
Abstract
There are technologies on the horizon that could dramatically change how informatics organizations design, develop, deliver, and support applications and data infrastructures to deliver maximum value to drug discovery organizations. Effective integration of data and laboratory informatics tools promises the ability of organizations to make better informed decisions about resource allocation during the drug discovery and development process and for more informed decisions to be made with respect to the market opportunity for compounds. We propose in this article a new integration model called ELN-centric laboratory informatics tools integration.
Background
The evolution of the use of informatics technologies in laboratories and drug discovery environments has resulted in the emergence of various kinds of systems, which will be described below. These systems are highly overlapping but have evolved independently: for example, informatics systems from laboratory equipment vendors developed differently than that from the database community.
An electronic laboratory notebook (ELN) is a system to create, store, retrieve, and share fully electronic records in ways that meet all legal, regulatory, technical, and scientific requirements.
The evolution of ELNs changed the industry’s traditional way of documenting the analysis and experiments in physical notebooks. Industry practitioners saw the benefits of ELNs and have implemented them widely since 2002, replacing paper notebooks.
An ELN for routine analyses takes over at the bench level, right at the point of analysis, providing real-time control and automation of testing procedures. An ELN ensures procedural execution, automates manual processes, collects instrument data, performs calculations, performs limit checking, and performs calibration checking and inventory checking and updating. ELNs also provide electronic documentation and access to test results. These controls ensure compliance with standard operating procedures (SOPs) during the analysis and protect the integrity of collected data. 1
The ELN complies with the Food and Drug Administra-tion’s (FDA’s) 21 CFR Part 11 2 and 21 CFR Part 820 guidelines with respect to digital signatures, electronic records management, and software quality systems management. In using standard PDF format for data storage, export, and printing, the ELN also complies with the FDA’s requirement that electronic copies be readily available for inspection.
A laboratory information management system (LIMS) is a software-based system that offers features that support a modern laboratory’s operations, including workflow and data-tracking support, flexible architecture, and smart data exchange interfaces, which support their use in regulated environments. LIMS have existed in industrial laboratories for more than 2 decades and have been customized and configured with the constant changing business requirements/processes. In late 1990s, LIMS were deployed globally for different manufacturing sites of the same company to share the data within the organization.
LIMS are focused on information management, storage, and reporting: logging sample information, test information, test results, instrument calibration, chemical inventory, billing information, and so forth. LIMS gets involved at the beginning of the analytical process when samples are logged in and tests are scheduled. LIMS comes back into play when the tests are completed: collecting, storing, and reporting results.
Some recently introduced LIMS can be also used as an electronic laboratory notebook because they can perform recording and sharing information captured from disparate sources including instrumental, graphical, and statistical data; office automation formats (doc, ppt, xls, etc); voice; pictures; and so on. These new LIMS enable lab personnel to securely capture and store a wide range of knowledge and procedures, making all captured information readily available for further references. These new LIMS can also be used as scientific data management system (SDMS) and provide a laboratory with single, seamless access point to all laboratory data. But currently, the Pharma/Biotech industry is not following this path because of legacy systems that are currently in use. The LIMS system as such will exist for many years to come; it might replace the ELN and the SDMS by adding more functionality to the application as add-on modules such as STARLIMS. 3
Chromatography data systems (CDS) collect, manage, and report chromatography test results with software. A CDS package is used for advanced data acquisition, distributed processing, and reporting and management of samples, as well as complete compliance with 21 CFR Part 11 regulated environments. 4
An SDMS provides scientific content management for all types of scientific data and documentation. 5 An SDMS easily integrates with existing informatics systems such as LIMS, ELN, enterprise resource planning (ERP), and instrument data systems.
Introduction
Developing new drugs and delivering them to market is a complex, time-consuming, expensive process. A typical drug discovery program involves designing, synthesizing, and evaluating hundreds or maybe thousands of candidates. Pharmaceutical companies pay a big price for their inability to get data where it is really needed, especially during drug discovery and clinical trials. Often, the same data are reentered during each step because standalone, automated systems are not designed or built to share information. New techniques have been designed and implemented to capitalize on the growing amount of information stored in the databases due to an increasing amount of public data.
Data-warehousing and -mining techniques allow better and effective analysis of millions of data points. But the research conducted in organizations is generally decentralized, with teams working in various geographical locations and therapeutic areas. The data generated by these teams and the accumulated interpretive knowledge or actionable data are generally retained in silos. The availability of data from varied and heterogeneous sources, coupled with the desire to build knowledge bases and collaborative networks, has driven the need for improved integration techniques at the fundamental data level. 6 Simple data points are easier to put into databases that have higher-level knowledge and insight. There has been a lot of activity in the public sphere for the storage of screening data in databases such as PubChem, which aims to offer comprehensive information on the biological activities of small molecules, including the results of high-throughput screening to assess the effects of compounds on target proteins. Some efforts have also been made to integrate the data sets: most NCBI databases are linked through its Entrez search engine, which provides integrated access to literature, sequence, mapping, taxonomy, and structural data. Public databases such as PubChem facilitate the process of research and discovery by linking records and terms to related information across NCBI databases. 7 However, higher levels of knowledge and interpretation (e.g., analysis of a screen or scientific insights) are generally not captured. This knowledge is still in silos with scientists or buried in their notebooks or in ELNs.
