
Abstract
The concept of complex acoustic environments has appeared in several unrelated research areas within acoustics in different variations. Based on a review of the usage and evolution of this concept in the literature, a relevant framework was developed, which includes nine broad characteristics that are thought to drive the complexity of acoustic scenes. The framework was then used to study the most relevant characteristics for stimuli of realistic, everyday, acoustic scenes: multiple sources, source diversity, reverberation, and the listener’s task. The effect of these characteristics on perceived scene complexity was then evaluated in an exploratory study that reproduced the same stimuli with a three-dimensional loudspeaker array inside an anechoic chamber. Sixty-five subjects listened to the scenes and for each one had to rate 29 attributes, including complexity, both with and without target speech in the scenes. The data were analyzed using three-way principal component analysis with a (2 3 2) Tucker3 model in the dimensions of scales (or ratings), scenes, and subjects, explaining 42% of variation in the data. “Comfort” and “variability” were the dominant scale components, which span the perceived complexity. Interaction effects were observed, including the additional task of attending to target speech that shifted the complexity rating closer to the comfort scale. Also, speech contained in the background scenes introduced a second subject component, which suggests that some subjects are more distracted than others by background speech when listening to target speech. The results are interpreted in light of the proposed framework.
Keywords
Introduction
Different Wording Used in the Literature to Designate Complex Acoustic Environments.

CAEs in the Literature
The concept of CAEs did not fully make it to the mainstream jargon of hearing research until recent times, although it first appeared much earlier in different variations (Carhart & Tillman, 1970; Durrant, 1967; Harrison & Beecher, 1969; Tillman, Carhart, & Nicholls, 1973). The main boost to the eventual popularity of the term has likely been the seminal work by Bregman (1990) about auditory scene analysis. Even though he did not use the term explicitly in his book, a follow-up paper (Bregman, 1993) explained: “The simple rules for spatial perception that classical psychophysics has discovered by testing listeners in simple, quiet environments cannot be applied without modification in acoustically complex ones” (p. 16). Listeners have evolved to continuously segregate sound events from their environments, which they achieve either by using learned schemas unconsciously, attentively, and voluntarily or by following regularities in acoustic streams, such as common temporal and harmonic patterns—attributable to a single source. Similarly, Yost (1991) referred to “complex sound fields” as containing more than one source, from which the hearing system creates auditory images. A more in-depth review on the link between auditory scene analysis and CAEs that includes additional usages of the term in acoustics and related fields can be found in Weisser (2018).
Even though CAEs are often considered in the same vein as realistic acoustic environments, many of the hearing studies that picked up the CAE terminology did not necessarily attempt to construct realistic environments. Instead, they rather aimed at creating more involved scenes in terms of the scene analysis challenge using traditional psychoacoustic stimuli (e.g., Bendor & Wang, 2006; Pelofi, De Gardelle, Egré, & Pressnitzer, 2017; Wilson & Strouse, 2002; Zwiers, Van Opstal, & Cruysberg, 2001). However, there have been mounting concerns that observations collected using traditional psychoacoustic and audiometric methods, which may not exert subjects’ cognitive systems as realistically as complex environments do, have low predictive power to daily situations (e.g., Arlinger, Lunner, Lyxell, & Kathleen Pichora-Fuller, 2009). The cocktail party paradigm (Cherry, 1953), in which listeners are able to attend to a specific talker among several competing talkers in their immediate environment, is thus deemed a more appropriate model for realistic listening conditions. It is, however, a challenging problem to study in controlled conditions (McDermott, 2009; Middlebrooks, Simon, Popper, & Fay, 2017) and one that is not very well handled by current hearing aid technology (Shinn-Cunningham & Best, 2008). Cherry suggested a number of mechanisms that enable listeners to segregate the multiple talkers. Segregating multiple talkers has been a recurrent theme in auditory scene analysis research, sometimes emphasizing reverberation or variable source to background levels as factors that specifically add complexity to the scenes (e.g., Faller & Merimaa, 2004; Girolami, 1998; Hawley, Litovsky, & Colburn, 1999; Kamkar-Parsi & Bouchard, 2011; Lesser, Nawab, & Klassner, 1995; Ma, Milner, & Smith, 2006).
The higher level attention-related tasks of auditory scene analysis and object formation were gradually merged with the everyday cocktail party problem (Best, Ozmeral, Kopčo, & Shinn-Cunningham, 2008). It has been repeatedly reported that listening to speech in CAEs is a prime interest of hearing-device users, but a situation that is difficult to assess using common experimental techniques (Ghent, 2005; Naylor, 2016). This notion was explored in different studies using highly elaborate acoustic setups to be able to deal with multiple simultaneous sources distributed in space, reverberation, audio-visual displays, as well as elaborate signal processing. These studies obtained results that were at odds with traditional tests performed in simpler environments (e.g., Best et al., 2015; Brungart, Cohen, Cord, Zion, & Kalluri, 2014; Brungart, Sheffield, & Kubli, 2014; Smeds, Wolters, & Rung, 2015).
Few attempts have been made to narrow down the scope that is entailed by the CAE concept. With hearing aid evaluation difficulties as the focus, Ghent (2005) proposed a straightforward definition for complex sound fields: “sound fields created with at least two uncorrelated sound sources on different axes that result in sound wave interference at the center of the listening position. A simple sound field, by contrast, has a single sound source.” According to Ghent, the CAEs are confined to enclosed spaces with an isotropic and homogenous propagation medium, of constant acoustic impedance. Different classes of environments are drawn according to the kind of acoustic fields: free, diffuse, anechoic, reverberant, and real sound fields, which are dynamic, uncontrollable, and unpredictable. These real sound field properties are largely missing from measurements obtained in the laboratory, which is one possible reason they often fail to predict real-life performance of hearing aids. A speech-communication-centric take on the problem was offered by Mattys, Davis, Bradlow, and Scott (2012), who were concerned with types of “adverse conditions.” In their formulations, adverse conditions occur at the source, receiver, and environment. The environment-related degradation may be the result of noise sources that mask the speech or distraction caused by informational masking. These problems may be further exacerbated due to reverberation or noisy electronic transmission channels, whenever amplification is used. In all cases, stream segregation becomes more difficult and may overload the listener’s working and short-term memory.
While the discussion about complex environments in the acoustic literature has been formulated independently of the complexity literature, complex systems are widespread in the real world and some of their most well-known features are relevant to CAEs as well (Mitchell, 2009). Complexity science has been grappling with the existence of a universal definition of complexity across scientific domains (Lloyd, 2001; Mitchell, 2009, Chapter 7). Therefore, complex systems are often described using a particular subset of characteristics out of many that are commonly associated with complexity (Badii & Politi, 1999, Chapters 1–2). One such important feature of complex systems that has not been explicitly mentioned earlier is the different levels of connection and interaction between the various elements of a complex system that define its overall information dynamics, as is characteristic for networks (Strogatz, 2001). Applied to acoustic environments, an example of such a network would be a group of people talking, whereby they interact with one another through conversation. Their overall acoustics and conversation dynamics does not resemble that of the same people talking to themselves in one space—a dialog is not the aggregate of two monologs (Branigan, Catchpole, & Pickering, 2011; Schober & Clark, 1989). Moreover, the talkers will adapt their behavior to the acoustic environment that may contain background noise or other people talking, which provides an additional level of interaction that is commonly described by the Lombard effect (Lombard, 1911). In the case of other interfering talkers, the Lombard effect will influence the behavior of all talkers, who may iteratively raise their voices to make themselves understood until an equilibrium is reached or they (temporarily) give up talking.
