
Abstract
Speech understanding in noise is poorer in bilateral cochlear-implant (BICI) users compared to normal-hearing counterparts. Independent automatic gain controls (AGCs) may contribute to this because adjusting processor gain independently can reduce interaural level differences that BICI listeners rely on for bilateral benefits. Bilaterally linked AGCs may improve bilateral benefits by increasing the magnitude of interaural level differences. The effects of linked AGCs on bilateral benefits (summation, head shadow, and squelch) were measured in nine BICI users. Speech understanding for a target talker at 0° masked by a single talker at 0°, 90°, or −90° azimuth was assessed under headphones with sentences at five target-to-masker ratios. Research processors were used to manipulate AGC type (independent or linked) and test ear (left, right, or both). Sentence recall was measured in quiet to quantify individual interaural asymmetry in functional performance. The results showed that AGC type did not significantly change performance or bilateral benefits. Interaural functional asymmetries, however, interacted with ear such that greater summation and squelch benefit occurred when there was larger functional asymmetry, and interacted with interferer location such that smaller head shadow benefit occurred when there was larger functional asymmetry. The larger benefits for those with larger asymmetry were driven by improvements from adding a better-performing ear, rather than a true binaural-hearing benefit. In summary, linked AGCs did not significantly change bilateral benefits in cases of speech-on-speech masking with a single-talker masker, but there was also no strong detriment across a range of target-to-masker ratios, within a small and diverse BICI listener population.
One of the most pervasive problems for individuals with hearing loss is difficulty understanding speech in the presence of background noise and competing talkers (Hallberg et al., 2008). In complex listening situations, such as restaurants and cocktail parties, normal-hearing listeners use cues from sound sources emanating from different locations to derive spatial-hearing benefits (Cherry, 1953; Hawley et al., 1999; Ibrahim et al., 2013). When listening with two ears, these benefits include summation, head shadow, and squelch (Culling & Lavandier, 2021; Dieudonné & Francart, 2019). Summation (sometimes called redundancy) is the performance benefit with a second ear because redundant and/or complimentary speech information is present in both ears (Culling & Lavandier, 2021; Dieudonné & Francart, 2019). Head shadow is the performance benefit from a monaural target-to-masker ratio (TMR) benefit at one ear, which is produced by sound attenuation caused by the physical obstruction of the listener’s head (Bronkhorst & Plomp, 1988; Sheffield et al., 2020). Squelch is the performance benefit of listening with two ears that is independent of changes in TMR (Culling & Lavandier, 2021; Dieudonné & Francart, 2019), thought to be from an improved internal TMR (Leclère et al., 2015) by calculating interaural timing and level differences (ITDs and ILDs, respectively). These different benefits combine to provide spatial release from masking (SRM), the improvement in understanding a target talker when there is spatial separation between a target and masker (Dieudonné & Francart, 2019).
Similar to normal-hearing listeners, bilateral cochlear-implant (BICI) listeners also have the opportunity to gain benefits from access to sound at both ears. The magnitude of these benefits can be compared between BICI and normal-hearing listeners, but the stimuli, procedures, and calculations used affect the size of the benefits measured (Dieudonné & Francart, 2019), making similarly designed studies the fairest comparisons. For summation, a benefit of about 1 to 2 dB is observed for both BICI (Schleich et al., 2004) and normal-hearing listeners (Bronkhorst & Plomp, 1988; Cox et al., 1981). For head shadow, similarly designed studies have found about 3 to 7 dB of benefit for BICI (Schleich et al., 2004) and normal-hearing listeners (Dubno et al., 2008). For squelch, similarly designed studies have found no benefit for BICI (Loizou et al., 2009) and 6 dB for normal-hearing listeners (Hawley et al., 2004). These values illustrate the disparity between these two groups in accessing squelch. Therefore, it is important to establish what contributes to this difference in performance with the overall goal of learning how to reduce this gap.
BICI listeners’ ability to access benefits with two ears is potentially limited by device factors. Lack of processor linking (e.g., automatic gain controls [AGCs]) has been proposed as a potential contributor to reduced head shadow and squelch in BICI listeners (Kan et al., 2015; Litovsky et al., 2012; Mosnier et al., 2009; van Hoesel, 2012) because a reduction or elimination of ILDs would occur with unlinked processors (Potts et al., 2019). Such negative effects might be mitigated by linking the two devices.
Potential Benefits From Linked AGCs
Linking output-limiting compression or AGCs, signal processing employed to ensure the output does not exceed the comfort levels of the listener, could improve bilateral benefits. For bilateral hearing-assistive device users (both hearing aids and BICIs), AGCs have historically been applied to each device independently. Independent AGCs in hearing aids can have relatively small effects on localization and SRM since these listeners often have access to low-frequency fine-structure ITDs (e.g., Keidser et al., 2006). Preserving ILDs could be especially important for BICI listeners, as they are unable to access low-frequency fine-structure ITD cues and instead rely heavily on ILDs (Aronoff et al., 2010; Churchill et al., 2014; Kan et al., 2015; Laback et al., 2015; Seeber & Fastl, 2008). Linked AGCs appear to preserve ILDs for BICI listeners, suggesting that this technology has the potential to also improve SRM (Chen et al., 2017; Gaskins et al., 2019).
There is evidence to suggest that linked AGCs increase SRM in both vocoder simulations and BICI listeners. Normal-hearing listeners presented with acoustic simulations of hearing-assistive devices have shown significant increases in speech understanding with linked AGCs, particularly when there was greater spatial separation between target and masker (Archer-Boyd & Carlyon, 2019; Schwartz & Shinn-Cunningham, 2013; Spencer et al., 2019; Wiggins & Seeber, 2011, 2013). For example, normal-hearing listeners presented with vocoder simulations of head-shadow benefit performed significantly better with linked AGCs compared with independent AGCs (Spencer et al., 2019). In BICI listeners, linked AGCs provided a significant improvement compared to independent AGCs in continuous and intermittent multi-talker babble with target speech from near the front at +10° azimuth and the masker from the left at –70° azimuth (Potts et al., 2019). The speech reception threshold (SRT), the TMR associated with 50% correct, improved by about 2.5 dB with linked AGCs. Previous studies did not examine the components of SRM independently in BICI listeners. Therefore, the linked AGC benefit for head shadow and squelch is currently unknown.
