
Abstract
Background:
Artificial intelligence (AI) chatbots are increasingly used for medical information provision. However, systematic evaluations of their accuracy and reliability in orthopaedic surgery, particularly in total knee replacement (TKR), remain limited.
Purpose:
To systematically compare and evaluate performances of various AI chatbots, focusing on their ability to provide accurate and reliable information related to TKR.
Study Design:
Cohort study; Level of evidence, 2.
Methods:
A total of 43 clinically relevant TKR-related frequently asked questions (FAQs) were selected based on Google search trends and expert consultation. Questions were categorized into 6 key domains: (1) general/procedure-related information, (2) indications and outcomes, (3) risks and complications, (4) pain and postoperative recovery, (5) specific activities after surgery, and (6) alternatives and variations. Each question was submitted to 5 different chatbot models (GPT-3.5, GPT-4, GPT-4 Omni, Gemini Advanced, and Gemini 1.5) for response generation. Two independent orthopaedic surgeons assessed the chatbot's responses for both accuracy and relevance using a 5-point Likert scale. Responses were anonymized, blinding evaluators to the chatbot identities to prevent bias. Accuracy differences among the chatbot models were analyzed by analysis of variance, and relevance was compared using the Kruskal-Wallis test.
Results:
GPT-3.5 (4.8 ± 0.5), GPT-4 (4.9 ± 0.4), GPT-4 Omni (4.9 ± 0.3), and Gemini 1.5 (4.8 ± 0.4) demonstrated high accuracy, whereas Gemini Advanced scored significantly lower (4.1 ± 1.4) (P < .001). However, general/procedure-related information, risks and complications, pain and recovery, and postoperative activities showed no significant differences among chatbots. Gemini Advanced underperformed in indications and outcomes (P = .04) and alternatives and variations (P = .002). Regarding relevance, all chatbots except Gemini Advanced (36/43; 83.7%) achieved a 100% relevance rate (P < .001).
Conclusion:
This study demonstrates that GPT-3.5, GPT-4, GPT-4 Omni, and Gemini 1.5 can provide highly accurate and relevant responses to TKR-related queries, while Gemini Advanced underperforms.
In recent years, the rapid development of artificial intelligence (AI) technology, particularly in the field of chatbots, marks a significant milestone in modern digital innovation. These AI-driven chatbots developed using large language models (LLMs) trained on extensive and diverse textual data ranging from news articles and novels to peer-reviewed journals and web content have become increasingly prevalent across numerous sectors. 5 Their ability to generate contextually relevant and linguistically coherent responses has opened new possibilities in areas such as customer service, education, and health care.5,16 AI chatbots are increasingly being studied for their potential application in orthopaedics, including rehabilitation planning, surgical decision support, and patient communication. 22 Recent studies have shown that ChatGPT is a promising tool for addressing clinical questions related to procedures such as anterior cruciate ligament reconstruction and total knee replacement (TKR), particularly in terms of accuracy and clinical utility.9,23 Additionally, ChatGPT has been proposed as a virtual assistant to enhance patient education and engagement by providing tailored information about orthopaedic conditions, treatment options, and postoperative care. 7
Although AI chatbots are gaining traction, concerns regarding the accuracy and reliability of the information they provide have emerged. 1 Data sources, collection periods, and training methodologies vary significantly across different chatbot platforms, leading to potential discrepancies in the information they disseminate. In the health care sector, where accurate information is critical, these discrepancies could have serious implications for patient care.
Given these concerns, conducting a comprehensive comparative analysis of chatbots is necessary to assess the reliability and accuracy of the information they provide. This research is particularly crucial in the field of orthopaedics, where patients frequently seek information about procedures such as TKR. Because TKR is one of the most common and significant surgeries in orthopaedics, it is a focal point for patients searching for medical guidance online.3,4,14
Previous studies have evaluated the performance of a single AI model, such as ChatGPT-3.5 or ChatGPT-4, in answering questions related to TKR.2,19,23 This study advanced previous works by evaluating multiple chatbot models, thereby allowing a broader investigation into performance differences across LLMs. The purpose of this study was to assess the accuracy and relevance of responses provided by different versions of OpenAI's ChatGPT (GPT-3.5, GPT-4, and GPT-4 Omni) and Google's Gemini (Gemini Advanced and Gemini 1.5) to frequently asked questions (FAQs) about TKR. We hypothesized that ChatGPT and Gemini chatbot models would perform similarly in providing accurate and relevant responses to TKR-related FAQs, with no significant differences.
