
Abstract
Wide dynamic range compression (WDRC) and noise reduction both play important roles in hearing aids. WDRC provides level-dependent amplification so that the level of sound produced by the hearing aid falls between the hearing threshold and the highest comfortable level of the listener, while noise reduction reduces ambient noise with the goal of improving intelligibility and listening comfort and reducing effort. In most current hearing aids, noise reduction and WDRC are implemented sequentially, but this may lead to distortion of the amplitude modulation patterns of both the speech and the noise. This paper describes a deep learning method, called Neural-WDRC, for implementing both noise reduction and WDRC, employing a two-stage low-complexity network. The network initially estimates the noise alone and the speech alone. Fast-acting compression is applied to the estimated speech and slow-acting compression to the estimated noise, but with a controllable residual noise level to help the user to perceive natural environmental sounds. Neural-WDRC is frame-based, and the output of the current frame is determined only by the current and preceding frames. Neural-WDRC was compared with conventional slow- and fast-acting compression and with signal-to-noise ratio (SNR)-aware compression using objective measures and listening tests based on normal-hearing participants listening to signals processed to simulate the effects of hearing loss and hearing-impaired participants. The objective measures demonstrated that Neural-WDRC effectively reduced negative interactions of speech and noise in highly non-stationary noise scenarios. The listening tests showed that Neural-WDRC was preferred over the other compression methods for speech in non-stationary noises.
Introduction
Individuals with sensorineural hearing loss usually experience loudness recruitment and a reduced dynamic range, probably mainly as a consequence of outer hair cell (OHC) dysfunction (Fowler, 1936; Moore, 2004, 2007; Steinberg & Gardner, 1937). Loudness recruitment is a more rapid than normal growth of loudness with increasing sound level once the level exceeds the elevated detection threshold. Wide dynamic range compression (WDRC) in hearing aids (HAs) is used to compress the wide range of input sound levels encountered in everyday life into the residual dynamic range of hearing-impaired listeners (Laurence et al., 1983; Villchur, 1973). Usually, the signal is filtered into several frequency bands or channels, and WDRC is applied independently in each channel. When speech is heard in the presence of background sounds (denoted here “noise”), the gain in each channel is determined by both the speech and the noise, and this leads to the application of spurious amplitude modulation patterns to the speech, which may reduce the intelligibility of speech (Naylor & Johannesson, 2020; Souza et al., 2006; Stone & Moore, 2007). Also, spurious amplitude modulation may be applied to the noise, altering its perceived quality. This paper focuses on the design of a two-stage neural network that implements noise reduction and WDRC simultaneously, while reducing the application of spurious amplitude modulation patterns to the speech and the noise.
WDRC is characterized by several key parameters, including the following:
The number of channels, which can vary from two to more than 20, and their degree of overlap. There is evidence for a benefit of having more than one channel (Moore & Glasberg, 1986) and of having many channels when the channels are used for frequency-response shaping (Woods et al., 2006; Yund & Buckles, 1995). However, when the channels are used solely to implement WDRC rather than for frequency-response shaping, there seems to be little benefit of having more than three channels (Salorio-Corbetto et al., 2020). The compression threshold (CT) for each channel, which is the sound pressure level (SPL) above which the compression becomes active. Below the CT, a fixed linear gain is applied, except that many HAs apply expansion (a reduction of gain) at very low levels to prevent microphone noise from being audible. The gain at the CT strongly influences the audibility of low-level sounds. The CT typically ranges from 20 to 45 dB SPL, being lower for channels with high center frequencies. The compression ratio (CR) in each channel, which is the change in input level (in dB) required to achieve a 1-dB change in output level when the input SPL is above the CT. For example, a CR of 2 means that for every 2-dB increase in the input level, the output level increases by 1 dB (Moore, 2008). Usually, the CR is set to increase with increasing hearing loss at the channel center frequency. The CR typically ranges from 1.3 to 5 (Moore et al., 2001). The attack time (AT) and release time (RT) for each channel, which are measures of how fast the gain changes in response to increases or decreases in the input sound level, respectively. They are typically measured using a sound whose input level changes abruptly between 55 and 90 dB SPL (ANSI, 2014). The time taken for the output to get within 3 dB of its steady value following an increase in level is the AT, while the time taken for the output to get within 4 dB of its steady value following a decrease in level is denoted the RT. The AT is usually set to be small (0.5 to 50 ms), to prevent loudness discomfort following sudden increases in sound level, while the release time can vary widely across different HA makes and models.
A WDRC system is typically classified as fast-acting, when the RT is shorter than 200 ms, or slow-acting, when the RT is longer than 200 ms (Souza, 2002). Loudness recruitment behaves like fast-acting multichannel expansion (Moore & Glasberg, 1993; Moore et al., 1996), so restoration of loudness perception for hearing-impaired listeners would in theory require fast-acting WDRC. Such WDRC can help to restore the audibility of weak consonants in the presence of background sounds with spectral and/or temporal dips (Moore et al., 1999). However, fast-acting WDRC reduces short-term changes in spectral shape, which can exacerbate the deleterious effects of reduced frequency selectivity (Plomp, 1988). Also, fast-acting WDRC can introduce across-source modulation effects when there are multiple talkers (Stone et al., 2009; Stone & Moore, 2004), and this may decrease the ability to perceptually segregate two or more voices, leading to reduced speech intelligibility, especially for an individual with little or no ability to process temporal fine structure (TFS) information (Moore, 2008). Furthermore, with fast-acting WDRC, ambient noise is rapidly amplified during brief pauses in speech, resulting in the perception of noticeable pumping noise by hearing-aid users (Stone et al., 1999).
Slow-acting WDRC reduces some of the deleterious effects described above, including cross-modulation and pumping effects, and generally leads to higher listening comfort than fast-acting WDRC. However, a HA with slow-acting WDRC may appear to become “dead” for a while when the user moves from a situation with a high sound level to one with a much lower sound level (Moore, 2008). In addition, brief low-intensity consonants may be inaudible to hearing-impaired listeners when they occur soon after higher-intensity vowels. Overall, fast-acting and slow-acting compressors both have advantages and shortcomings, and their relative effectiveness depends on the acoustical conditions and varies across individuals (Moore, 2008).
