
Abstract
For people with profound hearing loss, a cochlear implant (CI) is able to provide access to sounds that support speech perception. With current technology, most CI users obtain very good speech understanding in quiet listening environments. However, many CI users still struggle when listening to music. Efforts have been made to preprocess music for CI users and improve their music enjoyment. This work investigates potential modifications of instrumental music to make it more accessible for CI users. For this purpose, we used two datasets with varying complexity and containing individual tracks of instrumental music. The first dataset contained trios and it was newly created and synthesized for this study. The second dataset contained orchestral music with a large number of instruments. Bilateral CI users and normal hearing listeners were asked to remix the multitracks grouped into melody, bass, accompaniment, and percussion. Remixes could be performed in the amplitude, spatial, and spectral domains. Results showed that CI users preferred tracks being panned toward the right side, especially the percussion component. When CI users were grouped into frequent or occasional music listeners, significant differences in remixing preferences in all domains were observed.
Introduction
Cochlear implants (CIs) have been shown to be very successful in providing access to sounds that support speech perception, especially in quiet, for people suffering from profound sensorineural hearing loss. CIs stimulate the auditory nerve through electric pulses delivered by electrodes placed in the cochlea, bypassing the damaged hair cells. Today, many CI users are able to understand speech in favorable acoustic scenarios (e.g. Krueger et al., 2008) but face major problems in situations with background noise, reverberation, or multiple speakers, the so-called cocktail party scenario (Cherry et al., 1953). Moreover, CI users report difficulties when listening to music (McDermott, 2004; Limb & Roy, 2014), especially classical music (Gfeller et al., 2003). Classical music refers here to Western art music commonly utilizing polyphony. Music consisting of multiple instruments simultaneously resembles a cocktail party scenario, in which it is especially difficult for CI users to follow any of the sound sources. This work investigates methods of making instrumental music more accessible to CI users.
Especially for tasks related to melody and timbre perception, the vast majority of CI users perform substantially worse than normal hearing (NH) listeners. On the other hand, tasks involving rhythm perception are performed equally well by the two groups (Limb & Roy, 2014). Despite the limited music perception CI users obtain, they can still enjoy music. However, postlingually deafened CI users rate their music enjoyment lower than before their deafness (Migirov et al., 2009; Gfeller et al., 2000) and than their NH peers (Veekmans et al., 2009). Even though it has been shown that there are no strong correlations between perceptual acuity and music enjoyment for CI users (Wright & Uchanski, 2012), still, the self-reported perceived sound quality is correlated with self-reported music enjoyment (Lassaletta et al., 2007). Previous work showed that CI users tend to prefer pop music to classical music (Gfeller et al., 2003). This result can be explained by the simpler and often repeated rhythmic patterns in pop music, which are easier for CI users to recognize. In addition, in the same work, it was shown that NH listeners rated classical pieces higher than CI users. Moreover, it has been reported that CI users prefer music with fewer instruments (Kohlberg et al., 2015), and for this reason, increasing the number of instruments, such as in orchestral music, reduces music enjoyment. Following these insights, two datasets were evaluated in our study, one containing few instruments (such as trios with additional percussion) and one containing a full orchestral ensemble to represent both ends of the spectrum.
Signal processing techniques have been proposed to modify music and make it more enjoyable for CI users (Nogueira et al., 2019; Kohlberg et al., 2015; Buyens et al., 2014; Pons et al., 2016; Nagathil et al., 2017; Gajecki and Nogueira, 2018; Tahmasebi et al., 2020; Gauer et al., 2022). These techniques include the use of filters in the spectral domain, the separation of instruments in the spatial domain, or the emphasis on specific music elements in the amplitude domain.
In the spatial domain, it has been shown that bilateral CI users obtain improved speech understanding when noise and speech are spatially separated (e.g. Van Hoesel et al., 2003). Probably, bilateral CI users use interaural level differences (ILDs) to obtain this benefit, as the perception of interaural time differences with current CI technology is severely limited (Aronoff et al., 2010). In music-related experiments, Vannson et al. (2015) investigated the perception of dichotic, diotic, and monaural presentation of piano pieces for bilateral CI users. A dichotic presentation was rated as clearer than a diotic presentation, and a diotic presentation was rated as clearer than a monaural presentation. Buechner et al. (2020) showed that bilateral CI users prefer stereo over mono music for both direct coupling and free field sound presentation. This is likely due to the perception of ILDs, which are present in spatially separated music. Inspired by previous studies, we hypothesized that CI users would prefer instrumental classical music remixes with greater spatial separation of musical components than NH listeners in both datasets when participants can pan musical components (melody, bass, accompaniment, and percussion) separately. Additionally, we hypothesized that CI users prefer a remix with an asymmetric panning, as many CI users have an asymmetric speech understanding performance (Mosnier et al., 2009). Since music perception remains a difficult task for CI users, we assume that more exposure to music would impact its perception (Joshua et al., 2010). We assume that CI users who listen frequently to music may have an enhanced ability to distinguish different components in music enabling them to distribute across different spatial locations. Therefore, we hypothesized that CI users frequently listening to music would prefer a greater spatial separation in comparison to CI users who only listen occasionally to music.