Methods
Selection and Categorization of FAQs Related to Total Knee Replacement
This study did not involve human participants and therefore did not require approval from an institutional review board. The authors used chatGPT and DeepL to correct English grammar and improve sentence clarity and academic tone. To identify FAQs related to TKR, S.H.K. created a new Google account with no prior search history and entered the search term "total knee replacement" into Google web search (Google; Alphabet Inc). Initial questions were extracted from the "People also ask" section of the main search page. These were reviewed by 2 board-certified orthopaedic surgeons (H.L. and S.Y.S.) who consolidated duplicate and semantically similar entries, resulting in a refined list of 43 unique and clinically relevant questions. To facilitate structured evaluation and domain-specific comparison, the FAQs were categorized into 6 clinically relevant domains reflecting key aspects of the TKR perioperative process; (1) general/procedure-related information, covering basic information about the procedure; (2) indications for surgery and outcomes, addressing reasons for surgery and expected outcomes; (3) risks and complications, discussing potential risks associated with TKR; (4) pain and postoperative recovery, focusing on pain management and recovery time frames; (5) specific activities after surgery, related to activities that patients can resume after surgery; and (6) alternatives and variations, including alternatives such as partial knee replacement and robotic TKR (Table 1).
The 6 Categories and Frequently Asked Questions (FAQs)

Evaluation of Chatbot Responses
The FAQs were input into chatbot models (GPT-3.5, GPT-4, GPT-4 Omni, Gemini Advanced, and Gemini 1.5) for comparison, with responses collected in July 2024. To minimize potential bias from previous interactions, only initial responses were evaluated. Each question was submitted in a new chat session by selecting the “new chat” option before proceeding with the next inquiry. Chatbot models were assessed for both accuracy and relevance of their responses. Factual accuracy refers to the degree to which the chatbot’s responses align with the most up-to-date medical guidelines regarding TKR as of August 2024. Relevance indicated how useful and effective the responses were in addressing the questions. Each response was rated on a 5-point Likert scale. 17 To ensure clear evaluation, a description of the level of response represented by each scale was also provided (Tables 2 and 3). Two independent orthopaedic surgeons (H.L. and S.Y.S.) evaluated responses of chatbots based on predefined criteria. To minimize bias, evaluators were blinded to chatbot identities. All responses were anonymized and presented in a randomized order, ensuring that scoring was based solely on content rather than the source of the response. Each rating was guided by a structured rubric based on the descriptive criteria outlined in Tables 2 and 3, ensuring standardized and reproducible scoring. This evaluation is essential to ensure that the information provided by the AI is both scientifically sound and relevant to contemporary clinical practice. For each question, the scores from the 2 raters were averaged to obtain a final score.
Likert Scale for Grading Factual Accuracy

Likert Scale for Grading Relevance

Statistical Analysis
For accuracy, chatbot responses were evaluated using the mean and standard deviation of Likert scores. In contrast, relevance was dichotomized: responses with a score of ≥4 were classified as relevant, while those with a score <4 were considered irrelevant. Statistical analysis was performed using R Version 4.0.3 (R Foundation for Statistical Computing). Statistical significance of the difference in chatbot performance was assessed using analysis of variance (ANOVA) and Tukey honest significance post hoc test for accuracy and Kruskal-Wallis H test and Dunn post hoc test for relevance. A P value of <.05 was considered statistically significant. ANOVA was used to compare chatbot performance in terms of accuracy because the data followed a normal distribution, while the Kruskal-Wallis H test was used for relevance since the data did not meet normality assumptions. Interrater reliability was measured using Gwet AC2. Additionally, Pearson correlation coefficient (r) and Cronbach alpha (α) were used to evaluate the internal consistency of scoring patterns across questions.
Results
Overall Performance
Overall accuracies of different chatbots were as follows. GPT-3.5 scored 4.81 ± 0.45. GPT-4 scored 4.86 ± 0.35. GPT-4 Omni scored 4.91 ± 0.29. Gemini Advanced scored 4.07 ± 1.44 and Gemini 1.5 scored 4.84 ± 0.43 (Table 4; Supplemental Material Figure A1, available separately). Gemini Advanced achieved a significantly (P < .001) lower accuracy score than other chatbots, highlighting a clear performance gap. The relevance rate was 83.72% (36/43) for Gemini Advanced, while other chatbots achieved a rate of 100% (43/43). This difference was statistically significant (P < .001). Gemini Advanced avoided answering 7 questions, either by recommending consultation with a specialist or by stating that the question was beyond its capabilities (Table 5). Interrater reliability for the assessment showed substantial to excellent agreement. Gwet AC2 values were 0.85 for factual accuracy and 0.94 for relevance, indicating strong interrater agreement. In addition, Pearson correlation coefficient (0.93) and Cronbach alpha (0.96) supported excellent internal consistency of raters.