It is well known that hearing-impaired listeners have more difficulty than normal-hearing listeners in understanding speech in noisy environments (Kates, 2008; Plomp, 1978). To alleviate this problem, most digital hearing aids incorporate some form of noise reduction. This can be based on directional processing, using the signals picked up by multiple microphones (Kates, 2008; Launer et al., 2016). However, these usually depend on the HA user looking at the desired talker, and this is not always possible. For this reason, many HAs also incorporate noise reduction that can be applied to the signal from a single microphone (Holube et al., 1999). WDRC can partly counteract noise reduction when the WDRC is implemented after noise reduction (Ngo et al., 2012). Specifically, in relatively high signal-to-noise ratio (SNR) scenarios, WDRC applies greater gain to weak noise than to more intense speech, thereby decreasing the output SNR (Naylor & Johannesson, 2020; Souza et al., 2006). In low SNR scenarios, WDRC often fails to accurately track the envelope of the target speech, resulting in a reduction of the effective CR applied to the speech. Also, as described earlier, fast-acting WDRC introduces across-source modulation, so fluctuations in level of background sounds lead to spurious amplitude modulation of the target speech (Corey & Singer, 2021; Stone & Moore, 2007).
To reduce the above-mentioned negative interactions between speech and noise produced by the application of WDRC, several more elaborate compressors have been proposed. One such system is the dual front-end automatic gain control (AGC) system (Moore, 1993; Moore & Glasberg, 1988; Moore et al., 1991; Stone et al., 1999). This involves the use of two control systems, one with long AT and RT and the other with shorter AT and RT. Most of the time, the gain is controlled by the slow system, but if a sudden large increase in sound level occurs, the gain is rapidly reduced by the fast system. If the increase in level lasts for only a short time, the gain returns to the value set by the slow system, avoiding an extended “dead” time following the intense sound, although a short “dead” time can still occur (Stone et al., 1999). Another method, known as SNR-aware compression, adaptively changes the RT based on the estimated short-term SNR in different frequency channels (May et al., 2018). Fast-acting compression is applied when the SNR is high, while slow-acting compression is applied when the SNR is low. This method led to increased subjective preference and potential benefits across a range of acoustic conditions relative to conventional fast-acting and slow-acting compressors (Kowalewski et al., 2020; Overby et al., 2023).
Another method is to combine noise reduction and WDRC (Ngo et al., 2008, et al., 2012). This is generally realized by estimating the speech/noise power ratio or the probability of speech presence for a series of short time segments (frames) and applying less gain to noise-dominated segments. Such compressors reduce the excessive amplification of low-level noise during gaps in the speech, but they fail to track the envelope of the speech for segments with low SNRs and they do not completely avoid across-source modulation (Llave et al., 2020). Moreover, when non-stationary noise is present, such as a passing vehicle or a door slamming, these systems struggle to distinguish between speech- and noise-dominated segments when using traditional statistical estimation/detection methods (Zheng et al., 2023), which is a particularly serious problem when the SNR is low. Kortlang et al. (2018) found that for different combinations of single-channel noise reduction and multi-channel WDRC, a multiplicative approach could partially alleviate the speech distortions caused by WDRC, yielding the best overall listening quality for hearing-impaired listeners.
Recently, compressors have been designed to separate speech from noise and to apply independent WDRC to the speech and to the noise (Corey & Singer, 2017; Llave et al., 2020). These source-independent compressors are considered to be theoretically optimal (Hassager et al., 2017; Overby et al., 2023; Stone & Moore, 2007). However, source separation is a challenging task and the performance of current systems is far from ideal (Llave et al., 2020), especially in practical scenarios. In addition, conventional source-separation methods usually rely on beamforming techniques using at least two microphones, which may be within a single HA or in bilaterally fitted HAs (Corey & Singer, 2017).
Inspired by the excellent performance of deep learning noise reduction methods for both normal-hearing and hearing-impaired listeners (Zheng et al., 2023), this paper presents a deep learning-based single-microphone method, Neural-WDRC, that merges source-independent WDRC with noise reduction, utilizing a two-stage low-complexity neural network. It consists of two sub-networks, namely, a noise reduction network (dubbed NR-Net) and a wide dynamic range compression network (dubbed WDRC-Net). The two sub-networks were jointly trained in an end-to-end fashion. This method achieves source-independent compression by leveraging the ability of NR-Net to separate speech from noise within each time-frequency (T-F) unit. The speech signal is compressed with a fast-acting compressor so as to improve the audibility of brief low-level consonants, while the noise signal is compressed with a slow-acting compressor whose gain is smaller than that for speech. The difference in gains between the compressors for speech and noise controls the amount of noise reduction.
The rationale behind Neural-WDRC is based on three considerations. Firstly, WDRC involves a complex nonlinear mapping between input and output, and neural networks can show excellent performance in implementing such mapping. Secondly, efficient source-independent compression can be achieved with minimal additional parameters and computational complexity by utilizing the ability of deep learning-based noise reduction to separate speech from noise. Thirdly, monaural noise reduction systems involve a tradeoff between speech distortion and noise reduction (Li et al., 2020; Reinten et al., 2023). Greater noise reduction often leads to more speech distortion. There are significant individual differences in preferences for noise reduction systems and the desired level of noise reduction. Some individuals are “noise haters” while others are “distortion haters” (Brons et al., 2012; Moore, 2022; Nabelek et al., 2006). In principle, the amount of noise reduction produced by Neural-WDRC can be varied to suit individual preferences by changing the relative gain applied to the speech and to the noise. We did not aim for complete noise removal, since it is essential for hearing-impaired listeners to perceive ambient noise in their everyday lives.
Both objective measures and listening tests were used to assess the performance of Neural-WDRC. Neural-WDRC was compared with conventional fast-acting and slow-acting compression systems, as well as with an adaptive compression system based on the SNR-aware method described by May et al. (2018).
Signal Model and Problem Formulation
This paper considers an auditory scene composed of one speech source of interest denoted