All downstream activities, such as information exploitation and knowledge management, are crucially dependent on the effective integration of data and tools. Many of the applications for storing and retrieving chemical data have grown out of the rapid developments in chemical structure coding and searching. The advances in structure-based applications have led to integrated chemical information systems, more and more of which have Web interfaces and to specialized applications such as LIMS. The ability to search large secondary databases and to move seamlessly back and forth between the original primary journal literature and the abstracting and indexing databases is one of the truly great achievements of modern cheminformatics research. 8 Pharmaceutical companies spend significant and duplicated efforts aligning and integrating internal information with public data sources. This process is largely incompatible with massive computational approaches, and the vast majority of drug discovery sources cannot easily interoperate. 9 There are barriers between public data and internal data, and public data are stored in silos, although this has been addressed recently with integrative semantic resources such as Chem2Bio2RDF. 10 Although the semantic approach has been delivered in small-scale and targeted approaches so far, its promise for multiscale data integration has remained largely unfulfilled.
Effective integration of data promises the ability for organizations to make better decisions about resource allocation during the drug discovery and development process and for more informed decisions to be made with respect to the market opportunity for compounds. The process of automating laboratory operations by integrating laboratory information systems such as ELN, LIMS, molecular processing tools, and cheminformatics tools is the next logical step in the evolution of integrated chemical informatics. There are no set standards for the integration of informatics tools discussed above; the integration can be performed according to the user requirements. There are different technologies and ways to integrate data and tools.
Integration Technologies
Integration by Workflow-Based Architecture
Workflows have emerged as an important pillar of technology strategy for improving productivity and efficiency in the drug discovery processes through technological innovation. Workflow technology is a generic mechanism to integrate diverse types of available resources (databases, servers, software applications, and different services) that facilitate knowledge exchange within traditionally divergent fields such as molecular biology, clinical research, computer science, physics, chemistry, and statistics. 11 Workflow-based systems provide seamless access to data and analysis tools through an easy-to-use interactive graphical environment without presenting underlying complexity or details of the process.
Pipeline Pilot
Workflow systems allow nonprogrammers to interactively build data analysis pipelines by using novel combinations of tool sets and yielding new ideas about their data without actually writing the code. These systems are able to handle both increasingly large amounts and heterogeneity of data in the pharmaceutical research with increased efficiency. The workflow-based approach to drug discovery is accelerated, flexible (dynamic), repeatable, and efficient, and such an approach can be a model for future in silico experiments, leading to scientific discoveries that lie beyond traditional automation and integration. The SciTegic Pipeline Pilot 12 is one of the most widely used tools. It is based around a client-server platform that lets scientists construct workflows by graphically combining components for data retrieval, filtering, analysis, and reporting. Different client interfaces to the SciTegic platform enable chemists to work in the environment that best suits chemists’ needs ( Fig. 1 ).
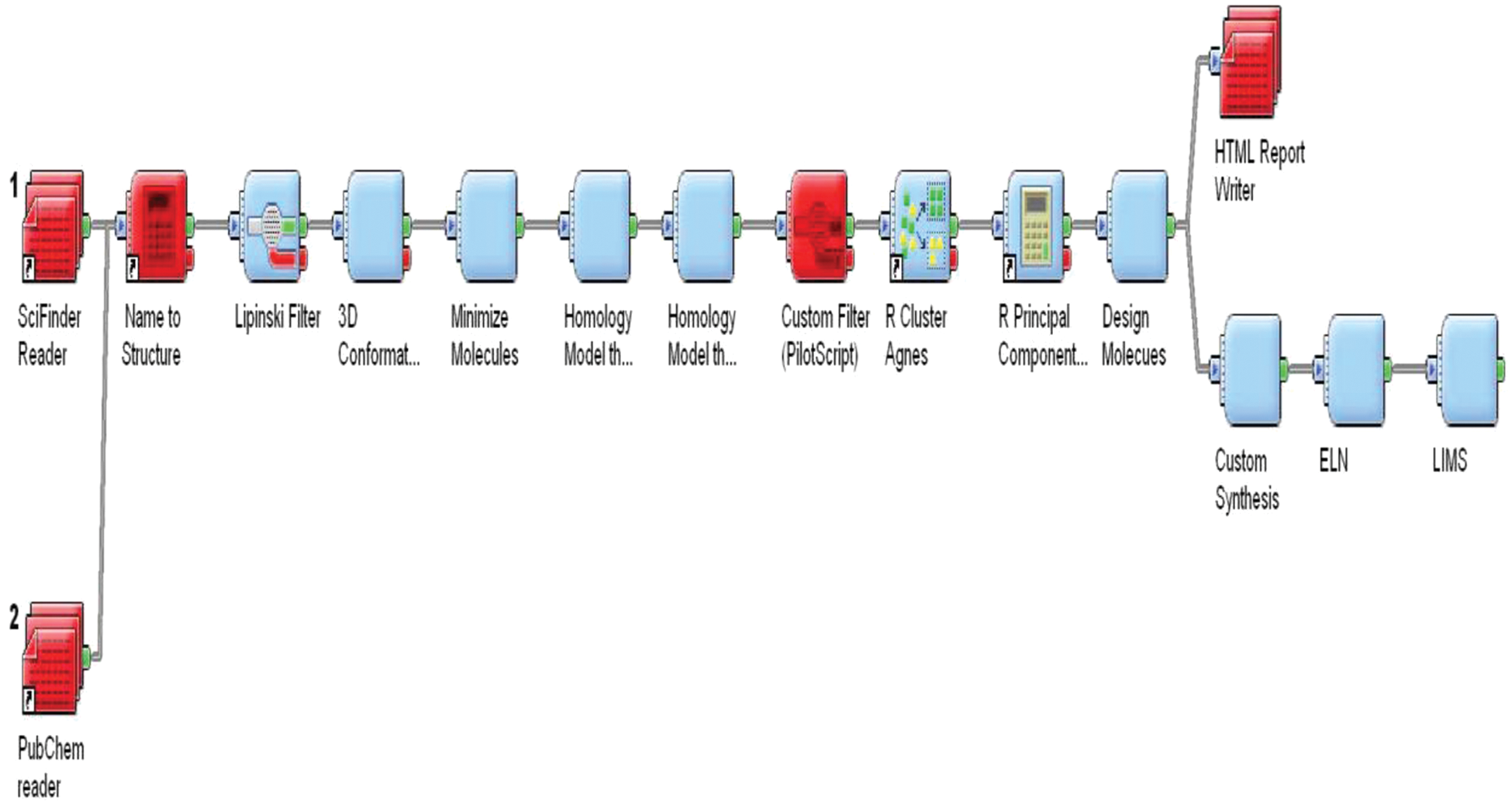
Pipeline pilot example with integration of laboratory information management systems, electronic laboratory notebook, public databases, and applications.