Accuracy of Various Chatbots According to Subcategories a

Data are presented as mean ± SD. One-way analysis of variance was used to compare different models.
The group causing the difference.
Instances of Gemini Advanced Avoidance of Responses to Specific Questions a
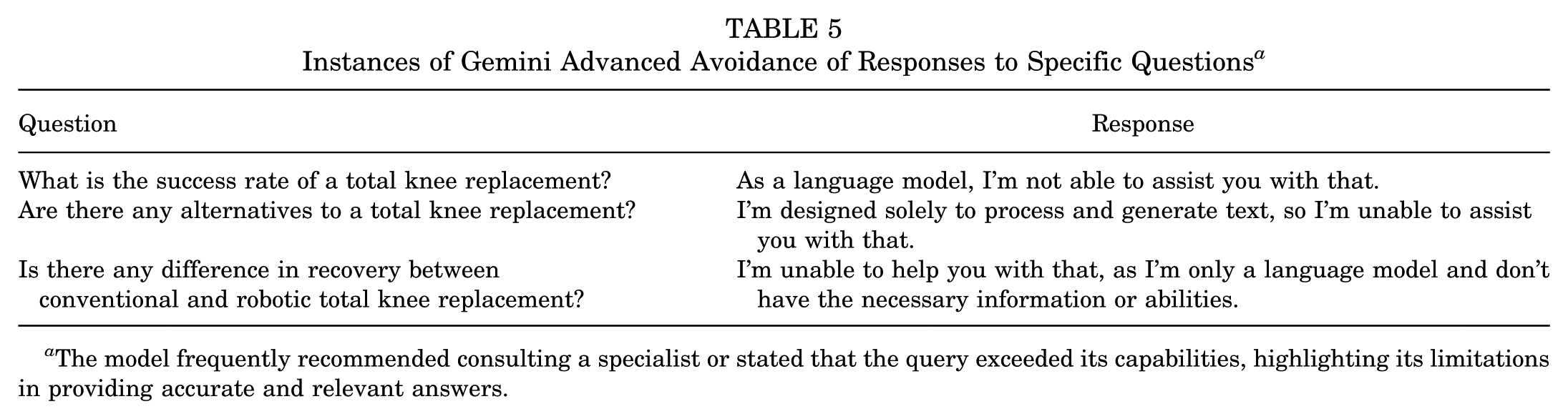
The model frequently recommended consulting a specialist or stated that the query exceeded its capabilities, highlighting its limitations in providing accurate and relevant answers.
General/Procedure-Related Information
The analysis included 7 FAQs. Regarding the accuracy for each chatbot, the score was 4.86 ± 0.38 for GPT-3.5, 4.71 ± 0.49 for GPT-4, 4.86 ± 0.38 for GPT-4 Omni, 4.29 ± 1.50 for Gemini Advanced, and 5.00 ± 0.00 for Gemini 1.5. These results showed no statistically significant differences among chatbots (P = .45). The relevance analysis revealed that Gemini Advanced showed relevance in 6 (85.71%) out of the 7 FAQs, while all other chatbots demonstrated relevance in all FAQs.
Indications for Surgery and Outcomes
There were 6 FAQs regarding the indications for TKR and outcomes from surgery. Of responses, accuracy for each chatbot was 5.00 ± 0.00 for GPT-3.5, 5.00 ± 0.00 for GPT-4, 5.00 ± 0.00 for GPT-4 Omni, 3.50 ± 1.97 for Gemini Advanced, and 4.67 ± 0.52 for Gemini 1.5. The difference in accuracy among chatbots was statistically significant (P = .04), with Gemini Advanced showing notably lower accuracy than other chatbots. Relevance rate was demonstrated in 4 (66.7%) out of 6 FAQs for Gemini Advanced, while all other chatbots achieved a relevance rate of 100%.
Risks and Complications
In the category of risks and complications comprising 4 FAQs, only Gemini Advanced demonstrated an accuracy of 4.75 ± 0.50, while all other chatbots achieved an accuracy of 5.00 ± 0.00 (P = .44). All chatbots demonstrated a relevance rate of 100%.
Pain and Postoperative Recovery
A total of 12 FAQs were analyzed. Regarding the accuracy for each chatbot, the score was 4.83 ± 0.39 for GPT-3.5, 4.83 ± 0.39 for GPT-4, 4.92 ± 0.29 for GPT-4 Omni, 4.50 ± 1.17 for Gemini Advanced, and 4.83 ± 0.39 for Gemini 1.5 (P = .51). Notably, all questions except 1 in the Gemini Advanced (91.67%) category demonstrated relevance.