A noise reduction method in conventional series-connected systems (Ngo et al., 2012) can be expressed as

In addition, a WDRC method in these systems can be expressed as

Description of Neural-WDRC
A diagram of Neural-WDRC is presented in Figure 1a. It consists of two sub-networks, namely, NR-Net and WDRC-Net. NR-Net had the same structure as “TaErLite” (Li et al., 2023), which has been shown to be effective in removing noise while having a relatively small number of trainable parameters (2.26 M) and multiply-accumulate operations (MACs) (0.28 G/s), making it possible to implement in low-resource hearing-assistive devices. The noisy complex spectrum Y was used as the input to NR-Net, the output of NR-Net being the estimated complex spectrum of the noise-reduced signal, denoted as





Diagram of the Neural-WDRC network. (a) Overview. (b) NR-Net: the 0th-order module provides a preliminary approximation of the magnitude of the target speech spectrum, while the high-order modules estimate the distribution of the residual component. (c) WDRC-Net. The “⊕” sign represents element-wise addition of two tensors with the same dimensions. LN = layer normalization; ICB = information communication block; GRU = gated recurrent unit; Relu = rectified linear unit.
Generation of the Target Output Used for Training Neural-WDRC
Figure 2 illustrates the method used for generation of the target output used for training Neural-WDRC, based on parallel signals (speech alone and noise alone). The AT was set to 5 ms for both speech and noise, so as to reduce the gain rapidly in response to sudden increases in level. Fast-acting compression with an RT of 40 ms was applied to the clean speech. This is based on the idea that the gain should change sufficiently quickly to restore the audibility of weak consonants following relatively intense vowels. It is less clear what compression speed should be used for noise. However, some authors have argued that slow compression may be preferable for noise to preserve its temporal characteristics (Llave et al., 2020; Overby et al., 2023). Here, slow-acting compression with an RT of 2000 ms was applied to the noise. The compressed speech and noise were added with weight



Diagram illustrating the method of target output generation.
Figure 3 shows a block diagram of the compressors used in generation of the target output. First, the input signal was transformed into the frequency domain using the STFT. The window function used was the asymmetric window described later in this paper. STFT bins were grouped to form one-octave-wide bands with center frequencies ranging from 0.125 to 8 kHz. The short-time level in each band was calculated and smoothed using a first-order infinite impulse response (IIR) filter whose coefficients were determined by the AT and RT. The smoothed short-time levels in decibels were used to compute the gain for each band using a broken-stick gain function (no compression below the CT, compression with a fixed CR above the CT). The gains for each band were interpolated across frequency using piecewise cubic interpolation to derive the gain for each frequency bin of the STFT. The interpolated gains were then multiplied with the STFT representations of the input signal. Finally, the output signal in the time domain was reconstructed through the inverse STFT (ISTFT) and the overlap-add method. Note that frequency-dependent gains based on the hearing loss of the individual were not applied during generation of the target output spectrum, but such gains were applied in the evaluation stage as described in the section Objective Measurements.

Block diagram of the compressors used in target output generation. ISTFT denotes inverse STFT.
Network Structure
The network structure was the same for training and for the trained network. As shown in Figure 1b, NR-Net simulated the calculation flow of a Taylor series expansion. It consisted of four main components: the 0th-order module, high-order encoder, high-order modules, and post-filter. The pipeline was as follows. The real and imaginary parts of the noisy spectrum were concatenated to serve as the network input. The 0th-order module initially transformed the frequency dimension of the network input into the ERBN-number scale, which is a perceptually relevant frequency scale with units Cams (Moore, 2012). A high-order encoder was employed to extract features from the input complex spectrum, denoted as F. These features were concatenated with the estimated magnitude spectrum of the 0th-order module to create the input for the high-order modules. The high-order modules were used to estimate the real and imaginary parts of the target speech spectrum,