Workflow tools have changed the way the traditional data-mining and -modeling experiments are carried out. For example, in virtual screening, the process starts with the input of a set of ligands and the selection of one or more existing virtual screens, continues with ligand selection and preparation, the application of model or models to predict ligand activities, and finally formatting and presenting the results. Traditionally, these have been manual steps performed by a computational expert, using a variety of tools that require data manipulations such as format conversion between steps. Workflow tools allow the entire process to be defined graphically, captured, and then executed in an automated fashion from beginning to end. The workflow model also allows the integration of different tools (LIMS and ELN) that permit the external code to be integrated, and the model allows data sources in various formats to be accessed.
The challenge in virtual screening is the assembly of information necessary for model building, model validation, and the application of the models in screening sets. Data may exist in files or databases, may be stored in a variety of different formats, and may reside on a variety of different hardware platforms. Pipeline Pilot provides data integration tools that assist in all parts of this problem. For example, it provides components that read and write a variety of file formats, including the most common molecular formats (e.g., SD files, SMILES, and MOL2). It allows direct retrieval of data from databases such as ISIS and Oracle, including chemistry databases stored in Oracle and accessed using one of the commonly available chemistry cartridges. Using these components, protocols can be built to automatically assemble training sets, for example, when data need to be retrieved, formatted, and joined from separate chemistry databases.
Knime
KNIME (Konstanz Information Miner) is a user-friendly and comprehensive open-source data integration, processing, analysis, and exploration platform. KNIME integrates various components for machine learning and data mining through its modular data-pipelining concept. A graphical user interface allows assembly of nodes for data preprocessing (extraction, transformation, loading), for modeling, data analysis, and visualization. KNIME allows users to visually create data flows (or pipelines), selectively execute some or all analysis steps, and later inspect the results, models, and interactive views. KNIME is written in Java and based on Eclipse and makes use of its extension mechanism to add plugins, providing additional functionality. The core version already includes hundreds of modules for data integration (file I/O, database nodes supporting all common database management systems), data transformation (filter, converter, combiner), and the commonly used methods for data analysis and visualization. With the free Report Designer extension, KNIME workflows can be used as data sets to create report templates that can be exported to document formats such as doc, ppt, xls, pdf, and others. 13
In the above workflow ( Fig. 2 ), (1) a conceptual workflow and (2) actual workflow in KNIME 13 are presented. In this example, the workflow reads the structure data file (SDF) file as input, calculates molecular properties and XLogP, and finally generates parallel coordinates and a line plot for data visualization. Node 1 (SDF reader) selects the input SDF file and reads the different molecules present in it and creates SDF molecule objects, which are converted into CDK molecule objects using node 2 (SDF to CDK). Node 3 calculates different molecular properties such as molecular weight, atomic polarizabilities, number of hydrogen bond donors/acceptors, topological polar surface area, and so forth. Node 4 calculates XlogP values for each molecule. Node 5 adds Lipinski value (1 or 0) based on the Lipinski Rule of Five. Node 6 (row filter) removes all molecules with Lipinski value 0. Node 7 (column filter) filters the CDK molecule object. Node 8 (MetaNode 1:2) creates two data streams, both containing the same data or data tables. Node 9 (parallel coordinates) and node 10 (line plot) generate corresponding visualizations.