In the amplitude domain, it may be also beneficial for CI users to emphasize the amplitude of specific music elements to improve the clarity and consequently their music enjoyment. Numerous studies have focused on pop western singing music. Buyens et al. (2014) showed that whereas CI users preferred a
In the spectral domain, current CI technology is limited by the low number of electrode contacts (12 to 22 depending on the manufacturer) and the interaction between channels caused by the spread of current in the highly conductive perilymph of the cochlea. For this reason, a detailed spectral information about instrumental music is distorted when transmitted through the CI. Spectral mixing techniques are commonly used in the music industry to emphasize certain elements of music, for example, the main melody or the singing voice (e.g. Ronen et al., 2015). Such spectral mixing techniques can not only emphasize certain frequency regions but can also be interpreted as a reduction in spectral complexity, for example, when low-pass filtering background instruments, result in fewer frequencies being present at the same time. Nagathil et al. (2017) performed spectral complexity reduction through principal component analysis (PCA) on sliding-window constant-Q transformed instrumental classical music. Participants preferred retaining only eight or 13 of these PCA components over the original version. This approach, however, reduced the information transmitted through the CI by removing PCA components. Regarding instrumental classical music, this method was applied to the whole excerpt, not considering that the underlying musical components (such as melody) might be of dissimilar importance for CI users, which is known to be the case for pop music. Tahmasebi et al. (2023) explored a different approach to spectral reduction specifically for CI users by reducing the number of bands selected in the sound coding strategy, thereby improving music enjoyment for vocal pop music. Hwa et al. (2021) used a median split in frequency to create a treble and bass component of each music excerpt. Participants adjusted the gain of the treble or bass component. For classical music, the average bass boost was 1 dB higher than the treble boost. It is unclear how well this result can be generalized given that only one excerpt per participant was evaluated. In this work, we investigate methods for remixing music using less complex and therefore easy-to-implement spectral techniques, namely low-pass and high-pass filters. We hypothesized that CI users would prefer different remixing than NH listeners in both datasets when musical components (melody, bass, accompaniment, and percussion) could be filtered separately. Specifically, we expected CI users, similar to in the amplitude domain, would make the melody or percussion more salient with respect to the accompaniment and bass. For this purpose, CI users could remove overlapping frequency content from the melody, accompaniment, or bass by a high-pass or low-pass filter applied to each component. Furthermore, we hypothesized that CI users who frequently listen to music preferred a different spectral remixing than their occasional listening peers.
In instrumental classical music, the recordings of the individual tracks are usually not available. If CI users have individual remixing preferences for instrumental music different than for NH listeners, source separation algorithms could be used to remix the music. In the present study, we investigated the remixing preferences of bilateral CI users and NH listeners for instrumental classical music using two datasets with different complexity due to the number of instruments involved. One of the datasets was newly created for this study. Different remixing modes were applied to each of the musical components. Furthermore, we evaluated differences in remixing preferences for both datasets and we investigated the influence of the CI users’ daily music listening time on their remixing preferences. Given the huge complexity and variability in instrumental classical music, we decided to simplify the problem by selecting and simplifying excerpts as well as creating well-controlled conditions. The idea of the experimental design was to maximize potential remixing effects by CI users.
Methods
Participants
Demographics of the CI participants (mean age: 60
CI Participants’ Demographics.

CI: cochlear implant; ID: identifier.