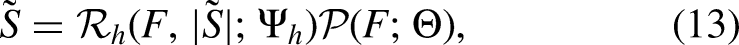
To achieve source-independent WDRC, WDRC-Net in the second stage was designed as a two-branch network with information communication implemented by the information communication block (ICB), as shown in Figure 1c. Each branch consisted of two linear layers, layer normalization (LN), two grouped gated recurrent units (GRUs), and a rectified linear unit (ReLU) layer. Grouped GRUs are a computationally efficient version of GRUs. Taking the upper branch of WDRC-Net as an example, the first linear layer was utilized to reduce the feature dimensionality, keeping the computational complexity of WDRC-Net low, and two-layer Grouped GRUs were then applied to model contextual information in speech. The outputs of the grouped GRUs were up-sampled by the output linear layer followed by ReLU to generate the compression gains for speech. There was inevitably noise leakage in the estimated speech in the first stage and vice versa. In light of this, the ICB was introduced to exchange information between the speech and noise branches. In Figure 1c, the two inputs of the ICB were fed into two different ICB modules, each corresponding to a distinct output that was added to another branch. The structure of the ICB is shown in Figure 4. Three 2-D convolutional layers and a 1-D convolutional layer were employed to estimate a multiplicative mask, which was multiplied with the input of the ICB to automatically extract the features that can be beneficial for the reduction of noise leakage and/or speech leakage. The kernel size of each convolution layer is shown by the numbers in parentheses in Figure 4. The strides, determining the shift of the kernel at each step, were set to (1, 2) for all 2-D convolutions in the ICB.

Illustration of an information communication block (ICB). The input at the top is from LN or grouped GRUs, and the output is added to the corresponding layer output of the other branch. The numbers in parentheses denote the kernel sizes.
The NR-Net had the same hyperparameters as described in Li et al. (2023). A detailed description of the WDRC-Net architecture is given in Table 1. The input sizes and the output sizes of the layers are specified in (FeatureMap × TimeStep × FeatureSize) format for 2-D convolutions, while the sizes are given in (TimeStep × FeatureMap) format for 1-D convolutions and (TimeStep × FeatureSize) format for linear layers. Here, FeatureMap denotes the number of channels or filters in a convolutional layer, TimeStep represents the total number of frames, and FeatureSize refers to the dimensionality of each feature in the input or output. The hyperparameters are specified with (KernelSize, Stride, FeatureMap) format for convolutions, (HiddenSize, SplitGroup, LayerNum) for Grouped GRUs, and (InputFeatureSize, OutputFeatureSize) format for linear layers. KernelSize denotes the size of the convolutional kernel, Stride denotes the step size of the filter across the input, HiddenSize denotes the number of units in the hidden layer of the GRU, SplitGroup denotes the number of groups in Grouped GRUs, and LayerNum indicates the number of stacked GRU layers. InputFeatureSize and OutputFeatureSize denote the sizes of each input and output sample of the linear layers, respectively.
Architecture of WDRC-Net. Since WDRC-Net has a Vertically Symmetrical Structure, Only Half of the Architecture Is Presented. T Denotes the Number of Frames.

Loss Function
The loss function
1
used during training and validation of a neural network evaluates how well a model is currently performing on a specific dataset and tunes the model parameters based on the gradient of performance with respect to these parameters. Here, a two-stage training pipeline was adopted. First, NR-Net was trained with a linear combination of the complex spectrum-based mean-square error (MSE) loss function and spectral-magnitude-based MSE loss function. This was intended to give a good balance between magnitude and phase distortion (Luo et al., 2022; Wang et al., 2021). An energy normalization coefficient 
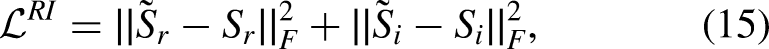
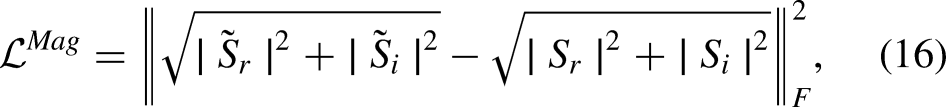

Finally, to jointly train NR-Net and WDRC-Net, the following overall loss function was used:
Low-Latency Signal Reconstruction
The time delay of modern digital hearing aids is usually in the range 0.5 to 10 ms. If the delay is longer than about 10 ms, it adversely affects speech production and perception (Stone & Moore, 1999; Stone et al., 2008). When performing hearing-aid signal processing in the time-frequency domain, the STFT and ISTFT are often used to process signals in frames using shaping windows, introducing a delay equal to the window size when the analysis window used before implementing STFT and the synthesis window used after ISTFT are symmetric. The delay can be decreased by reducing the window size at the cost of decreased spectral resolution. For example, a system with a 16-kHz sampling rate and a window size of 320 points introduces a time delay of 20 ms. To reduce the delay from 20 to 10 ms, the window size must be reduced to 160 points. This results in a decrease in frequency resolution (spacing of STFT bins) from 50 to 100 Hz, which can adversely affect noise reduction and WDRC implemented in the time-frequency domain. To address this problem, several traditional speech enhancement methods have used adaptive subband filtering to reduce the system latency (Andersen & Moonen, 2016; Löllmann & Vary, 2007; Schasse et al., 2015; Vary, 2006). Another approach to reducing latency involves a teacher-student learning-based wave-U-Net (Nakaoka et al., 2021). In this method, enhancement performance often worsens as the window size becomes smaller. Zheng et al. (2022a) introduced a deep learning-based filter-bank equalizer (DeepFBE) to reduce latency. However, DeepFBE is difficult to train because the subband weights need to be explicitly estimated in a first stage, and the real and imaginary parts of the target spectrum are then mapped in a second stage. In the present paper, the strategy used by Zheng et al. (2022b) was employed to reduce the system latency while preserving high spectral resolution. This was done via use of an asymmetric STFT window (Mauler & Martin, 2007) and an analysis window that was longer than the synthesis window, which achieves better enhancement performance than symmetric analysis and synthesis windows of the same size. For a given frame size N, the asymmetric analysis and synthesis windows were designed in such a way that their point-wise product formed a Hanning window with a size of 


