
Abstract
Scientific processes are often described in free text, making it difficult to represent and reason over them computationally. We present
Keywords
Introduction
Extracting structured information from scientific publications is essential for modeling complex real-world processes, yet most scientific knowledge remains locked in unstructured prose. In the context of the Semantic Web vision, there is a large semantic gap between the volume of unstructured literature and the available structured data (Martinez-Rodriguez et al., 2020). Information extraction (IE) methods aim to bridge this gap by converting text into formal representations (D’Souza et al., 2021; Yan et al., 2022), but traditional IE approaches require extensive labeled corpora and hand-engineered patterns, which are laborious in domains like materials science (Yan et al., 2022), life sciences, medicine, engineering, and so on (Rula & D’Souza, 2023). Recent advances show that large language models (LLMs) can significantly aid this effort: for example, LLM-based pipelines have mined millions of polymer–property records from materials literature (Gupta et al., 2024). Nevertheless, the highly specialized language and reporting conventions of scientific manuscripts continue to impede fully automated schema discovery or induction. A further challenge is semantic interoperability: terms and units often vary across publications. Ontologies of quantities (e.g., the OWL Ontology of Units of Measure) were developed to make quantitative data explicit for integration and reuse (Rijgersberg et al., 2013). However, without systematic grounding of text-derived concepts in such ontologies, automatically extracted information remains fragmented and ambiguous. Together, these factors motivate the need for methods that can discover high-quality domain schemas from literature and explicitly link them to formal ontologies.
Agent-based workflows introduce a transformative capability to Semantic Web technologies by embedding autonomy, memory, and modular reasoning into information extraction and grounding tasks. For the Semantic Web community, this signals a shift from static, rule-based knowledge population toward dynamic, explainable, and reproducible schema engineering. The integration of agentic systems with LLMs (Gao et al., 2024a) allows for semantically rich, ontology-grounded structures to be created with high precision and interpretability—traits critical for maintaining FAIR principles (Findability, Accessibility, Interoperability, and Reusability) (Wilkinson et al., 2016) and for scaling the population of Linked Open Data (LOD) resources across scientific domains. By supporting tool augmentation (e.g., embeddings-based vector search) and human validation, agent-based workflows exemplify how intelligent agents can act as semantic intermediaries, fostering stronger alignment between unstructured scientific discourse and formal knowledge graphs (Gao et al., 2024b).
Existing work on schema discovery and ontology learning has progressed from rule-based and statistical methods to neural approaches. However, most prior efforts target general or narrative text and do not fully address the complexity of scientific processes. In our prior work, we introduced the LLMs4SchemaDiscovery approach (implemented in the
Thus, as a systematic extension to our prior work, in this article we present
In addition to this architectural enhancement, we evaluate
At a high level,
This agentic design contrasts with naive prompting strategies in which ontology alignment is attempted through single-turn LLM queries, which are difficult to trace, evaluate, or debug. In contrast, our approach leverages the
In summary, the key contributions of
Agentic ontology grounding: We introduce an LLM-driven, tool-augmented agentic workflow that combines heuristic matching and semantic vector search to align schema elements with ontology concepts, integrating expert validation for high-precision grounding. End-to-end application to ALD/ALE: We demonstrate the full workflow on two complex semiconductor processes—ALD and ALE—showing its effectiveness across both experimental and simulation literature. Interactive web interface: We develop a publicly available chat-based interface (https://huggingface.co/spaces/SciKnowOrg/schema-miner) enabling domain experts to engage with schema discovery through natural language, lowering the barrier for adoption and enhancing expert–AI collaboration. Comprehensive evaluation: We conduct in-depth quantitative and qualitative analysis across LLM variants, schema stages, and grounding effectiveness using QUDT. Our evaluation highlights the stability and utility of LLMs and the impact of agentic grounding via FAISS (Douze et al., 2024).
The remainder of the article is organized as follows. Section 2 surveys related work on schema learning which is a type of structured information extraction. Section 3 describes the
Related Work
The
Schema induction or schema discovery from text
Early research on schema discovery explored how structured representations could be derived from raw text, often through rule-based or handcrafted techniques. Embley et al. (1999c) proposed foundational methods to identify record boundaries in web documents, contributing to early data integration pipelines. In the scientific domain, Kononova et al. (2019) introduced a domain-specific pipeline to mine synthesis protocols from materials science literature, converting thousands of paragraphs into structured ‘‘codified recipes.” Although impactful, these approaches required extensive manual curation or domain-specific engineering, highlighting the need for generalizable, scalable solutions.
Schema induction has also been studied in NLP as a way to learn structured event or relational representations from unstructured narratives. Chambers and Jurafsky (2009) pioneered script learning from co-occurring event sequences. More recent methods emphasize ‘‘complex event schema induction,” where schemas are modeled as graphs over events and participants. For instance, Hao et al. (2023) propose a discrete diffusion approach guided by LLM-generated knowledge to induce causal and hierarchical relations among events. Dror et al. (2023) use GPT-3 to synthesize artificial narratives from a high-level topic (e.g., “pandemic outbreak”) and then extract structured schemas from them, demonstrating that zero-shot LLM methods can exceed manual baselines. Regan et al. (2023) focus on causal schema induction in news data, modeling cause-effect chains using annotated graphs and discourse-level features.
These works illustrate the evolution from rule-based to neural schema discovery techniques, increasingly leveraging generative models to produce interpretable and composable structures. However, most focus on general or narrative domains and rarely address the complexities of scientific literature, which involves dense terminology, multi-step processes, and deep domain knowledge.
LLMs for schema and ontology learning
The emergence of LLMs has accelerated progress in schema induction and ontology engineering. In materials science, Dagdelen et al. (2024) fine-tune GPT-3 and Llama-2 on a few annotated papers to jointly perform named-entity recognition and relation extraction, producing structured JSON records of host materials, dopants, compositions, and so on. Similarly, Xie et al. (2024) introduce ByteScience, an automated AWS-based pipeline that fine-tunes a domain-specific LLM (DARWIN) with minimal annotations to extract complex scientific facts from literature. These works show that LLMs can be adapted to convert specialized text (chemistry and materials science) into structured form with high accuracy given only a small labeled seed. In ontology learning, Bakker et al. (2024) explore using GPT-4o to induce an ontology from news text: they compare direct, sequential, and sentence-level prompting strategies to extract classes, individuals, and relations, and then evaluate the LLM-generated ontology against a human-created ground truth. The authors find that multi-step prompting improves consistency and reliability of the induced ontology. Such studies suggest that LLMs can serve as “ontology generators” or knowledge graph learners, albeit often producing taxonomic or relational structures rather than full-fledged ontologies.
