
Abstract
Previously found effects of age on thresholds for speech reception thresholds in noise in adolescents as measured by an online screening survey require further study in a well-controlled teenage sample. Speech reception thresholds (SRT) of 72 normal-hearing adolescent students were analyzed by means of the online speech-in-noise screening tool Earcheck (In Dutch: Oorcheck). Screening was performed at school and included pure-tone audiometry to ensure normal-hearing thresholds. The students’ ages ranged from 12 to 17 years. A group of young adults was included as a control group. Data were controlled for effects of gender and level of education. SRT scores within the controlled teenage sample revealed an effect of age on the order of an improvement of −0.2 dB per year. Effects of level of education and gender were not significant. Hearing screening tools that are based on SRT for speech in noise should control for an effect of age when assessing adolescents. Based on the present data, a correction factor of −0.2 dB per year between the ages of 12 and 17 is proposed. The proposed age-corrected SRT cut-off scores need to be evaluated in a larger sample including hearing-impaired adolescents.
Introduction
Reduction in speech intelligibility performance in background noise is an early indicator of hearing impairment. Because expert assessment of hearing impairment and classical pure-tone audiometry have their drawbacks in large-scale studies, time efficient and easily accessible self-assessment screening tests, either by telephone or online, have been developed. They focus primarily on mid- to high-frequency hearing loss and the intelligibility of words in stationary masking noise (Dillon, Beach, Seymour, Carter, & Golding, 2016; Jansen, Luts, Dejonckere, van Wieringen, & Wouters, 2013; Leensen, de Laat, Snik, & Dreschler, 2011; Smits & Houtgast, 2005). These Internet-based speech-in-noise tests provide the opportunity to reach a large population and have proven to be reliable as self-administered hearing screening tools.
The Dutch Earcheck (Oorcheck, www.oorcheck.nl) is such an online hearing screening test and was developed by the Leiden University Medical Center (LUMC) and the Academic Medical Center Amsterdam (AMC; Leensen et al., 2011). It is specifically aimed at young people to raise awareness of the consequences of uncontrolled noise or music exposure, and reaches about 30,000 to 40,000 participants a year.
The speech-in-noise test uses nine monosyllabic words that are randomly presented in a fixed masking noise, while the signal level is varied in 2 dB steps to assess the speech reception threshold (SRT). In 2015, Oorcheck data comprising the five preceding years were analyzed. The test results of 96,803 Oorcheck users aged 12 to 24 years revealed a trend in SRT scores, improving by about 0.3 dB signal-to-noise ratio (SNR) per age-year, especially between 12 and 18 years of age (Sheikh Rashid, Leensen, & Dreschler, 2016).
While younger children and adults are age-groups that are regularly investigated in hearing research, there are fewer studies on (changes during) adolescence. Research on adolescents is made difficult by compulsory school attendance and class schedules, the consent process, and intersubject variation during this period of biological and psychosocial change.
There is well-documented evidence that normal-hearing (NH) children aged 5 to 12 years differ from adults in speech recognition performance (Hall, Buss, & Grose, 2016; Neuman, Wroblewski, Hajicek, & Rubinstein, 2010). The few studies on speech recognition during adolescence differ in stimuli and masker conditions. Nonetheless, they all indicate a steady improvement in the SRT from childhood to adulthood. In an early study, developmental changes were found between 3 and 17 years of age (Elliott, 1979; Goldman & Fristoe & Woodcock as cited in Elliott et al., 1979). In 2005, the data of a Dutch telephone survey revealed worse SRTs in 15 - to 19-year-olds compared with 20 - to 24-year-olds (Smits & Houtgast, 2005). In a more recent study by Corbin, Bonino, Buss, and Leibold (2016), the recognition of monosyllabic words in a speech-shaped noise masker was worse in 8 - to 12-year-olds compared with 13 - to 16-year-olds and adults. Wightman and co-workers (Wightman, Kistler, & Brungart, 2006; Wightman & Kistler, 2005; Wightman, Kistler, & O'Bryan, 2010) assessed subjects aged 5 to 18 years of age and found that the rate of change with age to be slower in ipsilateral masking with a single talker than in contralateral masking with a single talker, suggesting that informational masking in the two conditions is mediated by different processes.