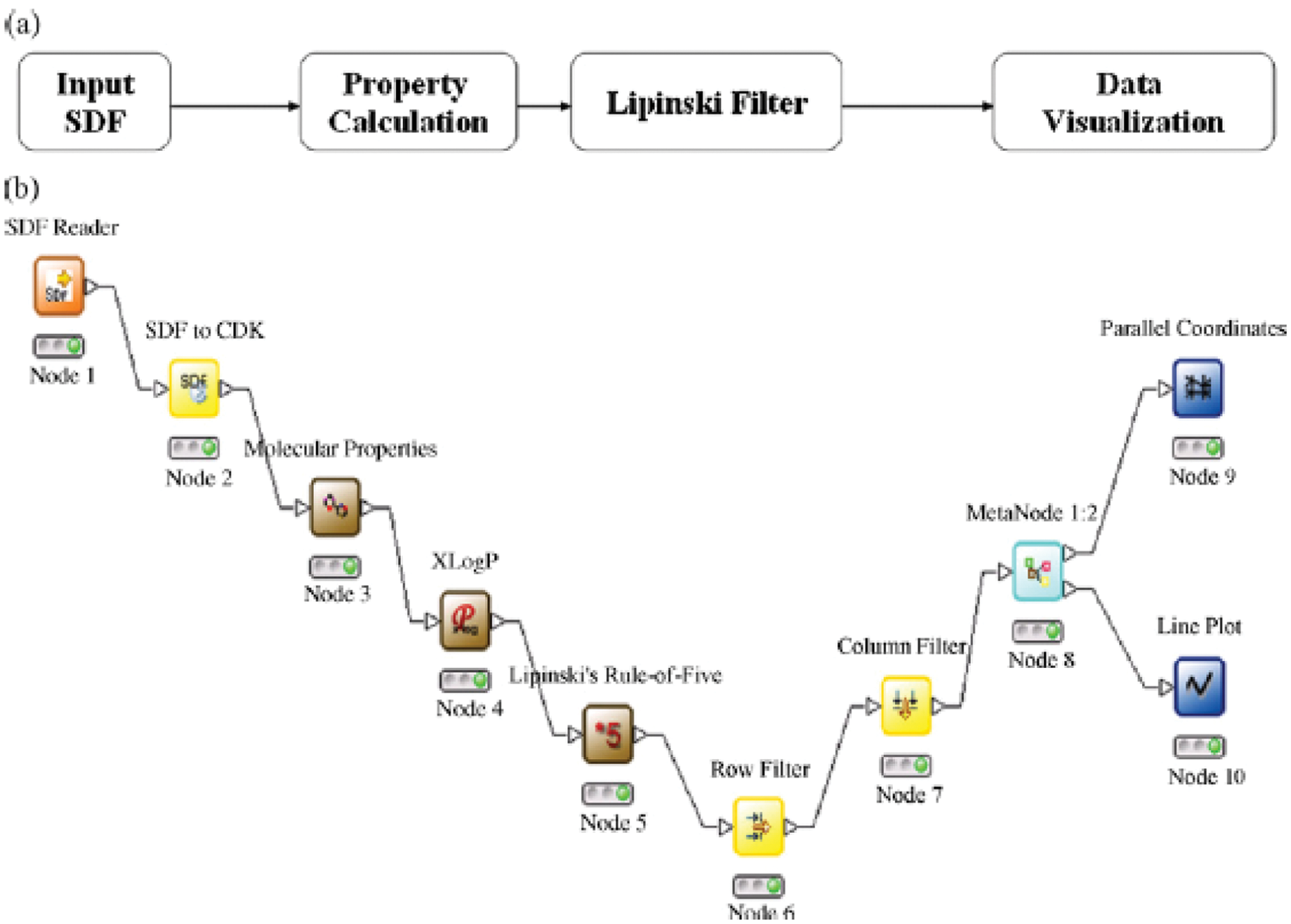
Workflow example using KNIME.
AZ Orange model
The AZ Orange model 14 is specifically developed to support the batch generation of 1uantitative structure-activity relationship (QSAR) models in providing the full workflow of QSAR modeling, from descriptor calculation to automated model building, validation, and selection. The automated workflow relies on the customization of the machine learning algorithms and a generalized, automated model hyperparameter selection process. Several high-performance machine learning algorithms are interfaced for efficient data set–specific selection of the statistical method, promoting model accuracy. This AZ Orange model is a step toward meeting the needs for an open-source high-performance learning platform, supporting the efficient development of highly accurate QSAR models fulfilling regulatory requirements.
Enterprise Modular Integration
By using modular integration, users may define streamlined workflows that exploit the advantages of different modules as needed while maintaining the ability to interoperate between them. This approach provides an extremely flexible platform to support changing workflows as companies evolve or business needs change. The integration tools allow for both data integration and interoperability with these enterprise systems. 15 This allows companies to extend the integrated and interoperable philosophy beyond the enterprise platform to include many different types of systems and data. These data also then become available to companies through visualization tools. These integration tools can also be used to interface with analytical instruments directly to enterprise platform modules or expose project data for access through corporate portals. Modular integration is not as simple and flexible as workflow integration; here, the modular integration primarily integrates different modules within a specific enterprise system or systems. For example, a LIMS system will have built-in modules (i.e., environmental module, stability module, compound registration and materials management); these individual modules can/will be integrated with external enterprise systems for seamless flow of data.