All of the utterances were sampled at 16 kHz, and the window size was set to 320 points with a shift of 80 points. To obtain the time-domain signals of the training targets based on the use of traditional compressors, each frame was zero-padded to have a length of 512 samples, and a 512-point STFT was applied. To reduce the model size and computational complexity, a 320-point FFT was used to obtain the complex spectrum of the signal in each window to provide the input and target output for Neural-WDRC. With these parameter settings, the system latency was 10 ms, ignoring the frame processing time 2 .
Experimental Setup
Training and Test Datasets
The clean speech used in this study was taken from the WSJ0-SI84 corpus (Paul & Baker, 1992), which includes 7138 utterances spoken by 83 speakers, 42 male and 41 female. From this corpus, 5428 utterances from 77 speakers were selected for training and 957 utterances from the same speakers were selected for model validation. To create pairs of noisy-clean data, approximately 20,000 environmental noise clips were randomly selected from the DNS-Challenge noise dataset (Reddy et al., 2021), lasting about 55 h in total. These environmental noise clips were mixed with randomly chosen clean utterances at various SNRs. The training dataset used an SNR range of −5 to 0 dB, in 1-dB intervals. Before mixing, each clean utterance was normalized to a randomly selected root-mean-square (RMS) level, ranging from 55 to 75 dB SPL at 5-dB intervals. This was done to ensure generalization to a range of sound levels. A total of 150,000 noisy-clean pairs was used for training and an additional 10,000 pairs for validation. The cumulative duration of the training dataset was about 300 h.
The test dataset consisted of 150 utterances produced by six speakers (three male and three female), none of whom were used for training, to assess the generalization capability of Neural-WDRC to different speakers. Each clean speech utterance in the test set was normalized to a level of 65 dB SPL prior to mixing with one of six noise types. Four of the noises in the test set were speech-shaped noise (SSN) and babble from the NOISEX92 dataset (Varga & Steeneken, 1993), traffic noise from the Demand dataset (Thiemann et al., 2013), and cafeteria noise from CHiME3 (Barker et al., 2015). Two additional challenging non-stationary noises were downloaded from freesound, a mouse clicking noise with dense multiple clicks and a siren noise. Four SNRs, −6, 0, 6, and 12 dB, were used in the test stage.
Parameter Setup
In the target mapping process, the following parameters were fixed: CT = 40 dB and β = 15 dB. For application to hearing-impaired participants, the CR would typically vary with center frequency, depending on the hearing loss of the individual. However, for simplicity and as proof of concept of the approach used here, the CR was fixed at 2:1 for all center frequencies. This is approximately as prescribed by the CAM2 fitting method (Moore et al., 2010; Moore & Sęk, 2016) for a 40-dB “flat” hearing loss. The floor for the mask estimated in the 0th-order module was set to 0.1. The Adam optimizer proposed by Kingma and Ba (2014) was used in the training stage. The training continued for 50 epochs at the utterance level with a batch size of 32. The initial learning rate was set to 5e−4, and it was halved if the loss did not decrease for two consecutive epochs.
Comparison Signal-Processing Methods
Our main goal was to evaluate the benefit of independent compression of the speech and background noise, rather than to evaluate the benefit of the noise reduction. Therefore, all of the methods that were compared incorporated similar forms of noise reduction. Neural-WDRC was compared with conventional fast-acting and slow-acting compression and a compression system based on the SNR-aware method described by May et al. (2018). To simulate the serial concatenation of noise reduction and WDRC, a neural network with identical structure and hyperparameters to Neural-WDRC was trained as the noise reduction module and was implemented before the fast-acting compression, slow-acting compression, and the SNR-aware compression systems.
In addition, we wished to evaluate the potential benefit of incorporating WDRC within Neural-WDRC rather than using conventional WDRC systems following noise reduction. For this purpose, we included a fourth comparison system, denoted as NR-Net-SI. This made use of NR-Net, but the second stage, WDRC-Net, was replaced with a fast-acting compressor acting on the speech and a slow-acting compressor acting on the noise, the speech, and noise estimates coming from NR-Net. The training target of the neural network in the comparison conditions was the enhanced spectrum, aiming for a noise reduction β of 15 dB. Similarly, the NR-Net-SI compression system was designed to achieve a noise reduction of 15 dB by applying a weighting factor to the compressed noise output of the slow-acting compressor. The parameters of these comparison compressors were set to be the same as for Neural-WDRC, i.e., AT = 5 ms, CR = 2:1, CT = 40 dB, and RT 40 ms for the fast compressor and 2000 ms for the slow compressor. The a priori SNR for the SNR-aware compressor was set to the “true” value (the ground truth), guaranteeing that the SNR-aware compression system worked at its best performance.
Results
Objective Measurements
The hearing-aid speech perception index version 2 (HASPI-V2) (Kates & Arehart, 2021) and the hearing aid speech quality index (HASQI-V2) (Kates & Arehart, 2014) were chosen as the objective metrics to evaluate the performance of the different WDRC methods. The two metrics use a model of the auditory periphery. Auditory model representations of the input signal are calculated for a reference model based on normal hearing and a model based on a specific hearing loss. For the latter, any signal processing is applied to the signal prior to input to the model. The similarity of the two representations gives the estimate of intelligibility or quality. The auditory model for impaired hearing takes into account some of the typical consequences of hearing loss based on the audiogram, such as reduced frequency selectivity (Glasberg & Moore, 1986) and reduced compression in the cochlea (Moore et al., 1996). The processed signal used as input to the auditory model for impaired hearing was filtered using the National Acoustic Laboratories linear fitting procedure-revised (NAL-R) (Byrne & Dillon, 1986). A “flat” hearing loss of 40 dB at all frequencies was simulated. The software packages for calculating HASQI and HASPI scores were used with the setting that a signal with a RMS value of 1 has a level of 95 dB SPL, which is consistent with the setting in the datasets. To evaluate the performance of the WDRC methods, the processed signals were not altered in level before calculating HASPI and HASQI scores. Values of the HASQI and HASPI range from 0 to 1, higher scores indicating better performance.
Results of Objective Measurements
Figures 5 and 6 show the HASPI-V2 and HASQI-V2 scores, respectively, as a function of the input SNR for the simulated hearing-impaired listener. Scores for the conventional slow-acting and fast-acting compression systems depended on the acoustic conditions. For example, for an SNR of −6 dB, slow compression gave higher HASPI and HASQI scores than fast compression for speech in SSN but gave lower scores for speech in the highly non-stationary mouse click. This is consistent with the conclusion of Neuman et al. (1995) and Kowalewski et al. (2020) that fast-acting compression applied to a mixture of speech and steady noise introduces greater “pumping” of noise in the speech gaps than slow-acting compression. The ideal SNR-aware compression method gave higher scores than the two conventional systems for speech in stationary noise and babble, but gave similar scores to fast-acting compression for speech in the mouse click. This probably happened because, despite the ideal SNR-aware compressor having access to the true a priori SNR, it could not track the envelope of the speech when the SNR was momentarily low, and so did not completely avoid the effects of across-source modulation.

