
Abstract
Most existing arithmetic word problem (AWP) solvers focus on solving simple examples. Transfer case-AWPs (TC-AWPs) involve scenarios where objects are transferred between agents. The widely used AWP datasets mainly consist of simple TC-AWPs (problems that involve a single object transfer). Current large language models (LLMs) are capable of solving most of these simple TC-AWPs effectively. In this work, we focus on assessing the solving capability of LLMs (ChatGPT and Gemini) for complex TC-AWPs (where multiple types of objects are transferred or more than one transfer of an object is performed). Since the popular AWP datasets contain only simple TC-AWPs, we first generate complex TC-AWPs using an ontological approach. We utilize these complex examples to assess LLMs’ word-problem-solving capabilities. We observe that the accuracy of LLMs falls down rapidly as the number of object transfers is increased to 3 or 4. An approach for solving TC-AWPs using ontologies and M/L exists in the literature. We propose an extension of this approach that can handle complex TC-AWPs and find that, compared to the current LLMs, the proposed solution gives better accuracy for complex TC-AWPs. We analyze the failed cases of the LLM approach and find that the reasoning capabilities of LLMs need a lot of improvement.
Keywords
Introduction
Arithmetic word problems (AWPs) are elementary math problems in which numbers are dispersed in the problem text, and they can be solved by combining these numbers with basic math operations (addition, subtraction, multiplication, and division). Transfer case-AWPs (TC-AWPs), a subset of AWPs, are those word problems where problem texts involve object transfers among agents. The popular AWP datasets such as AllArith (Roy & Roth, 2017), MAWPS (Koncel-Kedziorski et al., 2016b), and Dolphin (Huang et al., 2016) contain simple TC-AWPs (i.e., word problems involving a single object transfer). Kumar and Kumar (2024) focused on solving simple TC-AWPs by proposing a knowledge and learning-based approach. They developed TC-Ontology to encode domain knowledge and utilized it in the solution (i.e., automatic solver). Furthermore, Kumar and Sreenivasa Kumar (2024) extended the TC-Ontology and leveraged it for checking the mathematical validity of the machine-generated TC-AWPs. Our work extends the ideas proposed in these two approaches. The proposed work focuses on only the AWP-Tr domain (i.e., both simple and complex TC-AWPs expressed in English). Since the existing datasets do not contain complex TC-AWPs, we first generate such AWPs. We consider a TC-AWP complex when it involves more than one object transfer of either a single type or multiple types of objects. The examples of simple and complex TC-AWPs are given in Figure 1.
Examples of simple and complex transfer case-arithmetic word problems (TC-AWPs).
In the last decade, AWP solving has been widely attempted, and the state-of-the-art (SOTA) approaches have evolved around the following ideas: rule-based solution, statistical modeling, tree-based modeling, template-based solution, incorporating domain knowledge, neural-based models, etc. (Zhang et al., 2018). With the arrival of large language models (LLMs), all these models became less popular as LLMs could solve AWPs more effectively. Therefore, the proposed work focuses on assessing the AWP-solving capabilities of LLMs (ChatGPT-3.5 1 and Gemini 2 ). We focus on the SOTA language models that provide user interfaces to interact with and are also openly available. Therefore, we exclude the SOTA LLM models, such as WizardMath (Luo et al., 2023), MAmmoTH (Yue et al., 2023), and LLaMa-2 (Touvron et al., 2023), and non-LLM models, such as Text2Math (Zou & Lu, 2019). In this context, incorrect answers are dangerous and can mislead the users. It is assumed that a general user does not have an idea about how to use prompts. Therefore, we assess LLMs as they are. Our assessment includes only complex TC-AWPs. We observed that LLMs could not solve a large proportion of these examples. 3 A few example TC-AWPs that LLMs could not solve are given in Appendix 9. The proposed ontology-based approach performs better than LLMs while solving complex TC-AWPs.
Concerning the TC-AWP domain, the existing works that adopted ontology-based modeling, the solver (Kumar & Kumar, 2024), and the validity-checker (Kumar & Sreenivasa Kumar, 2024), focused on processing word problems sentence-wise. They identified the following four sentence categories: before transfer (BT; e.g., Stephen has 17 books), transfer (TR; e.g., Stephen gave 5 books to Daniel), after transfer (AT; e.g., Now Daniel has 15 books), and question (QS; e.g., How many books does Stephen have now?). These four sentence categories are represented as four ontology classes (details are in Section 3). The above-mentioned systems incorporated domain knowledge by developing an ontology (namely TC-Ontology). Since the proposed work leverages TC-Ontology, we include a summary in Section 3 and discuss the required extension.