Schilling-Wilhelmi et al. (2025) provide a comprehensive review of how LLMs can facilitate chemical informatics. They highlight that modern LLMs enable even non-experts to extract structured chemical knowledge from text, provided that domain expertise is used to guide and validate the LLM’s outputs. The chemical domain’s emphasis on precise terminology and context echoes the review’s recommendation that LLM-driven extraction be coupled with expert oversight to ensure accuracy and relevance.
Our prior work,
The present work,
D’Souza et al. (2025) present a related system in the ecology domain, where GPT-4 is used to induce and populate schemas capturing species, habitat, and ecosystem interactions from a large corpus of invasion biology literature. Their multi-stage approach combines schema discovery with large-scale fact extraction, resulting in a sizable ecological knowledge base. While their system automates many of the same tasks,
Human-in-the-loop knowledge extraction
Because fully automated induction can err, several recent systems integrate human oversight to refine schemas or extractions. Zhang et al. (2023) describe an interactive schema induction system where GPT-3 initially proposes schema “steps” (events) and tuple nodes, which human experts can edit via a graphical interface before assembling them into a schema graph. Their system allows prompt-based generation of candidate elements, manual curation of those elements, and conversion into a final graph, leading to more accurate schemas with less manual effort compared to previous IR-only methods. Similarly, Chang et al. (2024) present an end-to-end event-schema curation tool: LLMs propose event sequences and relations, but users can correct extracted tuples or relations at each stage. This pipeline includes a entity extraction and representation using entity mention detection. These human-in-loop designs demonstrate that user feedback and ontology linking can greatly improve the precision and interpretability of induced schemas.
Human expertise plays a central role in refining schema-miner’s outputs. In contrast to earlier efforts that relied heavily on post-hoc correction, our prior work
Other work has also explored interactive paradigms. OntoChat (Zhang et al., 2024) enables ontology engineers to iteratively co-develop ontologies with LLMs via multi-turn conversation. These approaches, like
Ontology grounding and alignment
Mapping schema components to standardized ontologies ensures interoperability and supports downstream reasoning. Historically, ontology alignment tools were benchmarked in OAEI tracks. More recently, He et al. (2023) and Amini et al. (2024) demonstrated that zero-shot and prompted LLMs outperform classical methods like BERTMap on various ontology matching tasks. Babaei Giglou et al. (2025) and Giglou et al. (2025) developed OntoAligner, 1 a modular Python toolkit that integrates retrieval-augmented LLM prompting and classical matching algorithms for complex alignment problems.
Foundational theories on schema mapping and conceptual model integration (e.g., Embley et al., 1999a, 1999b) remain relevant as underlying frameworks. Our agent-enhanced grounding design introduced as
Summary
To our knowledge, no existing system offers an end-to-end, domain-agnostic, human- and agent-in-the-loop workflow for schema induction, refinement, and ontology grounding from scientific literature. Existing systems address schema induction in specific domains, ontology alignment in isolation, or omit human oversight.
schema-miner —Overview
In our prior work, we introduced the

Overview of the LLMs4SchemaDiscovery workflow implemented in the
The schema discovery is initiated by a process specification document, which is iteratively refined using a curated collection of scientific publications and structured domain-expert feedback. This iterative, human-guided approach enhances both the structural and semantic characterization of the processes in the target domain. The final schema is grounded with established ontology using the ontology lookup service API, thereby facilitating interoperability and knowledge integration within the Semantic Web ecosystem. In the subsequent sections, we briefly describe each stage of the workflow to establish the foundation for the extended version of the framework,
In the first stage,
Stage 2: Preliminary Schema Refinement
The second stage is an iterative refinement of the initial schema, using a curated high-quality corpus of domain-relevant scientific literature and domain-expert feedback. A small collection of research papers is curated by the domain-experts of around 1–10 papers which are considered to be high-quality publications for the target process. There is no strict limit on the number of papers, it can be more or fewer than 10, it just depends on the availability of high-quality, specialized publication for the process. The purpose of this collection is to allow the LLM to extract properties and their relationship which are highly relevant for describing that process. This will help the LLM in generating schema which are both specific and generalizable with semantic consistency across various research scenarios.
The LLM is tasked with refining the schema by extracting additional properties, updating or clarifying property descriptions, incorporating missing constraints, and aligning terminologies with those used in the literature. An optional domain-expert feedback is requested based on the guideline provided to them, which defines two ways to provide a comprehensive feedback for the LLM to improve the schema: The first way is the descriptive text where the domain experts address questions like property merging, property grouping into a single unit, missing essential properties, and adequate property descriptions. The other method is through direct edits to the schema, where they can directly modify properties, constraints, and relationships as needed.
These feedback are embedded into the workflow for the next stage, where the descriptive text is incorporated directly into the LLM prompt, while edits to the schema are also incorporated into the prompt, enclosed within JSON start and end tags, allowing the LLM to interpret them as a structured JSON schema.
Stage 3: Finalize Schema Refinement
In the third stage, the schema undergoes further generalization and validation using a substantially larger and more heterogeneous corpus of scientific publications, which can comprise up to 100 papers. The non-curated corpus of scientific papers exposes the schema to a broader array of process descriptions, terminologies, and domain-specific edge cases. The primary objective is to ensure that the schema is not only robust and semantically precise but also generalizable across diverse representations of the target scientific process.