CAE Framework
Based on the literature summarized earlier, an attempt is made in the following to frame what makes an acoustic environment complex. The resulting CAE framework can be employed as a tool that enables a comprehensive qualitative characterization of arbitrary acoustic scenes in terms of their acoustic complexity, as will be illustrated further. The framework was conceived to be as exhaustive and inclusive as possible so that the complexity of arbitrary acoustic environments can be accounted for using its characteristics.
The Complex Acoustic Environment Framework.

The characteristics of the CAE framework sometimes require knowledge about the sources and the context that goes beyond their acoustics. Most notably, the source–environment–receiver delineation is not always applicable in practice. From the standpoint of the receiver, the environments and the sources can be inseparable. Also, the roles of sources and receivers are dynamic, as in a dialog, for instance, either of the interlocutors can be the listener and talker at times. Finally, the complexity of the medium in which they occur may be emulated using headphones that provide equivalent auditory cues. This can dissociate the spatial perception from the physical space outside the listener and thereby creates an environment completely localized around (or even inside) the listener’s head. The very last characteristic—the receiver’s task—is critical to framing all other characteristics, as it provides a context to the action of interest that takes place in the CAE system. This has recently been highlighted in a review by Lewicki et al. (2014) who noted that information gathered in ecologically valid (and biologically relevant) scene analysis must be directed by a particular goal of the perceiver. This, in turn, leads to modification of the perceiver’s actions in accordance with the information received through its senses and previous knowledge in memory.
Goals
The overarching goal of this study is to understand the factors that are most relevant for the subjective perception of complexity in acoustic scenes. This would allow a more effective use of CAEs in hearing research and thereby provide hearing outcomes with increased ecological validity. To achieve this goal, first, the CAE framework proposed earlier was applied to assess the characteristics of complexity that are most salient in everyday environments, considering a sample of 14 realistic acoustic scenes. These acoustic scenes were then used within an exploratory subjective experiment, which was designed with the specific aim to understand what listeners make out of the notion of complexity and how they deal with various aspects thereof. Subjects were asked to perceptually analyze the different acoustic scenes and to rate their perceived complexity as well as 28 additional subjective attributes. The responses were analyzed using a three-way principal component analysis (PCA) to reveal the most dominant connections between the acoustic scenes, rated attributes, and subjects.
Experimental Methods
Test Subjects
Sixty-five subjects participated in the test (48 females and 17 males) with an age range between 19 and 64 years (median 23 years). Subjects either had their hearing screened in the last year or were screened before the test began. Fifty subjects had normal hearing (pure tone thresholds below 20 dB HL at standard frequencies between 250 and 8000 Hz), and 15 had slight-to-mild losses (pure tone average, thresholds measured across 500, 1000, 2000, and 4000 Hz between 20 and 30 dB HL). Subjects were compensated for their participation either by payment or by course credit, if they were undergraduate students.
Test Setup
All stimuli were presented to the subjects using the 41-channel loudspeaker array located inside the anechoic chamber of the Australian Hearing Hub, Macquarie University, Australia. This spherical loudspeaker array is constructed from rings of equally spaced Tannoy V8 loudspeakers (Tannoy, Coatbridge, Scotland) at different elevation angles and a distance of 1.87 m from the center of the array (see Oreinos & Buchholz, 2016). All signals were processed on a PC at a sampling frequency of 44.1 kHz using MATLAB software and were presented to the subjects via an RME MADI PCIe sound card connected to two RME 32-channel M-32 digital-to-analog converters (RME, Haimhausen, Germany), which drove the 41 loudspeakers via 11 Yamaha XM4180 power amplifiers (Yamaha, Hamamatsu, Shizuoka, Japan). The power spectrum and sensitivity of each Tannoy loudspeaker were individually equalized using 2,048-sample long minimum-phase finite-impulse response filters. An additional Genelec 8020C loudspeaker (Genelec, Iisalmi, Finland), which was driven by the same audio system, was placed in front of the listener at a distance of 0.66 m to reproduce the direct sound of nearby target speech. This was required only for Part C of the questionnaire described later. The differences in sensitivity and distance of the nearby Genelec 8020C and the array loudspeakers were adjusted by applying a compensation gain and delay.
Realistic Acoustic Environments
The Complex Scene Stimuli Used in the Experiment, Which Were Taken From the ARTE Database.

Note. The scene names and descriptions are provided along with the unweighted (dB SPL) and A-weighted (dBA) SPLs, and the reverberation time T30. Data in the table are reproduced from Weisser et al. (2019). The right-most column contains the target speech levels from 0.66 m in dBA. SPL = sound pressure level; N/A = not applicable.
A Qualitative Breakdown of Relevant CAE Framework Characteristics for the ARTE Scenes Described in Table 3.

Note. This breakdown gathers the most salient dimensions according to which perceived complexity may vary. The CAE framework characteristics are shown in Table 2. A plus (+) indicates that the respective characteristic was judged to be highly relevant to the scene, whereas a minus (−) indicates the opposite. The zero (0) indicates that a nonuniform medium effect (5) may have been present but could not be captured with the recording technology used. CAE = complex acoustic environment.
Realistic Speech Material
According to the proposed CAE framework described earlier (Table 2, Characteristic 9), the subject’s task may have a significant effect on the perceived complexity of an acoustic scene. Therefore, the effect of attending to speech while rating the complexity of the different scenes was evaluated in addition to a general scene analysis task. To implement this task, a modified set of the 14 acoustic scenes described earlier was generated, which also contained natural speech that could have been experienced in the original scenes in the real world.
Realistic target speech material
The target speech was extracted from recordings from Weisser and Buchholz (2019), which were obtained by applying the methods for eliciting natural conversations between two people described in Beechey, Buchholz, and Keidser (2018). In brief, subjects were asked to follow a puzzle task that could only be solved by communicating information between each other. While performing this task, the subjects were listening to binaural versions of the aforementioned acoustic scenes, one at a time, which were presented to them at their original SPL (Table 3) via highly open Sennheiser HD 800 headphones (Sennheiser, Hanover, Germany). As is expected from the Lombard effect, the conversation partners adjusted their vocal effort level (and other acoustic, linguistic, and communicative characteristics of their speech) to the individual acoustic scenes. During this conversation task, the subjects were seated on chairs in an anechoic chamber at a mouth-to-ear distance of approximately 1 m, facing each other, and their voices were recorded using calibrated DPA d:fine FIO66 omnidirectional headset microphones (DPA Microphones, Allerød, Denmark). The recorded conversations were later mapped to a recording distance of 1 m, by applying a negative gain, using the method described in Beechey et al. (2018). Moreover, 2-min recordings from one representative female talker, whose speech levels were close to the mean of 12 female talkers and had a pleasant voice, were then edited to obtain natural low-contextual single-talker conversational speech with scene-specific vocal effort level. The final edits were typically 35-45 s long and were therefore repeated to match the durations of the 2-min long scenes.