HASPI-V2 scores for speech processed using different compression methods. Each panel shows results for one noise type.

As Figure 5 but for HASQI-V2 scores.
Neural-WDRC gave similar scores to ideal SNR-aware compression for speech in SSN, babble, and traffic, but gave higher HASPI scores for speech in cafeteria noise at SNR = −6 dB. For speech in the mouse click and siren, Neural-WDRC outperformed all of the comparison methods. For example, for speech in the siren, Neural-WDRC achieved on average 9% higher HASPI scores and 16% higher HASQI scores than ideal SNR-aware compression. The advantage of Neural-WDRC in the non-stationary noises tended to be greater at low SNRs, probably because it reduced interactions between speech and background noise, such as across-source modulation. NR-Net-SI compression gave higher HASPI scores for speech in mouse click and siren than the other comparison methods at SNRs of −6 and 0 dB, but gave lower HASPI scores for speech in SSN, babble, and cafeteria at the same SNRs. This pattern of results can probably be explained by the fact that the estimated speech from NR-Net still contains some residual noise, particularly at low SNRs.
Figure 7 shows spectrograms of speech in siren noise at SNR = −6 dB, for unprocessed speech in noise, compression applied separately to the speech and noise (ideal case), and the signals processed by the different compression systems. To better illustrate compression performance via spectrograms and waveforms in Figures 7 and 8, the gain at and below the CT of all compression systems was set to 15 dB instead of the NAL-R gains to prevent the omission of some low-level spectro-temporal details. The power spectral density of the siren noise was greatest in the frequency range from 1000 to 2000 Hz, as shown in Figure 7a. Comparison of Figure 7c with Figure 7d shows that slow-acting compression introduced less distortion of the temporal envelope of the siren than fast-acting compression, but low-intensity consonants were not sufficiently amplified by slow compression, whereas they were by fast-acting compression. As shown in Figure 7e, ideal SNR-aware compression achieved compression of the speech dynamic range similar to that for fast-acting compression, while introducing less distortion of the temporal envelope of the siren. As shown in Figure 7f, Neural-WDRC introduced only slight distortion of the temporal envelope of the siren, while improving the SNR and achieving effective compression of the speech dynamic range, like the spectrum processed by source-independent compression. In summary, both the objective measures and the comparison of spectrograms showed that Neural-WDRC outperformed conventional methods, especially for speech in non-stationary backgrounds.
Spectrograms of speech in siren noise when the SNR was −6 dB. (a) Unprocessed; (b) speech and siren compressed independently with fast compression for the speech and slow compression for the siren; (c) processed using slow-acting compression; (d) processed using fast-acting compression; (e) processed by the ideal SNR-aware compressor; (f) processed by Neural-WDRC.