Another aspect to consider for multiple source inputs (e.g., target and interferer talkers) is the effect of TMR on linked AGC. For a target in front of the listener and an interferer on the side, when the TMR is positive, the target will be the primary driver of the AGCs and both should be engaged similarly, likely having a minimal effect of linking. When the TMR is negative, the interferer on the side will be the primary driver of the AGC. In this situation, linked AGCs would have the largest potential to improve ILDs. Given that squelch benefits are typically seen at negative TMRs (Bernstein et al., 2016; Freyman et al., 2008), head-shadow and squelch improvements of linked AGCs should potentially appear at negative TMRs.
Potential Detriments to Linked AGCs
One concern regarding bilaterally linked AGCs is that implementation could result in reduced speech understanding, compared to independent AGCs, in the ear contralateral to the sound source. This is because the AGCs’ primary goal is to reduce the level so that stimulation stays within the individual ear’s dynamic range. This means that for a sound source that engages the AGC, independent AGCs result in similar output levels at both ears and the natural ILD is reduced or lost. In addition to preventing over-stimulation, linked AGCs also aim to preserve the ILD, meaning that one ear will need to be more intense than the other for a source away from the midline. This could be achieved by making the ipsilateral ear more intense, the contralateral ear less intense, or a combination of the two. Making the ipsilateral ear more intense (less gain reduction than indicated by an independent AGC) could potentially result in over-stimulation, whereas making the contralateral ear less intense (more gain reduction than indicated by an independent AGC) would naturally result in a reduction of the stimulation level of that ear. A conservative approach to avoid over-stimulation is to apply the higher gain reduction of the two independent AGCs to both ears, but this approach of more aggressive compression could result in a decrement in speech understanding. In other words, there might be a trade-off between bilateral benefit and monaural dynamic range reduction with this approach. Listeners may be differentially impacted depending on the degree to which they rely on each of their ears individually for this task. When functional speech understanding abilities are symmetrical, listeners have the opportunity to rely on the ear which is closer to the target. In cases of asymmetrical profiles, if the sound source is located contralateral to the functionally better ear, they may experience a decline in speech understanding as a result of reduced signal level at the functionally better ear.
BICI listeners with asymmetrical hearing profiles may also be unique with respect to their access to SRM benefits. Goupell et al. (2018) investigated squelch effects in nine BICI listeners, recruiting listeners with longer durations of deafness and more asymmetric hearing backgrounds than typical research participants. In that study, open-set sentence (Institute for Electrical and Electronics Engineering [IEEE]; Rothauser et al., 1969) scores in quiet were used as a baseline and closed-set sentence (coordinate response measure [CRM]; Bolia et al., 2000; Brungart et al., 2001) scores were used to assess binaural benefits in situations of speech-on-speech masking. They measured squelch without head-shadow effects by comparing speech understanding when the target and interferer were presented to one ear compared to when the interferer was presented to both ears. The information in the contralateral ear often resulted in interference, with worse performance in binaural compared to monaural conditions. SRM was also measured and was smaller than typically reported values in the BICI population. Their interpretation of the data was that the negative squelch values diminished the overall SRM when combined with the head-shadow benefit. Across several studies, this interference for both BICI and single-sided-deafness cochlear-implant listeners was noted to be greater for those with older age at implantation, longer duration of deafness, and other subject factors suggesting central deficits in binaural computations (Bernstein et al., 2016, 2020; Goupell et al., 2018). More symmetrical listeners and those with better speech understanding scores, with often younger ages of implantation and durations of deafness, showed greater access to squelch on this same task, suggesting that benefits from squelch are indeed attainable (Bernstein et al., 2020). This result is particularly important to the use of AGCs in asymmetrical listeners since access to these binaural benefits is critical to maximizing potential benefit from linking these controls. Although linked AGCs will likely provide the best chance of ILD preservation and obtainable bilateral benefits, the barriers in rendering squelch benefits may be too extensive to overcome for some listeners.
The purpose of this experiment was to examine the effect of linked AGCs on speech understanding abilities in the presence of interfering speech by measuring SRM and quantifying the individual contributions of summation, head shadow, and squelch in BICI listeners. We hypothesized that the preserved ILDs provided by the linking would increase both head shadow and squelch compared to independent controls, but that linking would not have a significant effect on summation. Increased head-shadow benefits were hypothesized with linked AGCs as the ILD and TMR benefit would be better preserved. An increase in squelch with linked AGCs was also hypothesized to result from the preserved ILDs. We also hypothesized that there would be an interaction between AGC type and TMR, with linked AGC increasing SRM more at lower compared to higher TMRs.
We investigated if linked controls would be detrimental for listeners with more severe asymmetries in their speech understanding abilities. We hypothesized that larger asymmetries in monaural speech understanding would correlate with poorer binaural speech understanding abilities in noise due to reduced audibility, leading to lower squelch and head-shadow benefits. In answering these questions, the goal was to obtain results that could provide directions for further implementation or modification of this technology to make it more broadly beneficial to a range of listeners.
Method
Listeners
Nine BICI listeners (42–75 years) participated in the experiment (see Table 1). All had at least 6 months of experience with each implant and were native speakers of English. Testing was completed at the University of Maryland, College Park, using procedures approved by the Institutional Review Board at the University of Maryland, College Park, prior to the collection of data. The Montreal Cognitive Assessment (MoCA) was used to screen for cognitive decline (Nasreddine et al., 2005). All listeners had scores ≥ 22 (Anderson et al., 2012; Goupell et al., 2017; Xie et al., 2019).
Demographic Information for BICI Listeners.

Note. SSNHL = sudden sensorineural hearing loss.