Realistic sound source properties of the target speech
The target speech edits were set to a realistic SPL and presented from a realistic distance along with matching reverberation. This follows observations by Pearsons, Bennett, and Fidell (1977, Figure 22), which suggest that talkers stand closer to one another the higher the background noise level is with an increase in effective speech level as a result. The realistic talker distances and target speech levels were derived from Weisser and Buchholz (2019), where conversational speech levels were recorded at 0.5 m and 1 m talker distance for the same 12 acoustic environments applied here. Thereby, it was assumed that the realistic talker distance is 1 m for the softest environment (the Library) and 0.5 m for the loudest environments (Food Court 2), which is slightly different from the distances of 0.9 m and 0.4 m derived in Weisser and Buchholz. For all other acoustic environments of intermediate noise levels, the target speech levels and talker distances were derived using a linear interpolation on a double-logarithmic scale (the abscissa being the SPL in dB and the ordinate the log distance). The resulting target speech levels are summarized in Table 3.
Realistic reverberation
For each of the 12 acoustic real-world scenes (excluding the Diffuse Noise scenes), the derived target speech material was convolved with a corresponding 41-channel room impulse response (RIR) from the ARTE database (Weisser et al., 2019). The RIR was measured in the same acoustic environment as the recorded scene using a Tannoy V8 loudspeaker at an azimuth angle of
Questionnaire
While listening to the acoustic scenes, the subjects were asked to fill out a questionnaire, which was divided into three parts that together covered from different angles all relevant aspects of complexity as were identified in the CAE framework. Part A served primarily as a scene familiarization round. It required the listeners to analyze the scenes by asking them to identify as many sounds as they could, classified into categories (e.g., human-made, kitchen, traffic) and subcategories (e.g., footsteps, dishes, moving cars). Subjects were also asked to guess what the scene is. Only summary data from this part were used here and details are described in Weisser (2018, Chapter 4). Once the subjects felt familiar enough with the scene, they proceeded to Part B, where the scene identity and location were revealed to the subjects. This part contained 19 rating questions, relating to various subjective attributes of the scenes, such as familiarity, loudness, busyness, annoyance, reverberance, pleasantness, or how hard it would be to follow a conversation on the phone. An explicit rating of perceived complexity was obtained as one of the final questions without any further explanation. The subjects were also not informed that the complexity rating was of any higher importance in comparison with other ratings. Part C was similar to B, but with a nearby target talker added to the scene just in front of the subject. While listening to the target speech, subjects answered 10 additional rating questions, such as self-estimated speech intelligibility, listening effort, and complexity of the scene given the specific (additional) task of listening to the target speech.
The questionnaire that was used in this study was the result of multiple reiterations by the authors based on pilot field and laboratory trials. Special attention was paid to refrain from using jargon in the question wording so that they could be easily understood by lay subjects. The full questionnaire is provided in Online Appendix A.
Procedure
Test subjects were seated at the center of a loudspeaker array in an anechoic chamber, while listening to three-dimensional recordings of real acoustic scenes. The recordings were 2 min long but played in a loop for as long as the subjects needed to complete the tasks. While listening to the scenes, subjects filled in (paper) questionnaires—one per scene—that probed into different attributes of the scenes. The playback system was optimized to the listener’s head position, but subjects were free to turn their heads to better focus on sounds when needed. A single training scene (Café 2 in Table 3) opened the test to familiarize the subjects with the questionnaire and concept of the test. Then, seven scenes were presented in a random order, followed by a mandatory break. In the second half of the test, seven more scenes were presented in a random order, the first of which was a repetition of one of the first seven scenes. As the data measured for the training scene were found to be as stable as for all other scenes, data for a total of 14 scenes (plus one repeated condition) were evaluated in this study. Each scene was repeated twice every 13 subjects. The entire test took 1.5 to 3 h per subject.
Statistical Modeling
Data Preparation
The raw data that were obtained from the questionnaire, as well as its preparation for statistical analysis, are described later. The unprocessed data array contained 31,850 observations out of which 178 points (0.56%) were missing. The data provided 36 observed variables, including 30 rating scales (1 question from Part A, 19 questions from Part B, and 10 questions from Part C), the test time for Part A and Part B combined, the test time for Part C, the scene presentation order, and three scales derived from Questions #1 to #3, that is, the nominal count of sound events, the nominal count of talking people (i.e., the estimated number of individual talkers in the scene), and a combined recognition score. In the following, all 36 variables will be collectively referred to as “scales.”
As these 36 scales measured fundamentally different quantities, they were not directly comparable and therefore only their relative variability was taken into account in the data analysis. Scales that were not in the standard rating range of 0 to 10 were therefore equalized to fit that range (Kroonenberg, 2008). Moreover, data that were not directly derived from a rating scale had to be transformed into an effective (equalized) rating score. Answers to the distraction questions specifically (#12 and #25) may have not been directly comparable because they often referred to different sounding objects. Nevertheless, to enable comparison, this aspect was ignored and where no distraction was reported, the rating was set to zero.
The nominal count of sound events scale was derived from the responses to Question #1 (excluding #1 a) by calculating the sum of all distinct events (or categories, in cases where subjects did not go into subcategorical details) that were identified by the subjects in each scene. Similarly, the nominal count of talking people was calculated from the identified number of people talking (Question #1 a). The latter count was constrained by the maximum number of people talking that the question allowed, whereby the “more than three people” option was counted as four events. These two scales were summed up to yield a combined nominal count of sound events that will be referred to as “event count” from here on. This reduced the total number of scales to 35.
It is unclear how many sound events (including talking people) that subjects recognized could be mapped to actual events in reality and whether their identification was correct (Weisser, 2018, Chapter 5). To take this aspect into account, a combined recognition score was derived from the subjects’ responses to Questions #1 to #3. As the “ground truth” about the number and type of events that were present in the original (real) scenes is unknown, a proxy measure was applied based on a “white list” that was iteratively developed by four experienced listeners. Based on a complete list of all the events that were identified by the subjects for all the scenes, these listeners eliminated all those events that they could not hear when carefully and repeatedly listening to the scenes. The resultant list was then screened again by a different group of four experienced listeners. The remaining events then formed the “white list.” Using this list and the knowledge of what the scene was, a combined recognition “event score” was calculated based on successfully identified attributes of the scene: 1/2 point was given for each correctly identified event category, 1 point for each event (or event sub-category), 2 points for the environment type, and 4 points for the scene location. While this score is somewhat arbitrary, it provided a simple way to include the binary recognition data as an additional variable. For example, a subject who was presented with the office scene and correctly identified more than three people talking, laughter and ventilation noise, and correctly classified that it was recorded indoors in an office received 12 points in total: 6 points for events, 2 points for environment type, and 4 points for location. It should be noted that because two Diffuse Noise and Church scene variations were presented, the place and space type recognition scores were counted only in their first presentations, as in many cases learning improved the scene identification performance in their second presentation.
All rating data were centered to zero and normalized to unity variance according to procedures explained in Kroonenberg (2008, Chapters 6 and 14) and Weisser (2018).