Datasets
For this study, a newly created dataset of quartets and an orchestral dataset were used. The datasets differed in the number of instruments to cover a broad range of classic instrumental music. For both datasets the tracks for each instrument were available. The multitracks were arranged to create four musical components: melody, bass, accompaniment, and percussion. While this separation was inspired by research on pop music, it was expanded in the current study to western instrumental classical music. In general, the percussion component fulfills different roles across these music genres, that is, repeating the rhythm and beat of a song and thereby giving a temporal basic structure for dances in pop music and a more supporting role of emphasizing and highlighting harmony in classical music. Still, the investigation of remixing the percussive elements in western classic instrumental music seemed to be important as it is one of the few components still well perceived by most CI users, as it mainly consists of temporal information. Note that in the remixing in the spectral domain and amplitude domain, it was possible to completely remove the percussion component and thereby obtain a more natural remix. To normalize these tracks, ReplayGain was used (Robinson, 2013), which is a technical standard to normalize the perceived loudness in music. It uses a psychoacoustic model to approximate the perceived loudness of an average listener through a gain that applied to a track would lead to consistent loudness across tracks. It has been used in previous experiments to balance the level of individual tracks for remixing music for CI users (Buyens et al., 2014; Pons et al., 2016; Gajecki and Nogueira, 2018). In this study, the software Foobar2000 (Pawlowski et al., 2022) was used to calculate the ReplayGain. A corresponding gain was then applied to each track.
Trio+ Dataset
This dataset was created and synthesized for this study. The Trio+ dataset consisted of audio stems obtained using MIDI files from the “classical archives,” including different eras and composers to potentially increase generalization. We selected pieces with clear melody, accompaniment, and bass. Moreover, pieces should have a clear bass distinct from the other components to allow for spectral remixing. Furthermore, pieces had no silence of more than 0.5 s for a single instrument and each instrument played the same voice or component during the 30 s excerpt duration. This ensured a consistent remixing preference during the whole excerpt. Only pieces containing a piano performing a percussive and an accompaniment role were selected. Different parts of the Piano Trio in E minor (Op. 90) by Antonin Dvorak, the Piano Trio No.1 in G by Claude Debussy, the Piano Trio No. 1 in D minor by Felix Mendelssohn, and Sonata in G major for two flutes and basso continuo by Johann Sebastian Bach were selected. Originally, these selected MIDI files consisted of trios with a clear melody, accompaniment, and bass. The MIDI files were synthesized in excerpts of 30 s using samples of instruments from the library Contact (Native Instruments, Berlin, Germany). To separate the accompaniment function of the piano from its percussion function, we additionally added a percussion track, which is grounded in the hammers of the piano, to be able to separately emphasize percussion. A percussion component was created based on the onsets of the piano track, emphasizing the inherent percussion of the piano and doubling its main accents and rhythm. This percussive component was synthesized using a sound sample of a hammer in a dampened piano. The percussion component was loudness balanced to the other instruments by an expert mixer, as the ReplayGain was not conceived for balancing transient or percussive components. With this extra track, an enhancement of the percussion was possible. During the synthesis, the assignment of instruments differed from the original piece to contain instruments from different instrument families within each piece. While this results in rarely occurring instrument arrangements, more instrument families could be regarded in this study. Furthermore, each excerpt was synthesized with two arrangements, as shown in Table 2. The percussive components in both arrangements differed by the material that the hammers hit against. The instruments assigned to melody and bass were swapped across arrangements to dampen instrument-specific effects. As this was not possible for accompaniment and percussion, different instruments were used across arrangements. Because the sample library was already recorded in stereo, no further panning was performed on this dataset.
The Selected Instruments for Both Arrangements in the Trio+ Dataset for Each Musical Component (Melody, Bass, Accompaniment, and Percussion). For the Dampened Piano, the Dampening Material is Noted in Brackets.

The synthesis of MIDI files sounds less natural than a live recording, however, none of the participants complained about the naturalness of the music during the experiments. The dataset can be found at: www.zenodo.org/record/7966531 (doi: 10.5281/zenodo.7966531).
Orchestral Dataset
The orchestral dataset was composed of live recordings of a full symphony orchestra in an anechoic chamber (Patynen et al., 2008). Each instrument was recorded separately. It contained Anton Bruckner’s Symphony No. 8, Gustav Mahler’s Symphony No. 1, and the Donna Elvira of the opera Don Giovanni of Wolfgang Amadeus Mozart. In the latter, only vocal-free parts were considered. Excerpts were selected based on the clarity and presence of melody, bass, and accompaniment. The multitracks were arranged into melody, bass, accompaniment, or percussion components depending on their music role. If excerpts did not contain any percussion component, a percussion component was created and added to the piece based on timpani and cymbals. Each instrument’s track was panned to simulate the location of the instruments in a typical orchestral arrangement with an American seating plan (Meyer et al., 2009).