Specific Activities After Surgery
The analysis included a total of 7 FAQs. Regarding the accuracy for each chatbot, it was 4.57 ± 0.79 for GPT-3.5, 4.86 ± 0.38 for GPT-4, 5.00 ± 0.00 for GPT-4 Omni, 4.00 ± 1.41 for Gemini Advanced, and 4.57 ± 0.70 for Gemini 1.5 (P = .22). Relevance rates were 100% for all chatbots except for Gemini Advanced (6/7; 85.71%).
Alternatives and Variations
There were 7 FAQs regarding indications for alternatives and variations. Regarding the accuracy of each chatbot's responses, the score was 4.71 ± 0.49 for GPT-3.5, 4.86 ± 0.38 for GPT-4, 4.71 ± 0.49 for GPT-4 Omni, 3.29 ± 1.60 for Gemini Advanced, and 5.00 ± 0.00 for Gemini 1.5. Statistically significant differences in chatbot accuracy were observed (P = .002), driven by the lower accuracy of Gemini Advanced compared with the other models. The relevance rate for Gemini Advanced was 71.43% (5/7), while other chatbots achieved a relevance rate of 100% (7/7).
Discussion
The major finding of this study was that AI chatbots vary in their ability to provide accurate and relevant responses to TKR-related FAQs. Among the models tested, GPT-3.5, GPT-4, GPT-4 Omni, and Gemini 1.5 demonstrated consistently high performance across all evaluated categories, with mean accuracy scores of ≥4.8 and 100% relevance, while Gemini Advanced showed significantly lower accuracy (4.1 ± 1.4; P < .001) and relevance (83.72%). These findings underscore the variability in chatbot quality and the importance of selecting and validating models before clinical application.
Various studies have demonstrated that chatbots can effectively respond to medical inquiries, showcasing their potential as supportive tools in the health care sector.6,10,21 These studies have illustrated that chatbots can provide accurate and contextually appropriate answers to a wide range of medical questions, ranging from general health advice to specialized clinical knowledge. Although previous studies have primarily assessed general capabilities of chatbots in medicine, this study specifically evaluated their accuracy within the domain of orthopaedic surgery, where precise clinical guidance is crucial for surgical decision-making and postoperative management. In fact, as chatbots become increasingly specialized, some have achieved a level of expertise sufficient to pass professional examinations such as the United States Medical Licensing Examination (USMLE).5,11 Furthermore, their integration into health care settings has garnered positive feedback by enhancing patient engagement, simplifying access to information, and supporting decision-making processes. This growing body of evidence highlights the role of chatbots as valuable assets in complementing traditional medical practices. Results of this study further support these findings.
All chatbot models, except for Gemini Advanced, demonstrated strong overall performance, achieving a mean score of ≥4.5 in response to questions related to TKR. When analyzed by category, all chatbots provided accurate answers without showing statistically significant differences in categories of general/procedure-related information, risks and complications, pain and postoperative recovery, and specific activities after surgery. In contrast, in indications and outcomes and alternatives and variations categories, Gemini Advanced was observed to provide less accurate responses. Notably, Gemini Advanced frequently exhibited a tendency to avoid answering specific questions, which can lead to decreased accuracy and relevance. Unlike other models that provided informative answers along with disclaimers (eg, "Always prioritize your surgeon’s and therapist’s advice"), Gemini Advanced tended to avoid answering entirely, instead stating its limitations (eg, "I’m only a language model"). This avoidance behavior likely reflects model-specific safety filters designed to minimize the risk of misinformation. While such a cautious approach may be appropriate in high-stakes contexts, it also limits the model's utility to deliver practical guidance in clinical decision-making or patient education scenarios.
In terms of relevance, consistent with findings on accuracy, only Gemini Advanced exhibited lower performance on certain questions, whereas all other chatbots demonstrated 100% relevance across all responses. Similar to findings on accuracy, a lack of relevance was observed exclusively in 7 instances where Gemini Advanced avoided providing a response. These results suggested that, aside from these exceptions, all chatbots consistently exhibited both accuracy and relevance in their responses.