Waveforms and gains for speech in SSN with a noise level of 55 dB SPL.
Figure 8 illustrates the effect of varying the SNR on the envelope of the processed signal for the two most effective systems, SNR-aware compression and Neural-WDRC, for speech in SSN, with the noise level set to 55 dB SPL and the long-term speech level changed every 2 s, giving the sequence 55, 65, 75, and 65 dB SPL. The SNR-aware compression system selected the RT based on the estimated SNR, thereby preventing large gain increases from being applied to the noise in the speech gaps. However, across-source modulation was not eliminated, so the gains applied to the background noise varied with the short-term speech level, disrupting the pattern of fluctuations in the noise. With Neural-WDRC, the estimated speech and noise components were compressed independently, thereby reducing the effects of across-source modulation and preserving the characteristics of the noise.
Four 2-s speech segments with levels of 55, 65, 75, and 65 dB SPL were concatenated. The top four traces show the noisy speech, speech in SSN processed by ideal source-independent compression (denoted target), the output of the ideal SNR-aware compression method, and the output of Neural-WDRC. The bottom panel shows the gain function applied to speech for the target, the ideal SNR-aware compression method and Neural-WDRC for a channel center frequency of 500 Hz, just for the initial 2 s.
Listening Test Using Simulated Hearing-Impaired Participants
A listening test was conducted to compare Neural-WDRC with slow-acting and fast-acting compression and ideal SNR-aware compression. Twelve young normal-hearing participants listened to signals processed to simulate three of the effects of hearing loss, threshold elevation, loudness recruitment, and reduced frequency selectivity, for a 40-dB “flat” hearing loss. NAL-R gains appropriate for a 40-dB “flat” hearing loss were applied prior to processing the signals to simulate hearing loss. Then, the signals were processed by a Python translation of the methods described by Moore and co-workers (Baer & Moore, 1993, 1994; Moore & Glasberg, 1993; Stone & Moore, 1999; Tu et al., 2021). The processing was based on 28 simulated auditory filters with bandwidths twice the normal values, to simulate the typical effect of a flat 40-dB hearing loss. Threshold elevation and loudness recruitment were simulated by applying fast-acting expansion to the output of each simulated auditory filter. Reduced frequency selectivity was simulated by spectral smearing, as described by Baer and Moore (1993, 1994). The overall presentation level was adjusted separately for each participant until it was judged to be at the most comfortable level. Participants listened binaurally through Sennheiser HD600 headphones in a soundproof booth. The experiments were approved by the ethics committee of the Sixth Medical Center of the Chinese People's Liberation Army General Hospital.
The participants were asked to compare three pairs of methods: slow-acting compression versus Neural-WDRC, fast-acting compression versus Neural-WDRC, and SNR-aware compression versus Neural-WDRC, tested in that order. The noise types were stationary white noise and SSN and non-stationary mouse click and siren noises. SNRs of −6, 0, and 6 dB were used for each noise type. For each pair of methods, the noise types were tested in the order: white noise, SSN, mouse click noise, and siren noise. For each noise type, the SNRs were presented in the order −6, 0, and 6 dB. In a given trial, the noise type and SNR were fixed and four successive stimuli were presented: noisy speech, clean speech, speech in noise processed using method A, and speech in noise processed using method B. The order of the method for stimuli 3 and 4 varied randomly from trial to trial. After each trial, the participant was asked to select one of three options: A better, B better, or equal, taking into account speech distortion, noise suppression, and noise naturalness. The participant could listen to the four stimuli repeatedly before making their selection. For each participant and each condition, 10 trials were used. The final score for a given pair of processing methods, a given noise type, and a given SNR was calculated by averaging the scores of all participants across all trials.
The chi-squared test was used to evaluate the statistical significance of the differences observed. Table 2 presents the results for the stationary noises. For the SNRs of −6 and 0 dB, Neural-WDRC was clearly preferred over all three conventional compression systems for speech in both SSN and white noise (all p < .0001). For SSN with the SNR of 6 dB, Neural-WDRC was preferred over fast-acting compression (χ2 = 65.33, p < .0001), but gave comparable preference scores to slow-acting compression (χ2 = .29, p = .865) and SNR-aware compression (χ2 = 1.45, p = .483). This pattern of results can probably be explained by the fact that fast-acting compression amplified the noise in the speech gaps more than the other compression methods.
Subjective Preference Scores for the Stationary Noises for Simulated Hearing-Impaired Participants.

Table 3 presents the results for the non-stationary noises. For all SNRs, Neural-WDRC was significantly preferred over the conventional compression systems (all p < .0001). The preference scores for Neural-WDRC relative to ideal SNR-aware compression were higher for speech in mouse click and siren noises than for speech in white noise and SSN. Additionally, there were fewer instances of “equal” ratings for the non-stationary noises, suggesting that Neural-WDRC was more effective in highly non-stationary noise than SNR-aware compression, consistent with the results of the objective measurements.
Subjective Preference Scores for the Non-stationary Noises for Simulated Hearing-Impaired Participants.

Listening Test with Hearing-Impaired Participants
To further evaluate the performance of Neural-WDRC, a listening test similar to that described above was conducted using eight hearing-impaired participants, aged from 30 to 80 years (average age: 55 years), all diagnosed with sensorineural hearing loss. Since Neural-WDRC was trained for a 40-dB “flat” hearing loss and would need to be retrained for other types of hearing loss, we recruited participants whose audiograms for at least one ear were close to a 40-dB “flat” hearing loss. The hearing loss of the tested ears fell within the range 35 to 45 dB for three out of four frequencies (0.5, 1, 2, and 4 kHz), or within the range 35 to 45 dB HL for two frequencies, with the remaining two frequencies falling within the range 30 to 50 dB HL. The audiograms for the test ear of each participant are shown in Figure 9. Stimuli were presented monaurally through Sennheiser HD600 headphones in a soundproof booth.