Experimental Setup
Participants were asked to remix musical components of a classical excerpt to produce their most pleasant listening experience. The experiments were performed in a double-walled sound booth with low reverberation. Music excerpts were presented through a personal computer (PC) connected to a universal serial bus audio interface (“Mobile Pre,” M-Audio, Cumberland, USA). An overview of the experimental setup is shown in Figure 1. The sound was sent either to the CI users’ sound processors through a TV audio streamer (Cochlear Ltd), which enabled stereo streaming, or through headphones (“DT 770 Pro 80 Ohm,” Beyerdynamic, Heilbronn, Germany) for NH listeners. The sound volume setting in the PC was fixed for CI users and the volume setting of the TV audio streamer was adjusted to produce a pleasantly sound sensation. For NH listeners, the volume setting of the PC was changed. For this, a specific sound excerpt was presented and the volume setting was changed until the participant reported a pleasant sound sensation. For both groups, a pleasant sound sensation is defined as a level of 6 on a 10-point loudness scale ranging from 1 (very soft) to 10 (very loud).
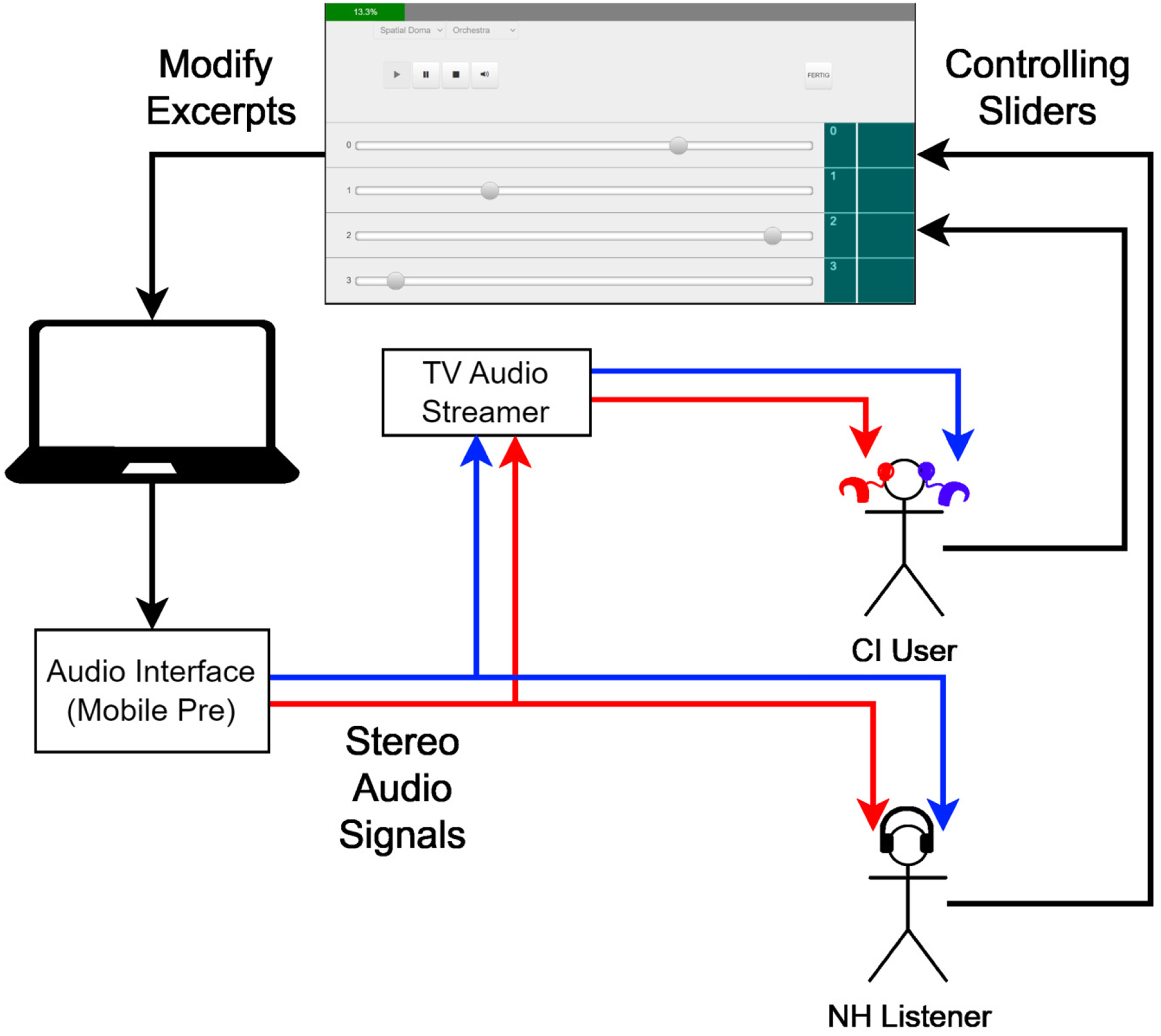
Experimental setup. A graphical user interface based on MT5 was used with which a participant was able to modify a musical excerpt by interacting with sliders. The audio was streamed via headphones for NH listeners or via the TV audio streamer to the CIs. NH: normal hearing; CI: cochlear implant.