Equipment
Listeners wore Advanced Bionics Naida Q90 BTE research processors configured with single-channel dual-loop AGCs, which are designed to compress high-level sounds to stay within the listener’s comfortable hearing range (Boyle et al., 2009). The AGC activation threshold (the level above which compression is applied) was defined with respect to the signal level at the output of the pre-emphasis filter and therefore depends on the frequency composition of the signal. For pink noise, the slow-loop threshold is approximately 62 dB SPL. For speech or speech-shaped noise, the threshold varies depending on the particular spectrum characteristics and can range from 62 to 67 dB SPL. The activation threshold of the AGC depends also, in part, on how quickly the amplitude rises in the input signal. Rapid changes in input level result in activating the fast-loop onset of the AGC (with threshold at 8 dB above the slow-loop threshold) to maintain protection from loudness discomfort. This fast-acting onset AGC works on stimuli at a syllabic/word level and therefore any effects of this being activated should be reflected in the performance of listeners presented with speech stimuli. The fast and slow attack times were 0.33 and 140 ms, respectively. The fast and slow release times were 46 and 383 ms, respectively. For linked AGC, the research processors used Phonak’s Hearing Instrument Body Area Network (HiBAN) wireless system to simultaneously transmit audio signals between the two processors. The AGCs on both processors used the audio information from both ears, and a common compression gain was derived for both AGCs. As a result of identical compression of the original signals, the ILDs were preserved. Independent verification that the speech stimuli used in this study engaged the AGC and the linking occurred was done via electro-acoustic recordings.
For testing, listeners were seated in a double-walled sound-attenuating booth (IAC, NY). The experiment was performed using a personal computer with custom MATLAB software (Mathworks, Natick, MA). Stimuli were delivered over a soundcard (UA-25 EX; Edirol/Roland Corp., Los Angeles, CA) and an amplifier (D-75A; Crown Audio, Elkhart, IN). Stimuli were presented through circumaural headphones (HD650; Sennheiser, Hanover, Germany). Headphones were positioned directly over the BTE processors and the T-Mic™ microphone, which was located at the entrance of the ear canal.
Stimuli
Speech understanding in quiet was assessed using IEEE sentences, which are open set format and have five keywords (Rothauser et al., 1969). The presentation level of the IEEE sentences was nominally 65 dB SPL. This level was chosen, as it has been found to result in improved speech understanding for BICI listeners compared to louder presentation levels (Firszt et al., 2004).
Speech understanding in the presence of a speech masker was assessed with sentences derived from the CRM corpus (Bolia et al., 2000). These sentences were made up of a carrier phrase (“Ready <call sign>, go to <color> <number> now”) with a color and number being the two key words. The target sentences were spoken by a male talker using the call sign of Baron. Sentence stimuli with single-talker maskers were presented binaurally using a head-related transfer function (HRTF) for an at-the-canal microphone placement measured on a head, torso, and ear simulator (large size T-Mic microphone; Advanced Bionics LLC, Research and Technology, Valencia, CA). This HRTF was specifically selected because ILDs using an at-the-canal microphone are bigger than a behind-the-ear microphone placement (Mayo & Goupell, 2020) and improve sound localization at lateral positions (>45°) (Gaskins et al., 2019; Kolberg et al., 2015). Although a medium T-Mic™ microphone was used on the research processors during testing, analyses of the HRTFs of short and long microphone lengths showed negligible differences indicating the application of either HRTF was appropriate. All targets were presented using HRTFs recorded at 0° azimuth (front). Interfering talkers were presented at three spatial locations: from 0° (front), 90° (right), or −90° (left) azimuth. In addition, the CRM sentences were presented at five different TMRs (0, ±4, and ±8 dB).
Signal processing was carried out to set the selected TMR by attenuating the target or interferer. The HRTF was then applied to the targets and interferers separately. In parallel, the attenuated signals were summed without the application of the HRTFs and a scaling factor was determined to maintain an overall 75 dB SPL stimulus presentation for the summed signal. The nominal level of the mixed talkers was fixed at 75 dB SPL so that individuals were tested at a level above the AGC activation threshold. Given AGC activation could occur at levels higher or lower than the approximate values, the signal level of 75 dB SPL was selected to ensure that the threshold was exceeded for the spectrally varying speech stimuli. In addition, this signal level was also consistent with that used in other studies testing effects of AGCs (e.g., Potts et al., 2019; Spencer et al., 2019). The scaling factor was then applied to the HRTF-applied signals after the target and interferers were summed. This signal processing approach was used to be congruent with how the levels would be chosen if the experiment was performed in the sound field; the stimuli were scaled to the calibrated value without influence of attenuation from the head.
Procedure
The listener’s everyday clinical maps were converted for use with BEPSnet research programming software (Advanced Bionics LLC, Research and Technology). Four experimental programs were included in the programming of the two research processors for the following combinations of programs across ears: (1) Independent AGC + Independent AGC, (2) Linked AGC + Linked AGC, (3) Mute + Independent AGC, and (4) Mute + Linked AGC. The third and fourth program combinations were included for use during the monaural testing conditions, with the muted ear AGC linked to the test ear in program combination (4). Noise reduction features (EchoBlock, SoundRelax, and WindBlock) were disabled for each program as the reductions in gain with loud, noisy, and/or reverberant sounds could affect the activation of the AGC during testing. After the processors were programmed, the listeners were allotted a 15-minute period to listen to the device settings to ensure comfort and to allow for acclimatization. This was considered adequate time as studies investigating the effect of acclimatization time on SRM with hearing technology have shown no significant changes in binaural cues with increased adjustment periods (Dawes et al., 2013). The listeners spent approximately 15 minutes prior to the beginning of testing in each of the two binaural experimental programs in an unstructured conversational format.