In summary, the proposed work shows the importance of incorporating domain knowledge in the tasks related to the AWP domain, such as generation and solving. Our contributions are: We extend the TC-Ontology to demonstrate the generation of complex TC-AWPs from the ontological representations of simple TC-AWPs. This process required enhancements to the ontology to accommodate the creation of more complex problems. We utilize complex TC-AWPs to evaluate the performance of LLMs in solving these problems. Furthermore, we propose an ontological approach for solving complex TC-AWPs, which showcases enhanced reasoning capabilities and proves to be more effective in solving these complex word problems.
The remaining article is organized as follows—Section 2 details the related work. Section 3 briefly discusses the background and TC-Ontology. Section 4 presents the proposed approach. Section 5 discusses the experimental setup and results. Limitations of the proposed approach and conclusions of the work are given in Sections 6 and 7, respectively.
In the proposed work, we focus on both the generation and solving aspects of TC-AWPs. 4 Various approaches have been proposed in the literature for solving word problems; however, the generation aspect of word problems is not widely attempted.
Approaches for AWP Generation
Williams proposes a prototype to convert Web Ontology Language (OWL) ontologies into word problems. The approach uses the SWAT tool (Robert et al., 2011) to convert the lexical entries into English statements. For example, the property “hasType” is converted to “is a kind of” natural language text. The generated sentences are then grouped together to form a word problem text. Polozov et al. (2015) use answer set programming to generate word problem text from student and teacher requirements. Koncel-Kedziorski et al. (2016a) proposed a theme-rewriting approach for generating algebra math word problems. The drawback of the approach is that it requires another word problem as an input, resulting in the new problem having a similar template to the input.
The neural network-based approach Zhou and Huang (2019) generates word problems from equations and topics. Two recurrent neural network encoders map equations and topics to hidden vectors and word representations, respectively. The outputs of these two encoders are then concatenated and fed to a decoder to generate word problems. The method requires a large amount of annotated data. The authors state that the following two types of errors are observed in the generated examples: (a) problem soundness-generated examples lack semantic coherence and (b) equation matchness-template of the input equation partially correlates to the output. However, they do not mention the proportion of such examples. Given an equation template:
Attempts have been made toward how to utilize commonsense knowledge (Liu et al., 2021; Qin et al., 2023) and improve mathematical validity (Wang et al., 2021) during generation. Multilingual language models for word problem generation are also being explored (Niyarepola et al., 2022).
Our proposed work generates word problems related to a specific topic, that is, transfer-type AWPs. It takes input as simple TC-AWPs and generates complex TC-AWPs. Like other learning-based approaches, our approach does not require additional training examples and annotations. Since the generation process is backed by domain knowledge, the generated word problems are always valid.
Approaches for AWP Solving
Before the LLM era, the following were the popular SOTA AWP solvers (Roy & Roth, 2017, 2018; Wang et al., 2018b; Zou & Lu, 2019). We skip the discussion on these solvers as we primarily focus on analyzing the AWP-solving capabilities of LLM-based solvers.
Wei et al. (2022) adopt and test the idea of chain-of-thought prompting in LaMDA (Thoppilan et al., 2022), generative pretrained transformer-3 (GPT-3; Brown et al., 2020), PaLM (Chowdhery et al., 2022), UL2 20B (Tay et al., 2023), and Codex (Chen et al., 2021) LLMs to improve the arithmetic reasoning. Word problem-solving ability of LLMs is highly dependent on how well the prompts are designed. Since we assess Gemini and ChatGPT LLMs as they are, we do not discuss the design of the prompts and also exclude the detailed discussion on prompt-based solutions. However, it appears that the current versions of LLM’s we have tested already incorporated chain-of-thought prompt-based training. In the output, we obtained on sample cases, intermediate statements were generated by the model before the final answer was given. In spite of this, the results on complex problems are not very good. The proposed approach provides a simple solution to this challenging problem (i.e., performing a series of intermediate reasoning steps effectively).