The changes across adolescence may be explained by the well-characterized changes in brain structure and functioning during that period (Gogtay et al., 2004; Litovsky, 2015; Vinette & Bray, 2015). During adolescence, many brain regions are still in development (Gogtay et al., 2004; Vinette & Bray, 2015), and auditory processing in the brainstem and cortex matures (Krizman, Skoe, & Kraus, 2016; Mahajan & McArthur, 2012; Ponton, Eggermont, Kwong, & Don, 2000; Skoe, Krizman, Anderson, & Kraus, 2015; Skoe, Krizman, Spitzer, & Kraus, 2013; Wunderlich & Cone-Wesson, 2006). Studies that correlate auditory brainstem responses with speech perception reveal a highly complex dynamic auditory system with sound representations that undergo changes during adolescence, with large effects of enriched or limited experience on auditory functioning and the subcortical system and continuous fine-tuning (de Boer & Thornton, 2008; Krizman et al., 2015; Strait, Slater, Abecassis, & Kraus, 2014; Tierney, Krizman, & Kraus, 2015).
Cognitive control of speech perception improves from childhood to adulthood. There are changes in the effects of attention on auditory stream segregation, and there is an increase in the precision of acoustic-phonetic properties and boundaries (McNealy, Mazziotta, & Dapretto, 2010; Medina, Hoonhorst, Bogliotti, & Serniclaes, 2010; Westerhausen, Bless, Passow, Kompus, & Hugdahl, 2015; Wunderlich & Cone-Wesson, 2006; Sussman, 1993). Sensory processing is refined significantly by cognitive skills (Kraus, Strait, & Parbery-Clark, 2012; Strait et al., 2014) and a comparison of auditory-evoked potentials in neurobiology studies shows that changes in speech perception processing and structural changes develop concurrently (Eggermont & Ponton, 2003). Less well investigated is the effect of experience on the maturation of the adolescent neurodevelopment (Tierney et al., 2015).
Although the age effect seen in the 5 years of Oorcheck data shows some correspondence with effects of maturation in other fields of research, the Internet survey carries some bias. This includes inclusion bias, a poorly controlled test condition, unknown hearing thresholds, and uncertainties with reference to the participants’ age specifications. Additional research is required to confirm the age-related findings from the online Oorcheck survey.
The primary aim of the present study was therefore to analyze to what extent an age-related trend can be found in the speech-in-noise test data of adolescents in a well-controlled sample. Oorcheck SRT data for NH adolescents were collected at two high schools, after which the effects of age, level of education, gender, and test repetition were analyzed. Adolescents were compared with a control group of young adults. A secondary aim was to estimate correction factors to compensate for the potential unwanted effect of age in the online screening tool.
Materials and Methods
Subjects
A total of 104 subjects were assessed in February 2016. Recruitment of the adolescents took place at two schools in the Netherlands: Zandvliet College, a higher secondary school in The Hague; and Haarlem College, a lower secondary school in Haarlem. With the consent of the school management and parents, students were sent information about the purpose and procedure of the study. Inclusion criteria required participants to be native Dutch speakers aged 12 to 17 years with NH. NH was specified as hearing thresholds of 25 dB Hearing Level (HL) or better at 250 and 500 Hz, and hearing thresholds of 20 dB HL or better at 1, 2, 3, 4, and 6 kHz in each ear. The threshold of 25 dB HL at 250 and 500 Hz was chosen to account for potential environmental noise, since no sound proof booths were available. The participants’ (intra-individual) standard deviation for the Oorcheck had to be lower than 3 dB (cf. Sheikh Rashid, Leensen, et al., 2016). A control group of young adult college students aged 18 to 20 years were recruited from the Avans Hogeschool in Breda.
Procedure
This cross-sectional study protocol was approved by the medical ethics committee of the University of Amsterdam (identification code 2015_297). Data on the subjects’ SRT in noise were obtained by their responses during the online hearing test Oorcheck, completed in a quiet room at school. Prior to testing, information on the subject’s age, grade, and gender was collected. To confirm NH, the Oorcheck was preceded by pure-tone audiometry in the same quiet room.
Pure-Tone Audiometry
Pure-tone audiometry was performed by two trained test operators and included air conduction thresholds at frequencies 250 Hz, 500 Hz, 1000 Hz, 2000 Hz, 3000 Hz, 4000 Hz, 6000 Hz, and 8000 Hz, using calibrated clinical audiometers (AC40 and Decos audioNigma), connected to TDH 39 headphones with sound attenuating cups (Amplivox audiocups).