Prior to testing, listeners were presented with several example sentences at 75 dB SPL using the independent AGC program to allow for loudness balancing between ears. Listeners used the processor volume controls to adjust the signal in each ear to ensure both were of equal, comfortable loudness when presented diotically. The level presented by the headphones was not changed at any time during the testing procedures to avoid an input signal that fell under the activation threshold of the AGCs. In a case when loudness balancing was not possible, the devices were left at the listener’s preferred clinical volume. Another listener required a two-step increase in volume on the left device. All other listeners reported equal loudness without any additional processor volume adjustments.
Listeners were presented with 100 IEEE sentences per condition (right monaural, left monaural, and binaural) in quiet. Testing with these sentences was completed using research processors set to the independent AGC program. The order of the conditions tested was randomized for each listener. Listeners were asked to repeat orally what they heard and guess when necessary. Five keywords per sentence were scored by an experimenter in real time. IEEE testing was completed with clinical processors for three of the listeners at previous appointments rather than during this experiment with research processors due to time constraints. For one listener, IEEE scores were only able to be collected for two conditions (left and both) prior to the implementation of restrictions on human research experiments at the testing site during the COVID-19 global health crisis. As a result, values for the right ear were taken from the listener’s most recent IEEE testing session in which research processors were not used. The number of sentences in a condition was reduced to 20 when performance was <10% after the initial 20 sentences.
Speech understanding in the presence of a single-talker speech masker was tested using the CRM sentences. Responses for these sentences were provided by the participant clicking on the testing computer and were scored for the two included keywords (color and number). Listeners were tested with the two AGC conditions (linked and independent). There were 16 CRM sentences per listening condition, noise location condition, and TMR for a total of 720 trials (16 Sentences × 3 Listening Conditions × 3 Noise Locations × 5 TMRs) for each AGC condition. The conditions were randomly presented within blocks of an AGC condition and listening condition combination (i.e., randomized within a block of all linked AGC left monaural presentations). This blocking was selected in order to avoid frequent program changes and to ensure listeners did not have any difficulties acclimatizing to the AGC type between each run. Listening conditions were presented such that the order of the conditions was randomized for each listener and then repeated backwards to complete a block. That is, they started and ended with the same listening condition (e.g., independent AGC right monaural presentation). The order of AGC conditions was also randomized across listeners resulting in five listeners starting with the independent AGC conditions and four listeners starting with the linked AGC conditions.
Data Analysis
IEEE performance was compared between the monaural conditions (left and right ears) as a measure of functional asymmetry. The absolute value of the difference in performance across ears quantified the asymmetry for each listener, and these asymmetry values were transformed to standard scores (z-scores), such that positive values were above the sample mean. In this way, asymmetry was included in CRM analyses as a continuous variable.
CRM keyword performance was scored as proportion correct per trial. Four linear mixed-effects models (LMMs) were used on subsets of the data set to assess summation, head shadow, squelch, and SRM overall. The conditions compared to estimate summation, head shadow, and squelch followed the framework of Dieudonné and Francart (2019).
The summation analysis was performed on the subset of the CRM data with co-located target and interferer. The monaural and bilateral co-located conditions were compared, with the benefit of a second ear as the measure of summation. Fixed effects included ear (monaural or bilateral, with monaural as the reference level), AGC type (independent or linked, with independent as the reference level), and asymmetry (a continuous variable).
The head-shadow analysis was performed on the subset of the CRM data with monaural co-located conditions and monaural spatially separated conditions where the interferer was located opposite the monaural ear, with improvement with spatial separation as the measure of head shadow. Fixed effects included interferer location (front or side, with front as the reference level), AGC type (independent or linked, with independent as the reference level), and asymmetry (a continuous variable).
The squelch analysis was performed on the subset of the CRM data with spatially separated target and interferers. The monaural conditions with interferer to the side of the non-test ear and the bilateral conditions with interferer spatially separated from the target were compared (the benefit of a second ear with a poorer TMR). Fixed effects included ear (monaural or bilateral, with monaural as the reference level), AGC type (independent or linked, with independent as the reference level), and asymmetry (a continuous variable).
The SRM analysis was performed on the binaural data (the benefit of spatial separation between target and interferer). The fixed effects of noise location (front or side, with front as the reference level), TMR (−8, −4, 0, 4, or 8 dB, with 0 dB as the reference level), asymmetry (a continuous variable), and AGC type (independent or linked, with independent as the reference level) on performance were tested in the SRM analysis. TMR was added as a fixed effect in this analysis only because inclusion of TMR in the other three analyses would unnecessarily complicate the model outputs. Considering this, we deemed the SRM analysis the most appropriate to investigate effects of TMR, since these conditions examine the benefit of spatial separation between target and interferer with both ears.
Analyses were performed in R 4.0.3 (R Core Team, 2020) with the buildmer v 1.5 (Voeten, 2020) package algorithm for model testing, which uses a backwards-elimination approach (Matuschek et al., 2017; Voeten, 2020) from the maximal model (Barr et al., 2013). The maximal model included fixed effects and their interactions, all random intercepts and slopes for every fixed effect of interest (excluding asymmetry) for listeners, and all random intercepts and slopes for every fixed effect of interest for target sentence (color-number pairs). All fixed effects were categorical with the exception of asymmetry. The buildmer algorithm took the input from the maximal model and ordered the random-effects by systematically reducing complexity and then reduced the fixed-effects structure until a model that converged and best explained the data was found. The systematic reduction of effects began with ordering of all effects present in the model using the likelihood-ratio test statistic. A backward stepwise elimination was then completed, which evaluated the significance of changes in log-likelihood. Buildmer defaults were used with the following exceptions. To ensure adequate convergence, the maximum number of iterations used for analysis was 200,000. The approach used for the p values of the mixed effects model was the Satterthwaite approximation (Luke, 2017). Nonsignificant effect terms and those not included in significant interactions (p > .05) were also removed from the model as part of the model-testing procedure with the buildmer function. To complete post hoc comparisons, the reference levels were systematically re-referenced using the lme4 package (v1.1-26; Bates et al., 2015). With this procedure, the model does not change; the releveling instead allows for pairwise examinations of the contrasts in the model.