The LLM is instructed to incorporate new properties, correct omissions or inaccuracies in property descriptions, and improve semantic coherence across the schema. While Stage 2 emphasizes domain grounding and precision via a curated literature set, Stage 3 prioritizes scalability and generalizability, capturing a wider spectrum of process variations and terminological differences. The resulting schema is therefore validated for both its foundational accuracy and its applicability to a diverse range of real-world scientific scenarios.
schema-miner
—Agent-Based Ontology Grounding Over Scientific Schemas
In this work, we extend the
Agentic Workflows
Agentic workflows represent a paradigm in which LLMs are embedded within structured, goal-driven processes that support autonomous decision-making, iterative reasoning, and adaptive interaction with dynamic environments. In such systems, AI agents plan, decide, and act through sequences of goal-oriented steps, incorporating memory, feedback, and tool use to iteratively refine their behavior (Yao et al., 2023). Unlike conventional LLM workflows—typically based on direct prompt-response interactions or static chain-of-thought sequences—agentic workflows maintain persistent stage management, integrate environmental feedback, and dynamically adjust task strategies (Liu et al., 2023). These capabilities allow agentic systems to go beyond reactive text generation, engaging instead in multistep, context-sensitive reasoning using various tools to refine both internal representations and external outputs. As such, agentic workflows provide a robust foundation for ontology grounding by enabling the alignment of schema properties with ontological concepts in a principled and adaptable manner.
A key motivation for adopting an agentic workflow—rather than relying exclusively on LLM-based prompting—is the need for improved modularity, transparency, and scalability in the grounding process. While LLMs exhibit strong performance in tasks involving text understanding and concept matching, they are susceptible to known limitations such as hallucinations and restricted context windows, particularly when used in monolithic, prompt-based settings (Norouzi et al., 2023). Recent studies indicate that purely LLM-based approaches, such as LLMs4OM, can achieve high recall on ontology alignment tasks but still require substantial human-in-the-loop validation to ensure precision (Babaei Giglou et al., 2025).
Agentic workflows offer an alternative by decomposing the ontology grounding task into smaller, manageable subtasks, each potentially handled by a dedicated agent. This modular architecture allows each agent to integrate specialized tools—such as memory, external knowledge graphs, or FAISS-based semantic retrieval (Douze et al., 2024)—and to apply task-specific reasoning strategies. For example, Wu et al. (2024) implement a multi-agent system to extend a medical symptom ontology, where distinct agents perform roles including extraction, validation, and classification. Their framework demonstrates that agentic workflows are flexible, scalable, and amenable to domain customization in ways that are difficult to replicate using purely LLM-based methods.
Compared to traditional manual ontology grounding, as used in our prior work (Sadruddin et al., 2025), the agentic approach introduced here offers a more efficient and reproducible alternative. Manual grounding is labor-intensive, error-prone, with errors arising from syntactic mistakes, semantic ambiguities, modeling errors, and disagreement among experts. These factors make manual grounding difficult to scale across diverse scientific domains. In contrast, agent-based systems automate significant portions of the ontology alignment process while retaining the opportunity for expert oversight and feedback. This semi-autonomous design strikes a balance between automation and expert control, and is particularly well-suited to knowledge integration in complex, high-stakes domains.
The schema-miner
Agentic Workflow
Building on the strengths of agentic workflows,

Overview of the AI agent-based ontology grounding. The agent receives a process schema, produced by
Our implementation adopts a single-agent architecture using the LangChain Agent framework. 2 This agent is responsible for completing the grounding process for all schema properties. Its behavior is governed by a system prompt 3 that specifies the agent’s objectives, required inputs, and expected outputs—including conditional logic, such as returning an empty JSON object when the input property does not correspond to a physical quantity.
The agent operates according to a heuristic-based execution strategy: it initially attempts to resolve schema properties through direct matching against ontology terms. When ambiguity is detected or no direct match is found, the agent invokes a semantic search tool to retrieve relevant ontology candidates. This staged approach promotes efficiency by minimizing unnecessary tool usage.
To support traceability and iterative reasoning, the agent maintains a message history and an internal scratchpad for storing intermediate results. The following sections describe the detailed design, operational stages, and evaluation of this agentic component within the
The first step of the ontology grounding workflow in
The input schema contains semantically enriched properties that must be aligned with corresponding ontology concepts. The second input is a concise textual description of the scientific domain or process associated with the schema. This description provides essential context for disambiguating schema properties during ontology lookup. For example, a statement such as “Atomic Layer Etching – Atomic Layer Etching (ALE) is a highly controlled, layer-by-layer etching process used in semiconductor fabrication to achieve atomic-scale precision in material removal.” helps guide the agent’s interpretation of domain-specific terminology during the grounding process.
The third input that agent receives is a machine-readable ontology, either via a URL or in a standard RDF serialization (e.g., Turtle or RDF/XML), which defines the relevant domain’s concepts, relationships, and metadata.
Step 2: Property Matching
The second stage of the ontology grounding workflow,
For properties that are ambiguous or lack a clear match in the ontology, the agent engages a specialized tool to resolve the semantic uncertainty. This process begins by partitioning the ontology’s knowledge base into smaller, overlapping chunks, motivated by the token limitations of large language models during inference. These chunks are indexed using FAISS (Douze et al., 2024), enabling fast, and vector-based semantic retrieval.
When grounding an ambiguous schema property, the agent queries the FAISS index to retrieve the most semantically similar chunk. The ontology chunks stored in the FAISS vector store are first vectorized and reside in memory, and each schema property is queried against this index once. We used the OpenAI embedding model “text-embedding-3-small” to generate these vectors. This retrieved chunks, along with the property in question, is then passed to an LLM, which selects the most appropriate ontology concept. The LLM is guided by a structured prompt 4 that specifies the required input format (property and ontology chunk) and output structure. If the property does not represent a physical quantity within the ontology’s domain, the agent returns an empty JSON object; otherwise, the output includes relevant metadata such as quantityKind, unit, and ontology URIs. The prompt also includes examples and instructs the LLM to use semantic reasoning and synonym recognition to improve mapping accuracy to formal QUDT concepts.
Step 3: Schema Integration
The third stage of the ontology grounding workflow,
This integration template provides a structural specification for representing ontology-derived metadata within the schema. For instance, a user may define a JSON schema format that includes fields such as description, URI, sameAs, and other metadata extracted from the ontology. The agent populates these fields based on the matched ontology class or property.
This template-based approach ensures both flexibility—allowing for adaptation across diverse domains—and consistency, enabling the generation of machine-readable, semantically enriched schemas. The resulting output is well-suited for downstream applications such as knowledge graph construction, semantic search, and automated reasoning.