Ambient Noise-Level Measurements
Ambient noise-level measurements were performed in all test rooms. Using a DVM805 digital sound-level meter (applicable standard: IEC651 type 2), the sound level in the room where the adult control subjects were measured was 37 dBA and the sound level in both rooms at Zandvliet college was 35 dBA. The sound-level measurements in the two rooms used at Haarlem College were done using a sound-level meter B&K 2260. The Z-weighted maximum sound levels for the mid-frequency third-octave bands (250–8000 Hz) ranged from 23.3 to 38.7 and 18.6 to 37.4 dB SPL, respectively. The audiometric test conditions at all test locations met the requirements of the international standards for hearing screening with sound attenuating cups in combination with headphones (i.e., unmasked air conduction starting at 500 Hz; ISO 8253, Part I).
Earcheck
After pure-tone audiometry, the subject’s SRT was assessed with the Oorcheck tool. The speech material used in this speech-in-noise test is based on a closed set of nine monosyllabic words (thumb [dœym], goat [xɛIt], chicken [kIp], lion [lew], cat [pus], rat [Rat], fire [vyr], wheel [wil], and saw [zax]) taken from the Dutch word lists for speech audiometry (Bosman, 1989), spoken by a Dutch female speech therapist. These stimuli were presented in random order with a stationary masking noise that was low-pass filtered with a cut-off frequency of 1600 Hz and a slope of 100 dB per octave. The original broadband masking noise and the speech stimuli had a matching long-term average spectrum. A more detailed description of the test material can be found in Leensen (2013). Testing is binaural and diotic. Prior to testing, a stimulus without noise is presented and the subject is instructed to adjust the volume to a comfortable level at which the stimuli can be clearly understood. Starting at a signal-to-noise ratio of −10 dB, the level of noise is fixed while the signal level is varied adaptively in 2 dB steps according to the up-down procedure described by Plomp and Mimpen (1979). After each word presentation, the subject has to choose one of nine corresponding pictograms on the screen or the button “not understood.” SRT is defined as the SNR at which 50% of the word material is identified correctly. In the Oorcheck, SRT is calculated as the average SNR for stimuli 8 to 27 and is stored in an online database. The result of the Oorcheck is either “pass” or “fail” (using a cut-off value of −18.4 dB SNR established during controlled experimental settings; Leensen et al., 2011) and is directly shown to the participant. The participants performed the online test individually twice (test and immediate retest) with minimal instructions from the researchers.
For the Oorcheck, a research laptop (HP) and a tablet (Surface) were used, in combination with Sennheiser HDA 200 and Sennheiser HD330 headphones. The control group performed the test using a Sennheiser HD330 headphone on their own mobile phone. Previous research on the Oorcheck presentation levels on the SRT's of NH subjects revealed no significant effects at presentation levels well above the absolute threshold, ranging from 65 to 77 dBA (Leensen & Dreschler, 2013).
Statistical Analyses
Descriptive statistics were applied on hearing thresholds, age, gender, level of education, and on the SRT results (test and retest) derived with the Oorcheck. To explore SRT scores as a function of age (in years), gender (male or female), and education level (low or high), multiple regression analyses were performed. To explore the correction factor for age, regression analysis was applied to the SRT scores. All data were analyzed using IBM SPSS Statistics 23.
Results
Subjects
Age-Group, Number of Participants, and Mean (SD) of PTA0.5/1/2 and PTA1/2/4 in dB HL for Right Ear, Left Ear, and Better Ear.

Note. PTA = pure-tone audiometry.
Test and Retest SRT
Mean SRT (SD) of Test and Retest and the Average of Test and Retest in dB SNR by Age-Group.

Note. SRT = speech reception thresholds; SNR = signal-to-noise ratio.