Tucker3 Model Selection and Simplification
The subjective data that resulted from the questionnaire were analyzed using a Tucker3 three-way PCA model (Tucker, 1966). Tucker3 modeling enables the reduction of high-dimensionality data to lower dimensionality, which is easier to interpret than the unreduced data, and can be associated with actual aspects of the stimuli and experiment. In the present analysis, this allowed the exploration of the variances of the three types of data involved in the results, as well as their interactions, that is, the 35 scales (rating question, object counts, test duration, and other variables), 14 scenes (acoustic environments or conditions), and 65 subjects. Each one of these types is referred to as a “mode” and represents a fundamentally different aspect of the data, which is not directly comparable with the other types (Kroonenberg, 2008, p. 28; Smilde, Bro, & Geladi, 2005, pp. 2–4). Simpler methods than three-way PCA would have required averaging data over modes and thereby removed information that could be important (Jolliffe, 2002, pp. 397–399; Thompson, 2004, p. 84). The Tucker3 method was selected over alternative three-way methods because it is particularly suitable for modeling rating data (Kroonenberg, 2008, Chapter 14; Murakami & Kroonenberg, 2003). The Tucker3 analysis method is described in more detail in Online Appendix B. All data modeling and analyses were performed using the N-Way toolbox for MATLAB (Andersson & Bro, 2000).
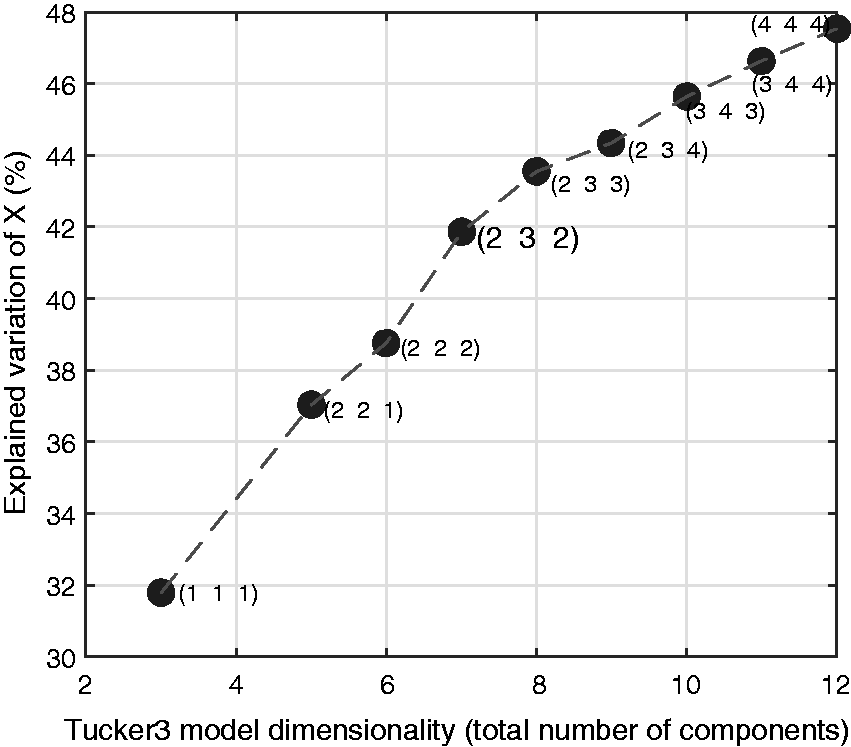
The Tucker3 analysis produced principal components, which can be thought of as the quintessential variables of each mode. To identify the three-way model that involves the lowest number of principal components while still accounting for the main behavior of the data, the scree plot of Figure 1 should be considered. This plot describes the variability accounted for in Tucker3 models using different combinations of components. The triplets on the plot refer to the number of modal components (scale scene subject). By definition, any PCA always lists the largest component first, which corresponds to a (1 1 1) model. The most informative point on the plot is where the addition of new components does not add any significant information anymore by modeling with more principal components. This appears in Figure 1 either at (2 3 2) or (2 3 3), where a knee point shows as the curve turns and asymptotically approaches 100% of explained variability. The (2 3 2) model turned out to be much more parsimonious than the (2 3 3) model and allowed a coherent interpretation within the theoretical and empirical framework of the experiment, as it contained only three elements in the core array—the three-dimensional array that weighs and combines the different modes to produce data points (see Online Appendix B). Henceforth, only the (2 3 2) model will be discussed. The final model—two of the three component loading matrices—and the simplified core array (Tables 5, 7 and 8) constitute the complete model parameters.
1
These parts of the model will be described in “Results” section. The explicit Tucker3 model Scree plot of different component combinations of Tucker3 models. The triplets on the plot designate the number of components for scales scenes subjects. The amount of explained variation is measured as percentage of the sum of square differences between the original data set to the fitted one. The final model that was selected (2 3 2) is emphasized. The Core Array, The Relative Contribution of the Core Array Elements to the Total Variation Explained by the Simplified (2 3 2) Tucker3 Model. The Loading Matrix Loading Matrix of the Three Scene Components ( Note. The first component mainly drives the comfort ratings, whereas the second drives the variability. The third component is only required to reveal the second subject component (see later).


Results
Acoustic Scene Classification
The CAE framework was applied to the 14 ARTE scenes to break down their complexity into the nine characteristics described in Table 2. The results are summarized in Table 4. This breakdown is coarse-grained, as it imposes a binary classification of characteristics that can vary continuously. This was done on purpose to indicate whether these aspects appear significant in the scenes or not and thereby to guide and inform the design of the exploratory study described later, including the analysis of the resulting data.
The information on multiple sound sources (1) and sound source diversity (2) was taken from an analysis of the data from Part A of the questionnaire (see later), where the subjects were asked to identify all the sound sources they could hear in the individual scenes. As shown in Table 4, all recorded scenes contained multiple sources, and most of them provided significant source diversity. The number of identified sources that were confirmed by expert listeners (see earlier), and also used as a scale in the main experiment (see later), ranged from two sources (i.e., many people talking and sibilant speech) in Church 2 (#6) to 18 sources in Café 1 (#9; Weisser, 2018, Chapter 5). The most dominant sources are mentioned in Table 3. Source–source interaction (3) was present in most scenes and mainly referred to conversations between two or more people. Reverberation (4) was also present in most scenes, and, if applicable, the corresponding reverberation time (RT60) is given in Table 3, ranging from 0.2 s in the Living Room (#5) to 1.2 s in the Church (#4 and #6). Nonuniform medium for sound propagation (5) was not addressed. Even though strong winds in some of the original recordings of the semiopen environments (i.e., the Train Station #11 and the Street/Balcony #12) may have resulted in a nonuniform medium, the wind also corrupted the microphone array recordings (Weisser et al., 2019) and the corresponding sound samples could not be utilized here. Loudspeaker amplification systems (6) were present in some scenes, and mostly referred to incidental music or television, except for the Train Station (#12), where an amplified announcement dominated a part of the scene. All observed source–environment adaptation (7) referred to the Lombard effect, except for the library, where people whispered due to social norms. Cues of other modalities (8) were not addressed because the study only considered audio recordings. The receiver’s task (9) was part of the design of the main experiment and is addressed in the next subsection.