The advantages of the modular integration are the following: modular integration can leverage the data-modeling capability within the enterprise suite to more effectively integrate enterprise systems such as LIMS, ELN, SDMS, data management systems, procurement systems, and other business systems such as systems, applications, products (SAP) or ERP; interface with instruments to directly capture information and store it securely; and securely share project information through corporate portals for better information sharing.
In the example in Figure 3 , the scientist can document all the work in an ELN for chemical analysis, reactions, synthesis of information, and so forth. The scientist can also use the different modules available to gather the information regarding compounds’ structural information and visualize the data; the modules also support the compound registration and inventory management of compounds. By using Web services, the scientists/chemists can also search the public databases for the valuable information and references.
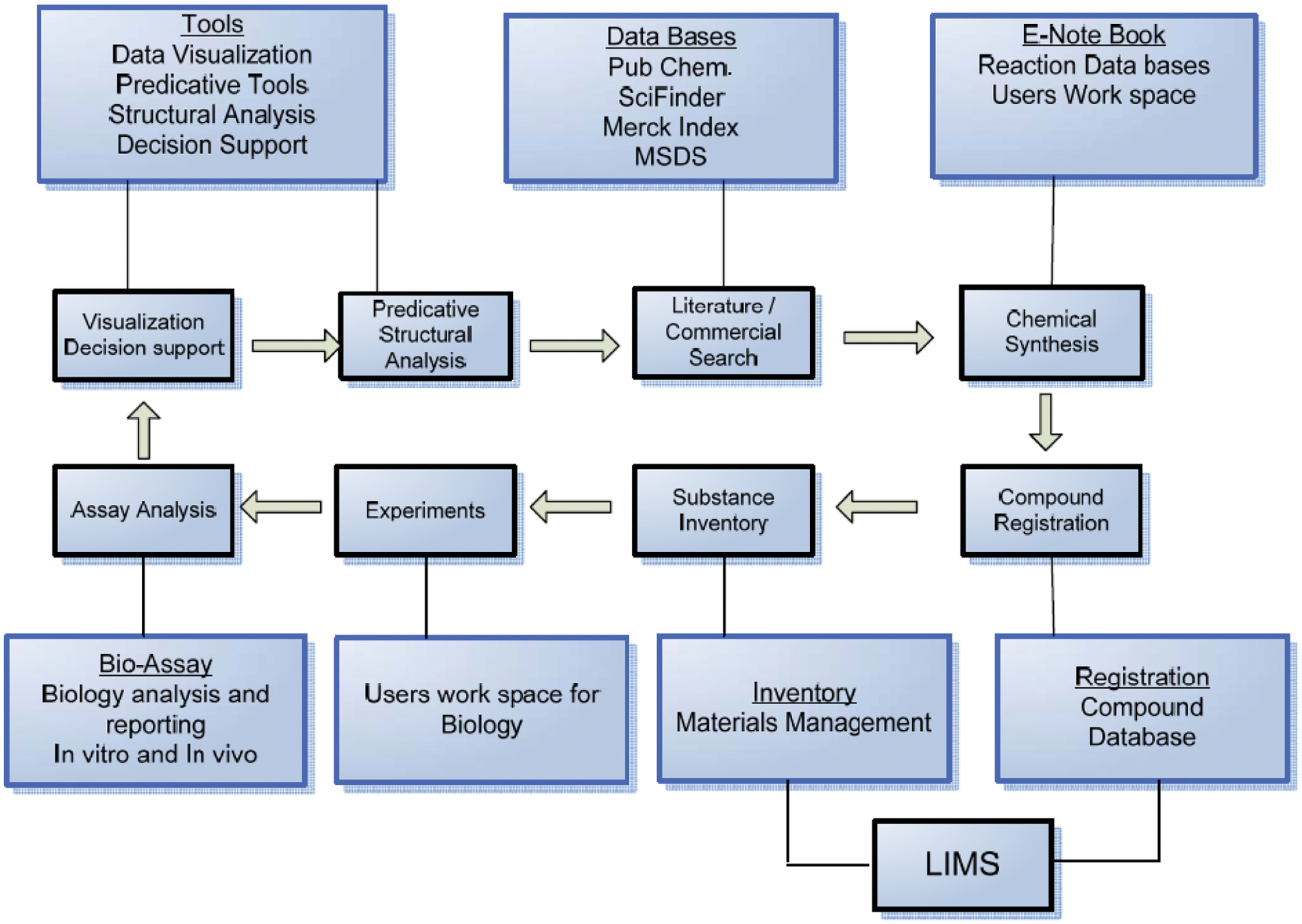
Modular integration of cheminformatics and bioinformatics tools.
Integration by Service-Oriented Architecture
Service-oriented architecture (SOA) can be defined as a group of computational services that communicate with each other. The process of communication involves either simple data passing or two or more services coordinating some activity. 16 Intercommunication implies the need for some means of connecting two or more services to each other. SOA is a design for linking computational resources (principally applications and data) on demand to achieve the desired results for service consumers (either end users or other services). The integration model is based on a service-oriented architecture framework in which there is integration of people, process, and application to realize the ultimate business process of optimizing the drug discovery. 17 The framework is based on the following:
Service orientation: a modular approach that reduces dependencies between systems, using open standards and protocols to promote data application and interoperability.