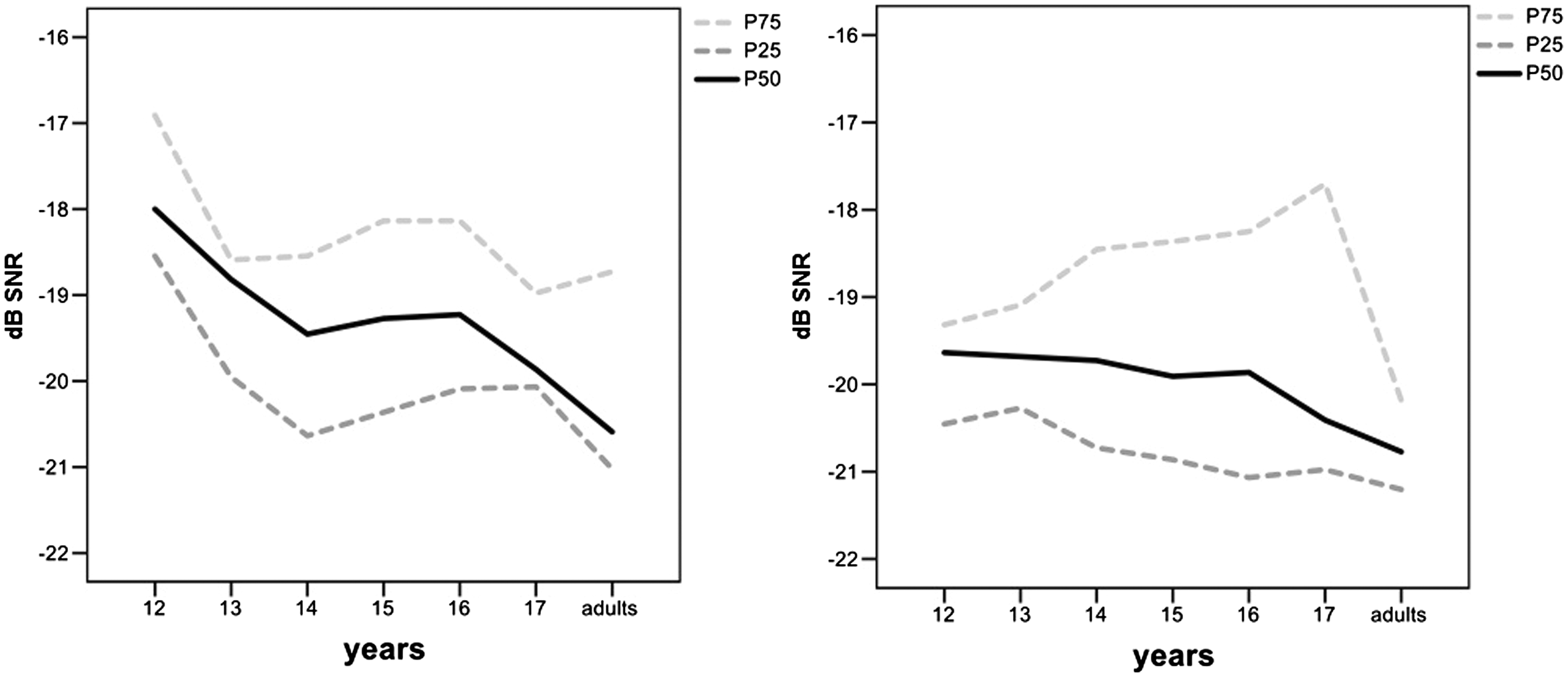
SRT in dB SNR (y-axis) by age-group (x-axis): Distribution in percentiles (25th, 50th, and 75th) of first test (left) and retest (right).
Repeated measures analysis on the test and retest SRT with age-group as a covariate showed a significant main effect of age-group, F(1,71) = 8.508, p = .005. The effect of the test versus the retest situation showed a trend of improvement but did not reach significance, F(1,70) = 3.331, p = .072. There was no significant interaction effect of age-group with the test–retest SRTs, F(1,70) = 2.334, p = .131.
Mean SRT and Effects of Age, Gender, and Level of Education
A regression analysis was conducted on the mean SRT results of test and retest. The mean SRT improved significantly by −0.2 dB with each year of age (95% CI: −0.364; −0.072, p = .004), while effects of gender (95% CI: −0.613; 1.323, p = .467) and level of education (95% CI: −0.660; 1.391, p = .479) were not significant. Post hoc tests between the age-groups (corrected α < .008) revealed a significant difference between the 12-year-olds (mean SNR = −18.7 dB, SD = 0.9) and the adults, mean SNR = −20.3 dB, SD = 0.9, t(18) = 3.75, p = .001; all other comparisons were not significant.