As evident from Table 4, the acoustic scenes varied along seven different complexity characteristics, although the combination of possible characteristics did not vary systematically between scenes. Moreover, the diffuse noise scenes were devoid of any obvious complexity according to the CAE framework and were mainly included as controls.
Model Prediction
The chosen (2 3 2) Tucker3 model explained 41.66% of the variability of the complete set of 31,672 data points collected from 65 subjects in 14 acoustic scenes using 35 scales from the developed complexity questionnaire. The robustness of model variability to outliers and missing data was cross-validated using a jackknife procedure (Jolliffe, 2002, pp. 120–127; Kroonenberg, 2008, pp. 188–189) and found only a 0.06% drop in explained variability when 1/9th or 1/13th of the data were replaced at random. Similarly, replacing the data in the array with the repeated condition for every subject (1/14th of the data) caused a maximum drop of only 1% in the explained variability. The repeated condition was used also to obtain a test–retest reliability measure using Pearson’s correlation between all replicated rounds over all variables and environments and their first presentation. The resulting correlation of R = .79 indicates a reasonable test–retest reliability (Crocker & Algina, 2008, pp. 131–146). Hence, the chosen (2 3 2) Tucker3 model was confirmed as a robust model of the data.
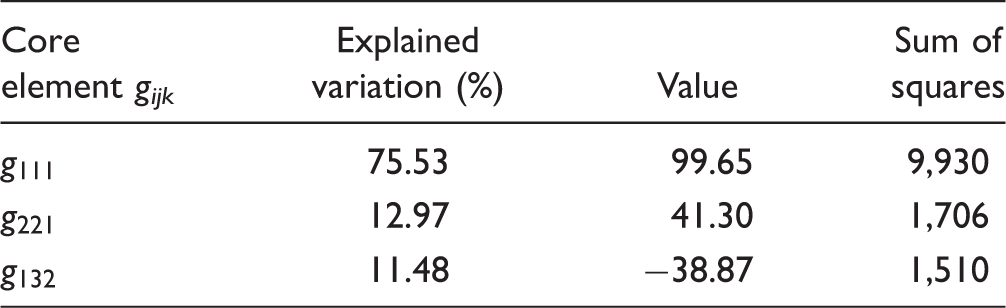
Core array
The core array of the (2 3 2) Tucker3 model was optimized for simplicity by forcing the minimally contributing elements to zero (see Equation 1)—costing only a 0.2% loss of explained variability (originally, 41.87%) through additional core array elements. The resultant three nonzero elements (
Scale mode
The scale mode of the model has two principal components, which span the scale space and are plotted as vectors in the joint biplot of Figure 2, along with the first two scene components that are given as points (see later). Several clusters are visible, which are summarized in Table 7. Most ratings are organized along the angled x-axis in what could be considered a measure of perceived “Comfort,” as it maps on the left-side positive attributes: pleasant sounding (Question #22) and highly intelligible (with target speech, #26). On the right side, it maps most other attributes, which are generally uncomfortable: loud (#8), annoying (with and without target speech, #10, #27), fatiguing (with and without target speech, #17, #30), difficult with target speech (#28), difficult to listen to the phone (#9), stressful (#20), hard to focus (with and without target speech, #18, #29), disturbing during target speech (#24), difficult to maintain attention (#19), and effortful during target speech (#31). The second scale component lined up with the ratings of “variability” (#11) and is surrounded to its left by realism (with and without target speech, #6, #33), familiarity (#5), event count (#1), and event score (#1–#3). An additional cluster appears to contain combinations of the comfort and variability components: complexity (with and without target speech, #21, #32), busyness (#7), distraction (with and without target speech, #12, #25), and effort (without target speech, #23). The rating of “distinction” (#13) is also a combination of comfort and variability, but mirrored to the other side of the variability axis than complexity, which sets it apart. Finally, some attributes are obviously much weaker than others (shorter vectors represent smaller correlations) and do not map well to the two principal scale components. These are envelopment (#14), spaciousness (#15), presentation order, and test time to completion of Parts A + B and C. Both difficulty (to complete Part A, #4) and reverberance (#16) have similar direction as loudness and fatigue but are much weaker and therefore less dominant.
Joint biplot of the scale and scene first and second components. The vectors represent the different scales, where names ending with (S) refer to target speech attributes in Part C of the questionnaire. The first two scene components are superimposed on the plot, with the large markers designating the scenes. If a marker is closer to a particular scale, then it is more closely related to that attribute. The biplot origin designates the average value of every scale over all scenes and subjects.
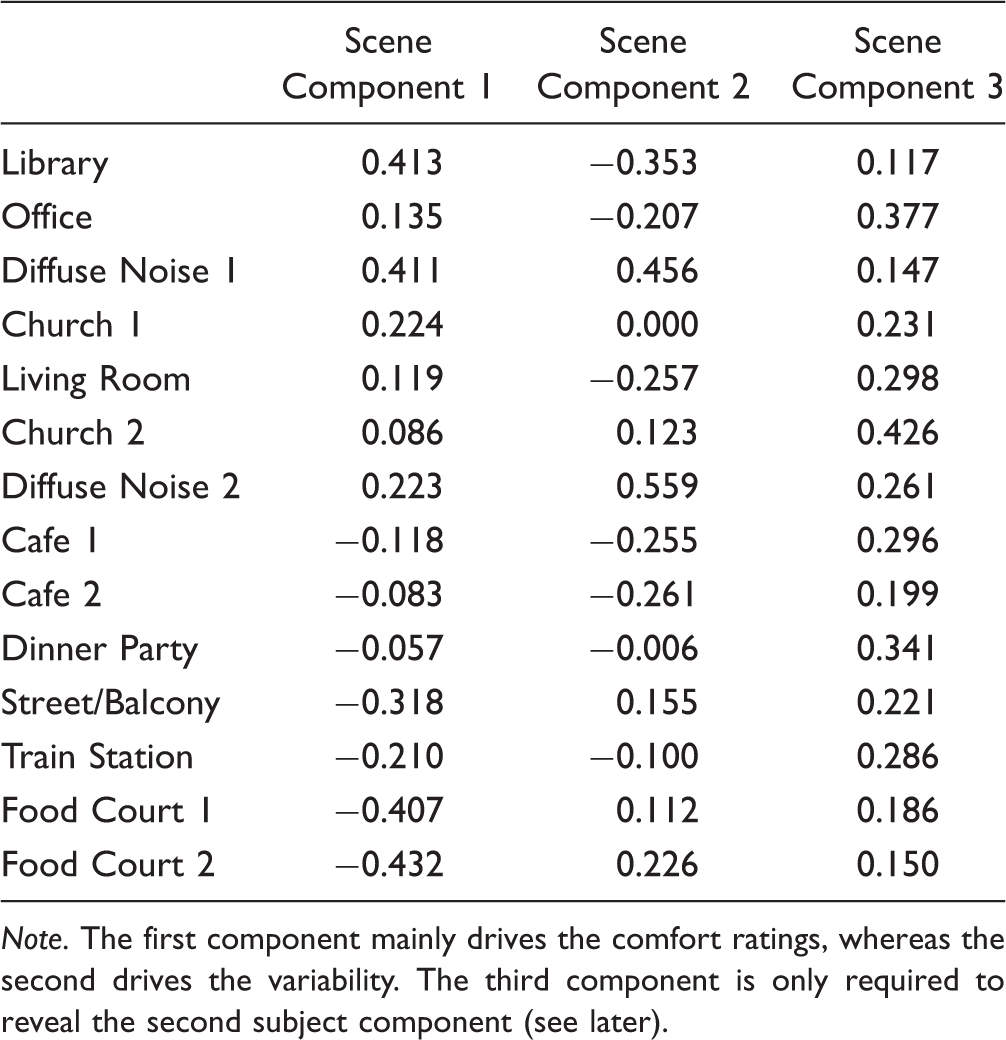
Scene mode
The loading matrix of the scene mode has three components (see Table 8). The first two components become clear when plotted together with the two scale components on a joint biplot (Figure 2) that illustrates how the two modes interact. The third scene component mainly helps to understand the differences between subjects and is further described later. The two scale and two scene components are connected through a single-subject component that is reflected in the two largest core array elements (see Table 5). The corresponding joint biplot was constructed by considering only part of the Tucker3 model, which contains a single “slice” r of the core array that connects the scene and scale matrices via 
Subject mode
Two subject components were considered to model the main features of the prototypical subject behavior. The first component is the most dominant one and, combined with the two scale and two first scene components in the core array, accounts for about 88.5% of the total core variability (sums of squares), which gives the average listener’s response. The second subject component accounts for the remainder of 11.5% (see Table 6) and represents a subset of the subjects that reacted differentially to some of the scenes. The second component is expressed only through the third scene component (Table 5), which suggests again that their combination is necessary to represent different subjective preferences about the scene attributes.
