
Abstract
Traditional tennis rating systems (e.g., Elo) summarize overall player strength but do not isolate the independent value of serving. Using point-by-point data from Wimbledon and the U.S. Open, we develop serve-specific player metrics that separate serving quality from return ability and other latent factors. For each tournament and gender, we fit logistic mixed-effects models of point outcomes using serve speed, speed variability, and placement features, with crossed server and returner random intercepts to capture unobserved player strengths. From these models we derive Server Quality Scores (SQS): partially pooled, opponent-adjusted estimates of players’ serving impact. In out-of-sample evaluation, SQS aligns more strongly with serve efficiency—the probability of winning points within three shots—than weighted Elo. We further benchmark SQS against task-aligned serve-stat baselines and model ablations, quantifying the incremental value of serve features and partial pooling. Associations with overall serve win percentage are smaller and dataset-dependent, and neither SQS nor weighted Elo consistently dominates that outcome. Overall, SQS is best interpreted as a measure of serve-induced short-point advantage (serve quality plus early-point conversion), complementing holistic ratings with actionable insight for coaching, forecasting, and player evaluation.
Keywords
Introduction
Current tennis rating systems, such as Elo, estimate player strength from match-level outcomes. While effective for forecasting, these models compress the complexity of play into a single number and do not isolate the value of specific skills. In particular, the serve—the only shot completely under a player’s control—is treated implicitly rather than modeled directly. In practice, practitioners often summarize serving performance with simple statistics such as ace rate, first-serve-in percentage, and first-serve-win percentage. These summaries are easy to compute, but each reflects only a narrow slice of serve quality and can mask the mechanisms that make a serve effective. Moreover, they conflate distinct dimensions of serving (pace, placement, and variability) and are sensitive to opponent quality and point context. Taken together, these limitations motivate a holistic, point-level measure of serving performance independent of other skills.
Our Contribution
This paper establishes a framework to estimate a serve-specific player metric using generalized linear mixed models (GLMMs). We call this metric a player’s Server Quality Score (SQS). SQS captures both measured skill derived from serve features (average speed, speed variability, and location characteristics) and unmeasured server effects modeled through player-specific random intercepts. To distinguish between aggressive and defensive serving contexts, we fit separate models for first and second serves. We treat SQS as a two-dimensional metric, reporting separate first-serve and second-serve scores.
Using point-by-point data from Wimbledon and the U.S. Open (2018–2019 and 2021–2024), we benchmark these server metrics against weighted Elo (wElo). We also compare against task-aligned baselines (standard serve statistics, random-effects-only GLMM scores, and fixed-effects-only scores) to test whether SQS adds information beyond simpler serve summaries and model ablations.
Organization
Section “Related Work” reviews related work. Section “Methodology” describes our methodology with data preparation, mixed effects models, and construction of SQS. Section “Results” discusses out-of-sample testing results and benchmarks SQS against wElo. Additional task-aligned baseline analyses, temporal validation, and point-level robustness checks are reported in the appendix. We conclude with a discussion in Section “Discussion”.
Related work
Match-level ratings and forecasting
Elo-style ratings, adapted from chess and widely used in tennis, estimate a player’s strength from match results. These ratings have consistently been effective for forecasting match winners using large datasets (Klaassen and Magnus, 2003; Kovalchik, 2016). A recent extension, weighted Elo (wElo), incorporates margins of victory and has been shown to outperform standard Elo and other common baselines, including in value-betting applications (Angelini et al., 2022).
Beyond pre-match ratings, other studies combine in-play information to improve point-by-point forecasting. For example, Kovalchik and Reid (2019) show that starting from a rating-based prior and updating dynamically during a match improves win probability estimates.
Alternative approaches model tennis as a hierarchical Markov process, where point-level win probabilities map recursively to game, set, and match win probabilities. Early work studied whether points are independent and identically distributed (IID), finding that this assumption is not always true due to changes in momentum and pressure (Klaassen and Magnus, 2001).
Despite these limitations, models under the IID assumption still provide a useful baseline. O’Malley (2008) derives exact game, set, and match win probabilities under an IID assumption and studies how these probabilities change with serve and return strength. Later studies relax the IID assumption by using state-dependent dynamics that better predict live win probabilities (Klaassen and Magnus, 2003; Newton and Aslam, 2009).
While these ratings and match models are valuable for forecasting, they intentionally aggregate performance across all phases of play. This motivates serve-specific modeling that can complement Elo-style summaries when the goal is interpretation and skill isolation rather than match prediction.
