abilities and Speech Recognition Scores of Cochlear Implant (CI) Participants and Normal-Hearing (NH) Peers

Note. N is the number of non-missing values. SD = standard deviation.
Prior to carrying out our main analyses, we aimed to determine how strongly each speech recognition outcome measure was correlated with the other speech recognition measures. If all speech recognition measures were strongly correlated, it might suggest that neurocognitive functions would be unlikely to impact speech recognition differentially across measures. Results of Spearman correlation analyses are shown in Tables 3 and 4 for CI users and NH peers, respectively. Results demonstrated that speech recognition scores were moderately-to-strongly, but not perfectly, correlated with each other in CI users (Spearman rho correlation coefficients between .57 and .91), and moderately in NH peers (Spearman rho correlation coefficients between .45 and .64). Similarly, we calculated the Spearman rho correlation coefficients between all neurocognitive scores, here collapsing across groups based on all participants completing the same visual neurocognitive tasks, with results shown in Table 5. Neurocognitive scores did not strongly correlate with each other (all Spearman ρ < .42). As a result of these findings, it seemed appropriate to carry out the separate regression models as described above in Data Analyses.
Spearman Correlations Between Speech Recognition Scores in CI Users

Spearman Correlations Between Speech Recognition Scores in NH Peers

Spearman Correlations Between Neurocognitive Abilities in Both CI Users and NH Peers

To test the relationships between each neurocognitive skill and each speech recognition measure in CI users and the NH group, and whether these relationships were different between the two groups in the presence of potential confounders (age, SES, MMSE, and WRAT), we performed multivariable linear regression analyses as described above. The results are summarized in Table 6 and described below for each speech recognition measure.
Association of Neurocognitive Ability (Rows) with Speech Recognition Scores (Columns) in Cochlear Implant (CI) Participants and Normal-Hearing (NH) Peers

Number of units increase in speech recognition score (number of correct) for certain units increase in neurocognitive ability for group (CI users or NH peers) with same age and/or socioeconomic status, MMSE, and standardized WRAT, estimate (95% confidence interval); P is the corresponding p value for testing the null hypothesis (estimate = 0). The bold cells are those with small p values ≤.05.
Shaded cells indicate p ≤ .05 for testing the interaction between group and the neurocognitive ability.
Isolated Word Recognition (CID W-22 Words)
The univariate relationship between isolated word recognition scores (relative to the maximum total) and each neurocognitive ability for CI users and NH peers is plotted in Figure 1. The isolated word recognition scores tended to be higher in CI users than NH peers. Even after adjusting for age, SES, MMSE, and WRAT, and the specific neurocognitive ability in multivariable analysis, this result still held (not shown). From the multivariable analysis for each neurocognitive ability, only speed of lexical access showed evidence of positive association with isolated word recognition for CI users (p = .01, Table 6). These analyses also showed evidence that the associations of isolated word recognition performance with inhibition-concentration and speed of lexical access could be different between CI users and the NH group (p for interactions <.05). The evidence that other neurocognitive abilities (working memory, speed of phonological access, nonverbal reasoning, and vocabulary size) were associated with isolated word recognition was absent (all p > .05).

Isolated word recognition. Scatter plots against each neurocognitive ability with linear trend. Y-axis units are percent words correct. X-axis units are as follows: Working Memory Capacity—Digit Span points; Inhibition-Concentration—Stroop Interference Score, msec; Speed of Lexical Access—TOWRE # words correct; Speed of Phonological Access—TOWRE # nonwords correct; Nonverbal Reasoning—Raven’s total # items correct; Vocabulary Size—WordFam mean familiarity score.
Semantically Meaningful Sentences (Meaningful Sentences)
Similar to the isolated word recognition score, the semantically meaningful sentence recognition scores also tended to be higher in CI users than the NH group in both univariate analysis (Figure 2) and multivariable analysis (not shown). The multivariable analyses revealed that only nonverbal reasoning was significantly associated with meaningful sentences recognition for NH peers (p = .02, Table 6). There is little evidence showing that other neurocognitive abilities impact performance on this task in CI users and/or NH peers.