Federated data: scientific data are specialized by subject matter with distinct data formats associated with each; generation of data and metadata at one site in some cases needs to reside locally whereas in others needs to be shared with other sites. It is important to provide caching of information at various levels within and across the environment (departmental, regional) to allow for different levels of service.
Federated security: allowing easier management of identities and security credentials by delegating aspects of authentication and role assignment to trusted parties.
Trustworthiness: reliable, fault-tolerant systems that just work.
The reference implementation architecture is centered on the use of the integrated drug discovery services hub, which enables the provision of a number of service components ( Fig. 4 ).
Identity management services
Privacy and security services
Presentation and point-of-access services
Service publication and location services
Research services
Research supplies services
Project services
Integration services
Data services
System management services
Communication services
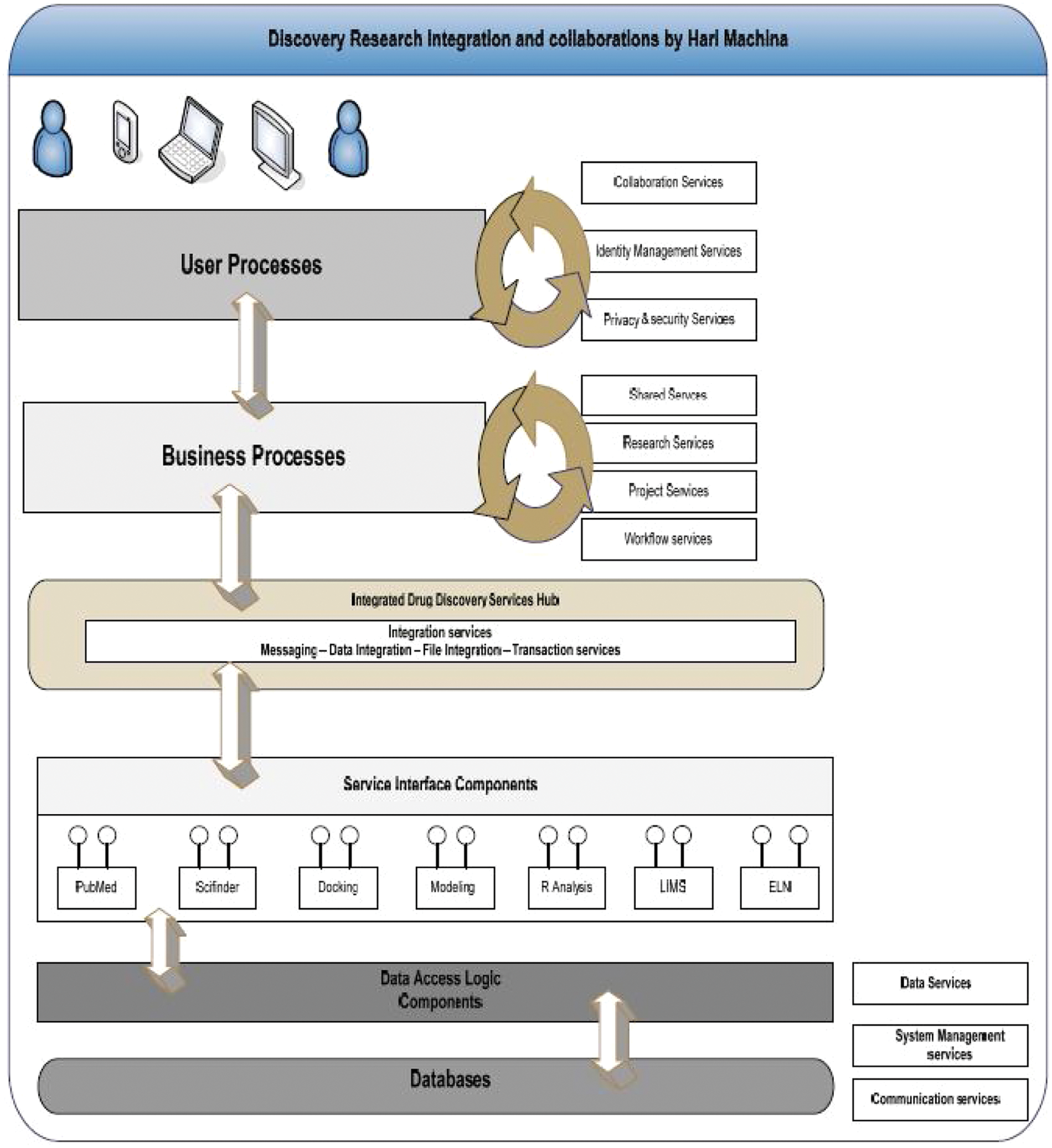
Discovery research integration and collaborations.
Semantic repositories
A triple store is a purpose-built database for the storage and retrieval of triples—simple subject-predicate-object relationships—using the resource description framework (RDF) language. In aggregate, these triples form a network database that can be treated as a mathematical graph (in which the subjects and objects are nodes and the predicates edges). Searching of triple stores is via SPARQL query language, which allows complex querying across data, which can be from many heterogeneous sources. Triples can be easily imported or exported using a variety of formats. A triple store can complement a relational database and act as a repository for semantic metadata referencing existing content. 18 Open PHACTS (the Open Pharmacological Concepts Triple Store) is an example of a large-scale semantic repository for drug discovery: it delivers a single view across available data resources and will be freely available to users. Scientific text, difficult to analyze by computer, will have factual assertions extracted as semantic triples, allowing for the first time the prospect of querying textual and database data together to give answers needed to identify new drug targets and pharmacologic interactions. Although the semantic approach has been delivered in small-scale and targeted approaches so far, its promise for multiscale data integration has remained largely unfulfilled. Open PHACTS is a major project including many of the top semantic Web experts, committed to deliver on this promise. 19 An overview of the impact of semantic technologies on drug discovery is given by Wild et al. 20
Nanopublications
As the amount of scholarly communication increases, it is increasingly difficult for specific core scientific statements to be found, connected, and curated. In addition, the redundancy of these statements in multiple fora makes it difficult to determine attribution, quality and provenance. To tackle these challenges, the Concept Web Alliance has promoted the notion of nanopublications (core scientific statements with associated context). 21
Nanopublications are a natural response to the explosion of high-quality contextual information that overwhelms the capacity of conventional research articles in scholarly communication. With nanopublications, it is possible to disseminate individual data as independent publications with or without an accompanying research article.22,23 Further, because nanopublications can be attributed and cited, they provide incentives for researchers to make their data available in standard formats that drive data accessibility and interoperability. 24
A nanopublication has three basic elements 25 :
An assertion whereby two concepts (called the subject and the object) are associated (using a third concept called the predicate).
Metadata regarding conditions under which the assertion holds.
Metadata regarding the provenance of the assertion, such as its author, a time stamp marking when it was created, links to DOIs, URLs, and so forth.
Nanopublications are based on open standards and the community-driven evolution of nanopublication formats to fit the changing needs of authors and publishers. Nanopublications can be serialized in many different ways, for example, using extensible markup language (XML) and RDF. Standards allow nanopublications to be machine readable, opening the door to many new communication possibilities. Nanopublications allow Internet-based search for and retrieval of specific data rather than for documents (that may or may not contain that data) or databases (that often have idiosyncratic data structures). Machine readability of nanopublications aims to enable universal interoperability and the automated discovery of new associations that would otherwise be beyond the capacity of human reasoning.
ELN-centric integration
We are proposing this new ELN-centric laboratory informatics tools integration model ( Fig. 5 ).
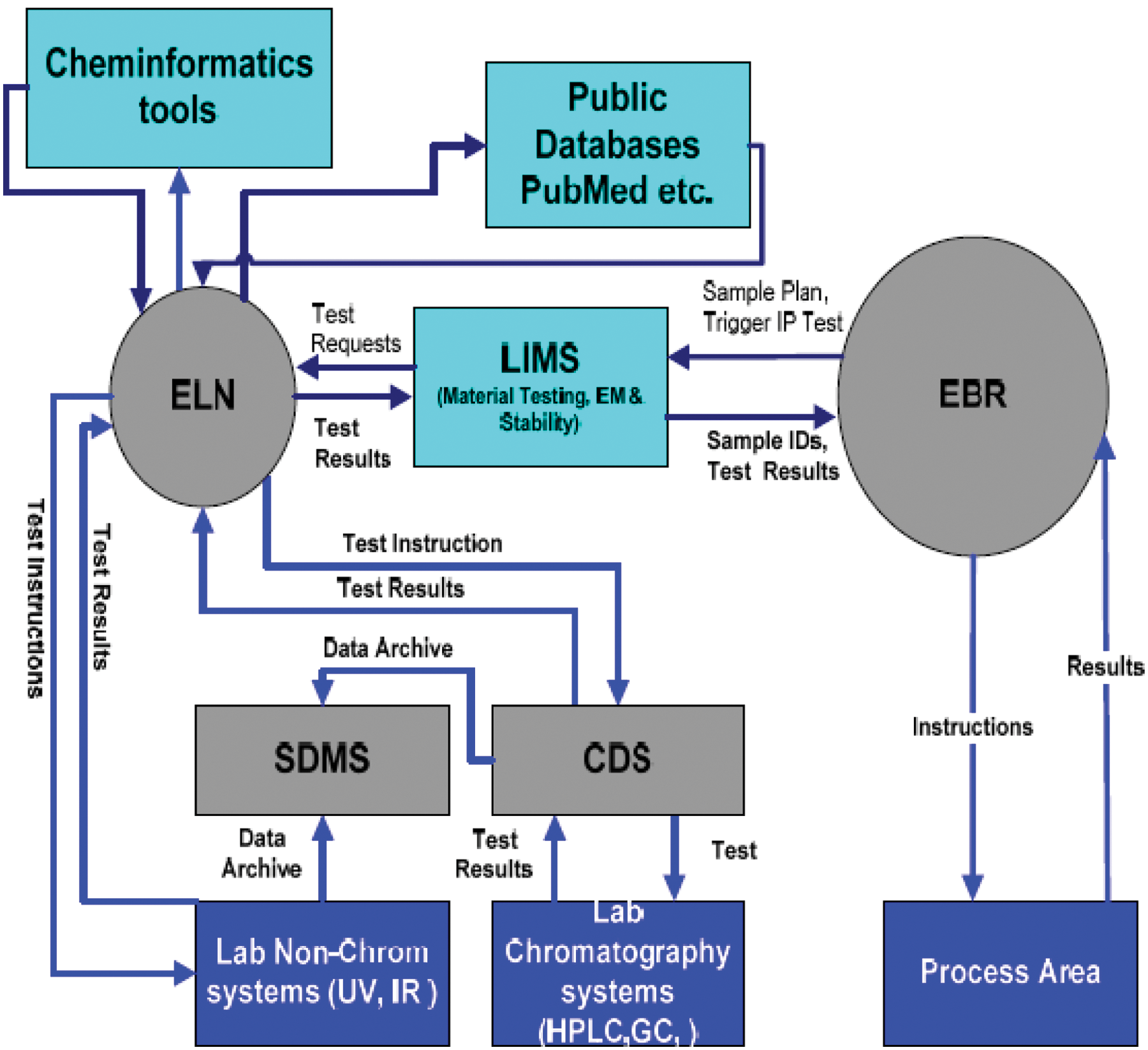
Electronic laboratory notebook–centric laboratory informatics tools integrations.
Currently, most laboratory information systems operate independently, requiring manual data entry by users into each individual system. This process creates data and information disparities as well as poor referential integrity within experimental metadata. ELNs would provide a logical point around which experiment details and observations could be centered electronically. Through an ELN, experimental documentation or metadata could be communicated automatically with a LIMS, SDMS, or CDS without analyst involvement. This electronically connected system would allow analysts to perform their responsibilities without the interruption of independent information systems, thus increasing analyst productivity and reducing user entry errors into data management systems and will avoid the storage and maintenance of these physical records.
Laboratories generate lot of data from various instruments with the help of different software. The process of drug discovery involves the identification of candidates, synthesis, characterization, screening, and assays for therapeutic efficacy. Once a compound has shown its value in these tests, it will begin the process of drug development prior to clinical trials. Despite advances in technology and understanding of biological systems, drug discovery is still a long process with a low rate of new therapeutic discovery due to lack of smart data integration. To expedite the drug discovery process, the proposed ELN-centric integration will help the chemists to eliminate the redundant and manual processes by automating the characterization and assays for the compounds.
The above proposed model is ELN centric, where the laboratory instruments can be registered within the instrument module of the ELN, rather than typical integration through LIMS. The integration of the CDS (bidirectionally), ELN (bidirectionally), LIMS (bidirectionally), SDMS (unidirectional), electronic batch record (EBR; bidirectionally), cheminformatic tools (bidirectionally), and PubMed (unidirectional), are shown diagrammatically ( Fig. 5 ). The customized adopters are used in the case of interfacing the ELN with CDS, the Empower CDS is integrated with ELN with the help of Empower adapter, and also instruments are interfaced with ELN with instrument adapters (i.e., network interface or RS232). By using the Web services, public databases such as Pubchem and Scifinder also can be accessed. The final laboratory data will be stored in SDMS, and the data can be archived from the SDMS in various ways to evaluate the data using visualization tools such as Spot Fire or trending data, or data mining or virtual screening can be performed.
These laboratory informatics tools can also be integrated by using LIMS-centric rather than ELN-centric integration. The advantages of ELN-centric integration are all the raw data that are generated during the analysis and research that reside in the ELN can be used for dynamic reporting. The LIMS is generally used to store the final results only. The LIMS system can also integrate the laboratory instruments. The integration of the CDS system (by using the Empower adapter) is technically feasible by using the ELN system rather than by using the LIMS system. Also, the LIMS system can only store the specifications and compare the results with the specifications, but the ELN system can also store the specifications and the associated SOPs for reference during analysis by the analysts and flag any out-of-specification results during automated testing of samples.
By using the proposed ELN, we can enforce laboratory workflow, documentation standards, and catalog results; capture molecular formulas of reactions and products; and allow ancillary data to be attached to notebook pages. ELNs can integrate and communicate with programs such as SDMS, LIMS, CDS, chemical informatics tools, data visualization software, and so forth. The modern ELNs are portable and easy to carry within the laboratory, and the wireless connectivity helps chemists to perform testing, documentation, and data analysis effectively.
Conclusion
There are a number of technologies on the horizon that could potentially dramatically change how informatics organizations design, develop, deliver, and support applications and data infrastructures to deliver maximum value to drug discovery organizations. Effective integration of data and laboratory informatics tools promises the ability for organizations to make better informed decisions about resource allocation during the drug discovery and development process and for more informed decisions to be made with respect to the market opportunity for compounds. The integration depends on the type (i.e., analytical laboratory, synthesis laboratory, clinical, discovery laboratory, research laboratory, etc.) of laboratory, the type of data generated, and the tools used that need to be integrated. Of the different integration schemes presented, the workflow-based framework is the most likely to be successful in the short term because large-scale data analysis needs flexible workflow-based integration of different software tools and application from diverse domains, which can provide in slico experimental design. By using a workflow-based framework, we can also integrate Web services, semantic Web, grids domain-specific tools, and ontologies for drug discovery.
Footnotes
Acknowledgements
The authors offer their sincere thanks to the manuscript reviewers.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.