Age-Based Cut-Off Score
SRT Distribution of Mean of First and Second Oorcheck in Percentiles by Age-Group.

Note. SRT = speech reception thresholds. To the right, the proposed Oorcheck cut-off SRTs are given based on a correction factor of −0.2 dB per year of age. N = 72.
Categorized Test Results and Corrections for Age and Rapid Learning
Number (%) of Subjects Who Scored Good (Poor) on Their First (Second) Oorcheck, According to a Cut-Off Value of −18.4 dB SNR and According to the Age-Dependent Criteria (N = 72).

In the lower part of Table 4, the test and retest Oorcheck results are given according to the new categorization with a correction factor of −0.2 dB per year of age. The present study showed a trend of improvement in the repeated measures analysis. For subjects whose first age-corrected score was “poor,” the retest score was used. Figure 2 shows the statistical distribution (in percentiles) of the deviations from the age-corrected cut-off scores after the application of both improvements, that is, after the application of age-corrected cut-off scores and with a replacement of the first test score by the retest score in those cases where the first score was categorized as “poor.” Ninety percent scored a “good” first test score, and in 10% of the cases, the retest score replaced a “poor” first test score. One of the 72 subjects failed to reach the age-corrected Oorcheck criterion both in test and in retest. As can be seen in Figure 2 and Table 4, with this procedure, 99% of the NH subjects obtained a good score.
Deviations from the age-corrected cut-off scores in dB SNR (y-axis) by age-group (x-axis): Distribution in percentiles (10th, 25th, 50th, 75th, and 90th) after the application of the Oorcheck procedure, that is, after “poor” first test scores were replaced by retest scores.
Discussion
The SRT results of the present sample of students with NH obtained by the Oorcheck revealed an effect of age. This supports the recent findings of a large survey that covered five years of (uncontrolled) online Oorcheck data (Sheikh Rashid, Leensen, et al., 2016), which showed an effect of 0.31 dB SNR per age-year in the SRT score of 12 - to 24-year-old males, and slightly better scores for females.
Furthermore, repeated testing revealed a small but consistent learning effect (p = .072) in our study. The SRT outcome of the 17-year-olds was comparable to the adults’ outcome. The effect of age on the present Oorcheck SRTs was independent of level of education and gender. However, given the small subgroups, the latter should be interpreted with caution.
The improvement in the SRTs from 12 years to adulthood was approximated by a regression analysis, and the effect of age could be corrected for by an age-dependent cut-off score for the pass or fail criteria of −17.2 dB SNR for 12-year-olds, with a decrease of 0.2 dB per year of age to a cut-off score of −18.4 dB SNR for 18 years and older. The resulting SRT of −18.4 dB SNR for adults coincides with the outcome of previous Oorcheck studies (Leensen et al., 2011; Sheikh Rashid, Leensen, et al., 2016). The correction of −0.2 dB per year of age seems to be a valid approximation and compensates for the unwanted effect of maturation on the Oorcheck outcome in NH adolescents. It is comparable to the results of school-age children who performed a similar Dutch online speech-in-noise test (Sheikh Rashid, Dreschler, & de Laat, 2017).
The present results also correspond with the results of Wightman and coworkers (Wightman et al., 2006; Wightman and Kistler, 2005; Wightman et al., 2010), that show monotonic improvement with age for subjects between 10 and 20 years of age in the ipsilateral masking condition. Corbin et al. (2016) found gradual improvement in the recognition of monosyllabic words in a speech-shaped noise masker when comparing a group of 8- to 12-year-olds with a group of 13- to 16-year-olds, and hardly any improvement when comparing a group of 13- to 16-year-olds with a group of adults. While the difference between the group of 8 - to 12-year-olds and the 13- to 16-year-olds corresponds with our study, the difference between the adolescents and the group of adults is difficult to compare, as the adults evaluated by Corbin et al. included listeners as old as 44 years of age.
The study by Elliott (1979) also revealed worse outcomes for children aged 13 years or younger compared with 15- and 17-year-olds, but used highly predictable sentences at three signal-to-babble ratios. When sentences are used, SRT screening is prone to effects of vocabulary or syntactic knowledge and differences in the ability to access the lexicon (Kaandorp, De Groot, Festen, Smits, & Goverts, 2016). The Oorcheck tool used in the present study may be assumed to reduce effects of lexical context by using short and context-free words that are familiar to children, and by using labels with pictograms instead of written labels only.