To get a handle on the meaning of the second subject component, it was examined how it correlates with different mean scale ratings throughout the test. Strong correlations (with The strongest correlation of any rating scale to the second subject component was with the listening effort rating during speech. Only the scenes with dominant background speech drove this differentiation. Hearing status does not appear to consistently predict the mean subjective ratings (four subjects with mild losses, >25 dB HL, were grouped separately from the slight losses for illustration purposes only).
Additional Analyses
Complexity ratings
The main goal of this exploratory study was to identify the attributes that contribute to the perceived complexity of an acoustic scene. Thereby, it was inherently implied that subjects were able to consistently and meaningfully rate acoustic scene complexity without any further clarification or training. This was confirmed by the strong weighting of the complexity scale within the Tucker3 model (Table 7) as well as by the decent test–retest reliability, which found a Pearson’s correlation coefficient of R = .81 and R = .78 for the complexity with and without target speech, respectively (Questions #21 and #32). The quality of the complexity data is further illustrated by considering the spread of the mean complexity ratings shown in Figure 4 as a function of acoustic environment (with and without target speech) as well as the relatively small 95% confidence intervals shown by the error bars. The complexity data reveal that the subjects utilized almost the entire rating scale, and the nonoverlapping confidence intervals found between many environments indicate significant differences between those environments. It is interesting to note that in two scenes the complexity rating increased significantly when subjects were asked to attend to additional target speech, that is, the Living Room and the Street/Balcony scenes. Both had strong modulated maskers—television speech, or noisy traffic—that readily interfered with speech reception but were apparently less complex on their own. As Figure 2 reveals, the mean rating of busyness (#7) is very close in length and direction to the mean rating of complexity (#21). If the scene average is considered, then busyness and complexity have a correlation of The scene complexity ratings averaged over all 65 subjects, ordered by increasing sound pressure level (dB SPL) from left to right. The error bars are the Tukey–Kramer 95% confidence intervals of pairwise comparisons of all ratings.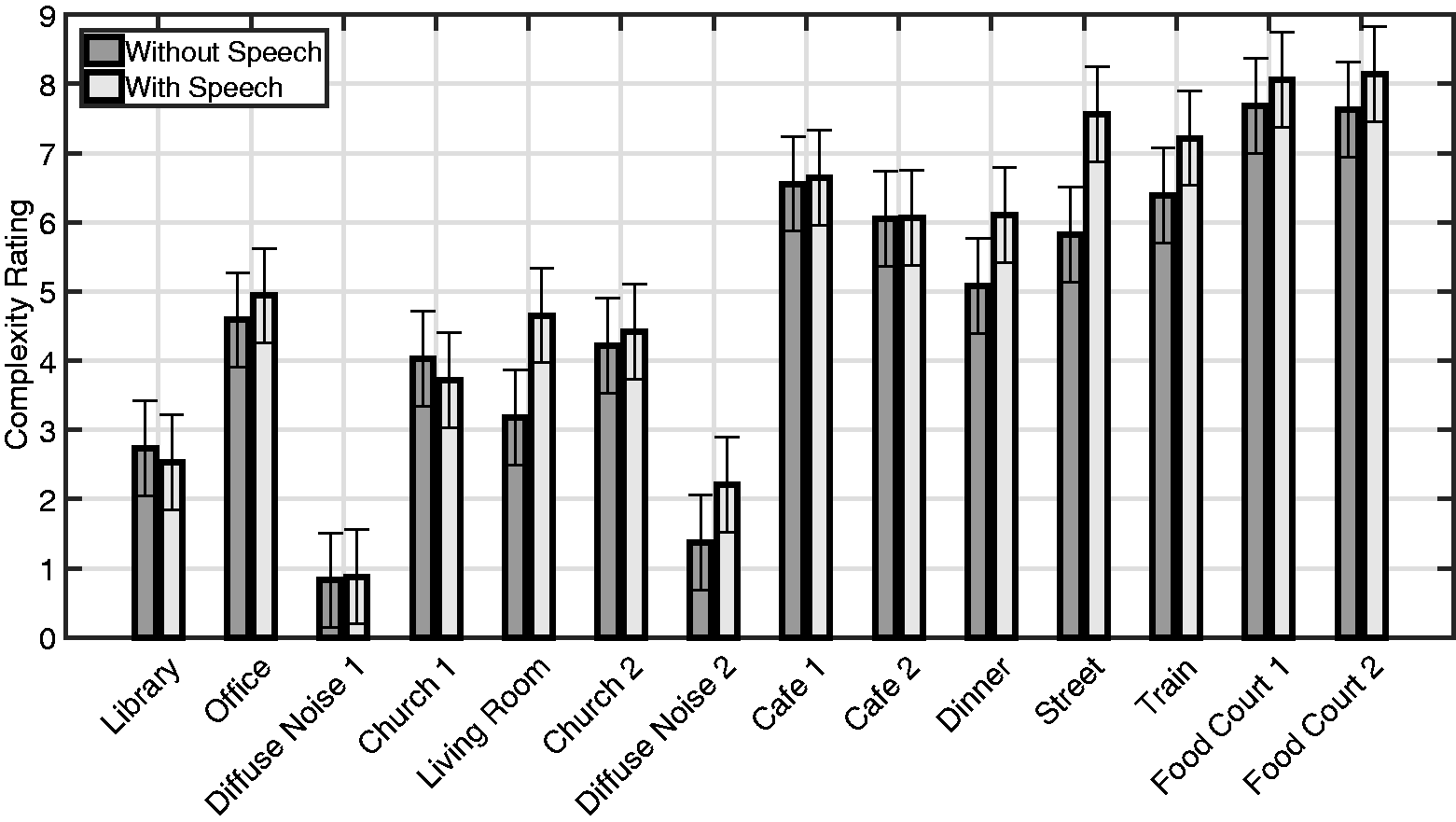
General Discussion
Principal Component Analysis
Most of the observed data could be modeled using two principal components of the scale mode and their equivalent scene mode components as well as one subject component (i.e., five components in total). A persistent second subject component with its corresponding third scene component accounted for a smaller fraction of the total variation but highlighted an interesting subject effect.