Step 4: Domain-Expert Validation
The final stage of the ontology grounding workflow,
This human-in-the-loop mechanism is essential for maintaining the validity of the schema, particularly in domains where subtle terminological or contextual nuances may influence downstream interpretation. By incorporating expert feedback into the refinement loop, the workflow enhances the precision of ontology grounding and allows the schema to evolve alongside domain knowledge.
The following pseudocode summarizes the complete agentic workflow implemented in
With expert validation complete, the refined schema is ready for practical use. In the next section, we demonstrate its utility in a materials science use case, showing how semantic grounding enhances process understanding, interoperability, and analysis in thin-film fabrication.
Application: Material Science Use Case
ALD and Etching Processes

Schematic illustration of one complete cycle of (a) atomic layer etching (ALE) and (b) atomic layer deposition (ALD). Every cycle consists of two half-cycles: the precursor is dosed in the reactor and reacts with the surface in the first step, and then a co-reactant is introduced in the second half-cycle. These steps are separated by purge steps to remove any leftover chemicals and reaction products from the reactor, ensuring clean and controlled growth. A complete cycle removes or adds an atomic layer from or to the film for ALE and ALD, respectively.© The Electrochemical Society. Reproduced by permission of IOP Publishing Ltd. All rights reserved (Faraz et al., 2015).
In both ALD and ALE, the self-limiting nature of the reactions is the key property that ensures exceptional control over film thickness, composition, and uniformity. These characteristics make ALD and ALE critical technologies for the production of cutting-edge electronic devices. Their applications extend beyond electronics to fields such as optics, photovoltaics, batteries, catalysis, and more (Alvaro & Yanguas-Gil, 2018). While the fundamental principles of ALD and ALE—self-limiting, sequential chemical processes—may seem straightforward, developing a successful ALD or ALE process requires careful design and execution. Conducting such experiments involves a series of steps to optimize parameters and ensure reliable outcomes (Shahmohammadi et al., 2022; Vos et al., 2019). Initially, researchers must define the intended application and accordingly select suitable precursors, co-reactants, and substrates. It is necessary to determine optimal pulse and purge durations, select an appropriate reactor type, and choose suitable process conditions such as temperature and pressure. Repeating experiments to validate results and ensure reproducibility is essential for establishing a robust ALD or ALE process.
Characterization of the results is another critical aspect. This includes determining the growth per cycle (for ALD) or the etch per cycle (for ALE), confirming the self-limiting nature of the process, and assessing material properties such as film structure (composition, crystallinity, and density) and morphology (surface roughness, texture, film uniformity and continuity, and conformality). Addressing these factors enables researchers to produce high-quality films tailored for advanced applications in material science (Knoops et al., 2015).
Computational simulations can further deepen our understanding of ALD and ALE processes and materials. These simulations are often combined with experimental studies to explain underlying mechanisms, but they can also serve as standalone research tools for investigating a wide range of properties. Simulations span various size scales, from atomistic simulations that explore mechanisms, reaction energies, and material properties of ALD (Mameli et al., 2017), to continuum modeling that examines reactor-scale phenomena such as the effect of gas flows on the processes (Yanguas-Gil et al., 2021). Across these simulation scales, certain properties are consistently studied—whether it’s the energy of a reaction step (Mameli et al., 2017) or the growth/etch rate of a film in kinetic Monte Carlo simulations (Sengupta et al., 2005; Yun et al., 2022). These properties play a crucial role in supporting process development efforts in experimental research.
The study of ALD and ALE processes, ranging from experimental process development data to simulation calculations, generates vast amounts of data, much of it remaining unexploited. In combination with the reproducibility of results across studies, the ALD and ALE processes make a suitable use case for the technology of the semantic web. The extraction of this key information into a structured format would allow the efficient study of literature around a certain process, material or even simulation type.
A major issue hindering the creation of a structured format of information is the unstructured method of reporting data found in scientific papers, especially those pertaining to ALD/ALE. There are many different ways used to report the same information, usually with no standard practice in place. This makes searching for literature and the comparison between studies more time-consuming and difficult than it should be. Therefore, the use of this methodology to allow extraction from unstructured to structured information would greatly improve the method of literature searching in this area, as well as in others.
An excellent starting point for this is the
It is evident that ALD and ALE have some clear similarities, but also differences. For example, for the ALD processes, conformality (a uniform thickness across the substrate surface for 3D structured surfaces) is a key characteristic, while for ALE this is not always the case. For the latter, choosing the right co-reactant will lead either to an anisotropic etching (etching of vertical structures) or to isotropic etching (etching of three-dimensional structures) (Lill et al., 2016) For that reason, it’s necessary for the context of this work to produce two types of schemas for the data extraction from ALD and ALE papers, respectively.
Experiments and Results
We evaluate
Experimental Setup
Our tool was implemented in Python using the LangChain framework to interface with both closed-source and open-source LLMs. All schema extraction experiments were run on a machine with a 16-core CPU and 32 GB of RAM. No dedicated GPU was used, as all LLM inferences were executed via cloud services. Users running open-source models locally may require significantly higher compute resources, as noted in each model’s documentation.
Following our prior work, we evaluated schema discovery using two types of expert feedback: descriptive text and direct schema edits. Accordingly,
These configurations were designed to assess the impact of different feedback modalities on schema quality. Based on domain expert evaluations,
Ontology Grounded Schema Refinement With QUDT
To enhance the semantic interoperability and machine-readability of the extracted or induced or discovered schemas from the LLM-based 3-stage workflow, as a novel contribution as described in this work, we incorporated an ontology grounding stage. For this we specifically chose the QUDT ontology. Specifically, for both ALD and ALE processes, the QUDT ontology was utilized to ground relevant physical quantities—such as temperature, pressure, and energy—providing consistent definitions and unit representations across the schema.
QUDT Ontology
The Quantities, Units, Dimensions, and Data Types (QUDT) ontology (QUDT.org, 2023) is a widely adopted semantic model for representing physical quantities, units of measurement, and dimensional relationships. QUDT defines a rich vocabulary covering over 800 units and quantity kinds across both SI and non-SI systems. It is designed to support semantic interoperability in scientific, engineering, and industrial contexts where quantitative data is critical.
Key constructs such as qudt:QuantityKind (e.g., Temperature, Pressure, and FlowRate) and qudt:Unit (e.g., Celsius, Pascal, and Second) enable consistent data interpretation, unit conversion, and validation in machine-readable form. QUDT aligns with international standards (e.g., SI and ISO) and is compatible with RDF/OWL models, making it a foundational component in domains such as manufacturing, materials science, and semantic web integration (Lambrix et al., 2024).