Zhang et al. have reported that ChatGPT-3.5 demonstrates an accuracy of 88% and a relevance of 100% in responses to 50 questions related to TKR. 23 A study comparing ChatGPT-4 and arthroplasty-trained nurses regarding responses to TKR-related questions has reported that both groups demonstrate an accuracy of 44/60 (73.3%). 2 These findings are consistent with results of our study. One study has reported that ChatGPT can effectively respond not only to general questions about TKR, but also to more specialized questions regarding periprosthetic joint infection after total hip and knee arthroplasty. Among the 12 questions analyzed, none was rated as “unsatisfactory.” One response was deemed accurate enough to require no clarification, while 7 responses required low clarification and 4 required moderate clarification. 8
Comparative analyses of chatbot models have generally demonstrated that newer, updated versions exhibit superior performance.12,18 However, our study found that GPT-3.5, GPT-4, and GPT-4 Omni showed similar performance levels, with minor differences that were not statistically significant. In contrast, for Gemini models, responses generated by Gemini 1.5, a subsequent iteration of Gemini Advanced, exhibited significantly improved accuracy and overall performance. Notable differences were observed in information delivery methods of the 2 chatbots. Specifically, Gemini can enhance the reliability and readability of the information it provides by meticulously citing sources and incorporating relevant images, thereby improving the overall user experience. In contrast, ChatGPT tends to generate lengthy textual responses and a higher volume of output. In the case of ChatGPT, the latest versions were observed to provide more detailed information. However, they occasionally included contents with slightly reduced relevance. While this can increase the overall output volume, it may decrease the proportion of relevant information, potentially causing confusion for patients. Some studies have reported that AI chatbots may occasionally provide inaccurate or misleading information and, in some instances, generate plausible but false statements—a phenomenon termed "artificial hallucination." This issue requires careful consideration and scrutiny.1,20 However, in our study, no instance of hallucination was observed, as all chatbot responses remained consistent with established medical knowledge and guidelines. This finding suggests that evaluated chatbot models can provide reliable information within the scope of TKR-related queries. While this result suggests a high reliability of TKR-related queries, it is important to note that the absence of hallucination might be context dependent. Further evaluation across broader clinical topics is warranted.
Given the rapid evolution of LLMs, the accuracy and reliability of chatbot-generated medical information may vary over time. Because this study presents a comparative evaluation of 5 AI models as of August 2024, the findings should be interpreted as a temporal snapshot rather than a generalizable conclusion. In particular, some models may undergo frequent updates in their knowledge base or response strategies, potentially altering their factual accuracy, relevance, or even clinical safety. Therefore, ongoing monitoring and reevaluation are essential to maintain up-to-date benchmarks and ensure that these tools remain reliable for patient-facing health care communication.
Strengths and Limitations
This study provides valuable insights into the accuracy and reliability of AI chatbots in delivering medical information. Findings of this study highlight both the potential utility and current challenges of chatbot-assisted patient education, emphasizing the need for continuous improvement in AI models to enhance their clinical applicability. Future investigations should focus on addressing these limitations to refine AI-based health care communication tools further.
The following limitations that should be considered when interpreting this study's findings. First, chatbot responses were evaluated at a single time point (August 2024), and given the rapid evolution of AI models, their performance may change over time.15,24 Therefore, the results of this study should be interpreted as a temporal benchmark rather than a permanent evaluation. Ongoing reassessment of these models is necessary to ensure their sustained clinical relevance and safety. Second, this study evaluated chatbot responses exclusively in English, which might limit the generalizability of our findings to non−English speaking populations. 13 Third, the evaluation of the chatbot responses was conducted exclusively by medical experts; however, the comprehensibility and readability from the perspective of patients was not assessed directly. Finally, the evaluation focused solely on factual accuracy and relevance. Other important dimensions of chatbot performance—such as clarity, completeness, consistency, adherence to evidence-based guidelines, and the potential for harmful or misleading content—were not assessed. Although no overtly unsafe responses were observed in this study, future research could address this and other limitations by incorporating longitudinal assessments, multilingual evaluations, and multidimensional performance metrics that may provide a more comprehensive understanding of chatbot performance and its clinical effect.
Conclusion
This study demonstrates that GPT-3.5, GPT-4, GPT-4 Omni, and Gemini 1.5 can provide highly accurate and relevant responses to TKR-related queries, while Gemini Advanced underperforms. These findings highlight the variability in chatbot performance and emphasize the need for ongoing assessments to ensure their reliability and maintain their value as trusted sources of medical information.
Footnotes
Appendix
Final revision submitted September 25, 2025; accepted October 19, 2025.
One or more of the authors has declared the following potential conflict of interest or source of funding: This work was supported by the National Research Foundation of Korea grant funded by the Korea government (RS-2024-00344750). AOSSM checks author disclosures against the Open Payments Database (OPD). AOSSM has not conducted an independent investigation on the OPD and disclaims any liability or responsibility relating thereto.
Ethical approval was not sought for the present study.