Results
Speech Understanding in Quiet
In our presentation of results to follow, qualitative descriptions of each finding will be provided at the beginning of the section, followed by statistical analyses. Speech understanding in quiet was assessed to determine the degree of difference in performance between the two ears for each listener. Listeners had a range of degrees of asymmetry in their unaided monaural speech understanding scores. Figure 1 shows the IEEE speech understanding scores for each listener for their functionally better ear (BE), functionally poorer ear (PE), and both ears together. The asymmetry difference cut-off of ≥ 20% difference between ears (Goupell et al., 2018; Mosnier et al., 2009) was met in four listeners. The right of the plot shows the averages and standard deviations of scores for each listening condition for the different listener groups.

Individual and Average Speech Understanding in Quiet for Listeners Grouped by Degree of Asymmetry. An interaural difference of ≥ 20% characterized a listener as asymmetrical. Five listeners were characterized as symmetrical and four were characterized as asymmetrical. Group averages based on this designation were also calculated. Error bars represent ± 1 standard deviation. BE = functionally better ear; PE = functionally poorer ear.
Bilateral Benefits and Spatial Release From Masking
Figure 2 depicts the summary data for the CRM corpus task of speech understanding in the presence of a speech masker. Each panel shows performance at each TMR for the two AGC conditions with a single combination of listening condition (e.g., BE) and noise location (e.g., noise on PE side). Each row depicts a single listening condition (e.g., PE) and varying noise locations (noise on PE side, noise front, noise on BE side). Conversely, each column shows varying listening conditions (from top to bottom: BE, PE, and both) within a single noise location condition. This plot demonstrates that on average there were minimal differences between the performance with the linked and independent AGCs.

Average Percent Correct on CRM Sentences in Noise. PE and BE were determined by listeners’ IEEE scores in quiet. The target was in the front for all test conditions. Error bars represent ± 1 standard deviation. AGC = automatic gain control; BE = functionally better ear; PC = percent correct; PE = functionally poorer ear; TMR = target-to-masker ratio.
Given that it was hypothesized that listeners’ performance may be differentially impacted by ear symmetry, performance data from Figure 2 was replotted with listeners grouped by degree of asymmetry (the same participant groups used in Figure 1). As shown in Figure 3, there is an overall trend for better performance with the symmetric listeners. The disparities between these two groups were particularly evident in the functionally PE conditions. Again, there was no clear advantage of linked over independent AGCs for either group of listeners.

Average Percent Correct Values for Listeners Separated into Symmetric and Asymmetric Groups Based on IEEE Scores. Conventions are the same as in Figure 2. AGC = automatic gain control; BE = functionally better ear; PC = percent correct; PE = functionally poorer ear; TMR = target-to-masker ratio.
Figure 4 shows the average bilateral benefit for symmetrical listeners, asymmetrical listeners, and all listeners together with linked and independent AGCs. Performance was averaged across TMR and listeners for each AGC condition and symmetry group to calculate these values. Summation benefit was the difference in performance between the both ears, co-located condition and the average of the single-ear, co-located conditions (data from middle column of Figure 3). Mean summation for all listeners was 5.5% (standard deviation [SD] = 4.7%). Head-shadow benefit was the difference in performance between the average of the single-ear conditions with the interferer on the opposite side of the head from the test ear (data from top left and middle right of Figure 3) and the average of the single-ear conditions with interferer co-located in front with the target (data from middle panel of top two rows of Figure 3). Mean head shadow for all listeners was 10.6% (SD = 5.1%). Squelch was the difference in performance between the average of the side-located interferer conditions with both ears (data from bottom-left and bottom-right of Figure 3) and the average of the single-ear conditions with interferer on the side opposite to the test ear (data from left-top and middle-right of Figure 3). Mean squelch for all listeners was –0.9% (negative number indicative of interference or no bilateral benefit; SD = 7.2%).

Average Value of Each Bilateral Benefit (Summation, Head Shadow, and Squelch) for Linked and Independent AGC Conditions. These benefits are shown for symmetrical listeners (≤20% difference in monaural IEEE scores), asymmetrical listeners (≥20% difference in monaural IEEE scores), and all listeners together. Filled bars represent benefits with linked AGCs and open bars represent benefits with independent AGCs. Error bars represent ± 1 standard deviation. AGC = automatic gain control.
Statistical analyses were performed on each bilateral benefit. The summation model summary is shown in Table 2. There was a significant interaction between listener asymmetry and ear (p = .003), such that higher asymmetry was related to higher summation benefit (a greater improvement with a second ear for co-located target and interferer). The improvement with a second ear, or summation benefit, at mean asymmetry was also significant (p < .001). AGC type was not significant (p > .05) and was removed from the model during model testing. The head-shadow model summary is shown in Table 3. There was a significant interaction between interferer location and asymmetry (p < .001), such that higher asymmetry was related to lower head-shadow benefit. The improvement with interferer location (from front, co-located with the target, to side opposite the test ear), or head-shadow benefit, at mean asymmetry was also significant (p < .001). AGC type was not significant (p > .05) and was removed from the model during model testing. The squelch model summary is shown in Table 4. Again, there was a significant interaction between asymmetry and ear (p < .001), such that higher asymmetry was related to higher squelch (a greater improvement with a second ear when the additional ear has a poorer TMR than the first). The squelch estimate at mean asymmetry showed no significant improvement in the bilateral ear condition (p = .31). There was also a significant main effect of asymmetry, with poorer monaural performance associated with higher asymmetry (p = .04). AGC type again was not significant (p > .05) and was removed during model testing.
Summation Analysis LMM Summary. CRM Accuracy was the Dependent Variable.

Note. Significant fixed effects are shown in bold. Interactions are indicated with “×” notation. A Satterthwaite approximation was used to generate p values. SE = standard error; SD = standard deviation; CRM = coordinate response measure.
aSummation benefit.
Head-Shadow Analysis LMM Summary. CRM Accuracy was the Dependent Variable.