Meaningful sentence recognition. Scatter plots against each neurocognitive ability with linear trend. Y-axis units are percent words correct. X-axis units are as follows: Working Memory Capacity—Digit Span points; Inhibition-Concentration—Stroop Interference Score, msec; Speed of Lexical Access—TOWRE # words correct; Speed of Phonological Access—TOWRE # nonwords correct; Nonverbal Reasoning—Raven’s total # items correct; Vocabulary Size—WordFam mean familiarity score.
Semantically Anomalous Sentences (Anomalous Sentences)
The semantically anomalous sentence recognition scores tended to be higher among CI users than the NH group, which is consistent with the isolated word recognition and semantically meaningful sentences (both univariate [Figure 3] and multivariable analyses). Multivariable analyses demonstrated that speed of lexical access and nonverbal reasoning showed evidence of positive association with this speech recognition measure for CI users (p = .01 and p = .01). Little evidence was found for working memory capacity, inhibition-concentration, speed of phonological access, and vocabulary size to affect semantically anomalous sentence recognition.

Anomalous sentence recognition. Scatter plots against each neurocognitive ability with linear trend. Y-axis units are percent words correct. X-axis units are as follows: Working Memory Capacity—Digit Span points; Inhibition-Concentration—Stroop Interference Score, msec; Speed of Lexical Access—TOWRE # words correct; Speed of Phonological Access—TOWRE # nonwords correct; Nonverbal Reasoning—Raven’s total # items correct; Vocabulary Size—WordFam mean familiarity score.
High-Variability Sentences (PRESTO Sentences)
The high-variability sentence recognition scores did not show much difference between the CI users and the NH peers in either univariate analysis (Figure 4) or multivariable analyses (not shown). The effect of speed of lexical access was larger in CI users than NH peers (p interaction = .05). From multivariable analyses, only speed of lexical access showed evidence of association with this speech recognition task among CI users (p = .02, Table 6).

High-variability sentence recognition. Scatter plots against each neurocognitive ability with linear trend. Y-axis units are percent words correct. X-axis units are as follows: Working Memory Capacity—Digit Span points; Inhibition-Concentration—Stroop Interference Score, msec; Speed of Lexical Access—TOWRE # words correct; Speed of Phonological Access—TOWRE # nonwords correct; Nonverbal Reasoning—Raven’s total # items correct; Vocabulary Size—WordFam mean familiarity score.
AV Sentences (CUNY)
The AV sentence recognition scores tended to be higher among CI users than NH peers in both univariate analysis (Figure 5) and multivariable analysis (not shown). Multivariable analyses demonstrated that inhibition-concentration and vocabulary size were associated with AV sentence recognition among NH peers (p < .01 and p = .03, respectively).

Audiovisual sentence recognition. Scatter plots against each neurocognitive ability with linear trend. Y-axis units are percent words correct. X-axis units are as follows: Working Memory Capacity—Digit Span points; Inhibition-Concentration—Stroop Interference Score, msec; Speed of Lexical Access—TOWRE # words correct; Speed of Phonological Access—TOWRE # nonwords correct; Nonverbal Reasoning—Raven’s total # items correct; Vocabulary Size—WordFam mean familiarity score.
Summary of results
To summarize the results, all the tested speech recognition scores, except for the high-variability sentences (PRESTO sentences) score, tended to be higher among CI users than NH peers. This finding can primarily be attributed to the fact that testing conditions were not the same between groups: NH listeners heard noise-vocoded speech, while CI users heard unprocessed speech. Among the 6 neurocognitive skills, working memory capacity and speed of phonological access did not show any evidence of effect on any of the speech recognition scores in either group (however, see the Discussion below for possible task-related interpretation of these findings). Inhibition-concentration showed an association with AV sentence recognition among NH listeners. Speed of lexical access was positively associated with isolated word, anomalous sentence, and high-variability sentence recognition among CI users. Nonverbal reasoning generally seemed to contribute to higher scores on meaningful sentence recognition among NH peers and anomalous sentence recognition among CI users. Vocabulary size only related significantly to AV sentence recognition in NH listeners. Overall, these results suggested differential relationships between speech recognition scores across measures and neurocognitive abilities, with the exception of working memory capacity and speed of phonological access, which did not relate for either CI users or NH peers.
Discussion
The current study enrolled experienced adult CI users and age-matched NH adults listening to noise-vocoded speech to determine the contributions of neurocognitive functions to speech recognition under conditions of spectral degradation. Listeners were tested using a variety of speech materials that differed in complexity in order to determine which neurocognitive functions contribute most to performance on each measure. Moreover, we aimed to determine whether noise-vocoding serves as a reasonable simulation of CI speech from the standpoint of the underlying neurocognitive functions that contribute to spectrally degraded speech.
The first major finding of this study was that, generally, better neurocognitive functions contributed to more accurate recognition of spectrally degraded speech. For all speech recognition tasks, one or more neurocognitive functions that were evaluated using visual testing materials predicted speech recognition abilities, either for the CI users or their NH peers. This finding provides further evidence that neurocognitive functioning supports speech recognition under spectrally degraded conditions. Moreover, findings are generally consistent with prior studies suggesting which neurocognitive functions most strongly contribute. For example, early work by Knutson and colleagues (1991) suggested that nonverbal reasoning (fluid intelligence) contributed to speech recognition abilities in adult CI users. In this study, nonverbal reasoning was associated with CI speech recognition outcomes for anomalous sentences. Similarly, nonverbal reasoning appeared to contribute to vocoded speech recognition for meaningful sentence recognition. Thus, it is reasonable to conclude that nonverbal reasoning should be considered when interpreting spectrally degraded sentence recognition abilities both in research studies and clinical applications.
The most consistent finding across speech tasks in this study was that speed of lexical access appears to contribute to the ability of listeners to recognize spectrally degraded speech, although this relationship emerged only in CI users and not in NH peers listening to vocoded speech. This finding appears to be consistent with results of Tamati and colleagues (2021) who found that speed of lexical access on a visual reading measure correlated with speech recognition performance in a group of adult CI users, which overlapped with the CI participants in the current study. In contrast, speed of phonological access appeared not to be associated with the recognition of spectrally degraded speech for either group. This difference between associations of speed of lexical versus phonological access may reflect the fact that NH listeners were not accustomed to listening to spectrally degraded speech and had not developed a particular listening strategy for noise-vocoded stimuli. CI users, on the other hand, had experienced at least 12 months of CI use, such that they might be more equipped to be sensitive to the lexical structure of the speech they hear (Tamati et al., 2021), rather than the specific phonological details of the speech signals (Moberly et al., 2017).
Contributions of other neurocognitive functions to recognition of spectrally degraded speech also differed between the two groups. However, these findings were not as consistent as demonstrated with speed of lexical access, suggesting they should be interpreted with caution. Inhibition-concentration abilities were significantly associated with recognition of AV sentences only in NH listeners hearing noise-vocoded speech. This finding conflicts with prior findings by Moberly and Reed (2019), who found that inhibition-concentration abilities in an overlapping group of CI users were related to the ability to make use of sentence context (operationalized there as recognition of meaningful sentences when controlling for anomalous sentence recognition scores). In the current study, analyses were performed differently, with each speech recognition material examined on its own, and each neurocognitive skill entered independently, such that the contributions of speed of lexical access and fluid intelligence may have removed variance shared with the effects of inhibition-concentration abilities on overall speech recognition performance. In contrast, in NH peers listening to noise-vocoded sentences, inhibition-concentration abilities may contribute to the ability to resolve semantic confusions (in AV sentences) (Sörqvist and Rönnberg, 2012; Banks et al., 2015). It is also worth considering that the Stroop measure assesses response inhibition, while other forms of inhibitory control may play a greater role in successful listening under adverse conditions, such as resistance to proactive interference (e.g., Pisoni et al., 2018).
On the other hand, our measure of working memory capacity was not associated with degraded speech recognition in our sample of CI users and NH peers. However, this lack of relationship between performance on the visual Digit Span measure and auditory speech recognition may be due to the nature of the forward Digit Span task, which arguably assesses short-term memory (i.e., storage ability) as compared with true working memory capacity (i.e., storage plus manipulation abilities). In fact, working memory capacity remains one of the more consistent predictors of degraded speech recognition abilities, especially in older listeners (Souza et al., 2015; Reinhart & Souza, 2018; Strori et al., 2021), and future work should include more comprehensive measures of working memory capacity to explain degraded speech recognition abilities. Similarly, our measure of vocabulary size only significantly predicted AV sentence recognition in NH participants listening to vocoded speech. This general lack of relationship stands in contrast with McLaughlin and colleagues (2018) who demonstrated that vocabulary predicted speech recognition performance across multiple adverse listening conditions. This finding could relate to our use of a word familiarity task as a proxy for actual vocabulary size, or to the fact that the speech recognition materials used lexical items with relatively high familiarity in the English language.
Although findings of this study support the premise that neurocognitive functions contribute to the ability to recognize spectrally degraded speech, the patterns showed some differences between our groups of CI users and NH listeners hearing noise-vocoded speech, but again with findings not highly consistent among measures. As an example, AV sentence recognition in CI users was not predicted by performance on any visual neurocognitive measures. In contrast, for NH peers, spectrally degraded AV sentence recognition was associated with inhibition-concentration ability and vocabulary size. These disparate findings between CI users and NH peers may reflect the differences in adaptation periods that CI users and NH peers experience during testing. That is, experienced CI users are highly accustomed to perceiving spectrally degraded speech in their daily lives, and they are also likely to rely more heavily on visual input during AV speech processing when compared to NH listeners (Rouger et al., 2007), whereas NH peers are listening to a spectrally degraded speech signal with which they are not familiar. This finding is important because it may reflect differences in listener processing strategies in research studies of experienced CI users versus NH peers tested under noise-vocoded simulations. As a result, performance on noise-vocoded simulations of speech recognition, even in a similarly aged control population, may not reflect the performance of actual CI users because the neurocognitive contributions to performance may differ between experienced CI users and NH peers who are previously naïve to listening to noise-vocoded speech.
An alternative but not mutually exclusive account might be that different memory systems and their interactions may be differentially sensitive to hearing loss in their contributions to speech recognition processes (Marsja et al., 2022). That is, according to the ELU model, long-standing hearing loss may result in relative disuse of phonological/lexical representations in episodic and semantic long-term memory systems (Rönnberg et al., 2021). Thus, there may be differences in the way CI and NH listeners’ memory systems interact online while processing speech under adverse listening conditions. It is also worth noting that the addition of visual information might impact NH and CI users differently. For example, Mishra and colleagues (2013) found that AV stimuli actually distracted young NH listeners while performing executive processing tasks, resulting in lower performance with AV stimuli than with auditory-only stimuli. Alternatively, it should be noted that AV sentence recognition scores were near ceiling, particularly for the CI users, which could explain a lack of association between AV accuracy scores and neurocognitive functions. Nonetheless, findings suggest that caution should be taken in interpreting performance of NH listeners hearing noise-vocoded speech as representative of how CI users process speech.
There are several limitations of the current study worth noting. First, although the neurocognitive assessments in this study have been applied in older adults with and without hearing loss and CIs in previous studies (Moberly et al., 2017, 2021, 2023; Pisoni et al., 2018; Tamati et al., 2020), they have not formally been tested for test-retest reliability in these populations. Second, in order to incorporate a relatively large battery of neurocognitive assessments in this study protocol, a limited number of trials were used to reduce the total duration of testing. Thus, interpretation of some scores, such as the difference score in response times computed for the Stroop task, should be considered with caution. Additionally, as mentioned above, AV sentence recognition accuracy scores for both groups were near ceiling, which may have limited the ability to identify associations with neurocognitive scores. Similarly, apparent differences in mean speech recognition accuracy between groups for several speech measures may have affected the results regarding which neurocognitive factors contributed to speech recognition scores for each group. That is, considering the ELU model, if one group's mean speech recognition performance is worse than another group's (e.g., NH peers scored more poorly overall than CI users on meaningful sentence recognition), it could be hypothesized that neurocognitive functions would be taxed more strongly in the group facing relatively greater sensory degradation. Our current data preclude us from testing this hypothesis directly. Future studies should aim to formally evaluate the test-retest reliability of the neurocognitive assessments used in these populations to strengthen confidence in the observed results. Lastly, further research should explore the differential effects of varying degrees of sensory degradation on contributions of neurocognitive functions across groups to better understand how these functions relate to speech processing.
Conclusions
Neurocognitive functions contribute to recognition of spectrally degraded speech in both CI users and NH individuals listening to noise-vocoded speech. Nonverbal reasoning contributed to anomalous sentence recognition in CI users but to meaningful sentence recognition in NH, while speed of lexical access contributed to word and sentence recognition only in CI users. Inhibition-concentration and vocabulary were related only to AV sentence recognition in NH participants listening to vocoded speech. Findings suggest that the linguistic features and complexity of the speech materials used during testing impact the particular contributions of neurocognitive skills to speech recognition, and that noise-vocoding as a CI simulation may not adequately represent how neurocognition contributes to spoken language processing in actual CI users.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work was supported by the American Otological Society Clinician-Scientist Award and the National Institutes of Health, National Institute on Deafness and Other Communication Disorders (NIDCD) Career Development Award 5K23DC015539 and R01DC019088 to A.C.M. ResearchMatch, used to recruit some normal-hearing participants, is supported by National Center for Advancing Translational Sciences Grant UL1TR001070. Preparation of this manuscript was also supported by VENI Grant No. 275-89-035 from the Netherlands Organization for Scientific Research (NWO) to T.N.T.