Point-level models and serve win probabilities
A central part of point-based tennis models is a player’s “serve win probability,” defined as the probability of winning a point as the server. These probabilities are often split between first and second serves, and they can be adjusted based on surface or match context.
Early work by Barnett and Clarke (2005) computes match-specific serve probabilities by combining each player’s historical serve and return performance with opponent strength. Subsequent work refines this approach by adding surface adjustments, shrinkage for small samples, and common-opponent comparisons. More recently, Gollub (2021) improves estimates of serve win probabilities by combining broader Elo-type player ratings.
However, serve win probabilities in point-based models are typically treated as context-dependent inputs for predicting match outcomes rather than as standalone measures of serving quality. Our goal is instead to estimate an interpretable server metric derived from serve characteristics while accounting for unobserved, player-specific effects via partial pooling.
Gap: isolating serve quality
Despite frequent use of serving variables in both match- and point-level models, there is still no widely adopted metric that isolates the serve as an independent component of player quality. In practice, separating the serve’s contribution from other aspects of play improves interpretability and supports decision-making. It clarifies how much advantage comes from the serve itself and informs coaching strategies that are specific to serving and returning.
Motivated by this gap, we introduce a framework for serve-specific player metrics focused solely on serving performance. Section “Methodology” describes the methodology used to construct these metrics.
Methodology
Data and feature construction
We use publicly available point-by-point data for singles matches at the Wimbledon and U.S. Open tournaments from Jeff Sackmann’s public tennis database. We pool six seasons of data (2018–2019 and 2021–2024) into four groups: Wimbledon men’s singles, Wimbledon women’s singles, U.S. Open men’s singles, and U.S. Open women’s singles (excluding 2020 due to COVID-19–related disruptions). All analyses are performed separately for each tournament and gender.
Within each dataset, matches are randomly split into training (80%) and testing (20%) sets within each year. This ensures that all points from a given match are assigned to the same split and that each season contributes to both training and testing, avoiding leakage from within-match dependence while balancing year-to-year variation. Server Quality Scores (SQS) are constructed using the training set, and the testing set is reserved for out-of-sample evaluation. As a complementary check, we also evaluate SQS under a temporal split (train on 2018–2022, test on 2023–2024); these results appear in Appendix C.
We begin by cleaning the raw point-level data, applying the following steps:
Removing serves with missing location information. Restricting the data to valid first and second serves. Excluding serves recorded with zero speed (due to faults). Defining serve location using two categorical variables,


Because these predictors summarize serve behavior at the player level, they compress within-player variation across individual points. As a robustness check, we implement alternative models using point-level serve features (serve speed, location bin, and an indicator for whether the serve matches the player’s modal location) and report the results in Appendix D. The alternative results are broadly consistent with the main specification, suggesting that the aggregated server-level model retains most of the predictive signal relevant to serve efficiency while remaining easier to interpret as a stable player-level serve profile.
Finally, we consider two complementary outcomes: overall point win percentage and serve efficiency. We define an efficient serve as one where the server wins the point within the first three shots (serve, return, and the server’s next shot). This restriction is deliberate: by focusing on the earliest phase of the point—when the server’s initial delivery most directly shapes the exchange—serve efficiency acts as a measure of serve-induced short-point advantage rather than overall point wins, which increasingly reflect baseline rally skill and endurance as the point lengthens. In this sense, serve efficiency captures situations in which the serve generates an immediate advantage (e.g., an ace, forced error, weak return, or short-ball put-away) that the server converts quickly, rather than points in which the serve merely initiates a neutral rally.
In our analysis, we model the point-level efficient-serve indicator (a
Mixed-effects model and server quality score (SQS)
Our goal is to quantify server quality in a way that reflects both observable serve characteristics and unobservable player effects. To do so, we fit separate logistic mixed-effects models for first and second serves to account for different serving contexts. This separation allows the relationship between serve features and short-point outcomes to differ across serve types.
Each model is fit at the point level, with the outcome being whether the serve was efficient, i.e., whether the server won the point within three total shots (as defined in Section 3.1).