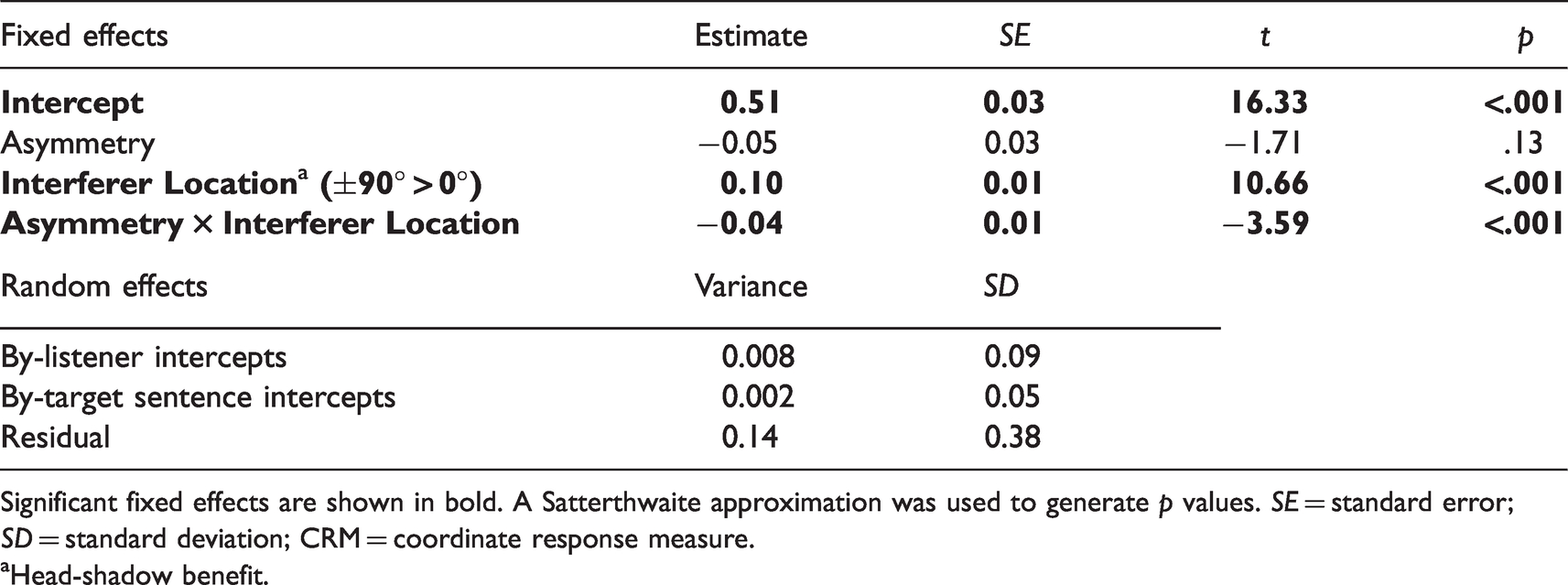
Significant fixed effects are shown in bold. A Satterthwaite approximation was used to generate p values. SE = standard error; SD = standard deviation; CRM = coordinate response measure.
aHead-shadow benefit.
Squelch Analysis LMM Summary. CRM Accuracy was the Dependent Variable.

Note. Significant fixed effects are shown in bold. Interactions are indicated with “×” notation. A Satterthwaite approximation was used to generate p values. SE = standard error; SD = standard deviation; CRM = coordinate response measure.
aSquelch benefit.
Figure 5 shows the calculated summation (top row) and squelch (bottom row) benefits for listeners’ ears separately to explore the source of increased benefit with greater asymmetry. Listeners are shown in ascending order based on degree of asymmetry. For symmetric listeners, summation and squelch are similar across ears. With increasing asymmetry, summation and squelch increase in the functionally PE (the benefit of adding the functionally BE increases). This was observed for both independent (left column) and linked (right column) AGC conditions.
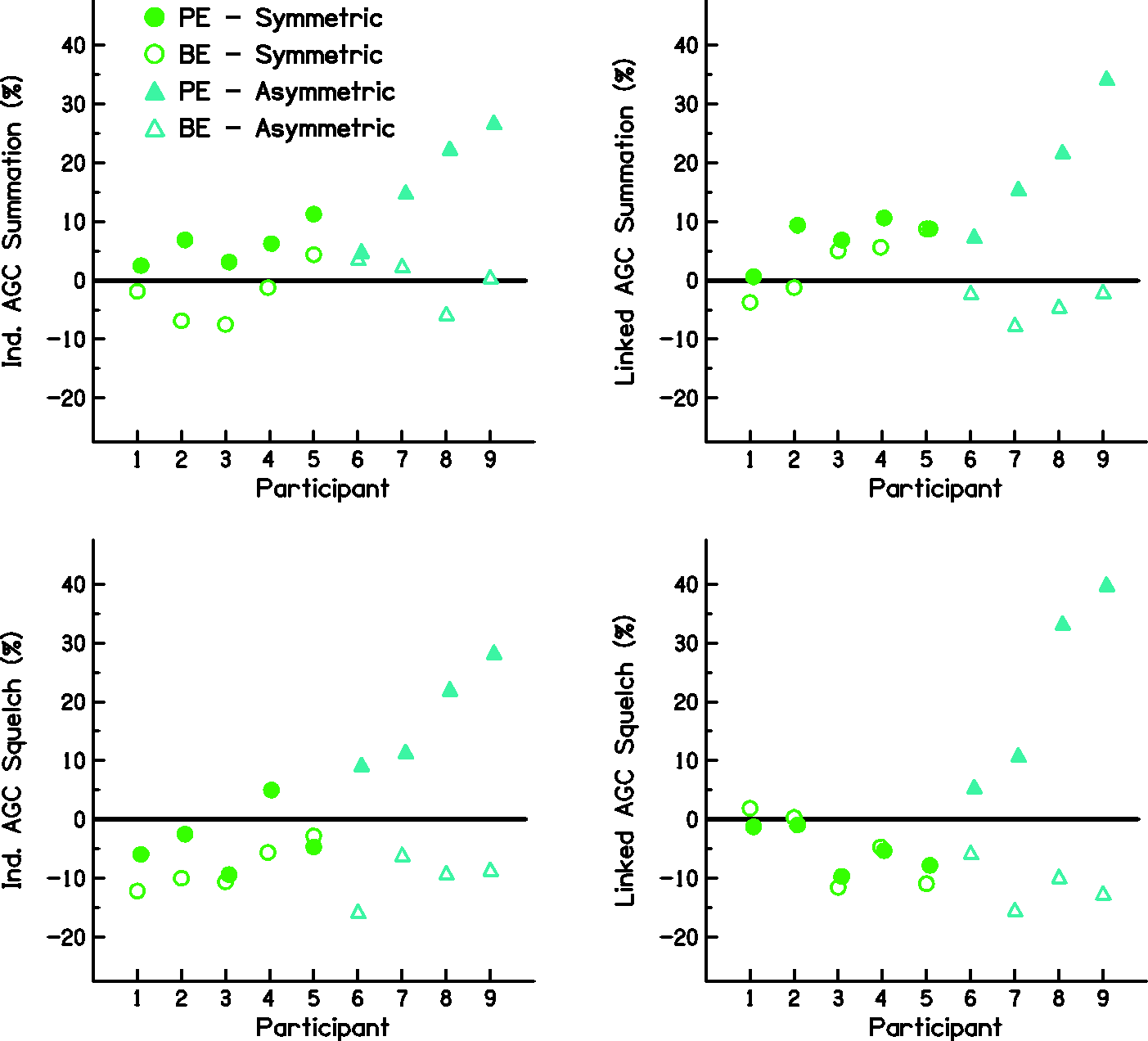
Summation and Squelch Values Averaged Across TMR. Summation (top row) and squelch (bottom row) values for each participant are shown for independent (left column) and linked (right column) AGC conditions. Participants are arranged in ascending order based on the difference in their monaural IEEE scores, with participants in the symmetric group plotted in green and participants in the asymmetric group plotted in blue. Open and filled symbols for each plot represent the values for the bilateral benefit calculated in reference to the monaural ear indicated. BE = functionally better ear; PE = functionally poorer ear; AGC = automatic gain control.
Finally, we examined the SRM in this paradigm. It was calculated as the difference between the bilateral condition with co-located target and interferers and the average of the bilateral conditions with spatial separation between target and interferers (bottom row of Figure 3). Mean SRM for all listeners was 4.1% (SD = 3.3%). The SRM model summary is shown in Table 5. There was significant improvement with spatial separation between the target and interferer (p < .001). In addition, all TMR conditions were significantly different from 0 dB (p < .001), where performance increased with increasing TMR. The model TMR reference level was changed to examine all pairwise TMR comparisons, and they were all significantly different from each other (p < .001). AGC type and asymmetry were not significant predictors of performance (p > .05) and were removed from the model during model testing.
SRM Analysis LMM Summary. CRM Accuracy was the Dependent Variable.

Significant fixed effects are shown in bold. A Satterthwaite approximation was used to generate p values. The fixed effect of SRM shown below is for the reference condition of 0 dB TMR. SE = standard error; SD = standard deviation; CRM = coordinate response measure; TMR = target-to-masker ratio; SRM = spatial release from masking.
aSRM benefit.
Discussion