Zong and Krishnamachari (2023) focused on solving math word problems using the GPT-3 model. They focused on analyzing the following three tasks using the GPT-3 model: classifying word problems, extracting equations from the problem text, and generating similar word problems using one given example. The work shows promising results for all three tasks mentioned above. However, the paper states that directly applying commonsense knowledge to improve word-problem solving remains an issue. Also, scaling up the model size alone seems not to be sufficient for achieving high performance on the reasoning tasks (i.e., arithmetic, commonsense, and symbolic; Rae et al., 2021). Therefore, the domain knowledge-based solutions should be explored further. In the proposed work, we show how to encode and utilize domain knowledge while solving word problems.
Background and TC-Ontology
In this section, we discuss the background of ontologies. Since our proposed approach extends and utilizes the TC-Ontology developed in previous work, we also provide a summary of that ontology.
Background
Ontology is a formal framework for representing knowledge within an application domain. It provides a structured way of modeling concepts (classes), properties (roles) that detail the attributes and relationships of these concepts, and constraints on these properties. This structured representation facilitates consistent understanding, interoperability, and reasoning across systems, making it crucial in fields such as artificial intelligence, the semantic web, and information science. The Resource Description Framework Schema (RDFS; Brickley & Guha, 2004) and the OWL (Bechhofer et al., 2004) are two widely used frameworks for computationally processing ontologies, each differing in their levels of expressive capabilities. The Resource Description Framework (RDF; Klyne & Carroll, 2004) is a data modeling standard that facilitates effective information exchange across the web with reasoning capabilities. It serves as the foundation for building RDFS and OWL technologies. In the following, we discuss RDF, RDFS, and OWL in brief. An OWL-DL ontology can be viewed as a pair (
TC-Ontology, developed using OWL-DL, was initially proposed in the KLAUS-Tr system (Kumar & Kumar, 2024) and was reused (after appropriate extension) in the validity-checker system (Kumar & Sreenivasa Kumar, 2024). In the proposed work, we reuse the extended TC-Ontology (Kumar & Sreenivasa Kumar, 2024) after making the appropriate changes. Kumar and Kumar (2024) analyzed the various TC-AWPs and first devised the vocabulary of the TC-Ontology. The summary is as follows:
Important Properties Devised in TC-Ontology Note. BT = before transfer; TR = transfer; AT = after transfer; TC = transfer case.

Since the KLAUS-Tr system focused on solving simple TC-AWPs (generally triggering one subtraction and one addition), the ontology and the SWRL rules developed were sufficient. However, to solve complex TC-AWPs, the proposed system needs to perform a sequence of reasoning steps. The SWRL rule shown in Figure 2 (developed using a similar logic as proposed in KLAUS-Tr), to perform the sequence of reasoning, will make the ontology inconsistent, as it will run forever and attempt to assign an infinite number of values to quantValue property.
This Semantic Web Rule Language (SWRL) rule will make the ontology inconsistent.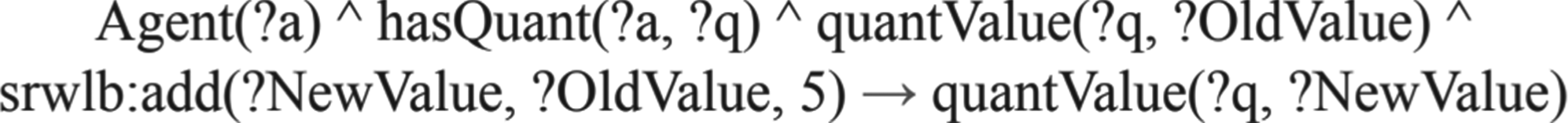
Therefore, to perform the sequence of reasoning, we use two additional properties and the Owlready2
6
Python library. In the following, we explain the required additional properties. We add hasTransferSequence data property to capture the sequence of the reasoning (i.e., sequence of the object transfers taking place). The domain and range are TR and Integer, respectively. We add hasUpdatedValue data property to capture the effect of the sequential reasoning. If the value of any quantity gets updated using an SWRL rule and it is required in the transfer that follows, it creates the sequential reasoning situation. The domain and range are TC-Quantity and literal, respectively.
Using Owlready2, we write the updated quantity value to the ontology and rerun the reasoner to perform the reasoning required by the next object transfer. Section 4.2 details how these properties are used in the solution design.