The presentation and remixing of the excerpts were conducted through the software “MT5” (Buffa et al., 2015), which was used in a previous experiment of our group (Pons et al., 2016). MT5 allows an online change in the audio stream by presenting a slider for each of the four musical components (melody, bass, accompaniment, and percussion). In each of the three sub-experiments, these sliders controlled either the level (dubbed “amplitude domain”), the panning (dubbed “spatial domain”), or the frequency content (dubbed “spectral domain”) of each track. The order of the sub-experiments was randomized across participants. Each sub-experiment was performed first using the Trio+ and then using the orchestral dataset. There was no visual cue as to which underlying musical component was changed by the movement of a slider. The matching of sliders and musical components was randomized for each excerpt so that a specific slider would not always modify, for example, the melody. A random offset was added to the range represented by the slider, ranging from zero to two steps to the left or to the right to compensate for any tendency to put the sliders in a specific pattern. The Trio+ dataset was presented first, containing a training part of four excerpts and a test part with 18 excerpts, which comprised the two arrangements each with nine pieces. In the training part, the task was explained to the participant as well as the randomized sliders and slider position and the mode of remixing. After the training, the test part started and the excerpts were presented in a random order. Participants were asked to press the “next” button, once they reached their most preferred remixing. They could take as much time as needed. This procedure was then repeated for the orchestral dataset, using four excerpts in the training set and nine in the test set. This procedure was repeated for each remixing domain.
Spatial Domain
Each musical component could be panned from 


Amplitude Domain
For each musical component, the gain could be modified by
Spectral Domain
For each of the four musical components, a spectral filter was applied with a varying cutoff frequency. At the center of each slider, an all-pass filter was implemented. Moving the slider to the left resulted in a low-pass filter and moving the slider to the right resulted in a high-pass filter (both second-order filters, 12 dB/octave roll-off). Each step on the slider corresponded to halving or doubling the cutoff frequency of a high- or low-pass filter, resulting in the following frequencies: 109, 219, 438, 875, 1750, 3500, 7000, or 14,000 Hz.
Statistical Analysis
For all three domains, the random offset was removed and all slider positions for a specific musical component for each dataset were averaged for each participant. First, it was evaluated whether NH listeners and CI users remixed a dataset differently in any of the remixing domains. Group differences for NH listeners and CI users were evaluated separately for each dataset using a Mann–Whitney
The Trio+ dataset was additionally split into two arrangements. For each group, a separate Friedman test (
Lastly, the self-estimated music listening times of CI users were used to investigate whether frequent music listeners had different remixing preferences than occasional music listeners.
The CI users were grouped based on their self-reported estimated daily music listening time because more exposure and training with music is associated with better music enjoyment (Looi et al., 2012). CI users with a daily music listening time of 1 h or more were regarded as “frequent listeners” and the others as “occasional listeners.” This separation resulted in two groups of four and six CI users, respectively. Due to the unequal group sizes, IBM SPSS Statistics (Version 28, Armonk, USA) was used to perform a generalized linear mixed model (GLMM) analysis of the influence of music listening time and dataset (fixed factors) on the remixing. As random effects, participants and songs were chosen. For the amplitude domain, relative gains of bass, percussion, and accompaniment were analyzed. For the spectral domain, the cutoff frequency of each musical component was analyzed. For the spatial domain, the spread and bias features were analyzed. Factors were considered significant if their
Results
Remixing Preferences of NH Listeners and CI users
Spatial Domain
The results of the remixing experiment in the spatial domain are presented in Figure 2. A Mann–Whitney

Spatial remixing preferences for the musical components for NH and CI users with the Trio+ dataset (left panel) and the orchestral dataset (right panel). The box denotes the 25

Spatial remixing preferences for the measures bias and spread for NH and CI users with the Trio+ dataset (left panel) and the orchestral dataset (right panel). The box denotes the 25
Amplitude Domain
The amplitude remixing preferences are presented as the gain in amplitude of each music component (bass, accompaniment, and percussion) relative to the amplitude of the melody component in dB in Figure 4. In the Trio+ dataset, a Mann–Whitney

Amplitude remixing preferences for NH and CI users with the Trio+ dataset (left panel) and the orchestral dataset (right panel). The box denotes the 25
Spectral Domain
The spectral remixing preferences are presented as the cutoff frequencies in Hz in Figure 5. In the Trio+ dataset, there was no significant difference between groups. In the orchestral dataset, a Mann–Whitney

Group comparison of NH (red) and CI users (blue) for remixing cutoff frequencies in the spectral domain for the Trio+ dataset (left) and orchestral dataset (right). Each data point corresponds to the average spectral cutoff frequency of each subject across all excerpts. The box denotes the 25
Remixing Preferences Across Datasets
Spatial Domain
Neither the spatial bias measure nor the spatial spread measure was significantly different across the Trio+ Arrangements 1 and 2 and the orchestral dataset for NH listeners and CI users.