Linked AGCs can lead to benefits in speech understanding in background noise, but previous research has not fully explored the effects of these controls on bilateral benefits for BICI listeners. This experiment assessed the effects of linked AGCs for listeners with varying degrees of symmetry in speech understanding in the presence of a single-talker masker.
There were two primary findings from the experiment. First, linked AGCs did not significantly improve performance. We had hypothesized a benefit of linked AGCs, with contributions from both head-shadow and squelch benefits, particularly at negative TMRs. Instead, results unexpectedly showed no significant difference between linked and independent AGCs (Figure 2). The present findings differed from those of previous studies investigating linked AGCs. For example, Wiggins and Seeber (2013) showed that in normal-hearing simulations of speech understanding in spatially separated noise, linked AGCs provided an approximately 8% improvement in scores compared to independent AGCs. Potts et al. (2019) found a 2.5-dB benefit of linked AGCs for BICI listeners with four-talker babble, an interferer more similar to the one used in the present experiment (a single talker). Although the Potts et al. (2019) experiment made use of speech maskers, the difference in benefit may be because they had more talkers, which could have allowed for more consistent engagement of the linked AGCs. In addition, the timing of their stimuli differed, with intermittent and continuous masking conditions. In the intermittent masking condition, they allowed 3 s of babble before the target was introduced on each trial but the babble ended with the conclusion of the target. In the continuous masking condition, they had babble presented continuously throughout the entire block. When linked AGC benefits were examined for these two types of stimuli, there was a larger benefit of linked AGCs in the continuous babble condition. Given that the evidence shows that linked AGCs are beneficial for speech-on-speech masking with multi-talker maskers but not with a single-talker masker and there is some effect of masker duration, there may be limitations in this technology providing a benefit in relatively shorter (specifically, sentence-long) speech-on-speech masking situations. Replicating this experiment with additional masker types and continuous maskers in the future would be informative to investigate how masker type and duration impact the effect of linked AGCs in more detail.
The second finding related to the results from the bilateral benefit and SRM calculations. We hypothesized that linked AGCs would increase head shadow and squelch compared to independent controls by preserving ILDs. We also expected that asymmetrical listeners would benefit less from linking than symmetrical listeners, since previous investigations have found reduced binaural benefits in listeners with asymmetric hearing histories (Goupell et al., 2018). Across listeners of varying degrees of symmetry there were no significant differences with AGC type for head shadow, summation, and squelch (Figure 4), as well as overall SRM. This finding did not support our initial hypothesis that linking of the AGCs would result in preserved ILDs, improving head shadow and squelch.