Individual audiograms for the test ears (thin gray lines) and mean audiogram (thick black line).
To simulate the wide range of input sound levels encountered in daily life, three test levels of the speech were used 50, 65, and 80 dB SPL. Level-independent NAL-R gains appropriate for the hearing loss of each participant were applied. First, participants were asked to adjust the overall gain for an overall input level of 65 dB SPL, so that the sound was clearly audible and had a comfortable loudness. This overall gain was fixed for subsequent testing, with input levels tested in the order 65, 50, and 80 dB SPL. For each sound level, participants were asked to compare four pairs of methods: slow-acting compression versus Neural-WDRC, fast-acting compression versus Neural-WDRC, SNR-aware compression versus Neural-WDRC, and NR-Net-SI versus Neural-WDRC, in random order. For each pair of methods, six types of noise were tested: SSN, babble, mouse click, siren, traffic, and cafeteria noise. For the speech level of 65 dB SPL, SNRs of 0 and 6 dB were used, while for the levels of 50 and 80 dB SPL, only 6 dB SNR was used. For each participant and each condition, three trials were used, with sentences randomly selected from the test dataset. In each trial, two successive stimuli were presented with speech in noise processed by methods A and B, the order varying randomly. Other testing details, including preference selection criteria and statistical methods, were the same as for the listening test with simulated hearing-impaired participants.
Tables 4 and 5 present the results for the SNRs of 0 and 6 dB for the input level of 65 dB SPL. Neural-WDRC was clearly preferred over all three conventional compression systems for mouse click and siren noise (all p < .01), but gave comparable preference scores to NR-Net-SI for siren noise (χ2 = 2.76, p = .25). For the other four noise types, Neural-WDRC was clearly preferred over fast-acting compression and NR-Net-SI (all p < .01), but showed smaller non-significant improvements over slow-acting compression (χ2 = 5.88, p = .053 for traffic noise) and SNR-aware compression (χ2 = 4.923, p = .085 for babble). The results were roughly consistent with those for the listening test with simulated hearing-impaired participants, although the latter showed more “equal” ratings. Tables 6 and 7 present the results for the input levels of 50 and 80 dB SPL, respectively. For the level of 50 dB SPL, the difference in preference scores between Neural-WDRC and fast-acting compression was smaller than for the input sound levels of 65 and 80 dB SPL for SSN and traffic noise. This can probably be explained by the fact that fast-acting compression amplifies noise less for input sound levels that lead to noise levels in the individual compression channels close to the compression threshold (40 dB SPL). Considering the overall data from all six noise types, Neural-WDRC was preferred over all four comparison methods for all three input levels (all p < .05), demonstrating its effectiveness across a wide range of input levels and noise conditions.
Subjective Preference Scores for the Input Level of 65 dB SPL and the SNR of 0 dB for the Hearing-Impaired Participants.

As Table 4 but for the SNR of 6 dB.

Subjective Preference Scores for the Input Level of 50 dB SPL and the SNR of 6 dB.

As Table 6 but for the Input Level of 80 dB SPL.

Conclusions and Future Prospects
The Neural-WDRC method described in this paper was intended to reduce interactions of speech and noise (across-source modulation) when applying WDRC to noisy speech combined with noise reduction. It is difficult to avoid these interactions using conventional compression methods. Neural-WDRC combines deep learning-based noise reduction utilizing a two-stage low-complexity network with source-independent compression. The speech and noise are initially separated, and frequency- and level-dependent gains are applied separately to the estimated speech and estimated noise. Neural-WDRC can introduce a controlled amount of noise reduction and apply WDRC simultaneously. Neural-WDRC allows fast-acting compression of speech signals and slow-acting compression of noise signals, preserving the temporal envelope of the noise in each frequency region while ensuring the audibility of brief low-level speech segments.
Neural-WDRC was compared with conventional slow- and fast-acting compression, SNR-aware compression, and source-independent NR-Net-SI compression using objective measures and listening tests based on normal-hearing participants listening to signals processed to simulate the effects of hearing loss and hearing-impaired participants. The objective measures demonstrated that Neural-WDRC effectively reduced negative interactions of speech and noise in highly non-stationary noise scenarios. The listening tests based on both simulated and real hearing-impaired participants showed that Neural-WDRC was preferred over the other compression methods for speech in non-stationary noises.
The overall preference for Neural-WDRC over NR-Net-SI may appear surprising, since both make use of NR-Net and both apply WDRC separately to the estimated speech and estimated noise. The difference between the two may be related to the fact that Neural-WDRC was trained to optimize the final noise-reduced and compressed signal. If the estimated compressed speech contains some residual noise, the compression gain applied to the estimated noise may decrease to meet the required amount of noise reduction. This dynamic adjustment probably contributes to the performance superiority of Neural-WDRC over NR-Net-SI.
Neural-WDRC can easily be incorporated into other network frameworks for noise reduction without a significant increase in computational complexity. Neural-WDRC involves a total of 2.67 million parameters with a computational complexity of about 720 million MACs per second, while WDRC-Net alone involves only 0.41 million parameters and 160 million MACs per second. Implementing Neural-WDRC on the digital signal processing chips used in most current hearing aid devices would still be challenging, prompting the need to reduce the model size and computational complexity. However, there are already some high-performance chips with relatively low power consumption, making Neural-WDRC feasible for implementation and deployment in the near future.
In the current study, Neural-WDRC was trained and implemented using a fixed CR of 2:1 at all frequencies. However, hearing-impaired listeners generally require CRs that vary with center frequency, being greater in frequency regions where the hearing loss is greater. To deal with this, Neural-WDRC needs to undergo retraining with different hearing loss levels and compression parameters. Future work may focus on designing a deep learning-based compression system combined with noise reduction that can generalize across various types of hearing loss. One potential implementation strategy is to use compression parameters obtained using a specific hearing-aid fitting method, covering a wide range of hearing losses, and to use the audiogram as the input to the neural network. This may not only improve generalization across various types of hearing loss but also support audiologists in the precise fine-tuning of hearing-aid compression parameters.
Footnotes
Acknowledgments
We thank three reviewers for the very helpful and constructive comments on an earlier version of this paper.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Chinese Academy of Sciences President’s International Fellowship Initiative, National Key Research and Development Program of China (grant numbers 2024DM0004 and 2021YFB3201702).
Data availability statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.