Amplitude Domain
There was no significant difference in remixing for the CI group across the datasets orchestral, Trio+ Arrangements 1 and 2 (A1 and A2), for any of the musical components. A Friedman test indicated that for the NH group, the accompaniment was remixed significantly differently across the datasets, where the average relative gain in the orchestral dataset was 0.71 dB, in A1
Spectral Domain
There was no significant difference in cutoff frequency selection for the CI group across datasets for any of the musical components. For NH listeners, a Friedman test indicated that only bass was remixed significantly differently across datasets (
Influence of Daily Music Listening Time
The results of the remixing experiment after a separation of the CI users into occasional and frequent music listeners based on their reported daily music listening time can be seen in Figure 6.
Spatial Domain
GLMM indicated that in the CI group, frequent music listeners preferred a significantly higher spatial spread than the occasional listeners, with
Amplitude Domain
GLMM indicated that in the CI group, frequent music listeners preferred a significantly higher relative gain for the bass component than occasional listeners with 1.24 and
Spectral Domain
GLMM indicated that in the CI group, occasional music listeners removed more low frequencies than frequent listeners, which was not significant after Bonferroni Holm correction, applying on average an 89 Hz cutoff high-pass filter and a 16,520 Hz cutoff low-pass filter, respectively (
Discussion
This study investigated if CI users have different remixing preferences than NH subjects when listening to instrumental classical music via streaming or headphones, respectively. For the amplitude domain, we hypothesized that CI users would increase the gain of melody and percussion, for the spectral domain we hypothesized the use of filters to reduce non-relevant spectral components, and for the spatial domain, we hypothesized that CI users would remix musical components further apart than NH listeners.
Spatial Domain
CI users showed a remixing preference with a significant bias toward the right side for the orchestral dataset and the Trio+ dataset. NH listeners on the other hand showed no preference toward either side. For CI users, all music components contributed to this effect with a median spatial remixing above
Amplitude Domain
There was no significant preference for the assumed increased gain for melody in either dataset. Our findings are in line with the result of Nagathil et al. (2017) where a 3 dB or 5 dB gain for the instrumental leading voice was not preferred by CI users. However, these results contrast with the preference by CI users for elevated vocals in pop music (Pons et al., 2016; Buyens et al., 2014; Tahmasebi et al., 2020; Gajecki and Nogueira, 2018). The differences between instrumental classical music and pop music might be explained by the strong salience of vocals in pop music, while the melody voice in classical music is often obscured by the surrounding instruments of the accompaniment. It is also possible that CI users increase the level of the vocals in pop music mainly because of the lyrics and not because of their melodic function.
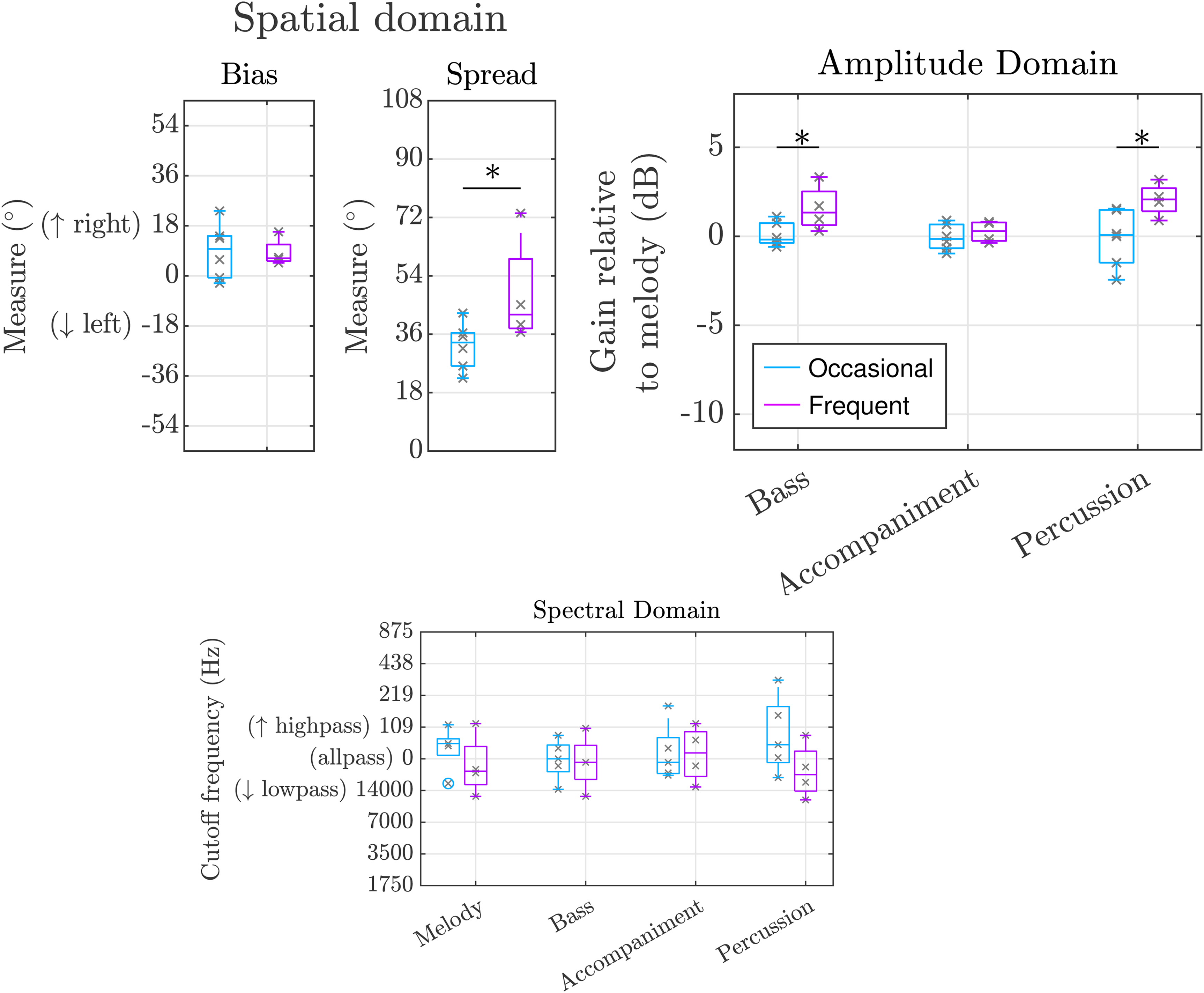
Group comparisons of occasional music listening cochlear implant (CI) users (light blue) and frequent music listening CI users (purple) for the bias and spread measure in the spatial domain (top left), for the relative gain in the amplitude domain (top right) and spectral domain (bottom). Each datapoint corresponds to the average remix value across all excerpts of a participant. The box denotes the 25
Another difference between the current study and previous ones that found a preference for more gain for vocals is that in previous studies the stimulation was provided monaurally through a single CI, while the current study and the study of Nagathil et al. (2017) provided bilateral stimulation. It has been shown that bilateral CI users obtain better music enjoyment than unilateral CI users (Veekmans et al., 2009).
In our study, CI users did not significantly increase the gain for the percussive element relative to the other musical components in either dataset. However, for the Trio+ dataset, CI users set the percussive gain on average 5 dB higher than NH listeners. NH listeners described the percussive component as unpleasant and reduced the gain by 5 dB. The authors argue that for CI users, the percussive component probably helped to follow the rhythm and tempo of the music while not causing an unpleasant sound sensation. Nonetheless, this result could also be explained by CI users being unable to perceive the unpleasantness of the sound itself without providing additional benefits. However, this has only been tested in the context of trios containing a piano and artificially emphasizing its onsets. The result is nonetheless supported by the results of Buyens et al. (2014), who observed that CI users preferred boosted percussion for pop music. For the orchestral dataset, percussion only occurred sparsely and was not useful in indicating the rhythm or tempo of the music as it did for the Trio+ dataset. This may explain why CI users did not enhance the percussion component in the orchestral dataset, when compared to NH listeners. These results are consistent with the findings of Hwa et al. (2021) that showed a trend toward a slightly increased level for percussion. For the remaining musical components, namely bass and accompaniment, there was no significant difference in remixing preferences across groups in either dataset. Tested CI users who frequently listen to music showed significant differences in the relative gains applied to the bass and the percussion. These results are consistent with the findings of Buyens et al. (2014), where enhanced bass and percussion were observed when using the harmonic percussion source separation approach to remix the music. There was no difference in remixing preference for the accompaniment component across music-listening groups.
Spectral Domain
Contrary to our expectations, no significant difference between NH and CI users was observed for the Trio+ dataset. Subjects preferred an all-pass filter, that is, no filtering was applied to any musical component. CI users reported that low- or high-pass filtering resulted in less full sound. In contrast to our approach, Nagathil et al. (2017) applied signal processing based on PCA to reduce the spectral complexity while keeping the harmonic structure of the music. In their study, CI users obtained a benefit from this processing. Hwa et al. (2021) reported that CI subjects preferred spectral processing of music consisting of bass and treble gains of 5 and 4 dB, respectively, resulting in a slight bass boost. For the orchestral dataset, NH listeners preferred low-pass filter to the bass component. No preference for spectral remixing was observed for CI users. For this particular dataset, the bass component contained a single instrument that after loudness equalization presented a high-pitched noise due to the recording. It is likely that NH listeners were able to perceive this noise and removed it through the low-pass filter, while CI users were unable to perceive it. While this does not directly influence better music remixing, it still underlines that artifacts in music affect NH listeners and CI users differently. When looking at the subgroups, the results of the study show that tested occasional CI music listeners set higher cutoff frequencies for the percussive component than frequent CI music listeners, even if it failed to reach statistical significance after multiple comparisons correction.
Further research is needed to investigate, how strong the confounding variables, that is, the difference in age and musical background across groups affect the results. A follow-up experiment should investigate how age difference is related to music style preference, sound perception in general, and its relation to music remix preferences. NH listeners tend to play music instruments or sing more often than CI users (Migirov et al., 2009), this may explain differences in remixing across groups. More exposure to music may allow them to capture more detailed differences across tracks and music in general.
To create a practical experimental paradigm some constraints to the selection of pieces have been made, for example, an instrument does not switch across musical components during an excerpt, all musical components are present every time, and instruments are playing steadily loud. These constraints need to be considered before generalizing to instrumental classical music. For example, in instrumental classical music, fast and frequent changes related to which instruments contribute to the melody component occur frequently. This aspect and others were not present in our datasets. In this study, we evaluated trios and orchestral music pieces. However, further research is required to determine the generalizability of our findings to the entire genre. We would argue that in pieces without any percussive element (e.g. string quartets), the percussion track could in the future remain empty, but the preferred remixing of the other components (melody, bass, and accompaniment) would stay the same as with our findings. However, it is possible that the addition of the percussion track in the Trio+ dataset led to a different preferred remixing than without it, even when it was possible for participants to remove it during the experiment. An additional point that needs to be investigated is the influence of the mode of listening. For example, the spectral characteristics of the microphone of the CI and the influence of the room acoustics may have an impact on remixing preference that could not be taken into account with our test setup based on the TV audio streamer. Additionally, a larger sample size of participants is needed to validate our findings for the different remixing preferences of frequent and occasional music-listening CI users. It also seems beneficial to investigate additional subjective confounding factors such as familiarity with classical music, musical concepts in general, or aesthetic preferences.
In summary, the current study showed that CI users had different remixing preferences for instrumental classical music than NH listeners. Specifically, CI users preferred higher gain on a percussion component that provided clear musical rhythm and tempo. Also, generally, the CI users preferred all instruments to be panned to their preferred side, that is,, the right side, with the percussive component panned the most. There are indications that the preferred remix is influenced by individual factors such as how often a CI user listens to music, however, further studies with a larger population are required to validate these findings. Additionally, it is of interest to investigate other factors such as familiarity with the music material or style on remixing preferences. As CI users experience limitations when listening to music and their experience of music is very individual, signal processing algorithms could be adapted to make music more accessible to them. Many people today listen to music through computers or smartphones, which can be similarly connected to the CI as in this study. Customized algorithms can be easily implemented in these devices. Generic source separation algorithms could be used to separate the tracks of instrumental music and remix them according to the needs of each CI user. For some CI users, improving music enjoyment might increase the amount of time spent listening to music, which in turn might be beneficial for their auditory rehabilitation (e.g. Dincer D’Alessandro et al., 2022).
Conclusions
For western instrumental classical music, CI users’ remixing preferences differ from those of NH listeners in the spatial domain. CI users panned the instruments toward the right side, especially the percussive element. There were individual differences in remixing preferences for occasional and frequently music-listening CI users, which suggests that a user-dependent remixing system is desirable.
Footnotes
Acknowledgements
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)—Project ID: 446611346.