This section presents our proposed approach, which consists of two components: a generator and a solver. Our work focuses on a specific subset of TC-AWPs. Figure 3 shows the overall system architecture of the proposed approach. The preprocessed text of simple TC word problems is transformed into ontological representations through three steps: sentence classification, a bidirectional encoder representations from transformers (BERT)-based language model, and a custom script that populates the ontology ABox. On the generation side, we address the issue of invalid machine-generated problems. We introduce a methodology that constructs complex TC problems from the ontological representations of simple problems, ensuring that the generated outputs are always valid. On the solving side, we use these ontology-validated complex problems to evaluate the problem-solving capabilities of two LLMs, ChatGPT and Gemini. We further demonstrate that our hybrid ontology- and machine learning (ML)-based solver achieves higher accuracy than both LLMs when solving these complex TC problems. We discuss the generation and solving aspects of our approach in the following sections.

Overall system diagram of the proposed approach.

RDF representation of the simple TC-AWP (Agent1: Stephen; Agent2: Daniel). The red circle represents the factual details of the transfer. The term tc represents the namespace of the TC-Ontology. Note. RDF = resource description framework; TC-AWP = transfer case-arithmetic word problem.
As mentioned earlier, the existing AWP datasets contain simple TC-AWPs. Therefore, we generate complex TC-AWPs as we plan to assess the solving capabilities of LLMs over these examples. The generation process makes use of the TC-Ontology.
Kumar and Sreenivasa Kumar (2024) extended the TC-Ontology to check the mathematical validity of the machine-generated TC-AWPs. Additionally, they showed a way to convert the single-transfer TC-AWPs into two-transfer TC-AWPs. In this work, we adopt a similar idea, use the RDF representations of the simple TC-AWPs, and generate complex TC-AWPs (up to four object transfers).

RDF representation of the complex TC-AWP (Agent1: Stephen; Agent2: Daniel; Agent3: Mike). To make the diagram simple and understandable, we do not show the edges representing factual details about the object transfers and the quantities owned by the agents. Note. RDF = resource description framework; TC-AWP = transfer case-arithmetic word problem.
The generation module takes input as ontology representation (
Generating triples of TR-type sentence(s): Our approach utilizes the structural information obtained from the triples of the first transfer and ABox information (such as agent-names and object-type) available in the ontology and generates triples of the additional transfer. Note that the information about the number of quantities held by the agents (involved in the additional transfer) is available in the existing graph; therefore, the quantity for the additional TR-type sentence is generated appropriately.
The sentences belonging to the simple TC-AWPs are available as annotations in the ontology. We convert the additionally generated triples into sentences using a template-based program script. We use one template for each sentence category. Note that the sequence numbers of the sentences belonging to the “simple TC-AWPs” are learned at the preprocessing stage and maintained in the ontology. However, these sequence numbers are adjusted once new sentences are generated. The newly generated BT-type sentence is placed at the beginning, and TR-type sentence(s) is/are placed after the existing TR-type sentence. Finally, we arrange all the sentences using the value of hasSequenceNumber property and form the complex TC-AWPs.

How the generated transfer case (TC)-word-problems can become invalid.

Semantic Web Rule Language (SWRL) rule showing the generation of additional object transfer.
Algorithm 1 shows the pseudo-code of the proposed solver. It takes input as TC-Ontology

Pop-Onto() is a BERT-based language model trained to pick sentence parts (agent names, etc.) from the word problem text. For ABox extraction from simple TC-AWPs, OLGA (Kumar & Sreenivasa Kumar, 2024) trained and deployed BERT-based language models (one for each sentence category). Since the number of sentence categories is the same in the simple and complex problems, we adopt the BERT-based model proposed in OLGA and leverage it for extracting ABox information from the problem texts of complex TC-AWPs. Compound sentences (such as Stephen has 5 books and 10 pens) are converted into two simple sentences using subject distribution at the preprocessing stage.
We develop the SWRL rule to perform reasoning in multiple object transfer situations. The value of the hasTransferSequence property (i.e., (l) represents the sequence of the object transfer. Sync-Reasoner (Algorithm 1, Step 10) is a core function in the Owlready2 Python library that triggers the ontology’s reasoning process. Since SWRL rules are integrated within the ontology, the reasoning process also considers the constructs defined by these rules. At each iteration, the hasUpdatedValue(q, v) atoms (refer to Figure 8) are indeed used to update the corresponding quantValue(q, v) atoms before reapplying the SWRL rules. Figure 8 presents the SWRL rule and its explanation.

Semantic Web Rule Language (SWRL) rule to affect object transfer.