Importance of QUDT in Materials Science
The materials science domain is inherently quantitative, relying on precise measurements of properties such as temperature, pressure, energy, and deposition rate. In this context, QUDT plays a critical role in enabling standardized, machine-readable representations of physical quantities across experimental and computational workflows.
By providing a formal vocabulary for quantities and units, QUDT ensures consistency when integrating heterogeneous data sources—such as synthesis protocols, simulations, and characterization results—where units often differ in notation or scale. It enables automated unit conversion, dimensional validation, and semantic integration of data from diverse systems (Lambrix et al., 2024).
Recent initiatives in materials informatics and scientific knowledge graphs, such as the Materials Data Science Ontology (MDS-Onto), have adopted QUDT as a mid-level ontology to bridge domain-specific concepts with foundational semantics, improving coherence and cross-dataset searchability (Rajamohan et al., 2025).
In process-driven domains like ALD and ALE, where experimental parameters are tightly controlled and often vary across publications or tools, QUDT supports precise encoding of properties like etch rate and ion energy. This enables machine-actionable comparisons across diverse settings and enhances reproducibility, interoperability, and integration—key pillars of semantic materials science in the era of open data and AI-driven discovery.
QUDT Schema Structure for Grounding a Physical Quantity
To systematically integrate physical quantities from ALD and ALE process schemas, we designed a dedicated schema structure for grounding properties using the QUDT ontology. The primary objective is to map each relevant physical property in the schema to its corresponding qudt:QuantityKind 7 and qudt:Unit, 8 where applicable.
During the grounding process, we observed two common cases. In the first case, several physical properties—such as Temperature, Pressure, and Flow Rate—could be clearly and directly linked to both a well-defined quantity kind (e.g., http://qudt.org/vocab/quantitykind/Temperature) and a valid unit (e.g., http://qudt.org/vocab/unit/DEG_C). These cases represent straightforward mappings fully supported by the QUDT ontology. An example RDF representation for such a mapping is shown below:

However, a second class of properties emerged that posed greater semantic ambiguity. Certain domain-specific properties, such as GrowthPerCycle, lack a direct match to any qudt:QuantityKind . For these cases, while appropriate QUDT units (e.g., http://qudt.org/vocab/unit/NanoM) could be identified, no explicit quantity kind was defined in the ontology. We can represent this as an example in encoded RDF representation as follows:

To address ambiguous cases, the agent was allowed to infer a semantically related quantity kind—such as http://qudt.org/vocab/quantitykind/Length for the property GrowthPerCycle—based on contextual relevance and expert feedback. When no suitable alternative existed, the schema permitted the quantityKind field to remain optional. This empirical differentiation informed a flexible schema design that accommodates both well-defined and ambiguous mappings. Specifically, making the quantityKind metadata optional allowed physical properties to be grounded without compromising the structural integrity of the schema when a quantity kind was unavailable.
To support this flexibility, we developed a dedicated sub-schema representation (Figure 4), referred to as the “Quantity” node. This serves as the foundation for linking physical properties in the ALD and ALE schemas to semantic concepts in the QUDT ontology.

Overview of the structured Quantity schema used to integrate physical properties from ALD and ALE process schemas with QUDT ontology. The schema captures key semantic components, including the numerical value, unit of measurement, and (optionally) the associated quantity kind (https://orkg.org/template/R1377474). ALD = atomic layer deposition; ALE = atomic layer etching; QUDT = Quantities, Units, Dimensions, and Types.
The quantity sub-schema comprises several nested components that collectively capture the semantics of a physical measurement. The QuantityValue object holds the numerical value along with its associated unit. The Unit object formally links this value to a QUDT concept, containing a quantityKind field that specifies the type of quantity measured (e.g., temperature and pressure) and a sameAs field linking to the canonical QUDT unit definition (e.g., http://qudt.org/vocab/unit/DEG_C).
The QuantityKind object defines the broader category of the quantity (e.g., Temperature or FlowRate), includes a list of applicable units, and provides a sameAs field pointing to the corresponding QUDT ontology concept (e.g., http://qudt.org/vocab/quantitykind/Temperature).
This structured approach ensures consistent and semantically grounded integration of physical quantities while offering the flexibility required for domain-specific scenarios frequently encountered in ALD and ALE process data.
Building on the foundational role of the QUDT ontology in grounding physical quantities, we applied this framework to the extracted ALD process schema to semantically enrich and standardize all identified physical properties with their corresponding quantity kinds and units. A portion of the grounded ALD experimental schema is shown in Figure 5, highlighting key process parameters such as delivery method, temperature, pressure, reactor, and thickness control. The reactor and thickness control fields are nested objects that include important experimental properties like growth per cycle, saturation, nucleation period, dosing time, and purge time.

Ontology-grounded schema fragment for the ALD experimental process, enriched using the QUDT ontology within the
As part of the
Following grounding, the augmented schema was reviewed by domain experts in ALD/ALE to verify that the assigned units and quantity kinds aligned with experimental standards reported in the literature. In addition, the semantic structure—covering the relationships between properties, data types, and constraints, was reviewed jointly by both ALD/ALE experts and the authors to ensure correctness and consistency. One key insight from this validation step concerned unit granularity. For example, while the agent correctly suggested “seconds” as the unit for dosing time, domain experts recommended “milliseconds” due to the fine temporal resolution typical of ALD experiments. This feedback was incorporated into the workflow, enabling the agent to return the revised, domain-appropriate unit.
The final, validated JSON schemas for both experimental and simulation cases in ALD are publicly available at: https://github.com/sciknoworg/schema-miner/tree/main/results/Ideal%20Schema/Atomic-Layer-Deposition.
We applied the QUDT ontology grounding process to the ALE process schemas—covering both experimental and simulation use cases—using the same agentic workflow employed for ALD. A portion of the grounded ALE experimental schema is shown in Figure 6, and the complete version in our Github repository. This schema segment defines the ALE window properties typically used during experimentation, including the temperature window and ion energy window. Each window contains nested properties specifying minimum and maximum values—namely, minimum temperature, maximum temperature, minimum ion energy, and maximum ion energy.
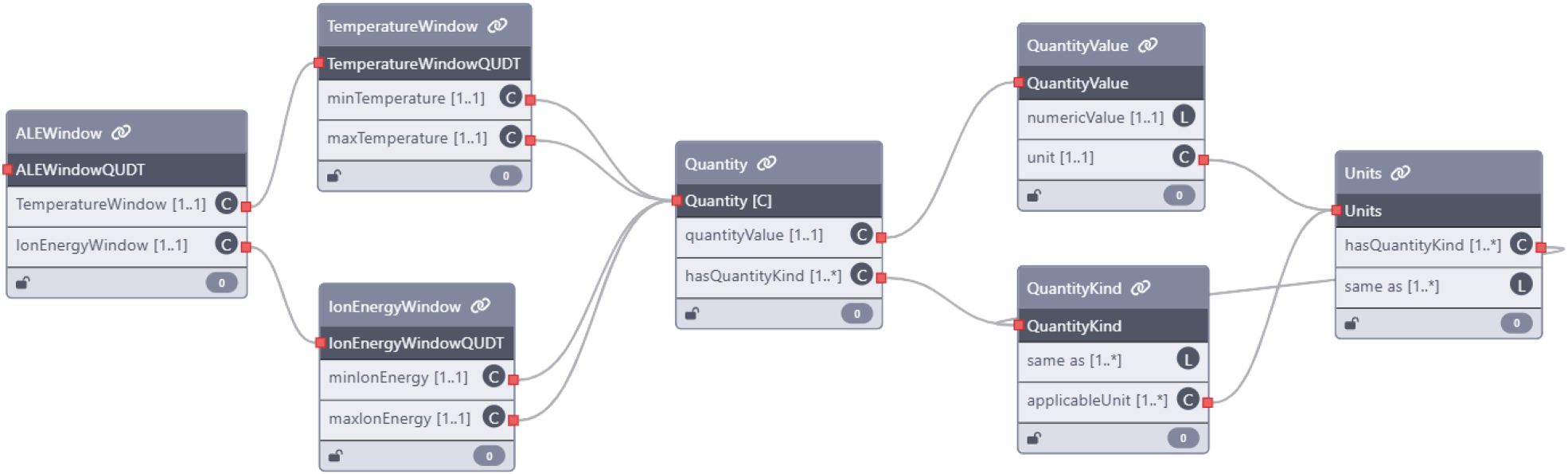
Ontology-grounded schema fragment for the ALE experimental process, enriched using the QUDT ontology within the

These four properties were processed by the ontology-grounding agent, which successfully identified them as physical quantities and linked them to appropriate QUDT concepts. Specifically, the agent assigned the quantity kind http://qudt.org/vocab/quantitykind/Temperature to the temperature-related properties, using the unit http://qudt.org/vocab/unit/DEG_C, and the quantity kind http://qudt.org/vocab/quantitykind/Energy to the ion energy-related properties, with the unit http://qudt.org/vocab/unit/KiloJ.
The grounded properties were then reviewed by domain experts, who again raised concerns about unit granularity—similar to observations made during ALD schema validation. While the assigned units were semantically correct, smaller-scale units were preferred to better reflect standard experimental practice. This feedback was incorporated into the agent’s refinement loop to adjust and improve unit selection.
The final, expert-validated ALE schemas for both experimental and simulation contexts are available at: https://github.com/sciknoworg/schema-miner/tree/main/results/Ideal%20Schema/Atomic-Layer-Etching.
In this section, we evaluate the performance of the
Quantitative Results
The objective of the quantitative evaluation is to evaluate property variance and structural differences across the schemas generated by three LLMs: GPT-4o, GPT-4-turbo, and LLaMA 3.1 (8B), over the three stages of schema refinement. We aim to measure how closely aligned the schemas are across models, and how they evolve from the initial stage to the final stage. Here, we present the quantitative results only for the experimental use cases of ALD and ALE processes. However, all generated schemas for each stage are made publicly available in our public repository.
To evaluate schema similarity (see Tables 1 and 2), we used three commonly used text generation metrics:
Quantitative Schema Variance Across Stages 1, 2, and 3 of schema-miner for ALD Experimental Processes, Evaluated Using ROUGE-L, BLEU, and BERTScore Metrics, Comparing Schemas From GPT-4o, GPT-4-turbo, and LLaMA 3.1 (8B).
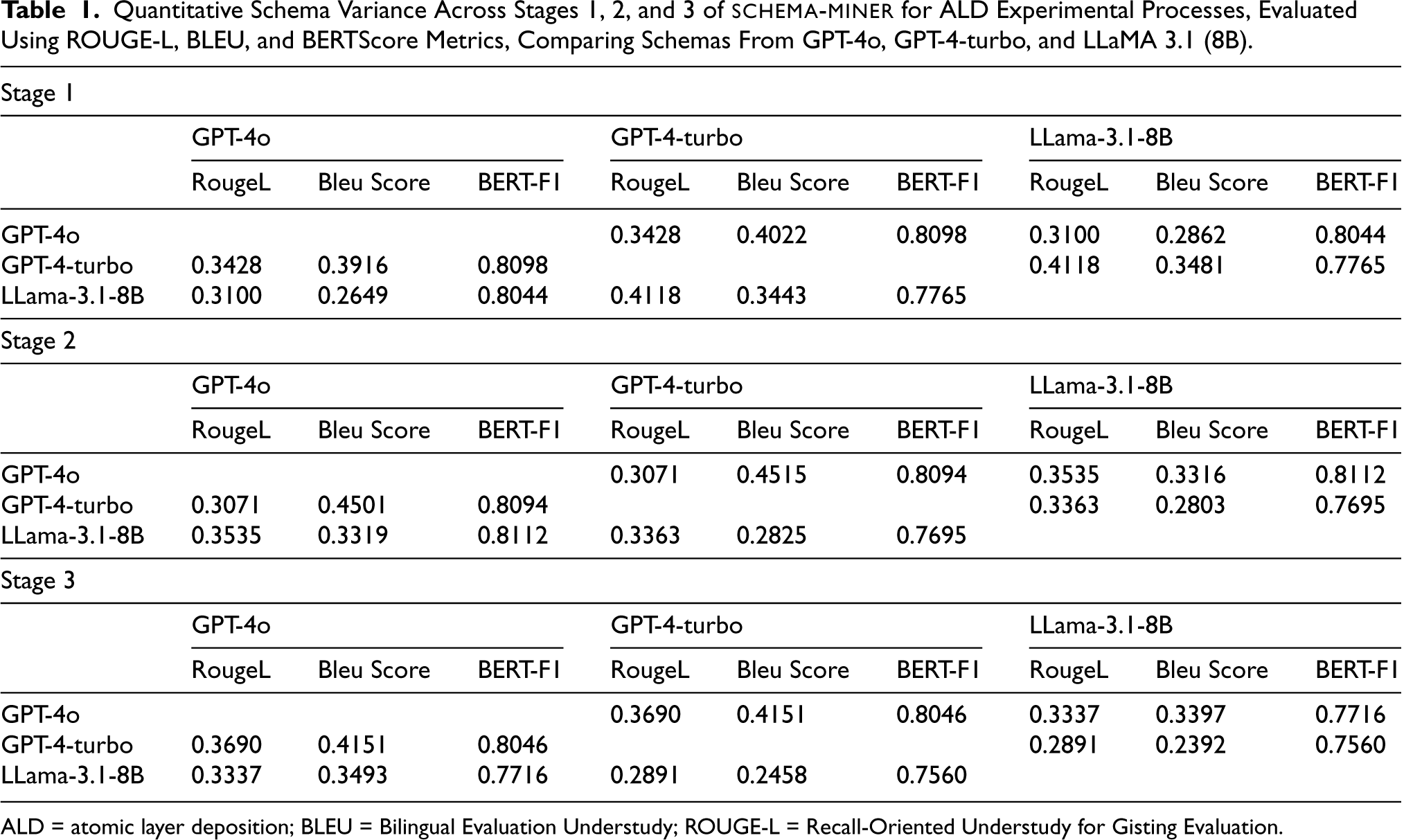
Quantitative Schema Variance Across Stages 1, 2, and 3 of
ALD = atomic layer deposition; BLEU = Bilingual Evaluation Understudy; ROUGE-L = Recall-Oriented Understudy for Gisting Evaluation.
Quantitative Schema Variance Across Stages 1, 2, and 3 of

ALE = atomic layer etching; BLEU = Bilingual Evaluation Understudy; ROUGE-L = Recall-Oriented Understudy for Gisting Evaluation.
ALD experimental schemas
In Stage 1, ROUGE-L scores shows differences between schemas across LLMs (see Table 1). GPT-4-turbo achieved a ROUGE-L of
ALE experimental schemas
In Stage 1, GPT-4o achieved a ROUGE-L of
Overall, for ALD experimental schemas, GPT-4o and LLaMA 3.1 (8B) demonstrated strong performance, with consistent semantic comprehension and structural robustness. While for ALE experimental schemas, GPT-4o and GPT-4-turbo emerged as the most reliable models, with superior performance in capturing the nuances and structure of the ALE processes.
LLM stability
The stability of an LLM refers to its ability to produce consistent outputs across multiple runs and avoid introducing irrelevant modification during schema refinement, particularly in Stage 2 and Stage 3 of the workflow. Through domain expert feedback for both the ALD and ALE processes, we observed notable difference in model behavior.
For the ALD process, both GPT-4o and LLaMA 3.1 (8B) demonstrated high stability, maintaining a coherent schema structure throughout the refinement stages. GPT-4-turbo, on the other hand exhibited instability, frequently introducing overly specific properties that were not validated by our domain experts.
In the case of the ALE process, GPT-4o and GPT-4-turbo were found to be relatively stable, while LLaMA 3.1 (8B) generated several irrelevant schema properties, particularly during the third stage of the workflow. These inconsistencies often detracted from the semantic accuracy of the extracted schema.
Effect of different experimental settings for domain feedback
As part of our evaluation, we investigated how different methods of domain expert feedback (descriptive text and direct schema edits) as introduced in
Among all, Experiment 3, which incorporated both descriptive text and expert edited schema at every iteration, consistently outperformed the others for both ALD and ALE processes. This hybrid approach provided the LLMs with richer contextual and structural semantic information with concrete structural corrections, resulting in more accurate and meaningful schema refinements. In contrast, Experiment 4, where no domain feedback was provided, gave the least satisfactory results. The schemas generated under this condition lacked semantic coherence and often introduced irrelevant or redundant properties. This performance gap strongly reinforces the importance of domain expert involvement in guiding and constraining the schema discovery process, especially in complex scientific domains.
Effect of using process specification document in Stage 1
The process specification document during stage 1 plays an important role in the schema extraction workflow by providing a foundational structure which LLMs can build upon. In both the ALD and ALE schema extraction tasks, the inclusion of these documents significantly enhanced the LLMs ability to generate coherent and semantically rich initial schemas. Each process specification document contains essential properties required to effectively model the respective processes, along with procedural descriptions outlining how these processes are been executed. This structured, domain-specific information allows the LLMs to ground their outputs and generalize effectively when identifying key concepts and relationships.
For instance, the ALD specification document includes properties such as precursors, co-reactants, growth rate, and various material properties. Similarly, the ALE document defines properties like thickness, etch rate, synergy, and other relevant properties. The presence of these properties enables the LLMs to construct well-formed initial schemas that capture essential physical and procedural characteristics for these processes.
These foundational schemas serve as a strong starting points for next refinement stages. When combined with scientific literature and expert feedback in Stages 2 and 3, they help maintain structural integrity and prevent semantic drift, ensuring that the final schema remains aligned with the core domain knowledge.
Effect of using small scientific corpus in Stage 2
In Stage 2 of the
This curated corpus helped the language models to refine and enhance the schema without deviating from the domain-relevant semantic framework. By integrating this carefully chosen literature, the LLMs were able to extract key properties that were not explicitly present in the initial process specification document but were critical to scientific reporting and comprehension.
For example, during the iterative refinement of the ALD process schema, LLM particularly GPT-4o and LLaMA 3.1 successfully incorporated properties such as material deposited and optical properties. Domain experts validated these additions as essential for accurately characterizing ALD procedures. Moreover, the semantic structure of the schema, including the relationships among properties, became more coherent and aligned with how domain experts conceptualize these processes.