Given the difference between child and adult perception, progressive improvement in SRT as seen in our data can be expected from childhood to adulthood. Younger listeners require a wider bandwidth to perform comparably with adults in speech identification tasks (Eisenberg, Shannon, Martinez, Wygonski, & Boothroyd, 2000; Hall et al., 2016). With the age effect depending on the spectral match between noise masker and speech stimuli, the low-pass filtered masker of the Oorcheck probably accentuated the performance differences between teenagers and adults in comparison to a speech-shaped masker.
Since our study group was homogeneous with respect to hearing thresholds (NH), the age effect in the adolescents’ SRT probably reflects the fact that the structures that facilitate behavioral learning and better speech-in-noise perception were not available to teenagers to the same degree as to adults. The SRT “deficits” in the adolescents and which decreased with age might be attributed to their developing cognitive abilities and cognitive control, including memory capacities, experience, and selective attention. They presumably affected auditory sensitivity, such as discrimination and processing of acoustic-phonetic cues (Medina et al., 2010; Sussman, 1993; Anderson & Kraus, 2010; Gogtay et al., 2004; Hornickel, Lin, & Kraus, 2013; Kraus et al., 2012; Moon et al., 2014; Parbery-Clark, Marmel, Bair, & Kraus, 2011; Strait et al., 2014; Westerhausen et al., 2015; Wunderlich & Cone-Wesson, 2006; Sussman & Steinschneider, 2009).
In addition to the age effect in our data, there was also a trend for SRT to improve between the first test and the immediate retest. The SRT improvements from test to retest in our data are probably an example of fast adaptation of auditory processes to incoming speech-in-noise signals (Skoe et al., 2013), including fast adaptation to the task, stimulus, or phonetic inventory of the speaker. In case of a failed first test, a retest is recommended. The relatively better first SRT score found in adults which hardly improved with retesting might show that the adults’ auditory system was already well-tuned or adapted instantly, leaving little room for improvement.
In summary, when screening by SRT, the effects of the still maturing cortical and subcortical system on auditory speech and noise processing have to be considered. The studies referred above indicate that experience-related factors or auditory pathologies other than increased hearing thresholds are involved in the tuning of speech (-in-noise) processing in adolescents. While online speech-in-noise tests can offer an efficient way to screen for hearing impairment on a regular basis, the auditory system is in flux during childhood and adolescence, and age-related cut-off scores in SRT should be considered for this age period.
To check for an effect of potential differences in cognitive skills within an age-group, we included the level of education. Larger samples are needed to confirm the insignificance of the level of education and gender in our data. Future research might also assess the adolescents’ musical training and bilingualism, since both have a significant effect on auditory processing of speech-in-noise (Krizman et al., 2016; Tierney et al., 2015). For musicians, auditory brain responses revealed superiority in the representation of timbre, pitch, and timing (Slater et al., 2015).
Since our study focused on the verification of an age effect in SRT scores of NH adolescents, it is not yet clear to what extent the proposed age-dependent “easing” of the cut-off scores might affect the test’s ability to detect hearing loss in the respective age-groups. More research is needed to rule out possible negative effects of an age correction on the sensitivity and specificity of Oorcheck as a screening test. Our results should be considered in light of these caveats.
From the point of view of awareness and prevention of hearing loss, and considering the effect that hearing loss can have on a student’s development, education, employment, rehabilitation costs, and retention rate (Bess, Dodd-Murphy, & Parker, 1998), it should be noted that 22% (23/104) of the participants in the present study had to be excluded due to their elevated pure-tone hearing thresholds.
Conclusion
Hearing screening tools which are based on thresholds for speech in noise should control for an effect of age when assessing adolescents. Based on the present data, we propose a correction factor of −0.2 dB per year of age for Oorcheck SRT cut-off scores for adolescents between the ages of 12 and 17 years. More data are needed to verify the present findings and proposed corrections.
Footnotes
Acknowledgments
The authors thank the Dutch National Hearing Foundation, Kelly Coenen for performing audiometric measurements and ZICHT for implementing and adapting the online test.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been funded by the Dutch Ministry of Health Affairs. The funder did not have any involvement in this study.