The key experimental subtasks in this work are: (i) sentence classification and (ii) information extraction for ontology population (ABox construction). Both components are essential for generating and solving complex TC-AWPs. Sentence classification is discussed in detail in Section 4.2. In this section, we present the results of ABox extraction and the overall word-problem-solving performance. All experiments were conducted on a macOS system equipped with 16 GB RAM and an Apple M1 processor. For integrating LLMs such as GPT-3.5 into the Scikit-learn workflow to support the sentence-classification task, we used Google Collab. 8 ABox extraction was performed using BERT-based language models. Ontology development and editing were carried out using the Python owlready2 library and the Protégé 9 tool.
Since the proposed approach is different from a typical ML/DL system, we provide details about reproducing the results in Appendix 10. The datasets, code, and all related resources are available at the following GitHub repository: https://github.com/projects-by-sk/phd-rp3.1/.
Dataset
We use the dataset AllArith-Tr Kumar and Kumar (2024), which contains simple TC-AWPs, and generate the complex TC-AWPs using the proposed ontological approach. We used only 200 problems (50 for each N

Comparing accuracy-of-solving of the proposed system w.r.t. LLMs. N
As mentioned in Section 4.2, we use BERT-based language models for extracting the ABox information for TC-Ontology (the idea was proposed by OLGA; Kumar & Sreenivasa Kumar, 2024). OLGA used 1K and 2K TC-AWP (these word problems included single object transfer only) sentences for training and achieved 76% ABox prediction accuracy (i.e., for 76% of TC-AWPs, ABox was extracted correctly, we refer to this as joint accuracy). However, increasing the number of object transfers results in a longer problem text, which lowers the joint accuracy. In Algorithm 1, we name the ABox prediction task PopOnto(), as the proposed system needs to populate the ABox into the ontology once it has extracted the information from the word problem text. On complex TC-AWPs, we achieve the following accuracy: 72% (#object-transfers = 2), 66% (#object-transfers = 3), and 58% (#object-transfers = 4).
Since ontology-based reasoning is built on deterministic constructs and SWRL rules, once sentence parts are correctly mapped to the ontology classes (i.e., successful ABox construction), the system deterministically produces the correct solution. Note that, given a correct ABox, an ontology-based solver always does the correct reasoning, provided domain knowledge is also encoded appropriately.
Solving Complex TC-AWPs
The results (Figure 9) indicate that as the complexity of the examples increases, the solving accuracy of LLMs declines sharply. In contrast, the proposed approach maintains strong performance across all complexity levels. This robustness arises from its use of explicit domain knowledge during the solving process, enabling it to handle complex reasoning more reliably. Next, we discuss the failed cases of the LLMs.
Gemini Versus ChatGPT—We Analyze the Failed Cases (Examples for Which LLMs Gave Wrong Answers) and Report What Percentage of These Examples Were Failed due to NLU and Reasoning.

Gemini Versus ChatGPT—We Analyze the Failed Cases (Examples for Which LLMs Gave Wrong Answers) and Report What Percentage of These Examples Were Failed due to NLU and Reasoning.
Note. LLM = large language model; NLU = natural language understanding.
While encoding and utilizing domain knowledge offer several advantages, it also presents some limitations. During the generation process, the encoded domain knowledge ensures the creation of mathematically valid examples. However, because the proposed system converts ontology triples (as part of the solution) into English text using predefined templates, language diversity may be diminished. Addressing this limitation will be a focus of our future work. Another potential limitation is the extension of the proposed approach to other types of AWPs. This would require the development of a separate ontology for the target domain. Nonetheless, the ML and deep learning (DL) based submodules of the solution are adaptable and can be extended to other types of AWPs.
Conclusions
We investigate the effectiveness of LLMs— in solving complex TC-AWPs. Although the latest SOTA LLMs, such as ChatGPT and Gemini, demonstrate remarkable proficiency in comprehending natural language, they encounter significant difficulties when it comes to solving these complex TC word problems. To address these challenges, we employ a strategy that incorporates domain knowledge, which is encoded through domain ontology and SWRL rules. This approach not only aids in generating valid complex word problems (from the ontological representation of simple problems) but also helps in effectively solving these complex examples. The ontology-based modeling proved effective in tackling complex word problems. The idea of utilizing domain knowledge can be extended to more sophisticated and challenging domains.