The first and most dominant scale component, comfort, included on the negative end various unpleasant attributes that listeners rated highly in the environments—annoyance, disturbance, distraction, loudness, fatigue, stress, difficulty to focus, difficulty to attend to speech, or talk on the phone—and two positively phrased qualities on the other end—pleasantness and high speech intelligibility. These relations are in line with a previous survey that found subjective comfort to be associated closely with quiet–noisy and pleasant–unpleasant subjective ratings of outdoor urban soundscapes (Kang & Zhang, 2010). The loudness rating question (#8) referred explicitly to the sound being comfortable or uncomfortable (see Online Appendix A), although subjective comfort is not exactly equivalent to perceived noise level, despite a strong correlation (Yang & Kang, 2005). Nonequivalence between these two factors is also visible in Figure 2, which shows that loudness does not fully account for the comfort component, as they are not exactly collinear. Nevertheless, the comfort component is strongly driven by the acoustic energy in the scene, which in most cases was the result of many incoherent sources of the same type being mixed together. The food courts clearly contained many more people talking than the Church scenes, which contained more distinct and sporadic conversations. Similarly, the Street/Balcony scene had heavy traffic that contained numerous vehicles. The Library, in contrast, contained many different sound events, which were all relatively quiet.
The second scale component, variability, appears to be more suitable to describe the diversity of the sound events, rather than their quantity. The subjective ratings of variability itself, the nominal subjective event count, and the event score all fit this notion well. The Diffuse-Noise sound scenes, with their monotonous sound, were perceived as completely unvarying to all subjects, whereas the Café and Train Station scenes sounded highly variable. The inclusion of the diffuse sound field scenes was central in revealing this component.
The additional scales that mapped to the variability component, realism and familiarity, may have been inadvertently confounded by the choice of scenes. The Diffuse-Noise scenes contained the lowest number of sound events, but were also unfamiliar to almost all participants, and were judged to be completely unrealistic. The Church scenes were rated higher on realism and they contained more events (mostly conversations), but they generally did not represent a convincing prototypical church, which resulted in significantly lower ratings than for most of the other scenes (Weisser et al., 2019). This was largely due to its uncharacteristically low reverberation time of 1.2 s, the everyday contents of the conversations it captured, and the lack of any ceremonial cues, such as an ongoing sermon or live music. Moreover, many test subjects verbally reported that they are not church-goers, so they were unfamiliar with this environment to begin with. All other scenes, in comparison, contained more distinctly recognizable sound events and were rated to be much more familiar and realistic.
Reverberation, envelopment, and spaciousness neither mapped clearly onto the two scale components, nor did they result in an additional independent component. In general, these ratings did not vary much between the scenes. A possible explanation to that was the usage of the ambisonic reproduction system. All scenes were spatialized in the same way, so subjects may have reacted to that uniformity. Reverberation in the recorded scenes did vary significantly (Table 3), but may have been confounded with the overall level, as louder scenes tended to be recorded in larger spaces (the Street/Balcony being the notable exception). This can be noticed in the joint biplot of Figure 2, where reverberance is parallel to comfort. Nevertheless, the effect of reverberation on the sound events may have been secondary to their overall level. This can account for the low correlation between reverberance and comfort, which is seen in the short length of its vector compared with the others in the joint biplot.
The first two scale components, comfort and variability, are mirrored in the two scene components, as prototypical scenes may be placed somewhere on the plane that is described by the level of comfort and degree of variability they induce. The description is correct for the average listener, who is represented by the first subject component. However, the individual reaction to dominant background speech in the scenes systematically modulates this average response for a subset of the listeners. Modeling this effect requires the third scene and second subject components. Unfortunately, the third scene component does not map directly to any attribute in the scenes, but can only be understood as a necessary feature to reorder the ratings for the different scenes, when the second subject component is moved away from its mean value. These extra components therefore should be included in the modeling when dealing with environments that contain background speech, if individual variation is to be accounted for. Finally, additional factors such as familiarity, realism, or envelopment may all be valid attributes of scenes as well but could not be disentangled from others with the scenes selected in this study.
The rating of subjective distinction of sound events in space is set apart—halfway between the components, but in opposite direction to complexity on the comfort axis—may also be interpreted in light of the above. Quieter scenes with fewer sound events, that is, rated of higher comfort, are usually indicative of sparser auditory displays, which enable easier stream segregation, a quality that was referred to as “hi-fi soundscapes” (Schafer, 1994, pp. 43–44). The contribution of the variability component to distinction may be that sound event diversity facilitates segregation. For example, segregating one out of many talkers is a more difficult task than distinguishing between a coffee machine and background music.
Perceived Scene Complexity
Subjects had no difficulty relating to the term scene complexity and reliably rating it, and they closely associated it with busyness. This can be seen by having complexity ratings that are both interpretable and reproducible. In addition, the test subjects did not ask for any clarifications regarding the questions related to complexity. Complexity turned out to be composed of at least two separate components. The ratings of the subjective complexity shifted when the task focus was switched from a more general scene analysis in Parts A and B of the questionnaire to the target speech in Part C. In the latter case, it was more strongly affected by the comfort component and was driven very close to the ratings of scene busyness and distraction. Possibly, this is because speech reception is more susceptible to masking by other speech (Kidd & Colburn, 2017; Kidd et al., 2008). Further examination of the subject components showed that the degree to which subjects were affected by speech in the relevant scenes was individual. However, the between-subject source of variation is unknown. It is possible that using a more fine-tuned selection of scenes, extra dimensions of complexity that are hidden now might appear, such as familiarity and envelopment. Also, scene complexity generally increased with loudness (Figure 4)—a natural side effect of having more acoustic sources in the environment. By artificially matching the levels of different scenes, another hidden aspect of the perceived complexity may be revealed. Only the Diffuse-Noise scenes were repeated at two levels, where the louder presentation (68.3 dB SPL) was rated as slightly more complex than at a lower presentation level (58.3 dB SPL). Level-dependent complexity rating difference was insignificant (half a rating point) for no-target speech, one-way analysis of variance
Subjective Complexity and the CAE Framework
All in all, the CAE framework was successfully employed to qualitatively describe diverse acoustic situations and identify their potential sources of complexity in a systematic way that would have been difficult to attain otherwise. The analysis with the applied statistical model directly addressed at least four of the nine characteristics of the CAE framework (Table 2), although only three proved to contribute significantly to subjective complexity.
The comfort component of the derived statistical model is highly related to the first characteristic of the framework, “Multiple acoustic sources distributed in space,” at least in environments where high acoustic energy is associated with multiple sources, as was the case in most of the considered scenes. This was indeed the most dominant characteristic that was hypothesized to be relevant to the scenes (see Table 4). This is in line with findings by Ghozi, Fraj, Salem, and Jaidane (2015), where the number of similar sources was shown to partially drive the complexity estimates in a survey of university cafeteria during lunch. In that study, the respondents’ rated complexity was correlated with the approximate number of people present in the surveyed cafeteria during lunch, which would be considered a measure of comfort in this study. Interestingly, the objective complexity of that scene, which was estimated from audio recordings using an entropy measure, also correlated with the occupancy level in the cafeteria.
Similarly, the variability component of the derived statistical model may be understood as a direct measure of the second characteristic of the framework, “Acoustic source diversity.” In contrast, reverberation, a central component of the fourth characteristic of the CAE framework, could not be clearly resolved from other features of the scenes and needs to be further investigated using additional or different scenes.
The “receiver’s task” characteristic (9) directly affected the perceived complexity when the subjects shifted from general unfocused listening to the scenes (questionnaire Part B) to attending to the target speech (questionnaire Part C; see Figure 2). The receiver’s task had an additional variation in the form of the sound events distinction rating (Question #13), which may be seen as a fundamentally different task to the explicit complexity rating, as it required an analytic listening to sound objects, rather than synthetic listening to the entire scene. It is simpler to perform when the events sound very different from one another and the environment is quieter and also when the sound events are more familiar. The effect can be seen in Figure 2, where the direction of the distinction and complexity vectors are mirrored against the variability axis.
Many potential sources of complexity as encompassed by the other CAE framework characteristics were not addressed by the applied stimuli. Even though it is possible to generate stimuli that vary on these complexity dimensions, the role such intricate acoustics may have in making hearing-relevant situations sound more complex is unknown. This means that variants of perceived scene complexity exist that are not covered by these stimuli and are not addressed in this study. However, adding more systematic variations in complexity would have been in conflict with the main approach of this study, that is, to use a set of different realistic everyday scenes.
Limitations
At this point, it is still unknown how the subjective components derived from the statistical model relate to acoustic measures that are inherent to the scenes and their recordings. Whereas the comfort component is strongly related to the SPL of the environments, it is unclear how variability can be best measured acoustically. A successful measures may need to quantify the temporal, spectral, and spatial variability of the acoustic scenes as captured by the auditory system. Therefore, it is likely that hearing loss will have an effect on such a complexity measure, as it is typically accompanied by degraded temporal acuity, spectral selectivity, and spatial resolution. A more quantitative approach will be necessary if realistic scene complexity is to be integrated in more advanced hearing research and hearing-device design and evaluation, where a growing interest in real-world performance drives much of the present work. Future research will have to address this aspect in depth.
Several aspects of this work may limit its generalizablity. By design, this study excluded all visual cues from the virtual environment presentations. This, along with the somewhat unusual task that lacks robust context for the listener, arguably constrains the ecological validity of the test, and therefore the level of realism that can be achieved with this particular method. This concern may be exacerbated by the particular choice of questions that went into the questionnaire that may create an unknown bias in the subjective data obtained. That said, the subjects reported that the questionnaire was straightforward to use and many commented that they found the task engaging and stimulating because it related to situations that they are generally familiar with from everyday life. In addition, they found the sound reproduction generally very convincing. The lack of visual cues was noticed but at no point constituted an impasse to completing the task. Combined with the analysis that provided a sensible and interpretable model, it suggests that there is a great deal that may be learned about CAEs before adding other modalities. Finally, the scene selection may also constrain the generalization of the conclusions universally to arbitrary scenes—especially scenes recorded outdoors in nonurban settings. This aspect of the test also shows in the uneven treatment of different characteristics of the CAE framework. Selection may also limit the universality of the target speech used, which was one specific female voice, processed to sound realistic within the scenes. However, some subjects noted that the fact that the speech was shorter than the scene and repeated, made it sound less realistic.
Another possible limitation is the sound presentation method, which provides limited fidelity at high frequencies, in direct proportion to the order of the reproduction system. Ahrens, Marschall, and Dau (2018), for instance, showed that the order of a horizontal ambisonic system (lower and higher than the one used in this study) can influence the spatial resolution of sound sources, which may affect subjects’ apparent source width perception and speech intelligibility that follows spatial release from masking. It is possible that some of the busiest scenes presented in this study were therefore more spatially distorted than quieter scenes in a way that influenced a subset of the ratings. However, as was suggested earlier, the measured spatially related attributes contributed little to the variation and interpretation of the data as a whole.
Finally, modeling the scene-based subjective ratings required significant investment of time and attention from the listeners, which resulted in a large amount of data that are based on different individual references for ratings. Several factors that were not estimated, such as individual sensitivity to noise and spatial awareness, may have also contributed to the spread of data. This means that a substantial portion of the variation (58%) could not be efficiently modeled using the three-way PCA.
Conclusions
The present work systematically probed the complexity aspect in CAEs by proposing a general framework with nine characteristics (Table 2), along with an empirical method that tested the subjective evaluation of 14 realistic, everyday scenes. Three characteristics of the CAE framework dominated the variation in the acoustic scenes: multiplicity of sources (1), diversity of source types (2), and the listener’s task (9). The subjective results revealed two orthogonal components of scene complexity—comfort and variability—driven by the scenes themselves that were characterized as varying along the same two dimensions. An additional component was observed when the acoustic scenes included significant background speech that can distract the listener while attending to target speech. Some listeners reacted more strongly to this distraction than others, which affected some of their ratings in relevant scenes, particularly the listening effort rating while attending to target speech. Other characteristics such as the amount of reverberation (4) and interaction between the sources (3) may have not been dominant enough in the considered acoustic environments to generate a clear effect on the subjects’ ratings. Moreover, specific perceptual attributes such as realism, familiarity, and envelopment may have been confounded by the experimental design, and future studies will need to investigate whether their influence on perceived complexity is significant.
Overall, subjects reported that they related well to the task, despite the lack of visual cues and detailed explanations of the various attributes in the questionnaire. While being based on exploratory subjective ratings, these results were statistically reliable. It remains to be seen in a confirmatory study whether the long questionnaires can be reduced to a shorter one with less question redundancy, which may still enable the reliable quantification of the perceived scene complexity. It is suggested that the CAE framework and empirical methods can be utilized in hearing research and other relevant areas in acoustics to systematically explore additional aspects of complexity in real-world environments.
Supplemental Material
TIA881346 Supplemental Material - Supplemental material for Complex Acoustic Environments: Review, Framework, and Subjective Model
Supplemental material, TIA881346 Supplemental Material for Complex Acoustic Environments: Review, Framework, and Subjective Model by Adam Weisser, Jörg M. Buchholz and Gitte Keidser in Trends in Hearing
Footnotes
Acknowledgments
The authors thank Katrina Freeston for her help with wording the questionnaire and Gerald Kidd, Jr., Virgina Best, Jan Rennies, and Sébastien Santurette for useful discussions.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Approval
The behavioral measurements in this study complied with the ethics guidelines of the Australian Hearing Human Research Ethics Committee, approval number AHHREC2016-13.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the Oticon Foundation and Macquarie University via an iMQRES PhD scholarship.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.