For serve type
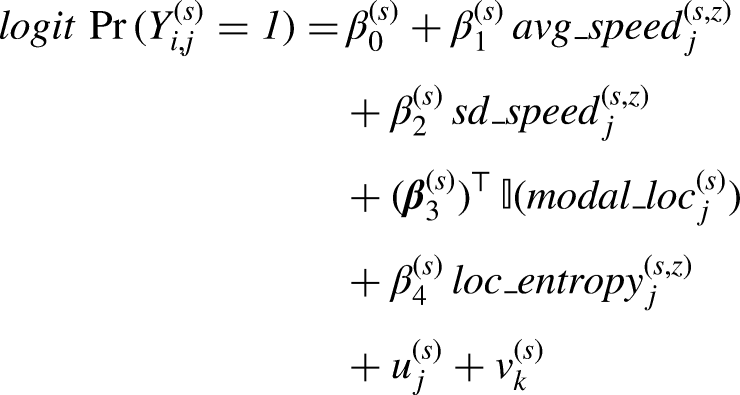
The fixed effects quantify the association between observable serve characteristics (pace, pace variability, and placement tendencies) and short-point success. The returner-specific random intercept
For each serve type, we summarize the fitted model into a single server quality score by combining each player’s estimated fixed and random effects:

Because the fitted model includes both server and returner effects, we define SQS as the server-side linear predictor evaluated at an average returner (i.e., setting
Out-of-sample evaluation and baselines
We evaluate Server Quality Scores (SQS) out of sample using the held-out matches in each tournament–gender dataset. Since SQS is defined at the server-by-serve-type level, we aggregate test-set points by server and compute two server-level outcomes: overall point win percentage and serve efficiency (defined in Section 3.1). Serve efficiency captures short-point success within three shots, while win percentage summarizes outcomes over all rally lengths:

As a baseline, we repeat the same evaluation using weighted Elo (wElo) in place of SQS. wElo scores are computed using the R package
To address task alignment directly, we also evaluate three additional baseline families: (i) standard serve statistics (ace rate, first-serve points won, unreturned-serve proxy rate, and first-serve-in%), (ii) a random-effects-only GLMM with server and returner intercepts but no serve covariates, and (iii) a fixed-effects-only score that uses the measured serve-feature component of SQS without the server random effect.
For comparability, each tournament–gender–serve-type evaluation uses a common complete-case server set across all predictors. Full baseline comparisons are reported in Appendix B.
In Section “Results”, we report regression coefficients and correlations between each predictor and the observed test-set outcomes.
Results
We report full out-of-sample results for Wimbledon men’s singles in Tables 1 and 2. Analogous tables for Wimbledon women’s singles and the U.S. Open (men and women) appear in Appendix A; we reference them here only to summarize cross-dataset patterns.
Out-of-sample performance for Wimbledon men’s singles (first serves).

Out-of-sample performance for Wimbledon men’s singles (second serves).

Expanded task-aligned baseline comparisons appear in Appendix B. In addition, results from the alternative point-level specification are reported in Appendix D. These results show similar qualitative patterns, indicating that the server-level specification used in the main analysis captures most of the predictive signal while remaining easier to interpret as a stable player-level serve profile.
Serve efficiency vs. point win percentage
Across tournaments and genders, SQS aligns most closely with serve efficiency, our serve-proximal target. On first serves, SQS is positively associated with serve efficiency in all four datasets and is especially strong at Wimbledon (e.g.,
Against the additional task-aligned baselines (Appendix B), SQS remains strongest on average for first-serve efficiency (
The ablation comparisons support incremental value from both model components. Relative to the random-effects-only model, SQS improves first-serve efficiency correlations in all four datasets, indicating added signal from serve-feature covariates. Relative to fixed-effects-only, SQS is higher in three of four datasets, suggesting that partial pooling via server random effects contributes in most settings.
Associations with overall point win percentage are generally weaker and more variable for both ratings. On first serves, SQS correlations remain positive across datasets, while wElo is small and sometimes negative. On second serves, both predictors show mixed performance, suggesting that overall point outcomes under second-serve conditions depend strongly on broader skills and contextual factors beyond the serve alone. Task-aligned baseline comparisons for win percentage (Appendix B) reinforce this pattern. On first serves, mean correlations are similar across several predictors (SQS:
First vs. second serves
Stratifying by serve type clarifies how serving context mediates the relationship between ratings and outcomes. On first serves, servers have the greatest opportunity to create immediate leverage; correspondingly, SQS shows its strongest and most reliable associations with the serve-efficiency target. On second serves, where pace is reduced and the returner typically sees more playable deliveries, efficiency and win-percentage outcomes depend more heavily on the ensuing exchange, making relationships with any serve-only summary less stable across datasets.
Implications
Overall, the out-of-sample results support interpreting SQS as a serve-focused metric. Across datasets, SQS is most informative for explaining variation in serve efficiency—an outcome designed to concentrate signal in the serve–return–first-strike phase—whereas associations with overall point win percentage are weaker and more heterogeneous, especially on second serves where immediate serve leverage is reduced. Although serve efficiency still reflects the return and the server’s next shot, restricting attention to a three-shot window reduces the influence of longer-rally dynamics. This provides empirical evidence that SQS captures a distinct, serve-proximal component of performance.
Discussion
Comparison with prior work
These results are consistent with prior tennis-rating research showing that match-level metrics such as Elo-type ratings are effective summaries of overall performance, while extending that literature by isolating a serve-proximal component. Relative to prior work on serve win probabilities as inputs to match forecasting, SQS is designed as an interpretable player metric rather than a match predictor. The direct comparison with weighted Elo and the additional win-percentage analyses show this distinction empirically: SQS is strongest for short-point serve efficiency, whereas weighted Elo is often more aligned with broader point outcomes, especially on second serves.
Conclusions and practical applications
This paper proposes a serve-specific framework for evaluating tennis performance using point-level data. We introduce a Server Quality Score (SQS), estimated via logistic mixed-effects models, that summarizes how effectively a player’s serve converts the opening exchange into an early-point advantage.
Across tournaments and genders, out-of-sample evaluation supports the intended interpretation of SQS as a serve-proximal metric. SQS aligns most strongly with serve efficiency, while relationships with overall point win percentage are smaller and more heterogeneous: especially on second serves where immediate serve leverage is reduced. Weighted Elo (wElo), by contrast, reflects broader point-winning ability and in some settings aligns more closely with win percentage; however, neither rating uniformly dominates for win percentage across all datasets. Taken together, these results provide empirical evidence that SQS captures a distinct, serve-driven component of performance that complements holistic match-level ratings.
Limitations and future work
Several limitations suggest directions for extending the SQS framework. We adjust for average return strength via a returner random intercept, but we do not model server–returner interaction effects (matchup-specific styles) or contextual shifts in return positioning. First, the model omits contextual factors such as score state, point importance, and fatigue. Because serve selection and execution change under pressure, incorporating context could help distinguish underlying serve quality from strategic adaptation within matches.
Second, our placement features (modal location and location entropy) provide interpretable summaries but compress richer spatial structure. Future work could incorporate continuous serve coordinates, spatial smoothing, or probabilistic location models to better represent placement strategies and their interaction with pace.
Third, data quality limits the characterization of risk. In particular, serves with recorded speed of zero (typically faults or missing tracking) were excluded, potentially omitting information about second-serve safety and risk–reward tradeoffs. More complete tracking of serve attempts and faults would enable models that jointly capture placement, speed, and error propensity.
Finally, our analysis is conducted separately by tournament and gender, which means the resulting SQS values are not directly comparable across tournaments or surfaces. For example, faster courts such as grass typically amplify serve advantage relative to slower hard or clay courts. In this study, we partially address this concern by estimating separate models for each tournament. The top-ranked servers in Appendix E are broadly consistent across the Wimbledon and U.S. Open datasets, suggesting that the metric captures stable aspects of serving ability despite surface differences. An extension to this would be to estimate a hierarchical model that pools information across tournaments and seasons while allowing surface-specific effects. This would enable direct comparisons of serving quality across surfaces and competitions.
Together, these extensions provide a path toward richer serve-specific metrics through contextual modeling and improved spatial representation, while preserving the interpretability and portability of SQS.
Footnotes
Acknowledgments
The authors thank Professor Abraham J. Wyner and Tianshu Feng for helpful feedback, Audrey Kuan for her contributions during the summer, and the Wharton Sports Analytics and Business Initiative (WSABI) for supporting this research.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and publication of this article.
Appendix A. Additional out-of-sample results
Out-of-sample performance across datasets (second serves).

| Dataset | Outcome | Predictor | n | Coefficient | p-value | Correlation (r) |
|---|---|---|---|---|---|---|
| Wimbledon women | Serve efficiency | SQS2 | 45 | 0.129 | 0.0061 | 0.331 |
| Wimbledon women | Serve efficiency | wElo | 45 | 0.033 | 0.531 | 0.121 |
| Wimbledon women | Win percentage | SQS2 | 45 | 0.048 | 0.254 | 0.215 |
| Wimbledon women | Win percentage | wElo | 45 | 0.100 | 0.034 | 0.287 |
| U.S. Open men | Serve efficiency | SQS2 | 82 | 0.009 | 0.782 | −0.081 |
| U.S. Open men | Serve efficiency | wElo | 82 | −0.154 | 3.9 × 10−7 | −0.321 |
| U.S. Open men | Win percentage | SQS2 | 82 | −0.036 | 0.196 | −0.139 |
| U.S. Open men | Win percentage | wElo | 82 | 0.070 | 0.0091 | 0.168 |
| U.S. Open women | Serve efficiency | SQS2 | 63 | 0.092 | 0.021 | 0.181 |
| U.S. Open women | Serve efficiency | wElo | 63 | −0.121 | 0.0050 | −0.279 |
| U.S. Open women | Win percentage | SQS2 | 63 | −0.004 | 0.921 | −0.096 |
| U.S. Open women | Win percentage | wElo | 63 | −0.022 | 0.574 | −0.067 |
Appendix B. Task-aligned baseline comparisons
To supplement the main SQS–wElo comparison, this appendix reports task-aligned baselines requested in review: standard serve statistics, a random-effects-only GLMM score (server/returner intercepts only), and a fixed-effects-only score (measured serve-feature component without server random effects). All values below use the within-year random split and the common complete-case server set per dataset and serve type.
The task-aligned baseline results are broadly consistent with the main analysis. For the serve-proximal target (serve efficiency), SQS is strongest on average for first serves and is top in three of four dataset splits, indicating that it captures short-point serve impact better than match-level wElo and most serve-stat baselines. The ablation rows also support incremental value from both components of SQS: compared with random-effects-only (RE-only), adding serve-feature covariates improves alignment in all first-serve datasets; compared with fixed-effects-only (FE-only), adding partial pooling improves alignment in most settings. For overall win percentage, predictor performance is flatter and more heterogeneous—especially on second serves, where wElo is often relatively stronger—consistent with this outcome reflecting broader point-construction skill beyond serve-proximal effects.
Appendix C. Temporal validation
The results in Section “Results” and Appendix A use an 80/20 random split within each year. To assess whether SQS generalizes across time, we conduct an additional out-of-time validation: models are trained on 2018–2019 and 2021–2022 data and evaluated on held-out 2023–2024 data, with no temporal overlap between training and testing. This design tests whether serve profiles estimated from earlier seasons remain predictive of future performance.
The temporal results are broadly consistent with the within-year random split. On first serves, SQS maintains stronger correlations with serve efficiency than wElo across all four datasets (Wimbledon men:
Appendix D. Point-level feature robustness check
The main model in Section “Methodology” constructs SQS using server-level summaries of serve behavior, such as average speed, speed variability, modal location, and location entropy. While this choice yields interpretable player-level profiles, it compresses within-player variation across points. To assess whether the main results depend on this aggregation, we estimate an alternative set of GLMMs using point-level serve features directly.
For each serve type, the alternative model includes point-level serve speed, point-level serve location bin, and an indicator for whether the observed serve location matches the player’s modal location for that serve type. As in the main model, we include crossed random intercepts for the server and returner. For the point-level mixed-effects model, let
From the fitted models, we then construct a point-level version of SQS, denoted
Tables 11 and 12 report out-of-sample results for serve efficiency and win percentage, respectively, alongside weighted Elo (wElo) as a benchmark. These results allow us to compare the predictive performance of the point-level specification with that of the main server-level model.
Relative to the main model, the point-level feature model produces a similar overall pattern:
For win percentage, the results are again weaker and less consistent, which matches the main analysis in Section “Results” and Appendix C. In particular, the point-level specification does not significantly strengthen the association between
Appendix E. Top server rankings by tournament
These tables report top-10 server rankings by SQS within each tournament and serve type. Values are centered by subtracting the tournament–serve-type mean SQS (log-odds). Positive values indicate above-average serving performance within the tournament and serve type, while negative values indicate below-average performance. We also report 95% confidence intervals for player SQS estimates—these intervals are calculated using the covariance matrix of the fixed effects and the conditional variance of the player-specific random intercepts from the mixed-effects models. These intervals also provide a practical ranking-stability diagnostic: when adjacent players’ intervals overlap materially, interpretation should emphasize performance tiers rather than exact ordinal rank positions.