Effect of large scientific corpus in Stage 3
In Stage 3 of the
For most of the experiments, this broader perspective offered valuable diversity, it also introduced potential risks related to schema over-specialization. In some experiments, the inclusion of this corpus led LLMs to incorporate highly specific properties into the schema that while scientifically accurate, were not generalizable to core conceptual representation of ALD or ALE processes. For instance, the ALE schema proposed by LLaMA 3.1 (8b) added a property called, diketoneEtchingMechanism, which represents a very specialized etching mechanism and cannot be generalized to all the ALE processes. Among the models tested for ALE, LLaMA 3.1 (8b) was particularly affected. It sometimes deviated from the original schema structure and produced highly specialized schemas.
Comprehension of ALD and ALE processes
A main objective for applying
Evolution of Selected ALD Experimental Schema Properties Across Three Key Stages of the schema-miner Workflow.

Evolution of Selected ALD Experimental Schema Properties Across Three Key Stages of the
The table highlights changes in property extraction and representation introduced by each stage. Only top-level properties are shown, but optional nested properties are included to illustrate the significant role of domain-expert feedback. ALD = atomic layer deposition.
For the ALD process, both GPT-4o and LLaMA 3.1 (8B) demonstrated strong comprehension. They not only identified the key properties of ALD but also structured them in a semantically meaningful way and the resulting schemas were well-aligned with expert expectations.
In contrast, for the ALE process, GPT-4o and GPT-4-turbo outperformed LLaMA 3.1 (8B). While these models produced coherent and generalizable schemas, LLaMA 3.1 introduced an highly specific properties, which limited the schema’s interpretability. These issues suggest that although LLaMA 3.1 showed promise for ALD, its performance on ALE was less consistent, likely due to its sensitivity to broader or more complex input corpora.
Difference between ALD and ALE process schema
An ideal schema representations for both ALD and ALE processes were derived from the output of Stage 3 of
As discussed in Section 5, ALD and ALE represent fundamentally opposite physical processes, where ALD is focused on the deposition of material layers, while ALE is concerned with the removal of material. Despite their opposing goals, the schemas for ALD and ALE share a subset of common properties, such as reactants, precursors, and substrates, which are essential to both processes. However, each process also has domain-specific properties that uniquely characterize it. For example, ALD schema (https://orkg.org/template/R1366244) typically include metrics like growth per cycle, whereas ALE schema (https://orkg.org/template/R1379646) uses properties such as etch per cycle. The schema differences underscore the importance of process-specific modeling, even within closely related domains.
Impact of using a hybrid heuristic approach for grounding schemas with QUDT
To semantically enrich the extracted schemas,
Specifically, the agent was provided with QUDT ontology and a process schema to be grounded. For all the unambiguous properties, the agent was able to perform direct lookup through the ontology without needing to invoke the LLM for each grounding task. This hybrid strategy significantly improved efficiency by reducing the number of API calls to the LLM for ontology concept retrieval and reasoning. It allowed the agent to ground many standard physical properties quickly, reserving LLM calls for less common or more ambiguous cases.
Impact of using FAISS for semantic search
For all the ambiguous physical properties which cannot be directly mapped with any ontology term, the agent uses a semantic search mechanism to retrieve relevant ontology information for grounding. This is achieved through the integration of FAISS (Douze et al., 2024), a vector-based search library designed for efficient similarity matching over large corpora.
Because of this approach of dividing the ontology into multiple chunks and allowing the agent to perform semantic search on these chunks, it significantly reduces the computational overhead of loading and parsing the full ontology during runtime, which would otherwise be infeasible due to its size and complexity.
Correctness of QUDT grounding with AI agent
To assess the accuracy of the semantic grounding process, the QUDT grounded schemas generated for ALD and ALE processes were reviewed and validated by domain experts. The goal was to evaluate both the correctness of the assigned quantityKind and the associated unit for each physical property.
Overall, the AI agent demonstrated a high level of accuracy in detecting and grounding all physical properties present in the schemas. However, some issues were observed with the selection of units, particularly in terms of practical suitability within experimental contexts. For example, in the ALD simulation schema, the property flowRate was correctly assigned a quantityKind and matched to the unit liter-per-minute, which is semantically accurate. However, domain experts noted that in practice, this unit is too big to be used in ALD experiments. A more appropriate unit, such as centicubicmeter-per-minute (cM
For example,
These biomedical scenarios are intentionally prospective: we have not yet instantiated or evaluated
Similarly,
This chemistry use case should therefore be read as a forward-looking application; empirical validation on real synthesis corpora, including less formulaic and more narrative procedures, remains future work.
Applying
Importantly, adapting
Finally, even within materials science, there is room to enhance semantic grounding by incorporating additional ontologies. In our ALD/ALE use cases, we grounded to QUDT for units (Simons et al., 2013). But many ontologies are relevant to materials and processes. For example, ChEBI (already mentioned) could cover any molecular precursors or by-products involved in deposition processes (Degtyarenko et al., 2007). The Materials Design Ontology (MDO) defines concepts for solid-state physics and materials structures (Li et al., 2020), and linking process parameters to MDO classes could capture high-level design intent. The European Materials and Modeling Ontology (EMMO; https://emmo-repo.github.io/versions/1.0.0-beta/emmo.html) provides a unified framework for physics, chemistry, and materials concepts; grounding to EMMO would align our schemas with a broad community standard. In fact, past studies have noted that combining QUDT with other vocabularies (e.g., SWEET or domain-specific ontologies) is desirable future work for richer models. Integrating these ontologies into
In summary, we argue that the
HuggingFace Chat Application
To enhance the usability and adoption of the
This user-facing interface is particularly valuable for facilitating iterative refinement cycles, a core design philosophy behind the
The application is implemented using the
Currently, the chat interface supports schema extraction using OpenAI-based models such as GPT-4o via secure API access. Future updates will expand support to include open-source LLMs (e.g., Hugging Face Transformers) to ensure broader accessibility and to reduce dependency on proprietary services. Importantly, the application is model-agnostic and can generalize to any domain involving structured process documentation, making it a powerful tool for fields such as materials science, biomedical workflows, manufacturing protocols, and beyond.
Conclusion
In this work, we presented
For example, an ontology-grounded ALD schema can be directly used to
Looking ahead, our next steps include aligning discovered schemas with
Footnotes
Funding
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.