As predicted, there was a significant head-shadow benefit and asymmetry interaction, where more asymmetrical listeners had smaller benefits than more symmetrical (Table 3). However, there were also significant interactions between summation and squelch benefits and asymmetry in the opposite direction, where more asymmetrical listeners had larger benefits than more symmetrical (Tables 2 and 4). This again was contrary to our initial hypothesis that benefit values would be smaller for asymmetrical listeners. The larger summation and squelch values for asymmetric listeners likely arise from adding a functionally better ear. For these listeners, monaural performance with the functionally poorer ear is so low that when the functionally better ear is added, there is a large improvement in the binaural score even when the additional ear has a poorer TMR (Figure 5). For the summation calculation, rather than measuring the benefit of added redundant information, there is a larger benefit of new information when the functionally better ear is added. For the squelch calculation, this larger improvement is not likely the result of improved binaural processing; instead again it is more likely the benefit of adding new information with a functionally better ear. The current results are similar to those of another study that examined bilateral benefits for BICI and bimodal (hearing aid plus cochlear implant) users (Kokkinakis & Pak, 2014). Although functional performance asymmetry across ears was not directly measured in that experiment, because bimodal listeners have acoustic and electric hearing, they likely are more functionally asymmetric than BICI listeners. They found, as in this study, that for the cues requiring a monaural and binaural comparison—summation and squelch—the bimodal listeners had larger bilateral benefits, reaching significance for summation. They also found that head shadow was reduced in the bimodal group, but this difference was not significant. This similar pattern of results is further evidence that functional asymmetry may artificially inflate bilateral benefits that depend on a monaural-binaural comparison. Another study in the bimodal literature defined bimodal benefit as improvement with the addition of the functionally poorer ear, rather than averaging the benefit across ears (Dieudonné & Francart, 2020). A similar approach could be taken in cases of functional asymmetry for BICI listeners to avoid artificial inflation of bilateral benefit measurements. In summary, for the asymmetrical CI listeners in this study and others in the literature, improvements in summation and squelch from adding a functionally better ear is a monaural consequence, not from binaural processing. The influence of monaural effects on classic measures of binaural benefits should be considered in future studies investigating binaural benefits with functionally asymmetric hearing (Dieudonné & Francart, 2019, 2020).
Significant squelch for BICI listeners, about 5 dB, has been shown before but only in conditions where the spatial locations were imposed artificially through a contralateral unmasking paradigm (Bernstein et al., 2016). This is in contrast to this study or others that have failed to find significant positive squelch using more realistic spatial configurations. The BICI listeners in Bernstein et al. (2016) were argued to be mostly symmetrical higher performers; in contrast to them, negative squelch (i.e., interference) was shown in asymmetrical lower performers using the same contralateral unmasking paradigm (Goupell et al., 2018). If one were to combine the listeners from both studies, there would likely be little squelch on average. This argues for careful consideration of subject selection and measures of functional asymmetry for assessing bilateral benefits in BICI listeners. One aspect that was consistent with the data and analysis in the current report and the interpretation of the data from Experiment 2 in Goupell et al. (2018) was that there was a reduced head shadow for more asymmetrical BICI listeners, when using spatialized talkers like those used in this study.
Moving beyond the individual head-shadow, summation, and squelch benefits, we can discuss SRM in BICI listeners. Overall SRM values from previous studies are on average between 3 and 5 dB, so the current results, though calculated in percent, are broadly consistent with other studies (Loizou et al., 2009). The results suggest that for spatially separated maskers BICI listeners achieve SRM primarily via head-shadow benefit, with little or no contribution from squelch (Baumgärtel et al., 2015; Loizou et al., 2009; Schleich et al., 2004; van Hoesel & Tyler, 2003).
In light of our findings, it is important to underscore that while linked AGCs were not found to be significantly beneficial under the conditions tested in this experiment, there were no detriments of the technology. We had hypothesized that some listeners, specifically those with large asymmetries, or at negative TMRs, could be adversely affected by the linking of controls, which turned out not to be the case. Given our limited testing, it seems plausible that there are many spatial configurations and stimuli that would produce advantages of linked AGCs. In addition to aforementioned discussion of masker types and duration effects, head movements could also interact with independent AGCs, altering ILDs in a way that depends on the speed and duration of head movement (Archer-Boyd & Carlyon, 2019). Linked AGCs have the potential to decrease the distortion of ILDs in these more realistic situations.
Conclusion
BICI listeners of varying degrees of interaural asymmetry did not benefit from linked AGCs for speech understanding with a single-talker speech masker. There were significant interactions between asymmetry and ear when calculating both squelch and summation benefits, such that more asymmetric listeners had higher values of these two benefits. These interactions were believed to be a result of improvements in speech understanding due to adding a second, more intelligible input compared to the likely distorted monaural input of their functionally poorer ear alone. That is, the increased summation or squelch was not a result of better binaural processing abilities but a monaural phenomenon. Interactions between asymmetry and interferer location when calculating benefits were in the predicted direction, with decreased head-shadow benefit with greater asymmetry. In summary, while the results do not show a change with linked AGCs under these conditions, they suggest that linked AGCs are not strongly detrimental across a range of TMRs and functional performance asymmetry in BICI listeners.
Footnotes
Acknowledgments
The authors thank Advanced Bionics, LLC for providing equipment and technical support. The authors thank Ginny Alexander for her assistance with subjects. The authors thank Paul Mayo for his assistance with stimulus signal processing. The authors also thank Paul Mayo and Jordan Abromowitz for their assistance with stimulus recordings and verification. The authors thank Stefanie Kuchinsky for her advice for statistical analyses used for this experiment.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: C. C. is an employee of Advanced Bionics, LLC. All other authors have no conflicts of interest to disclose.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research reported in this publication was supported by the National Institutes of Deafness and Other Communication Disorders of the National Institutes of Health under Award Number R01DC014948. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.