Footnotes
Acknowledgement
The authors thank IIT Madras for permitting the use of contingency funds to cover the APC charges.
Authors’ Note
Most of the work was carried out at IIT Madras.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Ontology: Details and Its Use in KLAUS-Tr and OLGA Systems
An ontology is a structured representation of knowledge that defines the concepts within a specific domain and the relationships between them. Ontologies typically consist of classes (representing concepts or categories), properties (depicting relationships between classes), and instances (individual members of classes). By organizing information in a hierarchical and interconnected manner, ontologies facilitate better knowledge management, interoperability, and reasoning about the entities and their interactions within a given domain.
Two major components of an ontology are the TBox and the ABox. The TBox defines the vocabulary, concepts, and their relationships within a specific domain, establishing a structured framework for understanding and representing knowledge. The ABox, on the other hand, captures instances and specific data related to those instances, providing a means to describe individual objects and their properties within the defined concepts. These components together form a comprehensive ontology, facilitating effective knowledge representation and sharing.
Axioms are logical statements of the TBox that say what is true in an application domain. In the following, we mention the important axioms devised for the TC-AWP domain. Here, A.01 to A.04 are concept inclusion axioms, whereas A.05 and A.06 are concept equivalence axioms.
A.01: ∃ hasQuant. TC-Quantity ⊑ Agent
(Anyone who owns a TC-Quantity is an agent)
A.02: TC-Quantity ⊑ PositiveQuantity
(Every TC-Quantity is a positive quantity)
A.03: MinuendQuantity ⊑ TC-Quantity
A.04: SubtrahendQuantity ⊑ TC-Quantity
A.05: MinuendQuantity ≡ (TC-Quantity
(A.05 expresses “Minuend quantity is a TC quantity that is owned by an agent”)
A.06: SubtrahendQuantity ≡ (TC-Quantity
(A.06 expresses “Subtrahend quantity is a TC quantity that is gained by an agent and lost by an agent”)
Note that the properties isOwnedBy, isGainedBy, and isLostBy are inverse properties of the object properties hasQuant, hasGained, and hasLost, respectively. Axioms A.05 and A.06 infer the minuend and subtrahend quantities of a subtraction operation, respectively.
In Section 3, we presented a summary of the vocabulary of the TC-Ontology, and some important axioms are mentioned above. The detailed information of the TC-Ontology is available in KLAUST-Tr (Kumar & Kumar, 2024). Both KLAUS-Tr and OLGA systems process word problems sentence-wise. Based on the type of sentence, these systems extract important information and populate the Ontology ABox. An example ABox extracted from a word problem is given in Figure A.1. In contrast, P1 represents an example word problem. Q1, Q2, and Q3 represent quantities and T1 represents the transfer. The data property assertions for quantities Q1, Q2, and Q3 (using the quantValue and quantType data properties) are straightforward and thus not shown.
Appendix B. Solving Complex TC-AWPs With ChatGPT and Gemini
The results on an example TC-AWP involving three object transfers are given below:
(Both ChatGPT and Gemini gave the answer as 8)
The results on an example TC-AWP involving four object transfers are given below:
(Gemini and ChatGPT gave answers 14 and 21, respectively)
Appendix C. Reproducing the Results
Note that the implementation of the proposed system is different from a typical ML/DL model. There are three key components of the proposed system:
The overall process flow of the proposed solver is: The sentences of the word problem at hand are labeled using the sentence-classification module. We deploy BERT-based language models (we use the architecture proposed by the OLGA system) to extract important information from the sentences (based on the labels). This information is populated into Ontology using the Owlready2 Python library (populating the ABox of ontology). A domain ontology has two components: TBox and ABox. Using the Protégé tool, we encode the domain knowledge about transfer-type word problems (TBox of the Ontology). To solve a given word problem, we utilize the encoded domain knowledge, ABox information, and SWRL rules (we develop these rules and make them available inside the ontology, under the SWRL tab) that update the state of the ontology (i.e., computes the effects of the object transfer). Therefore, building two splits (train and test) is relevant to the components/modules (A) and (B) only, which are similar to the modules used in the existing systems KLAUS-Tr Kumar and Kumar (2024) and OLGA Kumar and Sreenivasa Kumar (2024), respectively. Therefore, we skip these details.
Appendix D. Abbreviations
(A) Key abbreviations in the AWP domain or introduced in this work are:
(B) Key ontology and ML abbreviations used in this work are: